
ĐẠI HỌ TRƯỜNG ĐẠI H PHẠM VĂN...
85
ĐẠI HỌC QUỐC GIA HÀ NỘI TRƯỜNG ĐẠI HỌC CÔNG NGHỆ PHẠM VĂN HẬU THỰC THI THỜI GIAN THỰC MÔ HÌNH THUẬT TOÁN MELP TRÊN BỘ XỬ LÝ TÍN HIỆU SỐ TMS320C5509 LUẬN VĂN THẠC SĨ CÔNG NGHỆ ĐIỂN TỬ - VIỄN THÔNG Hà Nội - 2014
Transcript of ĐẠI HỌ TRƯỜNG ĐẠI H PHẠM VĂN...

ĐẠI HỌC QUỐC GIA HÀ NỘI
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
PHẠM VĂN HẬU
THỰC THI THỜI GIAN THỰC MÔ HÌNH THUẬT
TOÁN MELP TRÊN BỘ XỬ LÝ TÍN HIỆU SỐ
TMS320C5509
LUẬN VĂN THẠC SĨ CÔNG NGHỆ ĐIỂN TỬ - VIỄN THÔNG
Hà Nội - 2014

ĐẠI HỌC QUỐC GIA HÀ NỘI
TRƯỜNG ĐẠI HỌC CÔNG NGHỆ
PHẠM VĂN HẬU
THỰC THI THỜI GIAN THỰC MÔ HÌNH THUẬT
TOÁN MELP TRÊN BỘ XỬ LÝ TÍN HIỆU SỐ
TMS320C5509
Ngành: Công nghệ Điện tử Viễn thông
Chuyên ngành: Kỹ thuật điện tử
Mã số: 60 52 02 03
LUẬN VĂN THẠC SĨ CÔNG NGHỆ ĐIỆN TỬ VIỄN THÔNG
NGƯỜI HƯỚNG DẪN KHOA HỌC: PGS. TS. TRẦN ĐỨC TÂN
Hà Nội - 2014

LỜI CAM ĐOAN
Tôi xin cam đoan đây là công trình
nghiên cứu của riêng tôi.
Các số liệu, kết quả nêu trong luận văn là
trung thực và chưa từng được công bố
trong bất kỳ công trình nào khác.
Tác giả
Phạm Văn Hậu

MỤC LỤC
LỜI CAM ĐOAN
MỤC LỤC
MỤC LỤC BẢNG BIỂU
MỤC LỤC HÌNH VẼ
DANH MỤC VIẾT TẮT
MỞ ĐẦU ....................................................................................................... 1
Chương 1 - TỔNG QUAN NÉN THOẠI ...................................................... 4
1.1 Cấu trúc của hệ thống nén thoại .................................................................. 4
1.2 Các thuộc tính lý tưởng của nén thoại ........................................................ 6
1.3 Trễ nén ........................................................................................................ 7
1.4 Ứng dụng của các mô hình nén thoại .......................................................... 9
Chương 2 - MÔ HÌNH NÉN THOẠI MELP ............................................. 10
2.1 Mô hình tạo tiếng nói MELP .................................................................... 10
2.2 Biên độ Fourier (Fourier Manitudes) ........................................................ 11
2.3 Bộ lọc định hình ........................................................................................ 15
2.4 Pitch period và ước lượng voice strength ................................................. 17
2.5 Hoạt động mã hóa ..................................................................................... 24
2.6 Hoạt động giải mã ..................................................................................... 27
2.7 Kết chương ................................................................................................ 30
Chương 3 - CHIP XỬ LÝ TÍN HIỆU SỐ TMS320C55xx ........................ 32
3.1 Giới thiệu ................................................................................................... 32
3.2 Kiến trúc họ TMS32C55xx ....................................................................... 32
3.3 Công cụ phát triển ..................................................................................... 37
3.4 Các chế độ địa chỉ TMS320C55x ............................................................. 42
3.5 Đường ống và cơ chế song song ............................................................... 44
3.6 Tập lệnh TMS320C55x ............................................................................. 47
3.7 Lập trình hỗn hợp C và Assembly ............................................................ 48

Chương 4 - CÀI ĐẶT VÀ THỬ NGHIỆM ................................................. 51
4.1 Cài đặt MELP thời gian thực trên C5509 và C5510. ................................ 51
4.2 Thực hiện cài đặt ....................................................................................... 52
4.3 Đánh giá kết quả........................................................................................ 59
KẾT LUẬN ..................................................................................................... 63
Kết quả đạt được của luận văn ............................................................................ 63
Định hướng nghiên cứu tiếp theo ........................................................................ 63
TÀI LIỆU THAM KHẢO ................................................................................ 64
PHỤ LỤC ........................................................................................................ i
A. Mô hình mã hóa dự đoán tuyến tính LPC .................................................... i
B. Thuật toán Levinson-Durbin ...................................................................... iii
C. Lượng tử hóa véc-tơ nhiều lớp (MSVQ) .................................................. vii

MỤC LỤC BẢNG BIỂU
Bảng 2-1: Sơ đồ cấp phát bit của mã hóa MELP ................................................ 27
Bảng 3-1: Ví dụ về mã C và mã hợp ngữ được trình biên dịch C55x sinh ra .... 37
Bảng 3-2: Ví dụ về tệp lệnh liên kết sử dụng cho bộ mô phỏng C55x ............... 39
Bảng 3-3: Gán các loại tham số tới thanh ghi ..................................................... 49
Bảng 3-4: Sử dụng và duy trì thanh ghi .............................................................. 50
Bảng 4-1: Một số tệp chính của dự án ................................................................ 52
Bảng 4-2: Bảng cho điểm MOS .......................................................................... 60
Bảng 4-3: Mẫu âm thanh dùng để đánh giá ........................................................ 61
Bảng 4-4: Đánh giá PESQ của cài đặt C55x MELP ........................................... 61
Bảng A-1: Bảng so sánh MC đối với các độ phân giải thường gặp...................... x
MỤC LỤC HÌNH VẼ
Hình 1-1: Mô hình hệ thống nén thoại ................................................................ 4
Hình 1-2: Mô hình nén thoại ............................................................................... 5
Hình 1-3: Mô hình xác định trễ ........................................................................... 7
Hình 1-4: Mô tả các thành phần của trễ nén ....................................................... 8
Hình 1-5: Đồ thị mẫu truyền bit ở hai chế độ liên tục (trên) và gói (dưới) ........ 8
Hình 2-1: Mô hình tạo tiếng nói ........................................................................ 10
Hình 2-2: Mô phỏng xử lý tín hiệu với bộ lọc tạo xung ................................... 12
Hình 2-3: Mô hình tính toán và lượng tử hóa biên độ Fourier .......................... 12
Hình 2-4: Quá trình tạo kích thích xung ........................................................... 14
Hình 2-5: Sơ đồ bộ lọc tạo hình xung ............................................................... 16
Hình 2-6: Vị trí của các cửa sổ khác nhau tương ứng với khung tín hiệu ........ 18
Hình 2-7: Mô phỏng ước lượng Pitch period bước 1 ........................................ 19
Hình 2-8: Mô phỏng ước lượng voice strength băng thông .............................. 20
Hình 2-9: Một số tín hiệu và giá trị đỉnh của nó ............................................... 22
Hình 2-10: Đỉnh của chuỗi xung không gian đồng nhất ..................................... 22
Hình 2-11: Sai số dự đoán có được từ một sóng âm (bên trái) và đo đạc đỉnh áp dụng cho sai số dự đoán (bên phải) .................................................. 23
Hình 2-12: Mô hình mã hóa MELP..................................................................... 24

Hình 2-13: Mô hình giải mã MELP .................................................................... 28
Hình 2-14: Đáp ứng xung (trái) và đáp ứng biên độ (phải) của bộ lọc phân tán xung ................................................................................................... 30
Hình 3-1: Sơ đồ khối của CPU TMS320C55x .................................................. 33
Hình 3-2: Sơ đồ đơn giản hóa của IU ................................................................ 34
Hình 3-3: Mô hình đơn giản hóa của PU .......................................................... 34
Hình 3-4: Bộ điều khiển luồng dữ liệu địa chỉ C55x ........................................ 35
Hình 3-5: Mô hình cấu trúc bộ tính toán dữ liệu ............................................... 36
Hình 3-6: Công cụ và Luồng phát triển phần mềm TMS320C55X .................. 38
Hình 3-7: Phát triển phần mềm TMS320C55X với CCS .................................. 40
Hình 3-8: Ví dụ về lệnh hợp ngữ của TMS320C55X ....................................... 41
Hình 3-9: Sơ đồ hoạt động của đường ống C55x .............................................. 46
Hình 4-1: Mô hình hệ thống cho phát triển mô hình MELP ............................. 51
Hình 4-2: Mô hình triển khai thời gian thực trực tuyến .................................... 52
Hình 4-3: Mô hình tổng quát của một phương pháp đo phổ biến ..................... 60
Hình 4-4: Tệp Vn_M gốc và qua xử lý của C55x MELP ................................. 62
Hình 4-5: Tệp Vn_F gốc (và qua xử lý của C55x MELP ................................. 62

DANH MỤC VIẾT TẮT
Từ viết tắt Tiếng Anh đầy đủ Nghĩa tiếng Việt
2-D 2-Demensional Hai chiều
AbS Analysis-by-synthesis Phân tích bằng cách tổng hợp
ACELP Algebraic code-excited linear prediction
Dự đoán tuyến tính mã kích thích đại số
ACR Absolute category rating Tỉ lệ phân loại tuyệt đối
ADPCM Adaptive differential pulse code modulation
Điều chế mã xung sai phân thích nghi
APCM Adaptive pulse code modulation Điều chế mã xung thích nghi
AR Tự hồi quy Tự hồi quy
ARMA Tự hồi quy moving average Trung bình dịch chuyển tự hồi quy
CCR Comparison category rating Tỉ lệ phân loại so sánh
CDMA Code division multiple access Đa truy cập chia theo mã
CELP Code-excited linear prediction Dự đoán tuyến tính mã kích thích
CS-ACELP Conjugate structure algebraic code-excited linear prediction
Dự đoán tuyến tính mã kích thích đại số cấu trúc liên hợp
DC Direct current Dòng một chiều
DCR Degradation category rating Tỉ lệ phân loại suy giảm
DFT Discrete Fourier transform Biến đổi Fourier rời rạc
DPCM Differential pulse code modulation Điều chế mã xung sai phân
DSP Digital signal processing/processor Xử lý tín hiệu số
DTAD Digital telephone answering device Thiết bị trả lời thoại số
DTFT Discrete time Fourier transform Biến đổi Fourier thời gian rời rạc
DTMF Dual-tone multifrequency Âm kép đa tần
EFR Enhanced full rate Tăng cường đầy đủ tỉ lệ
FFT Fast Fourier transform Biến đổi Fourier nhanh
FIR Finite impulse response Đáp ứng xung hữu hạn
FM Frequency modulation Điều tần
FS Federal Standard Chuẩn liên bang
GLA Generalized Lloyd algorithm Thuật toán Generalized Lloyd
IDFT Inverse discrete Fourier transform Biến đổi Fourier rời rạc nghịch đảo
IIR Infinite impulse response Đáp ứng xung vô hạn
LD-CELP Low-delay code-excited linear prediction
Dự đoán tuyến tính mã kích thích trễ thấp
LMS Least mean square Bình phương trung bình tối thiểu

LP Linear prediction Dự đoán tuyến tính
LPC Linear prediction coding/coefficient Mã hóa dự đoán tuyến tính
MA Moving average Trung bình dịch chuyển
MNB Measuring normalizing block Khối chuẩn hóa đo đạc
MP–MLQ Multipulse–maximum likelihood quantization
Chuẩn hóa dạng tối đại đa xung
MSE Mean square error Sai số bình phương trung bình
MSVQ Multistage vector quantization Lượng tử hóa vector đa lớp
PCM Pulse code modulation Điều chế mã xung
PESQ Perceptual evaluation of speech quality
Đánh giá cảm nhận về chất lượng thoại
PSQM Perceptual speech quality measure Đo đạc chất lượng thoại
PVQ Predictive vector quantization Lượng tử hóa vec-tơ dự đoán
QCELP Qualcomm code-excited linear prediction
Dự đoán tuyến tính kích thích mã Qualcomm
RC Reflection coefficient Hệ số phản xạ
RV Random variable Biến ngẫu nhiên
SD Spectral distortion Sự biến dạng phổ
SNR Signal to noise ratio Tỉ lệ tín hiệu trên nhiễu
SPG Segmental prediction gain
SSE Sum of squared error Tổng sai số bình phương
SSNR Segmental signal to noise ratio Tỉ lệ tính hiệu phân đoạn trên nhiễu
TDMA Time division multiple access Đa truy cập phân chia thời gian
TI Texas Instruments
VoIP Voice over internet protocol Truyền âm qua giao thức internet
VQ Vector quantization Lượng tử hóa véc-tơ
VSELP Vector sum excited linear prediction
Dự đoán tuyến tính kích thích tổng vec-tơ

1
MỞ ĐẦU
1. Lý do chọn đề tài
Hiện nay, nén dữ liệu âm thanh nói chung và nén dữ liệu tiếng nói nói riêng đã và đang được các nhà khoa học, công nghệ trên thế giới quan tâm nghiên cứu, các kết quả đạt được đã được ứng dụng nhiều trong lĩnh vực truyền thông và giải trí. Đặc biệt, trong điều kiện công nghệ thông tin, truyền thông đang phát triển rất mạnh như hiện nay thì vấn đề xử lý âm thanh, tiếng nói càng được nghiên cứu và ứng dụng rộng rãi.
Đã có rất nhiều thuật toán và mô hình xử lý tiếng nói được nghiên cứu và sử dụng, trong đó, mô hình dự đoán tuyến tính (LPC) là một phần không thể thiếu của hầu hết tất cả các giải thuật mã hóa thoại hiện đại ngày nay. Ý tưởng cơ bản là một mẫu thoại có thể được xấp xỉ bằng một kết hợp tuyến tính của các mẫu trong quá khứ. Trong một khung tín hiệu, các trọng số dùng để tính toán kết hợp tuyến tính được tìm bằng cách tối thiểu hóa bình phương trung bình sai số dự đoán; các trọng số tổng hợp, hoặc các hệ số dự đoán tuyến tính được dùng đại diện cho một khung cụ thể. Mô hình MELP (dự đoán tuyến tính kích thích hỗn hợp) được thiết kế để vượt qua một số hạn chế của mô hình LPC, sử dụng một mô hình tạo tiếng nói phức tạp hơn, với các thông số bổ xung để cải thiện độ chính xác. MELP bắt đầu được phát triển bởi McCree từ năm 1995, tích hợp nhiều nghiên cứu tiến bộ vào thời điểm đó, bao gồm cả lượng tử hóa vec-tơ, tổng hợp tiếng nói và cải tiến từ mô hình LPC cơ bản.
Hiệu quả của MELP đã được chứng minh thực tế khi được NATO và Mỹ chấp nhận và sử dụng trong nhiều thiết bị quân sự. Tuy nhiên ở Việt Nam thì MELP chưa được chú ý nghiên cứu, phát triển vì tính ứng dụng hẹp: chủ yếu trong lĩnh vực quân sự. Xuất phát từ những lý do trên mà tôi đã chọn đề tài: “Thực thi thời gian thực mô hình thuật toán MELP trên bộ xử lý tín hiệu số TMS320C5509”.
2. Mục tiêu và nhiệm vụ nghiên cứu
Mục tiêu của luận văn này là triển khai trong thời gian thực thuật toán nén thoại MELP trên bộ xử lý tín hiệu số TMS320C55xx, với các nội dung như sau:
- Phân tích tổng quan về nén thoại. - Mô hình nén thoại MELP. - Phân tích, nghiên cứu bộ xử lý tín hiệu số TMS320C55X .

2
- Phân tích, xây dựng, triển khai thực thi thời gian thực mô hình MELP trên bộ xử lý tín hiệu số TMS320C5509, đề xuất cải tiến MELP và đánh giá kết quả thử nghiệm.
3. Đối tượng và phạm vi nghiên cứu
+ Đối tượng nghiên cứu
- Tìm hiểu tổng quan về nén thoại và thuật toán MELP, - Nghiên cứu bộ xử lý tín hiệu số TMS320C55xx.
+ Phạm vi nghiên cứu
- Các vấn đề về nén dữ liệu tiếng nói. - Ứng dụng thuật toán MELP trên bộ xử lý tín hiệu số TMS320C5509
4. Phương pháp nghiên cứu
+ Phương pháp nghiên cứu lý thuyết
- Nghiên cứu tài liệu, ngôn ngữ và công nghệ liên quan. - Tổng hợp các tài liệu. - Phân tích và thiết kế hệ thống.
+ Phương pháp nghiên cứu thực nghiệm
- Thiết kế và triển khai thuật toán trên chip TMS320C5509 - Đánh giá kết quả đạt được, đề xuất phương án mở rộng kết quả nghiên
cứu.
5. Kết quả dự kiến
Phân tích, thiết kế hệ thống và triển khai hoàn chỉnh thuật toán MELP trên chip TMS320C5509.
6. Ý nghĩa khoa học và thực tiễn của luận văn
+ Về mặt lý thuyết
- Tìm hiểu tổng quan về nén thoại và thuật toán MELP. - Đề xuất khả năng triển khai thuật toán MELP trên bộ xử lý tín hiệu số
+ Về mặt thực tiễn
- Ứng dụng các công cụ, ngôn ngữ hỗ trợ để triển khai, cài đặt thuật toán MELP trên bộ xử lý tín hiệu số TMS320C5509.
- Kết quả của luận văn có thể áp dụng cho ứng dụng thực tiễn, đặc biệt trong lĩnh vực quân sự.
7. Đặt tên đề tài
“THỰC THI THỜI GIAN THỰC MÔ HÌNH THUẬT TOÁN MELP TRÊN BỘ XỬ LÝ TÍN HIỆU SỐ TMS320C5509”

3
8. Bố cục luận văn
Nội dung chính của luận văn được chia thành 4 chương như sau:
Chương 1: Tổng quan về nén thoại
Chương 2: Mô hình nén thoại MELP
Chương 3: Chip xử lý tín hiệu số TMS320C55x
Chương 4: Cài đặt và thử nghiệm
Phụ Lục: Mô hình LPC và Lượng tử hóa véc-tơ nhiều lớp

4
Chương 1 - TỔNG QUAN NÉN THOẠI
[4] Nén thoại hay mã thoại, là một quá trình phân tích và sau đó có thể tái tạo lại tín hiệu tiếng nói yêu cầu: sử dụng càng ít bít càng tốt mà không làm giảm chất lượng tiếng nói. Do sự bùng nổ của viễn thông, nên nén thoại ngày càng được nghiên cứu và ứng dụng rộng rãi. Kỹ thuật vi điện tử và các bộ xử lý khả trình giá rẻ cũng góp phần thúc đẩy và trợ giúp phát triển, chuyển giao công nghệ nhanh chóng từ nghiên cứu đến thực tiễn. Nén thoại được thực hiện bằng nhiều bước và được đặc tả bằng một thuật toán.Thuật toán là một tập các lệnh, cung cấp các bước tính toán cần thiết để thực hiện công việc cụ thể. Máy tính hoặc bộ vi xử lý có thể thực hiện các lệnh này để hoàn thành nhiệm vụ mã hóa, giải mã. Các lệnh cũng có thể chuyển đổi sang cấu trúc mạch số, thực hiện các tính toán trực tiếp trên phần cứng: FPGA, CPLD…
1.1 Cấu trúc của hệ thống nén thoại
Hình 1-1: Mô hình hệ thống nén thoại
[4] Hình 1-1 thể hiện mô hình của một hệ thống nén thoại. Tín hiệu thoại tương tự liên tục theo thời gian từ nguồn phát sẽ được đi qua một bộ lọc tiêu chuẩn (khử nhiễu), lấy mẫu (biến đổi thời gian rời rạc), và chuyển đổi tương tự-số (lượng tử hóa chuẩn). Đầu ra sẽ là tín hiệu thoại thời gian rời rạc với các giá trị mẫu cũng được rời rạc hóa, tín hiệu này được gọi là thoại số.
Hầu hết các hệ thống nén thoại đều được thiết kế để hỗ trợ các ứng dụng viễn thông, với tần số giới hạn từ 300 đến 3400 Hz. Theo định lý Nyquist, tần số lấy mẫu phải gấp ít nhất là 2 lần băng thông của tín hiệu. Giá trị tần số khoảng 8kHz thường được chọn làm tần số lấy mẫu chuẩn cho tín hiệu thoại. Để chuyển

5
đổi mẫu tương tự sang tín hiệu số, ta sử dụng lượng tử hóa chuẩn và duy trì chất lượng thoại nhiều hơn 8 bits/mẫu. Việc sử dụng 16 bits/mẫu sẽ cung cấp chất lượng thoại cao hơn. Thông thường, chúng ta sẽ sử dụng các tham số cho tín hiệu thoại số như sau:
Tần số lấy mẫu: 8 kHz
Số lượng bit trên mẫu: 16
Khi đó, bit-rate = 8 * 16 = 128 kbps.
Giá trị bit-rate này được gọi là bit-rate đầu vào, chính là giá trị mà bộ mã hóa nguồn cố gắng giảm xuống. Đầu ra của mã hóa nguồn sẽ biểu diễn tín hiệu thoại số đã mã hóa có bit-rate thấp hơn đầu vào càng nhiều càng tốt.
Dữ liệu thoại số mã hóa sẽ được xử lý tiếp qua mã hóa kênh, cung cấp khả năng chống sai cho dòng bit trước khi truyền lên kênh truyền tải (bị ảnh hưởng từ rất nhiều nguồn nhiễu). Trong hình 1-1, bộ mã hóa nguồn và mã hóa kênh được tách biệt với nhau nhưng ta cũng có thể phối hợp 2 quá trình này trong một bước.
Quá trình giải mã kênh sẽ xử lý dữ liệu đã được chống sai số để lấy lại dữ liệu đã mã hóa, và truyền sang bộ giải mã nguồn để tạo ra tín hiệu thoại số đầu ra với bit-rate ban đầu. Tín hiệu thoại số đầu ra được chuyển đổi sang dạng tín hiệu tương tự thông qua bộ chuyển đổi số-tương tự.
Hình 1-2: Mô hình nén thoại
Có thể rút gọn quá trình mã hóa nguồn và giải mã nguồn như hình 1-2. Tín hiệu đầu vào (thời gian rời rạc, bit-rate 128 kbps) được đưa vào bộ mã hóa để tạo ra dòng bit đã mã hóa, hay dữ liệu thoại nén. Bit-rate của dòng bit này thường thấp hơn tín hiệu đầu vào. Bộ giải mã sẽ nhận dòng bit đã mã hóa làm đầu vào và khôi phục thành tín hiệu đầu ra, là tín hiệu thời gian rời rạc có cùng bit-rate của tín hiệu thoại đầu vào ban đầu.
Mô hình mã hóa/giải mã trên hình 1-2 được gọi là mô hình nén thoại, với tín hiệu thoại đầu vào được mã hóa tạo ra dòng bit có bit-rate thấp. Dòng bit này lại được truyền đi và làm đầu vào cho bộ giải mã, tạo thành xấp xỉ tín hiệu gốc ban đầu.
Mã hóa
Giải mã Tín hiệu vào
(128kbps) Dòng bit đã mã hóa
(<128kbps)
Tín hiệu ra
(128kbps)

6
1.2 Các thuộc tính lý tưởng của nén thoại
[4] Mục tiêu chủ yếu của nén thoại, hoặc là tối đa hóa chất lượng cảm nhận ở một bit-rate nhất đinh, hoặc là tối thiểu hóa bit-rate cho một chất lượng cảm nhận nhất định. Bit-rate phù hợp để tiếng nói có thể được truyền tải hoặc lưu trữ, sẽ phụ thuộc vào giá của việc truyền tải hoặc bộ nhớ, giá của việc mã hóa (nén) tín hiệu thoại số, và yêu cầu chất lượng thoại. Trong hầu hết các mô hình nén thoại, tín hiệu được tái tạo sẽ sai khác so với tín hiệu ban đầu. Bit-rate được giảm bằng cách biểu diễn lại tín hiệu thoại với độ chính xác cũng bị giảm và bằng cách loại bỏ các dư thừa từ tín hiệu, kết quả tạo thành một mô hình nén lossy. Các tính chất lý tưởng của một mô hình nén thoại bao gồm:
1.2.1 Bit-rate thấp
Bit-rate của dòng bit mã hóa càng thấp thì ta càng cần ít băng thông hơn cho việc truyền tải, hệ thống sẽ hiệu quả hơn. Yêu cầu này là xung đột với các tính chất tốt khác của hệ thống, như: chất lượng thoại. Trong thực tiễn, ta phải trả giá để cân bằng các tính chất tùy theo yêu cầu của ứng dụng cụ thể.
1.2.2 Chất lượng thoại cao
Tiếng nói được giải mã cần phải có chất lượng chấp nhận được cho ứng dụng mục tiêu. Có rất nhiều khía cạnh trong sự cảm nhận chất lượng tiếng nói, bao gồm tính dễ hiểu, tính tự nhiên, tính dễ gần, và nhận dạng người nói.
1.2.3 Thích ứng với ngôn ngữ
Hệ thống nén thoại cần phải được thiết kế đủ bao quát được đối với người nói khác nhau (người lớn/trẻ em, nam/nữ) và các ngôn ngữ khác nhau. Đây không phải làm một nhiệm vụ đơn giản, bởi vì mỗi tín hiệu âm thanh đều có các đặc trưng riêng.
1.2.4 Khả năng chịu đựng lỗi kênh
Điều này rất quan trọng trong truyền thông tín hiệu số, khi mà lỗi kênh có ảnh hưởng không nhỏ đến chất lượng thoại.
1.2.5 Hiệu suất cao đối với tín hiệu không tiếng (unvoiced)
Trong hệ thống viễn thông thông thường, nhiều tín hiệu khác sẽ xuất hiện bên cạnh tiếng nói. Các tín hiệu âm như sóng âm đa tần (DTMF) trong tiếng quay số, tiếng nhạc.. thường xuyên xảy ra. Cho dù các hệ thống nén thoại bit-rate cao cũng không thể tái tạo lại mọi âm thanh một cách trung thực, ta không nên tạo ra các tín hiệu thay thế có thể gây khó chịu cho người nghe.

7
1.2.6 Kích thước nhớ nhỏ và độ phức tạp tính toán thấp
Để triển khai các hệ thống nén thoại vào thực tế, giá thành cài đặt phải thấp, bao gồm bộ nhớ cần thiết và độ phức tạp tính toán phải thấp.
1.2.7 Trễ nén thấp
Trong quá trình mã hóa và giải mã tiếng nói, sẽ xuất hiện các trễ, nó là thời gian trễ giữa tiếng nói đầu vào của mã hóa với tiếng nói đầu ra của giải mã. Mức trễ quá cao sẽ khó được chấp nhận trong hệ thống đàm thoại thời gian thực.
1.3 Trễ nén
Hình 1-3: Mô hình xác định trễ
[4] Trễ có được theo mô hình xác định trên gọi là trễ nén, hoặc trễ nén một chiều, nó được tính bởi thời gian tiêu hao từ thời điểm khi một mẫu tiếng nói ở đầu vào mã hóa cho đến thời điểm mẫu đó xuất hiện ở đầu ra giải mã. Cách xác định này không tính tới các yếu tố khác mà thuật toán nén thoại không kiểm soát được như khoảng cách truyền thông hoặc trang thiết bị… Dựa vào định nghĩa này, trễ nén sẽ có 4 thành phần chủ yếu sau:
1.3.1 Trễ bộ đệm mã hóa
Nhiều bộ mã hóa tiếng nói cần phải thu thập một số lượng mẫu nhất định trước khi xử lý. Chẳng hạn, các mô hình nén dựa trên dự đoán tuyến tính LP đều cần 1 khung mẫu có phạm vi từ 160 đến 240 mẫu, hoặc 20 đến 30 ms, trước khi xử lý quá trình mã hóa thực sự.
1.3.2 Trễ xử lý mã hóa
Quá trình mã hóa tiêu tốn khá nhiều thời gian để xử lý dữ liệu trong bộ đệm và xây dựng dòng bit. Trễ này có thể được giảm bớt bằng cách tăng cường sức mạnh tính toán của phần cứng và sử dụng các thuật toán phần mềm hiệu quả. Trễ xử lý cần phải nhỏ hơn trễ bộ đệm, nếu không quá trình mã hóa sẽ không theo kịp với dữ liệu đưa vào ở khung kế tiếp.
Mã hóa Giải mã Tín hiệu vào
Dòng bit
Trễ Đo thời gian
Tiếng nói tổng hợp

8
Hình 1-4: Mô tả các thành phần của trễ nén
1.3.3 Trễ truyền tải
Khi bộ mã hóa hoàn thành công việc xử lý một khung dữ liệu đầu vào, dòng bít đã được nén sẽ được truyền tới bộ giải mã. Có rất nhiều chế độ truyền khác nhau và có thể được lựa chọn tùy theo yêu cầu của từng hệ thống. Ở đây, ta chỉ xem xét hai chế độ truyền: liên tục và theo gói.
Hình 1-5: Đồ thị mẫu truyền bit ở hai chế độ liên tục (trên) và gói (dưới)
Trong chế độ liên tục, dòng bit sẽ được truyền đồng bộ ở một tốc độ cố định, là số bit tương ứng trên một khung chia cho độ dài của khung. Ở chế độ này, trễ đường truyền bằng với trễ bộ đệm mã hóa: các bit của khung sẽ được truyền đầy đủ và ngay khi các bit của khung tiếp theo dồn đến. Chế độ này chủ yếu được dùng cho các hệ thống giao tiếp số truyền thống, ví dụ như mạng điện thoại hữu tuyến.
Khung đầu vào
bộ đệm
Mã hóa
Truyền
tải bit
Giải mã
Khung
đầu ra
Trễ mã hóa
Thời gian Trễ bộ đệm
mã hóa Trễ xử lý mã
hóa
Trễ truyền tải / Trễ bộ đệm
giải mã
Trễ xử lý
giải mã
Thời gian
Trễ bộ đệm mã hóa
Thời gian
Số lượng bit

9
Trong chế độ theo gói, mọi bit liên quan đến một khung nào đó sẽ được truyền hoàn toàn trong một khoảng thời gian ngắn hơn trễ bộ đệm mã hóa. Trong trường hợp này, mọi bit sẽ được đưa đi ngay sau khi chúng sẵn sàng, dẫn đến một chút trễ truyền tải không đáng kể. Chế độ này được sử dụng trong mạng internet, nơi mà dữ liệu được nhóm lại và truyền đi thành các gói.
Trễ truyền tải còn được gọi là trễ bộ đệm giải mã, bởi vì nó chính là lượng thời gian mà bộ giải mã phải chờ đợi để thu thập toàn bộ các bit liên quan đến một khung để bắt đầu quá trình giải mã.
1.3.4 Trễ xử lý giải mã
Đây là khoảng thời gian cần thiết để giải mã, tạo ra tiếng nói tổng hợp. Cũng giống như trường hợp trễ xử lý mã hóa, nó cũng phải nhỏ hơn trễ bộ đệm mã hóa vì toàn bộ một khung dữ liệu tiếng nói tổng hợp phải hoàn thành trong khung thời gian này, sẵn sàng cho khung tiếp theo.
Nói chung, trễ bộ đệm mã hóa đóng vai trò quan trọng nhất, nó ảnh hưởng đến cả 3 thành phần trễ còn lại. Bộ đệm mã hóa càng dài thì hiệu quả mã hóa càng cao và bit-rate sẽ thấp hơn. Do đó, hầu hết các mô hình mã hóa có bit-rate thấp thì thường có trễ cao. Trễ nén là trường hợp trả giá thường xuyên nhất để có được bit-rate tốt.
1.4 Ứng dụng của các mô hình nén thoại
[4] Nén thoại đóng một vai trò quan trọng trong kỹ thuật âm thanh hiện đại, đặc biệt cho truyền thông thoại số, nơi mà chất lượng và độ phức tạp ảnh hưởng trực tiếp đến giá thành và khả năng chiếm lĩnh thị trường của các sản phẩm, dịch vụ. Có rất nhiều tiêu chuẩn nén thoại được thiết kế đối với một ứng dụng nén thoại cụ thể, ví dụ:
- FS1015 LPC: mô hình này được tạo ra từ năm 1984 để cung cấp truyền thông bảo mật cho các ứng dụng quân sự. - TIA IS54 VSELP: mô hình này được tiêu chuẩn hóa từ năm 1989 cho hệ thống điện thoại di động số TDMA ở Bắc Mỹ. - ETSI AMR ACELP: mô hình này được chuẩn hóa năm 1999, là một phần của hệ thống viễn thông di động toàn cầu (UMTS) liên kết với 3GPP.
Những năm gần đây, cùng với sự bùng nổ của internet, rất nhiều công ty tập trung phát triển các ứng dụng dựa vào VoIP. Nén thoại cũng đóng vai trò trung tâm trong cuộc cách mạng này.

10
Chương 2 - MÔ HÌNH NÉN THOẠI MELP
[4] Mô hình MELP được thiết kế để khắc phục một số hạn chế của mô hình LPC (xem phụ lục). MELP sử dụng một mô hình tạo tiếng nói phức tạp hơn, với các thông số tăng cường để cải thiện độ chính xác. Việc này đòi hỏi thêm chi phí tính toán, nhưng thực tế chỉ cần sử dụng một bộ xử lý tín hiệu số DSP là đủ.
MELP bắt đầu được phát triển bởi McCree từ năm 1995, tích hợp nhiều nghiên cứu tiến bộvào thời điểm đó, bao gồm cả lượng tử hóa vec-tơ, tổng hợp tiếng nói và cải tiến từ mô hình LPC cơ bản. Trong chương này, luận văn sẽ mô tả mô hình tạo tiếng nói mà MELP dựa vào và so sánh với LPC, đồng thời phân tích một số kỹ thuật xử lý và hoạt động mã hóa và giải mã của mô hình MELP.
2.1 Mô hình tạo tiếng nói MELP
[4] Sơ đồ khối của mô hình tạo tiếng nói MELP được thể hiện trong hình dưới đây, đây là một cải tiến từ mô hình LPC đã có. Tuy mô hình MELP phức tạp hơn LPC nhưng cả hai cùng có một số điểm tương đồng: đều dựa trên một bộ lọc tổng hợp để xử lý tín hiệu kích thích nhằm tạo ra tiếng nói tổng hợp. MELP sử dụng kỹ thuật nội suy phức tạp để tạo ra các chuyển đổi liên khung.
Hình 2-1: Mô hình tạo tiếng nói
Những cải tiến chính của mô hình MELP so với mô hình LPC:
+ Sử dụng period jitter ngẫu nhiên để làm thay đổi giá trị của pitch period nhằm tạo ra một chuỗi xung không tuần hoàn.
Hạn chế cơ bản trong LPC là việc phân loại của một khung tiếng nói thành hai loại: không âm (unvoiced) và có âm (voiced). Mô hình MELP phân
Bộ tạo chuỗi xung
Lọc tạo
xung Lọc tạo
hình xung
Tạo nhiễu trắng
Lọc tạo hình nhiễu
Lọc tổng hợp
Đáp ứng xung
Hệ số lọc
Gain
Tiếng
nói voice strength
Kích thích tuần hoàn
Pitch
Period

11
thành ba loại: không âm, có âm, và âm jitter (jitter voiced). Trạng thái thứ ba này tương ứng với trường hợp khi các kích thích là không tuần hoàn nhưng không hoàn toàn ngẫu nhiên, mà thường gặp phải trong quá trình chuyển đổi âm thanh từ voiced sang unvoiced và ngược lại. Trạng thái này trong mô hình MELP được kiểm soát bởi tham số kích thích âm sắc và chủ yếu là một số ngẫu nhiên. Qua thực nghiệm, người ta thấy rằng một kích thích tuần hoàn phân bố đều lên đến ±25% của âm sắc sẽ cho các kết quả tốt.
+Hình dạng của xung kích thích dùng cho kích thích tuần hoàn được chiết xuất từ tín hiệu đầu vào và là một phần thông tin được đóng gói trong khung truyền.
Trong hình thức đơn giản nhất của LPC, kích thích âm bao gồm một chuỗi các xung kích thích. Mỗi kích thích xung có một hình dạng nhất định. Hình dạng của xung chứa các thông tin quan trọng và được phân tích bởi bộ mã hóa MELP thông qua giá trị Fourier manitudes .
+Kích thích tuần hoàn và kích thích nhiễu trước hết được lọc bằng cách sử dụng
bộ lọc hình dạng xung và bộ lọc hình dạng nhiễu tương ứng; sau đó đầu ra của chúng được cộng vào nhau tạo thành kích thích tổng được gọi là kích thích hỗn hợp.
Đây chính là ý tưởng cốt lõi của mô hình MELP và dựa trên những quan sát thực tế mà chuỗi các sai số dự đoán là sự kết hợp của một chuỗi xung với nhiễu. Như vậy, mô hình MELP là thực tế hơn nhiều so với mô hình LPC.
Trong hình vẽ 2-1, các đáp ứng tần số của bộ lọc định hình được điều khiển bởi tập hợp các tham số gọi là voice strength. Đáp ứng của các bộ lọc này thay đổi theo thời gian, với các tham số được ước lượng từ các tín hiệu âm đầu vào, và được truyền dưới dạng thông tin theo khung.
2.2 Biên độ Fourier (Fourier Manitudes)
[4] Mô hình MELP phụ thuộc vào tính toán các biên độ Fourier từ tín hiệu sai số dự đoán để bắt hình dạng của xung kích thích. Fourier magnitudes là độ lớn của biến đổi Fourier tín hiệu đầu vào. Tham số này được lượng tử hóa và truyền như thông tin trên các khung. Mục tiêu là tạo ra ở phía giải mã một chuỗi tuần hoàn càng gần tín hiệu kích thích ban đầu càng tốt. Ta chỉ tính Fourier manitudes cho khung voiced hoặc jitter voiced.
2.2.1 Bộ lọc tạo xung
Mô hình MELP dựa vào bộ lọc tạo xung để tạo ra các kích thích tuần hoàn. Xung kích thích với chu kỳ thời gian T qua bộ lọc tạo xung tạo ra một chuỗi xung ở đầu ra. Kết hợp với độ lớn của biến đổi Fourier (là phổ của chuỗi

12
xung được được tính bằng tích giữa phổ của chuỗi xung và độ lớn đáp ứng của các bộ lọc) ta có thể tính được độ lớn đáp ứng của bộ lọc tạo hình xung. Hình 2-2 mô tả quá trình tạo xung, việc đo độ cao được thực hiện ở các giá trị tần số ω = 2πi/T, i=1,2,.. khi tìm được đáp ứng độ lớn, thì ta cũng biết được đáp ứng xung của bộ lọc tạo xung và định hình được xung.
Hình 2-2: Mô phỏng xử lý tín hiệu với bộ lọc tạo xung
Trong quá trình mã hóa, ta đo được đỉnh của phổ độ lớn tương ứng với tần số âm sắc. Các giá trị này là Fourier manitudes được truyền tới các bộ giải mã để xây dựng các xung kích thích và đáp ứng xung của bộ lọc xung.
2.2.2 Biên độ Fourier (Fourier magnitudes): tính toán và lượng tử hóa
Hình 2-3: Mô hình tính toán và lượng tử hóa biên độ Fourier
Lọc tạo
xung
Chuỗi
xung
Đáp ứng xung
Chuỗi
xung
Miền thời gian
Miền
tần số
Lọc sai số dự đoán
Cửa sổ
Bổ sung mẫu zero
Mã hóa
VQ
Chuẩn
hóa
Tìm kiếm
đỉnh độ lớn
LPC
Tiếng nói
FFT
Chỉ
số
Pitch period

13
Đầu vào để tính toán Fourier manitudes là dữ liệu tiếng nói (khoảng 200 mẫu), tham số LPC và pitch period. LPC và pitch period đã được trích xuất từ tín hiệu trước đó. Sai số dự đoán sẽ được tính toán trước bằng cách truyền dữ liệu tiếng nói thông qua các bộ lọc sai số dự đoán. Cửa sổ Hamming nhân 200 mẫu chuỗi sai số dự đoán. Chuỗi 200 mẫu kết quả sẽ được bổ sung các mẫu 0 để tạo thành 512 mẫu, sau đó qua tính toán FFT tạo thành 512 mẫu phức.
FFT là triển khai nhanh của DFT, với DFT được xác định qua phương trình giải tích:
∑ / ; 0,1, . . 1 [2.1]
∑ / ; 0,1, . . 1 [2.2]
X[k] và x[n] tạo thành cặp biến đổi DFT, và N=512 là độ lớn của chuỗi. Việc thêm các mẫu 0 vào bộ 200 mẫu để có 512 mẫu nhằm tăng tốc độ tính toán. Giá trị 512 được lựa chọn là sự cân bằng giữa tần số và giá trị tính toán, và thường là bội số của 2. Do tín hiệu sai số dự đoán là giá trị thực, chuỗi DFT kết quả là đối xứng và chỉ có một nửa số mẫu là cần phải tính toán; do đó chỉ có 256 mẫu được đưa tới khối tính toán tiếp theo. Tính toán để tìm kiếm đỉnh độ lớn trong hình 2-3 (với pitch period T đã biết) sẽ được tổng kết như sau:
MAG_PEAKS_SEARCH(X[0 . . . 255], T, Fmag[1 . . . 10]) 1. fori = 1 to 10 2. freq = round(512 * i/T) 3. if freq > 255 4. Fmag[i] = SMALLEST_MAG 5. else 6. peak = 0 7. for j = freq - 5 to freq + 5 8. if j > 255 break 9. if abs( X[j] )> peak 10. peak = abs( X[j] ) 11. Fmag[i] = peak 12. return Fmag[1 . . . 10]
Mục đích của đoạn mã chương trình này là tìm kiếm lân cận quanh giá trị tần số 512i/T với i=1..10. Các giá trị này tương ứng với 10 giá trị hài đầu tiên ứng với tần số âm sắc. Nếu giá trị tần số là trên 255, thì hài đã vượt ra khỏi phạm vi ước lượng. Trường hợp thứ hai xảy ra khi tần số âm quá cao. Nếu các giá trị tần số nhỏ hơn hoặc bằng 255,việc tìm kiếm các đỉnh được thực hiện trong vòng phạm vi (512i/T)±5; phạm vi này có thể được điều chỉnh cho phù hợp tùy thuộc vào độ chính xác mong muốn. Kết thúc quá trình tìm kiếm, ta có

14
được 10 giá trị độ lớn mong muốn. Như vậy, Fourier magnitudes là những đỉnh giá trị độ lớn của 10 hài lân cận tần số pitch.
Chuỗi biên độ Fourier Fmag[i] được chuẩn hóa theo công thức:
. [2.3]
∑ / [2.4]
2.2.3 Quá trình tạo kích thích xung
Hình 2-4: Quá trình tạo kích thích xung
Trong quá trình giải mã, tín hiệu kích thích sẽ được tổng hợp trên cơ sở từng pitch period, nếu T là pitch period thì sẽ tạo ra T mẫu xung. Giả sử các biên độ Fourier đã được giải mã, chúng sẽ được nội suy trong quá trình giải mã MELP, chuỗi kết quả được ký hiệu là Fmag[i].
PULSE_GENERATION(Fmag[1 .. 10], T, y[0 .. T-1]) 1. Y[0] = 0 2. for k = 11 to T – 11 3. Y[k] = 1 4. for k = 1 to 10 // Mở rộng đối xứng 5. Y[k] = Fmag[k] 6. Y[T-k] = Fmag[k] 7. IDFT(Y[0 .. T-1], y[0 .. T-1], T) 8. CIRCULAR_SHIFT(y[0 .. T-1], T, 10) 9. NORMALIZE(y[0 .. T-1], T) 10. return y[0 ..T-1]
Thủ tục này nhận 10 giá trị biên độ Fourier và Pitch period làm đầu vào để tạo ra mảng T-mẫu Y bằng cách đặt Y[0]=0 còn các giá trị khác là 1. Mảng Y được sử dụng cho biến đổi Fourier ngược IDFT, biểu diễn thông tin trong miền tần số. Ở dòng 4, chúng ta tiến hành mở rộng đối xứng để tính chuỗi đối xứng, việc mở rộng này là cần thiết để tạo ra chuỗi các giá trị thực sau khi thực hiện IDFT. Ở dòng 7, IDFT được tính theo công thức:
Giải mã
VQ
Mở rộng
Mở rộng
đối xứng
Chuẩn
hóa
Dịch vòng
Pitch period
Chỉ số
IDFT
Xung

15
∑ / ; 0,1, . . , 1 [2.5]
Ở dòng 8, chuỗi kết quả y[n] được dịch vòng theo 10 mẫu và được chuẩn hóa ở dòng 9. Hoạt động dịch vòng được thực hiện như sau:
CIRCULAR_SHIFT(y, T, n) 1. for i = 0 to T - 1 2. x[i] = y[MOD(i-n, T)] 3. for i = 0 to T - 1 4. y[i] = x[i] 5. return y[0 . . . T _ 1]
Hàm tính modulo MOD(n, N) được xác định như sau:
MOD(n, N) 1. if n < 0 2. n = n + N 3. if n < 0 goto 2 4. else 5. n = n - N 6. if n>= N goto 5 7. return n
Mục đích của việc dịch vòng là tránh các thay đổi đột ngột khi bắt đầu chu kì.
2.3 Bộ lọc định hình
[4] Mô hình MELP sử dụng hai bộ lọc tạo hình (hình 2-1) để trộn kích thích xung với kích thích nhiễu nhằm tạo nên tín hiệu kích thích hỗn hợp. Phản hồi của các bộ lọc này được điều khiển bởi tập hợp các tham số gọi là voice strength, các tham số này được ước lượng từ tín hiệu đầu vào. Các bộ lọc này quyết định số lượng xung và số lượng nhiễu trong pha kích thích ở các tần số khác nhau.
Trong FS MELP, mỗi bộ lọc định hình được cấu thành từ 5 bộ lọc, gọi là bộ lọc tổng hợp vì chúng được sử dụng để tổng hợp tín hiệu kích thích hỗn hợp trong suốt quá trình giải mã. Mỗi bộ lọc tổng hợp điều khiển một dải tần số nhất định, với băng thông trong khoảng 0-500, 500-1000, 1000-2000, 2000-3000, 3000-4000 Hz. Các bộ lọc tổng hợp này được kết nối song song để xác định các đáp ứng tần số của bộ lọc định hình.
Ký hiệu đáp ứng xung của lọc tổng hợp là hi[n], với i=1..5, đáp ứng tổng của lọc định hình xung là:

16
5
1
p i ii
h n vs h n
[2.6]
Với 0 1ivs là voice strength. Bộ lọc tạo hình nhiễu thì có đáp ứng:
[2.7]
Hình 2-5: Sơ đồ bộ lọc tạo hình xung
Bộ lọc tổng hợp được cài đặt như FIR với 31 cổng. Bộ lọc FIR được sử dụng bởi các lý do sau:
- Pha tuyến tính: hệ thống pha tuyến tính chỉ đơn giản là trễ nhóm là hằng số với tần số, đó là một đặc tính của hệ thống FIR. Một trễ nhóm hằng số đối với tất cả các giá trị tần số sẽ không bóp méo hình dạng của một xung đi qua hệ thống, vì tất cả các thành phần được giữ trễ bởi cùng một lượng,việc này rất quan trọng trong việc xử lý một chuỗi kích thích xung.
- Đáp ứng tần số có thể thay đổi dễ dàng: Đáp ứng tổng của bộ lọc có thể đạt được thông qua các bước nhân và cộng, những bước này có thể được thực hiện trong thực tế với chi phí tương đối thấp. Thực tế, kết hợp các đáp ứng xung tổng hợp lại với nhau, ta chỉ cần tính toán đầu ra cho 1 đáp ứng thay vì làm năm lần.
5
1
[ ] 1 [ ]n i ii
h n vs h n
Lọc tổng hợp 1
vs1
Lọc tổng hợp 2
vs2
Lọc tổng hợp 5
vs5

17
- Nội suy có thể được thực hiện tương đối dễ dàng: Để đảm bảo thông suốt trong quá trình chuyển đổi giữa các khung, các đáp ứng xung của bộ lọc tạo hình sẽ được nội suy trong quá trình giải mã MELP. Bản chất của bộ lọc FIR cho phép nội suy tuyến tính các đáp ứng xung, hay các hệ số bộ lọc,với sự ổn định được đảm bảo.
2.4 Pitch period và ước lượng voice strength
[4] Mô hình MELP sử dụng một thủ tục phức tạp để ước lượng chính xác pitch period và voice strength, các tham số này đóng vai trò quan trọng trong chất lượng của tiếng nói tổng hợp. Trong thực tế, lọc phân đoạn được sử dụng trong suốt quá trình mã hóa. Một ngân hàng bộ lọc phân tích được sử dụng để tách tín hiệu đầu vào thành năm dải tần, để tìm ra voice strength trong mỗi băng tần. Các hoạt động được mô tả trong phần này chỉ được thực hiện trong quá trình mã hóa, khi các tín hiệu tiếng nói được phân tích với các thông số cần trích xuất.
2.4.1 Bộ lọc phân tích
Năm bộ lọc phân tích có cùng thiết lập băng thông cũng giống như bộ lọc tổng hợp. Khác với bộ lọc tổng hợp thảo luận ở trước, các bộ lọc này được thực hiện như Butterworth bậc 6, đó chính là IIR. Thiết kế này được chủ yếu dựa trên chi phí tính toán tương đối thấp kết hợp với cấu hình IIR. Chẳng hạn, Butterworth bậc 6 cần 12 bước nhân trên mỗi mẫu đầu ra, trong khi đó, bộ lọc FIR 31-cổng cần tới 31 phép nhân. Tính phi tuyến trong đáp ứng pha (một đặc trưng điển hình của hệ thống IIR) cũng khá là quan trọng vì được sử dụng cho tính toán tương quan.
2.4.2 Vị trí cửa sổ
Trước khi ước lượng chu kỳ âm sắc, ta cần xác định vị trí của một số cửa sổ xử lý tín hiệu đối với các khung tín hiệu. Hình 2-6 tóm tắt các cửa sổ lớn sử dụng bởi mã hóa MELP. Giống như LPC, mỗi khung bao gồm 180 mẫu. Các vị trí của các cửa sổ phân tích được lựa chọn để nội suy,vì các tham số của một khung cho trước sẽ được nội suy giữa hai tập hợp khác nhau, được tính toán từ cửa sổ phân tích sẽ nằm giữa mẫu bắt đầu và mẫu kết thúc của khung.

18
Hình 2-6: Vị trí của các cửa sổ khác nhau tương ứng với khung tín hiệu
Một số cửa sổ có thể chồng lấn lên nhau. Đối với hầu hết các tham số, cửa sổ phân tích tương ứng với khung hiện thời thì nằm giữa mẫu cuối cùng của khung hiện tại.
2.4.3 Ước lượng Pitch period bước 1.
Tín hiệu tiếng nói đầu vào được lọc qua bộ lọc phân tích thứ nhất, với băng tần từ 0 tới 500Hz. Đối với mỗi khung 180-mẫu ta tính toán tự tương quan chuẩn hóa với l= 40,41,..,160 (tương ứng với tần số từ 50 đến 200 Hz).
[0, , ]
[ ][0,0, ] [ , , ]
c l lr l
c l c l l l [2.8]
Với
/2 79
/2 80
[ , , ] [ ] [ ]k
n k
c l m k s n l s n m
. [2.9]
Kết quả phần nguyên của pitch period chính là giá trị T = l với r[l] đạt cực đại. Phương trình chuẩn hóa này được sử dụng cho tất cả các khung (trừ khung có năng lượng thấp).
Quá khứ Hiện tại Tương lai
Gain
đỉnh
Biên độ Fourier
Sai số dự đoán
Ước lượng Pitch
period
Khung tín hiệu
180

19
Hình 2-7: Mô phỏng ước lượng Pitch period bước 1
Phương trình tính tương quan [2.8] ở trên sử dụng 160 phép nhân. Đối với mỗi hoạt động ước lượng Pitch period phải sử dụng 320 mẫu liên tiếp của tín hiệu. 320 mẫu liên tiếp này tạo thành cửa sổ ước lượng pitch period. Cửa sổ này dựa trên 160 mẫu của khung hiện tại, cộng với 160 mẫu của khung kế tiếp. Các mẫu s[0] trong phương trình [2.9] tương ứng với các mẫu đầu tiên của khung kế tiếp. Ký hiệu T là giá trị nguyên của Pitch period, tiếp tục các bước thực hiện như sau:
+ Giá trị tương quan c[0,T+1,T] và c[0,T-1,T] được tính toán. Nếu c[0,T-1,T] > c[0,T+1,T], thì T = T-1; ngược lại thì chuyển sang bước tiếp theo. Mục đích của bước này là để kiểm tra khả năng điểm tương quan tối đa nằm ở vị trí [T,T+1] hay [T-1,T] thông qua việc so sánh giá trị tương quan ở độ trễ của T-1 và T+1.
+ Tính toán giá trị thập phân của Pitch period:
[0, 1, ] [ , , ] [0, , ] [ , 1, ]
[0, 1, ]( [ , , ] [ , 1, ]) [0, , ]( [ 1, 1, ] [ , 1, ])
c T T c T T T c T T c T T T
c T T c T T T c T T T c T T c T T T c T T T
[2.10]
+ Tính toán giá trị tương quán chuẩn hóa
2 2
(1 ) [0, , ] [0, 1, ][ ]
[0,0, ] (1 ) [ , , ] 2 (1 ) [ , 1, ] [ 1, 1, ]
c T T c T Tr T
c T c T T T c T T T c T T T
[2.11]
Giá trị Pitch period thực được ký hiệu là (1)T T , gọi là Pitch period
bước 1 (hình 2-7).
Tiếng nói đầu vào
Bộ lọc phân
tích thứ 1
Ước lượng Pitch
period
Quyết định cờ
Aperiodic af
vs1(1)
T(1)
r[T(1)]

20
2.4.4 Voice strength tần thấp
Voice strength ở dải tần thấp (0-500Hz, vs1 ) bằng giá trị tự tương quan chuẩn hóa theo T(1) tính theo công thức [2.11], tức là:
(1)1 [ ]vs r T [2.12]
2.4.5 Cờ không tuần hoàn (Aperiodic)
Giá trị cờ không tuần hoàn af phụ thuộc vào voice strength tần thấp:
11, 0.5
0,
vsaf
nÕu
ng−îc l¹i [2.13]
Đối với voice strength cao (> 0.5), khung là tuần hoàn mạnh và cờ được thiết lập về 0. Đối với tuần hoàn yếu, cờ được thiết lập là 1, báo hiệu cho các bộ giải mã MELP để tạo ra các xung kích thích không tuần hoàn. Cờ được truyền như một phần của khung MELP.
2.4.6 Ước lượng voice strength cho 4 dải tần cao
Hình 2-8: Mô phỏng ước lượng voice strength băng thông
Hình 2-8 cho thấy hệ thống sử dụng để ước lượng voice strength cho 4 dải băng tần còn lại, bao gồm các bước như sau:
+ Tính toán (1)1 [T ]r r , với r[.] là tự tương quan chuẩn hóa tính toán ở
công thức [2.11], và T(1) là Pitch period thực bước 1. Tín hiệu được sử dụng để tính toán tự tương quan chính là đầu ra từ bộ lọc băng tần tương ứng.
+ Tính toán (1)2 [T ]r r . Ở thời điểm này, tín hiệu được sử dụng chính là
đường bao của tín hiệu băng tần, đường bao có được bằng cách tinh chỉnh (giá trị tuyệt đối của các mẫu), sau đó là lọc thông thấp.
Tiếng nói đầu
vào
Bộ lọc phân tích
thứ 2,3,4,5
Trích xuất đường
bao
Tự tương quan
vs2,3,4,5
Pitch period T(1)
Bộ so sánh
Tự tương quan

21
+ voice strength của dải tần được tính theo công thức:
1 2m a x ( , )v s r r [2.14]
Lặp đi lặp lại quá trình này cho bốn bộ lọc còn lại để tìm ra các giá trị voice strength vs2, vs3, vs4, và vs5. Như vậy, voice strength được tính thông qua so sánh các giá trị tự tương quan có được trực tiếp từ tín hiệu băng thông và từ đường bao của bản thân tín hiệu, tìm lấy giá trị cao hơn.
2.4.7 Phân tích LP và sai số dự đoán
Phân tích LP bậc 10 được thực hiện đối với tín hiệu tiếng nói đầu vào sử dụng cửa sổ Hamming 200-mẫu (25-ms). Phương pháp tự tương quan được sử dụng cùng với thuật toán Levinson-Durbin (xem phụ lục). Các hệ số kết quả thì được mở rộng băng thông với hằng số 0.994, chúng được lượng tử hóa và được dùng để tính toán tín hiệu sai số dự đoán.
2.4.8 Xác định Peakness
Peakness của tín hiệu sai số dự đoán được tính toán thông qua cửa sổ 160-mẫu đặt giữa mẫu cuối của khung hiện tại. Giá trị Peakness được tính bởi công thức:
79 2
80
79
80
1[n]
1601
[n]160
n
n
ep
e
[2.15]
và được đo theo mức đỉnh của tín hiệu. Mức đỉnh ở đây chính là những mẫu có biên độ tương đối cao so với trung bình biên độ của các mẫu.
Trong ví dụ ở hình 2-9, hình trên bên trái là xung p =13.4, trên bên phải là một số xung bất thường p=7.3, dưới bên trái là sóng dạng sin p =1.1, dưới bên phải là nhiễu trắng p = 1.2. Nhiễu trắng có các đỉnh thấp bởi vì thực tế thì không có đỉnh nào xuất hiện ở đạng tín hiệu này.

22
Hình 2-9: Một số tín hiệu và giá trị đỉnh của nó
Hình 2-10: Đỉnh của chuỗi xung không gian đồng nhất
Trong hình 2-10 hiển thị giá trị các đỉnh của một chuỗi xung tuần hoàn có một chu kì cụ thể. Các đỉnh sẽ tăng dần đều theo chu kì khi đỉnh của sai số dự đoán được tính, thì giá trị đo đạc sẽ là cao hơn cho các khung có tiếng. Đặc biệt, giá trị của nó có thể được cực đại hóa khi số lượng các xung trong khung trở nên

23
thưa thớt (khung jitter voiced). Như thế, việc đo đạc các đỉnh sẽ rất hữu ích trong việc phân loại khung là có tiếng hay không tiếng, cũng như trong việc phát hiện các khung chuyển đổi.
Hình 2-11: Sai số dự đoán có được từ một sóng âm (bên trái) và đo đạc đỉnh
áp dụng cho sai số dự đoán (bên phải)
Hình 2-11 cho thấy một ví dụ về phép xác định đỉnh trong trường hợp tín hiệu sai số dự đoán thực tiễn. Ta thấy rằng đỉnh cao hơn nhiều đối với n ở giữa 1000 và 2000, ở đó tín hiệu là có tiếng. Đỉnh đặc biệt cao đối với khung có n=1000 chủ yếu do sự chuyển đổi tự nhiên, khi một số xung kích thích xuất hiện bất thường trong khung.
2.4.9 Peakness và voice strength
Theo giá trị của đỉnh, voice strength của ba dải tần thấp nhất sẽ được điều chỉnh như sau:
+ Nếu p > 1.34 thì vs1 = 1
+ Nếu p > 1.60 thì vs2 = 1 và vs3 = 1
Khi đỉnh là cao, nó sẽ ghi đè lên voice strength bằng cách đặt nó trực tiếp bằng giá trị cao. Mỗi voice strength sẽ được lượng tử hóa về 0 hoặc 1, khi truyền đi sử dụng 1 bit.
Sự kết hợp giữa đỉnh và phép đo tự tương quan có hiệu quả cao trong việc phân loại trạng thái âm. Thông thường, các khung không âm sẽ có đỉnh và tự tương quan thấp, dẫn đến voice strength là yếu. Đối với khung chuyển tiếp thì sẽ có đỉnh là cao và tự tương quan ở mức trung bình.Với những khung này, tương quan tương đối thấp sẽ đặt cờ không tuần hoàn bằng 1, khiến cho bộ giải mã sinh ra các chu kì ngẫu nhiên. Đối với khung có âm, đỉnh là trung bình với tương quan cao; điều này sẽ đưa giá trị cờ không tuần hoàn về 0: voice strength cao. Mô hình MELP dựa trên cờ không tuần hoàn aperiodic kết hợp với voice strength để quản lý thông tin trạng thái âm thanh.

24
2.4.10 Ước lượng chu kỳ âm sắc cuối cùng
Tín hiệu sai số dự đoán được lọc qua bộ lọc thông thấp với ngưỡng 1kHz, đầu ra được sử dụng để ước lượng pitch period. Kết quả thu được bằng cách tìm kiếm trong một phạm vi xung quanh giá trị pitch period bước 1 T(1). Ước lượng lại pitch period sử dụng sai số dự đoán sẽ có được kết quả chính xác hơn, do cấu trúc đỉnh cộng của tín hiệu tiếng nói gốc đã được loại bỏ.
2.5 Hoạt động mã hóa
Hình 2-12: Mô hình mã hóa MELP
2.5.1 Mã hóa voice strength băng thông
Voice strength của bốn dải tần cao được lượng tử hóa theo thủ tục mã giả sau:
QUANTIZE_VS(vs1, …, vs5) 1. if vs1<= 0.6 // không tiếng 2. for i = 2 to 5 3. qvsi= 0 4. else // có tiếng 5. for i = 2 to 5 6. if vsi > 0.6 7. qvsi= 1 8. else 9. qvsi= 0 10. if qvs2== 0 and vs3== 0 and qvs4== 0

25
11. qvs5= 0 12. return qvs2,.., qvs5
Thủ tục này có đầu vào là voice strength của 5 dải tần. Đối với trường hợp không phải tiếng nói, dựa vào biên độ vs1<= 0.6 , giá trị voice strength lượng tử hóa qvsi của bốn dải tần cao sẽ được đặt là 0. Ngược lại, chúng sẽ được lượng tử hóa là 0 hoặc 1 tùy theo biên độ là nhỏ hơn hay lớn hơn 0.6. Trường hợp (qvs2, qvs3, qvs4, qvs5 ) = (0,0,0,1) sẽ hoàn toàn bị loại ở dòng lệnh 10 và 11.
2.5.2 Lượng tử hóa pitch period và voice strength tần thấp
Pitch period T và voice strength thấp tần vs1 được lượng tử hóa cùng nhau sử dụng 7 bit. Nếu vs1<= 0.6, khung là không tiếng và một mã toàn giá trị 0 sẽ được gửi đi. Ngược lại, logT sẽ được lượng tử hóa với bộ lượng tử đồng nhất 99 cấp có phạm vi từ log20 tới log160. Giá trị vs1 đã lượng tử hóa được ký hiệu là qvs1, nó sẽ nhận giá trị 0 đối với trạng thái không tiếng và 1 đối với trạng thái có tiếng.
2.5.3 Tính toán gain
Gain được đo hai lần trên một khung sử dụng kích thước cửa sổ thích nghi âm sắc. Kích thước này được xác định như sau:
+ Nếu vs1> 0.6, kích thước cửa sổ là bội nhỏ nhất của T(1), thường lớn hơn 120 mẫu. Nếu kích thước này vượt quá 320 mẫu, nó sẽ được chia cho 2. Trường hợp này tương ứng với các khung tiếng nói, khi sự đồng bộ âm sắc được tìm trong suốt quá trình tính toán gain. Bằng cách sử dụng một bội nguyên của pitch period, sự biến thiên của gain tương ứng với vị trí của cửa sổ sẽ được giảm thiểu.
+ Nếu vs1<= 0.6, kích thước cửa sổ là 120 mẫu. Đây là trường hợp khung không tiếng hoặc khung tiếng chập chờn.
Tính toán gain cho cửa sổ đầu tiên sẽ tạo ra giá trị g1 và được tập trung vào 90 mẫu trước mẫu cuối cùng ở khung hiện tại. Tính toán gain cho cửa sổ thứ hai sẽ tạo ra g2 và được tập trung vào mẫu cuối cùng ở khung hiện tại. Phương trình tính giá trị gain là:
210
110log 0.01 [ ]
n
g s nN
[2.16]
Trong đó, N là kích thước cửa sổ, s[n] là tín hiệu tiếng nói đầu vào. Phạm vi của n phụ thuộc vào kích thước cửa sổ và từng giá trị gain cụ thể (g1 hoặc g2). Phần

26
tử 0.01 sẽ ngăn không cho biểu thức tiến về 0. Phép đo giá trị gain có giả thiết rằng tín hiệu đầu vào có phạm vi từ -32768 tới 32767 (16 bit trên mỗi mẫu).
2.5.4 Mã hóa gain
Giá trị g2 được lượng tử hóa bởi một bộ lượng tử đồng nhất 5 bit có phạm vi từ 10 tới 77 dB. Giá trị g1 thì được lượng tử hóa 3 bit theo thủ tục sau:
ENCODE_g1(g1, g2, g2,past) 1. if| g2- g2,past| < 5 and | g1- (g2+ g2,past)/2 |< 3 2. index = 0 3. else 4. gmax = MAX(g2,past, g2) + 6 5. gmin = MIN(g2,pastg2) - 6 6. if gmin < 10 7. gmin = 10 8. if gmax > 77 9. gmax = 77 10. index = UNIFORM(g1, gmin, gmax, 7) 11. return index
Thủ tục này sử dụng g1 và g2 của khung hiện tại, g2,past của khung trước đó. Ở dòng 1, một số điều kiện được xác định để xem khung là trạng thái ổn định hay không (năng lượng ít thay đổi ). Nếu điều kiện được thỏa mãn, thì thủ tục kết thúc với chỉ số bằng 0. Ngược lại, khung này là tạm thời và ta sử dụng bộ lượng tử hóa đồng nhất cấp 7. Giá trị giới hạn của bộ lượng tử (gmin, gmax) được tính toán từ dòng 4 tới dòng 9; mã hóa thông qua bộ lượng tử đồng nhất ở dòng 10; kết quả đưa đến là chỉ số tập hợp {1,2,…,7}. Như vậy, tổng cộng có 8 mức, có thể khai thác bằng 3 bits. Hàm UNIFORM() ở dòng 10 sẽ nhận giá trị đầu vào là g1 và mã hóa nó thông qua bộ lượng tử hóa đồng nhất với giới hạn đầu vào [gmin, gmax] và 7 từ mã. Phương pháp này là một mô hình lượng tử thích nghi với tham số của cả quá khứ và tương lại đều được sử dụng để cải thiện hiệu suất.
2.5.5 Cấp phát bit
Bảng 2-1 tổng kết sơ đồ cấp phát bit của mã hóa FS MELP. Ta đã biết, các mô hình LPC đều được lượng tử như là LSF sử dụng MSVQ. Việc đồng bộ hóa này là một mẫu thay đổi 1/0. Việc bảo vệ lỗi chỉ dành cho các khung không tiếng, sử dụng 13 bit. Mỗi khung sẽ được truyền tổng cộng là 54 bit, với độ dài là 22.5 ms. Kết quả ta có bit-rate là 2400 bps.

27
Bảng 2-1: Sơ đồ cấp phát bit của mã hóa MELP
Tham số Có tiếng Không tiếng
LPC 25 25
Pitch period/ VS thấp tần 7 7
VS băng thông 4 -
Gain thứ nhất g1 3 3
Gain thứ hai g2 5 5
Cờ không tuần hoàn 1 -
Biên độ Fourier 8 -
Đồng bộ hóa 1 1
Chống lỗi - 13
Tổng cộng 54 54
2.6 Hoạt động giải mã
[4] Hình 2-13 cho thấy sơ đồ giải mã MELP, ở đó, luồng bit MELP được bung gói với các chỉ số được đưa đến các bộ giải mã tương ứng. So với hình 2-12, ta thấy mô hình tạo tiếng nói đã được nhúng bên trong cấu trúc của giải mã. Có hai bộ lọc được bổ sung vào trong quá trình xử lý đó là bộ lọc nâng cao phổ với đầu vào là kích thích hỗn hợp và bộ lọc phân tán xung ở cuối của quá trình xử lý. Hai bộ lọc này được sử dụng để nâng cao chất lượng của tiếng nói tổng hợp.
2.6.1 Giải mã và nội suy tham số
Trong giải mã MELP, các tham số từ dòng bit sẽ được bung gói và giải mã theo các lược đồ tương ứng. Những tham số này bao gồm: LPC (LSF), pitch period/voice strength tần thấp, voice strength băng thông, gain (g1 và g2), cờ không tuần hoàn và các biên độ Fourier. Các tham số này đại diện cho thông tin của khung, hầu hết được nội suy một cách tuyến tính trong quá trình tổng hợp tiếng nói.
Đối với các khung không tiếng (được phát hiện thông qua mã voice strength thấp tần/ pitch period), chúng ta sẽ sử dụng các giá trị mặc định cho một vài tham số, đó là pitch period = 50, jitter = 0.25, tất cả các biên độ Fourier

28
đều là 1, và tất cả các giá trị voice strength đều là 0. Các giá trị mặc định này là cần thiết đối với khung không tiếng bởi vì việc nội suy tuyến tính được thực hiện trên cơ sở “pitch period – by – pitch period” trong suốt quá trình tổng hợp. Ở đây có xuất hiện một tham số mới: jitter, nó chỉ được sử dụng trong việc giải mã để điều khiển số lượng ngẫu nhiên xảy ra trong quá trình tạo ra các âm kích thích không tuần hoàn.
Đối với khung có tiếng, giá trị của jitter được sử dụng như sau: jitter = 0.25 nếu cờ không tuần hoàn là 1, ngược lại thì jitter = 0. Trong trường hợp này, pitch period được giải mã từ dòng bit. Sau khi nội suy, giá trị pitch period thực sự sẽ được tính theo công thức:
0 (1 * )T T j i t t e r x [2.17]
Với T0 là giá trị pitch period đã giải mã và suy ra được, còn x là một số ngẫu nhiên có phân bố chuẩn trong khoảng [-1,1]. Theo cách này, các chu kỳ bất thường sẽ được sinh ra, mô phỏng các điều kiện phát sinh trong quá trình dịch chuyển các khung. Chú ý rằng nhiễu tối đa đối với pitch period vào khoảng ±25%, đây là giới hạn cho hầu hết các tình huống thực tiễn.
Hình 2-13: Mô hình giải mã MELP
Trong quá trình tổng hợp tiếng nói, tín hiệu được sinh ra trên cơ sở “pitch period by pitch period”. Tức là, trong một khoảng thời gian n0 nhất định,

29
0 [0 ,1 7 9 ]n , gắn liền với khung hiện tại, tập hợp các tham số cần thiết để tổng
hợp tiếng nói sẽ được đánh giá từ nội suy tuyến tính của dữ liệu từ các khung quá khứ và hiện tại. Hệ số nội suy được tính theo công thức:
0 / 1 8 0n [2.18]
Hệ số nội suy này được áp dụng chung cho tất cả các tham số LPC, pitch period, jitter, biên độ Fourier, và các hệ số lọc định hình. Do voice strength có thể suy ra được, việc nội suy các hệ số bộ lọc định hình thường có chi phí tính toán thấp. Giá trị pitch period được tính theo công thức:
(1 ) p a s t p r e s e n tT T T [2.19]
Với kết quả được làm tròn tới số nguyên gần nhất. Giá trị gain được cho bởi công thức nội suy sau:
2, 1, 0
1, 2, 0
(1 ) 90,
(1 ) 90 180
past present
present present
g g ng
g g n
[2.20]
Đối với trường hợp mà 0 1 8 0n T , thì chu kỳ sẽ được xem xét đánh giá
ngang qua biên của khung, các tham số vẫn được nội suy theo cùng công thức. Đến chu kì tiếp theo, n0 được điều chỉnh bằng cách trừ đi 180 để xác định tọa độ của khung mới.
2.6.2 Tạo kích thích hỗn hợp
Chuỗi xung T-mẫu được sinh ra từ các biên độ Fourier sẽ có giá trị đơn vị rms. Chuỗi này được lọc thông qua bộ lọc định hình xung và cộng với chuỗi nhiễu đã được lọc để tạo thành kích thích hỗn hợp. Nhiễu được sinh ra bởi một số ngẫu nhiên phân bố chuẩn với giá trị trung bình là 0 có giá trị đơn vị rms. Các hệ số của bộ lọc được suy diễn đồng thời với pitch period.
2.6.3 Bộ lọc tăng cường phổ
Bộ lọc có hàm hệ thống:
10
1 110
1
1( ) (1 )
1
i ii
i
i ii
i
a zH z z
a z
[2.21]
Trong đó, ia là các hệ số dự đoán tuyến tính. Các tham số µ, α, β được tạo tùy
vào các điều kiện tín hiệu. Bộ lọc này đồng nhất với bộ lọc được sử dụng rộng rãi trước đây trong mô hình CELP. Bộ lọc này được sử dụng để nâng cao chất lượng tiếng nói tổng hợp thông qua làm nổi bật các đặc trưng phổ ban đầu.

30
2.6.4 Bộ lọc tổng hợp
Đây là một bộ lọc tổng hợp đỉnh cộng theo hình thức trực tiếp, với các hệ số tương ứng với LSF đã suy ra được.
2.6.5 Tính toán hệ số khuếch đại
Công suất đầu ra ở bộ lọc tổng hợp phải cân bằng với gain g suy diễn được (ở công thức 2.20) của chu kì hiện tại. Do kích thích được tạo ra ở mức tùy ý nên ta cần có một hệ số tỉ lệ để khuếch đại giá trị của đầu ra y[n] của bộ lọc tổng hợp để tạo ra giá trị ở mức thích hợp:
/20
02
10
1[ ]
g
n
g
y nT
[2.22]
Lấy giá trị g0 này nhân với y[n], chuỗi T-mẫu kết quả sẽ có công suất của (10g/20)2 , hoặc g dB.
2.6.6 Bộ lọc phân tán xung
Bộ lọc này là một bộ lọc FIR 65 lớp trích xuất từ một xung tam đỉnh phổ phẳng. Như ta thấy thì nó gần như là một bộ lọc thông suốt, khi mà các thay đổi trong đáp ứng biên độ là tương đối nhỏ.
Hình 2-14: Đáp ứng xung (trái) và đáp ứng biên độ (phải) của bộ lọc phân
tán xung
Bộ lọc phân tán xung được dùng để cải thiện cho bộ lọc tổng hợp băng thông với tiếng nói tự nhiên dạng sóng trong các vùng không có cộng hưởng đỉnh. Tiếng nói tự nhiên đã qua lọc băng thông thì có một tỉ lệ đỉnh-trũng nhỏ hơn so với tiếng tổng hợp.
2.7 Kết chương
Chương này chúng ta tìm hiểu về mô hình MELP, mô hình này có cải tiến hơn nhiều so với LPC, với nhiều thông số được sử dụng thêm để tăng cường

31
tính tự nhiên, độ mượt, và khả năng thích ứng với các điều kiện tín hiệu đa dạng hơn. Mô hình MELP đã đạt được tất cả các lợi thế mà không cần nâng cao bit-rate tổng thể, chủ yếu do việc sử dụng kỹ thuật lượng tử hóa véc-tơ. Phần lớn yếu tố chất lượng kém của LPC đã bị loại bỏ nhờ vào voice strength độc lập tần số..
MELP liên quan tới họ các lập trình tham số. Khi so sánh với các mô hình lập trình lai như CELP, yêu cầu bit-rate lại thấp hơn nhiều do tránh được các mô tả chi tiết hóa cho các kích thích. Thay vào đó, nó sử dụng một tập hợp thô các thông số được trích xuất để đại diện cho kích thích. Tương tự như LPC, nó cũng có thể được phân loại như là một bộ coder đa chế độ điều khiển nguồn, do sử dụng các lược đồ mã hóa khác nhau tùy thuộc vào tính chất của tín hiệu.
Ý tưởng sử dụng kích thích hỗn hợp, tức là kết hợp thành phần nhiễu trắng với thành phần tuần hoàn cùng nhau, đã được nghiên cứu rất sâu trong quá khứ. Coder kích thích nhiều dải tần đã được nghiên cứu thay thế cho việc phân loại có tiếng/không tiếng trong coder LPC với một tập hợp các quyết định trên miền tần số. Tuy nhiên, khi mô hình này không còn phù hợp với tín hiệu đầu vào, chất lượng tín hiệu đầu ra đã giảm đáng kể, đặc biệt khi có âm nhạc hay tiếng ồn trộn lẫn với tín hiệu tiếng nói. Trong khi đó, mô hình MELP hoạt động khá tốt đối với một số loại tín hiệu không phải tiếng nói. Chất lượng của nó chủ yếu là do sự mạnh mẽ và tính linh hoạt của các mô hình cơ bản, cho phép thích ứng tốt với nhiều lớp chung của các tín hiệu âm thanh.

32
Chương 3 - CHIP XỬ LÝ TÍN HIỆU SỐ TMS320C55xx
3.1 Giới thiệu
[2] Các bộ xử lý tín hiệu số với kiến trúc và lệnh được thiết kế đặc biệt cho các ứng dụng DSP đã được phát triển bởi các hãng Texas Instruments, Motorola, Lucent Technologies, Analog Devices.. Các bộ xử lý DSP đã được sử dụng rộng rãi trong nhiều lĩnh vực như viễn thông, xử lý tiếng nói, xử lý ảnh, thiết bị y sinh, điện tử.. Trong chương này, chúng ta tìm hiểu kiến trúc và lập trình của bộ xử lý họ TMS320C55x của Texas Instruments.
Một số đặc điểm quan trọng của họ C55x bao gồm:
- Mã nguồn tương thích với tất cả các thiết bị TMS32054x - Hàng đợi bộ đệm lệnh 64 byte làm việc như một bộ đệm chương trình và cải
thiện hiệu quả các hoạt động lặp khối. - 2 đơn vị MAC 17 bit có thể chạy song song phép nhân có nhớ trên cùng một
vòng lệnh đơn. - 1 bộ số học logic ALU 40 bit thực hiện các tính toán logic và số học chính
xác cao, kèm theo một bộ ALU 16 bit thực hiện các lệnh số học đơn giản song song với ALU chính.
- 4 bộ nhớ 40bit dành cho việc lưu trữ các kết quả tính toán nhằm giảm truy cập bộ nhớ.
- 8 thanh ghi phụ mở rộng cho việc lưu dữ liệu cộng với 4 thanh ghi dữ liệu tạm dành cho các dữ liệu đơn giản.
- Chế độ địa chỉ xoay vòng cho phép hỗ trợ tới 5 bộ đệm vòng - Hoạt động lặp đơn lệnh và khối lệnh hỗ trợ lặp không quá tải.
3.2 Kiến trúc họ TMS32C55xx
[2] CPU C55x bao gồm 4 thành phần: đơn vị bộ đệm lệnh (IU), đơn vị luồng chương trình (PU), đơn vị luồng dữ liệu địa chỉ (AU) và đơn vị tính toán dữ liệu (DU). Các đơn vị này được kết nối tới 12 địa chỉ và đường bus dữ liệu khác nhau như hình 3-1.

33
Hình 3-1: Sơ đồ khối của CPU TMS320C55x
3.2.1 Kiến trúc tổng thể
Bộ đệm lệnh (IU)
Bộ đệm lệnh chịu trách nhiệm lấy các lệnh từ bộ nhớ đưa vào CPU. C55x được thiết kế để tối ưu hóa thời gian chạy và mật độ mã. Các lệnh đơn giản được mã hóa sử dụng 8 bits (1 byte), trong khi đó các lệnh phức tạp thì phải dùng tới 48 bits (6 bytes). Trong mỗi nhịp đồng hồ, IU có thể lấy được 4 bytes mã chương trình thông qua bus dữ liệu đọc-chương trình 32bit của nó. Cùng trong thời gian đó, IU có thể giải mã tới 6 bytes chương trình. Sau khi 4 bytes mã được lấy về, IU đặt nó vào bộ đệm lệnh 64 byte. Cùng lúc đó, bộ logic giải mã sẽ tiến hành giải mã từ 1 tới 6 bytes đã được đặt trước đó trong bộ giải mã lệnh,

34
như hình 3-2. Các lệnh đã giải mã được thì được chuyển sang cho PU, AU hoặc DU.
Hình 3-2: Sơ đồ đơn giản hóa của IU
Bộ điều hướng chương trình (PU)
PU là đơn vị điều khiển dòng hoạt động của chương trình DSP, bao gồm 1 bộ đếm chương trình (PC), 4 thanh ghi trạng thái, 1 bộ sinh địa chỉ chương trình và một bộ bảo vệ đường ống.
Hình 3-3: Mô hình đơn giản hóa của PU
Bộ sinh địa chỉ tạo ra các địa chỉ 24 bit bao phủ hết 16Mb của không gian chương trình. Do hầu hết các lệnh sẽ chạy tuần tự, C55x sử dụng cấu trúc đường ống (pipe) để cải thiện hiệu năng chạy chương trình. Tuy nhiên, các lệnh rẽ nhánh, gọi hàm, trả về, chạy có điều kiện và ngắt sẽ gây ra các chuyển địa chỉ chương trình không tuần tự. PU sử dụng một bộ bảo vệ ống để tránh cho luồng chương trình gây tổn hại cho các đường ống bởi các hoạt động không tuần tự.
BUS dữ liệu đọc-chương trình PB
Hàng đợi bộ đệm lệnh
(64bytes)
Bộ giải mã
lệnh
IU PU
AU
DU
32 (4-byte opcode)
(1-6 byte opcode)
48
BUS địa chỉ đọc-chương trình PAB
Bộ đếm chương trình (PC) PU
24 bit
Thanh ghi trạng thái (ST0,ST1,ST2,ST3)
Bộ sinh địa chỉ
Bộ bảo vệ pipeline

35
Bộ điều khiển dòng dữ liệu-địa chỉ (AU)
AU hoạt động như một trình quản lý truy cập dữ liệu cho các bus đọc và ghi dữ liệu. AU chứa 8 thanh ghi phụ 23 bit (XAR0 tới XAR7), 4 thanh ghi tạm 16 bit (T0-T3), 1 con trỏ dữ liệu hệ số mở rộng 23 bit (XCDP), và 1 con trỏ stack mở rộng 23 bit (XSP).
Hình 3-4: Bộ điều khiển luồng dữ liệu địa chỉ C55x
AU chứa một bộ ALU 16 bit mở rộng dùng cho các tính toán số học đơn giản. AU sử dụng hai thanh ghi địa chỉ cùng với 1 con trỏ hệ số cho các tính toán dữ liệu song song với 1 hệ số chỉ trong 1 vòng đồng hồ. AU cũng hỗ trợ 5 bộ đệm vòng cho các tính toán cần thiết.
Bộ tính toán dữ liệu (DU)
DU xử lý dữ liệu cho hầu hết các ứng dụng C55x, bao gồm một cặp MAC, một bộ ALU 40 bit, 4 bộ tích lũy 40 bit (AC0, AC1, AC2, AC3), một bộ dịch thùng, 1 bộ logic điều khiển làm tròn và bão hòa.
KH
ÔN
G G
IAN
BỘ
NHỚ
DỮ
LIỆ
U
XAR0
AU
23 bit
XAR1
XAR2
XAR3
XAR4
XAR5
XAR6
XAR7
XCDP
XSP
16 bit
T0
T1
T2
T3
16 bit ALU
Bộ sinh địa chỉ dữ liệu
24 bit
FAB
DAB
EAB
CAB
BAB
FB
EB
DB
CB

36
Hình 3-5: Mô hình cấu trúc bộ tính toán dữ liệu
3.2.2 TMS320C55X bus
Như mô tả trong hình 3-1, TMS320C55x có một đường bus dữ liệu chương trình 32 bit, 5 đường bus dữ liệu 16 bit, 6 đường bus địa chỉ 24 bit. Các bus chương trình bao gồm bus dữ liệu đọc chương trình 32 bit (PB) và 1 đường bus địa chỉ đọc chương trình 24 bit (PAB). PAB chứa địa chỉ bộ nhớ chương trình để đọc mã từ không gian chương trình. Đơn vị được tính của địa chỉ chương trình được tính theo bytes, từ 0x000000 tới 0xFFFFFF. PB chuyển 4 bytes mã chương trình tới IU trong mỗi vòng đồng hồ. Các bus dữ liệu bao gồm 3 bus dữ liệu đọc dữ liệu 16 bit (BB, CB, DB), 3 bus địa chỉ đọc dữ liệu 24 bit (BAB, CAB, DAB). Kiến trúc này hỗ trợ 3 đường đọc dữ liệu đồng thời từ bộ nhớ dữ liệu hoặc không gian vào/ra. Các đường bus C và D có thể gửi dữ liệu tới PU, AU và DU; trong khi đường bus B chỉ làm việc với DU. Chức năng chính của BB là kết nối bộ nhớ tới cặp MAC; vì thế một số hoạt động đặc biệt có thể truy cập tới cả 3 đường bus dữ liệu, chẳng hạn hai đường đọc dữ liệu và 1 đường đọc hệ số. Các hoạt động ghi dữ liệu được thực hiện thông qua hai đường bus dữ liệu ghi-dữ liệu 16 bit (EB, FB) và hai đường bus địa chỉ ghi-dữ liệu 24 bit (EAB, FAB). Đối với việc ghi dữ liệu đơn 16 bit thì ta chỉ cần sử dụng EB. Việc ghi dữ liệu 32 bit sẽ sử dụng cả hai đường EB và FB trong cùng 1 vòng chạy. Các bus địa chỉ ghi-dữ liệu (EAB, FAB) đều có phạm vi địa chỉ 24 bit. Do việc truy cập địa chỉ sử dụng một từ (2 bytes), nên không gian bộ nhớ dữ liệu sẽ có phạm vi đánh địa chỉ 23 bit từ 0x000000 tới 0x7FFFFF.
Kiến trúc C55x được xây dựng dựa trên 12 bus này. Các bus chương trình sẽ làm việc với các mã lệnh và các toán hạng trung gian từ bộ nhớ chương trình, trong ghi các bus dữ liệu kết nối các đơn vị khác nhau. Kiến trúc này cực đại
ALU 40 bit
DU
Bộ dịch thùng
AC0
AC1
AC2
AC3
MAC
CB
BB
DB
16 bit
16 bit
16 bit MAC
Bộ điều khiển tràn và bão hòa
EB
FB
16 bit
16 bit

37
hóa sức mạnh xử lý bằng cách duy trì phân tách các cấu trúc bus bộ nhớ cho các tính toán tốc độ cao.
3.2.3 Ánh xạ bộ nhớ
C55x sử dụng một cấu hình bộ nhớ vào ra, dữ liệu và chương trình đồng nhất. Toàn bộ dung lượng 16Mbs của bộ nhớ đều dành cho chương trình và không gian dữ liệu. Không gian vào/ra thì được tách biệt khỏi không gian chương trình/dữ liệu, và được sử dụng cho các giao tiếp song công đối với thiết bị ngoại vi. Khi CPU lấy các lệnh từ không gian chương trình, bộ sinh địa chỉ C55x sử dụng bus địa chỉ đọc chương trình 24 bit. Mã chương trình được lưu thành các byte. Khi CPU truy cập vào không gian dữ liệu, bộ sinh địa chỉ C55x sẽ đánh dấu bit hiệu lực nhỏ nhất (LSB) của địa chỉ dữ liệu khi mà dữ liệu được lưu vào bộ nhớ thành các word (2 bytes). .
3.3 Công cụ phát triển
3.3.1 Giới thiệu
[2] Nhà sản xuất các bộ xử lý DSP thường cung cấp một tập hợp các công cụ phần mềm để người dùng có thể phát triển các phần mềm DSP hiệu quả. Các công cụ phần mềm cơ bản bao gồm bộ hợp dịch, bộ liên kết, bộ biên dịch C, và bộ mô phỏng. Các chương trình DSP thường được viết bằng ngôn ngữ C hoặc hợp ngữ. Để chạy thuật toán DSP trên các hệ thống đích, các chương trình C hoặc hợp ngữ trước hết phải được biên dịch sang mã máy, sau đó được liên kết với nhau để tạo thành mã khả thi cho phần cứng DSP đích. Quá trình chuyển đổi này được thực hiện thông qua công cụ phát triển, như mô tả trong hình 3-6.
3.3.2 Trình biên dịch C
Chúng ta đã biết, C là ngôn ngữ lập trình bậc cao phổ biến nhất để đánh giá các thuật toán DSP và phát triển các phần mềm thời gian thực trong các ứng dụng thực tiễn.
Bảng 3-1: Ví dụ về mã C và mã hợp ngữ được trình biên dịch C55x sinh ra
Mã Mã hợp ngữ gợi nhớ Mã hợp ngữ đại số
in_buffer[i] = sineTable[i]; mov * SP (#0), AR2 add #_sineTable, AR2 mov *SP(#0), AR3 add #_in_buffer, AR3 mov *AR2, *AR3
AR2 = *SP(#0) AR2 = AR2+#_sineTable AR3 = *SP(#0) AR3 = AR3 + #_in_buffer *AR3 = *AR2

38
Trình biên dịch C55x hỗ trợ ANSI C và các thư viện chạy của nó. Thư viện chạy rts55.lib bao gồm các hàm hỗ trợ xử lý chuỗi, cấp phát bộ nhớ, chuyển đổi dữ liệu, lượng giác, và tính toán lũy thừa.
Hình 3-6: Công cụ và Luồng phát triển phần mềm TMS320C55X
3.3.3 Trình hợp dịch
Trình hợp dịch chịu trách nhiệm biên dịch các tệp mã nguồn viết bằng hợp ngữ đã đặc tả theo chip xử lý (dưới dạng văn bản ASCII) sang các tệp đối tượng nhị phân COFF cho các bộ xử lý DSP. Các tệp mã nguồn có thể chứa các chỉ thị hợp ngữ, các chỉ thị macro và các lệnh. Chỉ thị hợp ngữ được sử dụng để

39
điều khiển các vấn đề khác nhau trong quá trình xử lý hợp ngữ, như là định dạng liệt kê tệp mã nguồn, căn chỉnh dữ liệu, nội dung các section.. Các tệp nhị phân đối tượng chứa các khối khác nhau (gọi là các section) của các mã và dữ liệu để có thể tải lên không gian bộ nhớ.
Các chỉ thị hợp ngữ được sử dụng để điều khiển quá trình hợp dịch và để đưa dữ liệu vào chương trình. Nó có thể được dùng để khởi tạo bộ nhớ, định nghĩa các biến toàn cục, thiết lập các khối hợp ngữ có điều kiện, và chuẩn bị không gian bộ nhớ cho lệnh và dữ liệu. Một số chỉ thị hợp ngữ quan trọng của C55x bao gồm: .BSS, .DATA, .SECT, .USET, .TEXT, .INT, .SET..
3.3.4 Trình liên kết
Trình liên kết được sử dụng để phối hợp các tệp đối tượng vào một chương trình khả thi. Nó sẽ xử lý các tham chiếu ngoài và thực hiện việc định vị lại mã để tạo ra mã khả thi. Trình liên kết C55x xử lý các yêu cầu khác nhau của các tệp đối tượng và thư viện khác nhau cũng như các cấu hình bộ nhớ của hệ thống đích.
Ta có thể đưa các tên tệp và tùy chọn vào một tệp lệnh, sau đó gọi trình liên kết kèm theo đặc tả tên tệp lệnh. Tệp lệnh liên kết đặc biệt hữu ích khi ta phải thường xuyên gọi trình liên kết với các thông tin giống nhau. Một đặc điểm quan trọng khác của tệp lệnh đó là ta có thể áp dụng các chỉ thị MEMORY và SECTION để tùy biến chương trình cho các cấu hình phần cứng khác nhau. Tệp lệnh thường là một tệp văn bản ASCII và có thể chứa các thành phần sau:
- Tệp đầu vào (các tệp đối tượng, thư viện..) - Tệp đầu ra (tệp ánh xạ và tệp khả thi) - Tùy chọn liên kết để điều khiển trình liên kết - Các chỉ thị MEMORY và SECTION để đặc tả cấu hình bộ nhớ đích và
thông tin để ánh xạ các section mã vào không gian bộ nhớ khác nhau.
Bảng 3-2: Ví dụ về tệp lệnh liên kết sử dụng cho bộ mô phỏng C55x
/* Đặc tả ánh xạ bộ nhớ hệ thống */ MEMORY { RAM (RWIX) : origin=0100h, length=01FEFFh /* Data memory*/ RAM2 (RWIX): origin=040100h, length=040000h /* Program memory*/ ROM (RIX) : origin=020100h, length=020000h /* Program memory*/ VECS (RIX) : origin=0FFFF00h,length=00100h /* Reset vector*/ } /* Đặc tả việc cấp phát section vào bộ nhớ */ SECTIONS

40
{ Vectors > VECS /* Bảng véc tơ ngắt */ .text > ROM /* Mã */ .switch > RAM /* thông tin chuyển bảng */ .const > RAM /* dữ liệu hằng số */ .cinit > RAM2 /* khởi tạo bảng */ .data > RAM /* dữ liệu đã khởi tạo */ .bss > RAM /* biến tĩnh và biến toàn cục */ .stack > RAM /* stack chính */
}
Bảng 3.2 mô tả một ví dụ về tệp lệnh của trình liên kết. Phần thứ nhất sử dụng chỉ thị MEMORY để xác định vùng bộ nhớ tồn tại vật lý ở trong phần cứng hệ thống đích. Mỗi khối nhớ đều có tên, địa chỉ bắt đầu và độ dài khối. Địa chỉ và độ dài sẽ tính bằng byte. Phần thứ hai là chỉ thị SECTIONS, cung cấp các tên section khác nhau để trình liên kết tiến hành cấp phát chương trình và dữ liệu vào trong các khối nhớ. Các thuộc tính bên trong ngoặc đơn là tùy chọn để hạn chế truy cập vào bộ nhớ (R –có thể đọc, W –có thể ghi, X –có thể chứa mã khả thi, I –có thể khởi tạo).
3.3.5 Code composer studio (CCS)
Hình 3-7: Phát triển phần mềm TMS320C55X với CCS
Hình 3-7 mô tả công cụ soạn thảo mã CCS, nó cung cấp giao diện người dùng với bộ mô phỏng C55x (SIM), bộ kit DSP đơn giản (DSK), mô-đun đánh giá (EVM), hoặc bộ giả lập trong mạch (XDS). CCS hỗ trợ cả chương trình C lẫn chương trình hợp ngữ. Do mọi hàm của TMS320C55X đều chạy trên máy tính chủ, nên việc mô phỏng có thể rất chậm, đặc biệt đối với các ứng dụng DSP
Soạn
thảo tệp
Khảo sát tệp vào
Khảo sát tệp ra
Gỡ rối
chương trình Biên dịch
Phân tích
hồ sơ
Hiển thị đồ
họa
SIM
DSK
EVM
DSP board
XDS

41
phức tạp. Tín hiệu thực chỉ có thể số hóa và đưa vào bộ mô phỏng như các dữ liệu kiểm tra. Ngoài ra, thời gian chạy thuật toán đối với mọi điều kiện đầu vào sẽ không được kiểm tra đầy đủ với bộ mô phỏng.
CCS cung cấp đầy đủ cửa sổ hiển thị và các lệnh khác nhau phục vụ cho việc gỡ rối. Ta có thể tải lên mã đối tượng khả thi, hiển thị phiên bản giải hợp ngữ của mã cùng với mã nguồn ban đầu, và xem nội dung các thanh ghi và bộ nhớ. Dữ liệu trong thanh ghi và bộ nhớ có thể chỉnh sửa được. Dữ liệu được hiển thị dưới dạng mã hex, số thập phân, hoặc dấu chấm động. Chương trình có thể chạy từng bước, chạy tới con trỏ, hoặc chạy theo các điểm dừng.
DSK và EVM là các board phát triển cùng với bộ xử lý C55x. Chúng được dùng để phân tích thời gian thực các thuật toán DSP, đánh giá logic mã, và kiểm thử các chương trình đơn giản. XDS cho phép sử dụng các điểm dừng để đánh giá các thanh ghi và bộ nhớ nhằm đánh giá kết quả trong thời gian thực với DSP board. Bộ giả lập cho phép phần mềm DSP có thể chạy đầy đủ tốc độ trong môi trường thời gian thực.
3.3.6 Cú pháp lệnh hợp ngữ
Các câu lệnh hợp ngữ TMS320C55X có thể chia thành 4 trường có thứ tự. Biểu thức cú pháp cơ bản như sau:
[label] [:] mnemonic[operand list] [;comment]
Trong đó, các thành phần bên trong ngoặc [] là không bắt buộc. Câu lệnh phải bắt đầu bằng một nhãn (label), dấu trống (blank), dấu sao (*), hoặc dấu chấm phẩy (;). Mỗi trường phải phân tách bởi ít nhất một dấu cách.
Hình 3-8: Ví dụ về lệnh hợp ngữ của TMS320C55X
+ Trường label: trường này có thể lên tới 32 ký tự chữ và số (A-Z, a-z, 0-9, _, $). Nó liên kết một địa chỉ biểu tượng với một vị trí trong chương trình duy
my_symbol .set 2 ; my_sumbol = 2 start mov #my_symbol, AR1 ; Load AR1 with 2
Nhãn
Label
Từ gợi nhớ
mnemonic
Toán hạng
operand
Ghi chú
comment

42
nhất. Dòng nào được gắn nhãn trong chương trình thì sau đó sẽ có thể được tham chiếu bằng một tên biểu tượng xác định. Các nhãn là không bắt buộc, nhưng nếu có thì nó phải ở ngay đầu dòng. Các nhãn là phân biệt chữ hoa chữ thường và bắt buộc phải bắt đầu bằng một ký tự alphabet (a-z, A-Z).
+ Trường mnemonic: trường này có thể chứa các hàm gợi nhớ, một chỉ thị hợp ngữ, chỉ thị macro, hoặc lời gọi macro. Tập lệnh C55x hỗ trợ cả các hoạt động đặc tả DSP và ứng dụng đa mục đích. Trường gợi nhớ không được xuất hiện ở đầu dòng nếu không nó sẽ được hiểu là nhãn.
+ Trường operand: trường này là danh sách các toán hạng. Một toán hạng có thể là hằng số, biểu tượng, hoặc biểu thức các biểu tượng lẫn hằng số. Một toán hạng cũng có thể là biểu thức của hợp ngữ tham chiếu tới bộ nhớ, cổng vào ra, hoặc các con trỏ, các thanh ghi hoặc bộ nhớ tích lũy. Các hằng số có thể là giá trị nhị phân, thập phân hoặc thập lục phân.
+ Trường comment: đây là trường ghi chú của người lập trình. Ghi chú thường bắt đầu bằng dấu sao (*) hoặc chấm phẩy (;) nếu ở ngay đầu dòng. Mọi ghi chú xuất hiện ở vị trí khác trong dòng lệnh thì bắt buộc phải sau dấu chấm phẩy.
3.4 Các chế độ địa chỉ TMS320C55x
[2] TMS320C55X có thể đánh địa chỉ trong toàn bộ 16Mb bộ nhớ với các chế độ sau:
3.4.1 Chế độ địa chỉ trực tiếp
Có bốn loại chế độ địa chỉ trực tiếp: con trỏ trang dữ liệu (DP) trực tiếp, con trỏ ngăn xếp (SP) trực tiếp, bit thanh ghi trực tiếp, và con trỏ trang dữ liệu ngoại vi (PDP) trực tiếp.
Chế độ con trỏ trang dữ liệu trực tiếp sử dụng trang dữ liệu chính, đặc tả bởi con trỏ trang dữ liệu mở rộng 23 bit (XDP): 7 bit cao của XDP (DPH) sẽ lưu về trang dữ liệu chính (0-127), 16 bit thấp hơn của XDP (DP) thì xác định địa chỉ bắt đầu trong trang dữ liệu được lựa chọn bởi DPH.
Chế độ con trỏ ngăn xếp trực tiếp (SP) tương tự với DP. Địa chỉ 23 bit có thể hình thành với con trỏ ngăn xếp mở rộng (XSP) cũng giống như XDP. 7 bit cao của SPH sẽ lựa chọn trang dữ liệu chính và 16 bit thấp (SP) sẽ ghi địa chỉ bắt đầu của con trỏ ngăn xếp. 7bit offset của stack thì được chứa trong lệnh. Khi SPH= 0, ngăn xếp sẽ không sử dụng vùng nhớ ưu tiên cho MMR, tính từ 0 tới 0x5F.

43
Chế độ không gian địa chỉ vào/ra chỉ có phạm vi địa chỉ 16bit. Có 512 trang dữ liệu ngoại vi được lựa chọn dựa trên 9 bit cao của con trỏ PDP. 7bit offset sẽ ghi vị trí định vị trong trang dữ liệu ngoại vi.
3.4.2 Chế độ địa chỉ gián tiếp
Chế độ địa chỉ gián tiếp sử dụng các chỉ số và hoán vị, là một chế độ địa chỉ mạnh mẽ và thường dùng nhất. Có 4 loại chế độ địa chỉ gián tiếp. Chế độ gián tiếp AR sử dụng một trong 8 thanh ghi phụ làm con trỏ tới bộ nhớ dữ liệu, không gian vào/ra và MMR. Chế độ AR-song song sử dụng hai thanh ghi phụ để truy cập bộ nhớ dữ liệu song song. Chế độ gián tiếp con trỏ dữ liệu hệ số (CDP) sử dụng CDP để trỏ tới không gian bộ nhớ dữ liệu. Chế độ gián tiếp AR-song song sử dụng CDP và chế độ gián tiếp AR-song song để tạo ra 3 địa chỉ.
Chế độ địa chỉ gián tiếp AR sử dụng thanh ghi phụ (AR0-AR7) để trỏ tới không gian bộ nhớ dữ liệu. 7 bit cao của thanh ghi phụ mở rộng XAR sẽ trỏ tới trang dữ liệu chính, còn 16 bit thấp sẽ trỏ đến vị trí lưu dữ liệu trong trang đó. Do không gian vào ra bị giới hạn 16 bit nên khi truy cập vào đây thì 7 bit cao của XAR sẽ bằng 0.
Chế độ địa chỉ gián tiếp AR-song song cho phép tạo hai đường truy cập bộ nhớ qua các thanh ghi phụ AR0-AR7.
Con trỏ dữ liệu hệ số mở rộng (XCDP) được nối thêm vào CDPH (7 bit cao) và CDP (16 bit thấp). Chế độ địa chỉ gián tiếp CDP sử dụng 7 bit cao để xác định trang dữ liệu chính, và 16 bit thấp để trỏ tới vị trí vùng nhớ dữ liệu trong trang đó.
3.4.3 Chế độ địa chỉ tuyệt đối
Vùng nhớ có thể đánh địa chỉ sử dụng chế độ trực tiếp trong chế độ k16 hoặc k23. Chế độ trực tiếp k23 đặc tả một địa chỉ là một hằng số không dấu 23 bit.
Chế độ địa chỉ tuyệt đối k16 sử dụng toán hạng *abs(#k16), với k16 là một hằng số không dấu 16 bit. DPH (7 bit cao) nhận giá trị 0 và kết hợp với k16 để tạo thành địa chỉ 23 bit. Chế độ địa chỉ tuyệt đối trên không gian dữ liệu vào/ra thì sử dụng toán hạng port(#k16).Địa chỉ tuyệt đối cũng có thể sử dụng tên biến: mov *(x), AC0 , lệnh này tải nội dung biến x vào thanh ghi tích lũy AC0.
Một điểm hạn chế của chế độ này là ta phải cần nhiều mã hơn để biểu diễn địa chỉ 23 bit.

44
3.4.4 Chế độ địa chỉ thanh ghi ánh xạ bộ nhớ
Các chế độ địa chỉ giới thiệu ở trên có thể sử dụng để đánh địa chỉ MMR. MMR nằm trong bộ nhớ dữ liệu từ địa chỉ 0 tới 0x5F trong trang dữ liệu 0. Để truy cập vào MMR sử dụng toán hạng tuyệt đối k16, DPH phải được đặt giá trị 0.Đối với chế độ địa chỉ trực tiếp MMR, ta phải sử dụng chế độ địa chỉ DP. Truy cập vào MMR sử dụng chế độ địa chỉ gián tiếp cũng giống như đánh địa chỉ trong không gian bộ nhớ dữ liệu. Con trỏ địa chỉ có thể là thanh ghi phụ hoặc là CDP. Do MMR nằm hoàn toàn trong trang dữ liệu 0, nên XAR và XCDP đều phải trỏ đến trang 0.
3.4.5 Chế độ địa chỉ bit thanh ghi
Cả hai chế độ địa chỉ gián tiếp và trực tiếp đều có thể sử dụng để xác định địa chỉ 1 bit hoặc nhiều bit của một thanh ghi cụ thể. Chế độ trực tiếp sử dụng một bit offset để truy cập tới từng bit của thanh ghi. Giá trị offset này là số lượng bit đếm được tính từ bit hiệu dụng nhỏ nhất (LSB) – bit 0.
Chế độ địa chỉ bit thanh ghi chỉ hỗ trợ các lệnh kiểm tra bit, đặt bit, xóa bit, và bù bit trên các thanh ghi tích lũy AC0-AC3, thanh ghi phụ AR0-AR7, và thanh ghi tạm T0-T3.
3.4.6 Chế độ địa chỉ vòng
Chế độ địa chỉ vòng cung cấp một phương pháp hiệu quả để truy cập các bộ đệm dữ liệu một cách liên tục mà không phải reset lại con trỏ dữ liệu. Sau khi truy cập dữ liệu, con trỏ bộ đệm dữ liệu sẽ được tính toán lại theo phương pháp chia modulo (phép chia lấy dư). Tức là, khi con trỏ bộ đệm chạm tới giới hạn của bộ đệm, nó sẽ được tính lại giá trị trỏ về đầu của bộ đệm ở bước tính tiếp theo. Các thanh ghi phụ AR0-AR7, và CDP có thể sử dụng làm con trỏ vòng trong chế độ gián tiếp.
3.5 Đường ống và cơ chế song song
[2] Kỹ thuật đường ống đã được sử dụng rộng rãi bởi nhiều nhà sản xuất DSP để cải thiện hiệu suất xử lý. Hoạt động của đường ống sẽ chia chuỗi thao tác thành các phân đoạn nhỏ hơn và chạy các phân đoạn này một cách song song. TMS320C55X sử dụng cơ chế đường ống để chạy các lệnh của nó một cách hiệu quả nhằm giảm thiểu thời gian chạy chương trình.

45
3.5.1 TMS320C55x pipeline
Hoạt động của đường ống được chia thành hai loại độc lập nhau: đường ống lấy chương trình và đường ống chạy chương trình, như trên hình 3-9. Đường lấy chương trình chia thành 3 giai đoạn (sử dụng 3 vòng đồng hồ):
PA (địa chỉ chương trình): Bộ lệnh C55x lấy địa chỉ chương trình từ bus địa chỉ đọc chương trình (PAB)
PM (ổn định địa chỉ bộ nhớ chương trình): C55x cần 1 nhịp đồng hồ để ổn định hóa bus địa chỉ bộ nhớ chương trình trước khi bộ nhớ có thể đọc.
PB (lấy chương trình từ bus dữ liệu chương trình): Lấy 4 byte mã chương trình từ bộ nhớ chương trình thông qua PAB 32 bit. Mã chương trình được đưa vào hàng đợi bộ đệm lệnh (IBQ). Cứ mỗi nhịp đồng hồ, IU sẽ lấy 4 byte vào IBQ.
Cùng thời gian đó, hoạt động đường ống bảy bước thực hiện các bước lấy mã chương trình, giải mã, địa chỉ, truy cập, đọc, và chạy:
F (fetch - lấy mã chương trình): các lệnh được lấy từ IBQ. Kích thước lệnh có thể là 1 byte cho lệnh đơn giản, hoặc lên tới 6 bytes cho các lệnh phức tạp.
D (decode - giải mã): Trong quá trình giải mã, logic giải mã sẽ lấy từ 1 đến 6 bytes từ IBQ và giải mã các byte này thành lệnh hoặc tập lệnh thực hiện song song. Logic giải mã sẽ đưa các lệnh này vào đơn vị điều khiển dòng chương trình (PU), đơn vị dòng địa chỉ (AU) hoặc đơn vị tính toán dữ liệu (DU).
AD (address - địa chỉ): AU sẽ tính toán các địa chỉ dữ liệu từ bộ sinh địa chỉ dữ liệu (DAGEN), chỉnh sửa con trỏ nếu cần, và tính toán địa chỉ không gian chương trình cho các lệnh rẽ nhánh.
AC (access cycles 1,2 – truy cập): vòng 1 được sử dụng cho CPU để gửi địa chỉ cho hoạt động đọc tới các bus địa chỉ đọc dữ liệu (BAB, CAB, DAB), hoặc truyền một toán hạng tới CPU thông qua C-bus (CB). Vòng truy cập thứ 2 cho phép các đường địa chỉ được ổn định hóa trước khi đọc bộ nhớ.
R (read – đọc): dữ liệu và toán hạng được truyền tới CPU thông qua CB cho toán hạng Ymem, BB cho toán hạng Cmem, và DB cho toán hạng Smem hoặc Xmem. Đối với việc đọc toán hạng Lmem, ta phải dùng cả CB và DB. AU sẽ sinh ra địa chỉ cho việc ghi toán hạng và gửi địa chỉ tới bus địa chỉ ghi dữ liệu (EAB, FAB).
X (execute – chạy): Hầu hết quá trình xử lý dữ liệu diễn ra ở bước này. ALU bên trong AU và ALU bên trong DU sẽ thực hiện quá trình xử lý, lưu toán hạng thông qua FB, hoặc lưu một toán hạng dài thông qua EB và FB.

46
Hình 3-9: Sơ đồ hoạt động của đường ống C55x
3.5.2 Hoạt động song song
Cơ chế song song của TMS320C55X sử dụng kiến trúc nhiều bus của bộ xử lý, cặp MAC song song, và các PU, AU, DU phân tách nhau. C55x hỗ trợ hai loại song song: ngầm và rõ. Các lệnh song song ngầm là lệnh được xây dựng sẵn (built-in), sử dụng kí hiệu “: :”, để phân tách các lệnh sẽ được xử lý song song. Các lệnh song song rõ thì do người dùng xây dựng nên (user-built), sử dụng biểu tượng “| |” để chỉ ra cặp lệnh song song. Hai loại này có thể sử dụng chung với nhau để tạo nên song song hỗn hợp. Ví dụ sau mô tả điều đó, đoạn lệnh chỉ chạy trong vòng 1 nhịp đồng hồ:
User-built: mpym * AR1+, *AR2+, AC0 ; Lệnh song song do người dùng tạo || and AR4, T1 ; Sử dụng DU và AU
Built-in: mac *AR0-, *CDP-, AC0 ; Lệnh song song có sẵn ::mac *AR1-, *CDP-, AC1 ; Sử dụng cặp MAC song song
Phối hợp Built-in và User-built: mpy *AR2+, *CDP+, AC0 ; Lệnh song song hỗn hợp ::mpy *AR3+, *CDP+, AC1 ; sử dụng cặp MAC và PU
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
F D AD AC1 AC2 R X
PA PM PB
F D AD AC1 AC2 R XF D AD AC1 AC2 R X
F D AD AC1 AC2 R XF D AD AC1 AC2 R X
F D AD AC1 AC2 R X
F D AD AC1 AC2 R XF D AD AC1 AC2 R X
F D AD AC1 AC2 R X
1 2 3 4 5 IBQ
64x8 4 byte 1-6 bytePA PM PB
PA PM PB PA PM PB
PA: lấy địa chỉ chương trình
PM: ổn định đường bus địa chỉ
PB: lấy chương trình vào bộ nhớ
Chạy đường ống:
F – fetch, lấy chương trình từ IBQ
D – decode, giải mã
AD – address, địa chỉ
AC1 – accesss 1, truy cập 1
AC2 – accesss 2, truy cập 2
R – read, đọc
X – execute, chạy
Clock

47
|| rpt #15
AU, PU va DU đều có thể đưa vào hoạt động song song. Việc hiểu rõ các thanh ghi bên trong mỗi đơn vị này sẽ giúp chúng ta tránh được các xung đột tiềm tàng khi sử dụng các lệnh song song.
3.6 Tập lệnh TMS320C55x
3.6.1 Lệnh số học
Các lệnh số học là các lệnh sử dụng để thực hiện phép cộng (ADD), trừ (SUB), nhân (MPY). Hầu hết mọi phép tính số học đều có thể chạy có điều kiện. Phối hơp các phép toán này sẽ tạo thành một tập các lệnh mạnh mẽ như phép nhân có nhớ (MAC) và nhân-trừ (MAS). C55x cũng hỗ trợ các phép toán số học chính xác mở rộng như cộng có nhớ, trừ có mượn, chia có dấu, chia không dấu..
3.6.2 Lệnh thao tác bit và logic
Lệnh thao tác logic như AND, OR, NOT, XOR trên các giá trị dữ liệu được sử dụng rất rộng rãi trong chương trình để ra quyết định hoặc điều khiển dòng chạy chương trình.
Các lệnh thao tác trên bit được thực hiện trên từng bit hoặc trên cặp bit của thanh ghi hoặc vùng nhớ dữ liệu. Các lệnh này bao gồm lệnh đặt bit, xóa bit, kiểm tra bit. Tương tự như các phép toán logic, các phép toán trên bit cũng được sử dụng cùng với phép toán logic trong việc hỗ trợ ra quyết định.
3.6.3 Lệnh dịch chuyển
Lệnh dịch chuyển (mov) được sử dụng để sao chép giá trị dữ liệu giữa các thanh ghi, vùng nhớ, từ thanh ghi vào vùng nhớ hoặc ngược lại.
3.6.4 Lệnh điều khiển luồng chương trình
Các lệnh điều khiển luồng chương trình được sử dụng để điều khiển dòng chạy của chương trình, bao gồm rẽ nhánh (B), gọi hàm con (CALL), chạy vòng lặp (RPTB), trở về hàm gọi (RET).. Tất cả các lệnh này đều là chạy có điều kiện hoặc vô điều kiện.
Nhiều ứng dụng DSP thời gian thực cần thực hiện một số lệnh lặp đi lặp lại. Nếu số lượng lệnh xử lý dữ liệu bên trong vòng lặp là nhỏ, thì tỉ lệ phần trăm chi phí cho điều khiển lặp sẽ rất cao. Các lệnh điều khiển lặp như kiểm tra và cập nhật biến đếm, con trỏ, và rẽ nhánh về đầu vòng lặp có thể sẽ gây chi phí lớn cho bộ xử lý. C55x có một cơ chế phần cứng được cài sẵn để giảm thiểu các chi phí vòng lặp này.

48
3.7 Lập trình hỗn hợp C và Assembly
Việc sử dụng hỗn hợp ngôn ngữ C và Assembly đã rất phổ biến trong các ứng dụng DSP. Ngôn ngữ C dễ bảo trì và có tính khả chuyển cao, còn assembly lại có ích lợi về mặt hiệu năng chạy và mật độ mã. Ta có thể phát triển các hàm C và thủ tục assembly và sử dụng chúng cùng với nhau. Các thủ tục assembly được gọi bởi hàm C cũng có thể có tham số và giá trị trả về giống như hàm C. Một số điểm chú ý khi viết mã assembly gọi bởi hàm C bao gồm:
a) Cách đặt tên: Nên sử dụng dấu gạch dưới (_) ở đầu tên các biến và thủ tục mà sẽ truy cập bởi hàm C, ví dụ tên hàm _my_asm_func và tên biến _my_var. Tiền tố gạch dưới (_) chỉ được sử dụng cho trình biên dịch C. Khi ta gọi hàm hoặc biến này trong C, ta không cần sử dụng tiền tố gạch dưới (_) nữa:
externint my_asm_func; /*Tham chieu toi ham assembly*/ void main(){ int c = my_asm_func(); /*Goi ham assembly*/ }
Chương trình C này gọi tới thủ tục assembly sau:
.global _my_asm_func ; Định nghĩa hàm assembly _my_asm_func ; Đặt tên thủ tục
mov #0x1234, T0 ret ; Trở về
b) Định nghĩa biến: Các biến mà được truy cập bởi cả hàm C và assembly cần phải được định nghĩa toàn cục, sử dụng chỉ thị .global, .def hoặc .ref.
c) Chế độ biên dịch: Khi sử dụng trình biên dịch C, bit CPL (chế độ biên dịch) của C55x sẽ tự động được bật để sử dụng chế độ địa chỉ tương đối con trỏ ngăn xếp (SP) khi đi vào một thủ tục assembly. Các chế độ địa chỉ gián tiếp sẽ được ưa thích khi sử dụng theo cách này. Nếu ta cần chế độ địa chỉ trực tiếp khi truy cập bộ nhớ dữ liệu trong thủ tục assembly mà có thể gọi bởi hàm C, ta phải chuyển sang chế độ địa chỉ trực tiếp DP. Việc này được thực hiện thông qua việc xóa bit CPL. Tuy nhiên, trước khi thủ tục assembly trở về hàm C, bit CPL cần phải được trả lại giá trị cũ (sử dụng các hàm bật/xóa bit: bclr CPL, bset CPL). Ví dụ sau đây được sử dụng để kiểm tra bit CPL, bật CPL nếu nó đang tắt, và trả lại giá trị CPL trước khi trở về hàm gọi:
btstclr #14, *(ST1), TC1 ; Tắt bit CPL nếu đang bật ... ; Thực hiện các lệnh khác xcc continue, TC1 ; TC1 được bật nếu ta tắt CPL

49
bset CPL ; Bật CPL continue
ret
d) Truyền tham số: Để truyền tham số từ hàm C sang thủ tục assembly, ta cần phải theo quy tắc chặt chẽ của trình biên dịch C. Khi truyền tham số, trình biên dịch C sẽ chỉ định cho nó theo một loại dữ liệu cụ thể và đặt nó vào thanh ghi theo loại dữ liệu đó. Trình biên dịch C C55x sử dụng 3 loại sau đây để xác định loại dữ liệu :
- Con trỏ dữ liệu: int *, long *. - Dữ liệu 16 bit: char, short, int. - Dữ liệu 32 bit: long, float, double, hoặc con trỏ hàm.
Nếu tham số là con trỏ tới bộ nhớ dữ liệu, chúng sẽ được đối xử như là con trỏ dữ liệu. Nếu tham số có thể nhét vừa vào thanh ghi 16bit như là kiểu inthay kiểu char, nó sẽ được xem như là dữ liệu 16 bit, ngược lại, nó sẽ được xem là dữ liệu 32 bit. Tham số cũng có thể là các cấu trúc. Một cấu trúc 32 bit hoặc ít hơn thì sẽ được xem là tham số dữ liệu 32 bit, và được truyền qua thanh ghi 32 bit. Đối với cấu trúc lớn hơn 32 bit, nó sẽ được truyền thông qua tham chiếu. Trình biên dịch sẽ truyền địa chỉ của cấu trúc như một con trỏ, và con trỏ này được truyền giống như tham số dữ liệu.
Đối với việc gọi thủ tục con, các tham số được chỉ định tới thanh ghi theo thứ tự mà nó được liệt kê trong hàm. Chúng được đặt vào các thanh ghi tùy theo loại dữ liệu, và theo thứ tự như bảng 3.5.
Bảng 3-3: Gán các loại tham số tới thanh ghi
Loại tham số Thứ tự thanh ghi
Con trỏ dữ liệu 16 bit AR0, AR1, AR2, AR3, AR4
Con trỏ dữ liệu 23 bit XAR0, XAR1, XAR2, XAR3, XAR4
Dữ liệu 16 bit T0, T1, AR0, AR1, AR2, AR3, AR4
Dữ liệu 32 bit AC0, AC1, AC2
e) Giá trị trả về: Hàm gọi sẽ thu thập giá trị trả về của hàm được gọi. Một giá trị dữ liệu 16 bit sẽ được trả lại bởi T0 và 32 bit thì được trả lại bởi AC0. Con trỏ dữ liệu thì được trả về ở AR0 hoặc XAR0. Nếu hàm được gọi trả về một cấu trúc thì cấu trúc đó nằm ở stack cục bộ.
f) Sử dụng và duy trì thanh ghi: Khi tạo một lời gọi hàm, việc sử dụng và duy thì thanh ghi giữa hàm gọi và hàm được gọi được xác định rất chặt chẽ.

50
Bảng 3-4 mô tả cách thức thanh ghi được duy trì trong suốt quá trình gọi hàm. Hàm được gọi phải bảo lưu nội dung của các ghi được sử dụng. Hàm gọi cũng phải lưu lại nội dung của mọi thanh ghi vào stack nếu nội dung này cần dùng đến sau khi gọi hàm con.
Bảng 3-4: Sử dụng và duy trì thanh ghi
Thanh ghi Duy trì bởi Sử dụng cho
AC0-AC2 Hàm gọi, lưu khi gọi hàm con dữ liệu 16, 32, 40 bit
con trỏ mã 24 bit
AR0-AR4 Hàm gọi, lưu khi gọi hàm con dữ liệu 16 bit,
con trỏ 16 , 23 bit
T0, T1 Hàm gọi, lưu khi gọi hàm con dữ liệu 16 bit
AC3 Hàm được gọi, lưu khi bắt đầu vào hàm
dữ liệu 16, 32, 40 bit
AR5-AR7 Hàm được gọi, lưu khi bắt đầu vào hàm
dữ liệu 16 bit
con trỏ 16, 23 bit
T2, T3 Hàm được gọi, lưu khi bắt đầu vào hàm
dữ liệu 16 bit

51
Chương 4 - CÀI ĐẶT VÀ THỬ NGHIỆM
Dựa trên các kết quả nghiên cứu lý thuyết về nén thoại và mô hình nén thoại MELP, chương 4 này sẽ giới thiệu một cài đặt mô hình MELP thời gian thực song-công 2400 bps trên chip TMS320C5509 DSP.
Các thử nghiệm được tiến hành để đánh giá chất lượng nén thoại vởi các mẫu tiếng Việt và tiếng Anh sử dụng thiết bị nghe trực tiếp và phương pháp khách quan ITU P.862 PESQ. Qua các thử nghiệm cho thấy cài đặt này không những đáp ứng được các yêu cầu chuẩn cho mô hình MELP (MIL-STD-3005) mà còn có thể cung cấp một giải pháp hiệu quả ngang với các sản phẩm MELP đã có trên thị trường.
Mô hình MELP đã được giới thiệu và chuẩn hóa từ năm 1997 qua chuẩn MIL-STD-3005. Nó cũng được nâng cấp và chuẩn hóa lại dưới cái tên mới MELPe bổ sung một số đặc điểm: tỉ lệ nén 1200bps, cải thiện quá trình mã hóa và giải mã, tiền xử lý nhiễu để giảm nhiễu nền, có thể chuyển đổi giữa tốc độ 2400bps và 1200bps và bổ sung thêm 1 bộ lọc hậu kì. Các thử nghiệm ở đây chỉ sử dụng mô hình MELP theo chuẩn MIL-STD-3005.
4.1 Cài đặt MELP thời gian thực trên C5509 và C5510.
[1] Mô hình hệ thống được sử dụng để phát triển MELP và mô hình thời gian thực được thể hiện trên hình 4-1 và 4-2 tương ứng sau đây:
Hình 4-1: Mô hình hệ thống cho phát triển mô hình MELP
Trong họ C5000 thì C5509 (tên đầy đủ là TMS320VC5509A) và C5510 (tên đầy đủ là TMS320VC5510A0 là những sản phẩm mạnh mẽ nhất, với một kiến trúc DSP phức tạp dựa trên cơ chế song song và giảm điện năng tiêu thụ,
Môi trường phát triển CCS
- Phân tích hiệu năng (MIPS, CPU, thời gian tiêu thụ)
- Điều chỉnh thuật toán, đánh giá chất lượng thoại (PESQ, SNR)
- Điều chỉnh cài đặt, tham số / biên dịch lại,
kiểm soát tài nguyên
Kênh giả lập
Mã hóa MELP
Giải mã MELP
Kênh giả lập
DSK board

52
chúng có thể thực hiện hiệu quả và trong thời gian thực các thuật toán có độ phức tạp cao. Một số đặc trưng phần cứng chủ yếu như cấu trúc bus phức tạp gồm 1 đường chương trình, 3 đường đọc dữ liệu, 2 đường ghi dữ liệu và 1 đường ngoài cho ngoại vi và DMA. Cả C5509 và C5510 đều có tập hợp các ngoại vi như bộ Timer, McBSP, DMA và Bộ sinh nhịp đồng hồ lặp khóa pha khả trình, nhưng C5509 thì có thêm giao diện USB 1.1 và I2C, còn C5510 lại được tăng cường dung lượng nhớ onchip: 64Kb DARAM, 256Kb SARAM.
Thiết bị phần cứng được sử dụng là C5509 và C5510 DSP Starter Kit (DSK). DSK này ngoài DSP C5509 và C5510 thì còn cung cấp thêm các ngoại vi hữu ích như bộ codec (TLV320AIC23B) 4 cổng 3.5mm, các công tắc, đèn led, và SDRAM được tăng cường.
Hình 4-2: Mô hình triển khai thời gian thực trực tuyến
4.2 Thực hiện cài đặt
Thuật toán MELP được viết với trên công cụ Code composer studio 3.3. Gói dự án bao gồm các tệp tiêu đề, tệp mã nguồn C và các tệp hỗ trợ biên dịch. Bảng dưới đây liệt kê một số tên tệp và mô tả chức năng chủ yếu của chúng trong dự án.
Bảng 4-1: Một số tệp chính của dự án
Tên tệp Mô tả chức năng
coeff.c Chứa các tham số bộ lọc
complex.c Chứa các hàm tính toán độ phức tạp
fec_code.c
fec_decode.c
Chứa các hàm mã hóa và giải mã FEC (Hamming codes) dựa trên các tham số MELP cho trước
dsp_sub.c Chứa các hàm con tổng quát của hệ thống
fs_lib.c Chứa các hàm con của chuỗi Fourier
lpc_lib.c Chứa các biến, cấu trúc, macro và hàm con của LPC
mat_lib.c Thư viện các hàm thao tác ma trận và véc-tơ
Đường vào
Mã hóa MELP
Giải mã MELP
DSK board
Đường ra
Nguồn âm Tai nghe

53
melp.h Chứa khai báo các MACRO, cấu trúc và nguyên mẫu hàm cho MELP
melp_ana.c Chứa các hàm phân tích MELP, nhận đầu vào là tín hiệu âm thanh, đầu ra sẽ là cấu trúc tham số MELP
melp_chn.c Chứa các hàm xử lý dòng bit để đọc/ghi MELP
melp_sub.c Chứa các hàm con đặc biệt của MELP
melp_sync.c Chứa các hàm tổng hợp MELP, chịu trách nhiệm nhận các tham số mới của một khung thoại và tổng hợp ra tiếng nói.
pit_lib.c Chứa các hàm phân tích Pitch
dsk_app.c Chứa hàm main và các hàm khởi tạo ngắt, DMA..
4.2.1 Một số tệp phụ trợ quan trọng
Tệp coeff.c chứa các ma trận tham số cho bộ lọc như lpf_num[], lpf_den[], ma trận tham số bộ lọc băng thông Butterworth bậc 2: bpf_num[], bpf_den[], ma trận các tham số cửa sổ Hamming: win_cof[], ma trận tham số bộ lọc băng thông bf_cof[], ma trận tham số bộ lọc xung tam điểm disp_cof[].
Tệp complex.c chứa các hàm tính toán độ phức tạp, bao gồm: hàm complexity_count()tính toán số đếm tối đa cho chỉ số hiện thời, hàm complexity_reset() sẽ thiết lập lại các bộ đếm, hàm complexity_print() sẽ in ra độ phức tạp cuối cùng.
/* Complexity_count: update max counter for current index */ int complexity_count() { long temp; /* Check maximum complexity for current index */ temp = complexity - prev_complexity; if (temp > cm_max[cm_index]) cm_max[cm_index] = temp; /* Check for saturations */ temp = saturation - prev_saturation; if (temp > 0) { sat_cnt[cm_index] += temp; printf("%d saturations in frame %d, index %d\n", (int) temp, (int) frame, (int) cm_index); } /* Increment index and previous value */ cm_index++; prev_complexity = complexity; prev_saturation = saturation; /* Check overall total complexity */ if (complexity > max_complexity)

54
max_complexity = complexity; return(0); }
Tệp dsp_sub.c chứa các hàm con dùng chung cho cả dự án, bao gồm một số hàm như envelope()dùng để tính toán thời gian đóng gói tín hiệu, hàm pack_code()/unpack_code()dùng cho đóng gói/bung gói các mã bit lên/từ kênh truyền, hàm median() tính giá trị trung vị, hàm peakiness() ước lượng đỉnh của tín hiệu đầu vào, hàm readdbl()/writedbl() dùng để đọc/ghi các khối dữ liệu vào/ra, hàm iir_2nd_*() cài đặt bộ lọc IIR bậc 2..
void pack_code(Shortword code, UShortword **p_ch_beg,Shortword *p_ch_bit, Shortword numbits, Shortword wsize) { Shortword i,ch_bit; UShortword *ch_word; ch_bit = *p_ch_bit; ch_word = *p_ch_beg; for (i = 0; i < numbits; i++) { /* Mask in bit from code to channel word */ if (ch_bit == 0) *ch_word = (UShortword)(shr((Shortword)(code & (shl(1,i))),i)); else *ch_word |= (UShortword)(shl((shr((Shortword)(code & (shl(1,i))),i)),ch_bit)); /* Check for full channel word */ ch_bit = add(ch_bit,1); if (ch_bit >= wsize) { ch_bit = 0; (*p_ch_beg)++ ; ch_word++ ; } } /* Save updated bit counter */ *p_ch_bit = ch_bit; }
Tệp mat_lib.c chứa các hàm thao tác ma trận và véc-tơ, bao gồm một số hàm như v_add() thực hiện phép cộng, trừ, nhân hai véc-tơ 16 bit, 32 bit; sao chép nội dung 2 véc-tơ 16 bit, 32 bit..
// Hàm cộng hai véc-tơ 16 bit :) Shortword *v_add(Shortword *vec1,Shortword *vec2,Shortword n) { Shortword i;

55
#if(USE_TMS320) for(i=0; i < n; i++) vec1[i] = _sadd(vec1[i],vec2[i]); //
return(vec1); #else for(i=0; i < n; i++) vec1[i] = add(vec1[i],vec2[i]); return(vec1); #endif }
Tệp pit.h và pit_lib.c chứa các hàm xử lý pitch như: hàm double_chk() kiểm tra trùng lặp và đồng thời tìm kiếm các pitch ngắn, hàm f_pitch_scale() khuếch đại bộ đệm tín hiệu pitch để có được độ chính xác tốt nhất, hàm find_pitch() để tìm kiếm pitch, hàm frac_pch() xác định giá trị pitch phân đoạn, hàm pitch_ana()phân tích và tìm kiếm ứng viên pitch..
4.2.2 Các tệp chính của MELP
Tệp melp.h chứa cấu trúc tham số của MELP và khai báo nguyên mẫu các hàm được sử dụng cho MELP. Cấu trúc tham số được định nghĩa như sau:
struct melp_param { /* MELP parameters */ Shortword pitch; /* Q7 */ Shortword lsf[LPC_ORD+1]; /* Q15 */ Shortword gain[NUM_GAINFR]; /* Q8 */ Shortword jitter; /* Q15 */ Shortword bpvc[NUM_BANDS]; /* Q14 */ Shortword pitch_index; Shortword lsf_index[LPC_ORD]; Shortword jit_index; Shortword bpvc_index; Shortword gain_index[NUM_GAINFR]; UShortword *chptr; Shortword chbit; Shortword uv_flag; Shortword fs_mag[NUM_HARM]; /* Q13 */ Shortword *fsvq_index; Shortword *msvq_index; Shortword msvq_stages; Shortword *msvq_bits; Shortword *msvq_levels; };
Các tệp melp_ana.c, melp_sub.c,melp_chn.c, melp_syn.c chứa hàm chính để thực thi mô hình MELP bao gồm: hàm melp_ana()và melp_ana_init() để phân tích MELP với đầu vào là tín hiệu âm thanh vào, đầu ra là cấu trúc tham số

56
MELP; hàm melp_chn_write() và melp_chn_read() dùng để ghi và đọc dòng bit của thuật toán MELP, với đầu vào là cấu trúc tham số MELP và đầu ra là cấu trúc tham số đã được cập nhật;
void melp_chn_write(struct melp_param *par) { Shortword i, bit_cntr; UShortword *bit_ptr; /* FEC: code additional information in redundant indeces */ fec_code(par); /* Fill bit buffer */ bit_ptr = bit_buffer; bit_cntr = 0; pack_code(par->gain_index[1],&bit_ptr,&bit_cntr,5,1); /* Toggle and write sync bit */ if (sync_bit) sync_bit = 0; else sync_bit = 1; pack_code(sync_bit,&bit_ptr,&bit_cntr,1,1); pack_code(par->gain_index[0],&bit_ptr,&bit_cntr,3,1); pack_code(par->pitch_index,&bit_ptr,&bit_cntr,PIT_BITS,1); pack_code(par->jit_index,&bit_ptr,&bit_cntr,1,1); pack_code(par->bpvc_index,&bit_ptr,&bit_cntr,NUM_BANDS-1,1); for (i = 0; i < par->msvq_stages; i++) pack_code(par->msvq_index[i],&bit_ptr,&bit_cntr,par->msvq_bits[i],1); pack_code(par->fsvq_index[0],&bit_ptr,&bit_cntr, FS_BITS,1); /* Write channel output buffer */ for (i = 0; i < NUM_CH_BITS; i++) { pack_code(bit_buffer[bit_order[i]],&par->chptr,&par->chbit, 1,CHWORDSIZE); if (i == 0) *(par->chptr) |= (UShortword)0x8000; /* set beginning of frame bit */ } }
Các hàm bpvc_ana() và bpvc_ana_init() dùng để phân tích băng thông với đầu vào là tín hiệu âm thanh vào và ước lượng pitch ban đầu, với đầu ra là quyết định băng thông và ước lượng pitch khung.
Hàm gain_ana() dùng để phân tích các mức gain cho tín hiệu đầu vào với đầu vào là tín hiệu vào, giá trị pitch, độ dài cửa sổ tối đa và tối thiểu, trả lại giá trị gain tính bằng đơn vị dB. Hàm q_gain() và q_gain_dec() dùng để lượng tử hóa và giải mã hai toán hạng gain sử dụng mã hóa tiệm cận sai phân.
Hàm melp_syn()và melp_syn_init()dùng để tổng hợp tiếng nói của MELP, nó sử dụng các tham số cho một khung và tổng hợp thành tiếng nói đầu ra.

57
4.2.3 Tệp chính
Tệp dsk_app.c chứa hàm main() và một số hàm điều khiển chính để chạy trên mạch TMS320C55X DSK như hàm khởi tạo ngắt, hàm khởi tạo DMA..
Hàm initMcbsp() dùng để khởi tạo McBSP để truyền dữ liệu codec.
void initMcbsp( ) { /* Open the codec data McBSP */ #if (USE_DSK5509A) hMcbsp = MCBSP_open( MCBSP_PORT0, MCBSP_OPEN_RESET ); #else hMcbsp = MCBSP_open( MCBSP_PORT1, MCBSP_OPEN_RESET ); #endif /* Configure the codec to match the AIC23 data format */ MCBSP_config( hMcbsp, &mcbspCfg0 ); /* Clear any garbage from the codec data port */ if ( MCBSP_rrdy( hMcbsp ) ) MCBSP_read16( hMcbsp ); /* Start the McBSP running */ MCBSP_start( hMcbsp, MCBSP_XMIT_START | MCBSP_RCV_START | MCBSP_SRGR_START | MCBSP_SRGR_FRAMESYNC, 220 ); }
Hàm initIrq() dùng để khởi tạo và cho phép DMA có thể nhận ngắt sử dụng CSL. Hàm dịch vụ ngắt cho ngắt này là hwiDma(). Việc gắn một ID sự kiện với một ngắt kênh DMA cho phép mã mô tả một sự kiện logic có thể ánh xạ tới một sự kiện vật lý thực sự trong thời gian chạy. Điều này giúp cải thiện tính khả chuyển của mã.
void initIrq( void ) { eventIdRcv = DMA_getEventId( hDmaRcv ); eventIdXmt = DMA_getEventId( hDmaXmt ); /* Clear any pending receive channel interrupts ( IFR ) */ IRQ_clear( eventIdRcv ); IRQ_clear( eventIdXmt ); /* Enable receive DMA interrupt ( IMR ) */ IRQ_enable( eventIdRcv ); IRQ_enable( eventIdXmt ); /* Make sure global interrupts are enabled */ IRQ_globalEnable( ); }

58
Các hàm setDmaSrc() và setDmaDst() dùng để thiết lập địa chỉ nguồn và đích DMA. Hàm initDma() dùng để khởi tạo trình điều khiển DMA.
Hàm dmaHwiRcv() là hàm dịch vụ ngắt cho việc nhận DMA. Nó sẽ được gọi khi nào một khung hoàn chỉnh của dữ liệu đã được nhận đủ từ codec và đã sẵn sàng trên bộ nhớ. Hàm dmaHwiXmt() là hàm dịch vụ ngắt cho việc truyền DMA. Nó được gọi khi một khung hoàn chỉnh của dữ liệu được truyền hết cho codec.
void dmaHwiRcv( void ) { Int16 bufin = gRcvBuf; /* Set DMA destination to next buffer */ if ( ++gRcvBuf >= BUFFERS ) gRcvBuf = 0; setDmaDst( hDmaRcv, gRcvBuf ); /* Restart DMA */ DMA_start( hDmaRcv ); /* Notify processBufferSwi( ) that there is data to process */ SWI_or( &processBufferSwi, bufin ); /* Read DMA status register to clear it so new interrupts will be seen */ DMA_RGETH( hDmaRcv, DMACSR ); }
Hàm main() thực hiện khởi tạo ứng dụng và truyền dữ liệu.
#if (WORK_ONLINE) // global variables for fixed-point library int saturation = 0; void main( ) { //MELP melp_ana_init(); melp_syn_init(); melp_par.chptr = chbuf; melp_par.chbit = 0; #if (!USE_DYNMEM) //Scratch memory management scrpointer = scrbuf; scrmem_depth = scrbuf; #endif #if USE_DSK5509A /* Initialize the board support library, must be called first */

59
DSK5509_init( ); // Initialize LEDs and DIP switches DSK5509_LED_init(); DSK5509_DIP_init(); DSK5509_LED_off(0); /* Enable codec data path */ DSK5509_rset( DSK5509_MISC, 1 ); /* Configure the codec */ AIC23_setParams( &config ); #else /* Initialize CSL library - This is REQUIRED !!! */ CSL_init(); GPIO_pinDirection(GPIO_PIN7, GPIO_OUTPUT); flag = 0; GPIO_pinWrite(GPIO_PIN7, flag); GPIO_pinDirection(GPIO_PIN6, GPIO_OUTPUT); #endif //Reference clock is 12 Mhz PLL_setFreq (12, 1); //144 Mhz /* Clear buffers */ memset( ( void * )gBuffer, 0, BUFFSIZE * BUFFERS ); /* Disable global interrupts during setup */ IRQ_globalDisable( ); /* Initialize the EDMA controller */ initDma( ); /* Initialize McBSP0 for audio transfers */ initMcbsp( ); /* Initialize interrupts */ initIrq( ); /* Re-enable global interrupts */ IRQ_globalEnable( ); } #endif
4.3 Đánh giá kết quả
Có một số phương pháp đánh giá chất lượng của mô hình nén tiếng nói. Đó là phương pháp khách quan với sự tham gia của con người (như phương pháp chấm điểm trung bình MOS), hoặc là phương pháp khách quan không có sự tham gia của con người (ví dụ như phương pháp đánh giá cảm quan về chất lượng thoại PESQ). Một trong những phương pháp đo chủ quan được sử dụng phổ biến nhất là Chấm điểm trung bình MOS, ở đó có những người nghe (thính giả) đã được huấn luyện và có kinh nghiệm sẽ đánh giá tín hiệu thoại theo thang điểm từ 1 tới 5 như trong bảng 4-2. Điểm cuối cùng của tín hiệu sẽ được tính bằng giá trị trung bình của tất cả các thính giả.

60
Bảng 4-2: Bảng cho điểm MOS
Điểm Chất lượng thoại Mức độ biến dạng
5 Xuất sắc Không nhận thấy
4 Tốt Cảm nhận được, nhưng không gây phiền
3 Khá Cảm nhận được và hơi khó chịu
2 Trung bình Khó chịu nhưng không phản đối
1 Kém Rất khó chịu và phản đối
Mặc dù phương pháp đo chủ quan có thể là rất đáng tin cậy nhưng chúng tốt nhiều thời gian và cần các thính giả phải được huấn luyện. Vì thế, người ta thường dùng phương pháp khách quan. Một điểm hạn chế của các phép đo khách quan là cần phải có tiếng nói rõ ban đầu để làm tham chiếu so sánh, do những hạn chế trong việc hiểu biết về cảm nhận âm thanh của con người, đặc biệt trong điều kiện có nhiễu. Tuy thế, phương pháp khách quan vẫn có nhiều hữu ích và có tương quan tốt so với phương pháp chủ quan như MOS.
Trong chương 4 này, phương pháp khách quan đánh giá cảm nhận chất lượng thoại PESQ đã được lựa chọn để đánh giá hiệu năng của mô hình nén thoại MELP. PESQ được thiết kế trực tiếp để truy cập vào chất lượng tiếng nói nhận được trên đường truyền. Phép đo này chấm điểm tương tự như MOS, cho kết quả từ 1 tới 4.5, điểm càng cao thì chất lượng càng tốt.
Hình 4-3: Mô hình tổng quát của một phương pháp đo phổ biến
Hình 4-3 cho thấy mô hình tổng quát của phương pháp đo phổ biến; tuy nhiên, các thí nghiệm được tiến hành mà không có nhiễu (và sau đó là SNR) và các kênh được giả thiết là lý tưởng (khối trong đường nét đứt trong hình 4-3 đã không xem xét).
Do các vectơ thử nghiệm để đánh giá cài đặt MELP rất khó để có được công khai, và thời gian hạn chế, nên chỉ có một số mẫu tiếng Anh hoặc tiếng
Mô phỏng kênh
Mã hóa
Giải mã
Đo đạc chất lượng
MOS, PESQ
Nhiễu
SNR
Tín hiệu thoại
rõ
Tham khảo

61
Việt đã được sử dụng để đánh giá cài đặt MELP trên C55x. Hơn nữa, cũng chưa có bất kỳ cơ sở dữ liệu âm thanh tiếng Việt nào để đánh giá các thuật toán xử lý tiếng nói chung và mã hóa nói riêng, trong khi đó đã có cơ sở dữ liệu tiếng Anh khác nhau được tiêu chuẩn hóa, đủ lớn và sử dụng rộng rãi như AURORA, TIMIT, ITU P50. Do đó, ở đây tác giả cùng các cộng sự đã phải tự ghi lại một số câu tiếng Việt tại chỗ dùng làm dữ liệu kiểm tra. Tuy nhiên, để có thể so sánh hiệu suất của C55x MELP với một số sản phẩm MELP khác trên thị trường (MELP của Sinalogic [5] hoặc của Vocal [6]), một số mẫu tiếng Anh được lấy trực tiếp từ các trang web của họ; bao gồm cả tệp âm thanh gốc và tệp âm thanh đã xử lý. Cụ thể, 6 câu ở tỷ lệ lấy mẫu 8000 mẫu/giây và được lượng tử hóa 16bit được đưa vào đánh giá (xem bảng 4-3), trong đó ngoại trừ Vn_M.wav và Vn_F.wav là ngắn, các tập tin còn lại là đủ dài để bao gồm các âm thanh khác nhau.
Bảng 4-3: Mẫu âm thanh dùng để đánh giá
Thứ tự Tên tệp Ngôn ngữ Nam/nữ
1 Eng_M.wav [5] Tiếng Anh Nam
2 Eng_F.wav [5] Tiếng Anh Nữ
3 Vn_M.wav Tiếng Việt Nam
4 Vn_F.wav Tiếng Việt Female
5 Vov1.wav Tiếng Việt Female
6 reference_64p0k.wav [6] Tiếng Anh Cả hai
Bảng 4-4 cho thấy so sánh điểm của PESQ đối với cài đặt C55x MELP và các sản phẩm thương mại khác.
Bảng 4-4: Đánh giá PESQ của cài đặt C55x MELP
Thứ tự Tên tệp C55x MELP Sản phẩm
thương mại
1 Eng_M.wav 2.641 2.666 [13]
2 Eng_F.wav 2.384 2.445 [13]
3 Vn_M.wav 2.631 -
4 Vn_F.wav 2.267 -
5 Vov1.wav 2.713 -
6 reference_64p0k.wav 3.106 2.970 (*)
(*): Tính điểm bằng công cụ ITU P.862.
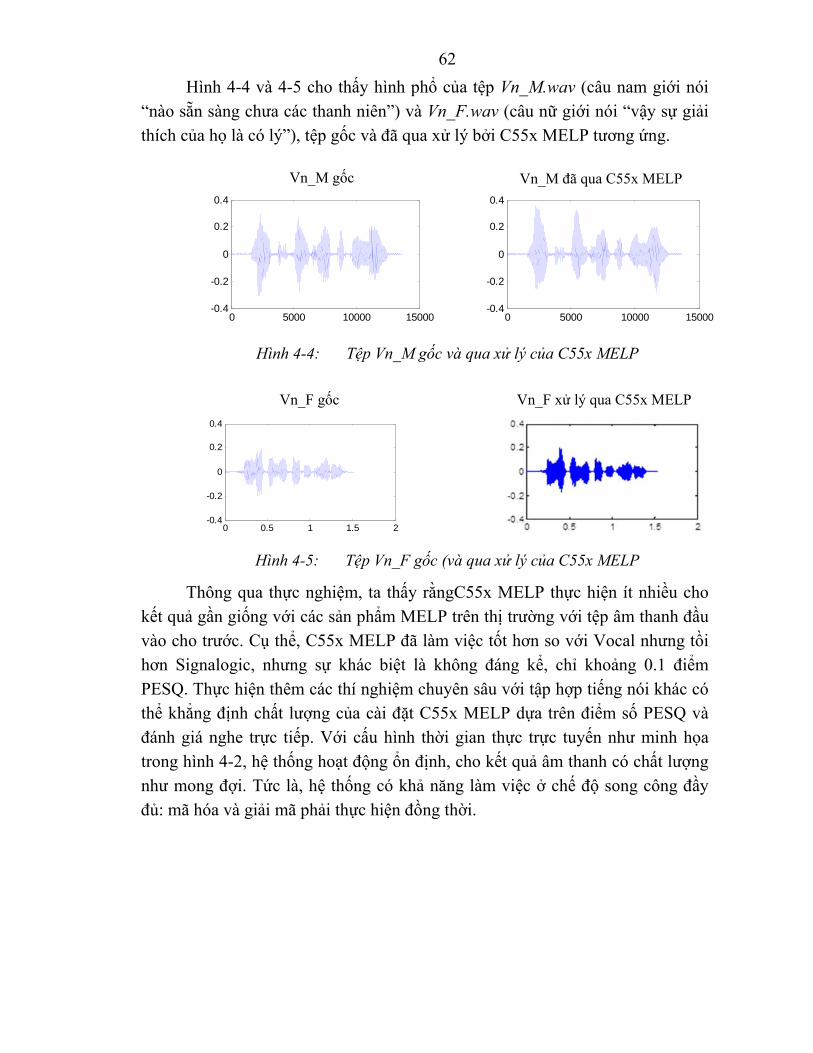
62
Hình 4-4 và 4-5 cho thấy hình phổ của tệp Vn_M.wav (câu nam giới nói “nào sẵn sàng chưa các thanh niên”) và Vn_F.wav (câu nữ giới nói “vậy sự giải thích của họ là có lý”), tệp gốc và đã qua xử lý bởi C55x MELP tương ứng.
Hình 4-4: Tệp Vn_M gốc và qua xử lý của C55x MELP
Hình 4-5: Tệp Vn_F gốc (và qua xử lý của C55x MELP
Thông qua thực nghiệm, ta thấy rằngC55x MELP thực hiện ít nhiều cho kết quả gần giống với các sản phẩm MELP trên thị trường với tệp âm thanh đầu vào cho trước. Cụ thể, C55x MELP đã làm việc tốt hơn so với Vocal nhưng tồi hơn Signalogic, nhưng sự khác biệt là không đáng kể, chỉ khoảng 0.1 điểm PESQ. Thực hiện thêm các thí nghiệm chuyên sâu với tập hợp tiếng nói khác có thể khẳng định chất lượng của cài đặt C55x MELP dựa trên điểm số PESQ và đánh giá nghe trực tiếp. Với cấu hình thời gian thực trực tuyến như minh họa trong hình 4-2, hệ thống hoạt động ổn định, cho kết quả âm thanh có chất lượng như mong đợi. Tức là, hệ thống có khả năng làm việc ở chế độ song công đầy đủ: mã hóa và giải mã phải thực hiện đồng thời.
0 5000 10000 15000-0.4
-0.2
0
0.2
0.4Vn_M original speech
Vn_M gốc
0 5000 10000 15000-0.4
-0.2
0
0.2
0.4MELP processed Vn_M speech
Vn_M đã qua C55x MELP
0 0.5 1 1.5 2-0.4
-0.2
0
0.2
0.4Vn_F original speech
Vn_F gốc Vn_F xử lý qua C55x MELP

63
KẾT LUẬN
Kết quả đạt được của luận văn
Luận văn này đã thực hiện nghiên cứu lý thuyết về mô hình nén thoại trong xử lý tiếng nói, đặc biệt đi sâu vào mô hình MELP, từ đó triển khai cài đặt thời gian thực mô hình MELP trên chip TMS320C55X DSP.
Chương 4 của luận văn mô tả triển khai cài đặt thời gian thực MELP trên mạch xử lý tín hiệu số TMS320C5509A DSK với chương trình được viết trên Code composer studio 3.3.
Các kết quả thử nghiệm cho thấy triển khai thời gian thực này đã hoạt động hiệu quả và cho kết quả có thể so sánh được với một số sản phẩm MELP thương mại: C55x MELP có khả năng tạo ra tiếng nói có chất lượng tốt, song-công trong thời gian thực với hiệu năng cao ở tốc độ 2400bps.
Kết quả của nghiên cứu triển khai thời gian thực MELP trên TMS320VC55x cũng đã được tổng hợp thành bài báo khoa học đăng trên Tạp chí Nghiên cứu KH &CN quân sự, số 02-2014 [1].
Định hướng nghiên cứu tiếp theo
Bên cạnh kết quả đạt được, vẫn còn một số vấn đề cần giải quyết sâu hơn. Thứ nhất, ta cần có cơ sở dữ liệu tiếng nói lớn hơn để thử nghiệm, đặc biệt là cơ sở dữ liệu tiếng Việt, để có thể chứng minh rõ ràng hiệu năng của cài đặt này.
Thứ hai, trong luận văn này chỉ đánh giá kết quả so sánh C55x MELP với các sản phẩm thương mại khác dựa trên chất lượng tiếng nói, còn những vấn đề khác như độ phức tạp (trên cùng một nền tảng phần cứng) và tiêu hao tài nguyên thì cần những nghiên cứu sâu hơn.
Thứ ba, việc tinh chỉnh và tối ưu cài đặt là cần thiết để chứng minh chất lượng tiếng nói, tăng cường hiệu năng và giảm thiểu tiêu hao tài nguyên có thể dẫn tới cài đặt nhiều MELP trên cùng một chip DSP.
Một hướng nghiên cứu khác là khai thác thuật toán MELP nâng cao (MELPe, NATO STANAG-4591) cho tốc độ dữ liệu thấp hơn (không chỉ 2400bps mà còn hỗ trợ 1200bps, 600bps) và cho chất lượng thoại tốt hơn.

64
TÀI LIỆU THAM KHẢO
Bài báo liên quan
1. Phạm Văn Hậu, Đinh Văn Ngọc, Nguyễn Anh Đức, Thái Trung Kiên (2014), Real-time Implemetation of MELP vocoder on TI fixed-point TMS320C55X DSP, Tạp chí Nghiên cứu KH&CN Quân sự, 02-2014, p7-15.
Tài liệu tham khảo
2. Sen M Kou, Bob H Lee (2001), Real-Time Digital Signal Processing – Implementations, Aplications and Experiments with the TMS320C55X, A JOHN WILEY & SONS, INC., PUBLICATION, p35-75.
3. USDoD,MIL-STD-3005,Department of Defense Telecommunications Systems Standard, 1999.
4. Wai C. Chu (2003), Speech coding algorithms – Foundation and evolution of standardized coders, A JOHN WILEY & SONS, INC., PUBLICATION, chapter 1,9,17, pp 1-32, 264-268, 454-485.
5. MELP product provided by Signalogic http://www.signalogic.com/index.pl?page=codec_samples
6. MELP product provided by Vocal http://www.vocal.com/audio-examples/

i
PHỤ LỤC
A. Mô hình mã hóa dự đoán tuyến tính LPC
Hình A-1: Mô hình tạo tiếng nói LPC
[4] LPC dựa trên mô hình đơn giản hóa để tạo tiếng nói, như mô tả trong hình A-1. Mô hình này xuất phát từ quan sát những tính chất cơ bản của tín hiệu tiếng nói và là một sự nỗ lực để mô phỏng cơ chế tạo tiếng nói của con người. Những kết hợp của thanh quản, khẩu hình môi được thể hiện trong bộ lọc tổng hợp. Tín hiệu đầu vào của bộ lọc hoặc tín hiệu kích thích được mô hình hóa như là các chuỗi xung (tiếng nói có âm) hoặc các nhiễu ngẫu nhiên (tiếng không âm). Do đó, tùy vào trạng thái tín hiệu là có âm hay không âm, một công tắc chuyển sẽ được thiết lập để lựa chọn đầu vào phù hợp. Mức năng lượng của đầu ra được điều khiển bởi tham số gain.
Các mẫu tiếng nói được tách thành các khung rời nhau, và với độ dài khung đủ lớn thì các thuộc tính của tín hiệu sẽ gần như không đổi. Trong mỗi khung, các tham số của mô hình được ước lượng từ các mẫu tín hiệu, bao gồm:
- Voicing: xác định xem khung tiếng nói này là có âm hay không âm. - Gain: liên quan chủ yếu đến mức năng lượng của khung. - Hệ số bộ lọc: đặc tả đáp ứng của bộ lọc tổng hợp. - Pitch period: đối với khung có âm, là khoảng thời gian giữa các xung
kích thích liên tiếp.
Quá trình ước lượng tham số sẽ lặp đi lặp lại ở các khung tạo thành các thông tin đại diện cho khung. Như thế, thay vì phải truyền đi các mẫu PCM, ta chỉ cần truyền đi các tham số của mô hình. Nhờ việc sắp xếp cẩn thận các bit cho từng tham số để giảm thiểu biến dạng ta sẽ có được tỉ lệ nén rất cao.
Bộ tạo chuỗi xung
Công-tắc chuyển
có âm/không âm
Tạo nhiễu trắng
Lọc tổng hợp
Hệ số lọc
Gain
Tiếng
nói
Pitch
Period
Voicing

ii
Việc ước lượng các tham số là trách nhiệm của bộ mã hóa. Bộ giải mã sẽ nhận các tham số này và sử dụng mô hình tạo tiếng nói để tổng hợp ra tiếng nói. Mô hình này sẽ hoạt động thế nào khi mà dạng sóng đầu ra hoàn toàn khác so với tín hiệu ban đầu? Trên thực tế, dạng sóng đầu ra sử dụng cùng một tập hợp tham số còn các điều kiện lọc ban đầu thì khác nhau do nhiễu trắng được tạo ngẫu nhiên. Mật độ phổ của tiếng nói ban đầu đã được bộ lọc tổng hợp thu giữ lại, vì thế mật độ phổ của tiếng nói tổng hợp khá gần với bản gốc nhờ vào phổ phẳng của kích thích đầu vào. Cách tiếp cận này sẽ loại bỏ hết mọi thông tin pha của dạng sóng ban đầu mà chỉ giữ lại biên độ của phổ tần số. Âm thanh của đầu ra tổng hợp sẽ nghe giống như bản gốc, bởi vì đối với người nghe, pha có phạm vi tương đối thấp so với thông tin biên độ.
Dự đoán tuyến tính là một phương pháp thực hành của ước lượng phổ, ở đó mật độ phổ sẽ được giữ lại thông qua các hệ số, những hệ số này được sử dụng để tạo thành bộ lọc tổng hợp. Bộ lọc tổng hợp sẽ tạo hình phổ phẳng của nhiễu đầu vào, để tạo ra mô phỏng của phổ ban đầu. Điều này chỉ đúng đối với kích thích nhiễu trong trường hợp không âm, tuy nhiên, đối với trường hợp có tiếng, đầu vào là chuỗi xung, là một chuỗi các xung cách đều, điều này lại vi phạm giả thiết của mô hình tự hồi quy. Trong mô hình tự hồi quy, tín hiệu kích thích có phổ phẳng, điều đó được thỏa mãn bởi nhiễu trắng hoặc một xung đơn lẻ. Đối với chuỗi các xung, phổ tương ứng khá là phẳng chỉ khi nào khoảng cách giữa các xung là đủ lớn. Sự vi phạm mô hình Tự hồi quy này đối với tín hiệu có âm là một trong những hạn chế cơ bản của mô hình LPC. Chuỗi xung cho kích thích được cho bởi công thức:
[ - ]i
n iT
với 1, 0
[ ]0, 0
nn
n
và T là chu kì, là một hằng số dương. Sử dụng
chuỗi xung tuần hoàn để tạo ra dạng sóng đầu ra tuần hoàn, khi đó tín hiệu đầu ra sẽ có mật độ phổ gần giống với tín hiệu có âm.
Do các hệ số của bộ lọc tổng hợp phải được lượng tử hóa và truyền đi, nên chỉ có một ít trong số đó được tính toán để duy trì bit-rate thấp. Sử dụng dự đoán bậc 10 nói chung là đủ để thu được toàn bộ phổ cần thiết. Bậc dự đoán này là dùng cho các khung không âm. Đối với khung có âm thì ta cần sử dụng bậc cao hơn tùy thuộc vào tương quan của các mẫu khác nhau. Mô hình LPC giải quyết vấn đề này bằng cách sử dụng đầu vào là một chuỗi xung: nếu chu kì của kích thích đầu vào phù hợp với giá trị Pitch period ban đầu, thì chu kì của tiếng

iii
nói tổng hợp với mật độ phổ tương tự như bản gốc. Theo cách này, ta sẽ tránh được dự đoán bậc cao, đảm bảo mục tiêu bit-rate thấp.
B. Thuật toán Levinson-Durbin
[4] Phương trình vi phân tối ưu của LPC được xác định như sau:
1
[ - ] - [ ]M
i s si
a R i k R k
, k = 1,2,...,M
Dưới dạng ma trận, ta có phương trình sau, được gọi là phương trình chuẩn:
s sR a = -r
Trong đó:
[0] [1] [M-1]
[1] [0] [M-2]
... ... ... ...
[ -1] [ - 2] [0]
s s s
s s s
s s s
R R R
R R R
R M R M R
sR
1 2 ...T
Ma a aa
[1] [2] ... [M ]T
s s sR R Rsr
Giả thiết nghịch đảo của ma trận tương quan Rs là tồn tại, véc-tơ LPC tối ưu sẽ là:
-1s sa = -R r
Phương trình này cho phép ta tìm được LPC nếu ta biết được các giá trị tự tương quan của s[n] (tính hiệu Tự hồi quy), với l = 0,1,2,..,M.
Phương trình chuẩn hóa có thể giải được bằng cách tìm ma trận nghịch đảo của Rs. Nói chung, việc nghịch đảo ma trận có thể tính toán tương đối dễ, và có khá nhiều thuật toán để giải phương trình này, dựa vào các ưu điểm về cấu trúc đặc biệt của ma trận tương quan. Phần phụ lục này giới thiệu thuật toán Levinson-Durbin, là một thuật toán tốt và phù hợp cho cài đặt thực tế.
Xét phương trình dưới dạng ma trận:
1
1[0] [1] [M]
[1] [0] [M-1] 0
...... ... ... ... ...
[ ] [ ] [0] 0M
R R R J
aR R R
aR M R M R

iv
Với mục tiêu là xác định nghiệm cho LPC: ai, i=1,2,...,M khi đã biết các giá trị tự tương quan R[i]. J là giá trị sai số dự đoán bình phương trung bình tối thiểu hoặc là phương sai của nhiễu trắng đầu vào của bộ tổng hợp quá trình AR. Trong thực hành, các giá trị tự tương quan được ước lượng từ mẫu tín hiệu và J thì thường chưa biết; tuy nhiên thuật toán Levison-Durbin có thể giải quyết vấn đề này rất tốt.
Thuật toán Levinson-Durbin tìm kiếm nghiệm cho dự đoán bậc M từ dự đoán bậc M-1. Đây là một quá trình lặp đệ quy với nghiệm dự đoán bậc 0 đã được tìm thấy từ đầu, và dừng lặp khi chạm đến bậc mong muốn. Thuật toán này dựa trên hai tính chất cơ bản của ma trận tương quan:
- Ma trận tương quan với kích thước cho trước chứa các khối con đều là các ma trận tương quan bậc thấp hơn.
- Thứ hai, nếu
0 0
1 1
[0] [1] [M]
[1] [0] [M-1]
... ...... ... ... ...
[ ] [ ] [0] M M
a bR R R
a bR R R
a bR M R M R
Thì:
11 1
0 0
[0] [1] [M]
[1] [0] [M-1]
... ...... ... ... ...
[ ] [ ] [0]
M M
M M
a bR R R
a bR R R
a bR M R M R
Tức là, ma trận tương quan là bất biến với sự thay đổi của các cột và các hàng. Tính chất này được suy ra trực tiếp từ định lý ma trận tương quan là Toeplitz. Một ma trận vuông là Toeplitz nếu mọi phần tử trên đường chéo chính của nó là bằng nhau, và nếu mọi phần tử trên các đường chéo song song với đường chéo chính cũng bằng nhau.
Dự đoán bậc không
Xét phương trình 00R J . Đối với bậc không, dự đoán luôn luôn là 0;
vì thế sai số dự đoán bằng với tín hiệu. Mở rộng phương trình này thành 2 chiều ta có:
0
0
[0] [1] 1
[1] [0] 0
JR R
R R
,

v
Đây là trường hợp 2 chiều với a1 = 0. Do a1 = 0 nên điều kiện lý tưởng sẽ
không thể đạt được, và hạng tử 0 xuất hiện ở vế phải để cân bằng phương
trình, và 0 1R . Từ tính chất thứ hai của ma trận tương quan, ta có:
0
0
[0] [1] 0
[1] [0] 1
R R
JR R
Dự đoán bậc một
Ta cần giải phương trình
1(1)1
0[0] [1]
[1] [0] 0
R R J
aR R
Với (1)1a là LPC của bộ dự đoán, chỉ số trên kí hiệu bậc của dự đoán. J1 là
giá trị sai số dự đoán bình phương trung bình tối thiểu có được từ dự đoán bậc 1. Như vậy ta cần tìm hai giá trị này. Xét nghiệm có dạng:
1(1)1
1 1 0
0 1k
a
, với k1 là một hằng số.
Nhân cả hai vế với ma trận tương quan, ta có:
1(1)1
1[0] [1] [0] [1] 1 [0] [1] 0
[1] [0] [1] [0] 0 [1] [0] 1
R R R R R Rk
aR R R R R R
Thế hai phương trình ở dự đoán bậc 0 vào, ta có:
0 011
0 00
JJk
J
Suy ra:
01
0 0
[1]Rk
J J
Vậy ta có:
(1)1 1a k , và 2
1 0 1(1 )J J k .
Như vậy, dự đoán bậc 1 đã hoàn thành. Tham số k1 được gọi là hệ số phản chiếu (RC), nó được suy ra từ bước dự đoán bậc 0.
Tương tự, ta mở rộng ba chiều như sau:
1(1)1
1
[0] [1] [2] 1
[1] [0] [1] 0
[2] [1] [0] 0
R R R J
R R R a
R R R
hoặc 1
(1)1
1
[0] [1] [2] 0
[1] [0] [1] 0
[2] [1] [0] 1
R R R
R R R a
R R R J

vi
Với 1 là phần tử thêm vào để cân bằng phương trình:
(1)1 1[2] [1]R a R
Dự đoán bậc hai
Ta cần giải phương trình
2(2)1(2)2
[0] [1] [2] 1
[1] [0] [1] 0
[2] [1] [0] 0
R R R J
R R R a
R R R a
Giá trị chưa biết là (2)1a , (2)
2a và giá trị sai số dự đoán bình phương trung
bình tối thiểu J2. Nghiệm của phương trình có dạng:
(2) (1) (1)1 1 2 1(2)2
1 1 0
0 1
a a k a
a
, với k2 là RC.
Nhân cả hai vế với ma trận tương quan, biến đổi và thế các phương trình ở bậc 1, ta có:
2 1 1
2
1 1
0 0 0
0
J J
k
J
và (1)2 1
1
1[2] [1]k R a R
J
Cuối cùng, ta có các giá trị cần tìm là:
(2)2 2a k
(2) (1) (1)1 1 2 1a a k a
22 1 2(1 )J J k
Dự đoán bậc ba
Nghiệm của dự đoán bậc ba có dạng:
(3) (2) (2)1 1 2
3(3) (2) (2)2 2 1(3)3
1 1 0
0 1
a a ak
a a a
a
Thực hiện tương tự bậc 2, ta có các giá trị cần tìm là:
(2) (2)3 1 2
2
1[3] [2] [1]k R a R a R
J

vii
(3)3 3a k
(3) (2) (2)2 2 3 1a a k a
(3) (2) (2)1 1 3 2a a k a
23 2 3(1 )J J k
Thủ tục này cứ lặp đi lặp lại cho đến khi gặp bậc mong muốn.
Thuật toán Levinson-Durbin có thể tóm tắt như sau. Đầu vào của thuật toán là các hệ số tự tương quan R[l], đầu ra là các tham số LPC và RC.
+ Khởi tạo: l=0, ta có: 00R J + Bước lặp: Đối với mỗi giá trị l = 0,1,2,.., M
- Bước 1: Tính RC thứ l: 1
( 1)
11
1[ ] [ - ]
ll
l iil
k R l a R l iJ
- Bước 2: Tính toán các LPC ở dự đoán bậc l: ( )ll la k
( ) ( 1) ( 1)l l li i l l ia a k a
, i = 1,2,3,.., l – 1.
Dừng lại nếu l = M.
- Bước 3: Tính toán sai số dự đoán bình phương trung bình tối thiểu liên
quan đến nghiệm bậc l: 21(1 )l l lJ J k .
Đặt l = l + 1, quay lại Bước 1.
Giá trị LPC cuối cùng là: ( ) , 1,2,...,Mi ia a i M
C. Lượng tử hóa véc-tơ nhiều lớp (MSVQ)
[4] Lượng tử hóa véc tơ (VQ): một lượng tử véc-tơ Q với số chiều M và kích thước N được ánh xạ từ một véc-tơ x trong không gian Ơ-cơ-lit M chiều RM vào một tập hợp hữu hạn Y chứa N đầu ra hoặc điểm M chiều, gọi là codevector hoặc codeword:
: MQ R Y ,
1 2, ,...,T
Mx x x x , 1 2, ,..., Ny y y Y , 1 2, ,...,T
i i i iMy y y y , 1,2,...,i N
Y được gọi là codebook của bộ lượng tử hóa.
( ) , 1, 2 , . . . ,iQ x y i N
Độ phân giải (resolution): Độ phân giải của một bộ lượng tử hóa véc-tơ được xác định là:

viii
lgr N
Đây là số bit cần thiết để xác định duy nhất một codeword nào đó.
Mã hóa và giải mã: Một bộ lượng tử hóa véc-tơ bao gồm hai thành phần: mã hóa và giải mã. Mã hóa E là một ánh xạ từ RM vào tập chỉ số I = {1,2,...,N}, và giải mã D là ánh xạ từ tập chỉ số I vào tập tái tạo Y. Công việc mã hóa là nhận dạng vùng nào mà véc-tơ đầu vào nằm ở đó. Giải mã thì đơn giản là một sự tìm kiếm trên bảng để xác định codebook. Hoạt động tổng quát của lượng tử hóa véc-tơ được mô tả qua phương trình sau:
ˆ ( ) ( ( ) ) ix Q x D E x y
Khoảng cách hoặc phép đo sai lệch: Một khoảng cách hoặc một phép đo sự biến dạng là một giá trị không âm d(x,Q(x)) liên quan đến quá trình lượng tử hóa một véc-tơ đầu vào x bất kỳ thành một véc-tơ kết quả Q(x):
0, ( )
( , ( ))0, ( )
Q x xd x Q x
Q x x
Gọi X là một véc-tơ ngẫu nhiên phân bố liên tục trong không gian RM với hàm mật độ xác suất fX(x), khi đó giá trị khoảng cách được tính theo công thức:
D = E{ d(X,Q(X))} = MR d(x,Q(x))fX(x)dx
Nếu véc-tơ đầu vào có phân bố rời rạc, hàm khối lượng xác suất pX(x) có thể được sử dụng thay thế:
D = E{ d(X,Q(X))} = k d(xk,Q(xk))pX(xk)
Người ta thường sử dụng phép đo khoảng cách Ơ-cơ-lít giữa hai véc-tơ:
2 2
1
ˆ ˆ ˆ( , ) ( )M
i ii
d x x x x x x
Cài đặt VQ: Cài đặt lượng tử hóa véc-tơ cần phải tính các chi phí về không gian (bộ nhớ cần thiết cho codebook – chi phí bộ nhớ) và thời gian (các hoạt động cần thiết cho tìm kiếm codeword tốt nhất – chi phí tính toán). Để giảm thiểu chi phí cài đặt, một vài cấu trúc đã được đưa ra nhằm giảm chi phí không gian hoặc thời gian, hoặc cả hai. Phụ lục này giới thiệu sơ lược một lược đồ cấu trúc cài đặt, gọi là lượng tử hóa véc-tơ nhiều lớp, giúp tiết kiệm chi phí cả không gian và thời gian. Trong thực tế, tiết kiệm chi phí cũng thường làm giảm hiệu năng hoạt động của ứng dụng.

ix
Hình A-2: Mã hóa (trên) và giải mã (dưới) MSVQ
Hình vẽ A-2 mô tả sơ đồ mã hóa và giải mã cho MSVQ với K lớp. Trong giai đoạn mã hóa, véc-tơ đầu vào x được so sánh với:
1 2
(1) (2) ( )ˆ ...K
Ki i ix y y y
Trong đó, ( )liy là codevector thứ i từ codebook ở lớp thứ l. Tức là,
codebook Y1 có kích thước N1 chấp nhận codevector 1
(1)iy , codebook Y2 có kích
thước N2 chấp nhận codevector 2
(2)iy .. Tất cả các codevector đều có cùng số
chiều bằng với véc-tơ đầu vào. Bộ giải mã từ D1 tới DK của các lớp khác nhau sẽ tạo ra codevector sử dụng chỉ số đầu vào.Bằng cách lựa chọn các chỉ số khác nhau, bộ mã hóa cố gắng cực tiểu hóa khoảng cách giữa x và x̂. Tập hợp chỉ số
1 2, ,..., Ki i i dùng để cực tiểu hóa thì sẽ được truyền tới bộ mã hóa MSVQ, ở đó
các codevectors từ các lớp khác nhau sẽ được tổng hợp lại thành lượng tử hóa của đầu vào.
Với MSVQ K lớp với codebook kích thước N1, N2, ..., NK. Độ phân giải của mỗi lớp sẽ là:
Tính toán khoảng cách
x Cực tiểu hóa
D1 i1
D2 i2
DK iK
...
D1 i1
D2 i2
DK iK
... ...
...
Q(x)
y(1) i1
y(2) i2
y(K) iK
y(1) i1
y(2) i2
y(K) iK

x
1 1 2 2lg , lg ,..., lgK Kr N r N r N
Và độ phân giải chung là:
1 1 1
lg lgKK K
l l ll l l
r r N N
, (bits)
Giả thiết rằng mỗi ô nhớ cần thiết để lưu 1 codevector thì chi phí bộ nhớ (MC- memory cost) cho MSVQ K lớp sẽ là:
1 1
2 l
K Kr
ll l
MC N
Như thế, ta sẽ cần MC ô nhớ để lưu trữ toàn bộ codebook.
Bảng A-1: Bảng so sánh MC đối với các độ phân giải thường gặp
Độ phân giải(bits) VQ MSVQ 2 lớp MSVQ 3 lớp
6 64 16 (3,3) 12 (2,2,2)
8 256 32 (4,4) 20 (2,3,3)
10 1024 64 (5,5) 32 (3,3,4)
15 32768 384 (7,8) 96 (5,5,5)
20 1048576 2048 (10,10) 320 (6,7,7)
Bảng A-1 cho thấy sự so sánh các kết quả MC đối với các độ phân giải thường gặp. Cột thứ nhất là giá trị phân giải (tính bằng bits), cột thứ hai là giá trị MC của VQ không ràng buộc, tính bằng 2r, cột thứ ba và thứ tư là MSVQ 2 lớp và 3 lớp tương ứng. Giá trị trong ngoặc là các giá trị r1, r2 và r3: r = r1+r2+r3. Quan sát từ bảng ta thấy giá trị MC cho MSVQ rất thấp, đặc biệt khi độ phân giải tăng lên. Chẳng hạn, ở độ phân giải r = 10, VQ không ràng buộc dùng tới 16 lần khối lượng bộ nhớ cần cho MSVQ 2 lớp. Khi số lượng lớp của MSVQ tăng lên thì càng cần ít bộ nhớ hơn. Nói chung, hệ thống chi phí cao thì cần nhiều bộ nhớ hơn và cung cấp hiệu năng tốt hơn.
Thủ tục tìm kiếm: MSVQ K lớp với codebook kích thước N1, N2, ..., NK. Công việc mã hóa là tìm kiếm bộ chỉ số tốt nhất tạo thành véc-tơ i = [i1, i2, ..., iK] để cực tiểu hóa sai số lượng tử hóa. Có nhiều kĩ thuật tìm kiếm khác nhau dẫn đến các thủ tục thiết kế, độ phức tạp tính toán, và hiệu năng tổng quát khác nhau.
Việc tìm kiếm một bộ chỉ số tối ưu đòi hỏi phải tìm kiếm toàn bộ (vét cạn) tất cả các tập chỉ số. Thực tế người ta thường sử dụng kĩ thuật tìm nghiệm tuần tự tối ưu cục bộ nhằm giảm độ phức tạp tính toán. Tìm kiếm tuần tự, tại mỗi bước sẽ tiến hành tìm 1 chỉ số tối ưu, sau đó cố định bộ chỉ số đã tìm được,

xi
tiếp tục tìm chỉ số tối ưu ở bước tiếp theo. Tìm kiếm theo cây cũng là một phương pháp tổng quát của tìm kiếm tuần tự, chỉ khác là khi sang bước tiếp theo ta sẽ truyền một tập các chỉ số.
Độ phức tạp tính toán (CC)
Đối với tìm kiếm toàn bộ, ta sẽ cần tính tất cả các khoảng cách ở tất cả các lớp:
1 2
1
...K
K ii
CC N N N N
Đối với tìm kiếm tuần tự, ở mỗi bước chỉ tìm kiếm một chỉ số, vì thế số lượng tính toán sẽ là:
1 21
...K
K ii
CC N N N N
Đối với tìm kiếm theo cây, nói chung thì số lượng tính toán khoảng cách là:
1 1 2 1 2 3m in ( , ) m in (m in ( , ) , ) . . .a a aC C N N M N N M N M N
Ở lớp thứ nhất, N1 là số tính toán khoảng cách cần thiết để xác định codevector Ma. Ở lớp thứ hai, N2 là số tính toán khoảng cách cần thiết cho mỗi Ma hoặc N1 (tùy xem giá trị nào nhỏ hơn)..
Thiết kế codebook
Thiết kế codebook dựa trên phép đo khoảng cách bình phương Ơ-cơ-lít nhằm cực tiểu hóa tổng khoảng cách:
ˆ ˆ( ) ( )Tk k k k k
k
D x x W x x ,
Trong đó, Wk là ma trận trọng số đường chéo liên kết với xk. Mở rộng phương trình này, ta có:
( ) ( )
2 .
Tk k k k k
k
T T T T Tk k k k k k k k k
k k k
D x B y W x B y
x W x y B W x y B W B y
Đặt:
Tk k k
k
v B W x ,
Tk k k
k
Q B W B ,
To k k k
k
D x W x .

xii
Ta có:
2 T ToD D y v y Qy .
Để cực tiểu hóa D, người ta tiến hành sai phân phương trình để tìm y(l) và
đưa kết quả về 0, dẫn tới: ( ) ( ) ( )l l lv Q y hay 1( ) ( ) ( )l l ly Q v
. Các nghiên cứu đã
chỉ ra rằng Q(l) là một ma trận đường chéo với các phần tử trên đường chéo chính khác 0, và nghịch đảo của nó là tồn tại và dễ tìm.

















