
Hyperoptとその周辺について
54
Hyperoptとその周辺について hskksk @ 2016/12/9
-
Upload
keisuke-hosaka -
Category
Data & Analytics
-
view
673 -
download
1
Transcript of Hyperoptとその周辺について

Hyperoptとその周辺について
hskksk @ 2016/12/9

アジェンダ
• はじめに
• SMBO
• Gaussian Processを⽤いたSMBO
• Tree-structured Parzen Estimatorを⽤いたSMBO
• 実験
1

はじめに
2
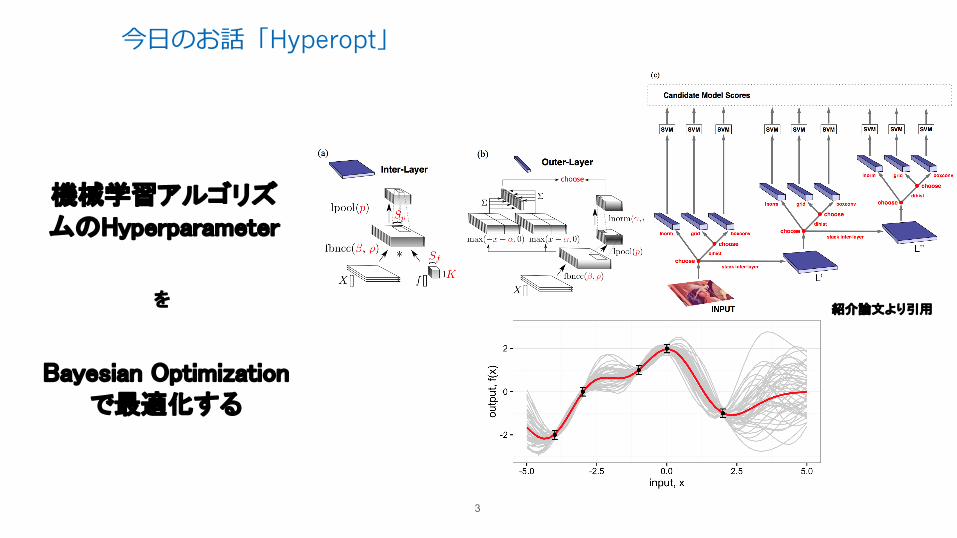
今⽇のお話「Hyperopt」
3
機械学習アルゴリズムのHyperparameter
を
Bayesian Optimizationで最適化する
紹介論文より引用

紹介する論⽂
• J. Bergstra, R. Bardenet, Y. Bengio, and B. Kegl. Algorithms for
hyper-parameter optimization, NIPS, 24:2546–2554, 2011.
• J. Bergstra, D. Yamins, and D. D. Cox. Making a science of model
search: Hyperparameter optimization in hundreds of dimensions
for vision architectures, In Proc. ICML, 2013a.
4
※2つめの論文は1つ目を整理し、新しいアプリケーションを紹介したものです。本資料ではこちらの論文については実験結果のみ紹介します。

事前準備:Hyperparameterとは?
• モデルのソルバが求めるパラメータ以外のパラメータ
• 機械学習全般:使⽤する説明変数※
• 決定⽊:Treeの深さ/Leafの最⼤数/・・・
• SVM:Slack変数の係数、kernelのパラメータ(C-SVCの場合)
• 以降でパラメータと書いたら必ずHyperparameterを指すものとする。
5
※変数選択をHyperparameterに含めるのは賛否両論あるかもですが

事前準備:Hyperparameterチューニングとは?
• よいHyperparameterを求めること
• 「よいHyperparameter」は問題によって異なるが、多くの場合、汎化性の⾼いHyperparameterを指す
• 通常⼤域最適解を得るのは無理なので何処かで妥協する
6
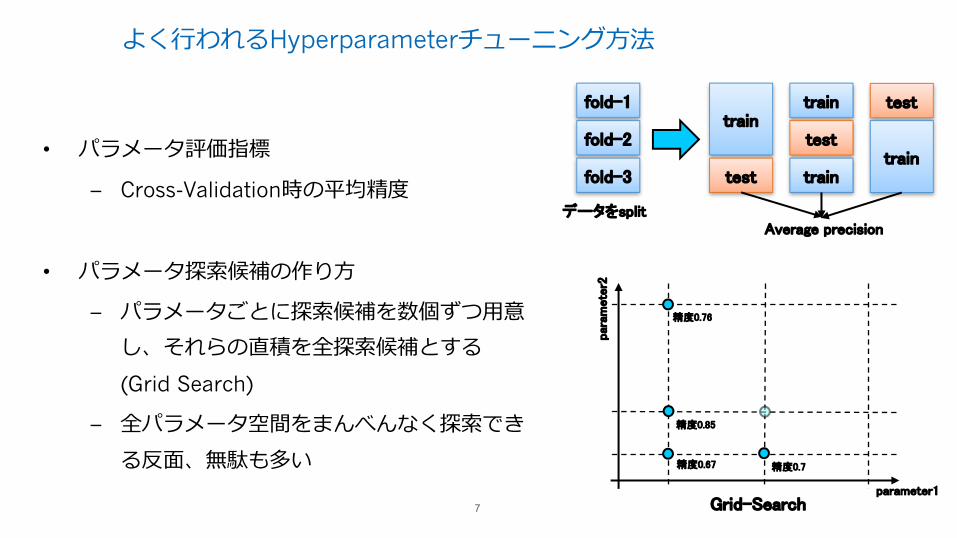
よく⾏われるHyperparameterチューニング⽅法
• パラメータ評価指標
– Cross-Validation時の平均精度
• パラメータ探索候補の作り⽅
– パラメータごとに探索候補を数個ずつ⽤意し、それらの直積を全探索候補とする(Grid Search)
– 全パラメータ空間をまんべんなく探索できる反⾯、無駄も多い
7
fold-1
fold-2
fold-3
train
test
train
test
train
test
train
データをsplitAverage precision
parameter1
par
amete
r2
精度0.7
精度0.85
Grid-Search
精度0.67
精度0.76
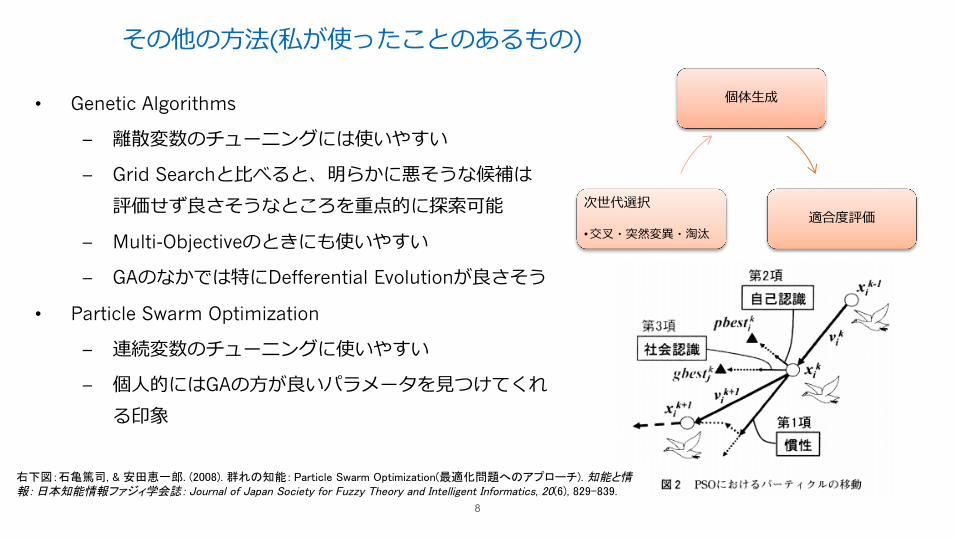
その他の⽅法(私が使ったことのあるもの)
• Genetic Algorithms
– 離散変数のチューニングには使いやすい
– Grid Searchと⽐べると、明らかに悪そうな候補は評価せず良さそうなところを重点的に探索可能
– Multi-Objectiveのときにも使いやすい
– GAのなかでは特にDefferential Evolutionが良さそう
• Particle Swarm Optimization
– 連続変数のチューニングに使いやすい
– 個⼈的にはGAの⽅が良いパラメータを⾒つけてくれる印象
8
個体⽣成
適合度評価次世代選択
•交叉・突然変異・淘汰
右下図:石亀篤司, & 安田恵一郎. (2008). 群れの知能 : Particle Swarm Optimization(最適化問題へのアプローチ). 知能と情報 : 日本知能情報ファジィ学会誌 : Journal of Japan Society for Fuzzy Theory and Intelligent Informatics, 20(6), 829–839.

ハイパーパラメータチューニングは⼤変
1. データセットが⼤きい/モデルが複雑だと、1度評価値を計算するだけでもかなりの計算時間に
– ⾃分の経験ではboschコンペではxgboostの3foldCVを回すのに12時間くらい(@24cores)
– LSTMのモデルで1モデルあたり1⽇(全5400runで1500年)というのがあった※
2. パラメータ数が多いと、探索候補が多くなりすぎる
– nパラメータでそれぞれ2候補⽤意するだけでも2nの探索候補
9
※Greff, K., Ch, K., Kumar, R., Ch, S. R., Koutník, J., Ch, H., … Ch, J. (n.d.). LSTM: A Search Space Odyssey.

SEQUENTIAL MODEL-BASED OPTIMIZATION
10

Sequential Model-based Optimization
• Sequential Model Based OptimizationはHyperparameterチューニングにピッタリな最適化アルゴリズムのフレームワーク
• Hyperparameterチューニングの難点
– 1parameterの精度評価が重い
– 探索候補が多い
• アイデア
– 解曲⾯を計算が軽い別の関数を使って近似
– 近似関数上で探索候補を絞り込む11

Sequential Model-based Optimizationのアルゴリズム
12
パラメータの評価関数解曲面を近似するモデル(Surrogate model)

GAUSSIAN PROCESSを⽤いたSMBO
13

Gaussian Processを⽤いたSMBOアルゴリズム
14
• Surrogate model
– Gaussian Process
• パラメータの評価関数
– GP上のExpected improvement

Gaussian Processを⽤いたSMBOアルゴリズム
15
• Surrogate model
– Gaussian Process
• パラメータの評価関数
– GP上のExpected improvement

参考:Gaussian Processとは
• Definition(Wikipedia(en)より)
– A Gaussian process is a statistical distribution Xt, t ∈ T, for which any
finite linear combination of samples has a joint Gaussian distribution. More
accurately, any linear functional applied to the sample function Xt will give a
normally distributed result.
• 実際上の意味
– (⾮可算)無限次元正規分布と捉えて良い。
– 多次元正規分布からのサンプルはベクトルになるが、Gaussian Processからのサンプルは関数になる。
16

参考:GPは多次元正規分布とのアナロジーで理解する
17
多次元正規分布 Gaussian Process分布からのサンプルはベクトル(v1,・・・,vn) 分布からのサンプルは関数f(x)
次元i ⼊⼒値 x
値vi 出⼒値 f(x)
• 平均ベクトル• 各次元の期待値に⼀致する量
• 平均関数• ある⼊⼒に対する出⼒の期待値に⼀致する量
• 分散共分散⾏列• 2つの次元の間の相関性の強さ✕ばらつきの⼤きさ
• 共分散関数• 2つの⼊⼒に対する出⼒の相関性の強さ✕ばらつきの⼤きさ
• ⼀部の次元を周辺化した分布は再び多次元正規分布になる
• ⼀部の⼊⼒に対応する出⼒は多次元正規分布に従う

参考:Gaussian Processにおける共分散関数
• N次元正規分布において、共分散⾏列はN⾏N列の半正定値⾏列となる。
• Gaussian Processでは、共分散関数は半正定値性を持つ2変数関数となる。
18 様々な共分散関数※ 持橋大地. ガウス過程の基礎と教師なし学習. 2015. よりグラフを引用。

GPによる回帰
19
• GPを使うとノンパラメトリック回帰を⾏うことができる。
– 統数研 持橋先⽣の資料※で勉強させていただいた。
• GPによりp(y|x,D)が求められる。これをSurrogate modelとする。
– D: 学習データ(Hyperparameterとその精度のセット)
– x: 精度を予測したいHyperparameter
– y: 精度
※持橋大地. ガウス過程の基礎と教師なし学習. 2015.

Gaussian Processを⽤いたSMBOアルゴリズム
20
• Surrogate model
– Gaussian Process
• パラメータの評価関数
– GP上のExpected improvement

Expected Improvement
• あるハイパーパラメータxに対するEIは、予め与えられたしきい値y*のもとで以下の式で表される。
• これは、あるハイパーパラメータxを⽤いた場合のlossの改善量の期待値を表す(改善量はしきい値y*を基準として測る)。
• y*には直前までに評価したlossの最も良い値などを⽤いる。
21

参考:Expected Improvement以外の評価関数
• EI以外にも以下のような評価関数が提案されている。
– Probability of Improvement
– minimizing the Conditional Entropy of the Minimizer
• 本論⽂では、EIが最も様々な条件でうまく⾏ったため採⽤したと述べている。
22

EIの最適化⽅法(典型的な⽅法)
• EIの最適化は典型的には以下のような⽅法を⽤いる。
– Exhaustive grid search
– Latin hypercube search(⾼次元の場合)
• EIが強い多峰性を持つため。
• しかしこれは⾮常に遅い。
23

EIの最適化⽅法(過去提案された⽅法)
• Bardenet&Kegl,2010ではCross-Entropy法の派⽣を使っている。
• 詳細は省くものの概略は以下の通り。
1. Cross-Entropy法によってEIが良いパラメータを探索。
2. EIの多峰性を考慮し、Cross-Entropy法のサンプリングに⽤いる分布としてmixtureを⽤いる。
3. mixtureを⽤いたCross-Entropy法の更新式がclosed-formで得られるのでそれを使う。
24
R. Bardenet and B. Kegl. Surrogating the surrogate: accelerating Gaussian Process optimization with mixtures. In ICML, 2010.

参考:Importance Sampling(CEM法のベースとなる⼿法)
• ある確率分布p(x|θ)上のある統計量H(x)の期待値を精度良く求める⼿法
• H(x)が有限の値を持つ領域が、p(x|θ)の定義域に⽐べて⾮常に⼩さい場合、期待値をモンテカルロ積分で求めようとすると精度が⾮常に悪い。
– H(x)が有限の値を持つ領域にサンプルが落ちる確率が⾮常に低いため。
• Importance Samplingでは、p(x|θ)とは別のH(x)と重なりが⼤きい分布q(x)からサンプリングし、p(x|θ)/q(x)で重み付けしてモンテカルロ積分する。
25

参考:Importance Samplingの概念図
26
H(x)p(x)
x
x
q(x)
• q(x)からサンプルすればH(x)を上手くカ
バーできる• q(x)からのサンプルにp(x)/q(x)の重みが
かかったものとしてモンテカルロ積分する
p(x)/q(x)
x

参考:Cross-Entropy法
• Importance Samplingにおいてはq(x)をうまく選ばないと積分の精度が上がらない。
• 理論的に最適なq(x)はq*(x) = H(x) p(x)/c (⾃明)
• そこで、p(x|θ)の中でq*(x)に最も近くなるθ*を求めて使うようにするθ*はp(x|θ)とq*(x)のCross-Entropy(KL-divergence)を最⼩化するθとして求める。
• Cross-Entropy法の考え⽅を応⽤すると最適化問題を解くアルゴリズムとして使⽤できる。
27

参考:Cross-Entropy法のアルゴリズム
28

EIの最適化⽅法(論⽂で⽤いる⽅法)
• 論⽂ではEIの最適化には Bardenet&Kegl,2010 の⽅法をベースに、独⾃拡張した⽅法を使っている。
• 独⾃拡張部分
– 離散変数に対してはBardenet&Kegl,2010と同様に EDA(≒CEM)を使う。
– 連続変数にCovariance Matrix Adaptation - Evolution Strategy(CMA-ES)を使う。
• ランダムウォークでサンプルを作って解曲⾯に合わせて分散共分散⾏列を更新
– EDAではmixtureを使う代わりにlocal searchを何度か繰り返す。
29

GPでパラメータの依存関係をどう扱うか?
• パラメータはお互いに依存関係を持つ。
– 依存関係はDAG構造で表現される。
• DBNの例
– Hidden layer数が1のモデルはlayer2,3のパラメータを持たない。
– 前処理にZCAを⽤いる場合のみZCA energyが意味を持つ。
• パラメータベクトルの⻑さや次元が変わってしまうので、単純には扱えない。
– 固定⻑ベクトルにしておいて、関係ない要素は無視する⽅法も考えられるが、、、
30

論⽂に於けるモデルのパラメータ依存関係
31
Pre-processing
raw ZCA
Learn rate
log U(0.001,10)
n.layers・・・
1 2 3
Common parameters
Layer1 parameters Layer2 parameters Layer3 parameters
n.hidden units ・・・
log U(128,4096)
・・・
・・・
・・・
・・・
・・・ ・・・
ZCA energy
U(0.5, 1)

パラメータの依存関係の取扱い
• 以下のような⽅法でパラメータ間の依存関係を取り扱う。
• パラメータにグループを定義
– Common parameter group
– ZCA parameter group
– Layer 1 parameter group
– ・・・
• グループごとに独⽴にGPを割り当てる
• 全パラメータの同時分布は(おそらく)全分布の積
32

TREE-STRUCTURED PARZENESTIMATORを⽤いたSMBO
33

Tree-structured Parzen Estimatorを⽤いたSMBO
34
• Surrogate model
– p(y|x)を直接モデル化する代わりにp(x|y)とp(y)をモデル化
– p(x|y)のモデル化にTree-structured Parzen Estimatorを⽤いる
• パラメータの評価関数
– TPE上のExpected improvement

Tree-structured Parzen Estimatorを⽤いたSMBO
35
• Surrogate model
– p(y|x)を直接モデル化する代わりにp(x|y)とp(y)をモデル化
– p(x|y)のモデル化にTree-structured Parzen Estimatorを⽤いる
• パラメータの評価関数
– TPE上のExpected improvement

p(x|y)のモデル化⽅法
36
• p(x|y) を以下の様にモデル化する。
• l(x)はlossがy*未満のパラメータから推定した分布
• g(x)はlossがy*以上のパラメータから推定した分布
• y*は全評価値のあるquantile(γとする)を設定する。
– このことからp(y < y*) = γ となる。
精度上位γ%のパラメータの分布
精度下位(1-γ)%のパラメータの分布

Tree-structured Parzen Estimatorを⽤いたSMBO
37
• Surrogate model
– p(y|x)を直接モデル化する代わりにp(x|y)とp(y)をモデル化
– p(x|y)のモデル化にTree-structured Parzen Estimatorを⽤いる
• パラメータの評価関数
– TPE上のExpected improvement

TPEにおけるExpected Improvement
• Expected Improvementの式にTPEのモデルを代⼊して計算すると、以下の式が得られる。
• EIが最⼤の点はg(x)/l(x)が最⼩の位置にあることを表す。
• つまり、
– lossが⼤きいグループで密度低
– lossが⼩さいグループで密度⾼
• の位置
38

参考:TPEにおけるEIの計算
39
• EIを式変形する。
• EIの分⺟を式変形する。
y>y*は常に0
ベイズの定理
p(y < y*)=γを代入

参考:TPEにおけるEIの計算
40
• EIの分⼦を式変形する。
• EIは以下の様になる。
p(y < y*)=γ
p(x|y) = l(x) (for y<y*)を代入

Tree-structured Parzen Estimatorを⽤いたSMBO
41
• Surrogate model
– p(y|x)を直接モデル化する代わりにp(x|y)とp(y)をモデル化
– p(x|y)のモデル化にTree-structured Parzen Estimatorを⽤いる
• パラメータの評価関数
– TPE上のExpected improvement

Tree-Structured Parzen Estimator(TPE)による密度推定
42
• l(x)やg(x)はTPEによって密度推定する。
• TPEの基本は昔から使われてきたParzen Estimator(=カーネル密度推定)
• なぜ「Tree-structured」なのか?
– パラメータ空間のtree構造をそのままモデル化するため
– 決定⽊などとは無関係Gaussianカーネルによる密度推定
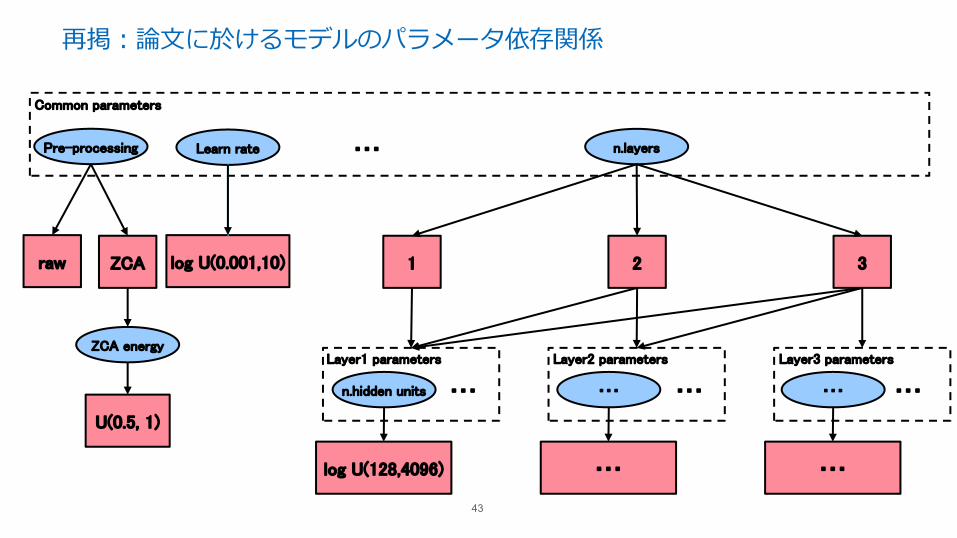
再掲:論⽂に於けるモデルのパラメータ依存関係
43
Pre-processing
raw ZCA
Learn rate
log U(0.001,10)
n.layers・・・
1 2 3
Common parameters
Layer1 parameters Layer2 parameters Layer3 parameters
n.hidden units ・・・
log U(128,4096)
・・・
・・・
・・・
・・・
・・・ ・・・
ZCA energy
U(0.5, 1)

TPEによるパラメータ空間のモデル化
44
Pre-processing
raw ZCA
Learn rate
log U(0.001,10)
n.layers・・・
1 2 3
Common parameters
Layer1 parameters Layer2 parameters Layer3 parameters
n.hidden units ・・・
log U(128,4096)
・・・
・・・
・・・
・・・
・・・ ・・・
ZCA energy
U(0.5, 1)
Multinomial Log PE
PE
Multinomial
Log PE ・・・ ・・・

TPEによるパラメータ空間のモデル化
• 各パラメータの密度分布を1次元Parzen Estimatorで推定する。
• 全パラメータの結合事後確率分布は以下となる。
45

実験
46

実験1
• 実験内容
– MLPについて、以下の⽅法を⽐較。
• Random Search
• SMBO by GP
– チューニングしたのは10個のhyperparameter
– 最初の30回はrandom searchで⾏い、それ以降にGPを使った。
• 使⽤データ
– Boston Housing
(506⾏, 13列, regression task)
47

実験結果
48
• ⻘がRandom Searchを続けた場合
• ⾚が30回⽬以降からGPを使った場合
• GPを使うとどんどん良い解が⾒つかるようになった。

実験2
• 実験内容
– DBNについて、以下の⽅法を⽐較。
• Random Search
• SMBO by GP
• SMBO by TPE
– 右表のhyperparameterのチューニングを⾏った。
• 使⽤データ
– Convex
– MNIST rotated background images
(MRBI) 49

実験2
• 実験詳細
– GPの最適化ではCMA+ESアルゴリズムで3回のrestartを許した。
– GPのカーネルはSquared exponential kernelを使⽤。
– GPのlength scaleのfittingには最⼤500iterationのCG法を使⽤。
– GPでの境界の取扱ではpenalty法を使⽤
– 30個のランダムサンプルを使⽤してGPを初期化
50

実験結果
51
• GPやTPEにより、より良い精度のHyperparameterが⾒つかった。
• 特にTPEはとても精度が良かった。
– 著者は、P(y|x)をモデル化するよりp(x|y)をモデル化するほうが近似精度がよいのではないか?と⾔っている。

著者が挙げていたHyperopt(TPE)の問題点
• The TPE algorithm is conspicuously deficient in optimizing each
hyperparameter independently of the others.
• It is almost certainly the case that the optimal values of some
hyperparameters depend on settings of others.
• Algorithms such as SMAC (Hutter et al., 2011) that can represent such
interactions might be significantly more effective optimizers than TPE.
• It might be possible to extend TPE to profitably employ non-factorial joint
densities P(config|score).
52

まとめ
• Hyperoptは
– Gaussian Processを使ったSMBO
– Tree-structured Parzen Estimatorを使ったSMBO
• でできている。
• hyperoptを使うと、少ない試⾏回数で、Manual search, random search, grid
searchより良い精度のHyperparameterが⾒つかる。
• ただし、すべてのHyperparameterを独⽴とみなしてチューニングするところに問題があるかもしれない。
53


















