
Giới thiệu về SPSS
31
NGHIÊN CỨU KHOA HỌC (Thực hành trên SPSS)
Transcript of Giới thiệu về SPSS

NGHIÊN CỨU
KHOA HỌC(Thực hành trên SPSS)

Mục tiêu buổi học
– Học viên biết cách đưa kết quả khảo sát và bảng câu hỏi vào SPSS.
– Học viên có khả năng tự thực hiện các kiểm định đơn giản.
– Học viên biết qui trình thực hiện EFA, hồi qui nhằm phục vụ cho việc thực hiện
luận văn.
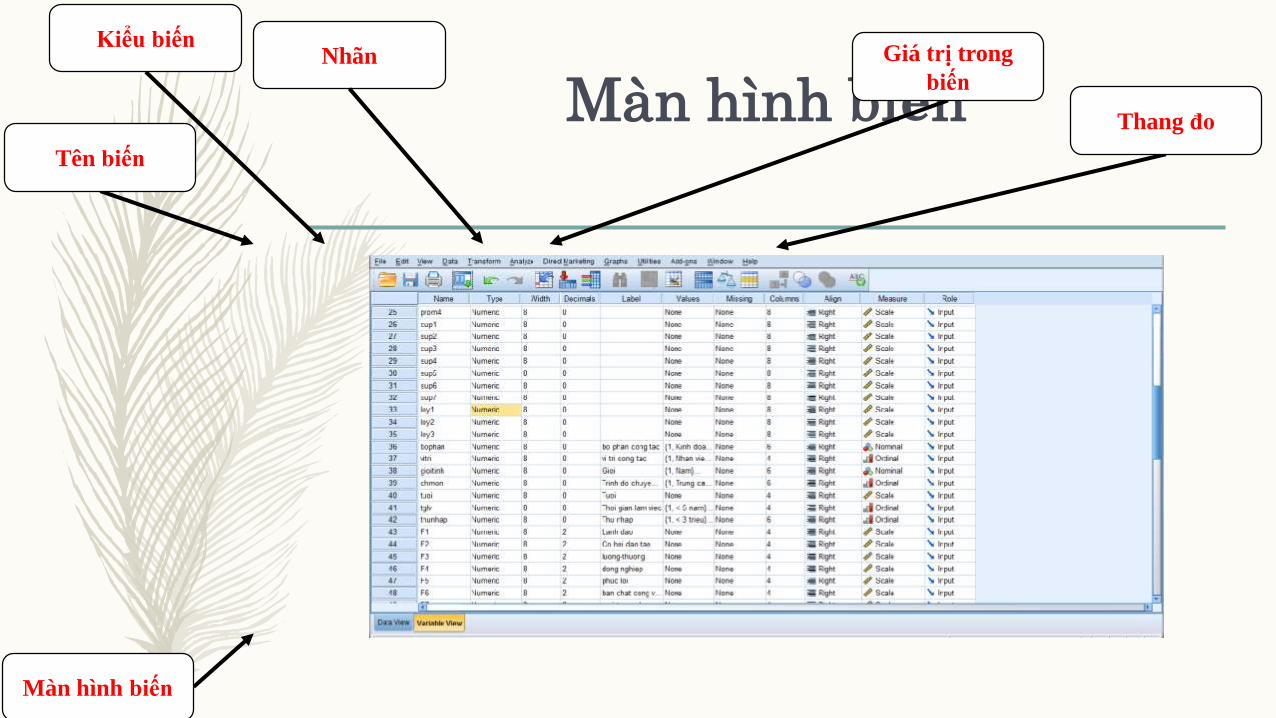
Màn hình biếnTên biến
Màn hình biến
Kiểu biếnNhãn Giá trị trong
biến
Thang đo

Màn hình dữ liệu
Màn hình dữ
liệu
Biến quan sát
Phiếu khảo sát

Tạo cơ sở dữ liệu
– Nhập thủ công tại màn hình dữ liệu
– Đưa từ bên ngoài vào thông qua File/Open/…

Cách phân loại thang đo cho biến
– Thang đo định danh (Nominal scale): dùng cho các biến định tính để phân loại,
giá trị không mang ý nghĩa khác.
– Ví dụ: giới tính, nghề nghiệp, bộ phận công tác, tình trạng hôn nhân, …

Cách phân loại thang đo cho biến
– Thang đo thứ bậc (Ordinal scale): các biến định tính có các giá trị cần sắp xếp
theo thứ bậc để chỉ rõ sự hơn kém.
– Ví dụ: Độ tuổi, vị trí công tác, trình độ chuyên môn, thu nhập, …

Cách phân loại thang đo cho biến
– Thang đo định lượng gồm thang đo khoảng cách (interval scale) và thang đo tỷ
lệ (ratio) dùng cho tất cả các biến định lượng.

Cách xác định cỡ mẫu cho EFA
– N = cỡ mẫu tối thiểu, M = số lượng biến quan sát, m = nhân tố độc lập
– EFA: N = 5*M (Hair & ctg, 1998)
– Phân tích hồi qui đa biến: N = 50 + 8*m (Tabachnick và Fidell, 1996)

Xác định tần suất
– Analyze/Descriptive Statistics/Frequencies

Kiểm định mối liên hệ giữa hai
biến định tính
– Dùng kiểm định Chi-square
– Analyze/Descriptive Statistics/Crosstabs
– Xác định độ tin cậy (SPSS mặc định là 95% => mức ý nghĩa α = 0.05)
– Xác định giả thuyết H0: không có mối liên hệ => H1
– Nếu Chi-square < α => bác bỏ H0
– Nếu Chi-square >= α => không bác bỏ H0

Hiển thị đồ
thị dạng cột
Kiểm định
Chi-square
Kiểm định
định danh
Kiểm định
thứ bậc
Giá trị Chi-
squareCần dưới
20%

Kiểm định ANOVA
– Dùng kiểm định độ đồng nhất giữa phương sai các nhóm
– Kiểm định sự khác biệt giữa biến định tính với biến định lượng
– Analyze/Compare Means/One-way ANOVA
– Kiểm định Levene: sig. <= α → phương sai giữa các lựa chọn khác nhau
– ANOVA: sig. <= α → có sự khác biệt giữa các nhóm định tính
– Nếu có sự khác biệt thì Mean của nhóm nào cao hơn sẽ tác động mạnh hơn đến biến định lượng
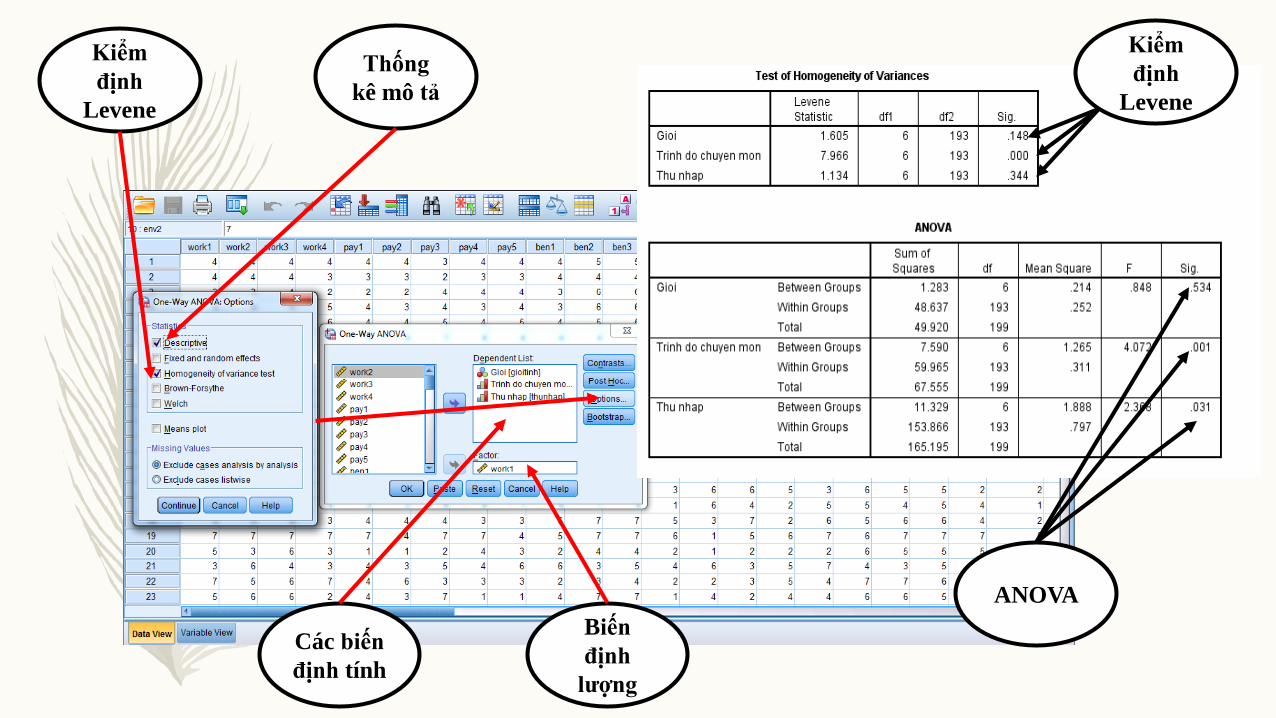
Kiểm
định
Levene
ANOVA
Kiểm
định
Levene
Thống
kê mô tả
Các biến
định tính
Biến
định
lượng

CRONBACH’s ALPHA
– Độ tin cậy của thang đo được đánh giá qua hệ số Cronbach’s Alpha
– “Sử dụng phương pháp hệ số tin cậy Cronbach’s Alpha trước khi phân tích nhân tố EFA để
loại các biến không phù hợp vì các biến rác này có thể tạo ra các yếu tố giả” (Nguyễn Đình
Thọ & Nguyễn Thị Mai Trang, 2009).
– “Hệ số tin cậy Cronbach’s Alpha chỉ cho biết các đo lường có liên kết với nhau hay không;
nhưng không cho biết biến quan sát nào cần bỏ đi và biến quan sát nào cần giữ lại. Khi đó,
việc tính toán hệ số tương quan giữa biến-tổng sẽ giúp loại ra những biến quan sát nào
không đóng góp nhiều cho sự mô tả của khái niệm cần đo” (Hoàng Trọng & Chu Nguyễn
Mộng Ngọc, 2008).

CRONBACH’s ALPHA– Các tiêu chí được sử dụng khi thực hiện đánh giá độ tin cậy thang đo qua hệ số Cronbach’s
Alpha:
– Sử dụng hệ số tương quan biến-tổng nhỏ >= 0.3 khi kiểm định Cronbach’s Alpha (Nguyễn Đình
Thọ, 2011).
– Mỗi lần chỉ xóa một biến “tồi” nhất.
– Mỗi khái niệm được đo bằng hai biến trở lên.
– Tiêu chuẩn chọn thang đo khi có độ tin cậy Alpha lớn hơn 0,6 (Alpha càng lớn thì độ tin cậy
nhất quán nội tại càng cao) (Nunally & Burnstein, 1994).
– Các mức giá trị của Alpha: lớn hơn 0,8 là thang đo lường tốt; từ 0,7 đến 0,8 là sử dụng
được; từ 0,6 trở lên là có thể sử dụng trong trường hợp khái niệm nghiên cứu là mới hoặc
là mới trong bối cảnh nghiên cứu (Nunally, 1978; Peterson, 1994; Slater, 1995)

CRONBACH’s ALPHA
– Analyze/Scale/Reliability Analysis
Model:
Alpha
Kiểm tra
xóa biến
Tương
quan
biến-tổng
Hệ số
Cronbach’
s Alpha

Phân tích nhân tố khám phá
(EFA)– Ba thuộc tính quan trọng trong kết quả EFA:
1) Số lượng nhân tố trích được: dừng khi nhân tố có Eigenvalue >=1 (Nguyễn Đình Thọ, 2011).
2) Hệ số tải nhân tố (factor loading): nhân tố có λ>= 0.5 là chấp nhận được (Hair & ctg, 1998).
3) Tổng phương sai trích: phải đạt >= 50% thì chấp nhận được (Gerbing & Anderson, 1988). Nguyễn
Đình Thọ (2011) cho rằng tổng này đạt từ 60% trở lên là tốt.

Phân tích nhân tố khám phá
(EFA)– Ngoài ra:
A) Hệ số Kaiser-Mayer-Olkin (KMO): là chỉ số dùng để xem xét sự thích hợp của phân tích nhân
tố. 0.5 <= KMO <= 1 là điều kiện đủ để phân tích nhân tố là thích hợp, còn nếu như trị số này
nhỏ hơn 0,5 thì phân tích nhân tố có khả năng không thích hợp với các dữ liệu (Hoàng Trọng &
Chu Nguyễn Mộng Ngọc, 2008).
B) Chênh lệch |Factor loading| lớn nhất và |Factor loading| bất kỳ phải >= 0.3 (Jabnoun & Al-Tamimi,
2003).
C) Phương pháp trích Principal Component Analysis với phép xoay Varimax cho tổng phương sai trích tốt
hơn. Còn Principal Axis Factoring với Promax sẽ phản ánh cấu trúc dữ liệu chính xác hơn (Gerbing &
Anderson, 1988).

Phân tích nhân tố khám phá
(EFA)– Analyze/Dimension Reduction/Factor
– Mỗi lần loại biến, chỉ được loại một biến “tồi nhất”

Barlett’s test
Phương pháp
trích
Eigenvalues
Phương pháp
xoay
Loại các hệ số
nhỏ
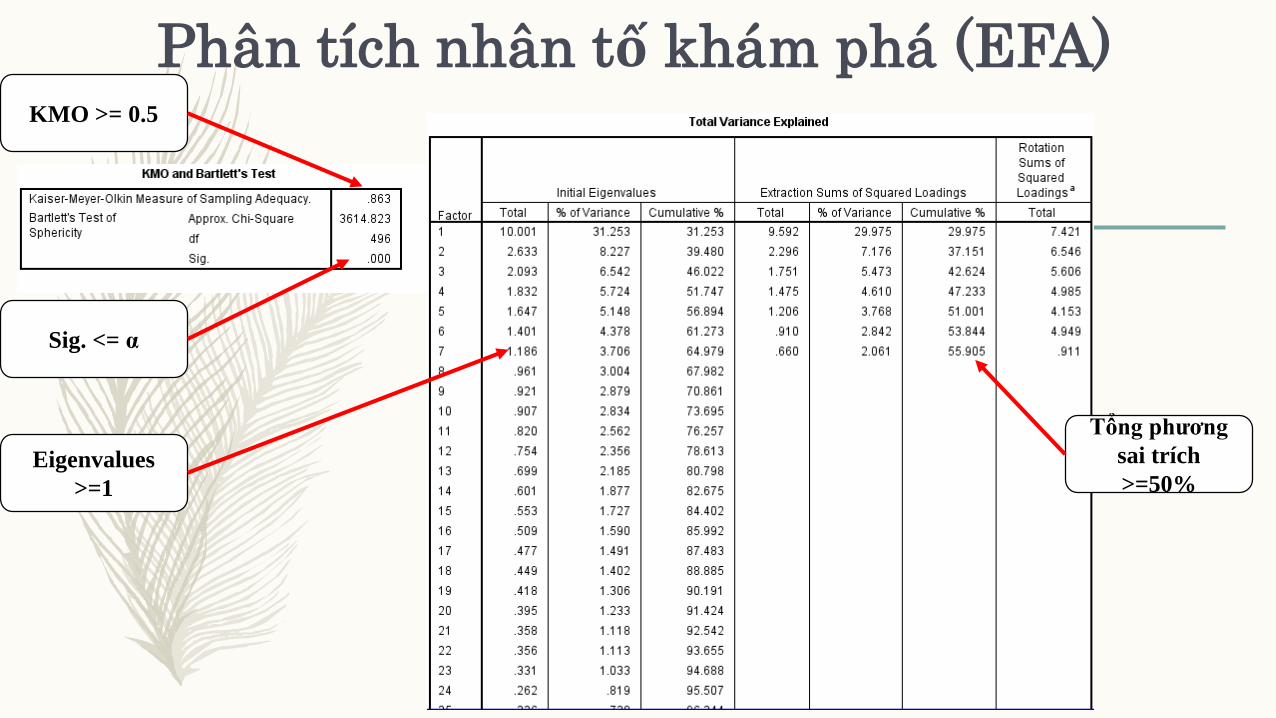
Phân tích nhân tố khám phá (EFA)KMO >= 0.5
Sig. <= α
Eigenvalues
>=1
Tổng phương
sai trích
>=50%
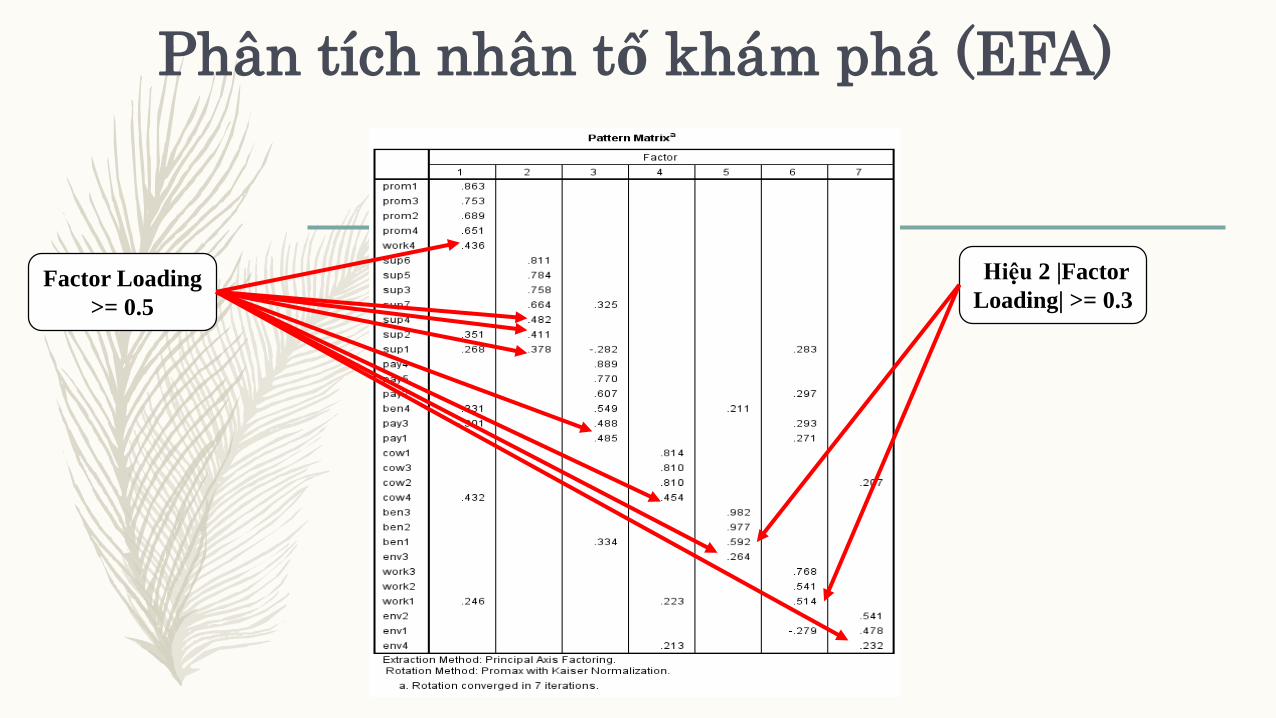
Phân tích nhân tố khám phá (EFA)
Factor Loading
>= 0.5
Hiệu 2 |Factor
Loading| >= 0.3

Phân tích tương quan Pearson– Kiểm tra mối tương quan tuyến biến phụ thuộc với các biến độc lập?
– Nhận diện vấn đề đa cộng tuyến khi các biến độc lập cũng có tương quan mạnh.
– Analyze/Correlate/Bivariate
– Hệ số tương quan r
- |r| <0.25: không tương quan hay tương quan kém chặt chẽ
- |r| từ 0.25 đến 0.5: tương quan yếu
- r từ 0.5 đến 0.75: tương quan trung bình
- r từ 0.75 đến <1: tương quan mạnh (Fraenkel & Wallen, 2006).
– Sig. < α.

Phân tích tương quan PearsonHệ số r
Sig.
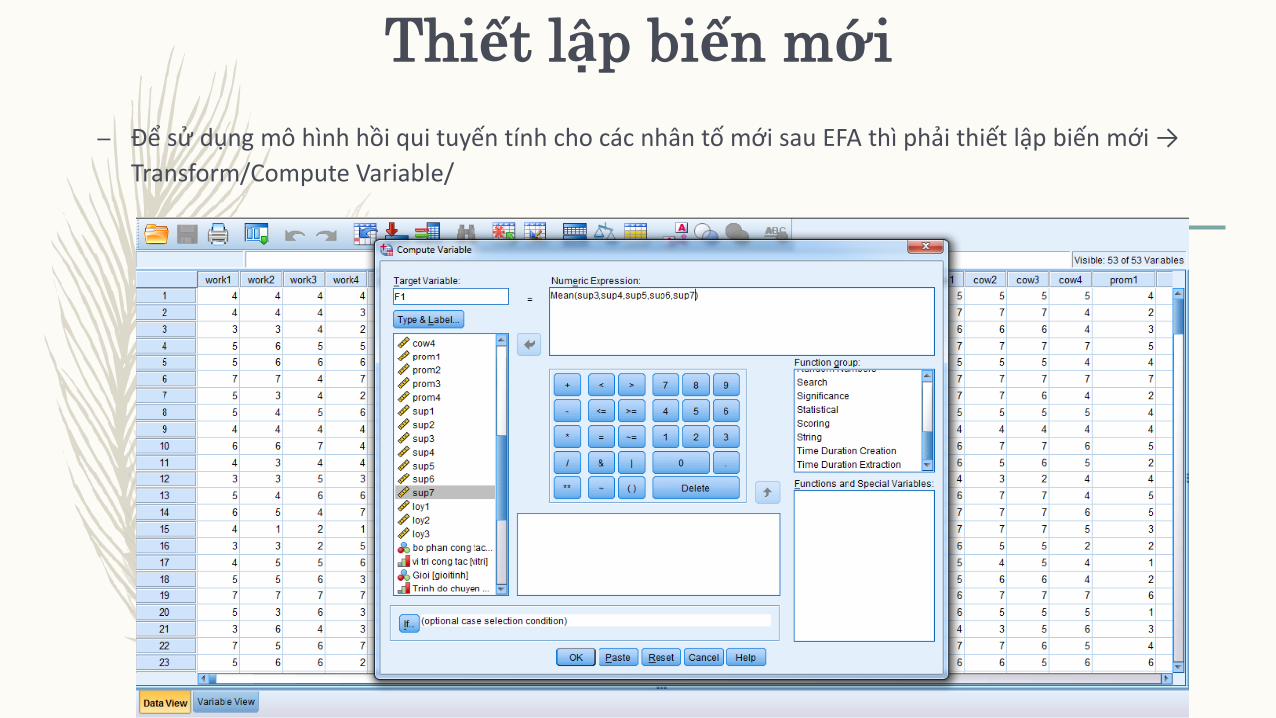
Thiết lập biến mới
– Để sử dụng mô hình hồi qui tuyến tính cho các nhân tố mới sau EFA thì phải thiết lập biến mới →
Transform/Compute Variable/

Phân tích hồi qui đa biến
– Analyze/Regression/Linear
– “Sau khi kết luận là hai biến có mối liên hệ tuyến tính thì có thể mô hình hóa mối quan hệ nhân quả
của hai biến này bằng hồi quy tuyến tính” (Hoàng Trọng & Chu Nguyễn Mộng Ngọc, 2008).
– “Kiểm tra giả định về hiện tượng đa cộng tuyến (tương quan giữa các biến độc lập) thông
qua giá trị của độ chấp nhận (Tolerance) hoặc hệ số phóng đại phương sai VIF (Variance
inflation factor): VIF > 10 thì có thể nhận xét có hiện tượng đa cộng tuyến” (Hoàng Trọng &
Chu Nguyễn Mộng Ngọc, 2008).
– R square > 0.5 trong các mô hình về nhận dạng, giải thích. Mô hình về mối quan hệ thì không cần
quan tâm đến chỉ số này.
– Nhân tố có Sig. < 0.05 mới được đưa vào mô hình hồi qui.

Phân tích hồi qui đa biến

Tài liệu tham khảo
– Comrey, A. L. (1973), A first course in factor analysis, New York: Academic.
– Fraenkel, J.R., & Wallen, N.E. (2006), How to design and evaluate research in education, New
York: McGraw-Hill.
– Jabnoun, N. and Al-Tamimi, H.A.H. (2003), “Measuring perceived service quality at UAE
commercial banks”, International Journal of Quality & Reliability Management, Vol. 20 Nos 4/5,
pp. 458-72.
– Hair, J.F. Jr. , Anderson, R.E., Tatham, R.L., & Black, W.C. (1998), Multivariate Data Analysis, (5th
Edition), Upper Saddle River, NJ: Prentice Hall.

Tài liệu tham khảo
– Gerbing, D.W & Anderson, J.C (1988), “Structural Equation Modeling in practice: a review and
recommended two-step approach”, Psychological Bulletin, 103 (3): 411-423.
– Nunally C. Jum (1978), Psychometric Theory, New York, McGraw-Hill.
– Nunally C. Jum & Burnstein H. Ira (1994), Psychometric theory (3rd ed.), New York, McGraw-Hill,
Inc.
– Peterson R. A.(1994), “A Meta-Analysis of Cronbach’s Coefficient Alpha”, Journal of Consumer
Research, No. 21 Vol 2, pp 381-391.
– Slater S. F.(1995), “Issues in Conduction Marketing Strategy Research”, Journal of Strategic, No. 3
Vol 4, pp 257-270.

Tài liệu tham khảo
– Tabachnick, B. G., & Fidell, L. S. (1996), Using multivariate statistics (3rd ed.),
New York: Harper Collins.
– Nguyễn Đình Thọ (2011), Phương pháp nghiên cứu khoa học trong kinh
doanh, TPHCM: NXB Lao động – Xã hội.
– Nguyễn Đình Thọ & Nguyễn Thị Mai Trang (2009), Nghiên cứu khoa học trong
quản trị kinh doanh, NXB Thống kê.
– Hoàng Trọng & Chu Nguyễn Mộng Ngọc (2008), Phân tích dữ liệu
nghiên cứu với SPSS, NXB Hồng Đức.

















