
Geode Meetup Apachecon
55
1 © Copyright 2013 Pivotal. All rights reserved. 1 © Copyright 2013 Pivotal. All rights reserved. Open Source Core GemFire Introducing Project Geode
-
Upload
upthewaterspout -
Category
Technology
-
view
565 -
download
1
Transcript of Geode Meetup Apachecon

1© Copyright 2013 Pivotal. All rights reserved. 1© Copyright 2013 Pivotal. All rights reserved.
Open Source Core GemFire
Introducing Project Geode

2© Copyright 2013 Pivotal. All rights reserved.
Agenda Intro
– History, Use Cases, Customers, 2015 Roadmap– Architecture Overview
Why OSS, Why Apache
Southwest experience
Code walk thru/deep dive– Build/source code– PDX - Serialization
– Transactions– Persistence & GII
Demo

3© Copyright 2013 Pivotal. All rights reserved.
Geode Team Members in the roomName Title Years with Technology
Catherine Johnson Product Manager 16 years GemFire, Coherence
Anthony Baker Software Engineer 3 years GemFire
Roman Shaposhnik Director of OS Pivotal 3 years in memory grids
Greg Chase Director of Community 20 years Poet, SAP, GemFire
Dan Smith Software Engineer 7 years GemFire
Jens Deppe Software Engineer 4 years GemFire
Swapnil Bawaskar Software Engineer 7 years GemFire
William Markito Enterprise Architect 6 years GemFire, Coherence
4© Copyright 2013 Pivotal. All rights reserved.
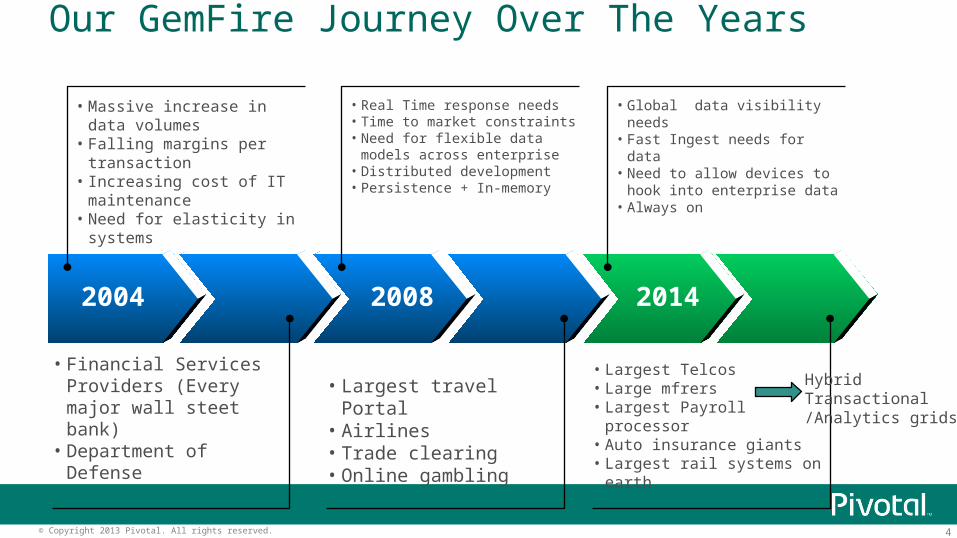
2004 2008 2014
• Massive increase in data volumes
• Falling margins per transaction
• Increasing cost of IT maintenance
• Need for elasticity in systems
• Financial Services Providers (Every major wall steet bank)
• Department of Defense
• Real Time response needs• Time to market constraints • Need for flexible data
models across enterprise• Distributed development• Persistence + In-memory
• Global data visibility needs• Fast Ingest needs for data• Need to allow devices to
hook into enterprise data• Always on
• Largest travel Portal• Airlines• Trade clearing• Online gambling
• Largest Telcos• Large mfrers• Largest Payroll processor• Auto insurance giants• Largest rail systems on
earth
Hybrid Transactional/Analytics grids
Our GemFire Journey Over The Years

5© Copyright 2013 Pivotal. All rights reserved.
Big Data Apps at Scale Have Unique Needs
Project Geode is the distributed, NoSQL, in-memory database for big data apps that need:
1. Scale-out performance
2. Consistent database operations across nodes
3. High availability, resilience, and elasticity
4. Powerful developer features
5. Easy administration of distributed nodes

6© Copyright 2013 Pivotal. All rights reserved.
1. Scale-Out PerformanceChina Railway Corporation
“The system is operating with solid performance and uptime. Now, we have a reliable, economically sound production system that supports record volumes and has room to grow”
Dr. Jiansheng Zhu, Vice Director of China Academy of Railway Sciences
• 4.5 million ticket purchases & 20 million users per day.
• Spikes of 15,000 tickets sold per minute, 40,000 visits per second.
In-Memory Storage
Optimized datadistribution
Elastic, linear scalability
Nodes
Ops
/ S
ec

7© Copyright 2013 Pivotal. All rights reserved.
2. Consistent Database Operations Across Globally Distributed Nodes
Indexing, triggers, event notification
Performance-optimizedpersistence
Configurableconsistency Partitioned Replicated Disabled
Distributed queries& regional functions
“Our global deployment of Geode’s distributed cache gives me a single version of the trade – resolving hard-to-test-for synchronization issues that exist within any globally distributed business application architecture”
Michael Benillouche, Global Head of Data ManaGEOent

8© Copyright 2013 Pivotal. All rights reserved.
3. High Availability and Resilence
“We can track and collect money at our 4,000+ kiosks and branches – even without a reliable Internet connection. Geode provides the core data grid and a significant amount of related functionality to help us handle this unreliable network problem”
Gustavo Valdez, Chief of Architecture and Development
• 19 million payment transactions per month
• 4000+ points of sale with intermittent Internet connectivity
Cluster resilience& failover

9© Copyright 2013 Pivotal. All rights reserved.
4. Powerful Developer Features
Data Structures:– User-defined objects– Complex object graphs– Documents (JSON)
Schema versioning– Multiple application versions can run
simultaneously against same data nodes
API’s– Java: Hashmap– Spring Data GemFire– Serialization API’s
Minimal to no code changes:– Web app session state caching– L2 Hibernate– Memchaced
Powerful application functions: – Data-aware functions– Scatter-gather functions– Object Query Language (OQL)– Publish & subscribe & continuous query
event framework– Reliable asynchronous event queues

10© Copyright 2013 Pivotal. All rights reserved.
5. Easy Administration of Distributed Data Grids
Auto tuning of distributed computing resources to optimize performance
Cluster monitoring dashboard– Cluster and node status & performance
Offline performance statistics analysis tool– View historical logs and events to diagnose performance and resource bottlenecks
Command-line tools for easy automation and scripting of administrative tasks
11© Copyright 2013 Pivotal. All rights reserved.
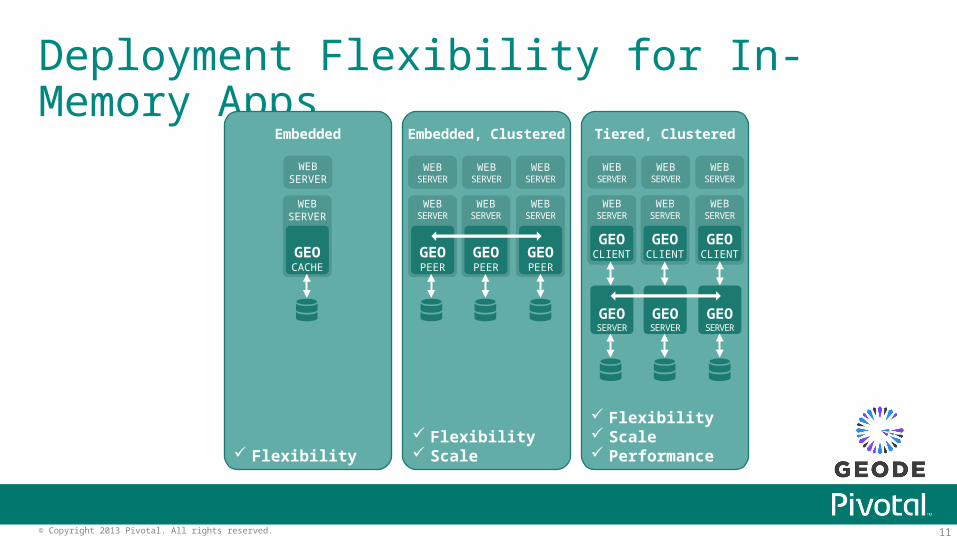
Deployment Flexibility for In-Memory Apps
Embedded Embedded, Clustered Tiered, Clustered
WEB SERVER
WEB SERVER
WEB SERVER
WEB SERVER
GEOCLIENT
WEB SERVER
GEOCLIENT
WEB SERVER
GEOCLIENT
GEOSERVER
GEOSERVER
GEOSERVER
Flexibility Flexibility Scale
Flexibility Scale Performance
Flexibility Scale Performance Availability Localization
WEB SERVER
WEB SERVER
WEB SERVER
WEB SERVER
WEB SERVER
WEB SERVER
GEOPEER
GEOPEER
GEOPEER
WEB SERVER
WEB SERVER
GEOCACHE

12© Copyright 2013 Pivotal. All rights reserved.
Difference between Geode and GemFire
Native Clients beyond Java– C++– C#
WAN connectivity between clusters
Continuous Queries from clients
13© Copyright 2013 Pivotal. All rights reserved.
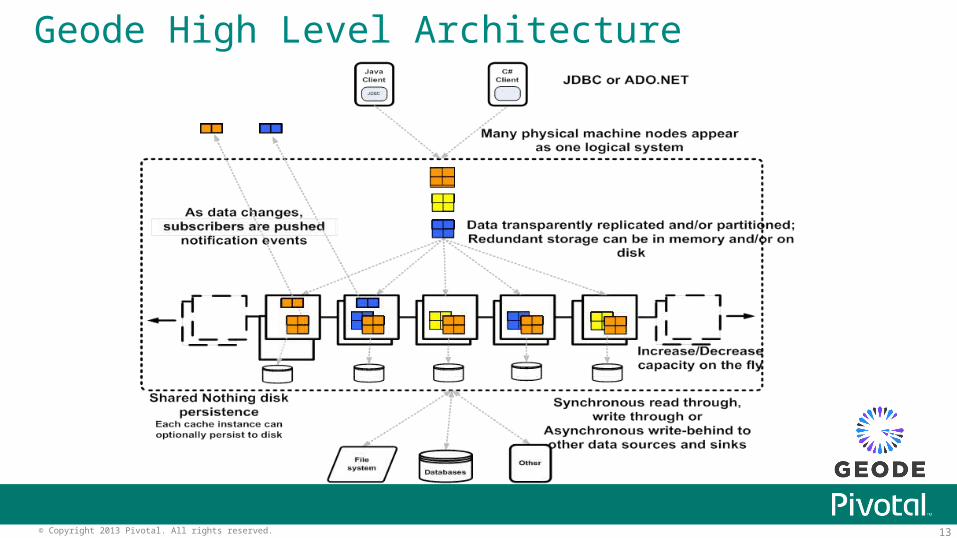
Geode High Level Architecture
14© Copyright 2013 Pivotal. All rights reserved.
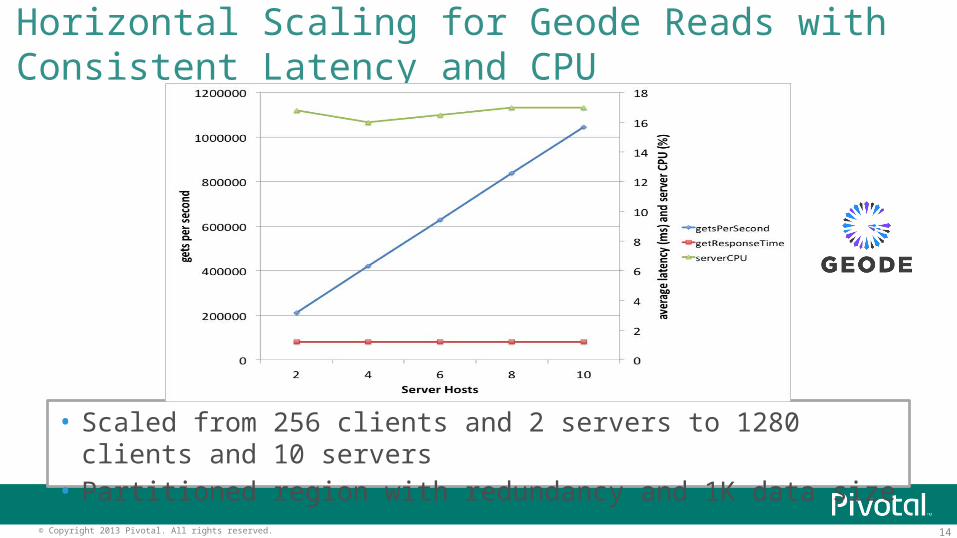
• Scaled from 256 clients and 2 servers to 1280 clients and 10 servers
• Partitioned region with redundancy and 1K data size
Horizontal Scaling for Geode Reads with Consistent Latency and CPU

15© Copyright 2013 Pivotal. All rights reserved. 15© Copyright 2013 Pivotal. All rights reserved.
Basic Design patterns
16© Copyright 2013 Pivotal. All rights reserved.
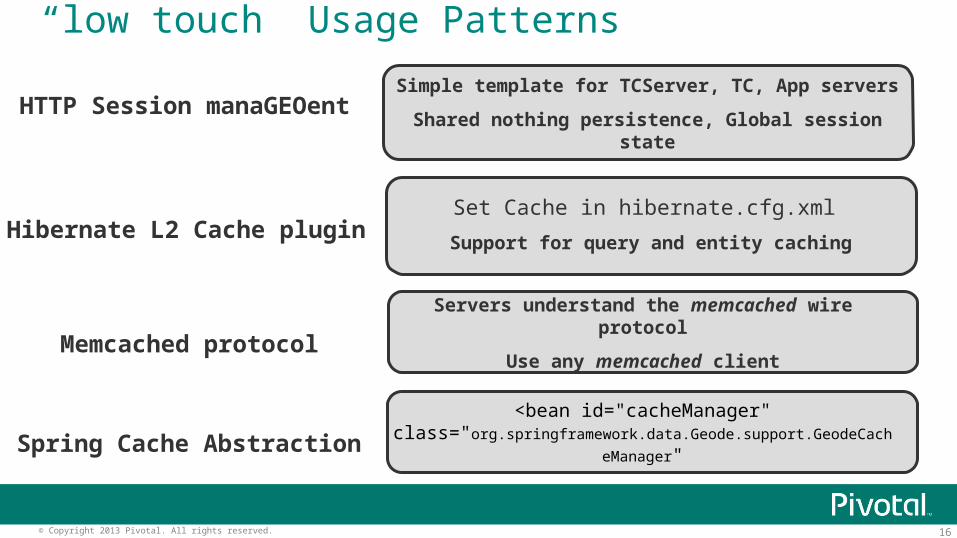
“low touch” Usage Patterns
Simple template for TCServer, TC, App servers
Shared nothing persistence, Global session stateHTTP Session manaGEOent
Set Cache in hibernate.cfg.xml
Support for query and entity cachingHibernate L2 Cache plugin
Servers understand the memcached wire protocol
Use any memcached clientMemcached protocol
<bean id="cacheManager" class="org.springframework.data.Geode.support.GeodeCacheManager"Spring Cache Abstraction
17© Copyright 2013 Pivotal. All rights reserved.
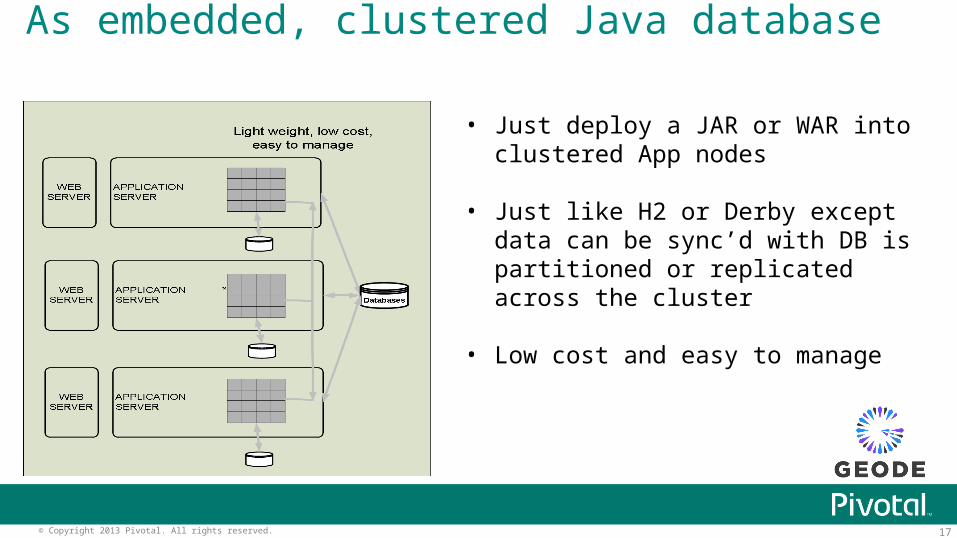
As embedded, clustered Java database
• Just deploy a JAR or WAR into clustered App nodes
• Just like H2 or Derby except data can be sync’d with DB is partitioned or replicated across the cluster
• Low cost and easy to manage
18© Copyright 2013 Pivotal. All rights reserved.
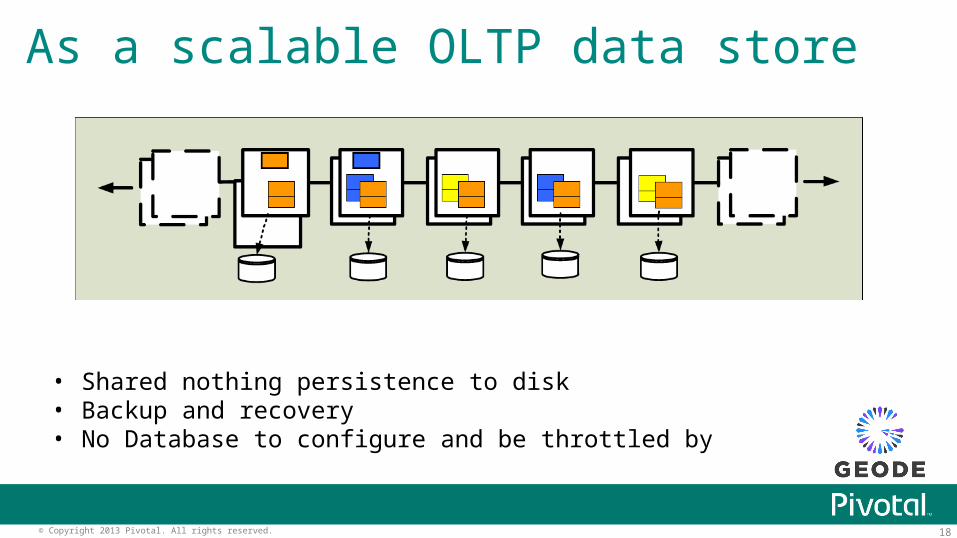
As a scalable OLTP data store
• Shared nothing persistence to disk• Backup and recovery• No Database to configure and be throttled by
19© Copyright 2013 Pivotal. All rights reserved.
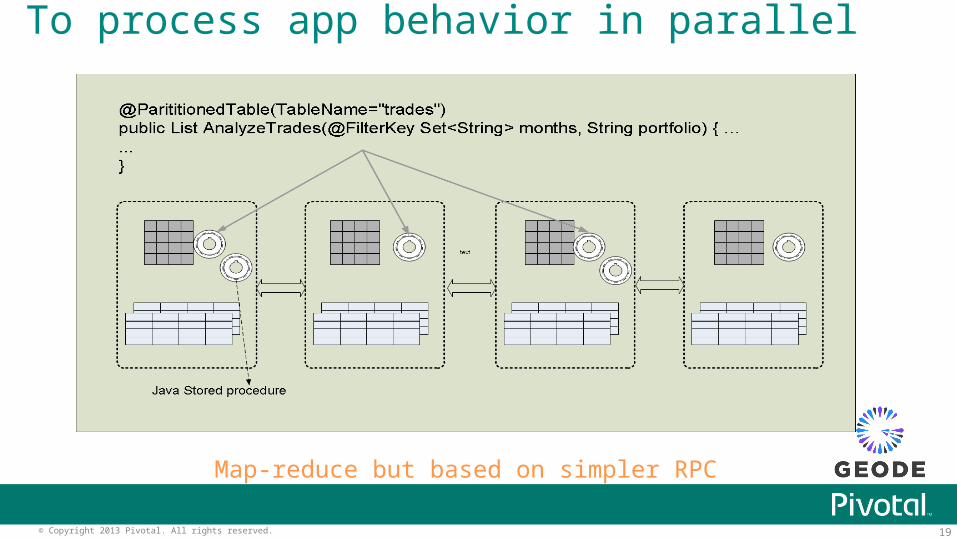
To process app behavior in parallel
Map-reduce but based on simpler RPC
20© Copyright 2013 Pivotal. All rights reserved.
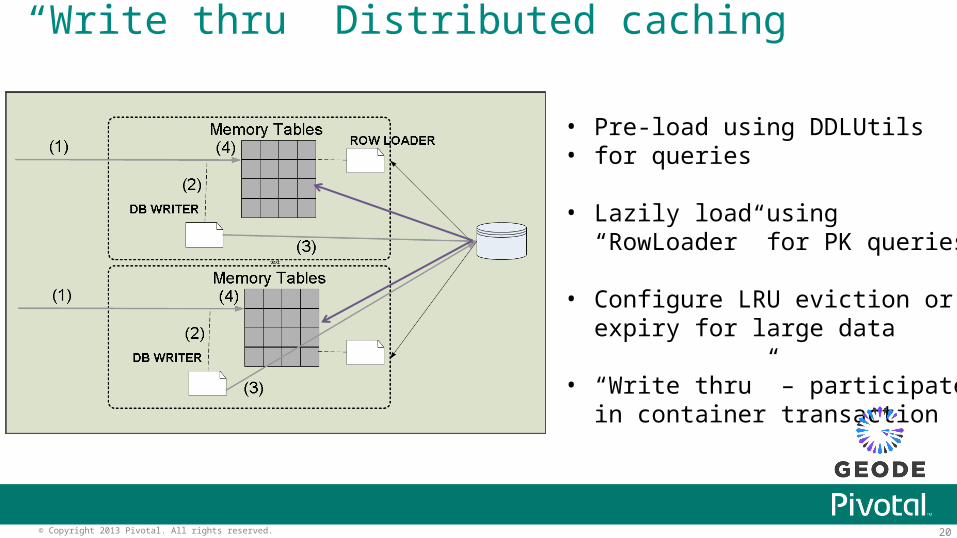
“Write thru” Distributed caching
• Pre-load using DDLUtils• for queries
• Lazily load using “RowLoader” for PK queries
• Configure LRU eviction or expiry for large data
• “Write thru” – participate in container transaction
21© Copyright 2013 Pivotal. All rights reserved.
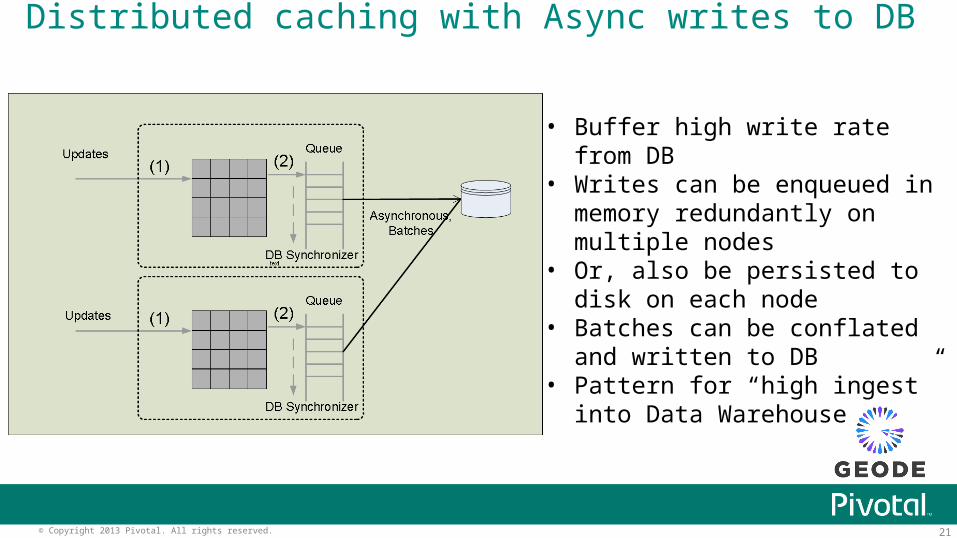
Distributed caching with Async writes to DB
• Buffer high write rate from DB• Writes can be enqueued in
memory redundantly on multiple nodes
• Or, also be persisted to disk on each node
• Batches can be conflated and written to DB
• Pattern for “high ingest” into Data Warehouse
22© Copyright 2013 Pivotal. All rights reserved.
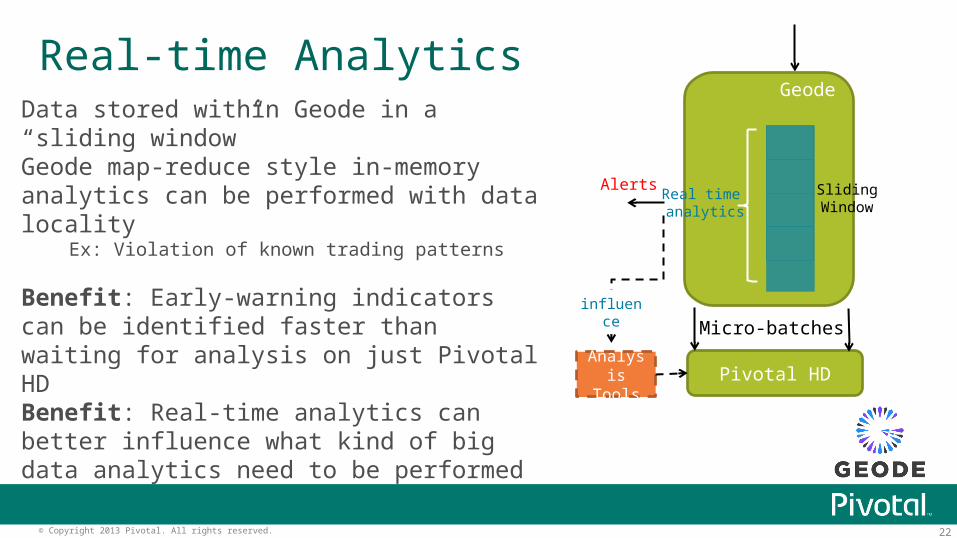
Real-time AnalyticsData stored within Geode in a “sliding window”Geode map-reduce style in-memory analytics can be performed with data locality
Ex: Violation of known trading patterns
Benefit: Early-warning indicators can be identified faster than waiting for analysis on just Pivotal HDBenefit: Real-time analytics can better influence what kind of big data analytics need to be performed Pivotal HD
Geode
Micro-batches
Analysis Tools
SlidingWindow
Real time analytics
Alerts
influence
23© Copyright 2013 Pivotal. All rights reserved. 23© Copyright 2013 Pivotal. All rights reserved.
What’s Next

24© Copyright 2013 Pivotal. All rights reserved.
Geode Roadmap for 2015
HDFS Integration
Off Heap Storage
Spark Integration
Lucene Indexing
Distributed Transactions

25© Copyright 2013 Pivotal. All rights reserved. 25© Copyright 2013 Pivotal. All rights reserved.
Why OSS, Why Apache?

26© Copyright 2013 Pivotal. All rights reserved.
Why OSS? Why Now? Why Apache?
Open Source Software is fundamentally changing buying patterns– Developers have to endorse product selection (No longer CIO handshake)– Community endorsement is key to product visibility– Open source credentials attract the best developers– Vendor credibility directly tied to street credibility of product
Align with the tides of history– Customers increasingly asking to participate in product development– Resume driven development forces customers to consider OSS products– Allow product development to happen with full transparency
Apache is where you go to build Open Source street cred– Transparent, meritocracy which puts developers in charge– Roman keeps shouting “Apache!” every few hours

27© Copyright 2013 Pivotal. All rights reserved.
Geode Will Be A Significant Apache Project
Over a 1000 person years invested into cutting edge R&D
Thousands of production customers in very demanding verticals
Cutting edge use cases that have shaped product thinking
Tens of thousands of distributed , scaled up tests that can randomize every aspect of the product
A core technology team that has stayed together since founding
Performance differentiators that are baked into every aspect of the product

28Pivotal Confidential–Internal Use Only 28Pivotal Confidential–Internal Use Only
Transactions
Swapnil Bawaskar

29Pivotal Confidential–Internal Use Only
Geode Transactions Across multiple Entries and Regions
Full ACID
Isolation level: Repeatable Read
JTA– Last Resource– Provider
Optimistic, conflict detection rather than locks
Faster than doing individual operations
Ability to suspend and resume
Work on Colocated data

30Pivotal Confidential–Internal Use Only
Usage
TransactionManager provides methods to begin, commit, rollback, suspend, resume.
E.g.– TransactionManager txMgr = cache.getTransactionManager();– txMgr.begin();– Region1.put(k1, v1)– Region2.get(k2)– Region2.put(k2, v2)– txMgr.commit();
Single entry operations supported via ConcurrentMap methods– putIfAbsent(K, V)– replace(K, V, V)– remove(K, V)

31Pivotal Confidential–Internal Use Only
Implementation
Repeatable Read ThreadLocal
At commit()– Grab a d-lock on key set. (tx with different key set can still execute concurrently)– Conflict detection Reference checks– Send the commit set to all replicas – no ack– Send a commit message– Recipients apply the commit only on getting the second message and keep track of last few transactions
Failure Scenarios– Replica fails No problem, it will do a GII operation when it starts up again– Coordinator fails Replicas gossip to arrive at the outcome of the transaction– If no member has commit message, some members may be missing commit set, abort transaction– If at-least one member has commit message, all members have commit set, apply transaction

32Pivotal Confidential–Internal Use Only 32Pivotal Confidential–Internal Use Only
Thanks!

33© Copyright 2015 Pivotal. All rights reserved. 33© Copyright 2015 Pivotal. All rights reserved.
Geode Demo
34© Copyright 2015 Pivotal. All rights reserved.
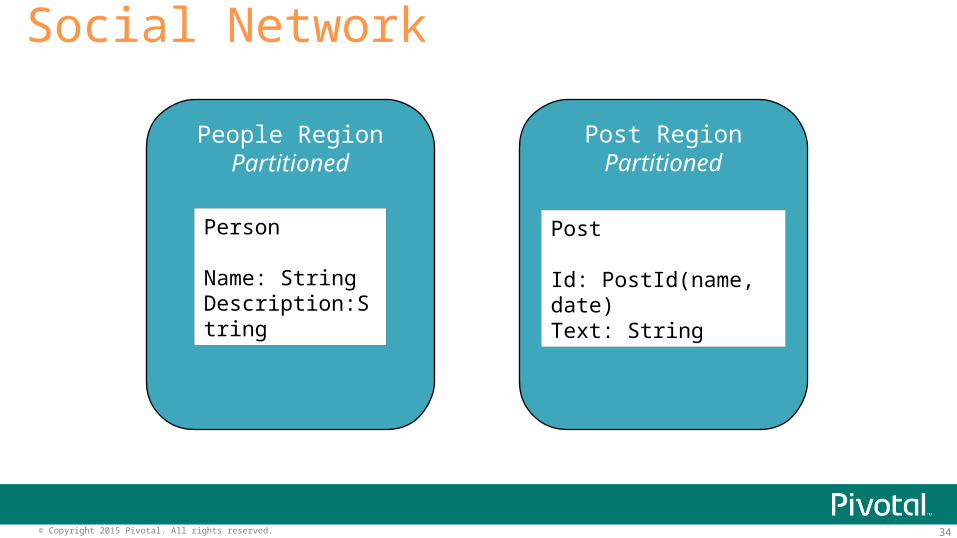
Post RegionPartitioned
People RegionPartitioned
Social Network
Person
Name: StringDescription:String
Post
Id: PostId(name, date)Text: String
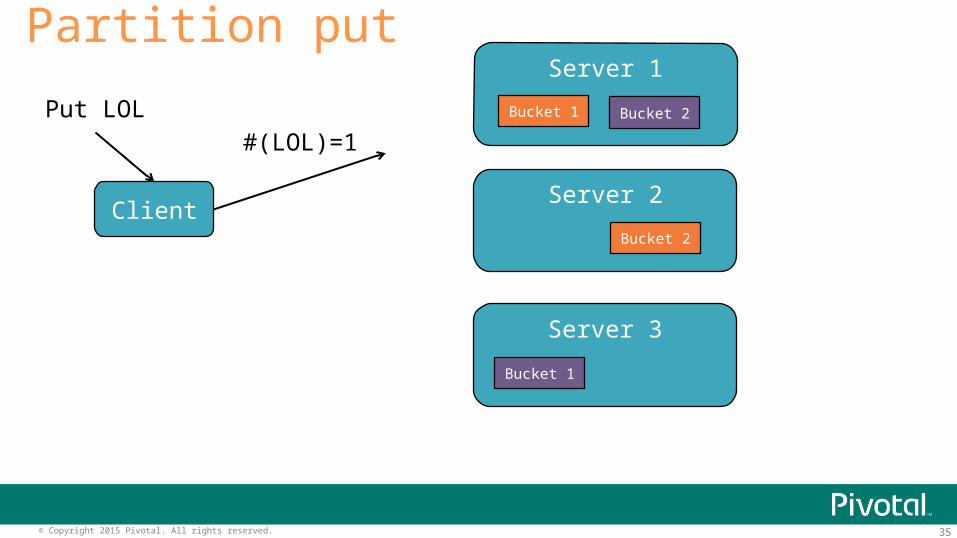
35© Copyright 2015 Pivotal. All rights reserved.
Partition put
Client
Server 1
Server 2
Server 3
Bucket 1
Bucket 1
Bucket 2
Bucket 2
#(LOL)=1Put LOL
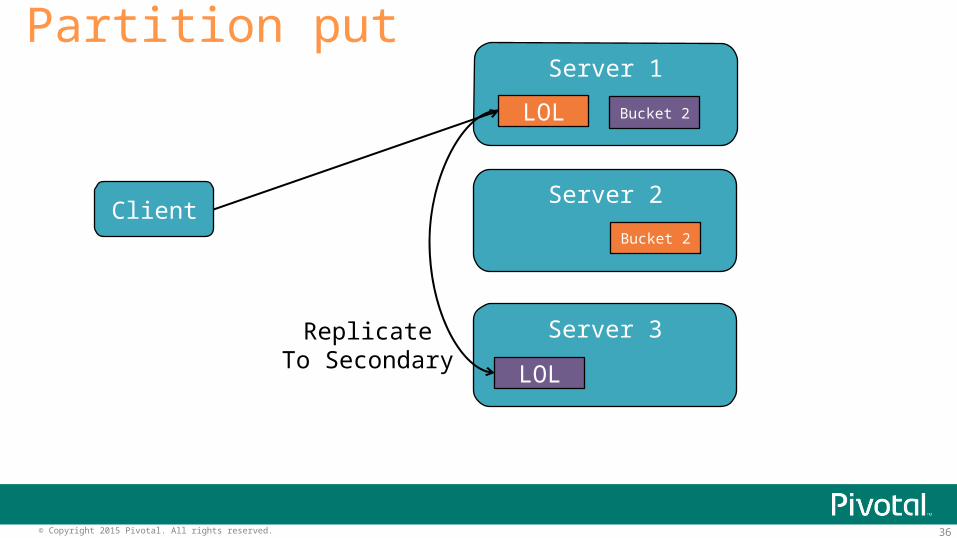
36© Copyright 2015 Pivotal. All rights reserved.
Partition put
Client
Server 1
Server 2
Server 3
LOL
LOL
Bucket 2
Bucket 2
ReplicateTo Secondary

37© Copyright 2015 Pivotal. All rights reserved.
public interface PersonRepository extends CrudRepository<Person, String> {}
“User” Use Case – Save Objects
@AutowiredPersonRepository people;
public static void main(String[] args) { people.save(new Person(name)); posts.save(new Post(new PostId(name, date), text));}
Nested Objects,Compound Keys

38© Copyright 2015 Pivotal. All rights reserved.
public interface PersonRepository extends CrudRepository<Person, String> {}
“User” Use Case – Save Objects
@AutowiredPersonRepository people;
public static void main(String[] args) { people.save(new Person(name)); posts.save(new Post(new PostId(name, date), text));}
Automatically SerializedWith PDX

39© Copyright 2015 Pivotal. All rights reserved.
<bean id="pdxSerializer" class="com.gemstone.gemfire.pdx.ReflectionBasedAutoSerializer">
<constructor-arg value="io.pivotal.happysocial.model.*"/></bean>
<gfe:cache pdx-serializer-ref="pdxSerializer"/>
<gfe:partitioned-region id="people" copies="1"/>
Configuration

40© Copyright 2015 Pivotal. All rights reserved.
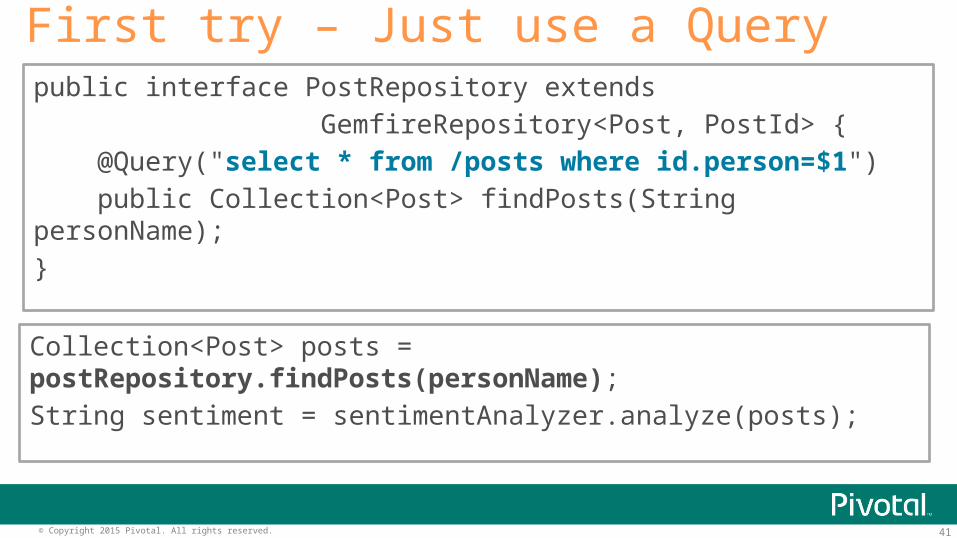
• Find all of the posts for a user• Analyze their content
Data Analyst – Determine Sentiment
41© Copyright 2015 Pivotal. All rights reserved.
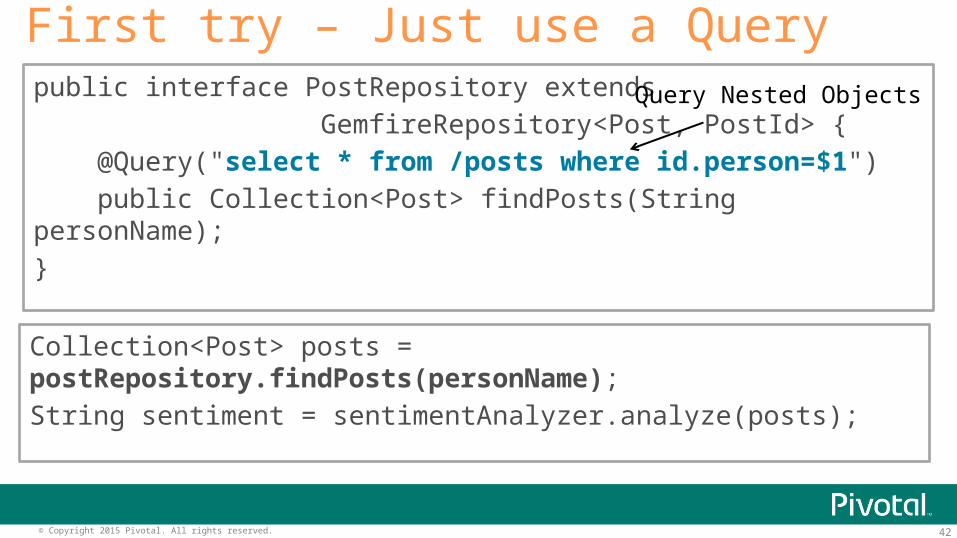
public interface PostRepository extends GemfireRepository<Post, PostId> { @Query("select * from /posts where id.person=$1") public Collection<Post> findPosts(String personName);}
First try – Just use a Query
Collection<Post> posts = postRepository.findPosts(personName);String sentiment = sentimentAnalyzer.analyze(posts);
42© Copyright 2015 Pivotal. All rights reserved.
public interface PostRepository extends GemfireRepository<Post, PostId> { @Query("select * from /posts where id.person=$1") public Collection<Post> findPosts(String personName);}
First try – Just use a Query
Collection<Post> posts = postRepository.findPosts(personName);String sentiment = sentimentAnalyzer.analyze(posts);
Query Nested Objects

43© Copyright 2015 Pivotal. All rights reserved.
Use an Index<gfe:index id="postAuthor" expression="id.person" from="/posts"/>
44© Copyright 2015 Pivotal. All rights reserved.
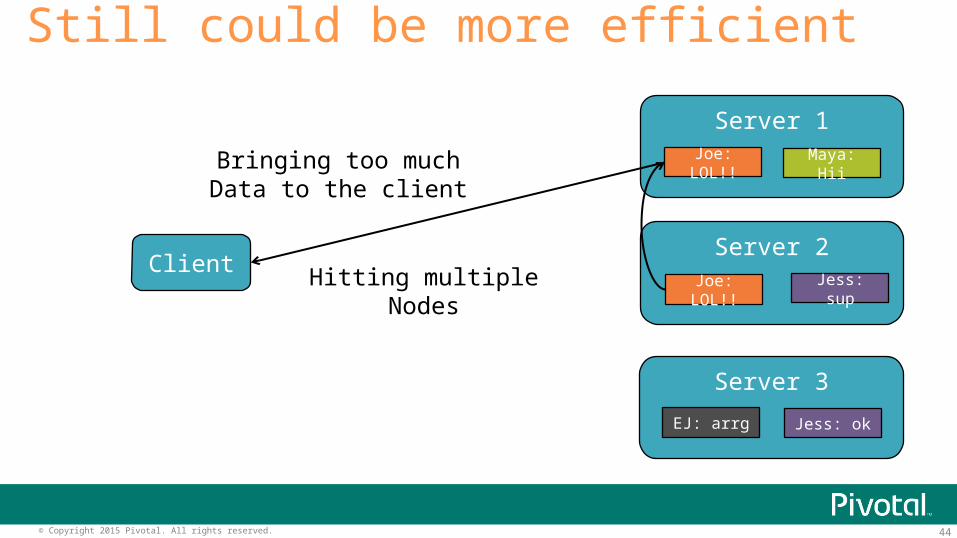
Still could be more efficient
Client
Server 1
Server 2
Server 3
Joe: LOL!!
Joe: LOL!!
EJ: arrg
Maya: Hii
Jess: sup
Jess: ok
Hitting multipleNodes
Bringing too muchData to the client
45© Copyright 2015 Pivotal. All rights reserved.
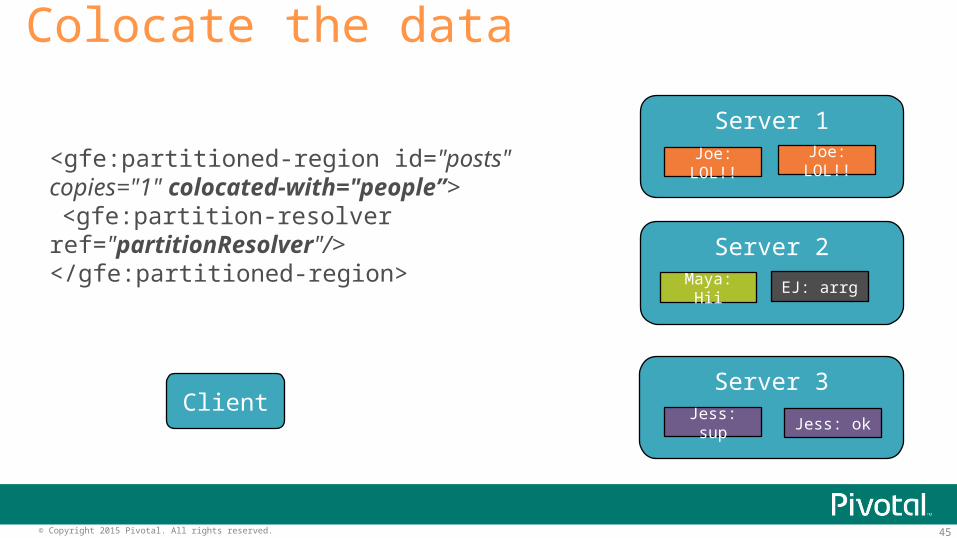
Colocate the data
Client
Server 1
Server 2
Server 3
Joe: LOL!! Joe: LOL!!
EJ: arrgMaya: Hii
Jess: sup Jess: ok
<gfe:partitioned-region id="posts" copies="1" colocated-with="people”> <gfe:partition-resolver ref="partitionResolver"/></gfe:partitioned-region>
46© Copyright 2015 Pivotal. All rights reserved.
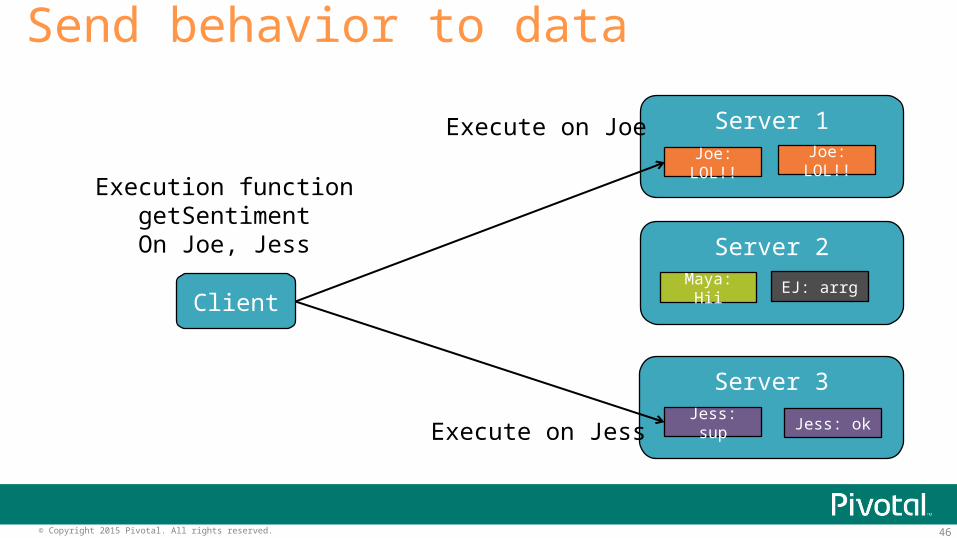
Send behavior to data
Client
Server 1
Server 2
Server 3
Joe: LOL!! Joe: LOL!!
EJ: arrgMaya: Hii
Jess: sup Jess: ok
Execution functiongetSentimentOn Joe, Jess
Execute on Joe
Execute on Jess

47© Copyright 2015 Pivotal. All rights reserved.
Sample Function – Client Side@Component@OnRegion(region = "posts")public interface FunctionClient { public List<SentimentResult> getSentiment(@Filter Set<String> people);}

48© Copyright 2015 Pivotal. All rights reserved.
Sample Function – Server Side
@GemfireFunction(HA=true) public SentimentResult getSentiment(Region<PostId, Post> localPosts, @Filter Set<String> personNames) throws Exception { String personName = personNames.iterator().next(); Collection<Post> posts = localPosts.query("id.person='" personName + "'"); String sentiment = sentimentAnalyzer.analyze(posts); return new SentimentResult(sentiment, personName);}

49© Copyright 2015 Pivotal. All rights reserved.
Sample Function – Server Side
@GemfireFunction(HA=true) public SentimentResult getSentiment(Region<PostId, Post> localPosts, @Filter Set<String> personNames) throws Exception { String personName = personNames.iterator().next(); Collection<Post> posts = localPosts.query("id.person='" personName + "'"); String sentiment = sentimentAnalyzer.analyze(posts); return new SentimentResult(sentiment, personName);}

50© Copyright 2015 Pivotal. All rights reserved.
Sample Function – Server Side
@GemfireFunction(HA=true) public SentimentResult getSentiment(Region<PostId, Post> localPosts, @Filter Set<String> personNames) throws Exception { String personName = personNames.iterator().next(); Collection<Post> posts = localPosts.query("id.person='" personName + "'"); String sentiment = sentimentAnalyzer.analyze(posts); return new SentimentResult(sentiment, personName);}

51© Copyright 2015 Pivotal. All rights reserved. 51© Copyright 2015 Pivotal. All rights reserved.
Demo
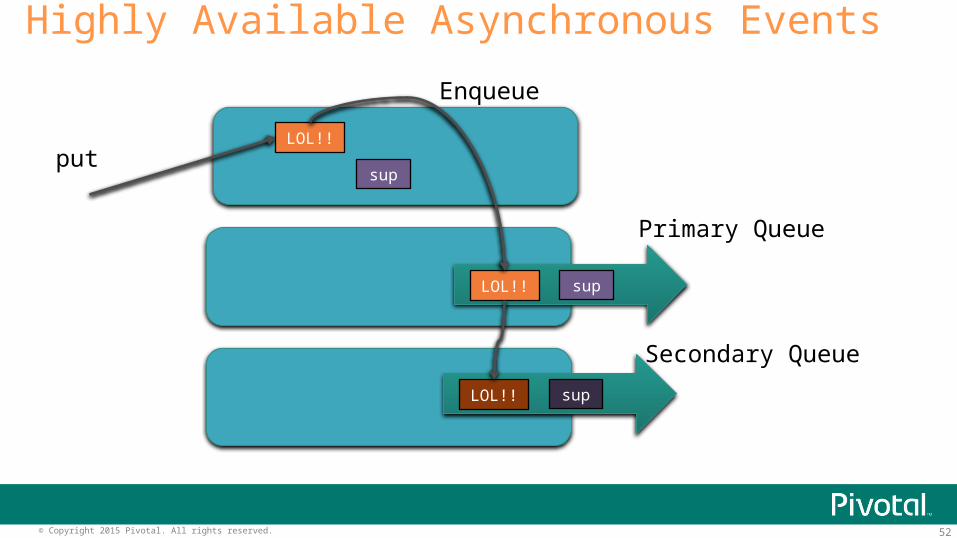
52© Copyright 2015 Pivotal. All rights reserved.
Highly Available Asynchronous Events
LOL!!
sup
LOL!! sup
put
LOL!! sup
Primary Queue
Secondary Queue
Enqueue
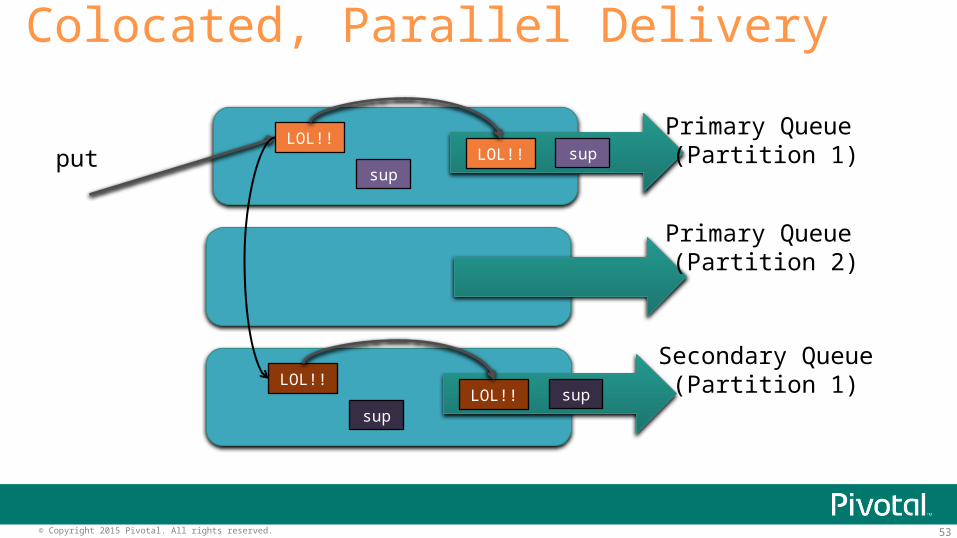
53© Copyright 2015 Pivotal. All rights reserved.
Colocated, Parallel Delivery
LOL!!
supLOL!! supput
LOL!!
supLOL!! sup
Primary Queue (Partition 1)
Secondary Queue(Partition 1)
Primary Queue (Partition 2)
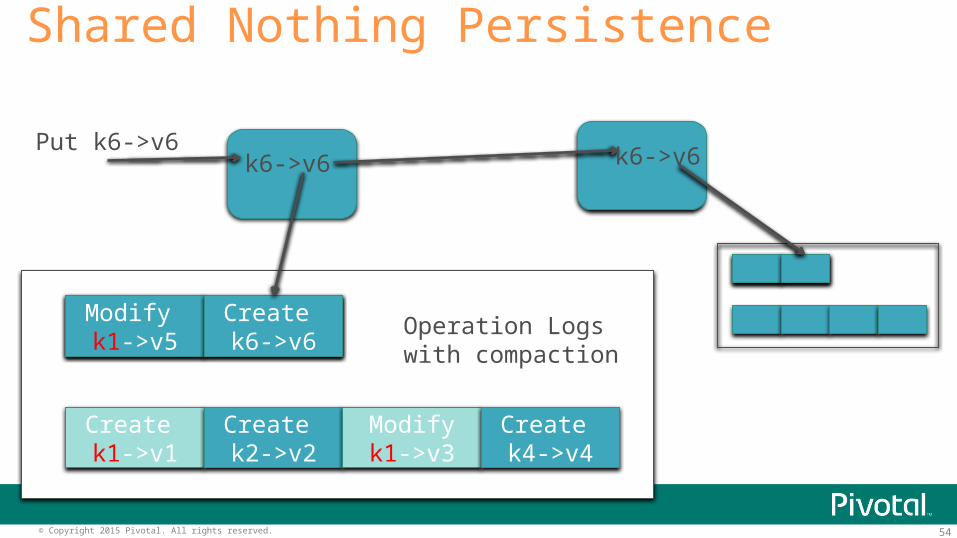
54© Copyright 2015 Pivotal. All rights reserved.
Modify k1->v5
Create k6->v6
Create k1->v1
Create k2->v2
Modifyk1->v3
Create k4->v4
Modify k1->v5
Create k6->v6
Shared Nothing Persistence
Put k6->v6k6->v6 k6->v6
Operation Logswith compaction
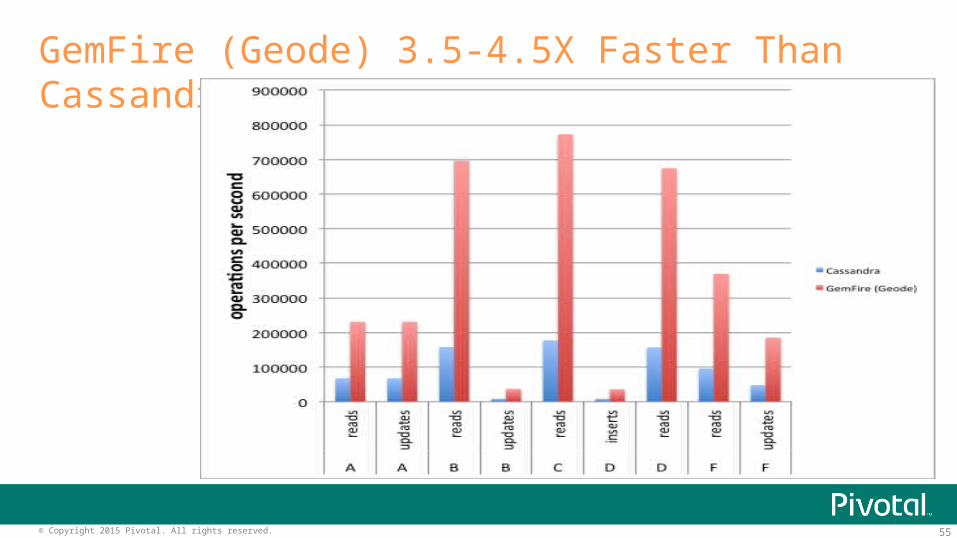
55© Copyright 2015 Pivotal. All rights reserved.
GemFire (Geode) 3.5-4.5X Faster Than Cassandra for YCSB


















