
FPGA・リコンフィギャラブルシステム研究の最新動向
51
若手による高性能コンピュータシステムの最新動向解説 FPGA・リコンフィギャラブル システム研究の最新動向 高前田 伸也 奈良先端科学技術大学院大学 情報科学研究科 E-mail: shinya_at_is_naist_jp 2015年3月11日 13:00-15:55
-
Upload
shinya-takamaeda-yamazaki -
Category
Technology
-
view
2.991 -
download
6
Transcript of FPGA・リコンフィギャラブルシステム研究の最新動向

若手による高性能コンピュータシステムの最新動向解説
FPGA・リコンフィギャラブル システム研究の最新動向
高前田 伸也
奈良先端科学技術大学院大学 情報科学研究科
E-mail: shinya_at_is_naist_jp
2015年3月11日 13:00-15:55
FPGAとは?
2015-03-11 Shinya T-Y, NAIST 2
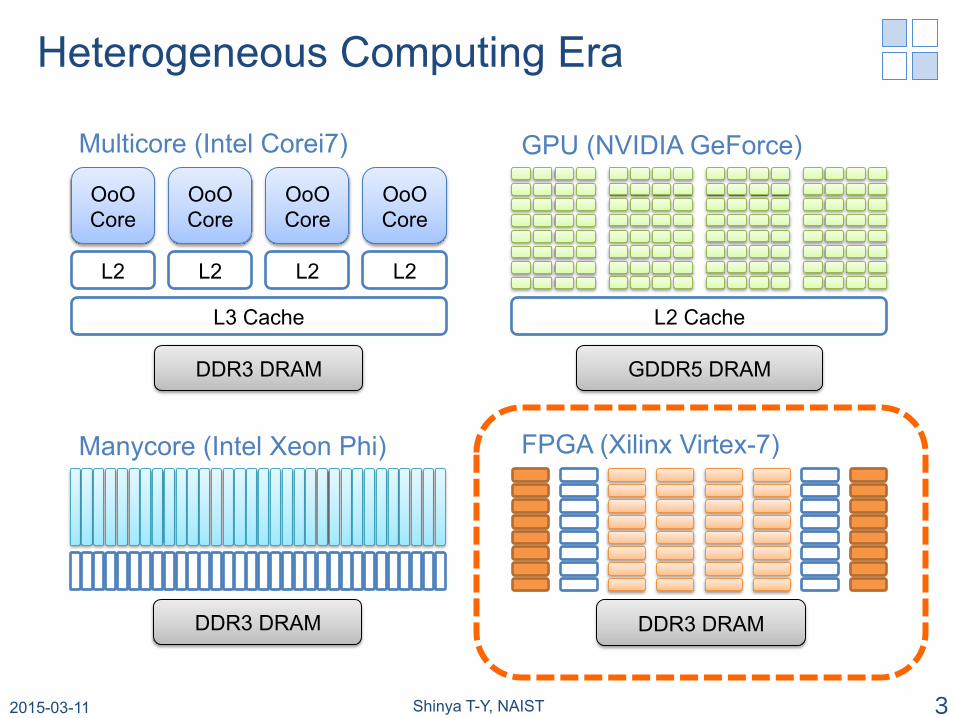
Heterogeneous Computing Era
OoO Core
OoO Core
OoO Core
OoO Core
L2 L2 L2 L2
L3 Cache
DDR3 DRAM
Multicore (Intel Corei7)
L2 Cache
GDDR5 DRAM
GPU (NVIDIA GeForce)
DDR3 DRAM
Manycore (Intel Xeon Phi)
DDR3 DRAM
FPGA (Xilinx Virtex-7)
2015-03-11 Shinya T-Y, NAIST 3
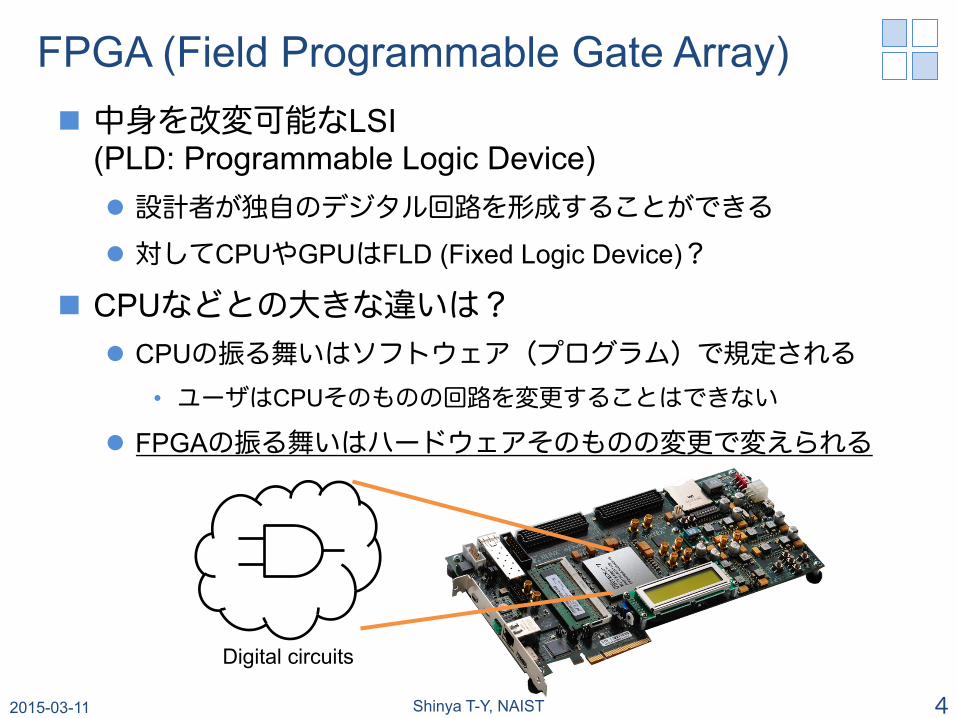
FPGA (Field Programmable Gate Array) n 中身を改変可能なLSI
(PLD: Programmable Logic Device) l 設計者が独自のデジタル回路を形成することができる
l 対してCPUやGPUはFLD (Fixed Logic Device)?
n CPUなどとの大きな違いは? l CPUの振る舞いはソフトウェア(プログラム)で規定される
• ユーザはCPUそのものの回路を変更することはできない
l FPGAの振る舞いはハードウェアそのものの変更で変えられる
Digital circuits
2015-03-11 Shinya T-Y, NAIST 4
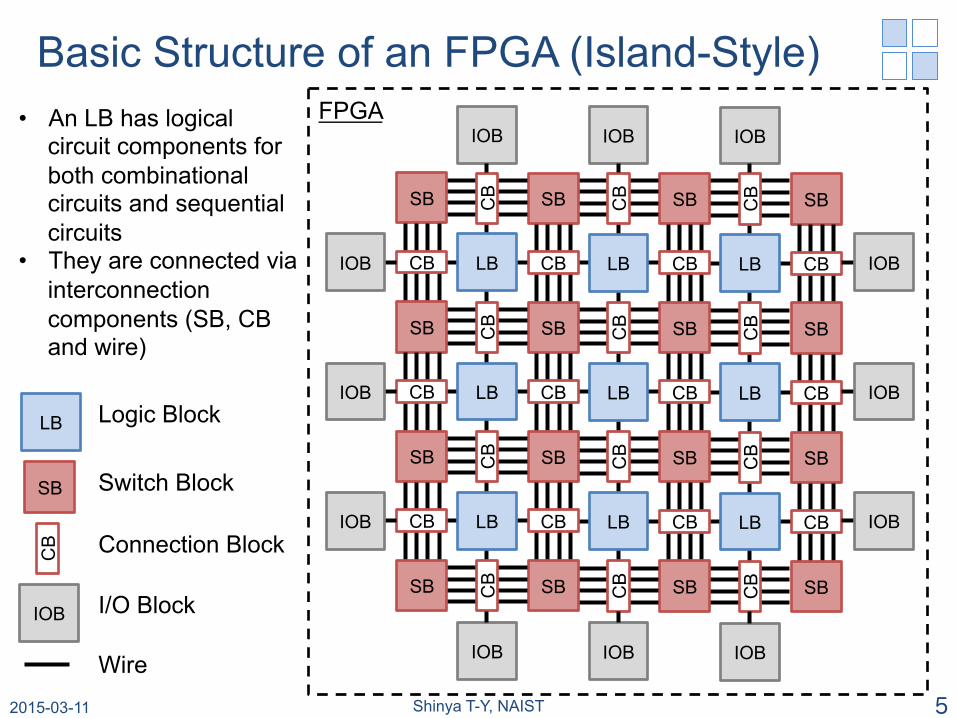
Basic Structure of an FPGA (Island-Style)
SB
CB
CB
LB
SB
CB
CB
LB
SB
CB
CB
LB
SB CB
SB
CB
CB
LB
SB
CB
CB
LB
SB
CB
CB
LB
SB CB
SB
CB
CB
LB
SB
CB
CB
LB
SB
CB C
B
LB
SB CB
SB
CB
SB
CB
SB
CB
SB
IOB
IOB
IOB
IOB
IOB
IOB
IOB IOB IOB
IOB IOB IOB
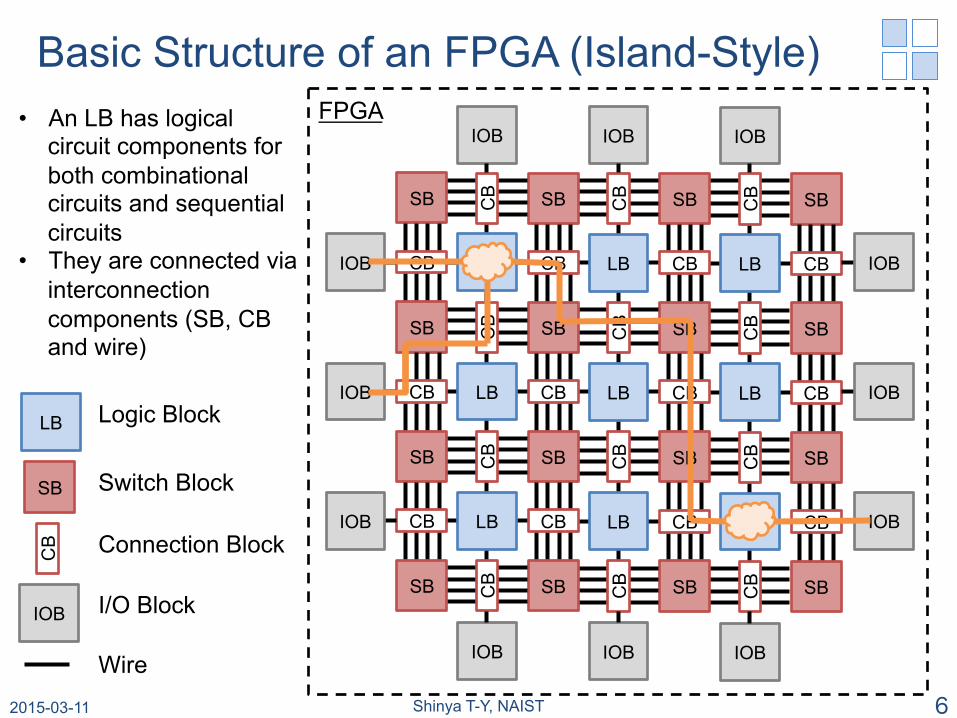
FPGA
SB
LB
CB
IOB
Logic Block
Switch Block
Connection Block
I/O Block
Wire
• An LB has logical circuit components for both combinational circuits and sequential circuits
• They are connected via interconnection components (SB, CB and wire)
2015-03-11 Shinya T-Y, NAIST 5
Basic Structure of an FPGA (Island-Style)
SB
CB
CB
LB
SB
CB
CB
LB
SB
CB
CB
LB
SB CB
SB
CB
CB
LB
SB
CB
CB
LB
SB
CB
CB
LB
SB CB
SB
CB
CB
LB
SB
CB
CB
LB
SB
CB C
B
LB
SB CB
SB
CB
SB
CB
SB
CB
SB
IOB
IOB
IOB
IOB
IOB
IOB
IOB IOB IOB
IOB IOB IOB
FPGA
SB
LB
CB
IOB
Logic Block
Switch Block
Connection Block
I/O Block
Wire
• An LB has logical circuit components for both combinational circuits and sequential circuits
• They are connected via interconnection components (SB, CB and wire)
2015-03-11 Shinya T-Y, NAIST 6
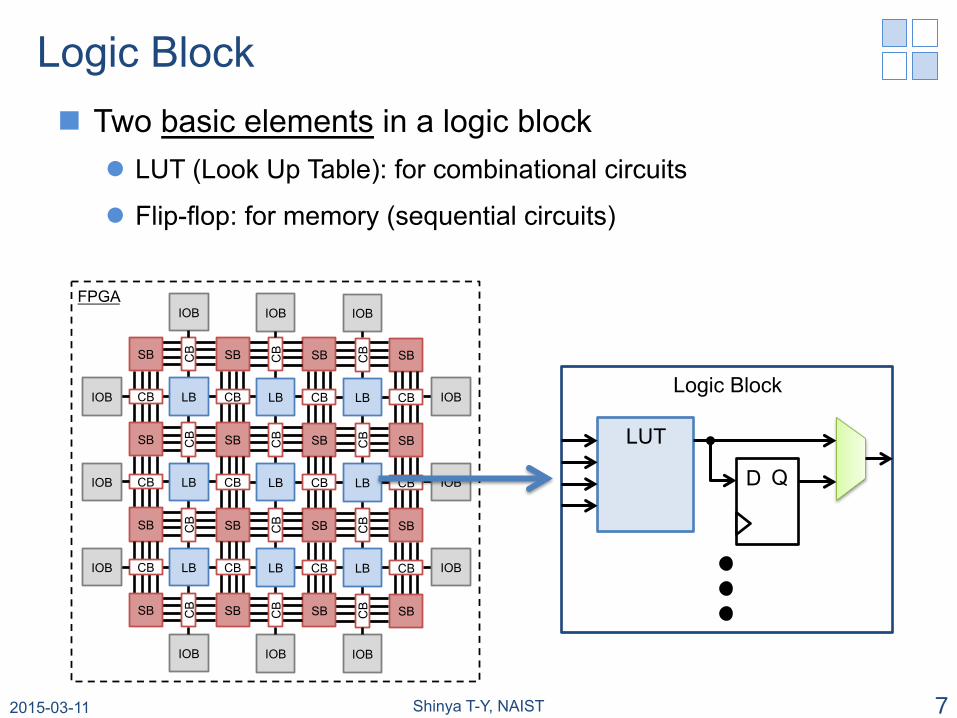
Logic Block n Two basic elements in a logic block
l LUT (Look Up Table): for combinational circuits
l Flip-flop: for memory (sequential circuits)
SB
CB
CB
LB
SB
CB
CB
LB
SB
CB
CB
LB
SB CB
SB
CB
CB
LB
SB
CB
CB
LB
SB
CB
CB
LB
SB CB
SB
CB
CB
LB
SB
CB
CB
LB
SB
CB
CB
LB
SB CB
SB
CB
SB
CB
SB
CB
SB
IOB
IOB
IOB
IOB
IOB
IOB
IOB IOB IOB
IOB IOB IOB
FPGA�
Logic Block
LUT
D Q
2015-03-11 Shinya T-Y, NAIST 7
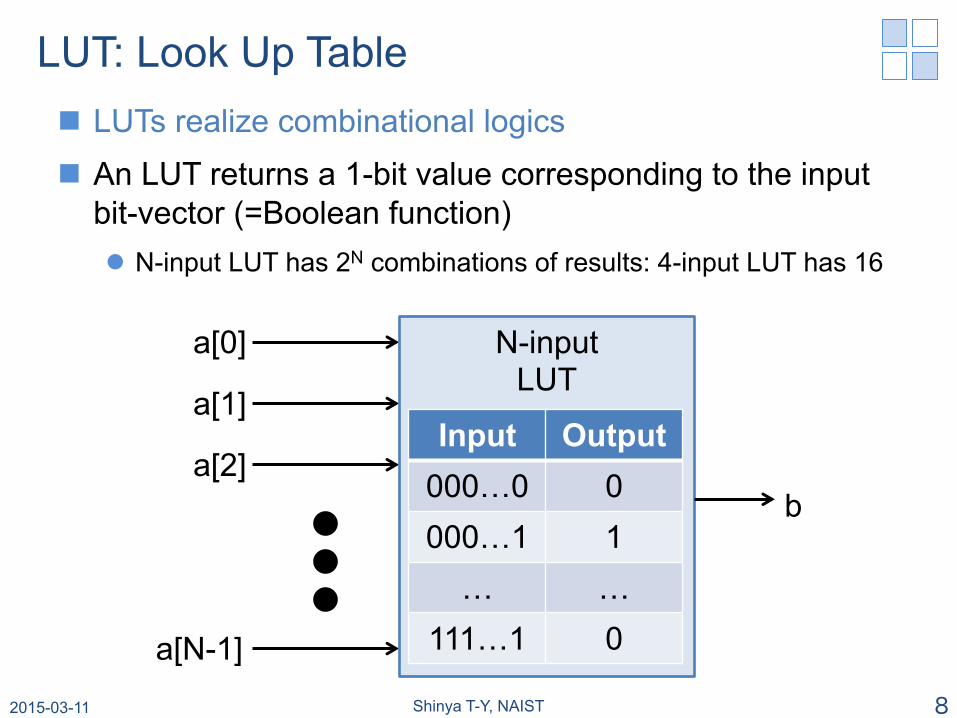
LUT: Look Up Table n LUTs realize combinational logics n An LUT returns a 1-bit value corresponding to the input
bit-vector (=Boolean function) l N-input LUT has 2N combinations of results: 4-input LUT has 16
a[0] a[1] a[2]
a[N-1]
N-input LUT
b
Input Output 000…0 0 000…1 1 … …
111…1 0
2015-03-11 Shinya T-Y, NAIST 8
FPGA in Anywhere n LSI設計・検証のプラットフォームとして
l LSIの機能を製造前に検証 l HWの完成を待たなくても
SWの開発検証ができる l ソフトウェアシミュレータによる 回路シミュレーションよりも 高速に検証できる
n 最終製品に組み込むLSIとして l 画像処理 l ネットワーク機器
n アクセラレータとして l データベースエンジン l ウェブ検索エンジン l 証券取引アクセラレータ
l 石油探索アクセラレータ
Object Detection
Stock Trading
2015-03-11 Shinya T-Y, NAIST 9
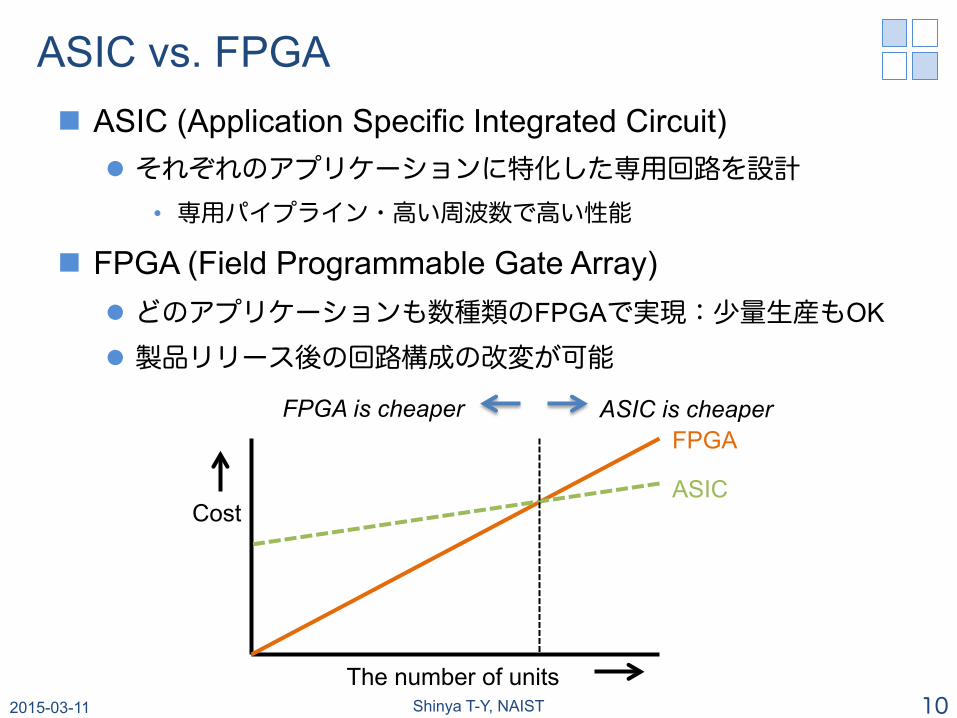
ASIC vs. FPGA n ASIC (Application Specific Integrated Circuit)
l それぞれのアプリケーションに特化した専用回路を設計 • 専用パイプライン・高い周波数で高い性能
n FPGA (Field Programmable Gate Array) l どのアプリケーションも数種類のFPGAで実現:少量生産もOK
l 製品リリース後の回路構成の改変が可能
The number of units
Cost ASIC
FPGA FPGA is cheaper ASIC is cheaper
2015-03-11 Shinya T-Y, NAIST 10

増え続けるFPGAの回路規模
n トランジスタの スケーリングにより FPGの回路規模も増大 l 5年で6倍以上に増加
l 今後も更なる増加が予想 • マルチダイ化
• 3次元積層
n その分設計が大変に l 設計検証の時間が増大
l 効率的な開発方式が必要 • RTLのみの開発の限界
• 高位合成処理系の利用
From Xilinx UG872 2015-03-11 Shinya T-Y, NAIST 11
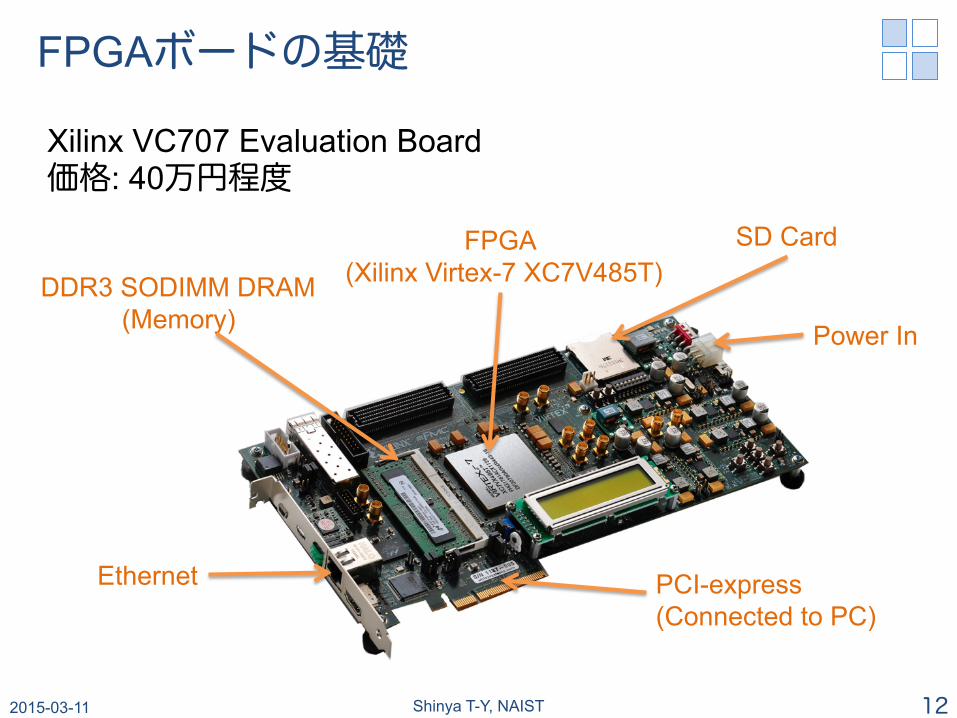
FPGAボードの基礎
Xilinx VC707 Evaluation Board 価格: 40万円程度
PCI-express (Connected to PC)
FPGA (Xilinx Virtex-7 XC7V485T)
Ethernet
DDR3 SODIMM DRAM (Memory)
SD Card
Power In
2015-03-11 Shinya T-Y, NAIST 12
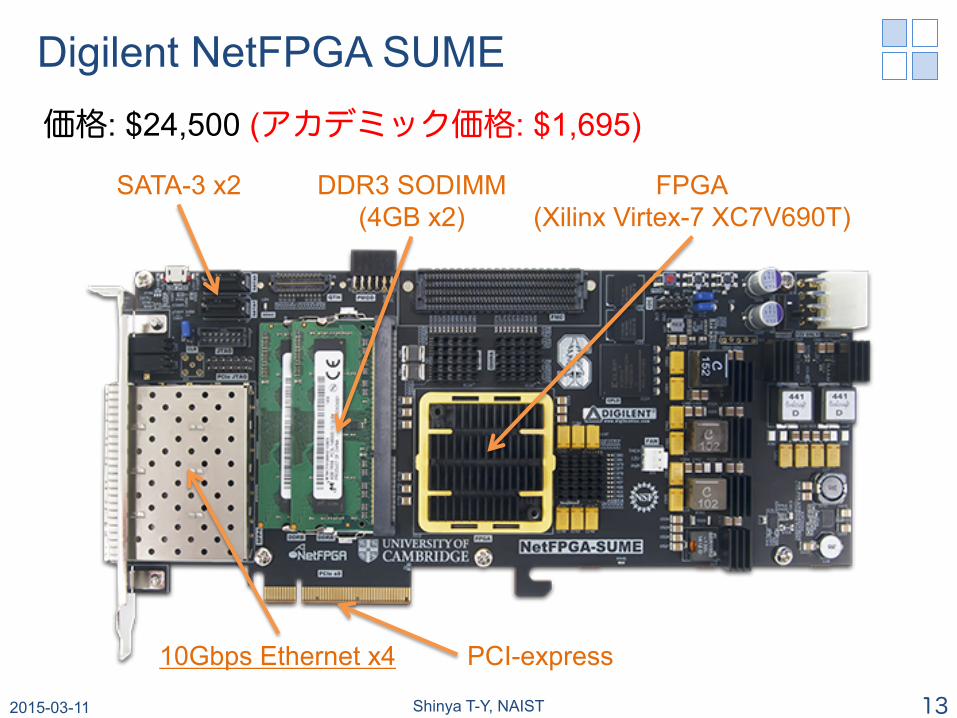
Digilent NetFPGA SUME
FPGA (Xilinx Virtex-7 XC7V690T)
DDR3 SODIMM (4GB x2)
PCI-express 10Gbps Ethernet x4
SATA-3 x2
価格: $24,500 (アカデミック価格: $1,695)
2015-03-11 Shinya T-Y, NAIST 13

Digilent Nexys3 FPGA: Xilinx Spartan-6 LX16 Size: Pipelined CPU ×2 Price: 2万円?(アカデミック)
Digilent ZedBoard FPGA: Xilinx Zynq-7020 Size: Pipelined CPU ×8 (+ ARM DualCore) Price: 5万円 (アカデミック)
2015-03-11 Shinya T-Y, NAIST 14

ScalableCore System FPGA: Xilinx Spartan-6 ×100 Size: Pipelined CPU x200? Price: 100万円程度?
2015-03-11 Shinya T-Y, NAIST 15
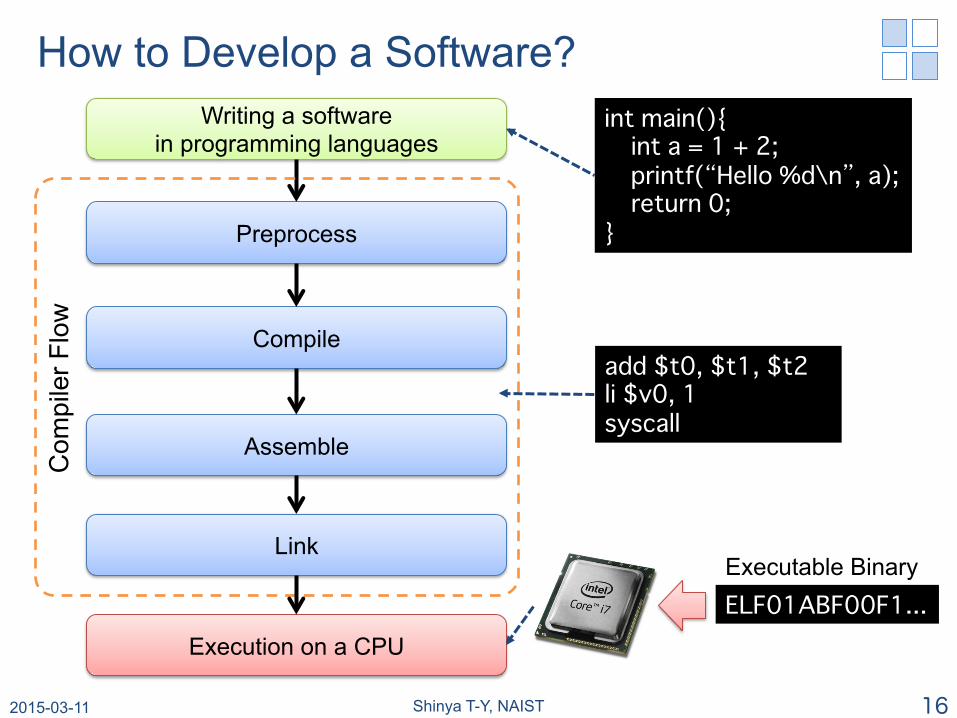
How to Develop a Software? Writing a software
in programming languages
Preprocess
Compile
Assemble
Link
Com
pile
r Flo
w
Execution on a CPU
int main(){� int a = 1 + 2;� printf(“Hello %d\n”, a);� return 0;�}�
add $t0, $t1, $t2�li $v0, 1�syscall�
ELF01ABF00F1...�
Executable Binary
2015-03-11 Shinya T-Y, NAIST 16
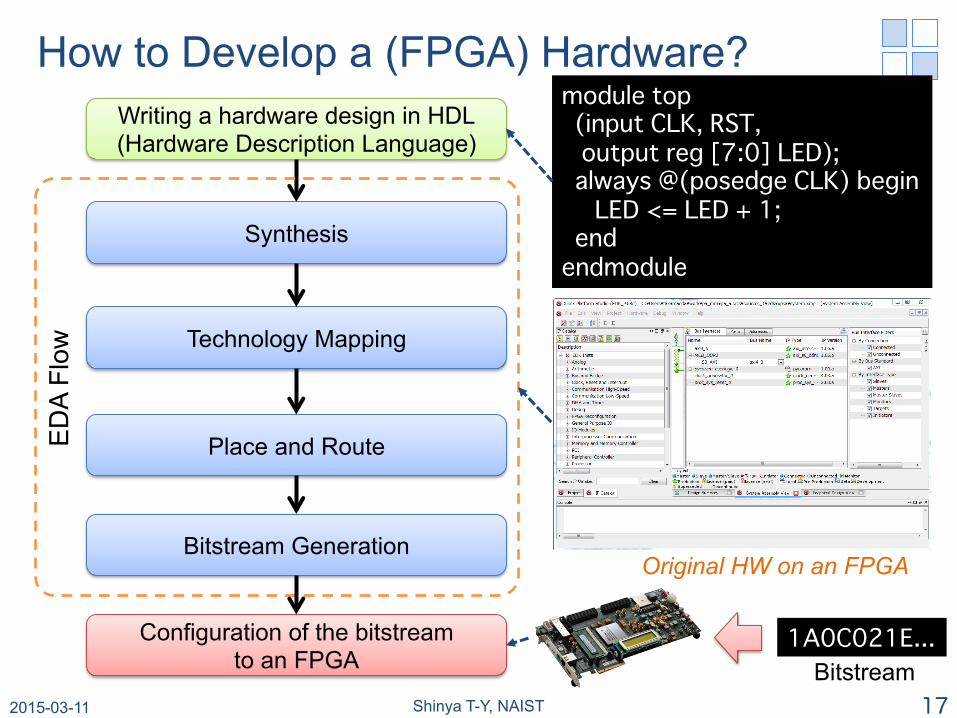
How to Develop a (FPGA) Hardware? Writing a hardware design in HDL (Hardware Description Language)
Synthesis
Technology Mapping
Place and Route
Bitstream Generation
ED
A Fl
ow
Configuration of the bitstream to an FPGA
module top� (input CLK, RST, � output reg [7:0] LED);� always @(posedge CLK) begin� LED <= LED + 1;� end�endmodule�
1A0C021E...�
Original HW on an FPGA
Bitstream 2015-03-11 Shinya T-Y, NAIST 17

近年のFPGAを取り巻く環境
2015-03-11 Shinya T-Y, NAIST 18
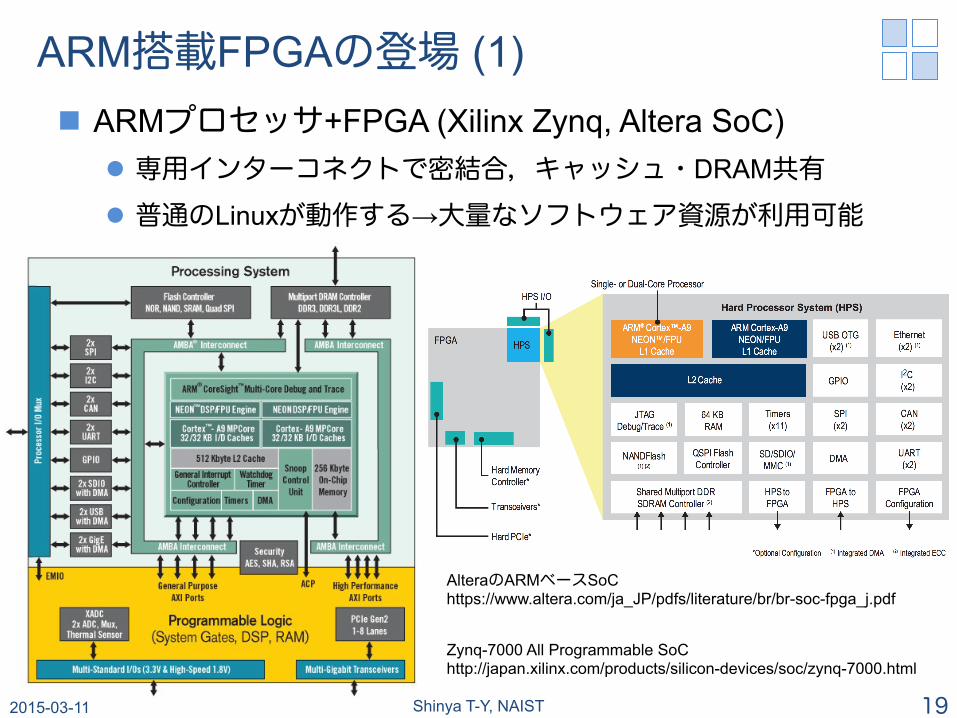
ARM搭載FPGAの登場 (1) n ARMプロセッサ+FPGA (Xilinx Zynq, Altera SoC)
l 専用インターコネクトで密結合,キャッシュ・DRAM共有
l 普通のLinuxが動作する→大量なソフトウェア資源が利用可能
Zynq-7000 All Programmable SoC http://japan.xilinx.com/products/silicon-devices/soc/zynq-7000.html
AlteraのARMベースSoC https://www.altera.com/ja_JP/pdfs/literature/br/br-soc-fpga_j.pdf
2015-03-11 Shinya T-Y, NAIST 19

ARM搭載FPGAの登場 (2) n 普通のFPGAとは何が違う?
l そもそも通常のFPGA上もCPU搭載可能(ソフトマクロ) l コア性能が数倍~10倍違う
• MicroBlaze: 100MHz~200MHz, In-order, Single issue
• ARM: 600MHz~1GHz, OoO, Super scalar
n 独自のHW/SW協調SoCの実現が容易になる l 面倒な処理は処理はCPU上のソフトウェアで実現
• ネットワーク・ファイルシステムなど
l 並列処理部はFPGA上の専用ハードウェアで実現 • 並列度とメモリ帯域に応じて演算器を追加し高速化
• 必要に応じて演算精度を削り更に高速化
l データ共有が遅いんじゃないの? • PCI-e経由よりも通信オーバーヘッドは小さい
– キャッシュ・DRAM共有のおかげ
2015-03-11 Shinya T-Y, NAIST 20

例)Zynq 7000 アーキテクチャ n ARM Cortex-A9 (Dual-core, OoO, 8-stage) n 3種類のCPU-PL間接続 (すべてAXIインターフェース)
AXI GP Port AXI HP Port
AXI ACP Port
Cache
DRAM
GP • 低速 • 制御レジスタ アクセス用
HP • 高バンド幅 • DRAMへの バースト転送向け
ACP • 低レイテンシ • キャッシュ コヒーレント
• CPUとの データ共有向け
http://www.ioe.nchu.edu.tw/Pic/CourseItem/4468_20_Zynq_Architecture.pdf http://japan.xilinx.com/support/documentation/data_sheets/j_ds190-Zynq-7000-Overview.pdf 2015-03-11 Shinya T-Y, NAIST 21

浮動小数点ユニット搭載FPGA n 従来FPGAのDSP(乗算)ユニットは整数のみ対応
l 浮動小数点演算は変換ロジックを組み合わせて実現 (ソフトマクロ)→大きな回路・電力オーバーヘッド
• そのため浮動小数点演算ではGPUが有利だった
n Altera次期モデルがハードマクロ浮動小数点DSPを搭載 l コンピューティングデバイスとしてのFPGAの利用が増加?
Altera Expands Floating-Point Hardware Support Across Its Product Lines http://www.bdti.com/InsideDSP/2014/07/22/Altera
2015-03-11 Shinya T-Y, NAIST 22

IPコアベースのシステム開発環境の普及 n IPコアを開発・追加して繋げばシステム完成J
l 標準的なインターコネクトでIPコア達を接続
l EDAツールが自動的にインターコネクトと(いくつかの) デバイス依存のインターフェースを生成してくれるため楽
l いかにしてIPコアを簡単に開発するかが重要
Xilinx Platform Studio (XPS)
IP-core List
Interconnect
FPGA
CPU HW Acc
DRAM I/F Ether PCI-E
Interconnect
HW Acc
DRAM
IP-core Instances
2015-03-11 Shinya T-Y, NAIST 23
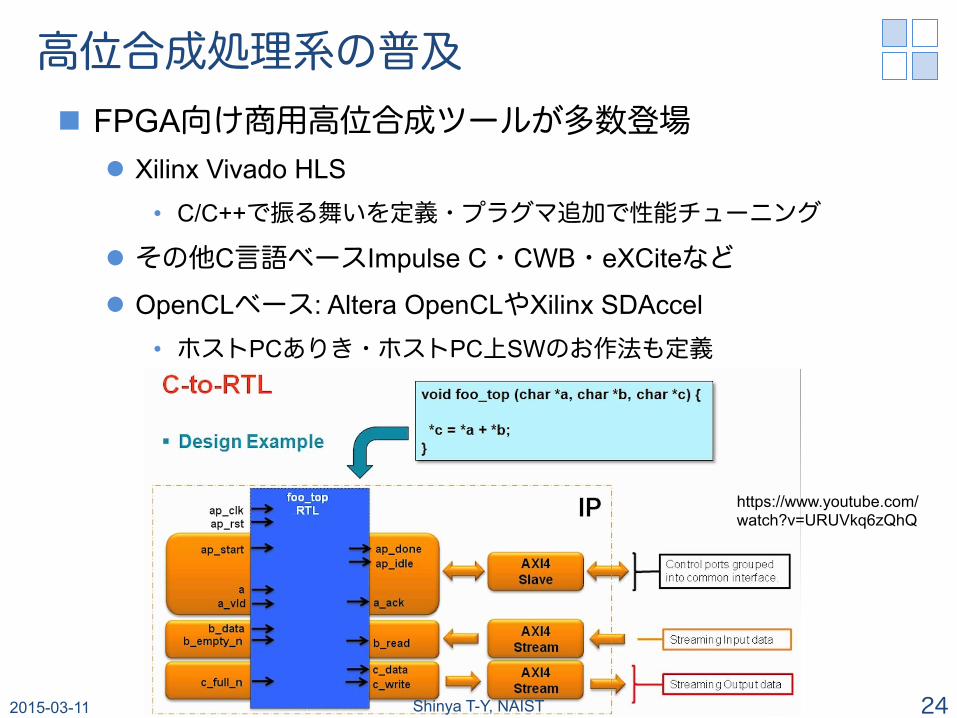
高位合成処理系の普及 n FPGA向け商用高位合成ツールが多数登場
l Xilinx Vivado HLS • C/C++で振る舞いを定義・プラグマ追加で性能チューニング
l その他C言語ベースImpulse C・CWB・eXCiteなど
l OpenCLベース: Altera OpenCLやXilinx SDAccel • ホストPCありき・ホストPC上SWのお作法も定義
https://www.youtube.com/ watch?v=URUVkq6zQhQ
2015-03-11 Shinya T-Y, NAIST 24

オープンソースな高位合成ツールの登場 n LegUp: トロント大で開発されているCベース処理系
l C記述をMIPS CPU用SW部とHW部に自動分割・論文多数
n Synthesijer: Javaによる高位合成処理系 l Java言語仕様に改変なし,サブセットをそのまま合成可能
9
クイックスタート 5/8(5) 間隔をおいて変数ledをtrue/falseするプログラムを書く
Lチカに相当する変数
適当なウェイト点滅
自動コンパイルが裏で動くので,Javaコードとしての正しさは
即座にチェックされる
2
Synthesijer とは
✔ JavaプログラムをFPGA上のハードウェアに変換
✔ 複雑なアルゴリズムのハードウェア実装を楽に
✔ オブクジェクト指向設計による再利用性の向上
✔ 特殊な記法,追加構文はない
✔ ソフトウェアとして実行可能.動作の確認、検証が容易
✔ 書けるプログラムに制限は加える
(動的なnew,再帰は不可など)
Javaコンパイラフロントエンド
Synthesijerエンジン
Javaコンパイラバックエンド
合成配置配線
while(){if(...){ … }else{ … … }….}
複雑な状態遷移も,Javaの制御構文を使って楽に設計できる
同じJavaプログラムをソフトウェアとしても
FPGA上のハードウェアとしても実行可能
Open-source
http://www.sigemb.jp/ESS/2014/files/IPSJ-ESS2014003-1.pdf 2015-03-11 Shinya T-Y, NAIST 25

国際会議等にみる傾向
2015-03-11 Shinya T-Y, NAIST 26

主要な国際会議・論文誌
n 国際会議 l FCCM, ACM FPGA, FPL, FPT, ASAP, ReConFig, ARC, HEART
l 計算機アーキテクチャ全般やLSI設計技術を対象とする国際会議でも頻繁に取り扱われる
• 計算機アーキテクチャ系: ISCA, MICRO, ASPLOS, HPCA
• LSI設計技術系: DAC, ASP-DAC, DATE
l その他データベース系やプログラミング言語系の国際会議でも
n 論文誌 l ACM Tr. on Reconfigurable Technology and Systems (TRETS)
l IEICE英文論文誌D Special Section on Reconfigurable Systems
2015-03-11 Shinya T-Y, NAIST 27

主要国際会議におけるRECONF研究動向
n 定番のテーマ l 画像処理
l バイオインフォマティクス
l ネットワーク処理 (IPv6パケット処理)
l ソフトプロセッサ (CPU on FPGA)
l CGRAアーキテクチャ
n 最近の流行 l データベース (NoSQL, memcached)
l 機械学習 (Deep Learning)
l 設計技術 (HW/SW協調設計・抽象化方式・設計支援)
l 高位合成言語 (C/Java/etc-to-HDLコンパイラ・最適化)
2015-03-11 Shinya T-Y, NAIST 28
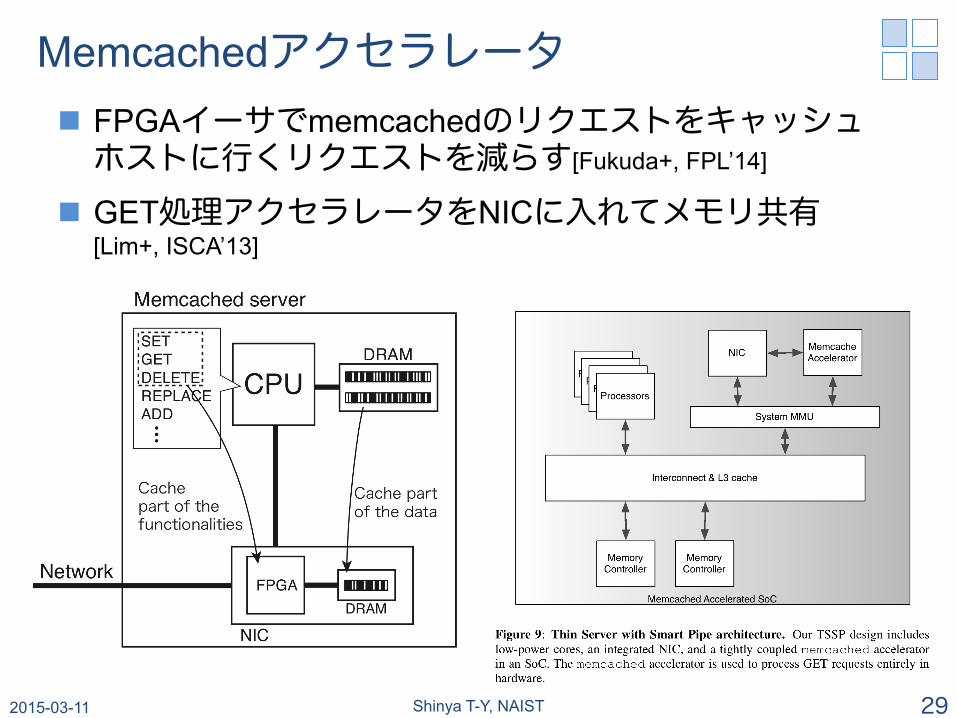
Memcachedアクセラレータ n FPGAイーサでmemcachedのリクエストをキャッシュ ホストに行くリクエストを減らす[Fukuda+, FPL’14]
n GET処理アクセラレータをNICに入れてメモリ共有 [Lim+, ISCA’13]
2015-03-11 Shinya T-Y, NAIST 29
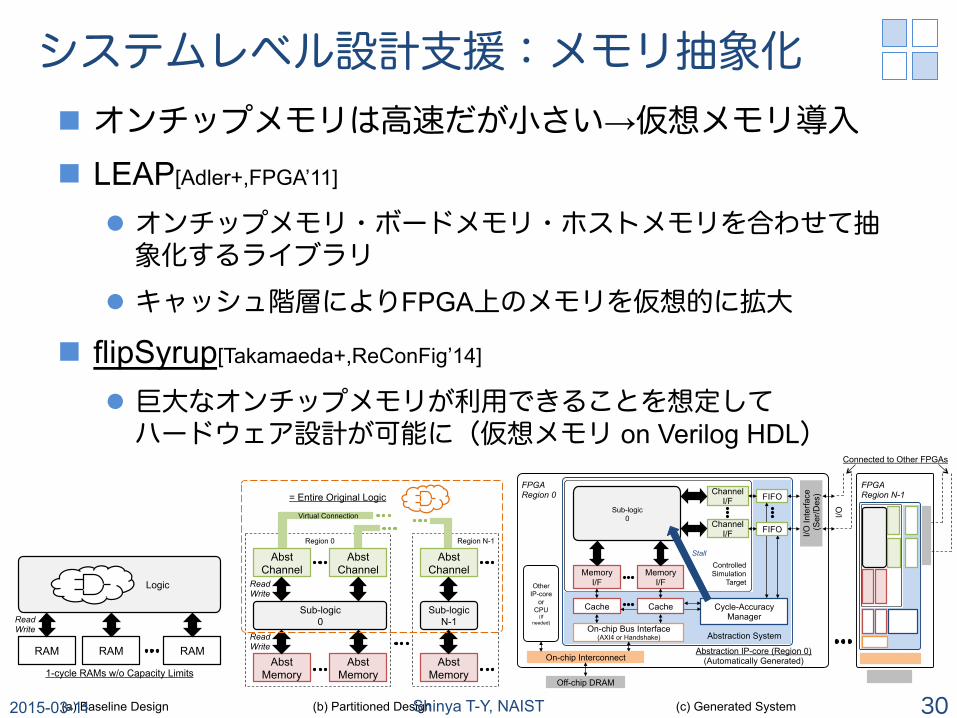
システムレベル設計支援:メモリ抽象化 n オンチップメモリは高速だが小さい→仮想メモリ導入 n LEAP[Adler+,FPGA’11]
l オンチップメモリ・ボードメモリ・ホストメモリを合わせて抽象化するライブラリ
l キャッシュ階層によりFPGA上のメモリを仮想的に拡大
n flipSyrup[Takamaeda+,ReConFig’14]
l 巨大なオンチップメモリが利用できることを想定して ハードウェア設計が可能に(仮想メモリ on Verilog HDL)
Read Write�
RAM�
1-cycle RAMs w/o Capacity Limits
RAM� RAM�
Logic
(a) Baseline Design�
Read Write�
Sub-logic 0
Abst Memory�
Abst Memory�
Abst Channel�
Abst Channel�
Read Write�
Virtual Connection�
Region 0�
Sub-logic N-1
Abst Memory�
Abst Channel�
Region N-1�
= Entire Original Logic�
(b) Partitioned Design�
Memory I/F
Memory I/F�
Channel I/F
Channel I/F�
Stall�
I/O In
terfa
ce
(Ser
/Des
)
Off-chip DRAM
On-chip Bus Interface (AXI4 or Handshake)
Cache
FIFO�
Controlled Simulation
Target�
Cycle-Accuracy Manager
Cache
FIFO�
On-chip Interconnect
Other IP-core
or CPU
(If needed)�
Abstraction IP-core (Region 0) (Automatically Generated)�
FPGA Region 0�
I/O�
Abstraction System�
Sub-logic 0
FPGA Region N-1�
Connected to Other FPGAs�
(c) Generated System�2015-03-11 Shinya T-Y, NAIST 30
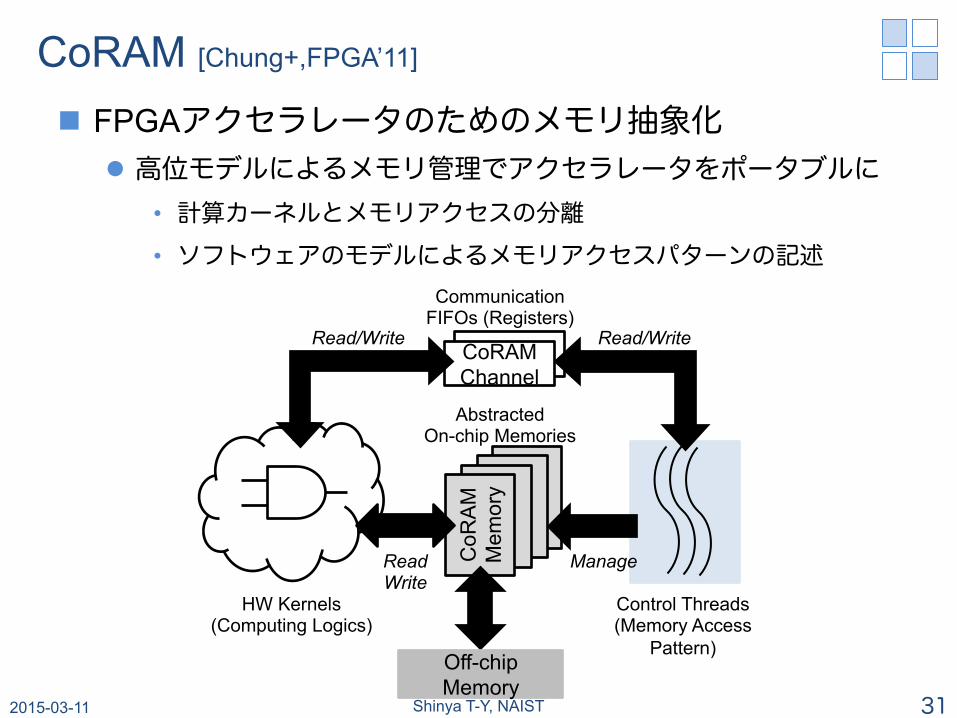
CoRAM [Chung+,FPGA’11] n FPGAアクセラレータのためのメモリ抽象化
l 高位モデルによるメモリ管理でアクセラレータをポータブルに • 計算カーネルとメモリアクセスの分離
• ソフトウェアのモデルによるメモリアクセスパターンの記述
HW Kernels (Computing Logics)
CoR
AM
M
emor
y
Read Write
Manage
Control Threads (Memory Access
Pattern)
CoRAM Channel
Read/Write Read/Write
Communication FIFOs (Registers)
Abstracted On-chip Memories
Off-chip Memory
2015-03-11 Shinya T-Y, NAIST 31
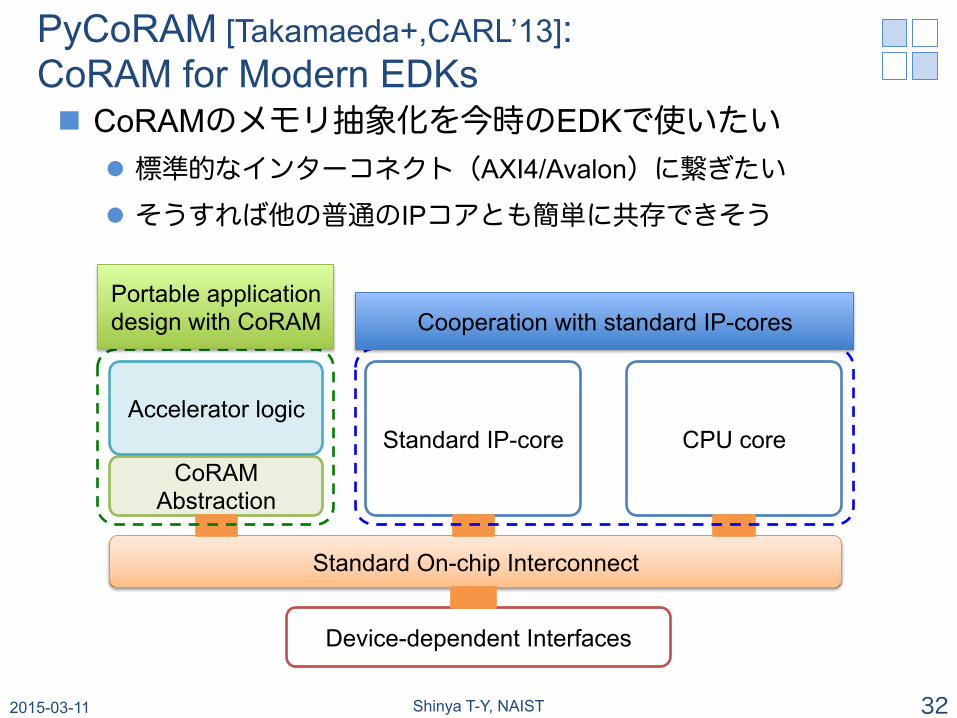
PyCoRAM [Takamaeda+,CARL’13]: CoRAM for Modern EDKs n CoRAMのメモリ抽象化を今時のEDKで使いたい
l 標準的なインターコネクト(AXI4/Avalon)に繋ぎたい
l そうすれば他の普通のIPコアとも簡単に共存できそう
Standard On-chip Interconnect
CoRAM Abstraction
Accelerator logic Standard IP-core
Device-dependent Interfaces
CPU core
Portable application design with CoRAM Cooperation with standard IP-cores
2015-03-11 Shinya T-Y, NAIST 32

PyCoRAMマイクロアーキテクチャ PyCoRAM IP
User I/O
User Logic
CoRAM Channel
CoRAM Register
Control Thread
Master DMAC
CoRAM Memory
Master DMAC
CoRAM Stream
FSM
GPIO
Slave DMAC
CoRAM IoChannel
2015-03-11 Shinya T-Y, NAIST 33

PyCoRAM IP User I/O
User Logic
CoRAM Channel
CoRAM Register
Control Thread
Master DMAC
CoRAM Memory
Master DMAC
CoRAM Stream
FSM
GPIO
Slave DMAC
CoRAM IoChannel
PyCoRAMマイクロアーキテクチャ
Modeled in RTL (Verilog HDL)
Memory Access Pattern
in Python
2015-03-11 Shinya T-Y, NAIST 34

PyCoRAMマイクロアーキテクチャの実装 PyCoRAM IP
Interconnect (AXI4/Avalon)
DRAM Controller FPGA
User I/O
User Logic
CoRAM Channel
CoRAM Register
Control Thread
Master DMAC
Master I/F
CoRAM Memory
Master DMAC
Master I/F
CoRAM Stream
Slave I/F
FSM
GPIO
Slave DMAC
CoRAM IoChannel
2015-03-11 Shinya T-Y, NAIST 35

PyCoRAMマイクロアーキテクチャの実装 PyCoRAM IP
Interconnect (AXI4/Avalon)
DRAM Controller FPGA
User I/O
User Logic
CoRAM Channel
CoRAM Register
Control Thread
Master DMAC
Master I/F
CoRAM Memory
Master DMAC
Master I/F
CoRAM Stream
Slave I/F
FSM
GPIO
Slave DMAC
CoRAM IoChannel Master:
メモリ等へ能動的にアクセス
Slave: プロセッサ等から読み書きされる
2015-03-11 Shinya T-Y, NAIST 36
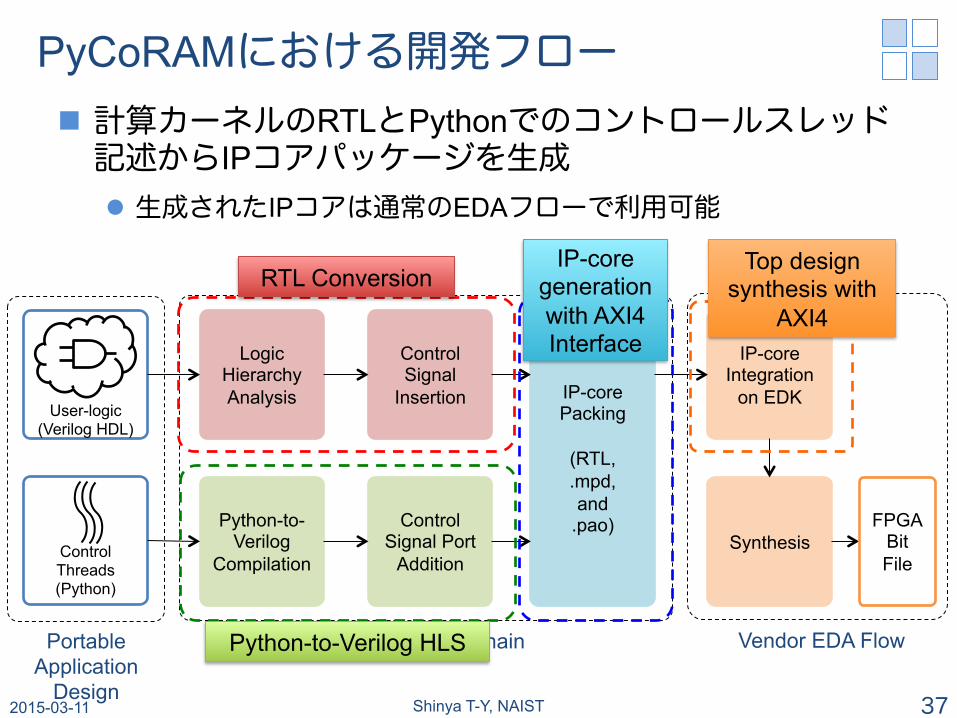
PyCoRAMにおける開発フロー n 計算カーネルのRTLとPythonでのコントロールスレッド記述からIPコアパッケージを生成 l 生成されたIPコアは通常のEDAフローで利用可能
User-logic (Verilog HDL)
Control Threads (Python)
Logic Hierarchy Analysis
Python-to-Verilog
Compilation
Control Signal
Insertion IP-core Packing
(RTL, .mpd, and
.pao)
IP-core Integration
on EDK
Synthesis Control
Signal Port Addition
FPGA Bit File
Portable Application
Design
PyCoRAM Tool-chain Vendor EDA Flow Python-to-Verilog HLS
RTL Conversion IP-core
generation with AXI4 Interface
Top design synthesis with
AXI4
2015-03-11 Shinya T-Y, NAIST 37

新たなハードウェア記述言語
n Verilog HDL/VHDLの問題点 l すべてをレジスタ転送レベルで書かなければならないため大変
l 抽象度・再利用性が低い
n Verilog HDL/VHDLに変わる新しいHDL l Bluespec: System Verilog + Haskell風味
l Chisel: Scalaベースのハードウェア設計DSL
l Synthesijer.Scala: ScalaでHDLを生成
2015-03-11 Shinya T-Y, NAIST 38

PyMTL [Lockhart+,MICRO’14]
Derek Lockhart+: PyMTL: A Unified Framework for Vertically Integrated Computer Architecture Research, ACM/IEEE MICRO-47 (2014)
Pythonでハードウェアを記述 3つのパラダイムをサポート • Functional Level (FL) • Cycle Level (CL) • Register Transfer Level (RTL)
2015-03-11 Shinya T-Y, NAIST 39

機械学習アクセラレータ
2015-03-11 Shinya T-Y, NAIST 40

CNN and DNN n CNN: Convolutional Neural Network
l 畳み込みニューラルネットワーク • 畳み込み演算・プーリング(選択)を多層に積む
From “DaDianNao: A Machine-Learning Supercomputer (MICRO’14)” 2015-03-11 Shinya T-Y, NAIST 41

Deep Learning on FPGAs n データフローアーキテクチャの採用
l ニューロン・シナプスの値が乗算・加算パイプラインを流れる
n ニューロンのネットワークをHW実装したわけではない l DNNモデルを高速化し何かを予測したいだけ
Zhang+, Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks, FPGA’15 2015-03-11 Shinya T-Y, NAIST 42

FPGA-based Machine Learning System n Microsoft Bing Search Engine (Catapult)
l A commercial FPGA-based web search engine
l Machine-learning (DNN) algorithms as hardware pipeline
Putnam+, A Reconfigurable Fabric for Accelerating Large-Scale Datacenter Services, ISCA'14 2015-03-11 Shinya T-Y, NAIST 43

DaDianNao: A Machine-Learning Supercomputer n CNN/DNNのためのプログラマブルアクセラレータ
n IEEE/ACM MICRO’14ベストペーパー l µアーキテクチャのトップカンファレンスでベストペーパー
We show that, on a subset of the largest known neural network layers, it is possible to achieve a speedup of 450.65x over a GPU, and reduce the energy by 150.31x on average for a 64-chip system.
2015-03-11 Shinya T-Y, NAIST 44

Chip Layout of DaDianNao
2015-03-11 Shinya T-Y, NAIST 45
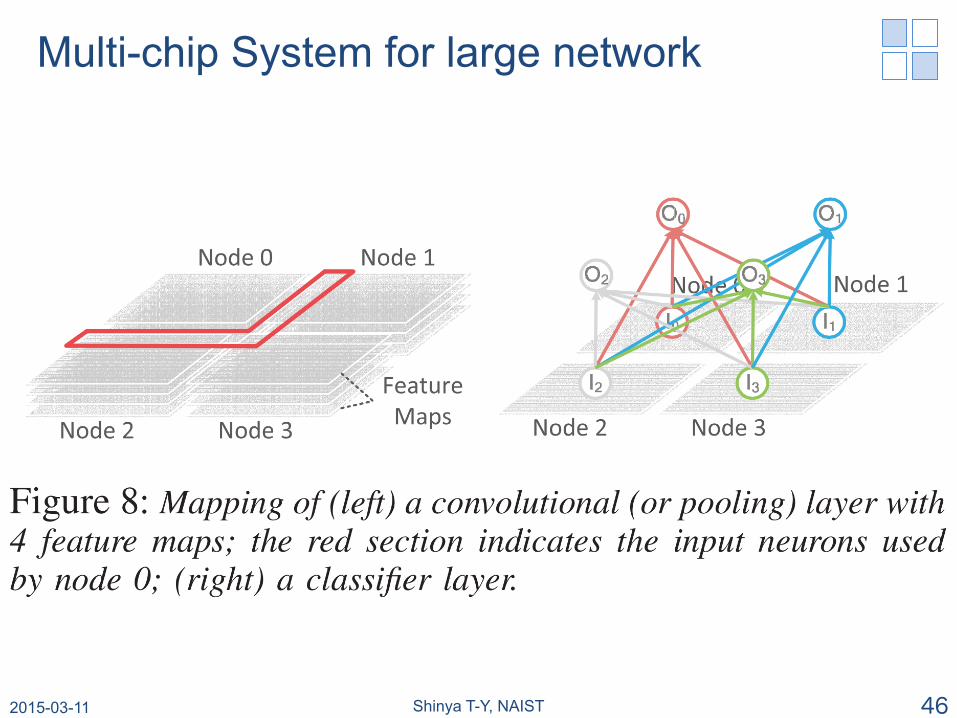
Multi-chip System for large network
2015-03-11 Shinya T-Y, NAIST 46

Various Operations on Identical NFU
2015-03-11 Shinya T-Y, NAIST 47
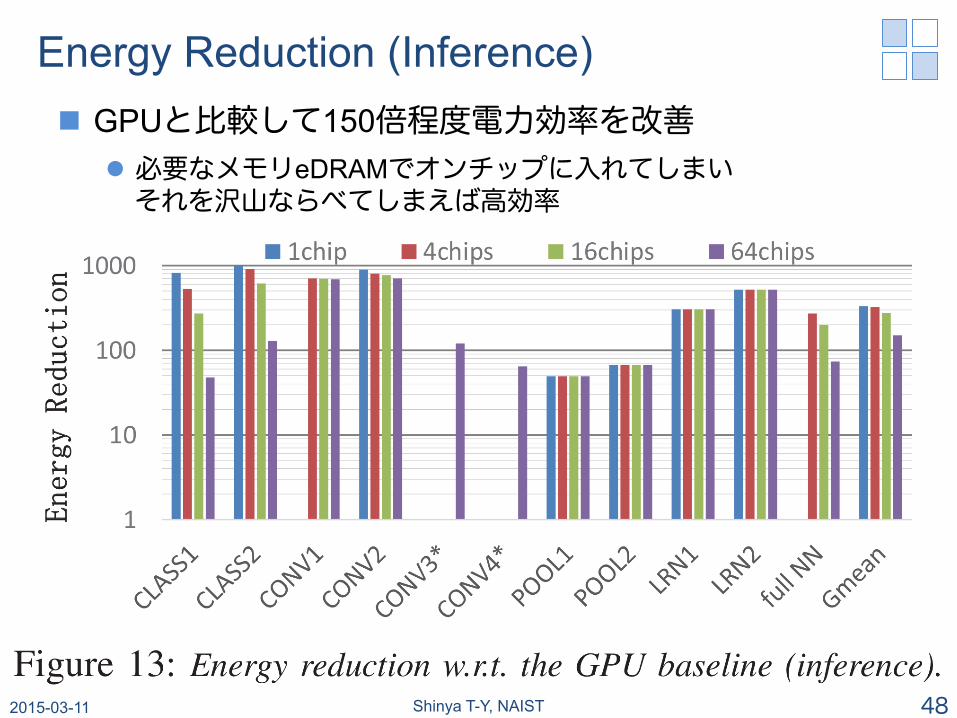
Energy Reduction (Inference) n GPUと比較して150倍程度電力効率を改善
l 必要なメモリeDRAMでオンチップに入れてしまい それを沢山ならべてしまえば高効率
2015-03-11 Shinya T-Y, NAIST 48

今後の展望
2015-03-11 Shinya T-Y, NAIST 49

今後の展望
n FPGA+CPU+GPU? l Zynq Ultrascale: ARM64 Quad-coreを搭載するFPGAをリリース
n →シングルチップヘテロジニアスシステムが普及 l 開発支援・プログラミングモデルがより重要に
l 高位合成処理系・デバッグ環境等の整備が必要
2015-03-11 Shinya T-Y, NAIST 50

まとめ
n FPGAとは? n 近年のFPGAを取り巻く環境
l ARM搭載FPGAの搭載
l ハードマクロ浮動小数点ユニットの搭載
l 安価な商用高位合成系の普及
l オープンソース高位合成系の登場
n 国際会議等にみる傾向 l データベース
l 機械学習(ディープラーニング)
l 設計支援・高位合成処理系
l 専用アクセラレータ
2015-03-11 Shinya T-Y, NAIST 51


















