ETL со Spark
19
ETL со Spark Старикам здесь не место
-
Upload
vasil-remeniuk -
Category
Technology
-
view
608 -
download
2
Transcript of ETL со Spark

ETL со SparkСтарикам здесь не место
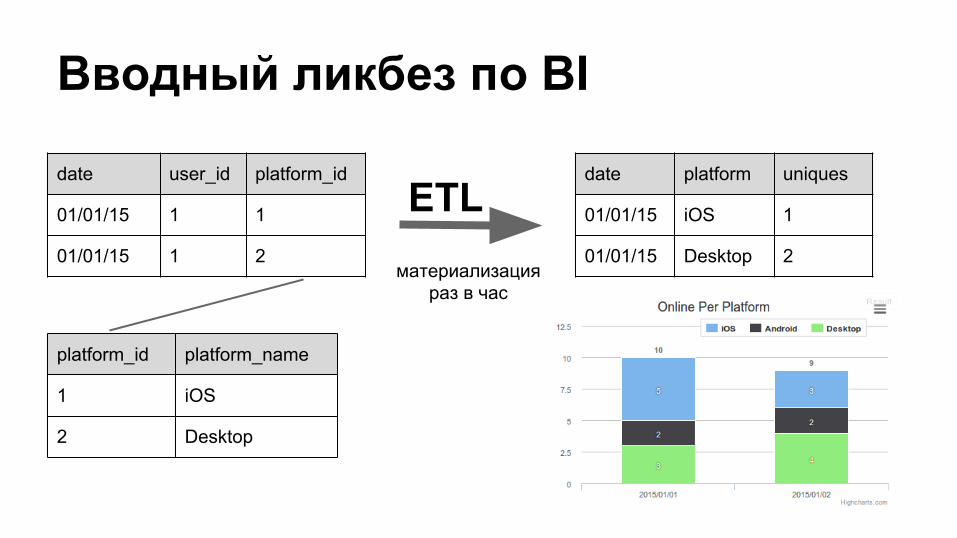
Вводный ликбез по BI
date user_id platform_id
01/01/15 1 1
01/01/15 1 2
platform_id platform_name
1 iOS
2 Desktop
date platform uniques
01/01/15 iOS 1
01/01/15 Desktop 2материализация
раз в час
ETL

Пример: BI-платформа для игр
- система получает от мобильных клиентов различные ивенты
- определяет к какому сегменту относится игрок- дает игроку таргетированный контент
- строит отчеты
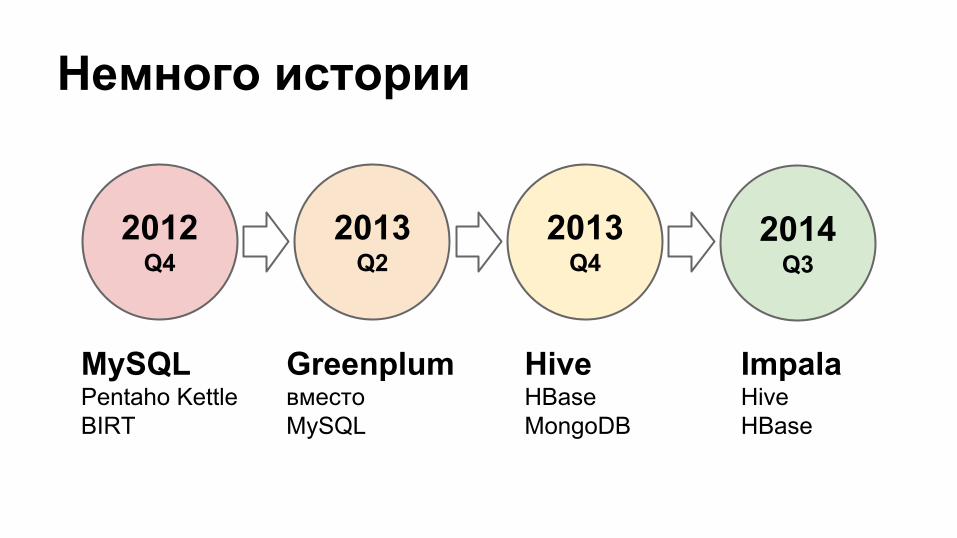
Немного истории
2012Q4
2013Q2
2013Q4
2014Q3
MySQLPentaho KettleBIRT
Greenplum вместоMySQL
Hive HBaseMongoDB
ImpalaHive HBase


С чем мы столкнулись
- методология и подходы, устаревшие 10 лет назад
- нет понятных решений для deployment, monitoring, scheduling, logging,...
- рынок BI-инженеров тормозит прогресс

Типичный ETL-job. Один из сотен

Нерешенные проблемы
- код-ревью: боль- мержи и бранчинг: постоянные проблемы- тестирование: только интеграционное, с
помощью FitNesse- и многое другое...

- deployment: ssh-скрипты и Jenkins - scheduling и запуск: опять Jenkins- аггрегация логов: снова Jenkins- мониторинг джобов: отчеты в BIRT
“Костыли” и “велосипеды”

Со всем лучшим уходим на Spark
- SQL из старых ETL переиспользуется с помощью Spark SQL
- прежний паттерн дизайна Job’ов: иерархия- scheduling и запуск на Jenkins

object SessionFactsJob extends SparkJob {
override def runJob(sc: SparkContext, jobConfig: Config) = {
...
sessionsRDD.registerTempTable("sessions")
sqlContext.sql(s"""
SELECT timestamp, count(distinct userId) uniqueUsersCount,
sum(duration)/count(*) avgSessionLength
FROM sessions WHERE timestamp > ${config.getLong(FromDate)}
ETL-job на Spark
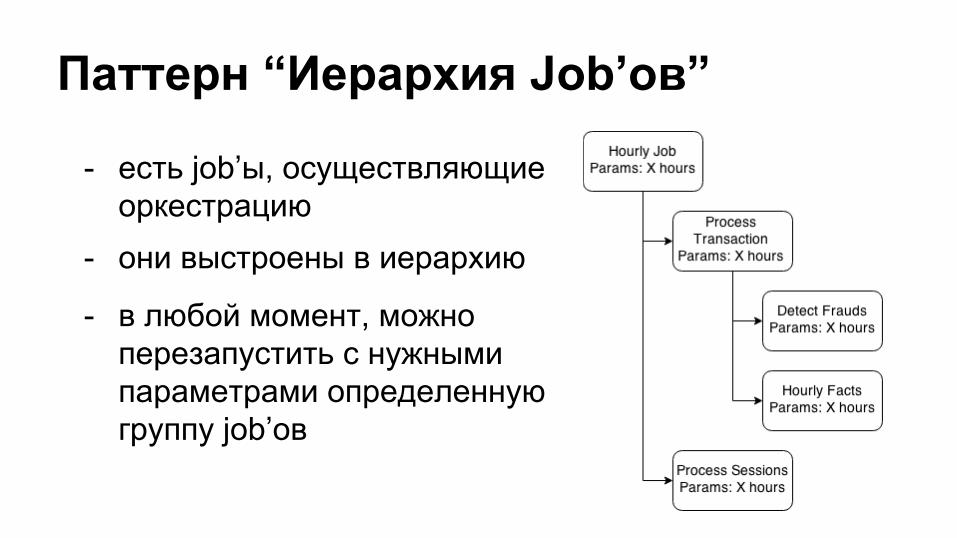
- есть job’ы, осуществляющие оркестрацию
- они выстроены в иерархию
- в любой момент, можно перезапустить с нужными параметрами определенную группу job’ов
Паттерн “Иерархия Job’ов”

ooyala/spark-jobserver
- сервер spark job’ов:- spray для REST-интерфейса- Typesafe Config для конфигурации
- Job реализует trait, запаковывается в jar и загружается POST’ом на сервер

Тестируемость
"Session facts job" should {
"overwrite aggregates, if they already exist" in {
...
SessionFactsJob.runJob(sc, config)
=== Array(DailySessionStats(parseDate("2014-10-30"), 1, 3, 12941))
}
}
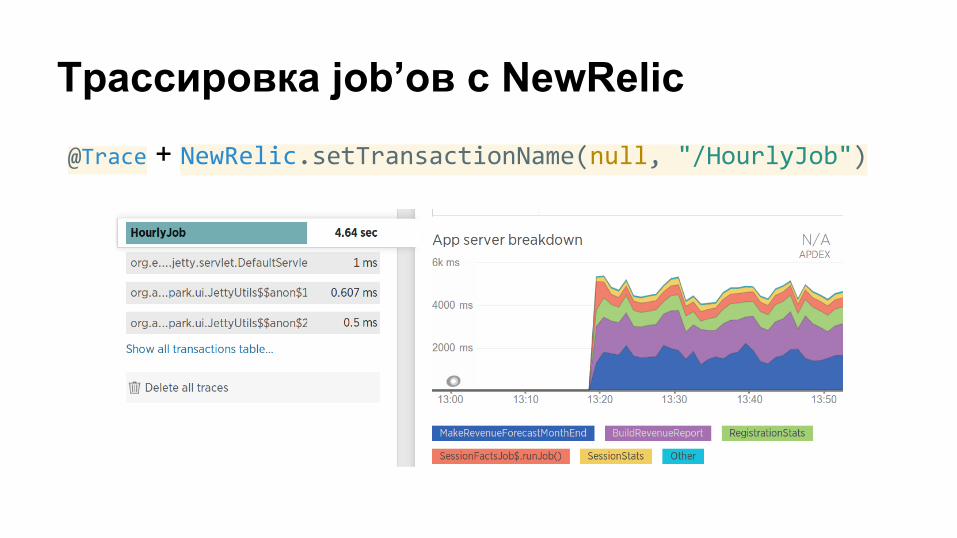
Трассировка job’ов с NewRelic
@Trace + NewRelic.setTransactionName(null, "/HourlyJob")

Кроме этого- кастомный процессинг (никаких UDF)- наследование- cross-cutting concerns- типобезопасность- удобство при интеграции с внешними системами

Перспективы
- Flume - это ночной кошмар Spark Streaming
- SQL-интерфейс поверх ElasticSearch - мечта
- Go-to для лямбда-архитектуры


Спасибо!
gitter.im/scalaby/publicFacebook: Scala Enthusiasts Belarusscala.by
Обсуждения вопросы
ответы
@remeniuk, scalaby#13