
跨媒体语义理解与搜索:结构性学习bf%e7%c3%bd%cc%e5%c0... ·...
129
跨媒体语义理解与搜索:结构性学习 吴飞 浙江大学计算机学院 http://www.dcd.zju.edu.cn/members/wf.htm http://mypage.zju.edu.cn/wufei 2012年7月2日 Email: [email protected]
Transcript of 跨媒体语义理解与搜索:结构性学习bf%e7%c3%bd%cc%e5%c0... ·...

跨媒体语义理解与搜索:结构性学习
吴飞
浙江大学计算机学院
http://www.dcd.zju.edu.cn/members/wf.htm
http://mypage.zju.edu.cn/wufei
2012年7月2日
Email: [email protected]

o 从多媒体搜索到跨媒体搜索
o 高维特征选择:稀疏性到结构性
o 结构性学习
提纲

n 人类共拍了35000亿张照片
n 其中1400亿在Facebook上,占
据4%
n Facebook已经成为世界上最大的图像数据库
How to retrieve favorite multimedia from Internet: A Great Challenge!
数据!数据!! 数据!!!4% of All Photos Ever Taken Are On

How to retrieve favorite multimedia from Internet: A Great Challenge!
数据!数据!! 数据!!!
1825年由法国人Joseph Nicephore所拍摄的人类第一张照片(现藏于French
National Library )
Facebook和国会图书馆(Library of Congress)以及手机照片分享应用Instagram中图像数的
对照图。Facebook仅占4%
187年过去了…

用户查询
Google有100亿的图片,YouTube拥有1亿多的视频,Youku每天上传1万多视频。
How to retrieve favorite multimedia from Internet: A Great Challenge!
大海捞针!大海捞针!! 大海捞针!!!

多媒体检索: 基于元数据的检索方式
o 图像精确的自动标注仍然困难重重
o 手工标注费时费力
o 一幅画胜过千言字:图像语义难以用语言刻画
Manually put meta-data to
image in order to
retrieve it
缺陷
Place: Berkeley
Photographer:
Date:
Size:
…
From Multimedia Retrieval to Cross-media Retrieval

多媒体检索: 基于元数据的检索方式
用文字作画
From Multimedia Retrieval to Cross-media Retrieval
西班牙艺术家Juan Osborne用Barack Obama在January 2009 to October 2011之间演讲发言中单词所拼出的图像(左图:拼出图像;右图:所用单词)

多媒体检索: 基于内容(底层特征)或样例检索
o 底层特征与高层语义之间存在“语义鸿沟”
n 毛与物,形与物是一样的么?
o 图像相似:
n 颜色相似?纹理相似?形状相似?或者包含相似对象?
Find similar images with users’ query imageH. J. Zhang, D. Zhong, Schema for Visual Feature-Based Image
Retrieval, Proceeding of SPIE, Storage and Retrieval for Image and Video Database, 36-46,1995
缺陷
检索样例 相似图像
Background and Motivation : Background
皮之不存,毛之焉附?水无常形,随物附形
所有语义就在像素中包含!

Image DatabaseRanked images
…How to retrieve favorite multimedia from Internet: A Great Challenge!
Yimeng Zhang, et. al., Image Retrieval with Geometry-Preserving Visual Phrases, CVPR 2011
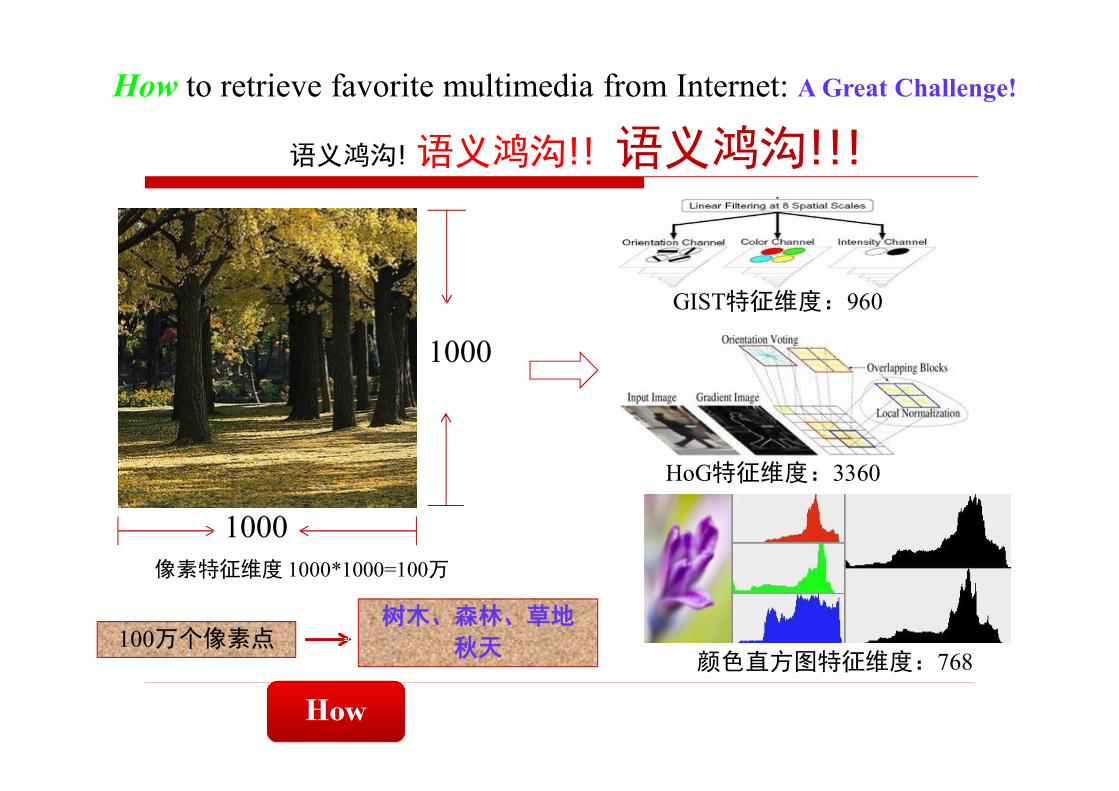
1000
1000
像素特征维度 1000*1000=100万
GIST特征维度:960
HoG特征维度:3360
颜色直方图特征维度:768
How to retrieve favorite multimedia from Internet: A Great Challenge!
语义鸿沟!语义鸿沟!! 语义鸿沟!!!
100万个像素点树木、森林、草地
秋天
How

计算机难以看图说话:底层视觉特征与高层语义之间难以建立准确联系
特征相似
语义不同
特征不同语义相似
How to retrieve favorite multimedia from Internet: A Great Challenge!
语义鸿沟!语义鸿沟!! 语义鸿沟!!!

通过无监督学习建立底层视觉特征与高层语义之间联系
How to retrieve favorite multimedia from Internet: A Great Challenge!语义鸿沟!语义鸿沟!! 语义鸿沟!!!
Building High-Level Features using Large Scale Unsupervised Learning. Quoc V. Le, Marc'Aurelio Ranzato, Rajat Monga, Matthieu Devin, Kai Chen, Greg S. Corrado, Jeffrey Dean and Andrew Y. Ng. In Proceedings of the Twenty-Ninth
International Conference on Machine Learning, 2012
Google和Stanford的研究人员使用16,000计算机,通过无监督深度学习机制,组建了一个包含10亿个连接的神经网络,使用这个神经网络实现了“猫”的识别。

多媒体检索: 语义标注
Background and Motivation : Background
Image-level AnnotationGroundTruth: animals, clouds, plant_life, sky标注结果: clouds, plant_life, structure, sky
Image Region Tagging
Image Interpretation or Generation of Image Description
语义标注涉及到对图像本身所蕴含内容理解的复杂问题。为什么难!

大数据!大数据!! 大数据!!!Examples of Big Data
Customer Transactions
TID Items
1 Bread, Milk
2 Bread, Diaper, Beer, Eggs
3 Milk, Diaper, Beer, Coke 4 Bread, Milk, Diaper, Beer
5 Bread, Milk, Diaper, Coke
Sensor Data
Walmart: 2.5 petabytes user transaction data per hour
Walmart: 2.5 petabytes user transaction data per hour
Rolls-Royce:Terabytes of data per day
Rolls-Royce:Terabytes of data per day
Scientific Research
Large Hadron Collider (LHC) : 13 petabytes per year
Large Hadron Collider (LHC) : 13 petabytes per year
Social Network
Facebook: Over 800 million active users
And 40 billion photos in its user base
Facebook: Over 800 million active users
And 40 billion photos in its user baseWebpages
Over 1 trillion webpages (Google)Over 1 trillion webpages (Google)
RFID
1.8 zettabytes in 20111.8 zettabytes in 2011
难点:数据大?

15
o互联网朝着更加社会化(social)和个性化方向演化
n互联网上数据以用户生成内容为主体(User-Generated Content )
Web 1.0 -> Web 2.0Publishing(发布) -> Participation(参与)
Personal Websites -> Blogging(博客)
Content Management Systems -> Wikis(维基百科)
Encyclopedia Online -> Micro Blog (微博)
Directories (taxonomy) -> Tagging (大众分类)
The Challenge for Multimedia Retrieval at Web 2.0:What Happening

截止2008年8月,Google 已经索引了1万亿张互联网网页.
l 1998: 26 million
l 2008: 1 trillion (1万亿)
截止2011年8月,Flickr有60亿张图像
l 图像标注词条过亿,涵盖千万多种概念
l 每分钟新增3000张图像l 每天400多万张图像被上传
The Challenge for Multimedia Retrieval Beyond Web 1.0:What Happening

截止2012年1月,YouTubel 每分钟上传到YouTube的视频为48小时l 占据了美国网络视频观看总量的76% l YouTube上的视频总共被点击了1万亿次
微软MSNl 构成了一张包含2.4亿节点(用户)、13亿条边(社会关系)的图
l 每月发送消息超过2.55亿条
The Challenge for Multimedia Retrieval Beyond Web 1.0:What Happening


截止2010年, Twitterl 14亿7000万社会关系l 4262个话题l 1亿600万条信息
Kwak, H., Lee, C., Oark, H., Moon, S., What is Twitter, a Social Network or a News Media? , Proceedings of the 19th International World Wide Web (WWW) Conference, 2010
www2010上一篇题为“What is Twitter, a Social Network or a News Media?”论文通过大量实验发现:Twitter不是一个社交网络(social network),而是一种更接近于传
统媒体的应用
The Challenge for Multimedia Retrieval Beyond Web 1.0:What Happening

n 图像检索的发展:从元数据检索,到样例检索,再到图像标注
nNow: 从“就图像论图像”到“就图像+X论图像”,即在一个具有context信息的环境下进行图像理解
n 图像标注:
n 用户上传图像中包含了tag、伴随文本、用户评价等
n 图像理解:
n 社会属性等额外信息给图像理解带来了便利
How to retrieve favorite multimedia from Internet: A Great Challenge!
context! Context!! Context!!!

需要对来自需要对来自不同源头、不同类型数据建立起智能计算的理论和方
法
图像分享网站
社交网站
论坛微博
其他传感器
…监控视频
视频分享网站
互联网网页
4
From Multimedia to Cross-media

视觉特征听觉特征空间特征时间特征链接特征元数据特征……
高维
异构
多阶
提取
不同类型数据及其相关属性被整合到一起,对所蕴含的语义进行表现
o Feature fusiono Heterogeneous feature selectiono Cross-modal metric learningo …
部分观点来自:面向公共安全的跨媒体计算理论与方法,国家重点基础研究发展计划(973计划)项目(2012年1月-2016年12月,项目编号2012CB316400,首席科学家:浙江大学计算机学院庄越挺教授)
From Multimedia to Cross-media

来自不同来源、彼此关联的各种类型媒体数据汇聚到一起,多侧面、多视点表达语义。
flickrYouTube
CNN新华网
facebooktwitter
不同来源的数据不均衡出现在不同来源站点,来共同表现语义
o Near-duplicated detectiono Cross-domain learningo Transfer Learningo …
From Multimedia to Cross-media

网络与现实社会相互融合与映照
谷歌流感趋势预测:Google Flutrends
网络世界 现实世界相互映照与影响
From Multimedia to Cross-media

现实世界(Reality)
网络世界(Cyberspace)
面临的挑战
“镜子”
客观反映
放大(缩小)
扭 曲
挑战之一:揭示网络与现实世界之间相互影响规律
6

面临的挑战
Viginia Gewin, Self-reflection, Nature , 471,667-669,2011, March
互联网数据是对客观世界
的 “自我映照”,与现实
世界相互补充。
….The ‘virtual’ world and the ‘real’ world
complement each ….
挑战之一:揭示网络与现实世界之间相互影响规律

27
Day 29
全国
骚乱
1月14日
首都Tunisia暴力冲突
1月11日
Day 26Day 20
Sidi Bouzid大规模游行
1月5日
青年
死亡
2011年
1月4日
Day 19Day 11Day 2Day 1
青年自焚2010年12月17日
人物:Bouazizi
城市:Sidi Bouzid
Sidi Bouzid市民游行
12月18日
首都Tunisia市民游行
12月27日
赛博空间与人类社会的相互影响(突尼斯事件): 互动

面临的挑战
挑战之二:发现来自不同渠道、不同类型数据之间(即跨媒体)的关联性
Tom M., Mitchell, Mining our Reality, Science, 326,2009,1644-1645
….use computers to mine data…. machine learning algorithms have
helped to analyze historical data, often revealing trends and patterns too subtle
for humans to detect.
美国CMU的Tom Mitchell教授在《Science》发表名为“Mining ourReality”的文章指出:….从相互关联的网络海量数据中寻找“蛛丝
马迹”,更有利于理解现实世界…
图像 视频
文本 网站

21世纪是数据关联学习的世纪Terry Speed, A Correlation for the 21st Century, Science, 2011,334,1502-1503
4
l 加州大学伯克利分校统计系前任系主任Terry Speed教授于2011年12月在Science发表题为“A Correlation for the 21st Century”的论文,提出“21世纪是关联性学习的时代”,即从庞大数据集中发现数据之间所潜在的重要关系变得十分重要。
l 哈佛大学和麻省理工学院的研究人员提出了一种基于最大信息系数(maximal information coefficient ,MIC)的方法,无需事前对其寻找的关系类型有所了解,就可检测由多种因素驱动的复杂模式。
l 注:从1880年提出Pearson correlation 以来,数据关联学习一直被认为是一个难题。

面临的挑战
David Lazer, Computational Social Science, Science, 323,721-723
美 国 Harvard University 的 DavidLazer等人在《Science》杂志发表论文 也 认 为 需 建 立 可 计 算 模 型(Computational Model)来理解现实世界。
…a computational social science isemerging that leverages the capacity to collect and analyze data with an
unprecedented breadth and depth and scale
挑战之三:建立可计算的模型和方法来理解现实世界
Stanford的Granovette教授提出弱链接优势与集体行为阈值模型等理论
(PNAS 107(51), 2010; PNAS 106(36),2009)
Berkeley的Peter Bickel教授提出了无参网络模型(PNAS,106(50),2009)
Yahoo公司Watts所提出的小世界和网络无尺度(Scale-Free)等模型( Nature,
393(6684),1998; Science, 311(5757), 2006)

o 2010年1月,自然(Nature)杂志邀请20位搜索、医药、能源、天文学、化学、人类健康、激光、石油、生态学的专家和政策制定者对下一个10年科技发展进行了展望,形成的报告《2020 Vision》发表于自然杂志2010年第1期。
o Google的研究主管Peter Norvig博士应邀写了对未来多媒体计算与搜索技术的预测:
n 文本、图像、视频将更加紧密混合在一起(跨媒体),亲朋好友之间交往的社会化属性等信息将被记录和分析(社会网络),传感器网络在定位、医疗等方面应用更加普遍(物联网)。
n 搜索请求不在是文本,而是语音和对大脑信号的理解(语音识别与人脑感知);搜索结果不再是罗列网页,而是以图或表来表示的更为形象的综合性知识(数据挖掘)。
2020 Visions, Nature, 463,26-32 (January, 2010)
跨媒体搜索是未来搜索的方式
Peter Norvig博士

32
第二部分:
高维特征选择:稀疏性到结构性

33
视觉领域两个基本理论
o Marr理论n David Courtnay Marr (January 19,
1945 - November 17, 1980) n Marr理论指出:人类视觉感知的计算过程是重构可见表面的几何形状(提取本征图像,intrinsic image)。
n 点、线、面,进而2.5D和3D信息
o Marr理论一定程度上揭示了人脑从上而下的深度学习机制(如何建立
反映这一过程的可计算模型)
色度强弱
线、边界与区域
表面与朝向
三维物体

34
视觉领域两个基本理论
o Gestalt理论n 这一理论指出:只根据图像数据本身不能对相应的物体空间结构提供充分约束,也就是说这是一约束不充分(underconstrained)问题。
n 其认为任何“形”都是知觉进行了积极组织或构造的结果或功能,而不是客体本身就有的。
CVPR 2011

视觉领域两个基本理论
Marr理论 Gestalt理论可计算模型?
存在即合理
算字为先境由心生

o 神经稀疏编码的概念由Mitchison提出,由牛津大学的Rolls等正式引用。灵长目动物颚叶视觉皮层和猫视觉皮层的电生理实验报告和一些相关模型的研究结果都说明了视觉皮层复杂刺激的表达是采用稀疏编码原则的。
o 研究表明:初级视觉皮层V1区第四层有5000万个,而负责视觉感知的视网膜和外侧膝状体的神经细胞只有100万个左右,而。说明稀疏编码是神经信息群体分布式表达的一种有效策略。
o G. Mitchison,The organization of sequential memory sparse representation and the targeting problem, In: Organization of Neural Networks, VCH Verlagsgesellschaft, Weinheim, 1988,347-367
o Edmund T Rolls and Alessandro Treves, The relative advantages of sparse verus distributed encoding for associative neuronal networks in the Brain, Network, 1990, 407-421
稀疏编码:生理认知的一个重要特点

o 1996年,加州大学伯克利分校的Olshausen等在Nature杂志发表论文指出:自然图像经过稀疏编码后得到的基函数类似V1区简单细胞感受野的反应特性。n 解释V1区简单细胞感受野的三个响应特性:空间局部性、空间方向
性以及信息选择性。
n This suggests that the spatiotemporal receptive field properties of V1 neurons could be optimized to represent time-varying images in terms of sparse, spike-like events. (稀疏与注意力)
n 考虑到基函数的过完备性(即基函数维数大于输出神经元的个数),1997年又提出了一种过完备基的稀疏编码算法,利用基函数和稀疏的概率密度模型建模V1区简单细胞感受野。o Olshausen BA, Field DJ,Emergence of Simple-Cell Receptive Field Properties by Learning a
Sparse Code for Natural Images,1996,Nature, 381: 607-609o Olshausen BA, Field DJ,Sparse Coding with an Overcomplete Basis Set: A Strategy Employed
by V1?,1997,Vision Research, 37: 3311-3325
稀疏编码:生理认知的一个重要特点

o 1996年,加州大学伯克利分校的Olshausen等在Nature杂志发表论文指出:自然图像经过稀疏编码后得到的基函数类似V1区简单细胞感受野的反应特性。
n 解释V1区简单细胞感受野的三个响应特性:空间局部性、空间方向性以及信息选择性。
n This suggests that the spatiotemporal receptive field properties of V1 neurons could be optimized to represent time-varying images in terms of sparse, spike-like events. (稀疏与注意力)
稀疏编码:生理认知的一个重要特点

o V1区简单细胞感受野的三个响应特性:空间局部性、空间方向性以及信息选择性。
n 局部性:字典学习(Locality-constrained Linear Coding/Local Coordinate Coding)o locality is more essential than sparsity, as locality must lead to sparsity but
not necessary vice versa. o NEC加州实验室研究人员与伊利诺斯香槟分校Thomas S. Huang教授课题组合作,将稀疏表
达应用于图像视觉对象识别,在PASCAL 视觉对象分类识别挑战 (VOC2009)取得了第一名的好成绩
o 矩阵分解:Non-negative Matrix Factorizationn “部分组成整体(parts of whole)”
o 流形学习: Locality Preserving Projections(Local embedding)o The Truth About Cats and Dogs (ICCV 2010): distinctive part (geometrical
local structure)is superior to BOW (bag of visual words)
稀疏编码:生理认知的一个重要特点

o V1区简单细胞感受野的三个响应特性:空间局部性、空间方向性以及信息选择性。
n 方向性:视觉方向性是注意力模型中的重要因素。o Recent biological studies indicate that retinal position, spatial frequency and
orientation selectivity properties have an important role in visual perception…. the responses of orientation-selective neurons are usually obtained through convolution by Gabor wavelets, which resemble biological impulse response functions.
o L. Itti and C. Koch, Computational modeling of visual attention, Nature Reviews Neuroscience, 2(3):194–203, 2001
稀疏编码:生理认知的一个重要特点
The Steerable Pyramid by Gabor Wavelet

o V1区简单细胞感受野的三个响应特性:空间局部性、空间方向性以及信息选择性。
n 选择性:从过完备信息中选择最有意义、最具区别性的属性。
n 结构性:o 局部性+方向性+…
n 选择性:
o 是一种具体的实现手段,选择怎样的局部属性、怎样的方向属性、怎样的…
n 如何进行选择?
稀疏编码:生理认知的一个重要特点

14th-century English logician and Franciscan friar, William of Ockham
Principle of Parsimony:
Entities must not be multiplied beyond necessity.
Wikipedia
Occam’s Razor
奥卡姆剃刀(Occam's Razor)是由14世纪逻辑学家、修士奥卡姆(William of Occam)提出的
一个原理:
如无必要,勿增实体
稀疏性选择

特征稀疏选择:从信号处理与重建的角度看
法国巴黎综合理工大学应用数学系StephaneMallat教授在其撰写的小波原理教科书第三版时,特别加上一个小标题作
为书名
:The Sparse WayStephane Mallat,A Wavelet Tour of Signal Processing,
Third Edition: The Sparse Way, Academic Press, 3rd edition, 2008
仅用2.5%的小波系数进行图像重建

o 图像等多媒体数据中异构、高维和多阶的特征n Local vs. Globaln Dense vs. Sparsen Shadow vs. Deepo 基于深度学习的特征提取:如Boltzmann机、深度信念网(Deep Belief
Nets)和卷积神经网络等深度学习方法,其基本思路是底层的无监督学习、不变性和选择性之间的权衡
n Multi-scale (Beyond of visual words: Spatial Pyramid Model)
代表性的图像特征:SIFT, Shape Context, Color Histogram, SURF, HOG, LBP, GLOH, Daisy, GIST (Spatial Envelope)
异构高维特征稀疏性选择机制

n 动机与目的
o 对某个图像对象或语义而言,所提取的高维异构特征往往是冗余的(over-complete ),如何选择有限的、最具区别性的特征?
异构高维特征稀疏性选择机制
Global Features
Local Features
Color
Texture
Shape
….SIFT
GLOH
LBP
….
SIFT or other local features?
Color or other global features?

Tibshirani, R., Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society: Series B (Statistical Methodology), 58(1): 267-288,1996
Breiman, L., Heuristics of instability and stabilization in model selection, The Annals of Statistics, 24(6):2350-2383,1996
异构高维特征稀疏性选择机制
斯坦福大学Tibshirani教授和加州大学伯克利分校Breiman教授在上个世纪90年代中期几乎同时提出了对特征系数施以 L1-范式约束的lasso(least absolution shrinkage and
selection operator)思想,促使被选择出来的特征尽可能稀疏
Rob Tibshirani (Lasso) Leo Breiman (non-negative garotte)

Tibshirani, R., Regression shrinkage and selection via the lasso, Journal of the Royal Statistical Society: Series B (Statistical Methodology), 58(1): 267-288,1996
Breiman, L., Heuristics of instability and stabilization in model selection, The Annals of Statistics, 24(6):2350-2383,1996
异构高维特征稀疏性选择机制
斯坦福大学Tibshirani教授和加州大学伯克利分校Breiman教授在上个世纪90年代中期几乎同时提出了对特征系数施以 L1-范式约束的lasso(least absolution shrinkage and
selection operator)思想,促使被选择出来的特征尽可能稀疏
Rob Tibshirani (Lasso)
Leo Breiman (non-negative garotte)

o 稀疏表达随着近几年来数学和统计学在压缩感知(Compressed Sensing)方面的突破也发展起来
n 压缩感知利用“数据是稀疏可压缩”先验知识进行信号重建,斯坦福大学的David Donoho和Emmanuel Candes以及加州大学洛杉矶分校的Terence Tao (陶哲轩)在这一方面进行了一些代表性研究工作,涉及随机矩阵、信号恢复、稀疏性度量等方面,值得注意的是,目前低秩(low rank)矩阵分析成为热中之热。即将稀疏选择从一维向量推广到二维矩阵。o Donoho, D., Compressed Sensing, IEEE Transactions on Information Theory, 52(4):1289-1306,2006o Cades, E., Tao, T., Reflections on Compressed Sensing, IEEE Information Theory Society Newsletter,
58(4), 20-23, 2008
David Donoho Emmanuel CandesTerence Tao
稀疏表达与特征选择已成为当前的学术热点
L0范式存在唯一解 在RIP条件下,L0范式与L1范式解一致

The number of features (p) is often larger than the number of samples(n) , that is to say p>>n(高维), and there are many of highly correlated
features(结构性)
Seek after one interpretable model for feature selection such as lasso (Tibshirani,1996) , subset
selection (Breiman, et al,1996), group lasso (Yuan, et al ,2006) and elastic net (Zou, et al, 2005)
Heterogeneous feature machines (Cao and Luo et al, 2009)
Face Recognition via sparse representation (John and Ma, 2009)
p>>n(高维特征选
择)
Tibshirani, R., Regression Shrinkage and Selection via the Lasso, Journal of the Royal Statistical Society: Series B (Statistical Methodology), 58(1): 267-288,1996Breiman, L., Heuristics of Iinstability and Stabilization in Model Selection, The Annals of Statistics, 24(6):2350-2383,1996L. Cao, J. Luo, F. Liang, and T. Huang, Heterogeneous Feature Machines for Visual Recognition, ICCV, 2009Wright, J., Yang, A., Ganesh, A., Sastry, S., Ma, Y., Robust face recognition via sparse representation, IEEE Transactions on Pattern Analysis and Machine intelligence, 31(2):210-227,2009
异构高维特征稀疏性选择机制

Highly correlated features(结构性)
avoid overfitting in situations of large numbers of highly correlated features
such as Penalized Discriminant Analysis (Hastie, et al, 1995) , Sparse
Discriminant Analysis (Clemmensen, et al,2008), or introduce structural penalty
such as Structured Sparsity-Inducing Norms(Bach, 2010), Structural
Grouping Sparsity( Fei Wu, et al ,2010)
T. Hastie, A. Buja, and R. Tibshirani, Penalized Discriminant Analysis, The Annals of Statistics,23(1):73–102, 1995L. Clemmensen, T. Hastie, and B. Ersbll. Sparse Discriminant Analysis, online: http://www-stat.stanford.edu/ hastie/Papers/, 2008F. Bach. Structured Sparsity-Inducing Norms through Submodular Functions, NIPS, 2010Fei Wu, Yahong Han, Qi Tian, Yueting Zhuang, Multi-label Boosting for Image Annotation by Structural Grouping Sparsity, ACM Multimedia,2010 (FULL Paper)
异构高维特征稀疏性选择机制
The number of features (p) is often larger than the number of samples(n) , that is to say p>>n(高维), and there are many of highly correlated
features(结构性)

异构高维特征稀疏性选择机制

异构高维特征稀疏性选择机制

异构高维特征稀疏性选择机制
Wright, J., Yang, A., Ganesh, A., Sastry, S., Ma, Y., Robust face recognition via sparse representation, IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(2):210-227,2009

异构高维特征稀疏性选择机制
Wright, J., Yang, A., Ganesh, A., Sastry, S., Ma, Y., Robust face recognition via sparse representation, IEEE Transactions on Pattern Analysis and Machine Intelligence, 31(2):210-227,2009

异构高维特征稀疏性选择机制
o 基于lasso思想的特征选择缺陷:
n 逐一对特征进行选择,忽略了特征之间的结构
n 需要进一步利用特征之间所存在的结构性先验(Structural Prior),建立稀疏特征选择(Structured Sparsity)机制,从而实现解释性更强(Interpretability)的特征选择模型与方法

从特征稀疏选择到结构性选择
o Structured sparsity-inducing norms
n http://www.di.ens.fr/~fbach
F. Bach, Structured Sparsity-Inducing Norms through Submodular Functions, NIPS, 2010

o Structured sparsity-inducing norms
从特征稀疏选择到结构性选择

o Structured sparsity-inducing normsn Sub-class: lasso
从特征稀疏选择到结构性选择

o Structured sparsity-inducing normsn Sub-class: (quasi) Ridge Regression
从特征稀疏选择到结构性选择

o Structured sparsity-inducing normsn Sub-class: Elastic Net
从特征稀疏选择到结构性选择

o Structured sparsity-inducing normsn Sub-class: Group Lasso
从特征稀疏选择到结构性选择

Our Solution: structural grouping sparsity(结构性组稀疏)
o The high-dimensional heterogeneous features could be naturallyencoded into different groups due to their different modalities.
Fei Wu, Yahong Han, Qi Tian, Yueting Zhuang, Multi-label Boosting for Image Annotation by Structural Grouping Sparsity, ACM Multimedia ,2010 (FULL Paper)
First Group Second Group Third Group
从特征稀疏选择到结构性选择

n 根据高维异构视觉特征存在的组效应这一先验知识,引入稀疏表达,构建了反映其结构性组稀疏( Structural Grouping Sparsity )的选择算子,用于图像标注
n 不仅选择异构特征组(group),而且识别组内的子组(Subgroup),使得所选择的区别性特征更为合理
Fei Wu, Yahong Han, Qi Tian, Yueting Zhuang, Multi-label Boosting for Image Annotation by Structural Grouping Sparsity, ACM Multimedia 2010 (FULL Paper)
从特征稀疏选择到结构性选择

o 结构性组稀疏( Structural Grouping Sparsity)选择算子构造
损失
函数
损失函数用来度量学习得到的模型与实际数据是否匹配
正则化因子
正则化因子给数据赋以一定先验知识或先验结构
从特征稀疏选择到结构性选择

o 结构性组稀疏( Structural Grouping Sparsity )选择算子构造
损失函数 L2-范式 L1-范式
子组选择异构特征组选择通过建立回归模型,可便利引入惩罚因子(即稀疏性先验知识)
从特征稀疏选择到结构性选择

o 结构性组稀疏( Structural Grouping Sparsity )选择算子构造
o 与 lasso、group lasso和elastic net等传统稀疏性选择算子不同, 这一方法不仅选择异构特征组,而且从被选择异构特征组中识别同构特征子组.
异构特征组选择 同构特征子组识别高维异构特征
从特征稀疏选择到结构性选择

o 结构性组稀疏( Structural Grouping Sparsity)选择算子构造
异构特征组选择算法同构特征子组识别算法
Fei Wu, Yahong Han, Qi Tian, Yueting Zhuang, Multi-label Boosting for Image Annotation by Structural Grouping Sparsity, ACM Multimedia 2010 (FULL Paper)
从特征稀疏选择到结构性选择

68
o The experimental result of feature selection with Structural Grouping Sparsity
Heterogeneous feature selection results from group lasso, lasso, and MtBGS for 10-round repetitionof label “bird” in MSRC dataset. Different colors indicate different rounds
从特征稀疏选择到结构性选择

n 动机与目的
o 在图像多标注过程中,多标签单词之间又可以形成层次化结构,可否利用这种层次化结构来提升图像标注性能?
我们的工作:基于结构性输入/输出正则化因子的学习机制
animals, clouds, plant_life, sky
clouds, sky, structure
people, transport, water
animals, flower, plant
Tree Structure of Annotated Labels
从特征稀疏选择到结构性选择
Yahong Han, Fei Wu, Qi Tian, Yueting Zhuang, Image Annotation by Input-Output Structural Grouping Sparsity, IEEE Transactions on Image Processing, 2012,21(6):3066-3079

o 基于结构性输入/输出正则化因子的结构化学习机制在图像特征选择(输入端)和图像多标签标注结构(输出端)同时施加结构性正则化因子的约束。
o 这一框架包括两层回归模型:第一层回归对图像异构视觉特征进行结构性组稀疏的特征选择,第二层回归基于训练数据多标签标记的层次结构对第一层特征选择系数的多标签标注性能进行提升
损失
函数
损失函数用来度量学习得到的模型与实际数据是否匹配
输入端结构化正则因子
输出端结构化正则因子
从特征稀疏选择到结构性选择

o 结构性输入端正则化因子进行特征选择n 根据高维异构视觉特征存在的组效应这一先验知识,引入稀疏表达,构建了反映其结构性组稀疏( Structural Grouping Sparsity )的选择算子。
n 这一算子不仅选择异构特征组(group),而且识别组内的子组(Subgroup),使得所选择的区别性特征更为合理。
71
特征组选择 特征子组识别高维异构特征
从特征稀疏选择到结构性选择

o 结构性输出端正则化因子对特征选择系数进一步进行优化
从特征稀疏选择到结构性选择

异构特征的群组效应
Input
Output
结构性输入/输出正则化因子 标签之间的结构性关联
从特征稀疏选择到结构性选择
Yahong Han, Fei Wu, Qi Tian, Yueting Zhuang, Image Annotation by Input-Output Structural Grouping Sparsity, IEEE Transactions on Image Processing, 2012,21(6):3066-3079

o 实验发现:结合了结构性输入/输出正则化因子的标注算法(Bi-MtBGS)在标注性能上强于仅在输入端结构性选择的算法(C&W)
从特征稀疏选择到结构性选择
Yahong Han, Fei Wu, Qi Tian, Yueting Zhuang, Image Annotation by Input-Output Structural Grouping Sparsity, IEEE Transactions on Image Processing, 2012,21(6):3066-3079

GroundTruth: animals, clouds, plant_life, skyMTL-LS: people, Indoor, plant_life, structureOur approach: clouds, plant_life, structure, sky
GroundTruth: clouds, sky, structureMTL-LS: people, clouds, structureOur approach: clouds, structure, sky
GroundTruth: people, transport, waterMTL-LS : people, clouds, indoorOur approach: water, structure, people
GroundTruth: animals, flower, plantMTL-LS: animals, flower, structureOur approach: flower, plant, bird
Figure Flickr image annotation results. The underlined tags are false annotations.
从特征稀疏选择到结构性选择
Yahong Han, Fei Wu, Qi Tian, Yueting Zhuang, Image Annotation by Input-Output Structural Grouping Sparsity, IEEE Transactions on Image Processing, 2012,21(6):3066-3079

异构高维特征稀疏性选择机制:从Convex到Non-Convex
Fei Wu, Ying Yuan, Yong Rui, Shuicheng Yan, Yueting Zhuang, Annotating Web Images using NOVA: NOn-conVex group spArsity, 2012 ACM International Conference on Multimedia (ACM Multimedia ),
conditionally accepted as Full Paper
特征选择过程中需要考虑的两个重要因素:
特征组成:individual or group 正则化因子:convex or non-convex

异构高维特征稀疏性选择机制:从Convex到Non-Convex
o 为什么要group features:o 特征自然成组
o 为什么要Non-convexo 保证所选择特征的consistency

异构高维特征稀疏性选择机制:从Convex到Non-Convex
o Non-convex的特征选择算子能够以最大概率保证所得到一个true model,使得选择的特征consistency
o NOVA (NOn-conVex group spArsity):结合特征之间组结构的非凸正则化因子
Fei Wu, Ying Yuan, Yong Rui, Shuicheng Yan, Yueting Zhuang, Annotating Web Images using NOVA: NOn-conVex group spArsity, 2012 ACM International Conference on Multimedia (ACM Multimedia ),
conditionally accepted as Full Paper

异构高维特征稀疏性选择机制:从Convex到Non-Convex
o NOVA (NOn-conVex group spArsity)
Fei Wu, Ying Yuan, Yong Rui, Shuicheng Yan, Yueting Zhuang, Annotating Web Images using NOVA: NOn-conVex group spArsity, 2012 ACM International Conference on Multimedia (ACM Multimedia ),
conditionally accepted as Full Paper

异构高维特征稀疏性选择机制:从Convex到Non-Convex
o NOVA (NOn-conVex group spArsity)的Oral Propertyo A good penalty that induces consistent feature selection
should result in an estimator with an oracle property:unbiasedness, sparsity and continuity
Fei Wu, Ying Yuan, Yong Rui, Shuicheng Yan, Yueting Zhuang, Annotating Web Images using NOVA: NOn-conVex group spArsity, 2012 ACM International Conference on Multimedia (ACM Multimedia ),
conditionally accepted as Full Paper

异构高维特征稀疏性选择机制:从Convex到Non-Convex
o NOVA (NOn-conVex group spArsity)选择consistency的例子
Fei Wu, Ying Yuan, Yong Rui, Shuicheng Yan, Yueting Zhuang, Annotating Web Images using NOVA: NOn-conVex group spArsity, 2012 ACM International Conference on Multimedia (ACM Multimedia ),
conditionally accepted as Full Paper

异构高维特征稀疏性选择机制:从Convex到Non-Convex
o NOVA (NOn-conVex group spArsity)标注结果对比
Fei Wu, Ying Yuan, Yong Rui, Shuicheng Yan, Yueting Zhuang, Annotating Web Images using NOVA: NOn-conVex group spArsity, 2012 ACM International Conference on Multimedia (ACM Multimedia ),
conditionally accepted as Full Paper

o 多任务学习过程中特征“组效应”o Why MtSDA does work
Loss Function L2-norm L1-norm
induces a (structural ) sparse selection
Avoid overfitting for highly correlated
features
Classification is transformed into a regression model by optimal scoring and has the ability to
introduce penalties
异构高维特征稀疏性选择机制
Yahong Han, Fei Wu, Jinzhu Jia, Yueting Zhuang, Bin Yu, Multi-task Sparse Discriminant Analysis (MtSDA) with Overlapping Categories, AAAI, 2010 (Oral Paper)

o 多任务学习中的特征“组效应(grouping effect )”
o The grouping effect in feature selection: given the jth task, the distance of the coefficients of highly positively correlated features will tend to be close when they have the same sign, if is large and is not too close to 1.
Theoretical proof for feature selection in term of grouping effect
异构高维特征稀疏性选择机制
Yahong Han, Fei Wu, Jinzhu Jia, Yueting Zhuang, Bin Yu, Multi-task Sparse Discriminant Analysis (MtSDA) with Overlapping Categories, AAAI, 2010 (Oral Paper)

An exemplar illustration of spare representation using nonnegative curds and whey
Sparse Representation for Sample Selection by Nonnegative Curds and Whey( NNCW )
NNCW= Supervised learning + Nonnegative matrix factorization + Sparse representation
稀疏选择+非负矩阵+监督学习的人脸识别
Yanan Liu, Fei Wu, Zhihua Zhang, Yueting Zhuang, Shuicheng Yan, Sparse Representation using nonnegative curds and whey, Proceedings of IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2010

Sparse Representation for Sample Selection by Nonnegative Curds and Whey( NNCW )
The first stage: Curds (Intra Class constraint optimization)
NNCW first obtains m independent representations (called curds) from
each class with nonnegative constraints
稀疏选择+非负矩阵+监督学习的人脸识别

Sparse Representation for Sample Selection by Nonnegative Curds and Whey( NNCW )
The second stage: Whey (Inter class constraint optimization)
NNCW then then usescurds to redefine a new representation (called whey) by the introduction of
discriminative label information
稀疏选择+非负矩阵+监督学习的人脸识别

The visualization of sample selection by NNCW
稀疏选择+非负矩阵+监督学习的人脸识别

It can be seen that some of the selection coefficients using traditional lasso is negative
The visualization of sample selection by traditional lasso
稀疏选择+非负矩阵+监督学习的人脸识别

NNCW Algorithm
稀疏选择+非负矩阵+监督学习的人脸识别

稀疏性选择算法的稳定性

稀疏性选择算法的稳定性

稀疏性选择算法的稳定性
Yueting Zhuang, Yahong Han, Fei Wu, Jiacheng Yang, Stable Multi-label Boosting for Image Annotation with Structural Feature Selection, Science in China Series F: Information Sciences, 2011,54 (12): 2508-2521
o 数据采样方法的不同对算法性能的影响n Three re-sampling methods
o Cross Validation, Jackknife, and Bootstrap

94
第三部分:
结构性学习

n 海量数据处理的输出:结构性输出!o 对海量数据的关联性进行深入分析,挖掘“结构化”的事件或主题
背景介绍
事件或话题的输出:Who, What, How, Why, When, Where

n 单一形式输出的传统机器学习
n 以结构性输出为核心的机器学习(Structured Output Learning or Complex Output Learning)
背景介绍
输入是结构性数据,输出是结构性单元

n 一般而言,在跨媒体语义理解和检索中,输入数据也存在着丰富的结构性先验知识的。o 如特征成组、特征之间的交互效应、特征之间存在层次性结构等等。
n 构造反映输入结构性和输出结构性的学习方法是目前一个难点和热点问题。
o NIPS 2008 Workshop: Structured Input - Structured Outputo Sebastian Nowozin, Christoph H. Lampert , Structured Learning and Prediction in
Computer Vision, Foundations and Trends in Computer Graphics and Vision 6(3-4): 185-365 (2011)
o IJCV Special Issue on Structured Prediction and Inference, Guest Editors: Matthew B. Blaschko and Christoph H. Lampert
n 典型的结构性学习方法o Probabilistic Structured Models: Conditional Random Fields (Lafferty, etc., ICML 2001)o Maximum Margin Structured Model: Structured Support Vector Machines (Tsochantaridis,
etc., JMLR 2006)
背景介绍

一种结构学习方法:Structural SVMo Let x denote a structured input example (x1,…,xn)o Let y denote a structured output target (y1, …,yn)
objective function:
Constraints :defined for each incorrect labeling y’ over input x(i) .
o Discriminant score for the correct labeling at least as large as incorrect labeling plus the performance loss.
o Another interpretation: the margin between correct label and incorrect label at least as large as how ‘bad’ the incorrect label is.
∑+i
iNCw ξ2
21
iiiTiiTi ww ξ−∆+Ψ≥Ψ≠∀ )',(),'(),( :' )()()()()( yyxyxyyy
Thorsten Joachims, Thomas Hofmann, Yisong Yue, Chun-Nam Yu, Predicting Structured Objects with Support Vector Machines, Communications of the ACM (CACM), Research Highlight, 52(11), 97--104, November, 2009

跨媒体数据中的结构性属性
o Each topic is a distribution over wordso Each document is a mixture of corpus-wide topicso Each word is drawn from one of those topicso In reality, we only observe the documents and the other structure are
hidden variables
文档中存在结构性属性:Beyond of Bag of Words

跨媒体数据中的结构性属性
图像中存在结构性属性:Beyond of Bag of Visual Words/Pixels
animals, clouds, plant_life, sky
clouds, sky, structure
图像的多标注单词 图像中共生对象区域 图像的层次化目录结构

n 数据分布在非欧式流形结构空间中o 数据本身所具有的高维数据在本质上是由有限自由度来决定其几何拓扑结构。
o 如ISOMAP、LEE、LPP等
跨媒体数据中的结构性属性
Saul, L., Weinberger, K., Sha, F., Ham, J., Lee, D., Spectral methods for dimensionality reduction, Semisupervised Learning, Cambridge, MIT Press , 293-
308, 2006

跨媒体数据中的结构性属性
社会媒体中存在的结构性属性:From Person to Community
8亿用户
复杂性网络中复杂结构

Lars Backstrom, et. al., Four Degrees of Separation, http://arxiv.org/abs/1111.4570Lars Backstrom, et. al., Four Degrees of Separation, http://arxiv.org/abs/1111.4570
8亿用户 复杂性网络中复杂结构时间(年) 人 物 事 件
179319591967197319981999
EülerErdǒs和Rényi
MilgramGranovetter
Watts和StrogatzBarabási和Albert
七桥问题
随机图理论
小世界实验(六度空间)
弱连接的强度
小世界模型
无尺度网络
迄今为止最大规模小世界验证:2011年,Facebook与意大利米兰大学公布了关于Facebook中用户之间六度分离验证的结果。2007年以来,Facebook上两个用户之间的平均距离仅为4.74,任何两个用户之间间隔不超过5度的概率99.6%。注意2011年5月数据包括了Facebook上大约7.21亿活跃用户以及69亿朋友关系链接。

数据中的结构性属性
数据排序中结构性学习:From Pairwise to Listwise
图像属性排序 福布斯2011年最具影响力人物排名

Peng Zhao, Guilherme Rocha, and Bin Yu, The composite absolute penalties family for grouped and hierarchical variable selection, Annals of Statistics, 37:3468–3497,2009
F. Bach, Structured Sparsity-Inducing Norms through Submodular Functions, Advances in Neural Information Processing Systems (NIPS), 2010
X. Chen, Q. Lin, S. Kim, J. Carbonell, E.P. Xing, Smoothing proximal gradient method for general structured sparse learning, Proceedings of the 27th Conference on Uncertainty in Artificial Intelligence (UAI), 2011J. Mairal, B. Yu, Supervised Feature Selection in Graphs with Path Coding Penalties and Network Flows ,
arXiv:1204.4539v1. 2012.
常见的自然结构:
层次化结构、字典树、叠加组、路径
Grouped and Hierarchical
Dictionary Tree Tree-guided multi-task learning Path Coding Penalty

基于图结构正则化约束的图像区域标注
n 动机与目的o 图像集中的某些区域之间存在着关联关系,充分利用这些关联关系所形成的图结构,可以提升图像区域标注的性能。
Yahong Han, Fei Wu, Jian Shao, Qi Tian, Yueting Zhuang, Graph-Guided Sparse Reconstruction for Region Tagging, IEEE CVPR 2012

Graph-guided Sparse Reconstruction Graph-Guided Fusion Penalty
Penalty of Graph-Guided Fusion: encourages highly correlated regions corresponding to a densely connected subnetwork in G to be jointly selected
as relevant
Yahong Han, Fei Wu, Jian Shao, Qi Tian, Yueting Zhuang, Graph-Guided Sparse Reconstruction for Region Tagging, IEEE CVPR 2012
基于图结构正则化约束的图像区域标注

基于图结构正则化约束的图像区域标注
Yahong Han, Fei Wu, Jian Shao, Qi Tian, Yueting Zhuang, Graph-Guided Sparse Reconstruction for Region Tagging, IEEE CVPR 2012
Graph Construction: kNN graph to consider visual similarity between training regions, matrix is
the label indicator matrix, to consider the semantic context.
{0,1}n J×∈Y

基于图结构正则化约束的图像区域标注
Yahong Han, Fei Wu, Jian Shao, Qi Tian, Yueting Zhuang, Graph-Guided Sparse Reconstruction for Region Tagging, IEEE CVPR 2012

Yahong Han, Fei Wu, Jian Shao, Qi Tian, Yueting Zhuang, Graph-Guided Sparse Reconstruction for Region Tagging, IEEE CVPR 2012
基于图结构正则化约束的图像区域标注

在多任务中引入图约束的图像相关属性迁移学习
n 动机与目的o 有别于图像底层视觉特征,图像属性近来在图像识别和分类起到了重要作用。可否在属性之间关联性上构造图结构,来预测未知图像的属性?
Yahong Han, Fei Wu, Yueting Zhuang, Qi Tian, Jiebo Luo, Correlated Attribute Transfer with Multi-task Graph-Guided Fusion, 2012 ACM International Conference on Multimedia (ACM Multimedia ), conditionally accepted as Full Paper

在多任务中引入图约束的图像相关属性迁移学习
ocean属性与其他属性之间的共信息熵
Yahong Han, Fei Wu, Yueting Zhuang, Qi Tian, Jiebo Luo, Correlated Attribute Transfer with Multi-task Graph-Guided Fusion, 2012 ACM International Conference on Multimedia (ACM Multimedia ), conditionally accepted as Full Paper

在多任务中引入图约束的图像相关属性迁移学习
图像属性之间的共生矩阵
Yahong Han, Fei Wu, Yueting Zhuang, Qi Tian, Jiebo Luo, Correlated Attribute Transfer with Multi-task Graph-Guided Fusion, 2012 ACM International Conference on Multimedia (ACM Multimedia ), conditionally accepted as Full Paper

在多任务中引入图约束的图像相关属性迁移学习
基于正则化因子的图像属性多任务学习T是source domain的属性集合
X是source domain图像特征集合Multi-task Graph-Guided Fusion Penalty
Yahong Han, Fei Wu, Yueting Zhuang, Qi Tian, Jiebo Luo, Correlated Attribute Transfer with Multi-task Graph-Guided Fusion, 2012 ACM International Conference on Multimedia (ACM Multimedia ), conditionally accepted as Full Paper

在多任务中引入图约束的图像相关属性迁移学习
Attribute predictions on the target set (underlined red texts denote the false positive predictions)
Yahong Han, Fei Wu, Yueting Zhuang, Qi Tian, Jiebo Luo, Correlated Attribute Transfer with Multi-task Graph-Guided Fusion, 2012 ACM International Conference on Multimedia (ACM Multimedia ), conditionally accepted as Full Paper

在多任务中引入图约束的图像相关属性迁移学习
Attribute - Visual words correlation example. Of the 6 example attributes, “ocean” and “water” share high mutual information, while “tree” and “desert” low mutual
information. With our method, attribute “ocean” and “water” share the same correlated visual
Yahong Han, Fei Wu, Yueting Zhuang, Qi Tian, Jiebo Luo, Correlated Attribute Transfer with Multi-task Graph-Guided Fusion, 2012 ACM International Conference on Multimedia (ACM Multimedia ), conditionally accepted as Full Paper

基于监督式LDA的跨域主题建模机制
LDA (Latent Dirichlet Allocation) 模型
D. Blei, A. Ng, and M. Jordan, Latent Dirichlet Allocation, Journal of Machine Learning Research, 3:993-1022, January 2003
DirichletPrior
DirichletPrior

基于监督式LDA的跨域主题建模机制
LDA (Latent Dirichlet Allocation) 模型
D. Blei, A. Ng, and M. Jordan, Latent Dirichlet allocation, Journal of Machine Learning Research, 3:993-1022, January 2003

基于监督式LDA的跨域主题建模机制
Supervised LDA (Latent Dirichlet Allocation) 模型
David M. Blei, Jon D. McAuliffe, Supervised Topic Models, NIPS 2007

数据
2011年7月26日至11月26日CNN刊发的关于体育,健康和科技的1910篇文章。
2011年7月27日至11月27日New York Times刊发的关于体育,健康和科技的3105篇文章。
2011年7月26日至2011年11月26日Xin Hua Net刊发的关于体育,健康和科技的3316篇文章。
词汇集
l 三个域中所提取单词总数为1, 915,607。l 去除无意义的stop words,然后通过自然语言处理工具(NLT,
http://www.nltk.org/)进行词性标注,仅保留形容词,名词,副词和动词之后,进行话题建模的单词表大小为59561。
挖掘不同来源数据所特有主题和共有主题,以便发现不同来源数据进行主题报道过程中的差异。
基于监督式LDA的跨域主题建模机制

简介 2011年7月26日至11月26日CNN刊发的12485篇文章,合7309244个单词。
2011年7月27日至11月27日New York Times刊发的15401篇文章。预处理后,余下12059082个单词。
单词 单词库大小为65860,如debt,syrian,syria,ceiling,reid。
单词库大小为120736,如republicans,police,dr,inning,essay。
共有单词
CNN和NYT(New York Times)共有27850个共有单词,如republicans,police,dr,inning,essay,bankruptcy,studying,stanley,administrations,operates等。
文章的类别标注信息
arts,business,health,realestate,science,technology,us,world等。
world,crime,us,politics,sport,opinion,business,showbiz,technology,health等。
挖掘不同来源数据所特有主题和共有主题,以便发现不同来源数据进行主题报道过程中的差异。
基于监督式LDA的跨域主题建模机制
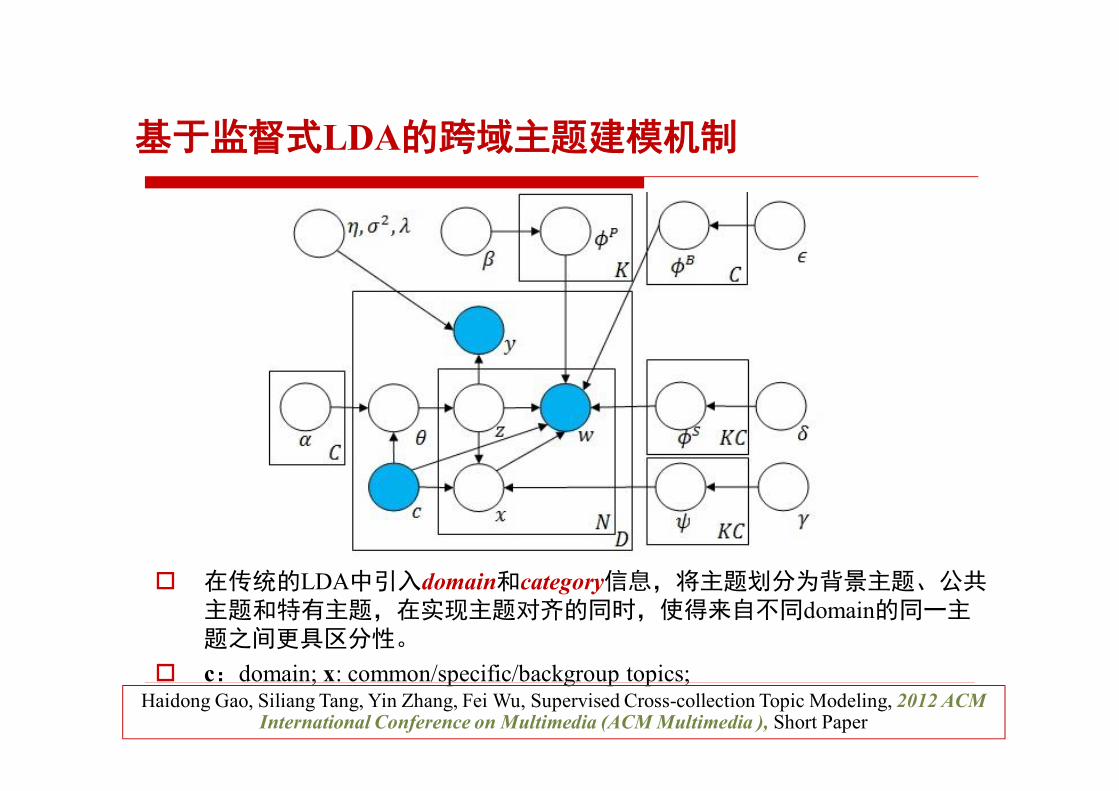
o 在传统的LDA中引入domain和category信息,将主题划分为背景主题、公共主题和特有主题,在实现主题对齐的同时,使得来自不同domain的同一主题之间更具区分性。
o c:domain; x: common/specific/backgroup topics;
基于监督式LDA的跨域主题建模机制
Haidong Gao, Siliang Tang, Yin Zhang, Fei Wu, Supervised Cross-collection Topic Modeling, 2012 ACM International Conference on Multimedia (ACM Multimedia ), Short Paper

可见:CNN,NYT以及XH在一段时间内对某些公共主题均进行了报导,但是在报导中存在一定差异性。
主题
公共 city, league, club, game, fans, stadium, soccer, new, team, player
足球
CNN vettel, english, premier, chlesea, red, messi, italian, circuit, streaming, fabregas
NYT team, plan, television, according, wright, hunter, book, buy, known
XH madrid, real, barcelona, season, players, midfielder, goals, champions, valencia, play
基于监督式LDA的跨域主题建模机制
在足球这个主题里面:三个domain的数据均谈及了球迷、俱乐部、球员等公有信息,CNN是多从球员的角度进行报道,NYT多从团队
的角度报道,而新华社多从俱乐部的角度来讨论问题。

主题
公共 company, apple, technology, phone, service, online, users, jobs, market, data
移动设备
CNN phone, users, google, android, web, security, siri, phones, video, wrote
NYT mr, company, business, executive, software, page, companies, apple, video, customers
XH dollars, ceo, steve, president, conference, business, reached, tuesday, opportunities, smartphone
基于监督式LDA的跨域主题建模机制
在移动设备这个主题里面:三个domain的数据均谈及了公司、技术、苹果等公有信息,CNN主要是描述苹果手机和Android手机之争,NYT多描述手机和手机应用,而新华社多从苹果集团商务运营的角
度来讨论问题。
可见:CNN,NYT以及XH在一段时间内对某些公共主题均进行了报导,但是在报导中存在一定差异性。

主题 公共 gadhafi, libya, tripoli, libyan, qaddafi, sandusky,rebels,rebel, paterno
卡扎菲和利比亚
CNN gadhafi, libya, al, forces, libyan, tripoli, council, nato, sandusky
NYT qaddafi, colonel, libya, loan, solar, al, football, coach, penn
主题 公共 Health, dr, cancer, medical, hospital, patients, study, drug, care
医疗和健康
CNN death, children, angeles, died, doctor, los, help, medical, family
NYT dr, food, water, scientists, doctor, university, farmers, medical, researchers
主题 公共 obama, republicans, tax, democrats, congress, senate, spending, cuts, republican
奥巴马和共和党
CNN obama, debt, republicans, congress, tax, plan, republican, spending, gop
NYT obama, republican, tax, republicans, percent, spending, democrats, congress, debt
基于监督式LDA的跨域主题建模机制
CNN和NYT在其他主题报道上的相同性和差异性
可见:CNN和NYT在一段时间内对某些公共主题均进行了报导,但是在报导中存在一定差异性。

结论
o 先有蛋还是先有鸡的问题n 结构性属性是我们预先定义好的,还是需要我们从数据中推断出来的?即:先验结构(Prior Structure) or 后验结构(Posteriori Structure)
n 结构是否具有可解释性?
从Gabor小波处理角度提取的反映空间局部性、空间方向性以及信息选择性的视觉词典
Olshausen BA, Field DJ,Emergence of Simple-Cell Receptive Field Properties by Learning a Sparse Code for Natural Images,1996,Nature, 381: 607-609
R. Jenatton, J. Mairal, G. Obozinski, F. Bach, Proximal Methods for Hierarchical Sparse Coding, Journal of Machine Learning Research, 12, 2297-2334
左:从5万个16×16大小Patch提取的层次化视觉词典; 右:从LableMe提取的稀疏
词典

n 结构化稀疏主成份分析所体现的“Part of the whole”
Structured Sparse PCA所获得人脸基
结构化稀疏主成份分析
传统PCA所获得人脸基
Jianshao, Fei Wu, Chuanfei Ouyang, Xiao Zhang, Sparse Spectral Hashing, Pattern Recognition Letters , 33(3):271-277,2012

结论
o Sparsity:原始数据中可利用信息是冗余的,注意选择的一致性(oracle model/ consistence model)
o Structure:原始数据以及输出结果本身具有结构性属性o Stability:对原始数据的采样将影响算法结果
128
Sparsity Structure Stability
Consistent
SelectionWell-defined
Structure
Optimized
Sampling

Most of works can be referred to Fei Wu, Yahong Han, Xiang Liu, Jian Shao, Yueting Zhuang, Zhongfei Zhang, The
Heterogeneous Feature Selection with Structural Sparsity for Multimedia Annotation
and Hashing: A Survey, International Journal of Multimedia Information Retrieval, 2012, 1(1): 3-15
谢谢大家
Email: [email protected]


















