工数見積もりにおけるモデル着脱式ソフトウェア 開...
21
1 工数見積もりにおけるモデル着脱式ソフトウェア 開発シミュレータCOCOMOモデルの比較 2006 年1月 31 日 花川ゼミ所属 学籍番号:5102107 氏名:妹尾 潤 5102245 伊藤 裕美
Transcript of 工数見積もりにおけるモデル着脱式ソフトウェア 開...

1
工数見積もりにおけるモデル着脱式ソフトウェア
開発シミュレータCOCOMOモデルの比較
2006 年1月 31 日
花川ゼミ所属
学籍番号:5102107 氏名:妹尾 潤
5102245 伊藤 裕美

2
目次
1.はじめに ・・・・・・・・・・・・・・・・・・ p3
2.関連研究 ・・・・・・・・・・・・・・・・・・ p4
3.新たなモデルの提案 ・・・・・・・・・・・・・ p8
3-1 基本アイデア ・・・・・・・・・・・・ p8
3-2 Communication-Efficiency モデルの提案・・ p11
3-3 他モデルの説明 ・・・・・・・・・・・ p13
4.考察 ・・・・・・・・・・・・・・・・・・ p15
5.まとめ ・・・・・・・・・・・・・・・・・・ p20
謝辞 ・・・・・・・・・・・・・・・・・・ p20
参考文献 ・・・・・・・・・・・・・・・・・・ p21

3
1 はじめに
最近の科学技術の進歩は早く、コンピュータの性能は日々進歩している。それに比例してハー
ドだけではなくソフトも進化している。ソフトの規模も大規模から小規模のものまで規模も用
途も様々である。その中でソフトウェア開発の工数・期間の見積もり手法も従来のものでは基
礎となる収集データ自体が古いだけではなく、昔と今とでは開発手法も見積もりの方法、人の
考え方も異なってきている。従来の方法ではソフトウェア開発における様々な複雑な現在の事
象をふまえた見積もりができなくなってきている。さらにもう一つの問題がソフトウェア開発
プロジェクトにおいて経験ベースの管理者の育成が非常に難しいことがある。その理由はプロ
ジェクト終了までに時間がかかりすぎるという点である。ひとつのプロジェクトが完全に終了
するまでに半年から1年かかり、そのプロジェクトを 10 回程度繰り返し経験することで優秀な
管理者へ成長する。ただし、約 10 年の期間を通して成長できた管理者であっても、現在の情報
業界では 10 年で新技術・新環境へ変わる可能性が高く、10 年前の古い環境の知識や技術は使え
ない。経験ベースの管理者育成はソフトウェア開発プロジェクトにおいて非常に困難な状況で
ある。ソフトウェア開発において重要なプロジェクト管理者の教育が従来のような経験ベース
の教育が役にたたなくなっていることである。これにより短期間での教育手段が必要になる。
代表的な見積もり手法としてCOCOMOやファンクションポイント法などの方法がある。しかし、
ソフトウェア開発は人がチームになって作っていくもので、人と人との関わりで最も大事なコ
ミュニケーションのことが上記の手法には計算にはいっていない。
そこで自分たちの所属している花川ゼミでは上記の問題の解決を目的とした「モデル着脱式プ
ロジェクトシミュレータ」を開発している。シミュレータ自体の説明やその他のモデルについ
ての説明は第三章で自分たちの提案したモデルを説明する前の段階で詳しく述べる。自分たち
が提案するのはこのシミュレータに組み込むことのできるモデルの一つとして「コミュニケー
ション効率(Communication Efficiency)モデル」を提案する。このモデルはコミュニケーション
を単なる会話として位置づけるのではなく、開発者同士の会話も仕事の一つと考え、さらに会
話する開発者の知識レベルの関係からその会話に効率をもたせさらに複雑な事象を表現すると
いうモデルである。
本論分の流れとしては第二章では関連研究として上記でも上げた代表的な見積もり手法の
COCOMO について詳しく述べる。第三章ではまず自分たちの提案する「コミュニケーション効率
(Communication Efficiency)モデル」を実装するにあたり基盤になっている「モデル着脱式プロ

4
ジェクトシミュレータ」について詳しく述べ、自分たちの提案するモデルについて述べる。第
四章では考察としてプロジェクトシミュレータと COCOMO で実際にデータを取りその違いを述べ、
第五章では本論文のまとめを述べる。
2 関連研究
この章では関連研究として 1981 年にバリー・ベーム(Barry Boehm)博士が提唱した COCOMO
(COnstructive COst MOdel)について詳しく述べていく[1]。COCOMO とは COnstructive COst
MOdel の頭文字を取ったもので 1981 年にバリー・ベーム(Barry Boehm)博士が提唱したソフト
ウェア開発の工数・期間の見積もり手法である[2]。これは階層化されたソフトウェア推定モ
デルで工数や開発期間などの推定式を導出している。COCOMO の階層は次のようになっている。
(1) 初級 COCOMO (Basic COCOMO)
LOC により推定されたプログラム規模の関数としてソフトウェア開発労力や開発コストを
計算する静的な単一変数モデル。
(2) 中級 COCOMO (Intermediate COCOMO )
プログラム規模および開発特性(ソフトウェア自体、ハードウェア、開発要因、プロジェク
ト)にする主観的評価を反映したコスト要因(Cost driver)の関数として開発労力を計算す
るモデル。
(3) 上級 COCOMO (Advanced COCOMO)
ソフトウェア開発過程の各工程(要求仕様定義、設計、コーディング、テスト)に与えるコ
スト誘因の影響の評価を中級 COCOMO に組み込んだモデル。
*今回比較のために使ったのは初級 COOMO と中級 COCOMO である。上級 COCOMO はコスト誘因の
分類が細かく複雑になっており比較には向かないと判断したため自分達の研究では上級
COCOMO を比較対象としていない。
これらの階層において、プロジェクトの開発形態を次の三つのモードに分類している

5
(1) organic モード
比較的小規模な開発チームで、自社開発のような熟練度の高い開発形態を指し、在庫管理シ
ステムや科学技術計算用パッケージなどを開発する場合に使用するモデル。
(2) embedded モード
開発チームが大規模であり、種々の厳しい制約条件の下でハードウェア、ソフトウェア、操
作手順などの複雑な開発環境や、要求仕様への厳しい一致性や、開発技法とテスト技法に関
する規制が求められ、革新的な OS(オペレーティングシステム)を開発する場合などに使用す
るモデル。
(3) semi-detached モード
organic モードと embedded モードの中間に位置する開発環境の場合に使用するモード
要求仕様は決定後ほとんど変更せず、開発工数および開発期間の見積もり範囲はシステム設計
以降システム統合テストまでを対象としている。
COCOMO の全階層に対して適用される開発工数(人・月)および開発期間(月)の見積もり値の
基本式は下記の通りである。
)0,0()( >>= baLaE b ・・・・・・・・・・(式1)
E = 開発工数
L = 開発規模(KLOC)
a、b= 定数
)0,0()( >>= dcEcD d ・・・・・・・・・・・(式2)
D = 開発期間
E = (式1)で求める。
c 、d = 定数
上記の式の定数 a、b、c、d は COCOMO の階層と開発モードに対応して決められる。定数 a、b、
6
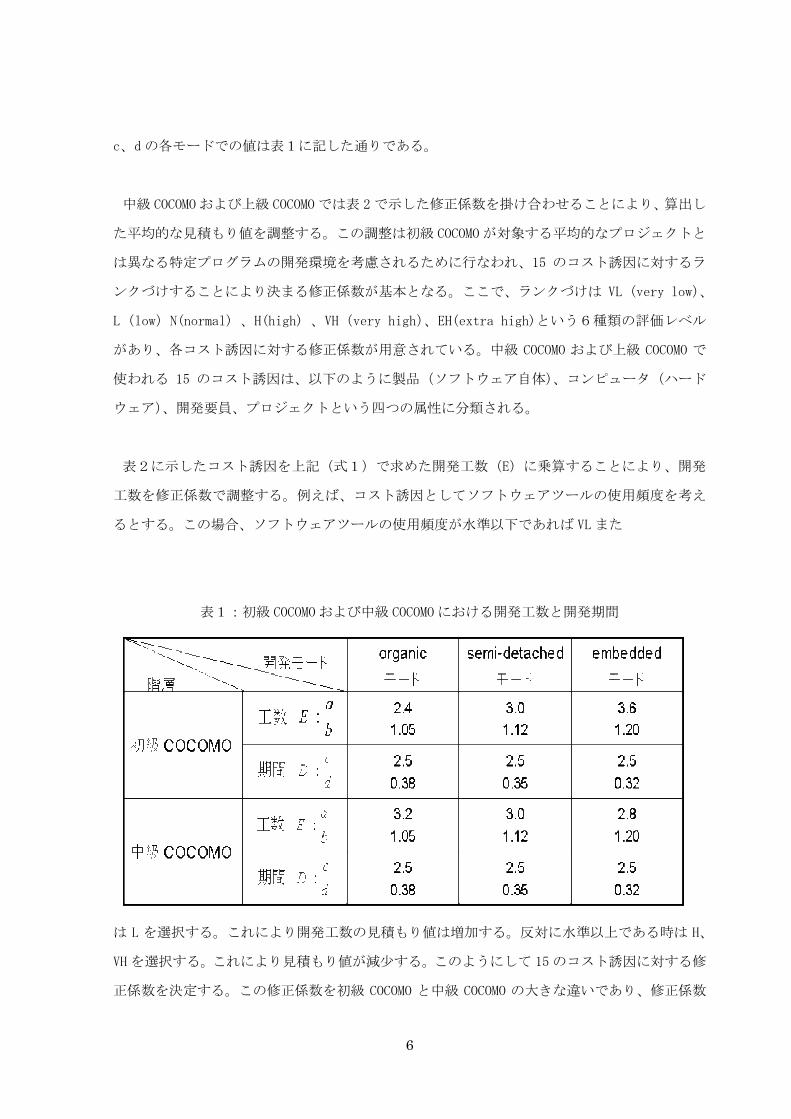
c、d の各モードでの値は表1に記した通りである。
中級 COCOMO および上級 COCOMO では表 2で示した修正係数を掛け合わせることにより、算出し
た平均的な見積もり値を調整する。この調整は初級 COCOMO が対象する平均的なプロジェクトと
は異なる特定プログラムの開発環境を考慮されるために行なわれ、15 のコスト誘因に対するラ
ンクづけすることにより決まる修正係数が基本となる。ここで、ランクづけは VL(very low)、
L(low)N(normal) 、H(high) 、VH(very high)、EH(extra high)という6種類の評価レベル
があり、各コスト誘因に対する修正係数が用意されている。中級 COCOMO および上級 COCOMO で
使われる 15 のコスト誘因は、以下のように製品(ソフトウェア自体)、コンピュータ(ハード
ウェア)、開発要員、プロジェクトという四つの属性に分類される。
表2に示したコスト誘因を上記(式1)で求めた開発工数(E)に乗算することにより、開発
工数を修正係数で調整する。例えば、コスト誘因としてソフトウェアツールの使用頻度を考え
るとする。この場合、ソフトウェアツールの使用頻度が水準以下であれば VL また
表1:初級 COCOMO および中級 COCOMO における開発工数と開発期間
は L を選択する。これにより開発工数の見積もり値は増加する。反対に水準以上である時は H、
VH を選択する。これにより見積もり値が減少する。このようにして 15 のコスト誘因に対する修
正係数を決定する。この修正係数を初級 COCOMO と中級 COCOMO の大きな違いであり、修正係数

7
があることにより、より細かい調整を行ようになっている。
上級 COCOMO と中級 COCOMO の違いは、コスト誘因のランクづけをもっと細かく分解し、開発工
程ごとにモジュールレベルあるいはサブシステムレベルで工数や期間を見積もる。モジュール
レベルでのコスト誘因は、モジュールの複雑度、プログラマの能力、プログラミング言語の経
験度、仮想計算機の経験度およびコードの再利用である。
表2:中級 COCOMO に用いる修正係数対応表
3.新たなモデルの提案
3-1 基本アイデア

8
図1:モデル選択例
基本アイデアとして、シミュレータの説明をする。モデル着脱式シミュレータは、プロジェク
ト途上で発生する複雑な事象をモデル化している。モデル式は複数あり、着脱式である。複数
事象を組み合わせた結果の現象をシミュレーションすることができる。複雑なプロジェクトの
振る舞いをモデル化し、さらにモデルを各々着脱式にすることで、モデルの組み合わせること
により様々なパターンの事象を実験できるようになった。ソースの規模は約 5000STEP と大きな
ものになっている。
本シミュレータの特徴は、プロジェクト途上で発生する複雑な事象を再現できることである。
まず、開発者の知識と作業実行に要求される知識の関係よりそれぞれの開発者の生産性を計算
できる。つまり、得意な作業を任されたときの作業は早く進み、不得意な作業の時は多くの時
間が必要になるという現象である。上記と関連して、得意な作業実施時には作業は早く進むが
作業者が学習することが少ない。つまり、すでに既知の知識で作業実施できるので学ぶことが
少ない。反対に不得意な作業実施時は作業の進捗は遅いが学ぶことが多く、結果として開発者
の知識が大きく増加する。このような開発者の知識に関する複雑な事象を扱うことができる。
さらに、作業の分担方法によって開発者間のコミュニケーション量が変化するという事象も再
現できる。つまり、作業間の関連が大きい作業を異なる開発者に分担してしまうと、開発者間
に多くのコミュニケーションを要求される。反対に作業間の関連の小さい作業を分割した場合
は、少ないコミュニケーションで開発ができるという状況である。またその開発者間で行われ
るコミュニケーションは、開発者同士の知識によってコミュニケーション量の消費は異なる。
9
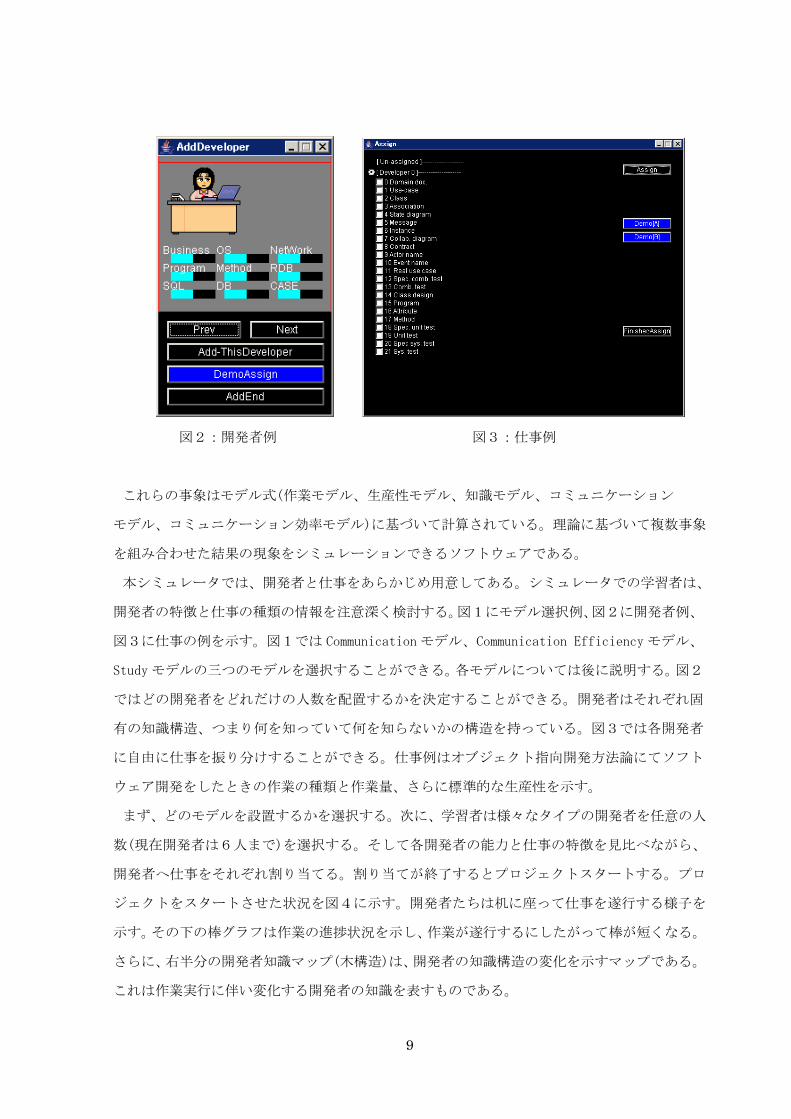
図2:開発者例 図3:仕事例
これらの事象はモデル式(作業モデル、生産性モデル、知識モデル、コミュニケーション
モデル、コミュニケーション効率モデル)に基づいて計算されている。理論に基づいて複数事象
を組み合わせた結果の現象をシミュレーションできるソフトウェアである。
本シミュレータでは、開発者と仕事をあらかじめ用意してある。シミュレータでの学習者は、
開発者の特徴と仕事の種類の情報を注意深く検討する。図1にモデル選択例、図2に開発者例、
図3に仕事の例を示す。図1では Communication モデル、Communication Efficiency モデル、
Study モデルの三つのモデルを選択することができる。各モデルについては後に説明する。図2
ではどの開発者をどれだけの人数を配置するかを決定することができる。開発者はそれぞれ固
有の知識構造、つまり何を知っていて何を知らないかの構造を持っている。図3では各開発者
に自由に仕事を振り分けすることができる。仕事例はオブジェクト指向開発方法論にてソフト
ウェア開発をしたときの作業の種類と作業量、さらに標準的な生産性を示す。
まず、どのモデルを設置するかを選択する。次に、学習者は様々なタイプの開発者を任意の人
数(現在開発者は6人まで)を選択する。そして各開発者の能力と仕事の特徴を見比べながら、
開発者へ仕事をそれぞれ割り当てる。割り当てが終了するとプロジェクトスタートする。プロ
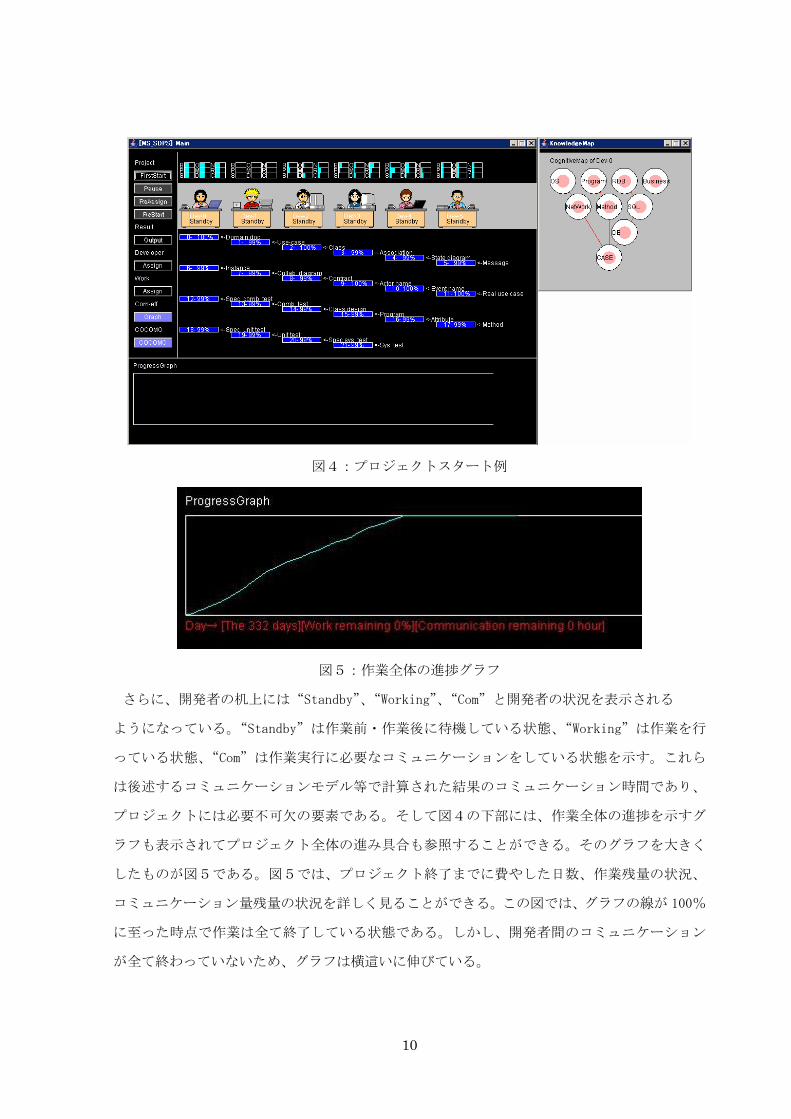
ジェクトをスタートさせた状況を図4に示す。開発者たちは机に座って仕事を遂行する様子を
示す。その下の棒グラフは作業の進捗状況を示し、作業が遂行するにしたがって棒が短くなる。
さらに、右半分の開発者知識マップ(木構造)は、開発者の知識構造の変化を示すマップである。
これは作業実行に伴い変化する開発者の知識を表すものである。
10
図4:プロジェクトスタート例
図5:作業全体の進捗グラフ
さらに、開発者の机上には“Standby”、“Working”、“Com”と開発者の状況を表示される
ようになっている。“Standby”は作業前・作業後に待機している状態、“Working”は作業を行
っている状態、“Com”は作業実行に必要なコミュニケーションをしている状態を示す。これら
は後述するコミュニケーションモデル等で計算された結果のコミュニケーション時間であり、
プロジェクトには必要不可欠の要素である。そして図4の下部には、作業全体の進捗を示すグ
ラフも表示されてプロジェクト全体の進み具合も参照することができる。そのグラフを大きく
したものが図5である。図5では、プロジェクト終了までに費やした日数、作業残量の状況、
コミュニケーション量残量の状況を詳しく見ることができる。この図では、グラフの線が 100%
に至った時点で作業は全て終了している状態である。しかし、開発者間のコミュニケーション
が全て終わっていないため、グラフは横這いに伸びている。

11
3-2 Communication Efficiency の提案
本シミュレータには開発者間に発生するコミュニケーションモデルがすでに実装されていた。
実装済みのコミュニケーションモデルだけでは、コミュニケーションはランダムに発生し、ど
のような知識を持った開発者同士でも一定のコミュニケーション量が一定時間で消費される。
しかし、現実はコミュニケーションを行う開発者間の知識差において、コミュニケーションが
効率的に進む場合もあり、また、コミュニケーションが遅々として進まない場合もある。よっ
てコミュニケーション効率は、各開発者知識によって変わるのである。
そこで我々が作成したのがコミュニケーション効率モデルである。このモデルはコミュニケー
ションモデルと連結しており着脱が可能である。更にコミュニケーション効率モデルを動作さ
せることによって、コミュニケーション効率に差を出す事ができる。またコミュニケーション
中に開発者は知識を獲得し、またコミュニケーションの効率状況を別ウィンドウに棒グラフで
表示することができる。(規模は 500STEP ほど)
次に、コミュニケーション中の知識獲得の仕組みの詳細を説明する。ここでのコミュニケーシ
ョンとは二人の開発者間で行なわれることを前提とし、三種類の知識を想定する。一つ目は、
コミュニケーション実施のために要求される知識 COM、二つ目は開発者 D1が持っている知識、
三つ目は開発者 D2が持っている知識の三種類とする。
ここで、新しい概念は一つ目のコミュニケーションを実施するときに要求される知識 COM であ
る。COM を決定するためにコミュニケーションする二人の開発者の担当仕事によって計算される。
仕事には Business、OS(Operating System)、NetWork、Program、Method、RDB(Relational Database)、
SQL(Structured Query Language)、DB(Database)、CASE(Computer Aided Software Engineering)
の九つの知識の種類があり、仕事によってそれぞれの値が異なる。COM はその仕事実施に要求さ
れる知識の低い方の値をそれぞれ九つとってきて計算される。この三種類の知識量の関係によ
ってコミュニケーションの効率が決定すると考える。
次にそれぞれの三種類の知識量の関係の場合を三つのケースに分けて説明する。
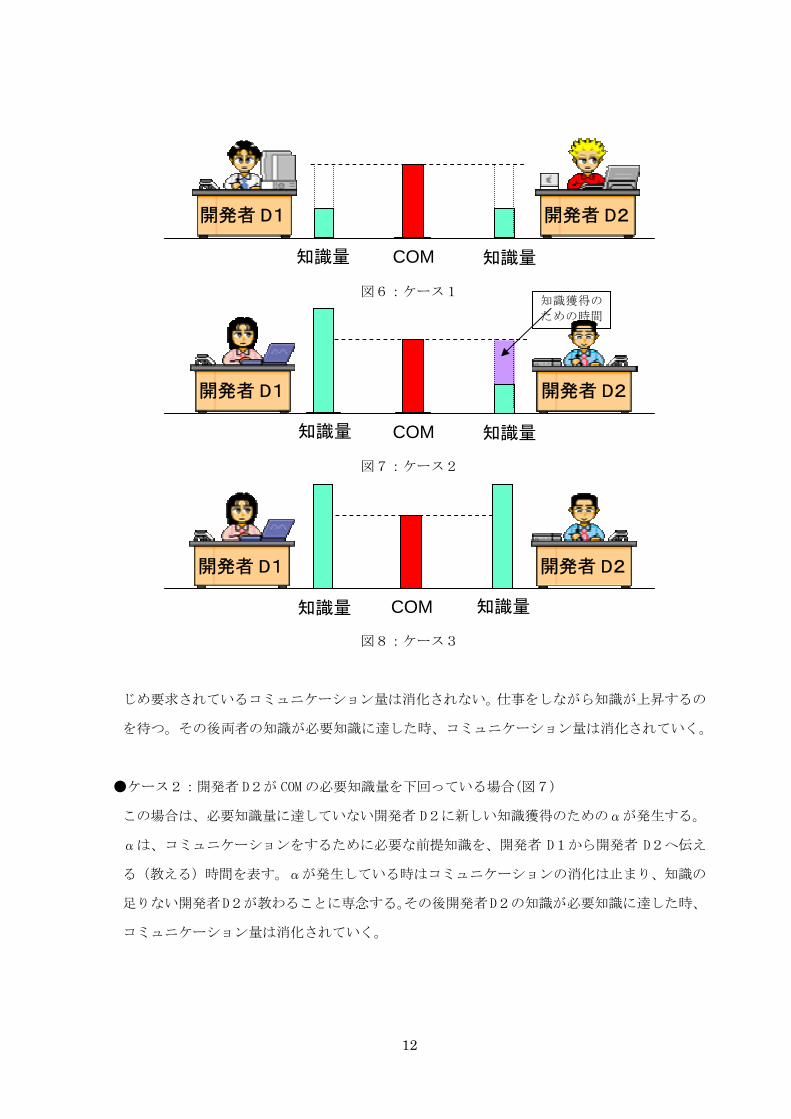
●ケース1:開発者が両方とも COM の必要知識量を下回っている場合(図6)
この場合は、COM に必要な知識の量を開発者 D1、D2ともに満たしていないので、あらか
12
図6:ケース1
図7:ケース2
図8:ケース3
じめ要求されているコミュニケーション量は消化されない。仕事をしながら知識が上昇するの
を待つ。その後両者の知識が必要知識に達した時、コミュニケーション量は消化されていく。
●ケース2:開発者 D2が COM の必要知識量を下回っている場合(図7)
この場合は、必要知識量に達していない開発者 D2に新しい知識獲得のためのαが発生する。
αは、コミュニケーションをするために必要な前提知識を、開発者 D1から開発者 D2へ伝え
る(教える)時間を表す。αが発生している時はコミュニケーションの消化は止まり、知識の
足りない開発者D2が教わることに専念する。その後開発者D2の知識が必要知識に達した時、
コミュニケーション量は消化されていく。
知識量COM知識量
開発者 D1 開発者 D2
知識量COM知識量
開発者 D1 開発者 D2
知識量知識量 COM
開発者 D1 開発者 D2
知識獲得の
ための時間

13
●ケース3:開発者の必要知識が両方上回っている場合(図8)
この場合は、両者が COM の必要知識を満たしているため、コミュニケーション量は最高の効率
で消費される。
3-3 他モデルの説明
このシミュレータには三つのモデルが実装されている。まず一つ目に Study モデル、二つ目に
Communication モデル、そして上記で説明した Communication Efficiency モデルがある。この
三つのモデルを着脱する事によってより複雑な事象をシミュレートすることができる。ここで
は Study モデルと Communication モデルについて説明する。
まず Study モデルについて説明する。このモデルを着脱することで開発者が作業中の知識上昇
の有無を設定することができる。何故、作業中に開発者の知識が上がるかというと、現実では
作業を行うには少なからず学ぶものがある。また、その開発者の持っている知識と作業内容に
よって、上昇する知識の範囲は異なる。それを図にしたのが図9である。つまり、担当してい
る作業に要求される知識(表3)より開発者の知識が低い場合は、作業を行うために多くのこと
を学ばなければならない。よって知識の増加は大きい。反対に、担当している作業に要求され
る知識より開発者の知識が高い場合は、作業に必要な知識は満たしているため新たに得る知識
知識量 作業に必要な
知識量
大きく増加する
知識量 作業に必要な
知識量
増加はするが小さい
図9:Study モデルの知識増加の仕組み

14
も少ない。よって知識の増加は小さい。これを可能としたのが Study モデルである。
表3:仕事に必要な知識量
Domain OS Network Program Method RDB SQL DB CASE
業務上資料 100 20 100
ユースケース図 70 30
クラス 30 30 40
関連 30 30 40
状態図 40 20 40
メッセージ 0 50 50
インスタンス 0 50 50
協調図 50 30 20
契約 50 30 20
アクタ名 50 30 20
イベント図 50 30 20
現実的ユースケース図 40 30 30
結合テスト仕様 10 20
結合テスト結果 10 20 20
クラス設計図 10 20 20 20 10
プログラム 20 20 10
属性 20 20 10
メソッド 20 20 10
単体テスト 50 50 20
単体結果 50 50 20
システムテスト仕様 80 20
システムテスト結果 50 50
15
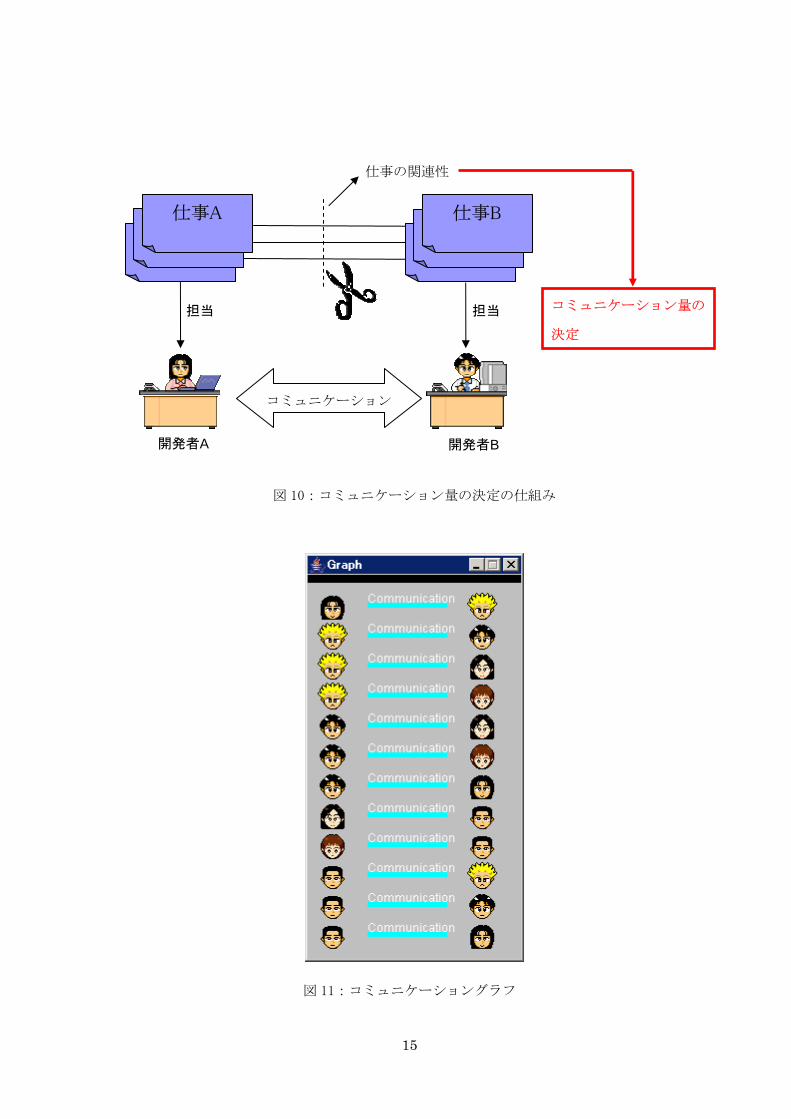
図 10:コミュニケーション量の決定の仕組み
図 11:コミュニケーショングラフ
開発者A 開発者B
仕事A
担当担当
コミュニケーション
仕事B
仕事の関連性
コミュニケーション量の
決定

16
次に Communication モデルの説明をする。このモデルを着脱することによって、開発者間
で行なわれるコミュニケーションの有無を設定することができる。またコミュニケーションが
行なわれる際には、コミュニケーション量が発生する。そのコミュニケーション量が全て消費
された時、コミュニケーションが終了する。ここで言うコミュニケーション量とは、開発者が
担当している各仕事の関連を元に計算し(参照図 10)、決定されている。また、コミュニケーシ
ョン量の変化状況は図 11 で参照することができる。左右にある作業者の絵で、どの作業者間で
コミュニケーションが行なわれているかがわかる。水色の棒グラフがコミュニケーション量を
表し、コミュニケーション量を消費すると水色の棒グラフが減っていく。
4 考察
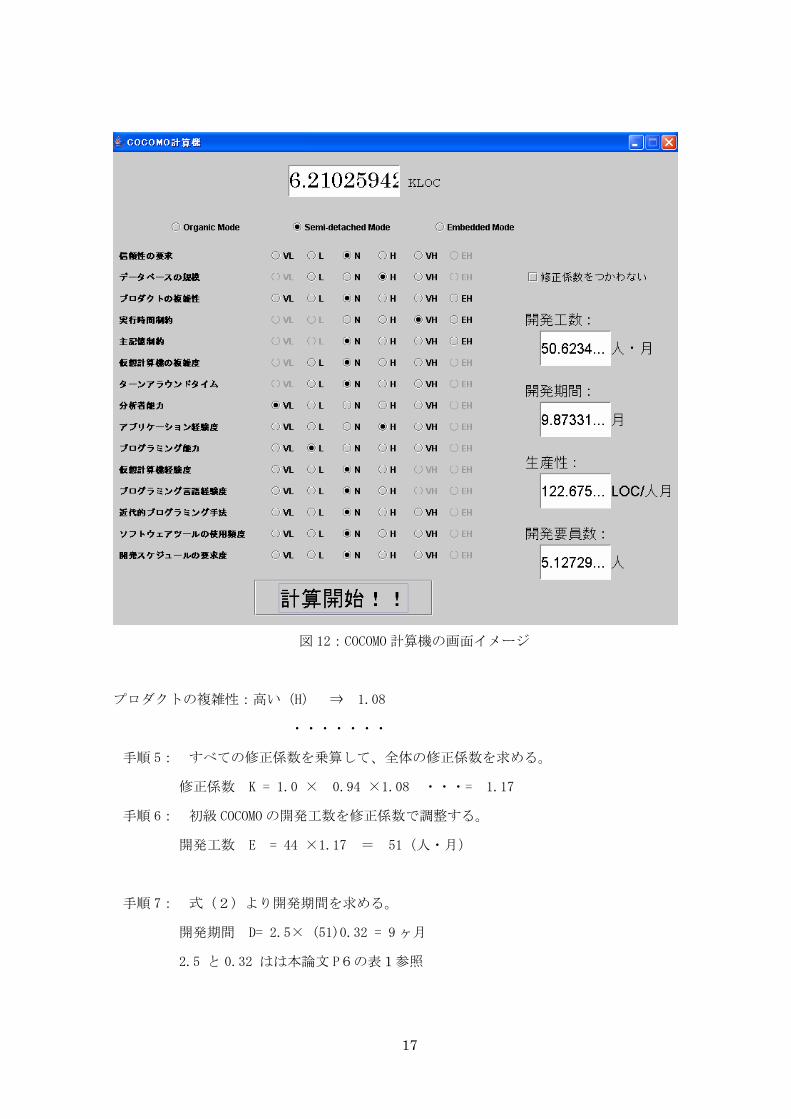
考察として既存の見積もりモデル COCOMO と我々のプロジェクトシミュレータを比較する。図
12 は考察用に JAVA 言語[3]で作成した COCOMO の理論で見積もり計算するプログラム(規模は
400STEP ほど)のサンプル画像である。これはプロジェクトシュミレータと連動しており、COCOMO
の計算で要になる開発規模(KLOC)はプロジェクトシミュレータで各開発者に割り当てた作業
の数により増減する。これにより同じ条件化での計算が可能となり、より違いがはっきりわか
るようになっている。
ここで順を追ってこのプログラムの手順を説明する。手順で使用している数値は例題である。
手順1: ソフトウェアの開発規模を決める⇒ プロジェクトシミュレータとの連動で自
動算出
手順 2: プロジェクトの開発形態を決める⇒ embedded モード
手順 3: 初級 COCOMO で開発工数を求める。
開発工数 E = 2.8 × (10) 1.20 = 44(人・月)
2.8 と 1.20 は本論文 P6の COCOMO 算出係数の表1参照
手順 4: 前頁の表より各コストのコスト誘引の修正係数を求める。
例 信頼性の要求度:普通(N) ⇒ 1.0
データベースの規模:小さい(L) ⇒ 0.94
17
図 12:COCOMO 計算機の画面イメージ
プロダクトの複雑性:高い(H) ⇒ 1.08
・・・・・・・
手順 5: すべての修正係数を乗算して、全体の修正係数を求める。
修正係数 K = 1.0 × 0.94 ×1.08 ・・・= 1.17
手順 6: 初級 COCOMO の開発工数を修正係数で調整する。
開発工数 E = 44 ×1.17 = 51(人・月)
手順 7: 式(2)より開発期間を求める。
開発期間 D= 2.5× (51)0.32 = 9 ヶ月
2.5 と 0.32 はは本論文 P6の表1参照

18
図 13:プロジェクトシミュレータの計算結果の一例
手順 8: 開発工数を用いて生産性と開発要員数を求める。
生産性P = L/E = 10,000/51 = 196.1(LOC/人月)
開発要員数S = E/D = 51/9 = 5.7(人)
COCOMOを発展させたCOCOMOⅡがあるが、今回自分たちが提案するモデルと比較するに当たり、
見積もり方法や考え方が大幅に違うため、今回は COCOMO の方と比較している。また上級 COCOMO
も複雑すぎて考察には向かないため今回の考察では除外している。
下記の表4が上記の手順で計算したデータを集計したものである。表4を見ると、一見すべて
が数値化されて完璧のように見える。しかしデータ自体が古いという最大の問題がある。デー
タ収集した時期が現在と開発環境はもとより、開発者の考え方も違っているため、データ自体
があまり意味をなさなくなっているのだ。結果しかでないため進捗状況などが把握できず、詳
しい解析ができない。
プロジェクトシミュレータを見てみる。手順は前章で説明した通りの手順で行なっている。表
4と図 13 を見比べてわかるように、明らかにプロジェクトシミュレータの方が分かりやすい。
COCOMO ではできなかった進捗状況の確認もできる。全体の進捗だけでなく、各開発者の作業ご
との細かい進捗まではっきりわかる。細かい進捗が出でることによってプロジェクトの分析が
し易くなり、次のプロジェクトに反省点などを反映させやすくなる。

19
表4は結果の一例で開発者、作業割り当て、モデルこれらの組み合わせ次第で様々なケースに
対応できる。これにより次のプロジェクトの予測などができるので事前に問題点などが発見で
きる確立が高くなる。結果を見ただけでも明らかにプロジェクトシミュレータのほうが実用的
で優れている事がわかる。
次に COCOMO とプロジェクトシミュレータの中身の違いについて考察する。COCOMO では人間同
士が仕事をしていく上で最も重要な要素「コミュニケーション」についてまったく考慮されて
いない。これはソフトウェア開発だけではなくどの分野の仕事にも言えることだが、人間同士
で仕事をする以上コミュニケーションは必要不可欠であり、ないと成立しないものである。む
しろ一番重要と思われる。
その次の特徴は開発者に知識が存在し、仕事をいろいろなケースに合わせて開発者を割り当て
られるというところである。これにより様々な状況の見積もりやシミュレーションができる。
COCOMO は入力できるデータは開発規模と修正係数ぐらいである。これでは現在発生している多
種多様な開発状況に対応しているとは言い難い。
COCOMO と我々のプロジェクトシミュレータには決定的な差がある。COCOMO は客観的データに
基づいた見積もり手法であるが、シミュレータは知識獲得やコミュニケーションなど開発者の
人的要因も考慮したモデルを採用している。これは、現在の複雑なソフトウェア開発では、客
観的データだけでは推測できない人的要因に左右される割合が大きいからである。このように、
表面に現れる客観的データの推移だけではなく、人的要因をモデルに採用したところが、本シ
ミュレータと COCOMO との決定的な差である。したがって、現在の多種多様な知識とスキルを要
求されるソフトウェア開発では COCOMO よりプロジェクトシミュレータによる工数見積もりを採
用するほうが、複雑な現象を予測する上でも、有効な手段であると考えられる。
表 4:COCOMO での計算結果
Mode organic semi-detached embedded
開発工数(人・月) 16.3296 23.1955 32.2132
開発期間(月) 7.22555 7.51331 7.5947
生産性(LOC/人月) 380.306 267.735 192.786
開発要員数(人) 2.25998 3.08725 4.24153

20
もう一つの差が新たにモデルを追加できることである。これにより大きな技術革新や、想定
外の事象が発生しても次々にモデルを追加していくことによりどんなケース対応できるように
なるのだ。モデルに我々が合わせるのではなく、我々に合わせたモデルで見積もりができると
いうのがもう一つの決定的な違いである。
5 まとめ
本論文ではモデル着脱式のプロジェクトシミュレータを提案し、その中でコミュニケーション
効率モデルについて提案した。さらにプロジェクトシミュレータと COCOMO を比較し、本プロジ
ェクトシミュレータの優位性を明らかにすることができた。第一章では、昨今のソフトウェア
開発の現状と代表的な見積もり手法、現在の問題点などについて述べた。第二章では関連研究
として第一章で述べた代表的な見積もり手法のひとつ COCOMO について説明し、第三章は第一章
であげた問題点の解決策としてプロジェクトシミュレータを紹介した。プロジェクトシミュレ
ータはモデル着脱式でその中のモデルのひとつとして今回我々は「Communication-Efficiency
モデル」を提案した。このモデルは人と人とのコミュニケーションに重点をおいたモデルで、
作業中に発生するコミュニケーションも重要な作業と考え、コミュニケーションが知識の獲得
から作業の進捗まで様々なところに影響するようになっている。第四章は考察としてプロジェ
クトシミュレータと既存の見積もりモデルの COCOMO を比較検証した。結果、COCOMO にはできな
かった進捗の表示を実現し、理論をより現実に近づけ、組み合わせ次第で多種多様なケースに
対応した我々のプロジェクトシミュレータの方が COCOMO より優れているという結果を得ること
が出来た。
今後の発展として、現在はまだ少ないモデルの数増やし、さらに現実に近い振る舞いを再現で
きるようにしていくことを考えている。その次に実証実験等も行ってより現実性を高めていき
たい。
謝辞
本プロジェクト遂行とソフトウェア開発にあたり、お仕事のお忙しい中、何度も指導に来てく
ださった株式会社日立システムアンドサービスプロダクトソリューション事業部開発第2部部
長の三原丈英氏、自分たちの卒業論文のあるのに色々面倒を見てくださった本学花川ゼミ卒業

21
生で現在奈良先端科学技術大学院大学の後藤慶多さん、そして学校業務や他学生の論文コンク
ールや卒業論文、ご自分の研究があるのにもかかわらず多くの時間を割いて我々の指導をして
くださった本学の花川典子先生には大変お世話になりました。この場をお借りいたしまして感
謝の言葉を述べさせていただきます。本当にありがとうございました。
参考文献
[1] 山田茂,高橋宗雄著:『ソフトウェアマネジメントモデル入門―ソフトウェア品質の可視
化と評価法―』,共立出版株式会社,1993.
[2] IT 用語辞書 e-words http://e-words.jp/
[3] Sun Microsystems 社 http://jp.sun.com/java/