
Die Linusbank Allgemeine Marktübersicht Unternehmenssicht Problembeschreibung Projektplan
76
Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research Prof. Dr. Andreas Hilbert [email protected] http://wiid.wiwi.tu-dresden.de 01062 Dresden Telefon +49 351 463-32359 Telefax +49 351 463-32736 Rico Ludwig Chris Reiche Patrick Schwabe Ausgewählte Aspekte der BI: Projektseminar Endpräsentation Mat. Nr.: 3111685 Mat. Nr.: 3206958 Mat. Nr.: 3235860
-
Upload
vivien-william -
Category
Documents
-
view
20 -
download
0
description
Die Linusbank Allgemeine Marktübersicht Unternehmenssicht Problembeschreibung Projektplan Deskriptive Analyse Kundenwertkonzept Klassifikationsmodell Kampagnenauswertung. Die Linusbank Allgemeine Marktübersicht. höhere Preissensitivität Häufig 2 bis 4 Bankverbindungen - PowerPoint PPT Presentation
Transcript of Die Linusbank Allgemeine Marktübersicht Unternehmenssicht Problembeschreibung Projektplan

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Prof. Dr. Andreas [email protected]
http://wiid.wiwi.tu-dresden.de01062 Dresden
Telefon +49 351 463-32359Telefax +49 351 463-32736
Rico LudwigChris ReichePatrick Schwabe
Ausgewählte Aspekte der BI:Projektseminar
Endpräsentation
Mat. Nr.: 3111685Mat. Nr.: 3206958Mat. Nr.: 3235860

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation
Die LinusbankAllgemeine Marktübersicht
Unternehmenssicht
ProblembeschreibungProjektplanDeskriptive AnalyseKundenwertkonzeptKlassifikationsmodellKampagnenauswertung
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 3
Die LinusbankAllgemeine Marktübersicht
• höhere Preissensitivität
• Häufig 2 bis 4 Bankverbindungen
• Entwicklung kostenloser Girokonten:– 2000: gesamt: 6 %
– 2005: gesamt: 10 % - 2 % Onlinekonten
– 2010: gesamt 20 % - 19 % Onlinekonten
• Allgemeine Demografie am Markt:– 21 % jünger als 30
– 15 % älter als 70 Jahre
– 19 % zwischen 40 und 49
– andere Altersgruppen jeweils ca. 15 %
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 4
Die LinusbankUnternehmenssicht
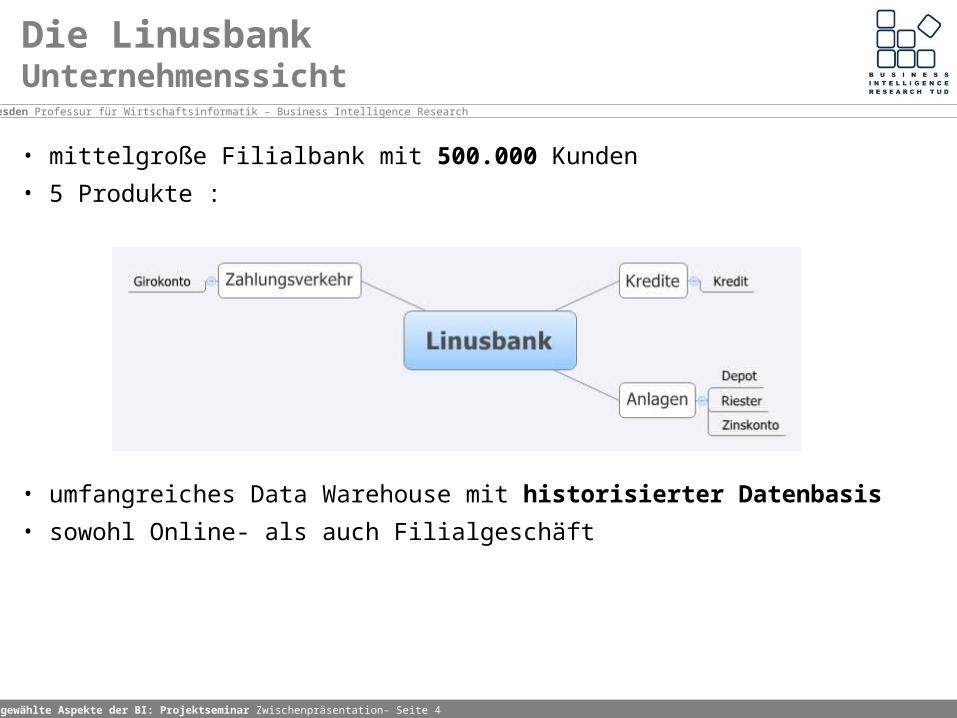
• mittelgroße Filialbank mit 500.000 Kunden
• 5 Produkte :
• umfangreiches Data Warehouse mit historisierter Datenbasis
• sowohl Online- als auch Filialgeschäft

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation
Die LinusbankProblembeschreibung
Was der Kunde sagt
Was der Kunde will
ProjektplanDeskriptive AnalyseKundenwertkonzeptKlassifikationsmodellKampagnenauswertung

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 6
ProblembeschreibungWas der Kunde sagt
"Wir wollen den Produktbesitz und die Produktnutzung unserer Bestandskunden intensivieren, um dem Wettbewerbsdruck zu begegnen. Allerdings sind die Kosten unserer jeweils produktbezogenen Cross- und Up-Selling-Kampangen hoch, und zu häufig sollten die Kunden auch nicht angesprochen werden. Deshalb wollen wir mit unseren Kampagnen vorranging die wertvollsten Kunden adressieren. Leider können wir den Erfolg von Kampagnen nur schwer beurteilen. Anhand von Vergangenheitsdaten wissen wir, dass sich unsere Kunden hinsichtlich ihres Produktbesitzes, ihrer Produktnutzung sowie ihrer Reaktion auf Kampagnen zum Teil deutlich unterscheiden.“
"Wir wollen den Produktbesitz und die Produktnutzung unserer Bestandskunden intensivieren, um dem Wettbewerbsdruck zu begegnen. Allerdings sind die Kosten unserer jeweils produktbezogenen Cross- und Up-Selling-Kampangen hoch, und zu häufig sollten die Kunden auch nicht angesprochen werden. Deshalb wollen wir mit unseren Kampagnen vorranging die wertvollsten Kunden adressieren. Leider können wir den Erfolg von Kampagnen nur schwer beurteilen. Anhand von Vergangenheitsdaten wissen wir, dass sich unsere Kunden hinsichtlich ihres Produktbesitzes, ihrer Produktnutzung sowie ihrer Reaktion auf Kampagnen zum Teil deutlich unterscheiden.“

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 7
ProblembeschreibungWas der Kunde will
• Kosten für Kampagnen sehr hoch
• Kunden nutzen wenige Produkte
• Keine Erfolgsmessung der Kampagnen
• Wertvolle Kunden unbekannt
• Ziele:– Kundenzufriedenheit und Bindung erhöhen
– Wertvolle Kunden identifizieren
– Kosten reduzieren
– Erfolgsmessung für Marketingkampagnen einführen

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation
Die LinusbankProblembeschreibungProjektplan
ProjektablaufKoordination der Projektarbeit
Deskriptive AnalyseKundenwertkonzeptKlassifikationsmodellKampagnenauswertung
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 9
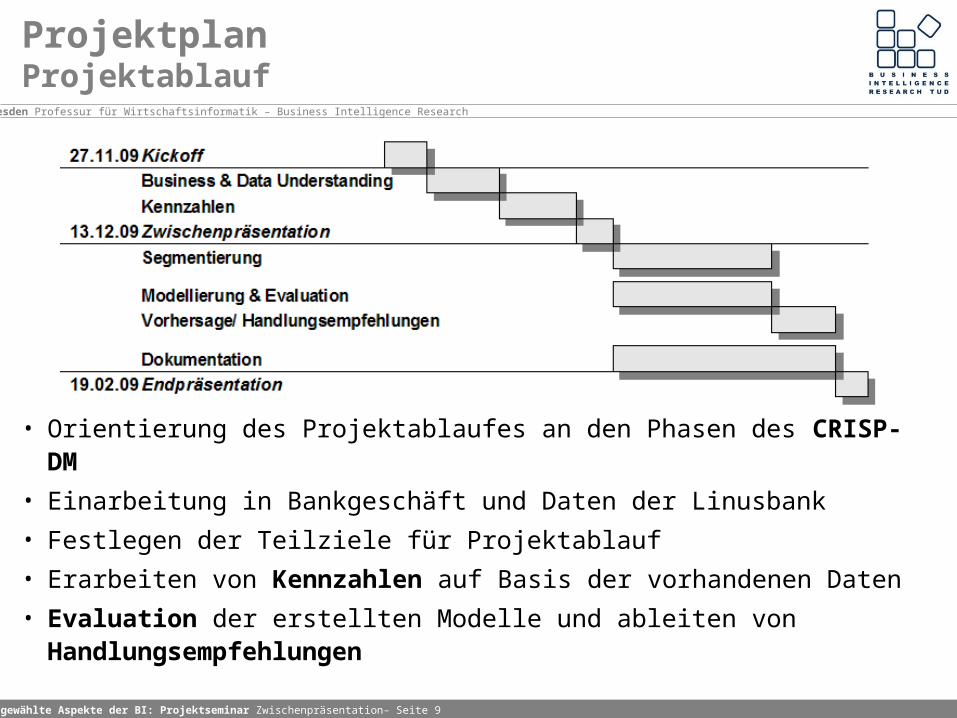
ProjektplanProjektablauf
• Orientierung des Projektablaufes an den Phasen des CRISP-DM
• Einarbeitung in Bankgeschäft und Daten der Linusbank
• Festlegen der Teilziele für Projektablauf
• Erarbeiten von Kennzahlen auf Basis der vorhandenen Daten
• Evaluation der erstellten Modelle und ableiten von Handlungsempfehlungen
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 10
ProjektplanKooperation der Projektarbei

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation
…ProjektplanData Understanding
Übersicht über vorhandene DatenProduktverteilungProdukterträgeKundenstruktur
KundenwertkonzeptKlassifikationsmodellKampagnenauswertung
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 12
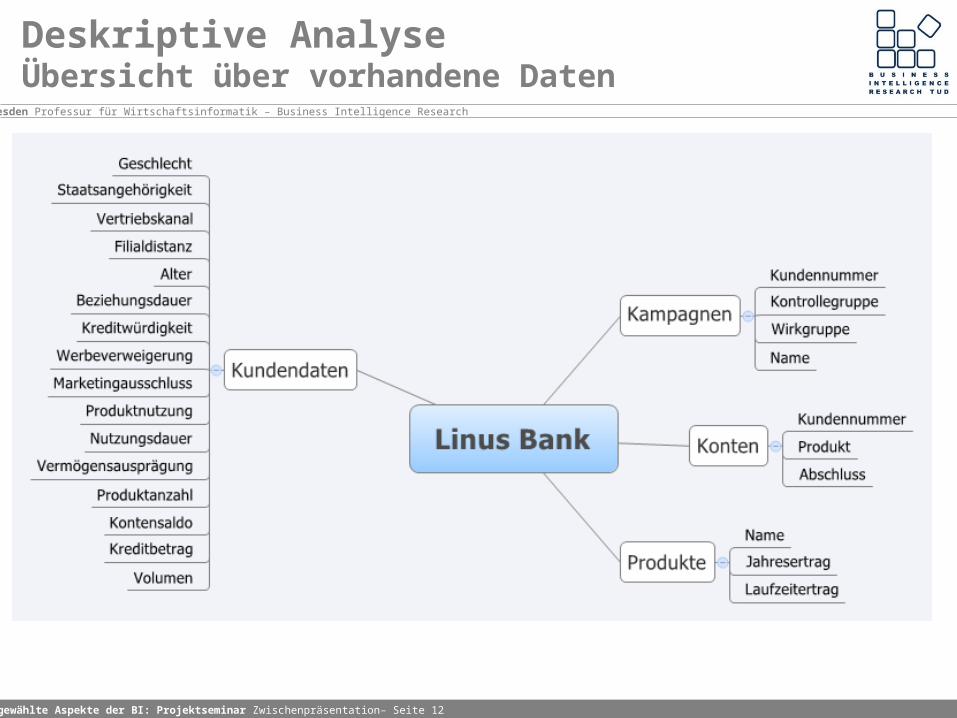
Deskriptive AnalyseÜbersicht über vorhandene Daten
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 13
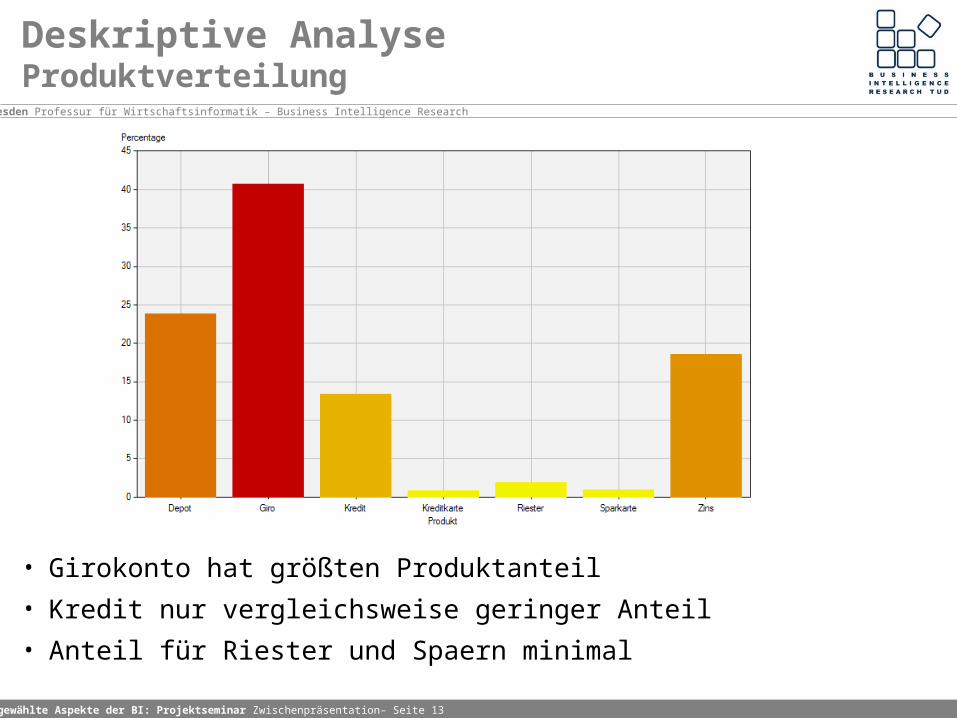
Deskriptive AnalyseProduktverteilung
• Girokonto hat größten Produktanteil
• Kredit nur vergleichsweise geringer Anteil
• Anteil für Riester und Spaern minimal

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 14
Deskriptive AnalyseProdukterträge
• Riester und Kredit haben die höchsten Anteile an den Erträgen
• Zins, Giro und Depot vergleichsweise niedriger Ertragsanteil
Jahresertrag Laufzeitertrag
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Riester
Zins
Giro
Depot
Kredit Jahresertrag Laufzeitertrag
530 1970
140 290
40 260
25 90
450 570
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 15
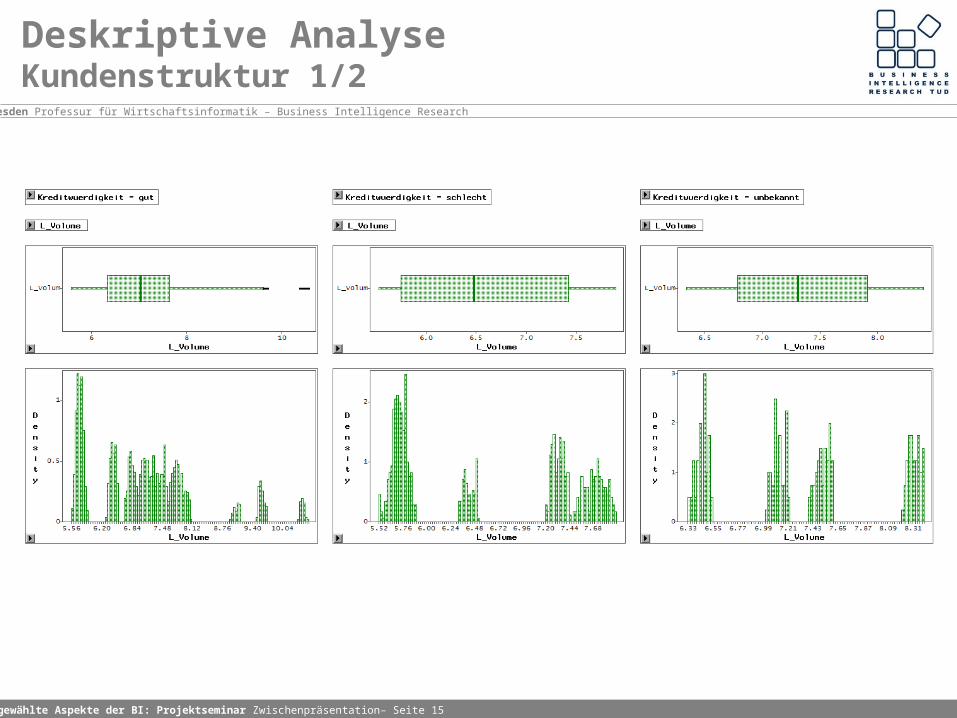
Deskriptive AnalyseKundenstruktur 1/2
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 16
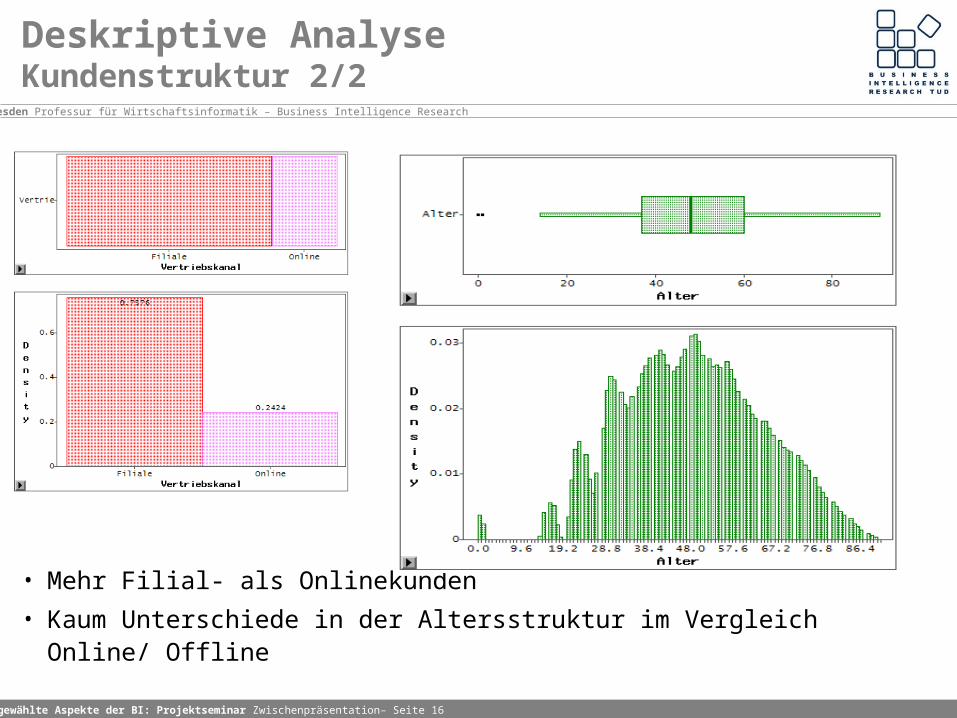
Deskriptive AnalyseKundenstruktur 2/2
• Mehr Filial- als Onlinekunden
• Kaum Unterschiede in der Altersstruktur im Vergleich Online/ Offline

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation
…Data UnderstandingData Preperation
Datenbereinigung
Kundenwertkonzept
…
Modeling…

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 18
Datenbereiningung
• Ausschluss von "toten" Kunden, um eine saubere Datenbasis für die
Folgemodelle zu erzeugen?
– Nur bedingt sinnvoll, da diese Kunden durch die Kampagnen reaktiviert werden!
– Denkbarer Nutzen etwa bei Assoziationsanalyse für den Warenkorb, wobei Konten-
Tabelle nur Kunden enthält, die mindestens ein Produkt besitzen
• Modelle arbeiten fehlerhaft, aber der gezielte Ausschluss (klar definierter)
wertloser Kunden ist fehlerfrei, sodass das Endmodell eine höhere Güte aufweist
• Normierung der Datensätze erforderlich, da Daten sowohl metrisch skaliert
vorliegen (z. B. Kredithöhe oder Beziehungsdauer) oder nominal bzw. ordinal (z.
B. Geschlecht, Familienstand, Kreditwürdigkeit)
• Verbindung der Datensätze über die Kundennummer möglich (jeder Kunde hat
eine eindeutige Kundennummer)

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 19
Ausschluss von Datenmaterial
• Produktnutzung_Giro und Dauer_Giro beinhalten die gleichen
Fakten:
• Wenn Dauer_Giro = 0 ist auch die Produktnutzung = 0
• Daraus folgt, dass Produktnutzung_Giro überflüssig ist
• ebenso bei Giro, Zins, Kredit, Riester, Depot, Kreditkarte, Sparkarte,
Baufinanzierung
• Ausschluss von Kreditkarte, Baufinanzierung und Termingeld laut
Aufgabenstellung (keine adäquaten Daten)

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 20
Erzeugung von Datensätzen
Tabelle Konten und Kunden• Verknüpfung der beiden Tabellen für
jeden Monat mit den Informationen:– Beziehungsdauer
– Alter
– Vertriebskanal
– Produktnutzungsdauer (Giro, Zins, Kredit, Riester, Depot, Sparkarte)
Einteilung der Zeiten in Intervalle
• Nutzungsdauer:
0 Jahre1-12: 1 Jahr13-24: 2 Jahre37-60: 3-5 Jahreab 61: 6-10 Jahre
• Alter:
bis 17: Minderjährig18-2930-3940-4950-59ab 60
• Beziehungsdauer:
0-3: Neukunde3-12: 1 Jahr13-24: 2 Jahre25-60: 3-5 Jahre51-120: 6-10 Jahreab 121: mehr als 10 Jahre

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 21
SQL
proc sql;
create table altranbi.joindb as
select *
From
altranbi.produkte
, altranbi.konten
where lower(name) = lower(produkt);
run;
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 22
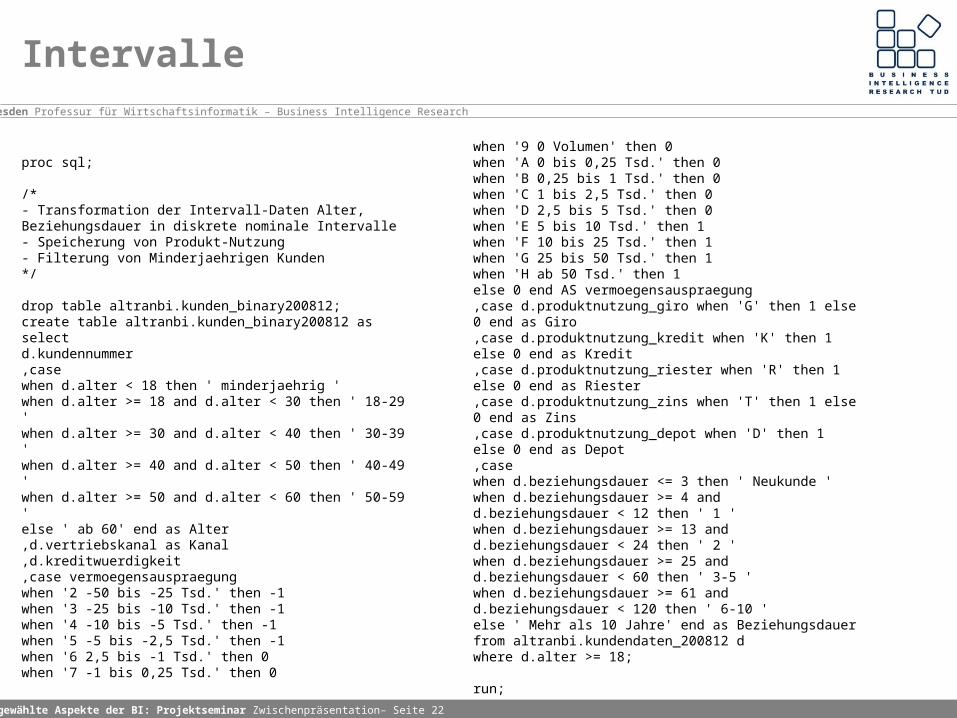
Intervalle
when '9 0 Volumen' then 0when 'A 0 bis 0,25 Tsd.' then 0when 'B 0,25 bis 1 Tsd.' then 0when 'C 1 bis 2,5 Tsd.' then 0when 'D 2,5 bis 5 Tsd.' then 0when 'E 5 bis 10 Tsd.' then 1when 'F 10 bis 25 Tsd.' then 1when 'G 25 bis 50 Tsd.' then 1when 'H ab 50 Tsd.' then 1else 0 end AS vermoegensauspraegung,case d.produktnutzung_giro when 'G' then 1 else 0 end as Giro,case d.produktnutzung_kredit when 'K' then 1 else 0 end as Kredit,case d.produktnutzung_riester when 'R' then 1 else 0 end as Riester,case d.produktnutzung_zins when 'T' then 1 else 0 end as Zins,case d.produktnutzung_depot when 'D' then 1 else 0 end as Depot,casewhen d.beziehungsdauer <= 3 then ' Neukunde 'when d.beziehungsdauer >= 4 and d.beziehungsdauer < 12 then ' 1 'when d.beziehungsdauer >= 13 and d.beziehungsdauer < 24 then ' 2 'when d.beziehungsdauer >= 25 and d.beziehungsdauer < 60 then ' 3-5 'when d.beziehungsdauer >= 61 and d.beziehungsdauer < 120 then ' 6-10 'else ' Mehr als 10 Jahre' end as Beziehungsdauerfrom altranbi.kundendaten_200812 dwhere d.alter >= 18;
run;
proc sql;
/*- Transformation der Intervall-Daten Alter, Beziehungsdauer in diskrete nominale Intervalle- Speicherung von Produkt-Nutzung- Filterung von Minderjaehrigen Kunden*/
drop table altranbi.kunden_binary200812;create table altranbi.kunden_binary200812 asselectd.kundennummer,casewhen d.alter < 18 then ' minderjaehrig 'when d.alter >= 18 and d.alter < 30 then ' 18-29 'when d.alter >= 30 and d.alter < 40 then ' 30-39 'when d.alter >= 40 and d.alter < 50 then ' 40-49 'when d.alter >= 50 and d.alter < 60 then ' 50-59 'else ' ab 60' end as Alter,d.vertriebskanal as Kanal,d.kreditwuerdigkeit,case vermoegensauspraegungwhen '2 -50 bis -25 Tsd.' then -1when '3 -25 bis -10 Tsd.' then -1when '4 -10 bis -5 Tsd.' then -1when '5 -5 bis -2,5 Tsd.' then -1when '6 2,5 bis -1 Tsd.' then 0when '7 -1 bis 0,25 Tsd.' then 0

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 23
Kundenwertkonzept
Motivation:
• Banken besitzen nur beschränkte Ressourcen für Aktivitäten der Kundenbindung
• Ziel ist es Kundensegmente zu identifizieren, die den Einsatz dieser Ressourcen
rechtfertigen
• Ermöglichung einer spezifischen Art der Betreuung von Bestandkunden und
potenziellen Neukunden
• Ausschöpfung von Cross- & Up - Selling Potenzialen
Mögliche Verfahren
• Qualitative Segmentierung
• ABC - Analysen
• Kunden - Deckungsbeitragsrechnung
• Kunden - Scoring - Modelle
• Kunden - Portfolio - Analyse
• Customer Lifetime Value

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 24
Kundenwertkonzept
Merkmale von "guten" Kunden:– mit hohem Kreditvolumen
– geringer Kreditausfallwahrscheinlichkeit
– mit hoher Einlage
– mit hohen Einkommen
– treu
Durch welche Daten lassen lassen sich solche Kunden erkennen?– Kreditvolumen (VOLUMEN_KREDIT)
– Kreditwürdigkeit
– Einalgen - Netto - Volumen
– Einlagenvolumen
– Saldo Girokonto
– Beziehungsdauer

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 25
Gegenwärtiger Kundenwert
• Kunden unterteilen in A, B und C Kunden
– A Kunden sind wertvoll
– B Kunden haben keinen besonderen Wert, schädigen die Linusbank aber nicht
– C Kunden schädigen die Linusbank
• Einflussreiche Größen
– Produktnutzung_X --> X ist die Menge an Produkten, welche einen besonders hohen Anteil am Umsatz/Gewinn der Linusbank haben
– Dauer_X --> Gewichtungsfaktor für die wichtigsten X Produkte der Linusbank
– Anzahl_X --> Gewichtungsfaktor für die wichtigsten X Produkte der Linusbank
– Volumen_X --> Gewichtungsfaktor für die wichtigsten X Produkte der Linusbank
– Kreditwürdigkeit --> Risikominimierung
– Vermögensausprägung --> viel Vermögen bedeutet viel Kapital für die Linusbank
– Beziehungsdauer --> Zeichen für Loyalität
– Cross-Selling_Potenzial_X --> Möglichkeit der Aufwertung des Kunden durch Kampagnen

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 26
Kundenwertbeispiel für Dez. 2008SQL
proc sql;
/*Berechne die Umsaetze fuer die Kunden im Monat Dezember*/
DROP TABLE altranbi.kundenwert_200812;CREATE table altranbi.kundenwert_200812 ASSELECTsum(p.laufzeitertrag) + sum(p.jahresertrag) AS Umsatz, k.kundennummer, Gesamtumsatz, Gesamtkunden, Avg_Umsatz_je_Kunde, a.AbschlussFROMaltranbi.produkte pJOIN altranbi.konten k ON lower(k.produkt) = lower(p.name)CROSS JOIN (SELECTsum(laufzeitertrag+jahresertrag) AS Gesamtumsatz, count(DISTINCT kundennummer) AS Gesamtkunden, sum(laufzeitertrag+jahresertrag) / count(DISTINCT kundennummer) AS Avg_Umsatz_je_Kunde, AbschlussFROMaltranbi.produkte pJOIN altranbi.konten k ON lower(k.produkt) = lower(p.name)WHERE Abschluss = 200812GROUP BY k.Abschluss) aGROUP BY k.kundennummer;
reset outobs=10000;
/*Ordne den Kundendaten die passenden Umsaetze zu*/
/* A KUNDEN */DROP TABLE altranbi.a_kunden;CREATE TABLE altranbi.a_kunden ASSELECT kundennummer, Umsatz FROM altranbi.kundenwert_200812 kORDER BY Umsatz DESC;
/* B KUNDEN */reset outobs=30000;DROP TABLE altranbi.b_kunden;CREATE TABLE altranbi.b_kunden ASSELECT kundennummer, Umsatz FROM altranbi.kundenwert_200812 kWHERE kundennummer NOT IN (SELECT kundennummer FROM altranbi.a_kunden)ORDER BY Umsatz DESC;
/* C KUNDEN */reset outobs=50000;DROP TABLE altranbi.c_kunden;CREATE TABLE altranbi.c_kunden ASSELECT kundennummer, Umsatz FROM altranbi.kundenwert_200812 kWHEREkundennummer NOT IN (SELECT kundennummer FROM altranbi.a_kunden)ANDkundennummer NOT IN (SELECT kundennummer FROM altranbi.b_kunden)ORDER BY Umsatz DESC;
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 27
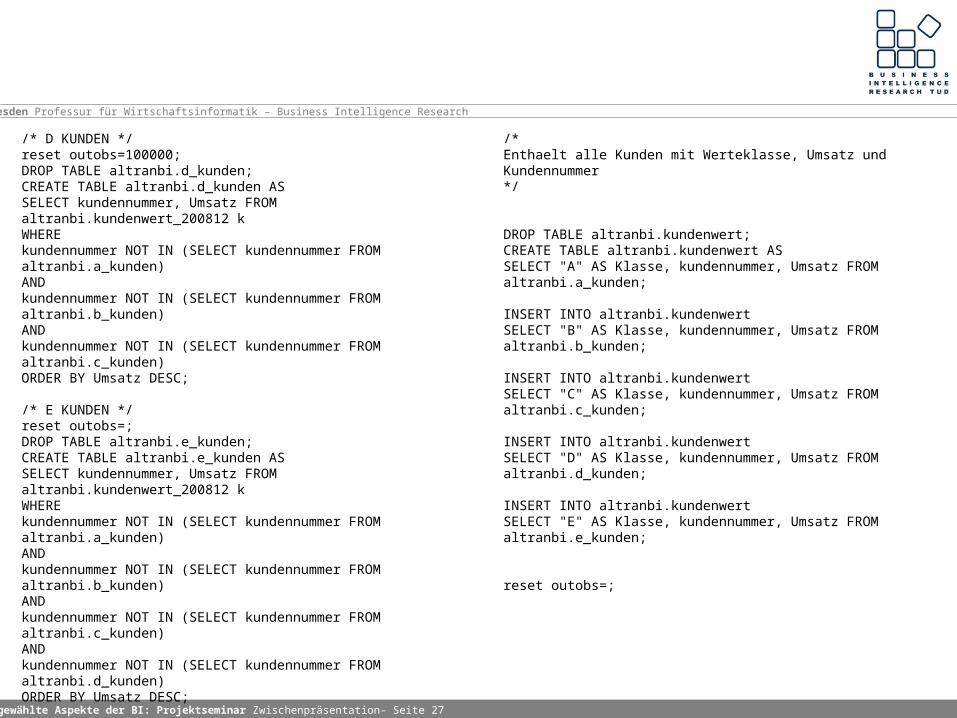
/* D KUNDEN */reset outobs=100000;DROP TABLE altranbi.d_kunden;CREATE TABLE altranbi.d_kunden ASSELECT kundennummer, Umsatz FROM altranbi.kundenwert_200812 kWHEREkundennummer NOT IN (SELECT kundennummer FROM altranbi.a_kunden)ANDkundennummer NOT IN (SELECT kundennummer FROM altranbi.b_kunden)ANDkundennummer NOT IN (SELECT kundennummer FROM altranbi.c_kunden)ORDER BY Umsatz DESC;
/* E KUNDEN */reset outobs=;DROP TABLE altranbi.e_kunden;CREATE TABLE altranbi.e_kunden ASSELECT kundennummer, Umsatz FROM altranbi.kundenwert_200812 kWHEREkundennummer NOT IN (SELECT kundennummer FROM altranbi.a_kunden)ANDkundennummer NOT IN (SELECT kundennummer FROM altranbi.b_kunden)ANDkundennummer NOT IN (SELECT kundennummer FROM altranbi.c_kunden)ANDkundennummer NOT IN (SELECT kundennummer FROM altranbi.d_kunden)ORDER BY Umsatz DESC;
/*Enthaelt alle Kunden mit Werteklasse, Umsatz und Kundennummer*/
DROP TABLE altranbi.kundenwert;CREATE TABLE altranbi.kundenwert ASSELECT "A" AS Klasse, kundennummer, Umsatz FROM altranbi.a_kunden;
INSERT INTO altranbi.kundenwertSELECT "B" AS Klasse, kundennummer, Umsatz FROM altranbi.b_kunden;
INSERT INTO altranbi.kundenwertSELECT "C" AS Klasse, kundennummer, Umsatz FROM altranbi.c_kunden;
INSERT INTO altranbi.kundenwertSELECT "D" AS Klasse, kundennummer, Umsatz FROM altranbi.d_kunden;
INSERT INTO altranbi.kundenwertSELECT "E" AS Klasse, kundennummer, Umsatz FROM altranbi.e_kunden;
reset outobs=;
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 28
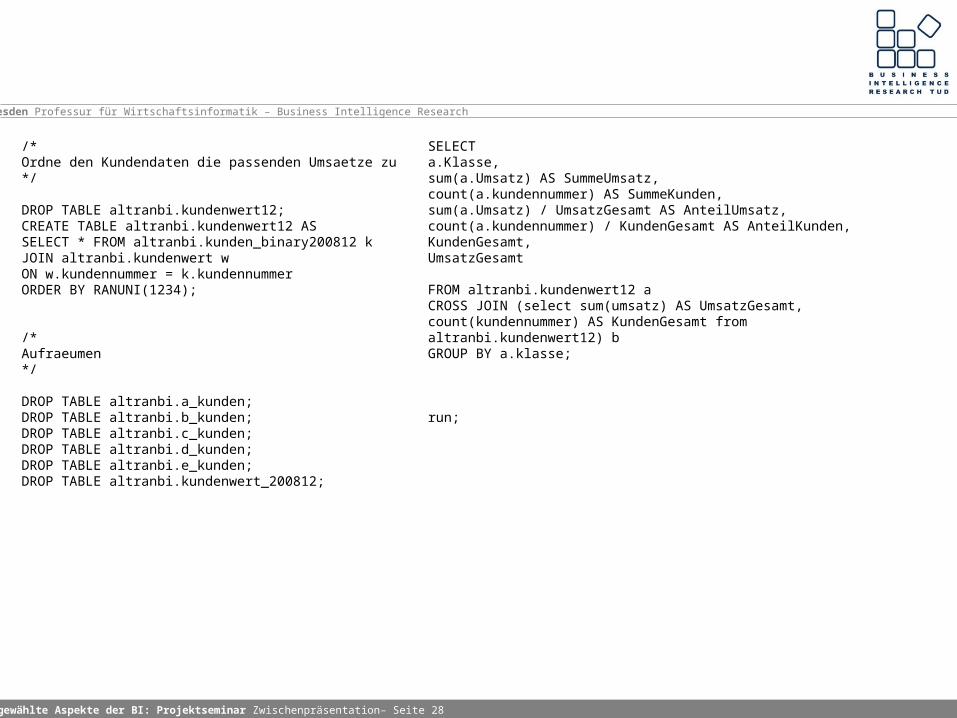
/*Ordne den Kundendaten die passenden Umsaetze zu*/
DROP TABLE altranbi.kundenwert12;CREATE TABLE altranbi.kundenwert12 ASSELECT * FROM altranbi.kunden_binary200812 kJOIN altranbi.kundenwert wON w.kundennummer = k.kundennummerORDER BY RANUNI(1234);
/*Aufraeumen*/
DROP TABLE altranbi.a_kunden;DROP TABLE altranbi.b_kunden;DROP TABLE altranbi.c_kunden;DROP TABLE altranbi.d_kunden;DROP TABLE altranbi.e_kunden;DROP TABLE altranbi.kundenwert_200812;
SELECTa.Klasse,sum(a.Umsatz) AS SummeUmsatz,count(a.kundennummer) AS SummeKunden,sum(a.Umsatz) / UmsatzGesamt AS AnteilUmsatz,count(a.kundennummer) / KundenGesamt AS AnteilKunden,KundenGesamt,UmsatzGesamt
FROM altranbi.kundenwert12 aCROSS JOIN (select sum(umsatz) AS UmsatzGesamt, count(kundennummer) AS KundenGesamt from altranbi.kundenwert12) bGROUP BY a.klasse;
run;

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 29
Zukünftiger Kundenwert
• Wahrscheinlichkeit für Abschluss?
• > Assoziazionsanalyse
• > Cross / Upselling
• > möglicher zusätzlicher Kundenwert
• >

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation…Data UnderstandingData PreperationModeling
AssoziationsanalyseClusteranalysePrognosemodelle
…

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 31
Teil der Aufgabenstellung:
Entwickeln Sie jeweils ein Produktbezogenes Data-Mining-Modell zur Prognose von Cross-Selling-Abschlüssen auf die Produkte Linuskredit, Linusdepot, Linusgiro, Linuszins und Linusriester.
Ziel der AnalyseEindruck darüber gewinnen, welche Produkte häufig gemeinsam genutzt werden.
Assoziationsanalyse
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 32
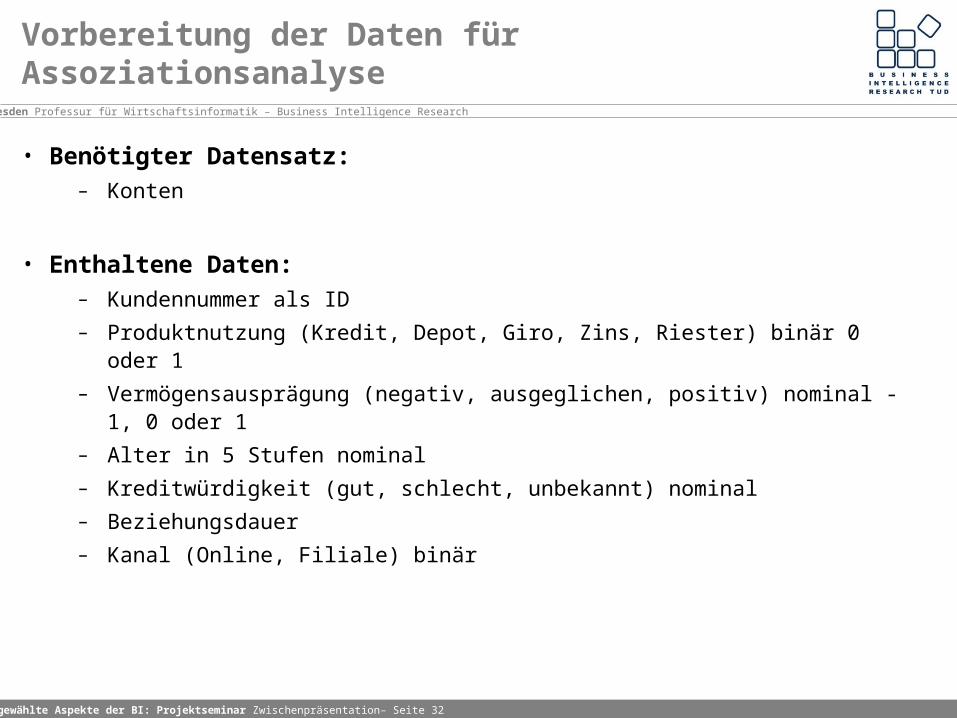
Vorbereitung der Daten für Assoziationsanalyse
• Benötigter Datensatz: – Konten
• Enthaltene Daten:– Kundennummer als ID
– Produktnutzung (Kredit, Depot, Giro, Zins, Riester) binär 0 oder 1
– Vermögensausprägung (negativ, ausgeglichen, positiv) nominal -1, 0 oder 1
– Alter in 5 Stufen nominal
– Kreditwürdigkeit (gut, schlecht, unbekannt) nominal
– Beziehungsdauer
– Kanal (Online, Filiale) binär

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 33
Der Datenfluss im Diagramm

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 34
Filtereinstellung

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 35
Einstellungen im Detail
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 36
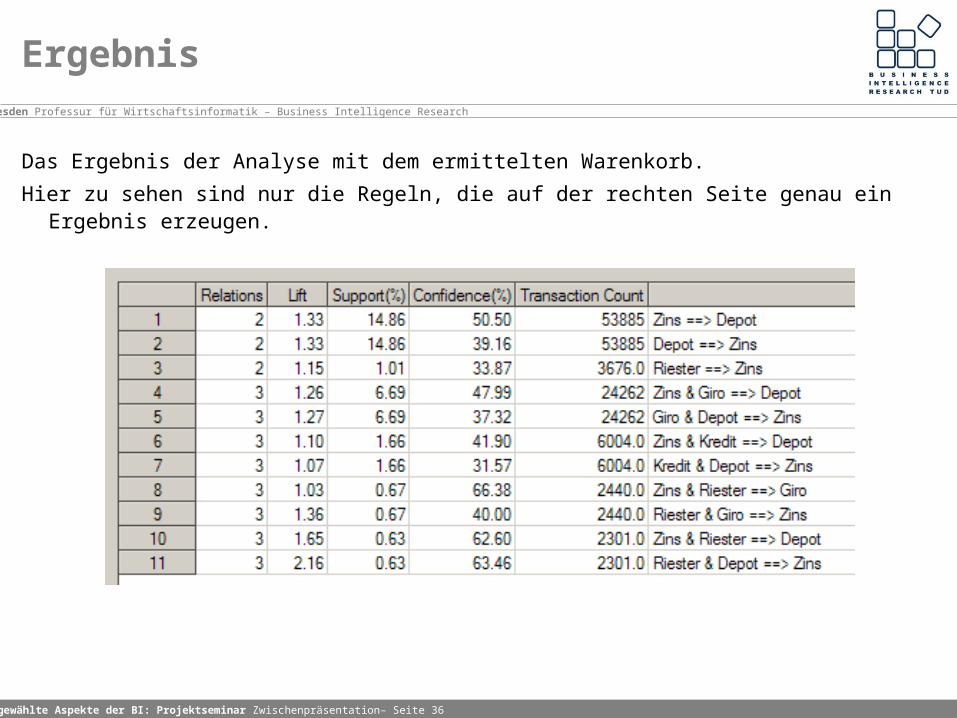
Ergebnis
Das Ergebnis der Analyse mit dem ermittelten Warenkorb.
Hier zu sehen sind nur die Regeln, die auf der rechten Seite genau ein Ergebnis erzeugen.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 37
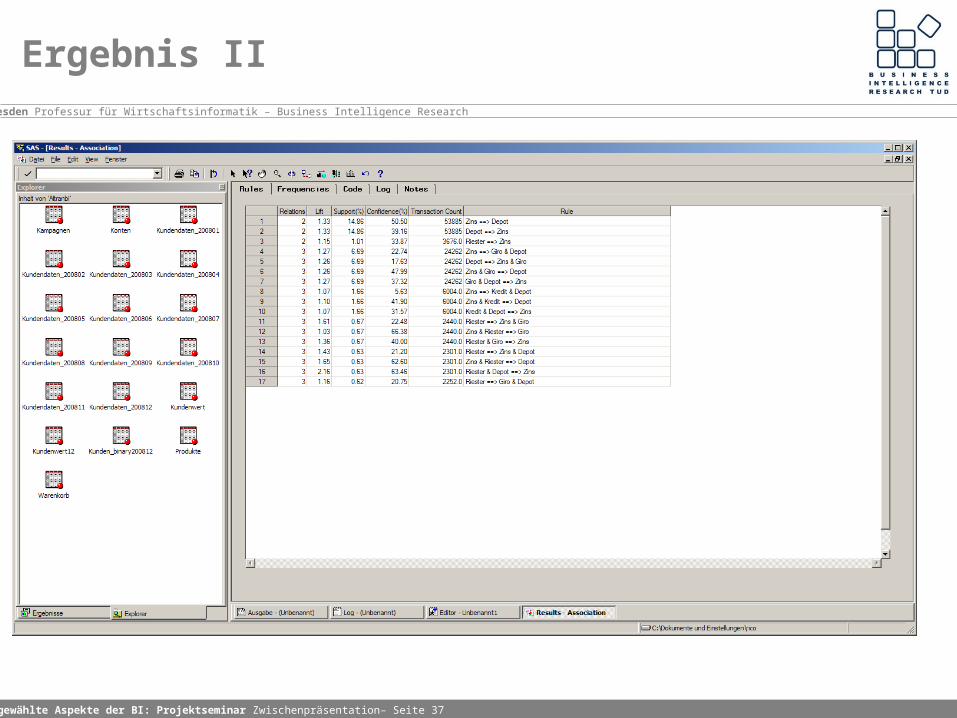
Ergebnis II

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 38
Fazit
Häufig zusammen gekauft werden Zins, Depot und Riester in allen möglichen Kombinationen. Das macht auch Sinn, da alle drei Produkte im Kern Sparprodukte darstellen. Einen starken Lift erzeugen Riester-Produkte, die sowohl für Zins, als auch Zins in Kombination mit Giro oder Depot häufig nachgefragt werden. Diese Produkte werden jedoch vergleichsweise selten verkauft.
Handlungsmöglichkeiten:
Kunden, die bereits ein oder mehrere Produkte besitzen, könnten entsprechend interessiert sein an den ermittelten Kombinationen. So bietet es sich an, Besitzer von Zins, die noch über kein Depot verfügen, ein Produktangebot vorzubereiten bzw. Depot-Besitzern auch Linuszins anzubieten.

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation…Data UnderstandingData PreperationModeling
AssoziationsanalyseClusteranalysePrognosemodelle
…

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 40
Clusteranalyse
Teil der Aufgabenstellung:Entwickeln Sie jeweils ein Produktbezogenes Data-Mining-Modell zur Prognose von Cross-Selling-Abschlüssen auf die Produkte Linuskredit, Linusdepot, Linusgiro, Linuszins und Linusriester.
Ziel der AnalyseEindruck über die Kundenstruktur gewinnen. Gibt es typische Nutzergruppen, die ähnliche Eigenschaften aufweisen?

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 41
Clusteranalyse
• Benötigter Datensatz: Kunden_binary200812
• Enthaltene Daten:– Kundennummer als ID
– Produktnutzung (Kredit, Depot, Giro, Zins, Riester) binär 0 oder 1
– Vermögensausprägung (negativ, ausgeglichen, positiv) nominal -1, 0 oder 1
– Alter in 5 Stufen nominal
– Kreditwürdigkeit (gut, schlecht, unbekannt) nominal
– Beziehungsdauer
– Kanal (Online, Filiale) binär

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 42
Clusteranalyse
Nachdem der Clusternode keine zufriedenstellenden Ergebnisse hervorbrachte, kam der SOM-/Kohonen-Node zum Einsatz.
Vorgehen: Sampling-Node mit Simple-Random (12345) als Starteinstellung und 4x6 Clustern. Anschließend Beobachtung des Distance-Plots auf eine gleichmäßige Verteilung der Cluster und Prüfung der Clusterhäufigkeit in den Statistics. Schrittweise Reduzierung der Clusterzahl brachte bei 2x3 Clustern das erste gute Ergebnis, bei dem die Cluster gut verteilt waren und keine Häufung mehr auftrat. Als wichtige Variablen zeigt sich stets die Beziehungsdauer, die Vermögensausprägung, Giro, Depot, Zins, Kredit.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 43
Der Datenfluss im Diagramm

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 44
Das Ergebnis der Analyse mit dem ermittelten Distanzgraphen
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
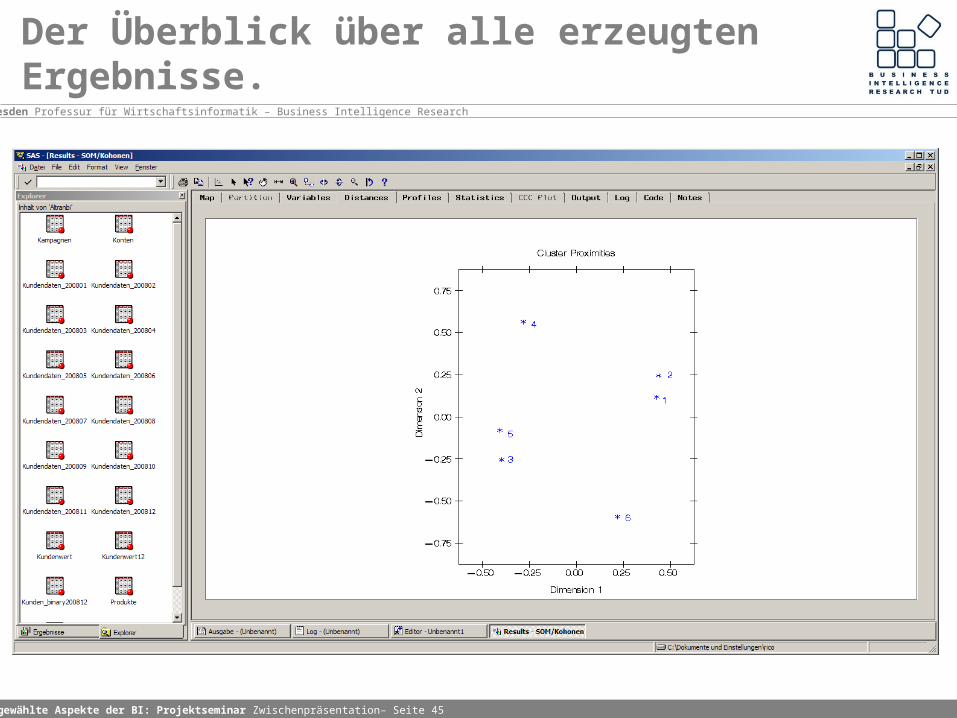
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 45
Der Überblick über alle erzeugten Ergebnisse.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 46
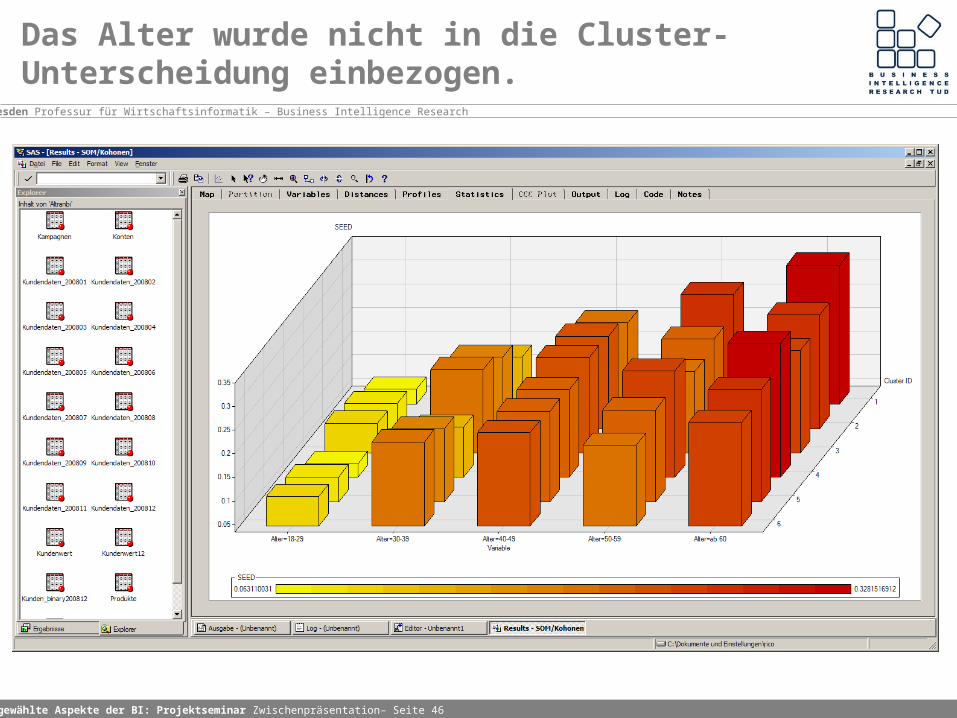
Das Alter wurde nicht in die Cluster-Unterscheidung einbezogen.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 47
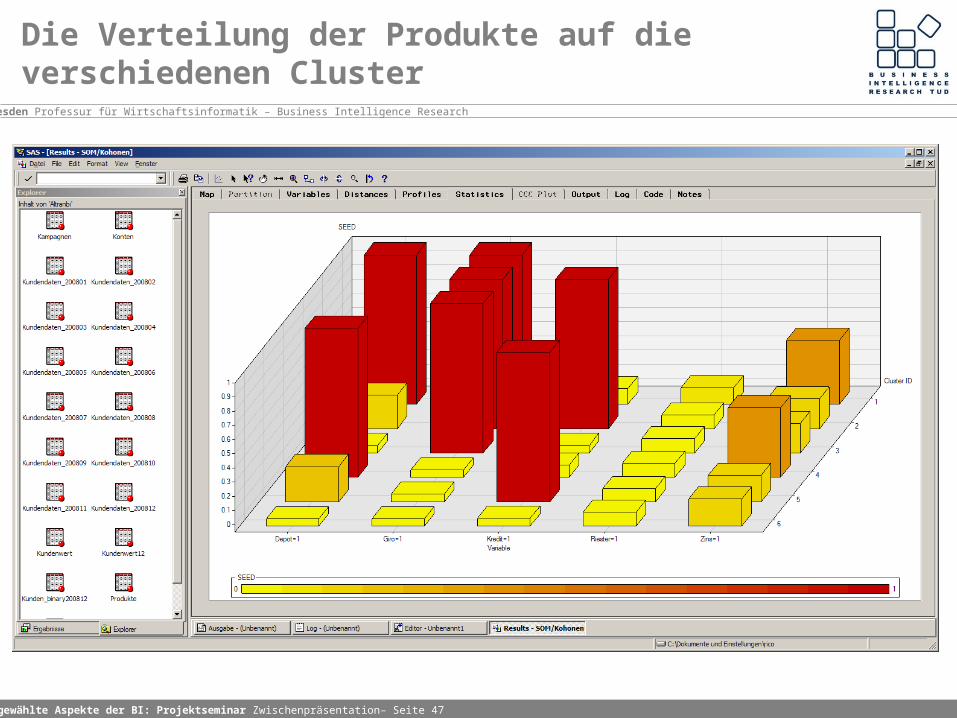
Die Verteilung der Produkte auf die verschiedenen Cluster
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 48
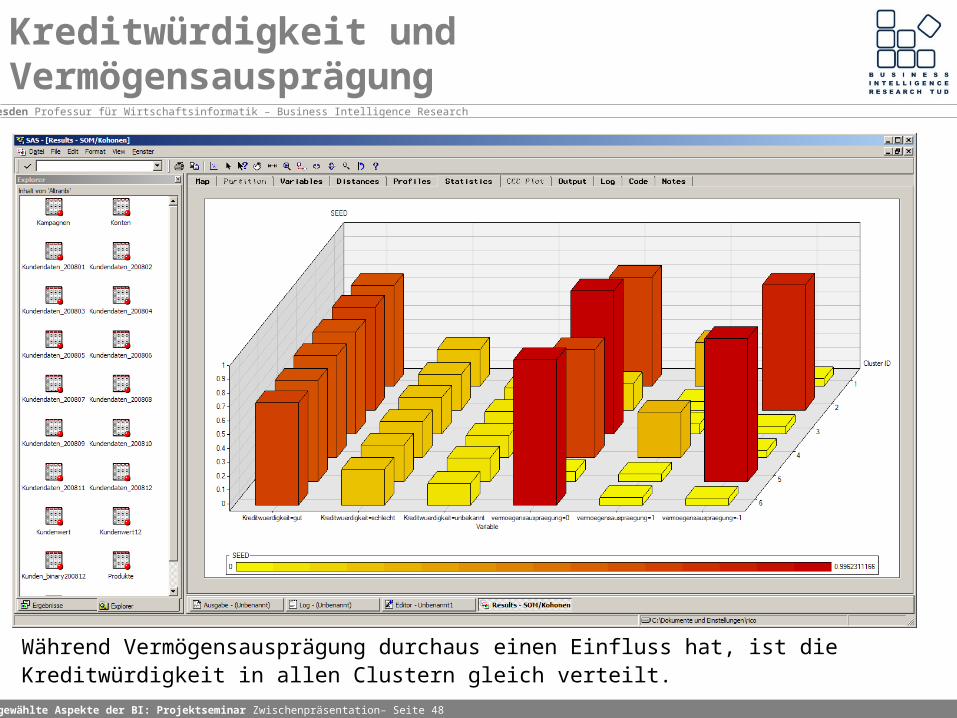
Kreditwürdigkeit und Vermögensausprägung
Während Vermögensausprägung durchaus einen Einfluss hat, ist die Kreditwürdigkeit in allen Clustern gleich verteilt.

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 49
Fazit
Es zeigen sich drei auffällige Cluster-Gruppierungen. So gibt es stets ein Cluster Kreditkunden, das einen erheblichen Anteil an Kreditkunden beinhaltet, die eine stark negative Vermögensausprägung aufweisen und eine mittlere Beziehungsdauer ab 3 Jahren erreichen.
Die zweite Gruppe sind die Sparkunden mit positiver Vermögensausprägung, langer Bindungsdauer teils über 10 Jahre und allen drei Spar-Produkten Zins, Depot und Giro.
Die dritte Gruppe umfasst die verbleibenden Cluster mit vorrangig ausgeglichenem Vermögen und häufig einem Girokonto oder Depot.
Handlungsmöglichkeiten:Es lässt sich erkennen, dass im Cluster der Sparkunden die klassischen Sparprodukte häufig nachgefragt werden. Ein Ansatz wäre, Kunden zu finden, die ebenfalls vermögend sind, aber noch nicht alle Produkte besitzen. Zusätzlich ist eine Aktion denkbar, bei der Kunden, die alle Produkte besitzen, aber nur geringe Einlagen aufweisen, zusätzliches Geld überweisen, weil sie mit hoher Wahrscheinlichkeit noch woanders über Konten mit Spareinlagen verfügen.

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation…Data UnderstandingData PreperationModeling
AssoziationsanalyseClusteranalysePrognosemodelle
…

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 51
Prognosemodelle
Teil der Aufgabenstellung:Entwickeln Sie jeweils ein produktbezogenes Data-Mining-Modell zur Prognose von Cross-Selling-Abschlüssen auf die Produkte linuskredit, linusdepot, linusgiro, linuszins und linusriester.
Ziel der ModelleKlassifikation von neuen Kunden, um Wahrscheinlichkeiten für Produktabschlüssen zu prognostizieren. Ist auch eine Hilfestellung um Cross-Selling-Potenzial von bereits bestehenden Kunden zu ermitteln.

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 52
Vorbereitung der Daten für die Prognosemodelle
• Benötigte Datensätze:
– kunden_binary200806
– kunden_binary200812 (Clustering)
– kundenwert_200806
– kundenwert_200812 (Kundenwert)
• Enthaltende Daten:
– Kundennummer (id)
– Alter (nominal 5 Klassen)
– Kanal (binär)
– Kreditwürdigkeit (nominal 3 Klassen)
– Vermögensausprägung (ordinal -1 0 und 1)
– Giro (binär)
– Kredit (binär)
– Riester (binär)
– Zins (binär)
– Depot (binär)
– Beziehungsdauer (nominal 5 Klassen)
– Klasse (nominal 5 Klassen)
– Umsatz (interval 115-4365)

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 53
Manipulation der Daten und Erstellung von Standartprognosemodellen
Über SAS Code die benötigten Datensätze erzeugen
Über "Input-Data-Source-Node" jeweils die komplette Kundenwert Tabelle von 06 und 12 laden (Model Role der Kundennumemr als ID deklarieren)

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 54
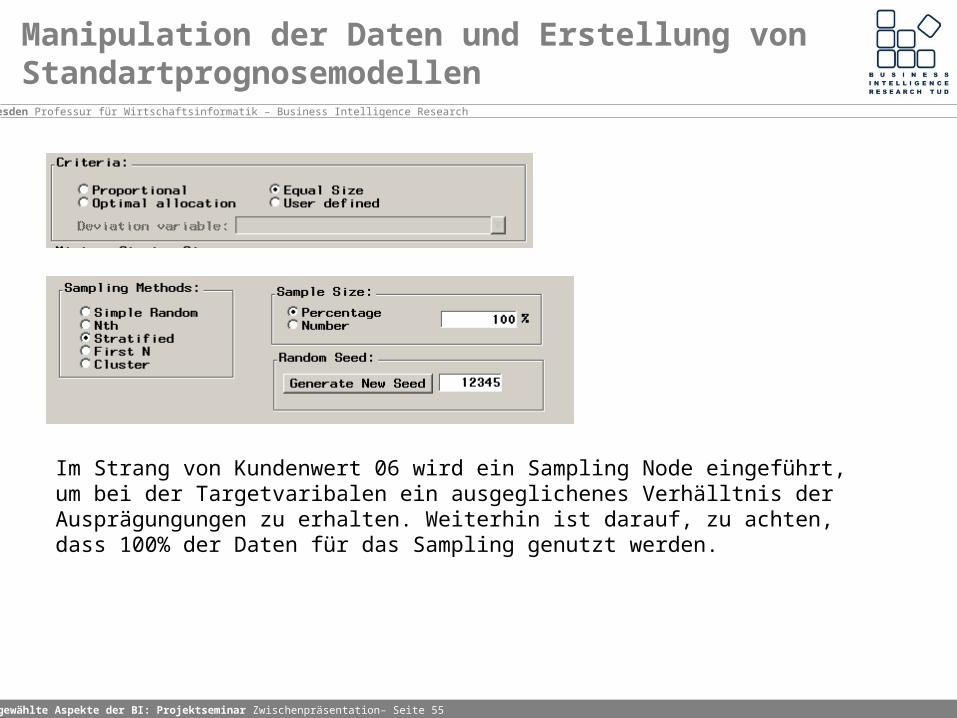
Manipulation der Daten und Erstellung von Standartprognosemodellen
Für jedes Prognosemodell je 2 "Data Set Attributes Nodes" erstellen und die für die für das jeweilige Modell interresannte Varibale als Target definieren. Pro Modell ist ein Data Set Attributes Node mit dem Kundenwert 06 bzw 12 verbunden. Weiterhin wird die Variabale Umsatz ausgeschlossen, da sie indirekt durch den Kundenwert repräsentiert wird.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 55
Manipulation der Daten und Erstellung von Standartprognosemodellen
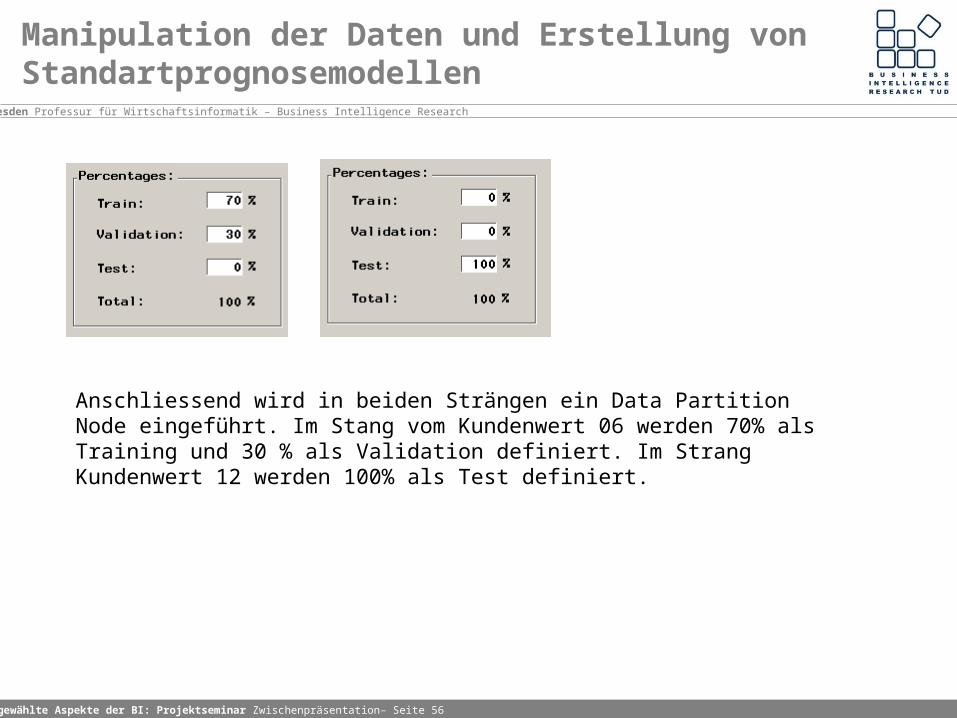
Im Strang von Kundenwert 06 wird ein Sampling Node eingeführt, um bei der Targetvaribalen ein ausgeglichenes Verhälltnis der Ausprägungungen zu erhalten. Weiterhin ist darauf, zu achten, dass 100% der Daten für das Sampling genutzt werden.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 56
Manipulation der Daten und Erstellung von Standartprognosemodellen
Anschliessend wird in beiden Strängen ein Data Partition Node eingeführt. Im Stang vom Kundenwert 06 werden 70% als Training und 30 % als Validation definiert. Im Strang Kundenwert 12 werden 100% als Test definiert.

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 57
Manipulation der Daten und Erstellung von Standartprognosemodellen
Nun werden für jedes Prognosemodell jeweils ein Regression Node, ein Tree Node und ein Neuronal Network Node erstellt. Diese sind mit den Data Partition Nodes aus den 2 Strängen zu verbinden. Wichtig ist, dass der Input der Daten für Training und Validation aus dem Strang Kundenwert 06 und der Input der Daten für den Test aus dem Strang Kundenwert 12 kommt. Im Model Manager werden Die Checkboxen Train, Validation und Test aktiviert, sowie Entire data set bei dem Score Data Set.
Abschliessend werden alle 3 Modelle für jedes Prognosemodell in einem Assesment Node zusammengefasst.

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 58
Zwischenergebnis

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 59
Zwischenergebnis
Für jedes Produkt ist nun eine Vorkonfigurierte Strucktur vorhanden. Diese beinhalten Trainings und Validierungsdaten vom Monat Juni, als noch keine Kampagne begonnen hat und Testdaten aus dem Monat Dezember, als die Kampagnen schon abgeschlossen waren. Durch das Aufbereiten der Test und Validierungsdaten können Modelle mit hoher Güte erstellt werden und durch die getrennte Betrachtung der Trainingsdaten auch mit der Realität verglichen werden. Zur Orientierung stehen vorerst die Standartversionen der drei Grundmodelle zur Verfügung, welche im Assessment Node verglichen werden können. Anhand der Vergleichswerte können Rückschlüsse gezogen werden, welches Modell ein guter Ausgangspunkt für Optimierungen ist. Durch die zusätzlichen Aktivierungen im Modelmanger ist es ausserdem Möglich gezielt auf den Fehler zweiter Art bei den jeweiligen Modellen einzugehen und ihn zu minimieren.

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation…Data UnderstandingData PreperationModeling
AssoziationsanalyseClusteranalysePrognosemodelle
GiroKreditRiesterZinsDepot
…

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 61
Giro
Die Misclassifikation Rates im Testdatensatz stellen sich wie folgt zusammen:
• Neuronal Network: 0.2329926461
• Tree: 0.2807847915
• Regression: 0.2863756762
Auf dem ersten Blick ist das Neuronale Netz klar besser als die beiden
Alternativen. Beim Versuch dieses Netz weiter zu optimieren wurden jedoch nu
rminimale Erfolge erzielt (auf 0.2330764674). Durch des gringe
Optimierungspotenzial wurde der Entscheigungsbaum wieder interresant. Mit
dem Entscheidugsbaum konnten signifikant bessere Ergebnisse erzielt werden,
welche nun Vergleichbar sind mit denen des Neuronalen Netzes (0.2478094685).
Ein großer Kritikpunkt ist jedoch der Fehler zweiter Art. Dieser liegt bei 32,11%.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 62
Giro II
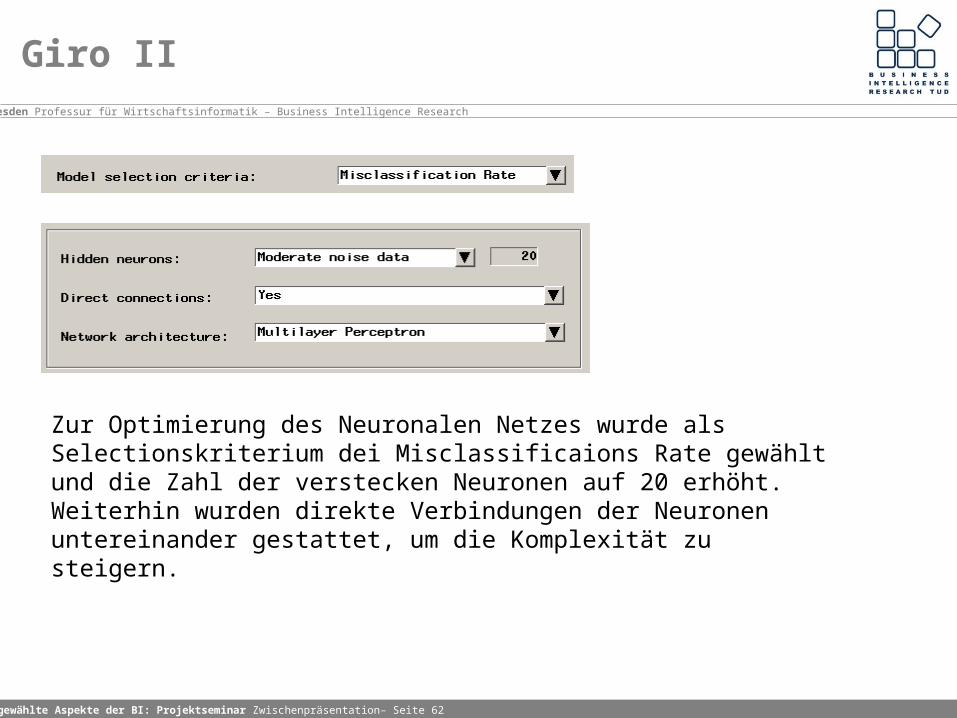
Zur Optimierung des Neuronalen Netzes wurde als Selectionskriterium dei Misclassificaions Rate gewählt und die Zahl der verstecken Neuronen auf 20 erhöht. Weiterhin wurden direkte Verbindungen der Neuronen untereinander gestattet, um die Komplexität zu steigern.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 63
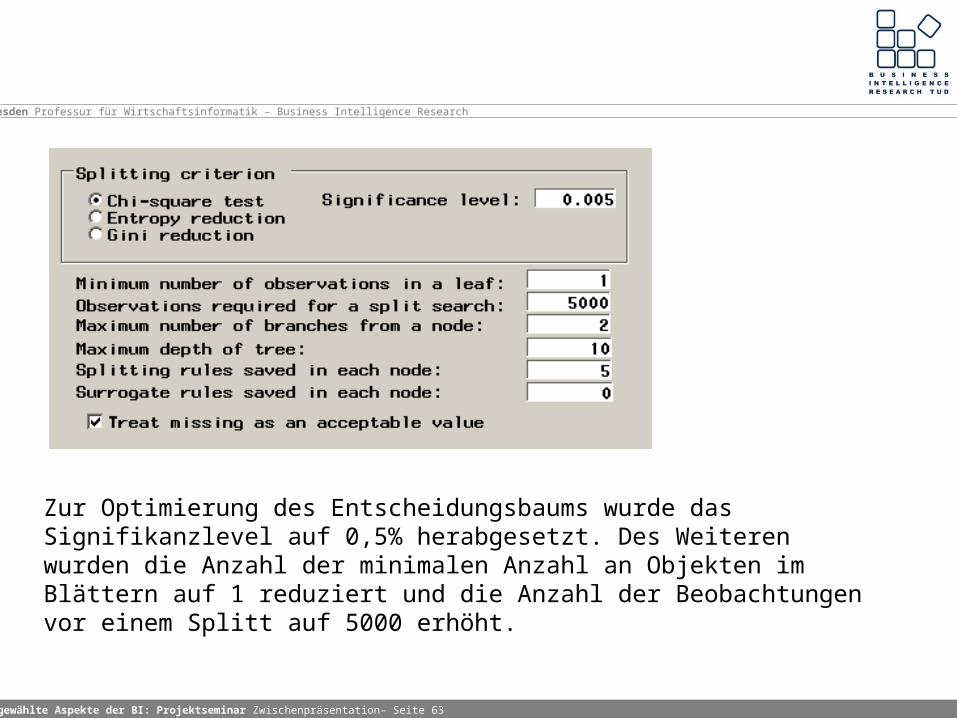
Zur Optimierung des Entscheidungsbaums wurde das Signifikanzlevel auf 0,5% herabgesetzt. Des Weiteren wurden die Anzahl der minimalen Anzahl an Objekten im Blättern auf 1 reduziert und die Anzahl der Beobachtungen vor einem Splitt auf 5000 erhöht.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 64
Giro IV

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 65
Fazit
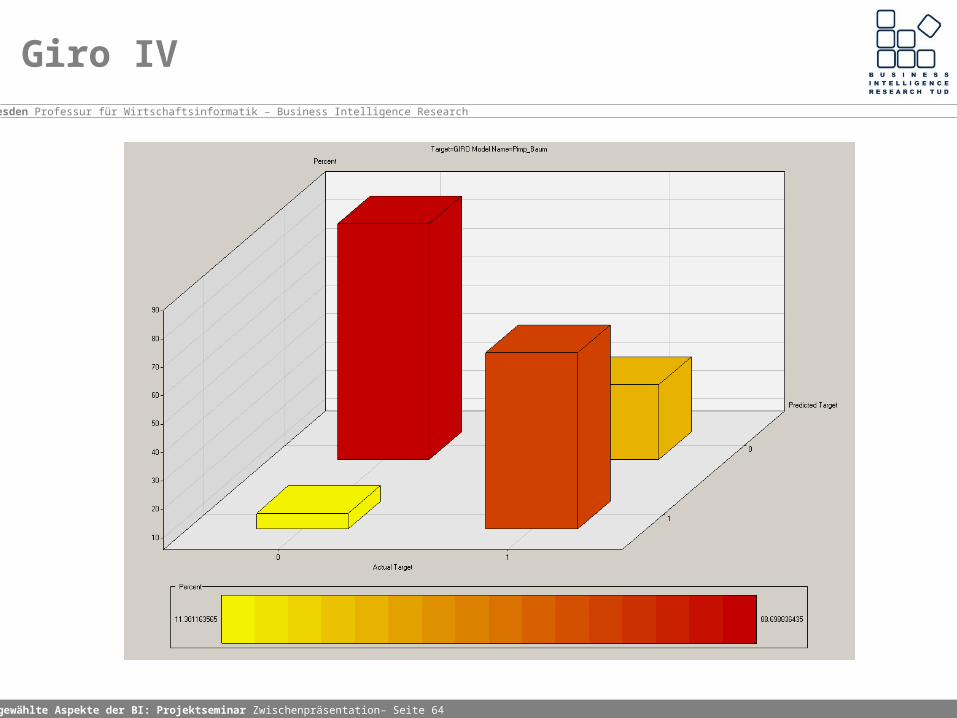
Die Test Misclassifikation Rate beläuft sich auf nun auf 0.2478094685. Der Fehler zeiter Art beträgt nur 32,11%. Das Model ist somit nicht besonders geeignet, um den Absatz von Giro zu optimieren, da viele potenzielle Kunden als nicht interessiert eingeordnet werden.
Handlungsmöglichkeiten: Den Umsatz wieder als Variable einschliessen. Damit lassen sich nahezu perfekte Modelle erstellen, allerdings mit der Gefahr einzelne Informationen überzubewerten und das Problem des Overfitting zu provozieren. Das Modell muss in einer Kosten-Nutzen Rechnung zeigen, ob es trotzdem lukrativ sein kann auf ca. 1/3 der potenziell interresierten Kunden verzichten zu können.

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation…Data UnderstandingData PreperationModeling
AssoziationsanalyseClusteranalysePrognosemodelle
GiroKreditRiesterZinsDepot
…

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 67
Kredit
Die Misclassifikation Rates im Testdatensatz stellen sich wie folgt zusammen:
•Neuronal Network: 0.0102094416
•Tree: 0.0173873441
•Regression: 0.0132717153
Alle Modelle liegen hier sehr nah bei einander und das auf hohen Niveau. Aus
vielfachgenannten Gründen wird der Entscheidungsbaum bevorzugt. Dieser soll
nun noch optimiert werden.
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 68
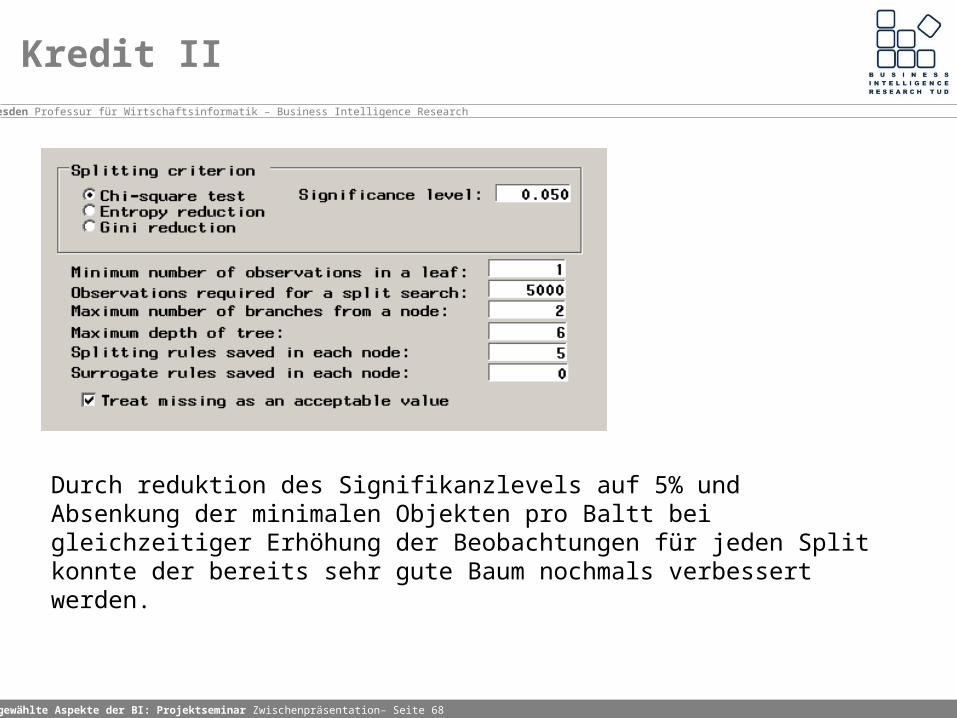
Kredit II
Durch reduktion des Signifikanzlevels auf 5% und Absenkung der minimalen Objekten pro Baltt bei gleichzeitiger Erhöhung der Beobachtungen für jeden Split konnte der bereits sehr gute Baum nochmals verbessert werden.

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 69
Kredit III

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 70
Fazit
Die Misclassifikationrate der Testdaten konnte auf 0.005364567
verbessert werden bei einem Fehler zweiter Art von nur 2,5%.
Damit liefert das Modell einen sehr guten Ansatz zur Prognose
von Krediten.
Handlungsmöglichkeiten: Im Zusammenhang mit der
Kreditwürdigkeit lassen sich nicht nur genaue sondern auch
relativ sichere Prognosen machen zur vergabe von Krediten.

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation…Data UnderstandingData PreperationModeling
AssoziationsanalyseClusteranalysePrognosemodelle
GiroKreditRiesterZinsDepot
…
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 72
Riester
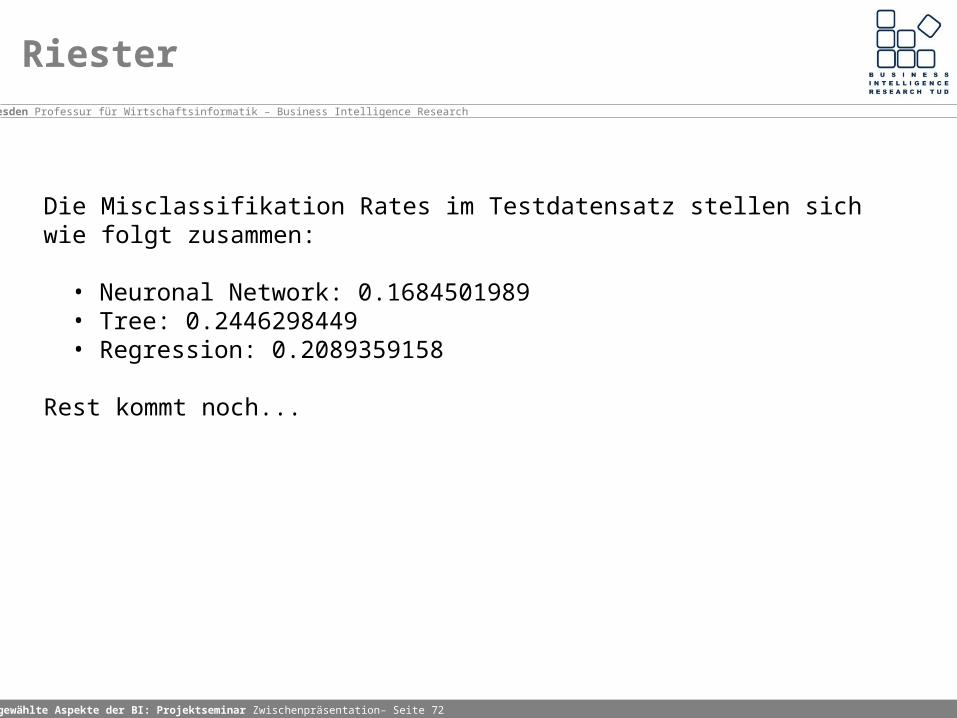
Die Misclassifikation Rates im Testdatensatz stellen sich wie folgt zusammen:
• Neuronal Network: 0.1684501989 • Tree: 0.2446298449 • Regression: 0.2089359158
Rest kommt noch...

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation…Data UnderstandingData PreperationModeling
AssoziationsanalyseClusteranalysePrognosemodelle
GiroKreditRiesterZinsDepot
…

TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 74
Zins
Die Misclassifikation Rates im Testdatensatz stellen sich wie folgt zusammen:
• Neuronal Network: 0.1569052036 • Tree: 0.1872764764 • Regression: 0.1576372435

Fakultät Wirtschaftswissenschaften Professur für Wirtschaftsinformatik – Business Intelligence Research
Endpräsentation…Data UnderstandingData PreperationModeling
AssoziationsanalyseClusteranalysePrognosemodelle
GiroKreditRiesterZinsDepot
…
TU Dresden Professur für Wirtschaftsinformatik – Business Intelligence Research
Ausgewählte Aspekte der BI: Projektseminar Zwischenpräsentation– Seite 76
Depot
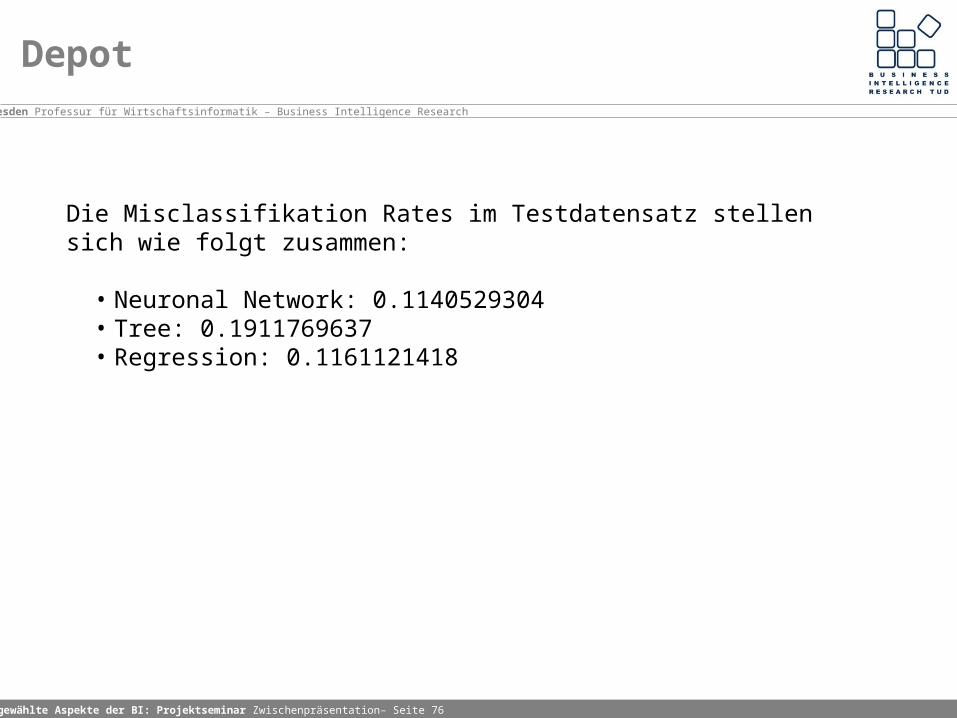
Die Misclassifikation Rates im Testdatensatz stellen sich wie folgt zusammen:
• Neuronal Network: 0.1140529304 • Tree: 0.1911769637 • Regression: 0.1161121418


















