
Descrever Voz em Sinais de Música
54
Descrever Voz em Sinais de Música Pedro Luís Allegro Faculdade de Engenharia da Universidade do Porto Departamento de Engenharia Electrotécnica e de Computadores Rua Roberto Frias, s/n, 4200-465 Porto, Portugal Fevereiro de 2008
Transcript of Descrever Voz em Sinais de Música

Descrever Voz em Sinais de Música
Pedro Luís Allegro
Faculdade de Engenharia da Universidade do Porto
Departamento de Engenharia Electrotécnica e de Computadores
Rua Roberto Frias, s/n, 4200-465 Porto, Portugal
Fevereiro de 2008


Descrever Voz em Sinais de Música
Pedro Luís Allegro
Aluno de Engenharia Electrotécnica e de Computadores pela Faculdade de Engenharia da Universidade do Porto
Trabalho realizado no âmbito da disciplina de Preparação da Dissertação,
do 1º semestre, do 5º ano, do Mestrado Integrado em Eng. Electrotécnica e
de Computadores da Faculdade de Engenharia da Universidade do Porto,
leccionada por José António Ruela com a orientação de Fabien Gouyon.
Faculdade de Engenharia da Universidade do Porto
Departamento de Engenharia Electrotécnica e de Computadores
Rua Roberto Frias, s/n, 4200-465 Porto, Portugal
Janeiro 2008

Resumo
Este relatório aborda interessantes perspectivas e técnicas de análise de sinais de música.
Este campo tem conhecido um enorme crescimento pois a musica cada vez mais faz parte do dia a
dia de muitas pessoas. Com o desenvolvimento das tecnologias como leitores portáteis de música e
aumento de tráfego da Internet, a musica ganhou um lugar de destaque pois torna-se fácil ouvir as
musicas que mais desejamos. Com o crescente interesse da população em aplicações de música,
cresceu também a necessidade de inovação. O objectivo deste campo de estudo será fornecer aos
utilizadores o máximo de informação sobre cada música podendo ser usada em seu benefício.
Neste relatório serão explicadas técnicas de análise de voz em músicas. A preponderância da voz
em músicas é sobejamente conhecida pois a voz é um instrumento extremamente versátil que pode
acompanhar qualquer registo musical. Torna-se por isso crítico que se criem técnicas robustas de
análise desta componente vocal tão importante na música.
A separação de sons para os humanos é fácil e simples mas para uma máquina esse processo não é
linear. Será interessante criar esta ponte aproximando estas duas realidades.

Abstract
This report focuses on some interesting perspectives and analysis techniques used on music signals.
This field has grown enormously in past few years due to the role that music plays in the daily life
of so many people. With the development of technologies such as portable music players and the
increase of internet transfer data rates, music has know a popularity increase because it becomes
easier to listen to the songs we like the most. With the increasing interest of general population in
music applications came the need for innovation on this field. The objective of this field is to supply
the users with the maximum information possible about each song so they can benefit from it. In
this report some voice analisys techniques in music will be explained.
The importance of voice in music is very well known because it is a very flexible instrument that
can accompain any type of music. Thus it becomes critical that several robust analisys technique are
created to wthdraw information about this important component of music.
The separation of sounds comes easy for humans but for a machine its by no means a simple task. It
would be interesting to bring these two realities closer together.

Índice
1. Introdução 1
1.1 Enquadramento.................................................................................................................... 1
1.2 Objectivos............................................................................................................................ 3
1.3 Estrutura do Relatório.......................................................................................................... 4
2. Análise de voz em sinais de música 5
2.1 Separação de voz dos sinais de música ............................................................................... 5
2.1.1 Processamento de sinal de entrada................................................................................ 6
2.1.2 Extracção de características .......................................................................................... 8
2.1.3 Classificação ............................................................................................................... 13
2.1.4 Outros métodos ........................................................................................................... 24
2.2 Analise de sinais de voz .................................................................................................... 30
2.2.1 Identificação do cantor................................................................................................ 30
2.2.2 Identificação de mudanças de orador.......................................................................... 32
2.2.3 Sistema de procura de timbres de voz similares ......................................................... 34
2.2.4 Aglomeração de músicas segundo o seu cantor.......................................................... 35
3. Implementações previstas 37
4. Planificação do trabalho de dissertação 40
5. Conclusões 42

LISTA DE FIGURAS VII
Lista de Figuras
FIGURA 1:ESTRUTURA SINGULAR DA SEPARAÇÃO DOS SINAIS DE VOZ............................................. 6
FIGURA 2:ESTRUTURA TRIPLA DA SEPARAÇÃO DOS SINAIS DE VOZ.................................................. 6
FIGURA 3:EXEMPLO DE UM FILTRO CHEBYCHEV .............................................................................. 7
FIGURA 4:DISTRIBUIÇÃO DE 2 COEFICIENTES MFCC PARA 3 INSTRUMENTOS ............................... 14
FIGURA 5: REPRESENTAÇÃO TRIDIMENSIONAL DE 2 MFCC PARA 3 INSTRUMENTOS .................... 15
FIGURA 6: ESQUEMA DE UM MODELO HMM................................................................................... 16
FIGURA 7: EXEMPLO 2-D DO ALGORITMO DE DECISÃO SVM ......................................................... 17
FIGURA 8:EXEMPLO DE UMA REDE NEURONAL .............................................................................. 18
FIGURA 9: PROBABILIDADE DE TRANSIÇÃO DE NOTA ..................................................................... 20
FIGURA 10:MODELOS DO CLASSIFICADOR HMM ........................................................................... 23
FIGURA 11:ESQUEMA FUNCIONAL DO MÉTODO DE CORTES NORMALIZADOS ................................ 24
FIGURA 12:MATRIZ HWPS PARA DUAS FONTES HARMÓNICAS ...................................................... 27
FIGURA 13:ESQUEMA DO SEPARADOR DE VOZ EM MÚSICAS ........................................................... 28
FIGURA 14:PLANO DE TRABALHOS DE SEPARAÇÃO DE VOZ............................................................ 41
FIGURA 15:PLANO DE TRABALHOS DA ANÁLISE DE VOZ................................................................. 41

LISTA DE TABELAS VIII
Lista de Tabelas
TABELA 1:SECÇÕES DE MÚSICAS..................................................................................................... 22
TABELA 2:RESUMO DE IMPLEMENTAÇÕES PREVISTAS PARA SEPARAÇÃO DE VOZ ......................... 39

GLOSSÁRIO IX
Glossário
Query by humming – É um sistema que aceita um input (uma query) e compara-a com um base de
dados existente. O sistema em resposta fornece uma lista classificada de músicas semelhantes à
requerida (input). Um exemplo deste sistema é o Pandora da Music Genome Project.
STFTs – Short Time Fourier Transform calcula uma distribuição de um sinal de entrada como uma
sequência de espectros de segmentos do sinal. A função retorna um gráfico tempo (xx) -frequência
(yy) com a amplitude a ser representada nos eixos dos zz.
PLP – Perceptual linear predictive coding é uma técnica de análise de voz que utiliza 3 conceitos da
psicoacustica para derivar uma estimativa do espectro auditivo:
• Resolução espectral da banda crítica
• Curva de intensidade semelhante
• Lei do poder da intensidade
Depois de processadas estas análises o resultado é aproximado por um método de auto regressão
criando o modelo dos pólos.
LPC – Linear Predictive Coding é uma ferramenta muito utilizada em processamento de áudio que
representa o envelope espectral numa forma comprimida (coeficientes) usando informação do
modelo de predição linear.
MFCC – Mel-Frequency Cepstral Coefficients são coeficientes que são derivados dum tipo de
representação cepstral do sinal de áudio. As bandas de frequência são posicionadas na escala loga-
rítmica para melhor se aproximarem do sistema auditivo humano permitindo assim um melhor pro-
cessamento de informação.
MIDI - Musical Instrument Digital Interface é uma tecnologia padronizada de comunicação de ins-
trumentos musicais e equipamentos electrónicos possibilitando que uma composição musical seja
executada, transmitida ou manipulada por qualquer dispositivo que reconheça esse padrão
LSP – Line Spectral Pairs representam os coeficientes LPC e possuem propriedades que os torna
superiores à quantização directa destes.

GLOSSÁRIO X
DFT – Discrete Fourier Transform, transforma uma função (que é normalmente no domínio do
tempo) para uma função no domínio das frequências.

Capítulo 1
1. Introdução
1.1 Enquadramento
O trabalho descrito neste relatório insere-se na área de MIR (Music information retrieval).
MIR é a ciência interdisciplinar de retirar informação de músicas. É talvez um conceito ainda pouco
conhecido devido à sua relativamente recente criação, apesar deste facto tem conhecido um grande
crescimento nos últimos tempos principalmente devido às suas potencialidades em aplicações aca-
démicas, industriais e de entretenimento. Ao grande crescimento testemunhado nesta área não será
alheio o facto de todos os seus membros trocarem informações criando um sistema de entreajuda
em que todos saem beneficiados.
Muitas áreas da MIR estão já bastante desenvolvidas, contudo a que será aqui estudada carece de
análises verdadeiramente eficientes.
A área alvo deste relatório é a extracção de informação de voz presente em músicas. A voz como
componente importante de músicas pode ajudar a fornecer informações sobre a mesma.
A música está de facto a tornar-se um dos tipos de dados mais importantes da Internet, mas não é
apenas nesta área que a musica é relevante, em muitos sistemas multimédia esta ganha preponde-
rância crescente.
Apesar destas necessidades as técnicas de análise de voz permanecem pouco desenvolvidas não
ajudando como poderiam ao desenvolvimento da MIR.
Certo tipo de análises beneficiariam bastante com a correcta segmentação de voz nas músicas, são
exemplos delas:
• Identificação do cantor
• Identificação de múltiplos cantores
• Transcrição da melodia vocal

CAPÍTULO 1: INTRODUÇÃO 2
• “Query by humming”
• Transcrição de letras
• Reconhecimento automático de letras e seu alinhamento (ex. Karaoke)
• Qualidade do cantor
• Selecção ou passagem automática para segmentos diferentes das musicas duma aplicação de
som
• Estilo musical
• Identificação do idioma
Como esta área de análise de voz da MIR está ainda em recente desenvolvimento, as técnicas exis-
tentes ainda não são muito robustas. Existem vários tipos de técnicas de análise.
Existem análises que dependem de informação inerente à música que lhes tem que ser fornecida,
como por exemplo:
• Género musical (música popular, rock, jazz, etc.)
• Sexo do cantor
• Número de cantores
Este tipo de análises devido à sua especificidade e conhecimento das músicas a analisar podem de
facto revelar-se ferramentas poderosas de extracção de voz. Contudo a sua fraqueza reside na
dependência de informação para poder funcionar correctamente. Se a informação for processada
pelo próprio algoritmo aumenta a complexidade e tempo de resposta do mesmo, se não o fizer con-
diciona o input pois este tem de conter informações específicas (requeridas pelo algoritmo) sobre a
música a analisar.
Alguns tipos de análises são bastante eficientes mas têm um tempo de resposta demasiado elevado
para análises em tempo real devido à carga computacional exigida.
A maioria dos métodos de análise estudados não estão preparados para identificação de múltiplos
cantores, o que pode induzir em erro o algoritmo.
Um problema comum é o do acompanhamento musical. De facto alguns géneros musicais possuem
um acompanhamento instrumental muito diversificado e/ou forte que dificulta a identificação da
voz.
Outro problema comum para todos os métodos será certamente a presença de ruído excessivo no
sinal de entrado. Contudo algumas análises lidam melhor com este problema do que outras pois
conseguem distinguir o que é essencial do que é ruído.

CAPÍTULO 1: INTRODUÇÃO 3
1.2 Objectivos
O objectivo deste projecto é criar módulos de software que identifiquem e analisem automaticamen-
te voz em músicas polifonicas.
Os módulos de software a ser criados serão integrados no software opensource MARSYAS. O seu
nome vem de “Musical Analysis, Retrieval and Synthesis for Áudio Signals” e é um software open-
source para criação de protótipos com o objectivo de se poderem fazer experimentações fáceis com
análise e síntese de sinais áudio. Já existem diversos blocos que simulam a maioria dos algoritmos
já publicados na área de computação de áudio. Os módulos a implementar serão programados na
linguagem C++.
Para ser possível identificar e analisar músicas é necessário criar técnicas robustas de processamen-
to de sinais de voz. Algumas técnicas candidatas serão descritas numa fase posterior deste relatório.
Quando escolhidas as técnicas estas terão de ser testadas para se avaliar o seu rendimento. Uma boa
escolha para testar a eficácia destas técnicas é a ferramenta MATLAB que é muito forte em proces-
samento de sinais.
Finalmente será necessário que o sistema funcione duma maneira automática. Para tal é necessário
que o programa aprenda a funcionar e mais importante a tomar decisões por ele. Para este efeito
utiliza-se o conceito de machine learning. Este sistema é um sub-campo da inteligência artificial
dedicado ao desenvolvimento de algoritmos e técnicas que permitam ao computador aprender, isto
é, que permitam ao computador aperfeiçoar seu desempenho em alguma tarefa pois está constante-
mente a aperfeiçoar-se automaticamente.
Para a implementação de machine learning será usado o software WEKA.
WEKA é um software opensource de machine learning escrito em Java que provém de “Waikato
Environment for Knowledge Analysis”. Contém uma colecção de algoritmos de machine learning
para manipulação de dados.
O objectivo específico deste relatório consiste no estudo de métodos utilizados para a extracção de
informação de voz em sinais de músicas.

CAPÍTULO 1: INTRODUÇÃO 4
1.3 Estrutura do Relatório
Este trabalho encontra-se estruturado em 5 capítulos dos quais, o primeiro é composto por esta
introdução ao trabalho.
O segundo capítulo está dividido em 2 secções. A primeira secção explica como pode ser realizada
a separação de voz em sinais de música. A segunda secção apresenta algumas técnicas de análise de
sinais de voz.
No terceiro capítulo são apresentados os métodos que serão alvo de estudo aprofundado durante a
dissertação.
No quarto capítulo é apresentado o plano de trabalhos da dissertação.
No quinto e último capítulo estão presentes as conclusões.

Capítulo 2
2. Análise de voz em sinais de música
Os temas abordados em seguida debruçam-se mais sobre como melhor preparar os sinais de música
para a análise de voz posterior. Alguns destes métodos de análise dos sinais de voz serão explicados
posteriormente como por exemplo identificação do cantor ou detecção de mudança de cantor. Para
se fazer estas análises com sucesso, é necessário identificar a parte vocal da música para a voz não
ser confundida com outros sons. Como uma boa separação do sinal de voz é essencial torna-se obri-
gatório encontrar um método robusto. Alguns dos métodos apresentados em seguida podem conter a
solução para este problema.
2.1 Separação de voz dos sinais de música
Esta secção separa nos sinais de música as secções que contêm voz das que não contêm voz. As
secções que contêm voz poderão conter instrumentos e as secções de não-voz contêm instrumentos
e pausas.
A separação pode ser atingida utilizando métodos bastante distintos. Em seguida será explicado
cada um deles mais pormenorizadamente.
A maioria dos investigadores utilizam estruturas aproximadas nomeadamente com módulos de
extracção de características (com respectivo processamento de sinal) e de classificação. Os módulos
de extracção de características e de classificação estão interligados pois a classificação baseia-se nas
características extraídas para tomar decisões.
Outros investigadores optam por realizar apenas algoritmos de processamento de sinal evidenciando
zonas de voz em detrimento das zonas de música.
Resumindo, os métodos investigados utilizam uma das duas estruturas:
1) Processamento de sinal

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 6
Figura 1:Estrutura singular da separação dos sinais de voz
2) Processamento de sinal – Extracção de características – Classificação
Figura 2:Estrutura tripla da separação dos sinais de voz
2.1.1 Processamento de sinal de entrada
O objectivo desta secção pode ser de isolar a voz e sinais de música como produto final ou então de
realçar certos aspectos do sinal de entrada fornecendo o resultado do processo à secção de extracção
de características que poderá desta maneira realizar o seu papel com maior rendimento.
Primeiro serão explicados 2 métodos que utilizam apenas processamento de sinal como identifica-
dor de voz em músicas. Os métodos que utilizam processamento do sinal de entrada como auxilia-
dor da secção de extracção de características serão explicados na respectiva secção da extracção de
características.
2.1.1.1 Filtro Chebychev e Inverse Comb Filter
Em [2] o autor utiliza primeiro um filtro chebychev seguido de outro inverse comb filterbank.
Como o objectivo é detectar regiões de voz, um bom método será identificar energia presente na
gama de frequências onde a voz se espalha. Deste modo a voz pode passar enquanto que sons que
caiam noutras zonas são atenuados. Para este efeito usou-se um filtro Chebychev (IIR) de ordem 12.
Estes filtros possuem uma banda de passagem e uma banda de atenuação. Têm a característica de
minimizarem o erro entre as características do filtro idealizado e o actual apesar de possuir ripples
na banda de passagem. Um exemplo destes filtros pode ser visto na figura seguinte.
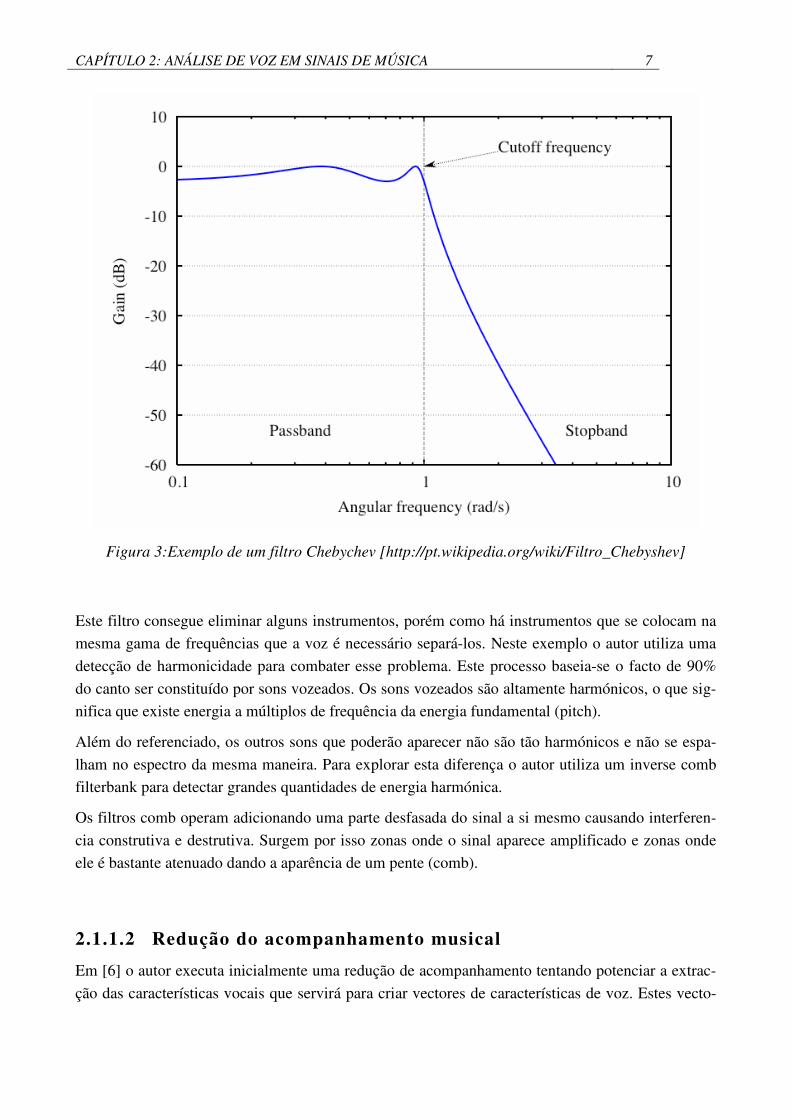
CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 7
Figura 3:Exemplo de um filtro Chebychev [http://pt.wikipedia.org/wiki/Filtro_Chebyshev]
Este filtro consegue eliminar alguns instrumentos, porém como há instrumentos que se colocam na
mesma gama de frequências que a voz é necessário separá-los. Neste exemplo o autor utiliza uma
detecção de harmonicidade para combater esse problema. Este processo baseia-se o facto de 90%
do canto ser constituído por sons vozeados. Os sons vozeados são altamente harmónicos, o que sig-
nifica que existe energia a múltiplos de frequência da energia fundamental (pitch).
Além do referenciado, os outros sons que poderão aparecer não são tão harmónicos e não se espa-
lham no espectro da mesma maneira. Para explorar esta diferença o autor utiliza um inverse comb
filterbank para detectar grandes quantidades de energia harmónica.
Os filtros comb operam adicionando uma parte desfasada do sinal a si mesmo causando interferen-
cia construtiva e destrutiva. Surgem por isso zonas onde o sinal aparece amplificado e zonas onde
ele é bastante atenuado dando a aparência de um pente (comb).
2.1.1.2 Redução do acompanhamento musical
Em [6] o autor executa inicialmente uma redução de acompanhamento tentando potenciar a extrac-
ção das características vocais que servirá para criar vectores de características de voz. Estes vecto-

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 8
res servirão para comparação com uma base de dados identificando assim cantores com as mesmas
características vocais.
Este método reduz influências negativas de acompanhamentos musicais. Ressíntetizando o sinal de
voz considerando a sua estrutura harmónica.
Este método consiste em 3 etapas:
1) Estimar a frequência fundamental da melodia vocal usando Goto´s PreFEst.
2) Extrair a estrutura harmónica correspondente da melodia.
3) Ressíntetizar o sinal de áudio correspondente à melodia usando síntese sinusoidal.
PreFEst estima a F0 mais predominante dentro duma gama de frequências limitada já que se sabe
que a melodia tem as estruturas harmónicas predominantes nas médias e altas-frequências.
Usando a F0 estimada pode-se extrair a amplitude dos componentes da frequência fundamental e
dos componentes harmónicos. Para cada componente permite-se uma margem de erro e extrai-se o
máximo local de amplitude.
Por fim utiliza-se um modelo sinusoidal para ressíntetizar o sinal de áudio da melodia usando as
estruturas harmónicas obtidas anteriormente. Variações na fase são aproximadas usando uma fun-
ção quadrática para que as frequências variem linearmente. Variações na amplitude também são
aproximadas usando uma função linear.
2.1.2 Extracção de características
A extracção de características tem por objectivo extrair informação dos sinais de música para forne-
cer dados para os classificadores processarem.
Para os dados serem correctamente extraídos é necessário preparar os sinais a serem analisados.
Esta preparação é feita de varias formas dependendo do método a aplicar.
Uma correcta extracção das características pretendidas é fundamental para o sucesso do método já
que são estas que traduzem a constituição do sinal de entrada.
Em seguida serão apresentadas algumas técnicas utilizadas para a extracção de características.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 9
2.1.2.1 Estimação dos múltiplos de frequência
Em [5] o autor baseia-se na estimação dos múltiplos de frequência fundamental (pitch). Este consi-
dera que uma melodia é uma sequência organizada e consecutiva de notas e pausas, onde uma nota
tem um pitch, um início e um fim.
Tendo em conta estas considerações, o papel do extractor de característica é fornecer dados que
permitam que a frequência fundamental (F0) e o início de uma nota sejam bem estimados.
Pode-se falar em 4 etapas para esta secção:
1) O sinal de entrada é passado inicialmente por um filtro de 70 canais.
2) Os sinais sub-banda são comprimidos, rectificados e filtrados com um filtro passa-baixo.
3) Na terceira etapa são calculadas as STFTs (Short Time Fourier Transforms) nas bandas e
são somados no espectro para análise posterior.
4) A 4ª etapa está dividida em dois processos:
• Estimação de F0
• Estimador de acentuação para inicio de notas
A secção de processamento estende-se até ao ponto número 3. A secção de extracção de caracterís-
ticas é a etapa numero 4.
As F0 são estimadas uma de cada vez por meio de filtros comb no domínio das frequências. O esti-
mador é usado para analisar o sinal áudio fazendo overlaping de frames em 92,9ms com 23,2ms de
intervalo entre inícios de frames sucessivos.
O estimador de acentuação junta quatro canais, soma os sinais e é decimado por 4.
Como já foi referido as informações retiradas nesta secção servirão de input para a secção seguinte
(classificação).
2.1.2.2 Posterior Probability Features
Em [9] o autor utiliza um modelo duma rede acústica treinada para descriminar entre classes fonéti-
cas de voz baseadas em inglês para criar um vector de PPFs (Posterior Probabitlity Features). Para
um discurso o posteriograma tem uma reacção por frame a cada som. Regiões que não são de dis-
curso normalmente mostram uma fraca reacção a vários fonemas ao mesmo tempo já que a correcta
classificação é incerta.
Nesta secção faz-se a modelização directa das características básicas das PPFs que servirão de
objecto de análise para a secção de classificação.
As características específicas investigadas foram:

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 10
1) Coeficientes PLP (Perceptual Linear Predictive) cepstrais de ordem 12 com deltas e duplos
deltas.
2) Vector Full log-PPF – É um vector de 54 dimensões para cada frame que contenham as pré-
não-linearidades da camada de output da rede neuronal que são aproximadamente os loga-
ritmos das probabilidades posteriores de cada classe fonética.
3) Semelhança dos logs – PPF nas classes de “canto” e “instrumentos”-É calculada a seme-
lhança do vector de 54 dimensões sobre a total covariância multidimensional gaussiana
derivada dos exemplos de treino de canto e instrumentos e usamos os logaritmos destas
semelhanças PPF para modelização subsequente.
4) Semelhança dos coeficientes cepstrais sobre 2 classes – Os coeficientes cepstrais de 39
dimensões são avaliados sobre modelos gaussianos singulares das 2 classes para produzir
vectores PPF.
5) Probabilidade logarítmica de fundo – A classe de fundo foi treinada para responder a não-
voz e já que o seu valor é 1-∑ (probabilidades de todas as classes de voz). Como tal é um
bom indicador da presença ou ausência de voz.
6) Entropia do classificador – É calculada a entropia por frame das probabilidades posteriores.
Este valor deve ser baixo quando o classificador está confiante que o som pertence a uma
determinada classe fonética.
7) Dinamismo – A média da soma quadrada da diferença entre PPFs adjacentes temporalmente.
Como a fala causa rápidas transições nas fonéticas posteriores, este valor será maior para
voz do que para outros sons.
2.1.2.3 HA-LFPC
A técnica apresentada em [12] baseia-se na observação de que músicas populares têm uma estrutura
definida por: intro, verso, chorus, bridge e outro. Diferentes secções mostram diferentes caracterís-
ticas por isso parece lógico que os modelos estatísticos de zonas vocais e não-vocais sejam consti-
tuídas sobre cada uma delas.
É implementado um MM-HMM (Multi Modal Hidden Markov Model) para desafiar as variações
intra e inter músicas. Este método é seguido duma técnica de bootstraping para aumentar o rendi-
mento.
Nesta secção em particular, o sinal de áudio é dividido em frames do tamanho de uma batida para
extrair informação na forma de detecção de nota quádrupla (musicas normalmente possuem 4 tem-
pos). Esta teoria suporta que dentro deste tempo a musica é quasi-estacionária pois as mudanças
ocorrem usualmente em tempos de batida.
Após a divisão, o sinal sofre uma atenuação harmónica. Este processo considera que cada música
tem uma nota principal. Usando esta informação pode-se atenuar apenas os padrões harmónicos que

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 11
originam das notas de pitch da nota principal. Para o efeito, utiliza-se um filtro triangular para ate-
nuar muito o sinal em zonas de frequências harmónicas regulares e pouco em zonas irregulares.
Quanto maior for o desvio, menos o sinal é atenuado. Após a atenuação, sinais não-vocais têm uma
energia inferior à dos sinais de voz.
Após a atenuação, cada frame é filtrado por um filtro passa-banda de 130Hz a 16KHz. Aqui termina
a secção de processamento de sinal na qual o sinal de entrada ficou preparado para ser analisado.
Em seguida são calculados os HA-LFPC (Harmonic Attenuated Log Frequency Power Coeffi-
cients), que indicam a distribuição de energia ao longo das sub-bandas. Conclui-se que os segmen-
tos vocais têm uma energia relativamente superior do que segmentos não-vocais.
A secção seguinte deste método é a da classificação que será explicada posteriormente.
Em [8] o autor sugere a análise de 13 características que podem revelar-se valiosas na distinção de
voz em sinais de música. Esta extracção de características não é precedida de segmentação e forne-
ce informação importante para os classificadores. As características fornecidas aos classificadores
são transformadas para a escala logarítmica pois permite uma melhor distribuição, ou seja, uma
análise mais fácil.
Das 13 características, 5 são de variância pois se um selector dá valores muito diferentes para dis-
curso vozeado e não-vozeado mas ser constante para instrumentos, o que é importante é a diferença
de voz para não-voz, ou seja a variância em vez do próprio selector.
2.1.2.4 Modulação de energia a 4Hz
A voz tem um pico de modulação de energia por volta dos 4Hz que tende a ser superior ao da músi-
ca. O autor utiliza uma porção do algoritmo MFCC para converter o sinal de áudio em 40 canais.
Extrai-se a energia em cada banda, filtra-se cada canal com um filtro de segunda ordem de frequên-
cia central de 4Hz e posteriormente é calculada a STE (Short Time Energy). A energia em cada
canal é normalizada e somada. Os resultados comprovam que a voz tende a possuir uma modulação
de energia superior a 4Hz.
2.1.2.5 Percentagem de frames de baixa energia
A distribuição de energia para voz tende mais para as baixas frequências do espectro (possui mais
“quiet frames”). A percentagem é calculada com a razão de frames com energia quadrada média
menor que 50% da energia quadrada média numa janela de 1 segundo.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 12
2.1.2.6 Ponto espectral de mudança
Distingue sons vozeados de sons não-vozeados. Sons não vozeados têm uma alta proporção de
energia contida nas altas-frequências ao contrário dos sons vozeados que estão localizados nas bai-
xas frequências. Além disso as frequências atingidas pela musica são mais altas do que as atingidas
pela voz.
2.1.2.7 Centróide espectral
O ponto de balanço da distribuição espectral de energia. Muitas músicas contem sons percussivos
que ao incluírem ruído de alta-frequência colocam a média espectral mais alta. Além do mais, as
energias de excitação podem ser superiores para musica do que para voz. Esta medida fornece ainda
diferentes resultados para sons vozeados e não-vozeados.
2.1.2.8 Fluxo espectral
A norma do vector da diferença da amplitude espectral entre frames consecutivos. A música tem um
ritmo de mudança de sons superior e sofre mais mudanças drásticas frame a frame em comparação
com a voz. O valor do fluxo espectral é superior para músicas do que para voz.
2.1.2.9 ZCR (Zero Crossing Rate)
O numero de vezes que o sinal cruza o eixo dos xx no domínio dos tempos para cada frame.
2.1.2.10 Magnitude residual da ressíntese cepstrum
A norma do vector residual depois da análise cepstral, suavização e ressíntese. Se se fizerem estas
operações obtêm-se melhores resultados para sons não-vozeados pois estes sons encaixam melhor
no filtro harmónico single source em comparação com a música.
2.1.2.11 Impulso métrico
Usa autocorrelação passa banda para determinar o grau de ritmo numa janela de 5 segundos. Con-
segue distinguir onde existe uma batida condutora forte no sinal. Este processo baseia-se na obser-
vação de que batidas fortes causam modulações rítmicas de grande largura de banda, ou seja, vêem-
se sempre as mesmas regularidades rítmicas. O algoritmo divide o sinal em 6 bandas diferentes e
encontra os picos nos envelopes em cada um deles seguido duma procura de modulação rítmica em
cada canal usando autocorrelação. Por fim basta comparar banda por banda e ver com que frequên-
cia se encontra o mesmo padrão de picos de autocorrelação.
As restantes 5 características para analise são as de variância que já foram mencionadas e são cons-
tituídas por:
• Variância: Ponto espectral de mudança.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 13
• Variância: Centróide espectral.
• Variância: Fluxo espectral.
• Variância: ZCR.
• Variância: Magnitude residual da ressíntese cepstrum.
2.1.3 Classificação
A classificação é a fase terminal de qualquer método. Nesta fase tomam-se decisões baseadas em
toda a informação analisada e processada em fases anteriores.
A classificação processa-se de maneira diferente para cada método pois depende do objectivo deste
e de todas as etapas que a antecederam. Pode-se dizer que a classificação adapta-se ao tipo de infor-
mações que a etapa de extracção de características lhe fornece.
Aqui abordaremos alguns processos de classificação tentando fazer uma ligação com as secções
mencionadas anteriormente.
2.1.3.1 GMM
Um Gaussian mixture model (GMM) é um modelo estocástico, que modela classes.
GMM utiliza múltiplos gaussianos para tentar capturar cada classe de treino. É um modelo muito
flexível que se pode adaptar a qualquer distribuição de informação. Os pontos de teste são classifi-
cados por meio duma função discriminadora de máxima verosimilhança calculada pelas distâncias
aos múltiplos gaussianos de cada classe.
O objecto de interesse de um modelo estocástico é o cálculo da chamada probabilidade a posteriori,
que pode ser calculada através da fórmula de Bayes.
Caso o elemento observado não corresponde a um único elemento, mas sim a uma sequência de
vectores, então, para uma sequência de T vectores, considerando a ocorrência de cada observação
como um evento independente, podemos construir uma regra de decisão para o problema através da
maximização da probabilidade a posteriori.
A decisão é feita, então baseada nas funções densidade de probabilidade (fdps) dos vectores. A
função da etapa da modelagem em um sistema é a de criar uma estimação a priori dessas fdps. Isso
é feito através de um algoritmo de re-estimação de parâmetros. De entre eles, o mais usado é o algo-
ritmo de Baum-Welch, também conhecido como Forward-Backward algorithm ou algoritmo de
avanço-retorno.
CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 14
Os modelos GMMs podem ser, então, definidos como na equação seguinte:
• Ci representa uma classe (Para um modelo com um total de M classes i = 1...M);
• o representa uma observação (vector observado);
• p(o| Ci) é a chamada probabilidade condicional;
• P(Ci) é a chamada probabilidade a priori.
A probabilidade condicional p(ot| Cj) é substituída por p(o| λj), onde λj é um modelo GMM para a
classe Cj e é, então escrita como uma mistura de gaussianas multivariadas, onde ci representa o
peso de cada gaussiana na mistura e N (ot ; µi ; Σi) representa uma gaussiana multivariada, com
vectores de médias e variâncias µi e Σi , respectivamente.
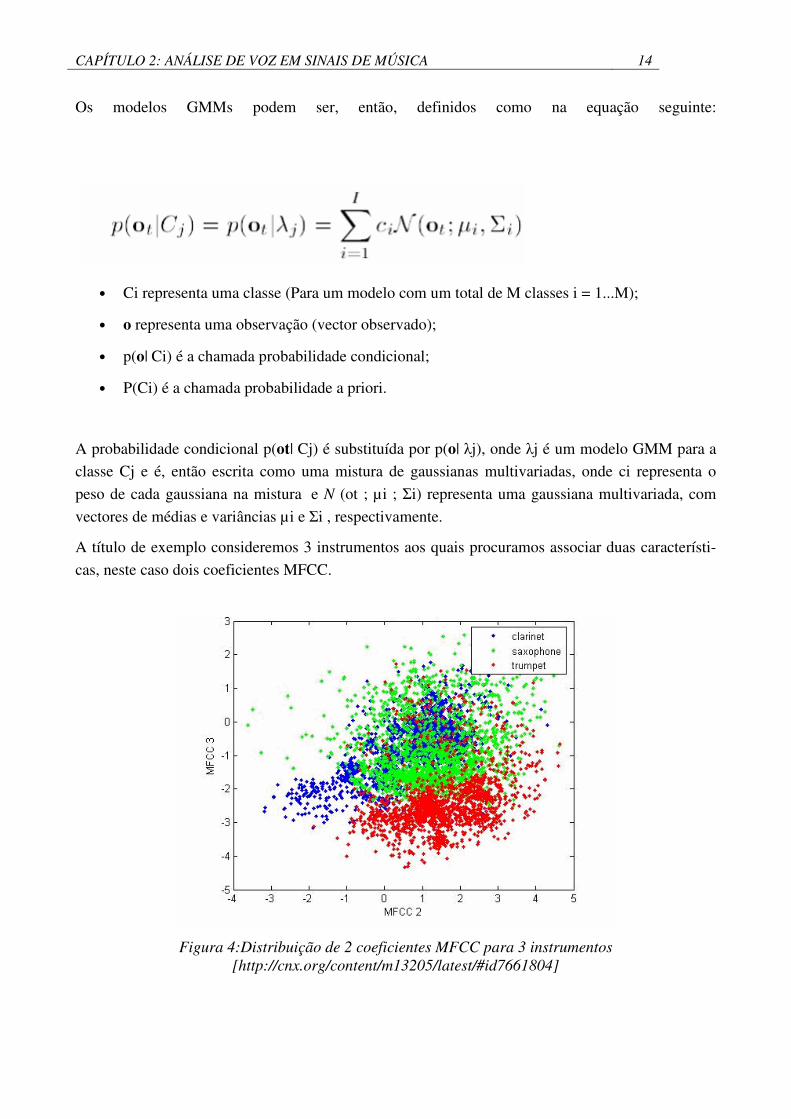
A título de exemplo consideremos 3 instrumentos aos quais procuramos associar duas característi-
cas, neste caso dois coeficientes MFCC.
Figura 4:Distribuição de 2 coeficientes MFCC para 3 instrumentos [http://cnx.org/content/m13205/latest/#id7661804]
CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 15
Como se pode observar pela Figura 4:Distribuição de 2 coeficientes MFCC para 3 instrumentos
[http://cnx.org/content/m13205/latest/#id7661804],existem diferenças de características em cada
instrumento.
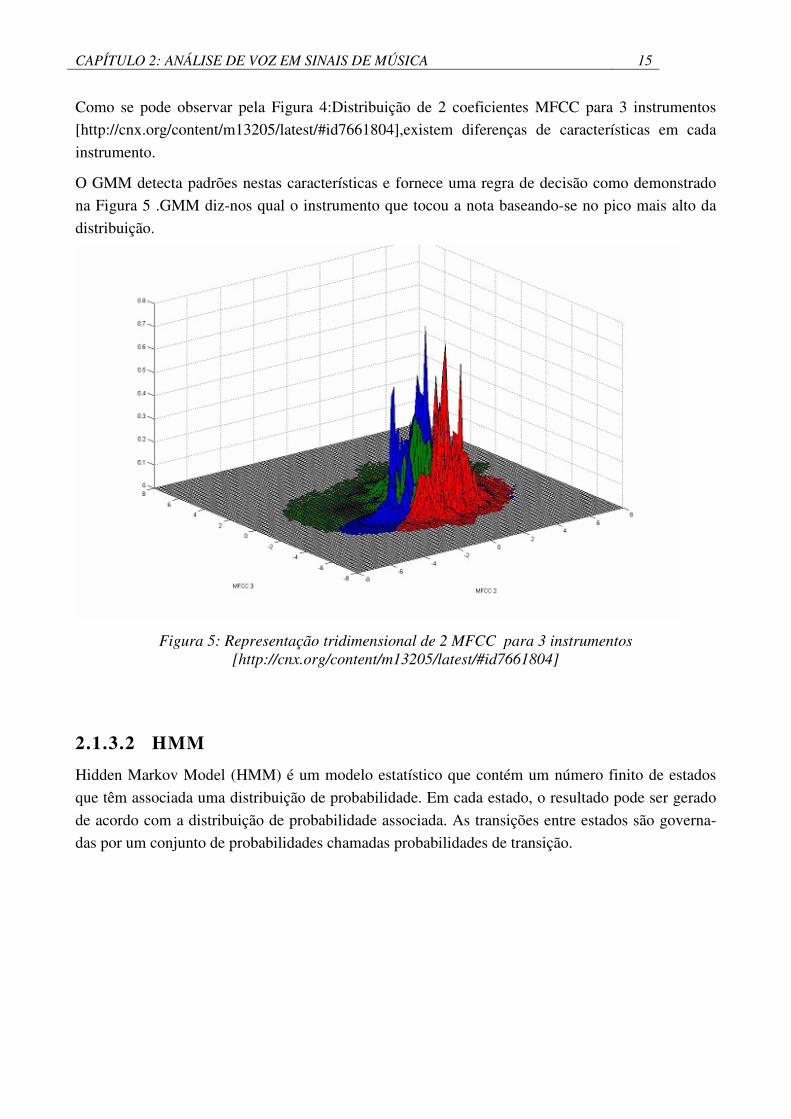
O GMM detecta padrões nestas características e fornece uma regra de decisão como demonstrado
na Figura 5 .GMM diz-nos qual o instrumento que tocou a nota baseando-se no pico mais alto da
distribuição.
Figura 5: Representação tridimensional de 2 MFCC para 3 instrumentos [http://cnx.org/content/m13205/latest/#id7661804]
2.1.3.2 HMM
Hidden Markov Model (HMM) é um modelo estatístico que contém um número finito de estados
que têm associada uma distribuição de probabilidade. Em cada estado, o resultado pode ser gerado
de acordo com a distribuição de probabilidade associada. As transições entre estados são governa-
das por um conjunto de probabilidades chamadas probabilidades de transição.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 16
Figura 6: Esquema de um modelo HMM[http://en.wikipedia.org/wiki/Hidden_Markov_model]
• x— estados
• y — possiveis observações
• a— probabilidade de transição de estado
• b — probabilidades dos outputs
2.1.3.3 Vizinho mais próximo
Este algoritmo é simples e tem uma performance alta.
O algoritmo do vizinho mais próximo não possui informação a priori acerca das distribuições dos
exemplos de treino. Este algoritmo exige o treino de casos positivos e negativos. Cada amostra é
classificada calculando a distância ao caso de treino mais próximo. O sinal do ponto mais próximo
determina a classificação do ponto analisado.
Existem alternativas dentro deste algoritmo como é o caso dos K-vizinhos mais próximos onde para
cada ponto são analisados os k vizinhos mais próximos sendo a média dos valores a classificação do
ponto de teste.
2.1.3.4 SVM
Support Vector Machine(SVM) é um algoritmo de predição de decisão que classifica dados em
grupos. É baseado no conceito de planos de decisão nos quais dados de treino são mapeados num
plano de dimensão superior e separados por um plano definindo uma ou mais classes.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 17
Um exemplo simples pode ser visto na figura seguinte na qual os quadrados representam uma clas-
se, os círculos outra classe. SVM cria um plano de decisão que neste caso é uma linha simples e
separa as duas classes:
Figura 7: Exemplo 2-D do algoritmo de decisão SVM [http://cnx.org/content/m13131/latest/]
2.1.3.5 Redes Neuronais
As redes neuronais artificiais (Artificial Neural Networks) são modelos computacionais criados
com o intuito de emular o funcionamento do cérebro humano. Pretende-se, à imagem do cérebro,
que as ANN tenham capacidade de aprendizagem, de adaptação e de generalização.
As redes neuronais com ligações para a frente constituem uma classe especial de ANN, nas quais
todos os neurónios de uma determinada camada l estão ligados a todos os neurónios da camada l-1.
Como se verifica na Figura 8:exemplo de uma Rede Neuronal[Sistemas de Classificação Musical
com Redes Neuronais], uma rede com ligações para a frente é constituída tipicamente por uma
camada de entrada, que corresponde aos dados que entram na rede, uma camada escondida cujos
neurónios recebem os dados produzidos pelos neurónios da camada de entrada e uma camada de
saída, cujos neurónios recebem dados da camada escondida e que correspondem à saída da rede.
A estrutura fundamental numa rede neuronal é o neurónio. Cada neurónio é estimulado ou seja,
recebe sinais dos neurónios vizinhos, enviando sinais após processamento, para outros neurónios.
Os resultados de saída da rede neuronal dependem dos dados de entrada, dos valores iniciais dos
parâmetros da rede e da relação entre os próprios neurónios. Essa relação, como se visualiza por
exemplo na Figura 8 para o s-ésimo neurónio da camada escondida, é representada pelo produto da
matriz de pesos que incide nesse neurónio. Para ajustar esses pesos para que a rede produza os
melhores resultados de validação possíveis, é necessário que a rede seja devidamente treinada.
No processo de treino, a rede irá ajustar os seus parâmetros (W e b) de forma a que, no final, os
dados de entrada sejam correctamente mapeados nos dados de saída. No exemplo, cada entrada da
rede é um vector com as 40 características extraídas do sinal de música e cada saída desejada tem o

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 18
valor 1 para o género musical correcto e zero para os restantes (Figura 8:exemplo de uma Rede
Neuronal[Sistemas de Classificação Musical com Redes Neuronais]). Na Figura 8, temos uma
matriz de entrada de dimensão 40x120, na qual cada linha corresponde a uma determinada caracte-
rística extraída e cada coluna corresponde ao vector de características de uma determinada música
utilizada para treinar a rede. Na mesma figura está definida a matriz das saídas desejadas para a
rede. Tem a dimensão 3x120 e cada coluna tem a informação sobre o género musical para a música
correspondente da matriz de entrada: todas as linhas têm valor zero, excepto para a linha correspon-
dente à classe correcta, que tem valor um.
Figura 8:exemplo de uma Rede Neuronal[Sistemas de Classificação Musical com Redes
Neuronais]

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 19
2.1.3.6 Exemplos do uso de classificadores
A) Transcrição da melodia vocal
A Classificação em [5] é constituída por 2 níveis de análise:
• Modelização acústica de baixo nível
• Modelização musical de alto nível
O modelo acústico pretende capturar o conteúdo acústico do canto enquanto que o modelo musical
tenta implementar informação sobre intervalos melódicos típicos.
Modelo Acústico
O modelo de evento de nota utiliza HMM. É atribuída uma nota HMM a cada nota MIDI estimada.
Utilizando as informações extraídas na secção anterior é possível construir o vector de observação.
Este vector é constituído por:
• Diferença F0 – Entre a F0 medida e a do pitch nominal da nota modelada.
• O respectivo valor de saliência.
• A diferença de onset de F0.
• A intensidade do onset de F0.
• O valor do sinal de acentuação.
O autor utiliza a diferença de F0 como característica pois desta maneira apenas um conjunto de
parâmetros HMM necessitam de ser treinados. Apesar de se ter uma nota HMM para cada pitch
nominal, partilham todos os mesmos parâmetros de treino.
É utilizado o GMM para modelizar segmentos onde nenhuma nota estiver presente (pausas). O vec-
tor de observação para pausas consiste na máxima saliência e intensidade do onset em cada frame.
O modelo GMM é constituído por quatro componentes treinado em segmentos não melódicos.
As verosimilhanças logarítmicas observadas para este modelo são escaladas na mesma escala dinâ-
mica do modelo de notas multiplicando por uma constante obtida experimentalmente.
Modelo Musical
Estimação de Alcance de notas.
CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 20
Tem como objectivo constringir o possível alcance de pitch das notas. Como as melodias normal-
mente estão num raio curto, este método faz com que seja mais robusto contra notas muito altas ou
muito baixas. O autor utiliza uma escala da nota MIDI 44 até à 84.
O procedimento proposto usa a máxima saliência de F0 estimada em cada frame. Se a sua estimati-
va está entre valores MIDI 50 a 74 e a sua saliência é superior a 1.0, a estimativa é considerada
valida. É calculada a média do peso da saliência dos F0s válidos para obter a média do alcance de
notas.
Em 95% das canções todas as notas de referência estão cobertas pelo alcance estimado.
Estimação de nota
O modelo de música controla transições entre modelo de notas e de descanso. Esta modelização
baseia-se no facto de que algumas sequências de notas são mais normais do que outras numa deter-
minada nota musical. Uma nota musical é definida pela escala de notas básicas usadas numa can-
ção. O modelo encontra a nota relativa mais provável usando um método de estimação.
O método produz verosimilhanças diferentes para diferentes notas das F0 estimadas para quais o
valor da saliência é maior do que um threshold fixo. O par de notas relativo mais provável é estima-
do para todo o sinal e é usado para escolher a probabilidade de transição entre modelos de notas e
modelo de repouso.
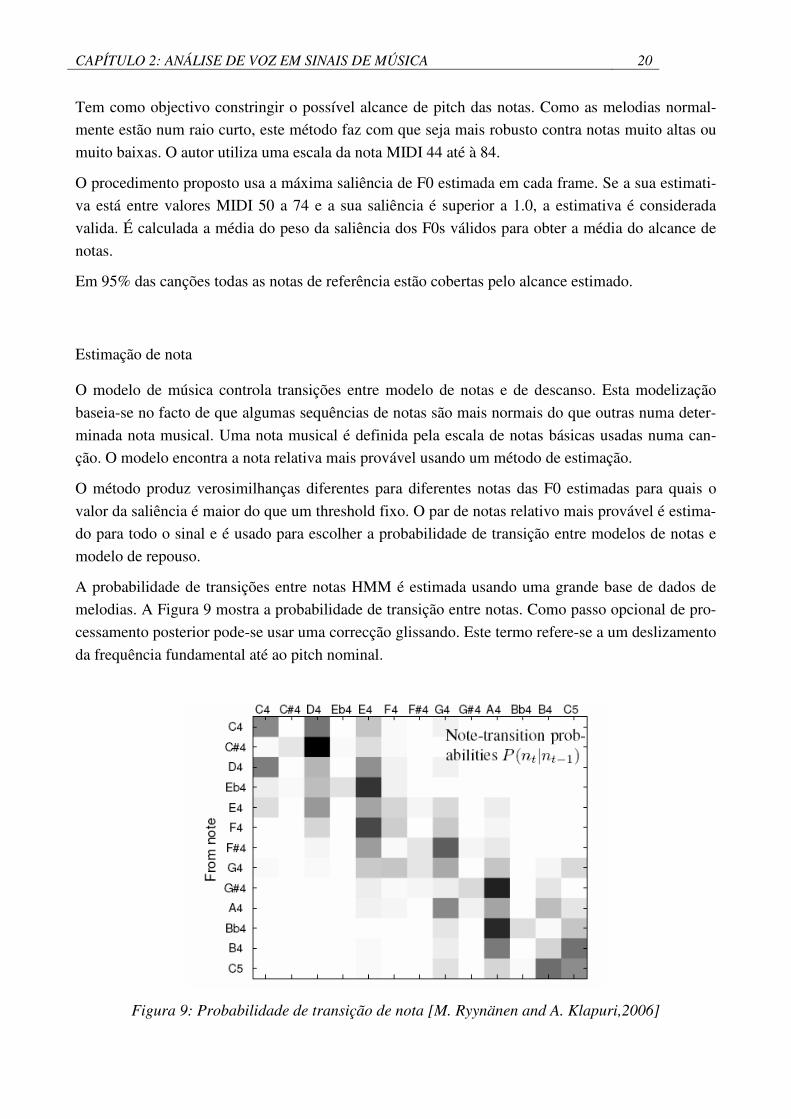
A probabilidade de transições entre notas HMM é estimada usando uma grande base de dados de
melodias. A Figura 9 mostra a probabilidade de transição entre notas. Como passo opcional de pro-
cessamento posterior pode-se usar uma correcção glissando. Este termo refere-se a um deslizamento
da frequência fundamental até ao pitch nominal.
Figura 9: Probabilidade de transição de nota [M. Ryynänen and A. Klapuri,2006]

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 21
Encontrar o melhor caminho e pós-processamento
O modelo de notas e de descanso formam uma rede de modelos onde as transições de repouso e de
nota são controlados pelo modelo musical. É utilizado o algoritmo de Viterbi para encontrar o
caminho mais provável na rede de modelos. É de referir que este modelo cria simultaneamente as
etiquetas das notas de pitch, os onsets e offsets das notas.
B) Discriminador voz/música
Em [8] Autor compara 4 métodos de classificação. Os classificadores utilizam os vectores de 13
características obtidos na secção anterior como input.
MAP Gaussiana Multidimensional
Para avaliar o peso de cada característica usa-se a classificação multidimensional MAP (Maximum
a Posteriori) Gaussiana, modelando cada classe (voz e música) como pontos aglomerados num
espaço de características (por exemplo um espaço de 13 dimensões). São criadas estimativas de
médias de parâmetros e covariância dentro de cada classe numa fase de treino. Este treino serve
para estimar parâmetros que possam ser usados na fase de classificação de novas amostras basean-
do-se na sua proximidade à média de cada classe.
Gaussian Mixture Model
O modelo GMM trata cada classe como a união de vários aglomerados Gaussianos no espaço de
características. Esta aglomeração pode ser derivada iterativamente pelo algoritmo EM. Ao contrário
do classificador MAP, os aglomerados individuais não são representados com as matrizes de cova-
riância mas apenas com as suas aproximadas diagonais.
GMM utiliza uma estimativa de verosimilhanças para cada modelo que mede quão bem um novo
ponto se insere nos aglomerados Gaussianos. Um novo ponto é então atribuído à classe que tiver o
melhor modelo (o mais provável) para o mesmo.
K Vizinhos mais próximos
O vizinho mais próximo coloca o ponto de treino no espaço de características. Para classificação
examinamos o ponto mais próximo do inserido e atribui-se a mesma classe do outro.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 22
Neste método faz-se uma votação entre os k vizinhos mais próximos para determinar a classe do
ponto analisado.
K-d vizinhos mais próximos
É uma variante do classificador anterior na medida em que a votação é feita entre os pontos vizi-
nhos que fazem parte da árvore de partição k-d. Estes pontos estão próximos uns dos outros mas
não são necessariamente os vizinhos mais próximos.
C) Detecção de voz em músicas
O autor utiliza em [12] um classificador MM-HMM seguido de um verificador de decisão e por fim
um processo de bootstraping para criar modelos específicos de voz e não-voz para cada música.
Classificador MM-HMM
Uma observação importante é que segmentos vocais e não-vocais demonstram variações nas carac-
terísticas das canções. Por exemplo, a força do sinal em secções diferentes (chorus, intro, etc.) é
normalmente diferente.
Intro Baixa energia
Chorus Energia mais forte
Verse Energia média e arranjo musical mais completo (mais instrumentos)
Bridge Energia média e arranjo musical mais completo (mais instrumentos)
Outro Normalmente tem um fade-out e repete alguma frase do chorus
Tabela 1:Secções de músicas
O tempo e intensidade são atributos importantes para a variação inter-canções, por isso está integra-
do nos modelos a estrutura da canção, a variação intra-musica e inter-musica.
Os dados de treino vocais e não-vocais são:
• Tipo de secção (Intro, verse, etc).

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 23
• Tempo.
• Intensidade.
Um modelo é criado para cada classe, perfazendo um total de 40 modelos, 20 para vocal e 20 para
não-vocal.
Figura 10:Modelos do classificador HMM [T. L. Nwe, A. Shenoy, and Y. Wang, Singing voice
detection in popular music, 2004]
Vários modelos para cada classe formam um espaço de modelização HMM para assegurar uma
mais correcta modelização em comparação com o modelo singular.
Verificação da classificação
A canção foi segmentada como foi explicado anteriormente, contudo alguns destes segmentos
podem estar mal classificados. Nesta etapa é avaliada a segurança da classificação medindo a dife-
rença da pontuação para os outros competidores. Usa-se a informação do vizinho no modelo HMM
para determinar as propriedades da possível fonte competidora. É executado um teste para criar um
resultado de confiança que é comparado com um threshold para reter apenas as frames que tenham
alta confiança de serem classificadas de vocais e não-vocais.
Processo de bootstrapping
As frames com alta confiança que são retidas na etapa anterior são usadas para criar modelos vocais
e não-vocais com um processo bootstrapping para aumentar a exactidão. Desta maneira o algoritmo
torna-se adaptável (a cada musica) e é capaz de atingir uma exactidão superior.
CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 24
2.1.4 Outros métodos
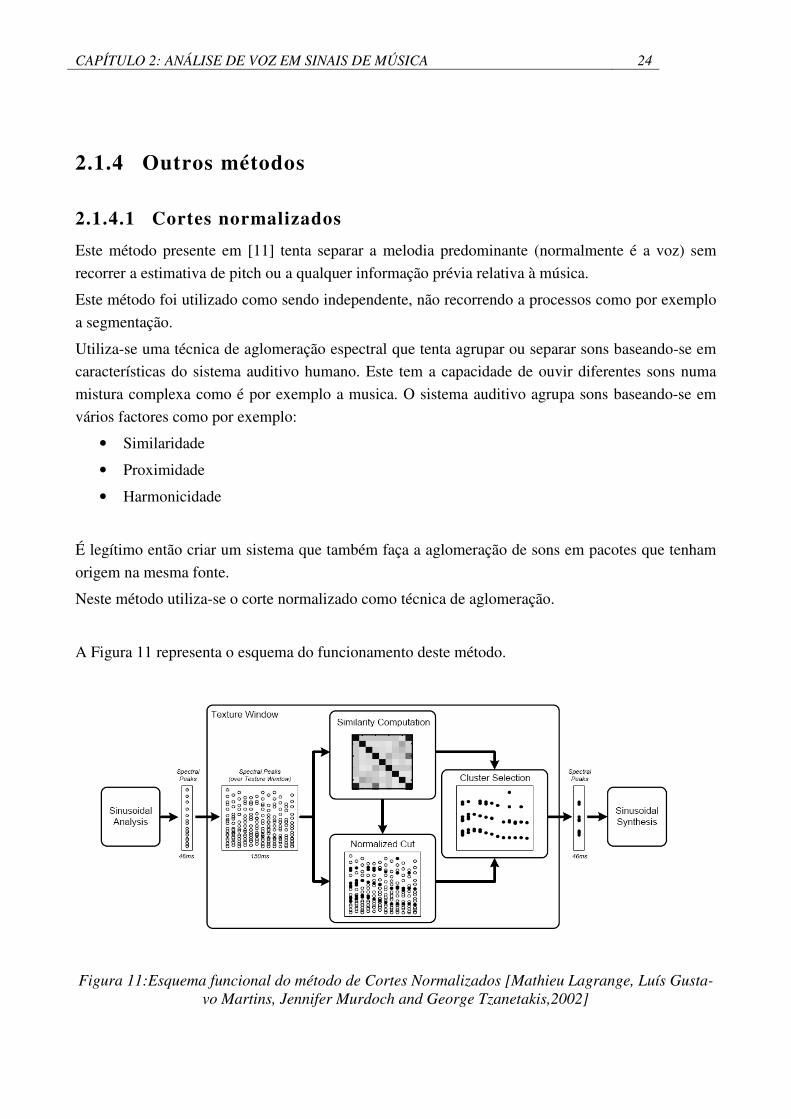
2.1.4.1 Cortes normalizados
Este método presente em [11] tenta separar a melodia predominante (normalmente é a voz) sem
recorrer a estimativa de pitch ou a qualquer informação prévia relativa à música.
Este método foi utilizado como sendo independente, não recorrendo a processos como por exemplo
a segmentação.
Utiliza-se uma técnica de aglomeração espectral que tenta agrupar ou separar sons baseando-se em
características do sistema auditivo humano. Este tem a capacidade de ouvir diferentes sons numa
mistura complexa como é por exemplo a musica. O sistema auditivo agrupa sons baseando-se em
vários factores como por exemplo:
• Similaridade
• Proximidade
• Harmonicidade
É legítimo então criar um sistema que também faça a aglomeração de sons em pacotes que tenham
origem na mesma fonte.
Neste método utiliza-se o corte normalizado como técnica de aglomeração.
A Figura 11 representa o esquema do funcionamento deste método.
Figura 11:Esquema funcional do método de Cortes Normalizados [Mathieu Lagrange, Luís Gusta-vo Martins, Jennifer Murdoch and George Tzanetakis,2002]

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 25
D) Analise sinusoidal
Inicialmente faz-se uma análise sinusoidal que tem por objectivo representar o sinal de entrada
como uma soma de sinusóides caracterizadas por amplitudes, frequências e fases. Uma prática
comum é segmentar o sinal de maneira a que esses parâmetros sejam considerados constantes em
cada frame.
São utilizadas frames de 46ms com hop size de 11ms para estimar os picos sinusoidais recorrendo
ás STFT (Short Time Fourier Transforms).
Em seguida é calculado para cada frame um número variável de picos correspondendo ao máximo
local do espectro.
E) Janelas de textura
Depois de calculados os picos para cada frame, faz-se a aglomeração destes em frequência e tempo
em janelas de textura. As janelas de textura têm 150ms e equivalem a 10 frames.
O algoritmo de rastreio parcial procura os parâmetros sinusoidais de frame para frame e determina
quando grupos começam e terminam. Desta maneira é possível fazer a ligação entre picos ao longo
do tempo.
F) Critério de corte normalizado
O critério de agrupamento foi criado com o objectivo de melhorar o algoritmo de rastreio. É traçado
um gráfico sobre cada janela de textura e este é particionado usando o critério global de corte nor-
malizado. Cada partição é um conjunto de picos que estão agrupados de maneira a que a similarida-
de dentro dela seja maximizada e minimizada em relação a outras partições.
G) Computação de Similaridade
A Computação de similaridade define a medida de similaridade entre 2 picos que deve ser alta para
picos harmonicamente relacionados e baixa para picos não harmonicamente relacionados.
Utiliza-se uma nova medida de similaridade chamada Harmonically Wraped Peak Similarity
(HWPS) que tem por objectivo tirar vantagem da flexibilidade duma similaridade harmonicamente
relacionada entre picos considerando não só picos isolados como também toda a informação espec-
tral associada aos restantes picos. Esta medida pode ser usada entre picos da mesma frame como em
picos de frames diferentes.
HWPS designa a cada pico um padrão espectral que captura informação sobre o espectro em rela-
ção ao respectivo pico. O grau de correspondência de dois padrões é usado como medida de compa-

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 26
ração entre dois picos usando-se assim mais informação espectral do que apenas a amplitude e fre-
quência.
O objectivo é que a semelhança entre dois picos pertencentes à mesma estrutura harmónica seja
maior do que a semelhança entre picos pertencentes a estruturas harmónicas diferentes.
Este processo está dividido em 3 etapas:
1) Padrão espectral desfasado.
2) Espaço de Wrapped Frequency.
3) Similaridade de cosseno discreto.
A primeira etapa descreve o conteúdo espectral usando estimativas da frequência e amplitude do
máximo local do espectro de energia (pico). Fornece-se a cada pico um determinado padrão espec-
tral. Este padrão espectral é essencialmente um desfasamento do conjunto de picos de frequência da
janela. Observa-se que 2 picos de frames diferentes mas da mesma janela terão padrões bastante
similares pois os parâmetros espectrais variam lentamente ao longo do tempo.
A segunda etapa usa uma medida para estimar se 2 picos pertencem à mesma fonte harmónica
medindo a correlação entre os respectivos padrões espectrais. Para o conseguir altera-se o padrão
espectral dos picos de maneira a que o valor da correlação seja mais alto para picos que pertençam
ao mesmo complexo harmónico do que picos que pertençam a fonte harmónicas diferentes.
A última etapa correlaciona 2 padrões “Wrapped” para obter a medida de HWPS entre 2 picos cor-
respondentes. Esta correlação pode ser conseguida discretizando os padrões num histograma balan-
ceado de amplitudes.
H) Aglomeração Espectral
A informação correspondente a cada fonte harmónica é particionada em aglomerados pelo método
de corte normalizado. A informação é modelizada num gráfico que indica a similaridade entre os
nós i e j como se pode ver pela Figura 12.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 27
Figura 12:Matriz HWPS para duas fontes harmónicas [Mathieu Lagrange, Luís Gustavo Martins, Jennifer Murdoch and George Tzanetakis,2002]
A partição é conseguida dividindo recursivamente os componentes até ficarem n componentes
completos.
I) Selecção de aglomerados espectrais
De todos os aglomerados identificados pelo critério de corte normalizado, queremos seleccionar
apenas aqueles que contenham sinais de voz. Como estes aglomerados correspondem a uma fonte
harmónica predominante, devem ser densos no espaço de características. Os picos da mesma fonte
tentem a ser muito semelhantes com outros picos pertencentes à mesma fonte, principalmente em
relação à harmonicidade. Sabendo isto é possível usar o calculo de similaridades sabendo que terá
valores altos para picos pertencentes à mesma fonte harmónica.
Por fim os picos correspondentes aos aglomerados seleccionados são usados para ressíntetizar o
sinal de voz recorrendo a osciladores sinusoidais.
2.1.4.2 Separador de voz em músicas
O método que será explicado em seguida utiliza uma estrutura diferente das que já foram mencio-
nadas. Em [3] (em [10] o mesmo método é utilizado) é realizada inicialmente uma separação do
sinal de voz que não será definitiva servindo apenas como auxiliar do processo de detecção da
envolvente espectral. Depois de detectada a envolvente espectral são extraídas características que
serão analisadas pelo classificador à semelhança dos métodos já explicados. Na secção de extracção
de características são criadas unidades T-F que serão explicadas posteriormente. Finalmente o clas-
sificador separa definitivamente o sinal de voz do sinal de música.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 28
Figura 13:Esquema do separador de voz em músicas
A) Separação inicial
O autor utiliza inicialmente um detector/particionador de mudanças espectrais seguido dum classifi-
cador de segmentos vocais/não-vocais.
Este processo baseia-se no facto de que quando um som entra na música produz alterações signifi-
cativas no espectro de frequências. Normalmente a voz junta-se a um acompanhamento musical em
tempo de batidas que produzem uma grande alteração no espectro de frequências.
O detector calcula a distância euclidiana no domínio complexo entre o valor espectral esperado e o
observado. Diferenças espectrais significativas traduzem-se como picos no gráfico de distâncias. De
acordo com estes picos o sinal é particionado.
Depois de particionado, cada segmento é classificado de vocal e não-vocal de acordo com a sua
verosimilhança. Para o classificador são usados os MFCCs (Mel Frequency Cepstral Coefficients)
como características de análise e GMM (Gaussian Mixture Model) como classificador.
B) Detecção da envolvente espectral
Alguns Investigadores optam por realizar uma detecção da envolvente espectral para ajudar tanto no
ajustamento da separação em sinais de voz e música como na extracção de características para pos-
terior classificação.
A detecção da envolvente espectral serve para detectar o pitch de voz predominante. A envolvente
espectral correctamente detectada pode fornecer preciosa informação para análises posteriores.
No entanto, a detecção da envolvente espectral da voz é bastante difícil quando esta está acompa-
nhada de instrumentos. Para combater esta fragilidade usa-se a já mencionada separação do sinal
em segmentos voz e não-voz. Após a obtenção de segmentos de voz a extracção da envolvente
espectral destes torna-se mais fácil.
Inicialmente, o algoritmo decompõe a porção vocal nos seus componentes de frequência com um
filterbank de 128 canais. Em seguida é calculado para cada canal e para cada frame um correlogra-

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 29
ma normalizado para se obterem informações de periodicidade. Os picos do correlograma contêm a
informação de periodicidade, contudo devido à presença de instrumentos podem ocorrer erros.
Para atenuar estes erros, o HMM observa a probabilidade de hipótese de pitch analisando informa-
ção de todos os canais e retira os pitch improváveis. Para reduzir a interferência de outros sons har-
mónicos, HMM segue até 2 contornos de pitch.
Finalmente o algoritmo de Viterbi selecciona o contorno mais verosímil.
C) Extracção de características
Em seguida o autor cria unidades T-F (Time-Frequency), retira informação destas e fornece-a à
secção de classificação.
A extracção de características tem como entrada o contorno da envolvente espectral mais verosímil
calculado pelo módulo de detecção da envolvente espectral.
As unidades T-F são criadas passando a envolvente espectral por um filtro gammatone de 128
canais dividindo-o depois em frames de 16ms com 50% de overlap.
Para cada unidade T-F são extraídas:
• Energia
• Autocorrelação
• Correlação com canais cruzados
• Correlação com envelope de canais cruzados
Na fase seguinte o algoritmo forma segmentos unindo unidades T-F contínuas baseando-se na sua
continuidade temporal e correlação de canal cruzado. Apenas as unidades T-F com energia e corre-
lação de canal cruzado elevadas são consideradas.
As características de cada unidade são o input da secção de classificação deste método que será
discutida posteriormente.
D) Classificação
A etapa de classificação recebe as características de unidades T-F calculadas na etapa anterior.
Comparando a informação de periodicidade local indicada na autocorrelação duma unidade T-F à
periodicidade estimada da voz no mesmo frame, cada unidade é catalogada de:
• Voz dominante
• Instrumento dominante

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 30
É usada a envolvente espectral detectada numa secção anterior para classificar cada unidade T-F.
Filtros que respondam a múltiplos harmónicos terão as suas respostas moduladas em amplitude.
Para resolver este problema dos harmónicos, o algoritmo extrai o rácio de modulação de amplitude
(AM) para cada unidade e compara-o com o rácio AM com o período estimado do pitch. Esta reso-
lução do problema foi apenas mencionada em [3].
No último passo deste algoritmo, segmentos onde a maioria das unidades é classificada de voz
dominante são agrupados formando o sinal de voz.
2.2 Analise de sinais de voz
Depois de realizada com sucesso a separação da voz nos sinais de música é possível aplicar técnicas
de análise de sinais de voz para obter diversas informações como por exemplo:
• Identificação do cantor
• Identificação de múltiplos cantores
• Transcrição de letras
• Reconhecimento automático de letras e seu alinhamento (ex. Karaoke)
• Qualidade do cantor
• Estilo musical
• Identificação do idioma
Em seguidas serão apresentadas 4 técnicas de análise de sinais de voz:
1) Identificação do cantor
2) Identificação de mudanças de orador
3) Extracção do timbre vocal para comparação com outras musicas
4) Aglomeração de músicas segundo o seu cantor
2.2.1 Identificação do cantor

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 31
Em [2] o autor primeiro utiliza uma segmentação que separa o sinal de música em secções vocais e
não-vocais e que já foi explicado na secção 2.1.1.1.
Este sistema tenta identificar automaticamente o cantor extraindo características da voz em músicas
e comparando-as com uma base de dados.
A extracção de características é feita por meio de análises LPC (Linear Predictive Coding) e War-
ped LPC.
O objectivo da análise LPC é obter uma estimativa do sinal baseado em x análises anteriores. Para o
caso foram usados 12 coeficientes. Esta análise é semelhante a um filtro da fonte onde o ar é modu-
lado para formar os sons pretendidos. Os coeficientes obtidos podem ser usados para determinar a
localização dos pólos que normalmente corresponde à localização das formantes do tracto vocal.
O problema desta análise é que trata todas as frequências numa escala linear. Contudo o ouvido
humano não ouve todos os sons da mesma maneira o que leva investigadores a sugerir que se faça
um reajustamento da escala.
A análise Warped LPC faz precisamente essa conversão de frequências baseando-se na escala de
Bark. Esta é uma escala psicoacustica que mede a sonoridade nas primeiras 24 bandas criticas da
audição.
O autor utilizou cada uma das análises em separado e um método que unia as duas análises. Na fase
de testes ficou provado que a melhor solução é usar as duas análises (LPC e Warped LPC).
A classificação foi realizada utilizando 2 classificadores previamente treinados:
• GMM(Gaussian Mixture Model)
• SVM(Support Vector Machine)
Para determinar os parâmetros gaussianos que melhor modelizam cada classe usa-se a EM (maxi-
mização esperada). EM é um algoritmo iterativo que converge em parâmetros que são localmente
óptimos de acordo com a função de verosimilhança logarítmica. É também útil realizar a PCA
(Analise de Princípios de Componentes) antes de EM pois normaliza a informação facilitando o
papel do mesmo. PCA é uma rotação Multidimensional da informação no eixo de máxima variân-
cia.
SVM baseia-se em técnicas de redução de erros estatísticos aplicado a um domínio de machine
learning. SVM funciona computando um hiperplano óptimo que consegue separar linearmente 2
classes de informação. Estes hiperplanos simplificam-se num conjunto de multiplicadores Lagrange
para cada caso de treino. O conjunto de pontos dentro dos vectores dimensionais de treino Lagran-
ges diferentes de zero são os SV (vectores de suporte). A máquina guarda os SVs e aplica-os a novo
sinal de teste para futura classificação.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 32
2.2.2 Identificação de mudanças de orador
Em [7] o autor apresenta 3 sistemas de identificação de mudança de orador baseados em BIC (Bayesian Information Criterion).
O primeiro investiga as características do AudioSpectrumCentroid e do AudioWaveformEnvelope,
aplica em seguida um threshold dinâmico e um esquema de fusão. Finalmente é aplicado o BIC.
O segundo sistema é um sistema em tempo real que utiliza os line spectral pairs e o BIC para vali-
dação dum eventual ponto de mudança de orador.
O terceiro método utiliza a distância euclidiana e a estatística Hotelling T2 seguido do BIC.
BIC é um critério estatístico para escolha de modelos. Este algoritmo mede o peso do favorecimen-
to de um modelo em relação a outro.
2.2.2.1 1º Sistema
Este sistema divide o sinal de entrada em pedaços de potêncial mudança de orador. Em seguida o
sinal é analisado em várias etapas para determinar se os pontos detectados correspondem realmente
a mudanças de orador. Após cada etapa o número de pedaços diminui aumentando também o tama-
nho de cada um. Quanto maior cada pedaço, maior é a performance pois existe mais informação
para analisar, minimizando por isso os erros.
O sistema é constituído por 10 etapas que realizam testes diferentes de mudança de orador:
1) MFCCs para as 4 primeiras etapas
5) Máxima magnitude DFT
6) STE (Short Time Energy)
7) MFCCs
8) AudioSpectrumCentroid
9) Máxima magnitude DFT
10) AudioWaveformEnvelope
Todos os oradores são representados com uma densidade de probabilidade que está constantemente
a ser renovada devido ao aumento dos pedaços. O thresholding dinâmico refere-se apenas a caracte-
rísticas escalares como a magnitude máxima da DFT, STE e AudioWaveformEnvelope.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 33
2.2.2.2 2º Sistema
Este sistema faz uma amostragem do sinal de entrada a 8khz e aplica pré-enfase. Em seguida o sinal
é dividido em frames de análise de 25ms sem overlap e são extraídos coeficientes LSP de ordem 10.
A detecção de mudança de orador é executada usando o cálculo da distância entre segmentos de voz
consecutivos. Cada segmento é constituído por 55 frames. Assumindo que os coeficientes LSP
seguem uma distribuição gaussiana cada segmento pode ser modulado por um sistema gaussiano.
É utilizado um threshold automático que se baseia nos valores das N distâncias anteriores entre
segmentos.
Para reduzir falsos alarmes é utilizado o BIC que faz a validação de potenciais pontos de mudança
de orador.
2.2.2.3 3º Sistema
Este sistema está dividido em 3 módulos. No primeiro módulo são investigadas 24 características e
é aplicado um algoritmo de selecção que escolhe as 5 melhores características a serem usadas. Estas
são:
• Média da magnitude da DFT
• Delta AudioEnvelopeWaveform
• Media da STE
• AudioEnvelopeWaveform
• Magnitude delta da DFT
Cada sinal é segmentado em janelas de duração de 2 segundos e as características são calculadas
para 2 janelas adjacentes. É utilizado um threshold ad-hoc para determinar se existe um ponto de
mudança entre as janelas.
No segundo modulo são usadas MFCCs como características juntamente com a distância euclidiana
seguido da estatística Hotelling T2 .
No módulo final é implementada a BIC que produz o conjunto final de pontos de mudança de ora-
dor.
Conclui-se que o primeiro sistema é mais exacto mas tem um tempo de execução elevado. O segun-
do sistema favorece operações em tempo real mas não obtém resultados tão seguros como o primei-
ro. O terceiro sistema tenta compensar entre os 2 primeiros.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 34
2.2.3 Sistema de procura de timbres de voz similares
Em [6] o autor desenhou um sistema que procura por canções numa base de dados que tenham tim-
bres vocais semelhantes. O autor consegue atingir este objectivo comparando vectores que contêm
as características dos sinais de voz de cada música.
O sinal de entrada é inicialmente trabalhado no sentido de reduzir o acompanhamento musical para
as características vocais serem mais fáceis de extrair. Este processo foi explicado em 2.1.1.2.
O sinal ressíntetizado serve de input para esta secção. Aqui será submetido a dois tipos de análise:
• Extracção de LPMCCs (LPC-derived Mel Cepstral Coefficients)
• Extracção de ∆F0
Estas duas analisem são realizadas separadamente mas contribuem ambas para a construção do vec-
tor de características que será usado na secção de classificação.
A extracção de LPMCCs trabalha sobre os envelopes espectrais da voz pois sabemos que é aqui que
as suas características estão espelhadas. O autor refere que se poderia usar MFCC (Mel Frequency
Cepstral Coefficients) mas este não representa as características com tanto sucesso.
A extracção de ∆F0 representa a dinâmica das trajectórias de F0 pois o canto tende a possuir varia-
ções temporais na sua frequência fundamental.
A classificação é realizada utilizando um selector de frames seguros.
Como a F0 da melodia é estimada como a mais predominante em cada frame, a ressíntese dos sinais
de áudio podem conter sons vocais e/ou instrumentais. Conclui-se por isso que poderão existir
regiões pouco seguras onde os outros acompanhamentos musicais são predominantes.
A secção de escolha segura de frames remove estas frames pouco seguros recorrendo a um método
de thresholding.
Para se proceder a esta separação utilizam-se 2 modelos gaussianos:
• GMM λv Vocal – É treinado em vectores de características extraídas de secções vocais
• GMM λn Não-vocal – É treinado nos vectores extraídos de secções intermédias.
É difícil escolher um threshold universal para uma grande variedade de músicas pois este pode ser
muito alto para algumas músicas e demasiado baixo para outras. Definimos por isso o threshold
como sendo dependente das canções de maneira a que uma percentagem fixa dos frames duma can-
ção sejam escolhidos como seguros.

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 35
Após serem escolhidos os frames seguros é possível proceder ao cálculo de similaridade. Este cál-
culo utiliza os vectores de características da música escolhida fazendo uma distribuição de probabi-
lidade usando GMM. Deste modo é possível comparar esta música às que se encontrem na base de
dados.
2.2.4 Aglomeração de músicas segundo o seu cantor
Em [14] o autor utiliza um classificador estatístico com modelos paramétricos treinados usando um
acompanhamento vocal para realizar a segmentação do sinal de música.
O classificador consiste num processador de sinal que converte ondas digitais e vectores espectrais
seguido dum processador estatístico que modeliza, iguala e toma decisões. Possui 2 fases, a de trei-
no e a de teste.
Durante a fase de treino a base de dados da música forma 2 modelos (vocal e não-vocal) GMM.
Durante o teste existe varias combinações de tomada de decisões:
1) Baseadas em frames
2) Segmentos de comprimento fixo
3) Segmentos homogéneos
Decisão baseada em frames
Usando um threshold, o decisor pode hipotizar se a frame é vocal ou não-vocal.
Decisão baseada em segmentos de comprimento fixo
Como melhoramento do exemplo anterior, podemos designar uma classificação por segmento.
Acumulando as semelhanças de frames ao longo do período conseguem-se resultados estatistica-
mente mais seguros. Contudo segmentos longos correm o risco de cruzar múltiplas fronteiras
vocais/não-vocais.
Decisão baseada em segmentos homogéneos
Podem-se obter melhores resultados se se juntarem segmentos adjacentes que não cruzem fronteiras
vocais/não-vocais. Faz-se a aglomeração de vectores dando a cada frame um índex associado ao
vector de características. A cada segmento é dada o majorante do índex dos seus frames constituin-

CAPÍTULO 2: ANÁLISE DE VOZ EM SINAIS DE MÚSICA 36
tes e segmentos adjacentes são juntados como um segmento homogéneo. A classificação é feita por
segmento homogéneo por meio dum threshold.
Após a segmentação segue-se a extracção das características a analisar.
Com o objectivo de agrupar os segmentos por cantor, as características deste devem ser destiladas
da mistura e acompanhamento. O autor utiliza GMMs para criar um modelo que analisa os segmen-
tos vocais e não vocais criando vectores para cada um deles.
Finalmente para comparar e aglomerar os cantores, cada gravação é actualizada contra cada modelo
solo de cada cantor. Da secção anterior são criados um modelo solo e outro de fundo. Usando o
modelo a solo com a porção vocal da gravação é calculada a aproximação.

Capítulo 3
3. Implementações previstas
O objectivo principal deste projecto é criar um método eficaz de separação de voz em sinais de
música. Como tal os primeiros esforços serão gastos no desenvolvimento desse método.
Se for possível criar um bom método de separação de voz em sinais de músicas o passo seguinte
será a análise de métodos que permitam extrair informações do sinal de voz para diferentes objecti-
vos como por exemplo identificação do cantor, identificação de mudanças de orador, extracção do
timbre vocal para comparação com outras musicas ou aglomeração de músicas segundo o seu can-
tor.
Para a separação de voz será necessário estudar 3 campos distintos:
1) Windowing ou divisão do sinal de entrada em frames de análise
2) Extracção de características
3) Classificação
Pretende-se encontrar uma configuração para cada um dos campos que beneficie a performance do
sistema. Será preciso analisar cada um dos campos separadamente e em seguida realizar as várias
combinações possíveis medindo os resultados.
Para o primeiro campo pretende-se descobrir qual a divisão que melhor potência a extracção de
características ou permite um melhor rendimento dos classificadores. As frames podem ser dividi-
das em frames fixos de vários comprimentos ou então podem ser usados frames dinâmicos que se
ajustam a cada sinal de música. Exemplos desta última divisão foram usados em [12] onde o autor
dividiu o sinal de entrada em frames correspondentes ao tempo de batida.
Para o segundo campo é necessário estudar diversas características de maneira a determinar a sua
utilidade para os classificadores. Além de medir a utilidade deve-se também encontrar os algoritmos
de processamento de sinal que melhor ajudem a extrair cada característica. Algumas das caracterís-
ticas a serem estudadas já foram mencionadas neste relatório, são elas:

CAPÍTULO 3: IMPLEMENTAÇÕES PREVISTAS 38
• Coeficientes PLP[9]
• HA-LFC[12]
• Modulação de energia a 4Hz[8]
• Percentagem de frames de baixa energia[8]
• Ponto espectral de mudança[8]
• Centroíde espectral[8]
• Fluxo espectral[8]
• ZCR[8]
• Magnitude residual da ressíntese cepstrum[8]
• Impulso métrico[8]
Para o campo da classificação à imagem dos campos anteriores o uso de um certo classificador pode
aumentar a performance final, por isso o ideal será testar vários tipos de classificadores. O estudo de
classificadores como GMM, HMM, SVM e Redes Neuronais parecem ser as escolhas mais adequa-
das.
Para cada classificador sugere-se a criação de um modelo de classificação geral de voz. No entanto
existem zonas onde a classificação é incerta podendo resultar em erros. Para evitar este problema é
possível criar diferentes modelos (mais específicos) onde estes pontos obtenham uma classificação
superior e possam ser classificados com segurança. Alguns deste modelos podem ser relativos ao
género musical e/ou à secção da música[12].
• Género Musical. As características do cantor e da própria música variam para cada estilo
musical. Alguns exemplos de estilos musicais a serem criados:
o Rock
o Jazz
o Pop
o Opera
• Secções de música:
o Intro
o Verso
o Chorus
o Bridge

CAPÍTULO 3: IMPLEMENTAÇÕES PREVISTAS 39
o Outro
Resumindo, na tabela seguinte encontram-se os estudos a realizar.
Campo Estudos
Windowing Frames fixos ou dinâmicos e qual o tamanho
Extracção de características Quais as relevantes e qual o respectivo processamento de sinal
Classificação Qual classificador e quais os modelos para cada um deles
Tabela 2:Resumo de Implementações previstas para separação de voz

Capítulo 4
4. Planificação do trabalho de disserta-ção
Como referi no capítulo anterior a dissertação pode ser dividida em duas etapas, a de separação de
voz dos sinais de música e análise dos sinais de voz.
Além destas duas etapas existem mais quatro objectivos que tem de ser cumpridos:
• Pagina web – Servirá para apresentar o projecto e para registar a evolução do mesmo.
• Relatório de Progresso – A ser entregue até ao fim das 4 primeiras semanas este relatório
servirá para determinar se o projecto está dentro dos prazos previstos e se o plano de estudos
previsto deve ser alterado. Alem disso este relatório poderá servir para alterar ou adicionar
alguns objectivos.
• Relatório Final – A versão final, após aprovação, será impressa, assinada pelo candidato e
pelo júri e arquivada no SDI .
• Apresentação Final – Apresentação pública do trabalho de investigação ou projecto final,
em formato de workshop, eventualmente acompanhado de uma sessão de posters ou de
outras formas de apresentação multimédia.
Em seguida apresentarei os plano de trabalhos em separado para cada etapa apesar de ambas faze-
rem parte dos objectivos da dissertação.

CAPÍTULO 4: PLANIFICAÇÃO DO TRABALHO DE DISSERTAÇÃO 41
Para a separação de voz dos sinais de música segue-se o seguinte plano :
Figura 14:Plano de trabalhos de separação de voz
Para a etapa de análise de sinais de voz o plano de trabalhos é o seguinte:
Figura 15:Plano de trabalhos da análise de voz

Capítulo 5
5. Conclusões
Pela análise dos métodos utilizados por alguns investigadores é possível verificar que a separação
de voz em sinais de música está ainda pouco desenvolvida. Existem muitos métodos mas nenhum
deles pode ser considerado de ideal. Apesar deste facto é possível que com o aprofundamento da
análise de algum deles ou a integração com outro método seja possível obter melhores resultados.
A falta de um separador de voz robusto afecta a performance dos métodos de análise de voz pois o
sinal de entrada pode conter informações que não sejam relativas à voz (instrumentos, ruído). Por
muito fiáveis que sejam estes métodos, se o sinal de entrada não for de qualidade, naturalmente que
erros surgirão como por exemplo erro na identificação do cantor ou detecção errada de mudança de
orador. Torna-se por isso essencial que se concentrem atenções na criação de um método robusto de
separação de voz antes de se proceder ao melhoramento de técnicas de análise de voz.
O uso de algoritmos de processamento de sinais como ferramenta única de separação de voz
demonstraram ser algo limitados, sendo a sua performance inferior a outros métodos de separação
aqui apresentados. Um dos seus problemas é o uso de um threshold fixo que cria uma zona de incer-
teza já que alguns segmentos são escolhidos perto do limite podendo por isso ser mal classificados.
Esta falha pode ser compensada pela utilização de classificadores que conseguem medir o peso de
cada valor de cada característica diminuindo a incerteza.

Referências Bibliográficas
[1] Martín Rocamora, Perfecto Herrera. Comparing audio descriptors for singing voice detection in
music audio files. Instituto de Ingeniería Eléctrica – Facultad de Ingenier´ıa de la Universidad de la
República.
[2] Kim, Y. E. and Whitman, B. P. (2002). Singer identification in popular music recordings using
voice coding features. In Proceedings of International Conference on Music Information Retrieval,
pages 164–169.
[3] Y.Li and D.Wang, Singing voice separation from monaural recordings in Proc. of Int.Conf. on
Music Information Retrieval (ISMIR), 2006.
[4] Emanuele Pollastri ,Some Considerations About Processing Singing Voice for Music Retrieval .
Dipartimento di Scienze dell’Informazione Università degli Studi di Milano
[5] M. Ryynänen and A. Klapuri, Transcription of the singing melody in polyphonic music in Proc. Int.
Conf. Music Inform. Retrieval, 2006.
[6] Hiromasa Fujihara and Masataka Goto, A Music Information Retrieval System Based on Singing
Voice Timbre. National Institute of Advanced Industrial Science and Technology (AIST)
[7] Automatic Speaker Segmentation using Multiple Features and Distance Measures: A Comparison
of three Approaches .Margarita Kotti, Emmanouil Benetos, Constantine Kotropoulos Department of

Informatics, Aristotle Univ. of Thessaloniki. Luís Gustavo P. M. Martins, Jaime Cardoso INESC Porto,
Porto.
[8] E. Scheirer and M. Slaney. Construction and evaluation of a robust multifeature speech/music
discriminator .Proc. ICASSP, Munich, April 1997.
[9] A. L. Berenzweig and D. P. W. Ellis, Locating Singing Voice Segments Within Music Signals.
Presented at IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz,
NY, 2001.
[10] Li, Y. and Wang, D. (2007). Separation of singing voice from music accompaniment for monaural
recordings. IEEE Transactions on Audio, Speech and Language Processing.
[11] Mathieu Lagrange, Member, IEEE, Luis Gustavo Martins, Jennifer Murdoch, Student Member,
IEEE, and George Tzanetakis, Member, IEEE. (2002).Normalized Cuts for Predominant Melodic
Source Separation.
[12] T. L. Nwe, A. Shenoy, and Y. Wang, Singing voice detection in popular music in Proc. 12th
Annu. ACM Int. Conf. Multimedia, 2004, pp.
[13] Davide Rocchesso and Pietro Polotti (2007), Sound to Sense, Sense to Sound A State of the Art in
Sound and Music Computing
[14] Wei-Ho Tsai, Hsin-Min Wang, Dwight Rodgers, Shi-Sian Cheng, and Hung-Ming Yu. Blind
Clustering of Popular Music Recordings Based on Singer Voice Characteristics . Institute of
Information Science, Academia Sinica Nankang, 115, Taipei, Taiwan, Republic of China




![Ouvindo a Voz de Deus [Estudo 06] Sinais da volta de Cristo](https://static.fdocument.pub/doc/165x107/5598a26b1a28ab950a8b4796/ouvindo-a-voz-de-deus-estudo-06-sinais-da-volta-de-cristo.jpg)













