
Deep Learningハンズオン勉強会「Caffeで画像分類を試してみようの会」
115
2015年7月期 AITCオープンラボ Deep Learningハンズオン勉強会 ~Caffeで画像分類を試してみようの会~ 1 2015/07/25
-
Upload
yasuyuki-sugai -
Category
Technology
-
view
2.178 -
download
0
Transcript of Deep Learningハンズオン勉強会「Caffeで画像分類を試してみようの会」

2015年7月期 AITCオープンラボ
Deep Learningハンズオン勉強会 ~Caffeで画像分類を試してみようの会~
1
2015/07/25

自己紹介
2
•菅井康之
•株式会社イーグル所属
• AITCクラウドテクノロジー活用部会 サブリーダー
https://www.facebook.com/yasuyuki.sugai
よろしくお願いしまーす ※この資料の内容は、
個人の見解です

- 本日の流れ -
3
• 環境構築編 – AWS上にCaffeの動作環境を準備
• Caffe Tutorial編 – チュートリアルの一つである、CIFAR-10を使ってお試し動作
• Caffe やって!Try編 – データセットを用意して、動かしてみよう

Deep Learning(Neural Network) 盛り上がってますね!
4

ライブラリも色々出てきて、Deep Learningも徐々に使える環境が整ってきましたね!
5
• Pylearn2(http://deeplearning.net/software/pylearn2/) • Caffe(http://caffe.berkeleyvision.org/) • Theano(http://deeplearning.net/software/theano/) • H2O(https://cran.r-project.org/web/packages/h2o/index.html) • Deeplearning4j(http://deeplearning4j.org/) • Torch(http://torch.ch/) • noleam(https://pythonhosted.org/nolearn/) • Chainer(http://chainer.org/) ←New!!

そもそもDeep Learning(深層学習)って?
6
• 従来からあるニューラルネットワークを多層構造にする、脳科学を応用した機械学習の一種
• 機械学習の重要な要素である、特徴量と言われる変数を自動で生成(発見)する • 本の要約を繰り返すと、本の特徴が現れるような感じ
• AI研究のブレークスルーと言われているハンズオンの中で もう少し具体的に説明します(たぶん)

というわけ(?)で、今日はDeep Learningのライブラリ「Caffe」を使ってみようかと思います。 Deep Learningの特徴量抽出技術を用いた画像分類にチャレンジしていきます。
7
やってみなきゃ 何も始まらないでしょ!

Why? Caffe
8
• DeepLearningの中でも画像処理に最適化 – 畳み込みニューラルネットワーク(CNN)を実装
• C++で実装されているが、Python用のライブラリも提供 • GPUだけでなく、CPUでも動作
– GPUでモデル作ってCPUで評価とか、お得 • リファレンスモデルが用意されている
– このモデルを基に、お試しですぐに評価が可能 • ドキュメントがそれなりに用意されている
– いざとなったらコードも公開されているし。。。

What We’re afraid of the Caffe
9
• 環境構築でハマる – GPUを利用するものは全般的にですが。。。
• 自前のデータ用意に若干敷居が。。 – データの格納形式がlmdb or leveldb なので

まぁ一番の理由は私もCaffeで 自宅警備員を育ててみたりもして、 慣れているってことで。。 (今だとChainerの方が需要ありそう?)
10http://www.slideshare.net/yasuyukisugai/io-t-deeplearning

環境構築編
11

今日の環境
12
• GPU環境で動作させるため CUDA + NVIDIAの構成が必要となりますので、 AWSのEC2を使います
• 普通に環境構築すると大変なので、 諸々セットアップしたAMIを準備しました

使用する環境
13
• NVIDIA+CUDA セットアップ済 – CUDA ver6.5
• Caffeセットアップ済み – 必要なlib(多数)インストール
• Pythonセットアップ済み – Python ver2.7 – numpy / pycaffe

環境用意しすぎると、何やってるかわからなくなるのでCaffeが動作する
低限にしています。 必要なものは都度入れていくことで 何となく仕組みを掴んでいただければと。。
14
近ではDockerで構築する 手順とかも公開されているので、 環境構築は何とかなるのでは

また、普段は安価にすむようスポットインスタンスを使うのですが、インスタンスの準備ができるまでに時間がかかるのと、需要によっては突然インスタンス落とされるので、今回のハンズオンでは通常のインスタンスでやります。
15
何百円かかかります
※一時間辺り、$0.67くらい

スポットインスタンスを使ってると・・・
16
ハンズオンでこれが 発生すると悲しいので・・・
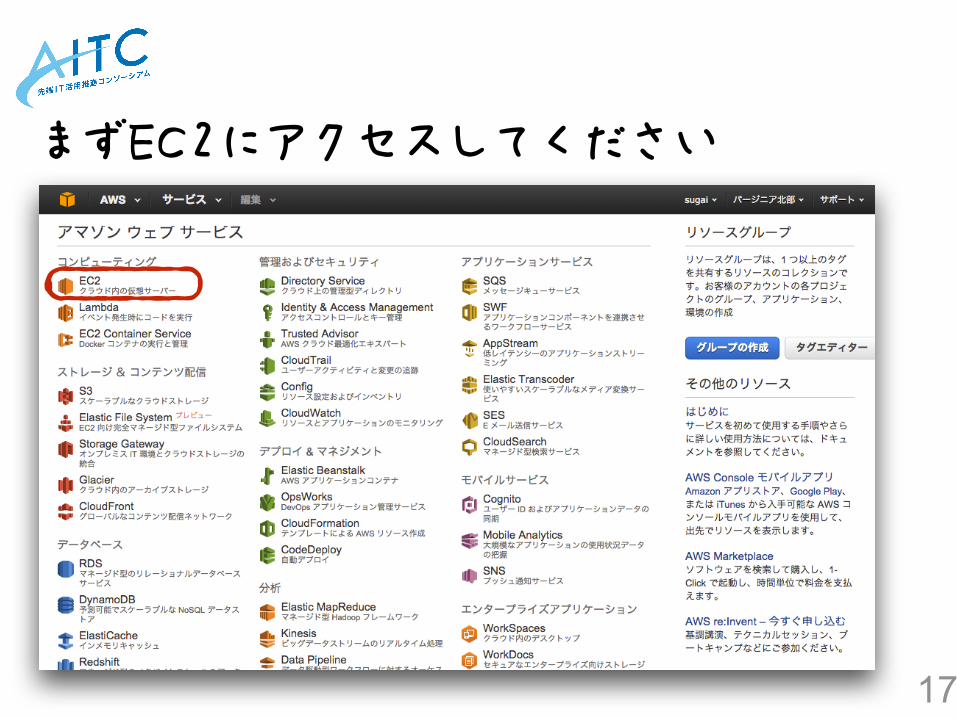
まずEC2にアクセスしてください
17
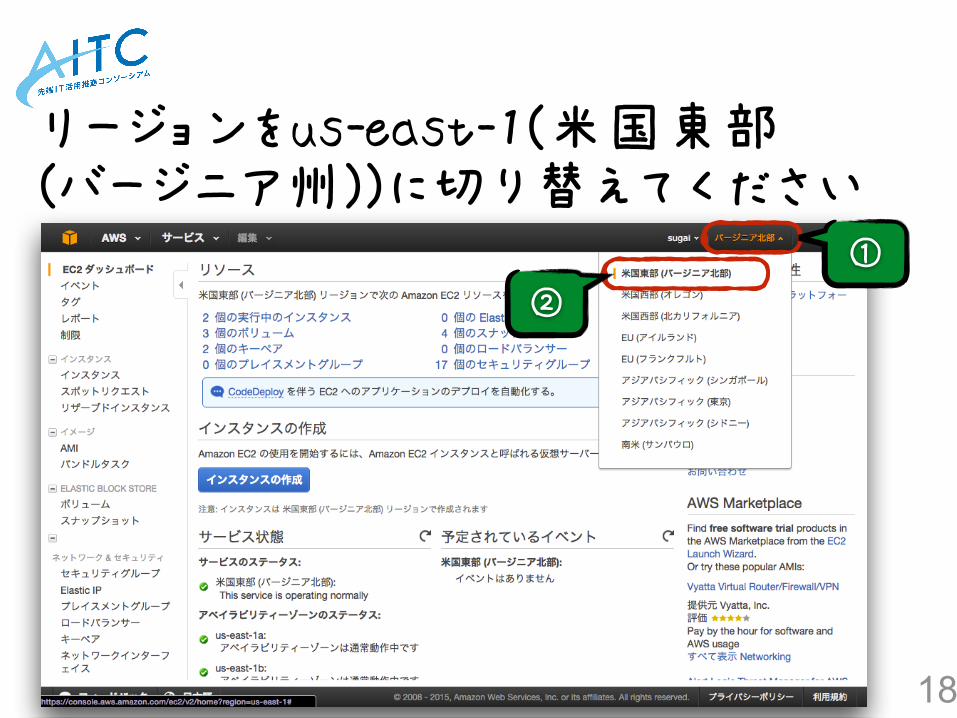
リージョンをus-east-1(米国東部(バージニア州))に切り替えてください
18
①
②

インスタンスを作成していきます
19
①
②

テスト用環境をAMIで公開していますので そちらを選択してください
20
①
②③

GPUインスタンスのg2.2xlargeを 選択します
21
②
③
①

あとは基本そのままで問題無いはず ですが、カスタマイズしたい箇所が あれば設定変更してください
22
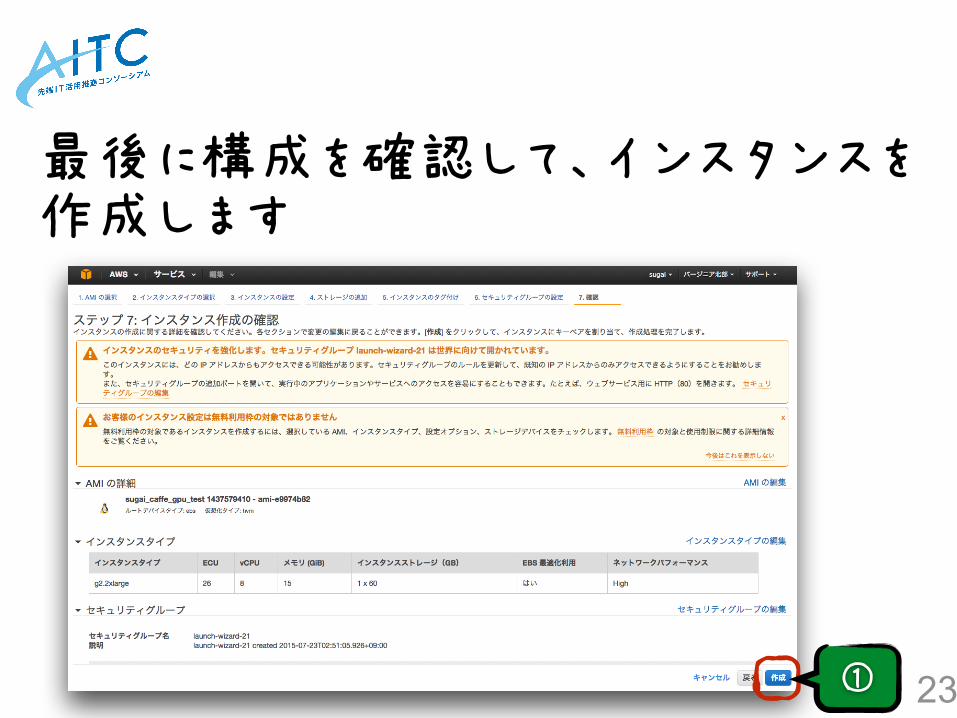
後に構成を確認して、インスタンスを作成します
23①

この画面で作成したキーペアは 無くさないよう気をつけてください。。。
24
①
②
作成中。。。
25

作成したインスタンスへの SSH接続手順を確認します
26
①
②
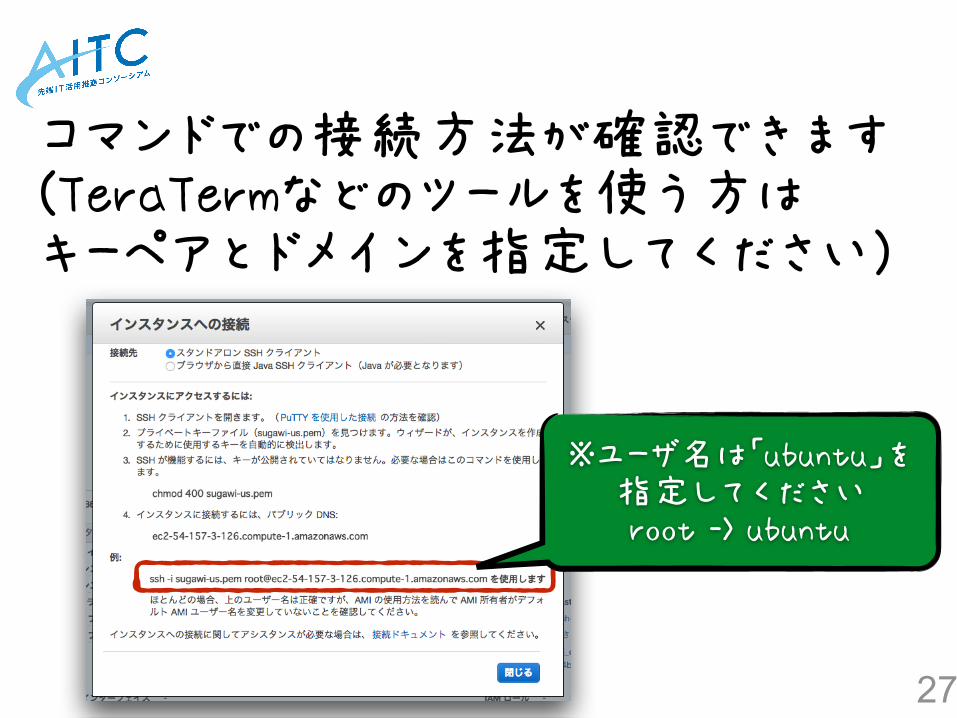
コマンドでの接続方法が確認できます (TeraTermなどのツールを使う方は キーペアとドメインを指定してください)
27
※ユーザ名は「ubuntu」を 指定してください root -> ubuntu

SSHでインスタンスに 接続できましたでしょうか?
28

Caffe Tutorial編
29

LeNet MNIST
30
• 手書き数字の認識精度テスト • 28x28ピクセル、70,000枚の画像 • チュートリアル
• http://caffe.berkeleyvision.org/gathered/examples/mnist.html
– やってもあまり面白みがなさそう(遊べることが少ない)なので、今回はパス。。。

ilsvrc12(ImageNet Large Scale Visual Recognition Challenge 2012 )
31
• 物体認識の精度を競う国際コンテスト • 画像に「何が映っているか」を検出、識別
• クラス数:1,000、画像枚数:150,000 • チュートリアル
• http://caffe.berkeleyvision.org/gathered/examples/imagenet.html
– 研究者向けに画像を提供しているため、画像の準備がめんどい。。。配布も不可。。色々遊べるのに。。。
– 申請してから利用できるまで1日かかるので、今回はパス。。。

CIFAR-10
32
• 犬や猫、飛行機など10クラスの分類精度テスト • 32x32ピクセル、1クラスあたり60,000枚の画像 • チュートリアル
• http://caffe.berkeleyvision.org/gathered/examples/cifar10.html
– 今回はこのチュートリアルを試してみます

Caffe Tutorial編 - CIFAR-10 -
33
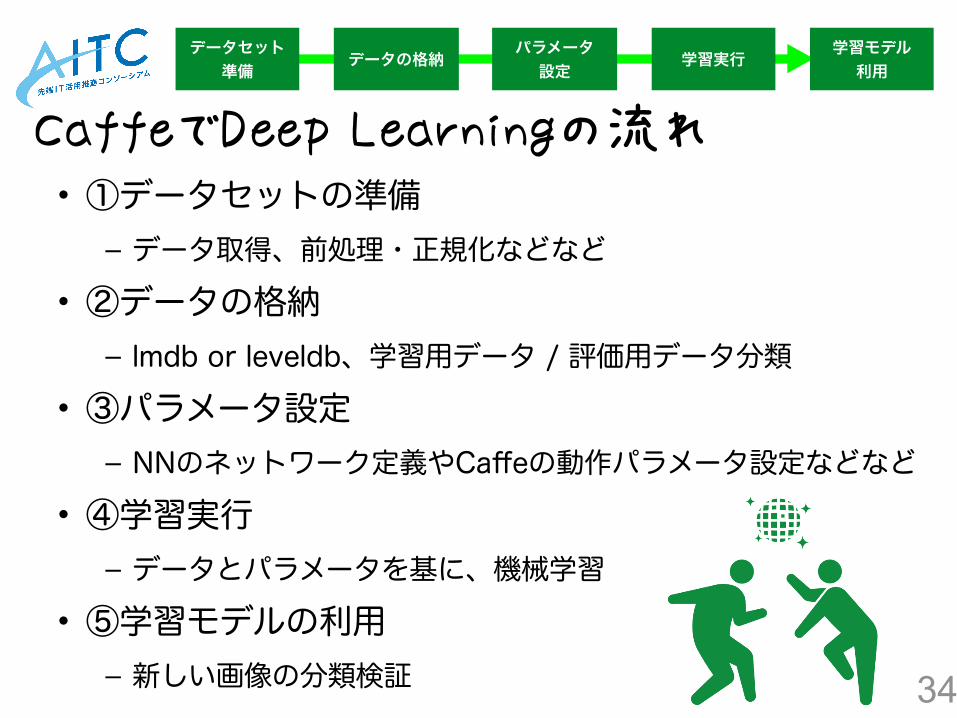
CaffeでDeep Learningの流れ
34
• ①データセットの準備 – データ取得、前処理・正規化などなど
• ②データの格納 – lmdb or leveldb、学習用データ / 評価用データ分類
• ③パラメータ設定 – NNのネットワーク定義やCaffeの動作パラメータ設定などなど
• ④学習実行 – データとパラメータを基に、機械学習
• ⑤学習モデルの利用 – 新しい画像の分類検証
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

コマンド実行時の注意事項
35
• コピペした際に、スペースや改行部分の文字コードが変わってしまう場合があります – コマンドが無いよ、などのエラーになったらスペースor改行を疑ってください
• ~ はチルダです – /home/ubuntu ディレクトリを指定する際に使用します –上手くいかない場合は、~ を /home/ubuntu に読み替えて実行してください
• 行頭の$ はプロンプトを意味しています – 実行時には入力しないでください
• 前のスライドの続きでコマンドを実行するため、カレントディレクトリには注意してください

36
①データセットの準備• 下記のコマンドを実行してください
シェルの中身 • CIFAR-10のデータをダウンロード(wget) • データを展開(tar展開+gunzip)
$ cd ~/caffe/data/cifar10 $ ./get_cifar10.sh Downloading... :(中略) Saving to: ‘cifar-10-binary.tar.gz’ 100%[==================================================>] 170,052,171 2.66MB/s in 59s 2015-07-24 21:12:05 (2.73 MB/s) - ‘cifar-10-binary.tar.gz’ saved [170052171/170052171]
Unzipping... Done.
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
37
①データセットの準備
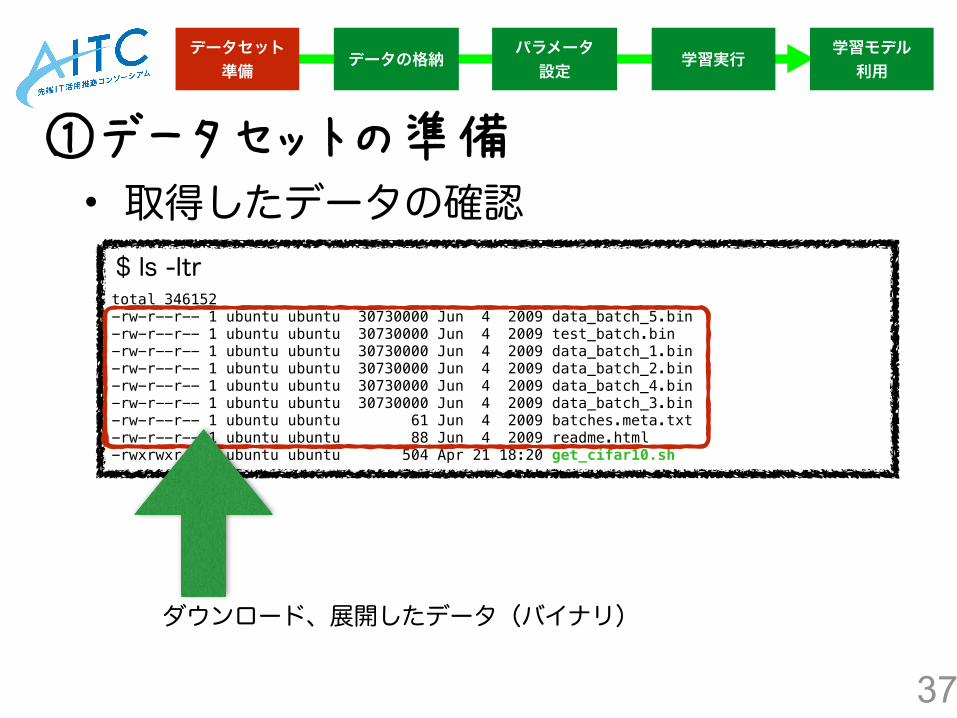
$ ls -ltr total 346152 -rw-r--r-- 1 ubuntu ubuntu 30730000 Jun 4 2009 data_batch_5.bin -rw-r--r-- 1 ubuntu ubuntu 30730000 Jun 4 2009 test_batch.bin -rw-r--r-- 1 ubuntu ubuntu 30730000 Jun 4 2009 data_batch_1.bin -rw-r--r-- 1 ubuntu ubuntu 30730000 Jun 4 2009 data_batch_2.bin -rw-r--r-- 1 ubuntu ubuntu 30730000 Jun 4 2009 data_batch_4.bin -rw-r--r-- 1 ubuntu ubuntu 30730000 Jun 4 2009 data_batch_3.bin -rw-r--r-- 1 ubuntu ubuntu 61 Jun 4 2009 batches.meta.txt -rw-r--r-- 1 ubuntu ubuntu 88 Jun 4 2009 readme.html -rwxrwxr-x 1 ubuntu ubuntu 504 Apr 21 18:20 get_cifar10.sh
ダウンロード、展開したデータ(バイナリ)
• 取得したデータの確認
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

38
$ cd ~/caffe $ ./examples/cifar10/create_cifar10.sh Creating lmdb... Computing image mean... Done.
②データの格納• 下記のコマンドを実行してください
シェルの中身 • LMDBにデータ格納(バイナリなので中身見れず) • 平均画像の作成(バイナリなので中身見れず)
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

39
②データの格納
$ ls -ltr examples/cifar10/ total 84 -rwxrwxr-x 1 ubuntu ubuntu 325 Apr 21 18:20 train_quick.sh -rwxrwxr-x 1 ubuntu ubuntu 508 Apr 21 18:20 train_full.sh -rw-rw-r-- 1 ubuntu ubuntu 5262 Apr 21 18:20 readme.md -rwxrwxr-x 1 ubuntu ubuntu 460 Apr 21 18:20 create_cifar10.sh -rw-rw-r-- 1 ubuntu ubuntu 3760 Apr 21 18:20 convert_cifar_data.cpp -rw-rw-r-- 1 ubuntu ubuntu 3088 Apr 21 18:20 cifar10_quick_train_test.prototxt -rw-rw-r-- 1 ubuntu ubuntu 859 Apr 21 18:20 cifar10_quick_solver.prototxt -rw-rw-r-- 1 ubuntu ubuntu 860 Apr 21 18:20 cifar10_quick_solver_lr1.prototxt -rw-rw-r-- 1 ubuntu ubuntu 1875 Apr 21 18:20 cifar10_quick.prototxt -rw-rw-r-- 1 ubuntu ubuntu 3122 Apr 21 18:20 cifar10_full_train_test.prototxt -rw-rw-r-- 1 ubuntu ubuntu 922 Apr 21 18:20 cifar10_full_solver.prototxt -rw-rw-r-- 1 ubuntu ubuntu 923 Apr 21 18:20 cifar10_full_solver_lr2.prototxt -rw-rw-r-- 1 ubuntu ubuntu 922 Apr 21 18:20 cifar10_full_solver_lr1.prototxt -rw-rw-r-- 1 ubuntu ubuntu 2128 Apr 21 18:20 cifar10_full.prototxt drwxr--r-- 2 ubuntu ubuntu 4096 Jul 20 08:47 cifar10_train_lmdb drwxr--r-- 2 ubuntu ubuntu 4096 Jul 20 08:47 cifar10_test_lmdb -rw-rw-r-- 1 ubuntu ubuntu 12299 Jul 20 08:47 mean.binaryproto
• 出来上がったデータファイルの確認
学習用データ格納DB、評価用データ格納DB、平均画像
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

Caffe特有な話①
40
• 学習用 / 評価用データはLMDB or LEVELDBに格納する – LEVELDB: key/valueの軽量データストア
» http://leveldb.org/
– LMDB: LEVELDBを高性能化、 pythonにバインディング
» https://lmdb.readthedocs.org/en/release/

なぜ学習用と評価用でデータを分けるか?
41
• 機械学習ではよくある手法 • 全てのデータで学習してしまうと、そのデータに最適化されてしまい、新たなデータに対応できないため

平均画像って?
42
• データセットの全画像から平均を求めたもの • 正規化(標準化)の一環
• データに偏りがあると学習の妨げになるため、分散をならすために使用
• 具体的には、データセットの画像から平均画素を引いて、標準偏差で割ることで、各成分の平均が0、分散が1とする、、など。
• 様々な正規化の手法があり、機械学習する上ではとても重要

43
③パラメータ設定
$ ls -ltr examples/cifar10 total 2372 -rwxrwxr-x 1 ubuntu ubuntu 325 Apr 21 18:20 train_quick.sh -rwxrwxr-x 1 ubuntu ubuntu 508 Apr 21 18:20 train_full.sh -rw-rw-r-- 1 ubuntu ubuntu 5262 Apr 21 18:20 readme.md -rwxrwxr-x 1 ubuntu ubuntu 460 Apr 21 18:20 create_cifar10.sh -rw-rw-r-- 1 ubuntu ubuntu 3760 Apr 21 18:20 convert_cifar_data.cpp -rw-rw-r-- 1 ubuntu ubuntu 3088 Apr 21 18:20 cifar10_quick_train_test.prototxt -rw-rw-r-- 1 ubuntu ubuntu 859 Apr 21 18:20 cifar10_quick_solver.prototxt -rw-rw-r-- 1 ubuntu ubuntu 860 Apr 21 18:20 cifar10_quick_solver_lr1.prototxt -rw-rw-r-- 1 ubuntu ubuntu 1875 Apr 21 18:20 cifar10_quick.prototxt -rw-rw-r-- 1 ubuntu ubuntu 3122 Apr 21 18:20 cifar10_full_train_test.prototxt -rw-rw-r-- 1 ubuntu ubuntu 922 Apr 21 18:20 cifar10_full_solver.prototxt -rw-rw-r-- 1 ubuntu ubuntu 923 Apr 21 18:20 cifar10_full_solver_lr2.prototxt -rw-rw-r-- 1 ubuntu ubuntu 922 Apr 21 18:20 cifar10_full_solver_lr1.prototxt -rw-rw-r-- 1 ubuntu ubuntu 2128 Apr 21 18:20 cifar10_full.prototxt drwxr--r-- 2 ubuntu ubuntu 4096 Jul 20 08:47 cifar10_train_lmdb drwxr--r-- 2 ubuntu ubuntu 4096 Jul 20 08:47 cifar10_test_lmdb -rw-rw-r-- 1 ubuntu ubuntu 12299 Jul 20 08:47 mean.binaryproto
• リファレンスモデルとして用意されているパラメータをそのまま使用 (*.prototxt)
cifar10_quick*.prototxtを使います
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

Caffe特有な話②
44
• examples/cifar10/cifar10_quick_solver.prototxt – Caffeの動作パラメータ的なメインのファイル
• 何回イテレーションするか • テストは何回毎に実施するか • スナップショット(学習モデル)は何回毎に記録するか
• CPU / GPU のモード定義 • NN構成やテストデータを記述したファイルの定義 • 開始時の学習率 / 重み遅延 … • etc..

Caffe特有な話②
45
• examples/cifar10/cifar10_quick_train_test.prototxt – DeapLearningのNN(NeuralNetwork)構成の定義 • 学習用 or テスト用のDBはどれか • NNを何層用意するか… • 各層のアルゴリズムは… • 各層のニューロン数… • etc..

Caffe特有な話②
46
• examples/cifar10/cifar10_quick.prototxt – DeapLearningのNN(NeuralNetwork)構成の定義 • cifar10_quick_train_test.prototxtと同様 • こちらは学習モデルを利用する際に使用

CIFAR-10のニューラルネットを見てみよう
47
• 今回はチュートリアルで定義されているモデルをそのまま利用しますが、機械学習を実施する前にどんな構成となっているかを見てみましょう
• ニューラルネットの構造を画像化しますが、EC2上の画像ファイルを参照できるようにHTTPサーバを立てます

CIFAR-10のニューラルネットを見てみよう
48
$ cd $ mkdir web $ cd web $ vi web_server.py #!/usr/bin/env python #coding: utf-8
import CGIHTTPServer CGIHTTPServer.test()
$ python web_server.py & [1] 12710 Serving HTTP on 0.0.0.0 port 8000 ...
• Pythonで簡易なHTTPサーバを立てます(Portはデフォルトで8000)
ファイルの中に記述

CIFAR-10のニューラルネットを見てみよう
49
• AWSのコンソールからインスタンスを選択し、セキュリティグループのリンクをクリックします
①
②
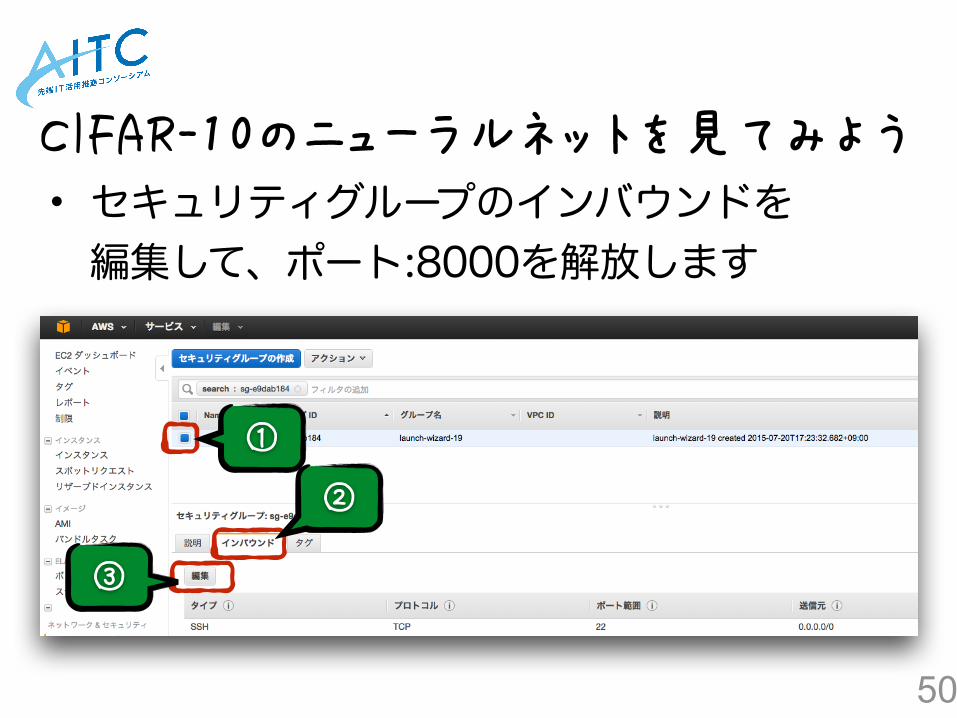
CIFAR-10のニューラルネットを見てみよう
50
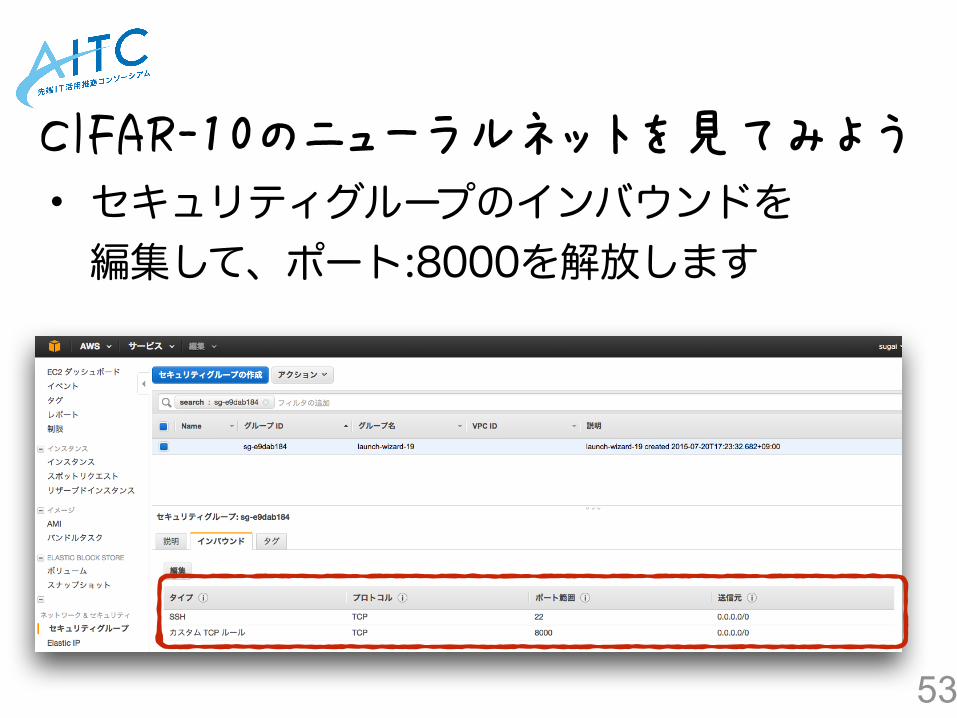
• セキュリティグループのインバウンドを編集して、ポート:8000を解放します
①
②
③

CIFAR-10のニューラルネットを見てみよう
51
• セキュリティグループのインバウンドを編集して、ポート:8000を解放します
①

CIFAR-10のニューラルネットを見てみよう
52
• セキュリティグループのインバウンドを編集して、ポート:8000を解放します
①
②
CIFAR-10のニューラルネットを見てみよう
53
• セキュリティグループのインバウンドを編集して、ポート:8000を解放します

CIFAR-10のニューラルネットを見てみよう
54
• ブラウザからポート:8000を参照できるか確認 • ドメインは自分の環境に合わせて設定してください • (セキュリティは一切考慮せず。。。)

CIFAR-10のニューラルネットを見てみよう
55
• ニューラルネットのレイヤを画像に出力します • Webから参照可能なディレクトリに画像を出力
$ sudo apt-get -y install graphviz :(省略) $ sudo pip install pydot :(省略) $ sudo pip uninstall pyparsing :(省略) $ sudo pip install -Iv https://pypi.python.org/packages/source/p/pyparsing/pyparsing-1.5.7.tar.gz :(省略) $ cd ~/caffe $ ./python/draw_net.py ./examples/cifar10/cifar10_quick.prototxt ../web/cifar10.png Drawing net to ../web/cifar10.png
※入っているpyparsingが上手く動かないので、個別に入れ直し。。。

CIFAR-10のニューラルネットを見てみよう
56
• ブラウザでアクセスすると、画像が増えています
CIFAR-10のニューラルネットを見てみよう
57
• Caffeで定義したニューラルネットの構成が確認できます
ちょっと横長で見づらいね。。。
CIFAR-10のニューラルネットを見てみよう
58
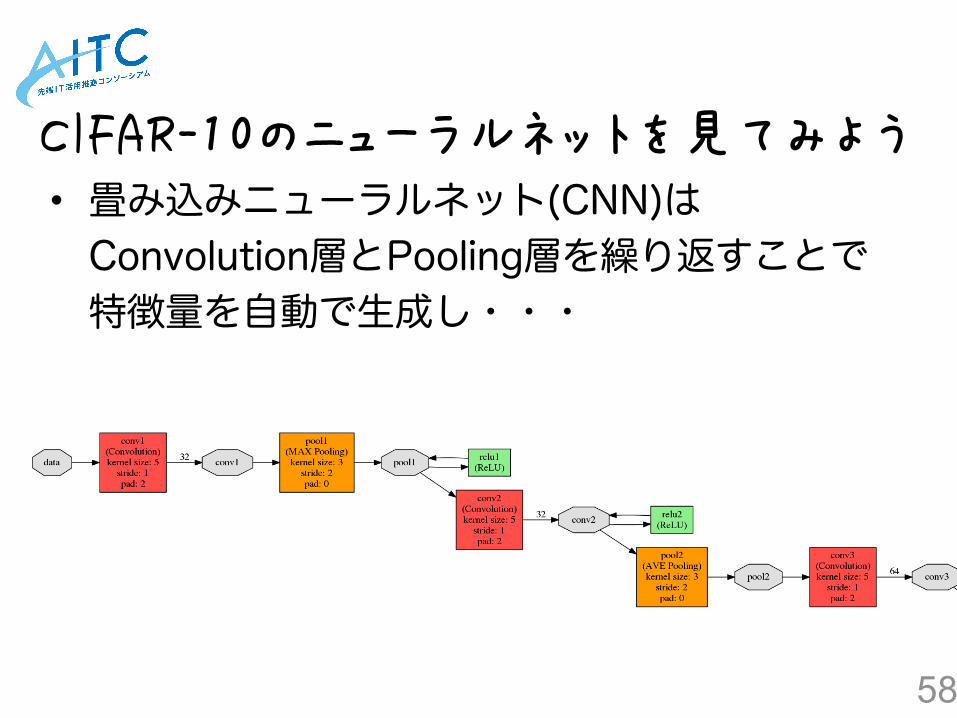
• 畳み込みニューラルネット(CNN)は Convolution層とPooling層を繰り返すことで 特徴量を自動で生成し・・・
CIFAR-10のニューラルネットを見てみよう
59
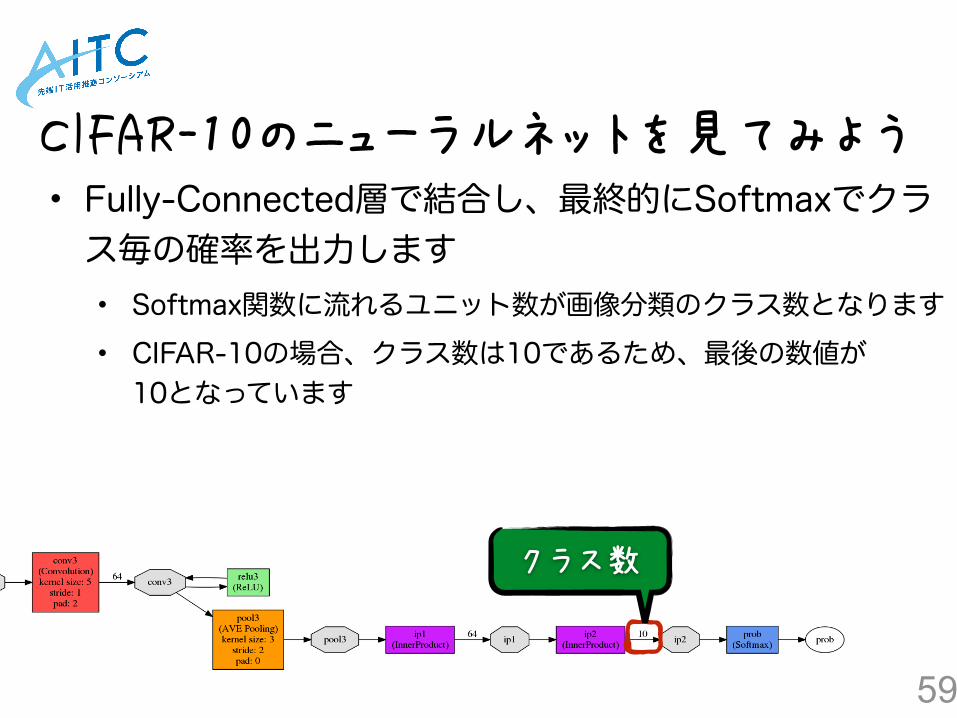
• Fully-Connected層で結合し、最終的にSoftmaxでクラス毎の確率を出力します • Softmax関数に流れるユニット数が画像分類のクラス数となります • CIFAR-10の場合、クラス数は10であるため、最後の数値が10となっています
クラス数

CIFAR-10のニューラルネットを見てみよう
60
特徴抽出 結合/識別/出力

ちょっと頑張って解説
61
• Convolution層:畳み込み層 • Pooling層:プーリング層
• 畳み込み層からプーリング層までで一纏り • ReLU(Rectified Linear Unit):正規化線形関数(活性化関数)
• プーリング層の出力で使用する活性化関数 なので、レイヤとして個別に扱わなくても。。。
• InnerProduct:所謂Fully-Connected層(全結合層) (たぶん..) • Softmax:ソフトマックス関数(活性化関数)

ちょっと頑張って解説
62
:
畳み込みフィルタ
畳み込みフィルタ
特徴抽出 結合/識別/出力
0.1
0.1
0.7
0.1
Convolution層 Pooling層 Full-Connected層 SoftmaxConvolution層 Pooling層
:::
::

63
$ cd ~/caffe $ build/tools/caffe train --solver examples/cifar10/cifar10_quick_solver.prototxt I0724 21:21:59.567821 4475 caffe.cpp:113] Use GPU with device ID 0 I0724 21:22:01.224532 4475 caffe.cpp:121] Starting Optimization I0724 21:22:01.224684 4475 solver.cpp:32] Initializing solver from parameters: test_iter: 100 test_interval: 500 base_lr: 0.001 display: 100 max_iter: 4000 lr_policy: "fixed" momentum: 0.9 weight_decay: 0.004 snapshot: 4000 snapshot_prefix: "examples/cifar10/cifar10_quick" solver_mode: GPU net: "examples/cifar10/cifar10_quick_train_test.prototxt" :(中略)
④学習実行
• ③で定義したファイルを指定し、機械学習を実行
• 下記のコマンドを実行してください
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

64
④学習実行
:(中略) I0720 09:26:33.801441 7750 solver.cpp:189] Iteration 1100, loss = 1.01867 I0720 09:26:33.801512 7750 solver.cpp:204] Train net output #0: loss = 1.01867 (* 1 = 1.01867 loss) I0720 09:26:33.801527 7750 solver.cpp:464] Iteration 1100, lr = 0.001 I0720 09:26:42.208279 7750 solver.cpp:189] Iteration 1200, loss = 1.0143 I0720 09:26:42.208398 7750 solver.cpp:204] Train net output #0: loss = 1.0143 (* 1 = 1.0143 loss) I0720 09:26:42.208413 7750 solver.cpp:464] Iteration 1200, lr = 0.001 I0720 09:26:50.614888 7750 solver.cpp:189] Iteration 1300, loss = 0.932997 I0720 09:26:50.614959 7750 solver.cpp:204] Train net output #0: loss = 0.932997 (* 1 = 0.932997 loss) I0720 09:26:50.614974 7750 solver.cpp:464] Iteration 1300, lr = 0.001 I0720 09:26:59.020402 7750 solver.cpp:189] Iteration 1400, loss = 0.881796 I0720 09:26:59.020475 7750 solver.cpp:204] Train net output #0: loss = 0.881796 (* 1 = 0.881796 loss) I0720 09:26:59.020490 7750 solver.cpp:464] Iteration 1400, lr = 0.001 I0720 09:27:07.344590 7750 solver.cpp:266] Iteration 1500, Testing net (#0) I0720 09:27:10.201467 7750 solver.cpp:315] Test net output #0: accuracy = 0.6719 I0720 09:27:10.201541 7750 solver.cpp:315] Test net output #1: loss = 0.967036 (* 1 = 0.967036 loss) I0720 09:27:10.245405 7750 solver.cpp:189] Iteration 1500, loss = 0.920801 I0720 09:27:10.245442 7750 solver.cpp:204] Train net output #0: loss = 0.920801 (* 1 = 0.920801 loss) :(中略)
• しばらくすると、こんな感じの標準出力が行われます
500回毎のテスト結果 accuracy = 0.6719 67.19%の正解率
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
accuracy : どれだけの精度か(正解率) loss : 予測と正解が一致すると小さくなる

65
④学習実行
:(中略) I0724 21:27:42.383982 4475 solver.cpp:464] Iteration 3800, lr = 0.001 I0724 21:27:50.766244 4475 solver.cpp:189] Iteration 3900, loss = 0.72959 I0724 21:27:50.766304 4475 solver.cpp:204] Train net output #0: loss = 0.72959 (* 1 = 0.72959 loss) I0724 21:27:50.766317 4475 solver.cpp:464] Iteration 3900, lr = 0.001 I0724 21:27:59.108741 4475 solver.cpp:334] Snapshotting to examples/cifar10/cifar10_quick_iter_4000.caffemodel I0724 21:27:59.111134 4475 solver.cpp:342] Snapshotting solver state to examples/cifar10/cifar10_quick_iter_4000.solverstate I0724 21:27:59.140338 4475 solver.cpp:248] Iteration 4000, loss = 0.641892 I0724 21:27:59.140404 4475 solver.cpp:266] Iteration 4000, Testing net (#0) I0724 21:28:01.943065 4475 solver.cpp:315] Test net output #0: accuracy = 0.712 I0724 21:28:01.943125 4475 solver.cpp:315] Test net output #1: loss = 0.844847 (* 1 = 0.844847 loss) I0724 21:28:01.943140 4475 solver.cpp:253] Optimization Done. I0724 21:28:01.943148 4475 caffe.cpp:134] Optimization Done.
• 最終的にこんな感じの出力になります
4000回のイテレーションの結果、71.2%の正解率
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
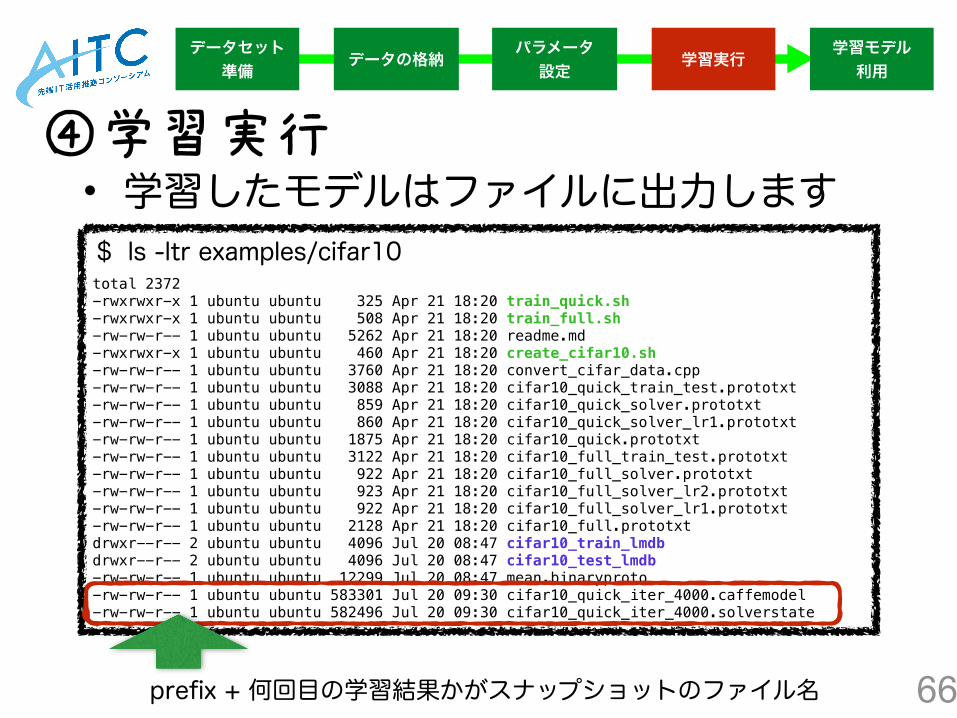
66
$ ls -ltr examples/cifar10 total 2372 -rwxrwxr-x 1 ubuntu ubuntu 325 Apr 21 18:20 train_quick.sh -rwxrwxr-x 1 ubuntu ubuntu 508 Apr 21 18:20 train_full.sh -rw-rw-r-- 1 ubuntu ubuntu 5262 Apr 21 18:20 readme.md -rwxrwxr-x 1 ubuntu ubuntu 460 Apr 21 18:20 create_cifar10.sh -rw-rw-r-- 1 ubuntu ubuntu 3760 Apr 21 18:20 convert_cifar_data.cpp -rw-rw-r-- 1 ubuntu ubuntu 3088 Apr 21 18:20 cifar10_quick_train_test.prototxt -rw-rw-r-- 1 ubuntu ubuntu 859 Apr 21 18:20 cifar10_quick_solver.prototxt -rw-rw-r-- 1 ubuntu ubuntu 860 Apr 21 18:20 cifar10_quick_solver_lr1.prototxt -rw-rw-r-- 1 ubuntu ubuntu 1875 Apr 21 18:20 cifar10_quick.prototxt -rw-rw-r-- 1 ubuntu ubuntu 3122 Apr 21 18:20 cifar10_full_train_test.prototxt -rw-rw-r-- 1 ubuntu ubuntu 922 Apr 21 18:20 cifar10_full_solver.prototxt -rw-rw-r-- 1 ubuntu ubuntu 923 Apr 21 18:20 cifar10_full_solver_lr2.prototxt -rw-rw-r-- 1 ubuntu ubuntu 922 Apr 21 18:20 cifar10_full_solver_lr1.prototxt -rw-rw-r-- 1 ubuntu ubuntu 2128 Apr 21 18:20 cifar10_full.prototxt drwxr--r-- 2 ubuntu ubuntu 4096 Jul 20 08:47 cifar10_train_lmdb drwxr--r-- 2 ubuntu ubuntu 4096 Jul 20 08:47 cifar10_test_lmdb -rw-rw-r-- 1 ubuntu ubuntu 12299 Jul 20 08:47 mean.binaryproto -rw-rw-r-- 1 ubuntu ubuntu 583301 Jul 20 09:30 cifar10_quick_iter_4000.caffemodel -rw-rw-r-- 1 ubuntu ubuntu 582496 Jul 20 09:30 cifar10_quick_iter_4000.solverstate
④学習実行• 学習したモデルはファイルに出力します
prefix + 何回目の学習結果かがスナップショットのファイル名
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

$ ls -ltr /tmp total 124 -rw-rw-r-- 1 ubuntu ubuntu 832 Jul 20 08:42 convert_cifar_data.bin.ip-10-123-220-57.ubuntu.log.INFO.20150720-084140.1490 -rw-rw-r-- 1 ubuntu ubuntu 1134 Jul 20 08:42 compute_image_mean.ip-10-123-220-57.ubuntu.log.INFO.20150720-084223.1491 lrwxrwxrwx 1 ubuntu ubuntu 76 Jul 20 08:47 convert_cifar_data.bin.INFO -> convert_cifar_data.bin.ip-10-123-220-57.ubuntu.log.INFO.20150720-084700.1495 -rw-rw-r-- 1 ubuntu ubuntu 832 Jul 20 08:47 convert_cifar_data.bin.ip-10-123-220-57.ubuntu.log.INFO.20150720-084700.1495 lrwxrwxrwx 1 ubuntu ubuntu 72 Jul 20 08:47 compute_image_mean.INFO -> compute_image_mean.ip-10-123-220-57.ubuntu.log.INFO.20150720-084741.1496 -rw-rw-r-- 1 ubuntu ubuntu 1134 Jul 20 08:47 compute_image_mean.ip-10-123-220-57.ubuntu.log.INFO.20150720-084741.1496 -rw-rw-r-- 1 ubuntu ubuntu 35406 Jul 20 09:15 caffe.ip-10-123-220-57.ubuntu.log.INFO.20150720-090857.1524 -rw-rw-r-- 1 ubuntu ubuntu 26593 Jul 20 09:16 caffe.ip-10-123-220-57.ubuntu.log.INFO.20150720-091503.6440 lrwxrwxrwx 1 ubuntu ubuntu 59 Jul 20 09:24 caffe.INFO -> caffe.ip-10-123-220-57.ubuntu.log.INFO.20150720-092452.7750 -rw-rw-r-- 1 ubuntu ubuntu 35412 Jul 20 09:30 caffe.ip-10-123-220-57.ubuntu.log.INFO.20150720-092452.7750
67
④学習実行• ちなみに標準出力を見逃した!コンソール閉じた!という時でも安心、/tmpに結果が出力されています
ファイルで残っているので、結果を加工しやすい ファイル名は随時変わるけど、caffe.INFOでシンボリックリンク張られるので便利
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
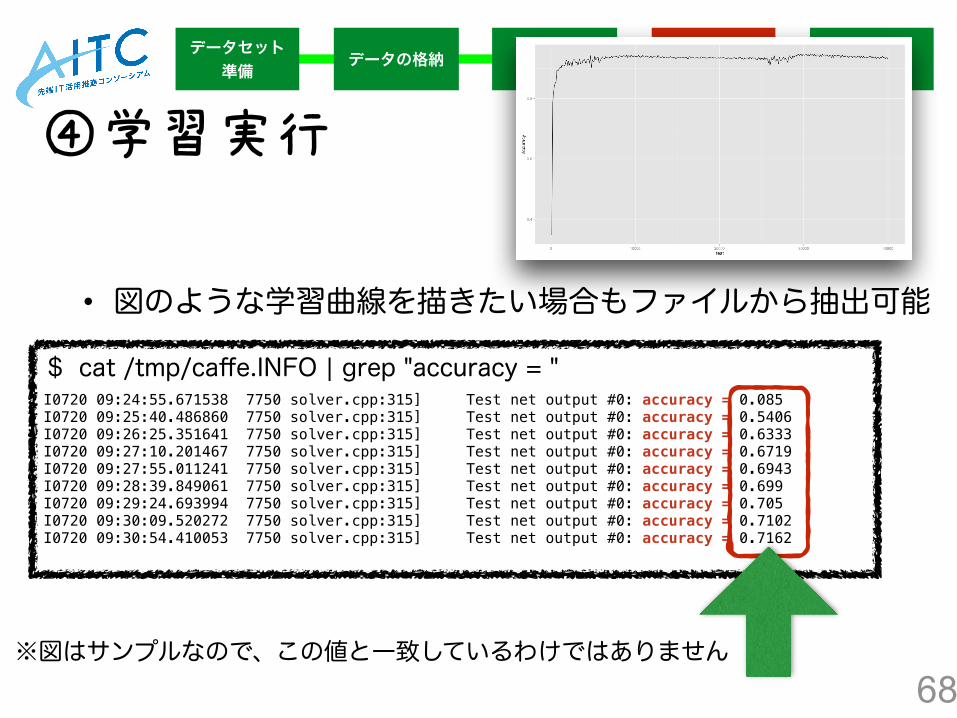
$ cat /tmp/caffe.INFO | grep "accuracy = " I0720 09:24:55.671538 7750 solver.cpp:315] Test net output #0: accuracy = 0.085 I0720 09:25:40.486860 7750 solver.cpp:315] Test net output #0: accuracy = 0.5406 I0720 09:26:25.351641 7750 solver.cpp:315] Test net output #0: accuracy = 0.6333 I0720 09:27:10.201467 7750 solver.cpp:315] Test net output #0: accuracy = 0.6719 I0720 09:27:55.011241 7750 solver.cpp:315] Test net output #0: accuracy = 0.6943 I0720 09:28:39.849061 7750 solver.cpp:315] Test net output #0: accuracy = 0.699 I0720 09:29:24.693994 7750 solver.cpp:315] Test net output #0: accuracy = 0.705 I0720 09:30:09.520272 7750 solver.cpp:315] Test net output #0: accuracy = 0.7102 I0720 09:30:54.410053 7750 solver.cpp:315] Test net output #0: accuracy = 0.7162
68
④学習実行
• 図のような学習曲線を描きたい場合もファイルから抽出可能
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
※図はサンプルなので、この値と一致しているわけではありません

69
⑤学習モデルの利用• 学習したモデルを基に、画像を分類してみようかと思います
• 画像はWebにある画像を使うのですが、安易に適当なファイルをスライドに張ると怒られそうなので、画像の探し方を考えてみます
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

使って良さそうな画像の探し方
70
• CIFAR-10のクラスにある、カエルの画像を探します • Googleの画像検索で検索条件を入れ、検索ツールからライセンスを指定すると、改変や再利用可能な画像を探せます(ライセンスの取り扱いは自己責任で。。)

使って良さそうな画像の探し方
71
• 良さ気な画像を見つけたら、画像をクリックすると下記のような画面になるので、「画像を表示」を選択します

使って良さそうな画像の探し方
72
• 画像のURLが確認できるので、このURLを利用してEC2上に画像を配置し、分類を試していきます
• 引用元URLの表記は、スライド内に全て記載済みです

73
⑤学習モデルの利用• 前スライドまで見ていたカエルの画像をEC2上に取り込みます
$ cd $ wget https://upload.wikimedia.org/wikipedia/commons/4/49/Green_treefrog.jpg $ ls -ltr total 2112 -rw-rw-r-- 1 ubuntu ubuntu 2143384 Oct 5 2013 Green_treefrog.jpg -rwx--x--x 1 ubuntu ubuntu 2175 Apr 21 18:19 aws1404.sh drwxrwxr-x 16 ubuntu ubuntu 4096 Apr 21 18:43 caffe drwxr-xr-x 2 root root 4096 Apr 21 20:20 data
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

74
⑤学習モデルの利用• 画像分類を実行するため、Pythonでプログラムを記述します(Caffeに用意されているのがうまく動かなかったので。。)
$ cd $ vi cifar10_classifier.py
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

75
import sys import caffe from caffe.proto import caffe_pb2 import numpy
cifar_map = { 0: "airplane", 1: "automobile", 2: "bird", 3: "cat", 4: "deer", 5: "dog", 6: "frog", 7: "hourse", 8: "ship", 9: "truck" }
mean_blob = caffe_pb2.BlobProto() with open('caffe/examples/cifar10/mean.binaryproto') as f: mean_blob.ParseFromString(f.read())
mean_array = numpy.asarray(mean_blob.data, dtype=numpy.float32).reshape( (mean_blob.channels, mean_blob.height, mean_blob.width) )
classifier = caffe.Classifier( 'caffe/examples/cifar10/cifar10_quick.prototxt', 'caffe/examples/cifar10/cifar10_quick_iter_4000.caffemodel', mean=mean_array, raw_scale=255)
image = caffe.io.load_image(sys.argv[1]) predictions = classifier.predict([image], oversample=False) answer = numpy.argmax(predictions) print(predictions) print(str(answer) + ":" + cifar_map[answer])
cifar10_classifier.py

76
⑤学習モデルの利用
$ wget https://dl.dropboxusercontent.com/u/8148946/Develop/aws/cifar10_classifier.py
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
• プログラムがうまくコピペできない方向けに、Dropboxにも同じものを置いてあります
• めんどくさい人はこちらでもOKです
pythonの場合、インデントがずれるとエラーになるので、コピペだと難しいかもしれません。。 改行もPDFだと怪しいかも。。 ※元ファイルは消してから実行してください

77
⑤学習モデルの利用• 画像分類を試してみましょう
$ python cifar10_classifier.py Green_treefrog.jpg :(省略) [[ 4.74744802e-03 2.51210417e-06 7.85273733e-05 3.28274607e-03 5.87507930e-06 2.04037860e-05 9.91847277e-01 1.77818379e-07 3.59641581e-06 1.14896684e-05]] 6:frog
クラス毎に、そのクラスである確率を表示(指数表記) 6番目=frogである確率が、99.184………%1と最も高い
最も確率が高いものを出力
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

78
⑤学習モデルの利用• 他のファイルでも試してみましょう
$ wget https://upload.wikimedia.org/wikipedia/commons/9/9b/Deaf_odd_eye_white_cat_sebastian.jpg $ python cifar10_classifier.py Deaf_odd_eye_white_cat_sebastian.jpg
$ wget https://upload.wikimedia.org/wikipedia/commons/7/75/Yonaguniuma.jpg $ python cifar10_classifier.py Yonaguniuma.jpg
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

Caffe やって!Try編
79

Tutorialだけだと、身についた感が足りないので、データセットを用意して
一通りの流れを試していきます
80

81
事前準備• CIFAR-10は汎用的に画像分類として利用できるモデルなので、これを真似して使います
• そのため作業用ディレクトリはCIFAR-10をコピーして用意しておきます$ cd ~/caffe/examples $ cp -pr cifar10 handson $ ls -ltr total 2832 -rw-rw-r-- 1 ubuntu ubuntu 1063 Apr 21 18:20 CMakeLists.txt -rw-rw-r-- 1 ubuntu ubuntu 240557 Apr 21 18:20 classification.ipynb drwxrwxr-x 2 ubuntu ubuntu 4096 Apr 21 18:20 feature_extraction -rw-rw-r-- 1 ubuntu ubuntu 623219 Apr 21 18:20 detection.ipynb -rw-rw-r-- 1 ubuntu ubuntu 994307 Apr 21 18:20 filter_visualization.ipynb drwxrwxr-x 2 ubuntu ubuntu 4096 Apr 21 18:20 finetune_pascal_detection drwxrwxr-x 2 ubuntu ubuntu 4096 Apr 21 18:20 finetune_flickr_style drwxrwxr-x 2 ubuntu ubuntu 4096 Apr 21 18:20 mnist drwxrwxr-x 2 ubuntu ubuntu 4096 Apr 21 18:20 images drwxrwxr-x 2 ubuntu ubuntu 4096 Apr 21 18:20 imagenet -rw-rw-r-- 1 ubuntu ubuntu 467938 Apr 21 18:20 hdf5_classification.ipynb drwxrwxr-x 2 ubuntu ubuntu 4096 Apr 21 18:20 hdf5_classification -rw-rw-r-- 1 ubuntu ubuntu 511846 Apr 21 18:20 net_surgery.ipynb drwxrwxr-x 2 ubuntu ubuntu 4096 Apr 21 18:20 net_surgery drwxrwxr-x 3 ubuntu ubuntu 4096 Apr 21 18:20 web_demo drwxrwxr-x 2 ubuntu ubuntu 4096 Apr 21 18:20 siamese drwxrwxr-x 4 ubuntu ubuntu 4096 Jul 24 21:27 handson drwxrwxr-x 4 ubuntu ubuntu 4096 Jul 24 21:27 cifar10

82
①データセットの準備• 自分でCaffeの動作を試そうとすると、一番頭を悩ませるのがデータセットに何を使うか、、ですね。。
• Googleの画像検索でライセンスフリーのものを探しても、そこまでの数の画像を用意できないため、あまり使い物になりません。。
• ImageNetには大量のデータがあるのですが、今回は使えないので。。。
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

LFW (Labeled Face in the Wild)
http://vis-www.cs.umass.edu/lfw/
• 研究用に作成された、著名人がラベル付けされた画像集 – 1万枚以上の画像が収録 – 一人あたりの画像枚数は少なめ
• ちなみに、過去の自宅警備員でも利用したデータ83

84
①データセットの準備• 今回はLFWのデータを使って、男女の顔画像を分類することにチャレンジしていきます
• ちなみに、LFWのデータそのままだと精度が悪いので、事前にデータをクレンジングしたものを用意しました • 不鮮明なデータの排除 • 顔部分の抽出 • 教師データとして、男性、女性を事前に分類
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

85
• クレンジング済みデータはDropboxに置いてあるので、ダウンロードしてください
①データセットの準備
$ cd $ wget https://dl.dropboxusercontent.com/u/8148946/Develop/aws/lfw3.zip : (省略)
$ sudo apt-get -y install unzip : (省略)
$ unzip lfw3.zip :(中略) inflating: lfw3/woman/Zhang_Ziyi_0002.jpg inflating: lfw3/woman/Zhang_Ziyi_0003.jpg inflating: lfw3/woman/Zhang_Ziyi_0004.jpg inflating: lfw3/woman/Zoe_Ball_0001.jpg inflating: lfw3/woman/Zorica_Radovic_0001.jpg $ cd lfw3
• 何故かunzipが無かったので入れます。。。
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

86
• 画像ファイルは man / womanディレクトリにそれぞれ分類して配置していますが、男性の方が画像が3倍以上あります
①データセットの準備
$ ls -ltr man | wc 8560 77033 585263 $ ls -ltr woman | wc 2574 23159 177992
• 分類するクラス毎に画像の枚数が著しく異なると、学習結果の精度が悪くなります • そのため、男性の画像は1/3を利用することにします (基画像を消すのではなく、DB格納時にサンプリング)
• 後で出てくるDB格納時のプログラムを見ると、削っている箇所がわかるので 時間があれば画像枚数が異なる状態で実施して結果がどうなるか試してください
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

87
• 画像はサイズがマチマチだったり、コントラストが効いてたりで、このまま学習に使うと精度が悪いので正規化していきます
①データセットの準備
$ sudo apt-get -y install imagemagick $ mogrify -equalize */*.jpg $ mogrify -geometry 32x32 */*.jpg
• 正規化にはImageMagickを利用しています • equalize : 画像のヒストグラム均等化 • geometry : サイズ変更 32x32px
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
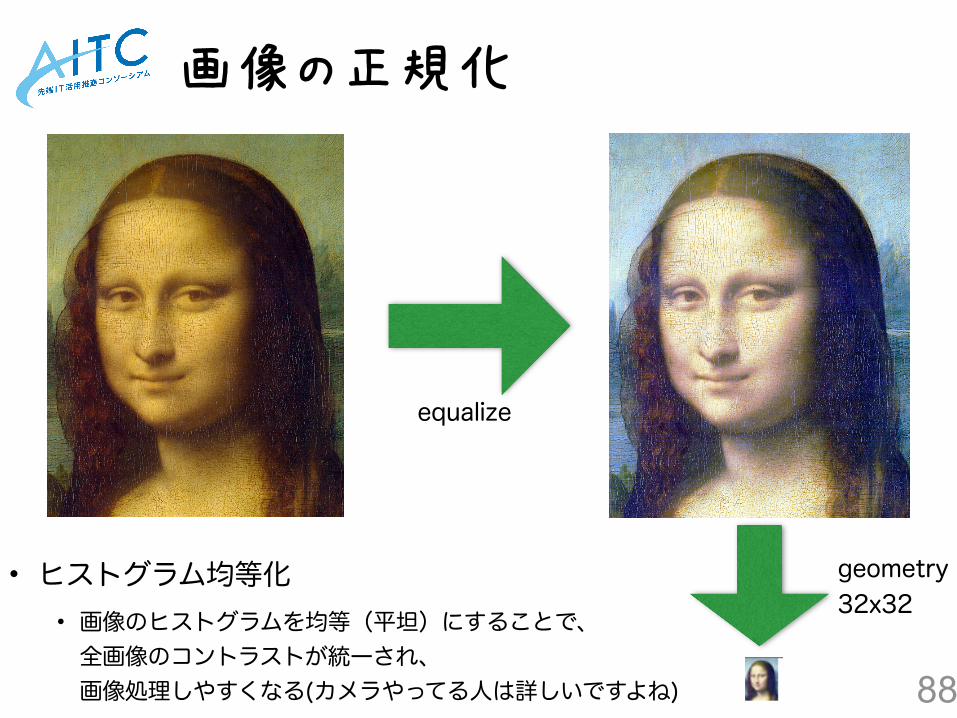
88
画像の正規化
equalize
geometry 32x32
• ヒストグラム均等化 • 画像のヒストグラムを均等(平坦)にすることで、全画像のコントラストが統一され、画像処理しやすくなる(カメラやってる人は詳しいですよね)

89
• 正規化済みの画像データをLMDBに格納します • 手作業では無理なので、pythonで書き込みます
②データの格納
$ vi create_lmdb.py
• 学習用データと評価用データは6:1の割合で振り分けています
• 何やっているかわかりやすいようにプログラムは冗長に書いています。。(という言い訳。。。)
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

90
import os
import caffe import lmdb
from caffe.proto import caffe_pb2 import numpy import PIL.Image import random
IMAGE_SIZE = 32
def make_datum(image, label): return caffe_pb2.Datum( channels=3, width=IMAGE_SIZE, height=IMAGE_SIZE, label=label, data=numpy.rollaxis(numpy.asarray(image), 2).tostring())
train_lmdb = '/home/ubuntu/caffe/examples/handson/handson_train_lmdb' test_lmdb = '/home/ubuntu/caffe/examples/handson/handson_test_lmdb'
os.system('rm -rf '+train_lmdb) os.system('rm -rf '+test_lmdb)
print 'filepaths'
label_file_map = {} filepaths = [] for dirpath, _, filenames in os.walk('./man'): for idx, filename in enumerate(filenames): if filename.endswith(('.png', '.jpg')): if idx % 3 == 0 : continue
file = os.path.join(dirpath, filename) filepaths.append(file) label_file_map[file] = 0 print file for dirpath, _, filenames in os.walk('./woman'): for filename in filenames: if filename.endswith(('.png', '.jpg')): file = os.path.join(dirpath, filename) filepaths.append(file) label_file_map[file] = 1 print file
random.shuffle(filepaths)
print 'train'
in_db = lmdb.open(train_lmdb, map_size=int(1e12)) with in_db.begin(write=True) as in_txn: for in_idx, file in enumerate(filepaths): if in_idx % 6 == 0 : continue
image = PIL.Image.open(file) datum = make_datum(image, label_file_map[file]) in_txn.put('{:0>5d}'.format(in_idx), datum.SerializeToString()) print '{:0>5d}'.format(in_idx) + ':' + file in_db.close()
print 'test'
in_db = lmdb.open(test_lmdb, map_size=int(1e12)) with in_db.begin(write=True) as in_txn: for in_idx, file in enumerate(filepaths): if in_idx % 6 != 0 : continue
image = PIL.Image.open(file) datum = make_datum(image, label_file_map[file]) in_txn.put('{:0>5d}'.format(in_idx), datum.SerializeToString()) print '{:0>5d}'.format(in_idx) + ':' + file in_db.close()
※長いので分けましたが、 一つのファイルです左をコピペした後、 その下に右をコピペしてください
create_lmdb.py

91
• プログラムがうまくコピペできない方向けに、Dropboxにも同じものを置いてあります
• めんどくさい人はこちらでもOKです
pythonの場合、インデントがずれるとエラーになるので、コピペだと難しいかもしれません。。 改行もPDFだと怪しいかも。。 ※元ファイルは消してから実行してください
$ wget https://dl.dropboxusercontent.com/u/8148946/develop/aws/create_lmdb.py
②データの格納
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

92
• 重要そうなところを補足 • プログラムの下記部分について
②データの格納
return caffe_pb2.Datum( channels=3, width=IMAGE_SIZE, height=IMAGE_SIZE, label=label, data=numpy.rollaxis(numpy.asarray(image), 2).tostring())
• channels : RGBの3色のカラー画像なので、3を指定 • labelで : クラスを示す値を指定
• 今回の場合: man = 0 / woman = 1
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

93
• プログラムを実行してLMDBに画像を格納します
②データの格納
$ sudo pip install lmdb : (省略) $ python create_lmdb.py filepaths ./man/Gunter_Pleuger_0002.jpg ./man/Adolfo_Aguilar_Zinser_0003.jpg ./man/Will_Young_0001.jpg ./man/Paul_Bremer_0011.jpg :(中略) 08256:./woman/Caroline_Kennedy_0001.jpg 08262:./woman/Elizabeth_Berkeley_0001.jpg 08268:./man/Howard_Dean_0001.jpg 08274:./man/Ken_Watanabe_0002.jpg
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

94
• 出来上がったDBを確認します②データの格納
$ ls -ltr ~/caffe/examples/handson total 1236 -rwxrwxr-x 1 ubuntu ubuntu 325 Apr 21 18:20 train_quick.sh -rwxrwxr-x 1 ubuntu ubuntu 508 Apr 21 18:20 train_full.sh -rw-rw-r-- 1 ubuntu ubuntu 5262 Apr 21 18:20 readme.md -rwxrwxr-x 1 ubuntu ubuntu 460 Apr 21 18:20 create_cifar10.sh -rw-rw-r-- 1 ubuntu ubuntu 3760 Apr 21 18:20 convert_cifar_data.cpp -rw-rw-r-- 1 ubuntu ubuntu 3088 Apr 21 18:20 cifar10_quick_train_test.prototxt -rw-rw-r-- 1 ubuntu ubuntu 859 Apr 21 18:20 cifar10_quick_solver.prototxt -rw-rw-r-- 1 ubuntu ubuntu 860 Apr 21 18:20 cifar10_quick_solver_lr1.prototxt -rw-rw-r-- 1 ubuntu ubuntu 1875 Apr 21 18:20 cifar10_quick.prototxt -rw-rw-r-- 1 ubuntu ubuntu 3122 Apr 21 18:20 cifar10_full_train_test.prototxt -rw-rw-r-- 1 ubuntu ubuntu 922 Apr 21 18:20 cifar10_full_solver.prototxt -rw-rw-r-- 1 ubuntu ubuntu 923 Apr 21 18:20 cifar10_full_solver_lr2.prototxt -rw-rw-r-- 1 ubuntu ubuntu 922 Apr 21 18:20 cifar10_full_solver_lr1.prototxt -rw-rw-r-- 1 ubuntu ubuntu 2128 Apr 21 18:20 cifar10_full.prototxt drwxr--r-- 2 ubuntu ubuntu 4096 Jul 24 21:15 cifar10_train_lmdb drwxr--r-- 2 ubuntu ubuntu 4096 Jul 24 21:16 cifar10_test_lmdb -rw-rw-r-- 1 ubuntu ubuntu 12299 Jul 24 21:16 mean.binaryproto -rw-rw-r-- 1 ubuntu ubuntu 582496 Jul 24 21:27 cifar10_quick_iter_4000.solverstate -rw-rw-r-- 1 ubuntu ubuntu 583301 Jul 24 21:27 cifar10_quick_iter_4000.caffemodel drwxr-xr-x 2 ubuntu ubuntu 4096 Jul 24 22:16 handson_train_lmdb drwxr-xr-x 2 ubuntu ubuntu 4096 Jul 24 22:16 handson_test_lmdb
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

95
• ファイルができているだけだと不安なので、 DBにちゃんとレコードが書き込まれているか 読み込んでみます
②データの格納
$ vi read_lmdb.py import caffe import lmdb import numpy as np from caffe.proto import caffe_pb2
lmdb_env = lmdb.open('/home/ubuntu/caffe/examples/handson/handson_train_lmdb') lmdb_txn = lmdb_env.begin() lmdb_cursor = lmdb_txn.cursor() datum = caffe_pb2.Datum()
for key, value in lmdb_cursor: datum.ParseFromString(value)
label = datum.label data = caffe.io.datum_to_array(datum) print str(key) +':'+str(label)
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

96
• プログラムがうまくコピペできない方向けに、Dropboxにも同じものを置いてあります
• めんどくさい人はこちらでもOKです
pythonの場合、インデントがずれるとエラーになるので、コピペだと難しいかもしれません。。 改行もPDFだと怪しいかも。。 ※元ファイルは消してから実行してください
$ wget https://dl.dropboxusercontent.com/u/8148946/develop/aws/read_lmdb.py
②データの格納
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
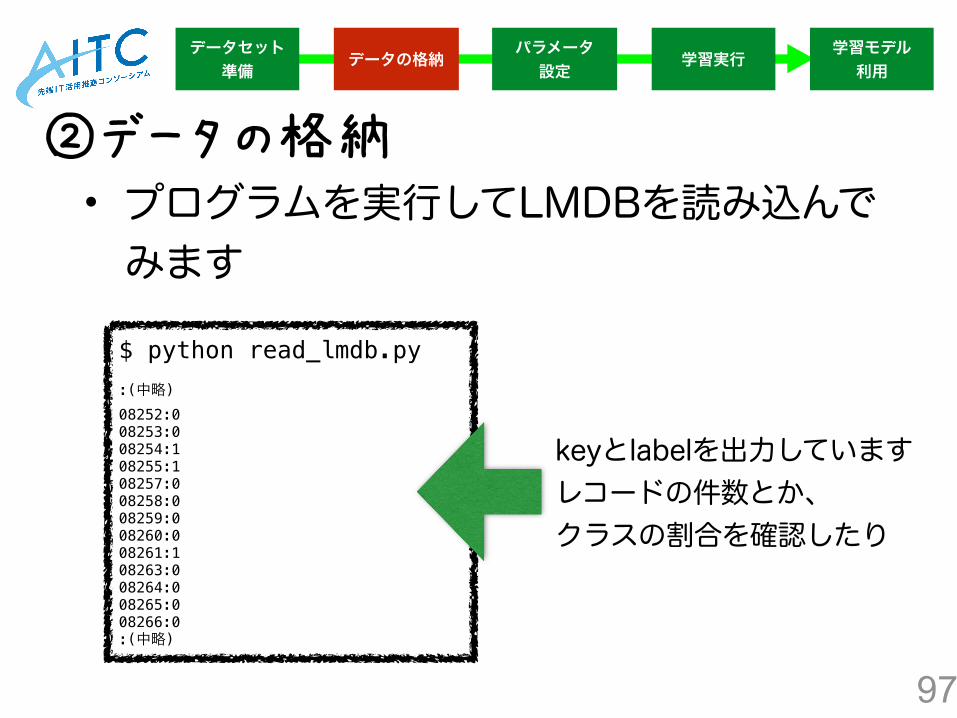
97
• プログラムを実行してLMDBを読み込んでみます
②データの格納
$ python read_lmdb.py :(中略) 08252:0 08253:0 08254:1 08255:1 08257:0 08258:0 08259:0 08260:0 08261:1 08263:0 08264:0 08265:0 08266:0 :(中略)
keyとlabelを出力しています レコードの件数とか、クラスの割合を確認したり
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

98
• 前処理(正規化・標準化)の一環として、作成したDBを使って平均画像を生成しましょう
• 平均画像作成用に用意された、Caffeのツールを利用します
$ cd ~/caffe $ build/tools/compute_image_mean -backend=lmdb \ examples/handson/handson_train_lmdb examples/handson/mean.binaryproto
②データの格納
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

99
• CIFAR-10のパラメータを基に、書き換えていきます
③パラメータ設定
$ cd ~/caffe/examples/handson
• ディレクトリごとコピーしているため、前のファイルは残っているのですが、ファイル名とか紛らわしいので必要なファイルをコピーしながら書き換えていきます
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

# reduce the learning rate after 8 epochs (4000 iters) by a factor of 10
# The train/test net protocol buffer definition net: "examples/handson/handson_quick_train_test.prototxt" # test_iter specifies how many forward passes the test should carry out. # In the case of MNIST, we have test batch size 100 and 100 test iterations, # covering the full 10,000 testing images. test_iter: 100 # Carry out testing every 500 training iterations. test_interval: 500 # The base learning rate, momentum and the weight decay of the network. base_lr: 0.001 momentum: 0.9 weight_decay: 0.004 # The learning rate policy lr_policy: "fixed" # Display every 100 iterations display: 100 # The maximum number of iterations max_iter: 4000 # snapshot intermediate results snapshot: 4000 snapshot_prefix: "examples/handson/handson_quick" # solver mode: CPU or GPU
100
• cifar10_quick_solver.prototxt③パラメータ設定
$ cp -p cifar10_quick_solver.prototxt handson_quick_solver.prototxt $ vi handson_quick_solver.prototxt
パスの変更
:%s/cifar10/handson/g でもいいかも
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
101
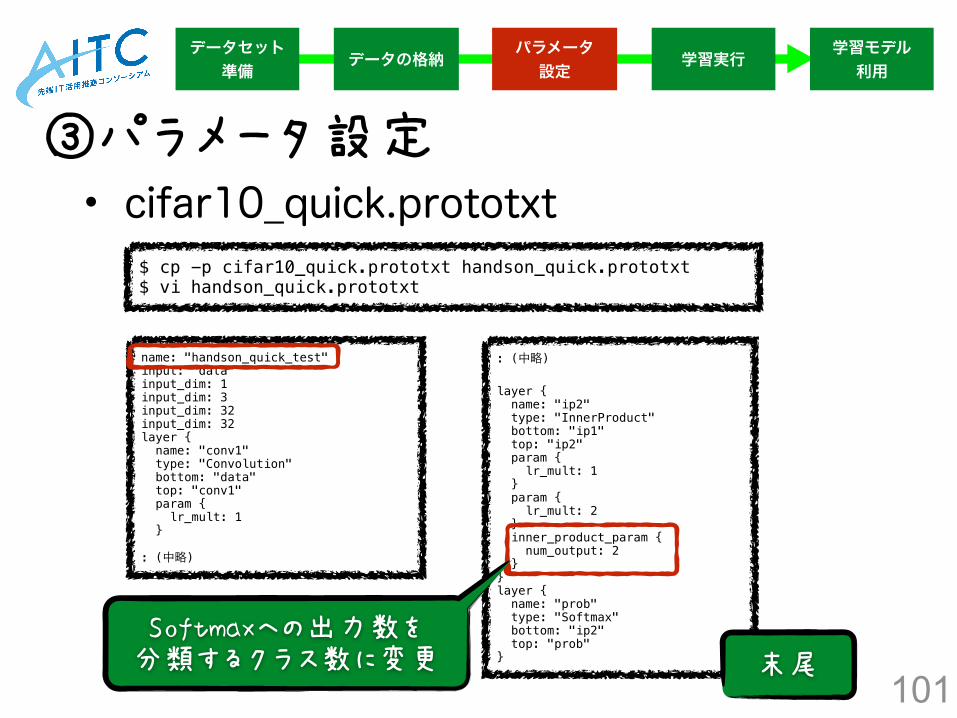
• cifar10_quick.prototxt③パラメータ設定
$ cp -p cifar10_quick.prototxt handson_quick.prototxt $ vi handson_quick.prototxt
name: "handson_quick_test" input: "data" input_dim: 1 input_dim: 3 input_dim: 32 input_dim: 32 layer { name: "conv1" type: "Convolution" bottom: "data" top: "conv1" param { lr_mult: 1 }
: (中略)
: (中略)
layer { name: "ip2" type: "InnerProduct" bottom: "ip1" top: "ip2" param { lr_mult: 1 } param { lr_mult: 2 } inner_product_param { num_output: 2 } } layer { name: "prob" type: "Softmax" bottom: "ip2" top: "prob" }
Softmaxへの出力数を 分類するクラス数に変更
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
末尾
102
• cifar10_quick_train_test.prototxt③パラメータ設定
$ cp -p cp -p cifar10_quick_train_test.prototxt handson_quick_train_test.prototxt $ vi handson_quick_train_test.prototxt
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
• 修正箇所がやや多いので、次スライドで
103
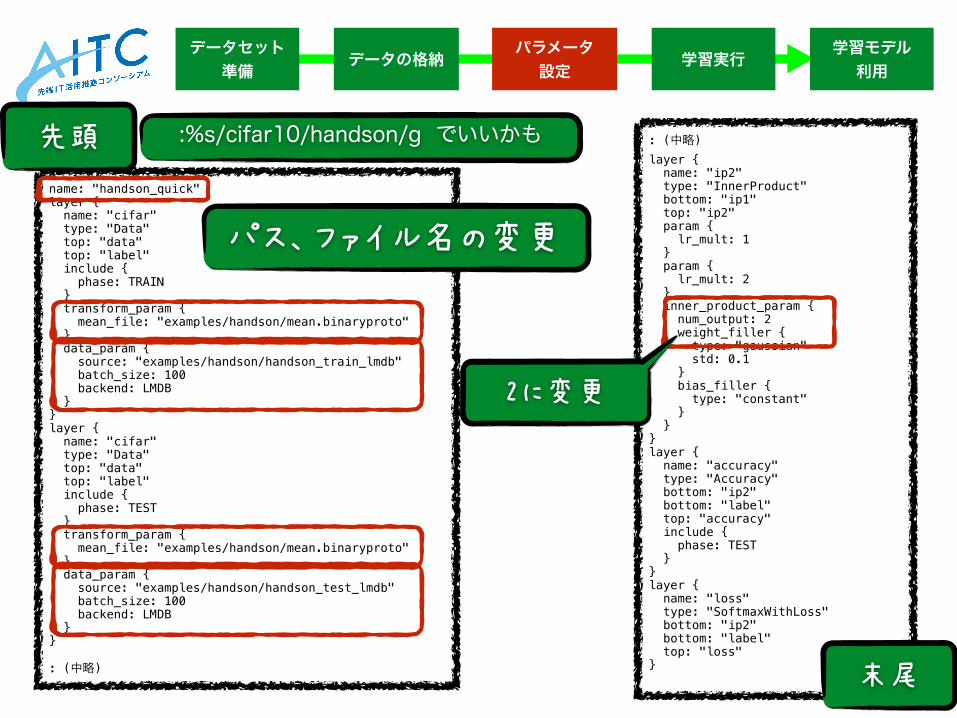
name: "handson_quick" layer { name: "cifar" type: "Data" top: "data" top: "label" include { phase: TRAIN } transform_param { mean_file: "examples/handson/mean.binaryproto" } data_param { source: "examples/handson/handson_train_lmdb" batch_size: 100 backend: LMDB } } layer { name: "cifar" type: "Data" top: "data" top: "label" include { phase: TEST } transform_param { mean_file: "examples/handson/mean.binaryproto" } data_param { source: "examples/handson/handson_test_lmdb" batch_size: 100 backend: LMDB } }
: (中略)
: (中略) layer { name: "ip2" type: "InnerProduct" bottom: "ip1" top: "ip2" param { lr_mult: 1 } param { lr_mult: 2 } inner_product_param { num_output: 2 weight_filler { type: "gaussian" std: 0.1 } bias_filler { type: "constant" } } } layer { name: "accuracy" type: "Accuracy" bottom: "ip2" bottom: "label" top: "accuracy" include { phase: TEST } } layer { name: "loss" type: "SoftmaxWithLoss" bottom: "ip2" bottom: "label" top: "loss" }
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
先頭
末尾
:%s/cifar10/handson/g でいいかも
パス、ファイル名の変更
2に変更

104
• 編集箇所が多いため、うまくいかない時のためにDropboxに編集後のファイルを置いてあります
• めんどくさい人はこちらでもOKです
※元ファイルは消してから実行してください
$ wget https://dl.dropboxusercontent.com/u/8148946/Develop/aws/handson_quick_solver.prototxt $ wget https://dl.dropboxusercontent.com/u/8148946/Develop/aws/handson_quick.prototxt $ wget https://dl.dropboxusercontent.com/u/8148946/Develop/aws/handson_quick_train_test.prototxt
③パラメータ設定
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

105
• 書き換えられているか、グラフ構造で確認してみます(Webから確認)
③パラメータ設定
$ cd ~/caffe $ ./python/draw_net.py ./examples/handson/handson_quick.prototxt ../web/handson.png Drawing net to ../web/handson.png
2
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

106
$ cd ~/caffe $ build/tools/caffe train --solver examples/handson/handson_quick_solver.prototxt I0724 22:58:56.684227 11048 caffe.cpp:113] Use GPU with device ID 0 I0724 22:58:57.038519 11048 caffe.cpp:121] Starting Optimization I0724 22:58:57.038648 11048 solver.cpp:32] Initializing solver from parameters: test_iter: 100 test_interval: 500 :(中略) I0724 23:04:54.502674 11048 solver.cpp:334] Snapshotting to examples/handson/handson_quick_iter_4000.caffemodel I0724 23:04:54.505038 11048 solver.cpp:342] Snapshotting solver state to examples/handson/handson_quick_iter_4000.solverstate I0724 23:04:54.534106 11048 solver.cpp:248] Iteration 4000, loss = 0.00121072 I0724 23:04:54.534142 11048 solver.cpp:266] Iteration 4000, Testing net (#0) I0724 23:04:57.330543 11048 solver.cpp:315] Test net output #0: accuracy = 0.9437 I0724 23:04:57.330601 11048 solver.cpp:315] Test net output #1: loss = 0.253835 (* 1 = 0.253835 loss) I0724 23:04:57.330615 11048 solver.cpp:253] Optimization Done. I0724 23:04:57.330624 11048 caffe.cpp:134] Optimization Done.
④学習実行• 下記のコマンドを実行してください
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

107
⑤学習モデルの利用• 画像分類を実行するため、Pythonで プログラムを記述します
前のファイルを使い回していないのは、 クラス数やディレクトリが違うだけでなく、 評価対象の画像もまた同じように 正規化してあげる必要があるので・・・
$ cd $ vi handson_classifier.py
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

108
import sys import os import caffe from caffe.proto import caffe_pb2 import numpy
answer_map = { 0: "man", 1: "woman" }
os.system('convert '+sys.argv[1]+' -equalize test.jpg')
mean_blob = caffe_pb2.BlobProto() with open('caffe/examples/handson/mean.binaryproto') as f: mean_blob.ParseFromString(f.read())
mean_array = numpy.asarray(mean_blob.data, dtype=numpy.float32).reshape( (mean_blob.channels, mean_blob.height, mean_blob.width) )
classifier = caffe.Classifier( 'caffe/examples/handson/handson_quick.prototxt', 'caffe/examples/handson/handson_quick_iter_4000.caffemodel', mean=mean_array, raw_scale=255)
image = caffe.io.load_image('test.jpg') predictions = classifier.predict([image], oversample=False) answer = numpy.argmax(predictions) print(predictions) print(str(answer) + ":" + answer_map[answer])
ファイルの中身

109
⑤学習モデルの利用
$ wget https://dl.dropboxusercontent.com/u/8148946/Develop/aws/handson_classifier.py
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行
• プログラムがうまくコピペできない方向けに、Dropboxにも同じものを置いてあります
• めんどくさい人はこちらでもOKです
pythonの場合、インデントがずれるとエラーになるので、コピペだと難しいかもしれません。。 改行もPDFだと怪しいかも。。 ※元ファイルは消してから実行してください

110
⑤学習モデルの利用• 画像分類を試してみましょう
$ wget https://upload.wikimedia.org/wikipedia/commons/a/a9/Mona_Lisa_detail_face.jpg $ python handson_classifier.py Mona_Lisa_detail_face.jpg ??????
モナリザは男性?女性?
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

111
⑤学習モデルの利用• 他の画像も試してみましょ教師データやクラス数も少なく、負例も入れてないので、実際の精度は今ひとつです。。。 今回は精度の高さを目指すよりも、手順の簡易さを優先しました。
データセット 準備 データの格納 パラメータ
設定学習モデル 利用学習実行

まとめ
112
• なんとなくCaffeの動作やDeepLearningがつかめましたかね・・・
• 今回のハンズオンでやったことを発展させて、自分の顔画像をOpenCVで撮影してクラスに追加すると、自分の顔判別ができるかも?
• 色々試行錯誤してみてください

自由時間?(あるかな・・・?)
113
• 色々試してみましょ – CPUモードで動かしてみるとか・・・ – イテレーションを増やしたり減らしたり・・・ – 画像の割合を変えてみたり・・・ – 正規化しないとどうなるかな・・・?
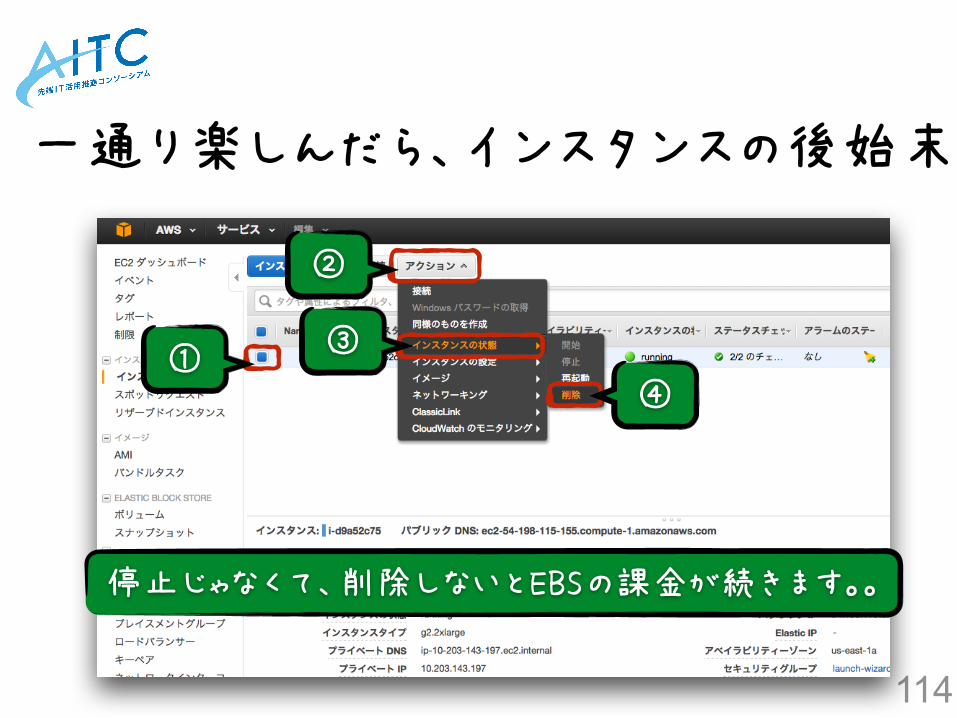
一通り楽しんだら、インスタンスの後始末
114
①
②
③
④
停止じゃなくて、削除しないとEBSの課金が続きます。。

おわり。
115


















