CV2011 Lecture 13. Real-time vision
89
Зрение реального времени
-
Upload
anton-konushin -
Category
Education
-
view
2.050 -
download
1
Transcript of CV2011 Lecture 13. Real-time vision

Зрение реального времени

Общая информация
Страница курса http://courses.graphicon.ru/main/vision
Этот курс подготовлен и читается при поддержке

План лекции
• Решаюшее дерево и решающий лес
• Отслеживание объектов в реальном времени • Системы расширенной реальности
• Распознавание и сегментация объектов
• Распознавание позы человека
• Другие применения Kinect

Решающие деревья
• Classification trees • Двоичное дерево • Узлы:
• Помечены некоторым предикатом
• Связи:
• Помечены
• Листья:
• Помечены ответами из Y
x0
x1 1y
1y 1y
boolX :
falsetrue
true
false
false
true
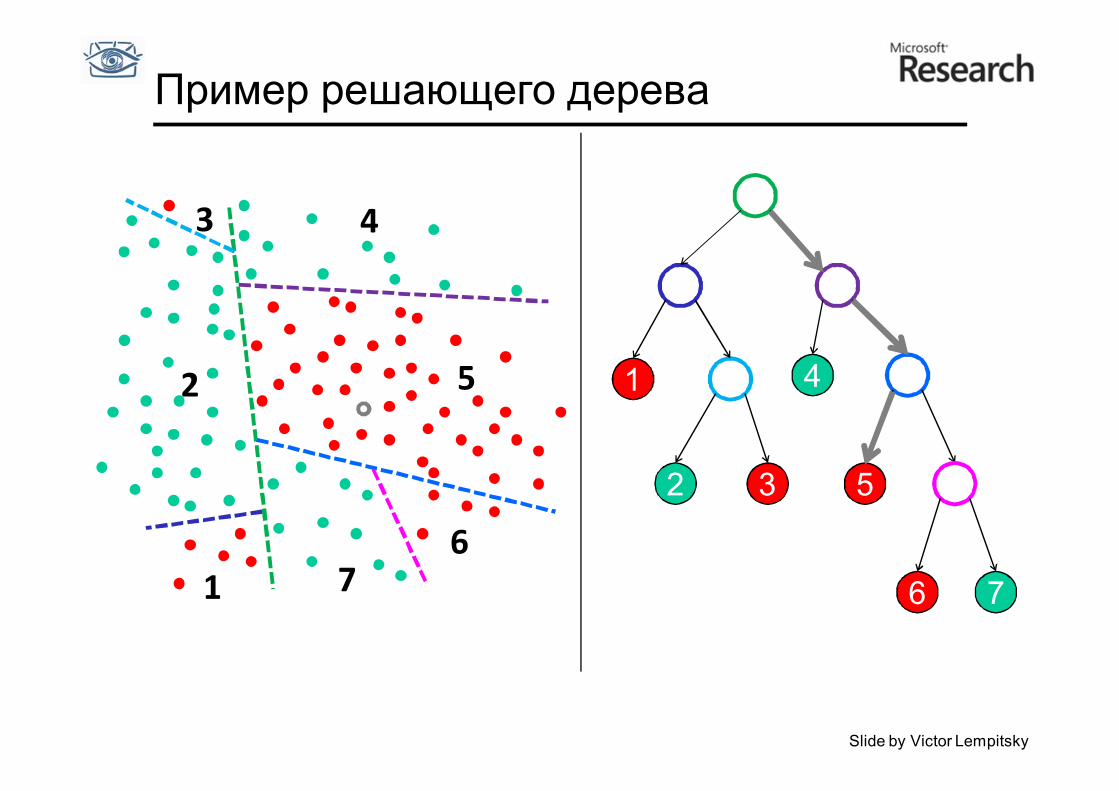
Пример решающего дерева
1
2
3 4
5
6 7
1 4
5 2 3
7 6
Slide by Victor Lempitsky

Качество разбиений: энтропия
Энтропия Шэннона E(S) :
E(S) = 0 E(S) = 1
MM
p jj
Slide by Victor Lempitsky

Обучение дерева решений
function Node = Обучение_Вершины( {(x,y)} ) { if {y} одинаковые
return Создать_Лист(y); test = Выбрать_лучшее_разбиение( {(x,y)} ); {(x0,y0)} = {(x,y) | test(x) = 0}; {(x1,y1)} = {(x,y) | test(x) = 1}; LeftChild = Обучение_Вершины( {(x0,y0)} ); RightChild = Обучение_Вершины( {(x1,y1)} ); return Создать_Вершину(test, LeftChild, RightChild);
} //Обучение дерева function main() {
{(X,Y)} = Прочитать_Обучающие_Данные(); TreeRoot = Обучение_Вершины( {(X,Y)} );
}
Slide by Victor Lempitsky

Переобучение и обрезка дерева
A
B
C D
Slide by Victor Lempitsky

Свойства решающих деревьев
• Плюсы + Просто и наглядно
+ Легко анализируемо
+ Быстро работает
+ Легко применяется для
задач со множеством классов и к регрессии
• Минусы – Плохо аппроксимирует
сложные поверхности
– В общем случае, требует сложных алгоритмов «обрезания» для контроля сложности

Комитетные методы
• Если взять множество правил (экспертов), с некоррелированной
ошибкой (ошибаются в разных местах), то их комбинация может быть работать во много раз лучше
• Такие методы называются комитетными
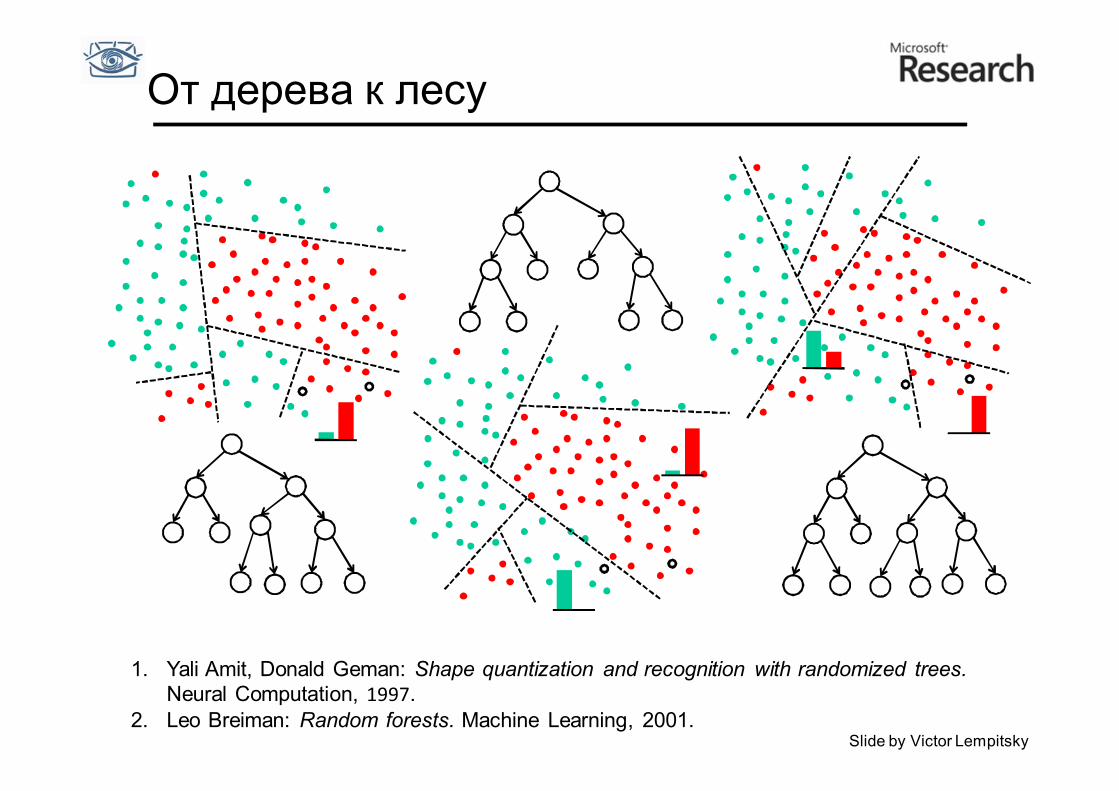
От дерева к лесу
1. Yali Amit, Donald Geman: Shape quantization and recognition with randomized trees. Neural Computation, 1997.
2. Leo Breiman: Random forests. Machine Learning, 2001. Slide by Victor Lempitsky

Решающий лес - применение
Slide by Victor Lempitsky

Решающий лес - обучение
function Node = Обучение_Вершины( {(x,y)}, Level) { if {y} одинаковые или Level == maxLevel
return Создать_Лист(Распределение y); {tests} = Создать_N_Случайных_Разбиений({(x,y)},N); test = Выбрать_лучшее_разбиение_из({tests}); {(x0,y0)} = {(x,y) | test(x) = 0}; {(x1,y1)} = {(x,y) | test(x) = 1}; LeftChild = Обучение_Вершины( {(x0,y0)}, Level+1); RightChild = Обучение_Вершины( {(x1,y1)}, Level+1); return Создать_Вершину(test, LeftChild, RightChild);
} //Обучение леса function main() {
{X,Y} = Прочитать_Обучающие_Данные(); for i = 1 to N {Xi,Yi} = Случайное_Подмнжество({X,Y})); TreeRoot_i = Обучение_Вершины({Xi,Yi}); end
}
Slide by Victor Lempitsky

Варианты метода
• Если только случайные подмножества данных (с повторениями) • Бэггинг (Bagging)
• Если и рандомизированные правила при построении решения • Рандомизированный решающий лес (Random Forest)

Решающий лес – свойства
1. Один из самых эффективных алгоритмов классификации 2. Вероятностное распределение на выходе 3. Применим для высоких размерностей пространства
признаков 4. Высокая скорость обучения и тестирования 5. Относительная простота реализации 6. Может занимать много памяти при большой глубине дерева
Caruana, R., Niculescu-Mizil, A.: An empirical comparison of supervised learning algorithms, 2006
Slide by Victor Lempitsky

Отслеживание
• Идея • Отслеживание объекта через сопоставление ключевых точек
между изображениями • Задачу сопоставления ключевых точек для заданного
объекта можно представить как задачу классификации ключевых точек
V. Lepetit, P. Lagger, and P. Fua, Randomized Trees for Real-Time Keypoint Recognition. CVPR 2005

Схема • Идея:
• N точек с номерами от 1 до N • Сделаем классификатор, который ставит номер {0,N}
• Обучим классификатор ключевых точек • Возьмём исходное изображение • Найдём на нём ключевые точки • Синтезируем обучающую выборку патчей по ним • Отберём наиболее надежные точки • Обучим решающий лес для их классификации
• Слежение • Найдём ключевые точки • Классифициируем их • Вычислим аффинное преобразование через RANSAC

Yet Another Keypoint Detector (YAKT)

YAKT - результаты
• Работает достаточно неплохо

Синтез данных
• Приближаем окрестность точки плоскостью • Подходит для гладких объектов
• Строим трехмерную модель объекта • Плоскую просто • Сложную через многовидовую реконструкцию объекта
• Рендерим новые виды объекта с других ракурсов

Синтез данных
• Ищем ключевые точки на исходном кадре • На каждом новом кадре ищем особые точки • Считаем, сколько раз точка с исходного кадра нашлась на
новых кадрах (знаем, где она должна быть) • Оставляем k=200 наиболее надежных точек
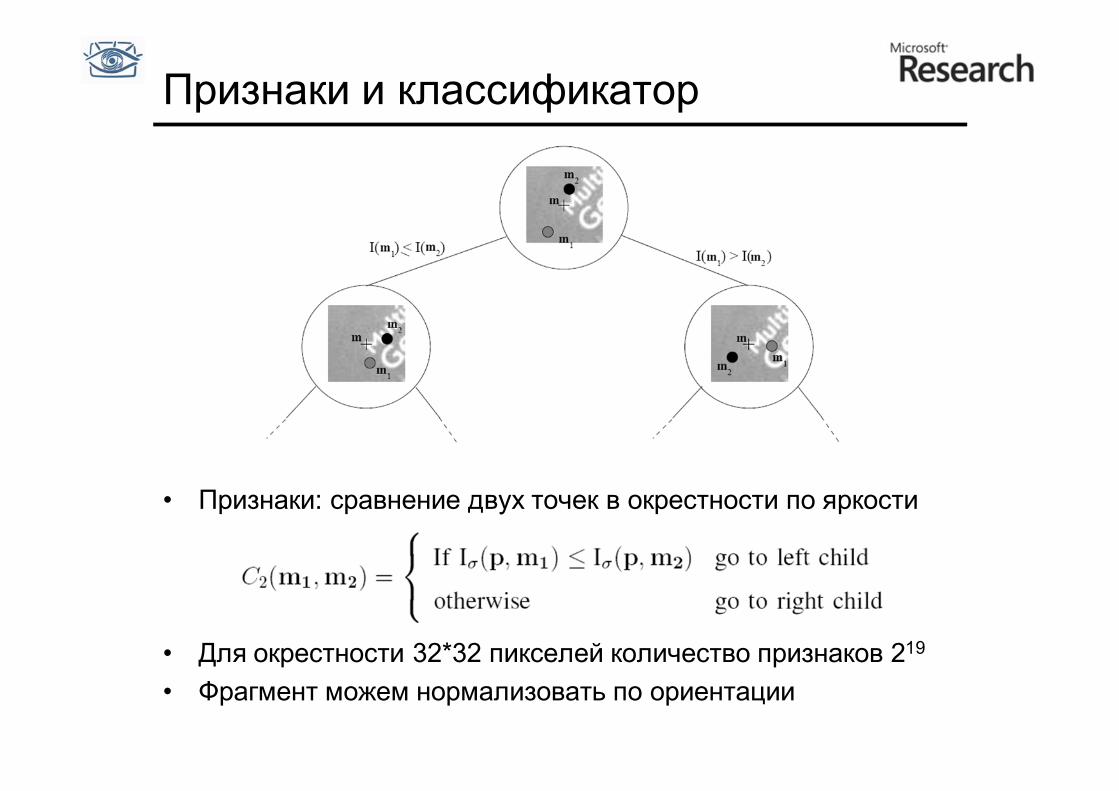
Признаки и классификатор
• Признаки: сравнение двух точек в окрестности по яркости
• Для окрестности 32*32 пикселей количество признаков 219 • Фрагмент можем нормализовать по ориентации

Обучение классификатора
• Классический подход • Генерируем n тестов для каждой вершины, выбираем
наилучший из них по критерию энтропии • n1=10, nd=100d • Строим дерево до тех пор, пока примеров в вершину
приходит достаточно много (>10)
• Экстремально случайный • Для каждой вершины берём случайный тест • Строим до максимальной глубины
• Качество классификации R: • Отношение правильно распознанных фрагментов к
общему числу

Обучение классификатора
Сравнение двух подходов по точности
Сравнение двух подходов по точности при использовании
нормализации фрагмента
• Выбрали вариант с нормализацией, поскольку по скорости/размеру классификатора он оказался предпочтительнее
• Обучение экстремально случайное, занимает несколько секунд (десятки минут для другого варианта)

Оценки обучения и признаков
С2 признаки
С4 признаки (сравнение 4х точек – два градиента)
Сh признаки (вычисление SIFT и двух случайных параметров из него)

Результат работы

Выводы
• Рандомизированные деревья можно очень быстро обучить и они быстро работают
• Можно обучать на синтезированных данных при недостатке данных
• Задачу сопоставления можно решить как задачу классификации достаточно быстро и эффективно
Код доступен: http://cvlab.epfl.ch/software/bazar/index.php

Магические книжки
C. Scherrer, J. Pilet, P. Fua, and V. Lepetit, The Haunted Book. In Proceedings of the International Symposium on Mixed and Augmented Reality, 2008

AR-настольные игры
E. Molla and V. Lepetit, Augmented Reality for Board Games. In Proceedings of the International Symposium on Mixed and Augmented Reality, 2010.

Видео

Развитие AR-книг
Множество иллюстраций с разным контентом
K. Kim, V. Lepetit, W. Woo, Scalable Real-time Planar Targets Tracking for Digilog Books. Computer Graphics International, 2010

Схема
• Совмещение распознавания страницы (в фоне) и быстрого отслеживания (первый приоритет)
• SIFT через GPU, матчинг через kd-деревья • Распознавание изображений через иерархический словарь по Нистеру

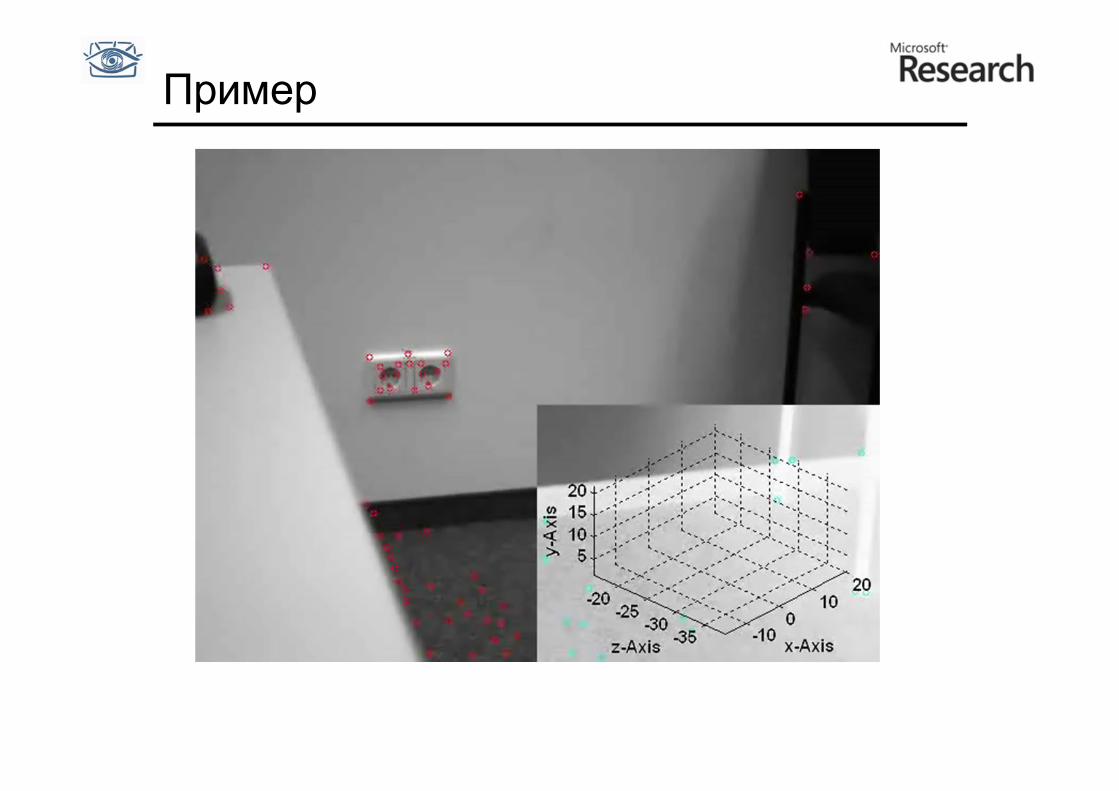
Пример

Обучение фрагментов
• Возьмем окрестность вокрут точки, предположим, что она на плоскости лежит
• Синтезируем много искаженных (с разных ракурсов) изображений окрестности этой точки
• Будем искать новое положение, сопоставляя шаблоны в окрестности точек с обученной базой
S. Hinterstoisser, O. Kutter, N. Navab, P. Fua, and V. Lepetit, Real-Time Learning of Accurate Patch Rectification. In Proceedings of the Conference on Computer Vision and Pattern Recognition, 2009
Пример

Пример 2

AR на телефоне
W. Lee, Y. Park, V. Lepetit, and W. Woo, Point-and-Shoot for Ubiquitous Tagging on Mobile Phones. In Proceedings of the International Symposium on Mixed and Augmented Reality, 2010

Сэмплирование ракурса
• Синтезируем виды на GPU телефона, с расстоянием в 20 градусов
• Рассматриваем только «вероятную» область

Сэмплирование
• Исходный фрагмент – 128*128 пикселей • Трансформация, затем радиальный смаз,
затем гауссов смаз • Затем шаблон уменьшается до 32*32
пикселей • 225 видов, всего около 900kb памяти • 0.3с на обучение на PC, 6-7с на телефоне

Результаты
• Слежение: поиск наилучшего фрагмента и оценка позы ESM-Blur • 10-15 кадров/с

Семантическая сегментация
• Задача: для каждого пикселя определить метку класса, которому он принадлежит
• Методов много, мы рассмотрим один из быстрых
J. Shotton, M. Johnson and R. Cipolla. Semantic Texton Forests for Image Categorization and Segmentation. CVPR 2008.

Метод • Простой метод:
• Обучим классификатор для каждого пикселя • Признаки будем измерять по квадратной окрестности
пикселя • В качестве вектор-признака можем взять «мешок слов»,
посчитанный по окрестности – Фрагменты будем брать плотно по окрестности
• Почему не очень хорошо? • Кластеризовать и квантовать фрагменты медленно, а
нам нужно быстро • Воспользуемся решающим лесом

Семантические текстоны
• Построим случайное решающее дерево, используя простые
признаки фрагмента в узлах • #вершины можем считать кластером • Построим целый лес • «Текстон» – элемент текстуры (одно слово из словаря)

Листья
• «Средние» фрагменты, дошедшие до листьев дерева
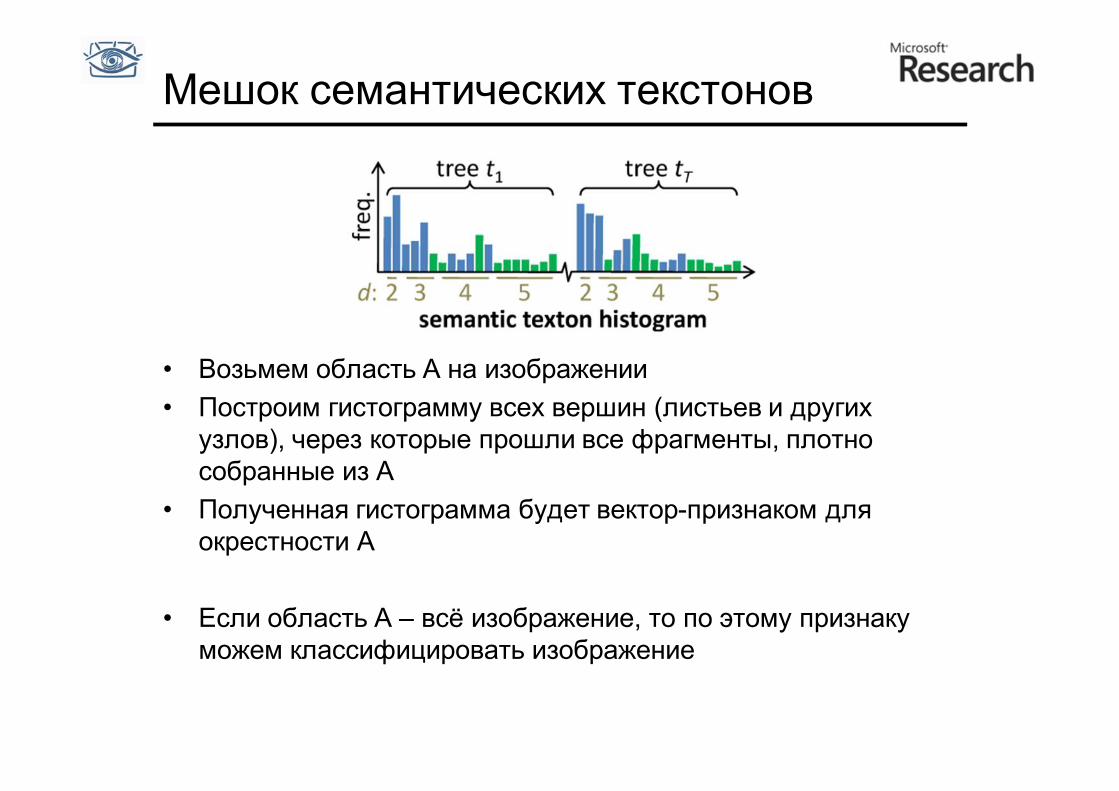
Мешок семантических текстонов
• Возьмем область А на изображении • Построим гистограмму всех вершин (листьев и других
узлов), через которые прошли все фрагменты, плотно собранные из А
• Полученная гистограмма будет вектор-признаком для окрестности А
• Если область А – всё изображение, то по этому признаку можем классифицировать изображение
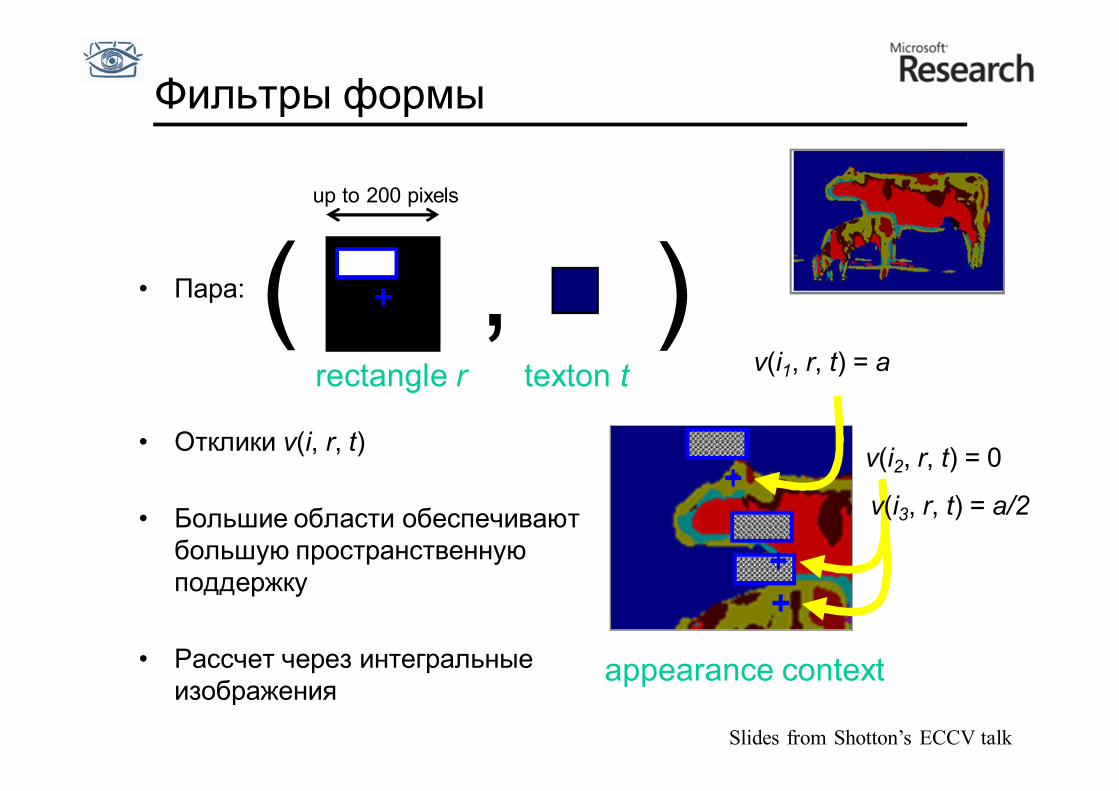
Фильтры формы
• Пара:
• Отклики v(i, r, t)
• Большие области обеспечивают большую пространственную поддержку
• Рассчет через интегральные изображения
rectangle r texton t
( , ) v(i1, r, t) = a
v(i2, r, t) = 0
v(i3, r, t) = a/2
appearance context
up to 200 pixels
Slides from Shotton’s ECCV talk

Попиксельная классификация
• Расширим список признаков для классификации за счёт «фильтров формы»
• Будем брать окрестность не вокруг пикселя, а смещенную, и в ней вычислять вектор-признак
• Обучим классификатор для пикселей по большой обучающей коллекции
• Результат классификации изображения можем использовать для повышения точности метода • Для одного класса изображений
рассчитыаем априорные вероятности встретить определенные объекты
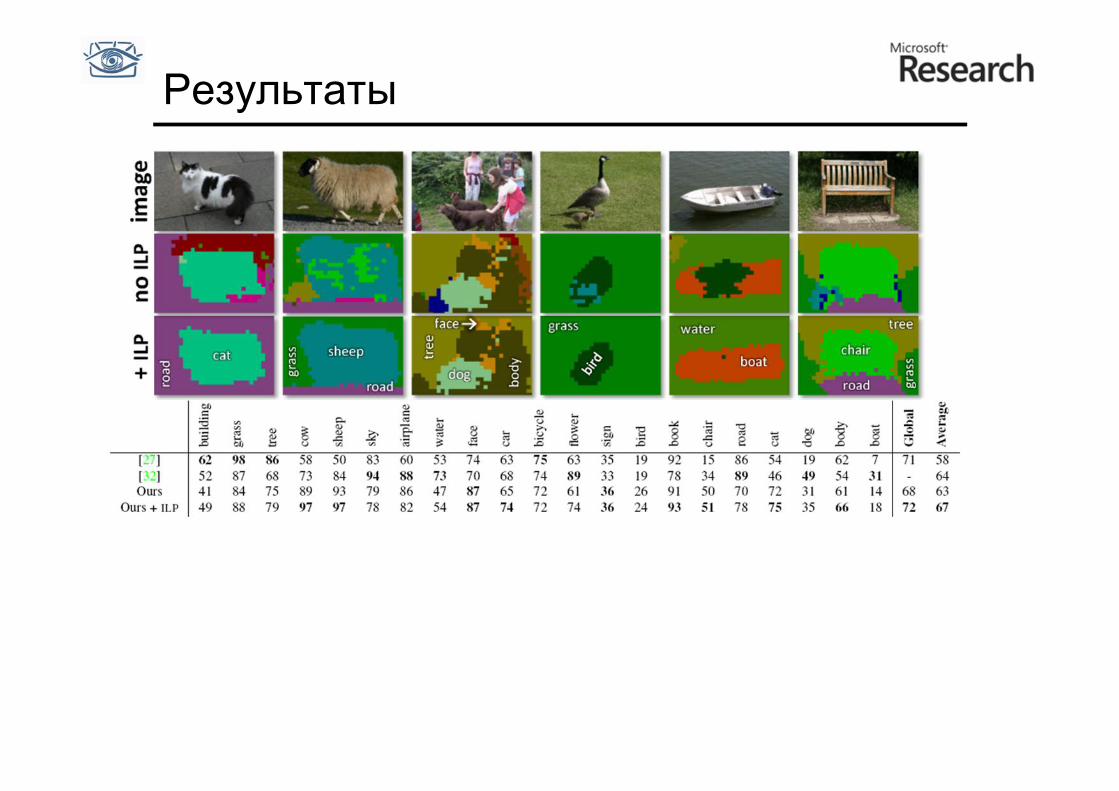
Результаты

Скорость работы
• Fast • STF feature extraction = 275 ms • Image categorization = 190 ms • Segmentation forest = 140 ms • Total ~ 605 ms
• TextonBoost = 6000 ms

Kinect

Реконструкция по фотографиям
Внешность объекта сильно зависит от материалов и освещения
жесткий деформирующийся
с текстурой
без текстуры

Системы сканирования
• Структурированный свет
[Zhang02]

Активное стерео
• Проецируем специальный «шаблон» на объект («структированный свет»)
• Шаблон даёт «текстуру» по всей поверхности объекта
• Решаем задачу стерео либо по 2м камерам, либо с калиброванным проектором
• Подсветка может быть в видимом диапазоне, а может быть ИК (“Kinect”)
Камера 2
Камера 1
Проектор

Пример реконструкции
Исходные видео-потоки Реконструкция

Пример реконструкции
Исходные видео-потоки Реконструкция

Artec-Group
http://artec-group.ru

Результаты
Задачи: • Распознавание по
лицу • Моделирование
челюсти • Совмещение челюсти
и модели лица

3D камеры и Microsoft
• 3DV Systems • Time of flight • Первая камера – в 2000 • Купили в 2009м
• Canesta • Time of flight • Первая камера – в 2002 • Купили в 2010м (цена неизвестна, инвестиции – 70М$)
• PrimeSense • Структурная подсветка • Получили лицензию?
• Все 3 компании предлагали решения с
перспективной ценой 100-200$

Time of Flight (TOF) • Pulsed light source with digital time counters
• Импульсный лазер, специальная фокусировка и матрица • Дистанция до 7км, разрешение до 128*128 пикселей
• RF-modulated light sources with phase detectors
• Источник – pulsed LED, фазовая модуляция излучения • Разрешение 176*144, 5-10 м, некоторые до 60м
• Range gated imagers
• После импульса света, матрица «пульсирует», получая серию «снимков», каждый снимок захватывает свет, вернувшийся с определенного расстояния
• ZCam (3DV), Canesta3D – 320*200/240, 256 градаций, расстояние 1.5 – 2.5м, разрешение 1 - 2 см
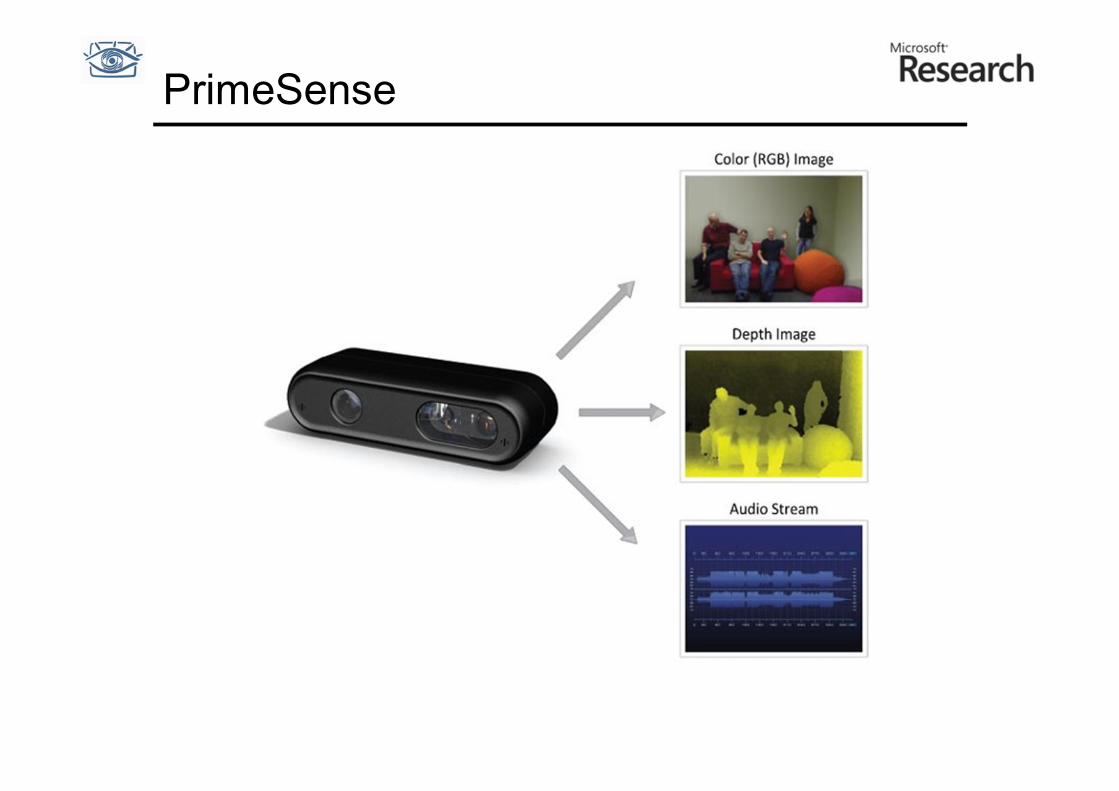
PrimeSense

Технология
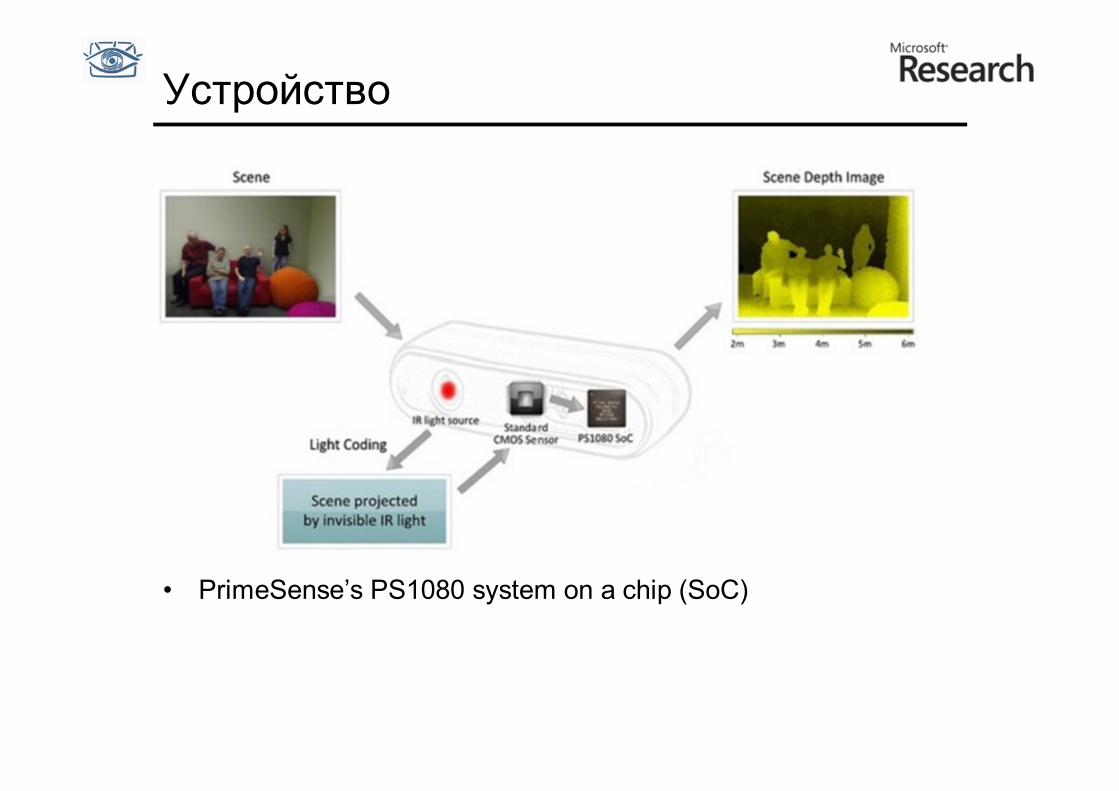
Устройство
• PrimeSense’s PS1080 system on a chip (SoC)

Specs

OpenNI
• Ассоциация для развития софта для камеры PrimeSense • PrimeSense, WillowGarage, ASUS, Side-Kick • Как оборудование предлагают камеру от ASUS, которую
ещё не выпустили (и будет только глубина) • Пока реально используют только Kinect (почти хак)

Kinect
• Цвет + глубина + аудио • Мотор для позиционирования по вертикали
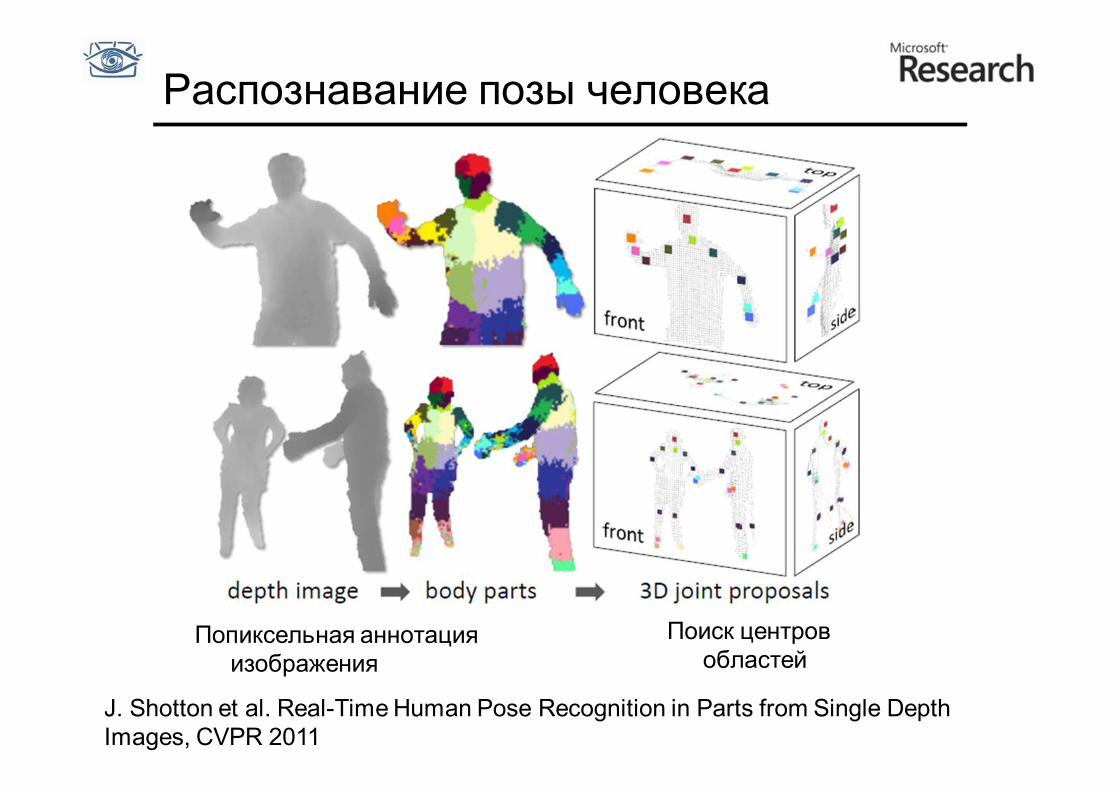
Распознавание позы человека
Попиксельная аннотация изображения
Поиск центров областей
J. Shotton et al. Real-Time Human Pose Recognition in Parts from Single Depth Images, CVPR 2011
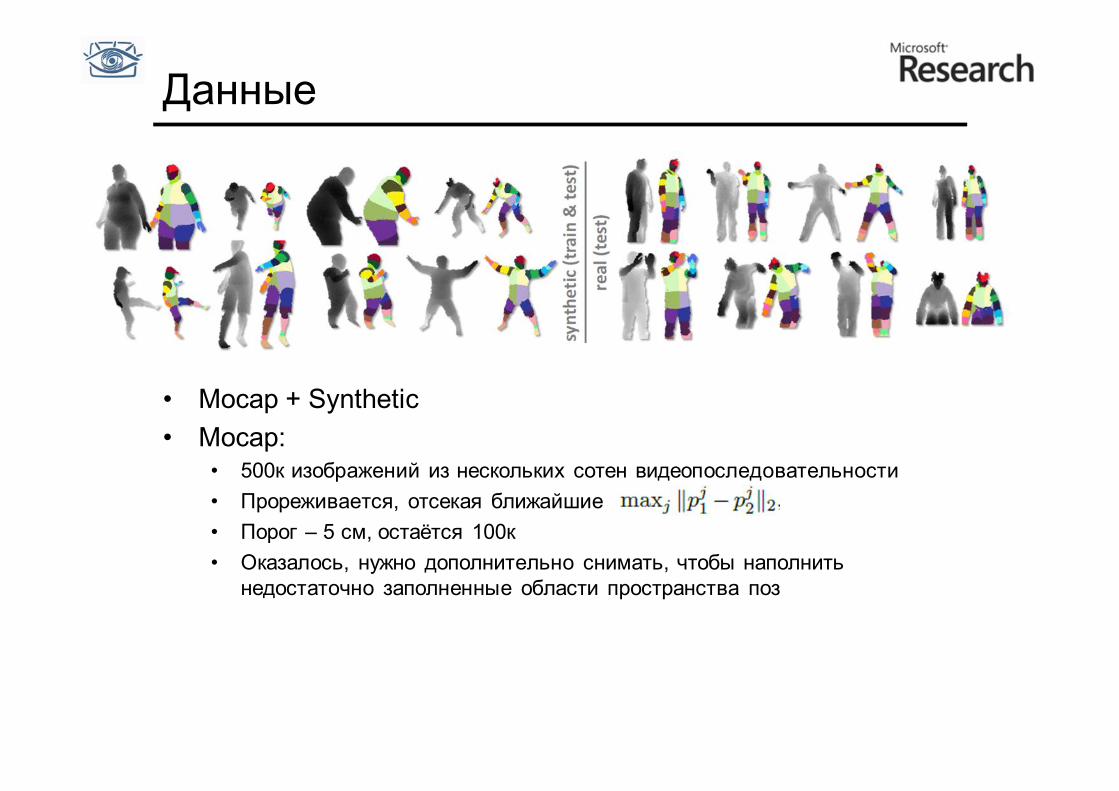
Данные
• Mocap + Synthetic • Mocap:
• 500к изображений из нескольких сотен видеопоследовательности • Прореживается, отсекая ближайшие • Порог – 5 см, остаётся 100к • Оказалось, нужно дополнительно снимать, чтобы наполнить
недостаточно заполненные области пространства поз

Синтетика
• Выбирается одна из 15 базовых моделей, варьируются параметры и визуализируется
• Поза (выбираем равномерно из Mocap данных) • Ракурс (равномерно поворачиваем / сдвигаем в области) • Вес/рост (равномерно меняем +/- 10%) • Волосы / одежда (добавляем модели из большого набора) • Шум камеры

Разметка
• 31 часть тела • Пробовали слить (17 частей), но при этом качество
серьёзно ухудшалось (bleeding effect, неравный вклад?)
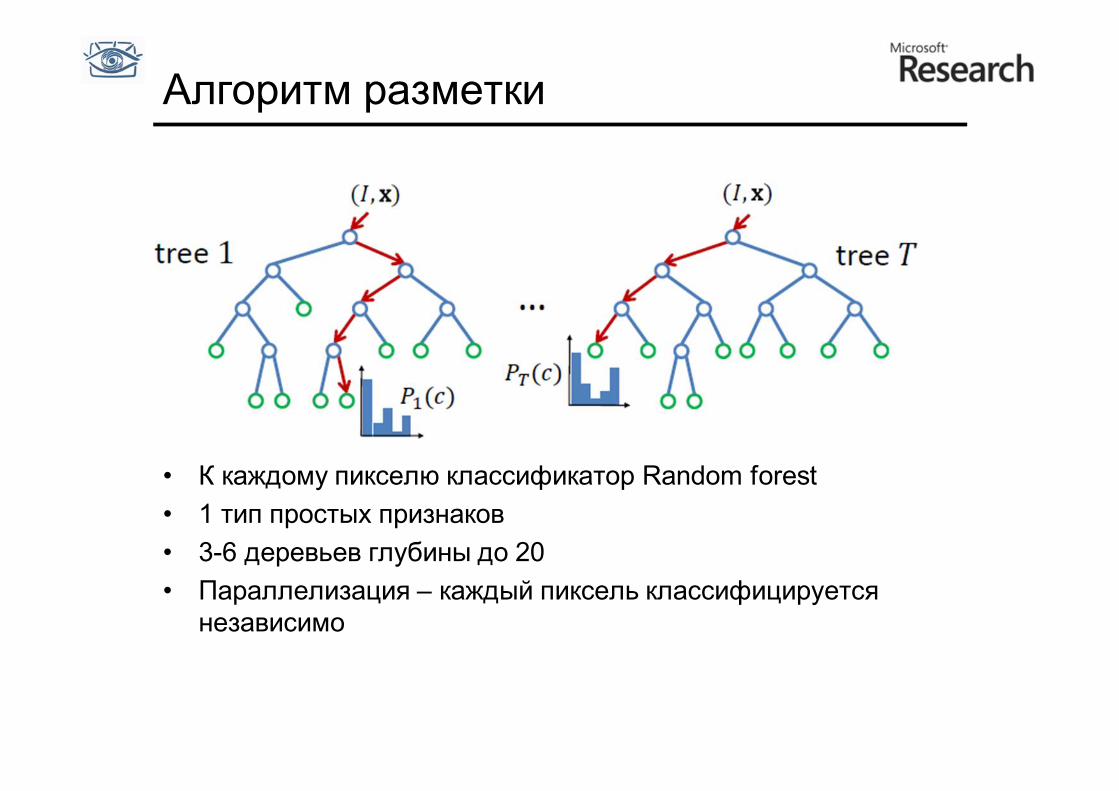
Алгоритм разметки
• К каждому пикселю классификатор Random forest • 1 тип простых признаков • 3-6 деревьев глубины до 20 • Параллелизация – каждый пиксель классифицируется
независимо

Признаки
• Сверхскоростные – 3 пикселя, 5 арифметических операций

Обучение

Вычисление точек тела • Шаг 1 – Сглаженный поиск моды по областям
• В результате найденные точки (моды) лежат на поверхности тела
• Шаг 2 – сдвиг точек «внутрь тела» вдоль луча от камеры

Обучение и тестирование • Обучение:
• На базе в 1М изображений обучение занимает 1 день на
1000 ядерном кластере
• Тестирование: • 5000 синтетических изображений • 8000 реальных изображений 15 человек
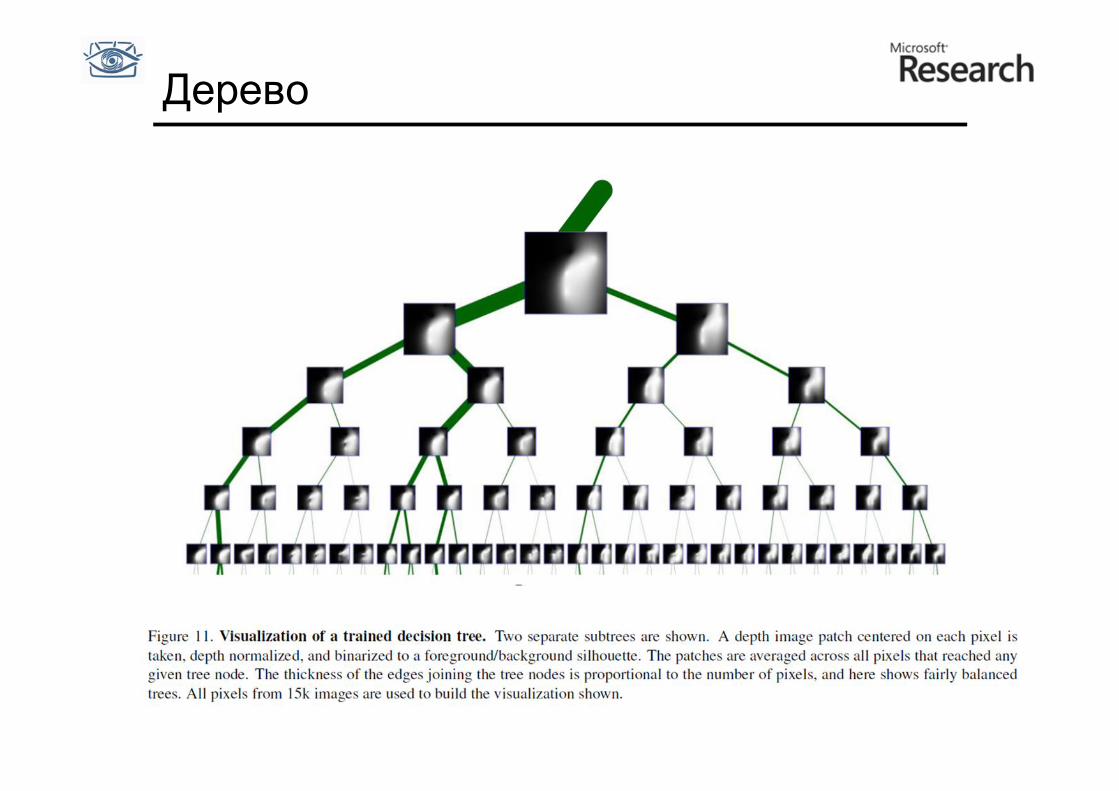
Дерево
Дерево

Эксперименты

Эксперименты

Эксперименты

Эксперименты

Сравнение

Резюме
• Некоторые задачи решаются простыми алгоритмами, но при очень больших объёмах данных
• Собрать такие данные в жизни крайне сложно, но можно их синтезировать
• Суперкомпьютеры применяются и в зрении!

Kinect для психологии
• Отслеживание детишек с заболеваниями (экономим 100К$)

Захват лица

Навигация по мед. данным
• http://www.crunchgear.com/2011/03/23/kinect-lets-surgeons-navigate-medical-data-in-the-or/

Minority Report

Видеоконференции

Роботы

Роботы