
Cox 비례위험 모형과 로지스틱 모형의 비교 : 예측모형의 ... · 2019-06-28 ·...
51
Cox 비례위험 모형과 로지스틱 모형의 비교 : 예측모형의 discrimination과 calibration 연세대학교 대학원 의학전산통계학협동과정 의학통계학전공 이 성 혁
Transcript of Cox 비례위험 모형과 로지스틱 모형의 비교 : 예측모형의 ... · 2019-06-28 ·...

Cox 비례위험 모형과 로지스틱 모형의
비교 : 예측모형의 discrimination과
calibration
연세대학교 대학원
의학전산통계학협동과정
의학통계학전공
이 성 혁

Cox 비례위험 모형과 로지스틱 모형의
비교 : 예측 모형의 discrimination과
calibration
지도 남 정 모 교수
이 논문을 석사 학위논문으로 제출함
2010년 6월 일
연세대학교 대학원
의학전산통계학협동과정
의학통계학전공
이 성 혁

이성혁의 석사 학위논문을 인준함
심사위원 인
심사위원 인
심사위원 인
연세대학교 대학원
2010년 6월 일

- i -
차 례
그림 차례 ⅲ
표 차례 ⅳ
국문요약 ⅴ
제 1 장 서론 1
1.1 연구 배경 및 목적 1
1.2 연구 내용 및 방법 2
1.3 논문의 구성 2
제 2장 이론적 배경 3
2.1 로지스틱 회귀모형 3
2.1.1 로지스틱 회귀모형의 정의 3
2.1.2 모형 적합도 검정 3
2.1.3 모형의 예측력 평가 4
2.2 생존 자료 4
2.2.1 중도절단의 정의 및 종류 4
2.2.2 위험함수 5
2.2.3 Cox 비례위험모형 6
2.2.4 생존 기저위험함수의 추정 6
2.3 Discrimination과 Calibration 7
2.3.1 Discrimination 7
2.3.2 Calibration 10
제 3장 모의실험 12
3.1 모형의 설정 12
3.2 공변량의 생성 12
3.3 모의실험 설계 15
제 4장 모의실험 결과 16

- ii -
4.1 사건 발생률에 따른 회귀계수의 비교(중도절단이 없는 경우) 16
4.2 사건 발생률에 따른 discrimination과 calibration의 비교(중도절단이 없는
경우) 22
4.3 사건 발생률에 따른 회귀 계수의 비교(중도절단이 있는 경우) 25
4.4 사건 발생률에 따른 discrimination과 calibration의 비교(중도절단이 있는
경우) 31
제 5장 결론 및 고찰 36
참고문헌 39
영문요약 42

- iii -
그 림 차 례
그림 1. 사건 발생률에 따른 discrimination의 변화(중도절단이 없는 경우) 23
그림 2. 사건 발생률에 따른 calibration의 변화(중도절단이 없는 경우) 24
그림 3. 사건 발생률에 따라 Cox와 로지스틱 모형의 calibration P-value 변화(중
도절단이 없는 경우) 25
그림 4. 사건 발생률에 따른 discrimination의 변화(중도절단이 있는 경우) 33
그림 5. 사건 발생률에 따른 calibration의 변화(중도절단이 있는 경우) 34
그림 6. 사건 발생률에 따라 Cox와 로지스틱 모형의 calibration P-value 변화(중
도절단이 있는 경우) 35

- iv -
표 차 례
표 1. 뇌졸중 연구 모집단 특성, 한국 암 예방 연구 13
표 2. Cox 비례위험모형을 이용한 한국인 10년 뇌졸중 예측모형 14
표 3. 사건 발생률 2.49%에서 Cox와 로지스틱 모형의 회귀계수 비교 17
표 4. 사건 발생률 5.63%에서 Cox와 로지스틱 모형의 회귀계수 비교 18
표 5. 사건 발생률 10.32%에서 Cox와 로지스틱 모형의 회귀계수 비교 19
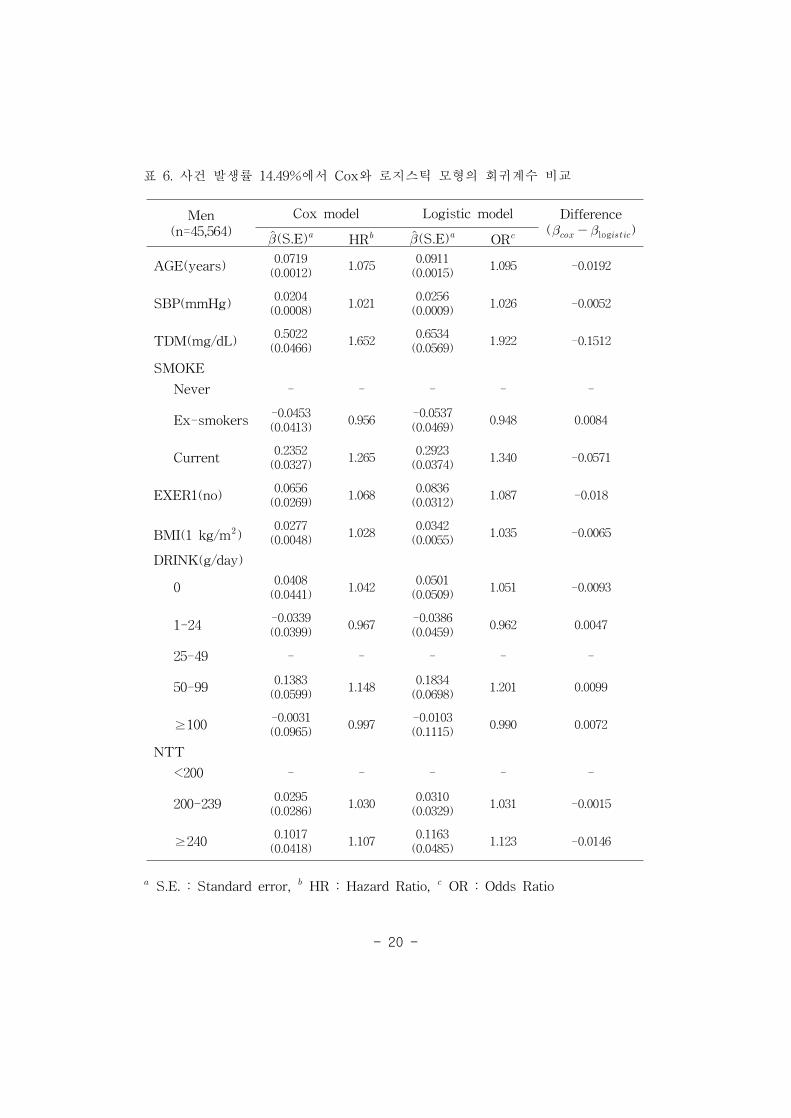
표 6. 사건 발생률 14.49%에서 Cox와 로지스틱 모형의 회귀계수 비교 20
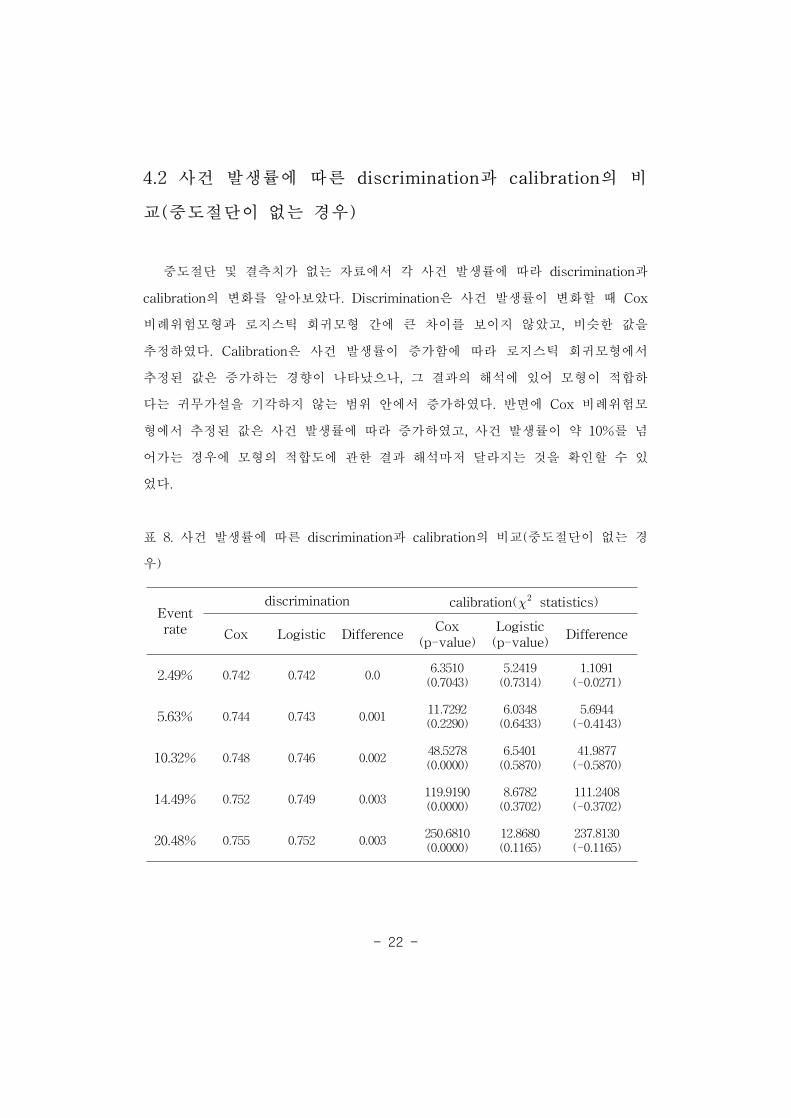
표 7. 사건 발생률 20.48%에서 Cox와 로지스틱 모형의 회귀계수 비교 21
표 8. 사건 발생률에 따른 discrimination과 calibration의 비교(중도절단이 없는 경
우) 22
표 9. 사건 발생률 2.27%에서 Cox와 로지스틱 모형의 회귀계수 비교 26
표 10. 사건 발생률 5.26%에서 Cox와 로지스틱 모형의 회귀계수 비교 27
표 11. 사건 발생률 9.38%에서 Cox와 로지스틱 모형의 회귀계수 비교 28
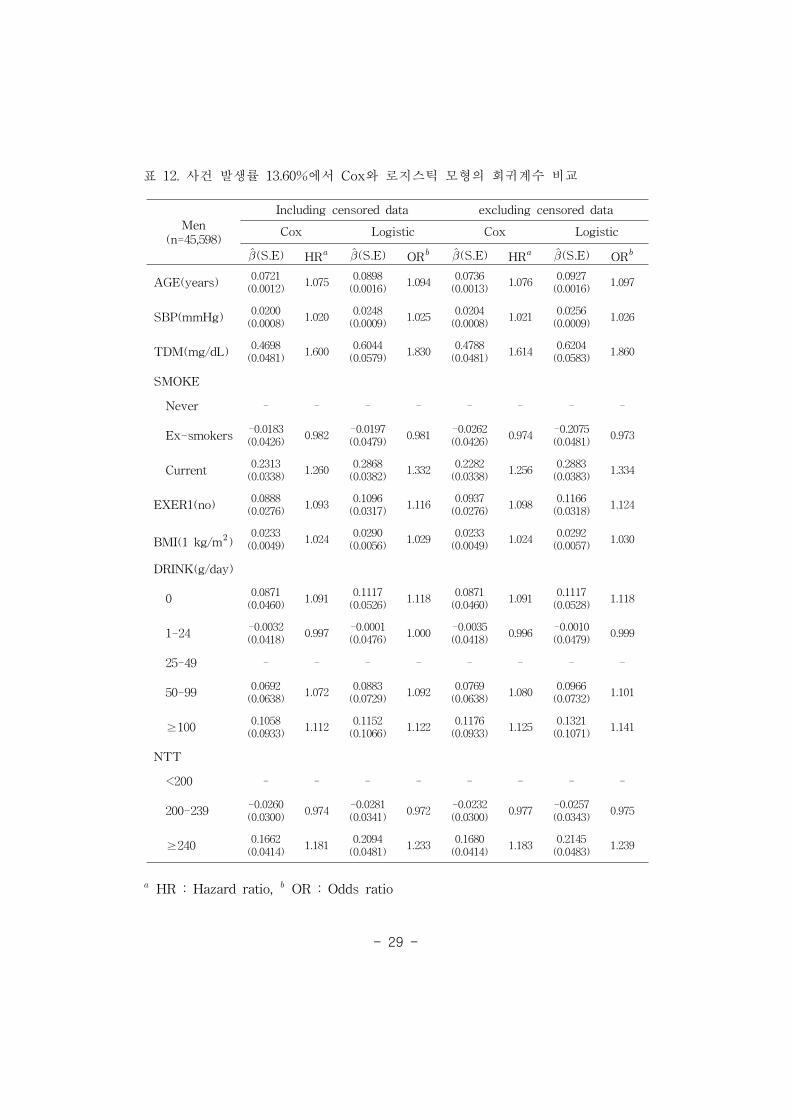
표 12. 사건 발생률 13.60%에서 Cox와 로지스틱 모형의 회귀계수 비교 29
표 13. 사건 발생률 19.20%에서 Cox와 로지스틱 모형의 회귀계수 비교 30
표 14. 사건 발생률에 따른 discrimination의 비교(중도절단이 있는 경우) 32
표 15. 사건 발생률에 따른 calibration의 비교(중도절단이 있는 경우) 32

- v -
국 문 요 약
Cox 비례위험 모형과 로지스틱 모형의 비교 : 예측 모형의
discrimination과 calibration
최근 임상 연구에서 다양한 질병의 사망 또는 재발과 같은 관심사건의 발생
여부에 대한 통계학적 예측 모형이 만들어지고 있다. 이러한 통계학적 예측모형은
주로 로지스틱 회귀모형이나 Cox의 비례위험모형을 이용하여 만들어진다.
본 논문에서는 생존 자료에서 사건 발생률 및 중도절단 된 자료 유무에 따라
Cox의 비례위험모형과 로지스틱 회귀모형을 이용하여 만들어진 예측모형 간의
discrimination(예측력)과 calibration(적합도)에 차이가 있는지 알아보았다.
예측된 모형의 discrimination과 calibration을 확인하고자 할 때, 로지스틱 회귀
모형에서는 AUC 값과 Hosmer-Lemeshow의 test 값을 사용하였고, Cox의 비
례위험모형에서는 %perfcox SAS macro(Nam, D'Agostino 2004)를 이용하여
AUC 값과 Kaplan-Meier 추정치를 이용한 test 값을 사용하였다.
모의자료는 한국인의 뇌졸중 10년 예측모형(지선하 외 2008)에 이용되었던 자
료를 기초로 생성하였다. 모의실험 결과, 사건 발생률에 따라 각 모형에서 회귀계
수의 값은 비교적 비슷하게 추정되었고, discrimination 값도 비슷하게 나타났다.
하지만 calibration의 경우 사건 발생률이 증가함에 따라 Cox의 비례위험모형에서
값이 급격하게 커지는 경향을 보였다.
핵심 되는 말 : Cox 비례위험모형, 로지스틱 회귀모형, Discrimination, Calibration

- 1 -
제 1장 서론
1.1 연구 배경 및 목적
최근 들어 임상 연구에서 다양한 질병에 대한 통계학적 예측 모형이 만들어지
고 있다. 예측 모형을 만들기 위해서 질병의 사망 또는 재발과 같은 관심사건의
발생 여부와 위험인자 그리고 관심사건이 발생할 때까지 시간이 조사된 자료를
흔히 이용한다. 이러한 자료의 형태를 생존자료(survival data)라고 하는데, 생존
자료를 이용하여 예측모형을 만들 때 로지스틱 회귀모형과 Cox 비례위험모형이
주로 이용된다. 이러한 예측모형은 뇌졸중(지선하 외 2008), 유방암(Domchek et
al. 2003), 담낭암(Wang et al. 2008), 심혈관 중재시술(Matheny et al. 2005), 심장
병(L'ltalien et al. 2000) 등 다양한 질병에서 찾아볼 수 있다.
Cox 비례위험모형과 로지스틱 회귀모형을 이용하여 만들어진 예측모형의 예측
력과 적합도를 알아보기 위해 discrimination과 calibration의 평가를 해야 하는 경
우가 있다. Cox 비례위험모형에서 두 지표의 측정을 위해 Zethelius et al.(2008),
Paul et al.(2008), Wilson(2009), Donald(2010) 등 다양한 연구에서 Kaplan-Meier
추정치를 이용하는 Nam과 D'Agostino(2004)의 방법을 사용하였다. 본 연구에서도
생존 자료를 이용한 예측모형의 discrimination과 calibration의 평가를 위해 개발
된 방법 중 Nam과 D'Agostino(2004)의 방법을 이용하였다. 로지스틱 회귀 모형에
서는 discrimination과 calibration의 평가를 Hosmer-Lemeshow의 test와
AUC(area under the receiver operating characteristic curve)를 이용하였다.
비록 Cox 비례위험모형과 로지스틱 회귀모형은 다른 척도로 관련성을 측정하
였고, 추적조사 기간에 대한 정보가 다르게 들어가지만, 이런 차이가 있음에도 불
구하고 특정 상황(추적조사 기간이 짧고, 위험 인자의 효과가 작고, 사건 발생이
적은 경우; Elandt-Johnson(1980), Green and Symons(1983), Hauck(1985)는 이
경우 두 모형으로부터 추정된 모수는 유사하다고 결론)에서 모수는 비슷하게 추정

- 2 -
된다는 사실은 이미 잘 알려져 있다(Deborah, Joel 1989).
본 연구는 중도절단 된 경우가 존재하는 생존 자료의 경우 사건 발생률에 따
라 Cox 비례위험모형과 로지스틱 회귀모형에서 discrimination과 calibration의 정
도를 비교 평가하고 그 변화 양상을 연구하고자 한다.
1.2 연구 내용 및 방법
본 연구는 실제 자료에 준하여 모의 자료를 생성한 후 Cox 비례위험모형과 로
지스틱 회귀모형의 discrimination, calibration을 비교하였다. Cox 비례위험모형에
서는 %perfcox SAS macro를 이용하여 discrimination과 calibration의 값을 구하
고, 로지스틱 회귀모형에서는 Hosmer-Lemeshow의 test와 C 통계량 값을 구
한다. 사건 발생률을 변화시키면서 자료를 생성하고 Cox 비례위험모형과 로지스
틱 회귀모형의 discrimination과 calibration의 변화를 비교한다.
1.3 논문의 구성
제 1장에서 연구 배경 및 목적에 대해 소개하고 연구 내용 및 방법에 대해서
제시한다. 2장에서는 이론적 배경으로 Cox 비례위험모형과 로지스틱 회귀모형의
이론적 개념과 discrimination과 calibration의 내용을 소개하겠다. 3장에서는 모의
실험에 관련된 자료의 생성 절차와 분석 방법을 소개한다. 4장에서는 모의실험 결
과에 대해 제시하고 비교 평가한다. 5장에서는 결론 및 고찰에 관하여 논의하였
다.

- 3 -
제 2장 이론적 배경
2.1 로지스틱 회귀모형
2.1.1 로지스틱 회귀모형 정의
로지스틱 회귀분석은 종속변수가 두 개의 범주로 이루어진 경우에 독립변수와
의 관계를 알아보기 위하여 이용된다. 일반적으로 종속변수가 취할 수 있는 값은
어떤 사건이 발생된 경우를 1로, 발생되지 않은 경우를 0으로 나타낸다. 이런 형태
의 이분형 종속변수와 독립변수가 주어졌을 때 사건 발생의 조건부 확률을 로짓
(logit)변환하여 사용한다.
ln
′
이를 로지스틱 회귀모형이라고 하며, 특히 독립변수가 둘 이상인 경우를 다중 로
지스틱 회귀모형이라 한다.
2.1.2 모형 적합도 검정
구축된 로지스틱 회귀모형의 적합도를 보기 위한 방법으로 잔차에 기초한
통계량과 Hosmer-Lemeshow의 적합도 검정이 있다. 이 중 잔차에 기초한 통계
량은 피어슨 통계량, 데비언스 통계량이 있다. Hosmer-Lemeshow의 적합도
검정은 첫째, 관측치를 추정된 사건 발생 확률로 정렬하여 g개의 집단으로 나눈
다. 여기서 나눠지는 집단의 수는 약 10개정도 이다. 그리고 관측 빈도와 예측 빈
도의 × 개의 표로부터 피어슨 통계량 값을 계산하여 얻어진다. 여기서 M

- 4 -
는 집단의 수이고, Hosmer-Lemeshow의 적합도 검정 통계량은 다음과 같다.
⋯
여기서, 는 j번째 집단의 대상자의 수, 는 j번째 집단에서 사건이 발생한 대상
자의 수이다. 그리고 는 j번째 집단에서 예측된 사건 발생 확률의 평균이다.
2.1.3 모형의 예측력 평가
로지스틱 회귀모형을 이용한 예측모형에서 예측력은 ROC(Receiver Operating
Characteristic) 곡선 아래의 면적(AUC)으로 평가한다. ROC 곡선을 작성하기 위
해서는 관측결과와 예측결과를 비교한 분류표에서 민감도(sensitivity)와 1-특이도
(specificity)라는 두 가지 예측 정확도 척도로 구성된다. 본 연구에서 AUC 값은
SAS proc logistic의 C 통계량 값을 이용한다.
2.2. 생존 자료
2.2.1 중도절단의 정의 및 종류
모든 연구 대상에서 관심 있는 사건이 모두 발생된 자료를 완전자료라 한다.
하지만, 종종 여러 가지 이유로 일부의 연구대상에 대해서는 사건 발생시간이 여
러 가지 이유로 측정되지 못하는 경우가 있다. 즉, 연구과정 중에 대상이 이탈을
한다거나 시간의 부족으로 연구를 마치지 못하는 경우를 말한다. 이러한 자료를
중도절단자료(Censored data)라고 하며, 중도절단에는 제 1종 중도절단, 제 2종 중
도절단과 무작위 중도절단이 있다.

- 5 -
2.2.2 위험함수(hazard function)
위험함수란 t시점까지 생존한 환자의 순간위험율(instantaneous risk of death
or failure)로서 수식적으로 표현하면 다음과 같다.
lim→
Pr ≤ ≥
Pr ≥ lim
→Pr ≤
여기서, T는 생존시간을 말한다. 위 식처럼 위험함수는 생존함수(survival
function)와 밀도함수로 표현할 수 있을 뿐만 아니라, 생존함수만으로도 표현이 가
능하다. 즉, 밀도함수와 생존함수의 관계 f(t)=-S'(t)를 이용하면 다음과 같다.
′
′
반면, 생존함수를 누적위험함수(cumulative hazard function)로 표현할 수 있다.
위 식을 다시 쓰면, log
와 같이 되므로,
exp
exp
여기서,
이고 누적위험함수라고 정의한다.

- 6 -
2.2.3 Cox 비례위험모형
생존시간과 공변량의 연관성을 설명하기 위하여 위험함수를 기초로 하는 회귀
모형을 제안한 것이 Cox 비례위험모형이다. 이 모형의 가정은 서로 다른 특성을
가지고 있는 개체의 위험함수의 비율,
은 시간 t에 따라 변하지 않는다는
것이다. Cox 비례위험 모형은 다음과 같다.
×exp
여기서는 ⋯는 공변량 벡터이고
는 해당하는 모수 벡터이다. 또
한 는 기저 위험함수(baseline hazard function)로 정의한다.
2.2.4 생존 기저위험 함수의 추정
비례위험 회귀모형으로부터 계수 의 추정치를 부분 최대 우도 방법으로 추정
하고, 새로운 개체에 대한 생존확률을 추정할 수 있다. 여기서 제시될 생존확률의
추정치는 Breslow's estimator에 기초한 값이다. 이 추정치를 구하기 위해 먼저
자료를 비례위험모형에 적합시켜 부분 최대우도 추정치인와 정보행렬
(information matrix)의 역수로부터 공분산 행렬 의 추정값을 구한다.
⋯ 를 사건 발생시점이라 하고, 를 시간 에서 일어난 사건의 수라
고 정의하면, 누적 기저 위험함수의 추정치
는 다음과 같이 주
어진다.
≤

- 7 -
여기서,
∈ exp
이다.
기저 생존함수의 추정치는 exp 이다. 이는 예측변수의 값이
인 경우 개체에 대한 생존함수의 추정치이다. 만약 예측변수의 값이
로 주어진다면, 생존함수 값을 추정하기 위해서 다음과 같은 추정치를 이용한다.
exp′
2.3 Discrimination과 Calibration
2.3.1 Discrimination
예측모형에서 discrimination이란 생성된 모형이 얼마나 정확히 결과를 예측하
는지 예측력의 평가를 하기 위한 척도이다. 이분형 종속변수를 가진 다중 로지스
틱 회귀모형에서는 discrimination을 측정하기 위해 AUC 값을 이용한다. 생존시간
을 고려해야하는 Cox 비례위험모형에서는 중도절단 된 자료가 있기 때문에 이를
해결하기 위해 Nam과 D'Agostino(2004)는 대상자를 사건, 비-사건, 중도절단 세
독립된 잡단으로 구분하여 AUC를 다음과 같이 추정하였다.
이 방법을 구체적으로 설명하면 다음과 같다. 먼저, 전체 대상의 수를 n으로
두었을 때, 관심있는 생존시간 이내에 사건이 발생한 수를 , 사건이 발생하
지 않은 수를 , 중도절단 된 사건의 수를 라고 한다.
또한, 는 i번째 대상의 생존시간, 는 시점 에서 i번째 대상이 사건이 발
생할 예측확률로 정의하자. 이때 , 은 사건이 일어난 집단의 생존시간과 예
측확률이며, , 는 비-사건 집단의 생존시간과 예측확률, , 는 중도절
단 된 집단의 생존시간과 예측확률이다.

- 8 -
AUC 값을 추정하기 위해 다음과 같은 세가지 상황을 비교하는데, 이 비교는
각각 독립이라고 가정한다.
(1) 사건 대 비-사건
(2) 사건 대 사건
(3) 사건 대 중도절단
첫 번째, 사건 대 비-사건의 비교를 위한 의 값은 다음과 같다.
그외
그외
여기서, ⋅이며, 사건이 발생하지 않은 대상의 모든 생존시간은 사건이
발생한 대상의 생존시간보다 크므로, 는 항상 1 이되는데 다음과 같이 표현할
수 있다.
⋅
⋅
여기서, 쌍의수
쌍의수 이다. 이 경우 은
정확하게 Mann-Whitney 검정통계량과 같아지게 되며, 점근적으로 정규분포를 따
른다.
두 번째, 사건 대 사건의 비교를 위한 값을 구하는데, 이 경우는 더 빠른 시
간에 사건이 발생한 대상이 더 높은 사건 발생 예측확률을 가지는 경우로 다음과
같이 정의할 수 있다.

- 9 -
⋯
그외
⋯
그외
는 순위 상관계수 와 상당히 관련되어 있으며(Kendall 1970), 다음과 같이 표
현할 수 있다.
이 점근적으로 정규분포를 따르므로(Kendall 1970), 역시 점근적으로 정규분
포를 따른다.
세 번째, 사건 대 중도절단의 비교를 위한 값은 다음과 같다.
그외
그외
중도절단 시간()가 사건시간()보다 긴 경우, 오직 의 비
교 쌍만을 가진다. 이 경우 중요한 가정은 는 와 독립이므로 완벽하게 임
의로 중도절단이 발생한다는 것이다. 는 오직 중도절단 시간이 사건 발생 시간
보다 더 긴 쌍만 포함되어있는 Mann-Whitney 통계량과 같다. 그러므로 는 조
건부 Mann-Whitney 통계량이라고 할 수 있다. 여기서, 를 다음과 같이 표현할
수 있다.

- 10 -
Mann-Whitney 통계량이 점근적으로 정규분포에 근사할 때, 또한 점근적으로
정규분포를 따른다고 할 수 있다. 전체 discrimination의 C는 다음과 같다.
⋅
⋅
⋅
⋅
⋅ ⋅ ⋅
여기서,
이다.
가 독립이고, 각각이 점근적으로 정규분포를 따르기 때문에 전체 C
통계량 역시 정규분포를 따른다(Nam, D'Agostino 2004).
2.3.2 Calibration
예측모형에서 calibration이란 예측된 모형이 얼마나 잘 적합한가를 알아보는
척도이다. Calibration은 사건이 발생할 확률의 크기를 이용하여 M개의 집단으로
분할하고, 각 집단에서 그 집단에 속한 개인들의 평균 예측 확률과 실제 결과를
비교하여 평가한다. 로지스틱 회귀모형에서 모형 적합도를 평가하기 위해 흔히 쓰
이는 것이 Hosmer-Lemeshow 통계량(1980, 1982)인데, 다음과 같다.

- 11 -
⋯
여기서, 는 각각 j번째 집단에서의 관측치 수, 사건 수, 로지스틱 회귀모
형으로부터 예측된 사건 발생 확률의 평균이다. 중도절단 된 자료를 가진 생존모
형에서 적합도를 평가하기 위해 Nam과 D'Agostino(2004).가 제안한 통계량은 다
음과 같다.
⋯
여기서 와는 j번째의 Kaplan-Meier 추정치, 그리고 Cox 비례위험모형으
로 추정한 사건 발생 확률의 평균이다. 각 계산에서 중 보다 작은 가장
큰 생존시간에 대응하는 (1-생존확률)을 사용한다.

- 12 -
제 3장 모의실험
3.1 모형의 설정
모의실험에 사용된 모형은 한국인 뇌졸중 예측모형(지선하 외 2008)을 참고로
하여 자료를 발생하였다. 위의 연구는 건강보험공단에 가입되어1992년부터 1995년
사이에 지역 병원에서 정기적으로 검진을 받은 기록이 있는 30세부터 95세 사이
의 한국인 1,329,525명을 대상으로 하였다.
위 연구에 포함된 공변량은 뇌졸중에 영향을 미치는 것으로 알려진 위험인자
들로, 나이, 체질량지수(body mass index ; BMI), 수축기 혈압(systolic blood
pressure ; SBP), 당뇨(diabetes ; TDM), 운동(physical activity ; EXER1), 혈중
콜레스테롤 농도(total serum cholesterol ; NTT), 흡연력(smoking status ;
Smoke), 음주력(alcohol intake ; DRINK)의 8개를 이용한다.
10년 예측 모형을 만들기 위해 각 성별로 나눈 10년 뇌졸중 위험(P)는 다음과
같다.
exp ⋯⋯⋯⋯⋯ 모형
⋯
여기서, ⋯ 는 회귀계수, ⋯ 는 각 개체의 위험인자, ⋯ 은 해
당하는 위험인자의 평균값이다. 또한, 는 모든 위험함수가 평균값을 갖는 기
저위험함수(baseline hazard function)이다.
3.2 공변량의 생성
생성된 독립변수에서 나이, 체질량지수, 수축기 혈압은 정규분포를 따르는 난수
생성을 통하여 연속형 변수로 생성하였고, 혈중 콜레스테롤 농도와 음주력은 연속

- 13 -
형 변수로 생성한 후 범주로 나눴다. 흡연력과 당뇨, 운동은 범주를 나눠 비율에
맞게 생성하였다. 총 생성된 대상자 수는 50,000명이다. 각 공변량을 생성한 후 극
단치(나이 : 30세 미만, 85세 이상, 체질량지수 16 미만)를 포함하는 대상자는 제
거하였다. 자료 생성에 필요한 모수는 다음 표 1, 표 2와 같다.
표 1. 뇌졸중 연구 모집단 특성, 한국 암 예방 연구(지선하 외 2008)
Independent VariableMale Female
mean(S.D.) or % mean(S.D.) or %
AGE 45.0 (11.0) 49.4 (12.1)
SBP 124.5 (16.0) 121.5 (19.1)
BMI 23.2 (2.6) 23.2 (3.1)
NTT 191.3(37.8) 194.5 (39.3)
TDM 4.8 % 4.1 %
EXER1 27.7 % 95.9 %
SMOKE
Never smokers 20.7 % 93.9 %
Ex-smokers 20.1 % 2.0 %
Current smokers 59.1 % 4.1 %
DRIMK
0 23.3 % 85.7 %
1-24 57.5 % -
25-49 11.3 % 14.3 %
50-99 5.9 % -
≥100 2.0 % -
Standard deviation

- 14 -
표 2. Cox 비례위험모형을 이용한 한국인 10년 뇌졸중 예측모형(지선하 외 2008)
Independent VariableMale Female
Coefficient HR Coefficient HR
AGE 0.08117 1.085 0.07836 1.082
SBP 0.02148 1.022 0.01606 1.016
BMI 0.03120 0.1032 0.02177 1.022
NTT
< 200 0.0 1.000 0.0 1.000
200-239 0.06051 1.062 0.02277 1.023
≥ 240 0.17653 1.193 0.12329 1.131
TDM 0.58797 1.800 0.66432 1.943
EXER1 0.06916 1.072 0.07184 1.074
SMOKE
Never smokers 0.0 1.000 0.0 1.000
Ex-smokers -0.02456 0.976 0.10626 1.112
Current smokers 0.27720 1.319 0.31315 1.368
DRIMK
0 0.06810 1.070 0.0 1.000
1-24 -0.02830 0.972 - -
25-49 0.0 1.000 0.01616 1.016
50-99 0.10992 1.116 - -
≥100 0.16459 1.179 - -
HR : Hazard Ratio
독립변수가 생성된 후 종속변수는 각 성별로 10년 뇌졸중 위험 확률(P)을 (모형1)
과 같이 생성하였다.
생존시간을 얻기 위해서는 에 대한 가정이 필요하고, 본 연구에서는 지수
분포 즉, 를 가정하였으며, 다음과 같다(Ralf et al. 2005).
exp′
log

- 15 -
exp′ exp × ×
×
×
×
× ×
×
×
×
×
× ×
여기서, U는 균등분포(uniform distribution) 을 따르고, 회귀 계수는 표 2
와 같다.
또한, 본 연구에서는 10년 이전에 중도절단이 없는 경우와 임의 중도절단을 가
지는 경우의 두 가지 모형을 가정하였다. 뇌졸중 예측모형(지선하 외 2008)에서
연구 종료 이전에 중도절단 된 비율 약 8%를 베르누이 분포를 이용하여 랜덤하게
발생시켰다.
3.3 모의실험 설계
본 연구에서 뇌졸중 발생률의 변화에 따른 discrimination과 calibration의 변화
를 알아보기 위하여 한국인 뇌졸중 예측모형(지선하 외 2008)의 남성 예측모형을
이용하였다. 또한, 모의실험의 사건 발생률이 약 2.5%, 5%, 10%, 15%, 20%가 되
도록 값의 크기를 조정하였으며, 값은 각각 0.98485, 0.9642, 0.9344, 0.9044,
0.8544이다.
중도절단이 있는 자료에서 Cox 비례위험모형과 로지스틱 회귀모형을 비교할
때 로지스틱 회귀모형에서 중도절단은 비-사건으로 정의하였다. 또한 생존시간이
10년 미만이면서 사건이 발생하지 않은 중도절단 된 자료를 제거한 후 분석하여
중도절단 자료 제거 전과 후의 비교를 수행하였다.

- 16 -
제 4장 모의실험 결과
4.1 사건 발생률에 따른 회귀 계수의 비교(중도절단이 없는
경우)
한국인을 위한 뇌졸중 예측 모형(지선하 외 2008)에 기초하여 50,000여명의 모
의실험 자료를 생성하여 사건 발생률에 따라 Cox 비례위험모형과 로지스틱 회귀
모형간의 회귀계수 값을 비교하여 보았다.
두 예측모형의 회귀계수 차이는 표 3에서 사건 발생률 2.49%인 경우 0.0002∼
0.030, 표 4에서 사건 발생률 5.63%인 경우 0.002∼0.055, 표 5에서 사건 발생률
10.32%인 경우 0.002∼0.118, 표 6에서 사건 발생률 14.49%인 경우 0.002∼0.152,
표 7에서 사건 발생률 20.48%인 경우 0.0009∼0.226 사이에서 나타났다. 사건 발생
률이 커질수록 회귀계수 차이의 최대값이 증가하였다.

- 17 -
표 3. 사건 발생률 2.49%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,482)
Cox model Logistic model Difference( log)(S.E) HR (S.E) OR
AGE(years)0.07624(0.0029)
1.0790.0799(0.0030)
1.083 -0.0037
SBP(mmHg)0.02078(0.0019)
1.0210.0218(0.0019)
1.022 -0.0010
TDM(mg/dL)0.54306(0.1116)
1.7210.5726(0.1163)
1.773 -0.0295
SMOKE
Never - - - - -
Ex-smokers-0.04118(0.1056)
0.960-0.0433(0.1079)
0.958 0.0021
Current0.38624(0.0817)
1.4710.4032(0.0836)
1.497 -0.0170
EXER1(no)0.16633(0.0635)
1.1810.1752(0.0654)
1.192 -0.0089
BMI(1 kg/m)0.02365(0.0115)
1.0240.0249(0.0119)
1.025 -0.0013
DRINK(g/day)
00.14126(0.1062)
1.1510.1497(0.1091)
1.161 -0.0084
1-24-0.03301(0.0975)
0.968-0.0332(0.1001)
0.967 0.0002
25-49 - - - - -
50-990.02055(0.1510)
1.0210.0236(0.1551)
1.024 -0.0031
≥1000.28644(0.2030)
1.3320.3127(0.2104)
1.367 -0.0263
NTT
<200 - - - - -
200-2390.04631(0.0687)
1.0470.0484(0.0706)
1.050 -0.0021
≥2400.05028(0.1009)
1.0520.0562(0.1039)
1.058 -0.0059
S.E. : Standard error, HR : Hazard Ratio, OR : Odds Ratio

- 18 -
표 4. 사건 발생률 5.63%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,502)
Cox model Logistic model Difference( log)(S.E) HR (S.E) OR
AGE(years)0.0773(0.0019)
1.0800.0854(0.0022)
1.089 -0.0081
SBP(mmHg)0.0223(0.0012)
1.0230.0246(0.0013)
1.025 -0.0023
TDM(mg/dL)0.4735(0.0762)
1.6060.5281(0.0828)
1.696 -0.0546
SMOKE
Never - - - - -
Ex-smokers0.0119(0.0679)
1.0120.0135(0.0715)
1.014 -0.0016
Current0.3201(0.0534)
1.3770.3516(0.0564)
1.421 -0.0315
EXER1(no)0.1254(0.0426)
1.1340.1388(0.0453)
1.149 -0.0134
BMI(1 kg/m)0.0311(0.0076)
1.0320.0345(0.0081)
1.035 -0.0034
DRINK(g/day)
00.0454(0.0728)
1.0460.0513(0.0770)
1.053 -0.0059
1-240.0325(0.0655)
1.0330.0392(0.0693)
1.040 -0.0067
25-49 - - - - -
50-990.2632(0.0942)
1.3010.2959(0.1006)
1.344 -0.0327
≥1000.1579(0.1444)
1.1710.1811(0.1541)
1.199 -0.0232
NTT
<200 - - - - -
200-2390.0783(0.0456)
1.0810.0868(0.0484)
1.091 -0.0085
≥2400.1664(0.0646)
1.1810.1876(0.0691)
1.206 -0.0212
S.E. : Standard error, HR : Hazard Ratio, OR : Odds Ratio

- 19 -
표 5. 사건 발생률 10.32%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,670)
Cox model Logistic model Difference( log)(S.E) HR (S.E) OR
AGE(years)0.0742(0.0014)
1.0770.0887(0.0017)
1.093 -0.0145
SBP(mmHg)0.0202(0.0009)
1.0200.0241(0.0010)
1.024 -0.0039
TDM(mg/dL)0.5315(0.0554)
1.7010.6488(0.0645)
1.913 -0.1173
SMOKE
Never - - - - -
Ex-smokers-0.0003(0.0494)
1.000-0.0044(0.0541)
0.996 0.0041
Current0.2516(0.0391)
1.2860.2990(0.0431)
1.349 -0.0474
EXER1(no)0.0172(0.0321)
1.0170.0214(0.0357)
1.022 -0.0042
BMI(1 kg/m)0.0300(0.0057)
1.0300.0355(0.0063)
1.036 -0.0055
DRINK(g/day)
0-0.0167(0.0517)
0.983-0.0194(0.0578)
0.981 0.0027
1-24-0.1082(0.0467)
0.897-0.1297(0.0521)
0.878 0.0215
25-49 - - - - -
50-990.0036(0.0724)
1.0040.0061(0.0808)
1.066 -0.0025
≥100-0.0178(0.1153)
0.980-0.0230(0.1278)
0.977 0.0052
NTT
<200 - - - - -
200-2390.0498(0.0339)
1.0510.0580(0.0376)
1.060 -0.0082
≥2400.1949(0.0466)
1.2150.2410(0.0525)
1.273 -0.0461
S.E. : Standard error, HR : Hazard Ratio, OR : Odds Ratio
- 20 -
표 6. 사건 발생률 14.49%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,564)
Cox model Logistic model Difference( log)(S.E) HR (S.E) OR
AGE(years)0.0719(0.0012)
1.0750.0911(0.0015)
1.095 -0.0192
SBP(mmHg)0.0204(0.0008)
1.0210.0256(0.0009)
1.026 -0.0052
TDM(mg/dL)0.5022(0.0466)
1.6520.6534(0.0569)
1.922 -0.1512
SMOKE
Never - - - - -
Ex-smokers-0.0453(0.0413)
0.956-0.0537(0.0469)
0.948 0.0084
Current0.2352(0.0327)
1.2650.2923(0.0374)
1.340 -0.0571
EXER1(no)0.0656(0.0269)
1.0680.0836(0.0312)
1.087 -0.018
BMI(1 kg/m)0.0277(0.0048)
1.0280.0342(0.0055)
1.035 -0.0065
DRINK(g/day)
00.0408(0.0441)
1.0420.0501(0.0509)
1.051 -0.0093
1-24-0.0339(0.0399)
0.967-0.0386(0.0459)
0.962 0.0047
25-49 - - - - -
50-990.1383(0.0599)
1.1480.1834(0.0698)
1.201 0.0099
≥100-0.0031(0.0965)
0.997-0.0103(0.1115)
0.990 0.0072
NTT
<200 - - - - -
200-2390.0295(0.0286)
1.0300.0310(0.0329)
1.031 -0.0015
≥2400.1017(0.0418)
1.1070.1163(0.0485)
1.123 -0.0146
S.E. : Standard error, HR : Hazard Ratio, OR : Odds Ratio

- 21 -
표 7. 사건 발생률 20.48%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,443)
Cox model Logistic model Difference( log)(S.E) HR (S.E) OR
AGE(years)0.0686(0.0010)
1.0710.0946(0.0014)
1.099 -0.0260
SBP(mmHg)0.0183(0.0007)
1.0180.0250(0.0008)
1.025 -0.0067
TDM(mg/dL)0.4789(0.0390)
1.6140.7040(0.0514)
2.022 -0.2251
SMOKE
Never - - - - -
Ex-smokers-0.0480(0.0348)
0.953-0.0669(0.0414)
0.935 0.0189
Current0.2146(0.0273)
1.2390.2887(0.0328)
1.335 -0.0741
EXER1(no)0.0636(0.0226)
1.0660.0885(0.0277)
1.092 -0.0249
BMI(1 kg/m)0.0265(0.0040)
1.0270.0370(0.0049)
1.038 -0.0105
DRINK(g/day)
00.0850(0.0379)
1.0890.1162(0.0461)
1.123 -0.0312
1-24-0.0106(0.0345)
0.989-0.0115(0.0418)
0.989 0.0009
25-49 - - - - -
50-990.0641(0.0515)
1.0660.0886(0.0630)
1.093 -0.0245
≥1000.1742(0.0767)
1.1900.2377(0.0948)
1.268 -0.0635
NTT
<200 - - - - -
200-2390.0636(0.0239)
1.0660.0858(0.0291)
1.090 -0.0222
≥2400.1267(0.0347)
1.1350.1908(0.0430)
1.210 -0.0641
S.E. : Standard error, HR : Hazard Ratio, OR : Odds Ratio
- 22 -
4.2 사건 발생률에 따른 discrimination과 calibration의 비
교(중도절단이 없는 경우)
중도절단 및 결측치가 없는 자료에서 각 사건 발생률에 따라 discrimination과
calibration의 변화를 알아보았다. Discrimination은 사건 발생률이 변화할 때 Cox
비례위험모형과 로지스틱 회귀모형 간에 큰 차이를 보이지 않았고, 비슷한 값을
추정하였다. Calibration은 사건 발생률이 증가함에 따라 로지스틱 회귀모형에서
추정된 값은 증가하는 경향이 나타났으나, 그 결과의 해석에 있어 모형이 적합하
다는 귀무가설을 기각하지 않는 범위 안에서 증가하였다. 반면에 Cox 비례위험모
형에서 추정된 값은 사건 발생률에 따라 증가하였고, 사건 발생률이 약 10%를 넘
어가는 경우에 모형의 적합도에 관한 결과 해석마저 달라지는 것을 확인할 수 있
었다.
표 8. 사건 발생률에 따른 discrimination과 calibration의 비교(중도절단이 없는 경
우)
Eventrate
discrimination calibration( statistics)
Cox Logistic DifferenceCox
(p-value)Logistic(p-value)
Difference
2.49% 0.742 0.742 0.06.3510(0.7043)
5.2419(0.7314)
1.1091(-0.0271)
5.63% 0.744 0.743 0.00111.7292(0.2290)
6.0348(0.6433)
5.6944(-0.4143)
10.32% 0.748 0.746 0.00248.5278(0.0000)
6.5401(0.5870)
41.9877(-0.5870)
14.49% 0.752 0.749 0.003119.9190(0.0000)
8.6782(0.3702)
111.2408(-0.3702)
20.48% 0.755 0.752 0.003250.6810(0.0000)
12.8680(0.1165)
237.8130(-0.1165)

- 23 -
그림 1. 사건 발생률에 따른 discrimination의 변화(중도절단이 없는 경우)

- 24 -
그림 2. 사건 발생률에 따른 calibration의 변화(중도절단이 없는 경우)

- 25 -
그림 3. 사건 발생률에 따라 Cox와 로지스틱 모형의 calibration P-value 변화(중
도절단이 없는 경우)
4.3 사건 발생률에 따른 회귀 계수의 비교(중도절단이 있는
경우)
한국인을 위한 뇌졸중 예측 모형(지선하 외 2008)에 기초하고, 중도절단 상태
를 포함하여 50,000여명의 모의실험 자료를 생성하였다. 그리고 사건 발생률과 중
도절단 자료의 포함 여부에 따라 Cox 비례위험모형과 로지스틱 회귀모형간의 회
귀계수 값을 비교하여 보았다.
표 9부터 표 13에서 사건 발생률이 증가함에 따라 중도절단 된 자료 포함 유
무의 회귀계수가 유사하게 나타났다. Cox 비례위험모형과 로지스틱 회귀모형 간
에는 사건 발생률이 증가함에 따라 회귀계수 차이가 증가하였다.

- 26 -
표 9. 사건 발생률 2.27%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,477)
Including censored data excluding censored data
Cox Logistic Cox Logistic
(S.E) HR (S.E) OR (S.E) HR (S.E) OR
AGE(years)0.0767(0.0030)
1.0800.0798(0.0031)
1.0830.0769(0.0030)
1.0800.0801(0.0031)
1.083
SBP(mmHg)0.0219(0.0020)
1.0220.0227(0.0020)
1.0230.0219(0.0020)
1.0220.0228(0.0020)
1.023
TDM(mg/dL)0.5489(0.1158)
1.7310.5742(0.1201)
1.7760.5538(0.1158)
1.7400.5803(0.1201)
1.787
SMOKE
Never - - - - - - - -
Ex-smokers-0.1605(0.1047)
0.852-0.1663(0.1070)
0.847-0.1602(0.1047)
0.852-0.1660(0.1070)
0.847
Current0.1527(0.0805)
1.1650.1580(0.0825)
1.1710.1542(0.0805)
1.1670.1598(0.0825)
1.173
EXER1(no)0.0990(0.0673)
1.1040.1024(0.0691)
1.1080.0989(0.0673)
1.1040.1022(0.0691)
1.108
BMI(1 kg/m )0.0245(0.0122)
1.0250.0251(0.0125)
1.0250.0248(0.0122)
1.0250.0255(0.0125)
1.026
DRINK(g/day)
0-0.0730(0.1108)
0.930-0.0804(0.1137)
0.923-0.0735(0.1108)
0.929-0.0810(0.1137)
0.922
1-24-0.1093(0.0996)
0.896-0.1162(0.1022)
0.890-0.1103(0.0996)
0.896-0.1174(0.1022)
0.889
25-49 - - - - - - - -
50-990.1664(0.1465)
1.1810.1737(0.1508)
1.1900.1672(0.1465)
1.1820.1750(0.1509)
1.191
≥1000.4038(0.2010)
1.4980.4169(0.2078)
1.5170.4048(0.2010)
1.4990.4186(0.2079)
1.520
NTT
<200 - - - - - - - -
200-2390.0581(0.0722)
1.0600.0607(0.0740)
1.0630.0565(0.0722)
1.0580.0586(0.0740)
1.060
≥2400.1575(0.1016)
1.1710.1642(0.1045)
1.1780.1585(0.1016)
1.1720.1653(0.1046)
1.180
HR : Hazard ratio, OR : Odds ratio

- 27 -
표 10. 사건 발생률 5.26%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,760)
Including censored data excluding censored data
Cox Logistic Cox Logistic
(S.E) HR (S.E) OR (S.E) HR (S.E) OR
AGE(years)0.0776(0.0020)
1.0810.0848(0.0022)
1.0880.0782(0.0020)
1.0810.0857(0.0022)
1.089
SBP(mmHg)0.0209(0.0013)
1.0210.0227(0.0014)
1.0230.0210(0.0013)
1.0210.0230(0.0014)
1.023
TDM(mg/dL)0.5040(0.0771)
1.6550.5574(0.0836)
1.7460.5152(0.0771)
1.6740.5730(0.0837)
1.774
SMOKE
Never - - - - - - - -
Ex-smokers-0.0777(0.0685)
0.925-0.0857(0.0719)
0.918-0.0765(0.0685)
0.926-0.0842(0.0720)
0.919
Current0.1935(0.0540)
1.2140.2075(0.0569)
1.2310.1991(0.0540)
1.2200.2148(0.0569)
1.240
EXER1(no)0.0853(0.0443)
1.0890.0936(0.0470)
1.0980.0833(0.0443)
1.0870.0913(0.0470)
1.096
BMI(1 kg/m )0.0273(0.0079)
1.0280.0300(0.0084)
1.0300.0271(0.0079)
1.0280.0298(0.0084)
1.030
DRINK(g/day)
00.0426(0.0732)
1.0440.0501(0.0774)
1.0510.0428(0.0732)
1.0440.0509(0.0774)
1.052
1-24-0.0386(0.0665)
0.962-0.0401(0.0702)
0.961-0.0392(0.0665)
0.962-0.0410(0.0702)
0.960
25-49 - - - - - - - -
50-990.1384(0.0997)
1.1480.1574(0.1058)
1.1710.1336(0.0997)
1.1430.1520(0.1059)
1.164
≥100-0.0435(0.1642)
0.957-0.0394(0.1731)
0.961-0.0365(0.1642)
0.964-0.0331(0.1730)
0.967
NTT
<200 - - - - - - - -
200-2390.1042(0.0465)
1.1100.1129(0.0492)
1.1200.1042(0.0465)
1.1100.1132(0.0492)
1.120
≥2400.1734(0.0683)
1.1890.1871(0.0724)
1.2060.1709(0.0683)
1.1860.1839(0.0725)
1.202
HR : Hazard ratio, OR : Odds ratio

- 28 -
표 11. 사건 발생률 9.38%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,533)
Including censored data excluding censored data
Cox Logistic Cox Logistic
(S.E) HR (S.E) OR (S.E) HR (S.E) OR
AGE(years)0.0741(0.0015)
1.0770.0867(0.0018)
1.0910.0749(0.0015)
1.0780.0883(0.0018)
1.092
SBP(mmHg)0.0204(0.0010)
1.0210.0238(0.0011)
1.0240.0204(0.0010)
1.0210.0240(0.0011)
1.024
TDM(mg/dL)0.5638(0.0563)
1.7570.6843(0.0650)
1.9820.5640(0.0563)
1.7580.6881(0.0652)
1.990
SMOKE
Never - - - - - - - -
Ex-smokers-0.0165(0.0517)
0.984-0.0161(0.0562)
0.984-0.0146(0.0517)
0.986-0.0128(0.0563)
0.987
Current0.2556(0.0406)
1.2910.3009(0.0443)
1.3510.2568(0.0406)
1.2930.3045(0.0444)
1.356
EXER1(no)0.0740(0.0332)
1.0770.0816(0.0366)
1.0850.0764(0.0332)
1.0790.0850(0.0367)
1.089
BMI(1 kg/m )0.0284(0.0060)
1.0290.0331(0.0066)
1.0340.0291(0.0060)
1.0290.0341(0.0066)
1.035
DRINK(g/day)
00.1201(0.0565)
1.1280.1404(0.0619)
1.1510.1174(0.0565)
1.1250.1370(0.0620)
1.147
1-240.0643(0.0514)
1.0660.0779(0.0562)
1.0810.0657(0.0514)
1.0680.0794(0.0563)
1.083
25-49 - - - - - - - -
50-990.1882(0.0764)
1.2070.2298(0.0844)
1.2580.1844(0.0764)
1.2020.2259(0.0846)
1.253
≥1000.3207(0.1049)
1.3780.3812(0.1173)
1.4640.3167(0.1049)
1.3730.3779(0.1176)
1.459
NTT
<200 - - - - - - - -
200-2390.0513(0.0356)
1.0530.0549(0.0391)
1.0560.0497(0.0356)
1.0510.0524(0.0392)
1.054
≥2400.2010(0.0499)
1.2330.2245(0.0554)
1.2520.2032(0.0499)
1.2250.2292(0.0556)
1.258
HR : Hazard ratio, OR : Odds ratio
- 29 -
표 12. 사건 발생률 13.60%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,598)
Including censored data excluding censored data
Cox Logistic Cox Logistic
(S.E) HR (S.E) OR (S.E) HR (S.E) OR
AGE(years)0.0721(0.0012)
1.0750.0898(0.0016)
1.0940.0736(0.0013)
1.0760.0927(0.0016)
1.097
SBP(mmHg)0.0200(0.0008)
1.0200.0248(0.0009)
1.0250.0204(0.0008)
1.0210.0256(0.0009)
1.026
TDM(mg/dL)0.4698(0.0481)
1.6000.6044(0.0579)
1.8300.4788(0.0481)
1.6140.6204(0.0583)
1.860
SMOKE
Never - - - - - - - -
Ex-smokers-0.0183(0.0426)
0.982-0.0197(0.0479)
0.981-0.0262(0.0426)
0.974-0.2075(0.0481)
0.973
Current0.2313(0.0338)
1.2600.2868(0.0382)
1.3320.2282(0.0338)
1.2560.2883(0.0383)
1.334
EXER1(no)0.0888(0.0276)
1.0930.1096(0.0317)
1.1160.0937(0.0276)
1.0980.1166(0.0318)
1.124
BMI(1 kg/m )0.0233(0.0049)
1.0240.0290(0.0056)
1.0290.0233(0.0049)
1.0240.0292(0.0057)
1.030
DRINK(g/day)
00.0871(0.0460)
1.0910.1117(0.0526)
1.1180.0871(0.0460)
1.0910.1117(0.0528)
1.118
1-24-0.0032(0.0418)
0.997-0.0001(0.0476)
1.000-0.0035(0.0418)
0.996-0.0010(0.0479)
0.999
25-49 - - - - - - - -
50-990.0692(0.0638)
1.0720.0883(0.0729)
1.0920.0769(0.0638)
1.0800.0966(0.0732)
1.101
≥1000.1058(0.0933)
1.1120.1152(0.1066)
1.1220.1176(0.0933)
1.1250.1321(0.1071)
1.141
NTT
<200 - - - - - - - -
200-239-0.0260(0.0300)
0.974-0.0281(0.0341)
0.972-0.0232(0.0300)
0.977-0.0257(0.0343)
0.975
≥2400.1662(0.0414)
1.1810.2094(0.0481)
1.2330.1680(0.0414)
1.1830.2145(0.0483)
1.239
HR : Hazard ratio, OR : Odds ratio

- 30 -
표 13. 사건 발생률 19.20%에서 Cox와 로지스틱 모형의 회귀계수 비교
Men(n=45,567)
Including censored data excluding censored data
Cox Logistic Cox Logistic
(S.E) HR (S.E) OR (S.E) HR (S.E) OR
AGE(years)0.0701(0.0011)
1.0730.0944(0.0014)
1.0990.0710(0.0011)
1.0740.0975(0.0015)
1.102
SBP(mmHg)0.0178(0.0007)
1.0180.0237(0.0008)
1.0240.0180(0.0007)
1.0180.0245(0.0008)
1.025
TDM(mg/dL)0.5640(0.0410)
12.7580.7830(0.0532)
2.1880.5694(0.0410)
1.7670.8044(0.0537)
2.235
SMOKE
Never - - - - - - - -
Ex-smokers-0.0014(0.0361)
0.9990.0022(0.0425)
1.002-0.0051(0.0361)
0.995-0.0015(0.0428)
0.999
Current0.2684(0.0288)
1.3080.3539(0.0341)
1.4250.2692(0.0288)
1.3090.3614(0.0343)
1.435
EXER1(no)0.0366(0.0234)
1.0370.0455(0.0283)
1.0470.0378(0.0234)
1.0390.0472(0.0285)
1.048
BMI(1 kg/m )0.0256(0.0042)
1.0260.0341(0.0050)
1.0350.0266(0.0042)
1.0270.0364(0.0081)
1.037
DRINK(g/day)
00.0138(0.0386)
1.0140.0276(0.0464)
1.0280.0173(0.0386)
1.0170.0358(0.0467)
1.036
1-24-0.0620(0.0350)
0.940-0.0776(0.0420)
0.925-0.0630(0.0350)
0.939-0.0782(0.0422)
0.925
25-49 - - - - - - - -
50-990.0775(0.0527)
1.0810.1161(0.0641)
1.1230.0765(0.0527)
1.0800.1160(0.0645)
1.123
≥1000.1373(0.0752)
1.1470.2255(0.0935)
1.2530.1291(0.0752)
1.1380.2200(0.0943)
1.246
NTT
<200 - - - - - - - -
200-2390.0709(0.0246)
1.0730.0917(0.0297)
1.0960.0720(0.0246)
1.0750.0944(0.0299)
1.099
≥2400.1340(0.0358)
1.1430.1836(0.0436)
1.2020.1337(0.0358)
1.1430.1869(0.0439)
1.206
HR : Hazard ratio, OR : Odds ratio

- 31 -
4.4 사건 발생률에 따른 discrimination과 calibration의 비
교(중도절단이 있는 경우)
모의실험을 통하여 생성된 중도절단이 존재하는 자료에서 중도절단 여부와 사
건 발생률에 따라 discrimination과 calibration의 변화를 알아보았다. 표 14에서
discrimination의 경우 중도절단 자료의 유무에 상관없이 각 사건 발생률에서 Cox
비례위험모형과 로지스틱 회귀모형의 추정값이 큰 차이를 보이지 않았다. 표 15에
서 calibration은 Cox 비례위험모형에서 사건 발생률에 따라 추정값이 크게 증가
하였고, 로지스틱 회귀모형에서는 증가하는 경향을 보이기는 하였지만 그 결과의
해석에 있어 크게 영향을 미치지 못하였다.

- 32 -
표 14. 사건 발생률에 따른 discrimination의 비교(중도절단이 있는 경우)
Eventrate
Including censored data Excluding censored data
Cox Logistic difference Cox Logistic difference
2.27% 0.736 0.733 0.003 0.735 0.734 0.001
5.26% 0.741 0.738 0.003 0.741 0.740 0.001
9.38% 0.749 0.745 0.004 0.749 0.747 0.002
13.60% 0.754 0.747 0.007 0.753 0.751 0.002
19.20% 0.760 0.752 0.008 0.760 0.757 0.003
표 15. 사건 발생률에 따른 calibration의 비교(중도절단이 있는 경우)
Eventrate
Including censored data Excluding censored data
Cox(p-value)
Logistic(p-value)
diffCox
(p-value)Logistic(p-value)
diff
2.27%5.0674(0.8284)
5.1577(0.7406)
-0.0903(0.0878)
5.8054(0.7592)
5.5103(0.7019)
0.2951(0.0573)
5.26%14.1168(0.1182)
13.0221(0.1111)
1.0947(0.0071)
15.3480(0.0818)
14.9458(0.0602)
0.4022(0.0216)
9.38%56.2194(0.0000)
13.6659(0.0909)
42.5535(-0.0909)
50.8011(0.0000)
15.4522(0.0509)
35.3489(-0.0509)
13.60%135.7160(0.0000)
12.8038(0.1188)
122.9122(-0.1188)
105.7220(0.0000)
11.6310(0.1684)
94.091(-0.1684)
19.20%286.0400(0.0000)
13.3622(0.1000)
272.6778(-0.1000)
244.3560(0.0000)
22.4819(0.0041)
221.8741(-0.0041)

- 33 -
그림 4. 사건 발생률에 따른 discrimination의 변화(중도절단이 있는 경우)

- 34 -
그림 5. 사건 발생률에 따른 calibration의 변화(중도절단이 있는 경우)

- 35 -
그림 6. 사건 발생률에 따라 Cox와 로지스틱 모형의 calibration P-value 변화(중
도절단이 있는 경우)

- 36 -
제 5장 결론 및 고찰
한국인의 10년 뇌졸중 예측모형(지선하 외 2008)을 바탕으로 모의실험 자료를
생성하였다. 이 경우 사건 발생률을 다양하게 생성(약 2%, 5%, 10%, 15%, 20%)
하여 Cox 비례위험모형과 로지스틱 회귀모형에서 추정치를 비교하여 본 결과, 사
건 발생률이 약 10%를 넘어가는 경우 추정된 회귀 계수 값의 차이가 증가하는 것
을 확인할 수 있었다. 하지만 모의실험에서 생성된 총 대상의 수가 약 50,000여명
으로 경향이 나타날 뿐 거의 유사하게 추정되었다고 볼 수 있다. 각각 모형에서
추정된 hazard ratio와 odds ratio의 값 또한 사건 발생률이 커짐에 따라 조금 더
차이가 나는 현상을 보였지만, 결론적으로 추정된 값을 볼 때 유사한 값을 추정하
였다.
사건 발생률이 높아짐에 따라 Cox 비례위험모형과 로지스틱에서 각각 계산한
discrimination 값들의 차는 사건 발생률의 증가함에 따라 0.000∼0.003 사이의 변
화를 보였고 사건 발생률에 큰 영향을 받지 않았다. 하지만 calibration의 경우 사
건 발생률이 증가함에 따라 Cox 비례위험모형에서 구한 통계량 값이 급격하게
커졌다. 반면에 로지스틱에서는 사건 발생률이 증가함에 따라 증가하는 경향은 보
였지만 Cox 비례위험모형에서 구한 calibration보다 상대적으로 안정적인 값을 유
지하였다. 또한 로지스틱 회귀모형에서 구한 calibration은 대부분의 경우에서 귀무
가설을 채택하여 모형이 적합하다는 것을 보였으나, Cox 비례위험모형에서 구해
진 calibration값은 사건 발생률 약 10% 이상인 경우에서 모형이 적합하지 않다는
결론을 내려, 로지스틱 회귀모형과 그 결과를 달리하였다.
다음으로 중도절단 된 자료(약 8%)를 포함하는 생존 자료를 생성하였다. 이 경
우 중도절단 자료를 포함하는 경우와 제거한 경우에 Cox 비례위험모형과 로지스
틱 회귀모형을 비교하여 보았다. 위의 경우와 마찬가지로 사건 발생률에 따라
Cox 비례위험모형과 로지스틱 회귀모형간의 차이는 증가하지만, 그 차이가 크지
않았고, 중도절단 된 자료의 제거 전후에 따라 큰 차이는 보이지 않았다. 중도절단
된 자료를 포함하는 경우, 사건 발생률에 따라 각 모형에서 중도절단 처리 유무에

- 37 -
따라 discrimination과 calibration을 비교하여 보았다.
Discrimination은 모든 사건 발생률에서 Cox 비례위험모형이 가장 높았고, 중
도절단 된 자료가 존재하는 경우에 로지스틱 회귀모형의 값이 가장 낮았다. 중도
절단 된 자료를 포함하는 경우에 사건 발생률에 따라 Cox 비례위험모형과 로지스
틱 회귀모형 간의 discrimination 값 차이가 중도절단 된 자료를 제거하고 분석한
경우의 차이보다 조금 더 높았다. 하지만 discrimination 값은 중도절단 자료 제거
유무와 Cox 비례위험모형, 로지스틱 회귀모형 간에 모두 비슷하게 추정되는 경향
을 보여주었다. Calibration에 있어서는 사건 발생률이 약 10% 이상이 되는 경우
Cox 비례위험모형과 로지스틱 회귀모형간의 차이가 급격하게 나타났다. 중도절단
자료 제거 유무에 따라서는 제거하지 않은 경우에 Cox 비례위험모형과 로지스틱
회귀모형에서 구한 calibration 값의 차이가 조금 더 컸다.
Deborah와 Joel(1989)의 연구에서는 추적조사 기간의 길이가 증가함에 따라
Cox 비례위험모형과 로지스틱 회귀모형에서 회귀계수의 차이가 나타났고, 사건
발생률이 증가함에 따라서도 차이가 남을 보고하였다. 본 논문에서는 추적조사 기
간을 상대적으로 긴 10년으로 설정했을 때 두 모형에서 회귀계수는 유사하게 추
정되었고, 사건 발생률이 증가할 경우에도 유사한 결과를 얻었다.
사건 발생률이 낮은 경우(약 5% 이하)에서는 중도절단 자료 포함 유무와 10년
예측 모형을 만들기 위해 사용한 Cox 비례위험 모형과 로지스틱 회귀모형에서 회
귀계수, discrimination, calibration 모두 큰 차이를 보이지 않고, 비슷하게 나타났
다. 하지만 사건 발생률이 높아짐에 따라 Cox 비례위험 모형에서 계산된
calibration 값인 통계량이 급격하게 증가하였다. Cox 비례위험모형에서
calibration 값인 값이 증가하는 이유 중 하나는 Cox 모형으로부터 계산된 평균
생존확률은 두 개의 사건발생 생존시간이 비록 보다 작다하더라도 이의 크기
관계가 모형에 반영되지만 Kaplan-Meier 추정치는 그러하지 못하다. 만약 특정
집단에 속한 대상이 모두 이전에 사건이 발생하였다면 Kaplan-Meier 추정치
는 0이 되나 Cox 비례위험모형의 결과는 0이 아니므로 그 차이가 커지는 것으로
생각된다.

- 38 -
본 연구의 결과로 생존 자료에서 예측 모형의 discrimination은 로지스틱 회귀
모형과 Cox 비례위험모형에서 비슷하였다. 그러나 두 방법간의 calibration 결과의
차이는 사건 발생률이 커질수록 더 커졌다. 추후 이에대한 이론적인 연구가 시행
될 필요가 있다.

- 39 -
참고문헌
김윤남, 조어린, 남병호, 박일수, 지선하. 2008. “뇌졸중 발생 예측모형을 위한 Cox
와 Weibull 모형의 비교 평가”. 한국역학저널. 30 : 41-48.
박재빈. 2006. 생존분석. 이론과 실제. 신광출판사.
여지은. 2000. 로지스틱 회귀모형과 Cox 비례위험 회귀모형의 분류율 비교연구. 연
세대학교 대학원.
D'Agostino, R. B., Nam, B. H. 2004. "Evaluation of the performance of survival
analysis models : discrimination and calibration measures" . N. Balakrishnan, C.
Rao, (Eds.), Handbook of Statistics, 23rd., Elsevier, Amsterdam, pp. 1-26.
Deborah, D. I., Joel, C. K. 1989. "Empirical comparisons of proportional hazards
and logistic regression model". Statistics in Medicine, 8 : 525-538.
Deborah, D. I. 1994. "Statistical issues in analyzing the NHANES I
Epidemiologic follow up study". Vital and health statistics. Series 2 : Data
evaluation and methods research,. 121: 94-1395.
Domchek, S. M. et al. 2003. "Application of Breast Cancer Risk Prediction
Models in Clinical Practice". Journal of Clinical Oncology, 21 : 593-601.
Donald, M. L. 2010. "Cardiovascular Risk Prediction : Basic concepts, Current
Status, and Future Directions". Circulation, 121 : 1768-1777.

- 40 -
Jee, S. H. et al. 2008. "Stroke risk prediction model : A risk profile from the
Korean study". Atherosclerosis, 197 : 318-325.
John, P. K., Melvin, L. M. 2003. Survival analysis. Techniques for censored and
truncated data. second edition. Springer.
L'ltalien, G. et al. 2000. "The Cardiovascular Event Reduction Tool(CERT)-A
simplified Cardiac Risk Prediction Model Developed from the West of Scotland
Coronary Prevention Study(WOSCOPS)". The American Journal of Cardiology,
85 : 720-724.
Matheny, M. E., Ohno-Machado, L., Resnic, F. S. 2005. "discrimination and
calibration of mortality risk prediction models in interventional cardiology".
J ournal of Biomedical Informatics, 38 : 367-375.
Michael, J. P., D'Agostino, R. B. 2004. "Overall C as a measure of
discrimination in survival analysis : model specific population value and
confidence interval estimation". Statistics in Medicine, 23 : 2109-2123.
Paul, M. R. et al. 2008. "C-Reactive Protein and Parental History Improve
Global Cardiovascular Risk Prediction : The Reynolds Risk Score for Men".
Circulation, 118 : 2243-2251.
Ralf, B., Thomas, Augustin., Maria, Blettner. 2005. "Generating survival times
to simulate Cox proportional hazards models". Statistics in Medicine, 24 :
1713-1723.

- 41 -
Wang, S. J. et al. 2008. "Prediction Model for Estimating the Survival Benefit
of Adjuvant Radiotherapy for Gallbladder Cancer". J ournal of Clinical
Oncology, 26 : 2112-2117.
Wilson, P. W. F. 2009. "Challenges to Improve Coronary Heart Disease Risk
Assessment". The Journal of the American Medical Association, 302 (21) :
2369-2370.
Wolf, P. A., D'Agostino, R. B., Belanger, A. J., Kannel, W. B. 1991.
"Probability of stroke: a risk profile from the Framingham study. Stroke. 22 :
312-318.
Zethelius, B. et al. 2008. "Use of Multiple Biomarkers to Improve the Prediction
of Death from Cardiovascular Causes". The New England Journal of Medicine,
358 : 2107 -2116

- 42 -
ABSTRACT
Comparison of Cox's proportional hazard and logistic
regression models : discrimination and calibration of
prediction models
Lee, Sung Hyuk
Dept. of Biostatistics and Computing
The Graduate School
Yonsei University
In recent clinical research, statistical prediction models have been developed for
events of interest such as death from certain diseases or recurrence of the
diseases. Such statistical prediction models are developed generally using
logistic regression or Cox's proportional hazard models.
In this thesis, Cox's proportional hazards and logistic regression models
were compared in terms of discrimination and calibration according to the
incidence rate and the presence of censored data. To evaluate the
discrimination and calibration in prediction models, the AUC and
Hosmer-Lemeshow test statistic were used in the logistic regression model
and the AUC and test statistic using the Kaplan-Meier estimates from
SAS macro %perfcox (Nam, D'Agostino 2004) were used in Cox's proportional
hazard regression model.
The simulation data were generated following the stroke risk prediction
model (Jee et al. 2008). The simulation results for the two prediction models
were relatively similar regarding the estimates of regression coefficients and

- 43 -
discrimination. As the incidence rate increases, however, the value of
calibration in the Cox's proportional hazard regression model tended to rapidly
increase.
Key words : Cox's proportional hazards, Logistic, discrimination, calibration


















