
COMPUTAÇÃO PARALELA - inf.unioeste.br · ... Java ...) – linguagens ... Berkeley Open...
45
v.2.0 COMPUTAÇÃO PARALELA uma visão geral Guilherme Galante
Transcript of COMPUTAÇÃO PARALELA - inf.unioeste.br · ... Java ...) – linguagens ... Berkeley Open...

v.2.0
COMPUTAÇÃOPARALELAuma visão geral
Guilherme Galante

Guilherme GalanteGuilherme Galante● Bacharel em Informática – Unioeste (2003)
● Mestre em Ciência da Computação – UFRGS (2006)
● Professor Assistente do curso de Informática/Ciência da Computação desde 2006
● Atualmente afastado para doutorado – UFPR (2010-2013)
Áreas de Atuação:
● Sistemas de Computação
● Computação Aplicada

Demandas computacionais são cada vez maiores
Ciências e Engenharia
Data Mining
Aplicações Corporativas
Ciências e Engenharia

Desempenho é fundamental...
Três formas de melhorar o desempenho:
1 - Usar um algoritmo/técnica melhor
2 - Usar um computador mais rápido
3 - Computação Paralela
=
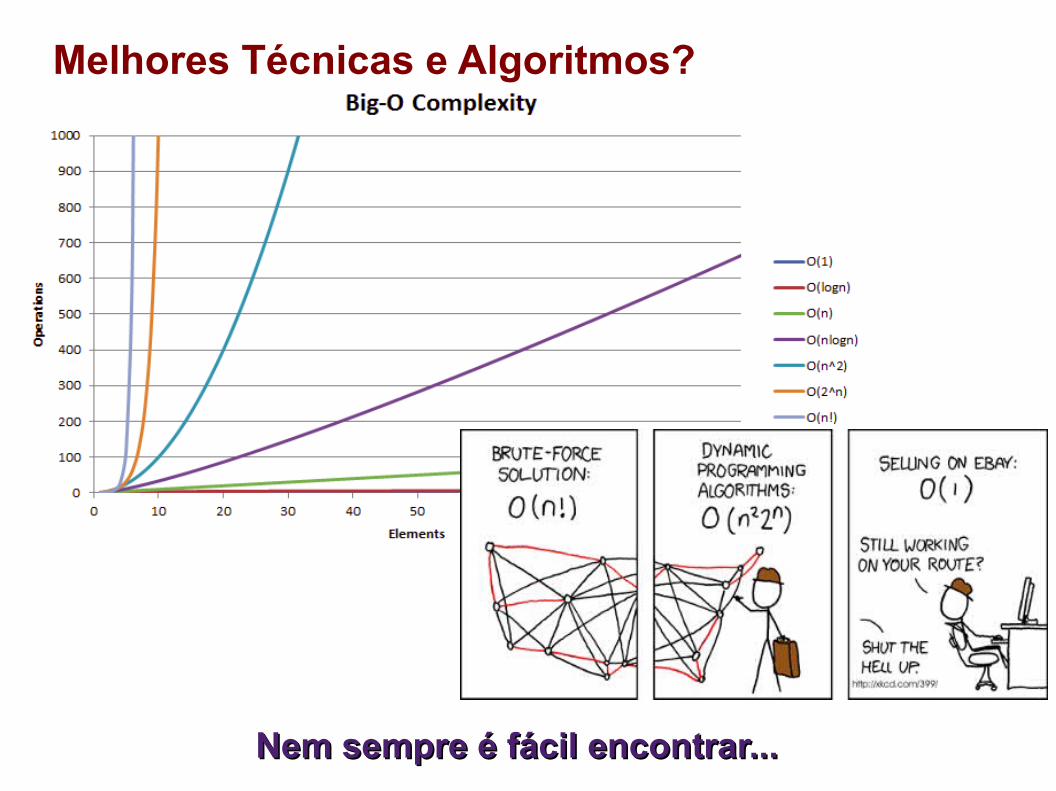
Melhores Técnicas e Algoritmos?
Nem sempre é fácil encontrar...Nem sempre é fácil encontrar...
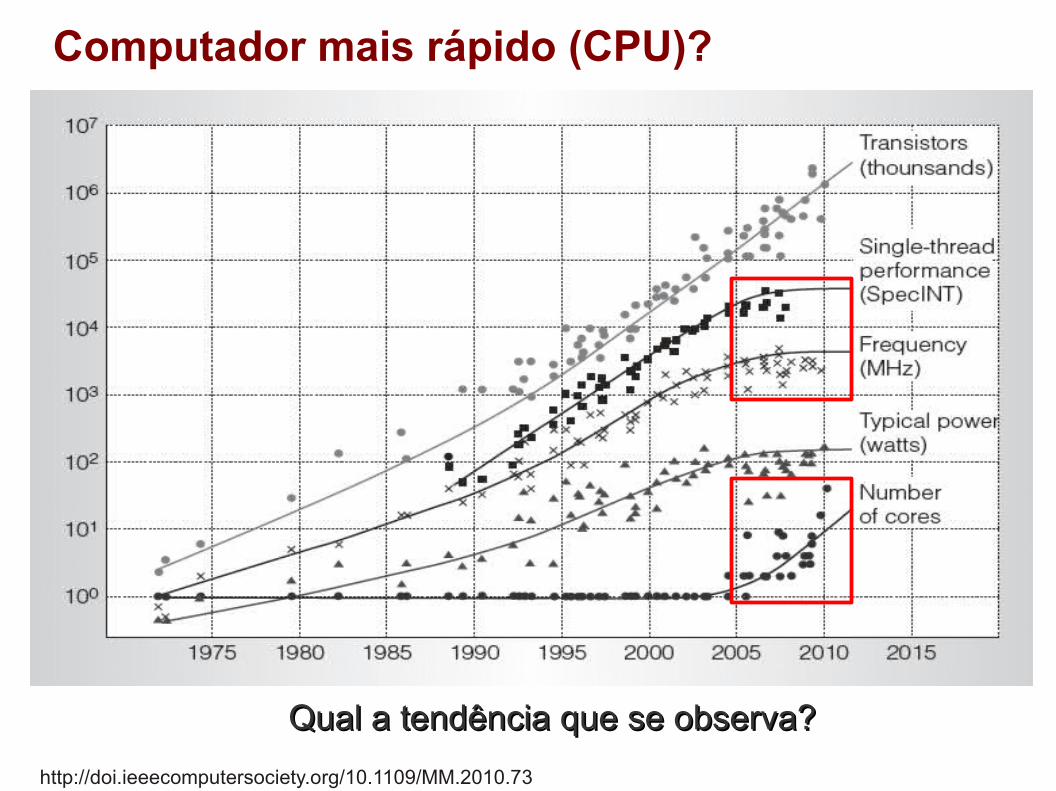
Computador mais rápido (CPU)?
http://doi.ieeecomputersociety.org/10.1109/MM.2010.73
Qual a tendência que se observa?Qual a tendência que se observa?
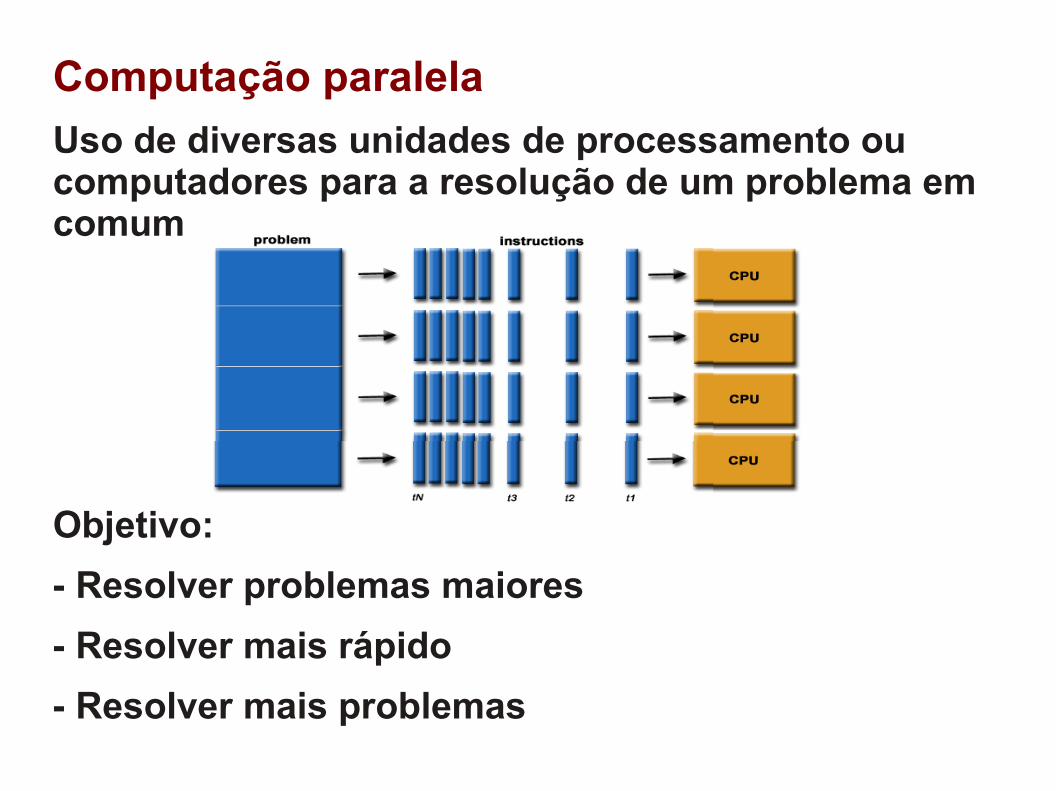
Computação paralela
Uso de diversas unidades de processamento ou computadores para a resolução de um problema em comum
Objetivo:
- Resolver problemas maiores
- Resolver mais rápido
- Resolver mais problemas
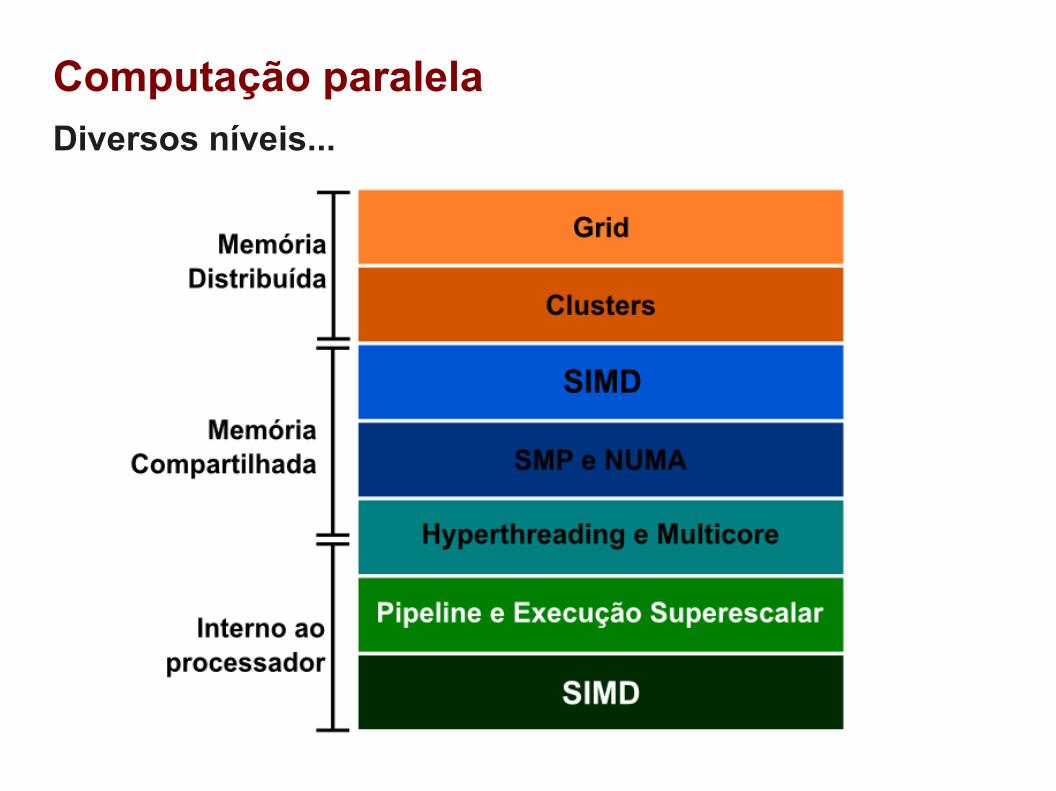
Computação paralelaDiversos níveis...
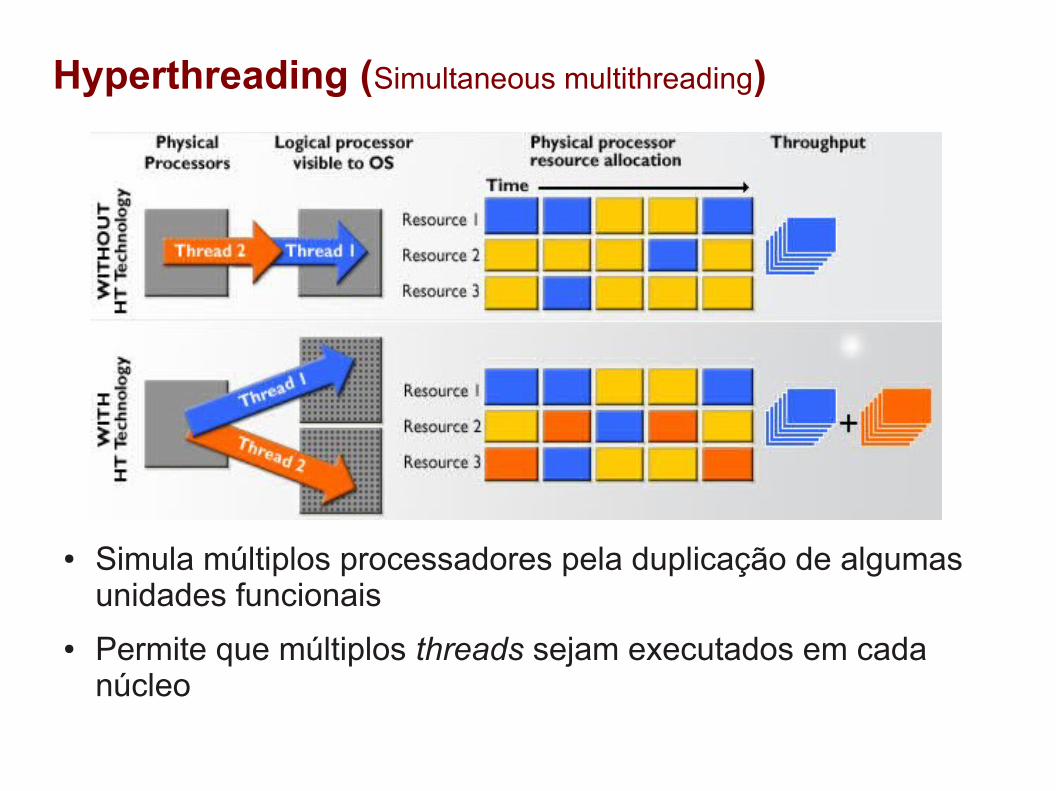
Hyperthreading (Simultaneous multithreading)
● Simula múltiplos processadores pela duplicação de algumas unidades funcionais
● Permite que múltiplos threads sejam executados em cada núcleo

Multicores● Consiste em colocar dois ou mais núcleos de processamento
(cores) no interior de um único chip
● Frequências menores
● Surgiu para minimizar alguns problemas:
– Consumo
– Delays na transmissão
– Aquecimento
– Latência da Memória● Previsão 2017: 512 cores (server) 128 (desktop)
● Presente hoje também em smartphones, tablets, videogames
“Power consumption increases by 60% with every400MHz rise in clock speed” - IEEE Review Setembro 2005
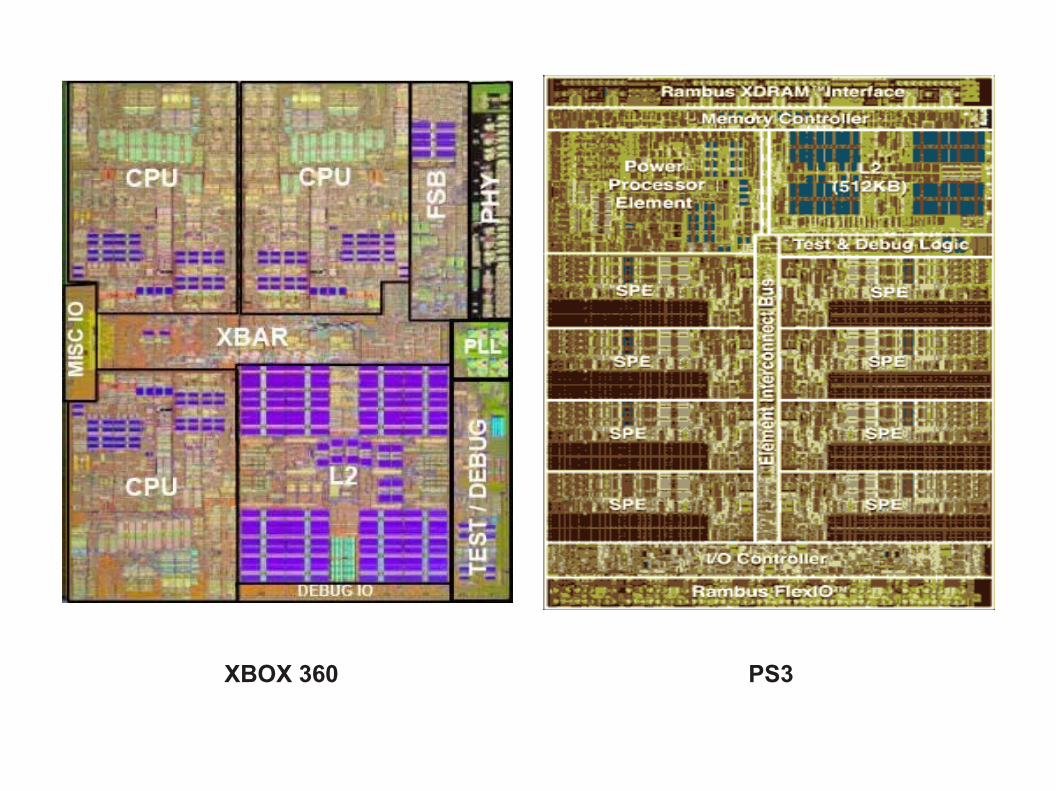
XBOX 360 PS3
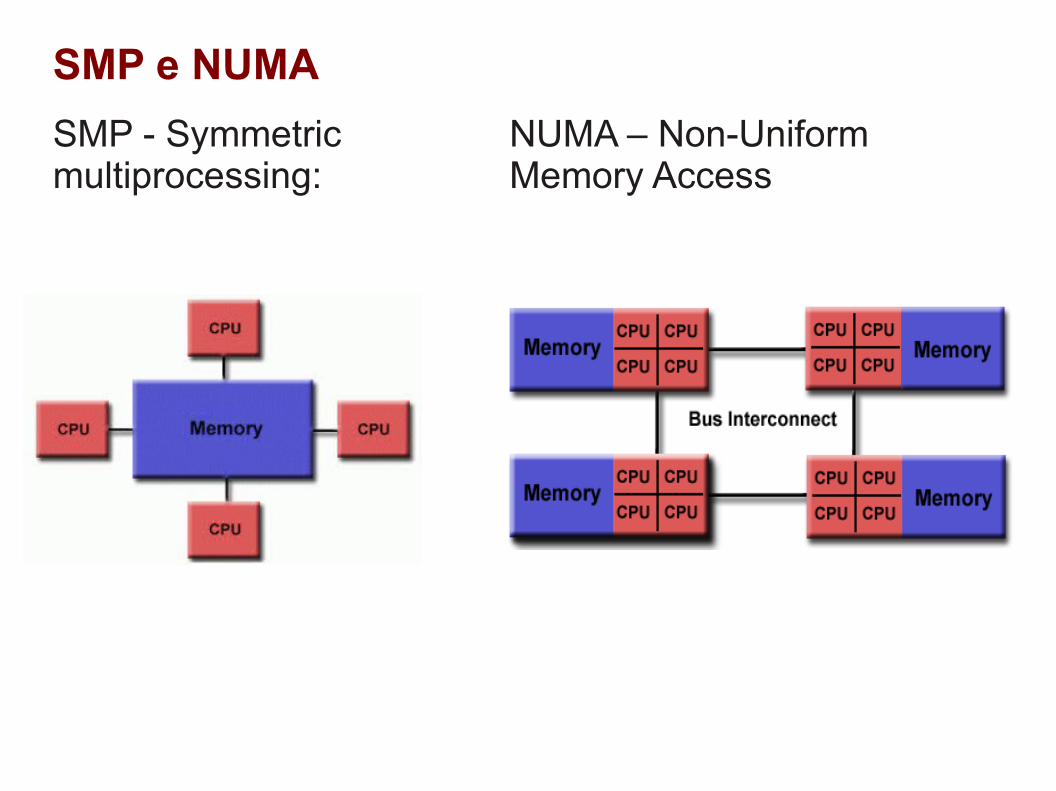
SMP - Symmetric multiprocessing:
SMP e NUMA
NUMA – Non-Uniform Memory Access

SMP
#procs: 2 a 32
NUMA
#procs: milharesAté 256 CPU sockets64 TB RAM
SGI - Altix

Paralelismo em memória compartilhada● Modelo de programação:
– Múltiplas threads compartilhando dados● Aspecto crítico:
– Sincronização quando diferentes tarefas acessam os mesmos dados
● Ferramentas para programação:
– linguagens concorrentes (Ada, Java ...)
– linguagens seqüenciais + extensões/biliotecas (OpenMP, Pthreads, Cilk, HPF)
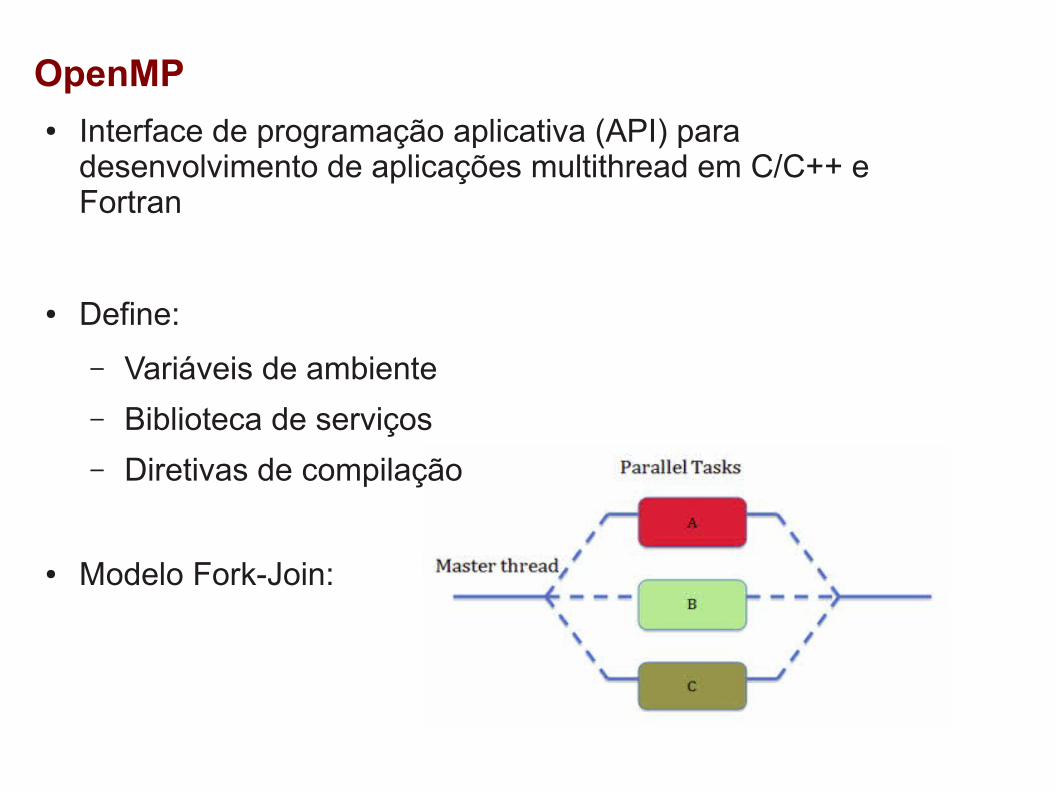
OpenMP● Interface de programação aplicativa (API) para
desenvolvimento de aplicações multithread em C/C++ e Fortran
● Define:
– Variáveis de ambiente
– Biblioteca de serviços
– Diretivas de compilação
● Modelo Fork-Join:

● Exemplo - #pragma parallel
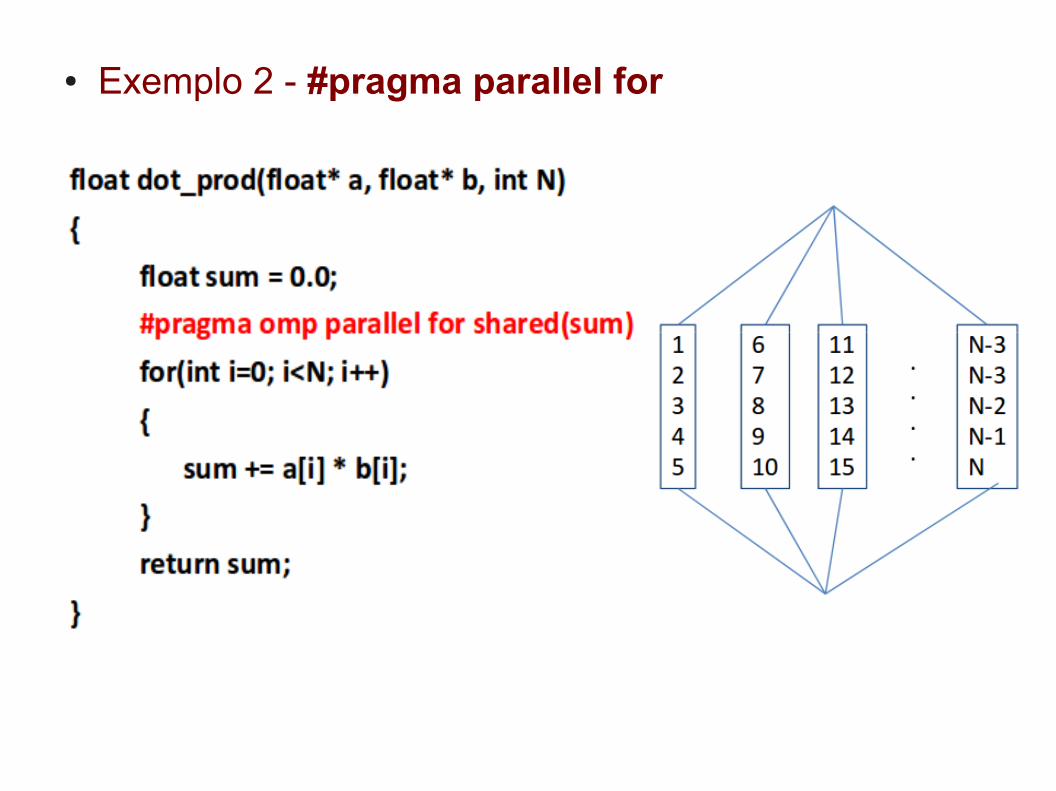
● Exemplo 2 - #pragma parallel for
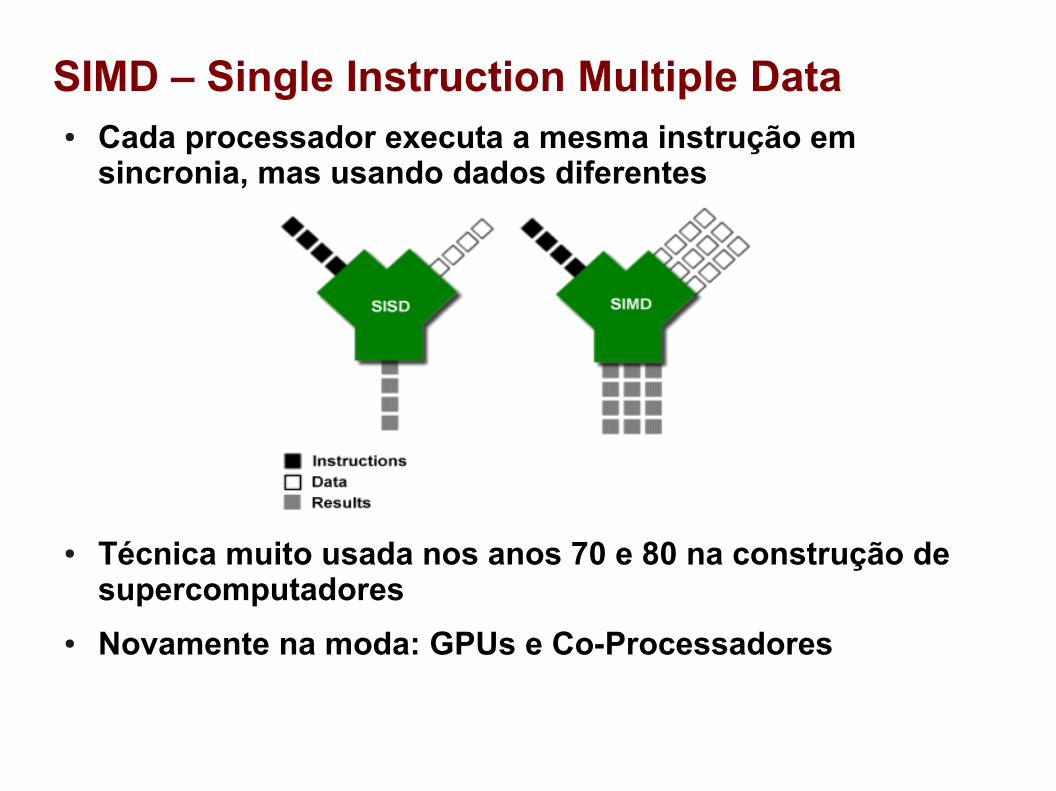
SIMD – Single Instruction Multiple Data● Cada processador executa a mesma instrução em
sincronia, mas usando dados diferentes
● Técnica muito usada nos anos 70 e 80 na construção de supercomputadores
● Novamente na moda: GPUs e Co-Processadores

GPUs e Aceleradoras
NVIDIA TESLA3072 coresProgramação: CUDA
INTEL Phi61 cores, 4 threads/core1-1.5 GhzProgramação: Ferramentas INTEL
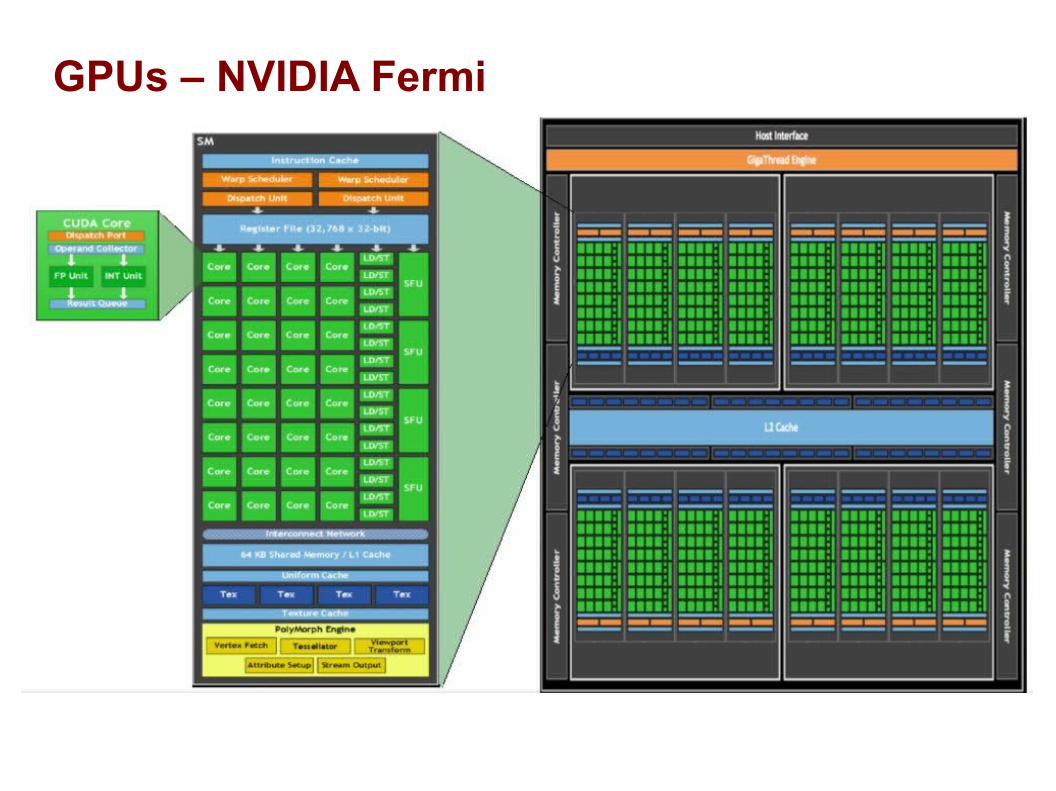
GPUs – NVIDIA Fermi

CUDA - Compute Unified Device Architecture
Extensão para a linguagem de programação C, a qual possibilita o uso de computação paralela nas GPUs NVIDIA
Permite a interação CPU → GPU
Execução do programa é controlada pela CPU que pode lançar kernels, que são trechos de código executados em paralelo por múltiplas threads na GPU
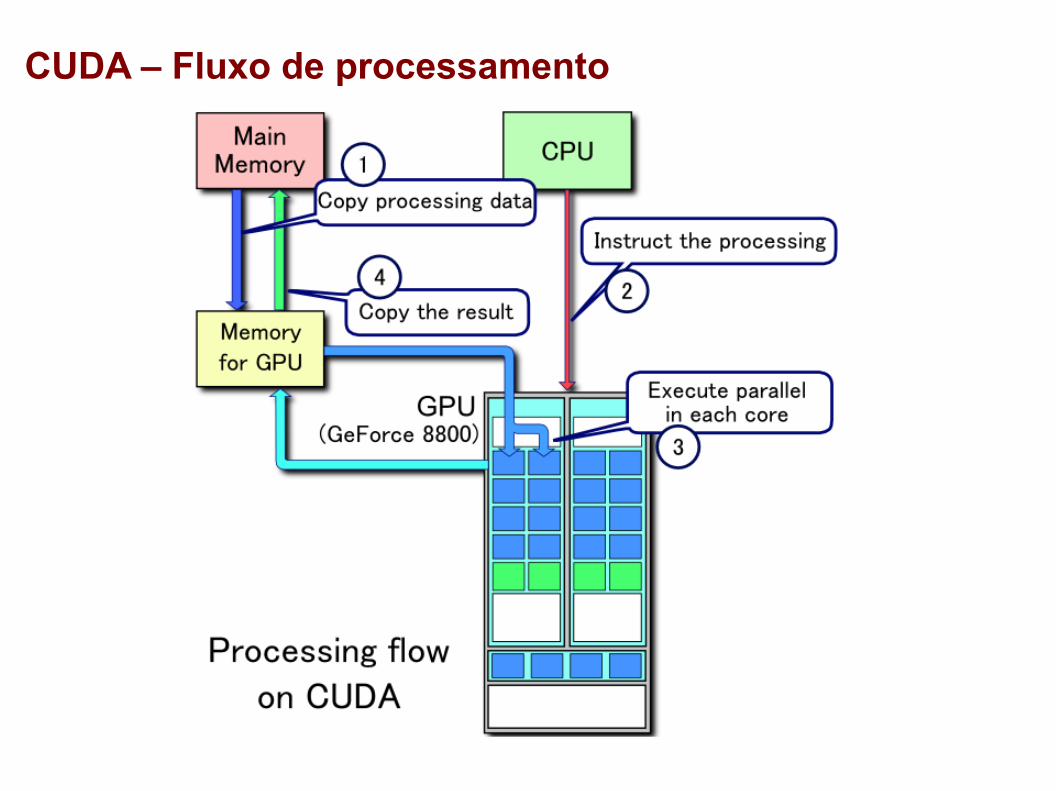
CUDA – Fluxo de processamento

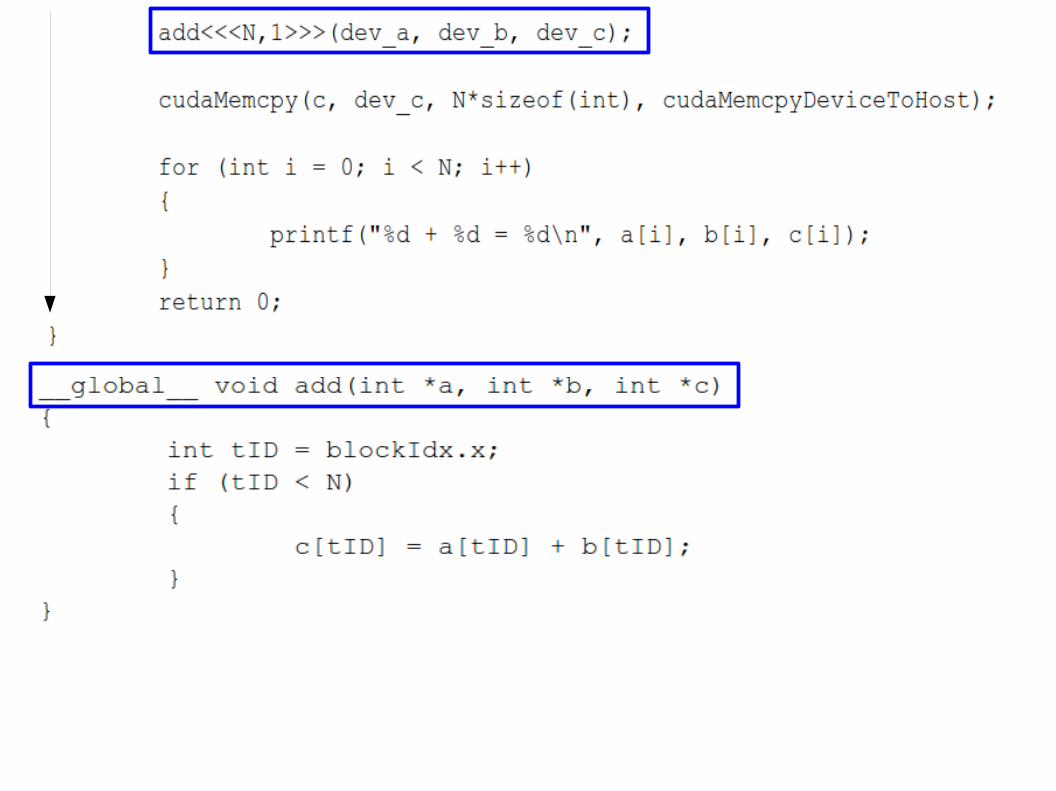
Exemplo código CUDA
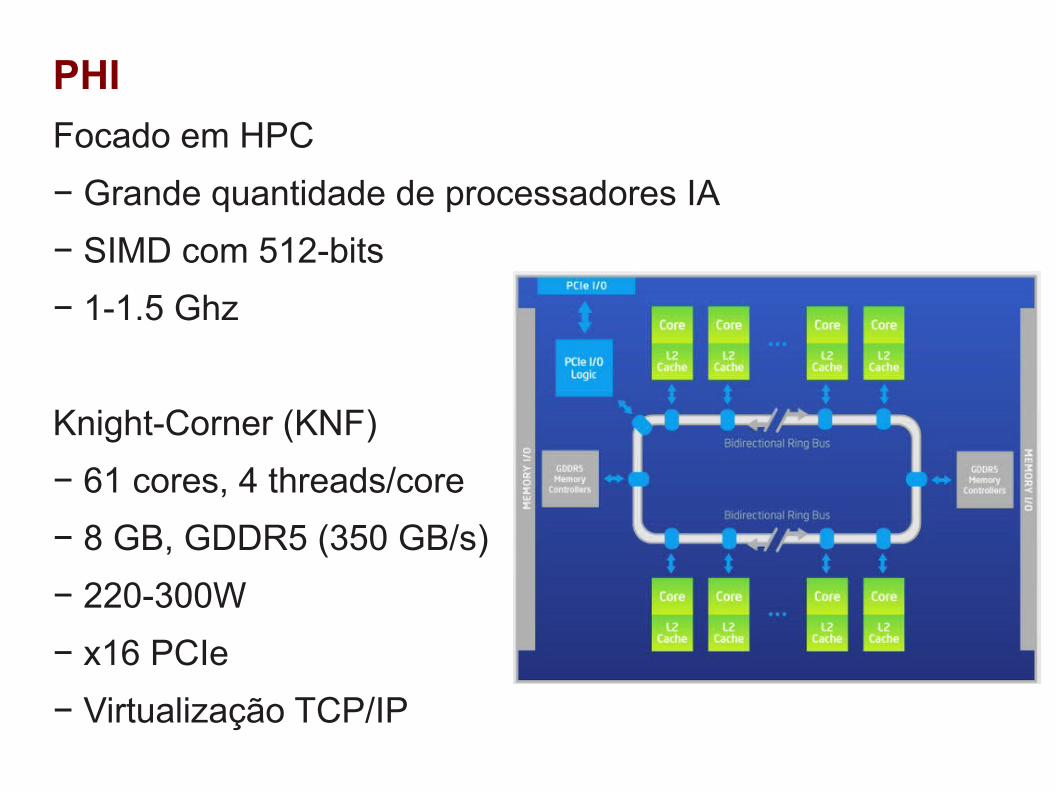
PHI
Focado em HPC
− Grande quantidade de processadores IA
− SIMD com 512-bits
− 1-1.5 Ghz
Knight-Corner (KNF)
− 61 cores, 4 threads/core
− 8 GB, GDDR5 (350 GB/s)
− 220-300W
− x16 PCIe
− Virtualização TCP/IP
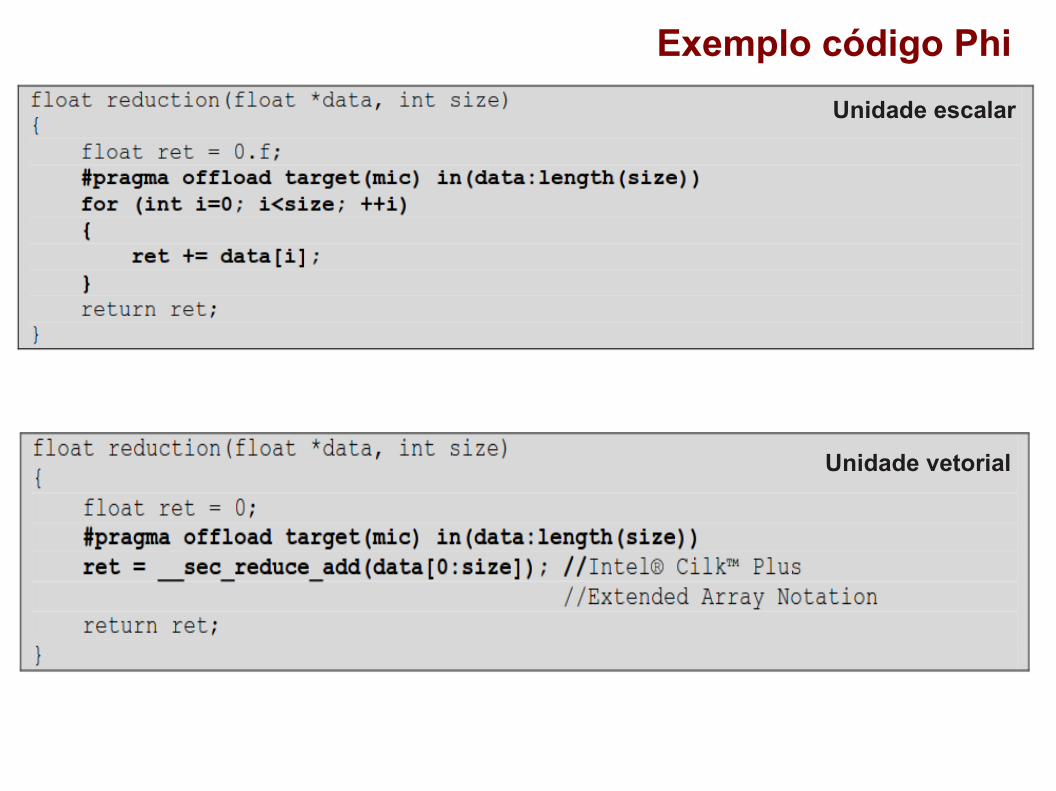
Exemplo código Phi
Unidade escalar
Unidade vetorial
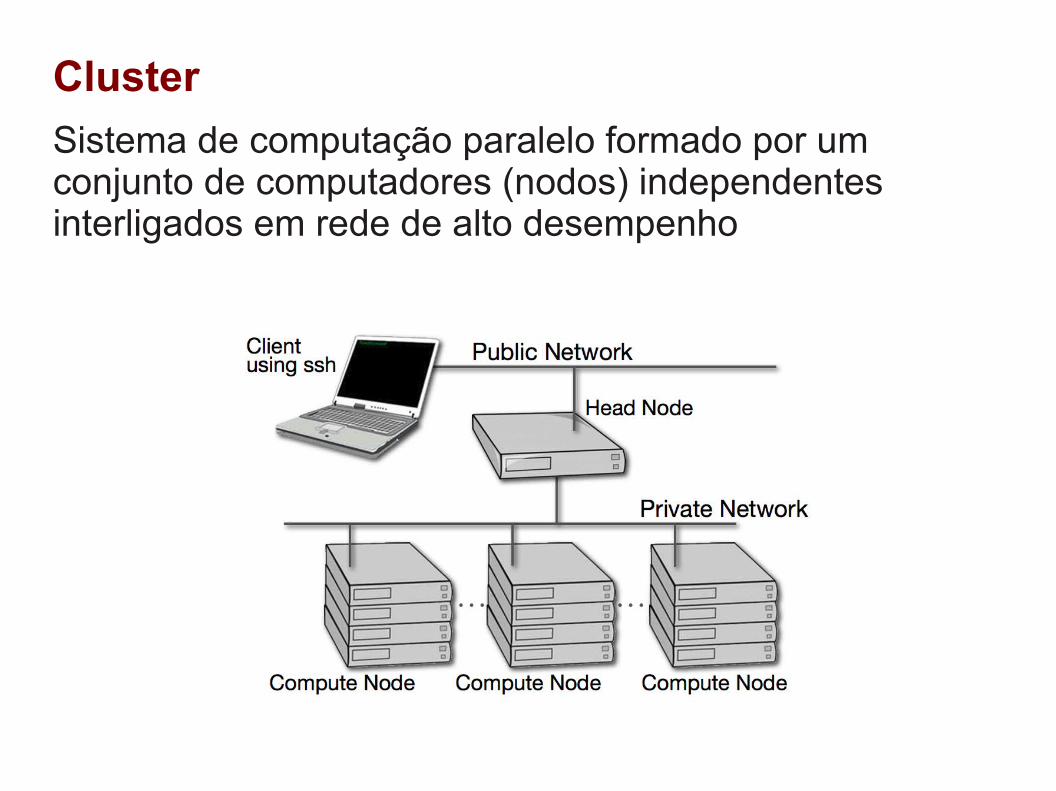
Cluster
Sistema de computação paralelo formado por um conjunto de computadores (nodos) independentes interligados em rede de alto desempenho
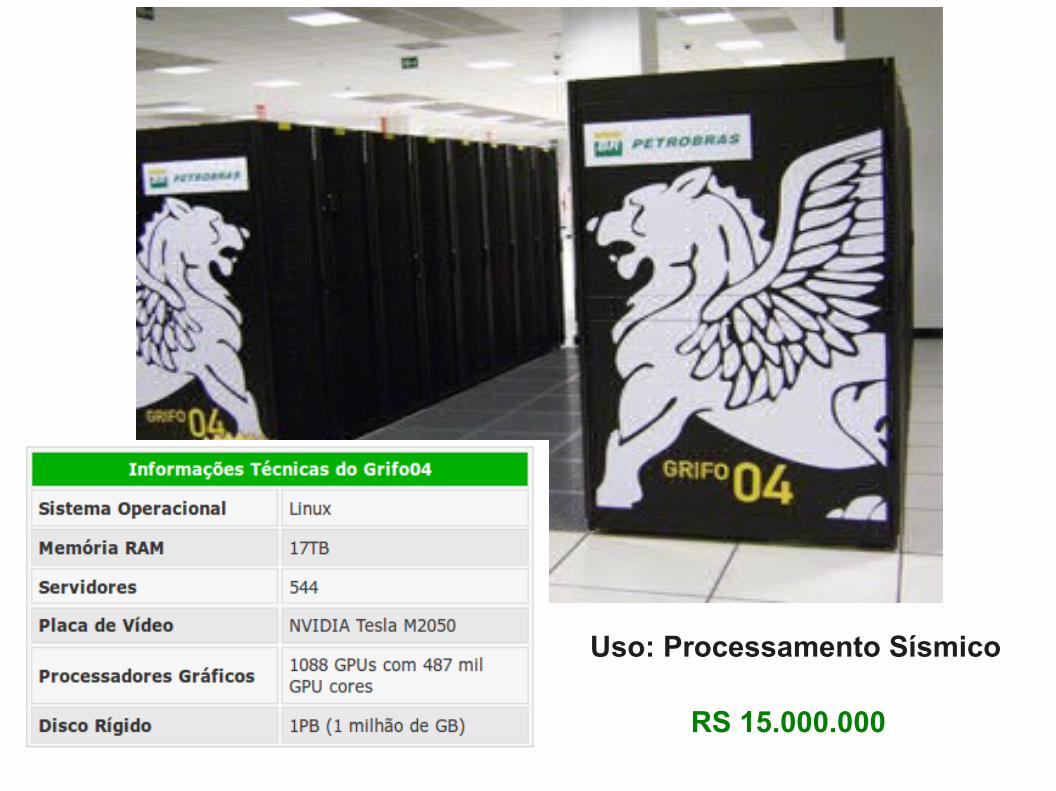
Uso: Processamento Sísmico
RS 15.000.000

Grid
Grid é um sistema paralelo distribuído no qual os recursos estão espalhados por múltiplos domínios administrativos
● Alusão aos Power Grids
Mais apropriada para aplicações fracamente acopladas
● Tarefas independentes com pouca comunicação
● Aplicações @home – BOINC
● Bag-of-tasks

GridPPUK e CERN

Paralelismo em memória distribuída● Modelo de programação:
– Troca de mensagens entre tarefas cooperantes
– Bag-of-tasks● Aspectos críticos:
– Comunicação e distribuição dos dados (balanceamento de carga)
● Ferramentas para programação:
– Linguagens sequenciais + extensões/bibliotecas
– MPI (C,C++, Fortran), PVM, Java+RMI, BOINC● Memória compartilhada distribuída:
– Linda, Threadmarks, ...
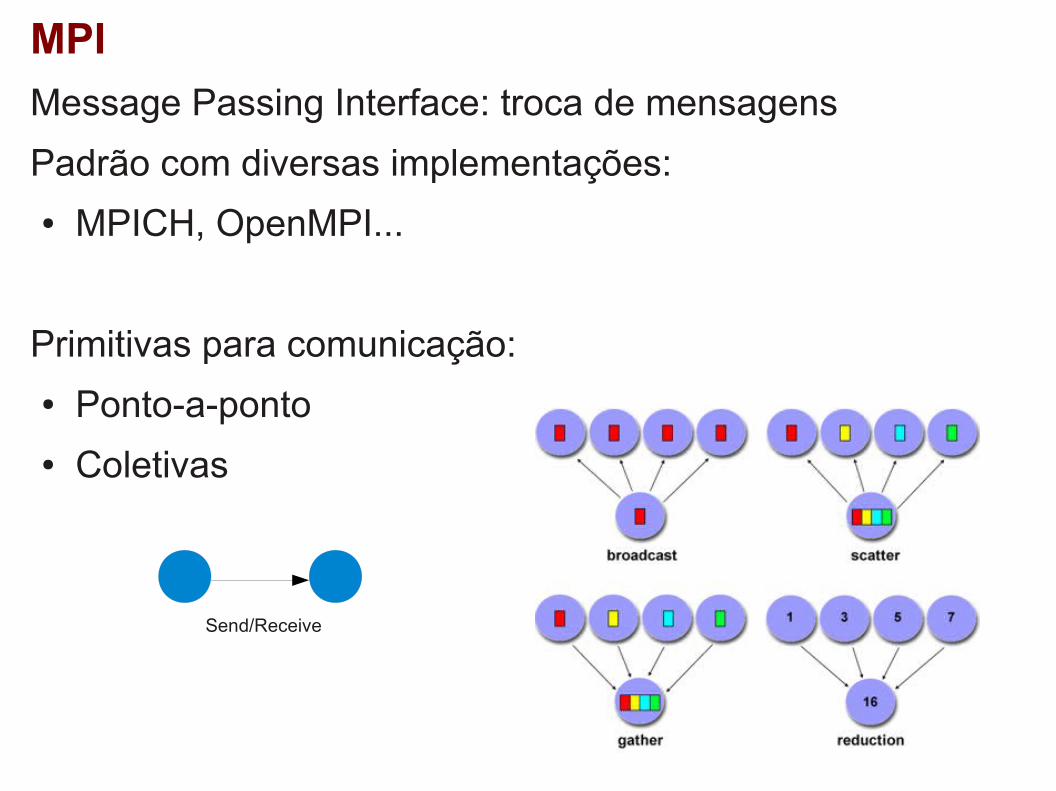
MPI
Message Passing Interface: troca de mensagens
Padrão com diversas implementações:
● MPICH, OpenMPI...
Primitivas para comunicação:
● Ponto-a-ponto
● Coletivas
Send/Receive

Exemplo MPI
#include <stdio.h>
#include <mpi.h>
int main (int argc, char *argv[])
{int rank, size,
MPI_Init (&argc, &argv);
MPI_Comm_rank (MPI_COMM_WORLD, &rank);
MPI_Comm_size (MPI_COMM_WORLD, &size);
printf( "Hello world from process %d of %d\n", rank, size );
MPI_Finalize();
return 0;
}

● Berkeley Open Infrastructure for Network Computing
● Computação voluntária
● Aplicações @home
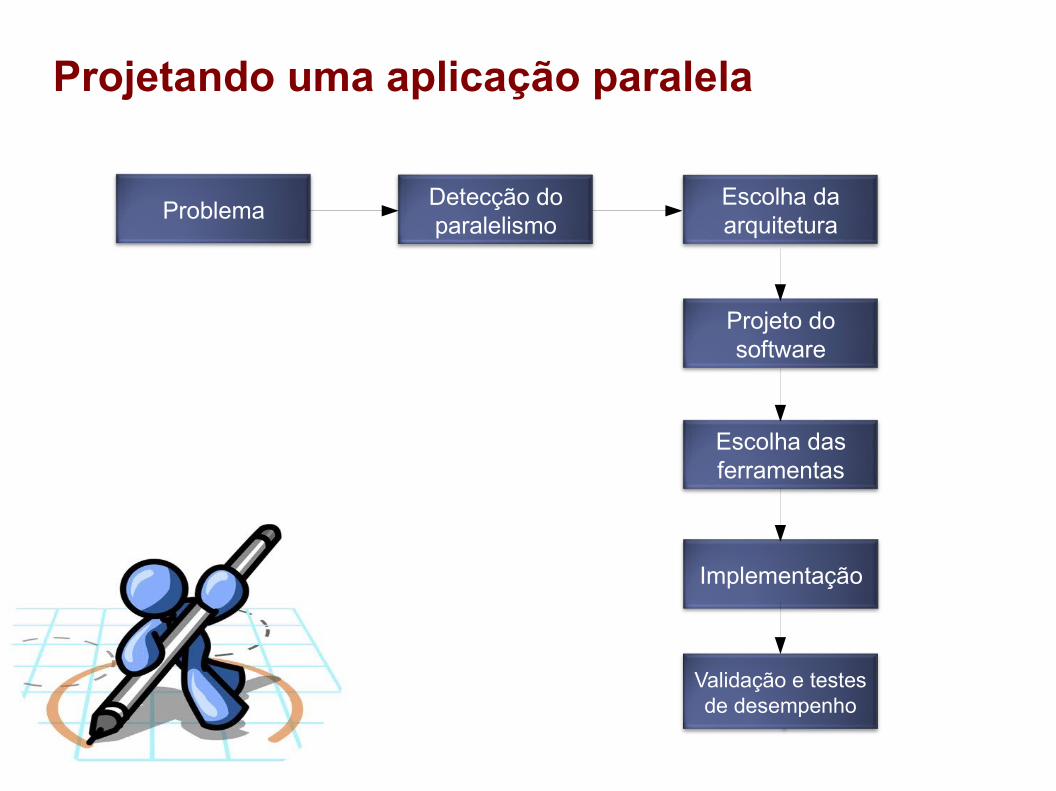
Projetando uma aplicação paralela
Escolha da arquitetura
Problema
Escolha das ferramentas
Detecção do paralelismo
Implementação
Validação e testes de desempenho
Projeto do software
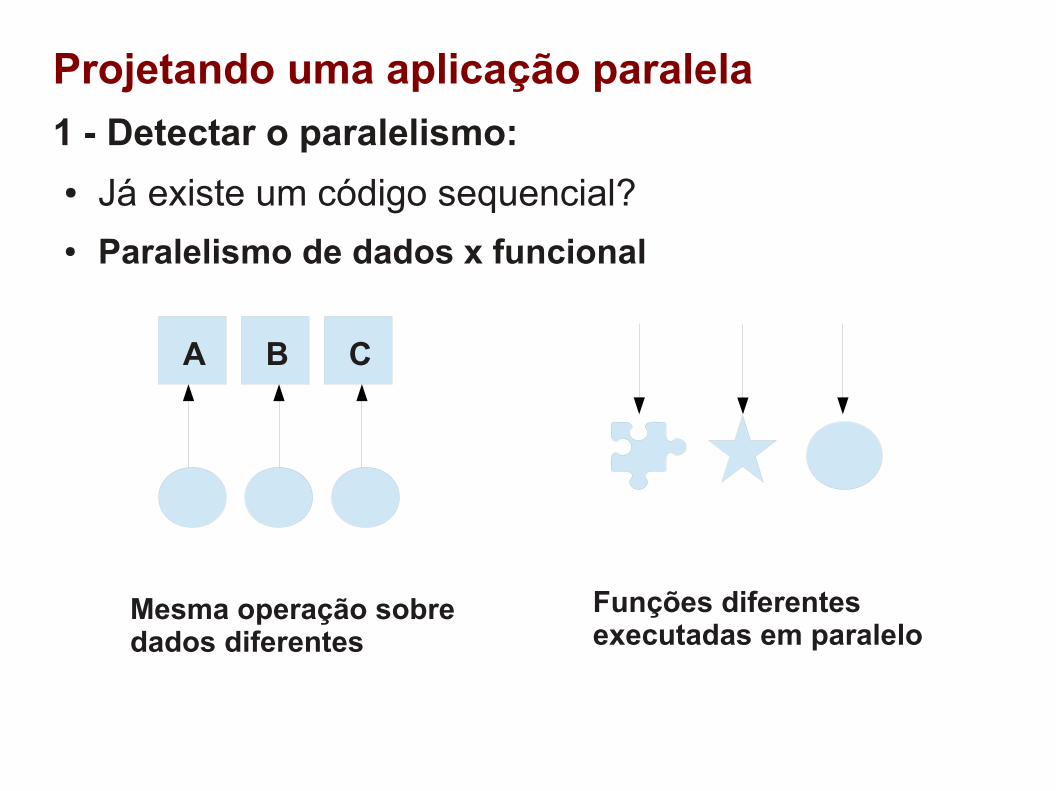
Projetando uma aplicação paralela
1 - Detectar o paralelismo:
● Já existe um código sequencial?● Paralelismo de dados x funcional
A B C
Mesma operação sobredados diferentes
Funções diferentesexecutadas em paralelo

Projetando uma aplicação paralela
2 - Escolha da arquitetura● Aplicação é desenvolvida em função do hardware
disponível
● Temos mais que uma opção? Usar uma ou combinar?

Projetando uma aplicação paralela
3 - Modelo da Aplicação● Definir entradas e saídas
● Modelo da aplicação:
– SPMD (single program multiple data)
– Bag-of-Task
– Pipeline
4 – Escolha da Ferramenta
– Escolha da ferramenta apropriada para a arquitetura e o modelo de aplicação
– Ferramentas de desenvolvimento e debug

Projetando uma aplicação paralela
5 - Implementação● Mãos à obra!!!
6 - Validação e testes de desempenho● Minha solução está correta?
● Houve ganhos de desempenho?
– Tempo de Execução
– Speedup
– Eficiência
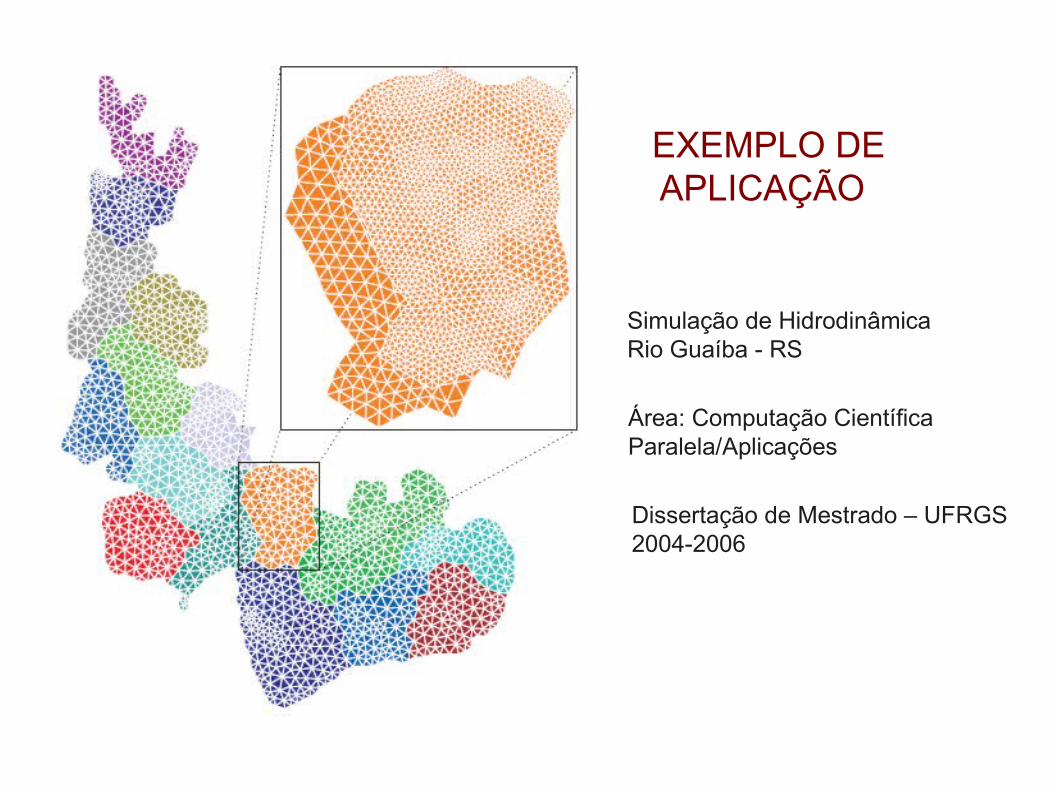
EXEMPLO DE APLICAÇÃO
Área: Computação CientíficaParalela/Aplicações
Dissertação de Mestrado – UFRGS2004-2006
Simulação de HidrodinâmicaRio Guaíba - RS
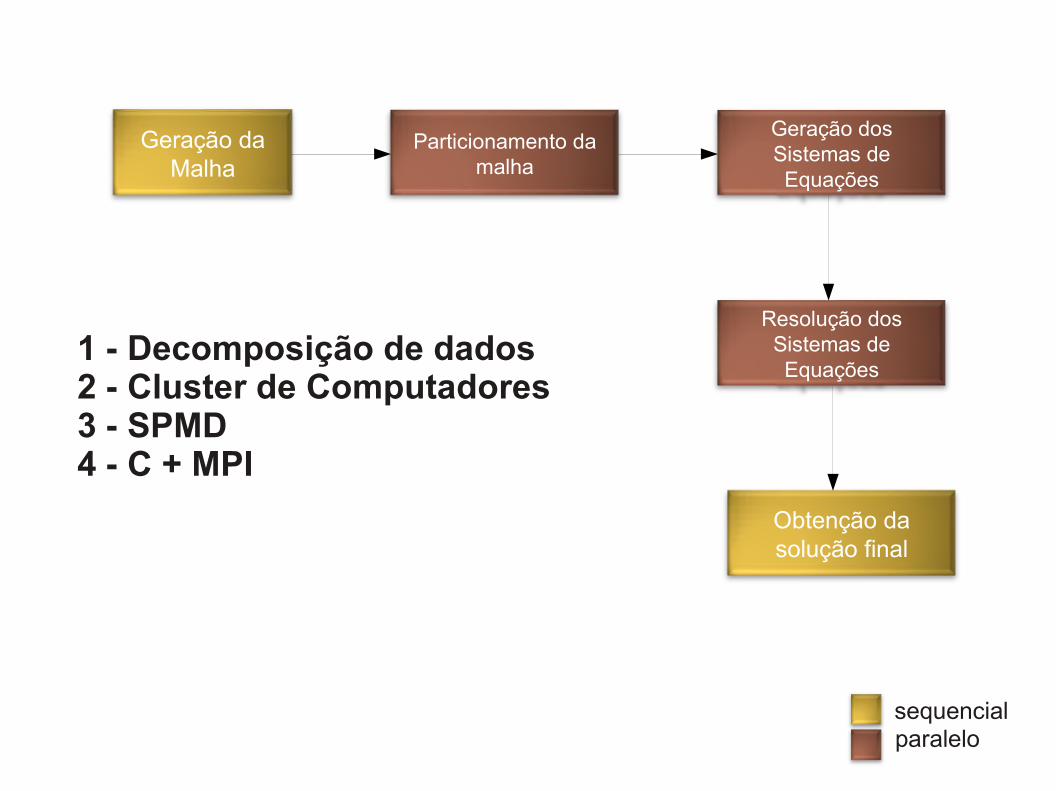
Geração da Malha
Particionamento da malha
Geração dos Sistemas de Equações
Resolução dos Sistemas de Equações
Obtenção da solução final
sequencialparalelo
1 - Decomposição de dados2 - Cluster de Computadores3 - SPMD4 - C + MPI
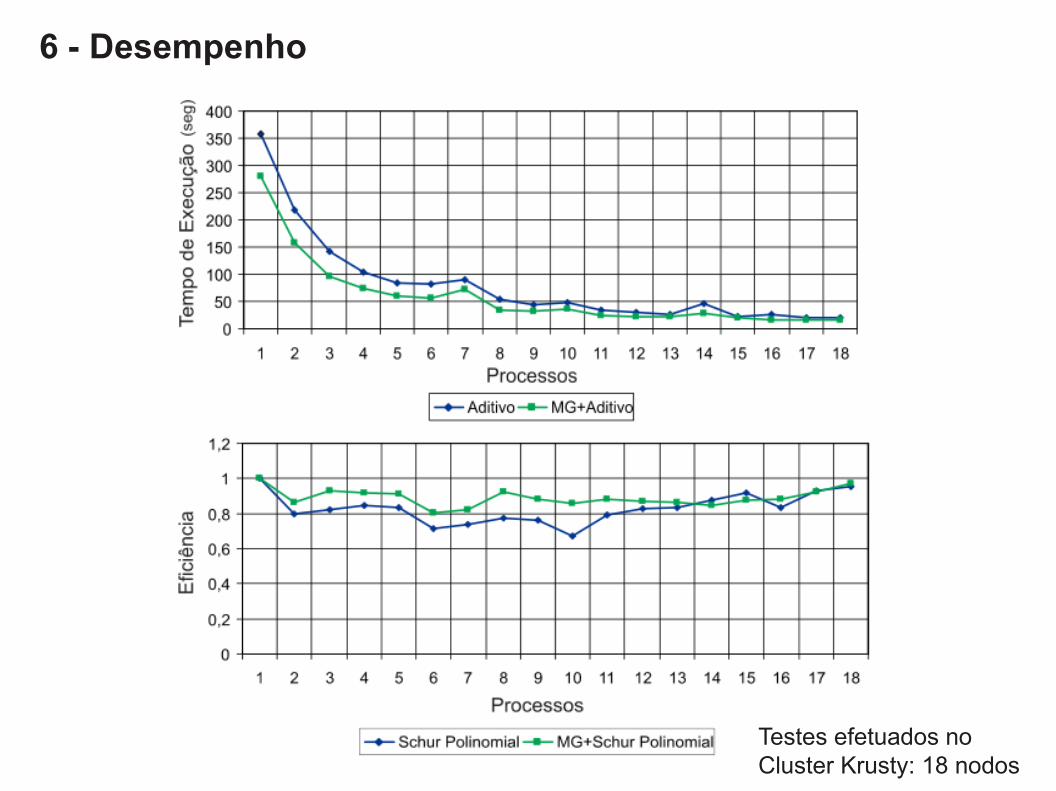
Testes efetuados no Cluster Krusty: 18 nodos
6 - Desempenho

“Para imitar um valor relativamente minúsculo de inteligência, os pesquisadores utilizaram o Fujitsu K para ligar um total de 1,73 bilhões de neurônios virtuais através de 10,4 trilhões de sinapses virtuais (com 24 bytes de memória em cada sinapse - 1PB)...a simulação demorou 40 minutos”
http://gizmodo.uol.com.br/supercomputador-1-por-cento-cerebro/
K (#4 TOP500)SPARC64 VIIIfx 2.0GHz
705.024 cores1.410.048 GB

TCC 2014● Temas:
– Paralelização MPI + OpenMP● Modelos Epidemiológicos● Conjunto com a prof. Claudia
– GPU + CUDA● Implementação de Métodos matemáticos● Conjunto com o prof. Rogério
– Cloud Computing● Elasticidade em Banco de Dados● Conjunto com os prof. Clodis, Marcio e Luiz
● Requisitos
– Conhecimentos em Linux e Programação C

[email protected]/~guilherme


















