
Computação de Alto Desempenho - dcce.ibilce.unesp.braleardo/cursos/hpc/introducao... ·...
117
Computação de alto desempenho Aleardo Manacero Jr. DCCE/UNESP Grupo de Sistemas Paralelos e Distribuídos
Transcript of Computação de Alto Desempenho - dcce.ibilce.unesp.braleardo/cursos/hpc/introducao... ·...

Computação de alto desempenho
Aleardo Manacero Jr.DCCE/UNESP
Grupo de Sistemas Paralelos e Distribuídos

Programa
1. Introdução
2. Processadores para CAD
3. Sistemas de memória
4. Paralelismo usando bibliotecas de baixo nível
5. Paralelismo usando openMP

Programa
6. Conectividade e condições de paralelismo7. Identificação de paralelismo e modelos de paralelização8. Avaliação de desempenho e otimização de programas paralelos9. Paralelismo usando MPI10. Paralelismo usando GP-GPUs

Bibliografia
Pacheco, P. – Parallel Programming with MPI
Pacheco, P. - Introduction to Parallel Programming
Shen, J.P., and Lipasti, M.H. - Modern Processor Design: Fundamentals of Superscalar Processors
Hwang, K. – Advanced Computer Architectures
Dowd, K. & Severance, D. – High Performance Computing

Bibliografia
Hennessy, J.L., Patterson, D.A., and Goldberg, D. - Computer Architecture: A Quantitative Approach, 5th edition, 2012
Patterson, D.A., Hennessy, J.L., et al - Computer Organization and Design: The Hardware/Software Interface, 3rd Edition, 2011
Culler, Singh e Gupta - Parallel Computer Architecture,
Etc......

Website da disciplina
http://www.dcce.ibilce.unesp.br/~aleardo/cursos/hpc
O que tem lá:
Avisos sobre a disciplina
Material de aula
Regras de avaliação

Introdução
Porque precisamos de desempenho?Porque queremos resolver problemas complexos, grandes ou com muitos dados
mas
Nossos computadores são LENTOS!!

Introdução
18 bilhões de operações aritméticas por segundo é rápido o suficiente?
Um i7 de sexta geração realiza mais ou menos isso por núcleo
Como saber se isso é suficiente!!
Vamos a um exemplo prático...

Introdução
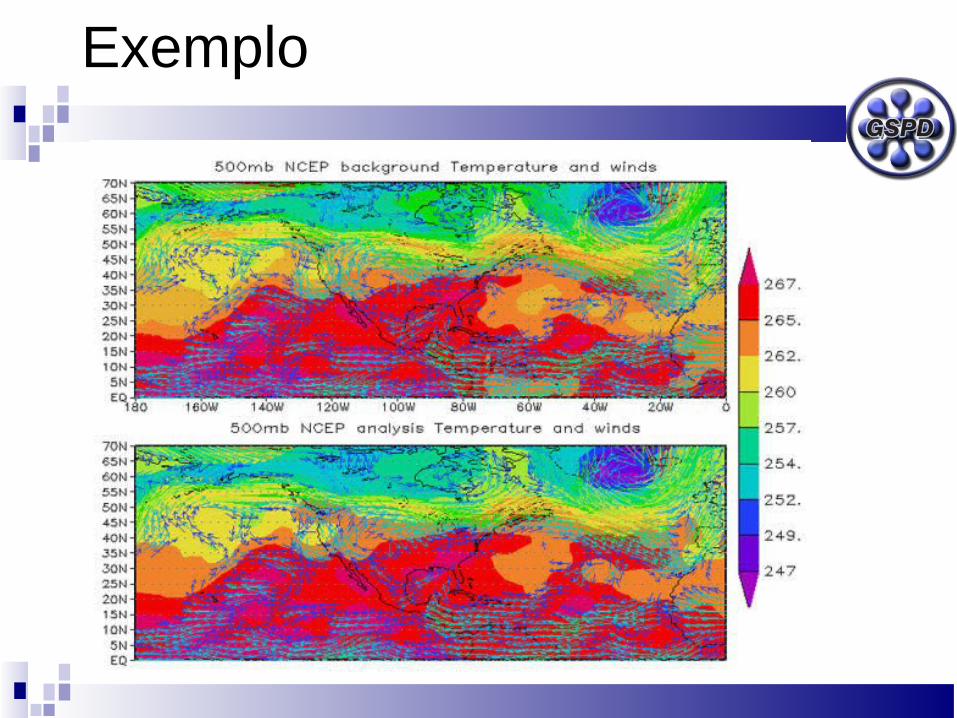
Um sistema de previsão metereológica trabalha usando um “cubo” cuja base é a área em que se quer prever o tempo e a altura corresponde a altitude a considerar.

Exemplo
Nesse cubo se faz um reticulado (formando uma matriz tridimensional), com o número de pontos determinado pela precisão desejada.
Exemplo

Exemplo

Exemplo

Exemplo

Exemplo
Considerando-se como sistema os EUA e Canadá (área de 20 milhões de km2), como sendo um cubo de altitude 20km, com pontos de discretização a cada 100m, teríamos 4.1011 pontos para cálculo.

Exemplo
Se para determinar as condições de cada ponto (temperatura, pressão, umidade, vento) realizarmos 100 operações aritméticas, teremos 4.1013 operações
Para fazer a previsão de dois dias, com informações de hora em hora, teremos aproximadamente 2.1015 operações no total.

Exemplo
Num computador que realize 18 bilhões de operações por segundo (18x109) isso levaria cerca de 111.103 segundos,
o que corresponde a cerca de 31 horas!!!
Para reduzir esse tempo para algo factível (meia hora), nosso computador teria que fazer um trilhão de operações por segundo!!

Conclusão do exemplo
Precisamos de um “supercomputador” para fazer essa previsão.
Mas será que dá para implementar esse supercomputador??
Apenas se usarmos paralelismo....

Porque só com paralelismo?
Suponham que temos uma máquina capaz de realizar um trilhão de operações por segundo.
Se a usarmos para executar o comando
for (i=0; i < Um_Trilhão; i++)
z[i] = x[i] + y[i];
O que acontecerá??

Porque só com paralelismo?
Para executar o comando listado é preciso fazer 3 trilhões de acessos à memória em um segundo
Se cada acesso ocorresse na velocidade da luz, teríamos como distância d, entre CPU e memória o seguinte:
d = v (um acesso) / num de acessos = 3.108 / 3.1012
= 10-4m = 0.1mm

Porque só com paralelismo?
Assim o diâmetro da memória é, no máximo, o dobro dessa distância, o que resulta em DIAM = 2 * d = 2.10-4m
Se a memória tiver que armazenar as posições dos três vetores do exemplo, então o diâmetro de uma posição é dado por
≈1 átomodiam ( pos )=DIAM×DIAM
3. 1012≃10−10m

Exemplos de aplicação
Produção de batatas pringles
Exploração de petróleo
Aerodinâmica
Geociências
Data mining
E-commerce

Exemplos de aplicação

Exemplos de aplicação

Exemplos de aplicação

Exemplos de aplicação

Exemplos de aplicação

Exemplos de aplicação

Exemplos de aplicação

Como se faz(ia) CAD?
Uso de supercomputadores (processamento vetorial)
Uso de máquinas massivamente paralelas
Uso de clusters de computadores
Uso de grids
Uso de processadores paralelos (multicores e GPUs)

Arquitetura de um computador
É como se definem a organização do hardware e as necessidades de software de um sistema
No hardware temos:CPUCacheMemóriaBarramentosMicrocódigosPipelines

Arquiteturas convencionais
A máquina de Von Neumann

Gargalo de von Neumann
A máquina de von Neumann, embora bastante eficiente em sua origem, é um problema pois...
... obriga que se faça sempre um acesso estritamente sequencial aos dados e instruções

Gargalo de von Neumann
Uma alternativa para esse problema é acelerar os processos de acesso aos dados e instruções e de execução das mesmas, o que é feito através de
Memória cache
Pipeline

Gargalo de von Neumann
Cache: Faz o armazenamento intermediário de dados e instruções (normalmente separados) em memória rápida.
Seu uso é possível graças ao Princípio da Localidade.

Gargalo de von Neumann
Pipeline:Substitui a unidade de controle (UC) por unidades especializadas em etapas do processo de execução de uma instrução.

Gargalo de von Neumann
Outra alternativa.....
.... o uso de arquiteturas não-convencionais (paralelas)

Arquiteturas paralelas
A forma de estruturação do hardware de sistemas paralelos pode variar bastante.
Essas variações envolvem a forma como as máquinas são ligadas e as maneiras de organização dos dados e das instruções dos programas.

Classificação de Flynn
Uma forma de sistematizar a variedade de configurações é a classificação proposta por Flynn, em termos do fluxo de instruções e dados, que resulta em:
SISD sistemas convencionais
SIMD computadores vetoriais
MISD arrays sistólicos
MIMD paralelismo massivo

Classificação de Flynn
Na classificação de Flynn as siglas têm o seguinte significado:
S / M = single ou multiple streams
I = instruction stream (fluxo de instruções)
D = data stream (fluxo de dados)

Como obter o paralelismo?
Basicamente são dois tipos de sistemas:
Os multiprocessadores
X Os multicomputadores
A diferença entre eles é a forma de acoplamento entre os elementos de processamento.

O que muda no processador?
Nada...
Exceto pelo maior número de elementos de processamento.

O que muda na memória?
Quase tudo....
No caso de multiprocessadores a memória aparece em três diferentes modelos de acesso:
UMA, NUMA e COMA

Memória UMA
Todos os dados, independente de sua localização física, têm tempo de acesso uniforme para todos os processadores.

Memória NUMA
Aqui os tempos de acesso mudam conforme a localização física dos dados.
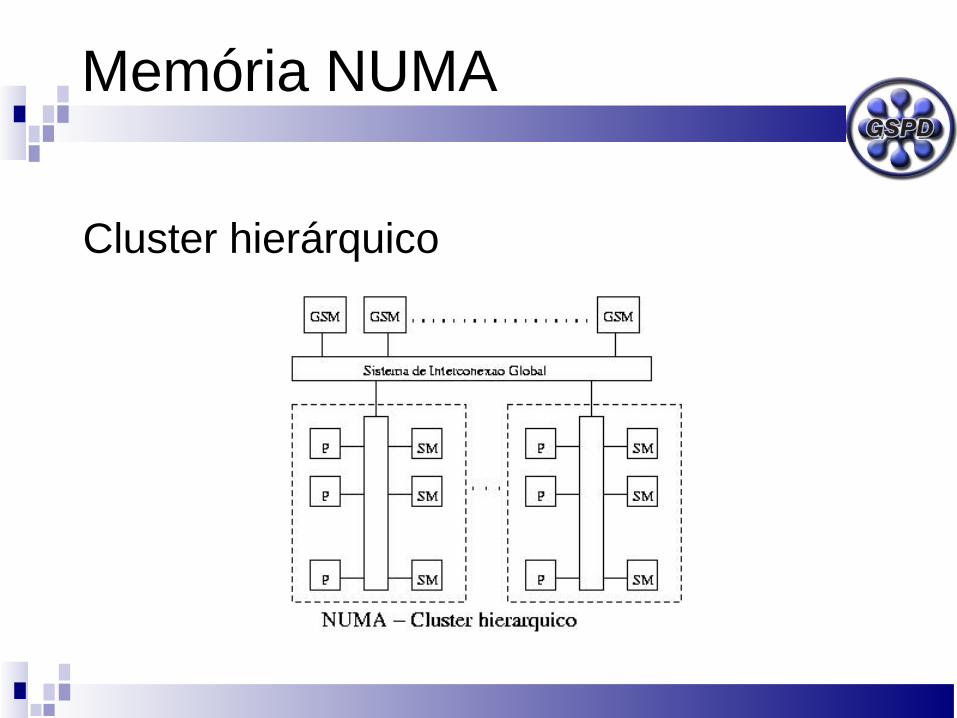
Memória NUMA
Cluster hierárquico

Memória COMA
O acesso aos dados é feito exclusivamente em memória cache.

E para os multicomputadores?
O padrão de acesso é através de troca de mensagens!

Como programas tratam a memória?
Os modelos de acesso descritos não consideram como se dá o direito de acesso dos programas aos dados na memória.
Isso é feito pelos modelos PRAM (Parallel Random Access Machine)

Modelos PRAM
Definem as formas de acesso para as operações de leitura e escrita na memória. Assim temos:
EREW Escrita e Leitura exclusivas
CREW Escrita exclusiva, Leitura concorrente
ERCW Escrita concorrente, Leitura exclusiva
CRCW Escrita e Leitura concorrentes

Um pouco de história
As máquinas de alto desempenho seguiram, em seus primeiros anos, quatro caminhos:
Multiprocessadores com memória compartilhada
Multiprocessadores com troca de mensagens
Máquinas vetoriais
Máquinas massivamente paralelas (SIMD)

Multiprocessadores com memória compartilhada
COMA
crossbar
Clusters de SMPs

Multiprocessadores com troca de mensagens
Caltech
Conectividade interessante

Máquinas vetoriais
Projeto fracassado
Seymour Cray fez projeto

Máquinas massivamente paralelas (SIMD)
Big fail
Big hit
Uso de transputers

Máquinas massivamente paralelas (SIMD)

Padrão atual
Incremento de ambientes multicomputadores: Clusters (Beowulf),
Grades (grid computing) e
Soluções multicores (incluindo GPUs)
Uso de ambientes mistos, com clusters de nós multiprocessadores
Uso de processadores auxiliares de baixo (muitas vezes nem tanto) custo

CAD no mundo
Quem produz equipamentos de CAD, hoje em dia, são empresas americanas e chinesas (poucas japonesas e européias)
Quem usa CAD, hoje em dia, está no hemisfério norte
Existe um levantamento que ranqueia equipamentos de alto desempenho em funcionamento, o Top500 Report

O que diz o Top500
Detalhes em www.top500.org
De novembro de 2017 destacam-se:
Clusters totalizam mais de 87% das máquinas, embora não sejam as mais potentes
Sunway TaihuLight é a atual nº 1, com 93 PFlops
80% das máquinas entre China (40,4), EUA (28,6), Japão (7.0) e Alemanha (4.2)

O que diz o Top500
Outros destaques:
1 máquina na América Latina (no México, posição 496)
6 máquinas no hemisfério sul (Austrália (4), Nova Zelândia (1) e África do Sul (1))
A máquina mais potente do Brasil é um cluster no LNCC (456 Tflops, pos. 472 em junho/17), a segunda na pos. 481 de um provedor de cloud
No hemisfério sul o sistema mais potente está na Austrália (posição 76, com 1676 TFlops)

O que diz o Top500
Santos Dumont - LNCC

O que diz o Top500
Outros destaques:
437 clusters, usando processadores Intel (Xeon), AMD (Opteron) e Power
104 sistemas com coprocessadores (principalmente Nvidia (93) e Intel Xeon Phi (10))
Uso intenso de Infiniband e 10G como redes de conexão, embora Cray Interconnect e outros padrões proprietários tenham maior desempenho total

Distribuição por países

Distribuição por países
USA
ChinaJapão
Alemanha
UK
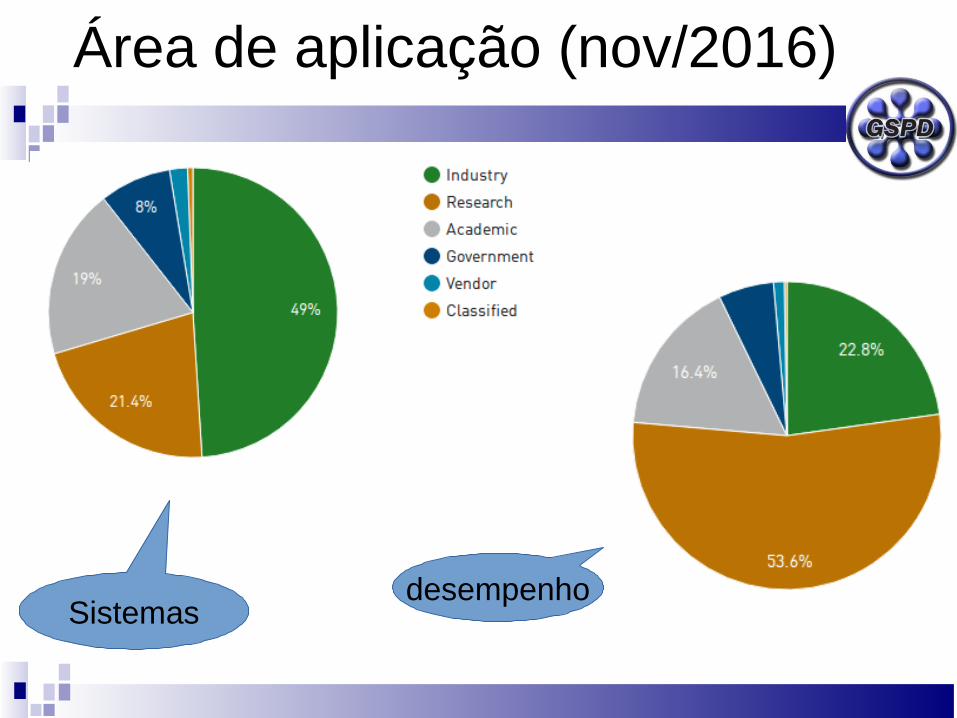
Área de aplicação (nov/2016)
desempenhoSistemas

Área de aplicação (nov/2016)
Universidades
Pesquisa
Indústria

Desempenho global
#1
#500
Total

Previsões do futuro (em 2015)
2016
2019/20
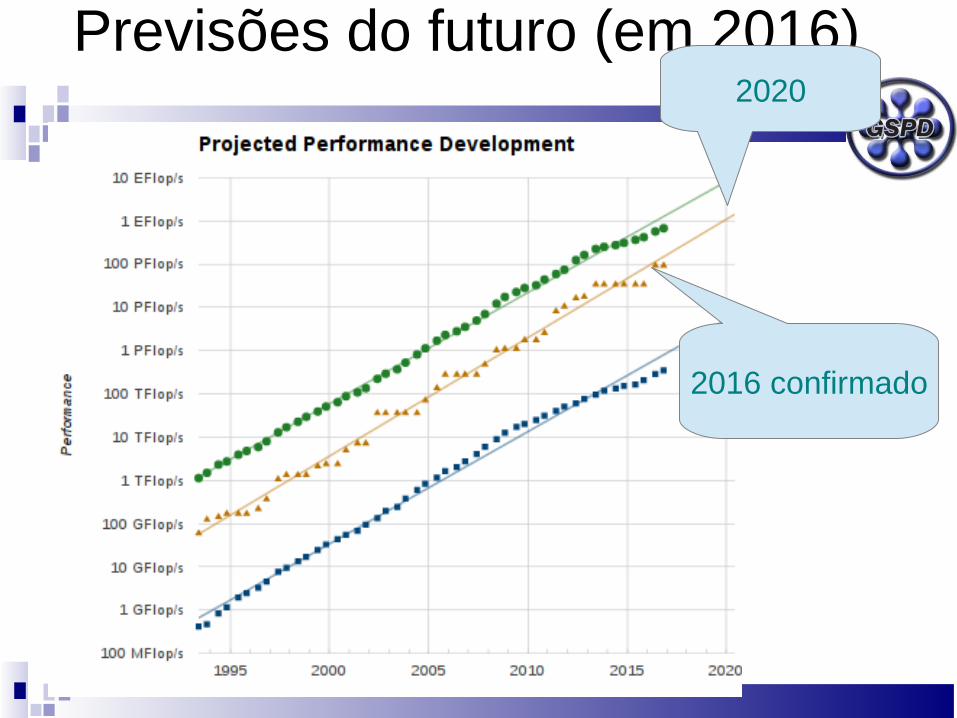
Previsões do futuro (em 2016)
2016 confirmado
2020

Previsões do futuro
Curva mudandoinclinação
2020 ??

Tipos de arquitetura
desempenhoSistemas

Tipos de arquitetura
Clusters
MPP
SMP
ConstelaçãoSingle
2003

Tipos de Sistema Operacional
Sistemasdesempenho

Mecanismos de comunicação
Sistemas desempenho

Mecanismos de comunicação
desconhecido
hipercubo
toróide
SP switch
hipercubohyperplex
myrinet
Gigabit Ethernet
Infiniband
10G
2000 2005 2010

ALGUNS SISTEMAS
(nem tão novos!) TEMAS EM USO

IBM Stretch Supercomputer

Capacidade de 100 bilhões de operações
Por dia!!!!
Lançado em 1961
Tinha 150 mil transistores....
i7 tem 1.17 bilhões
IBM Stretch Supercomputer

Algumas inovações importantes:
Multiprogramação
Pipeline
Proteção de memória
Byte de oito bits
IBM Stretch Supercomputer

NEC SX8

NEC SX8
Cada nó pode executar 128 Gflops
Um sistema pode ter até 512 nós, chegando a 65 Tflops e acomodando 64 Tbytes de memória

Cray XC-40
Desempenho esperado de 75 Tflops/rack
Até 128 Xeon E5 por rack
Cray Linux (versão do SuSE Linux)

Cray XC-40

Cray XT4

Cray XT5 (Jaguar)

Cray XT5

K Computer

Sequoia

Tianhe

Earth Simulator

Jaguar

Jaguar

Titan

Cray XD1

Cray XD1

IBM BlueGene/L

IBM BlueGene/L

IBM BlueGene/L

IBM BlueGene/P

IBM RoadRunner

IBM RoadRunner

IBM RoadRunner

IBM RoadRunner

IBM RoadRunner

D-Wave 2 Quantum Computer

D-Wave 2 Quantum Computer

O que usar?


Padrão atual
Incremento de ambientes multicomputadores, principalmente através dos conceitos de:
cluster de estações de trabalho (Beowulf),
computação por grades (grid computing) e
computação ubíqua (ubiquitious computing)

Padrão atual
Incremento no uso de processadores dedicados, como:
processadores gráficos (GPU),
FPGA e
cell processors (caindo em desuso)

Clusters

Clusters
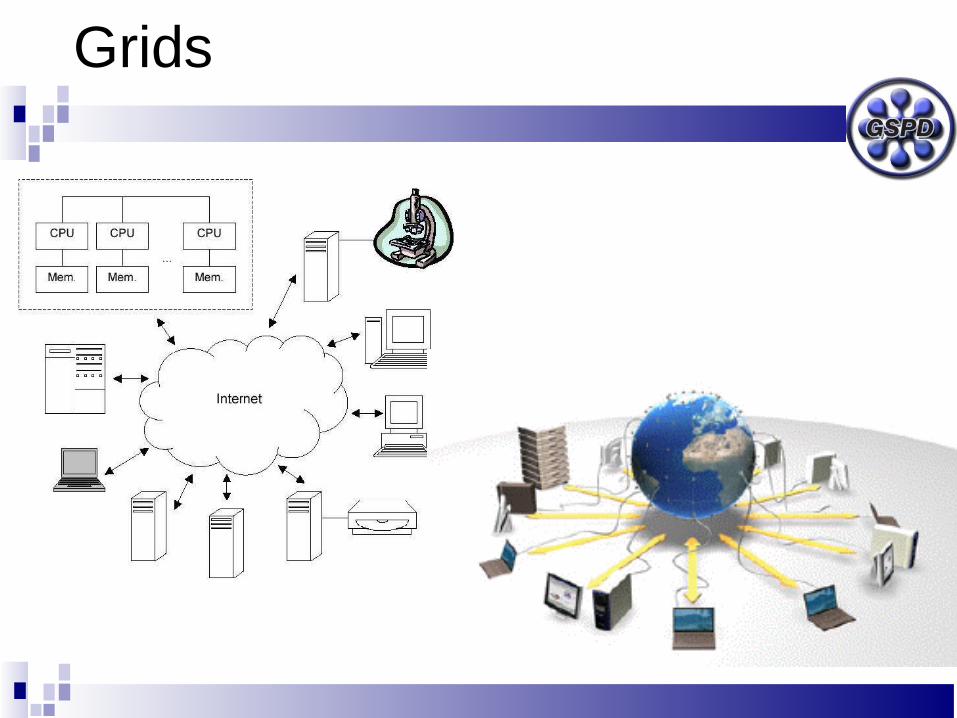
Grids

Grids

Onde chegaremos

Onde chegaremos
Lei de Moore
Problemas com consumo de energia e resfriamento dos processadores (top500 agregou dados sobre consumo de energia)
Uso cada vez mais intenso de clusters e suas derivações (multicores, grids, clouds, etc)
Tendência de máquinas orientadas para aplicação (Google e TPUs)

Onde chegaremos


















