
COLLABORATIVE EXECUTION ENVIRONMENT FOR HETEROGENEOUS PARALLEL SYSTEMS Aleksandar Ili´c, Leonel...
29
COLLABORATIVE EXECUTION ENVIRONMENT FOR HETEROGENEOUS PARALLEL SYSTEMS Aleksandar Ili´c, Leonel Sousa 2010 IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW 2010) present by 陳陳陳 2012.05.31 1
-
Upload
rodger-randall -
Category
Documents
-
view
216 -
download
2
Transcript of COLLABORATIVE EXECUTION ENVIRONMENT FOR HETEROGENEOUS PARALLEL SYSTEMS Aleksandar Ili´c, Leonel...

1
COLLABORATIVE EXECUTION ENVIRONMENT FOR HETEROGENEOUS PARALLEL SYSTEMSAleksandar Ili´c, Leonel Sousa
2010 IEEE International Symposium on Parallel & Distributed Processing, Workshops and Phd Forum (IPDPSW 2010)
present by 陳彥廷2012.05.31

2
Outline • Introduction• Unified execution model• Example• Experiment • Conclusion• Future work

3
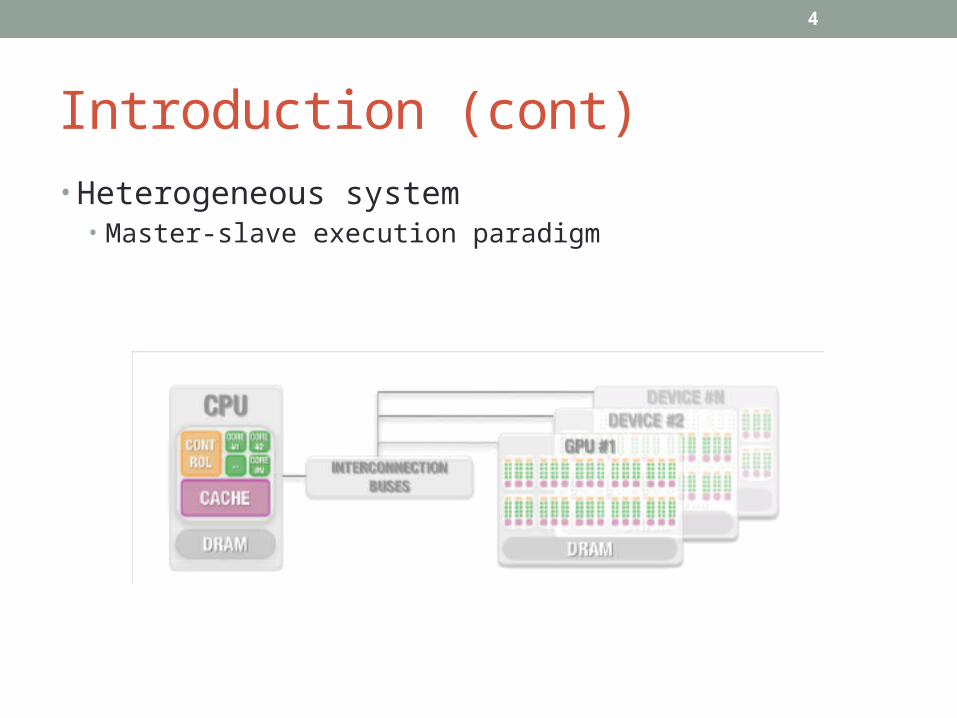
Introduction • Recent trends in computer systems are relying on a
heterogeneous paradigm as their basic architectural principle.
• At present, almost every currently available commodity desktop computer stands for a unique heterogeneous system.
• In general, heterogeneous systems can be modeled as a set of interconnected computational resources with distributed address spaces and diverse functionalities.
4
Introduction (cont)• Heterogeneous system
• Master-slave execution paradigm

5
Programming challenges in heterogeneous system
• Computation Partitioning• To fulfill device capabilities/limitations and achieve optimal load-
balancing
• Data Migration• Significant and usually asymmetric• Potential execution bottleneck
• Synchronization• Devices can not communicate between each other => CPU in charge
• Different programming models• Per device type and vendor-specific• High performance libraries and software
• Application Optimization• Very large set of parameters and solutions affects performance

6
Outline • Introduction• Unified execution model • Example• Experiment • Conclusion• Future work
7
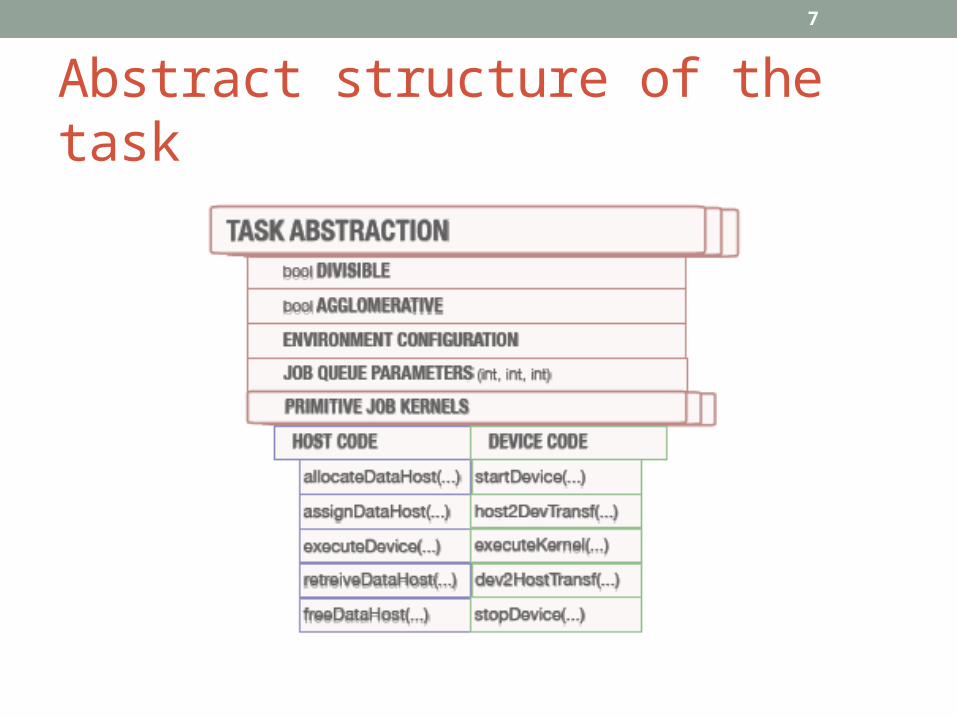
Abstract structure of the task

8
Abstract structure of the task (cont)• Task - coarser-grained, basic programming unit
• Primitive Jobs• Finer-grained• Minimal program portions for parallel execution• Partitioned into Host and Device Code
• Host Code - embraces the necessary data arrangement operations executed only on the host processor prior the any
device kernel call.• Device Code - a set of functions to drive direct on-device execution

9
Abstract structure of the task (cont)• Divisible
• into finer-grained Primitive Jobs
• Agglomerative• grouping of Primitive Jobs
Not Divisible
Divisible Not agglomerative
Agglomerative
10
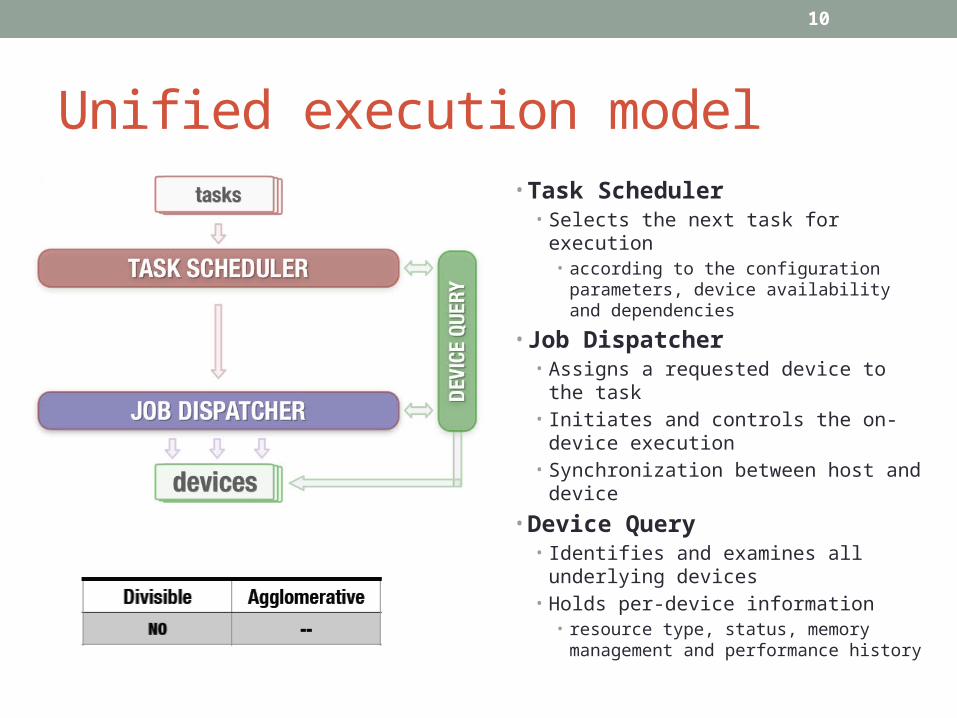
Unified execution model• Task Scheduler
• Selects the next task for execution• according to the configuration
parameters, device availability and dependencies
• Job Dispatcher• Assigns a requested device to the
task• Initiates and controls the on-device
execution• Synchronization between host and
device
• Device Query• Identifies and examines all
underlying devices• Holds per-device information
• resource type, status, memory management and performance history
11
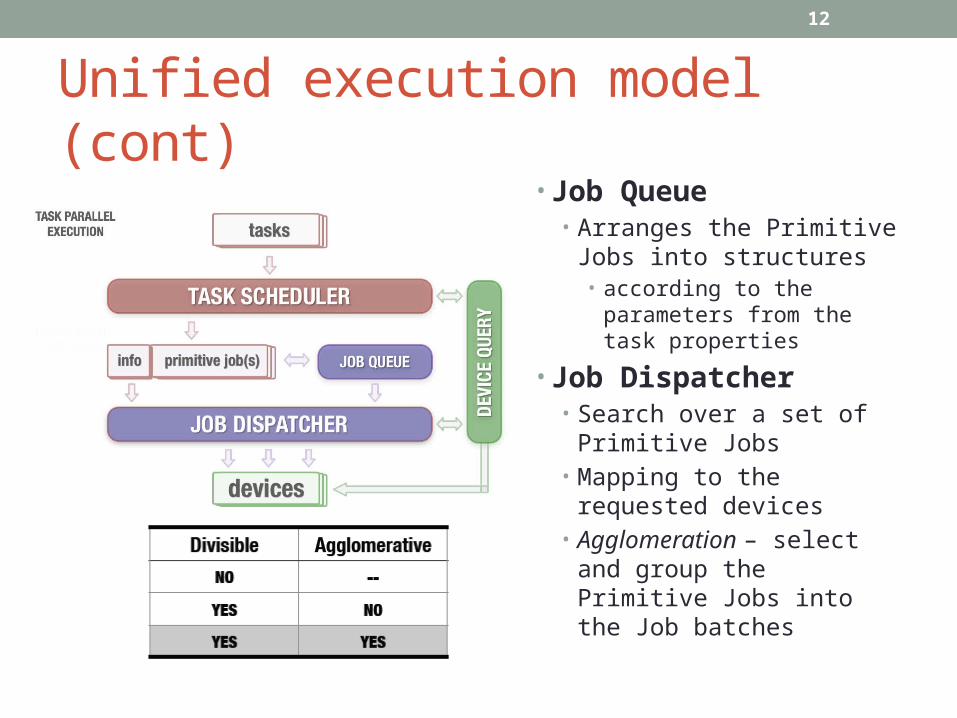
Unified execution model (cont)
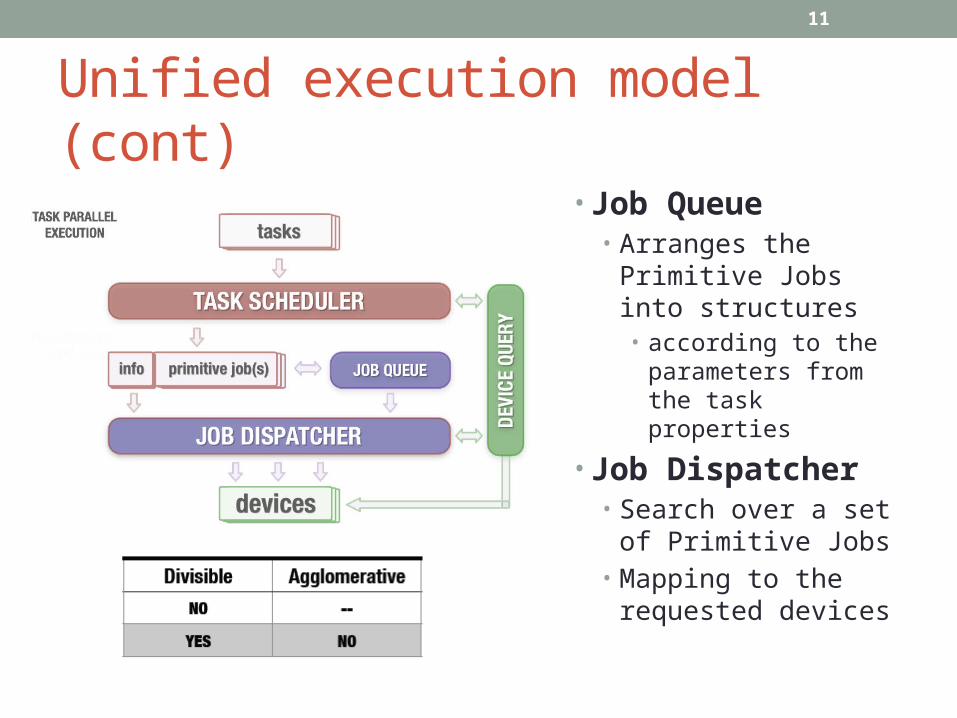
• Job Queue• Arranges the Primitive
Jobs into structures• according to the
parameters from the task properties
• Job Dispatcher• Search over a set of
Primitive Jobs• Mapping to the
requested devices
12
Unified execution model (cont)• Job Queue
• Arranges the Primitive Jobs into structures• according to the
parameters from the task properties
• Job Dispatcher• Search over a set of
Primitive Jobs• Mapping to the requested
devices• Agglomeration – select
and group the Primitive Jobs into the Job batches

13
Parallelism • Task Level Parallelism
• Scheduler free to send independent tasks to the Job Dispatcher
• Data Level Parallelism• Different portions of a single task are executed on several devices
simultaneously
• Nested Parallelism• Multi-core device is viewed as a single device by the Job
Dispatcher• If provided by application

14
Outline • Introduction• Unified execution model • Example• Experiment • Conclusion• Future work

15
Example• Matrix multiplication• 3D FFT(Fast Fourier transform)

16
Matrix multiplication

17
Matrix multiplication• Horowitz scheme
• Based on divide-and-conquer

18
3D FFT

19
Outline • Introduction• Unified execution model • Example• Experiment • Conclusion• Future work

20
Experiment platform• CPU - Intel Core 2 Quad Q9550 processor, 12 MB L2
cache, running at 2.83 GHz, and 4 GB of DDR2 RAM • GPU - nVidia GeForce 285 GTX with 1.476 GHz of core
frequency and 1 GB of global memory• Interconnection bus - via Memory Controller Hub with
1.33 GHz Front Side Bus to the CPU, whereas PCI Express 2.0 16x is used at the GPU side
• OS - Linux Open Suse 11.1

21
Experimental results – matrix multiplication
MKL (Math Kernel Library)
22
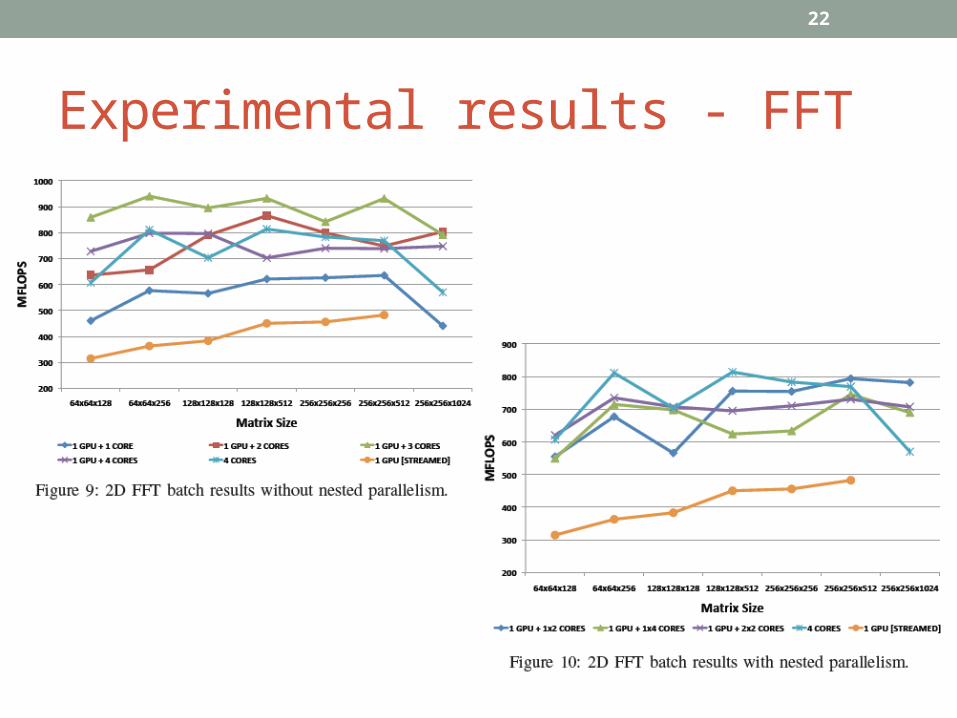
Experimental results - FFT
23
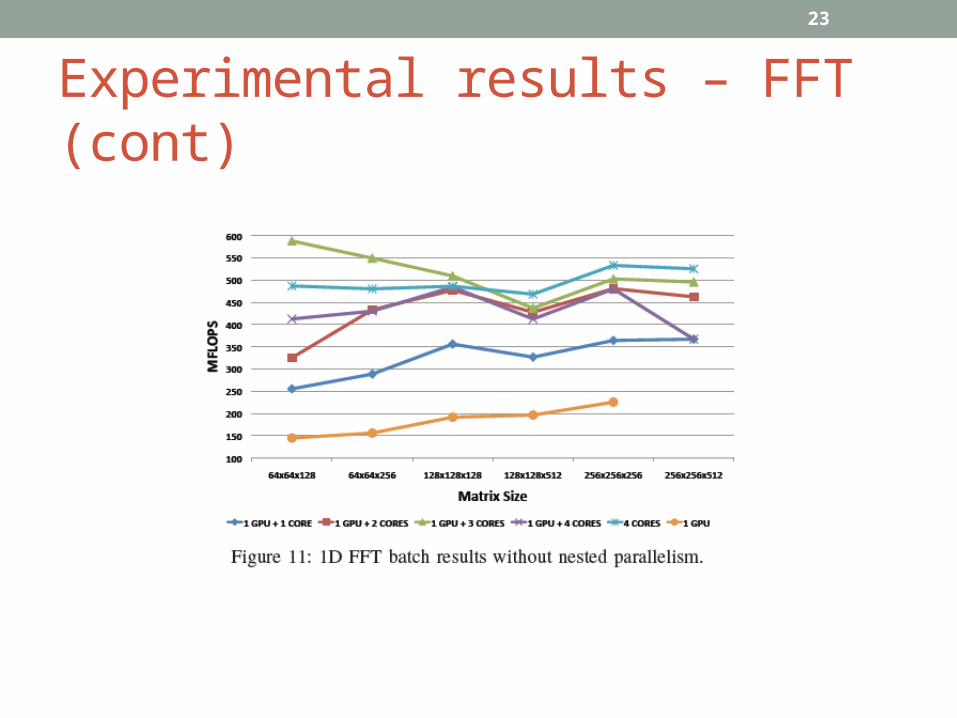
Experimental results – FFT (cont)

24
Experimental results – FFT (cont)

25
Outline • Introduction• Unified execution model • Example• Experiment • Conclusion• Future work

26
Conclusion • This paper proposed a collaborative execution
environment for such heterogeneous systems, which have been used to program parallel applications by exploiting task and data parallelism.
• Experimental results show that significant performance benefits are achieved when both CPU and GPU are used in case of matrix multiplication, whereas the available interconnection bandwidth between CPU and GPU limits the performance for FFT batches.

27
Outline • Introduction• Unified execution model • Example• Experiment • Conclusion• Future work

28
Future work• Systems with higher level of heterogeneity (more GPUs,
FPGAs, or special-purpose accelerators)• Performance modeling and application self-tuning• Adoption of advanced scheduling policies• Identification of performance limiting factors to
accommodate on-the-fly device selection (e.g GPU vs. CPU)

29
•Thank you for your listening!
•Q & A





![arXiv:2004.10908v2 [cs.DC] 26 Apr 2020arXiv:2004.10908v2 [cs.DC] 26 Apr 2020 Cpp-Taskflow v2: A General-purpose Parallel and Heterogeneous Task Programming System at Scale Tsung-Wei](https://static.fdocument.pub/doc/165x107/602bfde77a9b3b70114886fb/arxiv200410908v2-csdc-26-apr-2020-arxiv200410908v2-csdc-26-apr-2020-cpp-taskiow.jpg)












