
Cloud Architecture & Distributed Systems Trivia
30
Cloud Architecture & Distributed Systems Trivia Dr. Michael Menzel AQA Session @ Dev Team Meeting
-
Upload
dr-ing-michael-menzel -
Category
Software
-
view
88 -
download
0
Transcript of Cloud Architecture & Distributed Systems Trivia

Cloud Architecture & Distributed Systems
TriviaDr. Michael Menzel
AQA Session @ Dev Team Meeting

Agenda
1. Distribute & Scale
2. Stabilize & Prevent Failure
3. Deployment
4. Failure in Production
5. Scaling the Persistence Layer


Distribute & Scale“Distribution and Elasticity are king.”
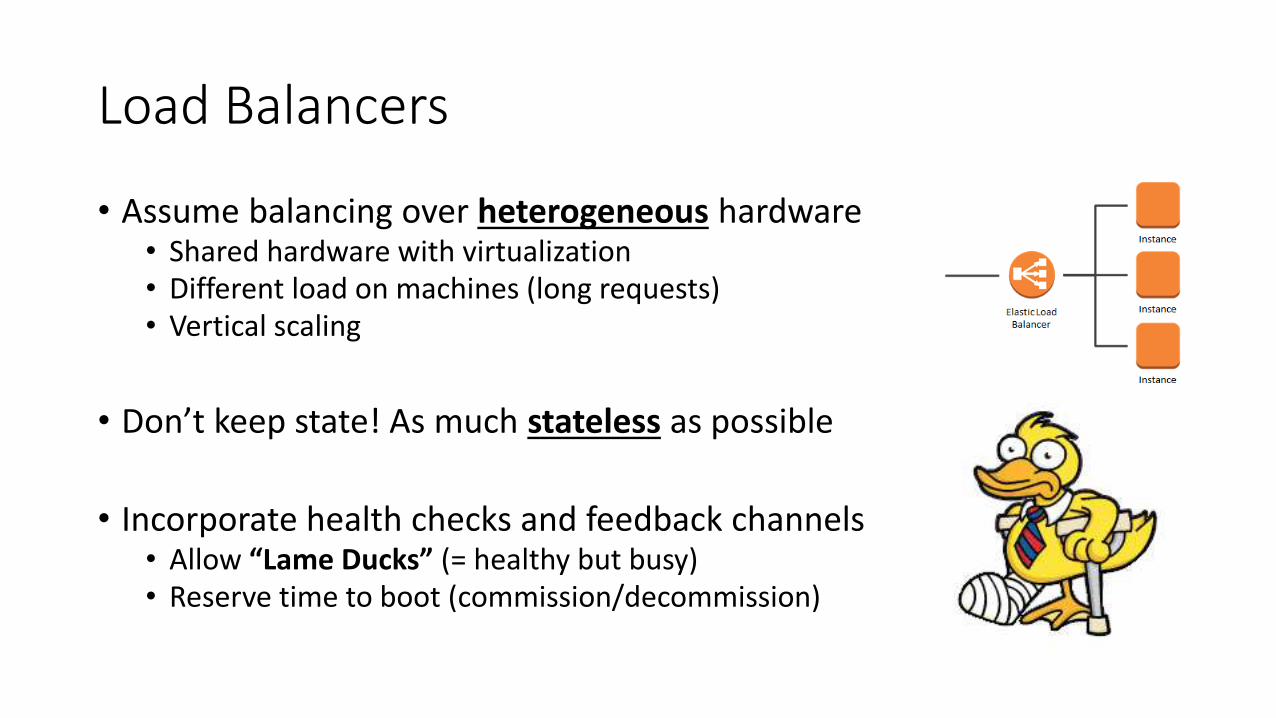
Load Balancers
• Assume balancing over heterogeneous hardware• Shared hardware with virtualization• Different load on machines (long requests)• Vertical scaling
• Don’t keep state! As much stateless as possible
• Incorporate health checks and feedback channels• Allow “Lame Ducks” (= healthy but busy)• Reserve time to boot (commission/decommission)

Health Checks & Monitoring
• Web services typically offer /health or /ping
• Test inwards to give more precise health score (lame duck)
• Don’t make health check too expensive to avoid extra load
• Use monitoring a lot to detect trends and history• Monitor basics: CPU, Mem, etc.• Add application-level monitoring
(queued requests, etc.)
Auto Scaling
• Start with capacity planning to skip initial scaling delay
• Benchmark to find scarce resource of your application
• Monitor ftw & apply rules• Custom metrics are better than generic
• Test behavior to learn about metrics
• Predict resource requirements (future)

Auto Scaling ctd.
• For best elasticity prepare your VM/docker images to boot quickly
• Test and measure your elasticity!!!• Stress testing: bursts, volatility
• Performance testing: grow, shrink
• Chaos testing
• Test with “Huge Scales”

Stabilize & Prevent Failure“Expect failures at all loads. Prevent failures before one cascades.”

Degrade Performance
• Introduce grades for important users (if possible)
• Know whose request is processed
• Process only important users on peak loads

Request Time Thresholds
• Long lasting requests are expensive, example:
“30 sec threshold, 1000 QPS with full load 5% of requests take ≥ 30 sec, after 20 sec (latest) you are blocked”
• Define thresholds and propagate sub-thresholds
ExampleFuture.firstCompletedOf(Seq(
Promise.timeout(InternalServerError("Oops"), 30 second),Webservice.call(“/fibonacci/next”, 10 second).map(Ok)
))
Web Service A
Web Service B
Web Service C

Request Time Thresholds!

Anti-Overload: Circuit Breakers & Back-off!
• Back off when web service endpoint does not respond (in time)
• Exponential is famous, but not best!
• Jitter back off strategy is better!!!1)
• Use circuit breakers (e.g. https://github.com/Netflix/Hystrix)
1) Source: https://www.awsarchitectureblog.com/2015/03/backoff.html
sleep = random_between(0, min(cap, base * 2 ** attempt))
sleep = min(cap, base * 2 ** attempt)

Random Jitter Back Off
Source: https://www.awsarchitectureblog.com/2015/03/backoff.html

Deployment“Prevent toil and remain stable!”

Package Deployments
• Prepare a full VM/docker image (if possible)• VMs bring operating system and only need virtualization stack• Dockers need docker environment but boot quicker
• Keep old versions for rollbacks and tests/comparisons
• If you don’t package:• Ensure you deploy into a reset environment (mem usage, temp files, etc.)• Ensure you use a bundling with all dependencies (Java? Node?)• Coordinate thoroughly to not interfere with other deployments

Maintain multiple environments
• “The more the merrier”, but costly – find your trade-off!
• Allow many testing environments for different types of tests• Stress & performance tests
• Integration & regression tests
• Chaos testing & Demos
• Automate the creation of new environments

Canary Deployments
• Canary allow you to monitor new software versions
• Keep track of which servers have which version• In monitoring
• In logging
• Activate extra logging and notifications for the canaries

Load Balancers during Deployment
• Two strategies1. Same load balancer: add new instances to existing load balancer2. Extra load balancer: add whole new load balancer and move over eventually
• Same load balancer tips• Add instance when ready for health checks• Tag new instances to differentiate versions
• Extra load balancer tips• Make sure all settings are identical (infrastructure as code!)• First run both load balancers in parallel, then switch (use DNS or other LB)

Failure in production“Goal is to make your pager obsolete.”
Anything can happen!

Countermeasures for Failures
• Install a immediate response channel (pager, SMS)
• Stop the bleeding first! – Symptoms before cause• Avoid looking for the cause, but prevent further failures
• Shut down parts of the system if necessary
• Declare a coordinator

Document Failures & Solutions
• Document every step and progress of failure resolutions• Define protocol templates to reduce overhead
• Analyze and replay old protocols
• Write regression tests with your solution• Tests make sure old bugs sneak back in
• You documented the symptoms of the bug in code

Scaling the Persistence Layer“Just hard. ‘Nough said.”

CDNs: grab the low hanging fruits
• CDNs are cheap web serving helpers• Take load from web servers
• Are quick due to in-mem caching of static content
• Edge location with shorter round-trip = best latency
• Digesting with MD5 hash8425b886b9a2184c48b34212dfaf103b-index.html
6269a326c6a2184d32b39881baac720c-main.js

ReCAP: CAP Theorem?
• Out of C, A, and P only two can be kept.
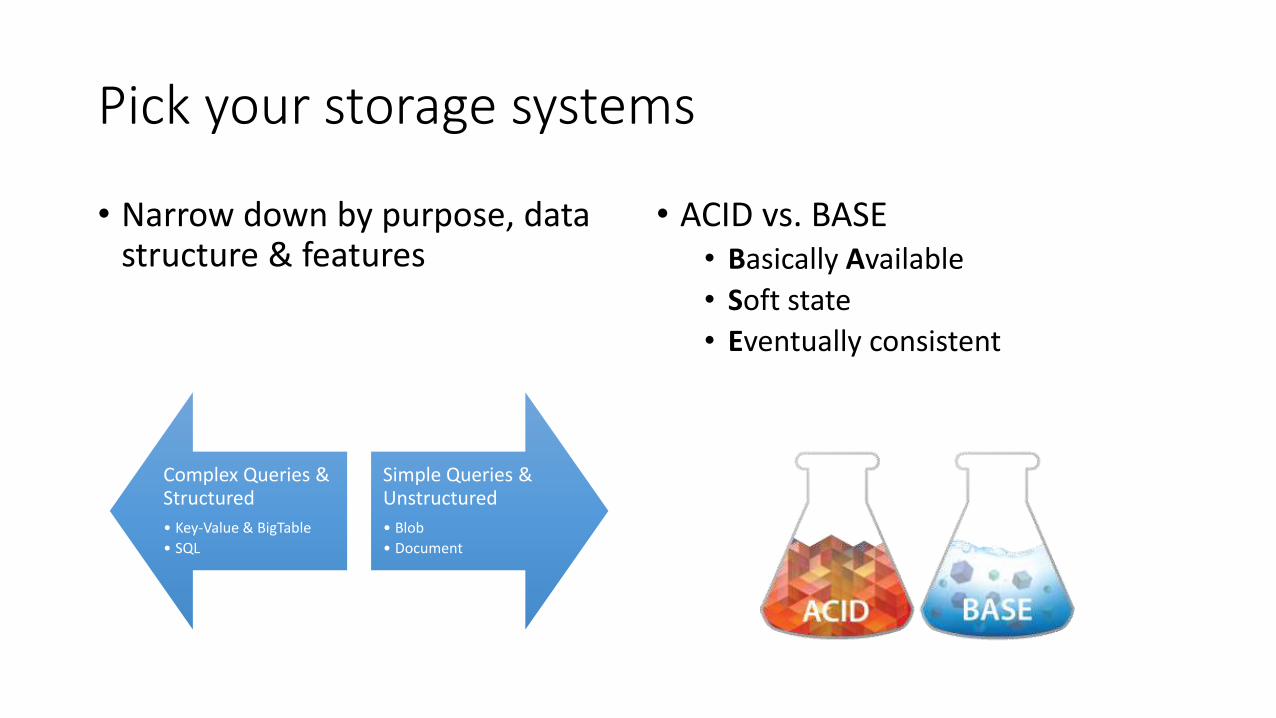
Pick your storage systems
• Narrow down by purpose, data structure & features
• ACID vs. BASE• Basically Available
• Soft state
• Eventually consistent
Complex Queries & Structured
• Key-Value & BigTable
• SQL
Simple Queries & Unstructured
• Blob
• Document

Examples of NoSQL usage
Use multiple stores and even redundant data (if necessary for A)
• Simple JSON-based web service: Document store• Requests to /profile/{id} loads document “profile-{id}”• Changes are simple and only per document
• Complex, but predictable queries: BigTable store• Avoid scans!!!• Create 1 table per query, don’t fear redundant data
• Video and Image service: Blob store (+ CDN)

Database goes global?
• Writing state is hard to distribute globally (c.f. Google Spanner)• Inconsistencies! (A over C)• http://research.google.com/archive/spanner.html
• Use distributed replicas & caches for read(?)• Local caches can drift (remember load balancing!)• Memcached clusters can help per data center• Expect eventual consistency with outdated reads
• Sharding & Partitioning (in a global cluster)• Divide data horizontally on application layer (primary keys)• Partition/Sharding key design is key• Be careful with JOINs or scans across partitions/shards!

Knowing your storage system(s) is crucial
• Consistency level & consensus protocols?Paxos, BFT, 2-phase commit, quorum, hashgraph, etc.
• Replication strategies? Backups?Replication keys, replication factors, rack/data center-awareness
• Performance? Fault-tolerance?Benchmark (data layouts, configurations), elasticity, chaos/stress tests



















