
Clase 4-Bioestadistica 2
23
Clase 3 Estadística descriptiva
-
Upload
marianramirez -
Category
Documents
-
view
27 -
download
0
description
bioestadistica
Transcript of Clase 4-Bioestadistica 2

Clase 3
Estadística descriptiva

Cualitativas
Si sus valores (modalidades) no se pueden asociar naturalmente a un número
(no se pueden hacer operaciones algebraicas con ellos)
• Nominales: Si sus valores no se pueden ordenarEstadio, color, sexo, grupo sanguíneo, religión, nacionalidad, fumar (Sí/No).
• Ordinales: Si sus valores se pueden ordenarGrado de infección, mejoría a un tratamiento, grado de satisfacción, intensidad del
dolor.
Cuantitativas o numéricas
Si sus valores son numéricos (tiene sentido hacer operaciones algebraicas con
ellos)
• Discretas: si toma valores enterosNúmero de hijos, número de cigarrillos, número de cumpleaños.
• Continuas: Si entre dos valores, son posibles infinitos valores intermedios.Peso, altura, superficie, concentración, presión intraocular, dosis de medicamento
administrado, edad.

Es buena idea codificar las variables como números para poder procesarlas con facilidad en un ordenador.
Es conveniente asignar “etiquetas” a los valores de las variables para recordar qué significan los códigos numéricos.
Sexo (Cualit: Códigos arbitrarios) 1 = Hombre
2 = Mujer
Raza (Cualit: Códigos arbitrarios) 1 = Blanca
2 = Negra,...
Felicidad Ordinal: Respetar un orden al codificar. 1 = Muy feliz
2 = Bastante feliz
3 = No demasiado feliz
Aunque se codifiquen como números, debemos recordar siempre elverdadero tipo de las variables y su significado cuando vayamos ausar programas de cálculo estadístico.
No todo está permitido con cualquier tipo de variable.

• Exponen la información recogida en la muestra, de forma que no se pierda nada de información (o poca).
– Frecuencias absolutas: Contabilizan el número de individuos de cada modalidad.
– Frecuencias relativas (porcentajes): Idem, pero dividido por el total.
– Frecuencias acumuladas: Indican la cantidad de datos acumulados hasta cierto valor de la variable inclusive. Pueden ser absolutas o relativas.
– Sólo tienen sentido para variables ordinales y numéricas.
• Sirven para ordenar los datos en cuanto a los valores de la
variable y la cantidad de veces que aparece en mi muestra.
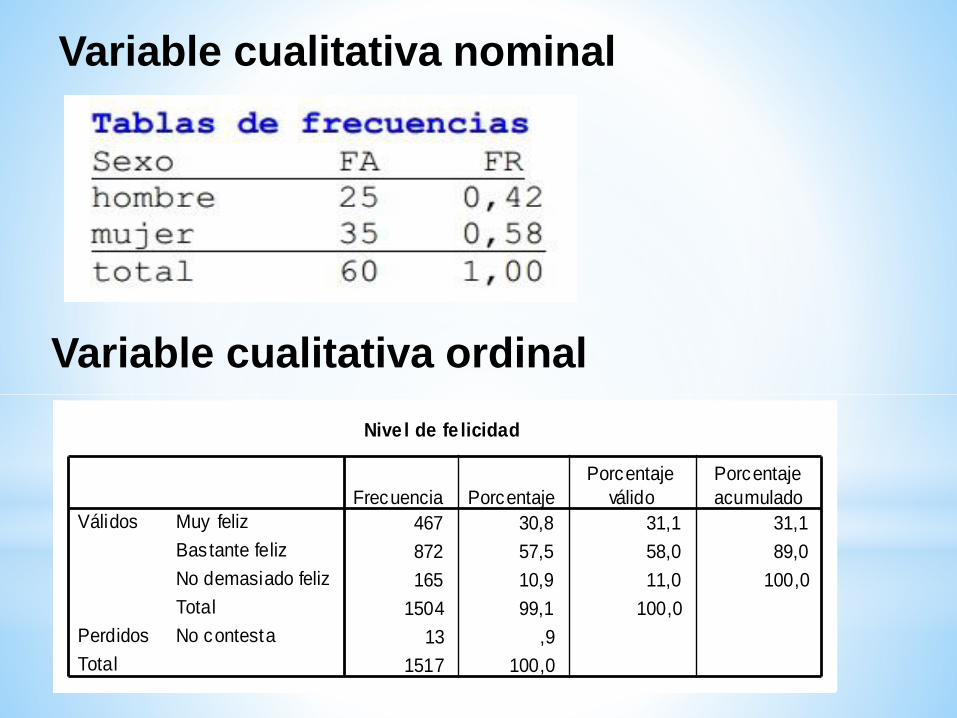
Nive l de fe licidad
467 30,8 31,1 31,1
872 57,5 58,0 89,0
165 10,9 11,0 100,0
1504 99,1 100,0
13 ,9
1517 100,0
Muy feliz
Bastante feliz
No demasiado feliz
Total
Válidos
No contestaPerdidos
Total
Frecuencia Porcentaje
Porcentaje
válido
Porcentaje
acumulado
Variable cualitativa nominal
Variable cualitativa ordinal

Diagramas de barras
Alturas proporcionales a las frecuencias (abs. o rel.)
Se pueden aplicar también a variables discretas
Diagramas de sectores (tortas, polares)
No usarlo con variables ordinales.
El área de cada sector es proporcional a su frecuencia (abs. o rel.)
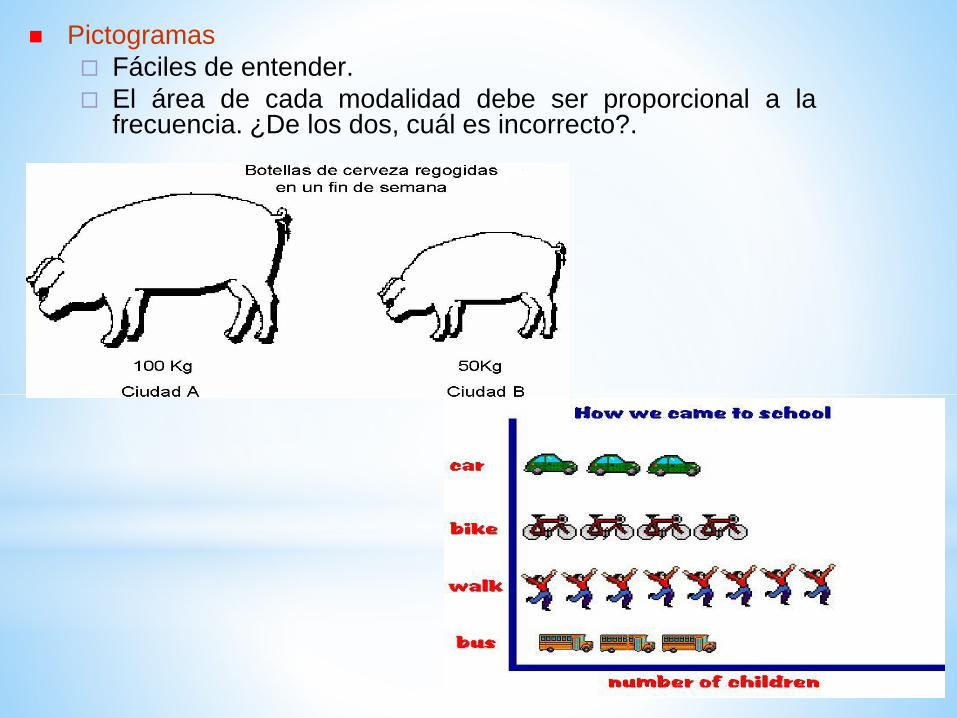
Pictogramas
Fáciles de entender.
El área de cada modalidad debe ser proporcional a lafrecuencia. ¿De los dos, cuál es incorrecto?.


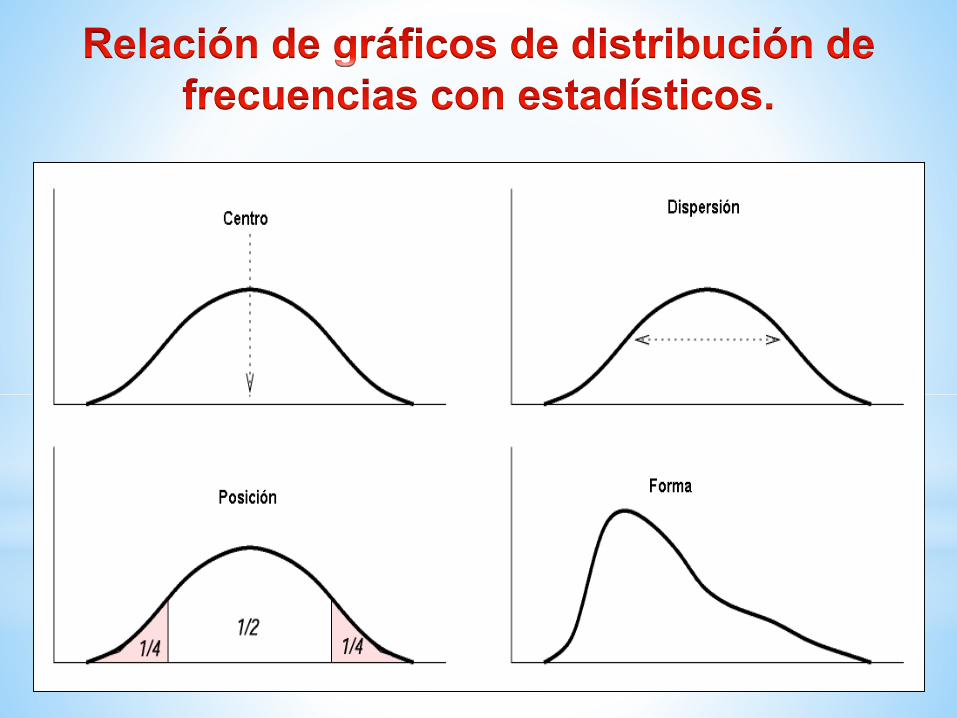
Tendencia Central
Indican valores con respecto a los que los datos parecen
agruparse.
Media, mediana y moda
Dispersión
Indican la mayor o menor concentración de los datos con
respecto a las medidas de tendencia central.
Desviación típica, coeficiente de variación, rango,
varianza
Posición
Dividen un conjunto ordenado de datos en grupos con la
misma cantidad de individuos.
Cuantiles, percentiles, cuartiles, deciles,..

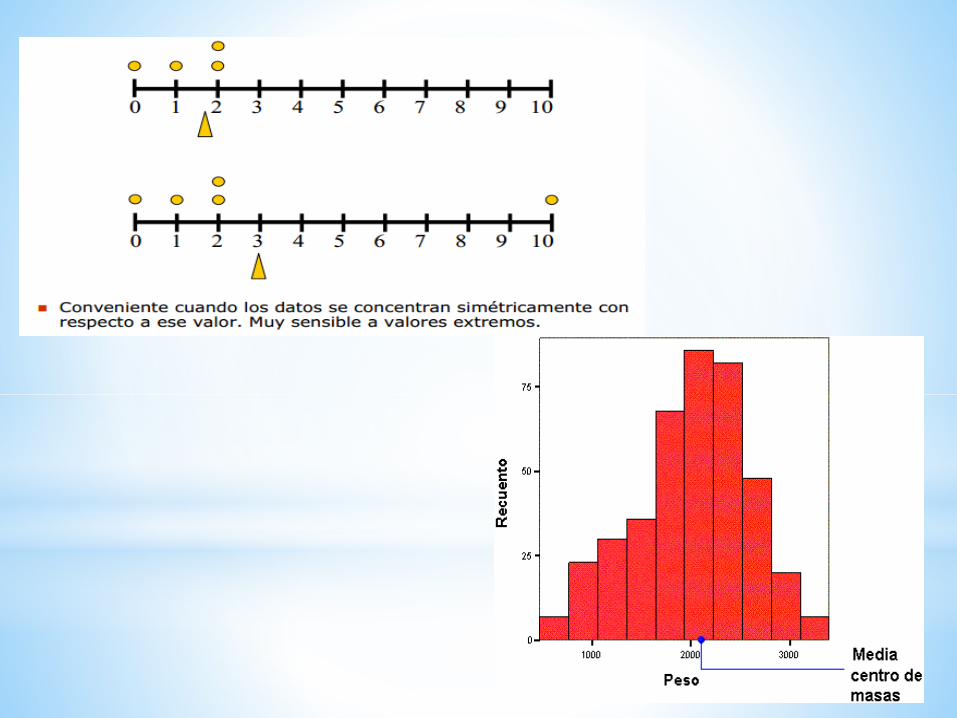
Son medidas que buscan posiciones (valores) con respecto a loscuales los datos muestran tendencia a agruparse.
Media aritmética o promedio: Suma de los valores (Xi) dividido por el tamaño muestral (n).
Media de 2,2,3,7 es (2+2+3+7)/4=3,5
= 2+2+3+7 = 3,5
4
Conveniente cuando los datos se concentran simétricamente con respecto a ese valor. Muy sensible a valores extremos.
n
xx i i

EJEMPLO: Considere la siguiente situación: cinco médicos que
trabajan en cierta área son llamados a declarar sus
cobros por realizar cierto procedimiento. Suponga
que se reporta lo siguiente: $75, $75,$80, $80 y
$280.
EI cobro medio para los cinco médicos es de $118,
un valor que no es muy representativo del conjunto
de datos.
El único valor atípico del conjunto tuvo el efecto
de inflar la media.

Mediana: Es un valor que divide a las observaciones ordenadas en dos grupos con el mismo número de individuos, de forma que el número de valores mayores o iguales a la mediana es igual al número de valores menores o iguales a ésta.
Si el número de datos es par, se elige la media de los dos datos centrales.
Mediana de 1,2,4,5,6,6,8 es 5
Mediana de 1,2,4,5,6,6,8,9 es (5+6)/2=5,5
Es conveniente cuando los datos son asimétricos. No es sensible a valores extremos.
Mediana de 1,2,4,5,6,6,800 es 5. ¡La media es 117,7!
Altura mediana

Moda: Es el valor de la variable que más se repite.
Es el único estadístico calculable en variables cualitativas nominales.
En variables cuantitativas continuas, es el/los valor/es donde la distribuciónde frecuencia alcanza un máximo, relativo o absoluto.

Varianza S2 : Mide el promedio de las desviaciones (al cuadrado) de las observaciones con respecto a la media.
A mayor variabilidad, mayor varianza.
Es sensible a valores extremos (alejados de la media).
Sus unidades son las de la variable pero al cuadrado.

Desviación estándar o típica: Es la raíz cuadrada de la varianza
*Tiene las mismas dimensiones (unidades) que la variable.
*A mayor variabilidad, mayor desvío estándar

DESVENTAJAS DE LA DESVIACION ESTANDAR:
• Cuando se quiere comparar la dispersión de dos conjuntos de datos, la
comparación de las dos desviaciones estándar puede dar un resultado
equivocado. Esto puede ocurrir si las dos variables involucradas tienen
medidas en diferentes unidades.
• Por ejemplo: se pretende conocer, para una población dada, si los niveles de
colesterol en el suero, medidos en mg%, son mas variados que el peso del
cuerpo, medido en libras o kilogramos.
• Además, aunque se utilice la misma unidad de medición, las dos medias
pueden diferir bastante.
• Por ejemplo: Si la desviación estándar de los pesos de los niños de primer
grado de primaria son comparadas contra la desviación estándar de los pesos
de los estudiantes de preparatoria de reciente ingreso, se encontrará que esta
última es numéricamente mayor que la anterior, debido a que los pesos
mismos son mayores y no porque la dispersión sea mayor.
• Lo que se necesita en situaciones como ésta es una medida de varianza
relativa en lugar de una de varianza absoluta. Tal medida la constituye el
coeficiente de variación.

Coeficiente de variación: Es una medida de variabilidad relativa: mide la desviación típica en forma de “ qué tamaño tiene con respecto a la media”
*No tiene unidades.
* Interesante para comparar la variabilidad de diferentes variables.
*Si el peso tiene CV=30% y la altura tiene CV=10%, los individuos presentan más dispersión en peso que en altura.
*No debe usarse cuando la variable presenta valores negativos o donde el valor 0 sea una cantidad fijada arbitrariamente
*Por ejemplo 0ºC ≠ 0ºF

Amplitud o Rango: Diferencia entre observaciones extremas.
*Es muy sensible a los valores extremos.
*Ejemplo: 2,1,4,3,8,4. El rango es 8-1=7
Rango intercuartílico: Es la distancia entre primer y tercer
cuartil.
*Parecida al rango, pero eliminando las observaciones más extremas inferiores y superiores.
* No es tan sensible a valores extremos.

Cuantiles permiten reconocer otros puntos característicos de la distribución los cuales no son centrales.
*Casos particulares son los cuartiles, deciles, percentiles...




















