
Cassandra 架构与应用
82
Cassandra 架架架架架 For Cassandra 0.7.0 架架架 架架
description
Cassandra 架构与应用. For Cassandra 0.7.0 淘宝网 文茂. Agenda. 基础知识 数据模型 数据分布策略 存储机制 数据读写删 最终一致性 Gossiper 面向未来. NoSql 背景. - PowerPoint PPT Presentation
Transcript of Cassandra 架构与应用

Cassandra 架构与应用For Cassandra 0.7.0淘宝网 文茂

Agenda• 基础知识• 数据模型• 数据分布策略• 存储机制• 数据读写删• 最终一致性• Gossiper• 面向未来

NoSql 背景 随着互联网大规模的 Web2 . 0 应用的兴起,随着云计算需要的大规模分布式服务和分布式存储的发展,传统的关系数据库面临着诸多全新的挑战,特别是在那些超大规模和高并发的 SNS 类型的应用场景下,使用关系数据库来存储和查询用户动态数据已经显得力不从心,暴露了很多难以克服的问题,例如需要很高的实时插入性能;需要海量的数据存储能力同时还需要非常快的查询检索速度;需要将数据存储无缝扩展到整个群集环境下,并且能够在线扩展等等。在这样的背景下,
NoSQL 数据库就应运而生了。

NOSQL is simply
Not Only SQL!

NOSQL 特点• 不要叫它们数据库• 它们可以处理超大量的数据• 它们运行在便宜的 PC 服务器集群上• 它们击碎了性能瓶颈• Bootstrap 支持

CAP

ACID/BASE
• ACID• 原子性 (Atomicity). 事务中的所有操作 , 要么全部成功 , 要么全部不做 .• 一致性 (Consistency) 在事务开始与结束时 , 数据库处于一致状态 .• 隔离性 (Isolation). 事务如同只有这一个操作在被数据库所执行一样 .• 持久性 (Durability). 在事务结束时 , 此操作将不可逆转 .( 也就是只要事务提交 , 系统将保证数据不会丢失 , 即使出现系统 Crash, 译者补充 ).
• BASE• Basically Available (基本可用)• Soft state (柔性状态) 状态可以有一段时间不同步,异步• Eventually consistent (最终一致) 最终数据是一致的就可以了,而不是时时一致

最终一致性• 场景介绍• ( 1 )存储系统 存储系统可以理解为一个黑盒子,它为我们提供了可用性和持久性的保证。 • ( 2 ) Process A ProcessA 主要实现从存储系统 write 和 read 操作 • ( 3 ) Process B 和 ProcessC ProcessB 和 C 是独立于 A ,并且 B 和 C 也相互独立的,它们同时也实现对存储系统的 write和 read 操作。• 强一致性 强一致性(即时一致性) 假如 A 先写入了一个值到存储系统,存储系统保证后续 A,B,C 的读取操作都将返回最新值 • 弱一致性 假如 A 先写入了一个值到存储系统,存储系统不能保证后续A,B,C 的读取操作能读取到最新值。此种情况下有一个“不一致性窗口”的概念,它特指从A 写入值,到后续操作
A,B,C 读取到最新值这一段时间。 • 最终一致性 最终一致性是弱一致性的一种特例。假如A 首先 write 了一个值到存储系统,存储系统保证如果在 A,B,C 后续读取之前没有其它写操作更新同样的值的话,最终所有的读取操作都会读取到最 A 写入的最新值。此种情况下,如果没有失败发生的话,“不一致性窗口”的大小依赖于以下的几个因素:交互延迟,系统的负载,以及复制技术中 replica 的个数(这个可以理解为 master/salve 模式中, salve 的个数)。

Casandra 是什么?• Cassandra 是一个高可靠的大规模分布式存储系统。高度可伸缩的、一致的、分布式的结构化 key-value 存储方案。• 2007由 facebook 开发– 已经在生产环境中使用,比如 email index
search• 2009年成为 Apache 的孵化项目

Cassandra 有什么特点?• 列表数据结构 在混合模式可以将超级列添加到 5维的分布式 Key-Value 存储系统。• 模式灵活 使用 Cassandra ,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。 • 真正的可扩展性 Cassandra 是纯粹意义上的水平扩展。为给集群添加更多容量,可以增加动态添加节点即可。你不必重启任何进程,改变应用查询,或手动迁移任何数据。 • 多数据中心识别 你可以调整你的节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。 • 范围查询 如果你不喜欢全部的键值查询,则可以设置键的范围来查询。 • 分布式写操作 有可以在任何地方任何时间集中读或写任何数据。并且不会有任何单点失败。

Agenda• 基础知识• 数据模型• 数据分布策略• 存储机制• 数据读写删• 最终一致性• Gossiper• 面向未来
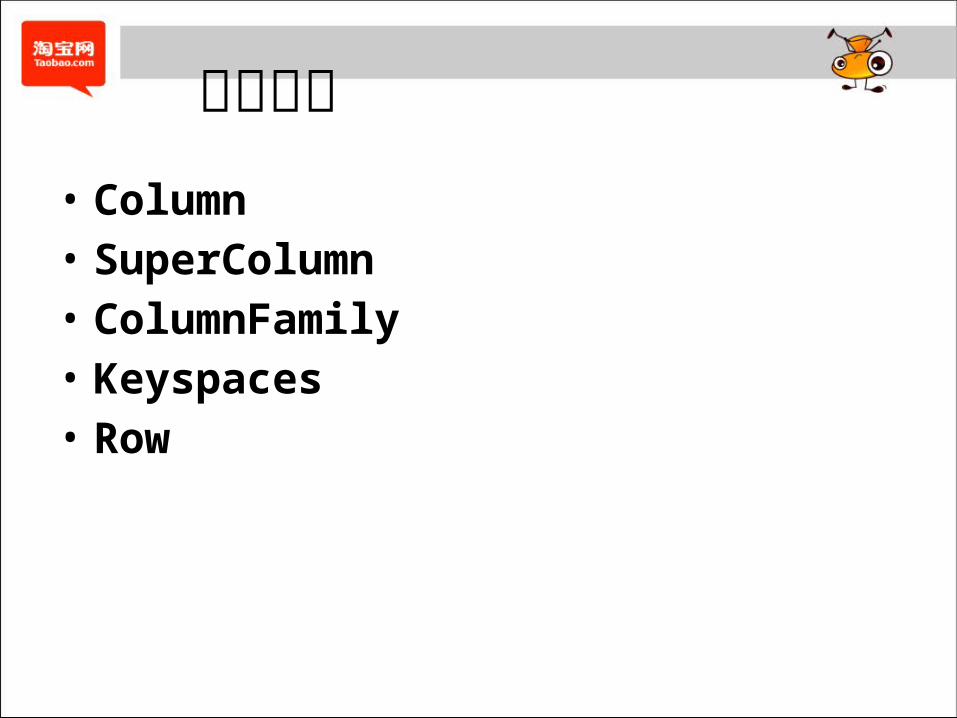
数据模型 • Column• SuperColumn• ColumnFamily• Keyspaces• Row

ColumnColumn
name value timestamp
User_id 18284805 1270073054
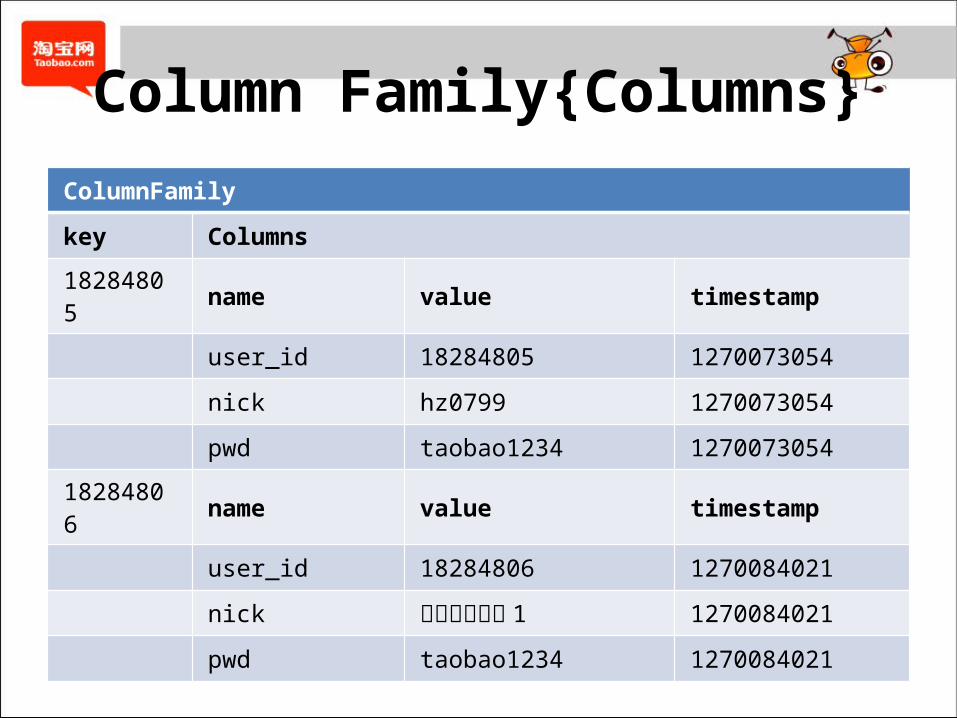
Column Family{Columns}ColumnFamily
key Columns
18284805 name value timestamp
user_id 18284805 1270073054
nick hz0799 1270073054
pwd taobao1234 1270073054
18284806 name value timestamp
user_id 18284806 1270084021
nick 刘刘商家测试 1 1270084021
pwd taobao1234 1270084021
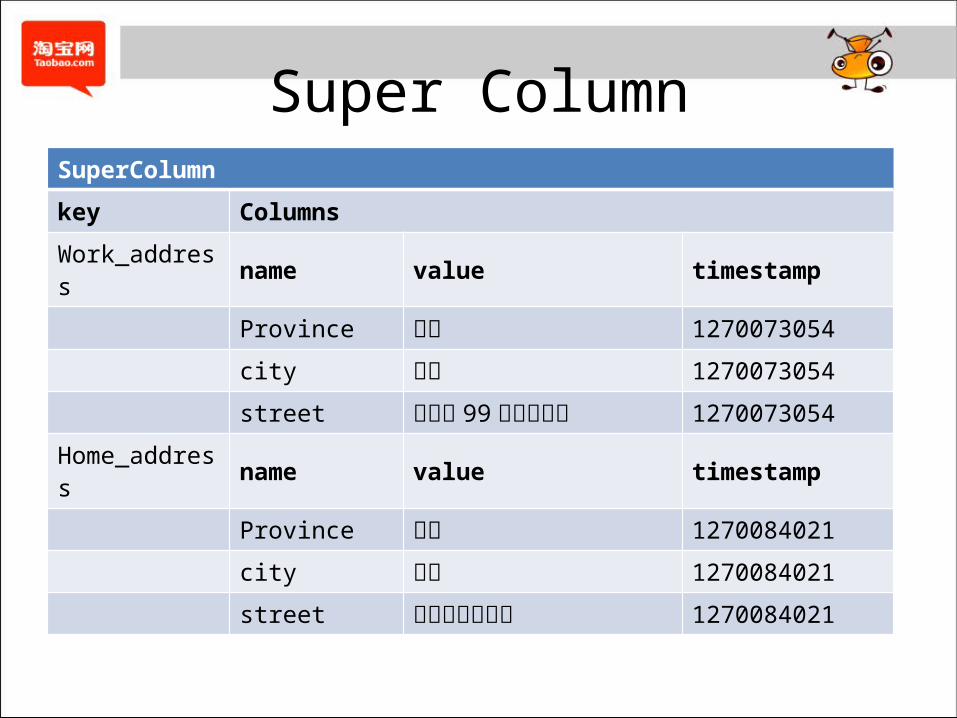
Super ColumnSuperColumn
key Columns
Work_address name value timestamp
Province 浙江 1270073054
city 杭州 1270073054
street 华星路 99号创业大厦 1270073054
Home_address name value timestamp
Province 广东 1270084021
city 深圳 1270084021
street 梅林路梅林四村 1270084021
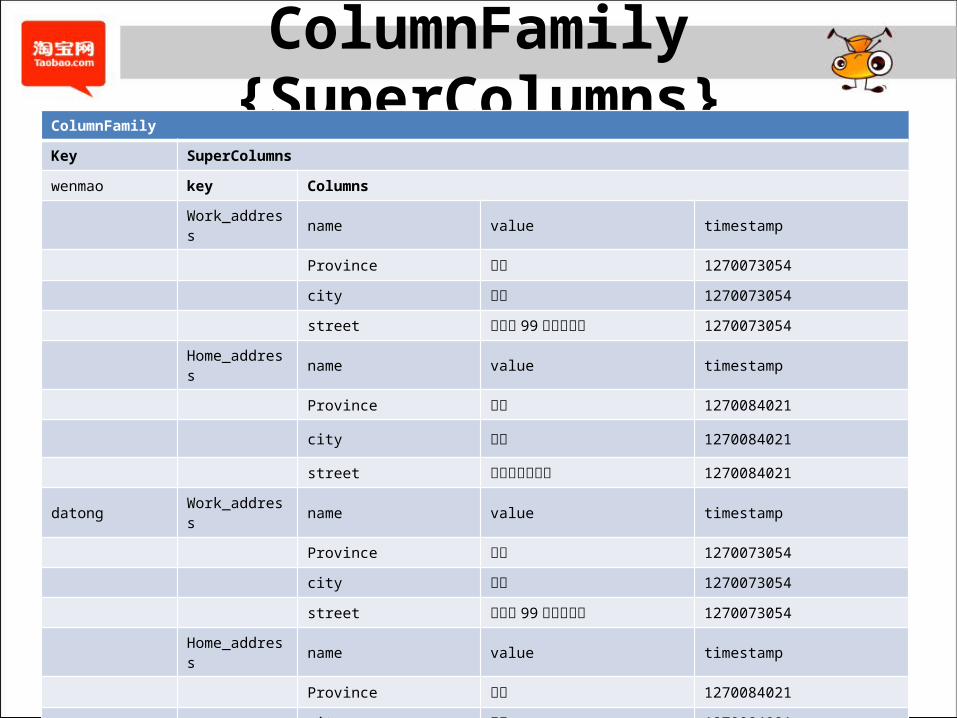
ColumnFamily {SuperColumns}ColumnFamily
Key SuperColumns
wenmao key Columns
Work_address name value timestamp
Province 浙江 1270073054
city 杭州 1270073054
street 华星路 99号创业大厦 1270073054
Home_address name value timestamp
Province 广东 1270084021
city 深圳 1270084021
street 梅林路梅林四村 1270084021
datong Work_address name value timestamp
Province 浙江 1270073054
city 杭州 1270073054
street 华星路 99号创业大厦 1270073054
Home_address name value timestamp
Province 广东 1270084021
city 深圳 1270084021
street 梅林路梅林四村 1270084021
Keyspaces
• 一个 Keyspace 是 Cassandra哈希第一维,是ColumnFamilies容器。
• 一般来说,我们的一个程序应用只会有一个 Keyspace ,相当于关系数据库的一个数据库 .

Row
• Row 以 key 为表示,一个 key 对应的数据可以分布在多个 column family 中,通常我们都只会存放在一个 column family 中。
数据定位• 第一层索引所用的 key 为 (row-key, cf-
name) , 即用一个 row-key 和 column-family-name 可以定位一个 column family 。 column family 是 column 的集合。
• 第二层索引所用的 key 为 column-name , 即通过一个 column-name 可以在一个 column family 中定位一个 column 。

Agenda
• 基础知识• 数据模型• 数据分布策略• 存储机制• 数据读写删• 最终一致性• Gossiper• 面向未来

数据分布策略• Distributed hash table• Partitioner 类型 RandomPartitioner OrderPreservingPartitioner ByteOrderedPartitioner CollatingOrderPreservingPartitioner• 副本策略 LocalStrategy RackUnawareStrategy RackAwareStrategy DatacenterShardStategy
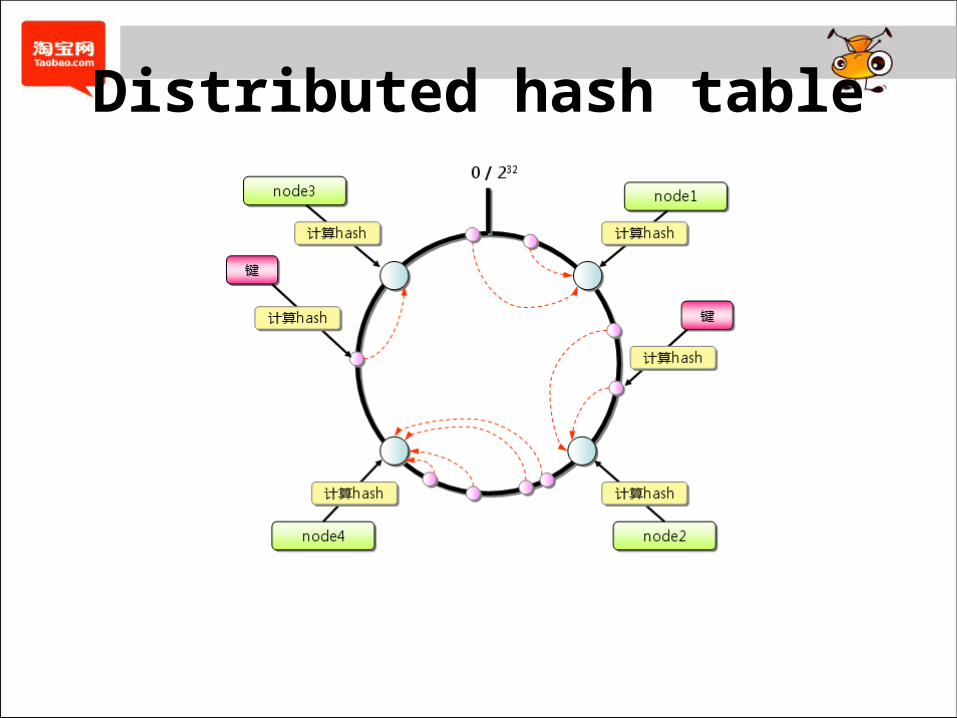
Distributed hash table

Partitioner 类型• RandomPartitioner 随机分区是一种 hash 分区策略,使用的 Token是大整数型 (BigInteger) ,范围为 0~2^127 ,因此极端情况下,一个采用随机分区策略的
Cassandra 集群的节点可以达到 2^127+1 个节点。• 为什么是 2^127 ? Cassandra采用了 MD5 作为 hash函数,其结果是 128位的整数值 ( 其中一位是符号位, Token取绝对值为结果 ) 。

Partitioner 类型• RandomPartitioner 4 个节点,随机分配的 Token 分布情况
• 采用随机分区策略的集群无法支持针对 Key 的范围查询。• 假如集群有 N 个节点,每个节点的 hash空间采取平均分布的话,那么第 i 个节点的 Token 可以设置为: i * ( 2 ^ 127 / N )

Partitioner 类型• OrderPreservingPartitioner 如果要支持针对 Key 的范围查询,那么可以选择这种有序分区策略。该策略采用的是字符串类型的 Token 。 如果没有指定 InitialToken ,则系统会使用一个长度为 16 的随机字符串作为 Token ,字符串包含大小写字符和数字。

Partitioner 类型KoRVD8989yf3rwBs
oeLFEM9K0p78I77N
ba6gv5zaE10Fj9ND
dOesQASXoGwygtel
cViC2OxAndA9oMTV
b36f65zWaeeIbgA3
7lRpHvIW48tuPXdJ
1ALaIi651cvO7GKq
C689MuiFyBVmOeUY
Mea0SbI9O9mOHs3R
Partitioner 类型• ByteOrderedPartitioner• 和 OrderPreservingPartitioner 一样是有序分区策略。只是排序的方式不一样,采用的是字节型 Token 。
Partitioner 类型[905b048d55dec3cae9cad20a3d21e26a]
[283d8672266470df5d8932f1de87d943]
[68f644b93515da49d0718206147d2508]
[00a4239c255033b8c1392c9af5ed85b5]
[8a1179c784d86f0dc0b25b77d97bb4fe]
[7dd56ccf16665c75b58bc7e3ffab604d]
[fb8436353232a4be28b804cb646c53d1]
[e8f885dce10e4f1a6eb125599d5db59f]
[d70b679aafc8977b855c7066ebeb7777]
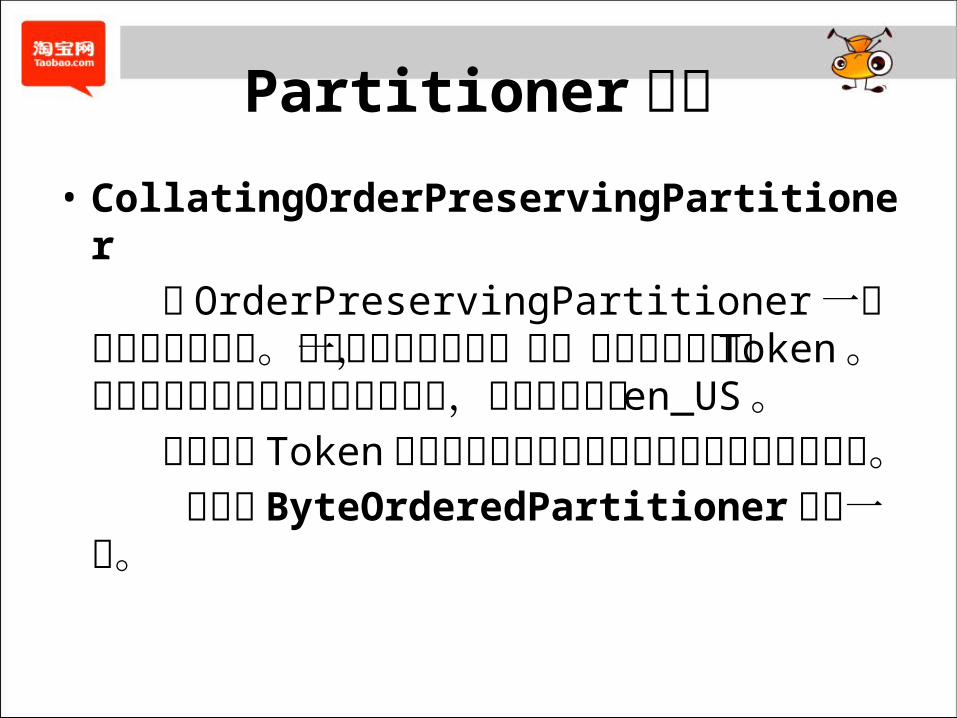
Partitioner 类型• CollatingOrderPreservingPartitioner 和 OrderPreservingPartitioner 一样是有序分区策略。只是排序的方式不一样,采用的是字节型 Token 。 支持设置不同语言环境的排序方式,代码中默认是 en_US 。 将制定的 Token信息按照不同语言环境来编组转化为字节数组。 其它与 ByteOrderedPartitioner完全一致。
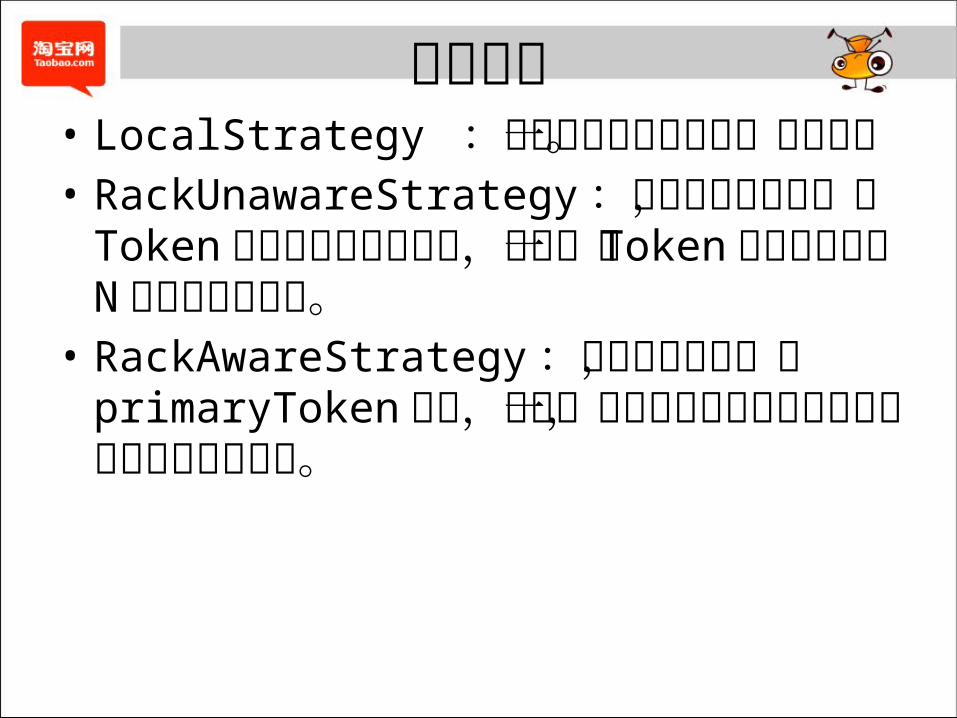
副本策略• LocalStrategy :只在本地节点中保持一个副本。• RackUnawareStrategy :不考虑机柜因素,将 Token按照从小到大的顺序,从第一个
Token位置处依次取 N 个节点作为副本。• RackAwareStrategy :考虑机柜因素,在
primaryToken 之外,先找一个处于不同数据中心的点,然后在不同机柜找。

副本策略• LocalStrategy :只在本地节点中保持一个副本。• RackUnawareStrategy :不考虑机柜因素,将 Token按照从小到大的顺序,从第一个
Token位置处依次取 N 个节点作为副本。• RackAwareStrategy :考虑机柜因素,在
primaryToken 之外,先找一个处于不同数据中心的点,然后在不同机柜找。
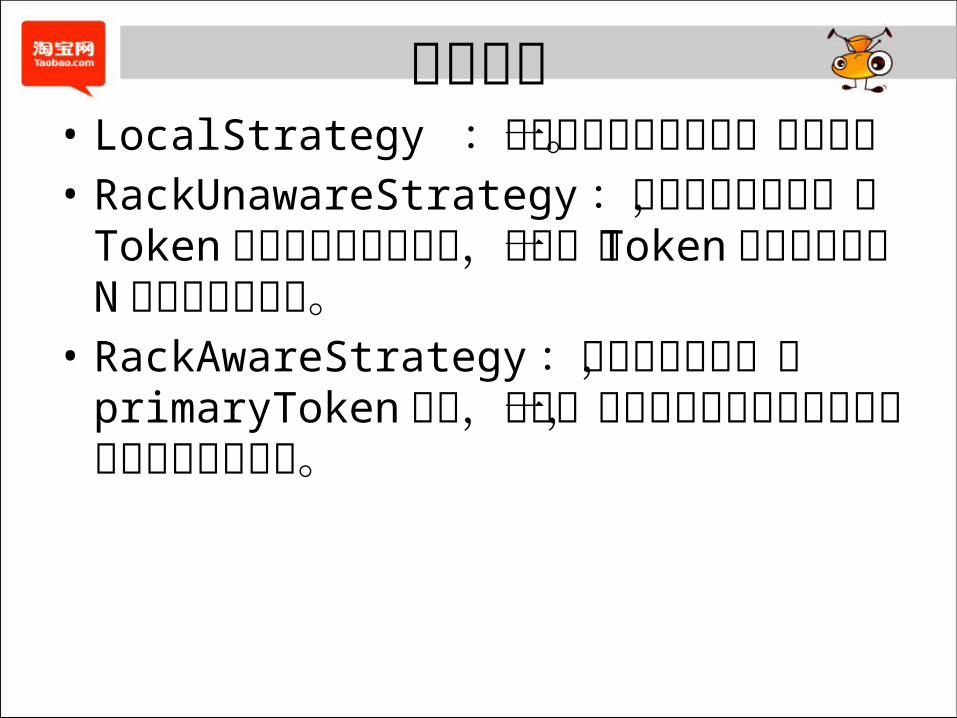
副本策略• LocalStrategy :只在本地节点中保持一个副本。• RackUnawareStrategy :不考虑机柜因素,将 Token按照从小到大的顺序,从第一个
Token位置处依次取 N 个节点作为副本。• RackAwareStrategy :考虑机柜因素,在
primaryToken 之外,先找一个处于不同数据中心的点,然后在不同机柜找。

副本策略• DatacenterShardStategy :这需要复制策略属性文件,在该文件中定义在每个数据中心的副本数量。在各数据中心副本数量的总和应等于 Keyspace 的副本数量。• 举例来说,如果 Keyspace 的副本总数是
6 ,数据中心副本因子可能是 3、 2 和 1 ,3 个副本、 2 个副本、 1 个副本分别在不同数据中心 - 共计 6 。

副本策略• Cassandra-rack.properties# Cassandra Node IP=Data Center:Rack192.168.1.200=DC1:RAC1192.168.2.300=DC2:RAC2
10.0.0.10=DC1:RAC110.0.0.11=DC1:RAC110.0.0.12=DC1:RAC2
10.20.114.10=DC2:RAC110.20.114.11=DC2:RAC1
10.21.119.13=DC3:RAC110.21.119.10=DC3:RAC1
10.0.0.13=DC1:RAC210.21.119.14=DC3:RAC210.20.114.15=DC2:RAC2
# default for unknown nodesdefault=DC1:r1

Agenda
• 基础知识• 数据模型• 数据分布策略• 存储机制• 数据读写删• 最终一致性• Gossiper• 面向未来

存储机制• Storage Model• Memtable• SSTable• Commitlog• Compaction

Storage Model
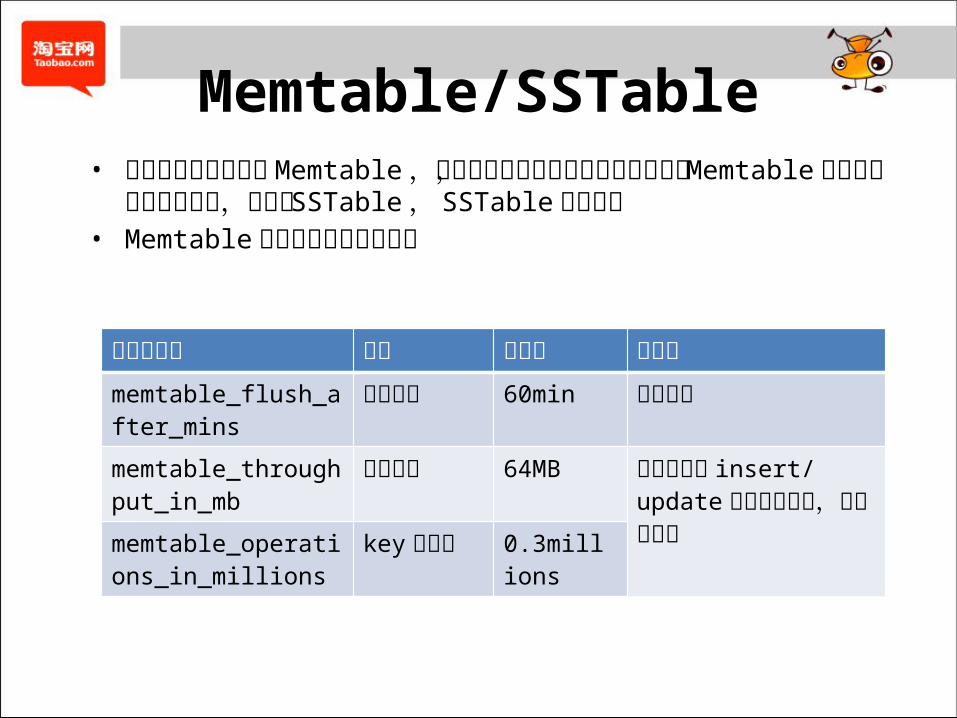
Memtable/SSTable• 数据先写入内存中的 Memtable ,写入关键路径上不需要持有任何锁, Memtable达到条件后刷新到磁盘,保存为 SSTable , SSTable不可修改 • Memtable刷新到磁盘的三个条件
配置项名称 描述 默认值 执行者memtable_flush_after_mins 时间间隔 60min 定时任务memtable_throughput_in_mb 内存大小 64MB 在每次执行 insert/
update 操作之前检查,超过则执行memtable_operations_
in_millions key 的数量 0.3millions
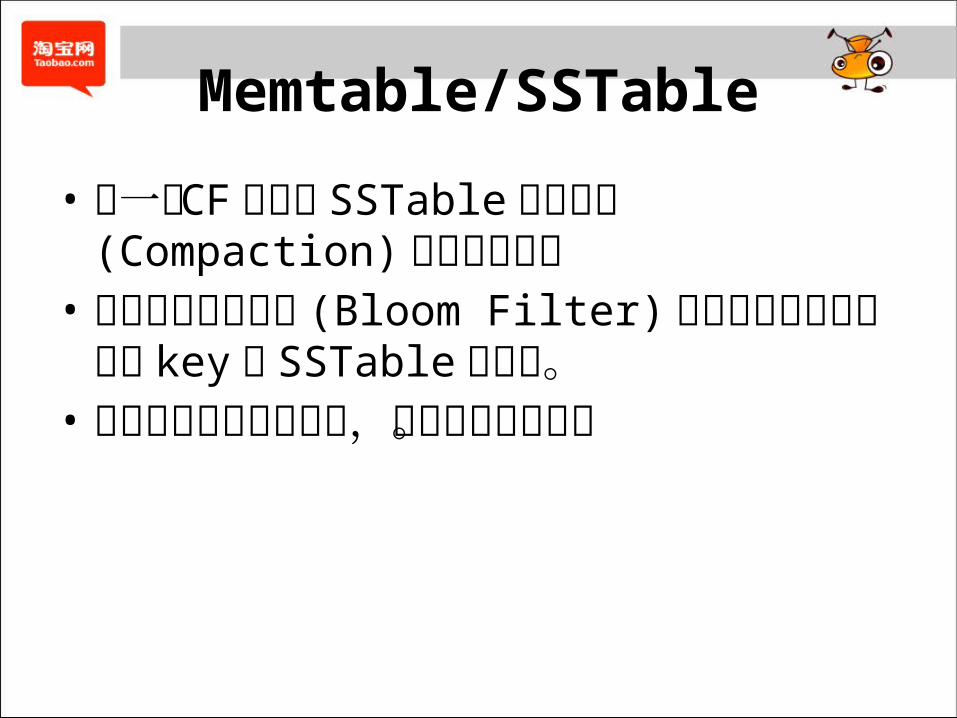
Memtable/SSTable
• 同一个 CF 的多个 SSTable 可以合并(Compaction) 以优化读操作
• 通过布隆过滤算法 (Bloom Filter)减少对不可能包含查询 key 的 SSTable 的读取。• 将随机写转变为顺序写,提升系统写性能。
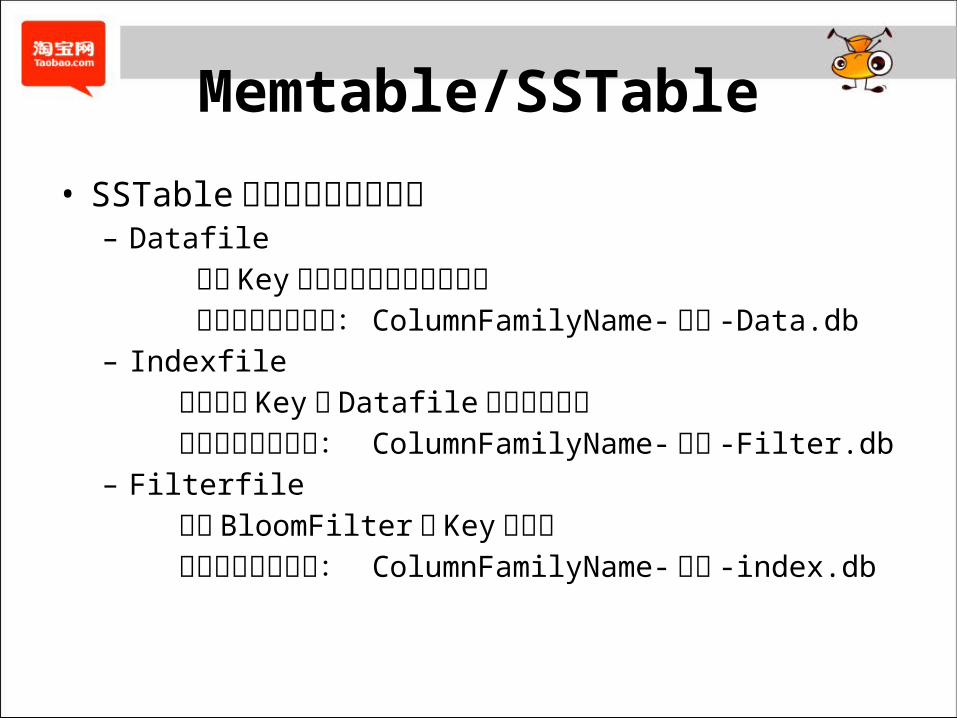
Memtable/SSTable
• SSTable包含对应的三种文件– Datafile 按照 Key排序顺序保存的数据文件 文件名称格式如下: ColumnFamilyName-序号 -Data.db – Indexfile 保存每个 Key 在 Datafile 中的位置偏移 文件名称格式如下: ColumnFamilyName-序号 -Filter.db – Filterfile 保存 BloomFilter 的 Key 查找树 文件名称格式如下: ColumnFamilyName-序号 -index.db
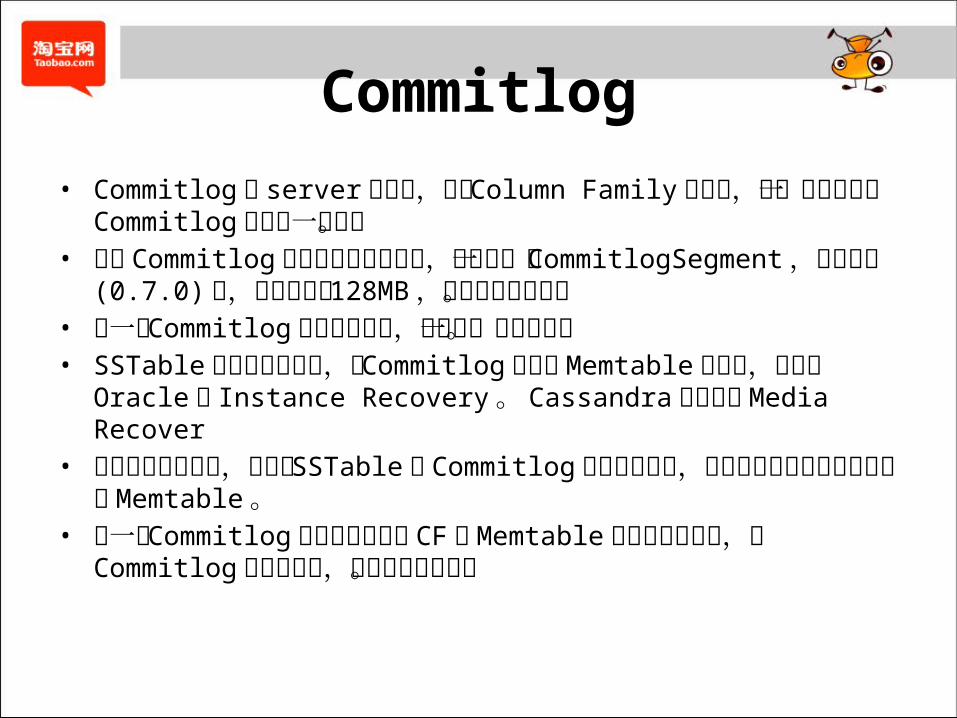
Commitlog• Commitlog 是 server级别的,不是 Column Family级别的,每一个节点上的 Commitlog 都是统一管理。• 每个 Commitlog 文件的大小是固定的,称之为一个
CommitlogSegment ,目前版本 (0.7.0) 中,这个大小是 128MB ,硬编码在代码中。• 当一个 Commitlog 文件写满以后,会新建一个的文件。• SSTable 持久后不可变更,故 Commitlog 只用于 Memtable 的恢复,相当于 Oracle 的 Instance Recovery 。 Cassandra 不需要做 Media Recover• 当节点异常重启后,将根据 SSTable 和 Commitlog进行实例恢复,在内存中重新恢复出宕机前的 Memtable 。• 当一个 Commitlog 文件对应的所有 CF 的 Memtable 都刷新到磁盘后,该 Commitlog 就不再需要,系统会自动清除。
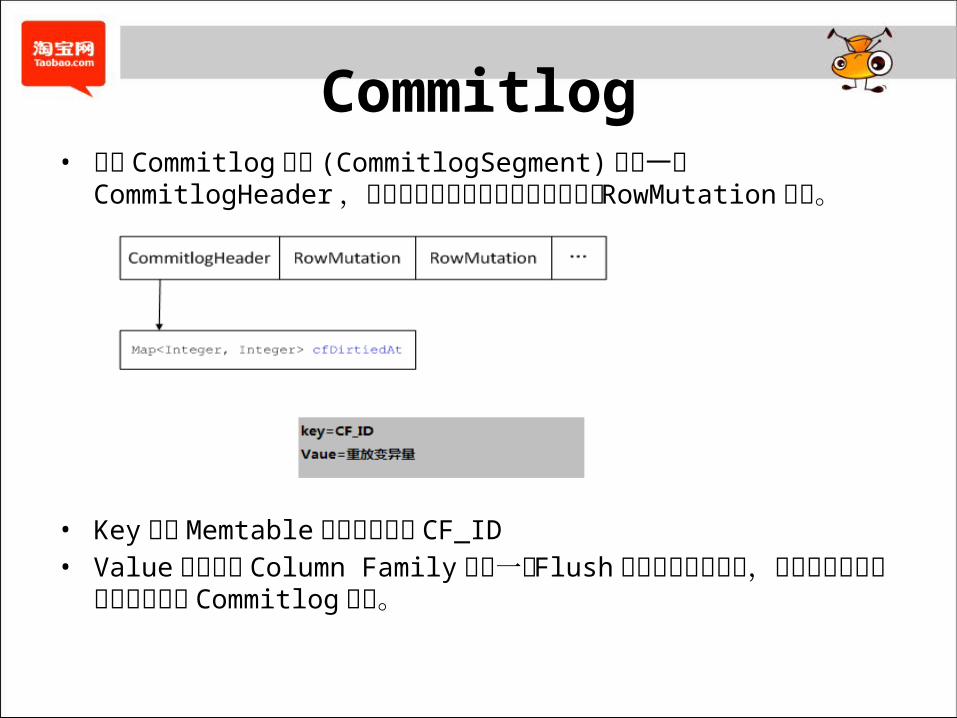
Commitlog• 每个 Commitlog 文件 (CommitlogSegment) 都有一个 CommitlogHeader ,紧随其后则是序列化之后的变更的 RowMutation 对象。
• Key 是在 Memtable 中存在更新的 CF_ID• Value 保存的是 Column Family 在上一次 Flush 时日志的偏移位置,恢复时则可以从这个位置读取 Commitlog记录。

Commitlog
• Commitlog刷新有两种机制:– Batch :当 CommitlogSegment刷新到磁盘后,插入
Memtable 操作才可继续。并且需要等待CommitLogSyncBatchWindowInMS毫秒(默认值 1 ,建议 0.1~10 )内的其他写操作一起批量刷日志到磁盘。可以类比为 Oracle 的 batch/wait 模式。
– Periodic :每隔 CommitLogSyncPeriodInMS毫秒(默认值 10000 )性刷新 CommitlogSegment ,不阻塞数据写操作,可以类比为 Oracle 的 batch/nowait 模式。

Compaction
Compaction• 一个 CF 可能有很多 SSTable ,系统会将多个 SSTable合并排序后保存为一个新的 SSTable ,称之为 Compaction 。• 一次 compaction 最多请求合并 32 个 SSTable ,最少 4 个。超过 32个则按时间排序分批进行(这两个阈值可以设置)。• 如果空间不足,则尝试去掉最大的 SSTable再合并,如果连合并两个最小的 SSTable 的空间都不足,则告警。• Major Comaction :合并 CF 的所有 SSTable 为一个新的 SSTable ,同时执行垃圾数据 ( 已标记删除的数据 tombstone)清理。• Minor Compaction :只合并大小差不多的 SSTable ,超过 4 个需要合并的 SSTable 就会自动触发。• 可通过 nodetool compact命令手动触发。• 数据目录最好保持 50% 以上的可用空间。

Compaction• Compaction 将旧的 SSTable 的记录按序写入到新的名字包含 tmp 的
SSTable ,完成后重命名去掉 tmp ,切换到新文件后,再将原 SSTable删除。• 可以通过设置 Compaction 的 minthreshold(默认 4) 和 maxthreshold(默认 32) 来改变触发一次 Comaction合并的最少 SSTable 数和最多
SSTable 数。• 如果设置 minthreshold=0或者 maxthreshold=0 ,则会禁止系统自动执行 Minor Compaction 。建议在业务高峰期禁止 Compaction ,定期到业务低峰期通过 nodetool compact手工执行 Major Compaction 。• 以上两个参数可以通过 nodetool设置:
Nodetool setcompactionthreshold [minthreshold] ([maxthreshold])

Agenda
• 基础知识• 数据模型• 数据分布策略• 存储机制• 数据读写删• 最终一致性• Gossiper• 面向未来
数据读写删• Quorum NRW• Read• Write• ConsistencyLevel• Delete

Quorum NRW
N: 复制的节点数量 R: 成功读操作的最小节点数 W: 成功写操作的最小节点数
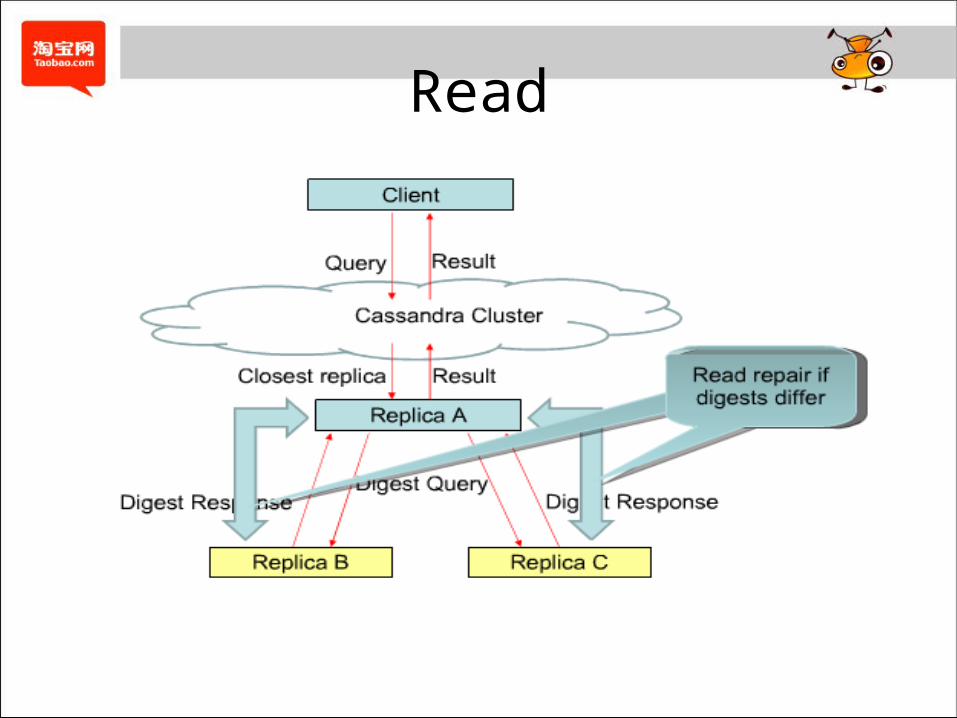
Read

Read
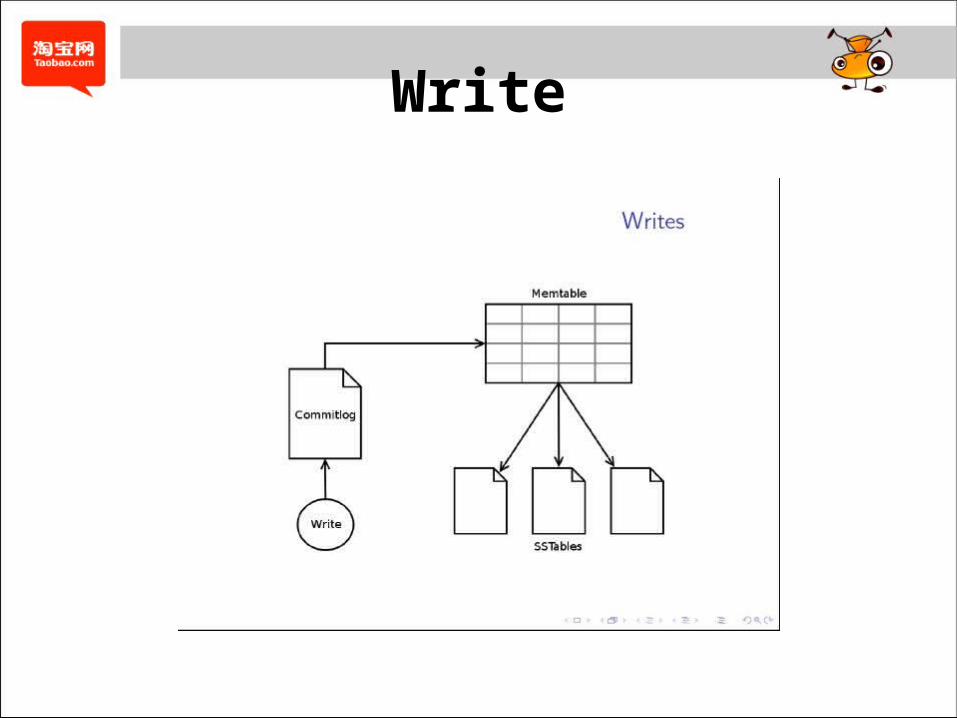
Write

ConsistencyLevel(Write)Level Behavior
ZERO Ensure nothing. A write happens asynchronously in background
ANY Ensure that the write has been written to at least 1 node, including hinted recipients.
ONE Ensure that the write has been written to at least 1 node's commit log and memory table before responding to the client.
QUORUM Ensure that the write has been written to <ReplicationFactor> / 2 + 1 nodes before responding to the client.
ALL Ensure that the write is written to all <ReplicationFactor> nodes before responding to the client. Any unresponsive nodes will fail the operation.

ConsistencyLevel(Read)Level Behavior
ZERO Not supported, because it doesn't make sense.
ANY Not supported. You probably want ONE instead.
ONE
Will return the record returned by the first node to respond. A consistency check is always done in a background thread to fix any consistency issues when ConsistencyLevel.ONE is used. This means subsequent calls will have correct data even if the initial read gets an older value. (This is called read repair.)
QUORUM Will query all nodes and return the record with the most recent timestamp once it has at least a majority of replicas reported. Again, the remaining replicas will be checked in the background.
ALL Will query all nodes and return the record with the most recent timestamp once all nodes have replied. Any unresponsive nodes will fail the operation.
Delete
• 分布式删除存在的问题? 一个删除操作不可能一下子就将被删除的数据立即删除掉:如果客户端执行一个删除操作,并且有一个副本还没有收到这个删除操作,这个时候这个副本依然是可用的,此外,该节点还认为那些已经执行删除操作的节点丢失了一个更新操作,它还要去修复这些节点。
zhangzhaokun

Delete
• Cassandra 中是怎么做的? 不会去直接删除数据, Cassandra 使用一个被称为墓碑的值。这个墓碑可以被传播到那些丢失了初始删除请求的节点。让每一个节点跟踪本地数据的墓碑值年龄。 常量 GCGraceSeconds ,默认为 10天。 一旦数据持有的墓碑值的年龄超过这个常量,它将进行收集。
Delete
• 什么时候才真正被删除掉呢? 我们在使用客户端从 Cassandra 中读取数据的时候,节点在返回数据之前都会主动检查是否该数据被设置了删除标志,并且该删除标志的添加时长已经大于GCGraceSeconds ,则要先删除该节点的数据再返回。

Agenda
• 基础知识• 数据模型• 数据分布策略• 存储机制• 数据读写删• 最终一致性• Gossiper• 面向未来
最终一致性• Hinted Handoff (提示移交)• Read Repair (读修复)• Anti Entropy (逆熵)

Hinted Handoff• Key A按照规则首要写入节点为 N1 ,复制到 N2• 假如 N1宕机,如果写入 N2 能满足 ConsistencyLevel 要求,则 Key A 对应的 RowMutation 将封装一个带 hint信息的头部(包含了目标为 N1 的信息),然后随机写入一个节点 N3 ,此副本不可读。同时正常复制一份数据到 N2 ,此副本可以提供读。如果写 N2 不满足写一致性要求,则写会失败。 • N1恢复后,原本应该写入 N1 的带 hint头的信息将重新写回 N1 。 • HintedHandoff 是实现最终一致性的一个优化措施,可以减少最终一致的时间窗口。
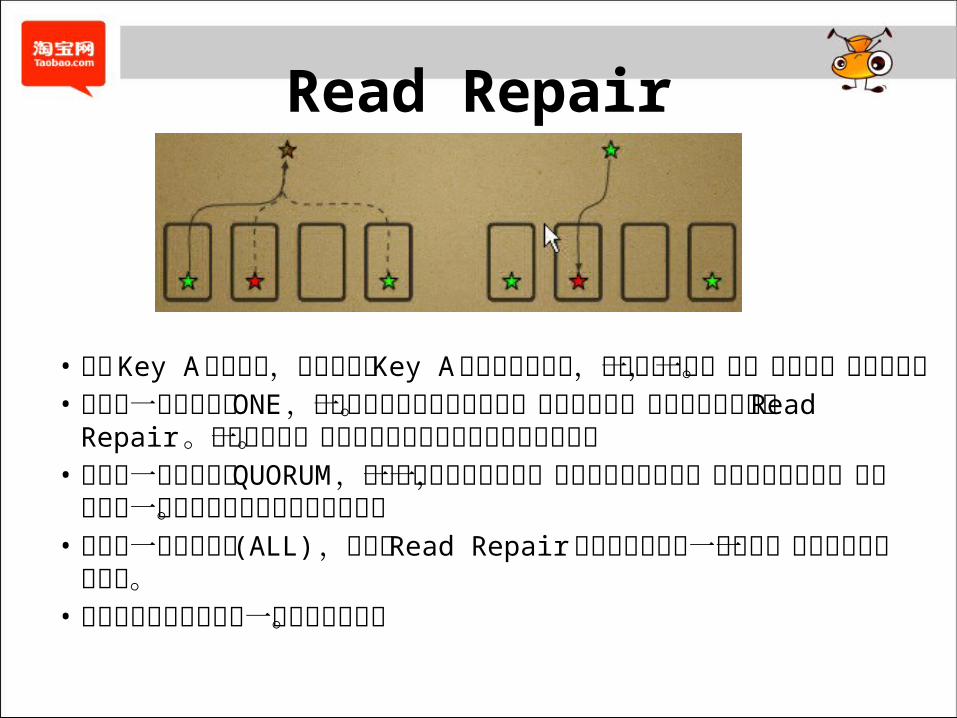
Read Repair
• 读取 Key A 的数据时,系统会读取 Key A 的所有数据副本,如果发现有不一致,则进行一致性修复。• 如果读一致性要求为 ONE ,会立即返回离客户端最近的一份数据副本。然后会在后台执行 Read Repair 。这意味着第一次读取到的数据可能不是最新的数据。• 如果读一致性要求为 QUORUM ,则会在读取超过半数的一致性的副本后返回一份副本给客户端,剩余节点的一致性检查和修复则在后台执行。• 如果读一致性要求高 (ALL) ,则只有 Read Repair完成后才能返回一致性的一份数据副本给客户端。• 该机制有利于减少最终一致的时间窗口。

Anti Entropy
Anti Entropy• 数据的最终一致性由 AntiEntropy (逆熵)所生成的
MerkleTrees 对比来发现数据复制的不一致,通过org.apache.cassandra.streaming 来进行完整的一致性修复。
• Merkle Tree 是一种 Hash Tree ,叶子节点是 Key 的 hash 值,父节点是所有子节点值的 hash 值,通过判断父节点的异同可以知道所有子节点的异同。• 通过判断 root 的异同可以快速判断所有叶子节点数据的异同。• 执行 nodetool repair 可以启动 Anti-Entropy ,此操作需要扫描所有数据,对系统的 IO 有较大压力,建议在业务低峰期定期执行。

Agenda
• 基础知识• 数据模型• 数据分布策略• 存储机制• 数据读写删• 最终一致性• Gossiper• 面向未来

Gossip 的作用• Cassandra 集群没有中心节点,各个节点的地位完全相同,它们通过一种叫做 gossip 的协议维护集群的状态。• 通过 gossip ,每个节点都能知道集群中包含哪些节点,以及这些节点的状态,这使得 Cassandra 集群中的任何一个节点都可以完成任意 key 的路由,任意一个节点不可用都不会造成灾难性的后果。
Gossip协议• gossip 的学名叫做 Anti-entropy (逆熵?),比较适合在没有很高一致性要求的场景中用作同步信息。信息达到同步的时间大概是
log(N) ,这里 N表示节点的数量。• gossip 有两种形式: anti-entropy 和 rumor-mongering 。• gossip 中的每个节点维护一组状态,状态可以用一个 key/value 对表示,还附带一个版本号,版本号大的为更新的状态。• 消息的处理有 3 种方式, Cassandra采用第三种方式—— Push-pull-
gossipPush-gossip A 节点将状态集合发送到 B , B 通过和本地的状态
集合比较,返回 S(A) 和 S(B) 的笛卡尔积Pull-gossip A 发送一个摘要( digest ,只包含 key 和 version )
给 B , B通过比较,仅仅返回 A上需要更新的状态Push-pull-gossip 这种方式和 pull-gossip 一样,在 B 发送给 A 其需要
更新的状态的同时,会向 A请求本地过期的状态
Gossip消息如何如何发送• 当一个节点启动时,获取配置文件( cassandra.yaml )中的 seeds配置,从而知道集群中所有的 seed节点。• Cassandra内部有一个 Gossiper ,每隔一秒运行一次(在 Gossiper.java的 start方法中),按照以下规则向其他节点发送同步消息: 1、随机取一个当前活着的节点,并向它发送同步请求 2、向随机一台不可达的机器发送同步请求 3、如果第一步中所选择的节点不是 seed ,或者当前活着的节点数少 于 seed 数,则向随意一台 seed 发送同步请求

Gossip消息如何如何发送• 如果没有这个判断,考虑这样一种场景,有 4台机器, {A, B, C, D} ,并且配置了它们都是 seed ,如果它们同时启动,可能会出现这样的情形: 1、 A节点起来,发现没有活着的节点,走到第三步,和任意一个种子同步,假设选择了 B 2、 B节点和 A完成同步,则认为 A活着,它将和 A 同步,由于 A 是种子, B 将不再和其他种子同步 3、 C节点起来,发现没有活着的节点,同样走到第三步,和任意一个种子同步,假设这次选择了 D 4、 C节点和 D完成同步,认为 D活着,则它将和 D 同步,由于 D 也是种子,所以 C也不再和其他种子同步• 这时就形成了两个孤岛, A 和 B 互相同步, C 和 D 之间互相同步,但是 {A,B}和 {C,D} 之间将不再互相同步,它们也就不知道对方的存在了。• 加入第二个判断后, A 和 B 同步完,发现只有一个节点活着,但是 seed 有 4个,这时会再和任意一个 seed通信,从而打破这个孤岛。
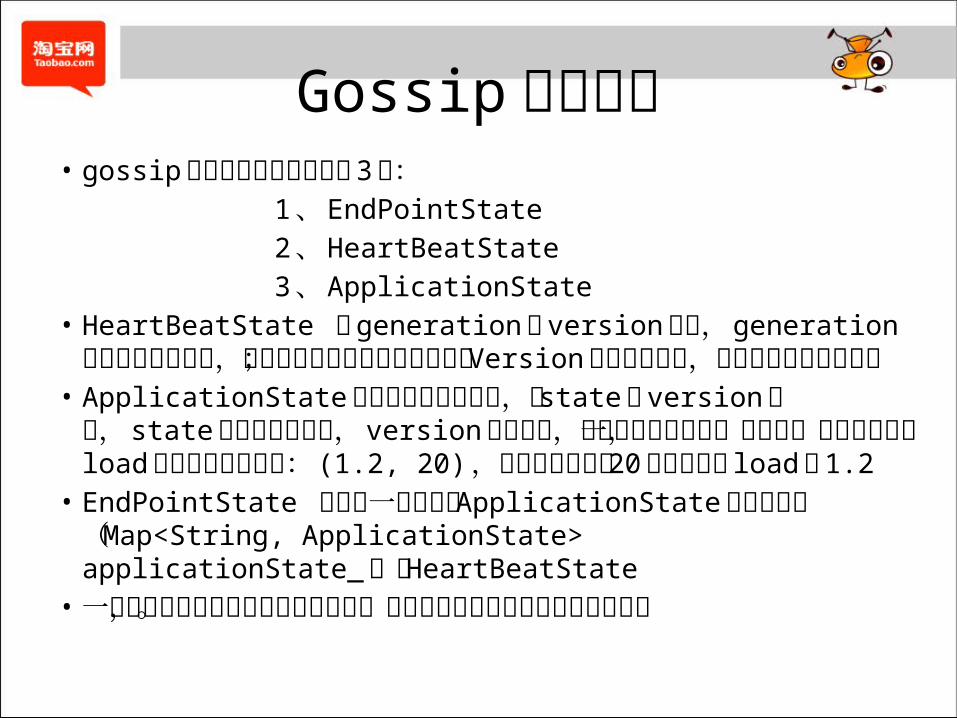
Gossip 数据结构• gossip通信的状态信息主要有 3 种: 1、EndPointState 2、HeartBeatState 3、ApplicationState • HeartBeatState 由generation 和 version组成, generation每次启动都会变化,用于区分机器重启前后的状态; Version 是只能增长的,每次心跳之前进行递增• ApplicationState 用于表示系统的状态,由 state 和 version组成, state表示节点的状态, version 是递增的,每个对象表示节点一种状态,比如表示当前 load 的状态大概是这样: (1.2, 20) ,含义为版本号为 20 时该节点的 load是 1.2• EndPointState 封装了一个节点的 ApplicationState 构成的映射( Map<String,
ApplicationState> applicationState_ )和 HeartBeatState• 一个节点自身的状态只能由自己修改,其他节点的状态只能通过同步更新。

Gossip 状态信息有哪些• 负载信息( LOAD-INFORMATION )• 迁移信息( MIGRATION )• 节点状态信息( MOVE ) BOOT (启动阶段)节点正在启动 NORMAL (正常)节点加入了 Token 的 ring ,可以提供读 LEAVING ,节点准备离开 Ring LEFT ,节点被踢出集群或者是 Token信息被手工变更
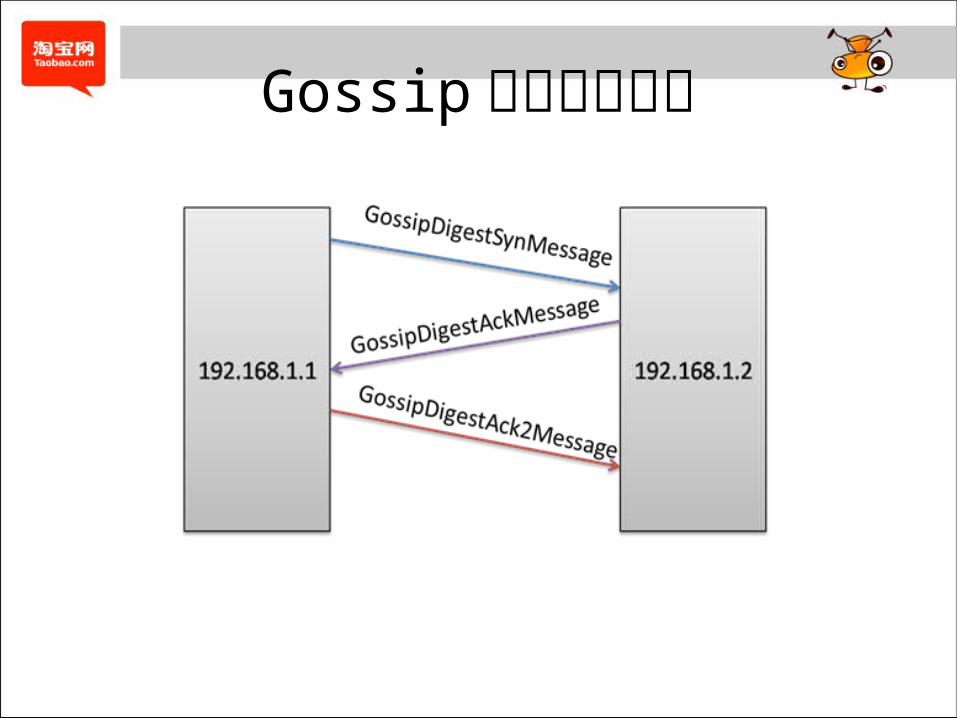
Gossip消息同步过程

Gossip消息同步实例( 1 ) Node 10.0.0.1(endPointStateMap):

Gossip消息同步实例( 2 ) Node 10.0.0.2(endPointStateMap):
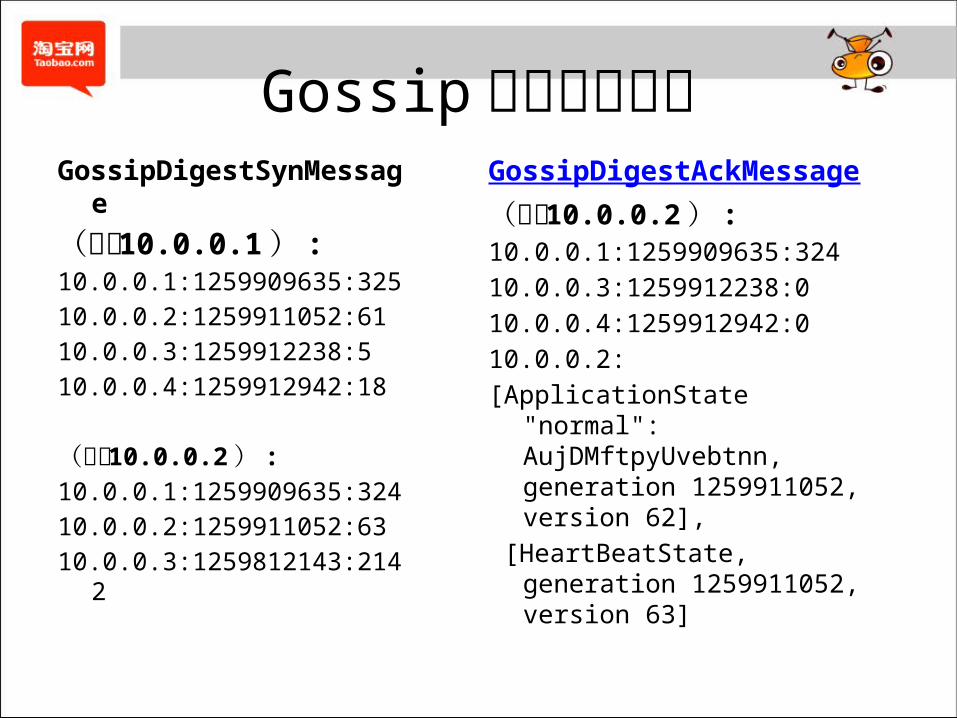
Gossip消息同步实例GossipDigestSynMessage(节点 10.0.0.1 ) :10.0.0.1:1259909635:325 10.0.0.2:1259911052:61 10.0.0.3:1259912238:5 10.0.0.4:1259912942:18
(节点 10.0.0.2 ) :10.0.0.1:1259909635:32410.0.0.2:1259911052:63 10.0.0.3:1259812143:2142
GossipDigestAckMessage(节点 10.0.0.2 ) :10.0.0.1:1259909635:32410.0.0.3:1259912238:0 10.0.0.4:1259912942:0 10.0.0.2:[ApplicationState "normal":
AujDMftpyUvebtnn, generation 1259911052, version 62],
[HeartBeatState, generation 1259911052, version 63]

Gossip消息同步实例GossipDigestAck2Message (节点 10.0.0.1 ) :10.0.0.1: HeartBeatState: generation 1259909635, version 325 ApplicationState "load-information": 5.2, generation 1259909635, version 45 ApplicationState "bootstrapping": bxLpassF3XD8Kyks, generation 1259909635, version 56 ApplicationState "normal": bxLpassF3XD8Kyks, generation 1259909635, version 8710.0.0.3: HeartBeatState: generation 1259912238, version 5 ApplicationState "load-information": 12.0, generation 1259912238, version 310.0.0.4: HeartBeatState: generation 1259912942, version 18 ApplicationState "load-information": 6.7, generation 1259912942, version 3 ApplicationState "normal": bj05IVc0lvRXw2xH, generation 1259912942, version 7

Agenda
• 基础知识• 数据模型• 数据分布策略• 存储机制• 数据读写删• 最终一致性• Gossiper• 面向未来

Twitter放弃 Cassandra• 1. Cassandra仍然缺少大并发海量数据访问的案例及经验, Cassandra来源自 Facebook ,但是在 Facebook内部 Cassandra目前只用在 inbox
search产品上,容量大约有 100-200T 。且 Inbox Search 在 Facebook的基础架构中也并非核心应用。• 2. 新产品需要一定稳定期, Cassandra代码或许还存在不少问题,但是 Twitter 如果投入大量的精力来改进 Cassandra 和比较优化MySQL的投入来看有点得不偿失。

Flowdock 转向 MongoDB• 稳定性问题 所有的节点都陷入无限循环 (infinite loop) ,运行垃圾回收工作 (GC ,
Garbage Collection) 并尝试压缩数据文件——并偶尔导致集群瘫痪。除了对集群进行重启并经常性的手工对节点做压缩工作以让其稳定一会外,无计可施。其他人也报告过类似的问题。在前面几周的时间里,我们的 Cassandra节点总是会吃掉给他分配的所有资源,而导致Flowdock 运行缓慢。
• 运维问题 从 Cassandra 0.4升级到 0.5 的时候,我们被迫关闭了整个集群,仅仅是为了将所有的数据刷新到磁盘上 (虽然,我们已经按照文档进行了手工刷新的操作 ) 。这个操作导致我们丢失了几分钟的讨论内容,以及我们手工创建的索引出现严重的不一致,以致于需要做完全的重建。
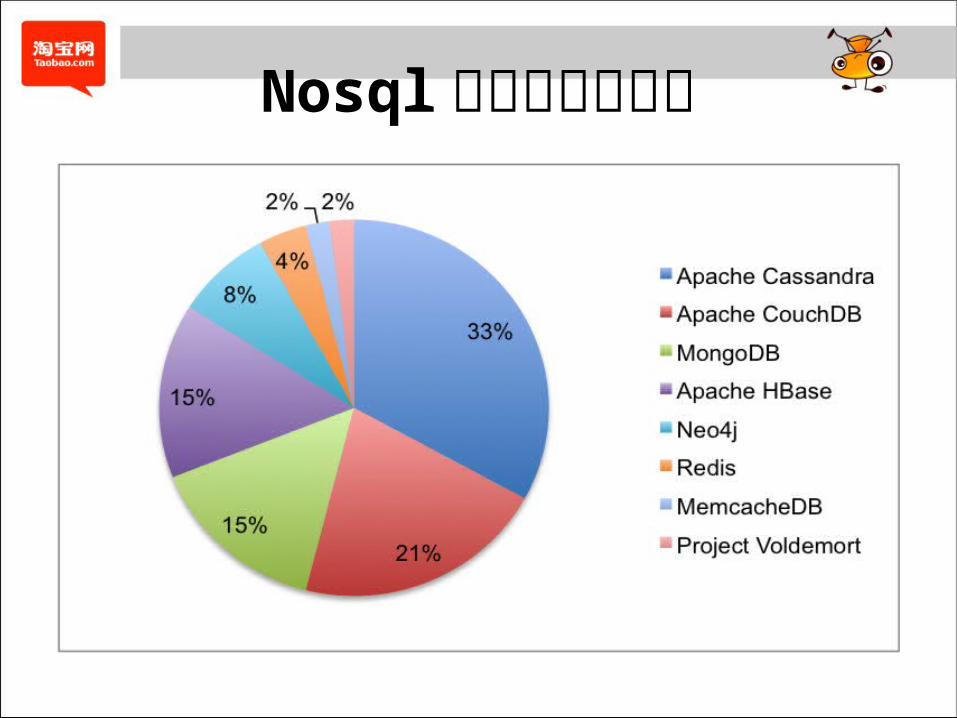
Nosql 支持率调查报告

Performance improve

路还很长……

Thanks !
















![[Baidu web frontend_conference_2010]_[豆瓣架构]](https://static.fdocument.pub/doc/165x107/55556fb4b4c9058a5a8b4a0b/baidu-web-frontendconference2010.jpg)
