Capítulo II. Estado del arte -...
41
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 16 Capítulo II. Estado del arte 1. Tecnología de códigos bidimensionales 1.1 Introducción 1.1.1 Códigos de barras Desde hace más de 50 años, el método de reconocimiento de productos de una forma eficiente era mediante el uso de códigos de barras. La primera patente se obtuvo en 1952 por parte de Joseph Woodland aunque hasta principios de 1970 no se creó el primer estándar para la identificación de productos. Existen cinco grandes grupos de códigos para la representación de información: - Barcode. Fue el primer tipo de código de barras industrial que se generó. - UPC. Universal Product Code que se convertiría en el estándar de identificación de productos. Se divide en UPC-A y UPC-E. - EAN. European Article Number. Versión europea del estándar anterior. Ejemplos de este tipo de códigos son los EAN-8 y EAN-13. - Código 39. Primer código de tipo alfanumérico creado en 1974. - PostNet. Creado a principios de los años 80 para el servicio postal. En la siguiente ilustración se presentan algunos ejemplos de los comentados anteriormente: Ilustración 4. Tipos de códigos de barras [2] El código de barras es un código basado en la representación mediante un conjunto de líneas paralelas verticales de distinto grosor y espaciado que en su conjunto contienen una determinada información. De este modo, el código de barras permite reconocer rápidamente un artículo en un punto de la cadena logística y así poder realizar inventario o consultar sus características asociadas. Actualmente, el código de barras está implantado masivamente de forma global. La estructura general de un código de barras se muestra en la siguiente ilustración:
Transcript of Capítulo II. Estado del arte -...

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 16
Capítulo II. Estado del arte
1. Tecnología de códigos bidimensionales
1.1 Introducción
1.1.1 Códigos de barras
Desde hace más de 50 años, el método de reconocimiento de productos de una forma eficiente era mediante el uso de códigos de barras. La primera patente se obtuvo en 1952 por parte de Joseph Woodland aunque hasta principios de 1970 no se creó el primer estándar para la identificación de productos.
Existen cinco grandes grupos de códigos para la representación de información:
- Barcode. Fue el primer tipo de código de barras industrial que se generó.
- UPC. Universal Product Code que se convertiría en el estándar de identificación de productos. Se divide en UPC-A y UPC-E.
- EAN. European Article Number. Versión europea del estándar anterior. Ejemplos de este tipo de códigos son los EAN-8 y EAN-13.
- Código 39. Primer código de tipo alfanumérico creado en 1974.
- PostNet. Creado a principios de los años 80 para el servicio postal.
En la siguiente ilustración se presentan algunos ejemplos de los comentados anteriormente:
Ilustración 4. Tipos de códigos de barras [2]
El código de barras es un código basado en la representación mediante un conjunto de líneas paralelas verticales de distinto grosor y espaciado que en su conjunto contienen una determinada información. De este modo, el código de barras permite reconocer rápidamente un artículo en un punto de la cadena logística y así poder realizar inventario o consultar sus características asociadas. Actualmente, el código de barras está implantado masivamente de forma global.
La estructura general de un código de barras se muestra en la siguiente ilustración:

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 17
Ilustración 5. Estructura de un código de barras. [3]
La Ilustración 5 se puede dividir en cuatro grandes grupos:
- Quiet Zone (1): Es la zona de impresión blanca que se deja a los lados del código de barras para poder distinguir el código del resto de la información donde se encuentre alojado.
- Caracteres de inicio y terminación (2): Son marcas predefinidas de barras y espacios específicos para cada tecnología. Marcan el inicio y la finalización del código de barras.
- Caracteres de datos (3): Contienen los números o letras particulares del código.
- Checksum (4): Barras y espacios usados para validar los caracteres anteriores.
El problema surge cuando se quiere almacenar una determinada cantidad de información. Con tan solo 20 caracteres, el código de barras deja de ser práctico y hace que se obtengan códigos kilométricos que ningún lector puede descifrar. En este sentido, este tipo de códigos se limitan a almacenar un determinado índice capaz de ser usado para buscar en una base de datos y así obtener la información que se requiera del producto.
En definitiva, los códigos de barra tradicionales se ven muy limitados en cuanto a la cantidad de información que son capaces de almacenar teniendo que dar paso a otro tipo de códigos más adecuados al mercado actual.
1.1.2 Códigos bidimensionales
Por todo lo explicado anteriormente, surge la necesidad de buscar una alternativa que permita un mayor almacenamiento de información de una forma eficiente teniendo en cuenta las limitaciones tecnológicas actuales. Es ahí cuando surge la idea de los códigos bidimensionales.
Los códigos bidimensionales son matrices formadas por la combinación de puntos de determinados colores permitiendo un escaneo posterior por parte de un lector de una forma muy rápida y eficiente. La información almacenada en este tipo de códigos se realiza en las dos dimensiones del plano, a diferencia con los códigos de barra donde la información se almacenaba en una única dimensión.
Esto hace que en una menor región del espacio se pueda almacenar una mayor cantidad de información pasando de 20 a más de 7000. De esta manera se pueden representar todo tipo

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 18
de caracteres numéricos y alfanuméricos: Kanji, Kana Hiragana, símbolos binarios y códigos de control.
En términos generales, los códigos bidimensionales se pueden dividir en dos grandes grupos:
- Códigos apilados. Son códigos de barras apilados uno detrás del otro en las dos dimensiones de la superficie.
- Códigos matriciales. Consisten en un patrón de celdas que conforman una matriz de datos donde cada celda se rellena de un determinado color.
Una comparación cualitativa sobre la eficiencia espectral de los códigos bidimensionales (apilados y matriciales) respecto a los códigos de barra se puede apreciar en la siguiente tabla donde se almacena la misma información (“12345678901234567890”) en diferentes tipos de codificaciones viéndose claramente el aumento de eficiencia en los códigos bidimensionales.
Código Tipo Representación gráfica
Código 39 Código de barras
ITF Código de barras
(entrelazado)
PDF417 Código bidimensional apilado
Datamatrix Código bidimensional matricial
Tabla 1. Comparación de eficiencia espectral [2]
Como se puede comprobar en la Tabla 1 los resultados son más que evidentes. Ante una misma cantidad de información, los códigos bidimensionales son capaces de reducir considerablemente el espacio de representación de los datos.
Además, proporcionan mecanismos de seguridad que no proporcionan los códigos de barras tradicionales. Son capaces de introducir mecanismos de redundancia pudiendo duplicar la información contenida en él haciendo que sea mucho más robusto frente a posibles ataques. Poseen códigos de corrección de errores (ECC) que consisten en la incorporación de bits extras de paridad de forma que se puedan corregir los errores en el mismo momento de la lectura.
En la siguiente tabla, se muestra una relación entre los errores producidos en los diferentes tipos de códigos:
Código Peor caso Mejor caso
Datamatrix 1 error cada 10.5 millones 1 error cada 612.9 millones PDF417 1 error cada 10.5 millones 1 error cada 612.4 millones
Código 128 1 error cada 2.8 millones 1 error cada 37 millones Código 39 1 error cada 1.7 millones 1 error cada 4.7 millones
UPC 1 error cada 394.000 1 error cada 800.000
Tabla 2. Errores de los diferentes tipos de codificación [2]

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 19
Existen una gran cantidad de tipos de códigos bidimensionales, como son los códigos QR (Quick Response Barcode), Datamatrix, Maxicode, Aztec code, PDF417, RSS (Reduced Space Symbology) o los códigos 49. Estos códigos pueden contener información de todo tipo, desde información adicional de un producto (descuentos, precios, cómo llegar a la tienda, etc.), hasta mensajes ocultos, juegos de pistas, teléfonos, direcciones de e-mail, enlaces web (descargas de juegos, canciones, etc.), SMS, etc.
La aparición de cada vez más terminales móviles capaces de leer estos tipos de códigos hace que a medida que pasa el tiempo, dichos códigos se hagan muy populares en el ámbito del marketing y la publicidad.
1.2 Datamatrix
El código DataMatrix fue inventado por RVSI/Acuity CiMatrix. DataMatrix está protegido por un estándar ISO, el ISO/IEC16022 —International Symbology Specification— , Data Matrix, y es de dominio público.
El símbolo DataMatrix está compuesto de módulos de celdas cuadradas definidas dentro de un perímetro marcado. Es posible codificar hasta 3116 caracteres numéricos, 2355 caracteres alfanuméricos y 1556 bits en binario. En la micropercusión superan los 100 caracteres. Cada símbolo consiste en zonas de datos que forman módulos cuadrados en una secuencia regular. Los símbolos más grandes contienen varios módulos y cada zona de datos está delimitada por una línea continua en 2 caras y discontinua en otras 2. Cada código individual está rodeado de una zona lisa que haga las veces de margen.
Ofrecen una enorme capacidad de almacenamiento pudiendo introducir en espacios muy reducidos una gran cantidad de información. Proporciona una alta fiabilidad de lectura gracias a sus sistemas de información redundante y corrección de errores (legible hasta con un 20%-30% dañado).
La estructura general de un código Datamatrix viene representada en la siguiente ilustración.
Ilustración 6. Estructura general de un código Datamatrix
Como se puede observar en la Ilustración 6, el símbolo está delimitado por dos bordes continuos en la parte izquierda e inferior y dos bordes punteados en la parte superior y derecha del código. Los bordes continuos sirven para definir la orientación y la desviación angular mientras que los bordes punteados sirven para definir como serán las columnas y las

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 20
filas interiores. En el interior del código se distribuye una rejilla matricial con zonas coloreadas en negro y en blanco que determinarán el contenido del código en si.
Existen diferentes tipos de códigos Datamatrix en función del nivel de corrección de errores que posea. En un principio surgieron la ECC000 y ECC140 (ya obsoletos). Actualmente se considera como código oficial el ECC200 capaz de usar un algoritmo mucho más eficiente para incluir los datos en la matriz así como un método de corrección de errores más avanzado.
Las características más importantes de los códigos datamatrix son:
- Tamaño máximo del punto: Es el diámetro del punto más grande colocado en el código. Recuérdese que la representación no tiene porqué ser con cuadrados sino también con círculos.
- Tamaño mínimo del punto: Diámetro del punto más pequeño colocado en el código.
- Tamaño de celda: Es el ancho del cuadrado de la matriz reservado para la colocación de un punto.
- Desplazamiento del punto: Es el desplazamiento máximo de un punto respecto al centro de su celda.
- Desviación angular: Es el ángulo que se desvían las columnas respecto al eje vertical del código bidimensional.
Un ejemplo de la representación de las características detalladas anteriormente se pueden apreciar en la siguiente ilustración.
Ilustración 7. Características de los códigos datamatrix. [2]
Para una correcta lectura de un código Datamatrix se han de cumplir una serie de condiciones:
- Zona silenciosa. Debe ser mayor o igual al tamaño de una celda.
- Dimensiones. La matriz puede ser cuadrada o rectangular aunque existe mayor probabilidad de éxito de lectura con una matriz cuadrada.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 21
- Tamaño del símbolo. En el caso de los códigos rectangulares, el tamaño del símbolo no debe ser mayor de 25,4 milímetros en su lado más largo.
- Desviación angular. No debe sobrepasar los ± 7 grados.
- Superficies curvas. Si se imprime el código sobre una superficie curva, la extensión total del símbolo debe ser menor al 16% del diámetro de la superficie.
- Color de las celdas. Debe haber contraste entre un color claro de las celdas y un color oscuro de las zonas sombreadas para su correcta lectura.
El nivel de eficiencia de estos tipos de códigos es relativo y dependerá del entorno donde se utilicen. En el ámbito comercial y de ocio, los lectores encargados de traducir la información de dichos códigos son terminales móviles, muy limitados cuanto menor sea el tamaño de la imagen a traducir. Es decir, no interesa disponer de códigos de un alto rendimiento y eficiencia espacial si después los dispositivos encargados de traducirlos no van a ser capaces de llevar a cabo su función.
Por ello, los códigos Datamatrix se emplean más en el etiquetado de componentes electrónicos, incluso marcando directamente las piezas donde los lectores de dichos códigos son elementos altamente cualificados y con una precisión más que sobresaliente. Las técnicas que se utilizan para marcar las piezas son variadas. Las más comunes son mediante micropercusión, tinta, láser y grabado por productos químicos. Este marcado permite, por ejemplo, la trazabilidad o la comprobación del stock.
Otras limitaciones que han encontrado los códigos Datamatrix en su uso comercial son el escaso desarrollo de aplicaciones orientadas a la estética y al marqueting, campo donde han avanzado más los códigos QR, y el hecho de no interpretar los símbolos de escritura japoneses (Kana). Este último motivo ha hecho que los códigos Datamatrix no se hayan usado en Japón y hayan tomado ventaja los QR. De hecho son los principales precursores de estos últimos.
1.3 Quick Response
El fundamento es el mismo que el anterior. Una matriz de datos que almacena información para leerse a alta velocidad. La principal diferencia respecto a los códigos anteriores es la capacidad de adaptación que han tenido respecto a los dispositivos móviles de hoy en día.
La estructura general de un código QR se aprecia en la siguiente ilustración.
Ilustración 8. Estructura de un código QR. [10]

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 22
Tal y como se puede observar en la Ilustración 8 que existen cuatro aspectos claramente diferenciados:
- Información de la versión (1). El tamaño de código QR viene definido en la versión. Existen versiones desde la 1 a la 40. Por ejemplo, la versión 1 consta de una matriz de 21x21. Al incrementarse una versión, se le añaden cuatro módulos. Para más información, consultar [13].
- Información del formato (2). Describe el nivel de corrección de errores, patrón de máscara y capacidad de almacenamiento.
- Corrección de errores y datos (3). Se incluye en esta región los datos en sí que se desean almacenar incluyendo la información referente al control y corrección de errores.
- Patrones requeridos (4). Se dividen en los patrones de posición (4.1) que sirven para ayudar a la detección del código QR por parte del lector, los patrones de alineamiento (4.2) usados para la corrección de errores por parte del lector y los patrones de sincronismo (4.3) que sirven para determinar la coordenada del símbolo que se esté decodificando dentro de la matriz de datos.
Su uso está tremendamente difundido en Japón, debido a que dichos códigos son capaces de almacenar un mayor número de caracteres japoneses (Kana) y chinos (Kanji). De ahí que en dichos lugares predominara el uso de los QR frente a otro tipo de almacenamiento.
La capacidad de almacenamiento en códigos QR dependerá de lo que se quiera almacenar. Si se almacenan números, se es capaz de almacenar hasta 7089 caracteres. Si se trata de caracteres alfanuméricos, se pueden almacenar hasta 4296 caracteres. En binario se almacenan hasta 2953 y en formato Kanji/Kana hasta 1817 caracteres.
Los códigos QR también poseen la capacidad de corrección de errores. Existen hasta cuatro niveles de corrección: L (El 7% se puede restaurar), M (15%), Q (25%) y H (30%).
El sistema QR es también un estándar abierto, definido en la ISO/IEC18004 que fue publicada en Junio del año 2000. Aunque el estándar japonés, JIS X 0510, es de Enero de 1999. En la siguiente tabla se muestra un pequeño historial del proceso de estandarización de los códigos QR.
Fecha Descripción
Octubre de 1997 Aprobado como estándar AIM internacional (ISS-QR Code) (Automatic Identification Manufacturers International)
Marzo de 1998 Aprobado como estándar JEIA (JEIDA-55) (Japanese Electronic Industry Development Association)
Enero de 1999 Aprobado como estándar JIS (JIS X 0510) (Japanese Industrial Standards)
Junio de 2000 Aprobado como estándar ISO (ISO/IEC18004) (International Organization for Standardization)
Noviembre de 2004 Los MicroQR son aprobados como estándar JIS (JIS X 0510) (Japanese Industrial Standards)
Tabla 3. Historial de estandarización del QR [13]
Además, tal y como se ha comentado antes, es el sistema por excelencia entre los códigos bidimensionales para proporcionar servicios al consumidor y una nueva forma de marqueting ya que los DataMatrix, en este aspecto, no han resultado ser los más eficientes.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 23
1.3.1 Códigos microQR
Una variante de los códigos QR son los llamados microQR que consisten básicamente en una simplificación del código anterior para evitar tener tantos patrones. Estos códigos tienen una menor capacidad pero debido a su espacio tan reducido puede ser útil en etiquetado de componentes, etc.
La estructura clásica de un microQR y su relación con un código QR convencional se aprecia en la siguiente ilustración.
Ilustración 9. Relación entre microQR y QRCode [13]
Como se puede observar, se han sustituido gran parte de los patrones necesarios para una correcta lectura de un código QR convencional. Por el contrario, el lado superior e izquierdo consiste en una línea discontinua que sirve para marcar el número de filas y columnas que tendrá la matriz de datos (muy similar a lo ocurrido con los códigos datamatrix).
De esta forma, la capacidad de almacenamiento de los microQR disminuye. En la siguiente ilustración se puede apreciar la relación entre el tamaño del símbolo y la capacidad de los códigos de barras, los códigos QR y los microQR.
Ilustración 10. Relación de capacidad de diferentes códigos [13]

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 24
En total, se pueden almacenar hasta un máximo de 35 caracteres numéricos, 21 caracteres alfanuméricos, 15 binarios y 9 caracteres Kanji.
1.4 ShotCode
Consiste en un código de barras circular creado por High Energy Magic de la Universidad de Cambridge en 1999 mientras se investigaba en un sistema de bajo coste basado en visión artificial para seguimiento de localizaciones y que denominaron, en un primer momento, TRIPCode.
En un primer lugar se usaron para el seguimiento en tiempo real con webcams. Posteriormente, se implementaron como códigos de barras para poder ser leídos a través de un teléfono móvil. Para ese tipo de aplicaciones lo denominaron SpotCode. En 1993 se fundó la empresa High Energy Magic cuya finalidad era comercializar el SpotCode creando en 1999 el definitivo ShotCode.
Los ShotCode usan un círculo central similar a una diana. A su alrededor, se disponen de círculos de datos. En función del ángulo y la distancia de dichos círculos al centro, quedan determinados los datos.
La diferencia de los ShotCode respecto a los códigos bidimensionales matriciales se basa en que, en realidad, dichos códigos no poseen la información en su interior sino que contienen una clave de 49 bits. En un servidor se almacenan las relaciones entre las claves y una URL. Por tanto, el dispositivo una vez lee el código, accederá al servidor y traducirá su clave por una URL dando acceso a la misma de forma automática.
Un esquema general de un código ShotCode se puede apreciar en la siguiente ilustración.
Ilustración 11. Esquema general de un ShotCode
Un ShotCode posee una serie de restricciones para poder ser decodificado adecuadamente por el lector:
- Debe poseer un margen blanco alrededor del código de una determinada anchura.
- Debe estar representado en blanco y negro.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 25
- Debe medir como mínimo 3.5 cm.
Según lo descrito anteriormente, se puede llegar a la conclusión de que su uso está enmarcado en el ámbito del marketing y la publicidad ya que posee una capacidad de almacenamiento bastante escasa, limitación que le impide el uso de dichos códigos para almacenar información de una longitud considerable.
1.5 Bi-Di
Es un sistema propietario de Movistar basado en la codificación EZCode, en un intento de monopolizar el mercado. Lógicamente, esto provoca una numerosa cantidad de limitaciones.
Este operador ha comenzado a promocionar sus códigos Bidi (código Bidimensional o 2D) como herramienta de marketing móvil e interacción con sus usuarios. Su funcionamiento se basa en una aplicación que permite que cuando la cámara capta la imagen del “código Bidi” ejecute una orden ya sea abrir un vídeo o acceder a una página Web.
Para poder leer este tipo de códigos es necesario descargarse una aplicación facilitada por Movistar y no es posible generar este tipo de códigos a no ser que se haga a través de la plataforma de Telefónica. Es decir, la aparición de un sistema propietario por parte de Movistar hace que, en realidad, no resulte competencia alguna ante los auténticos estándares de hoy en día.
A continuación se representa la forma de un código Bi-Di de Movistar:
Ilustración 12. Código Bi-Di de Movistar
1.6 Otros códigos
Los códigos expuestos anteriormente no son los únicos, aunque si los más conocidos. Existe una amplia gama de códigos bidimensionales que no han creado tanta expectación en el ámbito del marketing o industrial pero que poseen características propias.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 26
1.6.1 PDF417
El PDF417 es un código de longitud variable que puede codificar cualquier carácter alfanumérico. Cada carácter se codifica con 4 barras y 4 espacios en una estructura de 17 módulos. PDF viene de la palabra “Portable Data File” (“Archivo Portátil de Datos”) y “417” se deriva de la estructura del módulo.
Cada PDF417 consta de 3 a 90 renglones apilados rodeados por una zona inicial en cada uno de los 4 lados. Cada renglón consta de una zona inicial, un patrón de lectura, un carácter indicador de la columna izquierda, de uno a treinta caracteres de datos, un carácter indicador de la columna derecha, patrón de alto, y una zona final.
El código PDF417 tiene capacidad para hasta 340 caracteres por pulgada cuadrada con una capacidad máxima de 1,850 caracteres.
Una imagen de muestra de un código PDF417 se puede contemplar en la siguiente ilustración.
Ilustración 13. Código PDF417 [5]
1.6.2 MaxiCode
Este código es utilizado principalmente por UPS (United Parcel Service) para clasificar el correo a grandes velocidades, puede ser leído con gran velocidad y frecuentemente en cualquier dirección. El código MaxiCode es una simbología matricial de dos dimensiones de tamaño fijo que tiene 866 elementos hexagonales arreglados en 33 renglones alrededor de un patrón localizador central consistente en una serie de circunferencias concéntricas. El tamaño de un código MaxiCode es de 2.8 cms. Por 2.7 cms.
Un solo código MaxiCode puede codificar hasta 93 caracteres de datos y 256 caracteres ASCII.
Una imagen de muestra de un código MaxiCode se puede contemplar en la siguiente ilustración.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 27
Ilustración 14. Código MaxiCode [5]
1.6.3 Aztec Code
Este es otro tipo de código bidimensional matricial de alta densidad que puede codificar 3,750 caracteres del juego de caracteres completo de ASCII de 256 bytes. El símbolo se construye sobre un patrón en forma, esta vez, de cuadrados concéntricos en el centro. Puede leerse independientemente de su orientación y cuenta con mecanismos de corrección de errores seleccionables por el usuario.
A continuación se puede apreciar la forma de este tipo de codificación.
Ilustración 15. Código Aztec Code [5]
1.6.4 RSS
En los últimos años se han dado nuevos requerimientos para la información contenida en los códigos comerciales UPC y EAN (European Article Number), necesitándose codificar más información en un espacio menor, por lo cual se creó el código RSS ("Reduced Space Symbology" o "Simbología de Espacio Reducido"), que es una de las codificaciones lineales más compactas hasta la fecha. La familia RSS de simbologías comprende tres versiones: RSS-
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 28
14, RSS Limitada y RSS Expandida, donde la primera y tercera tienen un gran número de variaciones optimizadas para distintas aplicaciones.
A continuación se puede apreciar un ejemplo de su estructura.
Ilustración 16. Código RSS [5]
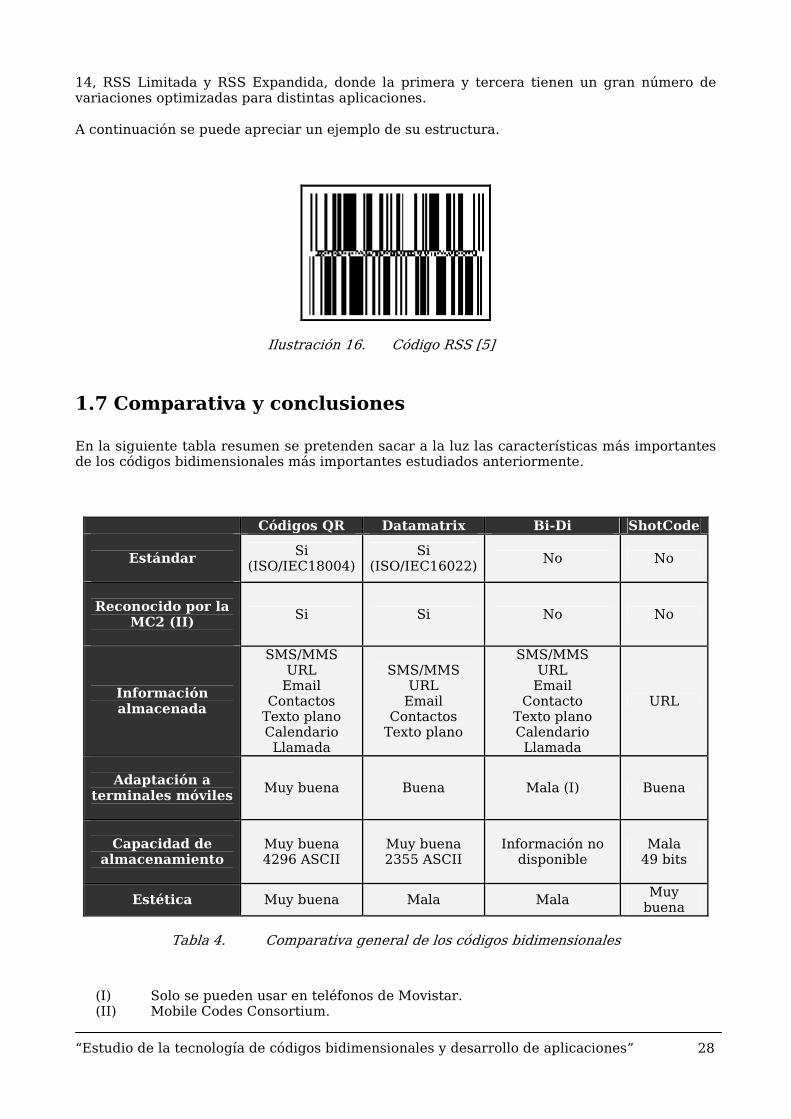
1.7 Comparativa y conclusiones
En la siguiente tabla resumen se pretenden sacar a la luz las características más importantes de los códigos bidimensionales más importantes estudiados anteriormente.
Códigos QR Datamatrix Bi-Di ShotCode
Estándar
Si (ISO/IEC18004)
Si (ISO/IEC16022)
No No
Reconocido por la
MC2 (II)
Si Si No No
Información almacenada
SMS/MMS URL
Email Contactos
Texto plano Calendario Llamada
SMS/MMS URL
Email Contactos
Texto plano
SMS/MMS URL
Email Contacto
Texto plano Calendario Llamada
URL
Adaptación a
terminales móviles
Muy buena Buena Mala (I) Buena
Capacidad de
almacenamiento
Muy buena 4296 ASCII
Muy buena 2355 ASCII
Información no disponible
Mala 49 bits
Estética Muy buena Mala Mala Muy buena
Tabla 4. Comparativa general de los códigos bidimensionales
(I) Solo se pueden usar en teléfonos de Movistar. (II) Mobile Codes Consortium.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 29
2. Lectores y generadores
2.1 Lectores
Existe una gran variedad de lectores para móviles de códigos QR. El principal problema de este tipo de aplicaciones es la incompatibilidad de los terminales móviles. Por ello, cada modelo se ve restringido al uso de una determinada aplicación existiendo casos en los que un modelo no es capaz de instalar un lector QR para su ejecución.
Incluso dentro de un mismo lector, existen diferencias sustanciales cuando se cambia de un terminal a otro. Esto produce que la elección no se base en una comparación general de los lectores disponibles y decidir en función de quien te ofrezca mejores prestaciones sino que se basa en decidir, en función del terminal que se vaya a usar y sus limitaciones así como las propias limitaciones del lector, qué aplicación es la que más se adecua al móvil en cuestión.
Características que aparentemente puedan parecer limitadas por el terminal móvil a usar, tras una serie de pruebas realizadas, se ha comprobado que depende también del lector que se utilice. Esto sucede con la modalidad de captura “al vuelo” donde, para un mismo terminal con altas prestaciones en la cámara, había lectores que facilitaban esta característica y otros lectores que no. Esto nos da a entender que, aun dependiendo del tipo de terminal y sus características, en la captura al vuelo un factor importante es que el lector que se use para leer los códigos sea capaz de soportarlo.
Los lectores más importantes actualmente en el mercado y de obtención totalmente gratuita son:
- I-nigma. Creado por 3GVision en colaboración con los más importantes fabricantes de móviles de Japón, para ser preinstalado en sus terminales, y atendiendo a las especificaciones de las operadoras. Como resultado de esta colaboración, el lector i-nigma está incorporado en más de 60 millones de terminales móviles y copa más del 75% del mercado en Japón.
- Kaywa Reader. El número de móviles compatibles con este lector es bastante menor que con el de I-Nigma.
- QuickMark. Es el lector de la empresa taiwanesa SimpleAct, Inc.
2.2 Generadores
Existen dos tipos de generadores: generadores on-line y generadores locales.
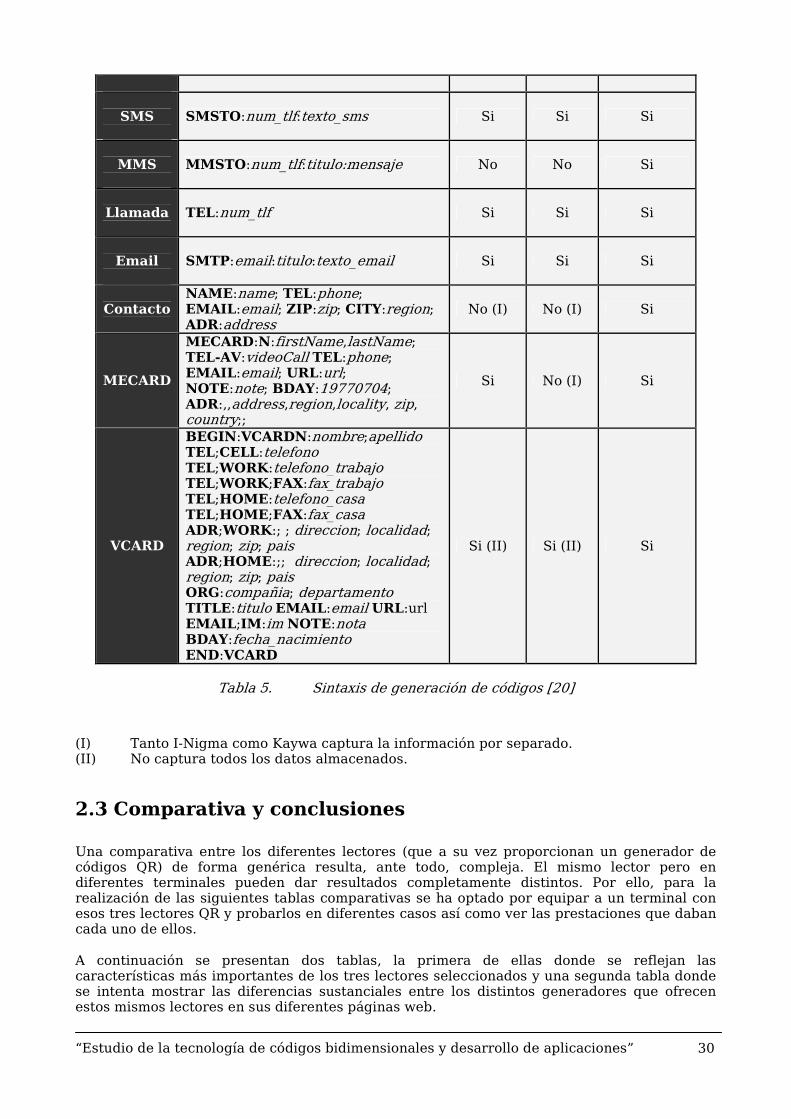
Nos ofrecen la posibilidad de codificar una aceptable variedad de mensajes: Dirección web, Contactos: meCard, vCard., envío de SMS., envío de MMS., envío de E-mail., texto plano codificado o llamada automática a un número de teléfono.
La sintaxis de generación de códigos QR se representa en la siguiente tabla en función de los lectores más utilizados en la actualidad.
Sintaxis I-nigma Kaywa QuickMark
URL:direccion_web Si Si No direccion_web (con http) Si Si Si
URL direccion_web (sin http) Si Si No
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 30
SMS
SMSTO:num_tlf:texto_sms Si Si Si
MMS
MMSTO:num_tlf:titulo:mensaje No No Si
Llamada
TEL:num_tlf Si Si Si
SMTP:email:titulo:texto_email Si Si Si
Contacto NAME:name; TEL:phone; EMAIL:email; ZIP:zip; CITY:region; ADR:address
No (I) No (I) Si
MECARD
MECARD:N:firstName,lastName; TEL-AV:videoCall TEL:phone; EMAIL:email; URL:url; NOTE:note; BDAY:19770704; ADR:,,address,region,locality, zip, country;;
Si No (I) Si
VCARD
BEGIN:VCARDN:nombre;apellido TEL;CELL:telefono TEL;WORK:telefono_trabajo TEL;WORK;FAX:fax_trabajo TEL;HOME:telefono_casa TEL;HOME;FAX:fax_casa ADR;WORK:; ; direccion; localidad; region; zip; pais ADR;HOME:;; direccion; localidad; region; zip; pais ORG:compañia; departamento TITLE:titulo EMAIL:email URL:url EMAIL;IM:im NOTE:nota BDAY:fecha_nacimiento END:VCARD
Si (II) Si (II) Si
Tabla 5. Sintaxis de generación de códigos [20]
(I) Tanto I-Nigma como Kaywa captura la información por separado. (II) No captura todos los datos almacenados.
2.3 Comparativa y conclusiones
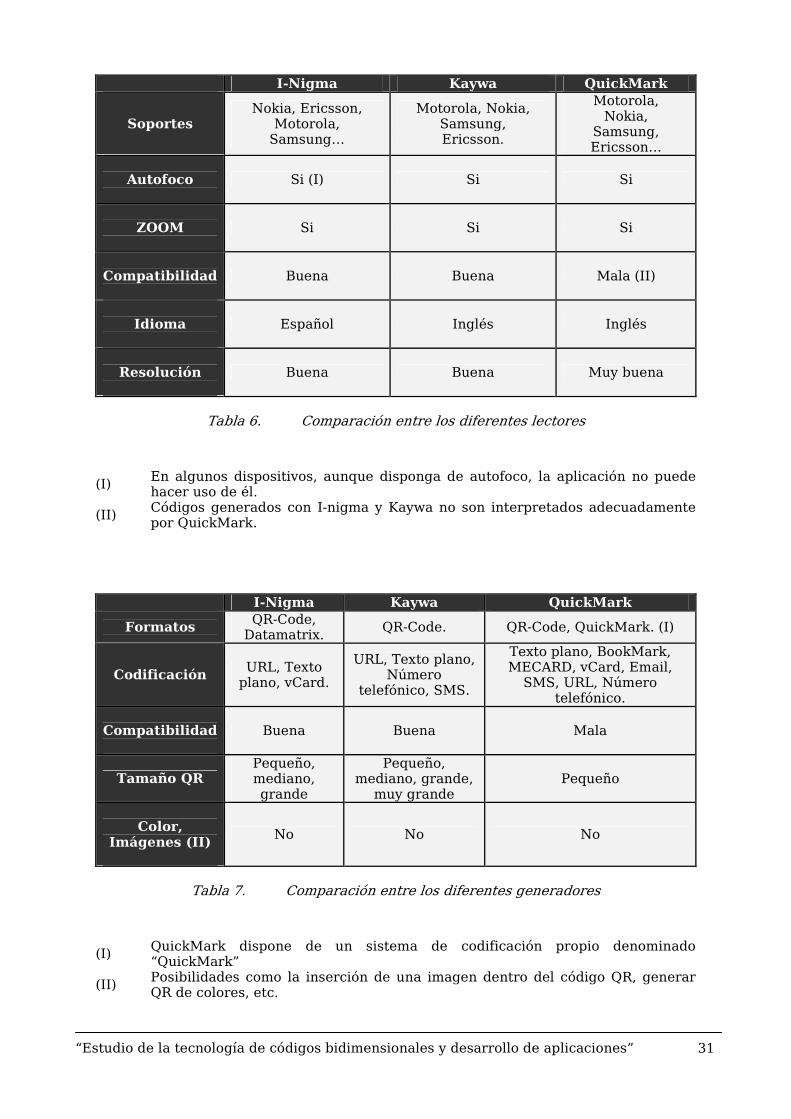
Una comparativa entre los diferentes lectores (que a su vez proporcionan un generador de códigos QR) de forma genérica resulta, ante todo, compleja. El mismo lector pero en diferentes terminales pueden dar resultados completamente distintos. Por ello, para la realización de las siguientes tablas comparativas se ha optado por equipar a un terminal con esos tres lectores QR y probarlos en diferentes casos así como ver las prestaciones que daban cada uno de ellos.
A continuación se presentan dos tablas, la primera de ellas donde se reflejan las características más importantes de los tres lectores seleccionados y una segunda tabla donde se intenta mostrar las diferencias sustanciales entre los distintos generadores que ofrecen estos mismos lectores en sus diferentes páginas web.
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 31
I-Nigma Kaywa QuickMark
Soportes Nokia, Ericsson,
Motorola, Samsung…
Motorola, Nokia, Samsung, Ericsson.
Motorola, Nokia,
Samsung, Ericsson…
Autofoco
Si (I) Si Si
ZOOM
Si Si Si
Compatibilidad
Buena Buena Mala (II)
Idioma
Español Inglés Inglés
Resolución
Buena Buena Muy buena
Tabla 6. Comparación entre los diferentes lectores
(I) En algunos dispositivos, aunque disponga de autofoco, la aplicación no puede hacer uso de él.
(II) Códigos generados con I-nigma y Kaywa no son interpretados adecuadamente por QuickMark.
I-Nigma Kaywa QuickMark
Formatos QR-Code,
Datamatrix. QR-Code. QR-Code, QuickMark. (I)
Codificación URL, Texto
plano, vCard.
URL, Texto plano, Número
telefónico, SMS.
Texto plano, BookMark, MECARD, vCard, Email,
SMS, URL, Número telefónico.
Compatibilidad
Buena Buena Mala
Tamaño QR Pequeño, mediano, grande
Pequeño, mediano, grande,
muy grande Pequeño
Color,
Imágenes (II)
No No No
Tabla 7. Comparación entre los diferentes generadores
(I) QuickMark dispone de un sistema de codificación propio denominado “QuickMark”
(II) Posibilidades como la inserción de una imagen dentro del código QR, generar QR de colores, etc.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 32
3. Plataforma multiservicio de mensajería. RedBox
3.1 Introducción
RedBox de Vodafone es una plataforma multiservicio que pone a disposición del cliente la posibilidad del envío y recepción de SMS, MMS o localización de terminales (exclusivamente a aquellos terminales que estén dados de alta en el servicio).
RedBox provee un punto único de acceso a diferentes servicios de red (SMS, MMS, LBS), independizando las aplicaciones de los servicios de red y permitiendo el envío y recepción de grandes volúmenes de mensajes cortos, multimedia o peticiones de localización. La conexión se lleva a cabo utilizando un interfaz SOAP (Simple Object Access Protocol).
En la siguiente figura se pueden observar los diferentes niveles en los que se divide el sistema, y el papel que juegan los interfaces SOAP y la base de datos.
Ilustración 17. Arquitectura de RedBox [21]
La plataforma RedBox permite el envío y recepción de mensajes SMS y MMS, así como el envío de peticiones de localización LBS y la recepción de la respuesta asociada.
Dispone de un descriptor estándar de servicios web (WSDL), basados en el estándar SOAP (HTTP/XML) con el que puede acceder a una serie de interfaces a través de los cuales podrá realizar envíos y obtener información sobre la plataforma. En otras palabras, se dispone de una herramienta de fácil integración con las aplicaciones de los terceros para poder usar los servicios de RedBox. Dicho descriptor simplifica la integración con sus aplicaciones, ya que las versiones más recientes de los entornos de desarrollo permiten la creación automatizada de bibliotecas a partir de un WSDL.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 33
Los mensajes enviados por los terminales móviles y que llegan a la plataforma de RedBox son devueltos a una determinada aplicación web (en función de una palabra clave) mediante conexiones HTTP (POST o GET) que ha sido definida previamente por el usuario.
RedBox actúa de intermediario entre las aplicaciones externas (programadas por el usuario) y RedBox, introduciendo las siguientes ventajas respecto a una comunicación directa entre ambas:
- Las llamadas a RedBox se realizan a través de una interfaz SOAP que dispone de un descriptor de servicios estándar (WSDL), lo cual simplifica la integración. Dichas llamadas, además, requieren menos parámetros que las equivalentes de RedBox.
- Añade limitación de créditos, personalizable para cada uno de los canales de una cuenta. La gestión de dichos créditos es automática. Es decir, cada usuario dispondrá de un número de mensajes SMS o MMS al mes para gastar en lo que más le convenga.
- Las notificaciones y mensajes entrantes son entregados a aplicaciones externas mediante HTTP-GET o HTTP-POST (configurable para cada canal), lo que facilita el procesamiento en las aplicaciones.
3.2 Principios de funcionamiento
El funcionamiento de RedBox es muy sencillo. Básicamente consiste en hacer de pasarela entre el móvil y las aplicaciones que se programen para envío y recepción de SMS, MMS, etc.
Todos los SMS enviados por un terminal móvil que llegan a la plataforma, son reenviados en función de la palabra clave introducida en el mensaje de texto a una determinada página web que se encargará de procesar la información recibida y actuar en consecuencia.
Desde dichas aplicaciones web, el usuario podrá ser capaz de realizar envíos de SMS, MMS o pedir la localización de un determinado terminal móvil que previamente se ha dado de alta en el servicio LBS.
Se pueden distinguir tres casos principalmente:
- Recepción de SMS (o MMS).
- Envío de SMS (o MMS) por parte de la aplicación.
- Petición de localización de un móvil (LBS) por parte de la aplicación.
3.2.1 Recepción de SMS
Este caso intenta explicar la recepción por parte de RedBox y posterior reenvío a las aplicaciones desarrolladas por el programador ante la llegada de un SMS proveniente de un teléfono móvil.
El esquema general de funcionamiento se puede apreciar en la siguiente ilustración.
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 34
Ilustración 18. Recepción de SMS por parte de RedBox
Es decir, RedBox, ante la entrada de un SMS o MMS originado en un móvil lo que hará será enviar una serie de parámetros a una página web definida por los usuarios de la plataforma.
Dicha página web, en función de los parámetros recibidos, procesará una determinada aplicación (por ejemplo, el envío de un MMS al móvil que ha enviado el SMS con un programa, imagen, vídeo, etc.).
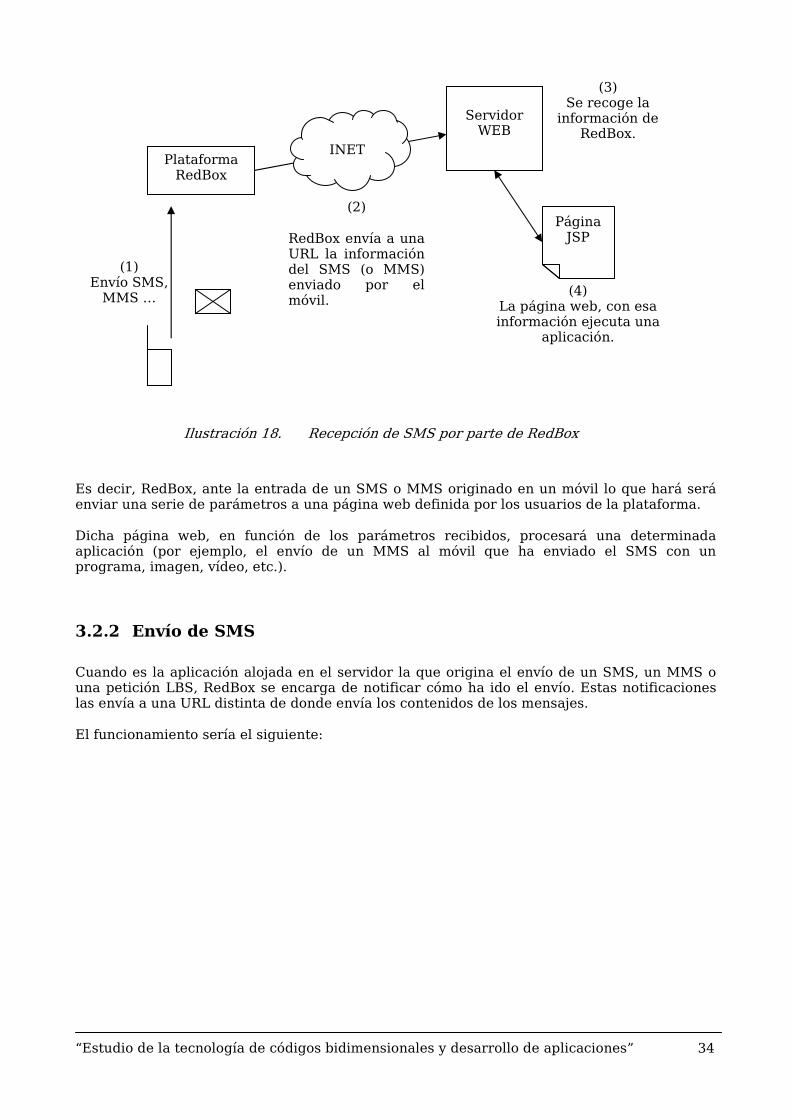
3.2.2 Envío de SMS
Cuando es la aplicación alojada en el servidor la que origina el envío de un SMS, un MMS o una petición LBS, RedBox se encarga de notificar cómo ha ido el envío. Estas notificaciones las envía a una URL distinta de donde envía los contenidos de los mensajes.
El funcionamiento sería el siguiente:
Plataforma RedBox
Servidor
WEB INET
(2)
RedBox envía a una URL la información del SMS (o MMS) enviado por el móvil.
(3) Se recoge la
información de RedBox.
Página JSP
(4) La página web, con esa información ejecuta una
aplicación.
(1) Envío SMS,
MMS …

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 35
Ilustración 19. Envío de SMS por parte del usuario
Por ejemplo, cuando se envía un SMS desde la página web, se recibe una notificación en otra página web con información de si ha sido recibido correctamente por RedBox o no, en cuyo caso explica el motivo del error. A continuación se recibe el acuse de recibo del SMS en el móvil.
El uso de dos URL’s distintas para el envío de mensajes y para recibir notificaciones es una especificación de RedBox.
3.2.3 Petición de localización
El procedimiento a seguir en este tipo de peticiones es similar al explicado anteriormente. La aplicación de la empresa, en su código, realiza una petición para localizar a un determinado móvil que esté dado de alta en el servicio. Cabe destacar que dicho móvil debe haber aceptado una serie de condiciones de localización para que RedBox pueda localizarle. En caso contrario, este tipo de peticiones serían imposibles de ser llevadas a cabo.
Una vez que la petición llega a la plataforma RedBox, ésta localiza al terminal móvil y devuelve a la aplicación de la empresa una serie de coordenadas (en el formato que se le indique) diciendo en que punto se encuentra el terminal.
Los formatos que se pueden solicitar al realizar una petición de localización son dos:
- SLIR. La respuesta de RedBox a la localización la da en función de la latitud y la longitud.
Plataforma RedBox
(3) RedBox
comprueba la autenticación y envía el SMS
Servidor
WEB
Página JSP 2
Página JSP 3
INET
(2) Se envía la solicitud a
RedBox
(4) RedBox notifica a al
servidor si el mensaje se ha enviado bien o
no.
(1) La página web
solicita el envío de un SMS
(5) Se recibe la
notificación en una página web.
Envío de notificaciones
Envío del SMS

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 36
- GRLR. La respuesta de RedBox a la localización la da en función de la calle, ciudad y país donde se encuentre el terminal móvil.
El proceso de notificaciones es exactamente igual que en los casos anteriores. Se dispondrá de una página donde RedBox indique los resultados de las operaciones.
4. Vídeos bajo demanda
4.1 Introducción
El concepto de vídeo bajo demanda consiste en la posibilidad de, a través de una determinada interfaz, poder visualizar un vídeo alojado en un servidor a través de la técnica conocida por “streaming”. Es decir, se reproducirá el vídeo a medida que se va recibiendo sin necesidad de descargarlo en el dispositivo desde donde se visualice. Esto aporta la ventaja de una mejora en el rendimiento del uso de la capacidad del dispositivo que accede al vídeo (en el caso del proyecto, el móvil).
“Video On Demand” (VoD) se define como “vídeo a la carta”. Este sistema, más desarrollado en Estados Unidos que en Europa, permite al usuario solicitar y visionar una película o un programa concreto en el momento exacto que el espectador desea, ofreciéndole a su vez el uso de funciones de video. Es decir, el cliente mientras ve la televisión digital puede detener el programa que ha pedido, también puede llevarlo hacia atrás, hacia delante, ponerlo a cámara lenta, etc. Esta aplicación está desarrollándose cada vez más en la actual televisión por cable (Un ejemplo de ello es el servicio OJO de ONO, Imagenio de Telefónica, etc). El funcionamiento del VoD consiste en el diálogo del terminal móvil con un servidor de VoD que procesará la petición para darle acceso al video que ha solicitado.
Cabe destacar que los vídeos transmitidos por videostreaming deben estar codificados adecuadamente para su correcta difusión a los terminales que lo codifiquen.
El protocolo de transmisión que se usa para la difusión de los vídeos a través de Internet (TCP/IP) es RTSP. La arquitectura de protocolos es como se muestra a continuación.
Ilustración 20. Torre de protocolos para RTSP
FÍSICO
ENLACE
IP
TCP UDP
(Control de
audio y vídeo)
(Datos de
audio y vídeo)
RTSP

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 37
Por último, los requisitos que se deben cumplir en un sistema de vídeo bajo demanda se detallan a continuación:
- Gran capacidad de almacenamiento. Debido a que el servidor va a contener un número ilimitado de vídeos, es necesario que la capacidad del servidor sea elevada para poder almacenar todos los vídeos que se requieran.
- Gran ancho de banda. Imprescindible para que el servidor pueda servir los vídeos a los dispositivos que lo soliciten ya que sino podría haber problemas en la recepción.
- Servicio en tiempo real. El sistema debe ser rápido respondiendo a las peticiones de un usuario.
- Calidad del servicio (QoS). Se debe cuidar la calidad del audio y la imagen así como la correcta sincronización entre ambas.
- Códecs. Aplicación software, hardware o combinación de ambos usados para transformar una señal en el emisor y decodificarla adecuadamente en el receptor para una transmisión más óptima.
- Protocolos. Como se ha comentado anteriormente, los usados para la transferencia de datos de vídeostreaming son UDP y RTSP entre otros. Este tipo de protocolos hace que la transferencia sea mucho más rápida que con protocolos más pesados como TCP o HTTP.
4.2 Arquitectura de los sistemas de VoD
Los sistemas de vídeo bajo demanda siguen el tradicional modelo cliente-servidor tal y como se puede apreciar en la ilustración siguiente.
Ilustración 21. Modelo Cliente-Servidor
Red
Petición 1
Petición 2
Respuesta 1
Respuesta 2
Cliente 1 Cliente 2 Servidor

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 38
Como se puede apreciar, el sistema consta de tres elementos principalmente: Cliente, red y servidor. A continuación se explicarán cada uno de ellos.
- Servidor. Es el encargado de suministrar un flujo continuo de vídeo a través de la red. Debe trabajar en tiempo real para atender a todas las peticiones que se les solicita. Consta de tres partes principalmente: Control, Almacenamiento y Comunicación
- Red. Es la encargada de unir cada elemento que compone el sistema. Debe tener unos requisitos mínimos de calidad para que la transmisión de vídeo se haga de forma fructífera.
- Cliente. Envía las peticiones al servidor y reproduce lo que le llega del mismo. Está formado por los siguientes subsistemas: núcleo de red, sistema de control, decodificador, buffers y sistema de sincronización.
Para terminar, se presentan algunas arquitecturas típicas de los sistemas de vídeos bajo demanda.
4.2.1 Arquitectura centralizada.
Todos los clientes se conectan a un único servidor que es el encargado de atender a todas las peticiones. Esto implica los clásicos problemas de la centralización como la aparición de cuellos de botellas, retrasos, pérdidas, escalabilidad, disponibilidad del servicio, etc.
Ilustración 22. Arquitectura de VoD centralizada. [26]
Una posible optimización del sistema anterior se podría dar con las siguientes arquitecturas centralizadas:
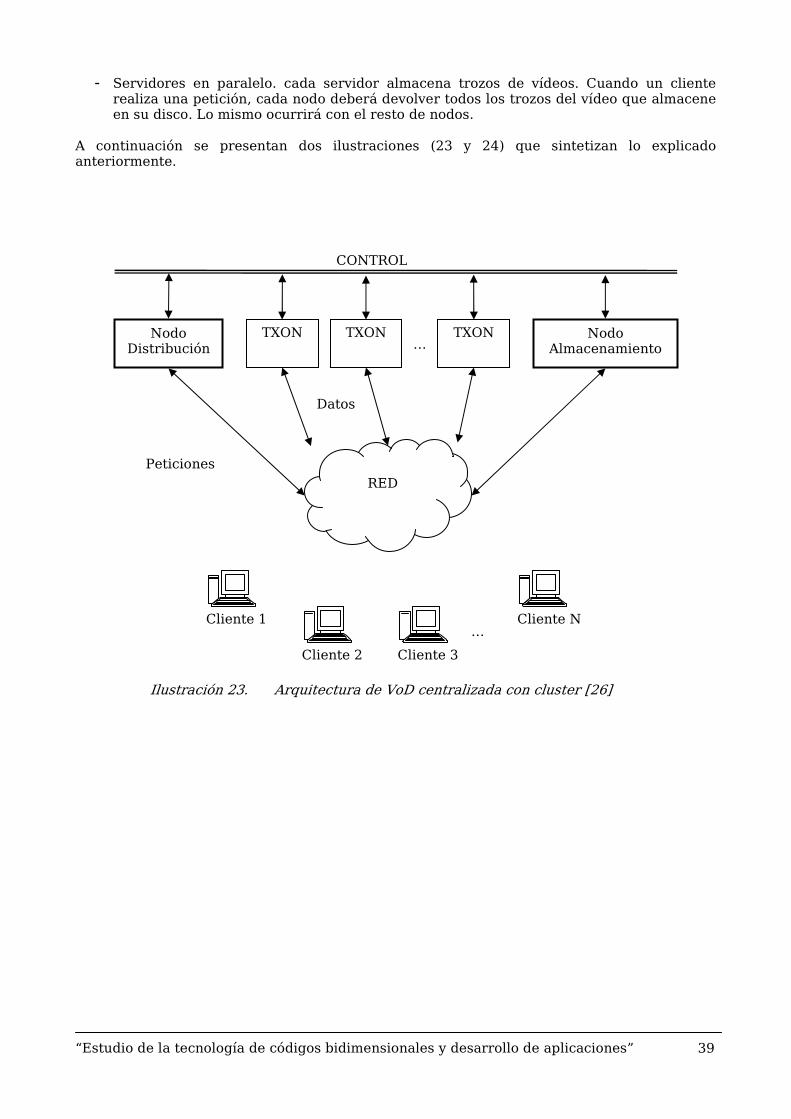
- Cluster de ordenadores. Varios nodos de transmisión encargados de transmitir la información del vídeo solicitado, uno de control y distribución encargado de recoger las peticiones externas y procesarlas adecuadamente y uno de almacenamiento que guarda el contenido de los vídeos. Todos ellos conectados a través de un bus.
RED
Cliente 1
Cliente 2
Cliente 3
Cliente N
… Servidor
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 39
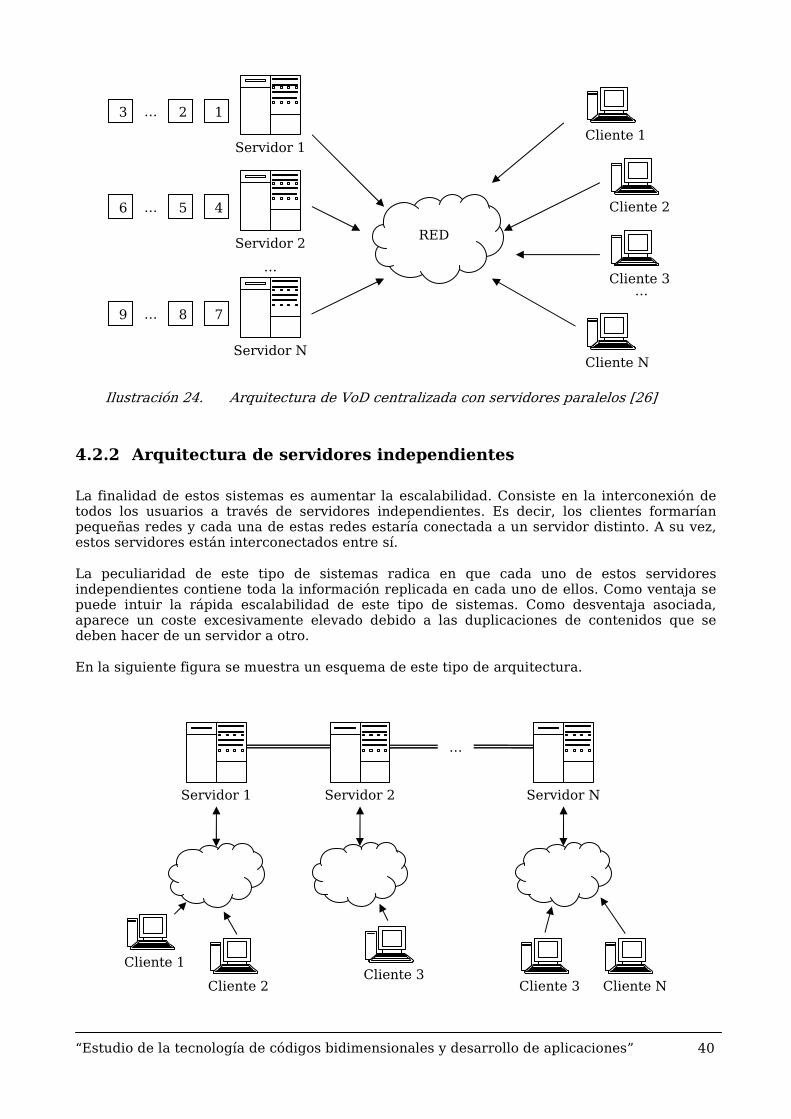
- Servidores en paralelo. cada servidor almacena trozos de vídeos. Cuando un cliente realiza una petición, cada nodo deberá devolver todos los trozos del vídeo que almacene en su disco. Lo mismo ocurrirá con el resto de nodos.
A continuación se presentan dos ilustraciones (23 y 24) que sintetizan lo explicado anteriormente.
Ilustración 23. Arquitectura de VoD centralizada con cluster [26]
TXON TXON TXON Nodo Almacenamiento
Nodo Distribución
RED
CONTROL
…
Peticiones
Datos
Cliente 1
Cliente 2 Cliente 3
Cliente N …
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 40
Ilustración 24. Arquitectura de VoD centralizada con servidores paralelos [26]
4.2.2 Arquitectura de servidores independientes
La finalidad de estos sistemas es aumentar la escalabilidad. Consiste en la interconexión de todos los usuarios a través de servidores independientes. Es decir, los clientes formarían pequeñas redes y cada una de estas redes estaría conectada a un servidor distinto. A su vez, estos servidores están interconectados entre sí.
La peculiaridad de este tipo de sistemas radica en que cada uno de estos servidores independientes contiene toda la información replicada en cada uno de ellos. Como ventaja se puede intuir la rápida escalabilidad de este tipo de sistemas. Como desventaja asociada, aparece un coste excesivamente elevado debido a las duplicaciones de contenidos que se deben hacer de un servidor a otro.
En la siguiente figura se muestra un esquema de este tipo de arquitectura.
Servidor 1 Servidor 2 Servidor N
…
Cliente 1
Cliente 2 Cliente N Cliente 3
Cliente 3
Servidor 1
Servidor 2
Servidor N
1 2 3
…
…
4 5 6 …
7 8 9 …
RED
Cliente 1
Cliente 2
Cliente 3
Cliente N
…

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 41
Ilustración 25. Arquitectura de VoD con servidores independientes. [26]
4.2.3 Arquitectura basada en servidores-proxy
Es una mejora del sistema anterior. Consiste en liberar de carga a los servidores independientes convirtiéndolos en servidores que únicamente almacenan un catálogo de los vídeos que existen disponibles en la red. Es a lo que se le llamará “servidor Proxy”.
En este tipo de arquitecturas, las peticiones realizadas por los clientes no se resuelven todas a nivel local sino que, en caso de no disponer del vídeo solicitado, se dirige a un servidor central que se encargará de gestionar la petición.
De esta forma, al servidor central únicamente le llegarán las peticiones que no ha podido gestionar el Proxy, no todas y cada una de las peticiones realizadas por los clientes. Esto hace que se libere de trabajo al nodo central evitando alguno de los problemas de los servidores centralizados.
Este tipo de arquitectura se puede clasificar en dos grandes grupos:
- Servidor principal centralizado. Se dispone de un único servidor centralizado que es el encargado de atender todas las peticiones que los proxys no son capaces de solventar.
- Servidor principal paralelo jerárquico. Se establece una distribución jerárquica de servidores para evitar posibles congestiones en un único servidor.
A continuación se presenta la arquitectura con un único servidor centralizado.
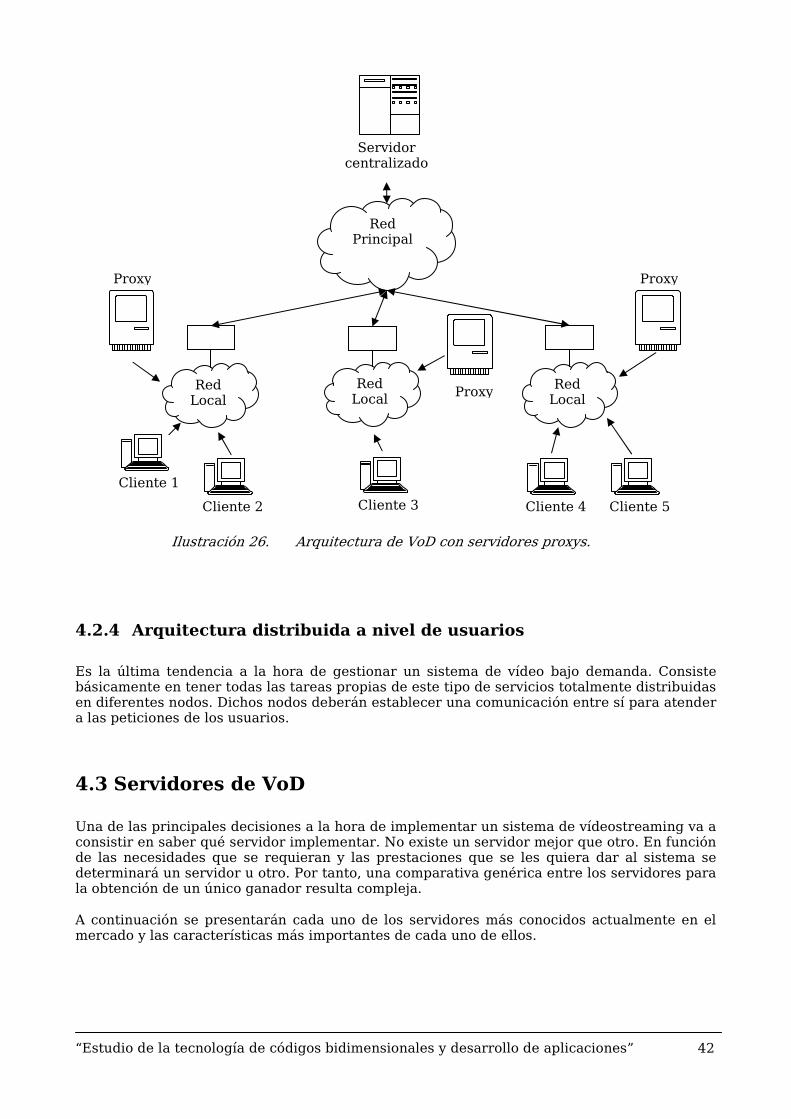
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 42
Ilustración 26. Arquitectura de VoD con servidores proxys.
4.2.4 Arquitectura distribuida a nivel de usuarios
Es la última tendencia a la hora de gestionar un sistema de vídeo bajo demanda. Consiste básicamente en tener todas las tareas propias de este tipo de servicios totalmente distribuidas en diferentes nodos. Dichos nodos deberán establecer una comunicación entre sí para atender a las peticiones de los usuarios.
4.3 Servidores de VoD
Una de las principales decisiones a la hora de implementar un sistema de vídeostreaming va a consistir en saber qué servidor implementar. No existe un servidor mejor que otro. En función de las necesidades que se requieran y las prestaciones que se les quiera dar al sistema se determinará un servidor u otro. Por tanto, una comparativa genérica entre los servidores para la obtención de un único ganador resulta compleja.
A continuación se presentarán cada uno de los servidores más conocidos actualmente en el mercado y las características más importantes de cada uno de ellos.
Servidor centralizado
Red Local
Red Principal
Red Local
Cliente 1
Cliente 2 Cliente 5 Cliente 3 Cliente 4
Red Local
Proxy
Proxy
Proxy

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 43
4.3.1 HTTP Server
Como se podría pensar, no resulta necesario el uso de un servidor específico para vídeostreaming. Una posible alternativa es usar un servidor web habitual usado para la visualización de páginas web.
El funcionamiento es muy sencillo, el protocolo HTTP v.1 es capaz de hacer que nos situemos en cualquier posición del flujo haciendo posible la reproducción por vídeostreaming. ¿Dónde reside la diferencia respecto a un servidor de streaming especializado? Básicamente en los protocolos que implementa.
Si recordamos la ilustración 20, el protocolo RTSP, para su transmisión usa por debajo UDP. Es decir, usa un protocolo no orientado a la conexión para la transmisión de los datos. Esto quiere decir que, en caso de enviar un trozo de vídeo incorrectamente, no se procederá a la retransmisión sino que se seguirá desde el punto donde se dejó.
En transmisiones de vídeo y audio, una de las características principales es poder evitar las retransmisiones ya que la señal recibida por el receptor se vería retrasada notablemente y es algo que no interesa. No importa perderse algún pequeño fragmento de audio a tener que esperar a que se retransmita todo para poder recibir correctamente el audio que antes dio problemas.
Este tipo de características las posee el protocolo RTSP (que solo usa TCP para las transmisiones de control, lógicamente, debido a que es necesario que esa información llegue adecuadamente de un extremo al otro). Sin embargo, HTTP no posee estas características según se puede apreciar en la siguiente ilustración.
Ilustración 27. Torre de protocolos para HTTP
Es decir, HTTP tiene por debajo el protocolo TCP que consiste en un protocolo orientado a conexión. Esto es, en caso de enviarse un paquete y que éste no llegue a su destino, por defecto, se procede a una retransmisión. Esto, para transmisiones de audio y vídeo (así como transmisiones en tiempo real) no resulta conveniente por lo explicado anteriormente.
En definitiva, si se usa un servidor HTTP y se sirven los vídeos a través de dicho protocolo, para una aplicación donde los usuarios que accedan al sistema sean reducidos o el medio por el cual se transmite la información tenga un elevado ancho de banda, el resultado podría ser positivo. Ahora bien, si se busca una herramienta más profesional capaz de atender a múltiples usuarios sin que se tenga que producir errores que hagan que se retrase en exceso las transmisiones o incluso si se requiere de una transmisión de vídeo en tiempo real, la solución del servidor HTTP ya no resulta óptima y hay que buscar nuevas alternativas.
FÍSICO
ENLACE
IP
TCP
HTTP

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 44
4.3.2 Apple QuickTime Streaming Server
Es un servidor multimedia basado en estándares con una enorme facilidad de uso. Los estándares que cumplen son:
- RFC 2326, Real Time Streaming Protocol (RTSP)
- RFC 1889, Real Time Transport Protocol (RTP)
- RFC 2327, Session Description Protocol (SDP)
- 3GPP Release 5 (TS 26.234 v5.6)
Es un servidor restrictivo, comercial y propietario de Apple. Es decir, hay que pagar para hacerse con sus servicios. Permite el alojamiento de vídeos así como la disponibilidad de los mismos no solo a través de interfaces web sino también de cualquier otro mecanismo (por ejemplo, para dispositivos móviles).
Soporta los formatos QuickTime Movie (.mov), MPEG-4 (.mp4) y 3GPP (.3gp). A su vez, soporta los siguientes protocolos:
- RTSP sobre TCP
- RTP sobre UDP
- RTP sobre Apple Reliable UDP
- RTSP/RTP en HTTP (a través de túneles)
- RTP sobre RTSP
- Transmisión por HTTP (solo para audio MP3).
Las limitaciones del servidor en cuanto al número de visualizaciones simultaneas reside en si se trata de un streaming en directo o si se basa en un vídeo bajo demanda. Dentro de los mismos, se calcularán las peticiones simultáneas en función de la capacidad de transmisión:
- Streaming en directo. Audio AAC a 20Kbps (10.000 usuarios), vídeo MPEG-4 y audio AAC a 64Kbps (2.500 usuarios) y vídeo MPEG-4 y audio AAC a 300Kbps (1.500 usuarios).
- Streaming bajo demanda. Audio AAC a 20Kbps (8.000 usuarios), vídeo MPEG-4 y audio AAC a 64Kbps (2.000 usuarios) y vídeo MPEG-4 y audio AAC a 300Kbps (1.000 usuarios).
Un esquema general de la arquitectura del sistema de vídeostreaming con QuickTime Streaming Server se muestra en la siguiente ilustración:

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 45
Ilustración 28. Esquema general de QuickTime Streaming Server [23]
4.3.3 Darwin Streaming Server
Darwin Streaming Server (DSS) es el primer servidor de vídeostreaming basado en RTP/RTSP. Nació en Marzo de 1999 y es un servidor capacitado para la transmisión de vídeos codificados en H.264, MPEG-4 y 3GP.
Es un servidor desarrollado por Apple. La versión gratuita del servidor QuickTime Streaming Server. De hecho, está basado en el mismo código. La diferencia respecto al primero es que no ofrece las mismas prestaciones que ofrece el servicio de pago como por ejemplo las herramientas y extensiones adicionales que son exclusivas de la versión comercial.
Compañías como Akamai usan exclusivamente este servidor para la transmisión de vídeo por streaming en formato MPEG-4. Otro claro ejemplo es la versión móvil de YouTube que usa Darwin Streaming Server para la transmisión de vídeo en formato 3GP usando H.263/AMR para la visualización en dispositivos móviles.
Este servidor nos permite transmitir vídeos a diferentes tipos de clientes soportados por Internet, una red local, redes inalámbricas, etc, mediante el uso de los protocolos RTP y RTSP. Al ser de código abierto, es un servidor altamente configurable y adaptable a nuestras necesidades, ya que podemos modificar, manipular y adaptar el código fuente del servidor pudiendo implementar fácilmente cualquier funcionalidad que necesitemos.
Este servidor esta recomendado para su uso por desarrolladores que necesitan enviar flujos de vídeo codificados en formatos Quick Time y MPEG-4 en plataformas alternativas a Mac, como pueden ser Windows, Linux, Solaris, etc.
Está soportado solo por la comunidad de código abierto, y no tiene en ningún momento soporte técnico de Apple. Apple se encarga del hospedaje de la web, herramientas, código, listas de correo,... para poder ser utilizadas por los desarrolladores de forma que puedan compartir ideas y discutir varios escenarios de uso de este servidor.
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 46
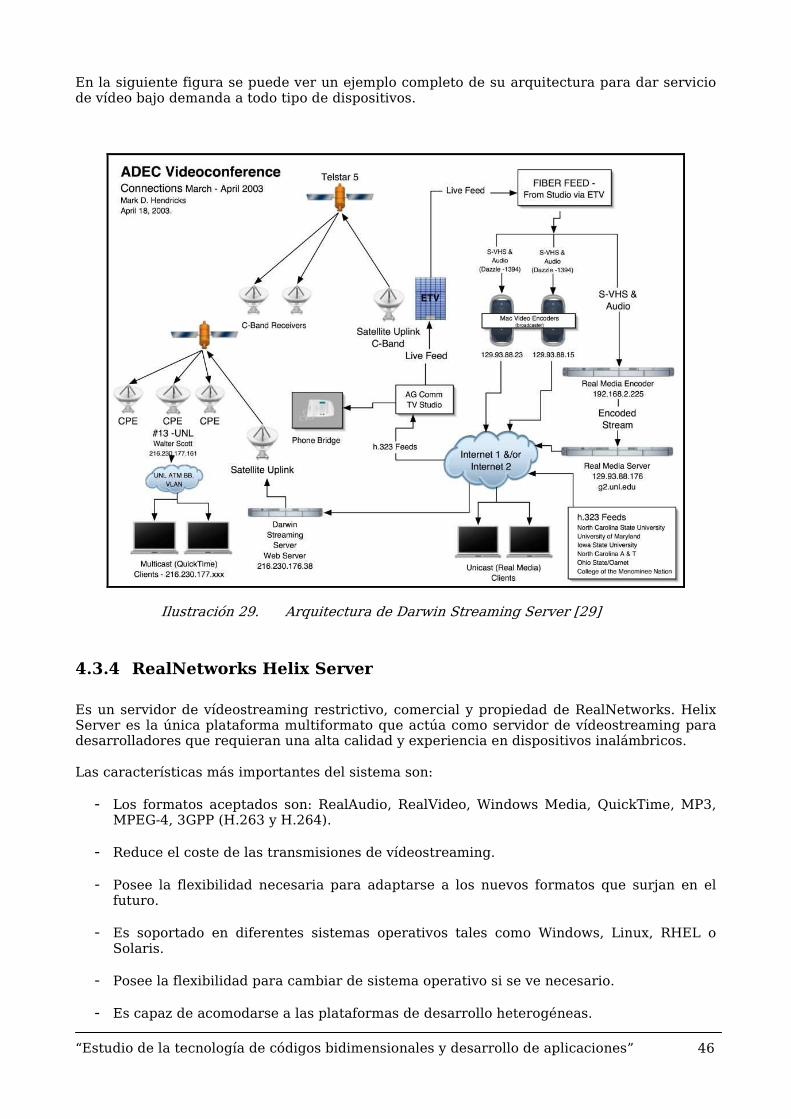
En la siguiente figura se puede ver un ejemplo completo de su arquitectura para dar servicio de vídeo bajo demanda a todo tipo de dispositivos.
Ilustración 29. Arquitectura de Darwin Streaming Server [29]
4.3.4 RealNetworks Helix Server
Es un servidor de vídeostreaming restrictivo, comercial y propiedad de RealNetworks. Helix Server es la única plataforma multiformato que actúa como servidor de vídeostreaming para desarrolladores que requieran una alta calidad y experiencia en dispositivos inalámbricos.
Las características más importantes del sistema son:
- Los formatos aceptados son: RealAudio, RealVideo, Windows Media, QuickTime, MP3, MPEG-4, 3GPP (H.263 y H.264).
- Reduce el coste de las transmisiones de vídeostreaming.
- Posee la flexibilidad necesaria para adaptarse a los nuevos formatos que surjan en el futuro.
- Es soportado en diferentes sistemas operativos tales como Windows, Linux, RHEL o Solaris.
- Posee la flexibilidad para cambiar de sistema operativo si se ve necesario.
- Es capaz de acomodarse a las plataformas de desarrollo heterogéneas.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 47
- Entrega la mayor calidad en vídeo y audio a los usuarios finales en cuanto a codecs e infraestructuras utilizadas.
- Los contenidos entregados inalámbricamente están basados en estándares de dispositivos inalámbricos.
4.3.5 Helix DNA Server
Es la versión gratuita del servicio anterior. Es un desarrollo capaz de soportar la transmisión por red en tiempo real de cualquier tipo de formato multimedia a cualquier tipo de dispositivo. Helix DNA Server puede servir para ser la base de los productos de una determinada empresa ofreciendo un rango ilimitado de posibilidades desde la posibilidad del vídeo bajo demanda hasta servicios orientados a móviles para la administración de suscripciones o ventas de determinadas aplicaciones.
Solo ofrecen el código disponible para las versiones más básicas del servicio. Aquellos servicios más complejos aun no están disponibles en código abierto.
En cuanto a la tecnología, Helix posee un amplio abanico de características y capacidades para hacer de la forma más simple, barata y realizables su uso.
Se pueden distinguir las siguientes características:
- Núcleo del servidor. Es robusto ante la transmisión de ficheros multimedia. Es capaz de generar estadísticas durante el tiempo en el que el servidor está funcionando. Acceso IP para el control del servidor.
- Formatos soportados. Audio MP3 (.mp3) y RealAudio y RealVideo (.rm, .ra y .rv)
- Protocolos. Hace uso de los protocolos RTSP/RTP especializados en transmisión por streaming. Es capaz de transmitir RTSP a través de HTTP. Los datos pueden ser transmitidos vía TCP, UDP y transportados de forma unicast y multicast a través del protocolo UDP. Los formatos RealAudio y RealVideo se transportan usando RTSP/RDT vía TCP, UDP unicast y UDP multicast.
- Sistema de ficheros soportado. Soporta un sistema de ficheros locales.
- Soporte para la transmisión. SDP para RTP vía UDP unicast y UDP multicast. Transmisión en directo para RealAudio y RealVideo desde Helix Producer 9.0.
- Sistema de autenticación. A través de HTTP o conexiones NT a través de redes LAN. Soporta la autenticación por grabación para “RealOne Player” y clientes “Helix DNA” usando un sistema de usuario/contraseña.
- Administración y monitorización. Configurable localmente usando ficheros de configuración XML. Soporta configuración remota a través de un sistema de administración web. Además, posee un cliente Java para conexiones y envíos de ficheros al servidor.
- Autenticación. Creación de logs personalizada que pueden ser directamente a través de un fichero local, un socket TCP de salida o una variable POST a través de HTTP.
A continuación se muestra un esquema general de la arquitectura:

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 48
Ilustración 30. Esquema general de Helix DNA Server [23]
4.3.6 Microsoft Windows Media Server
Es un servidor de vídeo bajo demanda restrictivo, comercial y propietario de Microsoft. Es una plataforma dedicada a la transmisión de contenido multimedia (audio y vídeo) en directo o bajo la petición del cliente a través de Internet (o Intranet).
Los clientes del servicio pueden ser equipos o dispositivos capaces de reproducir contenido multimedia con un reproductor, equipos que ejecuta el servidor en modo de proxy, caché o redistribución del contenido y aplicaciones personalizadas que se han desarrollado con el Kit de desarrollo de software (SDK) de Windows Media.
Las características más importantes de este servicio se presentan a continuación:
- Inicio rápido avanzado. Ofrece la posibilidad de reproducción instantánea al eliminar el tiempo de almacenamiento en el buffer.
- Reproducción durante archivado. El contenido archivado puede estar disponible para las solicitudes a petición o una redifusión incluso antes de que se termine de archivar la difusión.
- Avance rápido y posibilidad de rebobinado. Esta característica tiene como peculiaridad que fija el ancho de banda consumido de cada cliente pudiendo por tanto evitar imprevistos cuellos de botellas en determinados momentos de la transmisión.
- Inicio automático de difusión. Existe la posibilidad que, ante un reinicio del servidor multimedia, se pueda reiniciar de forma automática la difusión de ficheros sin necesidad de realizarse a mano por el administrador.
- Tiempo absoluto de la lista de reproducción. Se controla el tiempo de difusión emitido por el servidor a los usuarios.
- Modificadores de dirección URL de conmutación por error del codificador. Posibilidad de realizar uso de un codificador auxiliar cuando el codificador actual tiene algún tipo de problema.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 49
- Compatibilidad adicional con la plataforma del sistema de Windows Server (x64). Los Servicios de Windows Media están disponibles como un componente en las versiones basadas en x64 del sistema operativo Microsoft Windows Server 2003.
A continuación se muestra el esquema general de funcionamiento del servidor.
Ilustración 31. Esquema general de Windows Media Server [23]
4.3.7 VideoLan Server
VideoLan Server es una solución bastante completa para la transmisión de vídeo bajo demanda. Ha sido desarrollado por estudiantes de la “Ecole Centrale Paris” y desarrolladores de todo el mundo bajo licencia GPL (GNU General Public License).
VideoLan se puede dividir en dos grandes aplicaciones:
- VLS (VideoLan Server) el cual puede dar streaming en formato MPEG-1, MPEG-2 y MPEG-4, Vds., canales digitales de satélites, terrestres, televisión y canales de vídeo. Actualmente se encuentra en desuso ya que el VLC es capaz de cumplir con las funciones que anteriormente solo correspondían a VLS.
- VLC (VideoLan Client). Además de ser un reproductor de vídeo, es capaz de ser usado como servidor de streaming en formatos MPEG-1, MPEG-2 y MPEG-4 así como en formato DVD y vídeos en directo a través de la red de forma unicast o multicast.
VLC (streaming) es capaz de trabajar con los siguientes formatos:
- MPEG-1, MPEG-2 y MPEG-4 / Ficheros DivX
- Formatos provenientes de codificación MPEG.
- Formato DV

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 50
Es capaz de transmitir ese tipo de contenido multimedia a una única máquina (denominado unicast) o a un grupo dinámico de máquinas (llamado multicast) a modo de difusión de contenido.
A continuación se muestra una estructura básica de un servidor de vídeostreaming usando VLC como servidor.
Ilustración 32. Esquema general de VideoLan Server [30]
4.3.8 Otros
A modo informativo, se presenta un catálogo de servidores con menos importancia que los comentados anteriormente pero que sería conveniente hacer hincapié en el caso de que fuese necesario recurrir a ellos en algún momento.
- Icecast Server. Proyecto de código abierto de la fundación Xiph.org. Se basa principalmente en un servidor de audio aunque proporciona vídeo en las últimas versiones. Usa HTTP y soporta Vorbis, MP3, AAC, NVS y Theora.
- Kasenna. Se trata de una empresa que ha desarrollado una plataforma de vídeo bajo demanda a medida. Se basa en estándares, arquitectura flexibles, soporta formatos MPEG, H.264, etc.
- Concurrent. Empresa que dispone de una plataforma de VoD en tiempo real para Linux.
- BitBand. Plataforma propia para servir audio y vídeo.
- C-COR. Dispone de su propia plataforma de soluciones de VoD. Ofrece inserción de publicidad en tiempo real.
- Entone. Ídem que los anteriores solo que éste se centra en televisión bajo demanda y redes multimedia domésticas.
- SeaChange. Ídem que el anterior solo que es capaz de ofrecer la distribución de publicidad en medida a la zona y perfil del usuario.
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 51
- Más servidores: Flumotion, OpenTV, XL2 Media Server, VoDKA, Flash Media Server, Red5 Open Source Flash Server.
4.4 Comparativa y conclusiones
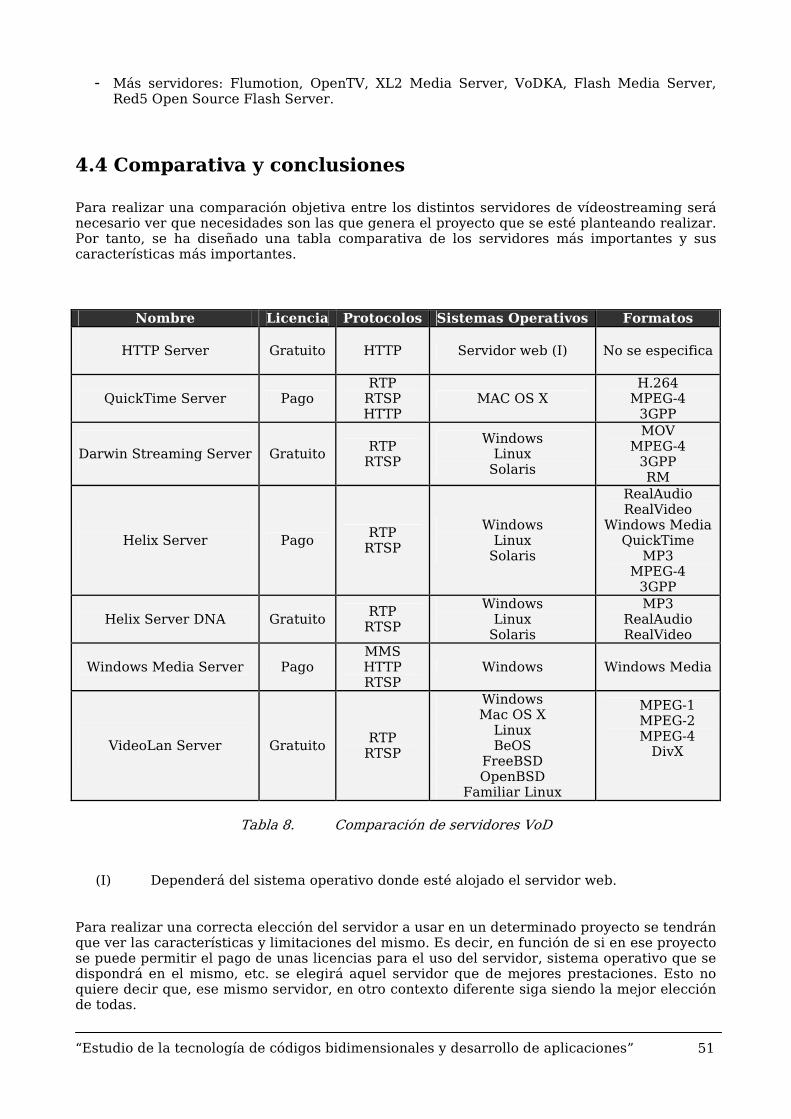
Para realizar una comparación objetiva entre los distintos servidores de vídeostreaming será necesario ver que necesidades son las que genera el proyecto que se esté planteando realizar. Por tanto, se ha diseñado una tabla comparativa de los servidores más importantes y sus características más importantes.
Nombre Licencia Protocolos Sistemas Operativos Formatos
HTTP Server
Gratuito HTTP Servidor web (I) No se especifica
QuickTime Server
Pago
RTP RTSP HTTP
MAC OS X H.264
MPEG-4 3GPP
Darwin Streaming Server
Gratuito RTP
RTSP
Windows Linux
Solaris
MOV MPEG-4
3GPP RM
Helix Server
Pago
RTP RTSP
Windows Linux
Solaris
RealAudio RealVideo
Windows Media QuickTime
MP3 MPEG-4
3GPP
Helix Server DNA
Gratuito RTP
RTSP
Windows Linux
Solaris
MP3 RealAudio RealVideo
Windows Media Server
Pago
MMS HTTP RTSP
Windows Windows Media
VideoLan Server
Gratuito
RTP RTSP
Windows Mac OS X
Linux BeOS
FreeBSD OpenBSD
Familiar Linux
MPEG-1 MPEG-2 MPEG-4
DivX
Tabla 8. Comparación de servidores VoD
(I) Dependerá del sistema operativo donde esté alojado el servidor web.
Para realizar una correcta elección del servidor a usar en un determinado proyecto se tendrán que ver las características y limitaciones del mismo. Es decir, en función de si en ese proyecto se puede permitir el pago de unas licencias para el uso del servidor, sistema operativo que se dispondrá en el mismo, etc. se elegirá aquel servidor que de mejores prestaciones. Esto no quiere decir que, ese mismo servidor, en otro contexto diferente siga siendo la mejor elección de todas.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 52
5. Bases de datos
5.1 Introducción
Una base de datos es un conjunto de información perteneciente a un mismo contexto y almacenados sistemáticamente para su posterior uso. Se puede considerar como un conjunto de datos exhaustivos, no redundantes y estructurados, accesibles en tiempo real y compartido por un número amplio de usuarios.
Las ventajas más apreciables en el uso de la base de datos son:
- Control sobre redundancia de datos. Se dispone de redundancia en los datos pero sin llegar a duplicar por completo la base de datos como ocurre con la redundancia en los sistemas de ficheros.
- Consistencia de datos. Con una sola copia de cada dato, el sistema debe ser capaz de realizar las modificaciones una única vez y estar disponible para todos los usuarios en ese mismo instante. En el caso de estar duplicado el dato y el sistema reconoce esa redundancia, la modificación se debe realizar tantas veces como proceda.
- Compartición de datos. Los datos son compartidos por todos los usuarios que tengan acceso a la base de datos.
- Mantenimiento de estándares. Se cumplen los estándares tanto a nivel de empresa como nacionales o internacionales. Estos estándares pueden establecerse sobre el formato de los datos, documentación, procedimientos de actualización y reglas de acceso.
- Integridad de los datos. Se consigue la validez y consistencia de los datos almacenados. Esta integridad se expresa en forma de relaciones que no se pueden violar.
- Seguridad. Las bases de datos poseen mecanismos encargados de dar seguridad al sistema permitiendo el acceso solo a usuarios autorizados.
- Accesibilidad de los datos. Posibilidad de interfaces sencillas para que cualquier usuario pueda hacer cualquier tipo de consulta sin necesidad de ser experto en la materia.
- Productividad. El programador no tiene que encargarse de las funciones de bajo nivel ya que los sistemas de gestión de bases de datos se encargan de desarrollar las mismas.
- Mantenimiento. Se simplifica las funciones de mantenimiento gracias a la separación de las descripciones de datos de las aplicaciones.
- Concurrencia. Ante accesos simultáneos de varios usuarios a una misma información accesible en la base de datos, el acceso se realiza sin romper la integridad de los datos.
- Copias de seguridad. Los sistemas de gestión de bases de datos (SGBD) hacen que el número de veces que se tienen que hacer copias de seguridad sea mínimo con la menor pérdida de información posible.
Las desventajas más apreciables son:
- Complejidad. Para la gestión de las bases de datos se requiere un mínimo de conocimientos que permita una gestión óptima.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 53
- Coste de equipamiento adicional. A veces, para adquirir las prestaciones que se buscan, es necesario invertir recursos en la obtención de nuevas máquinas y mejores lugares de almacenamiento.
- Vulnerabilidad de fallos. Al ser un sistema centralizado, la posibilidad de que se produzca un fallo se ve incrementada por lo que se requiere el uso de copias de seguridad.
5.2 Base de datos MySQL
MySQL es un sistema de gestión de bases de datos (SGBD). Es decir, para añadir, acceder o procesar los datos almacenados es necesario un sistema de gestión que lo realice. Y es ahí donde nace MySQL con el objetivo de actuar como SGBD.
Se trata de un SGBD relacional. Una base de datos relacional consiste en una serie de datos almacenados en diferentes tablas relacionadas entre sí.
La parte SQL de "MySQL" se refiere a "Structured Query Language". SQL es el lenguaje estandarizado más común para acceder a bases de datos y está definido por el estándar ANSI/ISO SQL. El estándar SQL ha evolucionado desde 1986 y existen varias versiones: SQL-92, SQL:1999 y SQL:2003.
MySQL posee licencia GPL y es Open Source. Es decir, que es posible modificar su codificación. Se puede, además, ser usado simplemente descargándolo desde Internet sin necesidad de pagar un precio adicional por su uso.
El servidor de base de datos MySQL es muy rápido, fiable y fácil de usar. El software de bases de datos MySQL es un sistema cliente/servidor que consiste en un servidor SQL multihilos que trabaja con diferentes bakends, programas y bibliotecas cliente, herramientas administrativas y un amplio abanico de interfaces de programación para aplicaciones (APIs).
Tiene un amplio soporte para una enorme gama de sistemas operativos. Entre ellos encontramos: AIX, Amiga, BSDI, Digital Unix, FreeBSD, HP-UX, Linux, Mac OS X, NetBSD, Novell NetWare, OpenBSD, OS/2 Warp 3, FixPack 29 y OS/2 Warp 4, FixPack 4, SCO OpenServer, SCO UnixWare, SGI Irix, Solaris, SunOS, Tru64 Unix y Windows.
6. Tecnologías web
Una de las posibles alternativas para el desarrollo de determinadas aplicaciones se basa en la programación web. Existe una multitud de lenguajes de programación a través de los cuales se ofrecen desarrollos web.
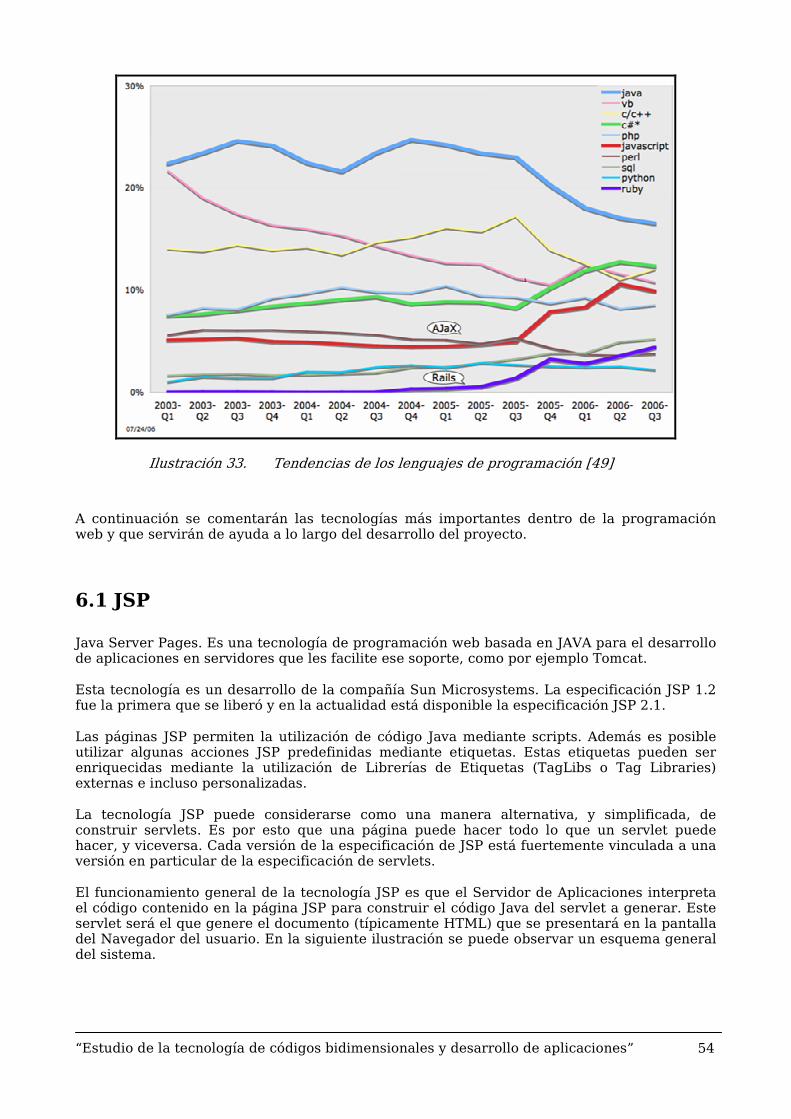
En la siguiente ilustración se puede observar que, durante los últimos años, JAVA ha sido el lenguaje de programación por excelencia por encima de lenguajes como Visual Basic, C o PHP. A su vez, se puede apreciar el incremento del uso de JavaScript para el desarrollo web que en los últimos años se ha colocado por encima de tecnologías como Perl, SQL o Python.
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 54
Ilustración 33. Tendencias de los lenguajes de programación [49]
A continuación se comentarán las tecnologías más importantes dentro de la programación web y que servirán de ayuda a lo largo del desarrollo del proyecto.
6.1 JSP
Java Server Pages. Es una tecnología de programación web basada en JAVA para el desarrollo de aplicaciones en servidores que les facilite ese soporte, como por ejemplo Tomcat.
Esta tecnología es un desarrollo de la compañía Sun Microsystems. La especificación JSP 1.2 fue la primera que se liberó y en la actualidad está disponible la especificación JSP 2.1.
Las páginas JSP permiten la utilización de código Java mediante scripts. Además es posible utilizar algunas acciones JSP predefinidas mediante etiquetas. Estas etiquetas pueden ser enriquecidas mediante la utilización de Librerías de Etiquetas (TagLibs o Tag Libraries) externas e incluso personalizadas.
La tecnología JSP puede considerarse como una manera alternativa, y simplificada, de construir servlets. Es por esto que una página puede hacer todo lo que un servlet puede hacer, y viceversa. Cada versión de la especificación de JSP está fuertemente vinculada a una versión en particular de la especificación de servlets.
El funcionamiento general de la tecnología JSP es que el Servidor de Aplicaciones interpreta el código contenido en la página JSP para construir el código Java del servlet a generar. Este servlet será el que genere el documento (típicamente HTML) que se presentará en la pantalla del Navegador del usuario. En la siguiente ilustración se puede observar un esquema general del sistema.

“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 55
Ilustración 34. Funcionamiento de JSP [50]
En JSP se crean páginas de manera parecida a como se crean en ASP o PHP (otras dos tecnologías de servidor). Se generan archivos con extensión “.jsp” que incluyen, dentro de la estructura de etiquetas HTML, las sentencias Java a ejecutar en el servidor. Antes de que sean funcionales los archivos, el motor JSP lleva a cabo una fase de traducción de esa página en un servlet, implementado en un archivo class (Byte codes de Java). Esta fase de traducción se lleva a cabo habitualmente cuando se recibe la primera solicitud de la página .jsp, aunque existe la opción de precompilar en código para evitar ese tiempo de espera la primera vez que un cliente solicita la página.
6.2 JavaScript
JavaScript se considera un lenguaje interpretado. Es decir, no requiere que se compile para su ejecución sino que se basa en pequeños scripts que son interpretados por el navegador. Con esto, lo que se quiere decir es que tiene que ser el navegador quien sea capaz de interpretar dichos códigos actuando en consecuencia. Por tanto, es un lenguaje interpretado en el cliente, no en el servidor.
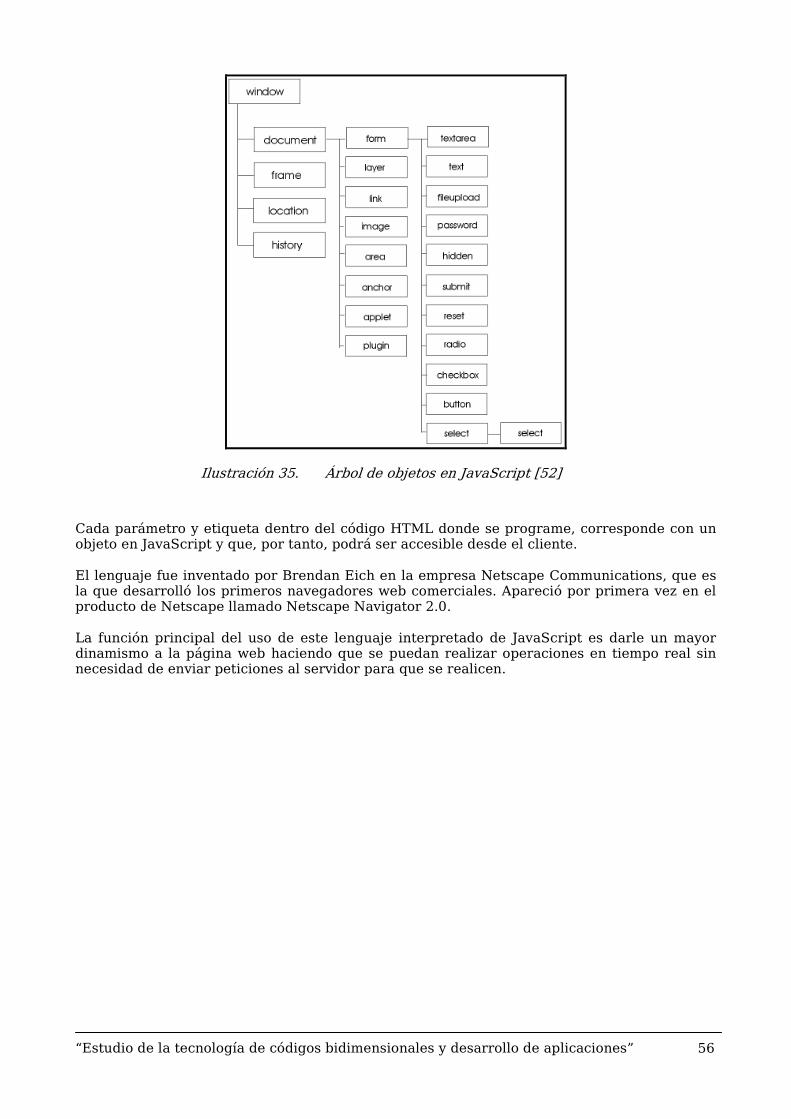
JavaScript, al igual que Java, es un lenguaje de programación orientado a objetos. En la siguiente ilustración se puede ver el árbol de objetos que pose el navegador y la división de cada uno de los mismos.
Plantilla
JSP
HTML
(1) El cliente realiza la petición
(4) El servidor le devuelve la página
HTML
(2) El servidor
recoge datos
(3) Con los datos
recibidos, forma la página HTML
“Estudio de la tecnología de códigos bidimensionales y desarrollo de aplicaciones” 56
Ilustración 35. Árbol de objetos en JavaScript [52]
Cada parámetro y etiqueta dentro del código HTML donde se programe, corresponde con un objeto en JavaScript y que, por tanto, podrá ser accesible desde el cliente.
El lenguaje fue inventado por Brendan Eich en la empresa Netscape Communications, que es la que desarrolló los primeros navegadores web comerciales. Apareció por primera vez en el producto de Netscape llamado Netscape Navigator 2.0.
La función principal del uso de este lenguaje interpretado de JavaScript es darle un mayor dinamismo a la página web haciendo que se puedan realizar operaciones en tiempo real sin necesidad de enviar peticiones al servidor para que se realicen.