

Big Data n Analytics
50
BIG DATA + Somil Asthana Presented to HP (CyberHub, Gurgaon)
-
Upload
somil-asthana -
Category
Documents
-
view
150 -
download
0
Transcript of Big Data n Analytics

BIG DATA + Somil Asthana
Presented to HP (CyberHub, Gurgaon)

WHAT IS BIG DATA ?
According to Wiki “Big Data is a term for data
sets that are so large or complex that traditional
processing applications are inadequate “
To big to fit on a single machine RAM
Painfully show to process on a single machine
How Large is Big Data
GB (Any application )
TB ( call logs, user click information )
PB ( facebook , linked-in)
But that’s

PUT IT ANOTHER WAY
Courtesy: Dilbert

WHAT IS (REALLY) BIG DATA ?
Big Data is mostly about Human Behaviour
What do people do ?
Where do they go ?
What do they buy ?
As a consequence, these observations are
recorded.
To predict what people will do ?

BIG DATA TYPES
What constitutes Big Data
Structured Data
Semi-Structured Data
Unstructured Data
Contradictory to popular belief
Big Data is NOT Hadoop or its variant
Big Data is NOT Cloud Computing
Big Data is NOT Analytics
VISUALIZE BIG DATA
There are two ways to look at it
...
.....
...
Field
1
Field
2
Field
3
Field
4
Field
X
Field
Y
Field
Z
Field
A

BIG DATA CHALLENGES
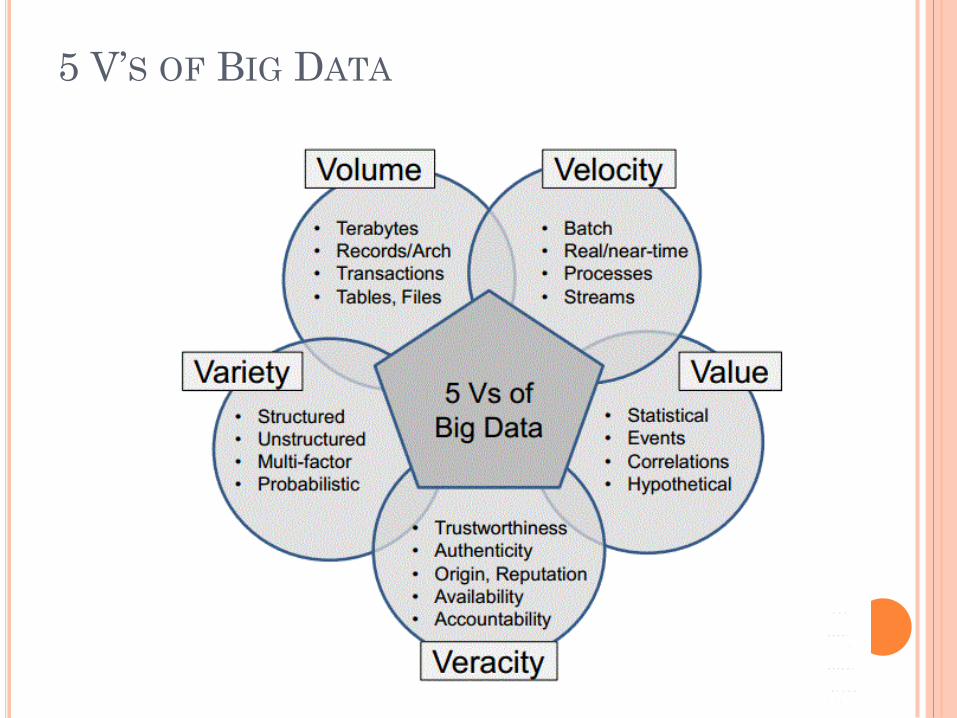
5 V’S OF BIG DATA
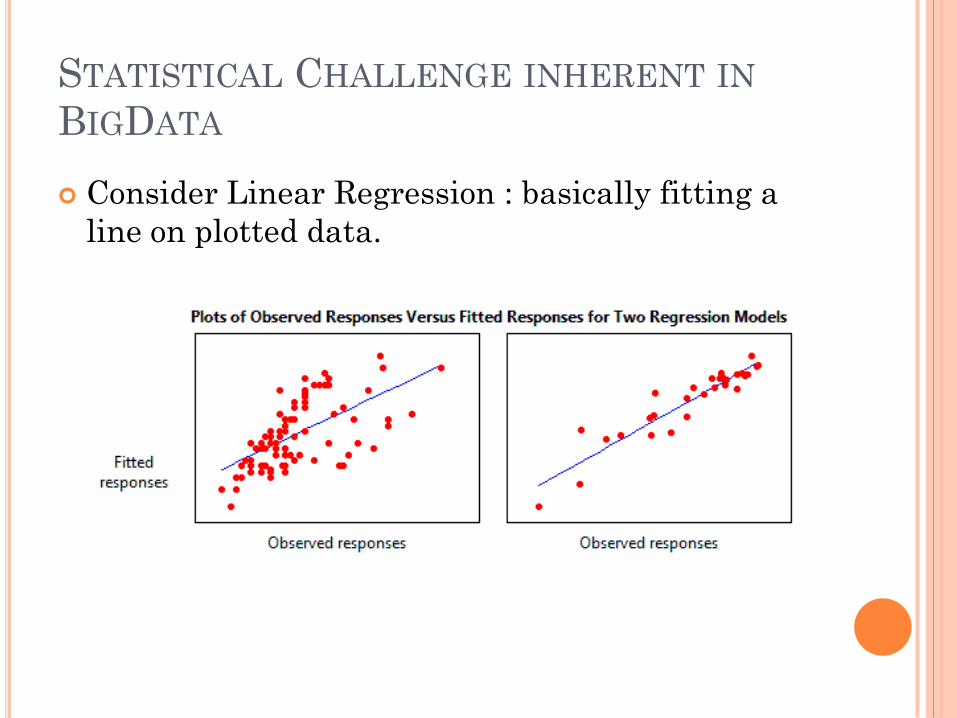
STATISTICAL CHALLENGE INHERENT IN
BIGDATA
Consider Linear Regression : basically fitting a
line on plotted data.

STATISTICAL CHALLENGE INHERENT IN
BIGDATA
Essentially what we are doing in Linear Regression
mathematically is minimizing R2
• Trying to find that Best
Fits and help predict
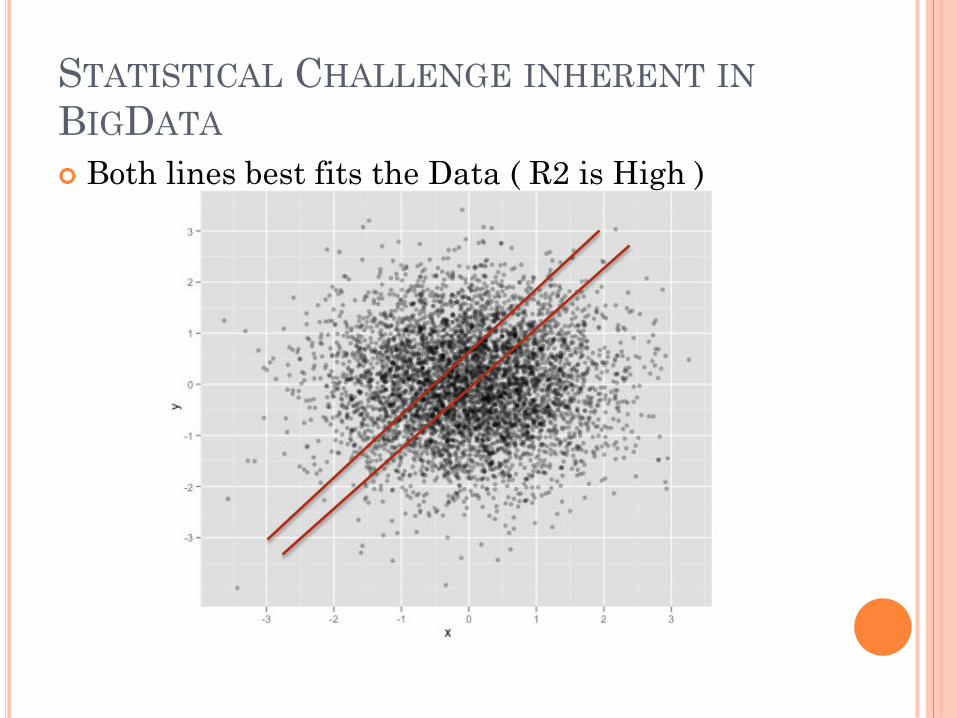
STATISTICAL CHALLENGE INHERENT IN
BIGDATA
Both lines best fits the Data ( R2 is High )

ESSENTIAL AND HIDDEN IN BIG DATA
What ? TRUTH
Consider rating data ( incorrect, biased )
Machine dysfunction ( incorrect, biased )
Human Error ( incorrect, biased )
Statistical Issue ( Model Over-fitting )
Validation & Verification
More efforts

CHALLENGES WITH BIG DATA IN
PRODUCTION SYSTEMS
Expect Out of Memory Error
Expect Network Failures
Expect Disk Failures
Expect I/O Performance Bottlenecks
Lack of Programming Skills
Statistical Model Fail

BIG DATA INDUSTRIAL INSIGHT

INDUSTRIAL DISSECTION OF BIG DATA
ANALYTICS MARKET
There are 3 different sub markets of Big Data
Infrastructure
Software
Services
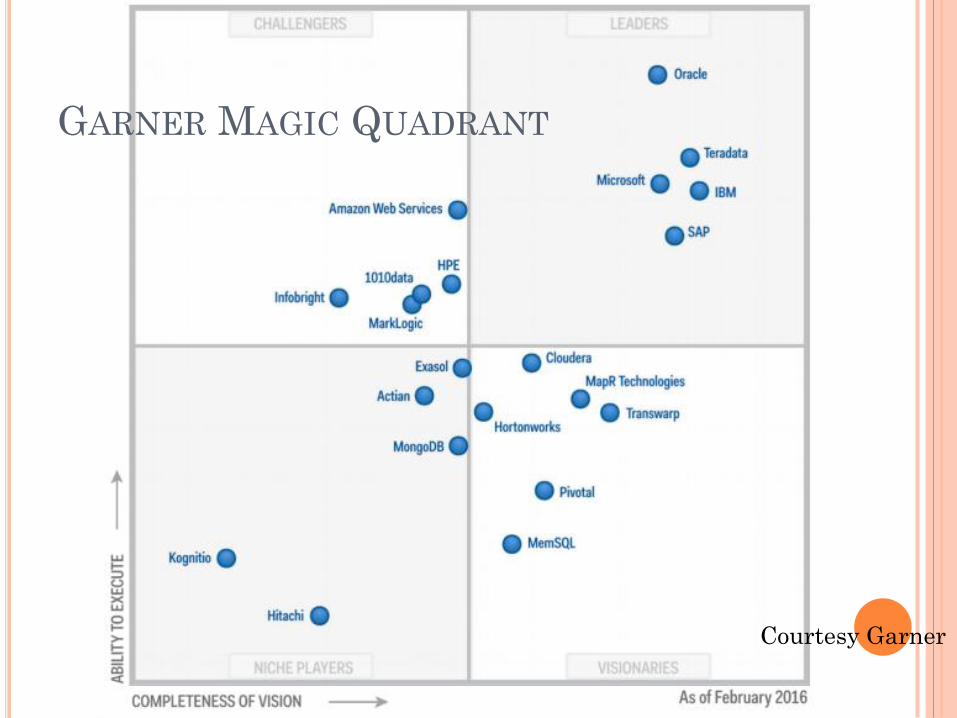
GARNER MAGIC QUADRANT
Courtesy Garner

BIG DATA INFRASTRUCTURE
Examples
Amazon AWS
Microsoft Azure
IBM SoftLayer
Rackspace Open Cloud
Google Compute Engine

BIG DATA INFRASTRUCTURE ( IAAS )
consist of
computing, storage, networking and data centre infrastructure and maintenance
IAAS Feature
On-Demand Use of Resource ( hence scalable )
Automation of Admin Tasks ( security to machine maintenance )
Facilitate platform ( which can be programmed )
Management Tools ( Backup, High Availability )
Load balancing
Machine Scaling ( Auto Scaling )
BI System
Data Warehouse
Work flow System
Machine Learning Tools & Software

BIG DATA INFRASTRUCTURE: WHY DO WE
CARE
Study Done ( courtesy IBM )
375 MB Data consumed per House Hold
20 Hours of You Tube Video uploaded per 60 sec
24 PB processed by Google
50 Million tweets per Day
700 Million minutes Spend on Face Book per Month
1.3 ExaBytes received or sent by Mobile Internet
User
72.9 Products ordered on Amazon per second.

BIG DATA SOFTWARE / PLATFORM
Distinguished by
Commercial Software (SAS, SAP, HANA, Tableau,
TeraData, SPSS, Talend)
Open Source Software ( Hadoop, Apache Spark,
Elastic Search )
Enterprise wrapping around or Extension of Open
Source Software (Cloudera Hadoop, Map R,
HortonWorks)

BIG DATA MARKET FRAGMENTED
Segments that provide Data Marts capabilities:
Data Sift & GNIP ( store tons of tweets )
Zomato & Indian Mart ( Directory Listing )
FreeBase ( acquired by Google, Knowledge Store)
Open Data initiatives
Infrastructure Extensions
MongoDB, Neo4j, DynamoDB, MarkLogic

BIG DATA STORAGE STRATEGY

SQL VS NO SQL
SQL supports ACID property ie Atomic
Consistent Isolated Durable ( require locks &
syncronization )
No SQL supports BASE ie Basic Availability,
Soft-state, Eventual consistency.

BIG DATA NOSQL DATABASE

REDIS NOSQL
Key Space of the hashmap spread across numerous
machines
To load balance.
Introduce Redundancy.
Supports storage in form of
Strings
Hashes
Lists
Sets
Sorted sets
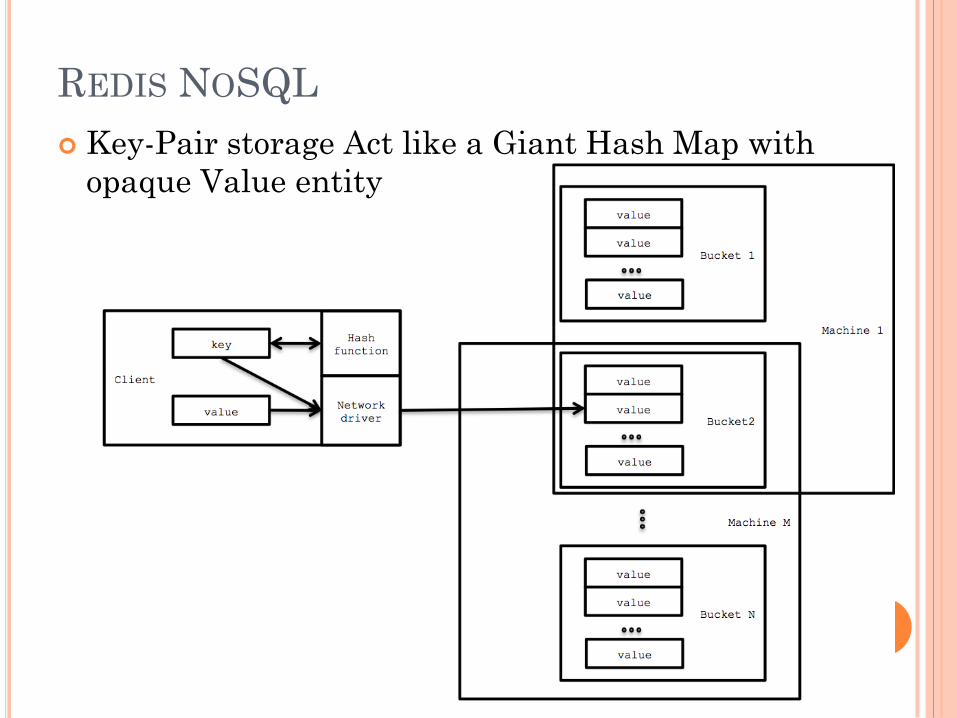
REDIS NOSQL
Key-Pair storage Act like a Giant Hash Map with
opaque Value entity

COLUMN NOSQL
4 Building Blocks
All data stored in the same column is of the same
type.
Row key used to dynamically partition the data
Load balancing
Locality of reference
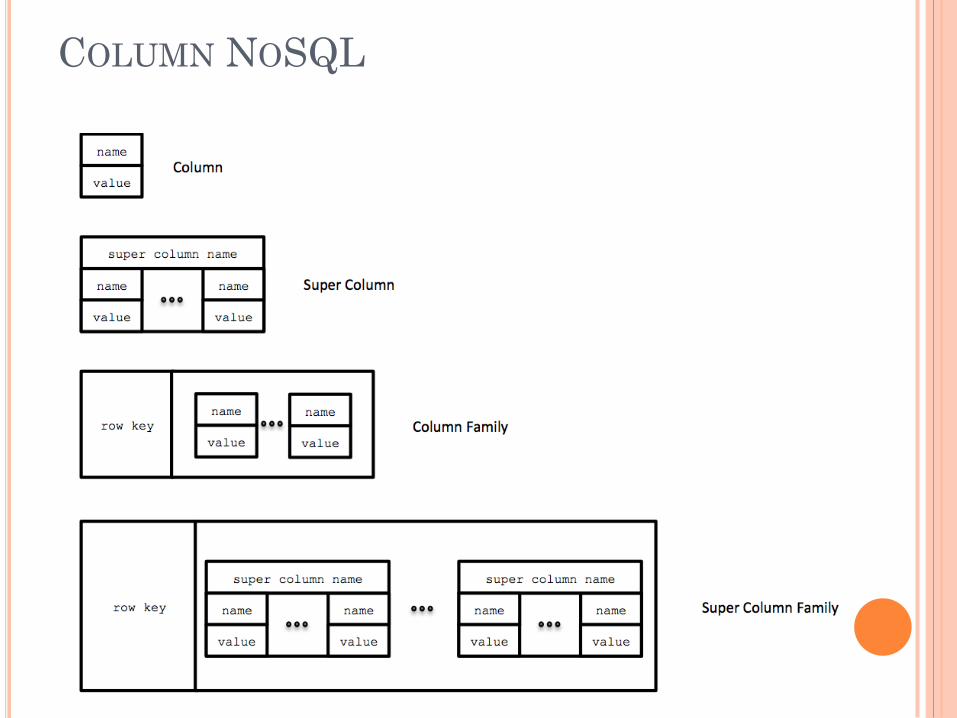
COLUMN NOSQL
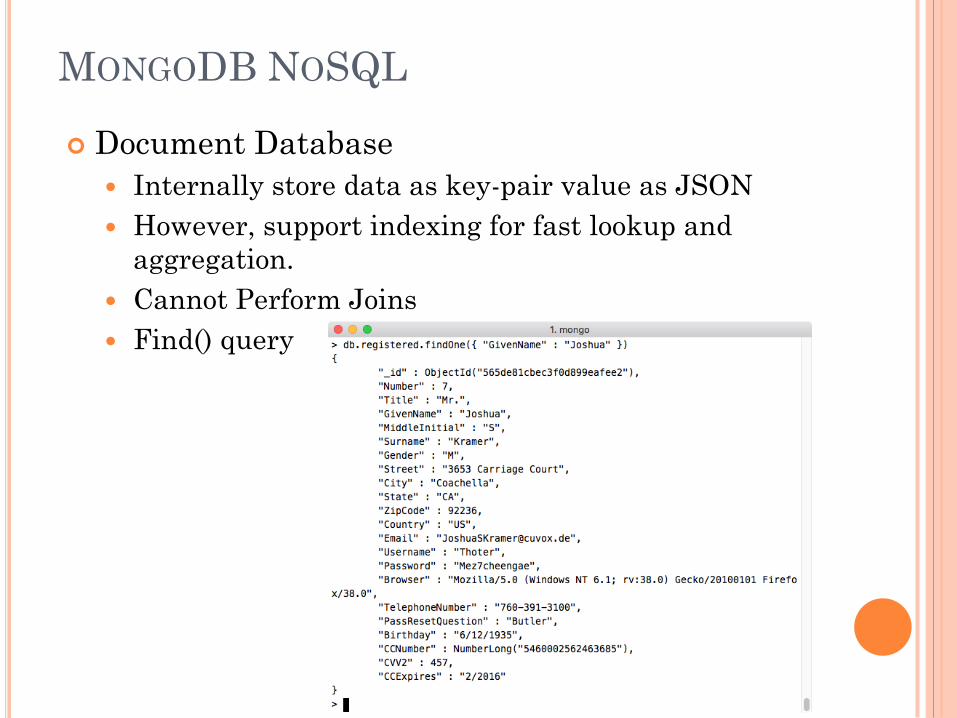
MONGODB NOSQL
Document Database
Internally store data as key-pair value as JSON
However, support indexing for fast lookup and
aggregation.
Cannot Perform Joins
Find() query
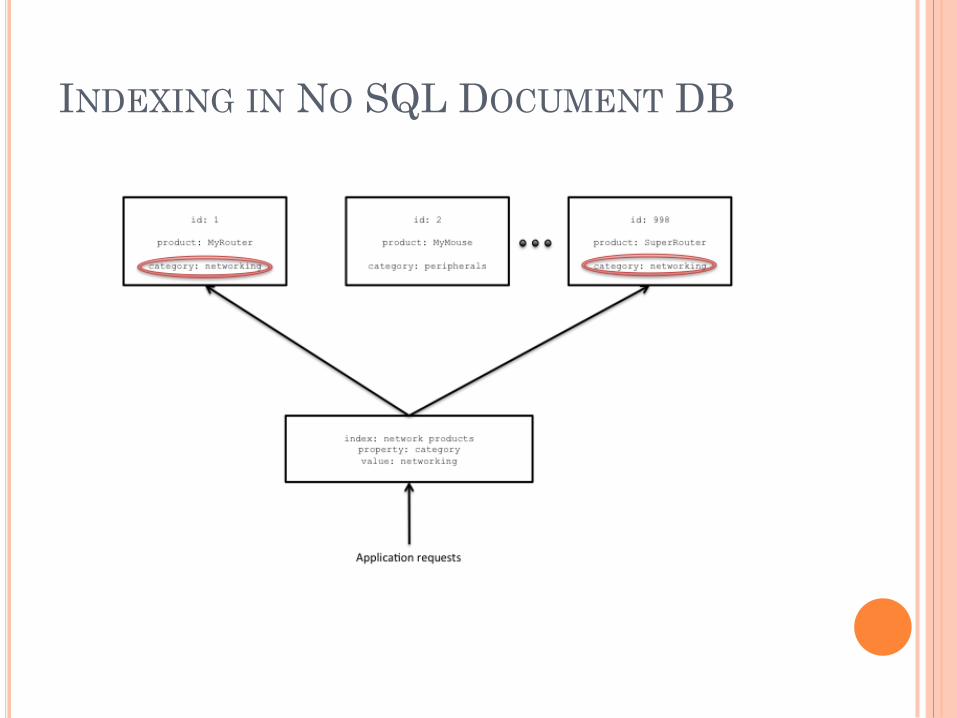
INDEXING IN NO SQL DOCUMENT DB
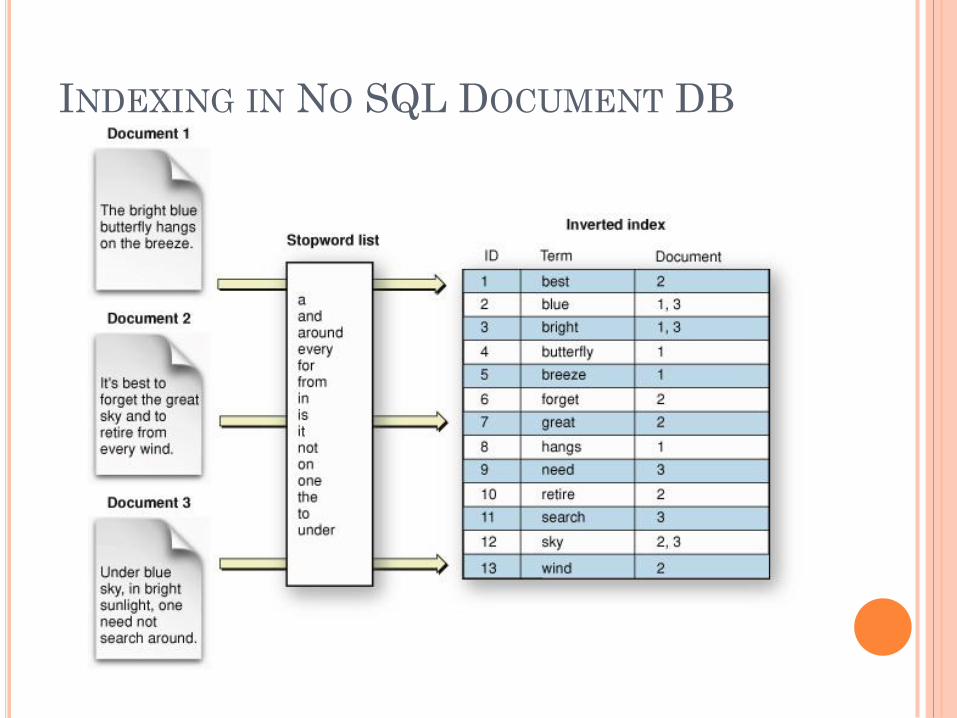
INDEXING IN NO SQL DOCUMENT DB

NEO4J NOSQL
Unique : stores, process and query connections
Network Graph
Nodes
Relationship
Properties
Exploit Structural Properties of Network Graph
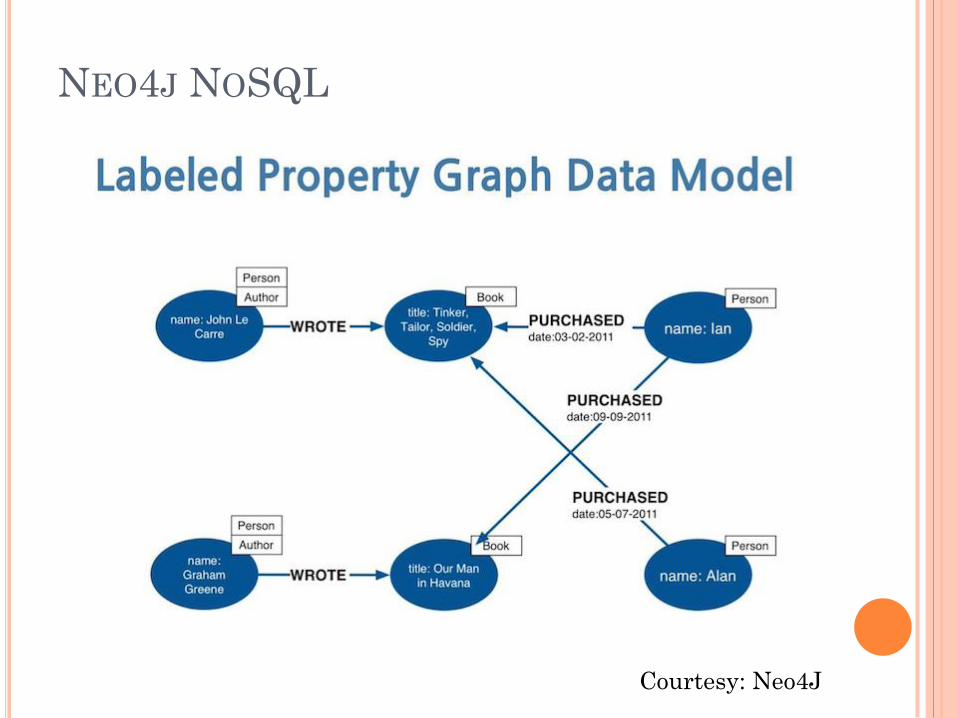
NEO4J NOSQL
Courtesy: Neo4J

NEO4J SYNTAX

MANIPULATING BIG DATA
Traditional Approach Fails
SELECT COUNT(column_name) FROM table_name;
SELECT cli_detail FROM table_name where
cli_number = X
Approach Possible
Index Data fields
Use Probabilistic Data Structure

BIG DATA PROCESSING MODEL
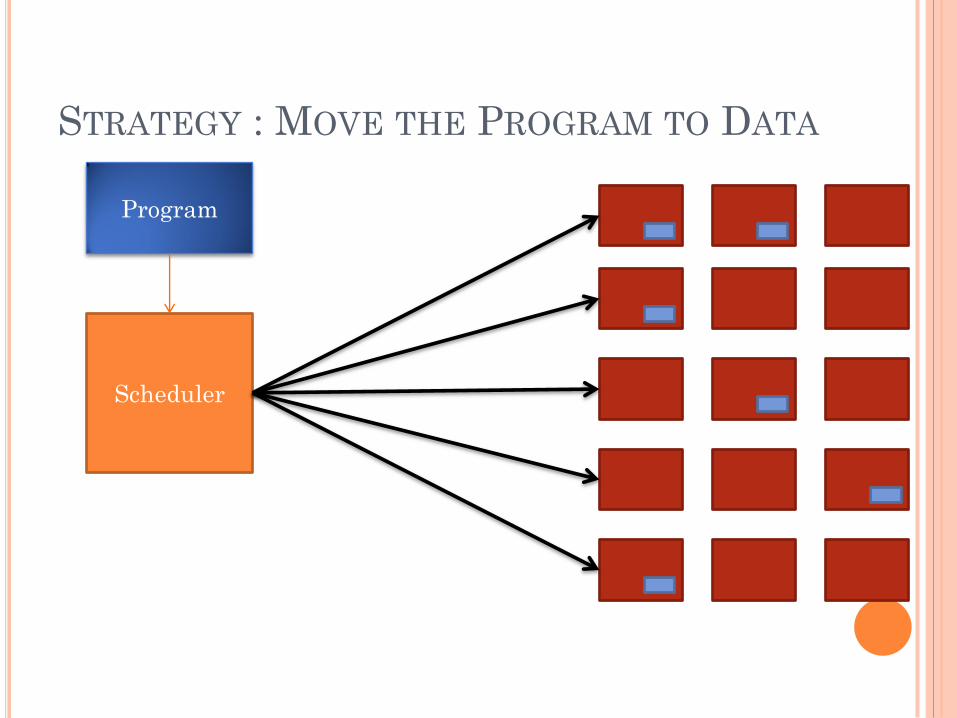
STRATEGY : MOVE THE PROGRAM TO DATA
Scheduler
Program
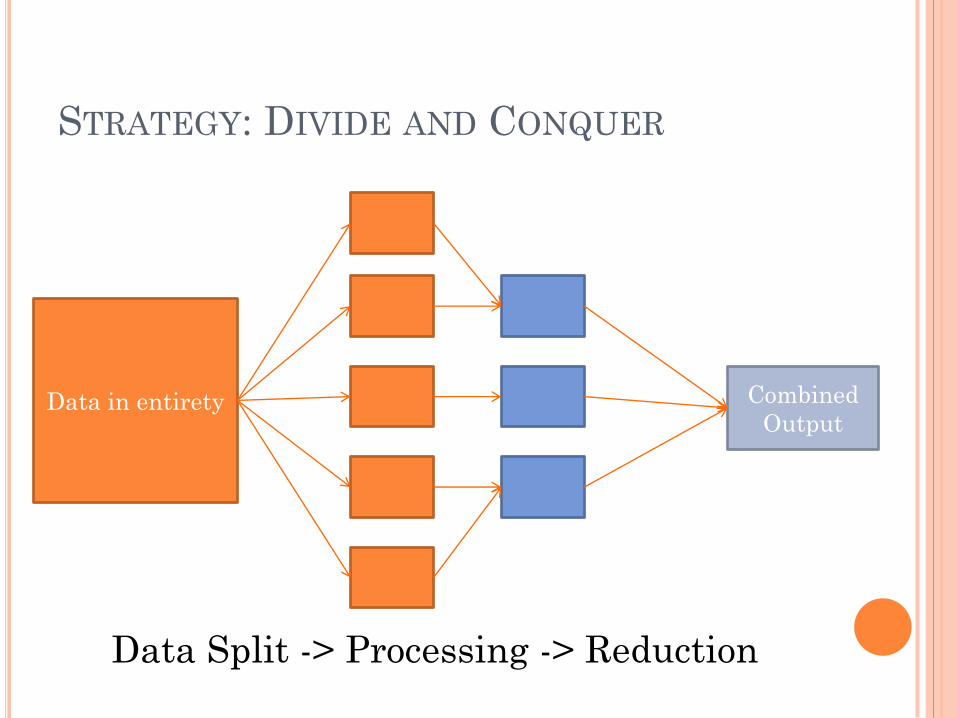
STRATEGY: DIVIDE AND CONQUER
Data in entirety
Data Split -> Processing -> Reduction
Combined
Output

BIG DATA USED AS ETL SYSTEM
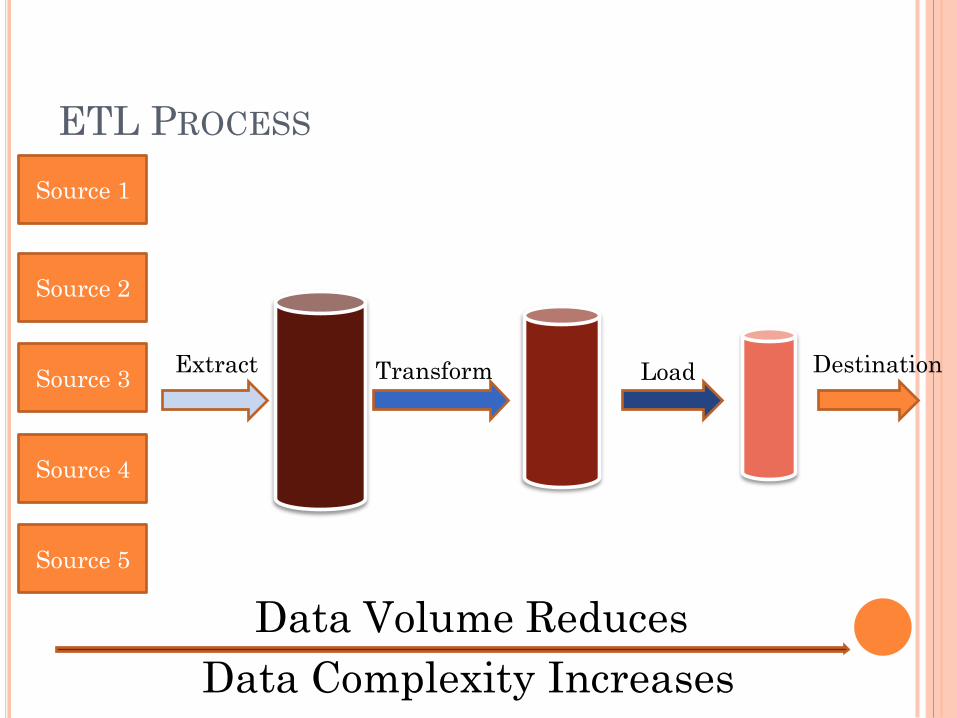
ETL PROCESS
Source 1
Source 2
Source 3
Source 4
Source 5
Data Volume Reduces
Data Complexity Increases
Extract Transform Load Destination

ETL DETAILS
Extraction
Annotation / Enriching
DeDuping
Cleaning
Transformation
Processing
Aggregating
Loading
Storing in easy consumable form / further processing.

BIG DATA ARCHITECTURE

TWO TYPES BIG DATA APPLICATIONS Batch Processing
Can handle Large Volume of Data
Can be used to implement iterative algorithms
Can reschedule failed job
Real-time Processing
The Data needs to be processed in buckets
Need to process the data at once
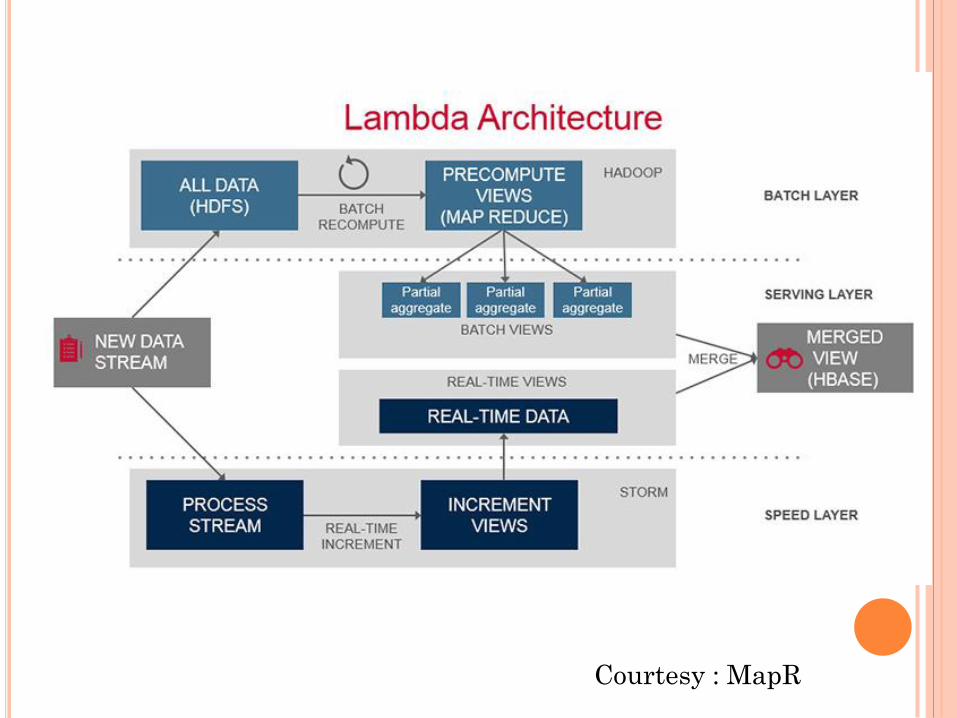
Courtesy : MapR
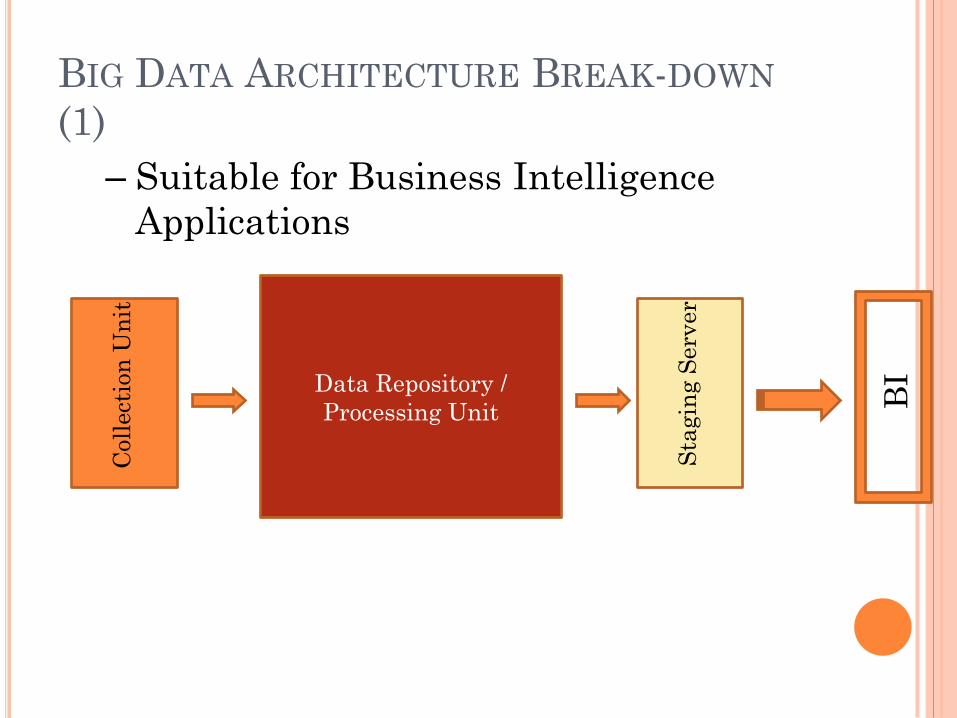
BIG DATA ARCHITECTURE BREAK-DOWN
(1)
Data Repository /
Processing Unit
Coll
ect
ion
Un
it
Sta
gin
g S
erv
er
BI
– Suitable for Business Intelligence
Applications
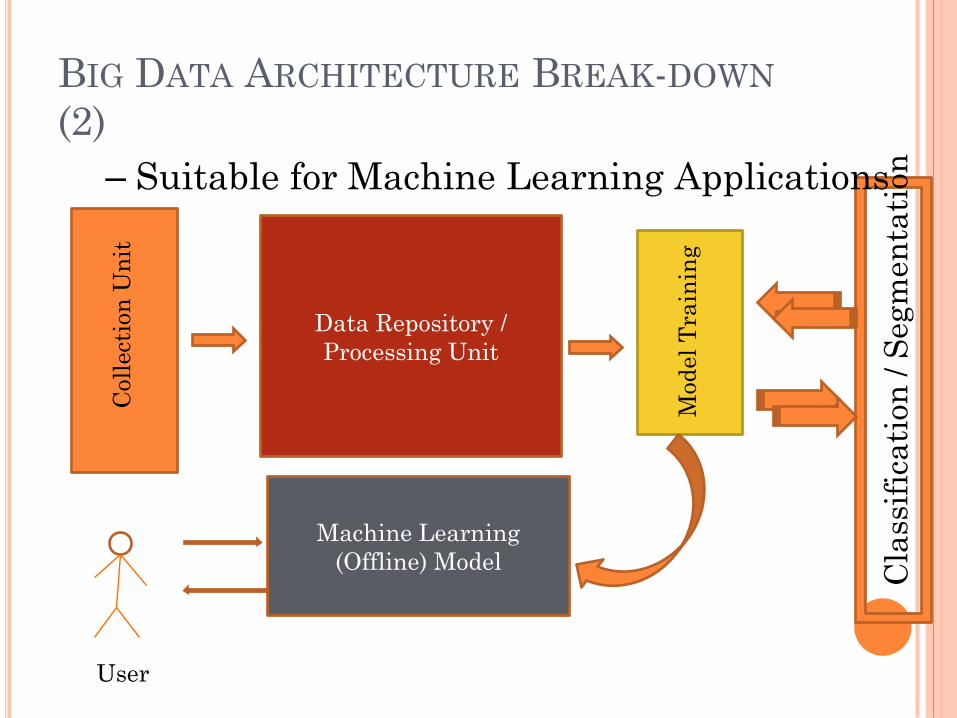
BIG DATA ARCHITECTURE BREAK-DOWN
(2)
Data Repository /
Processing Unit
Coll
ect
ion
Un
it
Mod
el
Tra
inin
g
Cla
ssif
ica
tion
/ S
egm
en
tati
on
– Suitable for Machine Learning Applications
Machine Learning
(Offline) Model
User

BIG DATA REAL APPLICATION
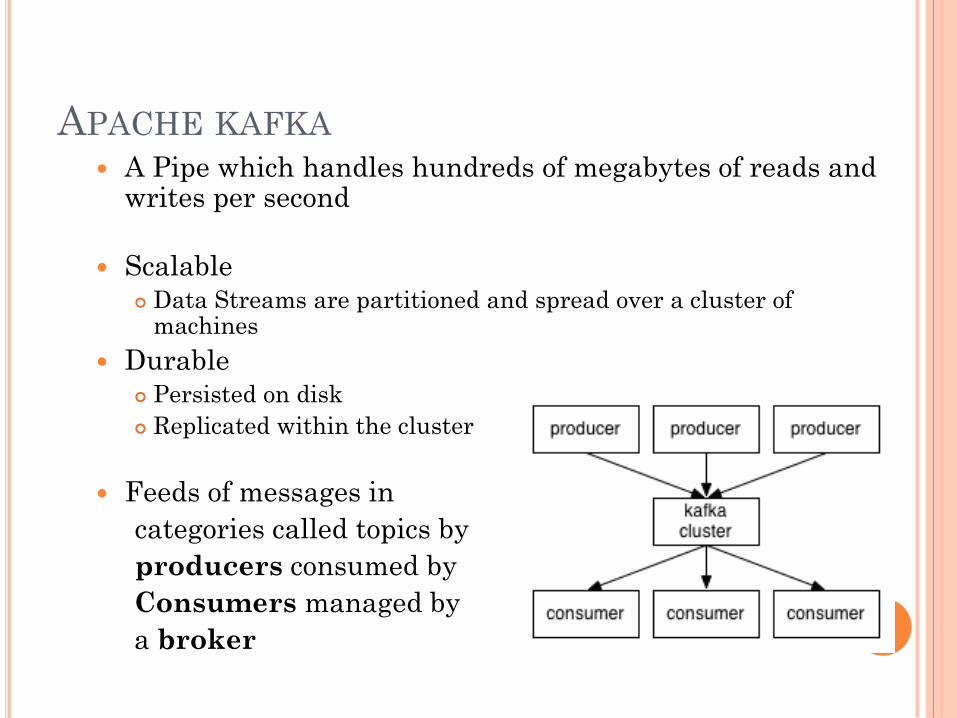
APACHE KAFKA A Pipe which handles hundreds of megabytes of reads and
writes per second
Scalable Data Streams are partitioned and spread over a cluster of
machines
Durable Persisted on disk
Replicated within the cluster
Feeds of messages in
categories called topics by
producers consumed by
Consumers managed by
a broker
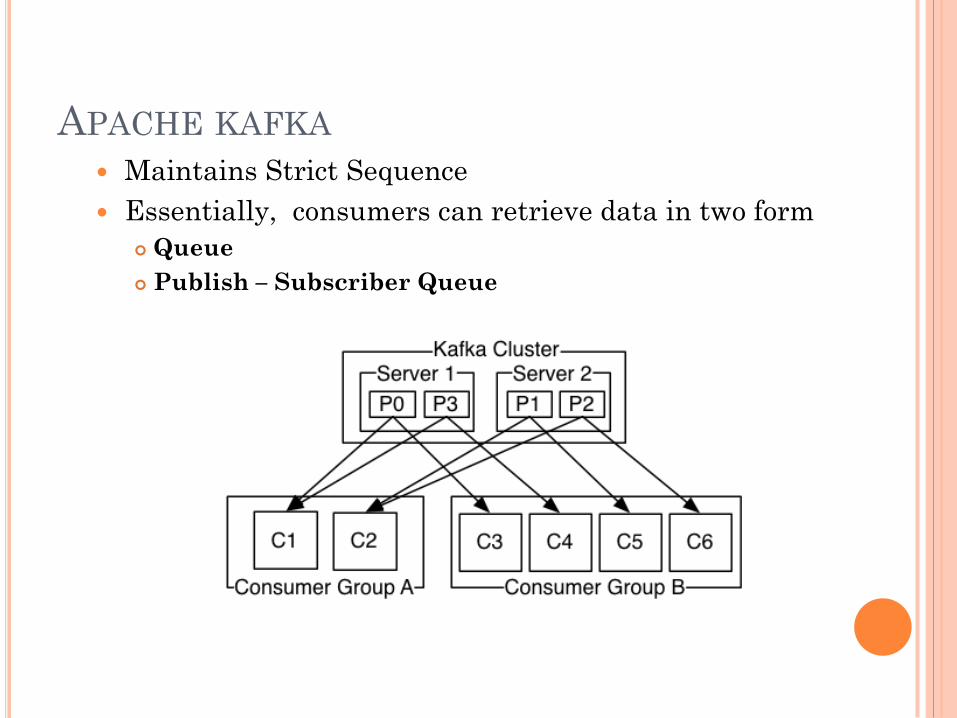
APACHE KAFKA Maintains Strict Sequence
Essentially, consumers can retrieve data in two form
Queue
Publish – Subscriber Queue


















