
Awsでつくるapache kafkaといろんな悩み
34
AWSでつくるApache Kafkaといろんな悩み もう1つのHadoop Summit 2016/12/14 Future Architect Inc, Keigo Suda
-
Upload
keigo-suda -
Category
Internet
-
view
1.670 -
download
2
Transcript of Awsでつくるapache kafkaといろんな悩み

AWSでつくるApache Kafkaといろんな悩みもう1つのHadoop Summit
2016/12/14
Future Architect Inc,Keigo Suda
AWS上でKafkaを利⽤するために考えたことü どのようなポイントがあったかü どのようにそのポイントに対応したかü (Kafka on クラウドの情報って以外と少ない)
Kafka on AWS(⼩中規模)の話
※資料は終了後公開します

* Technology Innovation Group スペシャリスト* 今の専⾨ -> ⼤きいデータを扱う領域(インフラ〜アプリ)* 最近はもっぱらKafkaとストリーム処理エンジンの諸々
須⽥桂伍 (すだ けいご)
@keigodasu

宣 伝l Kafkaの細かい話をします
もくじl IoTのためのデータプラットフォームを作っている話l Kafka on AWSの話

IoTのためのデータプラットフォームを作っている話
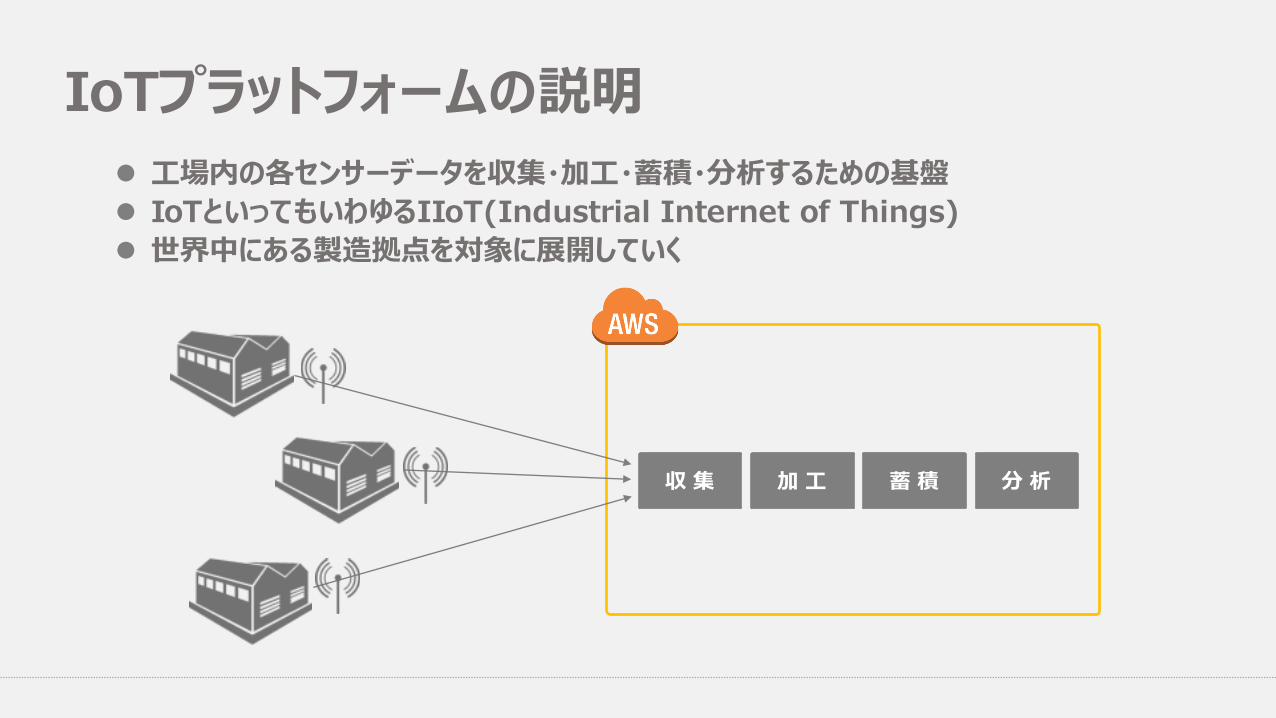
IoTプラットフォームの説明l ⼯場内の各センサーデータを収集・加⼯・蓄積・分析するための基盤l IoTといってもいわゆるIIoT(Industrial Internet of Things)l 世界中にある製造拠点を対象に展開していく
収 集 加 ⼯ 蓄 積 分 析
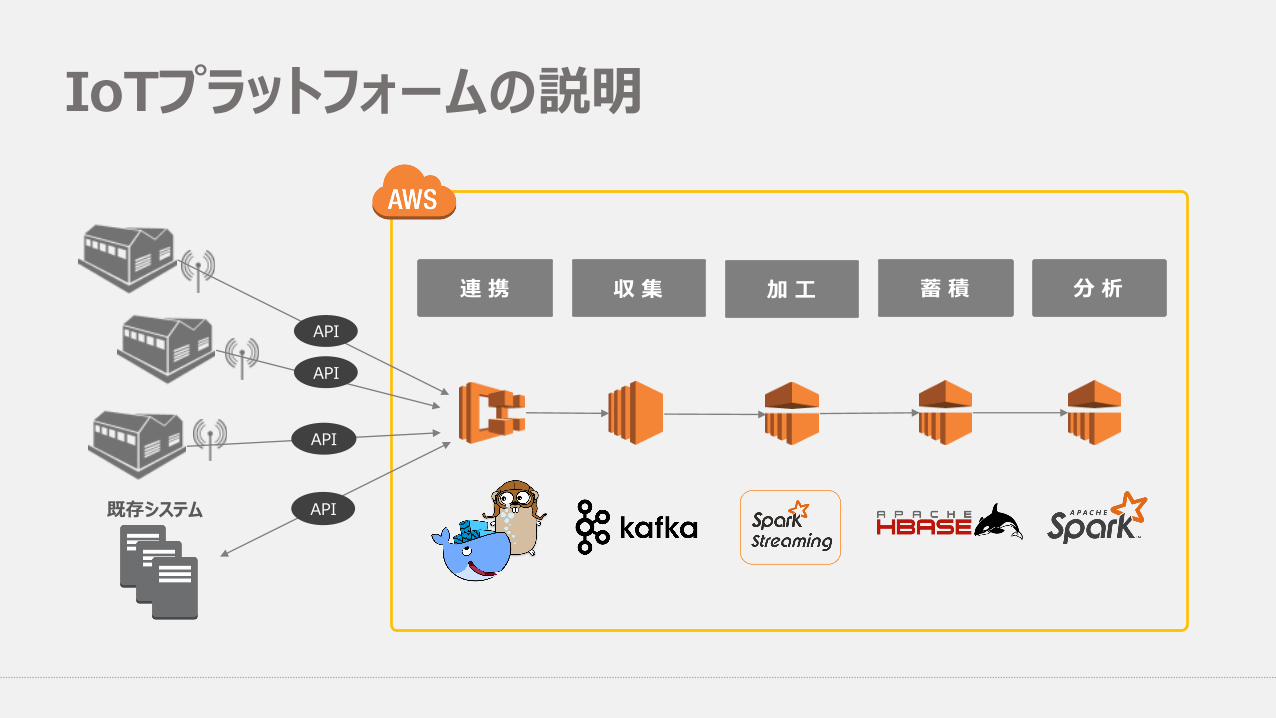
IoTプラットフォームの説明
収 集 加 ⼯ 蓄 積 分 析連 携
既存システム
API
API
API
API
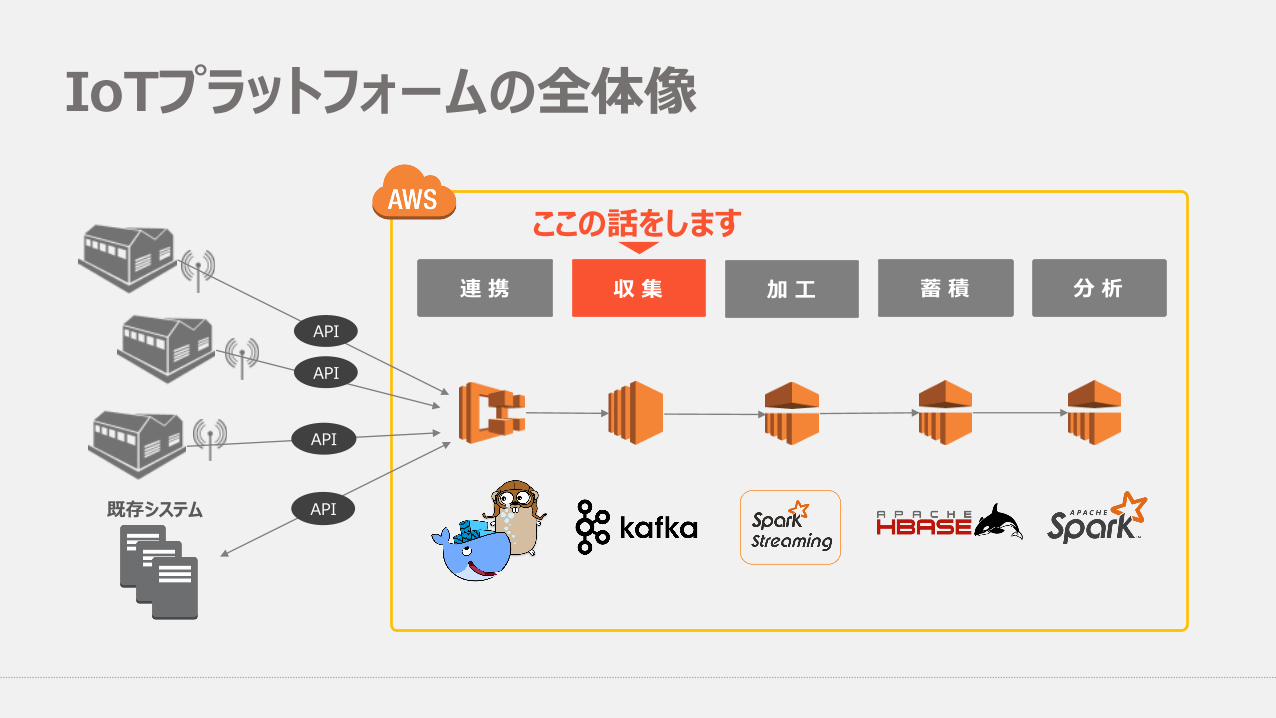
IoTプラットフォームの全体像
収 集 加 ⼯ 蓄 積 分 析連 携
既存システム
API
API
API
API
ここの話をします
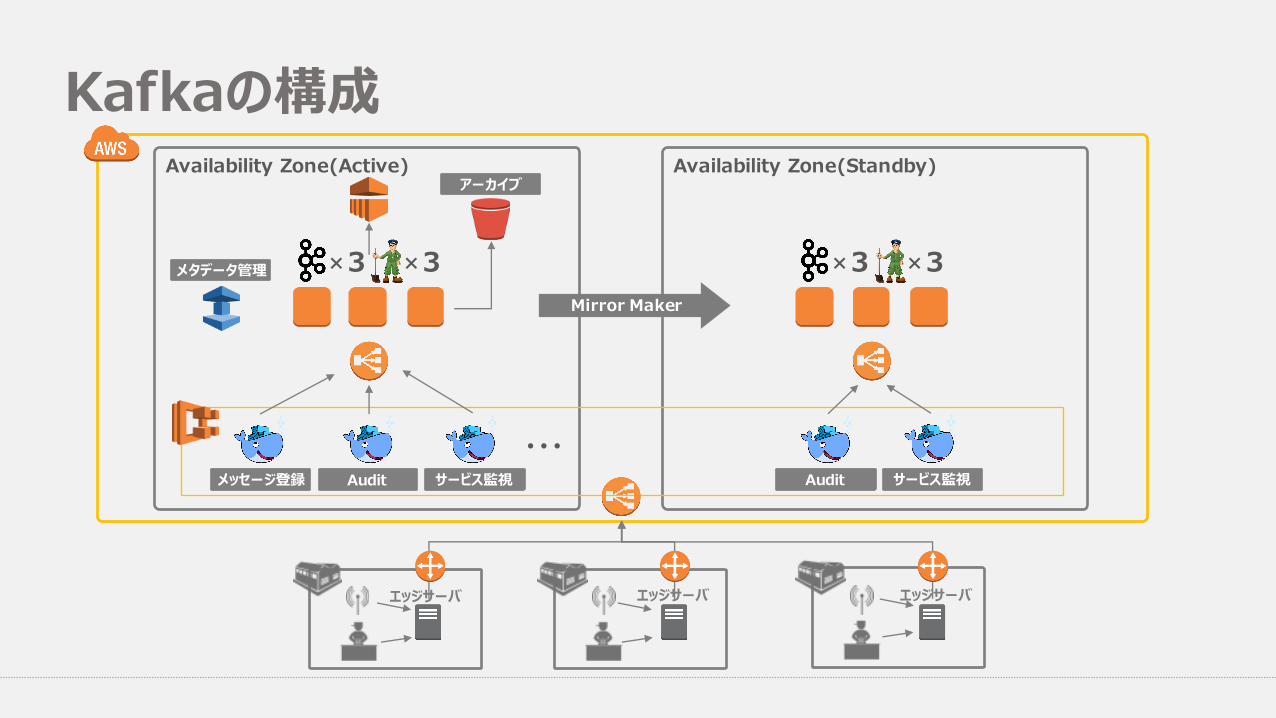
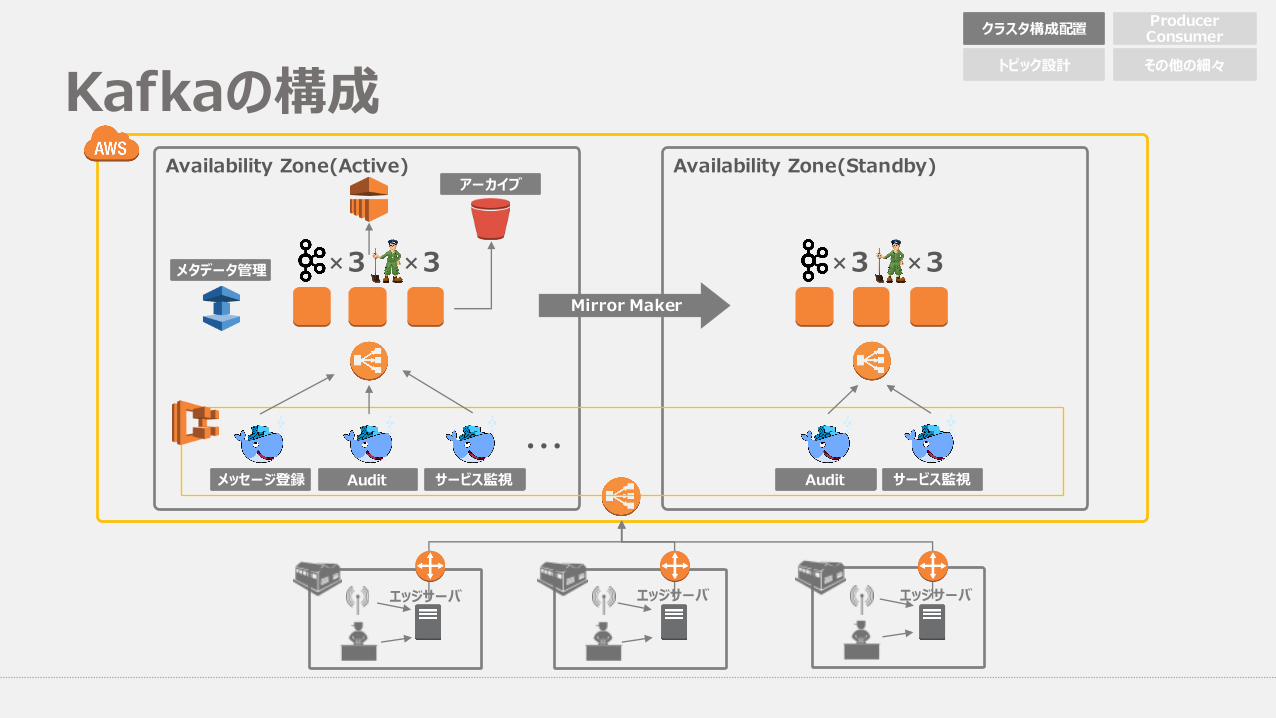
Kafkaの構成
3
Availability Zone(Active) Availability Zone(Standby)
Mirror Maker
✖ 3✖
メッセージ登録 Audit サービス監視
・・・
3✖ 3✖
Audit サービス監視
アーカイブ
メタデータ管理
エッジサーバ エッジサーバ エッジサーバ

Kafka on AWS
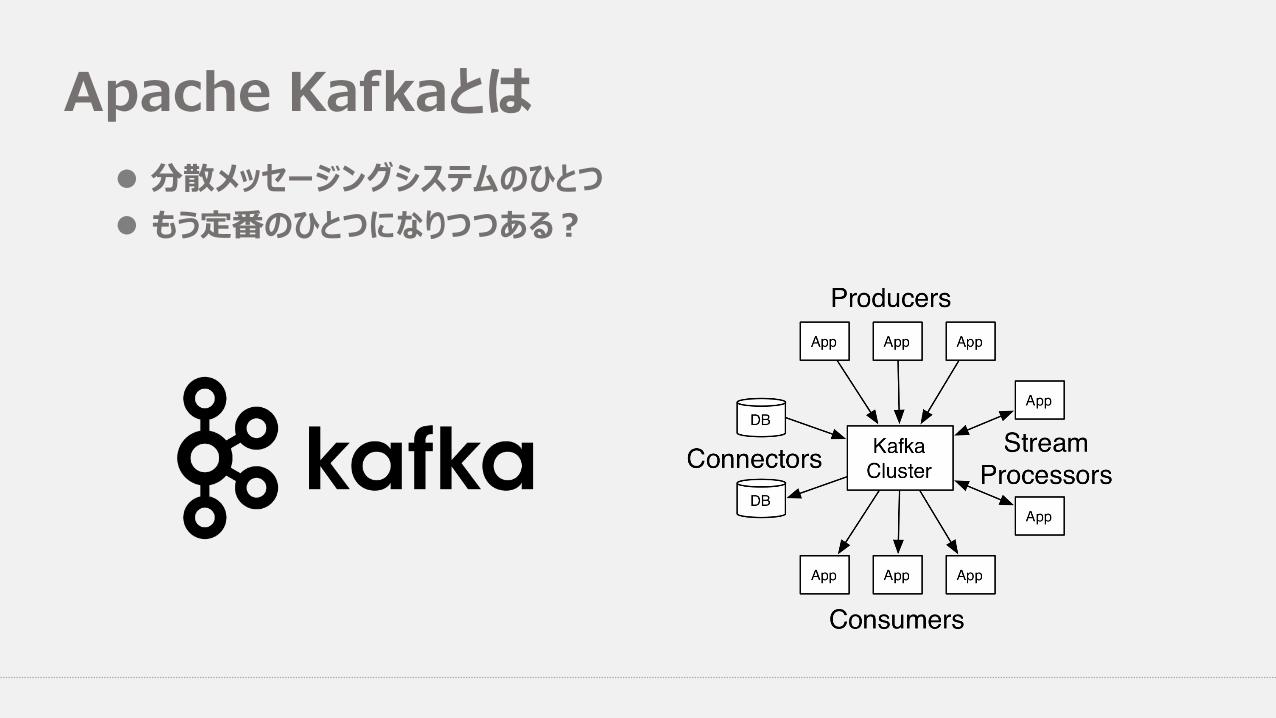
Apache Kafkaとはl 分散メッセージングシステムのひとつl もう定番のひとつになりつつある?

あれ?

あれあれ?(迫真)

そもそもなんでKafka on AWSl プラットフォーム⾮依存
l 海外への展開も考慮し、その都度適切なクラウドプラットフォームを選べるようにしたかった
l 肝であるプラットフォームの⼊り⼝はつくりこみたかったl 今回の仕組み上、⼊り⼝兼プラットフォーム全体のバッファであるメッセージングは⾊々とつく
り込みたかったため、挙動やクセも含め中⾝のわかるプロダクトが適していた
l 機密なデータも扱うのでVPC(閉域に閉じたかった) l 製造に必要な機密情報もやりとりされるため閉域網内でやりとりしたい・蓄積したい
Kafka on AWSといえばNetflixl ブログやスライドなど情報はちらほら公開されている
l そもそもスケール感が違いすぎるのでほんとに参考程度
設計にあたっての主なポイントl クラスタ構成配置l Producer/Consumerl トピック設計l その他の細々
本当はもっといろいろテッキーな話したい・・・別の機会に
Kafkaの構成
3
Availability Zone(Active) Availability Zone(Standby)
Mirror Maker
クラスタ構成配置 ProducerConsumer
その他の細々トピック設計
✖ 3✖
メッセージ登録 Audit サービス監視
・・・
3✖ 3✖
Audit サービス監視
アーカイブ
メタデータ管理
エッジサーバ エッジサーバ エッジサーバ
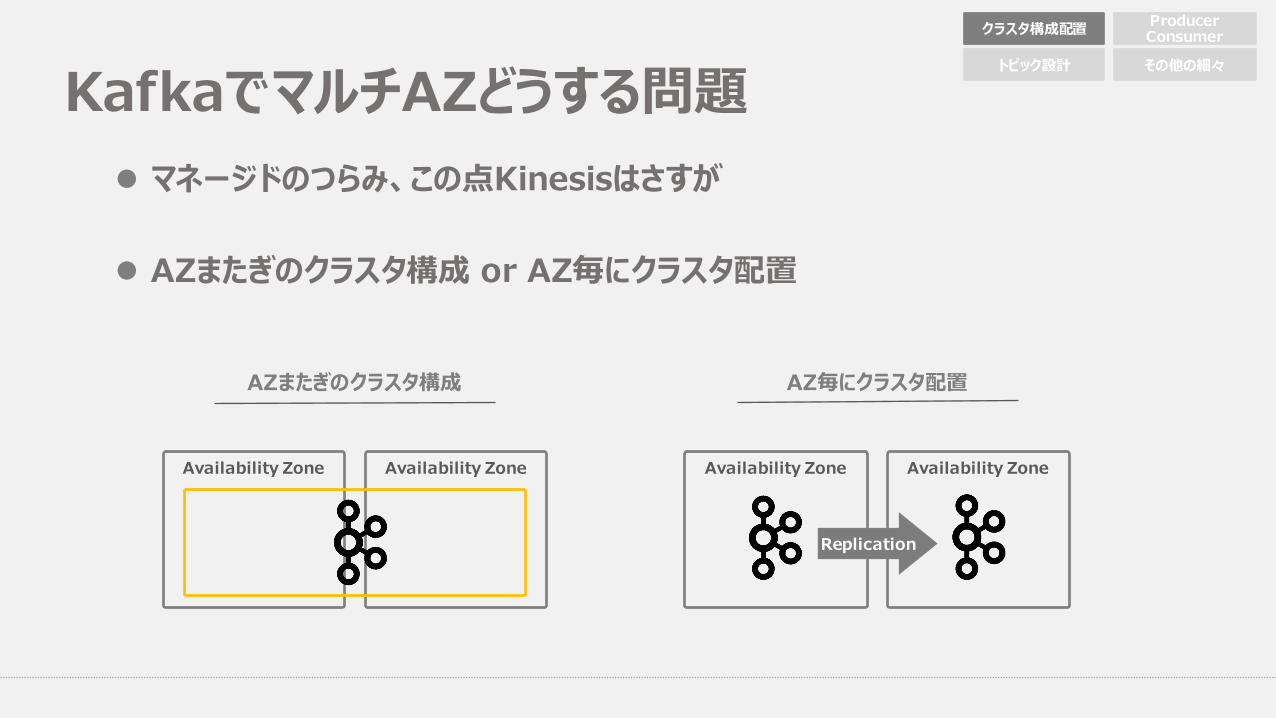
KafkaでマルチAZどうする問題l マネージドのつらみ、この点Kinesisはさすが
l AZまたぎのクラスタ構成 or AZ毎にクラスタ配置
Availability Zone Availability Zone Availability Zone Availability Zone
AZまたぎのクラスタ構成 AZ毎にクラスタ配置
Replication
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
AZ毎にクラスタを配置l ⾊々と最後まで決めかねた部分(今もちょっと迷う)
l 設定変更や稼働後のテスト等でのクロスチェックなどでは⾊々と都合がいい
l AZ障害時は切り替わるまでの時間の発⽣データを拠点のエッジサーバ上に蓄積できるため、復旧後に再送
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
Producer処理はAPIとして公開l 拠点にあるエッジサーバはライトに保ちたかった
l ⼯場ではそもそもサーバをメンテナンスできる⼈も少ないl 極⼒は単純な右から左の処理にとどめる
l プラットフォームの⼊り⼝としてKafkaを直接さらすのはいろいろつらいl セキュリティまわり(認証認可など)l 拠点側ではとりあえずデータを投げて、プラットフォーム側のロジックで救う
l OSSのツールはどれも結構機能が多すぎたためAPIは⾃作l HTTPのエンドポイントを設けられるものは増えてきたがそんなに機能いらない
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
Producerl API/Producer処理はGoで開発
l クライアントライブラリはSaramaを利⽤
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
(参考)いろいろあるよGoのクライアントl 主だったものは以下にまとまっている
l https://cwiki.apache.org/confluence/display/KAFKA/Clients
l どれも機能として惜しいものが多いので、シンプルな利⽤にとどめておく⽅がいいかもl 無難にJavaのAPIの⽅が何かと捗る・・・
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
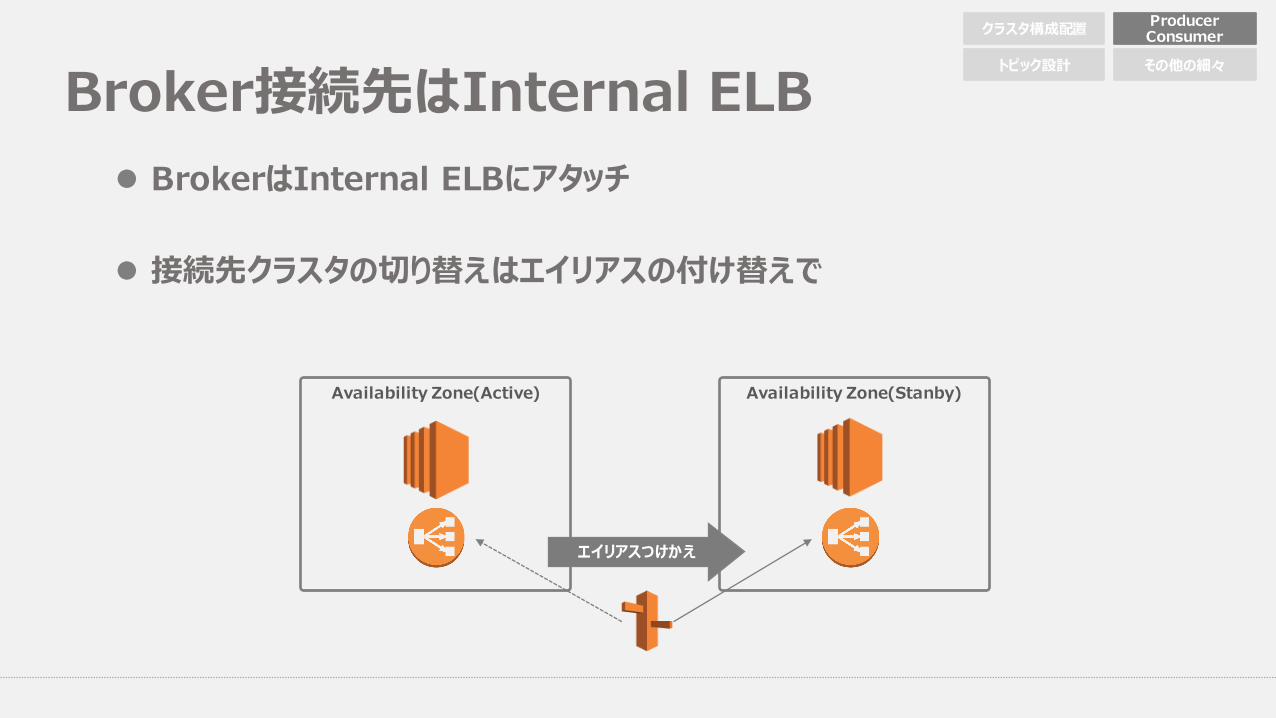
Broker接続先はInternal ELBl BrokerはInternal ELBにアタッチ
l 接続先クラスタの切り替えはエイリアスの付け替えで
クラスタ構成配置 ProducerConsumer
Availability Zone(Active) Availability Zone(Stanby)
トピック設計 その他の細々
エイリアスつけかえ
Consumerは無難l Spark Streaming on EMRがConsumerのメイン
l 待機系として利⽤するAZでは、当該AZに切り替わった時に⽴ち上げる
l ⼀部Consumerアプリケーションはあるが部分的l 正直SaramaはConsumer処理の実装が弱いため
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
トピック設計l トピックの作成単位は製造拠点(⼯場単位)
l ⼯場 * 製品 * ⼯程 * 利⽤⽤途(順序性を考慮するか等) * 連携システム などを考慮した単位でトピック作成していくと爆発的に増えていくことを懸念
l 後続のSpark Streamingでロジックに応じた加⼯やルーティングを実施l いったんKafkaにさえ⼊ってしまえばこっちのもの
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
レプリカ & Acksl トピックの利⽤⽤途に応じて設定は変更
l 業務利⽤(使えないと業務が⽌まるレベル)はロストさせない/早く失敗させるl 運⽤管理⽤途(ログの収集など)はほどほどに
l 業務的に重要なものは以下でトピック作成(それ以外は適宜)l acks = alll replication.factor=3l min.insync.replica=3
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
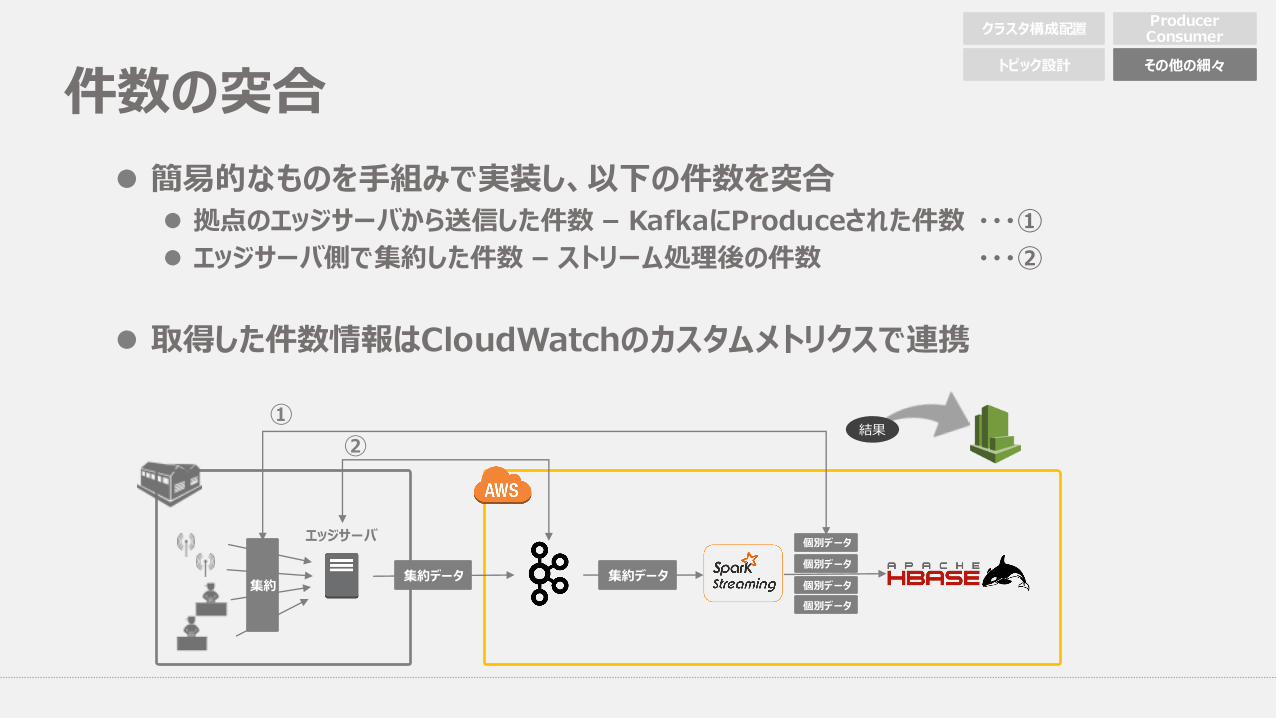
件数の突合l 簡易的なものを⼿組みで実装し、以下の件数を突合
l 拠点のエッジサーバから送信した件数 – KafkaにProduceされた件数 ・・・①l エッジサーバ側で集約した件数 – ストリーム処理後の件数 ・・・②
l 取得した件数情報はCloudWatchのカスタムメトリクスで連携
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
エッジサーバ
集約
①②
集約データ 集約データ
個別データ
個別データ
個別データ
個別データ
結果
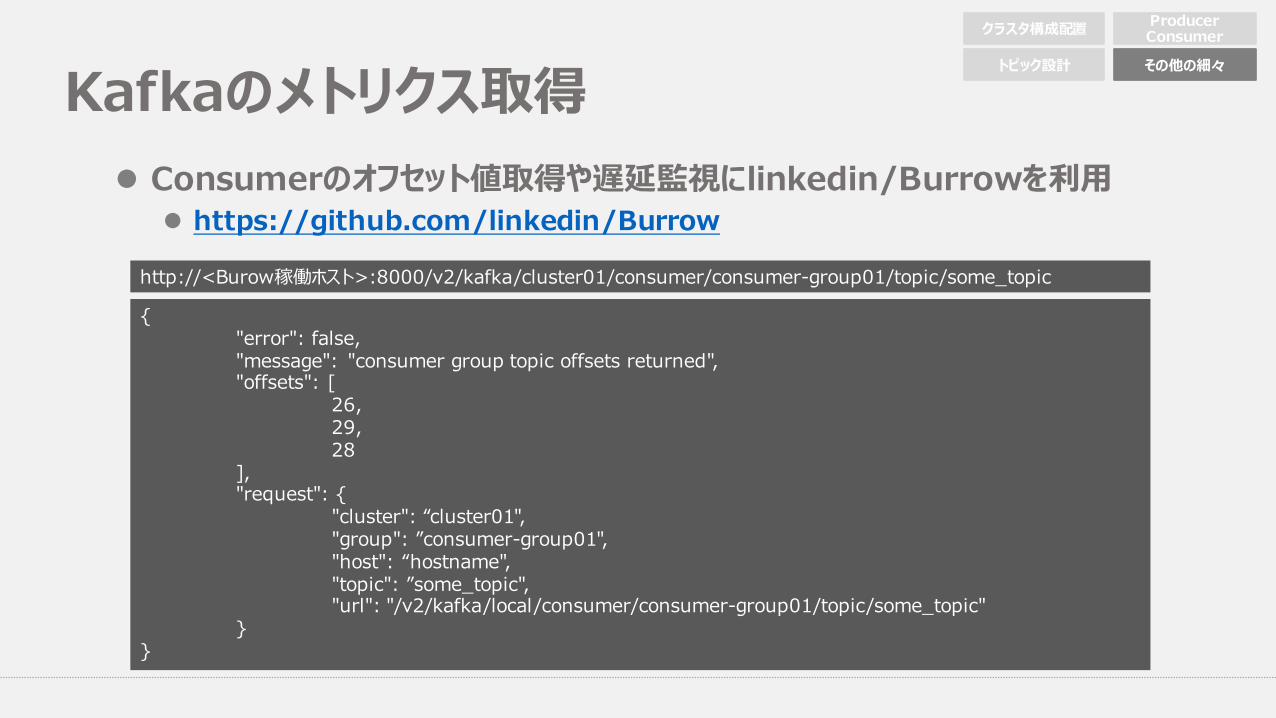
Kafkaのメトリクス取得l Consumerのオフセット値取得や遅延監視にlinkedin/Burrowを利⽤
l https://github.com/linkedin/Burrow
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
{ "error": false, "message": "consumer group topic offsets returned", "offsets": [
26, 29, 28
], "request": {
"cluster": “cluster01", "group": ”consumer-group01", "host": “hostname", "topic": ”some_topic", "url": "/v2/kafka/local/consumer/consumer-group01/topic/some_topic"
}}
http://<Burow稼働ホスト>:8000/v2/kafka/cluster01/consumer/consumer-group01/topic/some_topic
オブジェクトストレージへのアーカイブl 候補は⾊々あるがちょっとまだ決めかねている。
l Kafka Connectl Secorl Streamxl Embulk ・・・
l Kafkaを中⼼とするならKafka Connectだけど、より汎⽤性をもたせるならEmbulkあたり?
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々
その他l EC2でIPいろいろ変わっちゃう
l AnsibleとTerraformでつくり込み
クラスタ構成配置 ProducerConsumer
トピック設計 その他の細々

まとめ
まとめl マルチAZをどう⾃前で担保するかが⼀番のポイント(だと思った)
l クラウド上でKafka運⽤しているかた、どんどん発信してほしい

ありがとうございました!!


















