
AWS Data Pipelineitlib1.sakura.ne.jp/test380/pdfichuran/0453/005-AWS-Data...AWS Data Pipeline AWS...
139
AWS Data Pipeline ITライブラリーより (pdf 100冊) http://itlib1.sakura.ne.jp/ 解説 (全130ページ)
Transcript of AWS Data Pipelineitlib1.sakura.ne.jp/test380/pdfichuran/0453/005-AWS-Data...AWS Data Pipeline AWS...

AWS Data Pipeline
ITライブラリーより (pdf 100冊)http://itlib1.sakura.ne.jp/
解説
(全130ページ)

本資料の関連資料は下記をクリックして
PDF一覧からお入り下さい。
ITライブラリー (pdf 100冊)http://itlib1.sakura.ne.jp/
目次番号 453番 AWS詳細解説 全33冊 計6,100ページ
2

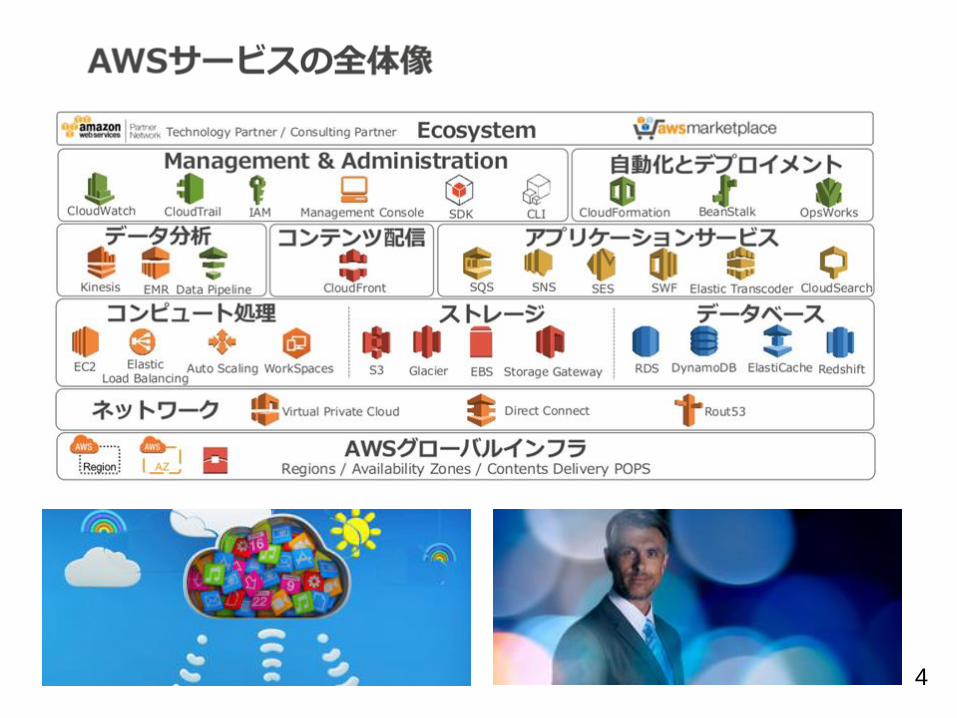
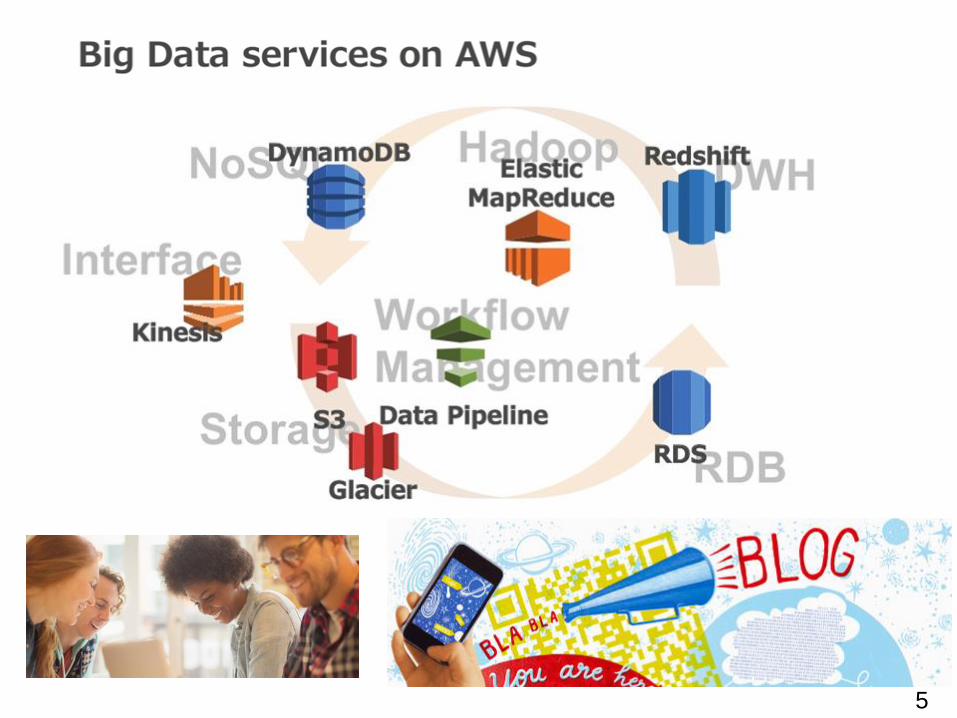
AWS Data Pipeline と ビッグデータ
3
4
5

6

7

8
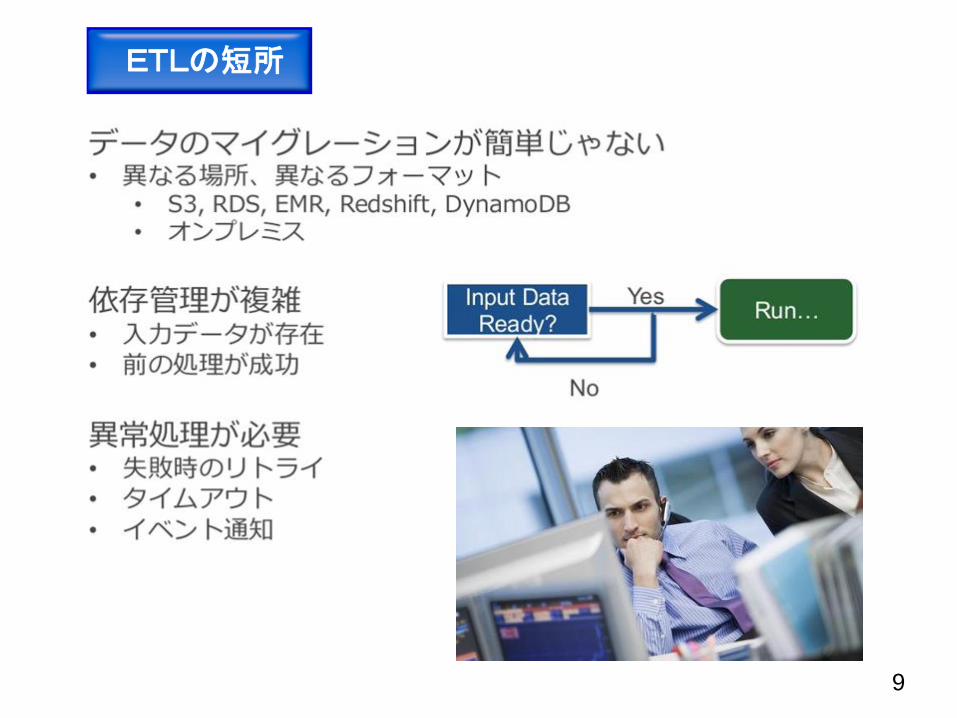
ETLの短所
9

10

11

AWS Data Pipeline
AWS Data Pipeline とは、AWS クラウドでの定期的なデータ移動やデータ処理の
アクティビティの スケジュールを簡単に設定 できるウェブサービスです。
AWS Data Pipeline によりオンプレミスとクラウドベースのストレージシステムが統合
されるため、開発者はそれらのデータを必要なときに 、使用したい場所で、必要な
形式で使用できます。
12

AWS Data Pipeline を使用して、データソース、送信先、および「パイプライン」
と呼ばれる データ処理アクティビティ(あらかじめ定義されたアクティビティまたは
カスタムアクティビティ)から 成る依存関係を すばやく定義できます。
13

パイプラインは、定義したスケジュールに基づき、
分散データのコピー、
SQL 変換、
MapReduce アプリケーション、
または
Amazon S3、Amazon RDS、Amazon DynamoDB などの
送信先に対するカスタムスクリプトといった処理アクティビティを
定期的に実行します。
14

スケジュール設定、再試行、これらのワークフローに対する障害ロジックを、
高スケーラブルかつ完全なマネージドサービスとして実行することにより、
堅牢で高可用性を備えたパイプラインのご利用を保証します。
AWS Data Pipeline を使用すると、パイプラインの準備がすばやく簡単に行える
ようになり、日次データ運用の管理に必要な開発と メンテナンスの手間が省ける
ため、そのデータを基にした将来の予測を立てることに集中できます。
15

ユーザーはデータソース、スケジュール、およびデータパイプラインに必要な
処理アクティビティ を指定するだけです。
処理アクティビティの実行 と モニタリングは、高い信頼性があり耐障害性を備えた
インフラストラクチャ上で行われ、AWS Data Pipeline が これを処理します。
16

さらに、開発プロセスを いっそう容易にするために、AWS Data Pipeline には、
Amazon S3 と Amazon RDS 間でのデータコピーや、Amazon S3 ログデータに
対するクエリの実行など、一般的な アクションの組み込みアクティビティが用意さ
れています。
17

パイプライン
パイプラインは AWS Data Pipeline のリソースです。
データソースの依存関係の定義、送信先、およびビジネスロジックの実行に
必要な定義済み または カスタムのデータ処理アクティビティ などが含まれます。
18

データノード
データノードとは、ユーザーのビジネスデータを表したものです。
例えば、データノードは特定の Amazon S3 パスを参照できます。
19

AWS Data Pipeline は、定期的に生成される データを簡単に参照する
式言語をサポートします。例えば、Amazon S3 データ形式は、
s3://example-bucket/my-logs/logdata-#{scheduledStartTime('YYYY-
MM-dd-HH')}.tgz
のように指定できます。
20

アクティビティ
アクティビティとは、AWS Data Pipeline がパイプラインの一部として
ユーザーの代わりに実行するアクションのことです。
アクティビティの例としては、
EMR または Hive ジョブ、
コピー、SQL クエリ、
コマンドラインスクリプト
などがあります。
21

22
23

Amazon Redshift
Amazon Redshiftはデータウェアハウス でありながら,従来の製品よりも
テラバイトあたりの価格が10分の1以下であり,さらにクラウド上に構築される
ため メンテナンスコストなどの追加費用が必要ないとあって,大変注目を集めて
います。
24

加えて,最低2TBから最大1.6PB までスケールでき,通常のPostgreSQL用
ドライバやJDBC/ODBCで接続することができるので,既存の資産を利用する
ことも可能です。
Amazon Redshiftの特徴
たとえばデータウェアハウスを導入するときは数TBの容量でも億単位の金額が
必要な場合もありますが,Amazon Redshiftは最低金額が年に$2,000から
利用できます (3年リザーブド・インスタンスで2TBストレージの場合)。
25

機能スペック的にはそれほど違いがなく, 唯一の大きな違いは クラウド上に
あるかどうか,ということです。
つまり,すでにクラウド環境を利用している企業でデータウェアハウス導入を
検討する場合,Amazon Redshift は最初の選択肢になるでしょう。
26

Redshiftの主な機能は,以下のようなものです。
・カラムナー(列指向)データベース
・カラム種別ごとの豊富な圧縮エンコード
・MPP(Massively Parallel Processing)
・簡単にインスタンス追加
もしクラウドを使っていない場合でも,このためにクラウド環境を検討する
価値があるかもしれません。
27

カラムナーデータベース
データウェアハウスは主にSQLを用いて大規模なデータに対する集計処理を
行うので,カラムに対する集計関数 (合計や平均など)の実行が基本になります。
そこで,カラムごとにデータをブロック化する という手法が有効だということで,
このカラムナー(列指向)データベースというものが生まれました。
28

逆に,通常のデータベースは行指向データベースとも呼ばれ,ランダムアクセス
(ある特定の行を取得する)に向いています。
さらに,同じカラムは同じデータの繰り返しが多く起こりやすいので,圧縮が効き
やすく,より少ない容量で大きなデータを 表すことができます。
29

たとえば,AAAABBCCCAAB という12文字のデータは,(順番を無視すると)
A6B3C3という 6文字のデータに置き換えられるわけです。
同じ種類のデータが多い(カーディナリティが低いとも言います)と,より圧縮
効率が良いというわけです。
30

圧縮効率が良いと何が良いかというと,データを小さくすることができるため
データベース処理スピードの一番のボトルネックである,ディスクからの
入出力を減らすことができます。
31

さらにメモリに乗せることもできる可能性も上がり,パフォーマンスに大きな
影響を与えます。
このように,カラムナーデータベースは,特に大きなデータの集計処理には
優れたパフォーマンスを発揮するのです。
32

豊富な圧縮エンコード種別
Amazon Redshiftは9種類の圧縮エンコーディングに対応しています。
たとえば,Byte dictionary や Delta,Mostlynなどと呼ばれるものです。
33

それぞれ独自のアルゴリズムがありますが,どれを適用するのが一番良いかは,
全体のデータの内容に依存するため,判断するのが難しいでしょう。
そのため,Redshiftには COPYコマンドという,バッチインポート用のコマンドを初回に
実行した時や,その時点で格納されているデータを元に ANALYZEコマンドを実行した
時に,一番有効なエンコーディングを自動で決定してくれる機能があります。
34

MPP (Massively Parallel Processing)
通常のデータベースの場合,クラスタ化しスケールさせた場合でもシェアード・
ナッシング(リソースを共有しないことにより線形スケールを可能にする
アーキテクチャ)にならないので,台数を増やすごとに性能を向上させるのは
難しいといわれています。
RedshiftはこのMPPという機構を用いてシェアード・ナッシングを実現し,
線形スケールを実現しています。
35

つまり,インスタンスを追加するたびにデータ容量だけでなく,処理性能も向上
していくということになります。
これは,Hadoopなどと同じ構造であり,ビッグデータ処理の上では必須の
機能と言えるでしょう。
36

Redshift内部では,Leader Node(SQLドライバなどが接続するインターフェースを
担うノード)とCompute Node(スケールする,実際に計算・データ保持するノード)に
分かれていて,適切にデータを保持したり,クエリ処理を分散させたりという仕組み
が内部的に動いています。
この中身はブラックボックスになっていて,基本的にAmazonが管理しているので,
ユーザは気にする必要がありません。
37

Hadoopとよく似ていますが,誰が管理するか,というところが大きな違いだと
思います(Hadoop クラスタの管理は大変です…)。
38

簡単にインスタンス追加
ハードウェア・アプライアンスはもとより,通常のデータウェアハウス・ソフトウェア
製品であっても,データ容量が足りなくなったり,思ったようなパフォーマンスが
出なくなったりするときに インスタンスを追加するという選択肢がありますが,
実際にそうするのは大変です。
39

追加には多額の費用 と 1ヵ月くらいの日数は必要でしょう。
Amazon Redshiftはほんの数クリックで,自由にインスタンスを
追加することができます。
40

41

42

43

AWS Data Pipeline
AWS Data Pipeline は、指定された間隔で、信頼性のあるデータ処理や
データ移動 (AWS のコンピューティングサービス や ストレージサービス、
ならびに オンプレミスのデータソース間)を行うことができるウェブサービスです。
44

AWS Data Pipeline を使用すると、保存場所にあるユーザーのデータに
定期的にアクセスし、そのスケールで変換と処理を行い、その結果を
Amazon S3、Amazon RDS、Amazon DynamoDB、Amazon Elastic
MapReduce(EMR)のような AWS サービスに効率的に転送できます。
AWS Data Pipeline により、耐障害性があり、繰り返し可能で、高可用性を
備えた、複雑なデータ処理ワークロードを簡単に作成できます。
45

リソースの可用性の保証、タスク間の依存関係の管理、タスクごとの一時的な
失敗による再試行やタイムアウト、失敗通知システムの作成などについて
心配する必要はありません。
また、AWS Data Pipeline により、オンプレミスのデータ格納庫に保管されていた
データの移動および処理も可能です。
46

47
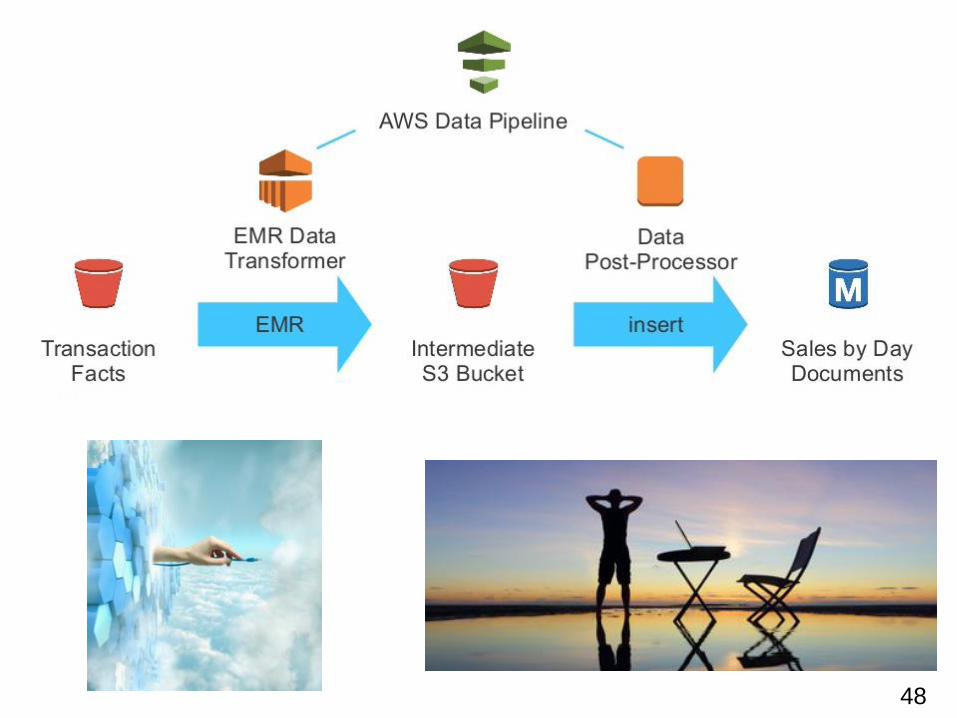
48

49

50

51

52

53
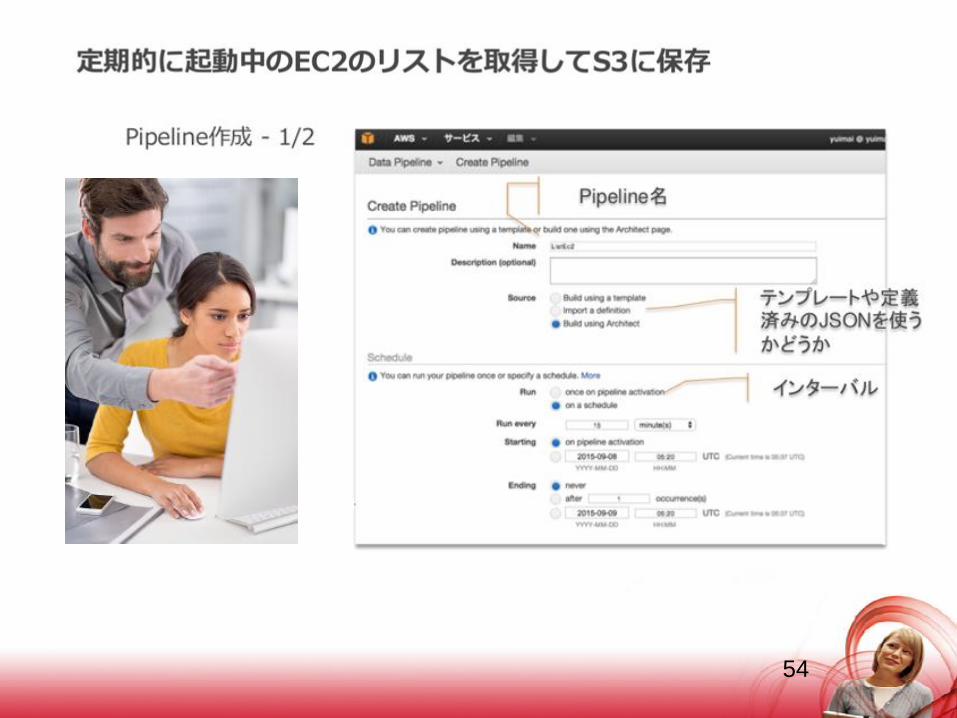
54
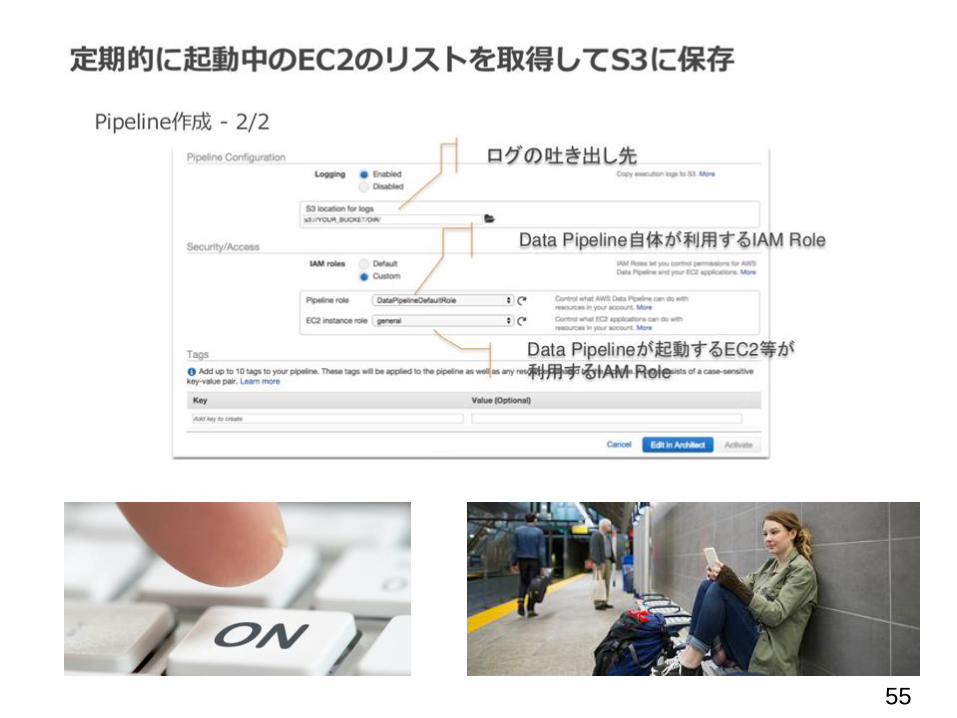
55
56

57

58

59

60

61

62

63

64

65

66

67

68
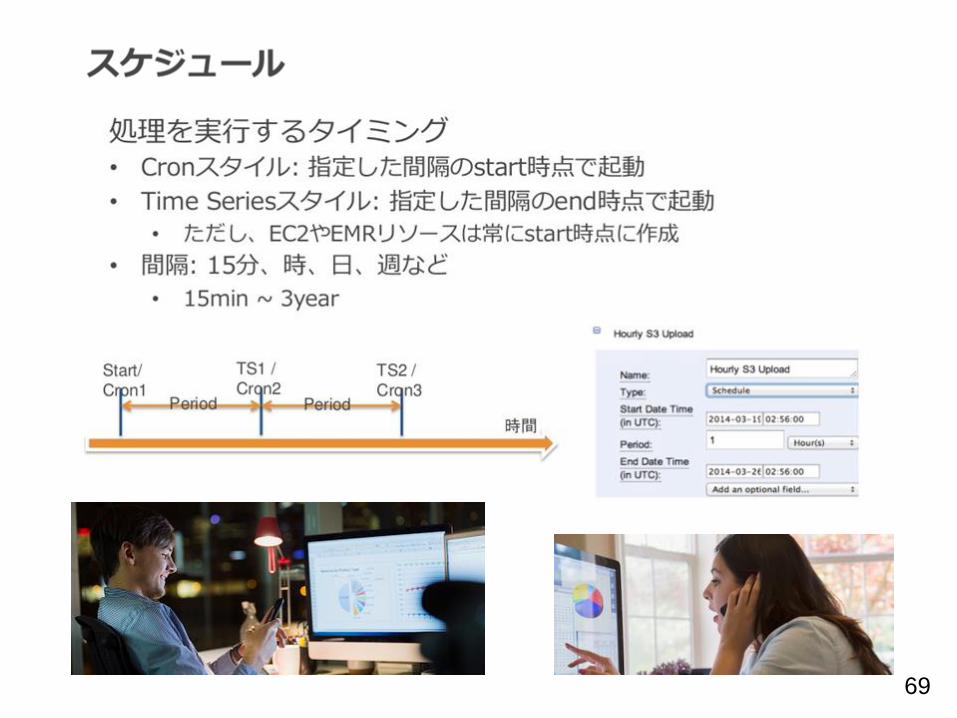
69

70

71
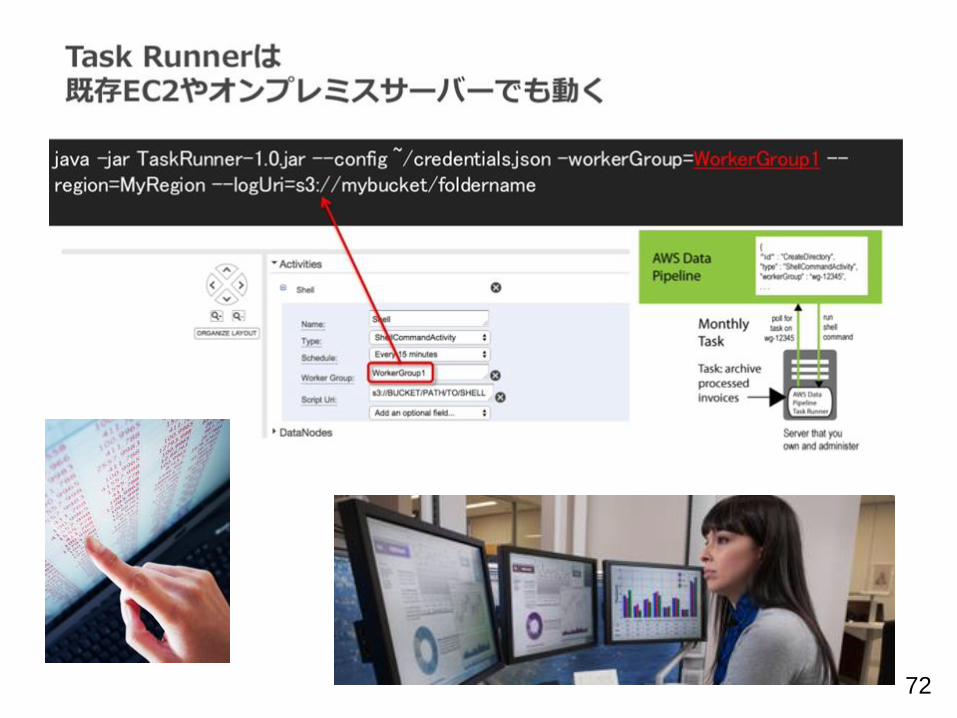
72

73
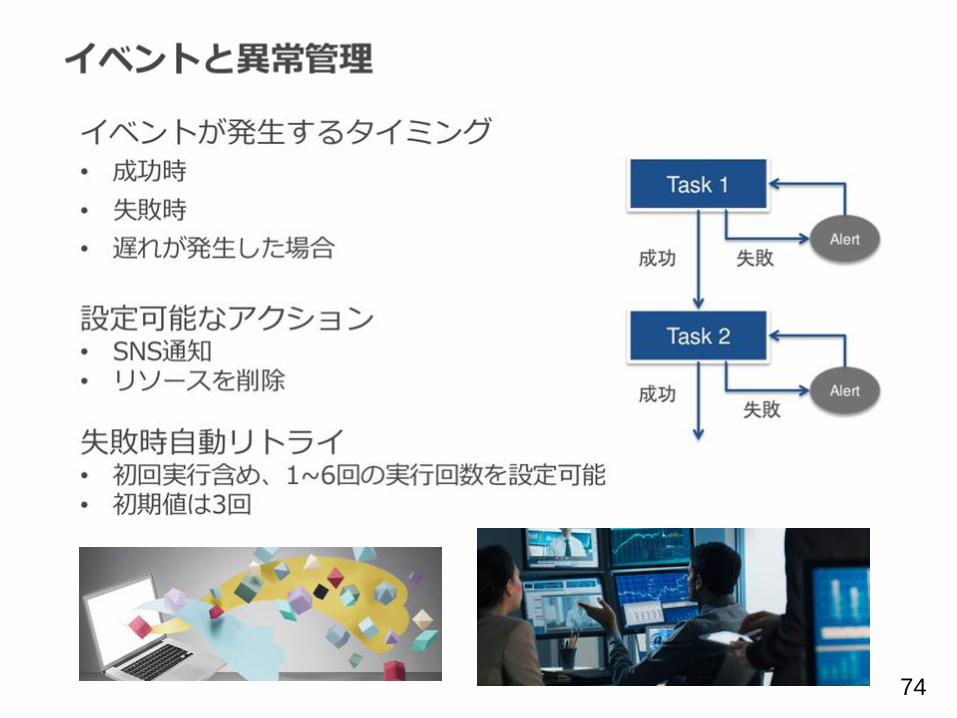
74

75

補足: AWS CLI AWS コマンドラインインターフェイス
AWS コマンドラインインターフェイス (CLI) は、AWS サービスを管理するための
統合ツールです。
ダウンロード および 設定用の単一のツールのみを使用して、コマンドラインから
複数の AWS サービスを制御し、スクリプトを使用してこれらを自動化することが
できます。
76
Amazon S3 との間で効率的にファイル転送を行うため、AWS CLI に
シンプルなファイルコマンドセット が追加されています。
77

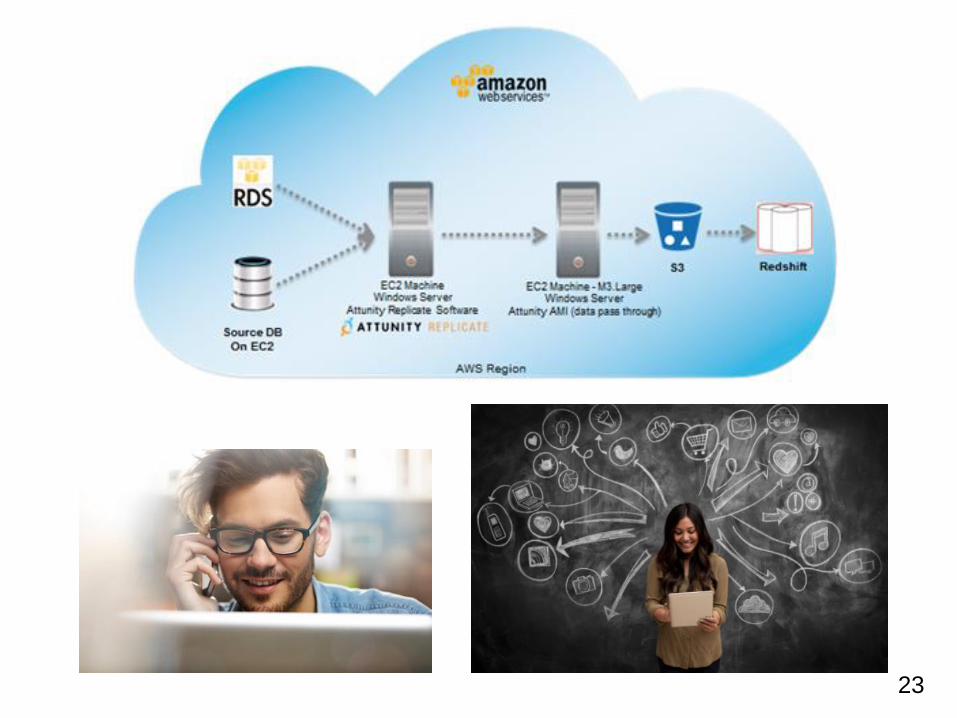
例 AWS CLI の処理を AWS Data Pipeline で実行する
AWS Data Pipeline 構成イメージ
AWS CLI (AWS Command Line Interface) はAWS に於ける諸々のサービスに
関する操作をコマンドラインベースで行えるユーティリティツールです。
78

任意の環境からオプション等を組み合わせる事で、自在にAWSの各種
操作を効率化・自動化する事が出来ます。
従来の利用方法であれば、このAWS CLIを適宜手動で実施、または稼働OS
環境上で何らかの スクリプト言語を介して、AWS CLIを実行すると言うような
形がまず先に浮かぶのではと 思われます。
79

今回はこの"稼働OS環境"の部分がAWS Data Pipelineからの指示として
置き換わる様なイメージです。
ちなみに今回はごくごく シンプルな『EC2インスタンスの起動・停止』を
例にして 進めてみたいと思います。
任意の時間にそれぞれ起動・停止に相当するAWS CLIが実行される
イメージです。
80

81
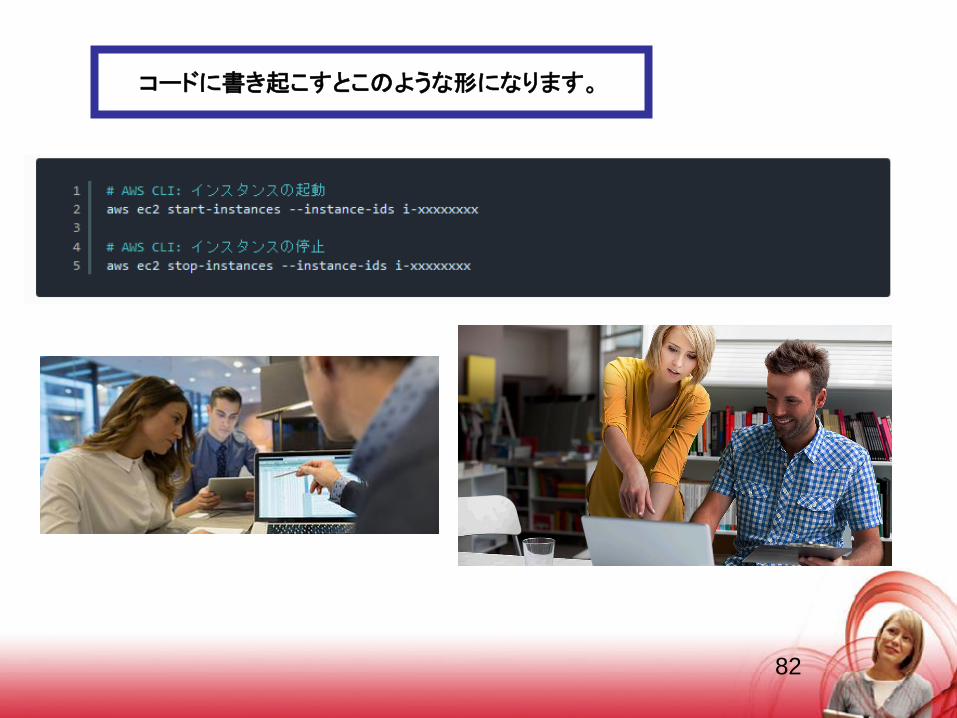
コードに書き起こすとこのような形になります。
82

AWS Data Pipeline パイプラインの構築
ではパイプライン本体の作成に進みます。 管理コンソールから
AWS Data Pipelineのサービスを選択し、[Get Started Now]をクリック。
83

84

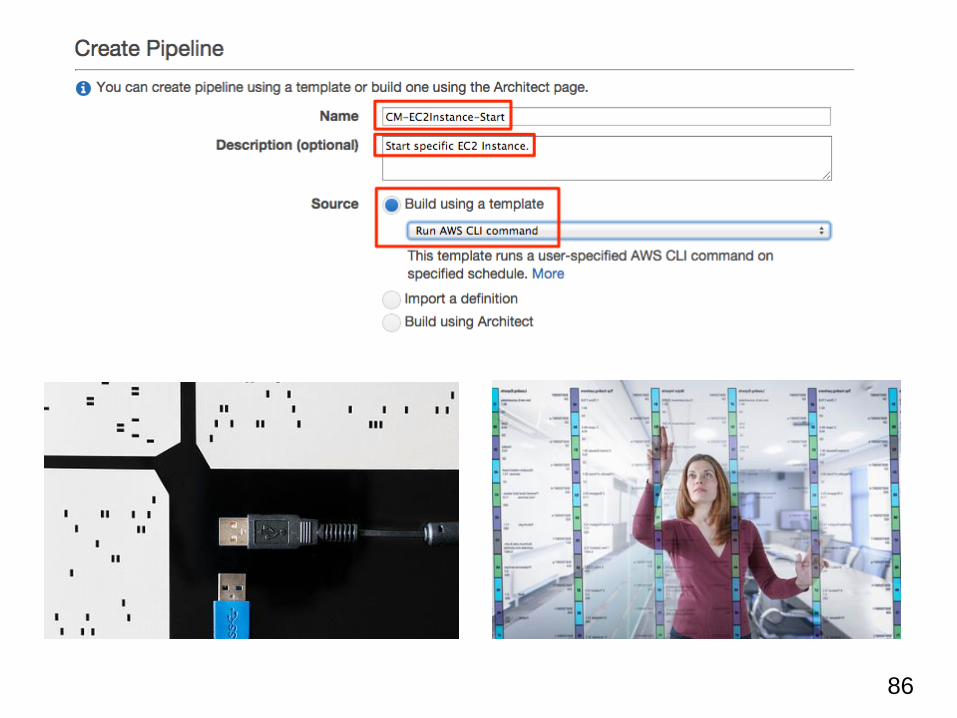
パイプラインの作成: 名称の設定と利用ソースの選択
パイプラインの 『名前』 と 『説明文』 (いずれも内容は任意)入力します。
そして、パイプラインを作成する際の『ソース』を選択。
ここでは、『Build using a template』→『Run AWS CLI command』を
選んでください。
85
86
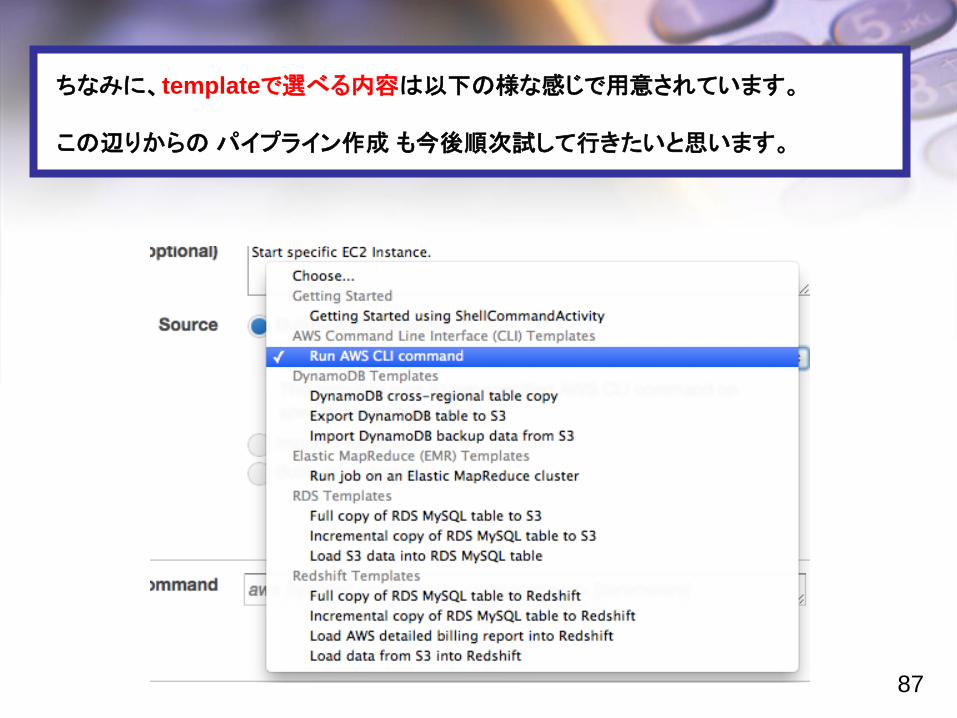
ちなみに、templateで選べる内容は以下の様な感じで用意されています。
この辺りからのパイプライン作成 も今後順次試して行きたいと思います。
87
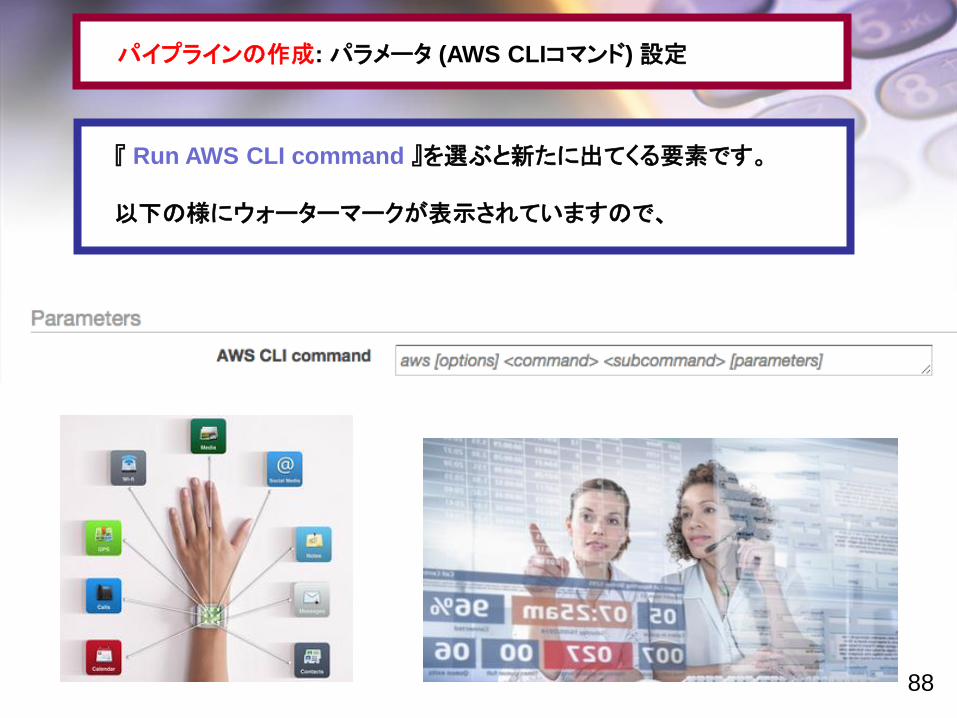
パイプラインの作成: パラメータ (AWS CLIコマンド) 設定
『 Run AWS CLI command 』を選ぶと新たに出てくる要素です。
以下の様にウォーターマークが表示されていますので、
88
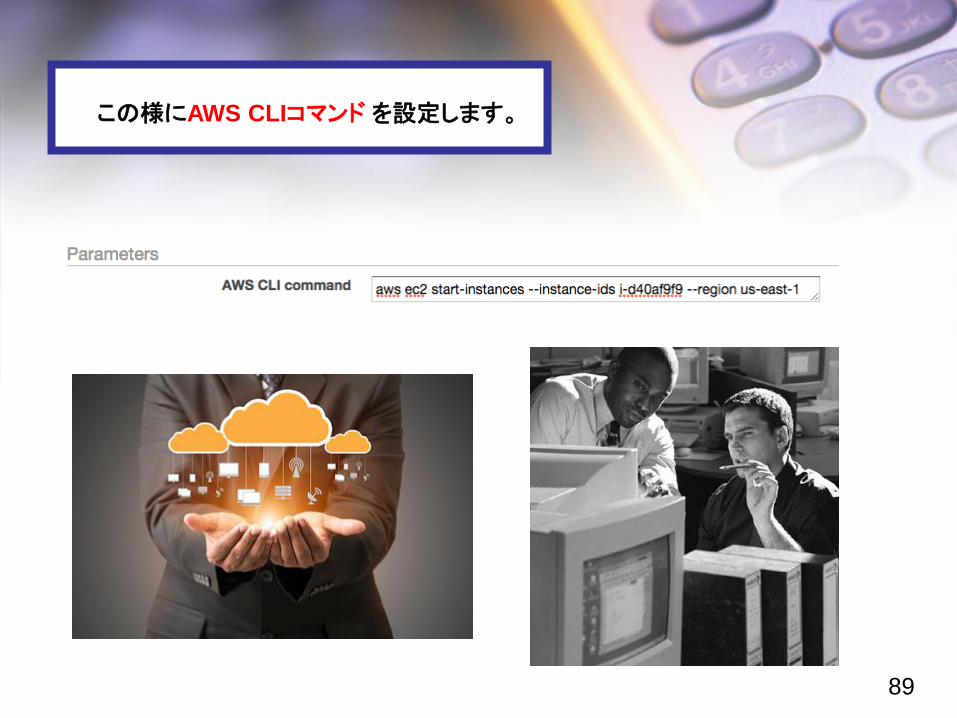
この様にAWS CLIコマンド を設定します。
89

パイプラインの作成: スケジュール設定
パイプラインを動かす為の『スケジュール』設定を行います。
スケジュールの設定内容には幾つかルールやタイプがありますが、ここでは
『毎日定められた時間に実行する』 というパターンで行ってみたいと思います。
90

以下の様な条件設定を行いました。
開始(Starting)-終了(Ending) はこのパイプラインを動かす期間を範囲で
指定する形となります。
Startingに定めた時間が初回実行の時間となります。 ここでは終了の日付を
適当(?)ではありますが2020年としてみました。
91

・Run: "on a schedule"(スケジュールに従う)
・Run every: "1 day(s)“
・Starting: 任意の日付時刻を設定(初回実行のタイミング)
・Ending: 任意の日付時刻を設定(最後の処理が行われるであろうタイミング)
92

93

パイプラインの作成: ログ出力設定
AWS Data Pipeline の実行ログ各種を出力する設定を行います。
無効(Disabled)とする事も出来ますが、ここは有効 (Enabled) が
推奨とされていますので、有効にしておきましょう。
94
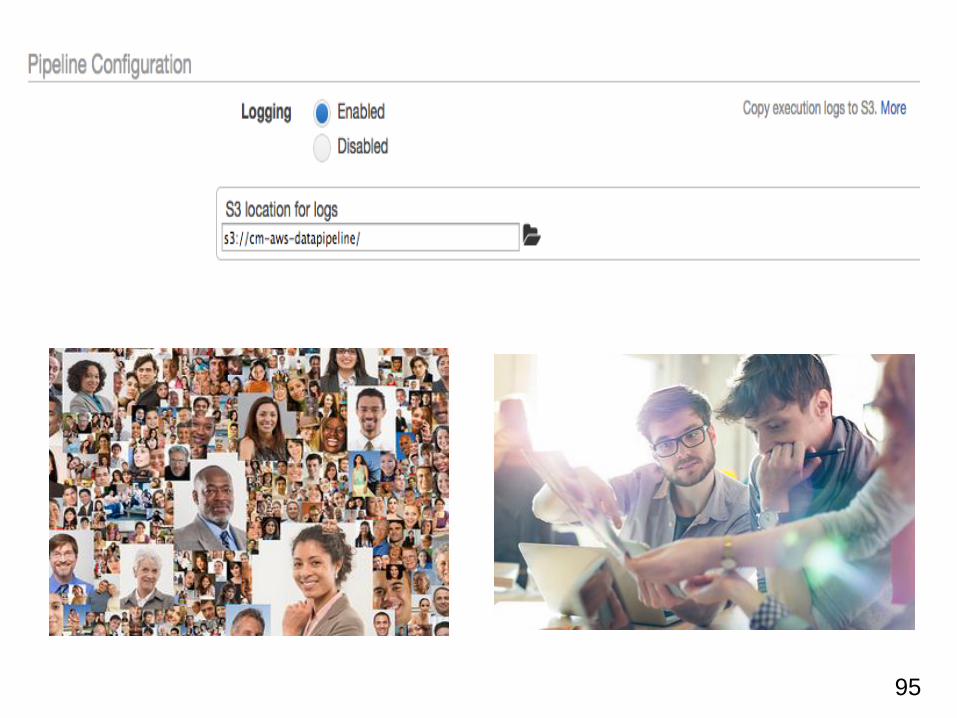
95

出力するバケット名及 びフォルダは事前に作成しておいたものを指定する形と
なっています。
予め作成しておいたものを管理コンソール上で指定しておいてください。
96
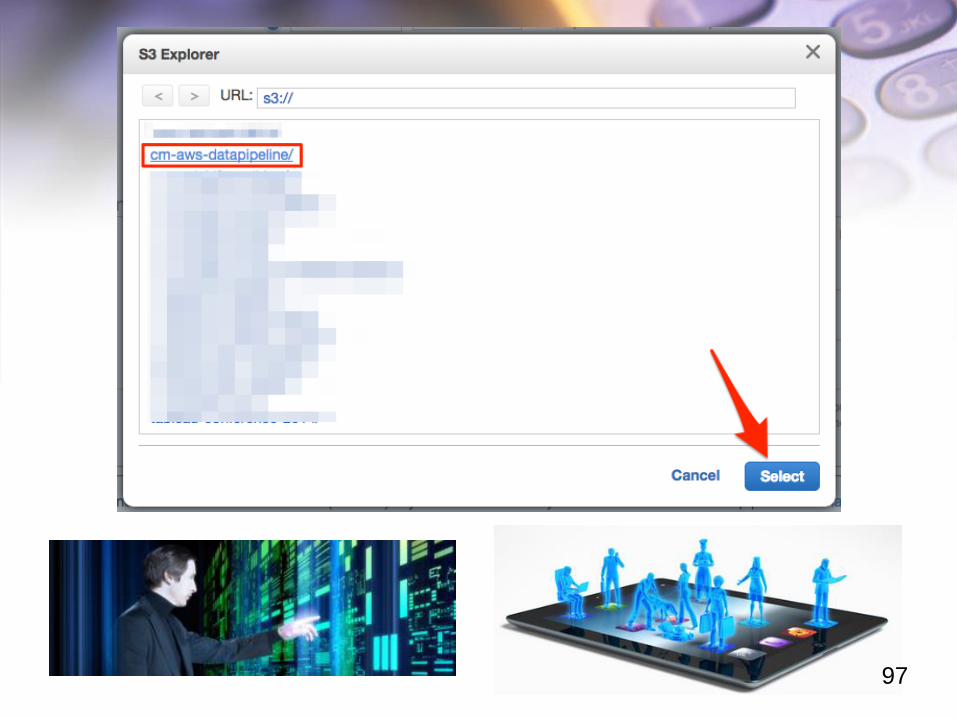
97

パイプラインの作成: IAM設定
AWS Data Pipelineで用いるIAM Roleを指定します。
AWS Data Pipelineでは『Role』(事前条件を実行する為に用いられるIAM Role)と
『ResourceRole』(Data Pipeline経由で稼働するEC2インスタンスが実行する際に
用いるIAM Role) の2つの IAM Roleを使う事になり、ここでDefaultを指定するとそれ
ら2つの IAM Roleのデフォルト指定のIAM Roleを作ってくれます。
98

ここでは初回実行ということでこの Defaultを指定します。
これでひと通りの設定作業が終わりました。
[Edit in Architect] を押下。
99

100
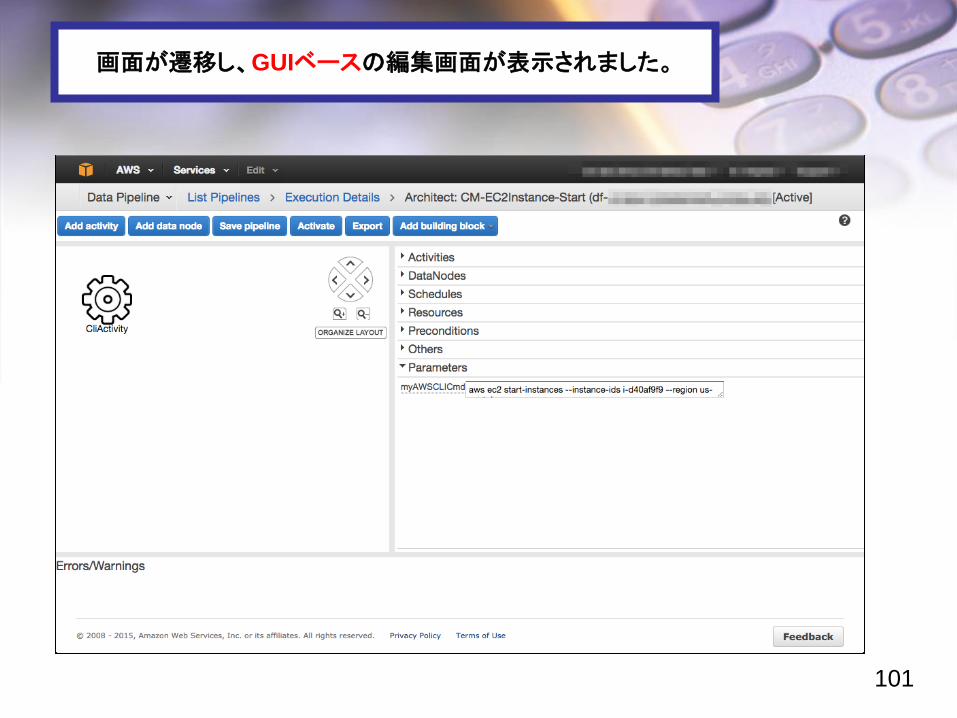
画面が遷移し、GUIベースの編集画面が表示されました。
101

IAM: デフォルト作成のIAM Role に権限付与
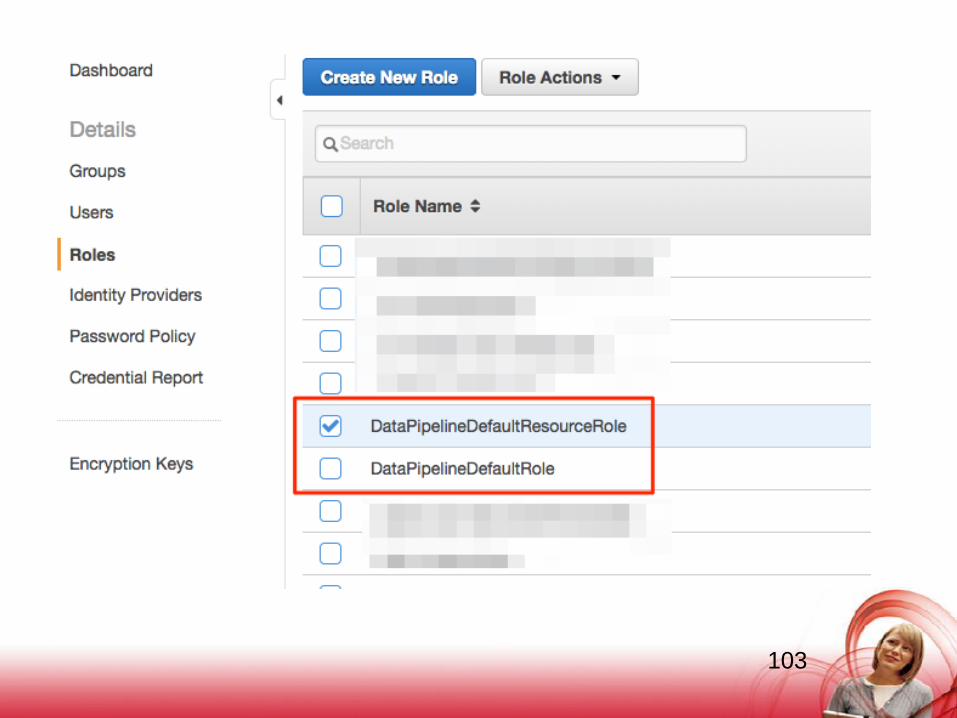
AWS Data PipelineでArchitectに進んだら、別ウインドウでIAMの管理画面を
開いてください。
[Roles]を見てみると、“DataPipeline”で始まる2つの IAM Roleが作成されて
います。
このうち、『DataPipelineDafaultResourceRole』 をクリックして編集画面に進んで
ください。
102
103

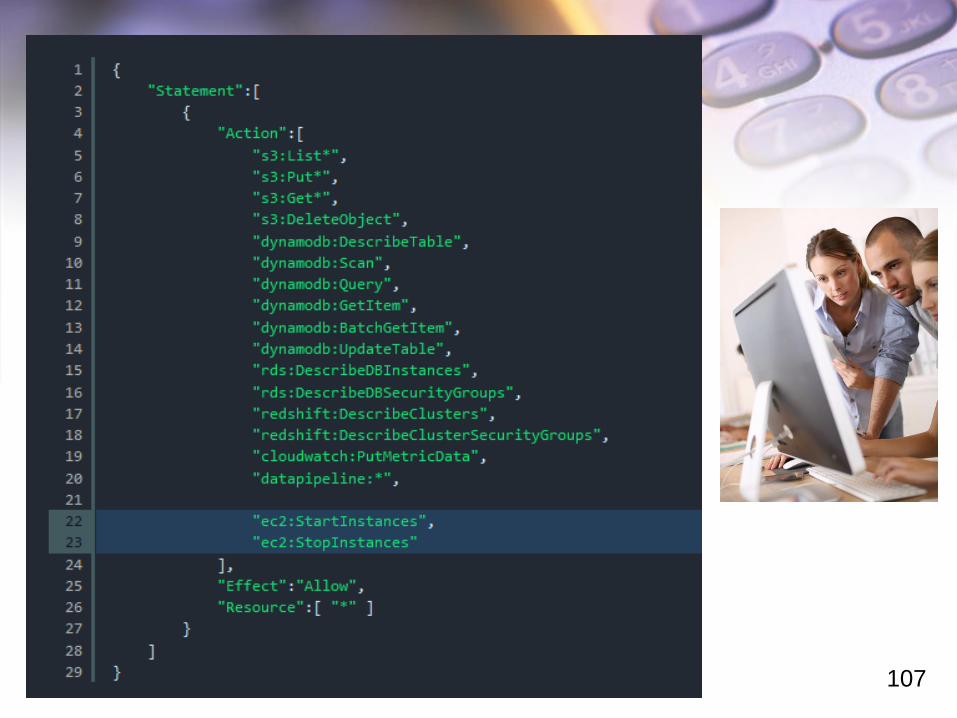
今回実行するアクションは 『EC2インスタンスの起動』 『EC2インスタンスの
停止』 なので、実行する際の権限がDataPipelineDafaultResourceRoleには
付与されておらず、追加する必要があります。
[Manage Policy] をクリックし、必要なアクションを IAM Role に追加します。
104

105

次のスライドがその設定例です。
(今後用途に応じたIAM Role権限が必要になるようであれば、デフォルトIAM Role
とは別に用途に応じた IAM Roleを作成して利用する事も検討すべきでしょう。)
106
107

動作確認
パイプラインのアクティベート
保存が完了したら、[Activate]ボタンを押下。
ここでもワーニングメッセージの警告が出て来ますが、実行には差し支えないので
そのまま[Continue]を押下します。
108

109

進捗の確認
パイプラインの一覧を見てみると、次のスライドの画面の様に各種要素が
一覧表示されています。
[Filter=all]を指定すると、Activityの他に、Activityで利用するEC2インスタンスも
表示されるようになります。
110
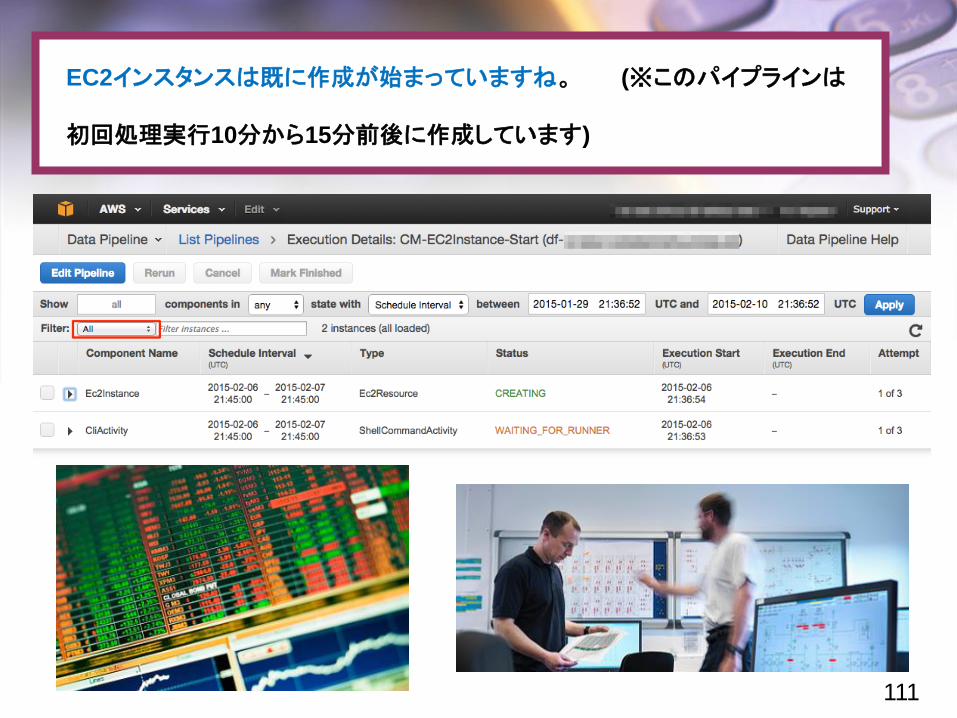
EC2インスタンスは既に作成が始まっていますね。 (※このパイプラインは
初回処理実行10分から15分前後に作成しています)
111

112
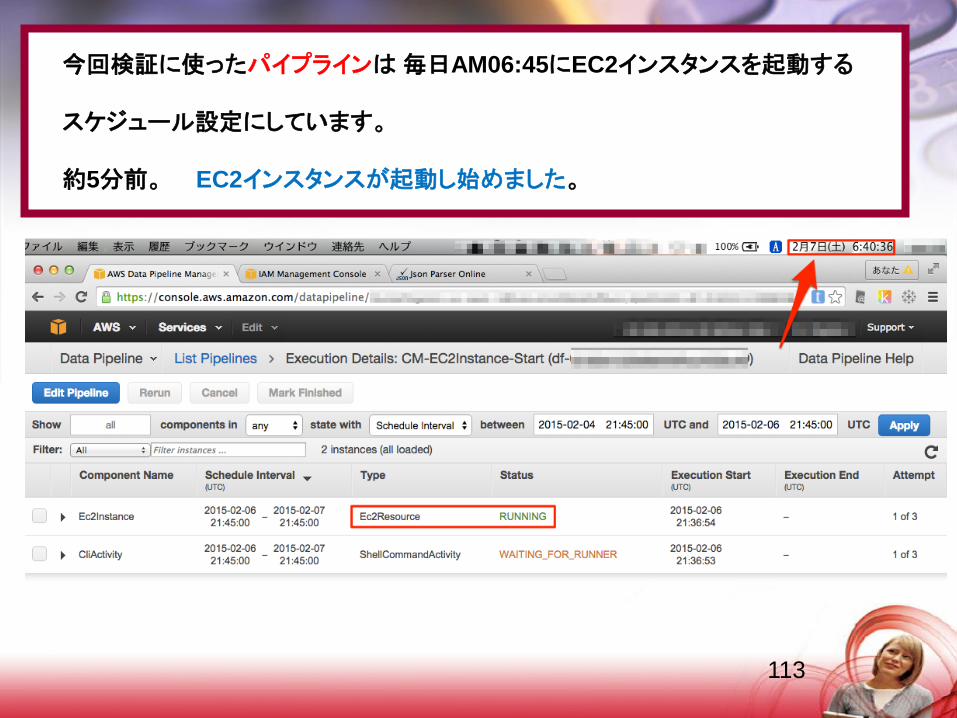
今回検証に使ったパイプラインは毎日AM06:45にEC2インスタンスを起動する
スケジュール設定にしています。
約5分前。 EC2インスタンスが起動し始めました。
113
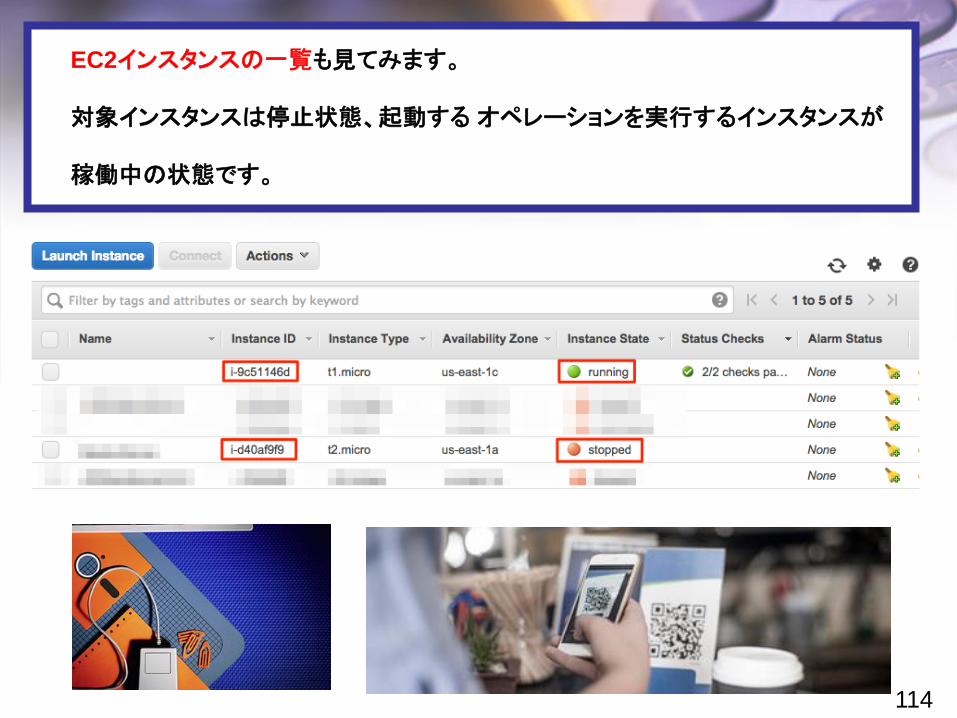
EC2インスタンスの一覧も見てみます。
対象インスタンスは停止状態、起動する オペレーションを実行するインスタンスが
稼働中の状態です。
114

所定の時間(AM06:45) が過ぎ、暫くして管理コンソールを見てみると
ログが生成されていました。
115
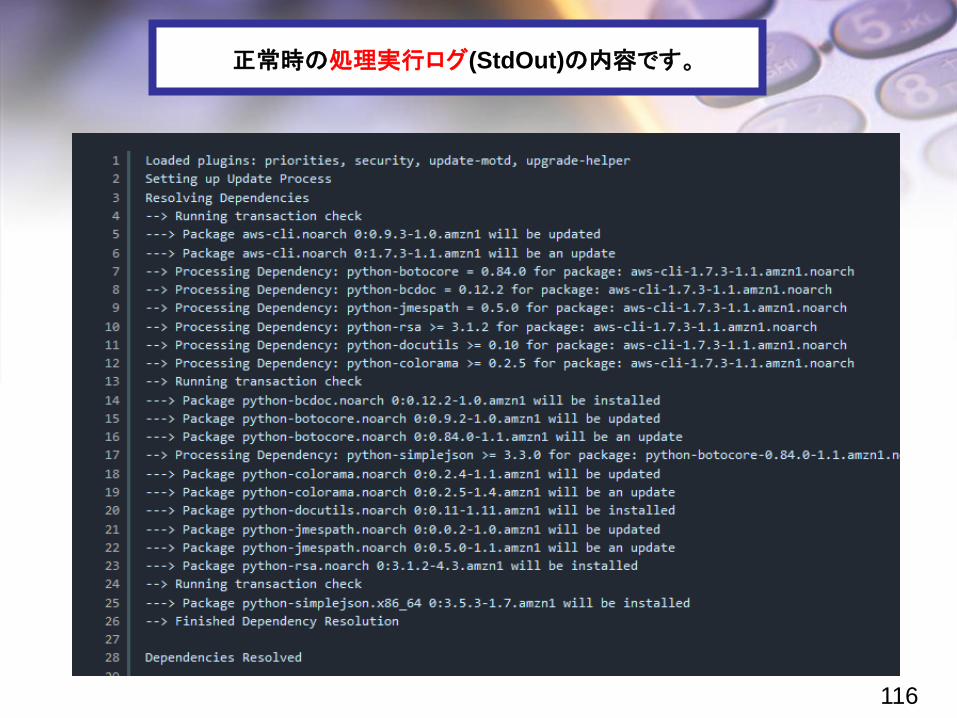
正常時の処理実行ログ(StdOut)の内容です。
116
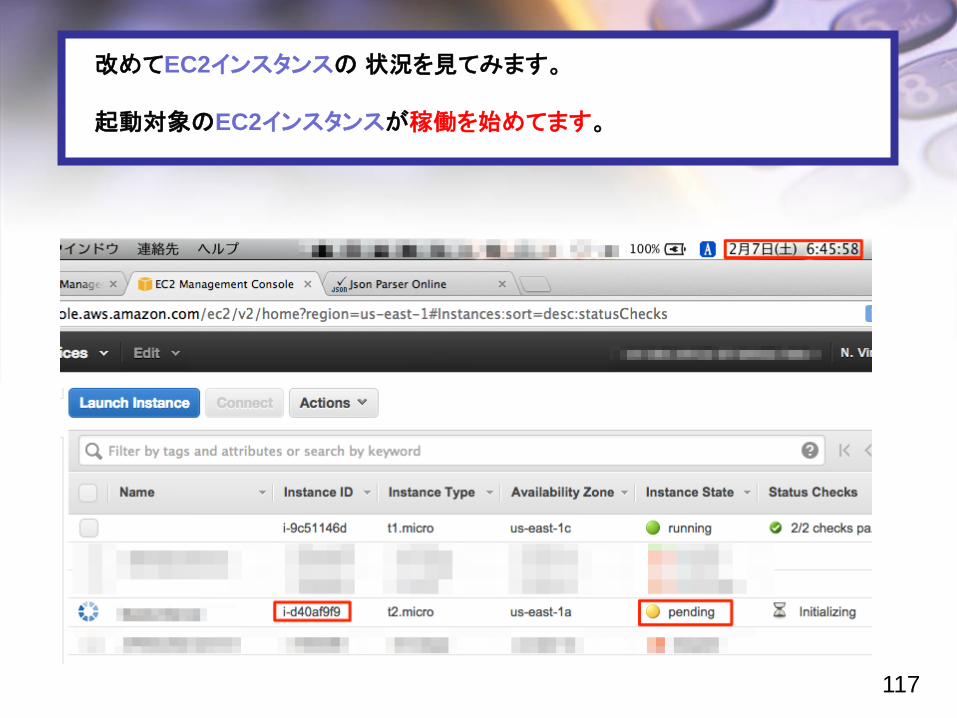
改めてEC2インスタンスの 状況を見てみます。
起動対象のEC2インスタンスが稼働を始めてます。
117
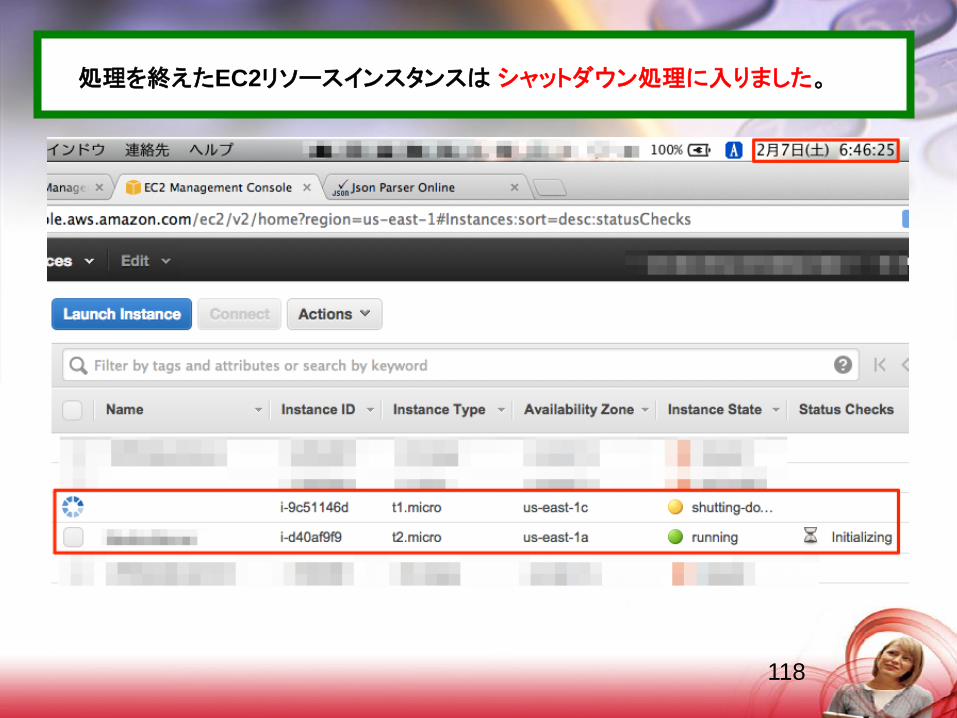
処理を終えたEC2リソースインスタンスは シャットダウン処理に入りました。
118
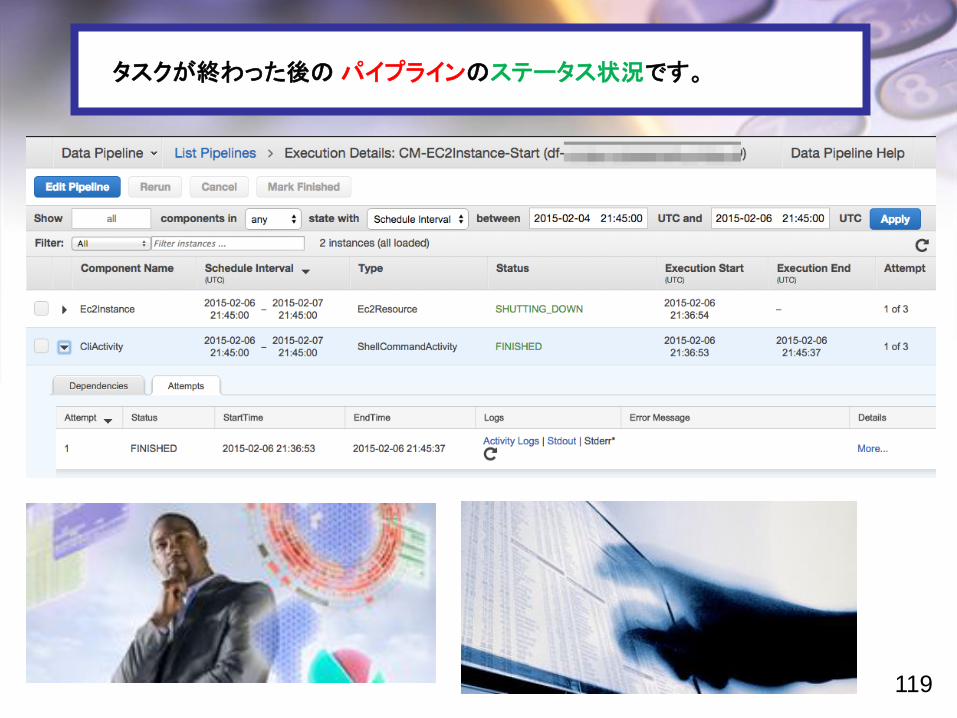
タスクが終わった後のパイプラインのステータス状況です。
119

実行ログも、該当バケット内に生成されていました。
120

121
122

123

124
125
126

補足: AWS Lambda
AWS Lambda を使用すれば、サーバーのプロビジョニングや管理なしでコードを
実行できます。
課金は実際に使用したコンピューティング時間に対してのみ発生し、コードが
実行されていないときには料金も発生しません。
127

Lambda を使用すれば、実質どのようなタイプの アプリケーション やバックエンド
サービスでも管理を必要とせずに実行できます。
コードさえアップロードすれば、 高可用性を実現しながら コードを実行および
スケーリングするために必要なことは、すべて Lambda により行われます。
128

コードは、他の AWS サービスから 自動的にトリガーするよう設定することも、
ウェブ や モバイルアプリケーション から直接呼び出すよう設定する ことも
できます。
129

Auto Scalingによる自動復旧
130

「AWS Lambda」 は、クラウド上でアプリケーションを
実行するプラットフォームです。
AWS Lambda を使えば何らかのイベントを トリガーに処理を実行することが
可能です。
131

Amazon Simple Storage Service (以下、Amazon S3)のバケットへの
ファイルのアップロード、Amazon Kinesis のストリームに届いたメッセージ、
Amazon DynamoDB におけるテーブルの更新といった イベントを受けて、
事前に用意したコードを自動的に実行することができます。
132

133

134

135

136

参考文献:
Amazon.com, Inc.社 公開資料
137

本資料の関連資料は下記をクリックして
PDF一覧からお入り下さい。
ITライブラリー (pdf 100冊)http://itlib1.sakura.ne.jp/
目次番号 453番 AWS詳細解説 全33冊 計6,100ページ
138



















