Appunti SDI Timing
66
Timing (09/12/11) È necessario avere questi registri di pipe tra uno stadio combinatorio e un altro? La risposta è Nì. Cioè ne sì ne no. Tutto dipende dal tipo di propagazione del segnale all’interno della mia struttura. Voglio dire se i blocchi combinatori avessero tutti le stesse caratteristiche in termini di ritardo i registri di temporizzazione sarebbero assolutamente inutili. Qui c’è un esempio (slide 4) di una fibra ottica che se voi mandate un impulso all’ingresso della fibra questo si propaga, dopo si manda un altro impulso , questo si propaga e si mantiene una distanza tra gli impulsi senza aver bisogno di meccanismi che memorizzino temporaneamente i dati. Questo è quello che si chiama il WAVE PIPELINING, che è una tecnica che si cerca di utilizzare nei circuiti di elaborazione digitale, il che vuol dire che è inutile andare a mettere tutte quelle tonnellate di registri di pipe. Se la propagazione combinatoria fosse a velocità costante facendo si che tutti i punti vengono raggiunti con lo stesso ritardo noi potremmo fare tranquillamente una struttura puramente combinatoria senza metterci i flip flop. PROBLEMA: va bene se ho una struttura in cui tutti i ritardi sono rigidamente uguali tra di loro. RISULTATO: con i circuiti con cui abbiamo a che fare ciò non succede. Questo qua arriva prima, quello dopo; c’è una dispersione nell’arrivo dei segnali che in qualche modo mi blocca, perché quello che arriva prima rischia di passare davanti agli altri perché fa il percorso più veloce, mi taglia la strada, allora l’unica cosa da fare è metterci dei ‘semafori’. Questi semafori mi permettono di riaccodare il tutto e quindi ripartire. Da qui nasce il concetto di pipe, il concetto di circuito sequenziale. Vado ad inserire degli elementi di ritardo che temporizzano l’evoluzione del processing in modo tale da garantire una tempistica corretta all’esecuzione. Prima considerazione: l’aggiungere dei flip flop alla nostra struttura inevitabilmente fa andare più piano il tutto, perché c’è un overhead (aumento) dovuto appunto all’inserzione di questi. Allora se vi ricordate dall’anno scorso quando calcolavamo la massima frequenza di funzionamento di un circuito avevamo un ritardo clock to output e consideravamo anche il ritardo combinatorio e il tempo di setup. Il tempo clock to output e quello di setup sono dei ritardi che dipendono dall’aver inserito un flip flop. Quindi avrò quello che si chiama ‘sequencing overhead’ che è il prezzo, in termini di tempo, che pago nel non poter fare un‘elaborazione puramente combinatoria. Riassunto delle puntate precedenti: questi elementi di sequencing possono essere di diversi tipi. Abbiamo latch e flip flop. Il latch è un dispositivo che mi fa passare il segnale o in modo trasparente o in modo opaco (di memoria), abbiamo i flip flop che invece sono sensibili ad un fronte di salita o di discesa e che quindi si chiamano edge triggered. Quando il latch è trasparente cambia l’ingresso e l’uscita cambia seguendo l’ingresso, nel caso di flip flop questo può avvenire solo su un fronte.
description
timing digital elettronic
Transcript of Appunti SDI Timing

Timing (09/12/11)
È necessario avere questi registri di pipe tra uno stadio combinatorio e un altro? La risposta è Nì.
Cioè ne sì ne no. Tutto dipende dal tipo di propagazione del segnale all’interno della mia struttura.
Voglio dire se i blocchi combinatori avessero tutti le stesse caratteristiche in termini di ritardo i
registri di temporizzazione sarebbero assolutamente inutili.
Qui c’è un esempio (slide 4) di una fibra ottica che se voi mandate un impulso all’ingresso della
fibra questo si propaga, dopo si manda un altro impulso , questo si propaga e si mantiene una
distanza tra gli impulsi senza aver bisogno di meccanismi che memorizzino temporaneamente i dati.
Questo è quello che si chiama il WAVE PIPELINING, che è una tecnica che si cerca di utilizzare
nei circuiti di elaborazione digitale, il che vuol dire che è inutile andare a mettere tutte quelle
tonnellate di registri di pipe. Se la propagazione combinatoria fosse a velocità costante facendo si
che tutti i punti vengono raggiunti con lo stesso ritardo noi potremmo fare tranquillamente una
struttura puramente combinatoria senza metterci i flip flop. PROBLEMA: va bene se ho una
struttura in cui tutti i ritardi sono rigidamente uguali tra di loro. RISULTATO: con i circuiti con cui
abbiamo a che fare ciò non succede. Questo qua arriva prima, quello dopo; c’è una dispersione
nell’arrivo dei segnali che in qualche modo mi blocca, perché quello che arriva prima rischia di
passare davanti agli altri perché fa il percorso più veloce, mi taglia la strada, allora l’unica cosa da
fare è metterci dei ‘semafori’. Questi semafori mi permettono di riaccodare il tutto e quindi
ripartire. Da qui nasce il concetto di pipe, il concetto di circuito sequenziale.
Vado ad inserire degli elementi di ritardo che temporizzano l’evoluzione del processing in modo
tale da garantire una tempistica corretta all’esecuzione.
Prima considerazione: l’aggiungere dei flip flop alla nostra struttura inevitabilmente fa andare più
piano il tutto, perché c’è un overhead (aumento) dovuto appunto all’inserzione di questi.
Allora se vi ricordate dall’anno scorso quando calcolavamo la massima frequenza di funzionamento
di un circuito avevamo un ritardo clock to output e consideravamo anche il ritardo combinatorio e il
tempo di setup. Il tempo clock to output e quello di setup sono dei ritardi che dipendono dall’aver
inserito un flip flop. Quindi avrò quello che si chiama ‘sequencing overhead’ che è il prezzo, in
termini di tempo, che pago nel non poter fare un‘elaborazione puramente combinatoria.
Riassunto delle puntate precedenti: questi elementi di sequencing possono essere di diversi tipi.
Abbiamo latch e flip flop. Il latch è un dispositivo che mi fa passare il segnale o in modo trasparente
o in modo opaco (di memoria), abbiamo i flip flop che invece sono sensibili ad un fronte di salita o
di discesa e che quindi si chiamano edge triggered. Quando il latch è trasparente cambia l’ingresso e
l’uscita cambia seguendo l’ingresso, nel caso di flip flop questo può avvenire solo su un fronte.

Vediamo quali sono i modi di realizzare le nostre strutture di memorizzazione.
Il modo più semplice di realizzare un latch è quello di mettere un transistor che funziona da pass
transistor.
Giocando sulle capacità parassite se phi=‘1’ Q=D, altrimenti Q mantiene il valore precedente di D
per un pò. Se passa troppo tempo si rischia di perdere il valore di Q. Il primo vantaggio è che uso
un solo transistore, quindi è piccolo. Un solo transistore vuol dire che il mio clock va ad un solo
transistore che mi fa da latch. Si hanno poi tutta una serie di aspetti negativi: sappiamo che in
questo modo mi passano dei buoni zeri ma non dei buoni uni (a causa della caduta della tensione di
soglia); per qualche motivo l’uscita potrebbe far variare l’ingresso cioè quello che si chiama back-
driving ovvero non è un flusso unidirezionale; è semplicemente un interruttore che chiude due punti
e di lì vince quello più forte. Il tutto è dinamico perché l’uscita dopo un po’ si scarica ecc.. ecc..

Allora qualcuno ha pensato che invece di mettere un solo transistor se ne mettono due (Pmos e
Nmos) cloccati su fasi differenti. Questo genera quello che si chiama il transmission-gate che è un
interruttore migliore perché l’Nmos mi fa passare molto bene gli zeri mentre il Pmos mi fa passare
molto bene gli uni. Li metto in parallelo così che ce ne sia sempre uno che mi passare bene il
segnale. Non ho più la caduta legata alla caduta legata alla tensione di soglia. Va meglio ma ho due
inconvenienti: invece di un transistor me ne bisognano due quindi raddoppia l’area; invece di un
clock ho bisogno di due fasi e quindi raddoppia anche tutta la parte di generazione del clock.
Per il resto è sempre dinamico, non si sa chi sia l’ingresso e chi sia l’uscita => non è unidirezionale.
Andando avanti si comincia a renderlo unidirezionale, ovvero dire all’uscita del transmission gate ci
metto un inverter oppure ce lo metto prima. In questo modo è una struttura invertente, però ho il
vantaggio che è unidirezionale e non ho perdita di segnale in nessun modo.
Poi si può discutere se è meglio mettere l’inverter a monte o a valle. Se sono meno sicuro sul
pilotare il mondo esterno lo metto a valle perché così è lui che pilota.
Se ho problemi con chi pilota me allora è meglio metterlo prima (a monte); quindi dipende dove
voglio avere una maggiore robustezza, se sulla parte di uscita o su quella d’ingresso.
Questo è sempre di tipo dinamico per cui quando va in memoria mantiene l’informazione. Se voglio
farlo diventare di tipo statico devo introdurre un feedback:

In questo modo diventa statico e posso scrivere lungo la mia catena di due inverter in reazione e
quando non scrivo chiudo il loop in modo da mantenere il segnale teoricamente per tutto il tempo
che voglio. Devo fare attenzione in questo caso al back-drive ovvero che il valore dell’uscita non si
ripercuota all’ingresso. Poi ci sono varie configurazioni:
Ci possiamo mettere un buffer d’ingresso per evitare appunto il back-drive.
Ci posso mettere un buffer d’uscita per svincolare il pilotaggio dell’uscita rispetto alla
memorizzazione del dato con tutta una serie di vantaggi e svantaggi:
Esistono quindi varie topologie e siamo arrivati ad avere una decina di transistori per realizzare un
solo latch! Se poi voglio fare un flip flop sappiamo che bisogna farlo con due latch in
configurazione master-slave:

Quindi con due stadi cloccati su fasi differenti. Da notare che una volta phi va sull’Nmos e una
volta va sul Pmos. Alla fine il risultato è che un oggetto di questo genere è composto da una ventina
di transistori. I flip flop visti lavorano su due fasi e ad ogni colpo di clock memorizzano il dato in
ingresso. PROBLEMA: questo va bene per una pipe pura, se io voglio usarli in una control pipe in
cui sono io che voglio decidere se usarli o meno devo aggiungerci il load enable.
Aggiungere l’enable vuol dire avere strutture che oltre al segnale di clock hanno un segnale di
controllo che dice si sul fronte clocca ma solo se ti abilito io.
Il progetto del flip flop in cui ho aggiunto l‘enable può essere fatto in due modi. Il modo classico è
quello di usare un approccio di tipo multiplexer. Ciò vuol dire: se c’è l’enable abilitato, sul fronte
memorizza l’ingresso, se no mantieni il valore vecchio.
Quando vado a definire la struttura con enable oltre a tutto quello già visto devo metterci pure
questo multiplexer che decide se caricare un nuovo dato o mantenere il vecchio.
In questo modo il flip flop viene campionato ad ogni colpo di clock. È il Mux che decide se fargli
campionare il dato vecchio o il nuovo.
Un approccio alternativo da NON USARE, tranne in certi casi, consiste nel fare il clock gating,
ovvero mettere in and l’enable con il clock. Questa è una tecnica assolutamente da
SCONSIGLIARE, perché fatta semplicemente così può portare a circuiti che non funzionano.
Se l’enable che viene da una macchina a stati ha dei glitch (commutazioni spurie e indesiderate) e il
clock è uno si ha un controllo errato in uscita alla and e il flip flop campiona senza volerlo!

Si vedrà in realtà che esiste il modo di generare quest’enable senza glitch e questo porterà nel corso
di low power a realizzare strutture che usano questa tecnica per ridurre il consumo di potenza.
Il concetto è che se un blocco in un certo momento non mi serve che faccia nulla allora lo disabilito
evitando che gli arrivi il clock.
Ovviamente a tutti questi flip flop vogliamo aggiungere anche il reset e sappiamo che esistono due
tipi di reset: quello sincrono e quello asincrono.
La differenza principale è che il reset sincrono entra esclusivamente sull’ingresso del mio flip flop e
quindi richiede che in qualche modo il dato in ingresso sia filtrato attraverso una porta e quindi il
reset sincrono va ad agire solo sulla parte d’ingresso e quindi solo sul setup dei dati; aumenta il
ritardo in ingresso e basta. Il reset asincrono richiede l’inserimento del reset anche nell’anello che
mantiene il dato e questo vuol dire che il reset asincrono richiede l’intervento nell’anello perché
quando il reset diventa attivo deve essere immediatamente operativo.
Il reset sincrono invece l’ho fatto semplicemente con un filtraggio del dato d’ingresso.
Se poi oltre al reset voglio metterci pure il set il risultato è il seguente:

Abbiamo quindi strutture di flip flop con una ventina di transistori. Questo è il motivo per cui una
trentina di anni fa si preferiva usare il latch con il minor numero possibile di transistor. Adesso che i
transistor non costano nulla e hanno aree infime si preferisce usare il flip flop perché lavorare sui
fronti dà tutta una serie di vantaggi. Gli elementi visti devono essere usati con dei regimi di
temporizzazione. Principalmente abbiamo tre regimi con cui lavorare; diciamo due perché il terzo è
molto meno utilizzato e ci interessa solo sapere che esiste.
Metodo Principale: Sincronizzazione a Fronti.
Il concetto è avere flip flop-rete combinatoria-flip flop e i due flip flop sono campionati sullo stesso
fronte:

Ho un flusso di dati che impiega un colpo di clock intero per andare da un flip flop al successivo.
Questa è la struttura tradizionale.
Un’altra struttura con cui si aveva a che fare in passato e si ha ancora a che fare quando si vuole
risparmiare area, è una struttura a latch: latch con fase1- rete combinatoria- latch con fase2- rete
combinatoria- latch con fase1. Quindi si usano due fasi che per poter funzionare sfruttano degli
intervalli di non-overlap tra loro, in cui nessuna delle due fai è attiva. In questo tempo di non-
overlap entrambi i latch sulle due fasi sono in stato di memoria. Praticamente in ogni fase avanzo di
mezzo step. Questa struttura a latch in due fasi è una struttura che è stata usata tantissimo nei
circuiti integrati ed è tutt’ora usata abbastanza perché vedremo che ha una serie di vantaggi.
Dal punto di vista del timing è una struttura estremamente robusta e facilmente scalabile.
Un progetto fatto con questo metodo infatti è possibile riportarlo su qualunque tipo di tecnologia
senza avere problemi di timing.
Per completezza vediamo anche il terzo metodo che useremo MAI che è quello che si chiama
PULSED LATCH. Notiamo che ho un latch su una fase- rete combinatoria- latch sulla stessa fase.
Quindi i latch hanno fase unica. Do un impulso al latch in modo che passi il dato, il dato si propaga
nella logica combinatoria, si presenta sul latch successivo con lo stesso clock al prossimo impulso.
Ho ridotto da due ad una la fase su cui lavorano i latch. Si hanno però un po’ di problemini.
Per esempio nella nostra logica combinatoria ci possono essere percorsi più o meno lenti. Siccome i
due latch sono attivi sulla stessa fase, se c’è un percorso nella rete combinatoria particolarmente
veloce, questo rischia di arrivare già al prossimo latch mentre la fase di quest’ultimo è ancora alta e
venire memorizzato da esso quindi. Quindi non funziona più tutto il meccanismo, cioè ad ogni
colpo di clock vai avanti solo di uno stadio per volta. Non è che questa struttura non funzioni ma è
più difficile da progettare, meno robusta e più sensibile a quello che metto nella logica
combinatoria.
Quindi tipicamente, come nell’FPGA, si usano solo strutture a flip flop. Nei circuiti integrati si può
anche usare la struttura a latch su due fasi non-overlapped per i vantaggi che abbiamo visto.
Nella slide in figura si trovano i vari tempi con cui abbiamo a che fare:

Abbiamo a che fare con tempi di propagazione da un ingresso ad un’uscita con tempi di setup.
I tempi di propagazione li abbiamo visti l’anno scorso utilizzando tempi di propagazione minimi e
massimi. Cosa vuol dire tempo minimo di 2 ns e massimo di 4 ns? Vuol dire che prima di 2 ns
l’uscita sicuramente non cambia. Solo dopo 2 ns l’uscita potrà cambiare (può essere contaminata) e
cambia certamente prima di un tempo massimo (4 ns).
tcd è proprio il tempo di contaminazione del blocco logico, ovvero da quando cambia l’ingresso il
primo istante in cui l’uscita può cambiare è quello che chiamiamo tempo di contaminazione. È
quello che abbiamo chiamato ritardo minimo. Invece il propagation delay (tpd) è il ritardo
massimo di propagazione tra ingresso e uscita. Tcd quindi è il tempo minimo per cambiare l’uscita.
Nella nostra analisi worst case lavoriamo con tempi di contaminazione minimi e tempi di
propagazione massimi.
Nella prossima slide si vede che da quando cambia il clock a quando può cambiare l’uscita è il
tempo di contaminazione clock to output, da quando cambia il clock a quando cambia l’uscita al
valore massimo è il tempo di propagazione clock to output.
Questa slide non è esatta perché alcune di queste frecce non hanno il minimo senso. Il tempo di
setup non è una freccia! Non significa cambia D2 e questo provoca una variazione del clock!

Allora sul tempo di setup e il tempo di hold vanno cancellate tutte le frecce, perché questi tempi
sono dei tempi che io devo garantire, ma non sono dei ritardi del progetto.
Il tempo di setup mi dice semplicemente che se voglio campionare correttamente il dato devo
avere l’ingresso stabile almeno un tempo di setup prima del fronte di clock.
Il tempo di hold non vuol dire fronte di salita allora … !
È necessario che il dato resti stabile anche per un tempo successivo al fronte del clock. Si definisce
allora tempo di hold, il minimo intervallo di tempo che deve trascorrere dal fronte attivo del clock
prima che si verifichi una variazione del dato.
Allora i tempi di setup e di hold NON SONO dei ritardi/tempi di propagazione. Sono delle
grandezze che devo tenere in conto per capire il timing del nostro sistema.
Andiamo ad identificare delle disequazioni che permettono di farci capire qual è la massima
frequenza e quali sono le condizioni operative con le quali può funzionare il nostro circuito.
Meglio usare la tecnica con i flip flop o la tecnica con i due latch?
Caso che ben conosciamo: flip flop – logica combinatoria- fronte, da quando cambia il clock
l’uscita Q1 cambia con un ritardo di propagazione clock to output, a questo punto inizia il ritardo
della logica combinatoria cioè quello che viene chiamato tpd, questo porta a un certo punto a
cambiare definitivamente l’ingresso D2 del secondo flip flop; bisogna che ci sia almeno un tempo
di setup prima del fronte del clock per essere sicuro che quel dato venga campionato correttamente.
Questo ha portato a dire che in un colpo di clock deve passare il tempo di propagazione clock to
output + il tempo di propagazione della logica combinatoria + il tempo di setup.
Questo vuol dire che con questa struttura fissata una frequenza di funzionamento, quindi un periodo
di clock Tc, il massimo tempo a disposizione della logica combinatoria tpd è minore di un colpo di
clock meno il ritardo clock to output meno il tempo di setup.
Il sequencing overhead è la somma del tempo di setup + il ritardo clock to output. È una parte del
tempo che non viene usato per fare calcoli. È una parte che viene utilizzata per prendere il dato,
mandarlo in uscita al flip flop e stare a aspettare il prossimo colpo di clock.
Questo concetto è da applicare a tutti i percorsi combinatori della mia macchina. Definiti tutti i flip
flop e conoscendo le loro caratteristiche, mi fanno capire qual è il massimo ritardo combinatorio che
posso permettermi per garantire che tutto funzioni correttamente.
Esiste un discorso da fare anche sul minimo tempo di propagazione, ovvero abbiamo dei vincoli sul
massimo tempo della logica combinatoria ma abbiamo anche un vincolo sul tempo minimo.
Perché? Perché se è vero che tutti questi flip flop sono tutti in pipelining e lavorano tutti sullo stesso
colpo di clock, sullo stesso colpo di clock io campiono il dato in ingresso e campiono anche il dato

D2. Campiono il dato in ingresso; dopo un tempo minimo (quello di contaminazione clock to
output) incomincia a cambiare D1, che poi potrà cambiare anche dopo ma non importa.
Questo vuol dire che posso incominciare a cambiare della parte combinatoria e quindi dopo un
tempo minimo di passaggio attraverso la parte combinatoria, ovvero il contamination-time ingresso
uscita, D2 potrebbe incominciare a variare. Potrebbe variare più e più volte fino ad un certo punto a
stabilizzarsi. Qual è il problema? Il problema è che se D2 cambia troppo presto il rischio è che
questo flip flop che comunque campiona e continua a campionare il valore vecchio, si trova il suo
valore vecchio che incomincia a cambiare prima del tempo di hold del flip flop stesso.
Quindi io so che per campionare F2 il dato in ingresso, deve essere verificato il setup e questo lo
verifichiamo con questa disequazione; campiono e prendo D2 che deve essere stabile almeno un
setup prima, però quello che deve essere chiaro è che dopo il campionamento per almeno un tempo
di hold D2 non deve cambiare e il problema è che D2 cambia dopo un ritardo di contaminazione
clock to output + il tempo di contaminazione della logica combinatoria. Che cosa deve succedere
affinchè funzioni correttamente? Deve succedere che la somma di questi due tempi minimi deve
comunque essere più grande del tempo di hold. Il che vuol dire che l’uscita comincerà a cambiare
quando ormai ho finito la memorizzazione del dato. Questo vuol dire che il tempo di hold deve
essere minore di questi due tempi combinatori.
Questo è un punto che crea delle turbe non trascurabili ai sistemi di sintesi, perché questo mi porta
comunque ad un vincolo sul minimo tempo di contaminazione della logica combinatoria.
Va tutto bene, il sistema funziona, però attenzione perché il rischio è che se il sistema è troppo
veloce rischia di non funzionare più e l’uscita va già a sporcare la memorizzazione del dato che c’è
in F2. Se si vìola questa disequazione il sistema non funziona a qualunque frequenza. Il
sistema, cioè, non riesce a campionare in modo corretto i dati, qualunque sia la frequenza.
Attenti dunque alla violazione del tempo di hold.

Mentre se ho una violazione del setup posso allungare il clock e avendo più tempo a disposizione
prima o poi il setup viene garantito, sugli hold non c’è verso!
Se facendo la sintesi il sintetizzatore vi dice Alt Hold Violation, fermi tutti, si devono
necessariamente eliminare le violazioni dei tempi di hold.
Nelle slide da 32-35 ci sono degli esempi sui latch impulsati ma non ci interessano. L’unica cosa
fondamentale da notare è che anche qua il ritardo della logica combinatoria deve essere inferiore
alla differenza tra un periodo di clock e il massimo tempo di inserzione. Ho un limite sul massimo
ritardo combinatorio. Anche qua ho un limite sul minimo tempo di propagazione e contaminazione.
Vediamo invece adesso il discorso delle due fasi, molto più usato.

Qui il concetto è: fase 1 attiva, dopo un po’ di tempo varia l’uscita del primo latch. Dopo il tempo di
propagazione di Q1, quindi del primo latch, cambia l’uscita Q1. A questo punto inizia la
propagazione verso la rete combinatoria, quindi quello che chiamiamo tpd1; questo a un certo punto
arriva al secondo latch, il secondo latch a un certo punto è attivo; quando è attivo passo attraverso il
secondo latch, inizia la propagazione nella logica combinatoria e a questo punto mi presento al terzo
latch. Da quando arriva il dato D1 a quando arriva il dato D3 è passato un periodo di clock. In un
periodo di clock ho il ritardo ingresso-uscita del primo latch, ritardo combinatorio 1, ingresso-uscita
del secondo latch, ritardo combinatorio 2. Il tempo di propagazione della logica combinatoria tpd1
+ tpd2 è uguale a un periodo intero meno i due ritardi ingresso-uscita che guardate in questo caso
diventa il sequencing overhead. In questo caso il tempo di propagazione a disposizione dei due
blocchettini, io ho diviso il tempo combinatorio in due parti, è uguale praticamente al periodo meno
il tempo di attraversamento dei due latch. Questo semplicemente per dire che anche in questo caso
ho un tempo di inserzione, il sequencing overhead. Questa volta il sequencing overhead è pari alla
somma, supponendo che siano uguali i latch, sono due volte i tempi di propagazione ingresso-uscita
del latch. Quindi se vogliamo da questo punto di vista le cose vanno un po’ peggio perché devo
passare attraverso 2 oggetti anziché 1. Però se vado nei dettagli vedo che i latch sono più piccoli
quindi i tempi di propagazione sono inferiori a quelli dei flip flop.
La cosa fondamentale è che questa parte di non overlap mi permette di garantire che non ci sarà mai
la situazione che c’era nel caso dei latch impulsati. Non può mai verificarsi un errore per cui il dato
di qua nello stesso colpo di clock buca L2 e si presenta su L3, perché c’è comunque un momento in
cui i latch sono tutti in memoria. Sono tutti nella zona opaca, nessuno è trasparente quindi la
propagazione si blocca prima del latch. Per quanto riguarda il discorso del tempo minimo:

Per quanto riguarda l’hold time qui il discorso è molto più semplice. Guardiamo, phi1 diventa attivo
in questo momento, quindi solo in questo momento può iniziare a passare il dato attraverso L1.
Dopo un tempo minimo che è il tempo di contaminazione clock to output, inizierà a cambiare Q1,
inizierà a cambiare la logica combinatoria e dopo un tempo di contaminazione tcd il dato si
presenterà a D2. Si presenta a D2 ma la fase a D2 è già finita ed è finita un tempo di overlap prima
di questa cosa. Se andiamo a vedere i due percorsi da una parte ho un tempo di hold, da quando
scende phi2, che devo garantire, dall’altra ho il tempo di non overlap + il tempo di contaminazione
clock to output + il tempo della logica combinatoria. Bisogna che questo percorso sia più lungo del
tempo di hold. Il tempo di hold deve essere minore dell’overlap + i due tempi di contaminazione,
ovvero che i tempi di contaminazione debbano essere maggiori dell’hold meno il tempo di
contaminazione clock to output meno il tempo di non-overlap. Rispetto al caso precedente il tempo
di overlap si sottrae quindi mi permette di essere molto più tranquillo. Molto spesso a causa
dell’overlap la parte sulla destra è negativa il che vuol dire qualunque sia il ritardo minimo il
sistema funziona. Il sistema diventa molto più robusto. Non ho più, o quasi, di dover considerare
ritardi minimi. Non ho problemi di violazione dell’hold time. Il non overlap mi aiuta a non avere
problemi legati all’hold time del nostro sistema. Risultato: questo metodo di temporizzazione a due
fasi è un metodo che è molto robusto. Mi permette di agire sugli hold time. Sono in crisi, allora
aumento il tempo di non overlap tra le due fasi. Andando ad agire sulla frequenza e sul tempo di
non overlap sono in grado di far funzionare questa macchina su una qualunque tecnologia.
Basta scegliere un regime di temporizzazione delle due fasi che abbia un non overlap minimo e che
sia in grado di lavorare a una certa frequenza garantendo un tempo di ciclo minimo. Che cosa pago?
Ho il doppio delle linee di clock da portare in giro, le due fasi. A parte il fatto che devo generare i
due segnali di clock, pago il fatto che devo avere una struttura che comunque mi garantisca di avere
una zona di non overlap dappertutto. È così importante che molto spesso si realizzano strutture in
cui la logica combinatoria viene divisa in due metà.

Quello che devo realizzare è fatto con una prima metà in cui metto un latch su una prima fase, la
seconda metà ci metto un latch su una seconda fase e così via. Rispetto alla sintesi con flip flop in
cui tutta la mia parte combinatoria viene messa insieme in modo combinatorio da un flip flop e il
successivo, qui la parte combinatoria è divisa in due metà e ci metto in mezzo un latch su una fase
diversa. Questa è una struttura di temporizzazione assolutamente generale. Se lavoriamo con un
sistema di temporizzazione a due fasi non-overlapped tutti i percorsi combinatori devono essere
sempre e comunque interrotti da una sequenza alternata di latch su fasi diverse. Se si fa questo tipo
di scelta garantiamo che comunque si possa trovare un regime di temporizzazione per cui il mio
circuito funzionerà sicuramente. Applico in maniera alternata la fase 1 e la fase 2 sui vari stadi in
cascata così come sono previsti. Il concetto è che sempre una struttura qualsiasi richiede che ci
siano dei percorsi combinatori, questi percorsi sono percorsi in cui faccio di tutto e di più tra un
evento di temporizzazione e un evento di temporizzazione successivo. Dopodichè possono essere
flip flop tutti su un fronte, possono essere latch su fasi diverse, non importa. La mia macchina avrà
tanti oggetti di questo tipo, tante parti combinatorie, è chiaro che perché la macchina funzioni
correttamente tutti questi percorsi combinatori tra un elemento di memoria a monte e uno a valle
deve essere in grado di terminare il lavoro in modo corretto. Questo vuol dire che io ho una
limitazione sulla massima frequenza legata a quello che è il percorso critico. Il percorso critico
(critical path) è il più lungo. Per questo un passo di progetto è cercare di bilanciare il più possibile i
ritardi combinatori della macchina cercando di rendere minimo il percorso critico. Infatti, chi mi
limita la frequenza di funzionamento è il massimo ritardo combinatorio. Se per esempio ho un
percorso che ci sta 1 ns e uno che ce ne sta 10 ns, si cerca di modificare la struttura in modo che per
esempio ci stiano entrambi 5 ns. Allora ho dimezzato il percorso critico e ho raddoppiato la
frequenza di funzionamento. Si tratta dunque di fare un RETIMING, ovvero cercare di distribuire
gli elementi di memoria in modo da minimizzare i percorsi critici.

Nell’esempio in slide se la porta Nand fa parte di un percorso critico e mi basta bypassare il suo
ritardo per migliorare le cose, posso spostare l’elemento di memoria dalla sua uscita agli ingressi, al
costo in questo caso di duplicare il numero di elementi di memoria. Ovviamente se alla destra della
Nand c’è un altro percorso combinatorio, dopo tale spostamento, tale percorso avrà un ritardo che
risulterà incrementato del ritardo della Nand. Si tratta dunque di bilanciare i percorsi. È una tecnica
che può essere dispendiosa dal punto di vista del numero di flip flop con cui vado a lavorare.
Bisogna stare molto attenti perché se ho loop rischio di fare danni; introducendo latch/flip flop nei
loop cambio la tempistica del loop e le cose non vanno più come dovrebbero.
Posso usare questa tecnica quando ho un flusso di esecuzione senza loop, tipo datapath.
Abbiamo visto la struttura a due fasi, vediamo ora come generare queste due fasi in modo da avere
quei tempi di non overlap.
Metodo banale: un bel set/reset pilotato da un segnale di clock che fa lavorare il set/reset sempre
nelle condizioni o set o reset attivo, nel feedback ci metto in maniera voluta delle reti di ritardo
delta1 e delta2 in modo che ritardino di una certa quantità la generazione delle fasi delle porte. Si
può dimostrare che i tempi di non-overlap sono esattamente uguali a delta1 + delta2. Andando cioè
a inserire nel feedback dei ritardi opportuni io posso generare i tempi di non-overlap che voglio.
Questo è un vantaggio notevole perché vuol dire che il sistema che genera le due fasi è banale.
Prendi il tuo generatore di clock lo mandi dentro a questo circuito e automaticamente in uscita
avremo due fasi non sovrapposte. Per costruzione questo è un circuito in cui le due uscite non
saranno mai entrambe a ‘1’.

Avremo segnali che arrivano da una logica combinatoria e andranno ad essere campionati o sulla
fase phiA o sulla fase phiB. La domanda è: come deve essere il segnale che arriva per essere
campionato correttamente da phiA? Esso deve essere stabile per almeno un tempo di setup prima
che venga campionato e dopo per almeno un tempo di hold. La stessa cosa per phiB.
Quindi diciamo che il segnale è valido A o valido B in dipendenza del fatto che può essere
correttamente campionato da A o B rispettivamente.
Un segnale si dice stabile A o stabile B se esso non varia per tutto il tempo in cui la
corrispondente fase è attiva ed è già valido sul fronte precedente dell’altra fase.
Tva = TsetupA + TholdA
Tsa = TsetupB + Tnonoverlap + T1phiA + TholdA
Se noi ipotizziamo di lavorare con queste quattro possibili configurazioni, cioè i segnali possono
essere o validi o stabili su una delle due fasi, possiamo costruirci un regime di temporizzazione a
due fasi non-overlapped generale, che funziona sempre, scalabile, portabile da una tecnologia
all’altra, robusto. Può essere adattato a qualunque tecnologia semplicemente cambiando la
frequenza di funzionamento della macchina. Su ogni nodo interno io appiccico un’etichetta che mi
dice qual è la sua caratteristica dal punto di vista del timing. Uso quest’etichetta per fare un’analisi
dal punto di vista della correttezza del timing del sistema.
In questo modo è facile capire dal progetto se le cose funzionano o no. Se fatto bene, il progetto
funziona per costruzione, evito tutti i problemi legati al timing nel mio sistema.
Questo sistema a latch a due fasi è usato pesantemente nei circuiti integrati. Non tanto
nell’FPGA, là si usano i flip flop.

Il fatto di lavorare a segnali validi e stabili è un meccanismo molto facile da usare e comprensibile
da tutti gli strumenti CAD senza che si commettano errori e senza dover fare nessuna simulazione
elettrica. Garantisco che i dati arrivino validi e stabili quando devono essere campionati.
Ultima considerazione: Un altro vantaggio della tecnica a due fasi non-overlapped rispetto alla
tecnica a flip flop è legato a questo aspetto. Nella tecnica a flip flop abbiamo detto che possiamo
avere circuiti combinatori con ritardi differenti, e usando il retiming si può arrivare ad avere un
numero davvero troppo eccessivo di flip flop. La tenica a due fasi mi permette di gestire molto
meglio i casi in cui i miei percorsi combinatori sono sbilanciati, senza fare tanti trucchi tipo il
retiming. In particolare la tecnica a due latch mi permette di fare quello che si chiama il TIME
BORROWING ovvero farmi prestare del tempo.
Il concetto è questo: visto che tu hai bisogno di poco tempo per fare l’elaborazione, mi presti un po’
del tempo che hai perché io ho tante cose da fare.
Vediamo l’esempio: lasciamo perdere per adesso il non-overlap, qui non c’interessa. Partiamo, sulla
fase 1 io campiono sul latch1, inizia il percorso combinatorio, magari la prima fase finisce, devo
finire prima della prossima fase, questo vuol dire che in teoria avrei dovuto finire il tutto pima della
seconda metà del ciclo. Io continuo la mia elaborazione anche se è già attiva la fase phi2, sono in
fase trasparente, chiedo un prestito al semiciclo successivo, ad un certo punto io finirò, l’importante
è che phi2 mi campioni correttamente il dato. Inizia la propagazione di phi2 e ragionevolmente io
posso andare ancora avanti anche quando phi2 è tornato a zero. Cioè, posso in qualche modo
continuare a lavorare sulla fase successiva quindi ho più tempo a disposizione di quello che è

garantito da un mezzo ciclo. È chiaro che a un certo punto dovrò recuperare e di molto anche. Tutti
i prestiti prima o poi dovranno in qualche modo essere restituiti. Vediamo nell’esempio di un loop:
Parto, la prima parte combinatoria impiega più di metà ciclo, vuol dire che io finisco già durante la
fase phi2, dopodichè partirà la seconda parte combinatoria. È chiaro che se vado poi a richiudermi
sullo stesso latch di prima, è chiaro che il prestito deve essersi concluso in un ciclo intero. Il
vantaggio è che io ho un vicolo, a questo punto, sulla somma dei due tempi. È importante che la
somma dei due tempi combinatori stia dentro un ciclo. Ho meno vincoli sul fatto che ci sia un
bilanciamento perfetto tra le varie sottofasi. Posso avere questo prestito tra le fasi giocando sul fatto
che i nostri elementi di memoria sono dei latch, quindi il dato passa comunque se in fase
trasparente; non ho il vincolo del flip flop al quale il dato deve essere valido sul fronte. È aperto il
latch, quando arrivi arrivi ma è chiaro che se arrivi dopo hai meno tempo per quello che devi fare
dopo, però comunque in ogni caso si può giocare su questo prestito. L’overlap c’è lo stesso. Ma Lui
può lavorare anche quando c’è l’overlap e non ha ancora finito, va avanti quando si attiva la
seconda parte. Il concetto del BORROWING è un concetto del tipo guarda, dato che nella prima
fase ho una zona morta l’importante è che quando attivi la parte successiva anche se non ha ancora
finito chi se ne frega. Si ha più tempo prima di passare attraverso questo latch. È ovvio che hai
meno tempo dopo. Non è che questo mi permette di andare a frequenze infinite grazie ai prestiti
però il concetto è che prima o poi quando si chiude da qualche parte devo recuperarlo. È solo un
modo che mi permette di bilanciare meglio i ritardi e non dover garantire di dire no guarda…

Siccome essendo una struttura pipelinata i dati variano nel tempo io devo comunque mettermi in un
punto di partenza. Supponiamo che questo sia l’inizio della mia pipe. Questo vuol dire che il dato
che arriva in ingresso è stabile e quindi quando la fase è attiva inizia la sua propagazione. Il risultato
di questa tecnica è che se io ho un sistema con dei loop ovviamente non vado più in fretta. Cioè se
uno impiega 2 ns e l’altro 10 ns io devo aspettarne almeno 12 ns in un ciclo. Io posso non dover
bilanciare questi due percorsi grazie al fatto che ho il meccanismo del prestito, tu hai poco da fare
ok allora io impiego più tempo tanto poi quando ti arriva il dato tu fai in fretta. Il meccanismo del
latch trasparente mi permette di avere una maggior flessibilità nella definizione dei ritardi
combinatori delle varie sottofasi, cosa che con un sistema a fronti non posso fare, perché in tal caso
il concetto è guarda se arrivi in tempo campioni se no non campioni. Qui il concetto è guarda arriva
quando ti pare l’importante è che io abbia tempo a sufficienza per chiudere la mia fase.
L’importante è che faccia in tempo a passare il latch e fare questa parte combinatoria prima del
prossimo giro. La slide precedente mi dice qual è il massimo prestito che posso avere. Qui è
ricomparso il non-overlap, la mia struttura è una struttura che teoricamente ha due semi periodi,
dove il tempo di ciclo complessivo è dato da 2 volte Tc/2. Qual è il massimo tempo che posso avere
in prestito? È mezzo ciclo, non di più, meno il tempo di non overlap meno il tempo di setup del
secondo latch. Questo è il massimo che io posso prendere in prestito. Vuol dire che io ho una
maggiore flessibilità nel fare il mio progetto dal punto di vista del timing. Io posso andare ad usare
le tecniche di Retiming se voglio, ma non ho il vincolo sulla singola fase. Il vincolo ce l’ho sulla
coppia di due fasi in cascata. La tecnica a latch a doppia fase è quindi più facilmente
ottimizzabile rispetto a quella a flip flop. Il mio progetto quindi al momento di essere sintetizzato
finirà dunque in uno strumento CAD e avrò dei vincoli di timing su ogni percorso combinatorio che
unisca due elementi di memoria. Abbiamo visto come il non-overlap porta il nostro progetto ad
essere più flessibile, però in questo momento abbiamo ipotizzato una cosa che non è realistica.
Ovvero che il segnale di temporizzazione sia stabile nel tempo.

L’ho generato con un oscillatore che dà un segnale ad una certa frequenza e non cambia per nessun
motivo. In realtà nella struttura con cui io vado a lavorare questi clock non sono così precisi.
Ovvero non arrivano in tutti i punti della mia architettura esattamente in modo così preciso secondo
quella che è la frequenza di funzionamento che mi serve. Perché? Per tutta una serie di motivi, di
incertezze e per quello che si chiama clock delivery. Quest’incertezza del clock ha un effetto
estremamente negativo sul timing, praticamente tutta l’incertezza che ho sul clock si ripercuote in
un peggioramento drastico delle caratteristiche di timing della mia architettura. L’incertezza sul
clock peggiora le cose, sia sul discorso dell’hold time, sia sul discorso del massimo tempo di
propagazione, sia su quanto posso prendere in prestito nel caso dei sistemi su due fasi.
Partiamo dal primo punto. Perché io ho un’incertezza sul clock? Ho un’incertezza sul clock che è
tipicamente legata a una serie di fattori più o meno indipendenti. Questi fattori sono visibili in parte
in slide. Il clock è generato da un oscillatore che ha una sua precisione e la precisione
dell’oscillatore non è infinita. Questo vuol dire che se io vado a misurare due periodi del clock
questi sono più o meno uguali ma non identici. Non è garantito a monte che tutti i periodi di clock
abbiano esattamente la stessa durata, a causa del fatto che l’oscillatore non è ideale. Magari una
frequenza dipende in qualche modo anche dalla tensione di alimentazione, dalla temperatura, per
cui ho uno scostamento da quella che dovrebbe essere la forma d’onda ideale. Questo segnale che
viene generato e mandato all’interno della mia architettura dovrà passare attraverso dei buffer, delle
strutture che danno la potenza necessaria, la corrente necessaria per essere distribuito. Questi sono
dispositivi reali e quindi sono caratterizzati dall’avere delle tolleranze. Vuol dire che se questo
segnale lo mando a due dispositivi per andare a due flip flop diversi, questi dispositivi non sono
identici quindi magari qualcuno è più veloce dell’altro, vuol dire che il segnale che passa attraverso
questo dispositivo impiega meno tempo a propagarsi rispetto a questo. Il clock che era uguale per
tutti, passando attraverso differenti driver può arrivare in momenti differenti. Non solo, questi
segnali viaggiano su delle interconnessioni, su delle linee; queste linee sono più o meno lunghe, più
o meno caricate. Risultato: far viaggiare un fronte su una linea di 1 mm e una linea di 5mm, 1 cm,
10 cm vuol dire impiegare più o meno tempo. Se quella linea è più o meno caricata ha una capacità
maggiore o minore. Capacità maggiore o minore vuol dire impiegare più tempo prima di convincere
le capacità a cambiare stato. Risultato: tutte queste cose, portano a dire che è bello dire che tutti i
flip flop sono raggiunti dal clock nello stesso momento ma in realtà non è così. È una bufala!
Tutto questo ce lo giochiamo identificando dei parametri che ci servono per fare il progetto.
Definiamo due parametri legati all’incertezza sul clock. Il primo è quello che chiamiamo clock
skew. Il clock skew è praticamente il discorso visto in cui il clock arriva in due punti diversi con
tempi diversi. A causa dello skew due flip flop non sono raggiunti dal fronte di clock nello stesso

momento ma c’è una differenza di fase nell’arrivo del segnale di clock tra tali flip flop. È quella che
si chiama una variazione spaziale. Ci possiamo giocare questo come vogliamo. Si parla di skew
minimo e di skew massimo. Oppure parliamo di un valore deterministico più un’incertezza rispetto
a un valore nominale. Il concetto fondamentale è che questi flip flop sono raggiunti dal clock con
un’incertezza che ha valore minimo e valore massimo. Secondo punto: se io vado a prendere lo
stesso flip flop e vado a vedere più impulsi che raggiungano lo stesso flip flop temporalmente vedo
che questi impulsi non arrivano a multipli del periodo ma hanno anche lì un’incertezza.
Quest’incertezza temporale si chiama jitter.
Allora ho il clock skew che è l’incertezza nell’arrivo, tra due oggetti separati, dello stesso fronte e
ho il clock jitter che è l’incertezza nell’arrivo di più fronti consecutivi nello stesso punto. Sono due
fenomeni separati. Sono legati a cause tipicamente diverse. Risultato: il clock non arriva nello
stesso momento e in più nello stesso punto non è sempre uguale. Se lavoriamo in un sistema a
impulsi in realtà si scosta a seconda di ciò visto. Vediamo una rappresentazione dei concetti appena
esposti:

Lo skew è la distanza che c’è tra i segnali di clock che raggiungono due qualunque flip flop diversi.
Quindi lo skew è tra un fronte che arriva a un flip flop e quello che arriva ad un altro flip flop. Il
jitter si riferisce invece alla differenza tra il tempo atteso di arrivo e il tempo in cui fisicamente
arriva il fronte nello stesso flip flop. Il jitter è quindi un’incertezza che riguarda me, non riguarda gli
altri. È una variazione sul tempo che arriva a me. Lo skew è un qualcosa legato all’incertezza su tra
arriva il clock a me e quando arriva ai miei vicini. Il jitter è legato in qualche modo a un’incertezza
che non nasce solo dall’oscillatore ma da tutta la catena per cui magari il jitter all’inizio è più
contenuto rispetto ai circuiti più a valle. Cosa posso farci allora?
Quello che vado a fare è che vado a prendere il massimo di tutti gli skew possibili e il massimo di
tutti i jitter possibili. Questo è quello che faccio per poter lavorare. Lavorerò considerando questi
due termini. La domanda che ci poniamo è: Se io ho uno skew e uno jitter come interveniamo
nell’analisi della massima frequenza di funzionamento? Andiamo a considerare le disequazioni che
abbiamo visto prima. Prima considerazione: limitiamoci allo skew.
Lo skew vuol dire che flip flop differenti nella mia catena vengono raggiunti dal clock in momenti
differenti. Si identificano tipicamente due diverse situazioni. La prima è questa: Guardiamo la
seguente struttura di pipe.
Il clock arriva da sinistra e viene propagato verso destra, nella stessa direzione dei dati. Questa
situazione (percorso in alto) è una situazione che si dice di skew positivo. Il clock skew viaggia
nello stesso senso dei dati. Il caso di sotto è detto skew negativo nel senso che il clock viaggia in
direzione opposta a quella di avanzamento dei dati. Il clock del primo registro è in ritardo rispetto al
clock del secondo registro che è in ritardo rispetto al clock del terzo.

Nel caso dello skew positivo il clock dei registri più a valle arriva ritardato, spostato verso destra in
figura. Se le cose fossero così saremo estremamente contenti. Perché? Perché la propagazione ha a
disposizione quanto tempo? Non un periodo solo ma un periodo più lo skew. In questo caso si
dice che lo skew è positivo perché questo mi da più tempo per la propagazione del segnale e per
finire le mie cose. D’altra parte lo skew negativo invece è brutto, perché lo skew negativo mi dice
che io parto già in ritardo rispetto al fronte del ricevitore. Vuol dire che io parto ma non ho a
disposizione un clock intero. Il ricevitore è in anticipo rispetto a me e quindi al periodo di clock
devo sottrarre questo skew. Lo skew negativo rema contro. Se io uso uno skew negativo rischio di
non starci con la frequenza, devo andare a lavorare con una frequenza minore con un periodo di
clock maggiore per recuperare quello skew. Detto questo vediamo cosa si può dire sul tempo
minimo di ciclo. Se io ho un milione di flip flop sparsi qua e là è chiaro che ci saranno delle zone in
cui ho skew positivo e zone in cui ho skew negativo.

Siccome lo skew negativo mi limita la propagazione, io posso dire, nel caso generale, che se delta è
il modulo dello skew, non sapendo se è negativo o positivo, nel calcolo del percorso del minimo
tempo di ciclo al periodo devo per forza togliere questo skew massimo. Lo skew massimo è un
termine che mi peggiora il comportamento del sistema dal punto di vista del timing. Tutte le
formule che abbiamo visto in cui il tempo di propagazione è minore di.. adesso a quelle formule
devo sottrarre comunque lo skew. Quelle formule sono state calcolate ipotizzando che tutti i flip
flop fossero raggiunti tutti nello stesso momento. Risultato: lo skew gioca pesantemente un ruolo
negativo nella riduzione del tempo a disposizione della logica combinatoria e in particolare è lo
skew negativo che gioca pesantemente. Ma non è finita qui. Andiamo a vedere il discorso dell’hold
time. Il discorso dell’hold time è dire ok, quando io campiono questo signore devo garantire che il
dato cambi almeno un tempo di hold dopo il fronte per garantire che non venga campionato
erroneamente. Questa volta lo skew, se positivo, gioca di nuovo a sfavore, perché questo vuol dire
che io prendo il dato, lo carico, passo attraverso la rete combinatoria ma deve essere stabile per
almeno un tempo di hold dopo il fronte. Se il fronte è ritardato in avanti, questo vuol dire che devo
prendere anche lo skew come tempo aggiuntivo di stabilizzazione del dato. La seconda
disequazione mi dice che il ritardo clock to output + il ritardo del minimo tempo di contaminazione
della logica, la somma dei due deve essere maggiore del tempo di hold + lo skew. Quindi il
concetto finale è che lo skew gioca due volte contro. Gioca contro nel ridurre il tempo a
disposizione della logica combinatoria e gioca contro nell’aumentare il tempo di contaminazione
della logica per evitare violazioni sull’hold. Lo skew gioca contro due volte, sui tempi massimi e sui
tempi minimi. Cosa vuol dire jitter? Vuol dire che anche nel momento in cui io vado a considerare
quello che succede a me come flip flop io devo considerare il fatto che rispetto al clock, quando
dovrebbe arrivare, prima o dopo io posso avere un’incertezza pari a questo jitter. Se io devo
mandare il segnale qui, ma io ho un jitter positivo per cui in realtà lo lancio dopo, il signore
dall’altra parte dovendo ricevere il dato qui, però lui ha un jitter negativo per come è fatto per cui lo
riceve prima.

Vuol dire che il mio jitter e anche quello del ricevitore sono da sommare allo skew. Ci sono un po’
di slide con un po’ di esempi 65-70, ma quello che mi interessa è il risultato. Il risultato è questo:
nel calcolo del ritardo massimo, quindi clock to output, ritardo combinatorio + setup, io non ho un
ciclo a disposizione ma al ciclo devo togliere lo skew e 2 volte il jitter.
Lo skew + 2 volte il jitter rappresenta il tempo che ho nella mia logica combinatoria per portare a
casa il risultato. Skew -> spaziale, jitter -> temporale. Nel progetto worst case devo semplicemente
togliere dal tempo a disposizione lo skew e 2 volte il jitter. Questo vuole anche dire che dal punto di
vista dell’hold time, non solo ho a disposizione uno skew in più in cui devo mantenere il dato fisso,
ma a questo punto il jitter gioca al contrario e mi allunga il tempo che devo utilizzare mantenendo il
dato costante per evitare una violazione dell’hold time. Tutti i discorsi fatti sui tempi devono essere
modificati in peggio aggiungendo il tempo di skew + 2 volte il tempo di jitter. Lo skew + 2 volte il
jitter è un tempo da sommare al tempo di contaminazione minimo, è una quantità da sottrarre al
tempo di propagazione massimo. Ancora una considerazione che è questa: per quanto riguarda
andare in fretta, preoccupiamoci dell’hold time. Se io mandassi il clock nello stesso verso dei dati in
realtà ho più tempo a disposizione. Dal punto di vista del tempo massimo di propagazione il
positive skew è vantaggioso per me perché ho più tempo a disposizione.
Se io ho dei datapath che non hanno dei feedback, delle reazioni, posso immaginare di adottare
delle tecniche di clock delivering in modo tale che il clock segua il flusso dei dati. In questo caso
posso avere dei vantaggi. Il problema è che la maggior parte dei datapath con cui abbiamo a che
fare fanno tutti delle elaborazioni che hanno dei risultati parziali che vengono riportati in reazione.

Esempio:
Si vede in figura che la reazione è un percorso che va in senso opposto rispetto al flusso dei dati, è
quindi affetto da skew negativo. Risultato: per cercare di migliorare le cose il più possibile l’unica
cosa che posso fare è andare è cercare di ridurre il più possibile lo skew e il jitter, perché possono
essere abbastanza pesanti. Lo skew comunque rappresenta un limite invalicabile per la frequenza di
funzionamento della mia macchina. Abbiamo visto che in tutte queste equazioni il tempo minimo è
pari allo skew più qualche cosa. Ciò vuol dire che se ho uno skew di 2 ns non posso fare il tempo di
ciclo inferiore a 2 ns. Nel caso del flip flop, che è quello che ci interessa di più, il tempo di
propagazione è il tempo di clock meno il tempo di inserzione, che è il ritardo di propagazione clock
to output + il setup + lo skew + 2 volte il jitter.

Questo vuol dire che lo skew e il jitter mi riducono la frequenza massima di funzionamento della
macchina, o detto in altri termini mi aumenta il periodo minimo di ciclo della macchina.
Quello che c’è scritto sotto, in slide a pagina precedente, è analogo. Il tempo di contaminazione è
incrementato dallo skew + eventualmente 2 volte il jitter. Questa è la realtà, ovvero l’incertezza sul
clock rischia di penalizzare pesantemente la massima frequenza di funzionamento della mia
macchina. Ci sono altri esempi sui latch, ma non ci importano più di tanto.
Risultato della chiaccherata: io ho tre opzioni dal punto di vista del timing: a fronti, due fasi non
overlapped, latch impulsati. Lasciamo perdere i latch impulsati. Con le due fasi è molto più facile
ottimizzare il mio sistema, posso fare il borrowing tra le varie zone, posso garantire che il mio
progetto può essere trasferito su un’altra tecnologia. Cambiando semplicemente l’intervallo di non
overlap il mio progetto funziona sicuro. Posso fare tutta una serie di scelte per cui vado a definire
degli istanti dal punto di vista del timing per cui posso fare tutta una serie di controlli di
temporizzazione senza fare simulazioni. L’inconveniente è che viaggiano due fasi, raddoppio le
linne di clock, raddoppio il carico su queste linee. Ovviamente Se ho già uno skew su un segnale,
adesso che ne ho due che viaggiano i problemi di skew sono ancora più grandi.
La soluzione a flip flop è molto più semplice da fare, non ho il meccanismo del prestito, devo starci
in un colpo di clock, e o ci sto o non ci sto, questo mi porta dei vincoli sulla massima frequenza di
funzionamento, ho comunque un vincolo sul tempo di contaminazione, minimo ritardo per evitare
una violazione dell’hold time, quello che è fondamentale è che se io ho una violazione sull’hold
time in un sistema a flip flop quel sistema non funziona a qualunque frequenza operativa. Mentre il
sistema a latch a doppia fase abbassando opportunamente la frequenza il sistema mi funziona in un
sistema a fronti se c’è una violazione di hold il sistema non funziona mai.

Immaginiamo di dovere realizzare un nuovo processore. Vediamo come limitare i problemi dello
skew. Solo per portare il segnale da un punto all’altro del circuito potrebbero tranquillamente
passare un paio di ns. Ciò significa che due flip flop lontani possono essere raggiunti dal clock in
istanti diversi con un ritardo tra i due dell’ordine del ns.
Devo quindi in fase di progetto pagare un sacco di ingegneri per prevedere reti di distribuzione del
clock che si occupino di inviarmi il clock alle diverse parti di circuito nella maniera più uniforme
possibile, riducendo al minimo lo skew. Ci sono quindi ingegneri che passano il loro tempo a
progettare alberi di distribuzione del clock, visibile in slide, per ottenere tale obiettivo.
Tecniche possibili: distribuzione ad H, consiste nel fornire il clock nel punto centrale, poi faccio
una bella H prevedendo dei buffer che rigenerino in qualche modo il clock, poi nei punti opportuni
faccio altre H e così via. La distribuzione del clock avviene secondo uno schema ad albero. Vado a
fare una scelta di carichi e di distanze tali per cui cerco di rendere lo skew nullo. Questo è vero in
teoria ma poi nella realtà vado a scoprire che il mondo che ci sta sotto non è così regolare, per cui la
distribuzione è più o meno quella visibile in slide ma ciò è più o meno realistico. Quindi riuscirò a
ridurre lo skew del clock ma non riuscirò assolutamente a portarlo a zero.
Un metodo sicuramente migliore rispetto alla distribuzione ad albero vista, è quello che si chiama
distribuzione a griglia, dove il concetto è che l’albero di distribuzione del clock è un’immensa
griglia che viene alimentata dai quattro lati, con un controllo sul clock che arriva dai quattro lati
effettivamente con skew nullo, e questa distribuzione a griglia garantisce che tutti i punti siano
raggiunti con uno skew estremamente ridotto. Tutti i processori odierni, si basano più o meno sul
principio di questa distribuzione a griglia, proprio perché mi permette di gestire quelle situazioni in
cui la struttura che ci sta sotto non è caricata uniformemente, garantendo un certo bilanciamento
interno.

I primi processori, con una decina di milioni di porte, presentavano un carico totale per il clock di
3,75 nF (tenere presente che un singolo gate presenta una capacità di pochi fF). Essi consumavano
50 W, 20 W dei quali erano usati solamente per la generazione e gestione del clock.
In slide si possono vedere delle piazzole per la gestione del clock poste in maniera strategica, questo
era un processore a 2 fasi non-overlapped. Nell’immagine a destra si vede la differente
distribuzione dello skew in un chip di 1.7cm x 1.7cm. Se vediamo i valori massimi dello skew sono
50 ps. Cioè per riuscire a lavorare a 300MHz ho bisogno di uno skew al di sotto dei 50 ps.
Questo lo vediamo per capire la complessità nella distribuzione del clock.
Una tecnica più evoluta, visibile nella slide seguente, è consistita nel dividere la rete di
distribuzione in quattro zone con una distribuzione a griglia. C’è una parte centrale della griglia e
dopodichè distribuisco il tutto. In questo modo si è riusciti a migliorare, infatti l’esempio in slide
mostra un processore che va al doppio della frequenza (600MHz) rispetto al caso visto prima.

Faccio una struttura gerarchica, ho una griglia generale che va a delle sottogriglie che poi
localmente fanno da dispatcher del clock. Nel progetto di sistemi che lavorano sopra i 100MHz la
parte di distribuzione del clock è la parte più difficile e più lunga da risolvere.
Conclusione della chiaccherata: quando io vado a fare il progetto di un sistema digitale complesso,
oltre a fare tutte le considerazioni viste sulla derivazione architetturale, control unit, execution unit,
ecc, il punto finale ma fondamentale a cui devo prestare la massima attenzione è la rete di gestione
del timing, perché esso mi può limitare le prestazioni della macchina in modo estremamente
pesante. A questo si aggiunge un punto ulteriore: se io sto progettando un sistema complesso, tipo
un’interfaccia seriale con regimi di clock multipli, cioè un clock per la ricezione, uno per la
trasmissione, il clock del microprocessore questi sono tutti scorrelati tra loro.
Molto spesso la mia architettura ha delle zone che lavorano a frequenze differenti. La frequenza
operativa è legata, nei sistemi odierni a basso consumo, a quanti calcoli devo fare, per cui se magari
non devo far niente una zona di circuito la forzo a lavorare a frequenza più bassa così da consumare
di meno. Tutte le volte che ho zone che lavorano a frequenze diverse e queste devono parlare devo
garantire che queste dialoghino in modo corretto.
Ci sono diversi protocolli di timing possibili. Essi sono riportati nella slide successiva.
Il più semplice è il primo, quello sincrono detto GATED, con stessa frequenza e sfasamento nullo
tra i due regimi. Quando devo mandarti qualcosa ti do un segnale di controllo. Questo mi dice ok
campiona, no non campionare, funziona bene. Secondo caso possibile: regime MESOCRONO: è un
regime in cui i clock lavorano a stessa frequenza ma esiste uno sfasamento tra i due regimi che è
fisso ma non è noto a priori. Ho regimi di clock isofrequenziali ma con sfasamento incognito. Qui
cominciano a esserci dei problemi che nascono dal setup e hold. Ti mando il dato perché secondo

me il momento è quello giusto, peccato che a causa dello sfasamento il dato ti cambia mentre tu lo
campioni: violazione dei tempi di setup e di hold.
Questo vale nel momento in cui la sorgente di clock è la stessa. Il passo successivo è quello che si
chiama il regime PLESIOCRONO: è il caso per esempio di un’interfaccia seriale da una parte,
un’interfaccia seriale dall’altra, si scambiano i dati, tutti sono d’accordo per parlarsi a una certa
frequenza, peccato che questa frequenza è derivata da un oscillatore che è diverso da quello del
ricevitore. È vero che magari i due oscillatori sono entrambi a 100MHz ma sappiamo che quegli
oscillatori non oscilleranno mai e poi mai alla stessa frequenza. Vuol dire che le frequenze potranno
essere leggermente differenti, vuol dire che questa struttura plesiocrona ipotizza che ci sia una
variazione di frequenza tra i due regimi molto piccola ma che porta ad avere uno shift nello
sfasamento continuo dei clock. Mesocrona vuol dire che lo shift è fisso, plesiocrona vuol dire che lo
shift varia, lentamente ma varia. Quanto lentamente? Questi sono problemi di progetto nella scelta
della precisione dell’oscillatore. Siccome vengono generate due strade diverse con due oscillatori
diversi tipicamente non è proprio zero la differenza, la differenza è molto piccola ma il risultato è di
avere due frequenze leggermente differenti che lo shift della fase varia. L’ultimo caso è un sistema
puramente ASINCRONO: le due frequenze sono generate in modo qualunque, non esiste nessuna
relazione di fase tra i due regimi. Nasce dunque il problema della sincronizzazione della
trasmissione. Nei processori tipicamente all’interno si può avere una frequenza variabile, ma
l’interfaccia verso il bus esterno lavora a frequenza fissa. Quello che cambia è un adattamento della
frequenza interna a seconda del carico. La frequenza esterna è tipicamente molto più bassa di quella
interna.

Timing 2 (13/12/11)
Vediamo adesso come poter far comunicare tra loro e come fanno a scambiarsi i dati oggetti che
lavorano con regimi di clock differenti. Il problema è proprio un problema di sincronizzazione dei
dati perché chi manda il dato ha le sue tempistiche, lavora con i suoi tempi di setup e hold sui dati,
chi riceve il dato ha le sue tempistiche e lavora con i suoi tempi di setup e hold e bisogna che i due
si parlino. Bisogna considerare due grandi classi di sistemi: quelli in cui i regimi di temporizzazione
differenti sono on-chip, sulla stesso chip, e qui è più facile perché c’è un solo clock master da cui si
derivano tutti gli altri. Ci sono invece casi di strutture di sincronizzazione off-chip, abbiamo due
oggetti che si scambiano dei dati, questi due oggetti sono fisicamente diversi, possono essere 2
circuiti integrati ma anche due schede diverse e allora lì i problemi di sincronizzazzione possono
essere di tipo differente. La lezione scorsa abbiamo visto tutti i protocolli di temporizzazione con
cui possiamo avere a che fare. Il concetto è quello di avere 2 regimi, R1 e R2, che si scambiano
delle informazioni, dei dati, e hanno 2 clock , clock1 e clock 2, e questi due regimi di
temporizzazione possono essere più o meno differenti. Allora abbiamo detto che la prima
considerazione è quella di avere uno stadio di formazione tra i due regimi che in realtà hanno lo
stesso clock, quindi stessa frequenza e sfasamento nullo. È ovvio che lo scambio di informazioni
può avvenire con la tecnica del gating, ovvero vuol dire se devo mandare un dato ti abilito, se non
devo mandare un dato disabilito il ricevitore.
La seconda possibilità è Mesocrona, cioè la frequenza del trasmettitore e ricevitore è la stessa ma
non so nulla sullo sfasamento. Vuol dire che i due clock sono due forme d’onda esattamente
identiche però la differenza in fase tra le due forme d’onda è incognita. Perché incognita? Perché
magari trasmettitore e ricevitore non sono vicini e quindi il clock impiega del tempo per andare da
un posto all’altro e non è garantito che ci sia una sincronizzazione dal punto di vista della fase.

I sistemi plesiocroni sono caratterizzati dall’avere due clock che nominalmente sono alla stessa
frequenza ma sono generati in modo differente. La scheda di ricezione e quella di trasmissione
hanno ognuna il suo quarzo. Avrò una certa precisione sulle frequenze dei quarzi ma non avrò mai
la certezza che le due frequenze siano uguali. Se le due frequenze non sono uguali c’è uno shift
continuo nello sfasamento. Ho una variazione di frequenza molto lenta, nominalmente la frequenza
è uguale ma non lo è, quello che cambia è uno sfasamento continuo nel tempo. La differenza
fondamentale tra il mesocrono e il plesiocrono è che nel mesocrono lo sfasamento è incognito ma
fisso, nel plesiocrono lo sfasamento continua a crescere nel tempo. Il modello è un modello,
abbiamo detto, a schede di ricezione e trasmissione separate e quindi un modello a rete. Quindi io
trasmetto col mio clock, il ricevitore riceve col suo clock, nominalmente ho la stessa frequenza ma
in realtà non è proprio identica, dopodichè c’è il caso generale di un sistema di ricezione e
trasmissione completamente asincrono. Non c’è nessuna relazione né di fase né di frequenza tra chi
parla e chi riceve. E allora devo preoccuparmi di fare le sincronizzazioni del caso.
Sincronizzazione MESOCRONA: il clock è lo stesso, lo sfasamento è incognito. Io trasmetto dei
dati in modo sincrono col mio clock, questo vuol dire che i miei dati viaggiano e arrivano al
ricevitore. Il problema è che quando arrivano al ricevitore arrivano in modo assolutamente
scorrelato rispetto al clock del ricevitore. Il rischio è che i dati cambino nel momento in cui il
ricevitore va a campionare i dati. Cosa vuol dire andare a campionare i dati in un qualunque
momento? Vuol dire che non ho nessuna sicurezza del fatto che il campionamento possa avvenire in
modo corretto. Posso avere delle violazioni dei tempi di setup e hold time del ricevitore e se io ho
queste violazioni vuol dire che mi posso ritrovare in uno stato metastabile e quindi campionare un
dato fasullo. Si tratta di capire quali possano essere le soluzioni possibili per garantire che la
ricezione del dato avvenga in modo corretto. Ci sono diverse tecniche più o meno costose dal punto
di vista di complessità energetico e di banda del sistema. La prima tecnica consiste nel dire, siccome
non so come interfacciare i due oggetti, non so come ricavare in qualche modo la fase, il metodo più
semplice consiste nel prendere il clock del trasmettitore e iniettarlo in qualche modo nel segnale che
viaggia, ovvero fare una codifica dell’informazione in cui ci sia in qualche modo il clock e far sì
che quest’informazione viaggi annegata nel segnale e in ricezione io vado a estrarre
quest’informazione. Questo porta a tutta una serie di codifiche del segnale usatissime in alcune
applicazioni. Il metodo può voler dire che se questo è lo spazio a disposizione di un bit, io definisco
per esempio che trasmettere uno zero vuol dire trasmettere un segnale che ha un fronte di salita a
metà dello spazio, trasmettere un uno vuol dire magari trasmettere un segnale che ha un fronte di
discesa a metà dello spazio. Tipo la codifica Manchester o cose del genere. Posso studiare quindi un
circuito in ricezione che vada a sincronizzarsi esattamente su quell’istante e quindi vada ad estrarre

in qualche modo l’informazione di fase per fare il campionamento corretto. Questo metodo tutto
sommato costa poco ed è ragionevole. L’inconveniente qual è? L’inconveniente è molto semplice,
se andiamo a vedere quello che succede per esempio in questa struttura, può benissimo capitare che
ci siano due fronti all’interno dello spazio di un bit, quindi se io ho una limitazione in banda questo
metodo mi porta a dire che posso utilizzare al massimo metà della banda disponibile per mandare
l’informazione. L’unica cosa che pago è che va tutto bene se non devo andare a frequenze elevate,
perché il tipo di codifica fa si che io devo prevedere che in un periodo di un bit possa avere due
fronti. Mentre se invece uso un metodo di trasferimento dell’informazione a livello in un periodo io
ho un solo fronte quindi vuol dire che posso lavorare al doppio della velocità di trasmissione.
Il secondo metodo è usato quando uno va ad utilizzare interfacce di trasmissione seriali, tipo
l’RS232 o robe del genere, è un metodo che è usatissimo e consiste nel dire, è vero che hai in
ricezione un clock, ma mi genero in qualche modo in ricezione un clock a frequenza molto
maggiore e campiono tante volte il segnale in ricezione e così capisco quando il segnale sta
variando e di lì riesco a ricostruire in modo ragionevole, dove sia presente la transizione, la forma
d’onda e la fase del segnale. Uso quindi un clock in ricezione a frequenza alta, multiplo di quello
del trasmettitore ovviamente, e vado a scoprire dove ci sono le transizioni del segnale. Questo è un
metodo che costa pure poco. Ha solo un inconveniente, se io trasmetto a 1 GHz, il ricevitore che
deve lavorare a frequenza molto più alta magari deve lavorare a 10GHz, allora non è l’ideale!
Quindi è un metodo che va bene per trasmissioni a bassa velocità. Infatti nell’RS232 funziona
benissimo perché la velocità di trasmissione è bassa. Sia il primo che il secondo modo hanno tutta
una serie di vantaggi e svantaggi. Quello che permette di raggiungere il massimo delle prestazioni è
sicuramente il terzo. Il terzo prevede il fatto che io in qualche modo vada a spostare la fase del
ricevitore andando a recuperare quello sfasamento, andando ad analizzare i segnali che mi arrivano,
utilizzando una linea di ritardo analogica controllata in qualche modo che mi permetta di ottenere
una sincronizzazione tra trasmettitore e ricevitore shiftando la fase al ricevitore fino a quando
ottengo l’aggancio. Questa è una sincronizzazione che avviene mediante quello che si chiama un
circuito di recupero dello sfasamento (Self Recovery Circuit). Qui c’è praticamente il concetto:
regime numero 1, clock 1, trasmette alla frequenza del clock 1; regime numero 2, macchina a stati
numero 2, stessa frequenza, sfasamento incognito. Il concetto è che i dati che viaggiano passano
attraverso questa linea di ritardo analogica programmabile, dove è il controllo della macchina a stati
che va a spostare, va a aumentare o diminuire il ritardo in modo tale che il dato che arriva alla
macchina a stati numero 2 arrivi in fase con le caratteristiche del ricevitore. La linea di ritardo
controllata da un segnale opportuno va a shiftare i dati che arrivano al ricevitore fin tanto che questi
risultano in qualche modo agganciati correttamente.

Problema: Come fa il ricevitore a sapere come shiftare se lo sfasamento è incognito? Il meccanismo
è semplice e consiste nel dire prima di fare la trasmissione dei dati, il trasmettitore e il ricevitore si
mettono d’accordo e il trasmettitore per esempio trasmette una serie di dati di prova a frequenza
opportuna, quello che si chiama il preambolo, prima della trasmissione. Questi colpi di clock
iniziali noti al ricevitore vengono utilizzati dal ricevitore per andare ad adattare la linea di ritardo.
Col preambolo il ricevitore va a fare il Pweauning??? della linea di ritardo sua fin tanto che ottiene
l’aggancio. Nel momento in cui ottiene l’aggancio può partire la trasmissione del segnale e il
ricevitore da quel momento in poi ha uno sfasamento nullo rispetto al trasmettitore e quindi la
trasmissione avviene correttamente. Perdo il tempo dell’aggancio ovviamente. Ogni quanto viene
effettuato l’aggancio dipende dal tipo di regime, nel senso che se il regime è mesocrono la
frequenza è la stessa e una volta che ho recuperato la fase quello è agganciato. Se il clock invece
non è effettivamente lo stesso l’aggancio dura per un certo periodo che possiamo calcolare, nota la
precisione con cui so la frequenza del trasmettitore e del ricevitore. Il concetto è che se sicuramente
la frequenza è identica una volta che ho agganciato mantengo l’aggancio per tutta la vita e so che
non è vero! Posso avere sistemi più o meno complessi che cercano di recuperare l’aggancio, però
teoricamente con sistemi di tipo mesocrono una volta che ho l’aggancio quello rimane. Preambolo
iniziale, e lì nel preambolo non invio sicuramente dei dati. Se non è certo che i due clock abbiano
esattamente la stessa frequenza, entriamo nel caso del sistema plesiocrono. Il concetto è lo stesso, io
posso recuperare lo sfasamento, ma quello che so per certo è che quello sfasamento cambierà nel
tempo. In questo caso devo andare a fare proprio dei calcoli sull’incertezza che ho sui due clock del
trasmettitore e ricevitore per capire ad ogni trasmissione di quanto mi posso spostare di fase ed è
ovvio che io devo ripetere l’aggancio, riutilizzando di nuovo il preambolo per il segnale di
sincronismo o quello che si manda in questi tipi di protocolli, prima che sia troppo tardi, ovvero
prima che lo sfasamento sia tale per cui io vado a campionare il dato quando non devo.
Si tratta di capire, in base alla precisione dei due clock, quanto dura l’aggancio prima di dover
rieffettuare il prossimo aggancio. La durata dipende dalla precisione dei due clock. Nel caso più a
basso livello, pensiamo all’RS232, l’aggancio dura al massimo 8 bit. Tutte le volte ho uno start bit
che serve per agganciarmi in qualche modo, dopo di che trasmetto un dato a 5 o 8 bit o quanti sono
e alla fine ricomincio da capo. In quel modo ho un’incertezza sul clock ammissibile che è
abbastanza vasta perché vuol dire che l’aggancio deve essere garantito per otto colpi di clock della
trasmissione. È chiaro che va bene per trasmettere pochi bit, pochi byte in generale, e infatti se vado
su tecniche un po’ più moderne le tecniche sono completamente differenti. In questo caso
l’aggancio avviene con una trasmissione di tipo burst, quindi aggancio trasmetto una serie di bit
tutti insieme, poi ricomincio, trasmetto, ecc.. .

L’unica cosa che posso fare è avere un aggancio più o meno continuo, tipo nella trasmissione
sincrona in cui mando un carattere di sincronizzazione, poi mando una serie di caratteri di dato, in
modo tale che la sincronizzazione viene in qualche modo mantenuta con un PLL o quello che è, sto
perdendo un pochino perché non ho più l’informazione, prima che sia troppo tardi rimando un
carattere di sincronismo per riagganciarmi in modo più o meno corretto.
Dopo di che posso avere due frequenze teoricamente differenti, f1 e f2. Se sono differenti entriamo
nel mondo teorico dei sistemi asincroni. I due clock sono teoricamente qualunque e devo scambiare
dei dati tra due oggetti con due clock qualunque. Prima di dire che i due clock sono qualunque,
analizziamo un caso frequente: cioè di sistemi e di interfacciamenti Pseudo-asincroni. Cioè il caso
in cui è vero che i due regimi hanno frequenze differenti ma queste frequenze sono sempre e
comunque derivate da un clock master uguale per tutti. È il caso che ho per esempio dentro un
circuito integrato, ho blocchi che lavorano a diverse frequenze ma tutti e due i clock sono generati
da un clock master unico. È il caso in cui le due frequenze sono derivate da un’unica frequenza
master del sistema, che prevede anche divisioni di frequenza. In questo caso esiste comunque una
qualche relazione di fase tra i clock. Supponiamo di lavorare con due clock, uno a una frequenza e
uno a metà frequenza. Il concetto è che se sono generate dallo stesso clock esiste comunque una
relazione di fase tra le due frequenze. Io posso identificare degli intervalli temporali in cui è
garantito un tempo di setup e un tempo di hold che può essere utilizzato. Il master trasmette alla
frequenza maggiore, trasmette per cui può scambiare i dati in corrispondenza del clock, il ricevitore
riceve con la sua frequenza, è ovvio che lavorando a frequenza più bassa il master non può
trasmettere a ogni colpo di clock ma come minimo, in questo caso, una volta ogni due colpi di
clock, quindi il ricevitore sa che quando riceve questo dato questo è stato trasmesso al colpo di
clock precedente, lo va a campionare poin andrà a campionare questo dato e quindi se i due sono in
qualche modo agganciati, è vero che lavorano a frequenze differenti ma posso comunque definire
dei meccanismi di gating e dire ok, adesso lo ricevi, adesso no, adesso sì, adesso no.

Questa è una tecnica molto utilizzata, lavoro con due clock a frequenza differente però essendo tutti
e due generati dallo stesso clock sorgente posso ricavare delle finestre in cui i dati vengono inviati e
vengono ricevuti teoricamente in modo corretto, garantendo il setup e l’hold time. Dentro un
circuito integrato questa è una soluzione che tutto sommato è abbastanza semplice ed efficiente.
Richiede dei segnali di gating, quindi di abilitazione, per dire ok adesso prendi il dato perché
disponibile, adesso non prenderlo, ecc.. Quindi basta che i due, ricevitore e trasmettitore, sappiano
qual è il fronte in cui deve avvenire lo scambio di informazione. Avrò bisogno di pochi segnali di
controllo che vadano a stabilire qual è la finestra in cui fare il campionamento e in quelle che invece
non deve essere fatto. È una tecnica molto usata nei sistemi di ricezione dell’informazione. Avete
un sistema che trasmette via radio, avete un ricevitore che riceve in maniera seriale, si ha bisogno
quindi di un qualcosa che prende i dati in modo seriale, li parallelizzi e poi mi dia un blocchetto che
lavora a frequenza più bassa. Un serializzatore prende i dati in arrivo dal canale, li serializza, li
manda ad un oggetto che farà quello che deve fare, tipicamente lavora a frequenza molto più alta e
talvolta multipla di quella di byte, word o quello che è a seconda del parallelismo
dell’informazione. Quindi ci sono due frequenze oggettivamente diverse ma legate dal fatto di avere
una relazione di fase. Il concetto è che i dati arrivano in modo seriale ad uno shift register che
lavora alla frequenza abbiamo detto fck1, questo li parallelizza e tira fuori i dati e questi vanno ad
un registro campionato ad una frequenza fck2. Le due frequenze sono differenti, stanno in un
rapporto che è dato dal parallelismo con cui impacchetto i dati e quindi magari questo signore
lavora a 640MHz e questo signore magari lavora a 80MHz. Divide per otto. C’è solo un rischio da
tenere in conto, può capitare che questi due oggetti non siano all’interno dello stesso circuito
integrato, ma siano in due integrati differenti, uno che lavora a frequenze più elevate e l’altro a
frequenze più basse, infatti può capitare che questi due oggetti siano realizzati con tecnologie
differenti. C’è un problemino che può capitare: se chi trasmette trasmette a frequenza più elevata
quando cambiano i dati rispetto a questo clock, i tempi con cui i dati cambiano sono legati alla
tecnologia con cui ho a che fare. Se questa tecnologia è veloce, vuol dire che i dati cambiano
immediatamente dopo il fronte di salita del clock con tempi molto veloci perché la tecnologia lo
permette. Il problema è che quel dato cambia e viene campionato da un sistema a frequenza molto
più bassa, molto più bassa vuol dire che magari per come è fatto ha bisogno di tempi di hold più
grandi. Tipicamente se io lavoro con una stessa tecnologia i tempi di hold sono compatibili con i
tempi di propagazione. Quindi quando si collegano insieme i due oggetti non si hanno tanti
problemi da questo punto di vista. Il problema nasce quando chi manda i dati è così veloce che sul
fronte di salita, subito dopo, già cambia. Quello stesso dato è campionato da un oggetto molto più
lento, che quindi ha bisogno magari di un tempo di hold maggiore. Lì posso avere delle violazioni.

Quindi devo fare molta attenzione quando si interfacciano due oggetti con due diversi regimi di
clock, che presentano però due tecnologie differenti e la tecnologia a frequenza più alta ha magari
dei tempi di propagazione molto inferiori dei tempi di hold della tecnologia a valle. In questo caso
rischio. Allora mi devo preoccupare di adottare tutta una serie di trucchi per evitare violazioni di
questi tempi. Il metodo del gated clock funziona benissimo, il ricevitore sa quando deve campionare
e quando il dato è valido e fa il campionamento in modo corretto senza particolari problemi. Se il
clock è unico, ho due regimi di temporizzazione, due frequenze qualunque ma il clock è unico, io
posso comunque garantire che ci siano queste finestre in cui i fronti del trasmettitore e del ricevitore
sono effettivamente in fase utilizzando delle tecniche ad aggancio di fase che aggancino in qualche
modo le fasi dei due oggetti. Queste sono tecniche basate sul Phased Locked Loop.
Essi usano dei DLL e sono usati soprattutto nei sistemi nell’aggancio tra chip, quindi per circuiti
differenti, oppure le tecniche dentro il circuito integrato basate sui DLL (Delay Locked Loop).
Queste sono tecniche che permettono comunque di garantire l’aggancio tra le due frequenze, in
modo tale che durante la trasmissione del segnale lo sfasamento tra trasmettitore e ricevitore sia
nullo. Adesso vedremo qualcosetta relativa a queste tecniche di aggancio. Qual è la condizione da
cui si parte comunque? La condizione da cui si parte e che vale praticamente sempre è questa: un
sistema dentro un circuito integrato tipicamente lavora a frequenze molto maggiori rispetto a un
sistema su scheda, il che vuol dire che il clock che io mando sulla scheda viaggia ad una frequenza
inferiore rispetto alla frequenza operativa interna di un circuito integrato. Se andiamo a smontare un
computer troviamo il uP che lavora a 2GHz ma il clock del sistema viaggia ad una frequenza molto
più bassa. Esso talvolta viene incrementato in frequenza da moltiplicatori di frequenza che lavorano
con i DLL. Vediamo come funziona un sistema di moltiplicazione di frequenza.

Il concetto è che io ho un clock off-chip, che arriva dall’esterno, che lavora ad una certa frequenza
f, questo clock viene confrontato col clock prodotto all’interno della macchina che lavora ad una
frequenza n volte più grande, questo clock viene diviso da un contatore in modulo, in modo che il
segnale che ritorna indietro sia ad una frequenza esattamente uguale a quella dell’ingresso, dopo di
chè sappiamo che esiste un circuito che è il Phase Detector che mi calcola lo sfasamento tra il clock
che arriva e l’on chip clock diviso per n.
Questo circuito che calcola lo sfasamento utilizza questo sfasamento per andare ad agire
opportunamente filtrato su un VCO (Voltage Comparator Oscillator) per variare la frequenza di
uscita in funzione di questo sfasamento in modo tale che il segnale di uscita ritornando indietro
abbia a regime sfasamento nullo rispetto al segnale d’ingresso. Questa è la tecnica base sui DLL,
ma non entreremo molto nei dettagli. Quindi il concetto è ho un clock di riferimento, ho un clock
locale che viene prodotto dal sistema interno mediante questo divisore per n, il Phase Detector si
accorge quale dei due clock è in anticipo, e a secondache sia in anticipo o l’uno o l’altro dice ok,
aumenta up oppure diminuisci il segnale che poi dovrà andare al VCO per far cambiare il segnale
prodotto. Questa operazione che va a cambiare la tensione di controllo del VCO avviene mediante
due oggetti. Il primo che fa praticamente da integratore dello sfasamento mediante quei due segnali
up e down, che vanno poi a un filtro passa basso che stabilizza in qualche modo le variazioni per
rendere meno nervoso l’anello di reazione in modo tale che ci sia un effetto di smoothing, di
variazione lenta della frequenza prodotta in uscita. Cosa deve fare il Phase Detector? Deve andare a
vedere lo sfasamento tra il segnale di riferimento e il segnale che torna indietro. Devo calcolare in
qualche modo la differenza tra questi due segnali, capire quanto sono sfasati. Il metodo più
semplice per fare un Phase Detector è metterci uno XOR tra i due segnali di riferimento,
l’XOR sarà 1 tutte le volte che i segnali sono differenti. Più sono sfasati più il valore dell’Xor a 1

aumenta e quindi io ho un andamento che teoricamente è lineare, mi da una tensione di uscita, una
volta filtrata, che è proporzionale allo sfasamento. Oltre i 180 gradi lo sfasamento torna a zero
perché non ho nessun tipo di controllo ovviamente sui flip flop. Questo è un metodo che ha un
inconveniente enorme. L’inconveniente enorme è che la curva visibile in slide (a sinistra) è
simmetrica per ovvi motivi perché lo sfasamento mi dice solo quanto è sfasato ma non chi è in
anticipo rispetto all’altro. In realtà può andar bene se il meccanismo cerca di farmi ottenere
l’aggancio ma non so se devo andare più in fretta o più piano, perché non so quale dei due arriva
prima. È molto meglio, anche se leggermente più complicato, il Phase-Frequency-Detector nel
senso che quest’oggetto invece di avere uno XOR ha due flip flop e una porta; semplicemente
utilizza i fronti che arrivano dalla sorgente e dalla reazione, e semplicemente la sorgente fa
un’operazione di reset; la sorgente provoca l’accensione del segnale up, il che vuol dire vai verso
l’alto, il fronte sul segnale B invece accende il segnale down e quando ci sono tutti e due a 1 attivi,
automaticamente il sistema si resetta, quindi quando up e down sono entrambi a 1 resetto entrambi i
sistemi. In questo modo può succedere che se A arriva prima di B il segnale up è attivo per questo
tempo, mentre B è un impulsino piccolo, se B arriva prima di A questa volta è down che è più
grande rispetto all’up. Se quindi si va a fare una differenza tra i due si vede che in un caso prevale
up e quindi vuol dire che abbiamo anche un senso in cui far muovere i circuiti a valle. Nell’altro
caso in cui c’è prima B prevale il segnale down e quindi posso avere l’informazione non solo sullo
sfasamento ma su come muovermi. Si può vedere il diagramma degli stati che fa quello sopra
descritto. Le due condizioni sono o prima up attivo oppure prima down attivo a seconda di quale dei
due segnali è in anticipo. Questo vuol dire che io posso andare a recuperare in qualche modo lo
sfasamento, avendo a disposizione non solo l’ampiezza dello sfasamento ma anche quale dei due in
anticipo e quindi capire se devo aumentare o se devo ridurre la frequenza di funzionamento. Se
andiamo a vedere la caratteristica del Phase frequency detector questa non è più simmetrica come
prima e quindi so che se ho un errore di fase positivo l’errore è positivo, una tensione positiva, se ho
un errore negativo il segnale è negativo e quindi posso sfruttare quest’informazione per andare ad
aggiornare il valore del VCO.
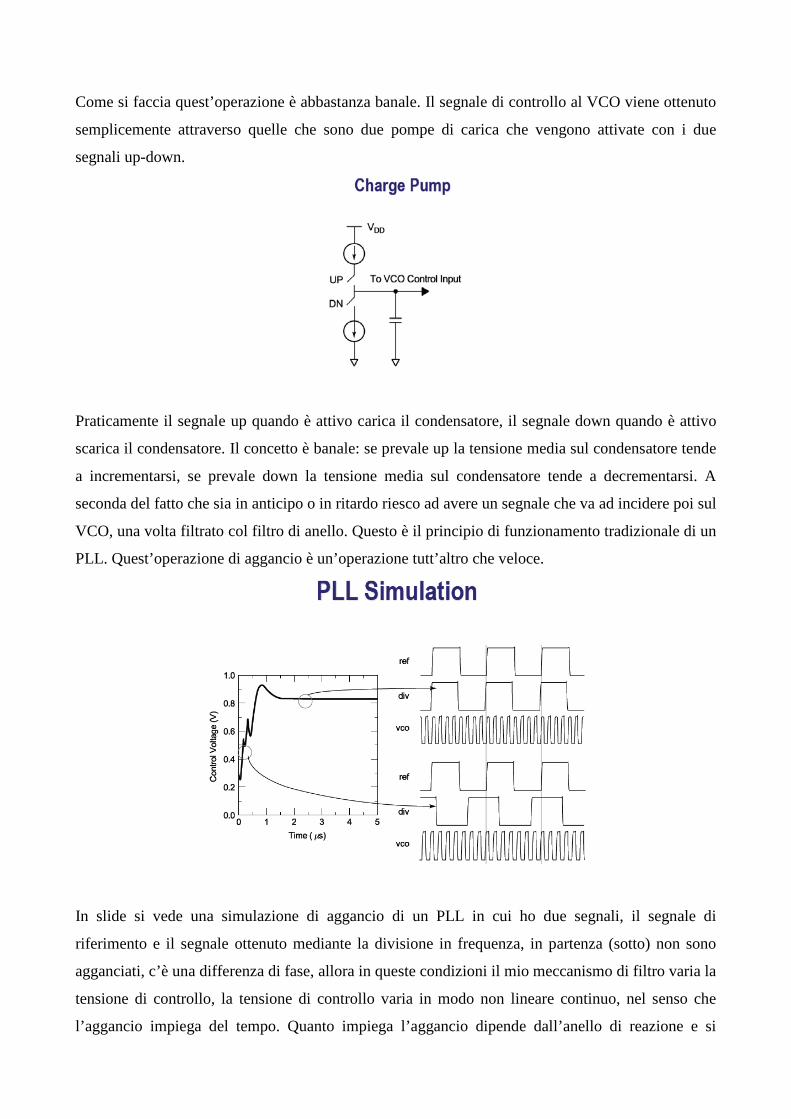
Come si faccia quest’operazione è abbastanza banale. Il segnale di controllo al VCO viene ottenuto
semplicemente attraverso quelle che sono due pompe di carica che vengono attivate con i due
segnali up-down.
Praticamente il segnale up quando è attivo carica il condensatore, il segnale down quando è attivo
scarica il condensatore. Il concetto è banale: se prevale up la tensione media sul condensatore tende
a incrementarsi, se prevale down la tensione media sul condensatore tende a decrementarsi. A
seconda del fatto che sia in anticipo o in ritardo riesco ad avere un segnale che va ad incidere poi sul
VCO, una volta filtrato col filtro di anello. Questo è il principio di funzionamento tradizionale di un
PLL. Quest’operazione di aggancio è un’operazione tutt’altro che veloce.
In slide si vede una simulazione di aggancio di un PLL in cui ho due segnali, il segnale di
riferimento e il segnale ottenuto mediante la divisione in frequenza, in partenza (sotto) non sono
agganciati, c’è una differenza di fase, allora in queste condizioni il mio meccanismo di filtro varia la
tensione di controllo, la tensione di controllo varia in modo non lineare continuo, nel senso che
l’aggancio impiega del tempo. Quanto impiega l’aggancio dipende dall’anello di reazione e si

dovrebbero andare a rivedere tutti i discorsi sui PLL. La cosa importante è che quest’operazione
impiega un po’ di tempo prima di arrivare a regime, quando io ho ottenuto fisicamente l’aggancio.
Se si va a vedere la scala il regime si ottiene dopo qualche us, questo vuol dire che se io devo
lavorare e agganciare due segnali a 1GHz, qualche us vuol dire che io devo aspettare parecchie
migliaia di colpi di clock prima che ci sia l’aggancio vero e proprio. Questo spiega tutta una serie di
cose: è tutt’altro che banale fare per esempio un microprocessore di quelli in cui la frequenza varia
in funzione del carico computazionale. Tutte le volte che io cambio la frequenza devo aspettare che
la frequenza si stabilizzi. Il sistema impiega un bel po’ di tempo prima di ottenere l’aggancio
completo. Questo per quanto riguarda il PLL. Il PLL ha quindi la struttura di frequenza di
riferimento, frequenza operativa che nasce dal VCO, divisione per n, Phase-detector, pompa di
carica, filtro e controllo del VCO. Questo è il metodo principe che viene usato per sincronizzare un
clock esterno in un circuito integrato con un clock interno al circuito stesso ed è il tipico caso di un
sistema di elaborazione dove io arrivo con una frequenza di clock bassa, e internamente il PLL mi
genera una frequenza di clock interna alta, ottenuta mediante questo meccanismo di reazione con la
moltiplicazione per n. Questa diventa la frequenza di riferimento e internamente può capitare che ci
siano due regimi, n regimi, in cui so che la frequenza deve essere la stessa ma voglio recuperare
quello sfasamento che avevo definito prima nei sistemi mesocroni. Capita di avere cioè dei regimi
di temporizzazione dove voglio che sia in qualche modo garantito l’aggancio in fase del clock
attraverso i due regimi. In queste condizioni il PLL non mi serve, il PLL mi serve tutte le volte che
io devo variare la frequenza. Qui la frequenza è la stessa, voglio semplicemente ottenere l’aggancio
in fase. Se voglio ottenere l’aggancio in fase il metodo consiste nell’utilizzare quelli che si
chiamano Delay Locked Loop, o DLL.
I DLL sfruttano quelle linee di ritardo che abbiamo visto all’inizio. Cioè io ho una linea di ritardo
controllata da un segnale che non fa nient’altro che prendere la frequenza di riferimento e mandarla
in uscita semplicemente shiftandola nel tempo. Il controllo di quanto shiftarla nel tempo avviene

mediante un anello del tutto simile a quello visto nel caso del PLL. Praticamente prendo il segnale
della frequenza operativa sul campo, vado a fare la differenza con la frequenza di riferimento,
questo mi da uno sfasamento, lo sfasamento lo utilizzo, con lo stesso circuito di prima, per avere
un’informazione se devo sfasare di più o di meno, e questo segnale se sfasare di più o di meno una
volta filtrato lo utilizzo semplicemente come segnale di controllo ad una linea di ritardo. Vado cioè
a spostare il fronte del segnale del mio regime, una volta che io conosco il segnale di partenza
semplicemente andando a spostare, a incrementare o a diminuire il ritardo introdotto da quella delay
line. Il tutto è controllato dallo stesso circuito, con lo stesso sfasamento ecc.. Questa struttura mi
garantisce che i due oggetti abbiano uno sfasamento nullo durante il funzionamento reale. I DLL
sono usatissimi nei sistemi digitali. Nell’esempio del processore della lezione scorsa ho un sistema
esterno con clock di sistema a bassa frequenza. Là dentro c’è un PLL che genera la frequenza di
funzionamento massima della parte del core, della CPU, e mediante tutta una serie di DLL genero i
segnali di temporizzazione, i segnali di clock che viaggiano, che garantiscono in qualche modo
l’aggancio in fase dei vari punti delle varie regioni. Quindi tutte le volte che io passo da un regime
all’altro io utilizzo questo meccanismo di aggancio in fase a frequenza costante per portare la fase a
zero. L’operazione anche per quanto riguarda i DLL è comunque un’operazione che richiede del
tempo per cui lo sfasamento nel tempo tende a ridursi per cui il segnale che va a variare la tensione
di controllo del delay line cambia nel tempo in modo abbastanza lento e di conseguenza cambia il
ritardo introdotto finchè ottengo l’aggancio e una volta che il sistema è agganciato questo aggancio
viene mantenuto. Tutta le volte che devo cambiare la frequenza di funzionamento della mia
macchina tutti i DLL si devono riagganciare prima di poter essere operativi. Questo spiega perché
ogni volta che cambio la frequenza di funzionamento di un processore tipicamente c’è un intervallo
di tempo in cui il processore non fa niente perché deve aspettare che il nuovo regime sia stabilizzato
prima di cominciare a lavorare altrimenti il rischio è di fare errori.

In slide si vede l’esempio di prima riportato a questo caso. C’è un clock globale, vari DLL che
vanno a lavorare con i vari blocchi, i vari moduli, garantendo l’aggancio ovvero garantendo il fatto
che tutti questi circuiti digitali abbiano lo stesso sfasamento nullo e quindi riduco anche i problemi
di skew, utilizzando questi metodi, mediante l’aggancio attraverso gli anelli di reazione di tutti i
sistemi di temporizzazione con cui ho a che fare. In realtà questi sistemi sono Pseudo-asincroni
perché ho un clock di riferimento.
Vediamo adesso effettivamente i sistemi completamente asincroni, cioè sistemi in cui il ricevitore e
il trasmettitore hanno frequenze assolutamente scorrelate tra di loro. Prima considerazione: se le
frequenze sono scorrelate non posso più avere nessuna relazione di fase tra chi trasmette e chi
riceve. Non posso più parlare di segnali validi, setup, hold time, ecc.. I segnali possono cambiare in
qualunque istante e possono essere campionati in qualunque istante. La domanda che uno si può
porre è: ma questi sistemi sono presenti spesso nei sistemi di elaborazione con cui abbiamo a che
fare o no? Risposta: Sì, ci stiamo muovendo sempre di più verso sistemi di questo genere. Cioè
avere dei processing element (PE) che lavorano a frequenze differenti e che si scambiano delle
informazioni quando serve. Gli si dà anche un nome: si parla di sistemi di tipo GALS (Globalmente
asincrono localmente sincrono).
Vuol dire che io ho delle macchine ognuna che lavora in modo sincrono e fa quello che deve fare
però queste macchine hanno regimi di temporizzazione assolutamente scorrelati per cui l’interfaccia
tra queste macchine è per definizione asincrona. Tutte le volte che si parla di sistemi GALS stiamo
parlando di sistemi con più regimi di clock assolutamente scorrelati tra di loro. Perché ci si juove
verso sistemi di tipo GALS? Principalmente per due motivi. Il primo motivo è il motivo dello skew
e della sincronizzazione. Più il sistema è grande più garantire che ci sia una differenza di fase nulla
tra tutti i punti del sistema diventa un’impresa, soprattutto se aumenta la frequenza di
funzionamento. Questo è il primo motivo.

Il secondo motivo è in realtà meno grave ma è in realtà il motivo per cui ci si sposta verso questi
tipi di sistema. Immaginiamo di lavorare su un circuito integrato ad una certa frequenza con un
milione di flip flop che commutano. Cosa succede quando abbiamo tutti questi flip flop che
commutano nello stesso istante? Si ha un assorbimento di corrente che è impulsivo ad ogni colpo di
clock. Mediamente la corrente è limitata, magari tra un colpo di clock e l’altro è quasi zero, e poi ci
ritroviamo dei picchi di centinaia di Ampere dovuti al fatto che tutti commutano esattamente in quel
momento. Questo vuol dire che si ha una potenza media che è quella che è e una potenza di picco
che può essere enorme. Potenza di picco vuol dire corrente di picco che si deve far passare da
qualche parte. Si rischia di avere circuiti piccolissimi che però necessitano di cavi di alimentazione
grossi così per riuscire a far passare quel centinaio di Ampere in qualche centinaio di ps!
Diventa un limite invalicabile: conduttore, passa corrente, caduta sul conduttore I∙R, risultato:
quando abbiamo l’impulso di sincronizzazione la tensione di alimentazione si siede e non funziona
più un tubo. Sistema di tipo GALS vuol dire che magari i miei cento milioni di flip flop li faccio
commutare con regimi differenti per cui questo vuol dire ridurre l’unico picco di prima e farlo
diventare tanti picchi più piccoli col risultato che diventa molto più facile andare a portare
l’alimentazione. Il sistema diventa anche molto meno rumoroso, alla fine si può dimostrare che si
va a consumare anche molto molto di meno. Cosa dobbiamo fare allora quando abbiamo due regimi
qualunque? Escludiamo il caso semplice in cui il ricevitore lavori a frequenza molto maggiore del
trasmettitore, capita quasi mai. Se il ricevitore lavora a frequenza molto maggiore del trasmettitore
cadiamo in piedi, perché vuol dire che il dato viene trasmesso con tempi molto più lunghi rispetto a
quelli con cui vado a campionare. Posso quindi campionare tante volte e scoprire quando cambia il
dato. È un caso abbastanza raro. In questo caso posso usare un sincronizzatore tradizionale, molto
semplice. Sincronizzatore tipico di un’interfaccia tra un mondo asincrono e un mondo sincrono, è su
questo che vado a muovermi: da una parte ho un segnale che viene generato in modo più o meno
casuale, gli si da una frequenza statistica, si dice in gergo, quella che chiamiamo fin, vuol dire che
mediamente quello commuta fin volte a secondo, ma mediamente. La variazione del segnale può
avvenire come riportato lì in tempi qualunque, però è importante sapere e avere una statistica del
segnale d’ingresso. Dall’altra parte ho il mondo sincrono con una frequenza di clock e quindi quello
che ci devo mettere in mezzo è un oggetto, quello che si chiama sincronizzatore che permetta di
trasformare il segnale asincrono in un segnale che il mondo, cloccato a fclk, sia in grado di
campionare in modo corretto. Quali sono i problemi di quest’interfaccia dal mondo asincrono al
mondo sincrono? Riassunto: com’è fatto un sincronizzatore? Il sincronizzatore funziona da arbitro,
cioè un tizio che deve riconoscere quale di due eventi si verifica per primo. Il sincronizzatore deve
semplicemente capire se è arrivato prima il clock o se è arrivata prima la variazione del segnale

esterno. Se è arrivato prima l’evento di clock non campiono, tengo il vecchio, se è arrivato prima il
segnale campiono il valore. Il problema è che deve decidere in un tempo fisso, ragionevolmente
piccolo. Il problema è che decidere in un tempo piccolo, in modo corretto, sempre, non è possibile.
È impossibile garantire un funzionamento corretto del sincronizzatore tanto più riduco il tempo di
intervento. Vuol dire che per definizione prima o poi esso sbaglierà. Quello che possiamo cercare di
fare è dare degli aiuti in modo che diminuisca la probabilità di errore, che esso sbagli. Qual è il
problema degli errori del sincronizzatore? Vediamo il più semplice sincronizzatore che possiamo
immaginare.
Ingresso D, transmission gate come interruttore che si apre e chiude, segnale che entra dentro
l’anello di reazione in cui vado a memorizzare. Il concetto è che quando l’interruttore è chiuso e il
dato in ingresso cambia, cambia il valore memorizzato dentro l’anello di reazione e funziona
benissimo. Il problema nasce quando io apro l’interruttore e in quel momento il dato stava
cambiando. Vuol dire che apro l’interruttore quando il dato non aveva ancora modificato lo stato del
nostro loop. Il caso peggiore in assoluto, per fortuna non realizzabile, è quando io ho i 2 inverter
esattamente identici e il dato stava cambiando ed era esattamente a metà strada durante la
transizione: Se io apro l’interruttore quando il dato interno è esattamente a metà strada entro in
quello stato metastabile per cui teoricamente, se i due inverter sono esattamente identici, stesse
condizioni operative, stessa tensione, stessa lavorazione di processo ecc ecc, quella condizione di
metastabilità vene mantenuta infinitamente. Vuol dire che quello funziona come una bilancia, allora
se io apro il circuito esattamente quando la bilancia è in equilibrio instabile e i due bracci sono
esattamente identici quello rimane lì fino alla fine dei secoli. Se quando apro l’interruttore i due
bracci non sono esattamente in equilibrio ma sono inclinati da una parte prima o poi finisco in uno
stato stabile. Quello che posso dire è che più sono squilibrato quando tolgo il clock e più in fretta
arrivo allo stato finale. Cosa che si può vedere dal diagramma seguente in cui si vede praticamente

che in funzione del valore d’ingresso quando io ho tolto il clock, questo è il valore che spero non
succeda mai, se sono esattamente in equilibrio quando tolgo il clock teoricamente rimango in
equilibrio per sempre. Tanto più vado lontano dalla situazione di equilibrio quando tolgo il clock
quanto più in fretta arrivo alla condizione stabile. Ci sono due curve perché stiamo parlando di due
inverter, qui è ovvio che un’uscita tende al valore alto e l’altra uscita tende al valore basso.
Queste due curve tendono ad allontanarsi tanto più in fretta quanto maggiore è la distanza dal valore
che si chiama metastabile nel momento in cui io ho aperto l’interruttore. Si può dimostrare, ma non
ci interessa più di tanto, che la variazione dei segnali segue un sistema del primo ordine, a un polo,
per cui vado a calcolare la costante di tempo del sistema e scopro che la tensione raggiunta da una
delle due uscite è la tensione metastabile + un esponenziale che dipende dalla differenza tra il valore
iniziale quando ho aperto l’interruttore e il valore metastabile, quindi che dipende in qualche modo
dalla distanza iniziale. Tanto maggiore è la distanza tanto più in fretta vado in fondo in uno stato
stabile. Tanto che se quel valore è sufficiente da avere una distanza che mi permette di avere un
segnale d’ingresso più piccolo di VIL o più grande di VIH, questo diventa la propagazione normale
del funzionamento tradizionale del mio sistema. Queste sono traiettorie che si chiamano traiettorie
di uscita del sincronizzatore. Qual è il problema? Il problema è questo: siccome io vado a
campionare un segnale che varia ma non so quanto varia esiste una probabilità non nulla che io
vada a campionarlo quando il segnale d’ingresso è vicino al valore metastabile per cui l’uscita è
vero che cambia, ma cambia così lentamente da non darmi un risultato valido nei tempi di
commutazione ritardo clock to output del mio sistema. In questo caso si dice che si va in uno stato
metastabile. Qual è il problema di uno stato metastabile? Il problema di uno stato metastabile è
banale: questo è il segnale d’ingresso, questo è il clock, questa è un’uscita che ha uno stato
metastabile. Problema: se io questa uscita la mando ad altri due flip flop per motivi vari, cloccati su
un clock comune che cloccano questo segnale quando non si è ancora stabilizzato, quello che può
capitare è che uno lo interpreti come un uno, l’altro come uno zero col risultato che qui faccio degli

errori. Sbaglio, uno dei due mi dice guarda il dato è arrivato fai delle cose, l’altro mi dice no guarda
il dato non è ancora arrivato non fare altre cose e il sistema s’impalla. Il problema di avere un dato
in metastabilità è che i circuiti a valle possono tranquillamente incominciare a sbagliare alla grande.
Quello che devo fare è garantire in qualche modo che la probabilità che questi circuiti prendano
decisioni differenti sia ragionevolmente piccola. Esiste tutta una teoria con formule ma non ci
interessa. Qual è la probabilità di essere in queste condizioni? È la probabilità di andare a
campionare il segnale d’ingresso nel momento in cui questo si trova nella zona proibita. Cioè
quando io vado a campionare il segnale in quest’intervallo in cui il segnale sta cambiando ed è nella
fascia proibita tra VIL e VIH, lì ho la probabilità di entrare in stato metastabile e quindi di avere
problemi. Si può andare a misurare questa probabilità. Qual è la probabilità di avere delle false
memorizzazioni? Basta andare a fare il rapporto tra la probabilità di essere in uno stato appunto
indefinito, rispetto al periodo in cui io vado a fare il campionamento. La probabilità di essere in uno
stato indefinito è uguale alla probabilità di essere quindi in questa zona, rispetto ad un periodo del
segnale. Tsignal è quella frequenza statistica, quindi il periodo statistico del segnale d’ingresso, c’è
un 2 di mezzo che è sparito ma non importa; quanto vale questo tempo in cui sono a rischio? Se so
in quanto tempo faccio tutto lo swing, che è il tempo di salita del segnale, questo salto vale VIH-
VIL, questo tempo lo posso fare con una proporzione quindi vale (VIH-VIL)/Vswing moltiplicato
per il tempo di salita e quindi quello mi da poi l’intervallo. Quell’intervallo diviso il tempo statistico
del segnale mi dà la probabilità di beccare il dato mentre questo sta cambiando, c’è un 2 che manca
ma non importa. Preso questo tempo, questa probabilità, diviso l’intervallo di campionamento del
segnale questo mi dà quest’informazione che è praticamente il numero medio di volte in cui mi
trovo in questo stato metastabile, in cui campiono il dato quando non dovrei campionarlo. Questo è
importante perché mi dice praticamente ogni quanto tempo rischio di campionare il dato nella
condizione di metastabilità. Come funzionano i sincronizzatori? I sincronizzatori sono una cosa di
questo genere: dicono ma, visto che questo signore non è così affidabile prima di mandarlo avanti
aspettiamo del tempo, un ritardo T e mandiamolo ad un altro flip flop esattamente identico che
campiona questo segnale dopo un ritardo T. Vuol dire che vado a campionare questo segnale
quando il valore del segnale si è già spostato dalla condizione di metastabilità e sta cercando di
convergere. Ovvero vuol dire che noi invece di andare a campionare in questo momento il segnale,
è come se noi ci spostassimo in avanti e lo campionassimo in un momento in cui quel segnale si sta
stabilizzando. È ovvio che più è grande T più sto arrivando in condizioni corrette e stabili. Siccome
l’evoluzione del segnale varia secondo quell’esponenziale e(-T/tau), vuol dire che se io aspetto un
tempo T quella probabilità viene moltiplicata per quell’esponenziale, ovvero, che è quello che
compare sotto, il numero medio di errori di sincronizzazione che ottengo lasciando passare un

tempo T è uguale al numero medio di errori che avevo campionando all’istante 0 moltiplicato per
e(-T/tau). Più passa il tempo più si riduce la probabilità di campionare un dato nel suo intervallo
proibito. Esempio: supponendo di lavorare a una frequenza di clock di 100MHz, quindi 10 ns di
tempo di clock, un segnale che statisticamente ha un tempo di ciclo di 50 ns, tempo di salita 1 ns,
tau = 310 ps, ecc viene fuori per esempio che se noi campioniamo il segnale così come arriva,
abbiamo praticamente questo MTF (Min Time to Fall), vuol dire il tempo che passa prima di
sbagliare è dell’ordine di 2.5 us; risultato: non funziona mai!
Se voi aspettate un colpo di clock il tempo medio diventa 2.6∙108 = 8.3 anni. Ovviamente parliamo
di tempo medio, non vuol dire che se partiamo adesso sbagliamo tra 8.3 anni, ma vuol dire che
mediamente facciamo un errore ogni 8.3 anni. Questa, detta in termini molto semplici, è la teoria
che sta alla base dei sincronizzatori. I sincronizzatori non sono nient’altro che una successione di
flip flop che vengono campionati sullo stesso clock e che fanno sì che il primo campioni e
statisticamente va sempre in metastabilità, il secondo vede già un segnale che è già più stabile
quindi farà molti meno errori e tipicamente quello dopo ne farà ancora di meno. Metto un numero di
flip flop in cascata sufficienti a garantire un MTF che sia sufficientemente grande da garantirmi che
quello sia un evento assolutamente improbabile.

L’esempio che si fa di solito è che se io sto facendo un sincronizzatore per un segnale che va
all’interno di un PC, con Windows, una volta che io vado a mettere un MTF confrontabile coi tempi
con cui si inchioda Windows vuol dire che il sistema lo prendo e lo butto!
Il numero di elementi da mettere dentro il sincronizzatore dipende dalla probabilità che io voglio
avere di errore, a valle del processo di sincronizzazione. Quindi dipende dal tipo di applicazione, se
quello è un segnale che è particolarmente critico e viene magari da un segnale di controllo di una
centrale nucleare, magari mettiamo qualche flip flop in più, chi se ne frega dello spreco l’importante
che siamo più sicuri. L’unico inconveniente del mettere tanti flip flop in cascata è il tempo di
reazione. È ovvio che se il mio segnale entra e poi va in 2500 fli flop e mi dice guarda che dieci
minuti fa è successo qualcosa, allora la cosa non funziona anche se la sincronizzazione è perfetta.
Bisogna dunque raggiungere un compromesso tra la probabilità che voglio ottenere e tempi di
risposta. A questo punto il problema è, è vero che io posso usare dei sincronizzatori per trasformare
il segnale asincrono in un segnale corretto dal punto di vista sincrono ma devono anche prendere
delle decisioni irrevocabili in un tempo limitato. La domanda che può nascere è questa: se viene
presa una decisione sbagliata? Può voler dire che per esempio il segnale stava cambiando e io sono
andato a campionare beccando il valore vecchio. Il concetto è: il segnale stava cambiando e il
sincronizzatore o si è accorto della variazione o non si è accorto della variazione. Non è un errore,
vuol dire semplicemente essermi accorto in tempo o al ciclo dopo che c’è stata una variazione del
segnale. Per mettere insieme queste cose ho bisogno di avere dei meccanismi di sincronizzazione
tra le due regioni che permettano di far si che il sincronizzatore possa lavorare in modo corretto.
Questi meccanismi sono i cosìddetti handshake, cioè tutti i protocolli di comunicazione tra due
regimi di clock, che permettono ai due regimi di fare lo scambio di dati in modo corretto
indipendentemente dalle frequenze in gioco. Come si gestiscono gli handshake? Vediamo solo
alcuni punti importanti per la sincronizzazione architetturale che ci interessa.
Vuol dire trovare delle regole tra chi trasmette i dati e chi riceve i dati in modo tale che la
trasmissione avvenga in modo corretto. Un protocollo di comunicazione è un insieme di regole che
permette ai due oggetti di scambiarsi delle informazioni in modo sicuro. Di protocolli ce ne sono
tanti. Una prima categoria di protocolli, quelli che si chiamano BUNDLED DATA (o single rail),
vuol dire che ogni segnale fisico è associato ad un segnale logico. Ogni linea porta
un’informazione. Se i due devono scambiarsi le informazioni e vanno ognuno per i fatti propri le
regole del protocollo rappresentano le azioni che i due si scambiano per ottenere il risultato.
Più che partire a vedere questo vediamo prima quello più conosciuto che è l’HANDSHAKE A 4
FRONTI:

È un protocollo in cui ho n dati, n bit che viaggiano, ogni bit una line, un segnale e due segnali di
controllo, un segnale di Request e uno di Acknowledge. Questi due segnali sono quelli che
permettono di giocare col protocollo. Il concetto base è: metto i dati, il fronte di Request è il primo
fronte che mi dice ehi guarda che ho messo i dati, allora l’altro risponde con l’Acknowledge, che
vuol dire ah ho capito che hai messo i dati, ho preso i dati, sono stati accettati. Terzo fronte, ah ho
capito che hai accettato i dati allora aspetta, guarda che li tolgo perché non servono più. Quarto
fronte: ho capito che hai tolto i dati, per me il ciclo è chiuso qua, possiamo ripartire col prossimo.
Si chiama protocollo a 4 fronti perché richiede la propagazione di 4 fronti lungo il canale, due
gestiti dalla sorgente, in questo caso il segnale Req, due gestiti dalla destinazione, in questo caso il
segnale di Acknowledge. Questo permette che i due parlino e sempre e comunque riescano a
mandare un’informazione comprensibile all’altro. Il principio base di questo protocollo è che ogni
attore fa una sola azione e poi aspetta un’azione dell’altro. Valido i dati, poi non faccio niente
finché non mi ritorna qualcosa indietro. Accetto i dati, non faccio niente finchè l’altro non mi da un
segnale. È un continuo balletto tra sorgente e destinazione che fanno un’operazione per volta, ma
questa alternanza forzata garantisce che la sincronizzazione avviene coi tempi necessari. Sono
lentissimo nel mettere i dati, e chi se ne frega, gli altri aspettano. Ho dato i dati subito, io sono
lentissimo nell’accettarli, va bene tanto la sorgente in ogni caso non si schioda finché io non ho
preso i dati. Questo permette di adattare la velocità del trasmettitore e del ricevitore.
Protocollo con dati Bundled (o single rail): ogni segnale fisico è un bit. Il protocollo a 4 fasi è
sicuramente il più sicuro per scambiare informazioni tra due regimi qualunque. Ha solo un
inconveniente: ogni volta che trasmetto un’informazione ho 4 fronti che si propagano. Ogni fronte
si propaga impiegando del tempo, va tutto bene se non voglio andare a frequenze molto elevate,
perché se no il rischio è che il tempo maggiore impiegato dal protocollo è quello che impiegano i
segnali di controllo a dire ehi i dati sono validi, ehi i dati sono stati accettati, ah va bene tolgo i dati,
ah...

Per rendere più veloce il protocollo posso, a scapito di una complicazione della mia architettura,
passare a un protocollo a 2 fronti o a 2 fasi.
Ho sempre un’alternanza trasmettitore, ricevitore, trasmettitore, ricevitore però questa volta le
informazioni che viaggiano sono semplicemente le informazioni: dato valido, dato accettato. È
implicito il fatto di togliere un dato e sostituirlo. Se io faccio in questo modo, metto i dati, li valido,
il ricevitore li riceve, questo fa si che io automaticamente cambio subito i dati e la prossima
validazione è un altro fronte sullo stesso segnale ed è il fronte complementare. Tutti i fronti del
segnale Req rappresentano un dato valido, tutti i fronti sul segnale Ack rappresentano un dato
accettato. Il vantaggio è che raddoppio la velocità se l’elemento critico era la propagazione dei
controlli. Ogni volta che trasmetto un segnale ho solo due transizioni sulle linee di controllo, ho
dimezzato il numero di linee di controllo e il dimezzamento mi porta come conseguenza il fatto di
andare più in fretta. Pago esclusivamente il fatto che diventa più complicata la logica di controllo.
Perché la logica sia di invio dell’informazione che di ricezione non è più legata su un fronte, un
livello, ma è legata su una qualunque variazione. Quindi ho bisogno di un circuito che sia in grado
di riconoscere qualunque transizione. Quindi ad ogni transizione c’è un evento.

Questi protocolli si basano su un principio: il principio base è che la successione di azioni fatta dal
trasmettitore e dal ricevitore deve essere sempre la stessa. Vuol dire che se io metto i dati, il segnale
di validazione deve essere mandato dal trasmettitore dopo un tempo opportuno. La cosa
fondamentale è che anche al ricevitore prima devono arrivare i dati almeno un tempo di setup prima
di quando arriva il segnale di validazione. Devo garantire un certo timing al trasmettitore e al
ricevitore durante il funzionamento normale della mia macchina. Questa sembra una cosa
abbastanza normale vista così, peccato che ci siano tutti i problemi di skew dei segnali dovuti al
fatto che i segnali fanno percorsi differenti, sono più o meno caricati. È dovuto al fatto che magari i
segnali di temporizzazione vengono da un clock, direttamente e indirettamente e ho un jitter. Queste
incertezze devono comunque non violare la successione di azioni previste dal protocollo. Questo
non è detto che sia così banale. Soprattutto quando vado a velocità elevate. Più vado su in
frequenza, più lo skew diventa dell’ordine dei tempi con cui ho a che fare. Il limite verso l’alto di
questi protocolli è di fermarmi ad un certo punto perché non sono più in grado di garantire questa
successione corretta di azioni durante il trasferimento. Per evitare questi problemi o diciamo per
attenuarne un po’ l’effetto, sono nati dei protocolli che non sono più di tipo bundled, ovvero sono
nati dei protocolli in cui si cerca di codificare la validità del segnale direttamente dentro le linee di
segnale. Io cerco di codificare l’informazione che voglio inviare più la validazione dentro le linee
del segnale. Il primo effetto è questo: per mandare un bit non mi basta più una pista, un segnale, ma
ne ho bisogno di almeno due. Questo è il primo esempio in cui codifico ogni bit di dato
direttamente su due fili. Questa è una codifica che ha avuto molta fortuna in una serie di
applicazioni di nanoelettronica, per esempio l’NCL (Non Conventional Logic). Essa è una codifica
di questo tipo: il mio dato, il mio bit, viene codificato su due segnali, in cui mando l’informazione
nella forma vera e falsa, t ed f, secondo questa caratterizzazione: quando non mando niente mando 2
zeri, se voglio mandare uno zero mando zero su vero e 1 su falso, se voglio mandare un 1 mando un
1 su vero e zero su falso. Per il momento assumiamo la codifica 11 vietata. Vuol dire che su quelle
linee di segnale viaggia anche l’informazione di validità. Quando vedo arrivare 00 non ho bisogno
di una validazione, vuol dire guarda che non c’è dato, non è stato inviato il dato. Quando invece
mando dei dati veri e propri, automaticamente l’invio dei dati ha dentro di se il concetto di
validazione. Non ho più bisogno di un segnale di valid, la validazione è annegata, embedded, dentro
il segnale che viaggia. L’unico segnale di controllo a questo punto è l’acknowledge che torna
indietro. Non ho più bisogno di garantire la tempistica tra la validazione e i dati perché la
validazione è intrinseca. Questo è il protocollo: Empty -> siamo pronti, inizia il prossimo ciclo,
metto i dati e sono automaticamente validi, ok ho preso i dati, allora li tolgo, empty, ah va bene ho
capito, siamo pronti e ricominciamo.

Questo è l’equivalente del protocollo a 4 fronti, usando questa tecnica a 4 fasi. Dual rail nel senso
che ho bisogno di due segnali per ogni bit trasmesso. Il vantaggio è che non devo più garantire la
relazione tra i dati inviati e la validazione. Non ho più questo tipo di problema. Lo svantaggio è che
siccome il valid è annegato dentro il segnale, devo fare attenzione a far sì che i segnali quando
viaggiano non abbiano mai dei glitch. Un glitch equivale ahimè ad un cambiamento di stato. Un
glitch diventa pericolosissimo perché se il segnale era a zero, empty, è arrivato un glitch, e quel
glitch viene riconosciuto come se il segnale era valido e viene già tolto. Quindi i problemi di glitch
e di hazard qua sono più critici rispetto ai casi precedenti. Se facciamo viaggiare tanti bit in
parallelo, nell’esempio ho due segnali A e B che viaggiano, il segnale di richiesta diventa locale,
non viaggia più lungo la linea, quando la richiesta è attiva questo segnale d’ingresso provoca la
propagazione del segnale da una parte all’altra. In ricezione so che B è arrivato quando o il valore
vero o il valore falso è a 1. Basta un’operazione di OR per capire che questo bit è arrivato. Itero
quest’operazione su tutti i bit in arrivo, faccio una specie di AND particolare e il concetto è che io
rilevo il segnale di richiesta direttamente dai dati senza la validazione che viaggia. Questo permette
di avere una validazione che è inserita dentro il flusso di dati e quindi il segnale di controllo è nei
miei dati. Quella visibile in figura con il simbolo C non è una porta AND vera e propria, è una porta
particolare che si chiama C-Muller; è una porta con memoria che è utilizzata moltissimo con sistemi
di sincronizzazioni asincroni. Non entriamo nei dettagli ma vediamo il concetto: questa porta ha
memoria della storia precedente. Si può vedere anche la regola con cui si genera l’uscita Z. Essa è
uguale ad a*b, quindi quando entrambi sono a uno l’uscita va subito a 1. Nel caso precedente
quando tutti i bit sono arrivati sicuramente il dato è completo. Però, l’uscita Z non cambia il valore
precedente finchè almeno uno degli ingressi è attivo. Se guardiamo la tabella di verità risulta più
chiaro: quando gli ingressi sono entrambi a zero l’uscita è sempre zero. Gli ingressi possono
cambiare, uno per volta, prima uno poi l’altro, non importa. La mia porta non cambia. Solo quando

tutti sono a 1 l’uscita va a 1, mi da la validazione e rimane valida anche quando gli ingressi
ritornano a zero finchè tutti sono vuoti, quindi questa è una porta che va bene per riconoscere quelle
due configurazioni di valid (tutti i bit sono attivi) ed empty (tutti i bit sono a zero).
Questa può essere realizzata con una specie di doppio inverter con una reazione. Su questa fase è
possibile realizzare controlli ed handshake tra i vari oggetti senza particolari problemi. Prima
abbiamo visto il caso in cui ogni bit era codificato su due linee, per mandare due bit ho bisogno di 4
segnali. Una codifica alternativa è quella che si chiama 1-of-4 Signaling:
In questo caso faccio semplicemente una codifica diversa di due bit su quattro. Vuol dire non stai
mandando niente -> null, tutti 0; mandi 00 -> 1000; mandi 01 -> 0100; e così via secondo quanto
visibile in slide. È una codifica One-hot. Anche in questo caso vale il meccanismo visto prima. Vale
il meccanismo per cui empty equivale a tutti zeri. In questo caso valid equivale ad almeno un bit ad
uno. Il dato è valido inviato quando ho almeno un bit. Il vantaggio rispetto alla codifica precedente
è tipicamente uno solo: ho molte meno transizioni rispetto alla codifica vista prima. Meno
transizioni vuol dire meno potenza in gioco. Sempre 4 linee sono, solo che invece di avere la

codifica in cui ogni singolo bit è codificato su due, quindi ogni volta che ho una transizione in
ingresso in realtà cambia o l’uno o l’altro in opposizione, qui sono messi in qualche modo insieme e
si ha una codifica unica per i bit che io voglio inviare. Numero di fili identico, più fili per segnale,
metà delle transizioni più una serie di altre cose in cui non val la pena meditare in questo corso. Il
circuito di ricezione e trasmissione sono ovviamente leggermente differenti, perché uno deve fare la
decodifica, c’è un decoder abilitato in qualche modo, e in ricezione devo semplicemente fare l’OR
dei vari segnali su cui può essere codificato il segnale. Tutto questo poi va alla solita C-Muller per
scoprire quando sono in uno stato Valid, oppure in uno stato empty.
Concludiamo il discorso sulla C-Muller facendo un esempio per capire come questo concetto di
empty e valid è utilissimo per realizzare gli handshake. Il primo protocollo che abbiamo visto è un
protocollo a 2 fasi, c’è un sender e un receiver, in questo caso i due si scambiano i segnali di
richiesta e di Acknowledge e sappiamo che un protocollo a due fasi fa sì che ci sia un trasferimento
ogni coppia di transizioni sui componenti. Quindi dato valido, dato accettato, dato valido, dato
accettato, ecc.. Le azioni sono sempre alternate tra il sender e il ricevitore.
Vediamo questo tipo di operazione come può essere realizzata dal punto di vista hardware. Dal
punto di vista hardware si può realizzare quest’operazione esattamente con la C-Muller. Il nostro
oggetto realizza la logica di handshake. Allora, il segnale di acknowledge arriva e prima di andare
nella C-Muller viene invertito. La C-Muller è un oggetto che fa commutare l’uscita quando i suoi
ingressi sono tutti a zero, diventano tutti e due a uno, allora lei commuta, e poi quando ritornano
tutti e due a zero. La configurazione di tutti a zero o di tutti a uno è la configurazione in cui ho il
segnale di data ready, il segnale di Acknowledge che ritorna invertito di fase, tale per cui questa
struttura quando c’è il data ready e l’Acknowledge a zero, zero diventa uno, ho due uni quindi
quello commuta e quindi il protocollo va avanti. A quel punto a un certo punto torna il segnale di
acknowledge e quando il data ready è cambiato, cioè c’è un nuovo dato, e l’acknowledge ha

cambiato stato diventano due zeri e quindi l’uscita commuta. Due commutazioni sugli ingressi,
quindi, provocano la commutazione sull’uscita. Questo genera la sequenza corretta del protocollo.
Questa struttura, col meccanismo di passare da tutti zeri, tutti uni, è il modo migliore per
gestire le macchine che lavorano ad handshake. Per fare un esempio, MA QUESTO NON VE
LO CHIEDO, in slide si vede una FIFO autotemporizzata in cui queste C-Muller lavorano proprio
come macchine di handshake tra un oggetto e il successivo. Non entriamo nei dettagli, però si vede
come prima lavora e faccia una scrittura nel primo oggetto, dopodichè questo si propaga ed entra in
funzione il secondo, poi entra il terzo che da un feedback al primo allora il primo è pronto per
lavorare di nuovo allora parte e va avanti e intanto il terzo dato esce e così via. La cosa che ci
interessa è il concetto di un oggetto semplice che permette di sincronizzare degli eventi basandosi
sul riconoscimento di due condizioni: quando tutti gli ingressi sono zero (condizione empty) e
quando tutti gli ingressi sono a 1 (condizione valid o full). Questa è una struttura più complicata
per realizzare per esempio un protocollo a 4 fasi:
Da notare che negli esempi fatti non c’è il clock. Sono circuiti assolutamente asincroni.
L’ultimo passo che ci resta da vedere è dire: Se noi vogliamo realizzare quest’oggetto ma con due
regimi, quindi col clock, come può avvenire la sincronizzazione a livello di controlli e di dati?
Parliamo di quello che si chiama SINCRONIZZATORE GENERALE O UNIVERSALE. Cioè un
oggetto che permetta di sincronizzare degli eventi tra due macchine a frequenze qualunque
garantendo di non avere metastabilità ovvero che la sua probabilità sia così piccola da renderla
trascurabile e garantendo l’evoluzione temporale delle azioni tra chi trasmette e chi riceve dei dati.
Il sincronizzatore generale è una macchina fatta in questo modo: regime numero 1, col suo clock
ck1, regime numero 2 col suo clock ck2. Questi due regimi vogliono scambiarsi delle informazioni
di controllo garantendo il fatto che non ci sia mai metastabilità. Allora abbiamo detto mando i dati,
poi abbiamo magari il segnale di request, o di valid, c’è un fronte. Questo fronte viaggia dalla
sorgente verso la destinazione che deve leggere questo segnale.

Il problema qual è? Che se la destinazione è una macchina sincrona col suo clock, leggere quel
segnale vuol dire che quel segnale entrerà nella macchina e sarà campionato. Rientriamo nei
problemi che abbiamo appena abbandonato perché se io vado a campionare il segnale delayed, lo
campiono col mio clock, non so quando cambi, risultato: posso campionare il segnale quando sta
cambiando, lo sto campionando in metastabilità, col risultato che posso prendere lucciole per
lanterne. Ho bisogno di un meccanismo che mi garantisca che il segnale di controllo arriva alla
destinazione sincronizzato con il regime di arrivo. Anche il segnale che torna indietro che è il
segnale di Acknowledge parte dal regime numero 2, torna verso il regime numero 1 e deve arrivare
in fase con il regime in questione. Questo vuol dire che sicuramente tutti i segnali che entrano nel
rispettivo regime di sincronizzazione devono prima passare attraverso quei sincronizzatori che
abbiamo identificato precedentemente. Questi oggetti che ho chiamato synch sono quella
successione di flip flop che permettono di far si che quel segnale, che cambia quando vuole, venga
in qualche modo adattato alla frequenza di arrivo. Siccome io voglio un segnale d’ingresso qui e
uno lì, ecco che ognuno ha il suo sincronizzatore. Notate che ogni sincronizzatore viene
sincronizzato col regime di clock d’arrivo. Quindi il sincronizzatore di qua viene sincronizzato col
clock 1, l’altro sincronizzatore è cloccato col clock 2. Adesso entriamo nei dettagli e supponiamo
che quelle due macchine vogliono scambiarsi delle azioni del tipo: ehi c’è il dato valido, ehi ho
capito. Sono informazioni che ognuno dei due genera, quindi la sorgente manderà un’informazione,
tipicamente un fronte, qui per farla semplice supponiamo che sia un fronte di salita, questo fronte
deve generare poi un qualche cosa che viene riconosciuto dall’altra parte. Quando lui risponde sul
suo segnale di uscita manderà un altro fronte, che prima o poi deve generare qualcosa dall’altra
parte. Questo è il concetto. Ora entriamo nei dettagli. Per capire come lavora il tutto, immaginiamo
che i due oggetti lavorino praticamente su un segnale di controllo che ha due stati, uno stato forzato
da chi trasmette e un altro stato forzato da chi riceve. Quando io ho dei dati validi forzo questa

bandierina, quella che si chiama flag. La forzo io, io sono l’unico che può forzare a 1 quella
bandierina. Il ricevitore è l’unico che può forzare a zero quella bandierina. L’operazione di forzare a
uno o a zero la bandierina è un’operazione che viene fatta con un set-reset in cui io ho le chiavi del
set e l’altro ha le chiavi del reset. Siccome io lavoro su fronti nell’esempio, perché funzioni questo
sincronizzatore interno è necessario che il mio fronte sia trasformato in un impulso. Per trasformare
un fronte in un impulso basta prendere il segnale così com’è, mandarlo ad un inverter, quando ho un
impulso in ingresso questo mi da un impulso in uscita di larghezza pari al ritardo dell’inverter.
Quindi il pulse generator è tutto sommato abbastanza semplice. Possiamo farlo un pochino più
complicato mettendoci dentro anche il clock per garantire che abbia una larghezza minima da
tenere. Quindi ho bisogno di un oggetto che mi trasformi il mio fronte di salita in un impulso.
Risultato: il sincronizzatore di controllo parte da zero, quando forzo l’uscita di set questo mi genera
un impulso sul set che fa andare a 1 flag. Allora io ho tirato su la bandierina (flag) questo va in
qualunque istante, in modo assolutamente scorrelato col mondo. Bisogna che questo segnale venga
riconosciuto dal ricevitore. Questo segnale passa attraverso il sincronizzatore sul clock di arrivo, per
generarmi questo che chiamo output-flag. È il valore del flag riconosciuto in uscita. Questo vuol
dire che quando io decido che il dato è valido do il fronte, si trasforma in impulso, setta il flip flop,
questa operazione viene sincronizzata in ricezione e a un certo punto output-flag diventa attivo.
Output-flag sincrono col clock 2. A questo punto in ricezione dice ehi guarda c’è il dato pronto,
oppure, la bandierina è su, allora facciamo qualche cosa. In ricezione faccio quello che devo fare e
quando ho finito devo avvertire dall’altra parte, cioè dire ehi io ho finito. Come avviene questa
azione al contrario? Avviene con un’attivazione del reset, questo fronte diventa un impulso,
l’impulso va sul reset, questo mi provoca il passaggio del flag a zero, questo andare a zero viene
mandato al sincronizzatore da tutte e due le parti, dopo un ritardo opportuno l’input flag dalla mia
parte riconosce che è cambiato lo stato. Questa macchina quindi, è una macchina che permette ai
due regimi di scambiarsi delle azioni in sequenza. Faccio un’azione, ne faccio un’altra, faccio
un’azione, ne faccio un’altra.. in modo sicuro qualunque sia il regime di clock, qualunque sia il
momento in cui avviene l’operazione, quindi questo è un generico sincronizzatore di comandi tra
due regimi qualunque. Ciò mi garantisce se i due oggetti sono progettati ad hoc che ci sia un flusso
sicuro di azioni una da una parte, una dall’altra, una da una parte, una dall’altra.. Ogni attore fa
un’azione e sta in attesa di una controazione dell’altro prima di ripartire.
Se noi vogliamo applicare questo sincronizzatore di comandi a un invio di dati andiamo alla slide
vista prima: il segnale di set è quello che chiamiamo di load ed è un segnale che va sul registro ed è
la validazione da parte del trasmettitore. Il segnale di load, quindi di set, è il segnale che mi agisce
in qualche modo sul campionamento dei dati verso il ricevitore. Nell’esempio tale segnale è quello

che mi attiva il flag. Dopo un po’ di tempo quel segnale diventa attivo al ricevitore. Quel segnale
dopo un po’ di tempo arriva al ricevitore ed è quello che il ricevitore percepisce come un data
available. Quindi quando il ricevitore vede il segnale data available attivo dice: oh guarda c’è un
dato disponibile. Quando arriva data available i dati sono già validi da un po’, perché io li ho scritti
qua dentro, quindi data available diventa attivo e il ricevitore dice tò guarda c’è posta per te. Lui
prende i dati, fa quello che deve fare e quando i dati sono stati accettati dice va bene, ok, puoi
rimuoverli se vuoi -> segnale di reset. Il segnale di reset è un segnale di remove, torna indietro; il
segnale di flag aveva la funzione di full che vuol dire ok, guarda che in questo momento il dato, il
buffer o quello che è, è pieno. Quando lui dà il remove questo genera l’andar via del full. Quindi il
trasmettitore dice tò guarda non è più pieno, posso mandare un altro dato. Questo automaticamente
mi toglie il data available per cui in ricezione automaticamente sa che non ci sono più dati
disponibili e quindi sta in attesa. Quindi questo è il flusso con cui trasforma il sincronizzatore di
controllo in sincronizzatore di dati. Questo genera gli handshake, la scrittura è generata dal segnale
di hold e tutto il resto viene garantito da chi parla e chi riceve i dati, lavorando in modo asincrono,
ognuno col proprio regime però in piena sicurezza. Nel senso che ho i sincronizzatori in ingresso
che garantiscono che i controlli che arrivano, arrivano sempre con setup e hold time validi durante
la ricezione. Il full serve dal mio lato per sapere che non posso mandare nient’altro perché
l’interfaccia è piena. Quando questo è pieno il segnale di full che torna indietro mi dice ok,
semaforo rosso, l’interfaccia è piena. Quest’interfaccia è piena diventa ehi ci sono dati disponibili
dall’altra parte. Quando l’altra parte prende i dati il remove cosa fa, mi tira giù la bandierina, mi
dice ehi ho preso il dato quindi ehi è vuota ormai l’interfaccia, perché il full va a zero e la stessa
cosa serve dall’altro lato per dire ehi guarda non ci sono altri dati disponibili. Circuiti del genere
sono usati dappertutto ogni volta che ci si trova a lavorare con differenti regimi di temporizzazione.
Questi oggetti esistono come celle di libreria e servono appunto se si vanno a fare circuiti integrati
che lavorano con diversi regimi di temporizzazione. Tutto sommato è semplice, ce la caviamo con
7-8 registri. C’è solo un piccolo inconveniente con questa struttura che è il tipico problema
produttore-consumatore. C’è uno che produce i dati e l’altro che li consuma. Questo problema
funziona e porta a risultati ottimi quando la statistica associata alla produzione e al consumo sono
più o meno simili. Se le statistiche non hanno gli stessi parametri e sono differenti il sistema visto
entra in crisi. In questo caso questo sistema mette in crisi la capacità di trasporto dell’informazione.
Vediamo un esempio: il mio sistema sta ricevendo dati a pacchetti (a burst), vuol dire che io ricevo
200 pacchetti e poi basta. Ma non posso dire al bit in ricezione no aspetta fermati che prima cerco di
capire quest’altro bit e poi dopo andiamo avanti. Quando c’è una scorrelazione notevole tra la
statistica del trasmettitore e quella del ricevitore il meccanismi di trasferimento e di handshake su

singolo dato entra in crisi. Il meccanismo che si usa allora è l’equivalente di una FIFO d’interfaccia
tra i due regimi. Il trasmettitore trasmette i dati riempiendo la FIFO che fa da tampone, con tutta
l’interfaccia dei segnali di temporizzazione. Finchè la fifo non è piena io posso continuare a
scrivere, questo è gestito col clock del trasmettitore che gestisce le scritture dentro la fifo. Il
consumatore lavora sulla parte di controllo: se la fifo è vuota non scaricare niente, oppure la fifo
non è empty, cioè non è vuota, allora ti dico io quando leggere il prossimo dato. Il tutto è gestito col
clock del ricevitore.
Il concetto di fifo è un concetto che permette di separare la statistica del trasmettitore da quella del
ricevitore. È ovvio che parliamo di considerazioni statistiche ma i valori medi della ricezione e della
trasmissione ovviamente devono essere gli stessi. Questo è un problema complesso nei sistemi
digitali e ci sono corsi interi dedicati all’argomento. È un problema di dimensionamento della FIFO.
La fifo ha un costo in termini di area, di potenza. È inutile dire mettiamo una fifo da 2 GB così
siamo sicuri. Devo andare a dimensionare tutte le fifo d’interfaccia tra i regimi. In funzione di
quanto sono scorrelate le statistiche di chi parla e di chi riceve. Tanto maggiore è la differenza tra il
burst di chi produce e la frequenza di chi riceve e tanto maggiore deve essere la Fifo. Il
dimensionamento della fifo è uno dei punti cruciali più difficile da gestire. L’interfaccia Fifo,
quindi, la devo usare quando le due statistiche degli interlocutori sono scorrelate e quindi è ovvio
che usare il protocollo sulla singola informazione rischia di abbassare la velocità del tutto. Il nostro
caso prevede un canale unidirezionale tra trasmettitore e ricevitore. Se entrambi i dispositivi
funzionassero alternativamente da trasmettitore/ricevitore avrei un canale bidirezionale e quindi
ogni canale deve avere una FIFO associata. È possibile che in questi casi su alcuni canali io debba
avere la fifo, su altri non ce n’è di bisogno, dipende tutto dalle statistiche dei comunicatori.
Apriamo adesso, in ultima analisi, una finestra introduttiva su un certo mondo, il quale bandisce il
concetto di clock. Cioè preoccupiamoci di realizzare degli oggetti che non solo scambiano

informazioni ma lavorano in modo asincrono (o self timed), cioè senza clock. Vediamo qual è la
funzione del clock in un sistema sincrono. Il clock agisce come evento di fine operazione, io so che
i dati viaggiano e quando arriva il clock devono essere stabili. Il clock è il garante ed il mezzo con
cui vengono verificate la corretta sequenza di azioni. Il clock è un evento e ad ogni vento faccio
qualcosa. Vantaggi: facile da fare, facile da debuggare, non si hanno particolari sorprese, si riesce
ad andare a frequenze anche molto elevate. In sistemi complessi ha un sacco di vantaggi positivi.
L’unico svantaggio del mondo sincrono è che tutti commutano in quel momento: picchi di corrente,
picchi di rumore, problema di portare la corrente, ecc..
Universo opposto: mondo completamente asincrono. Il timing è garantito unicamente dal progetto
preciso e sicuro dei ritardi dei vari blocchi. Il concetto di completamento di un’azione viene
garantito esclusivamente da un’analisi perfettamente corretta del timing e dei ritardi. La stessa
analisi dei ritardi, ogni singolo progetto di un blocco che ritarda, è garante del fatto che la sequenza
di azioni è quella voluta. Il fatto che tutto funzioni esclusivamente tramite i ritardi è il motivo per
cui tutti i circuiti con cui abbiamo a che fare sono sincroni. Un processore completamente asincrono
non si è ancora visto. Nel mondo asincrono si va a lavorare di lima sulla singola porta e subentrano
tanti fattori quali temperatura, umidità, rumore, ecc ecc.. per cui è tutto molto complicato.
Il vantaggio del mondo asincrono è che ogni segnale cambia quando vuole. Vuol dire che se vado a
fare misure di assorbimento di corrente in un circuito asincrono questa è ragionevolmente costante
nel tempo, è statisticamente mediamente distribuita. Il tutto però diventa irrealizzabile se non in
sistemi molto semplici. Esiste però un mondo intermedio che è usato molto spesso anche dal punto
di vista commerciale e che si basa su quello che si chiama Self Timed Design. Cioè il concetto di ho
finito è un segnale che può avere una sua valenza su un fronte e che può essere usato da un oggetto
che è a valle. La differenza dal mondo sincrono è che i segnali vengono generati localmente in
modo completamente asincrono. Esiste anche qui tun mondo di handshake e protocolli.

Per capire il concetto della logica Self timed partiamo dal concetto che ben conosciamo di un
sistema sincrono. Un sistema sincrono è fatto da registri, logica combinatoria e tutto va avanti;
pipeline: ad ogni colpo di clock prendo il dato in ingresso e lo porto in uscita.
Sistema Self Timed: esiste sempre la logica del pipeline, però il caricamento del registro viene
generato da una macchinetta di handshake tipo quella che abbiamo vista prima, che lavora
localmente con una coppia di segnali. Un segnale di start quando il dato è disponibile e quando
questo ha finito lui dà un segnale di done, finito che va alla macchinetta che lo utilizzerà per
interfacciarsi col resto del mondo. Il concetto è Start: parto, faccio quello che devo fare; ho finito,
questo ho finito genererà sicuramente un segnale al blocco dopo per dire ehi può partire e allora
questo farà campionare il registro R2 e darà un segnale a quello che c’è prima per dire dammi il
prossimo dato perché io sono qui con le mani in mano. Questo ha il vantaggio che ogni blocco
lavora ad una frequenza che è legata alla complessità di quello che deve fare. Questo è un mondo in
cui se ognuno ha una sua idea del tempo che impiega per fare la sua operazione è un mondo che
permette di far sì che localmente ogni oggetto capisce, da quando parte l’elaborazione, quando può
finire in modo corretto l’operazione stessa ed è un mondo che ha tutti i vantaggi sia del mondo
sincrono che del mondo asincrono. Vantaggi: tutto è gestito da un flusso di temporizzazioni locali
che vengono garantite dai segnali di temporizzazione. Vantaggio: l’handshake gestisce la
successione degli eventi in modo opportuno. Vantaggio: ognuno lavora alla massima frequenza,
mentre in un sistema sincrono una rete combinatoria, più veloce delle altre, finisce e poi se ne sta
con le mani in mano ad aspettare il clock. Ultimo vantaggio: ognuno commuta quando vuole, non
tutti insieme: non ho i picchi di corrente. Allora il Self Timed dove applicabile è sicuramente il
migliore dei mondi possibili. L’inconveniente è quello che devo accorgermi quando ho finito. Ogni
blocco logico, quindi, deve essere in grado di accorgersi quando ha finito. In alcuni casi questo è
abbastanza facile, in altri casi posso trovare delle soluzioni ad Hoc. Avere la percezione completa
del termine di un’operazione può essere estremamente complicato. Mi spiego: se prendo un
moltiplicatore da un punto di vista logico come faccio a sapere quando è finita la moltiplicazione?
Ciò è tutt’altro che banale. Il limite più grande delle logiche Self Timed è che per tutta una serie di
operatori capire quando ha finito può essere più complicato che fare l’operazione stessa. Lo si fa
quando è facile oppure lo si fa usando dei trucchi. Un trucco molto semplice è questo: faccio
un’indagine della rete logica per capire qual è il percorso più lungo e mi ricreo il percorso più lungo
in un mondo, quello che si chiama dummy line (linea fantasma), che praticamente ricalca/ricopia il
percorso più lungo del mio blocco. Son sicuro che quando parte lo start, e qua percorre il percorso
più lungo prima di uscire e qui percorre una copia di questo percorso più lungo, questo mi
garantisce che quando arrivo in fondo il segnale è done, finito. È un progetto fisico che consiste

nell’andare a vedere qual è il percorso più lungo del mio blocco e generare un ritardo pari al più
lungo. Un’applicazione tipica di questi oggetti sono le memorie. La memoria è in qualche modo un
array in cui ci sono dei driver, bitline e in qualche modo prendo la parola e la tiro fuori.
Si mette un’extra line alla memoria che fa il percorso più lungo. Allora tutti i dati saranno
sicuramente già in uscita prima che arrivi il percorso più lungo. Questo è un metodo molto usato
nelle memorie sia per prestazioni, nel senso che la posso fare lavorare effettivamente al massimo
della velocità, sia dal punto di vista dei consumi. È inutile lasciare attivi tutti i circuiti interni
quando so di essere arrivato in fondo. In altri casi è molto più facile capire che ho finito usando
codifiche ridondanti.
Tipo quella che abbiamo visto prima dell’empty e valid. So subito che ho finito quando cambiano
dei bit. Questa è un tipo di codifica Self Timed. Uso cioè una codifica tale per cui all’interno dei
dati c’è l’informazione di validità. L’NCL vista prima è una logica Self Timed che funziona in
questo modo. Io faccio la mia elaborazione locale, quando finisco codifico i dati in uscita dal
moltiplicatore con questa codifica per cui mi basta andare a vedere che cosa ho in uscita e quando in
uscita vedo che tutti i bit sono validi vuol dire che il moltiplicatore ha finito.
L’ultimo esempio è un esempio molto più semplice che si usa nelle logiche dinamiche nonché in
alcuni tipi di memoria. Immaginiamo di avere una struttura logica che lavora in due fasi , una prima
fase in cui precarico le uscite e una seconda fase in cui vado in valutazione. Quanto deve durare la
precarica? La precarica dura il tempo necessario in cui quelle due uscite diventano tutti 1. Quando
diventano tutti 1, OR sui negati vuol dire che è una Nand, dico: fine della precarica, tutti hanno
finito e possiamo passare al ciclo successivo. Questo è un altro metodo, questa volta logico, che
permette di accorgermi quando un’operazione è finita.
L’ultimo metodo si basa sull’avere a che fare con una logica di tipo CMOS, dove il consumo di
corrente, se non ho problemi di conduzione sotto soglia e altre robe che al momento non ci

interessano, si ha solo durante le commutazioni. Finite le commutazioni il circuito non consuma
più. In questo circuito CMOS statico metto un sensore di corrente, che sta a vedere quando il
sistema consuma. È partita la commutazione, lo start, aspetto un tempo minimo per evitare di dire
ho finito perché lui in realtà non aveva neanche cominciato a consumare, cioè aspetto un tempo
minimo per garantire che lui sia andato in conduzione e che quindi stia consumando. Nel momento
in cui finisce il consumo dico ok guarda..
Se c’è il leakage lo risolvo mettendo semplicemente un sensore di corrente a una soglia. Un sensore
di corrente non è detto che misuri solo un livello ma può anche andare a misurare la derivata della
corrente. Comunque il 98% dei progetti industriali sono sincroni quindi noi lavoreremo su quelli
perché è importante saper fare bene quelli. La butterfly potrebbe benissimo essere fatta in modo
Self Timed: entrano i dati codificati in qualche modo, automaticamente quando i dati in uscita sono
validi all’interno dei dati metto la validazione per andare ad esempio alla butterfly successiva.


















