
イントロダクション・並列処理の基礎並列化:逐次プログラムを並列実行できるようにすること 並列化の目的は高速化! 並列処理の対象となる科学技術計算では、繰り返し文で書かれた部分が計
Upload
shinya-takamaeda-yamazakiCategory
view
555download
4description

APGAS言語X10を用いた ネットワークオンチップ シミュレーションの並列化
高前田(山崎) 伸也†‡
†計算工学専攻 吉瀬研究室 博士課程2年 ‡日本学術振興会 特別研究員 (DC1)
2013年1月30日 10:45-12:15 データストリーム処理特論
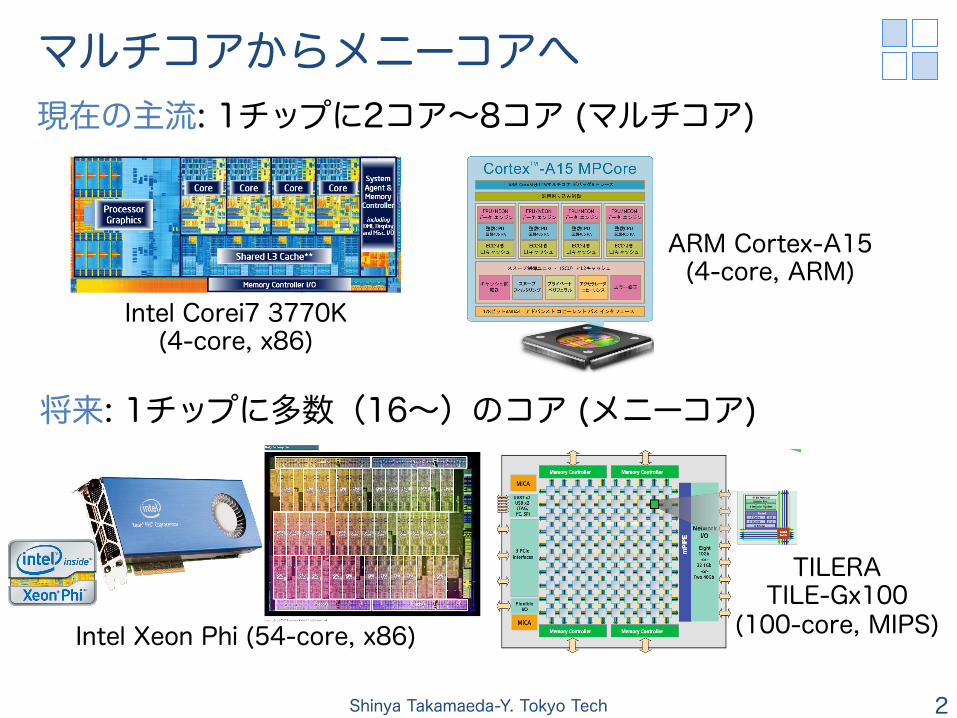
マルチコアからメニーコアへ
Shinya Takamaeda-Y. Tokyo Tech 2
Intel Corei7 3770K (4-core, x86)
ARM Cortex-A15 (4-core, ARM)
TILERA TILE-Gx100
(100-core, MIPS) Intel Xeon Phi (54-core, x86)
現在の主流: 1チップに2コア~8コア (マルチコア)
将来: 1チップに多数(16~)のコア (メニーコア)
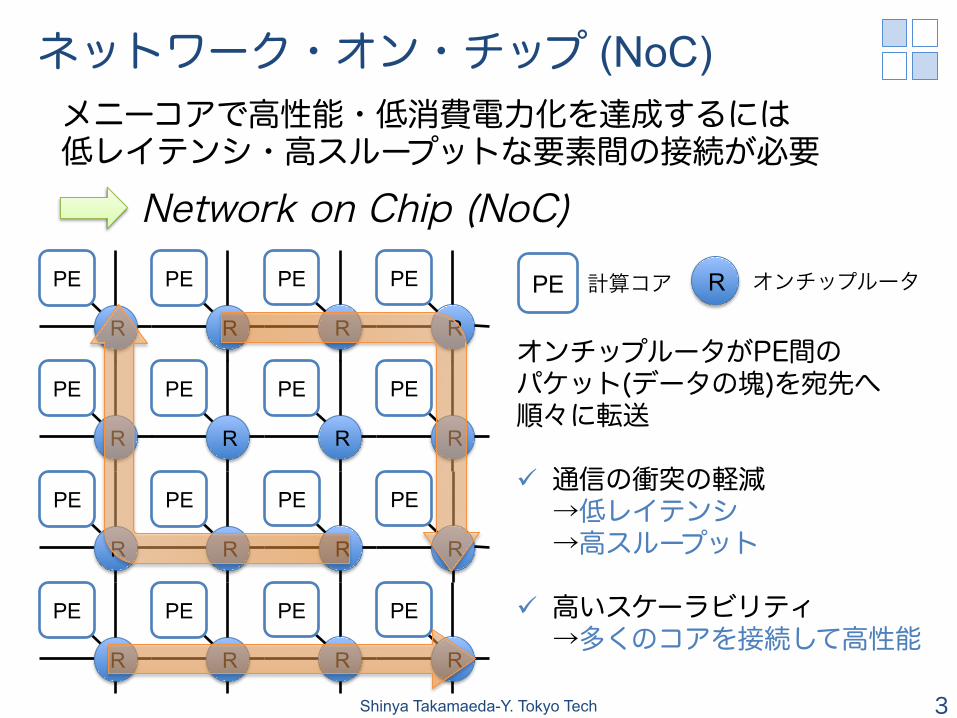
ネットワーク・オン・チップ (NoC)
Shinya Takamaeda-Y. Tokyo Tech 3
メニーコアで高性能・低消費電力化を達成するには 低レイテンシ・高スループットな要素間の接続が必要
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
Network on Chip (NoC) PE 計算コア R オンチップルータ
オンチップルータがPE間の パケット(データの塊)を宛先へ 順々に転送 ü 通信の衝突の軽減 →低レイテンシ →高スループット
ü 高いスケーラビリティ →多くのコアを接続して高性能
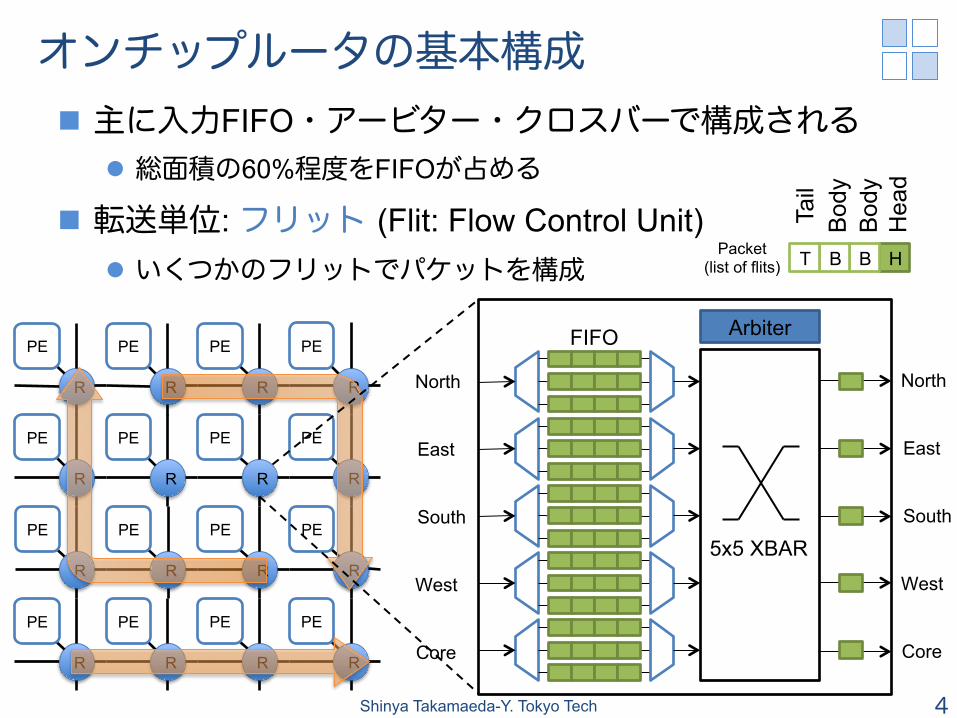
オンチップルータの基本構成 n 主に入力FIFO・アービター・クロスバーで構成される
l 総面積の60%程度をFIFOが占める
n 転送単位: フリット (Flit: Flow Control Unit) l いくつかのフリットでパケットを構成
Shinya Takamaeda-Y. Tokyo Tech 4
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE Arbiter
5x5 XBAR
North
East
South
West
Core
North
East
South
West
Core
FIFO
HBBTPacket (list of flits)
Hea
d B
ody
Bod
y Ta
il

オンチップルータの基本パイプライン構成 n 以下の6段をベースに最適化(通常は3段程度)
l IB (Input Buffer): 隣接ルータからのフリットを入力FIFOに格納
l RC (Routing Computation): 宛先情報を元に進行方向を計算
l VA (Virtual Channel Allocation): 進行方向の仮想チャネルを確保
l SA (Switch Allocation): 進行方向へのスイッチ経路を確保
l ST (Switch Traversal): スイッチをフリットが通過
l LT (Link Traversal): ルータ間のリンクをフリットが通過
n 例) 3つのルータをパケット(4フリット)が通過
Shinya Takamaeda-Y. Tokyo Tech 5
IB RC VA SA ST LT
IB SA ST LT
IB SA ST LT
IB RC VA SA ST LT
IB SA ST LT
IB SA ST LT
IB RC VA SA ST LT
IB SA ST LT
IB SA ST LT
Router 1 Router 2 Router 3
HEAD
BODY 0
BODY 1
IB SA ST LT IB SA ST LT IB SA ST LT TAIL t
Router 1 Router 2 Router 3 HBBTPacket (list of flits)

ネットワークオンチップのいろいろ n ネットワークトポロジ
l 2Dメッシュ・2Dトーラス・3D積層TSV+メッシュ・・・ n ルーティング
l どの経路を辿って宛先に届けるのか?
n フロー制御 l パケットをロスレスで届けるには どのようにして後続の転送を止めれば良いのか?
n 仮想チャネル l ひとつの物理レーンを複数の仮想的なレーンで共有し
Head of Lineブロッキングを防止 l 入力バッファは仮想チャネルごとに持つ
n 調停方式(仮想チャネル・クロスバー) l ラウンドロビン・iSlip・・・
Shinya Takamaeda-Y. Tokyo Tech 6
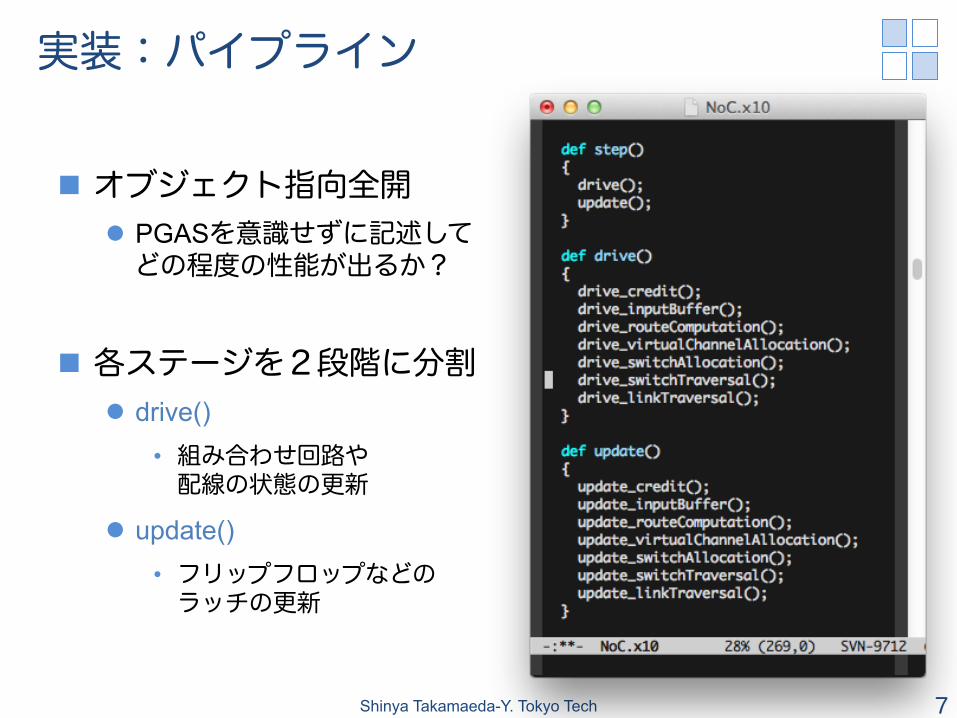
実装:パイプライン
n オブジェクト指向全開 l PGASを意識せずに記述して どの程度の性能が出るか?
n 各ステージを2段階に分割 l drive()
• 組み合わせ回路や 配線の状態の更新
l update() • フリップフロップなどの ラッチの更新
Shinya Takamaeda-Y. Tokyo Tech 7

実装:並列化 n ネットワーク空間をコア毎に領域分割
l 2Dステンシル計算のように分割・並列実行
l 袖領域のデータを通信し共有 • 隣接ルータの入出力信号(フリット・フロー制御)
Shinya Takamaeda-Y. Tokyo Tech 8
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE

評価:セットアップ n x86マルチコア計算機1台で評価
l スケーラビリティが悪かったのでTSUBAMEでの評価はなし
n 一般的な通信パターンでネットワークにパケットを注入
n NoCのノード数とX10プレース数を変化
Shinya Takamaeda-Y. Tokyo Tech 9
Machine Simulation Target CPU Intel Corei7 2600 (4-core, 8thread) Topology 2D-mesh
Memory 8GB (DDR3-1333) # Virtual channels 2 OS Ubuntu 12.04 Packet length 8
Compiler x10-2.3.0 # FIFO entries per VC 4 gcc 4.6.3 Arbitration iSlip
(Option) -cxx-prearg -g -O Flow control Credit-base -NO_CHECKS Transfer control Warmhole -define NO_BOUNDS_CHECKS Routing XY-DOR
# places 1 ~ 8 Traffic pattern Uniform Injectoin rate 0.1
# Cycles 500 256 (16x16)
Network size 1024 (32x32) 4096 (64x64)
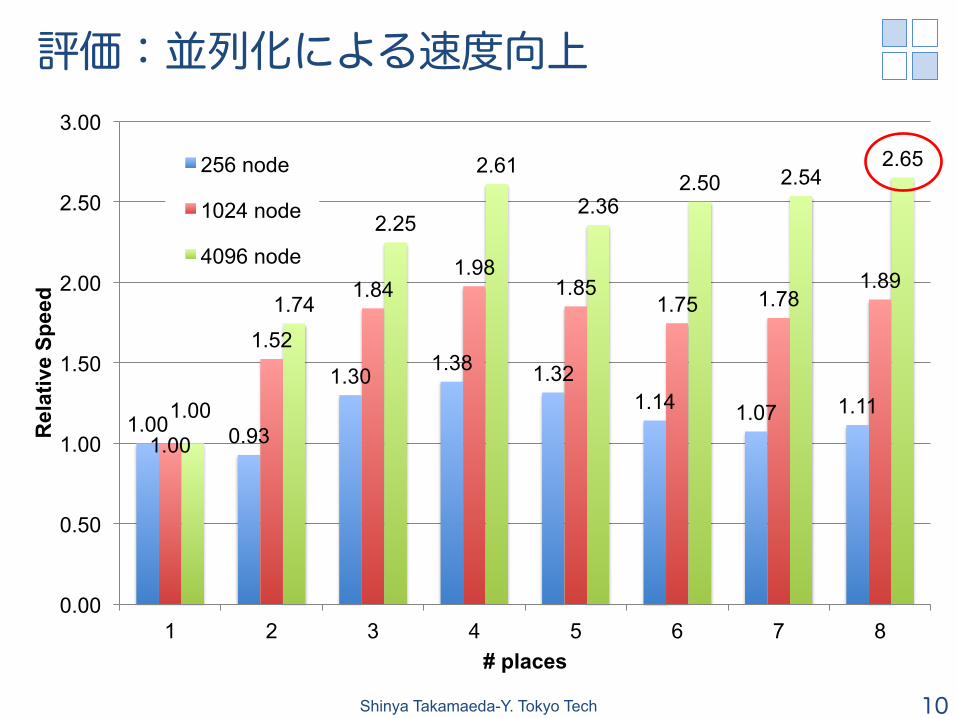
評価:並列化による速度向上
Shinya Takamaeda-Y. Tokyo Tech 10
1.00 0.93
1.30 1.38 1.32 1.14 1.07 1.11
1.00
1.52
1.84 1.98
1.85 1.75 1.78
1.89
1.00
1.74
2.25
2.61
2.36 2.50 2.54
2.65
0.00
0.50
1.00
1.50
2.00
2.50
3.00
1 2 3 4 5 6 7 8
Rel
ativ
e Sp
eed
# places
256 node
1024 node
4096 node

考察
n 性能向上率がイマイチな理由 l 8プレース・1スレッドで実行しているのがそもそも良くない?
• スレッドレベル並列性とプロセスレベル並列性をかき分ける記述がよくわからなかったので今回はこうなりました
l 袖領域の同期時にオブジェクトのdeep copyが発生している? • オブジェクト内の一部だけをコピーなしで参照する良い記述が不明
l 各アクティビティに割り当てられたノードの数が少ない? • 10000コア程度のシミュレーションであればうまくスケールする?
• アクティビティ間通信レイテンシと計算量のバランシングが重要
Shinya Takamaeda-Y. Tokyo Tech 11

今後の課題
n ボトルネック解析 l gprofが使えるらしいので解析できそう
n 2Dメッシュ以外のトポロジへの対応 l トーラスや3D系,ランダムショートカットなど
n ルータの電力評価機構 l 各要素のドライブ回数の計測により実現可能
n トレースリーダとの連携 l PARSECベンチマークの実行トレースを元にしたパケット生成
C++ライブラリのNetraceとの連携
l アプリケーションの実行時間への影響が評価できるように
Shinya Takamaeda-Y. Tokyo Tech 12
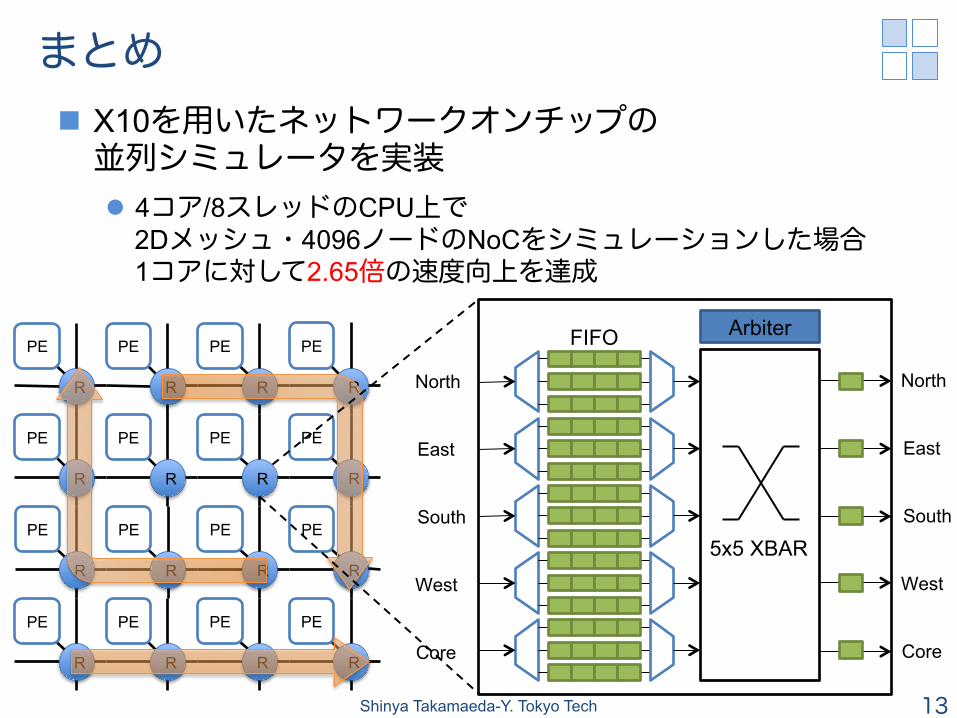
まとめ n X10を用いたネットワークオンチップの 並列シミュレータを実装 l 4コア/8スレッドのCPU上で
2Dメッシュ・4096ノードのNoCをシミュレーションした場合 1コアに対して2.65倍の速度向上を達成
Shinya Takamaeda-Y. Tokyo Tech 13
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE
R
PE Arbiter
5x5 XBAR
North
East
South
West
Core
North
East
South
West
Core
FIFO


















