
Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)
19
takemikami’s note – http://takemikami.com/ 三上 威 (フリーランスITエンジニア) twitter: @takemikami マーケティングデータ分析基盤技術勉強会 『Apache Hadoop & Hive 入門』 ApacheHadoop&Hiveの概要とAWSでの構成イメージ 1 Hadoop Hive AWS 2016.11.4 株式会社フロムスクラッチ 社内勉強会 Copyright (C) 2016 Takeshi Mikami. All rights reserved. フロムスクラッチ 社内勉強会
-
Upload
takeshi-mikami -
Category
Software
-
view
584 -
download
2
Transcript of Apache Hadoop & Hive 入門 (マーケティングデータ分析基盤技術勉強会)

takemikami’s note– http://takemikami.com/
三上威 (フリーランスITエンジニア)twitter:@takemikami
マーケティングデータ分析基盤技術勉強会
『ApacheHadoop&Hive入門』ApacheHadoop&Hiveの概要とAWSでの構成イメージ
1
HadoopHiveAWS
2016.11.4株式会社フロムスクラッチ社内勉強会
Copyright(C)2016TakeshiMikami.Allrightsreserved.
フロムスクラッチ社内勉強会
takemikami’s note– http://takemikami.com/
アジェンダ
• ApacheHadoopとは– ApacheHadoopとは– HDFSとは– MapReduceとは– YARNとは– HadoopClusterの全体像– AWS上でのHadoop
• ApacheHiveとは– ApacheHiveとは– metastoreとは– Partitionとは– externaltableとは– AWS上でのHive
2Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoop&Hive入門のアジェンダを示します。

takemikami’s note– http://takemikami.com/
ApacheHadoopとは
• 「データ保存のための分散ファイルシステム」「データ処理のための並列処理システム」によってビッグデータの分散処理を実現する
• 4つのモジュールで構成される– 共通ユーティリティ (HadoopCommon)– 分散ファイルシステム (HadoopHDFS)– クラスタリソース・ジョブ管理 (HadoopYARN)– 並列データ処理システム (HadoopMapReduce)
3Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
ApacheHadoopの紹介をします。
ビッグデータ分散処理のフレームワーク
takemikami’s note– http://takemikami.com/
HDFS(HadoopDistributedFileSystem)とは
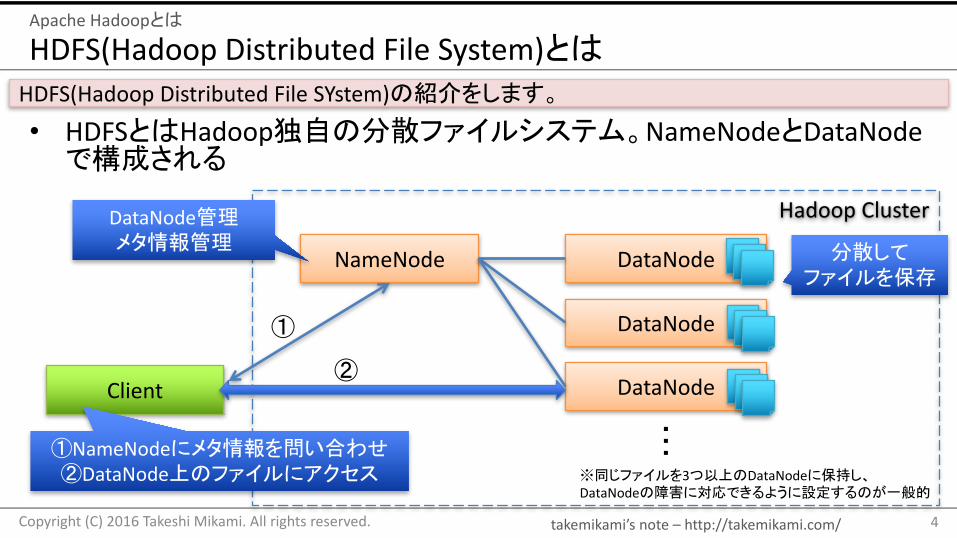
• HDFSとはHadoop独自の分散ファイルシステム。NameNodeとDataNodeで構成される
4Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
HDFS(HadoopDistributedFileSYstem)の紹介をします。
NameNode DataNode
HadoopCluster
DataNode
DataNode
・・・
DataNode管理メタ情報管理 分散して
ファイルを保存
Client
※同じファイルを3つ以上のDataNodeに保持し、DataNodeの障害に対応できるように設定するのが一般的
①NameNodeにメタ情報を問い合わせ②DataNode上のファイルにアクセス
①
②
takemikami’s note– http://takemikami.com/
MapReduceとは
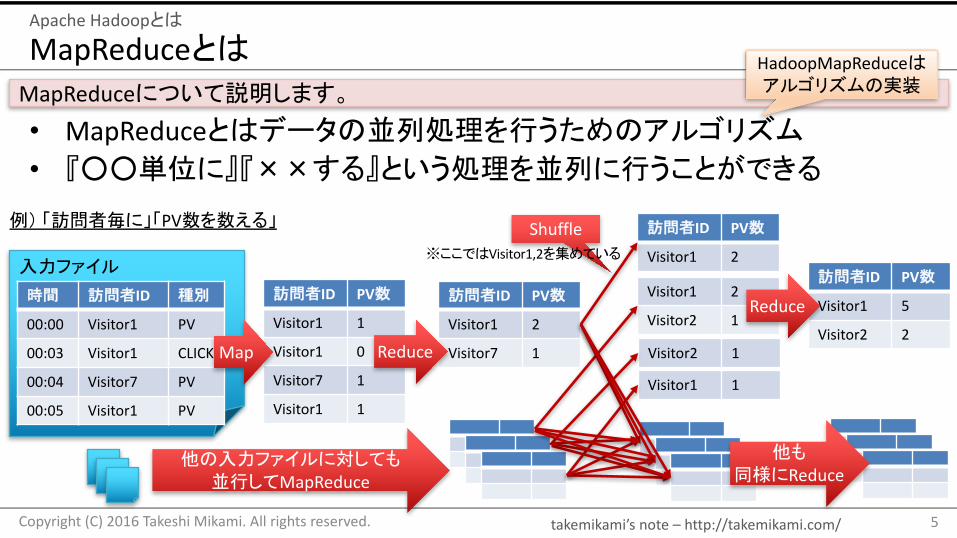
• MapReduceとはデータの並列処理を行うためのアルゴリズム• 『○○単位に』『××する』という処理を並列に行うことができる
5Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
MapReduceについて説明します。
入力ファイル
例) 「訪問者毎に」「PV数を数える」
時間 訪問者ID 種別
00:00 Visitor1 PV
00:03 Visitor1 CLICK
00:04 Visitor7 PV
00:05 Visitor1 PV
訪問者ID PV数
Visitor1 1
Visitor1 0
Visitor7 1
Visitor1 1
訪問者ID PV数
Visitor1 2
Visitor7 1
訪問者ID PV数
Visitor1 2
Map Reduce
他の入力ファイルに対しても並行してMapReduce
Visitor1 2
Visitor2 1
Visitor2 1
Visitor1 1
訪問者ID PV数
Visitor1 5
Visitor2 2
Reduce
他も同様にReduce
Shuffle※ここではVisitor1,2を集めている
HadoopMapReduceはアルゴリズムの実装
takemikami’s note– http://takemikami.com/
MapReduceの例:①Map処理
6Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
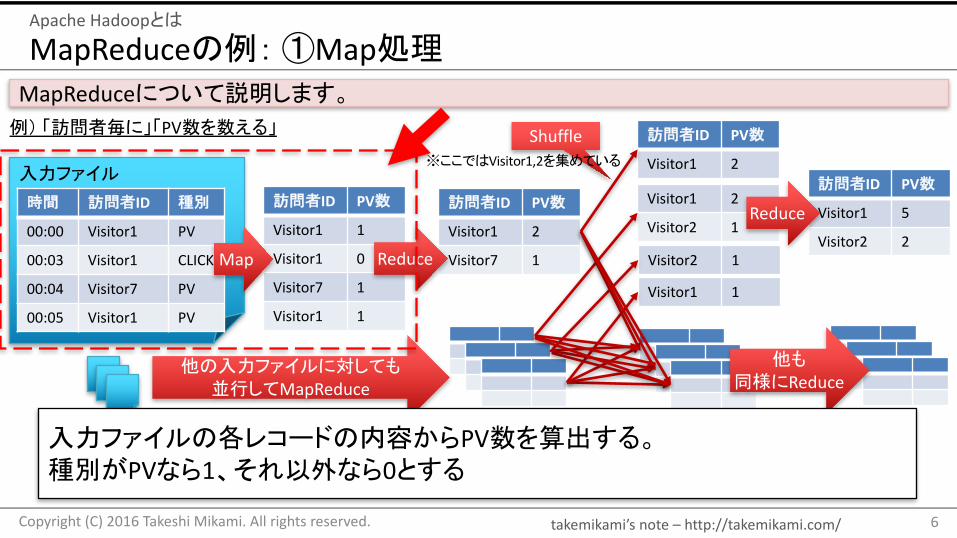
MapReduceについて説明します。
入力ファイル
例) 「訪問者毎に」「PV数を数える」
時間 訪問者ID 種別
00:00 Visitor1 PV
00:03 Visitor1 CLICK
00:04 Visitor7 PV
00:05 Visitor1 PV
訪問者ID PV数
Visitor1 1
Visitor1 0
Visitor7 1
Visitor1 1
訪問者ID PV数
Visitor1 2
Visitor7 1
訪問者ID PV数
Visitor1 2
Map Reduce
他の入力ファイルに対しても並行してMapReduce
Visitor1 2
Visitor2 1
Visitor2 1
Visitor1 1
訪問者ID PV数
Visitor1 5
Visitor2 2
Reduce
他も同様にReduce
Shuffle※ここではVisitor1,2を集めている
入力ファイルの各レコードの内容からPV数を算出する。種別がPVなら1、それ以外なら0とする
takemikami’s note– http://takemikami.com/
MapReduceの例:②Reduce処理(Shuffle前)
7Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
MapReduceについて説明します。
入力ファイル
例) 「訪問者毎に」「PV数を数える」
時間 訪問者ID 種別
00:00 Visitor1 PV
00:03 Visitor1 CLICK
00:04 Visitor7 PV
00:05 Visitor1 PV
訪問者ID PV数
Visitor1 1
Visitor1 0
Visitor7 1
Visitor1 1
訪問者ID PV数
Visitor1 2
Visitor7 1
訪問者ID PV数
Visitor1 2
Map Reduce
他の入力ファイルに対しても並行してMapReduce
Visitor1 2
Visitor2 1
Visitor2 1
Visitor1 1
訪問者ID PV数
Visitor1 5
Visitor2 2
Reduce
他も同様にReduce
Shuffle※ここではVisitor1,2を集めている
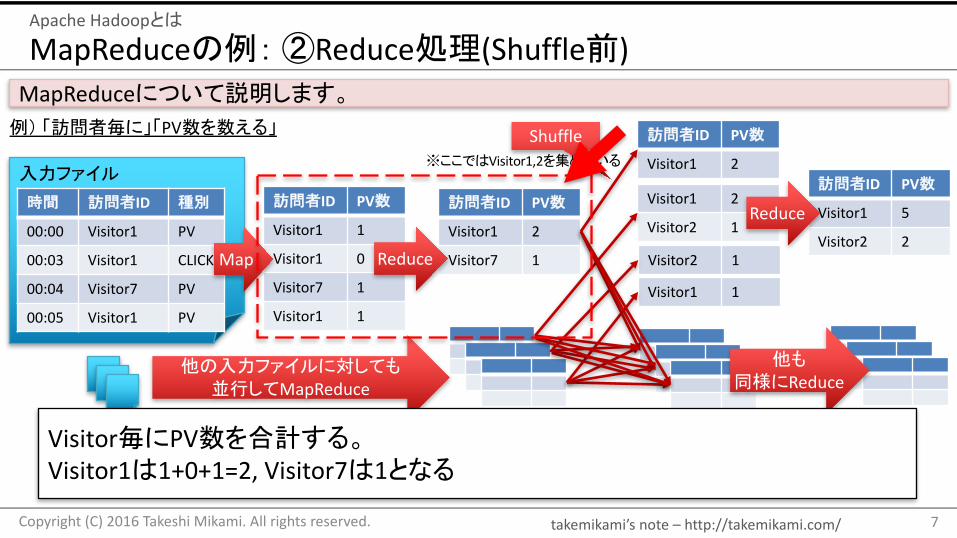
Visitor毎にPV数を合計する。Visitor1は1+0+1=2,Visitor7は1となる
takemikami’s note– http://takemikami.com/
MapReduceの例:③Shuffle処理
8Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
MapReduceについて説明します。
入力ファイル
例) 「訪問者毎に」「PV数を数える」
時間 訪問者ID 種別
00:00 Visitor1 PV
00:03 Visitor1 CLICK
00:04 Visitor7 PV
00:05 Visitor1 PV
訪問者ID PV数
Visitor1 1
Visitor1 0
Visitor7 1
Visitor1 1
訪問者ID PV数
Visitor1 2
Visitor7 1
訪問者ID PV数
Visitor1 2
Map Reduce
他の入力ファイルに対しても並行してMapReduce
Visitor1 2
Visitor2 1
Visitor2 1
Visitor1 1
訪問者ID PV数
Visitor1 5
Visitor2 2
Reduce
他も同様にReduce
Shuffle※ここではVisitor1,2を集めている
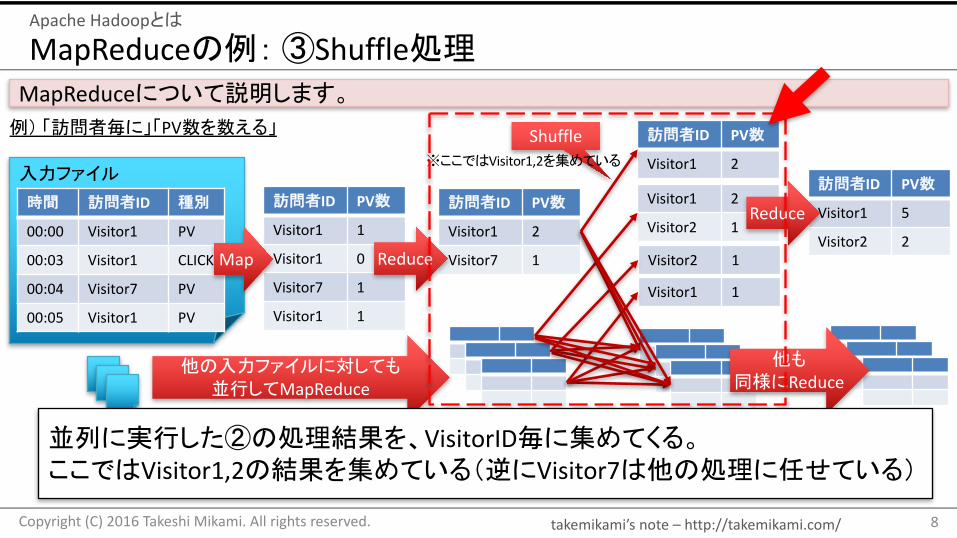
並列に実行した②の処理結果を、VisitorID毎に集めてくる。ここではVisitor1,2の結果を集めている(逆にVisitor7は他の処理に任せている)
takemikami’s note– http://takemikami.com/
MapReduceの例:④Reduce処理(Shuffle後)
9Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
MapReduceについて説明します。
入力ファイル
例) 「訪問者毎に」「PV数を数える」
時間 訪問者ID 種別
00:00 Visitor1 PV
00:03 Visitor1 CLICK
00:04 Visitor7 PV
00:05 Visitor1 PV
訪問者ID PV数
Visitor1 1
Visitor1 0
Visitor7 1
Visitor1 1
訪問者ID PV数
Visitor1 2
Visitor7 1
訪問者ID PV数
Visitor1 2
Map Reduce
他の入力ファイルに対しても並行してMapReduce
Visitor1 2
Visitor2 1
Visitor2 1
Visitor1 1
訪問者ID PV数
Visitor1 5
Visitor2 2
Reduce
他も同様にReduce
Shuffle※ここではVisitor1,2を集めている
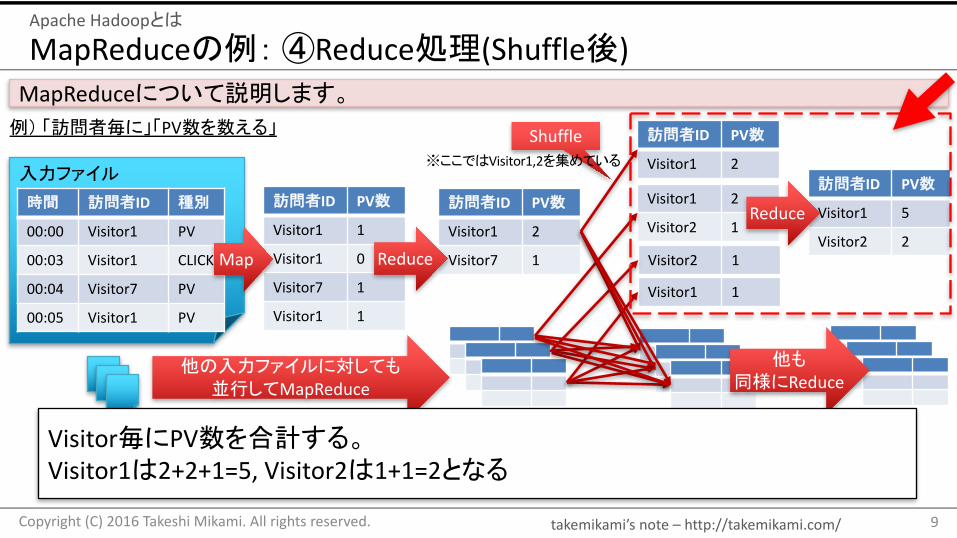
Visitor毎にPV数を合計する。Visitor1は2+2+1=5,Visitor2は1+1=2となる
takemikami’s note– http://takemikami.com/
YARN(YetAnotherResourceNegotiator)とは
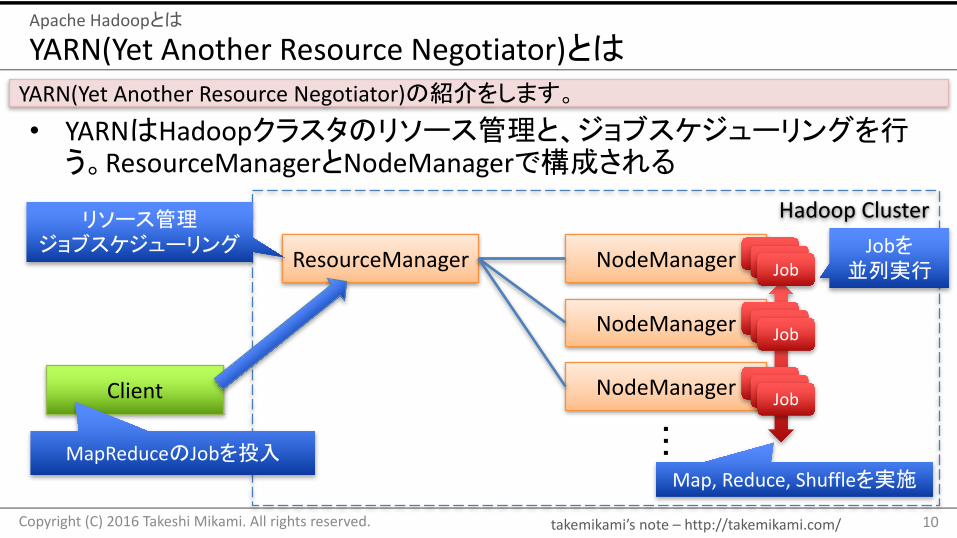
• YARNはHadoopクラスタのリソース管理と、ジョブスケジューリングを行う。ResourceManagerとNodeManagerで構成される
10Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
YARN(YetAnotherResourceNegotiator)の紹介をします。
ResourceManager NodeManager
HadoopCluster
NodeManager
NodeManager
・・・
リソース管理ジョブスケジューリング Jobを
並列実行
Client
MapReduceのJobを投入
JobJobJob
JobJobJob
JobJobJob
Map,Reduce,Shuffleを実施
takemikami’s note– http://takemikami.com/
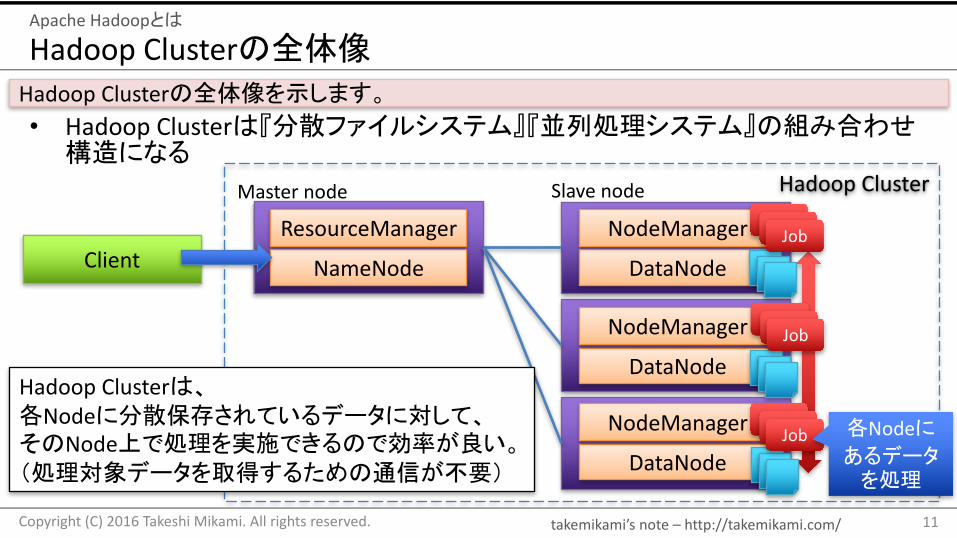
HadoopClusterの全体像
• Hadoop Clusterは『分散ファイルシステム』『並列処理システム』の組み合わせ構造になる
11Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
HadoopClusterの全体像を示します。
HadoopCluster
Client NameNode
ResourceManager
DataNode
NodeManager
DataNode
NodeManager
DataNode
NodeManager
JobJobJob
JobJobJob
JobJobJob
Masternode Slavenode
各Nodeにあるデータを処理
HadoopClusterは、各Nodeに分散保存されているデータに対して、そのNode上で処理を実施できるので効率が良い。(処理対象データを取得するための通信が不要)
takemikami’s note– http://takemikami.com/
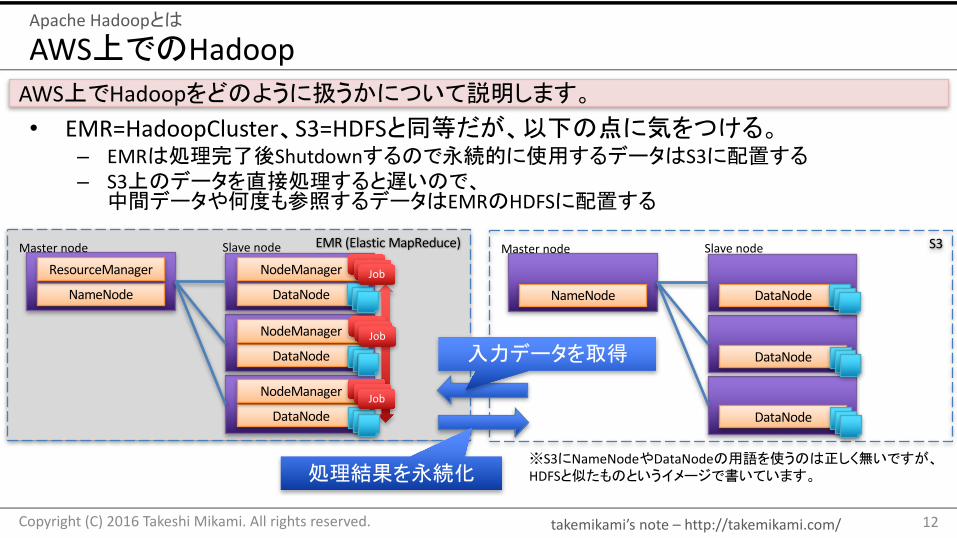
EMR(ElasticMapReduce)
AWS上でのHadoop
• EMR=HadoopCluster、S3=HDFSと同等だが、以下の点に気をつける。– EMRは処理完了後Shutdownするので永続的に使用するデータはS3に配置する– S3上のデータを直接処理すると遅いので、中間データや何度も参照するデータはEMRのHDFSに配置する
12Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHadoopとは
AWS上でHadoopをどのように扱うかについて説明します。
NameNode
ResourceManager
DataNode
NodeManager
DataNode
NodeManager
DataNode
NodeManager
JobJobJob
JobJobJob
JobJobJob
Masternode Slavenode S3
NameNode DataNode
DataNode
DataNode
Masternode Slavenode
※S3にNameNodeやDataNodeの用語を使うのは正しく無いですが、HDFSと似たものというイメージで書いています。処理結果を永続化
入力データを取得
takemikami’s note– http://takemikami.com/
ApacheHiveとは
• Hadoopのファイルシステム上に格納されたファイルに対して、データの問い合わせを行うことができる
• HiveQLというSQLライクな言語を、MapReduceジョブに変換し、Hadoopに渡し実行する
• コマンドでの実行(hive)、またはサーバプロセスで実行する(hiveserver2)
13Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHiveとは
ApacheHiveの紹介をします。
Hadoop上のファイルに対するクエリ実行環境
takemikami’s note– http://takemikami.com/
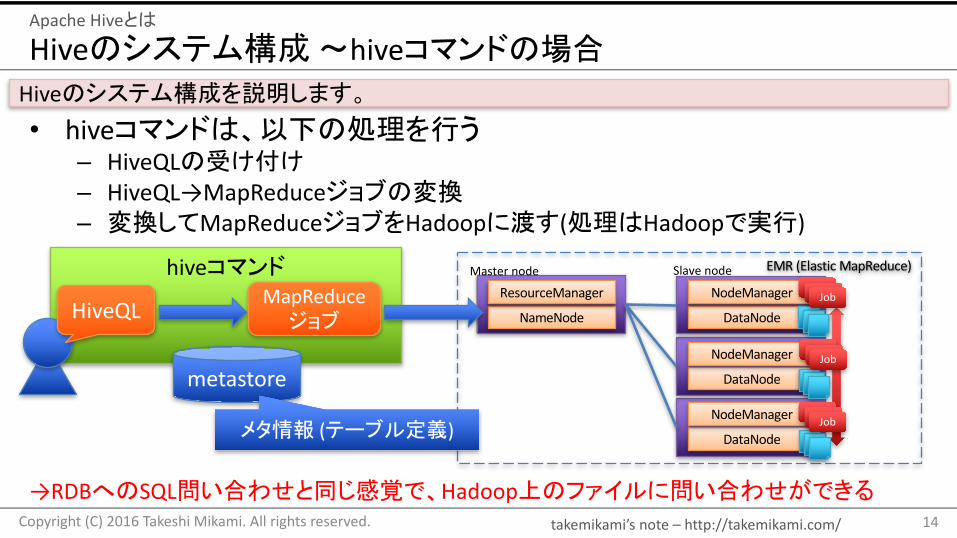
Hiveのシステム構成〜hiveコマンドの場合
• hiveコマンドは、以下の処理を行う– HiveQLの受け付け– HiveQL→MapReduceジョブの変換– 変換してMapReduceジョブをHadoopに渡す(処理はHadoopで実行)
14Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHiveとは
EMR(ElasticMapReduce)
NameNode
ResourceManager
DataNode
NodeManager
DataNode
NodeManager
DataNode
NodeManager
JobJobJob
JobJobJob
JobJobJob
Masternode Slavenode
Hiveのシステム構成を説明します。
hiveコマンド
metastore
MapReduceジョブHiveQL
メタ情報 (テーブル定義)
→RDBへのSQL問い合わせと同じ感覚で、Hadoop上のファイルに問い合わせができる
takemikami’s note– http://takemikami.com/
beelineなど
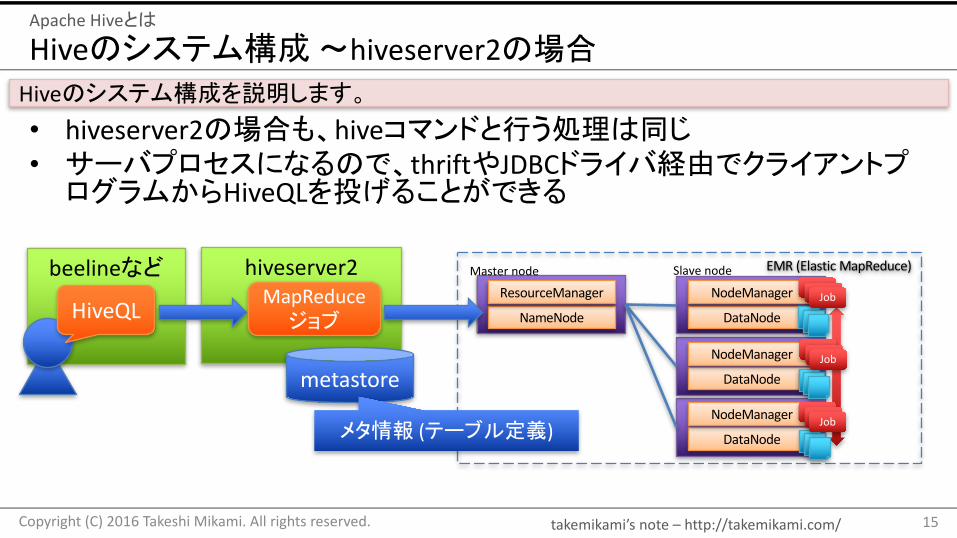
Hiveのシステム構成〜hiveserver2の場合
• hiveserver2の場合も、hiveコマンドと行う処理は同じ• サーバプロセスになるので、thriftやJDBCドライバ経由でクライアントプログラムからHiveQLを投げることができる
15Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHiveとは
EMR(ElasticMapReduce)
NameNode
ResourceManager
DataNode
NodeManager
DataNode
NodeManager
DataNode
NodeManager
JobJobJob
JobJobJob
JobJobJob
Masternode Slavenode
Hiveのシステム構成を説明します。
hiveserver2
metastore
MapReduceジョブHiveQL
メタ情報 (テーブル定義)
takemikami’s note– http://takemikami.com/
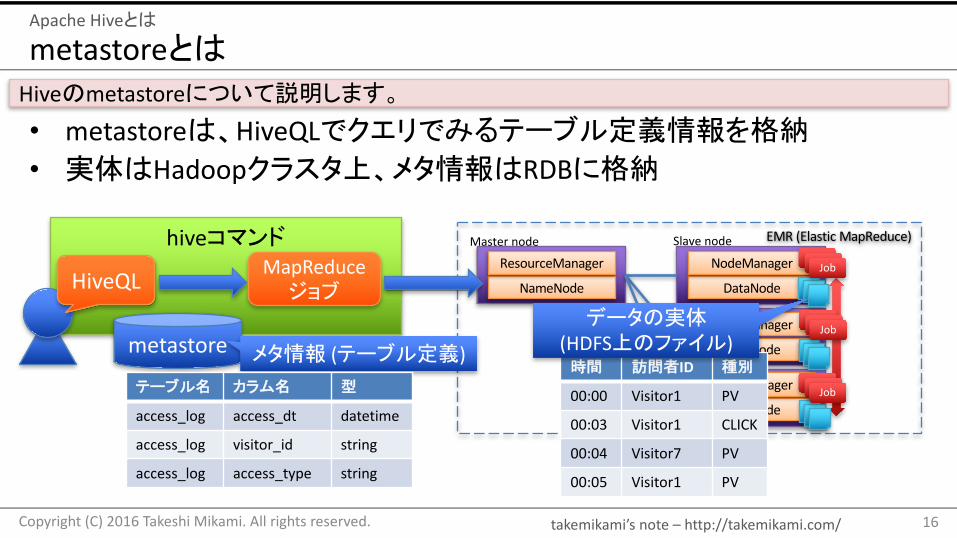
metastoreとは
• metastoreは、HiveQLでクエリでみるテーブル定義情報を格納• 実体はHadoopクラスタ上、メタ情報はRDBに格納
16Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHiveとは
Hiveのmetastoreについて説明します。
EMR(ElasticMapReduce)
NameNode
ResourceManager
DataNode
NodeManager
DataNode
NodeManager
DataNode
NodeManager
JobJobJob
JobJobJob
JobJobJob
Masternode Slavenodehiveコマンド
metastore
MapReduceジョブHiveQL
メタ情報 (テーブル定義)時間 訪問者ID 種別
00:00 Visitor1 PV
00:03 Visitor1 CLICK
00:04 Visitor7 PV
00:05 Visitor1 PV
テーブル名 カラム名 型
access_log access_dt datetime
access_log visitor_id string
access_log access_type string
データの実体(HDFS上のファイル)
takemikami’s note– http://takemikami.com/
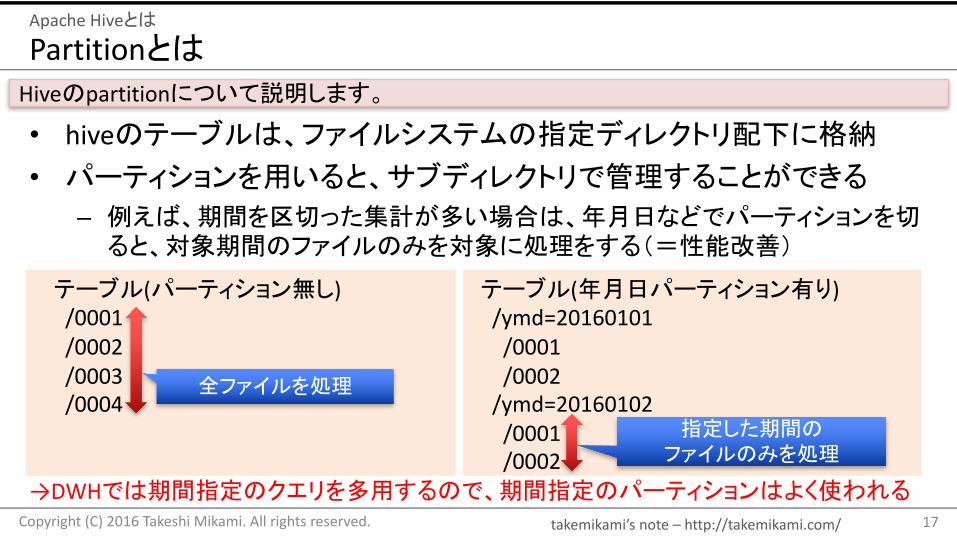
Partitionとは
• hiveのテーブルは、ファイルシステムの指定ディレクトリ配下に格納• パーティションを用いると、サブディレクトリで管理することができる
– 例えば、期間を区切った集計が多い場合は、年月日などでパーティションを切ると、対象期間のファイルのみを対象に処理をする(=性能改善)
17Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHiveとは
Hiveのpartitionについて説明します。
テーブル(パーティション無し)/0001/0002/0003/0004
テーブル(年月日パーティション有り)/ymd=20160101/0001/0002/ymd=20160102/0001/0002
全ファイルを処理
指定した期間のファイルのみを処理
→DWHでは期間指定のクエリを多用するので、期間指定のパーティションはよく使われる
takemikami’s note– http://takemikami.com/
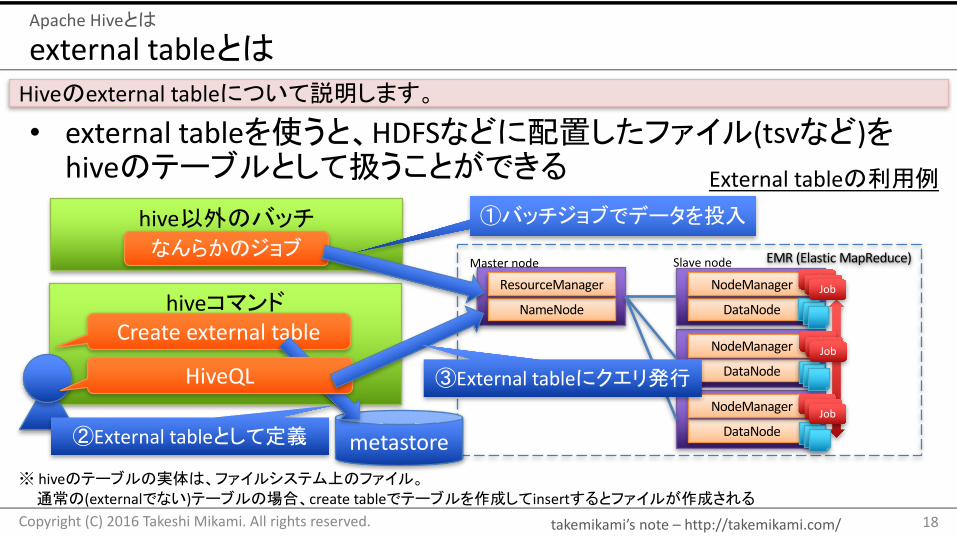
externaltableとは
• externaltableを使うと、HDFSなどに配置したファイル(tsvなど)をhiveのテーブルとして扱うことができる
18Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHiveとは
Hiveのexternaltableについて説明します。
※ hiveのテーブルの実体は、ファイルシステム上のファイル。通常の(externalでない)テーブルの場合、createtableでテーブルを作成してinsertするとファイルが作成される
EMR(ElasticMapReduce)
NameNode
ResourceManager
DataNode
NodeManager
DataNode
NodeManager
DataNode
NodeManager
JobJobJob
JobJobJob
JobJobJob
Masternode Slavenode
hiveコマンド
metastore
hive以外のバッチなんらかのジョブ
①バッチジョブでデータを投入
Createexternaltable
②Externaltableとして定義
HiveQL ③Externaltableにクエリ発行
Externaltableの利用例
takemikami’s note– http://takemikami.com/
EMR(ElasticMapReduce)
AWS上でのHive
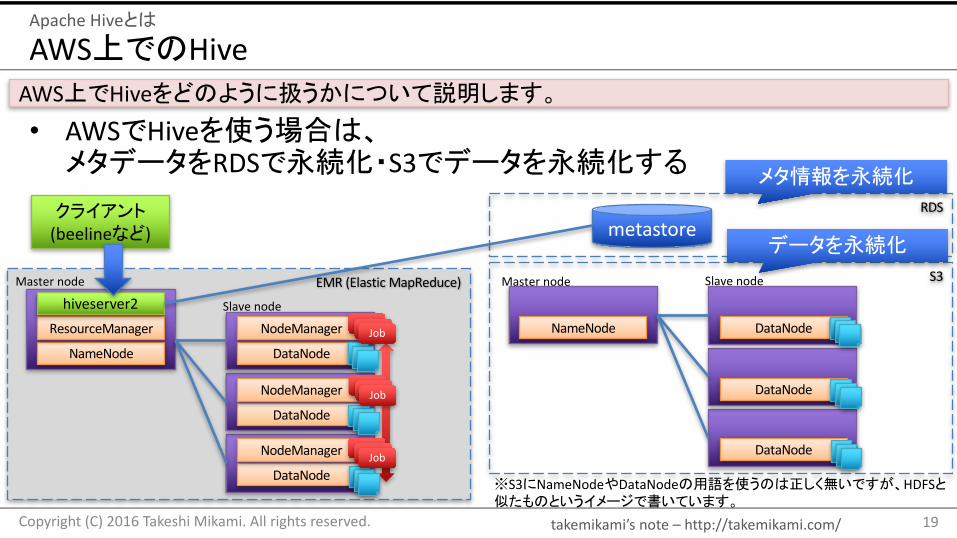
• AWSでHiveを使う場合は、メタデータをRDSで永続化・S3でデータを永続化する
19Copyright(C)2016TakeshiMikami.Allrightsreserved.
ApacheHiveとは
AWS上でHiveをどのように扱うかについて説明します。
NameNode
ResourceManager
DataNode
NodeManager
DataNode
NodeManager
DataNode
NodeManager
JobJobJob
JobJobJob
JobJobJob
Masternode
Slavenode
S3
NameNode DataNode
DataNode
DataNode
Masternode Slavenode
hiveserver2
metastoreRDSクライアント
(beelineなど)
メタ情報を永続化
データを永続化
※S3にNameNodeやDataNodeの用語を使うのは正しく無いですが、HDFSと似たものというイメージで書いています。







![Folder BigData [WEB] - infnet.edu.br · PARA BIG DATA: VOLUME MAP REDUCE / HADOOP ... programação Map Reduce; Ecossistema Hadoop (HDFS, Hive ... e é constituído por um projeto](https://static.fdocument.pub/doc/165x107/5c0db07c09d3f258548be872/folder-bigdata-web-para-big-data-volume-map-reduce-hadoop-programacao.jpg)










