
Analysis of Learning from Positive and Unlabeled Data
15
Analysis of Learning from Positive and Unlabeled Data Marthinus C, etc 担当: Quasi_quant2010 NIPS2014読み会 1 【NIPS2014読み会】
-
Upload
quasiquant2010 -
Category
Data & Analytics
-
view
3.408 -
download
0
Transcript of Analysis of Learning from Positive and Unlabeled Data

Analysis of Learning from Positive and Unlabeled Data
Marthinus C, etc
担当: Quasi_quant2010
NIPS2014読み会1
【NIPS2014読み会】

本論文を読んだ動機- ラベルなしデータにおける情報推薦の考察 -
NIPS2014読み会2
PU Learning + 表現学習
表現学習で正例らしさを自動獲得する半教師有学習が流行る?
語義曖昧性解消・同義語獲得の際、データに意味が必ずしも付与されてない為、データが与えられた時、自動獲得できれば最高
その他
例①:混合モデルによる定式化 [G.Blanchard, 10]
正例以外はラベルなしとして扱い、ラベルなしデータは正例・負例を混合した分布に従うとして定式化
例②:Delayed Feedback [O.Chapelle, 14]
1/18に推薦した記事は閲覧しなかったが、1/19に閲覧した
タイミングを考慮し、負例->正例の変化をモデル化する

本論文の貢献- 損失関数を適当に選んではいけない!! -
期待誤分類率に従って正しい決定境界を得る際、PU--Learningでは、損失関数は対称で、非凸な関数にすべき
PU LearningとCost-Sensitive Learningの関係
期待誤分類率の事前分布(P[X~f1])は主に、有効事前分布に従う
ラベルなしデータの多くが正例に従っていれば(現実に確認できないが) 、誤分類率は事前分布の選択にあまり影響されない
PU Learningにおける期待誤分類率の汎化誤差解析
NIPS2014読み会3

問題設定とノーテーション- PU Learningにおける期待誤分類率最小化- 正例 : X1,…,Xm ~ f1(x)
ラベルなしデータ:Xm+1,…,Xm+n ~ fX(x) = (1-α) f-1(x) + α f1(x)
α ∈ [0, 1], label ∈ {-1, 1}
Unkown Prior P[X ~ f1(x)]
期待誤分類率(=JL(g))を最小にする
JL(g) ≡ α*E1[Loss{g(X)}] + (1-α)*E-1[Loss{-g(X)}]
g(・) : Learning Function
NIPS2014読み会4
ノーテーション 確率
FPR R-1 P[g(X)=1 | X~f-1]
FNR1 R1 P[g(X)=-1 | X~f1]
FNRx Rx P[g(X)=1 | X~fx]
ん?f1の分布は推定できるが、f-1の分布は分からない→ f-1をfxに変換し定式化。すると, PUでは損失関数が対称であって欲しい

Cost-Sensitive Learning- FNRとFPRの非対称性 -
対象によって予測の誤りに非対称性がある
FPR = 癌と診断したものの、実際は癌でなかった
FNR = 癌と診断しなかったものの、実際は癌だった
誤診という意味では等しいが、FNRは起こってはいけない誤り
定式化
R(g) = α*c1*R1(g) + (1-α)*c-1*R-1(g)
注1) g(・)はlearning function, α = P[X~f1(x)]
注2) 詳細は[C.Elkan, 01] ・ [G.Blanchard, 10]参照
式の通り、非対称性を考慮しており、混合比率αをreweightしていると解釈できる
NIPS2014読み会5

PU LearningとCost-Sensitive Learning- PUは f1 と fx を混合したCost-Sensitive Learningと同等 -
期待誤分類率 in Cost-SensitiveR(g) = α*c1*FNR1 + (1-α)*c-1*FPR
= α*c1*R1(g) + (1-α)*c-1*R-1(g)
, α = P[X~f1(x)]
期待誤分類率 in PU LearningR(g) = α*FNR1 + (1-α)*FPR
= α*R1(g) + (1-α)*R-1(g)
= 2α*R1(g) + (1-α)* Rx(g) – α
= c1*η*R1(g) + cx*(1-η)*Rx(g) - α
, Rx(g) = α*TPR + (1-α)*FPR
= α*(1-R1(g)) + (1-α)*R-1(g)
c1=2α/η, cx=1/(1-η)
NIPS2014読み会6
R-1をRxに変換上式と比較すると、
CS設定 = f1とf-1を混合PU設定 = f1とfxを混合
とみることができる
FNRとFPRの非対称性を考慮してreweight

なぜ損失関数を適当に選んではいけないのか- 損失関数の非対称性がSuperfluous penaltyを生む -
Surpervied 設定:損失関数はHinge Loss
JH(g) ≡ α*E1[LH{g(X)}] + (1-α)*E-1[LH{-g(X)}]
, LH(z) = 1/2 * max(1-z,0)
PU 設定:損失関数はHinge Loss
JPU-H(g) ≡ α*E1[LH{g(X)}] + (1-α)*E-1[LH{-g(X)}]
+ α*E1[LH{g(X)} + LH{-g(X)}] – α
JPU-H(g) = JH(g) + α*E1[LH{g(X)} + LH{-g(X)}] – α
Hinge Lossの場合、PU設定はSupervied設定と比べ、Superfluous penaltyが決定境界を悪化させる
NIPS2014読み会7
Superfluous penalty

Surpervied 設定:損失関数はRamp Loss
JR(g) ≡ α*E1[LH{g(X)}] + (1-α)*E-1[LH{-g(X)}]
, LR(z) = 1/2 * max(0, min(2,1-z))
PU 設定:損失関数はRamp Loss
JPU-R(g) ≡ α*E1[LR{g(X)}] + (1-α)*E-1[LR{-g(X)}]
+ α*E1[LR{g(X)} + LR{-g(X)}] – α
JPU-R(g) = JR(g) (∵ LR{g(X)} + LR{-g(X)} = 1 )
Ramp Lossの対称性よりPU設定はSupervied設定の決定境界と等しくなる
NIPS2014読み会8
Superfluous penalty
なぜ損失関数を適当に選んではいけないのか- 損失関数の対称性がSuperfluous penaltyを消去 -
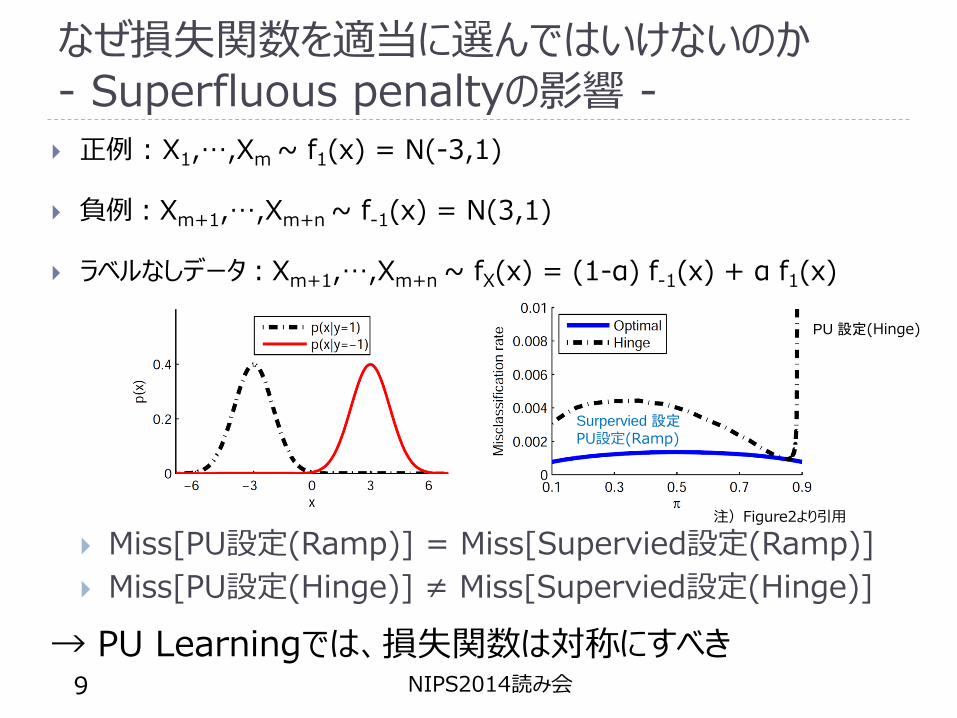
なぜ損失関数を適当に選んではいけないのか- Superfluous penaltyの影響 - 正例 : X1,…,Xm ~ f1(x) = N(-3,1)
負例:Xm+1,…,Xm+n ~ f-1(x) = N(3,1)
ラベルなしデータ:Xm+1,…,Xm+n ~ fX(x) = (1-α) f-1(x) + α f1(x)
Miss[PU設定(Ramp)] = Miss[Supervied設定(Ramp)]
Miss[PU設定(Hinge)] ≠ Miss[Supervied設定(Hinge)]
→ PU Learningでは、損失関数は対称にすべきNIPS2014読み会9
注)Figure2より引用
Surpervied設定PU設定(Ramp)
PU 設定(Hinge)

事前分布が超過リスクに与える影響- 有効事前分布は超過リスクを最小にする - 超過リスクを小さくしたい
ExR(α) ≡ R(g*, α) - R(g, α)
g* = infg∈G R(g, α), g*は誤分類率を最小化する学習関数
R(g,α) ≡ 2α × R1(g) + (1-α) × Rx(g) – α
この時、有効事前分布をtilde{α}とすると
tilde{α} = argminα∈P[X ~ f1(x)] ExR(α)
= (2*hat{α} – α) / Z(hat{α}, α)
, Z(hat{α}, α) = (2*hat{α} – α) + (1-α), Zは正規化項
導出? 次ページのグラフにて示唆
R(g, hat{α}) ≡ 2*hat{α}*R1(g) + Rx(g) - hat{α}
=(2*hat{α} – α)*R1(g) + (1-α)*R-1(g) + (hat{α} – α)
NIPS2014読み会10

最小化問題に対する事前分布の感応度- 事前分布の選択方法 -
①:超過リスクは有効事前分布の時、最小
tilde{α} =
argminα∈P[X ~ f1(x)] ExR(α)
が成立している
→ 推定事前分布が有効事前分布に一致すると最高
②:真の事前分布が大きい程、有効事前分布は真値の周辺でほぼ一定
→ P[X~f1(x)]が大きければ、
事前分布の推定はラフでいい
注)Figure3より引用
①:超過リスク
有効事前分布
事前分布推定は[G.Blanchard, 10]を参照
推定事前分布= 真の事前分布
事前分布
誤分
類率
有効
事前
分布
推定事前分布
②

評価実験- 損失関数の対称性で誤分類率が下がるか -
タスク
”0”と”N”が異なることを認識, N=1,…,9
手書き数字データ: USPSセット
米国郵便公社より収集した数字の画像データ(MNIST)
訓練データ:7291サンプル、テストデータ:2007サンプル
サイト報告のエラーレートは2.5%が最高
実験では、Positive・Unlabel、各々550サンプルを使用
モデル(損失関数・事前分布)
Hinge Loss
Ramp Loss
α = P[X~f1(x)]は0.2~0.95から決め打ちNIPS2014読み会12

評価実験- 損失関数の対称性で誤分類率が下がった!!-
見どころ
損失関数にRampを用いた方がHingeより予測が正確
さらに、αが大きければその結果は顕著
→ superfluous penalty termによるバイアスに起因
結果: 0 vs 6,8,9
サイト報告の最高エラーレート2.5%を上回っている
Ramp > Hinge
αが大きくなる程エラー率が低下
NIPS2014読み会13
注)Table1より引用

感想- PU設定では損失関数を適当に決めない!! -
NIPS2014読み会14
全体
PU設定では、対称な損失関数を使えばSupervised設定と同程度の性能が見込める
有効事前分布という量を導入し、誤分類率が推定した事前分布にどの程度、依存するかを考察
超過リスクの上限バウンドに関する理論は整理されているので、事前分布が超過リスクに及ぼす影響をKLDなどで整理し、既存の上限バウンドがタイトになる理論ができれば凄い
実験
PU設定下、Ramp・Hingeの違いによる予測率を比較するだけでなく、負例も使い、Supervied設定の予測も比較すべきでは?
Miss[PU設定(Ramp)] ≒ Miss[Supervied設定(Ramp)]
Miss[PU設定(Hinge)] ≠ Miss[Supervied設定(Hinge)]

参照 [C.Elkan, 01] The Foundations of Cost-Sensitive
Learning, IJCA
*[T.Zhang, 04] Statistical behavior and consistency of classification methods based on convex risk minimization, The Annals of Statistics
*[G.Blanchard, 10] Semi-Supervised Novelty Detection, JMLR
[M.C.Plessis, 14] Class prior estimation from positive and unlabeled data, TIS
[O.Chapelle, 14] Modeling Delayed Feedback in Display Advertising, KDD
NIPS2014読み会15


















