
Analiza danych nieustrukturyzowanych: Text Miningkuligowska.com/wne/textmining/tm2.pdf · Przykład...
122
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS” Analiza danych nieustrukturyzowanych: Text Mining dr Karolina Kuligowska Wydział Nauk Ekonomicznych Uniwersytet Warszawski
Transcript of Analiza danych nieustrukturyzowanych: Text Miningkuligowska.com/wne/textmining/tm2.pdf · Przykład...

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Analiza danych nieustrukturyzowanych: Text Mining
dr Karolina Kuligowska
Wydział Nauk Ekonomicznych
Uniwersytet Warszawski

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
49
dr Karolina Kuligowska
dr Karolina Kuligowska
SAS Institute na polskim rynku od 1992 r.
SAS Enterprise Miner
analizy data mining
interaktywna wizualizacja danych
SAS Text Miner
przetwarzanie tekstu
wydobywanie wiedzy z dokumentów tekstowych
interaktywna wizualizacja danych
SAS

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
50
dr Karolina Kuligowska
dr Karolina Kuligowska
Komponent wewnątrz SAS Enterprise Miner
Umożliwia wydobywanie informacji oraz dotarcie do tematów i konceptów zawartych w dużym zbiorze dokumentów
Obsługiwane formaty dokumentów: PDF, ASCII, Corel Presentations, HTML, Lotus Word Pro, WordPerfect, MS Excel, MS PowerPoint, MS Word, MS Outlook, MS Outlook Express
SAS Text Miner

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
51
dr Karolina Kuligowska
dr Karolina Kuligowska
SAS Text Miner zawiera makro %tmfilter, które:
wydobywa tekst z plików o różnym formacie lub
wydobywa tekst ze stron internetowych
a następnie
tworzy bazę danych SAS gotową do dalszych analiz
Funkcjonalności

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
52
dr Karolina Kuligowska
dr Karolina Kuligowska
SAS Text Miner może wydobywać tekst z plików w formacie PDF, ale nie obraz tekstu z pliku PDF
Jeśli plik zawiera zeskanowany tekst (tj. obraz tekstu), należy go przekonwertować na dokument tekstowy za pomocą dowolnego programu OCR (Optical Character Recognition)
Uwaga!

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
54
dr Karolina Kuligowska
dr Karolina Kuligowska
1. Wstępna analiza plików tekstowych (file preprocessing)
przetworzenie zbioru dokumentów w jedną bazę danych SAS - input dla Text Miner
2. Parsowanie - rozbiór struktury tekstu (text parsing)
a) dekompozycja danych tekstowych
b) ilościowa reprezentacja zbioru dokumentów
Etapy procesu text mining

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
55
dr Karolina Kuligowska
dr Karolina Kuligowska
3. Transformacja i redukcja wymiarów (transformation, dimension reduction)
a) transformacja reprezentacji ilościowej tekstu
b) redukcja wymiarów do zwartego formatu informacyjnego
4. Analiza (document analysis)
klastrowanie, klasyfikacja, predykcja
Etapy procesu text mining

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining 1. Wstępna analiza plików tekstowych
2. Parsowanie - rozbiór struktury tekstu a) dekompozycja danych tekstowych b) ilościowa reprezentacja zbioru dokumentów
3. Transformacja i redukcja wymiarów a) transformacja reprezentacji ilościowej tekstu b) redukcja wymiarów do zwartego formatu informacyjnego
4. Analiza
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
57
dr Karolina Kuligowska
dr Karolina Kuligowska
Wstępna analiza plików tekstowych (file preprocessing)
Makro %tmfilter
tworzy bazę danych SAS, która zawiera tekst wydobyty z plików o różnym formacie
Źródła danych tekstowych
lokalne pliki tekstowe
bazy danych SAS
tabele w zewnętrznych bazach danych
pliki dostępne w sieci internetowej

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining 1. Wstępna analiza plików tekstowych
2. Parsowanie - rozbiór struktury tekstu a) dekompozycja danych tekstowych b) ilościowa reprezentacja zbioru dokumentów
3. Transformacja i redukcja wymiarów a) transformacja reprezentacji ilościowej tekstu b) redukcja wymiarów do zwartego formatu informacyjnego
4. Analiza
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
59
dr Karolina Kuligowska
dr Karolina Kuligowska
Termin wielowyrazowy to grupa wyrazów rozpatrywana jako pojedynczy termin
Zazwyczaj jest to czasownik złożony lub nazwa własna, rzadziej zwrot idiomatyczny
due to, because of
Web browser, interest rate
Terminy wielowyrazowe są obsługiwane w językach: angielski, francuski, niemiecki, włoski, portugalski, hiszpański
Terminy wielowyrazowe

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
60
dr Karolina Kuligowska
dr Karolina Kuligowska
SAS Text Miner identyfikuje części mowy
W rezultacie każde wyrażenie jest przyporządkowane do gramatycznej kategorii, bazując na kontekście użycia w danym zdaniu
Analiza ta jest obsługiwana w językach: angielski, francuski, niemiecki, hiszpański
Części mowy

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
61
dr Karolina Kuligowska
dr Karolina Kuligowska
Dokumenty z reguły zawierają pewne szczególne jednostki tekstu, takie jak:
adres, firma, organizacja, kwota, waluta, data, godzina, adres internetowy, lokalizacja, miara, procent, osoba, tytuł naukowy, telefon, produkt
SAS Text Miner identyfikuje jednostki specjalne dla języków: angielski, francuski, niemiecki, hiszpański
Jednostki specjalne

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
62
dr Karolina Kuligowska
dr Karolina Kuligowska
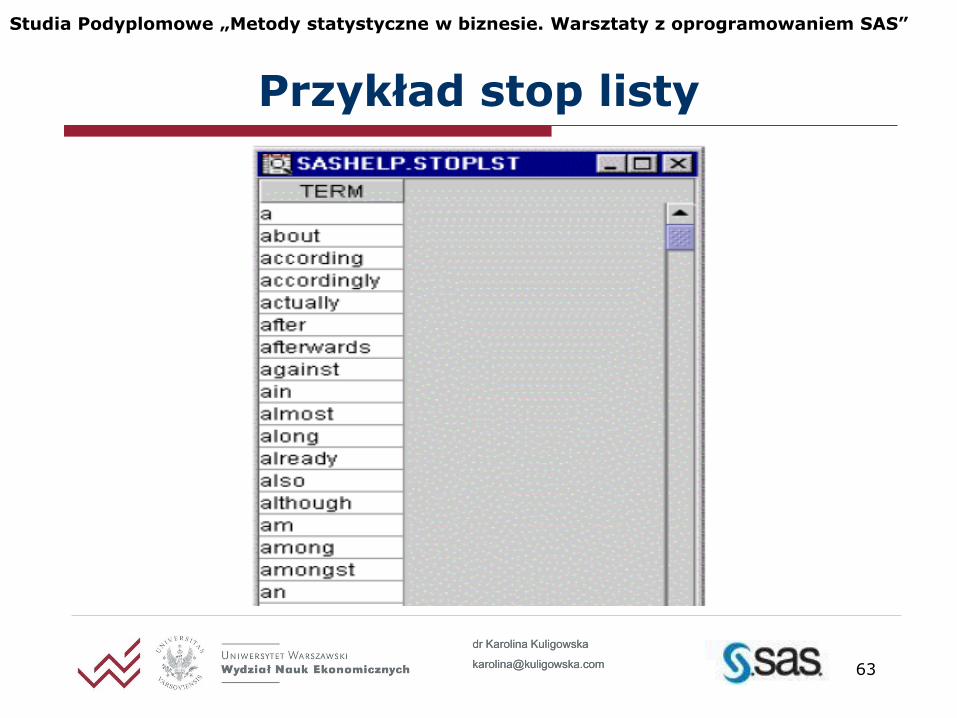
Stop lista: słowa o mało znaczącej treści zebrane w formie tabeli
Umożliwia pominięcie konkretnych słów, co przyspiesza analizę tekstu i prowadzi do uzyskania lepszych rezultatów
SAS Text Miner posiada stop listy dla języków: angielski, francuski, niemiecki
Stop lista
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
63
dr Karolina Kuligowska
dr Karolina Kuligowska
Przykład stop listy

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
64
dr Karolina Kuligowska
dr Karolina Kuligowska
Start lista: słowa o znaczącej treści zebrane w formie tabeli
Umożliwia włączenie konkretnych słów do analizy i zbadanie tylko wybranych słów
SAS Text Miner nie posiada domyślnej start listy
Start lista

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
65
dr Karolina Kuligowska
dr Karolina Kuligowska
SAS Text Miner może zostać skonfigurowany w celu znajdowania podstawy fleksyjnej słów (stemming, lematyzacja)
Jedno słowo może grupować różne części mowy np. słowo „nauka” może grupować „uczyć” oraz „nauczyciel”
Jednocześnie SAS Text Miner rozróżnia te słowa jako czasownik i rzeczownik w grupie „nauka”
Znajdowanie podstawy fleksyjnej

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
66
dr Karolina Kuligowska
dr Karolina Kuligowska
Podstawa fleksyjna
Wyrażenia
reach reaches, reached, reaching
big bigger, biggest
aller (francuski) vais, vas, va, allons, allez, vont
Przykłady podstawy fleksyjnej

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
67
dr Karolina Kuligowska
dr Karolina Kuligowska
SAS Text Miner korzysta z listy synonimów w celu pogrupowania słów
Synonimy nie mają wspólnej podstawy fleksyjnej, ale niosą tę samą informację
Np: „uczyć” ma synonimy: instruować, edukować, kształcić
Synonimy

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
68
dr Karolina Kuligowska
dr Karolina Kuligowska
Oprócz synonimów słów istnieją także formy kanoniczne („synonimy”) jednostek specjalnych
Jednostki specjalne, pomimo różnych nazw, są traktowane przez SAS Text Miner tak samo jak ich bazowa forma kanoniczna
Forma kanoniczna

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
69
dr Karolina Kuligowska
dr Karolina Kuligowska
DATA i rok 07/03/07
7 marzec
7 marzec 2007
’07
Procent 50%
Pięćdziesiąt procent
Pięćdziesiąt pt. proc
Forma kanoniczna
2007-03-07
-03-07
2007-03-07
2007
Forma kanoniczna
50%
Przykłady formy kanonicznej

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
70
dr Karolina Kuligowska
dr Karolina Kuligowska
SAS Text Miner umożliwia stworzenie własnych synonimów oraz form kanonicznych
W tym celu należy stworzyć zbiór danych SAS zawierający listę synonimów, która uwzględnia min. trzy zmienne:
słowo (term)
baza fleksyjna (parent)
kategoria części mowy (category)
Własne ustawienia

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
71
dr Karolina Kuligowska
dr Karolina Kuligowska
Słowo Baza Kategoria
wiele dużo liczebnik synonim
pracownicy pracować czasownik stemming
EM Enterprise Miner SAS
produkt forma kanoniczna
Przykłady własnych synonimów

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining 1. Wstępna analiza plików tekstowych
2. Parsowanie - rozbiór struktury tekstu a) dekompozycja danych tekstowych b) ilościowa reprezentacja zbioru dokumentów
3. Transformacja i redukcja wymiarów a) transformacja reprezentacji ilościowej tekstu b) redukcja wymiarów do zwartego formatu informacyjnego
4. Analiza
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
73
dr Karolina Kuligowska
dr Karolina Kuligowska
Oparta o zbiór słów kluczowych („bag of words” document representation) dokument tekstowy reprezentowany jest przez zbiór
słów kluczowych opisujących dokument (wypisywanych najczęściej ręcznie przez osobę tworzącą dokument). Wyszukiwanie dokumentów realizowane jest poprzez podanie słów kluczowych
Oparta o przestrzeń wektorową (vector space document representation) dokument tekstowy reprezentowany jest przez
wektor częstości występowania słów kluczowych, a całość zebrana jest w macierzy Term_Frequency_Matrix
Reprezentacja dokumentu

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
74
dr Karolina Kuligowska
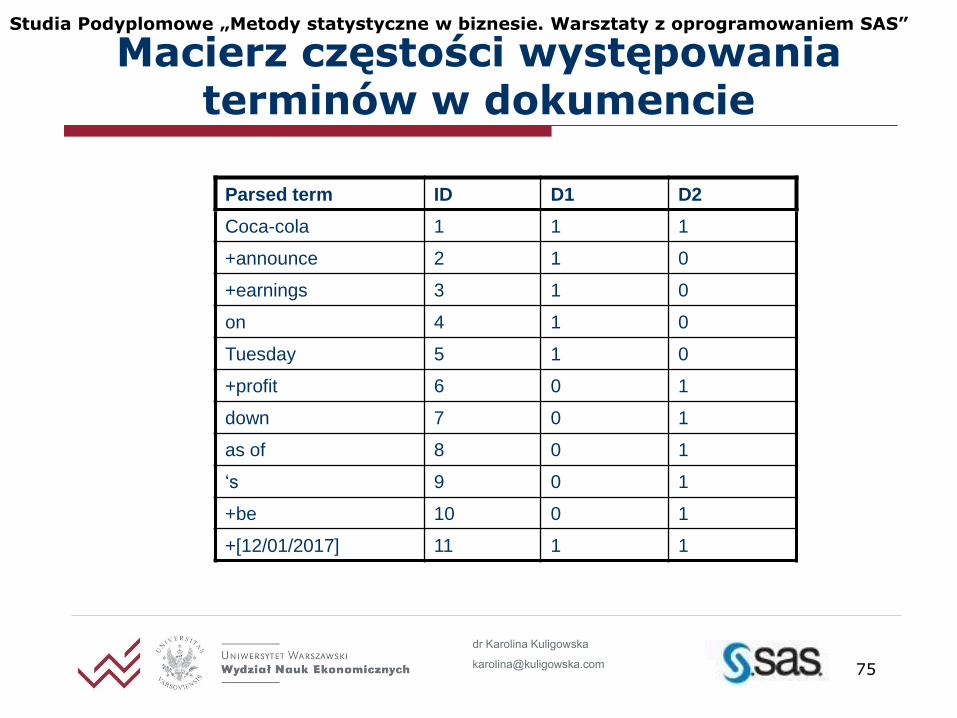
Doc 1 Coca-Cola announced earnings on Tuesday, Jan 12, 2017
Doc 2 Coca-Cola’s profits are down as of 12/01/2017
powyższy zbiór dwóch jednozdaniowych dokumentów SAS Text Miner przekształci do postaci macierzy częstości (term-by-document frequency matrix)
Zbiór dokumentów
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
75
dr Karolina Kuligowska
Parsed term ID D1 D2
Coca-cola 1 1 1
+announce 2 1 0
+earnings 3 1 0
on 4 1 0
Tuesday 5 1 0
+profit 6 0 1
down 7 0 1
as of 8 0 1
‘s 9 0 1
+be 10 0 1
+[12/01/2017] 11 1 1
Macierz częstości występowania terminów w dokumencie

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
76
dr Karolina Kuligowska
dr Karolina Kuligowska
wiersze reprezentują rozłożone wyrażenia (rdzenie oraz formy kanoniczne)
w kolumnach odnoszących się do dokumentów przedstawiona jest liczba wystąpień (częstość) danego wyrażenia w tym dokumencie
niektóre wyrażenia zostały usunięte przez stop listę
macierz częstości służy jako podstawa analizy zbioru dokumentów
Macierz częstości występowania terminów w dokumencie

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
77
dr Karolina Kuligowska
dr Karolina Kuligowska
Macierz częstości jest olbrzymia, zawiera tysiące wyrażeń
Jak polepszyć macierz?
transformacja (funkcje ważące)
redukcja wymiarów macierzy do znacznie mniejszych rozmiarów (poprawia wydajność i efektywność procesu text mining)
Dopiero później: analiza
Ilościowa reprezentacja to za mało...

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining 1. Wstępna analiza plików tekstowych
2. Parsowanie - rozbiór struktury tekstu a) dekompozycja danych tekstowych b) ilościowa reprezentacja zbioru dokumentów
3. Transformacja i redukcja wymiarów a) transformacja reprezentacji ilościowej tekstu b) redukcja wymiarów do zwartego formatu informacyjnego
4. Analiza
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
79
dr Karolina Kuligowska
dr Karolina Kuligowska
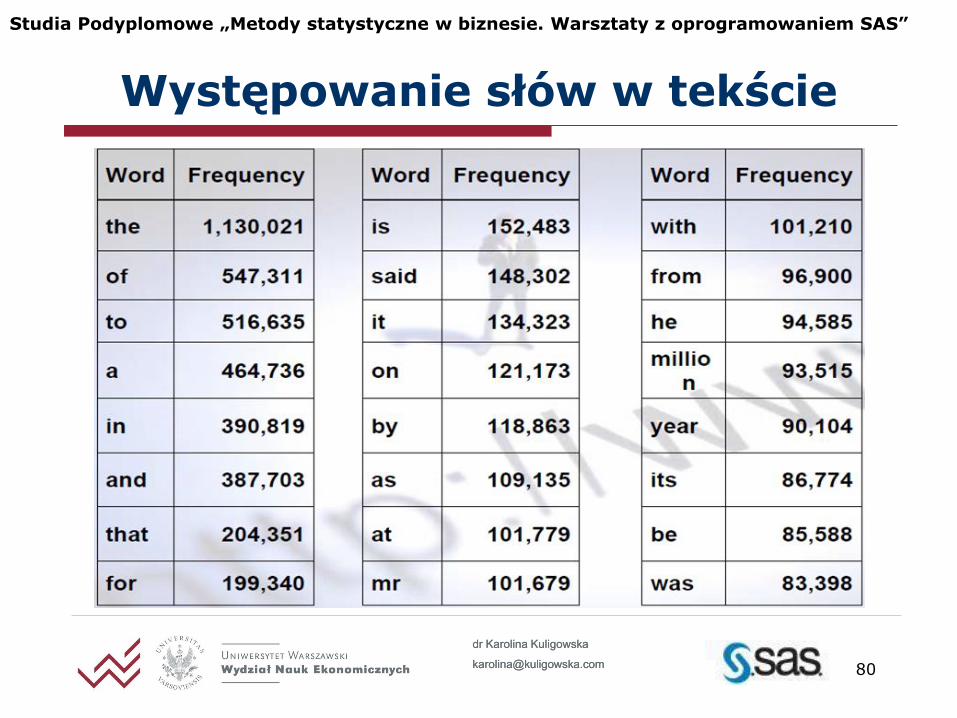
Tematyka większości dokumentów jest zazwyczaj wystarczająco dobrze określona przez niewielką ilość słów
Pozostałe informacje słowne - zbędny „balast”
Celowość transformacji
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
80
dr Karolina Kuligowska
dr Karolina Kuligowska
Występowanie słów w tekście
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
81
dr Karolina Kuligowska
dr Karolina Kuligowska
Prawo Zipfa
częstotliwość występowania słowa w tekście jest odwrotnie proporcjonalna do jego rangi (pozycji w rankingu)
Prawo Zipfa

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
82
dr Karolina Kuligowska
dr Karolina Kuligowska
Słowa o największej mocy dyskryminacyjnej mają od niskiej do średniej częstotliwości
Prawo Zipfa i moc dyskryminacyjna

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
83
dr Karolina Kuligowska
dr Karolina Kuligowska
Potrzebna jest funkcja wybierająca słowa najbardziej istotne dla zbioru dokumentów
dziedzina - elementy reprezentacji (słowa)
wartości - określać będą przydatność tych elementów dla dalszej analizy
Transformacja reprezentacji ilościowej tekstu

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
84
dr Karolina Kuligowska
dr Karolina Kuligowska
Macierz częstości występowania terminów w dokumencie (term-by-document frequency matrix) jest podstawą analizy zbioru dokumentów, lecz nie uwzględnia siły dyskryminacyjnej słów/terminów
Funkcje ważące ulepszają macierz częstości: im rzadsze słowo, tym większa jego waga i tym bardziej dokumenty zawierające to słowo są do siebie podobne (dzięki temu można tworzyć podzbiory podobnych dokumentów)
Funkcje ważące

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
85
dr Karolina Kuligowska
dr Karolina Kuligowska
Waga częstości (lokalna) Lij
Informacje o 1 dokumencie, jakie niesie dane słowo/termin
Waga wyrażenia (globalna) Gi
Informacje o zbiorze dokumentów, jakie niesie dane słowo/termin
Wzór ogólny całkowitej wagi danej pozycji w macierzy częstości: âij = LijGi
Funkcje ważące

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
86
dr Karolina Kuligowska
Są to funkcje częstości występowania słowa i w dokumencie j
Dostępne funkcje:
Binarna (binary)
Logarytmiczna (log)
Pusta (none)
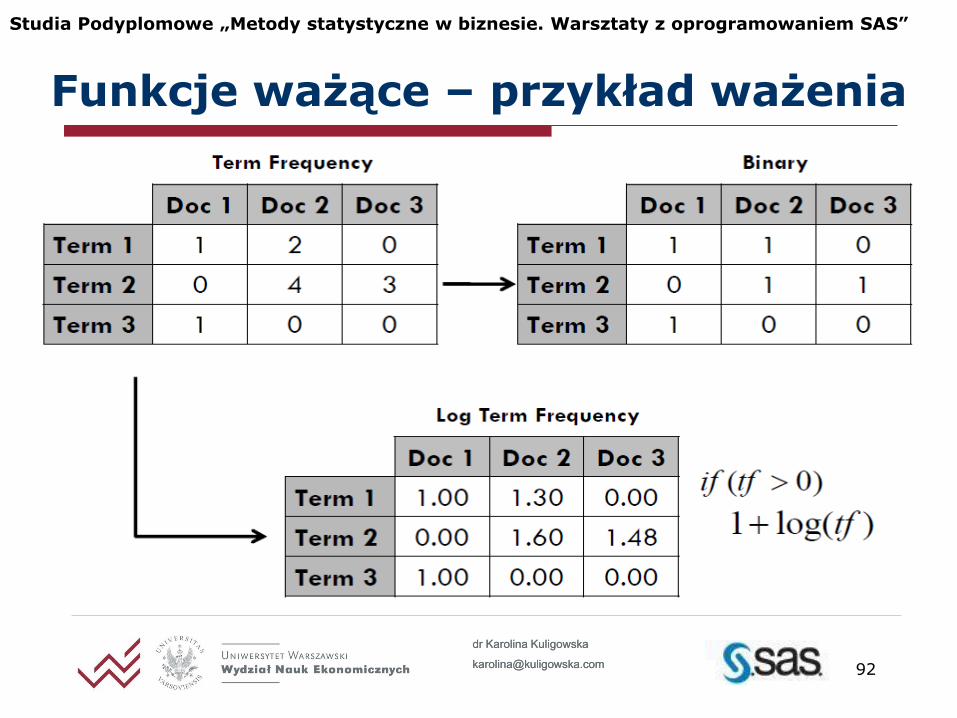
Wagi częstości (Lij)

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
87
dr Karolina Kuligowska
Binarna (0-1), używana dla prostych dokumentów o nieskomplikowanej składni
Logarytmiczna, obniża efekt często
powtarzanego pojedynczego słowa
Pusta, wszystkie wagi mają wartość 1
)1(log 2 ijij aL
1ijL
0
1
ij
ij
L
L - gdy słowo i występuje w dokumencie j
- w przeciwnym przypadku
Wagi częstości (Lij)

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
88
dr Karolina Kuligowska
Są to funkcje zliczające wystąpienia słowa i w całym zbiorze dokumentów
Dostępne funkcje:
Entropia (entropy)
GF-IDF (Global Frequency x Inverse Document Frequency)
IDF (Inverse Document Frequency)
Normalna (normal)
Pusta (none)
Wagi wyrażenia (Gi)

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
89
dr Karolina Kuligowska
Entropia, kładzie nacisk na słowa, które występują tylko w kilku dokumentach z całego zbioru. Największą wagę otrzymują słowa rzadkie w zbiorze dokumentów
-liczba dokumentów w zbiorze
-częstość występowania słowa i w dokumencie j
j
ijij
in
ppG
)(log
)(log1
2
2n
ijf
i
ij
ijg
fP ig -liczba wystąpień słowa i w całym zbiorze
Wagi wyrażenia (Gi)

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
90
dr Karolina Kuligowska
GF-IDF, podobnie jak Entropia, kładzie nacisk na słowa, które występują tylko w kilku dokumentach w całym zbiorze. Największą wagę otrzymują słowa rzadkie w zbiorze dokumentów
i
i
id
gG
id -liczba dokumentów, w których pojawia się słowo i
-liczba wystąpień słowa i w całym zbiorze ig
Wagi wyrażenia (Gi)

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
91
dr Karolina Kuligowska
IDF, tzw. odwrotna częstość, podkreśla słowa występujące tylko w kilku dokumentach
Normalna, podkreśla bardziej proporcję ilości pojawień słowa w zbiorze dokumentów, niż samą liczbę wystąpień
Pusta, wszystkie wagi mają wartość 1
1iG
1log 2
i
id
nG
j
ij
i
fG
2
1
Wagi wyrażenia (Gi)
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
92
dr Karolina Kuligowska
dr Karolina Kuligowska
Funkcje ważące – przykład ważenia

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining 1. Wstępna analiza plików tekstowych
2. Parsowanie - rozbiór struktury tekstu a) dekompozycja danych tekstowych b) ilościowa reprezentacja zbioru dokumentów
3. Transformacja i redukcja wymiarów a) transformacja reprezentacji ilościowej tekstu b) redukcja wymiarów do zwartego formatu informacyjnego
4. Analiza
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
94
dr Karolina Kuligowska
dr Karolina Kuligowska
Modelowanie oraz obliczenia wykonywane na wielowymiarowych przestrzeniach słów są kosztowne i trudne do przeprowadzenia
Duża ilość wymiarów oznacza rozrzedzone dane wejściowe (sparse data)
dziesiątki tysięcy wyodrębnionych słów
niewielki procent istotnych słów (prawo Zipfa)
Redukcja wymiarów macierzy zwiększa efektywność analizy
Celowość redukcji wymiarów

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
95
dr Karolina Kuligowska
Singular Value Decomposition -rozkład macierzy według wartości szczególnych
Metoda ta generuje k wymiarów, które najlepiej przybliżają macierz częstości
parametr k określany jest przez użytkownika mała wartość k (2 - 50) jest przydatna
w dalszej klasteryzacji duża wartość k (30 - 200) jest przydatna
w dalszej predykcji lub klasyfikacji
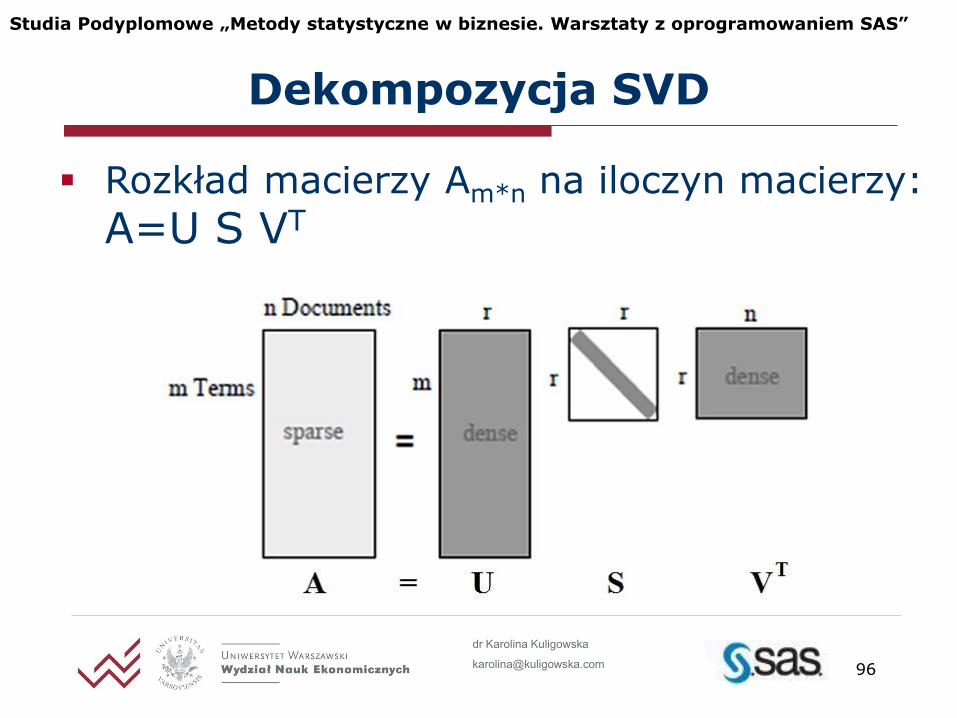
Redukcja wymiarów: Dekompozycja SVD
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
96
dr Karolina Kuligowska
Rozkład macierzy Am*n na iloczyn macierzy:
A=U S VT
Dekompozycja SVD

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
97
dr Karolina Kuligowska
dr Karolina Kuligowska
Zastosowanie dekompozycji SVD pozwala na redukcję wymiaru macierzy częstości bez utraty informacji
Szczególnie ważna, gdy dokumenty są długie i jest w nich wiele homonimów
Homonimy – wyrazy wieloznaczne, mają tę samą postać, ale różne znaczenie np. zamek/zamek, granat/granat, itp.
Dekompozycja SVD

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Przebieg dekompozycji SVD - przykład

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
99
dr Karolina Kuligowska
Document 1: deposit the cash and check in the bank
Document 2: the river boat is on the bank
Document 3: borrow based on credit
Document 4: river boat floats up the river
Document 5: boat is by the dock near the bank
Document 6: with credit, I can borrow cash from the bank
Document 7: boat floats by dock near the river bank
Document 8: check the parade route to see the floats
Document 9: along the parade route
Przykład dekompozycji SVD

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
100
dr Karolina Kuligowska
Zbiór 9 dokumentów
dokumenty 1,3,6 dotyczą bankowości i pożyczek
dokumenty 2,4,5,7 dotyczą brzegu rzeki
dokumenty 8, 9 dotyczą trasy defilady
Niektóre z dokumentów zawierają homonimy
„bank” jako instytucja finansowa lub brzeg rzeki
„check” jako rzeczownik w dokumencie 1 lub jako czasownik w dokumencie 8
„float” jako czasownik w dokumencie 4 lub jako rzeczownik w dokumencie 8
Przykład dekompozycji SVD

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
101
dr Karolina Kuligowska
d1 d2 d3 d4 d5 d6 d7 d8 d9
the 2 2 0 1 2 1 1 2 1
cash 1 0 0 0 0 1 0 0 0
check 1 0 0 0 0 0 0 1 0
bank 1 1 0 0 1 1 1 0 0
river 0 1 0 2 0 0 1 0 0
boat 0 1 0 1 1 0 1 0 0
+ be 0 1 0 0 1 0 0 0 0
on 0 1 1 0 0 0 0 0 0
borrow 0 0 1 0 0 1 0 0 0
credit 0 0 1 0 0 1 0 0 0
+ floats 0 0 0 1 0 0 1 1 0
by 0 0 0 0 1 0 1 0 0
dock 0 0 0 0 1 0 1 0 0
near 0 0 0 0 1 0 1 0 0
parade 0 0 0 0 0 0 0 1 1
route 0 0 0 0 0 0 0 1 1

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
102
dr Karolina Kuligowska
Obserwując elementy macierzy można zauważyć na pierwszy rzut oka, że:
dokumenty 1 i 2 są do siebie bardziej podobne niż dokumenty 1 i 3, gdyż dokumenty 1 i 2 zawierają słowo „bank”, podczas gdy dokumenty 1 i 3 nie mają wspólnych wyrazów
W rzeczywistości dokumenty 1 i 2 nie są wcale ze sobą powiązane; to dokumenty 1 i 3 dotyczą tych samych zagadnień
Dekompozycja SVD pozwala przezwyciężyć powyższe problemy
Przykład dekompozycji SVD

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
103
dr Karolina Kuligowska
W wyniku dekompozycji SVD macierz częstości została zredukowana do 2 wymiarów
Przestrzeń semantyczna staje się 2-wymiarowa
Przewidywany rozkład dokumentów można zobrazować w 2-wymiarowej przestrzeni
Przykład dekompozycji SVD

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
104
dr Karolina Kuligowska
2-wymiarowy rozkład dokumentów

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
105
dr Karolina Kuligowska
Dokument 1 jest bliżej dokumentu 3 niż 2 (jest to zgodne z prawdą, chociaż dokumenty 1 i 3 nie zawierają takich samych słów)
Dokument 5 jest ściśle powiązany z dokumentami 2,4,7
Przewidywania umiejscawiają podobne dokumenty obok siebie, nawet jeśli zawierają one niewiele wspólnych słów
2-wymiarowy rozkład dokumentów

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining 1. Wstępna analiza plików tekstowych
2. Parsowanie - rozbiór struktury tekstu a) dekompozycja danych tekstowych b) ilościowa reprezentacja zbioru dokumentów
3. Transformacja i redukcja wymiarów a) transformacja reprezentacji ilościowej tekstu b) redukcja wymiarów do zwartego formatu informacyjnego
4. Analiza
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
107
dr Karolina Kuligowska
Celem analiz Text Mining jest określenie tematyki zbioru dokumentów bez konieczności czytania każdego słowa
Text Mining opisowy (descriptive text mining) – klastrowanie, klasyfikacja (wykrycie konceptów, wzorców i powiązań tematycznych w zbiorze dokumentów)
Text Mining predykcyjny (predictive text mining) – predykcja (wykorzystanie wykrytych konceptów, wzorców i powiązań tematycznych w zbiorze dokumentów do formułowania prognoz)
Analiza

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
108
dr Karolina Kuligowska
Metoda hierarchiczna
jeden klaster może zawierać inny
brak innych rodzajów nałożeń klastrów
Klastrowanie

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
109
dr Karolina Kuligowska
Metoda EM (Expectation Maximization)
oblicza prawdopodobieństwa przynależności do skupień przy założeniu jednego lub wielu rozkładów prawdopodobieństwa
dozwolona różna wielkość i kształt klastrów
Klastrowanie

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
110
dr Karolina Kuligowska
Sortowanie dokumentów tekstowych wg wcześniej zdefiniowanych kategorii
Wymaga zbioru treningowego
Opiera się na
wnioskowaniu pamięciowym
sieciach neuronowych
drzewach decyzyjnych
Klasyfikacja

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
111
dr Karolina Kuligowska
Ogólne nieautomatyczne wnioskowanie na podstawie wykrytych konceptów, wzorców i powiązań tematycznych w zbiorze dokumentów
Przykłady
przewidywanie wystąpienia problemu na podstawie zapisów rozmów z call center
prognozowanie kosztów usługi, bazujące na tekstowym opisie problemu
przewidywanie poziomu satysfakcji klientów na podstawie ich komentarzy i opinii
prognozowanie wahań cen akcji na podstawie wiadomości prasowych i ogłoszeń biznesowych
Predykcja

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
113
dr Karolina Kuligowska
dr Karolina Kuligowska
Text Parsing - parsowanie zbioru dokumentów w celu stworzenia ilościowej reprezentacji tekstu i macierzy częstości
Text Filter - czyszczenie danych przez redukcję całkowitej liczby analizowanych słów i/lub dokumentów
Text Topic - eksploracja zbioru dokumentów przez wyznaczenie kategorii tematycznych
Komponenty

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
114
dr Karolina Kuligowska
dr Karolina Kuligowska
Text Cluster - klastrowanie dokumentów, bazując na macierzy częstości (Text Parsing) z oczyszczonymi danymi (Text Filter)
Text Rule Builder - tworzenie reguł do opisywania zmiennej celu
Text Profile - profilowanie zmiennej celu na podstawie słów odkrytych w dokumentach
Text Import - import tekstu źródłowego
Komponenty

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1. Krótka charakterystyka narzędzia
2. Etapy procesu text mining
3. Komponenty Text Parsing
Text Filter
Text Topic
Text Cluster
Text Rule Builder
Text Profile
Text Import
4. Makro % tmfilter
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
116
dr Karolina Kuligowska
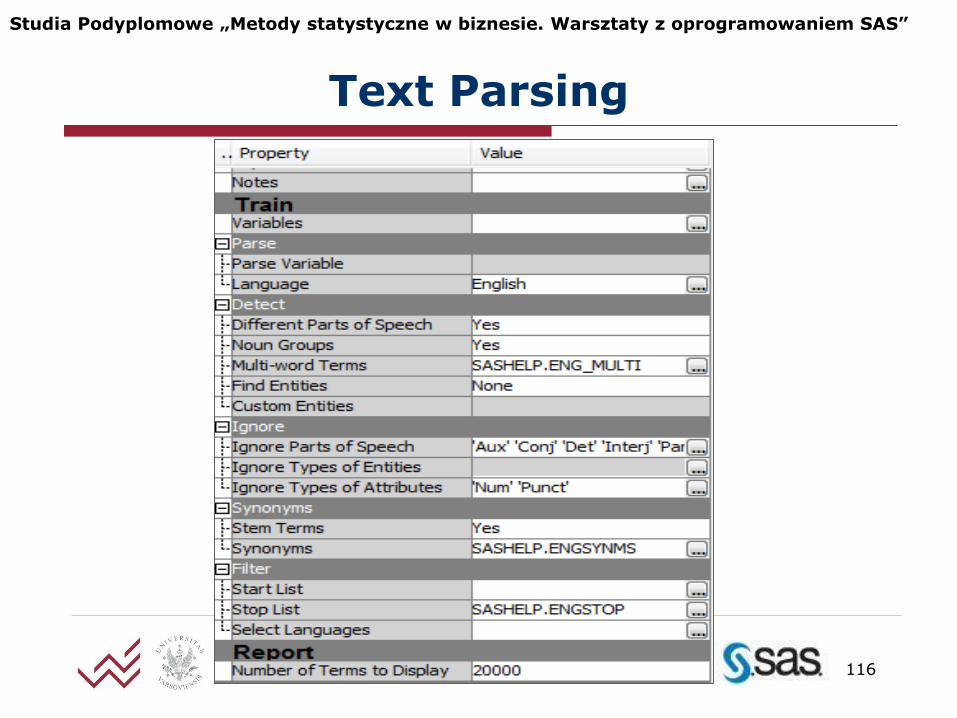
Text Parsing

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
117
dr Karolina Kuligowska
dr Karolina Kuligowska
Język: ENGLISH / POLISH
Wykryj wyrażenia
to samo słowo jako różne części mowy
grupy rzeczowników
terminy wielowyrazowe
jednostki specjalne
Ustawienia Text Parsing

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
118
dr Karolina Kuligowska
dr Karolina Kuligowska
Ignoruj części mowy
Ignoruj typy jednostek specjalnych
Ignoruj typy atrybutów
liczby
interpunkcja
Ustawienia Text Parsing

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
119
dr Karolina Kuligowska
dr Karolina Kuligowska
Rozpoznawane części mowy:
Det – rodzajnik (a, an), zaimek wskazujący (this, that...)
Conj – spójnik
Aux – czasownik posiłkowy
Prep – przyimek
Pron – zaimek
Part – bezokolicznik, partykuła przecząca (not, ain’t), zaimki dzierżawcze (my, your, her, his…)
Interj – wykrzyknik
Noun – rzeczownik
Verb – czasownik
Prop – nazwa własna (proper noun)
Adj – przymiotnik
Adv – przysłówek
Abbr – skrót
Num – liczby i liczebniki (napisane słownie)
Ustawienia Text Parsing

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
120
dr Karolina Kuligowska
dr Karolina Kuligowska
Synonimy
Słowa mające wspólną podstawę fleksyjną sprowadź do formy rdzenia (stem terms)
Lista synonimów
SASHELP.ENGSYNMS (angielski)
Ustawienia Text Parsing

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
121
dr Karolina Kuligowska
dr Karolina Kuligowska
Filtruj listy słów włączonych do/wyłączonych z analizy
Start lista
Stop lista
SASHELP.ENGSTOP (angielski)
SASHELP.FRCHSTOP (francuski)
SASHELP.GRMNSTOP (niemiecki)
Liczba słów do wyświetlenia
Ustawienia Text Parsing

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1. Krótka charakterystyka narzędzia
2. Etapy procesu text mining
3. Komponenty Text Parsing
Text Filter
Text Topic
Text Cluster
Text Rule Builder
Text Profile
Text Import
4. Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
123
dr Karolina Kuligowska
Text Filter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
124
dr Karolina Kuligowska
dr Karolina Kuligowska
Funkcje ważące wagi częstości
Binarna
Logarytmiczna [domyślnie]
Pusta
wagi wyrażenia Entropia [domyślnie]
GF-IDF
IDF
Normalna
Pusta
Chi-kwadrat
MI
IG
Ustawienia Text Filter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
125
dr Karolina Kuligowska
dr Karolina Kuligowska
Interactive Filter Viewer

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
126
dr Karolina Kuligowska
dr Karolina Kuligowska
Concept Linking

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1. Krótka charakterystyka narzędzia
2. Etapy procesu text mining
3. Komponenty Text Parsing
Text Filter
Text Topic
Text Cluster
Text Rule Builder
Text Profile
Text Import
4. Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
128
dr Karolina Kuligowska
dr Karolina Kuligowska
Text Topic

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
129
dr Karolina Kuligowska
dr Karolina Kuligowska
Tematy użytkownika
Liczba tematów jednowyrazowych
Liczba tematów wielowyrazowych
Tematy skorelowane
Ustawienia Text Topic
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
130
dr Karolina Kuligowska
dr Karolina Kuligowska
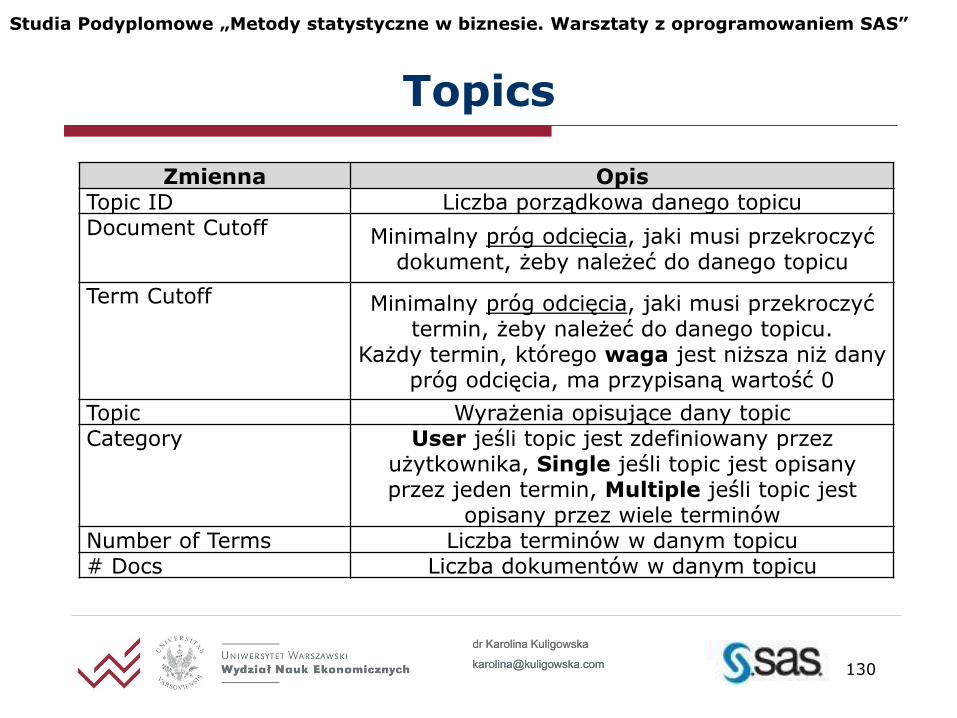
Zmienna Opis Topic ID Liczba porządkowa danego topicu Document Cutoff Minimalny próg odcięcia, jaki musi przekroczyć
dokument, żeby należeć do danego topicu
Term Cutoff Minimalny próg odcięcia, jaki musi przekroczyć termin, żeby należeć do danego topicu.
Każdy termin, którego waga jest niższa niż dany próg odcięcia, ma przypisaną wartość 0
Topic Wyrażenia opisujące dany topic Category User jeśli topic jest zdefiniowany przez
użytkownika, Single jeśli topic jest opisany przez jeden termin, Multiple jeśli topic jest
opisany przez wiele terminów Number of Terms Liczba terminów w danym topicu # Docs Liczba dokumentów w danym topicu
Topics

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1. Krótka charakterystyka narzędzia
2. Etapy procesu text mining
3. Komponenty Text Parsing
Text Filter
Text Topic
Text Cluster
Text Rule Builder
Text Profile
Text Import
4. Makro % tmfilter
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
132
dr Karolina Kuligowska
dr Karolina Kuligowska
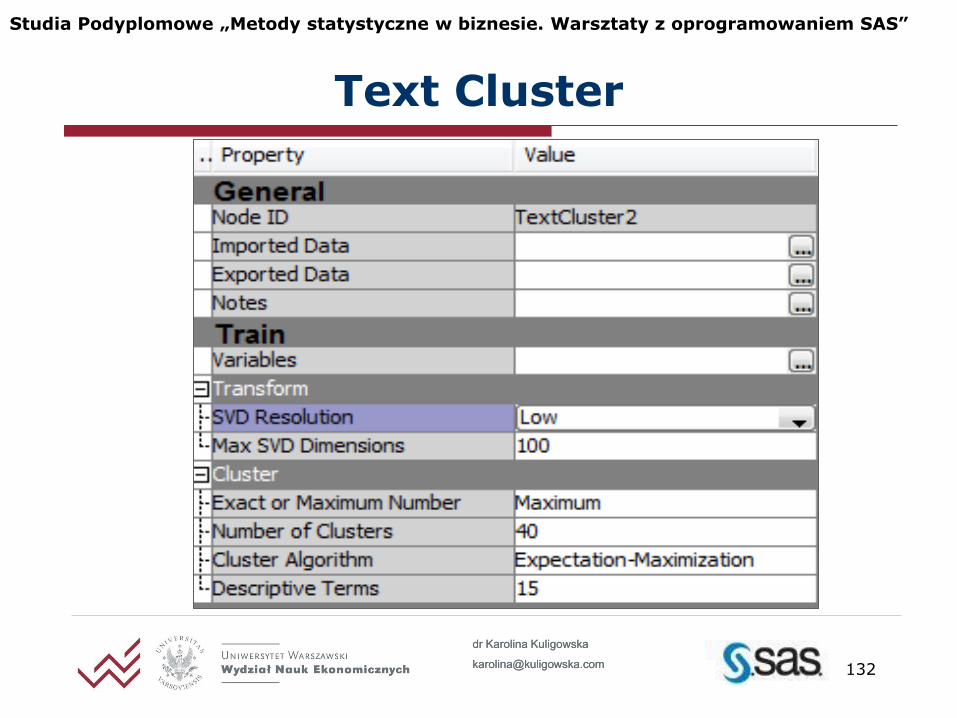
Text Cluster

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
133
dr Karolina Kuligowska
dr Karolina Kuligowska
Dekompozycja SVD wielkość wymiaru macierzy do jakiego ma być
przeskalowana dekompozycją SVD [low, medium, high]
maksymalna liczba wymiarów (>1)
Ustawienia Text Cluster

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
134
dr Karolina Kuligowska
dr Karolina Kuligowska
Liczba klastrów: dokładna lub maksymalna
Algorytm klastrowania
metoda hierarchiczna
metoda EM (Expectation Maximization)
Obserwacje nietypowe
hierarchiczna: outliers nie są brane pod uwagę
EM: tworzone są osobne jednoelementowe klastry
Liczba terminów opisujących klaster
Ustawienia Text Cluster

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1. Krótka charakterystyka narzędzia
2. Etapy procesu text mining
3. Komponenty Text Parsing
Text Filter
Text Topic
Text Cluster
Text Rule Builder
Text Profile
Text Import
4. Makro % tmfilter
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
136
dr Karolina Kuligowska
dr Karolina Kuligowska
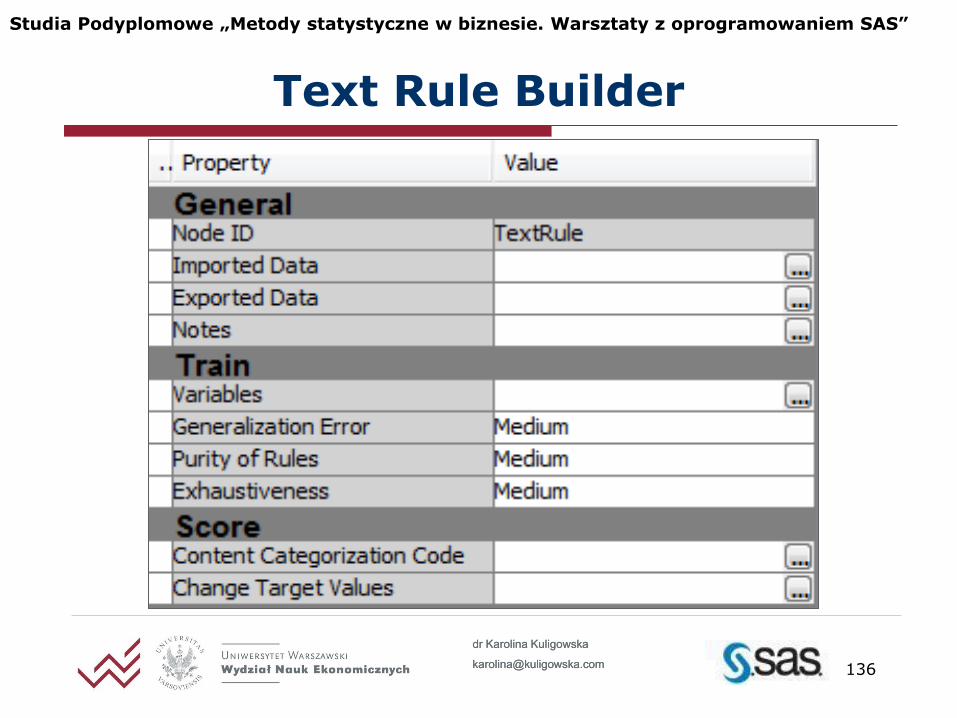
Text Rule Builder

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
137
dr Karolina Kuligowska
dr Karolina Kuligowska
Błąd uogólnienia wyznacza przewidywane prawdopodobieństwo wykrycia reguł na nietrenowanym zbiorze danych (wyznaczany w celu uniknięcia przetrenowania modelu)
very low
low
medium [domyślnie]
high
very high
Ustawienia Text Rule Builder

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
138
dr Karolina Kuligowska
dr Karolina Kuligowska
Klarowność reguł wyznacza maksymalny poziom p-value niezbędny, by dodać termin do reguły (wartości - medium, high i very high - dają mniej liczne, "czystsze" reguły)
very low (p<0.17)
low (p<0.05)
medium (p<0.005) [domyślnie]
high (p<0.0005)
very high (p<0.00005)
Ustawienia Text Rule Builder

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
139
dr Karolina Kuligowska
dr Karolina Kuligowska
Kompletność wyznacza kompletność procesu szukania reguł, czyli ile potencjalnych reguł jest branych pod uwagę w każdym kroku (wyższe wartości powodują wzrost czasu potrzebnego do pracy węzła oraz mogą powodować przetrenowanie modelu)
very low
low
medium [domyślnie]
high
very high
Ustawienia Text Rule Builder

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1. Krótka charakterystyka narzędzia
2. Etapy procesu text mining
3. Komponenty Text Parsing
Text Filter
Text Topic
Text Cluster
Text Rule Builder
Text Profile
Text Import
4. Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
141
dr Karolina Kuligowska
dr Karolina Kuligowska
Text Profile

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
142
dr Karolina Kuligowska
dr Karolina Kuligowska
Ustawienia Text Profile
Zmienne
Maksymalna liczba słów
Przedział czasu

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1. Krótka charakterystyka narzędzia
2. Etapy procesu text mining
3. Komponenty Text Parsing
Text Filter
Text Topic
Text Cluster
Text Rule Builder
Text Profile
Text Import
4. Makro % tmfilter
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
144
dr Karolina Kuligowska
dr Karolina Kuligowska
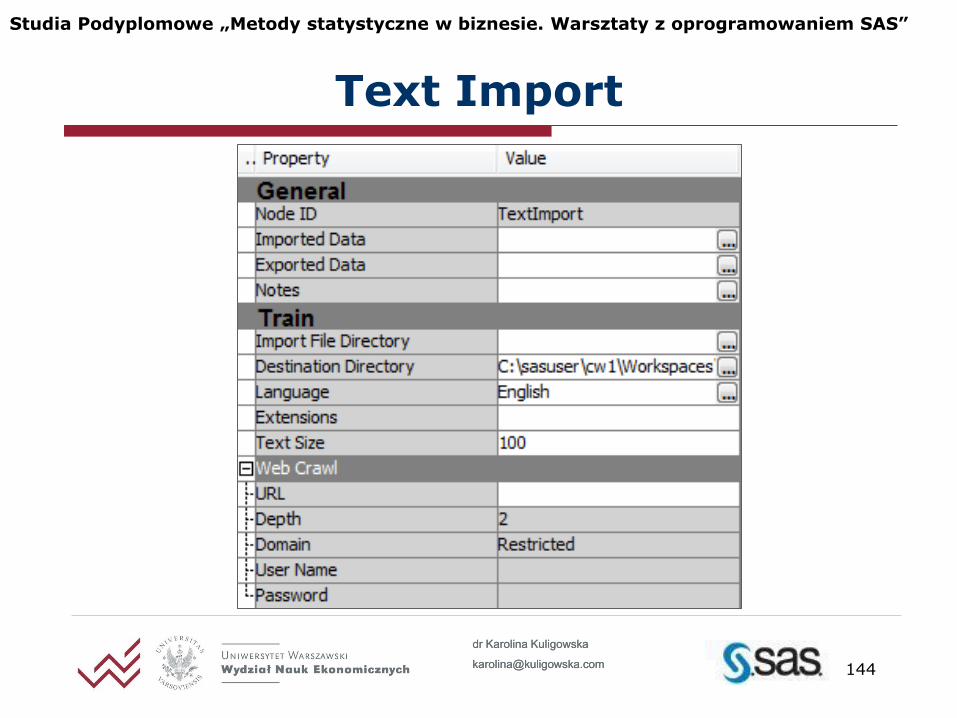
Text Import

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
145
dr Karolina Kuligowska
dr Karolina Kuligowska
Importuje tekst źródłowy i przetwarza go w bazę danych SAS używaną jako input w dalszej analizie tekstu
Text Import to zamiennik Data Source

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1) Krótka charakterystyka narzędzia
2) Etapy procesu text mining
3) Komponenty
4) Makro % tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
147
dr Karolina Kuligowska
dr Karolina Kuligowska
Rozbiór struktury tekstu (text parsing) wymaga użycia tekstu zakodowanego w ASCII lub Latin1
Makro %tmfilter umożliwia:
odczyt plików tekstowych o różnym formacie
przetworzenie ich w bazę danych SAS
Pozwala to na użycie bazy danych SAS jako input w dalszej analizie tekstu
Makro %tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
148
dr Karolina Kuligowska
dr Karolina Kuligowska
HOST
określa nazwę hosta lub adresu IP komputera, na którym działa makro [domyślnie: localhost]
DATASET
określa nazwę tworzonej bazy danych [domyślnie: WORK.DATA]
Atrybuty konfiguracji %tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
149
dr Karolina Kuligowska
dr Karolina Kuligowska
DIR
określa ścieżkę dostępu do folderu z oryginalnymi plikami tekstowymi
EXT
określa rozszerzenie plików. Tylko pliki o wskazanym formacie, znajdujące się w folderze DIR, będą przetwarzane w bazę danych SAS. Pusta wartość oznacza, że będą przetwarzane wszystkie formaty plików
Atrybuty konfiguracji %tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
150
dr Karolina Kuligowska
dr Karolina Kuligowska
NUMCHARS
określa liczbę bajtów z każdego pliku umieszczoną w zmiennej tekstowej TEXT.
Ustawienie domyślne: 100 B Wartość maksymalna: 32 000 (=32KB)
LANUGAGE
określa języki, które mają być rozpoznane w tekście.
Dla krótkich tekstów <256 znaków rozpoznanie języka jest mniej dokładne
Atrybuty konfiguracji %tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
151
dr Karolina Kuligowska
dr Karolina Kuligowska
URL
określa adres URL w dowolnej formie: http://www.sas.com lub www.sas.com, ale nie dłuższy niż 255 znaków
DEPTH
określa liczbę poziomów URL [domyślnie: 2, tj. dana strona i wszystkie linki w niej zawarte oraz linki w tych linkach]
DESTDIR
określa ścieżkę dostępu do folderu, w którym pliki z folderu DIR zostaną przekonwertowane na html
Atrybuty konfiguracji %tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
152
dr Karolina Kuligowska
dr Karolina Kuligowska
NORESTRICT
określa czy przetwarzać pliki poza wskazaną domeną. Pusta wartość oznacza ograniczenie tylko do danej domeny
USERNAME
określa nazwę użytkownika dla domeny chronionej hasłem
PASSWORD
określa hasło użytkownika dla domeny chronionej hasłem
Atrybuty konfiguracji %tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
153
dr Karolina Kuligowska
dr Karolina Kuligowska
Utworzona przez makro baza danych SAS zawiera tekst każdego pliku [TEXT]
Jeśli analizowane pliki są większe niż 32KB, utworzona baza danych obejmuje ścieżkę dostępu do każdego pliku [URI], a zmienna tekstowa [TEXT] zawiera wówczas fragment tekstu każdego pliku
Output %tmfilter

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
154
dr Karolina Kuligowska
dr Karolina Kuligowska
TEXT
tekst każdego pliku [domyślnie: 100B ustawione w NUMCHARS]
NAME
nazwa oryginalnego pliku
URI
ścieżka do oryginalnego pliku
FILTERED
ścieżka do pliku html, który powstał po przekonwertowaniu oryginalnego pliku do formatu html. Zmienna nie powstaje, gdy nie ma określonego folderu DESTDIR
Zmienne generowane przez makro

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
155
dr Karolina Kuligowska
dr Karolina Kuligowska
LANGUAGE
rozpoznany język oryginalnego pliku
TRUNCATED
wskazuje, czy tekst pliku został obcięty (>32KB). Wartość 1 oznacza obcięcie tekstu
OMITTED
wskazuje, czy plik został pominięty podczas próby ekstrakcji tekstu. Wartość 1 oznacza pominięcie pliku
Zmienne generowane przez makro

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
156
dr Karolina Kuligowska
dr Karolina Kuligowska
CREATED
data i czas utworzenia pliku
ACCESSED
data i czas ostatniego otwarcia pliku
MODIFIED
data i czas ostatniej modyfikacji pliku
SIZE
wielkość pliku w bajtach
Zmienne generowane przez makro

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1. Krótka charakterystyka narzędzia
2. Etapy procesu text mining
3. Komponenty
4. Makro % tmfilter Pliki tekstowe
Strony WWW

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
158
dr Karolina Kuligowska
dr Karolina Kuligowska
Najprostsze makro zawiera nazwę tworzonej bazy danych oraz ścieżkę dostępu do folderu z oryginalnymi plikami
%tmfilter(dataset=mylib.pliki1, dir=C:\sasuser\pliki1);
Makro %tmfilter – przykład 1

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
159
dr Karolina Kuligowska
dr Karolina Kuligowska
Makro odczytuje folder źródłowy oraz podfoldery (jeśli są)

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
160
dr Karolina Kuligowska
dr Karolina Kuligowska
Plik jest obrazkiem, dlatego nie wyłuskano z niego tekstu
Powstaje baza danych MYLIB.PLIKI1

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
161
dr Karolina Kuligowska
dr Karolina Kuligowska
Makro zawiera nazwę tworzonej bazy danych, ścieżkę dostępu do folderu z oryginalnymi plikami oraz określa liczbę bajtów z każdego pliku umieszczoną w zmiennej TEXT
%tmfilter(dataset=mylib.pliki2, dir=C:\sasuser\pliki2, numchars=32000);
Makro %tmfilter – przykład 2

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
162
dr Karolina Kuligowska
dr Karolina Kuligowska
Makro określa języki, które mają być rozpoznane w tekście
%tmfilter (dataset=mylib.pliki3, dir=C:\sasuser\pliki3, language=english german dutch french swedish italian spanish portuguese);
Makro %tmfilter – przykład 3

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
163
dr Karolina Kuligowska
dr Karolina Kuligowska
Powstaje baza danych MYLIB.PLIKI3

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
Część 2 SAS Text Miner
1. Krótka charakterystyka narzędzia
2. Etapy procesu text mining
3. Komponenty
4. Makro % tmfilter Pliki tekstowe
Strony WWW

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
165
dr Karolina Kuligowska
dr Karolina Kuligowska
Makro %tmfilter używane do odczytania tekstu ze stron WWW powinno zawierać atrybuty: URL, DEPTH, DATASET, DIR, DESTDIR
Jeśli adres internetowy zawiera ampersandę &, wówczas należy zastosować funkcję %NRSTR() w specyfikacji adresu URL
Odczytanie danych ze stron WWW

Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
166
dr Karolina Kuligowska
dr Karolina Kuligowska
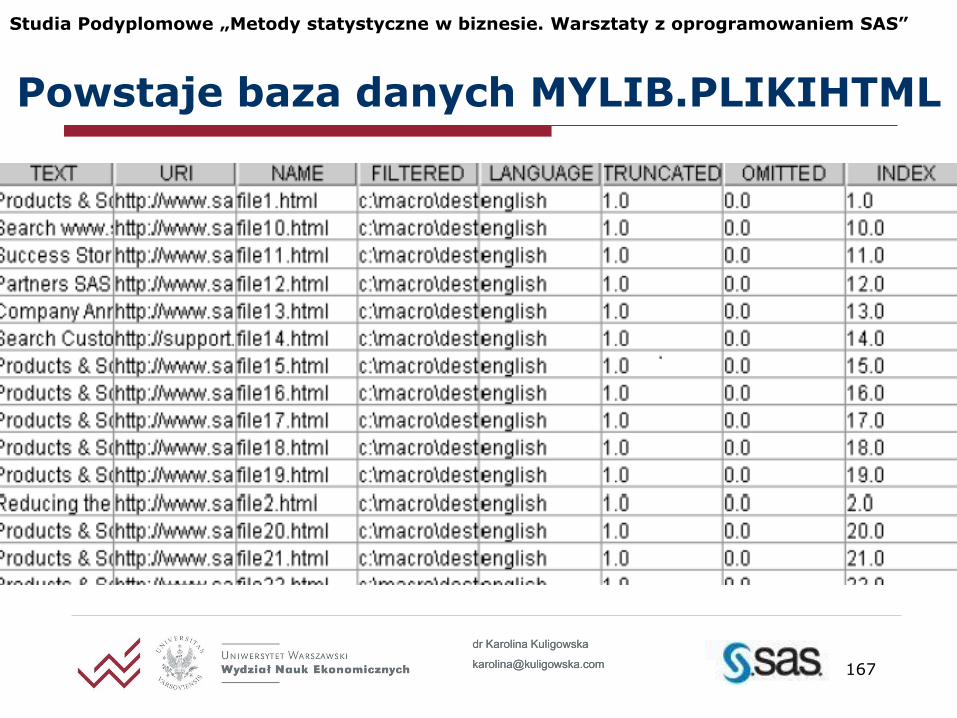
Najprostsze makro określa adres URL, liczbę poziomów DEPTH oraz ścieżkę dostępu do folderu DESTDIR, gdzie zostaną zapisane pliki z DIR przekonwertowane na html
%tmfilter(url=http://www.sas.com, depth=1, dataset=mylib.plikihtml, dir=C:\sasuser\dir, destdir=C:\sasuser\destdir);
Makro %tmfilter – przykład WWW
Studia Podyplomowe „Metody statystyczne w biznesie. Warsztaty z oprogramowaniem SAS”
167
dr Karolina Kuligowska
dr Karolina Kuligowska
Powstaje baza danych MYLIB.PLIKIHTML


















