
An Efficient Parallel Approach for Identifying Protein Families from Large-scale Metagenomics Data...
28
An Efficient Parallel Approach for Identifying Protein Families from Large-scale Metagenomics Data Changjun Wu, Ananth Kalyanaraman School of Electrical Engineering and Computer Science Washington State University
-
date post
19-Dec-2015 -
Category
Documents
-
view
218 -
download
0
Transcript of An Efficient Parallel Approach for Identifying Protein Families from Large-scale Metagenomics Data...

An Efficient Parallel Approachfor Identifying Protein Families from
Large-scale Metagenomics Data
Changjun Wu, Ananth Kalyanaraman
School of Electrical Engineering and Computer Science
Washington State University

Outline Problem Introduction Related Work Our Parallel Approach for Protein Family
Identification Experimental Results Conclusions & Future Work Acknowledgments
11/19/2008SC08, Austin, TX2

Outline Problem Introduction Related Work Our Parallel Approach for Protein Family
Identification Experimental Results Conclusions & Future Work Acknowledgments
11/19/2008SC08, Austin, TX3
Metagenomics Application of genomics techniques to the
study of microbial communities in their natural environments. Without isolation and lab cultivation of individual
species.
11/19/2008SC08, Austin, TX4
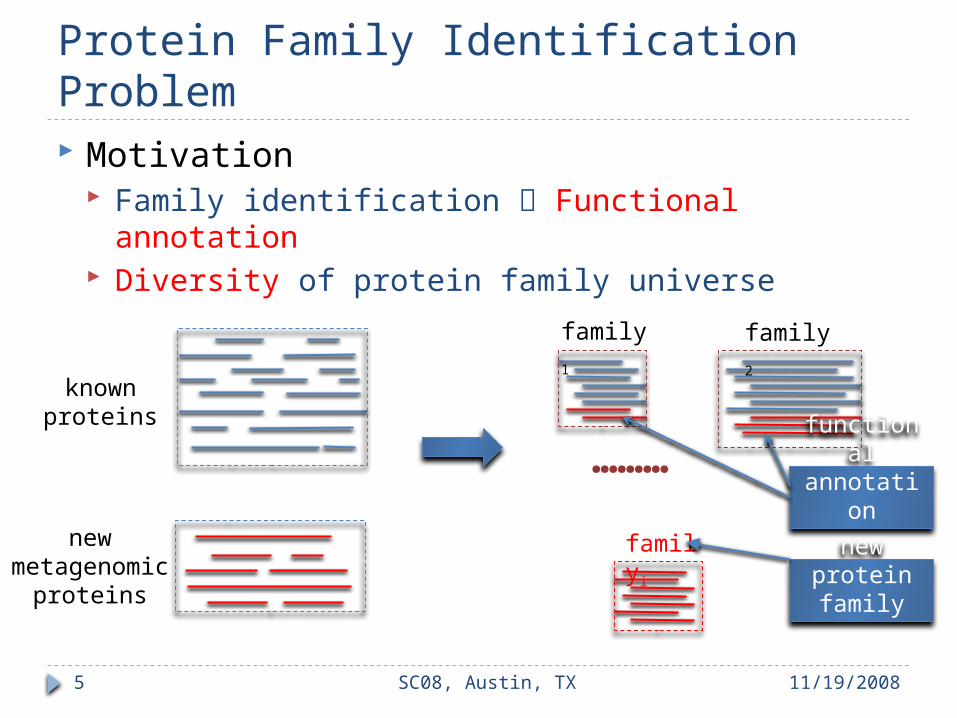
Protein Family Identification Problem Motivation
Family identification Functional annotation Diversity of protein family universe
11/19/2008SC08, Austin, TX5
………
family1 family2
knownproteins
newmetagenomic
proteins
familyi new protein family
functionalannotatio
n
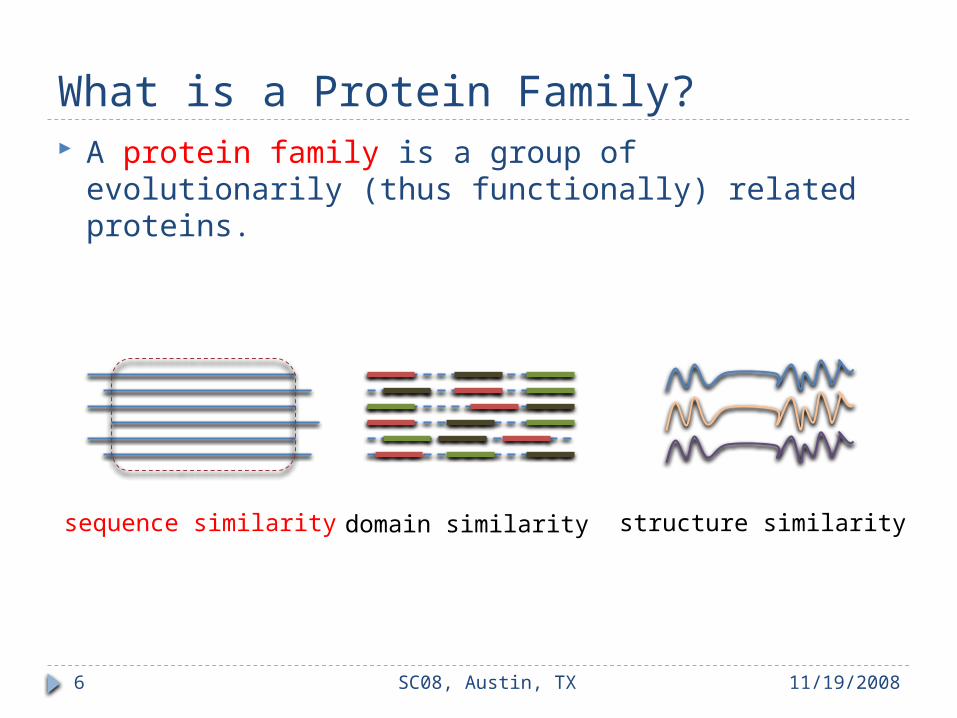
What is a Protein Family? A protein family is a group of evolutionarily (thus
functionally) related proteins.
11/19/2008SC08, Austin, TX6
sequence similarity domain similarity structure similarity

Outline Problem Introduction Related Work Our Parallel Approach for Protein Family
Identification Experimental Results Conclusions & Future Work Acknowledgments
11/19/2008SC08, Austin, TX7

Related Work General approach
Perform all-against-all sequence comparison (BLAST)
Group proteins based on pair-wise similarity
Related work Kriventseva et al. (2001) Enright et al. (2002) Pipenbacher et al. (2002) Kelil et al. (2007) Yooseph et al. (2007) … 11/19/2008SC08, Austin, TX7
sequential
approach
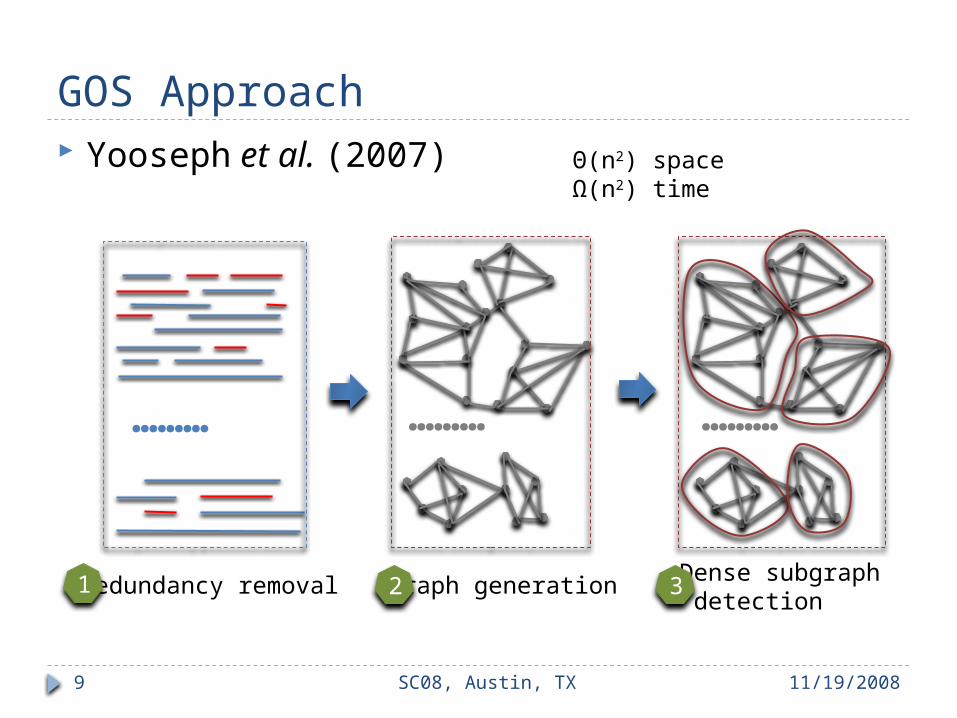
GOS Approach Yooseph et al. (2007)
11/19/2008SC08, Austin, TX9
……… ………
Redundancy removal
………
Graph generation Dense subgraph detection
1 2 3
Θ(n2) spaceΩ(n2) time

Limitations of Current Approaches Constructing large graphs can be time-
consuming ~106 CPU hours for ~28.6 million proteins – GOS
approach
Quadratic space requirement
Brute-force parallel approach
11/19/2008SC08, Austin, TX9

Outline Problem Introduction Related Work Our Parallel Approach for Protein Family
Identification Experimental Results Conclusions & Future Work Acknowledgments
11/19/2008SC08, Austin, TX11

Main Ideas of Our Approach Idea#1: A dense subgraph cannot span two
connected components
11/19/2008SC08, Austin, TX12
DSCC
CC
CCDS
CCDS
use divide and conquer to drastically reduce problem size!
Challenge: find connected components without generating the whole graph
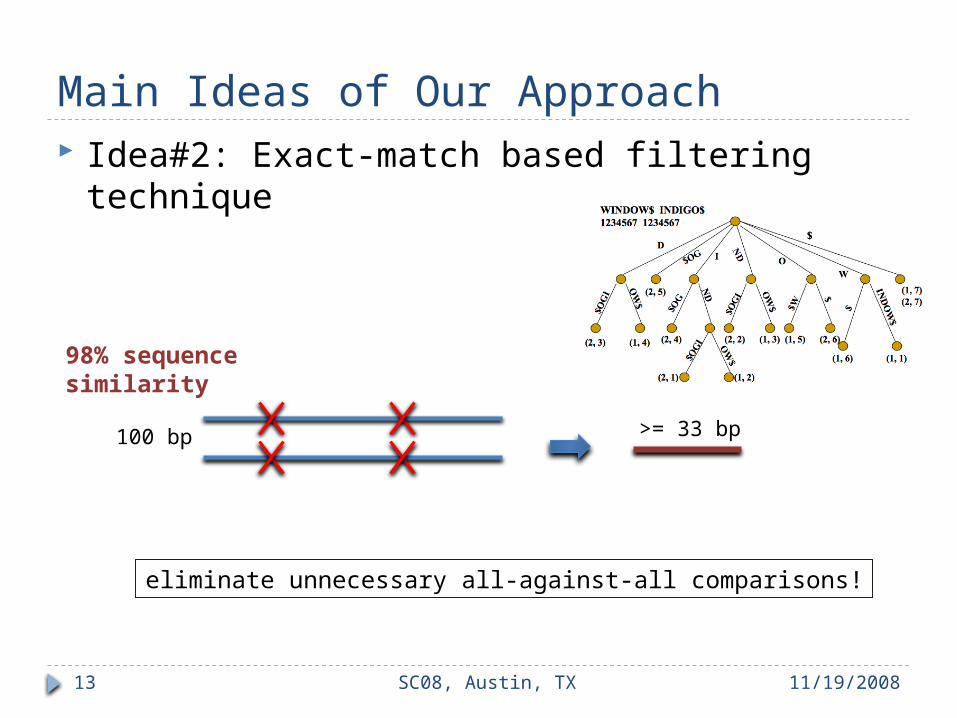
Main Ideas of Our Approach Idea#2: Exact-match based filtering technique
11/19/2008SC08, Austin, TX13
100 bp
98% sequence similarity
>= 33 bp
eliminate unnecessary all-against-all comparisons!

Main Ideas of Our Approach Idea#3: High overlap of outlinks dense
subgraph
11/19/2008SC08, Austin, TX14
……
u
v
v
u
web community
outlinks
use outlinks comparison to group vertices into dense subgraph!
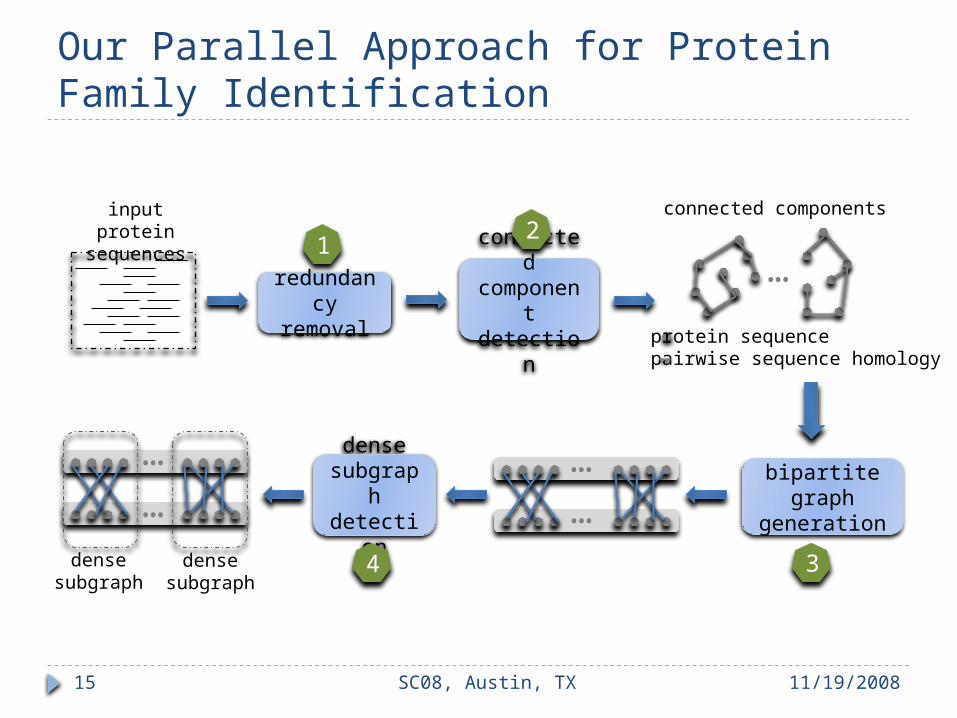
Our Parallel Approach for Protein Family Identification
11/19/2008SC08, Austin, TX15
connected componen
t detection
redundancy
removal
……
densesubgrap
hdetectio
n
input protein sequences
…
connected components
protein sequence pairwise sequence homology
……
densesubgraph
densesubgraph
bipartite graph
generation
4 3
21
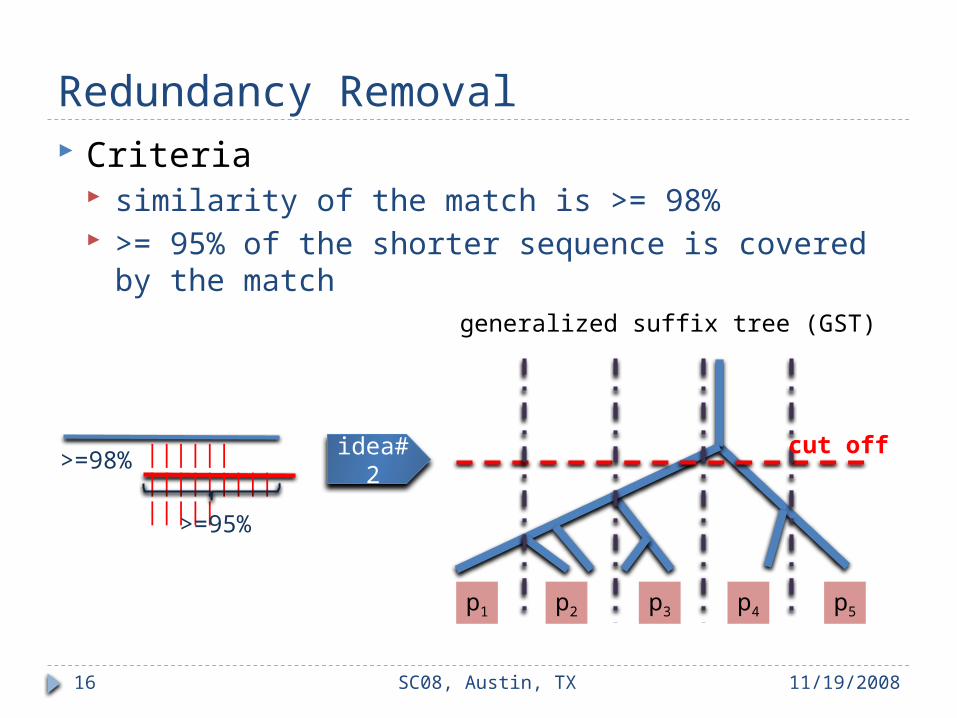
Redundancy Removal Criteria
similarity of the match is >= 98% >= 95% of the shorter sequence is covered by the
match
11/19/2008SC08, Austin, TX16
|||||| ||||||||||||||
>=95%
generalized suffix tree (GST)
p1 p2 p3 p4 p5
cut off>=98%
idea#2
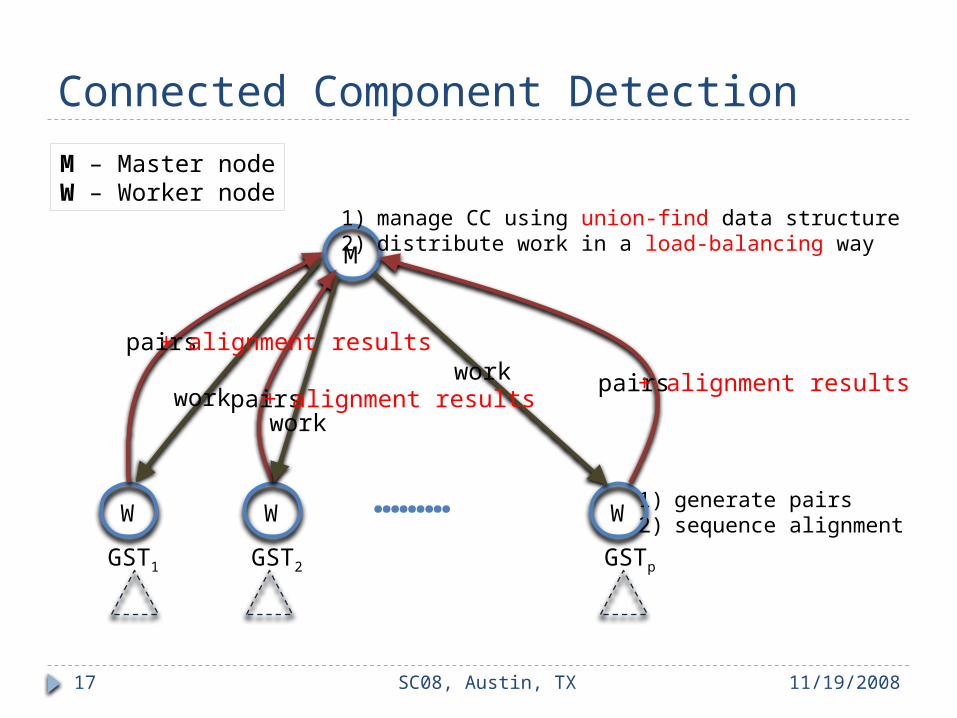
Connected Component Detection
11/19/2008SC08, Austin, TX17
M
GST1 GST2 GSTp
………
1) manage CC using union-find data structure2) distribute work in a load-balancing way
1) generate pairs2) sequence alignmentW W W
pairs
pairspairs
workwork
work
M – Master nodeW – Worker node
+ alignment results+ alignment results
+ alignment results
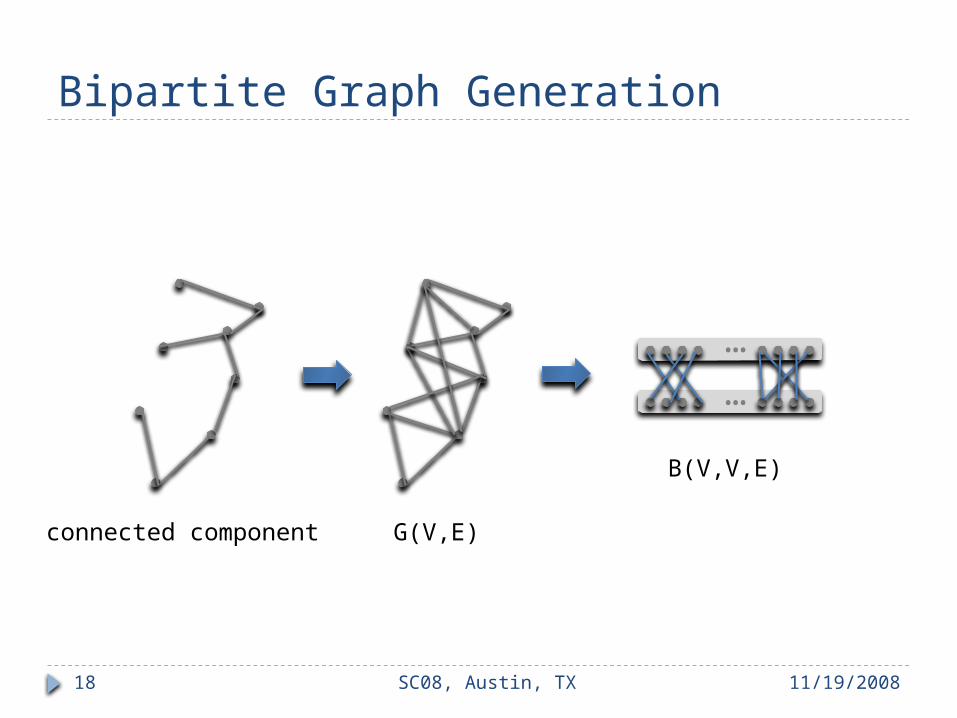
Bipartite Graph Generation
11/19/2008SC08, Austin, TX18
…
connected component G(V,E)
B(V,V,E)
…
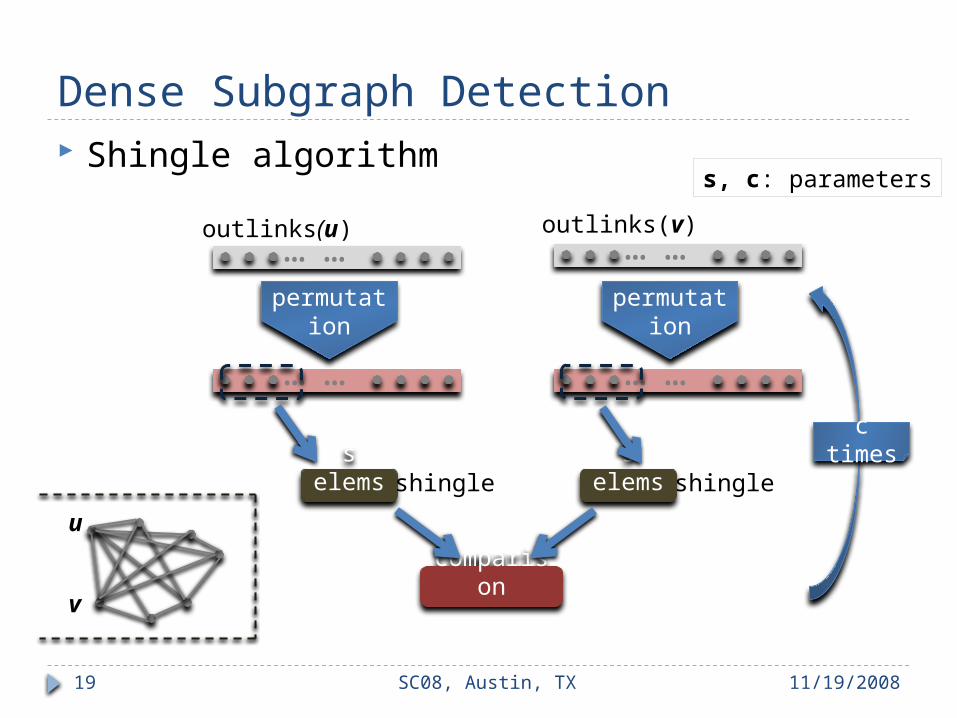
Dense Subgraph Detection Shingle algorithm
11/19/2008SC08, Austin, TX19
outlinks(u)
s elems shingle shingle…………
permutation
permutation
s elems
comparison
c times
outlinks(v)
u
v
s, c: parameters
…… ……
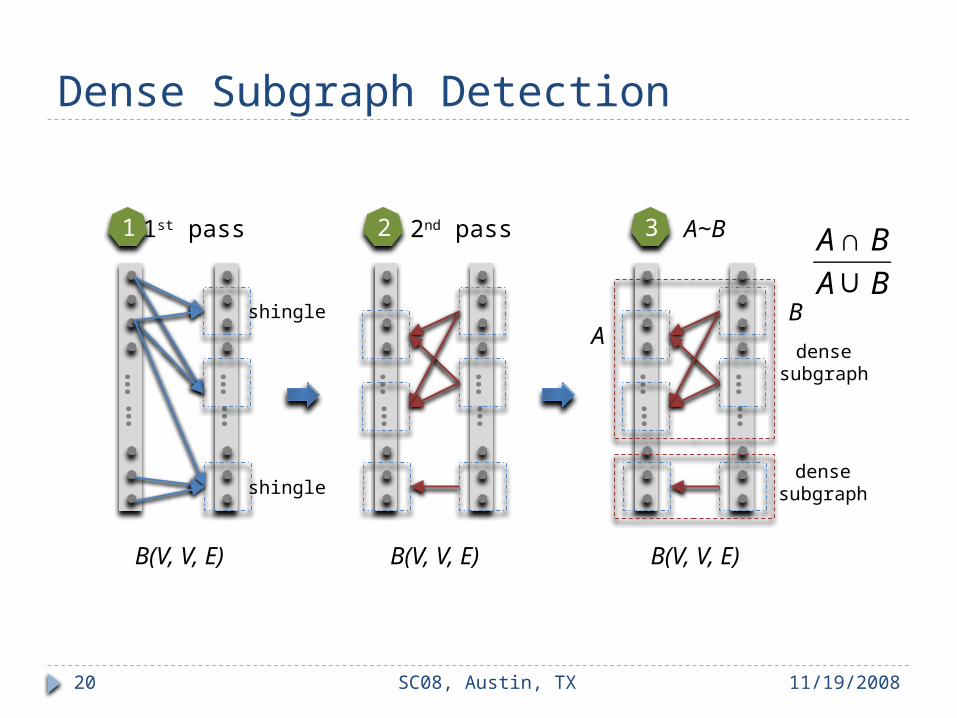
Dense Subgraph Detection
11/19/2008SC08, Austin, TX20
……
……
……
……
……
……
shingle
shingle
densesubgraph
densesubgraph
1 2 31st pass 2nd pass A~B
B(V, V, E) B(V, V, E) B(V, V, E)
AB
€
A∩ B
A∪B

Outline Problem Introduction Related Work Our Parallel Approach for Protein Family
Identification Experimental Results Conclusions & Future Work Acknowledgments
11/19/2008SC08, Austin, TX21

Qualitative Validation with GOS Data
160k data set Our results vs. GOS results
11/19/2008SC08, Austin, TX22
#inputseq #NR #CC #DS
mean degre
e
mean density
size of largest
DS
160,000 138,633
1,861
850 26 76% 13,263
22,186 21,348 1 134 20 78% 6,828
Precision Rate (PR) = 95.75% Sensitivity (SE) = 56.89%
Overlap Quality (OQ) = 55.49%

Drastical Work Reduction 40k input data
11/19/2008SC08, Austin, TX23
~800 million
~8 million
all-against-allBLAST
our parallelapproach
#(sequence alignment work)
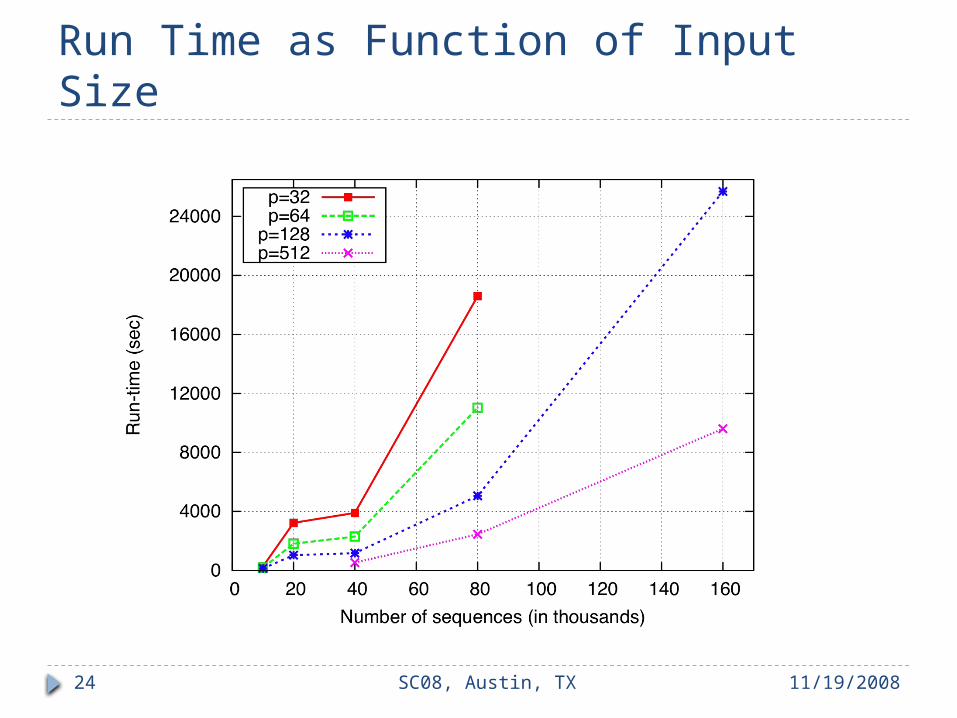
Run Time as Function of Input Size
11/19/2008SC08, Austin, TX24
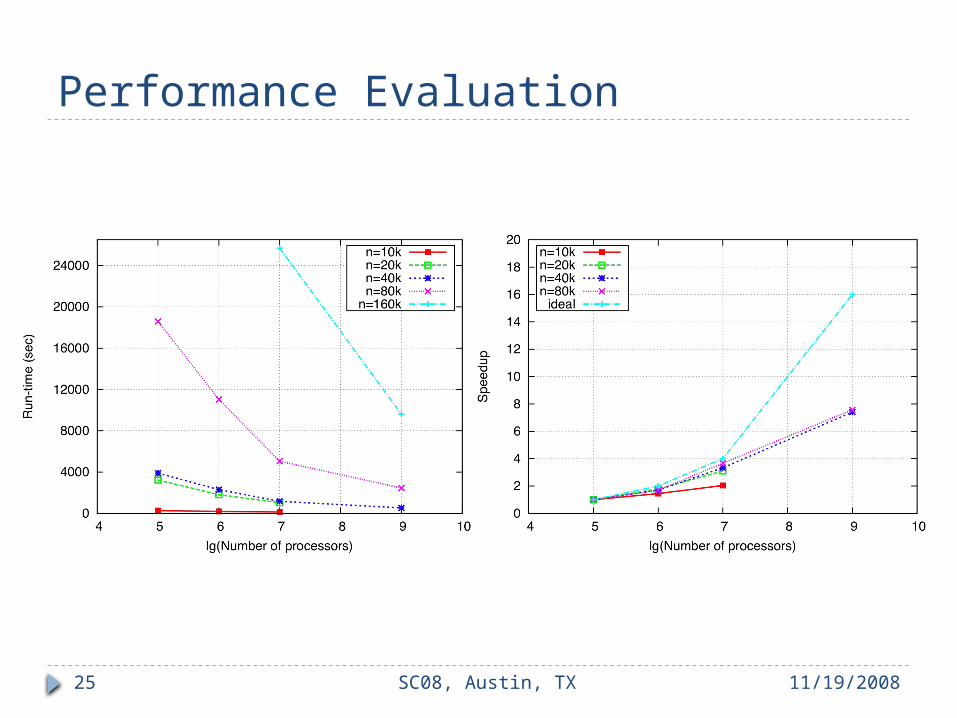
Performance Evaluation
11/19/2008SC08, Austin, TX25

Conclusions & Future Work Presented a parallel approach for protein
family identification
Quality testing – better “benchmark” Parallelization of Shingle algorithm – potential
memory problem Large-scale application – 28.6 million
11/19/2008SC08, Austin, TX26

Acknowledgments Prof. Srinivas Aluru at Iowa State University for
BlueGene/L access Anonymous reviewers Funding: Washington State University
Foundation and the Office of Research
11/19/2008SC08, Austin, TX27

Thanks!Questions?
11/19/2008SC08, Austin, TX


















