
Ako na návrh relačných databáz (pokročilé)
135
A.K.A. AKO MA Ť LEP Š IU DATABÁZU ADAM@OKRUHLICA.EU PREDNÁŠKA PRE SPOTEDU AUGUST 2013 RÝCHLOKURZ GENIALITY …AKO MÁ SUSEDOV STARTUP
-
Upload
adam-okruhlica -
Category
Technology
-
view
121 -
download
1
Transcript of Ako na návrh relačných databáz (pokročilé)

A.K.A. AKO MAŤ LEPŠIU DATABÁZU
PREDNÁŠKA PRE SPOTEDU
AUGUST 2013
RÝCHLOKURZ GENIALITY
…AKO MÁ SUSEDOV STARTUP


PART 1: DOBRE SI NA ZAČIATKU NAVRHNITE, AKO ROZVRHNETE DÁTA DO STĹPCOV A TABULIEK

PREČO?
Spôsob akým reprezentujete dáta určí ako rýchlo, spoľahlivo a efektívne budete schopný s nimi pracovať
1. normalizácia

PREČO?
Spôsob akým reprezentujete dáta určí ako rýchlo, spoľahlivo a efektívne budete schopný s nimi pracovať Už stredne veľké zmeny db schémy za behu projektu predstavujú nezanedbateľné náklady
1. normalizácia

PREČO?
Spôsob akým reprezentujete dáta určí ako rýchlo, spoľahlivo a efektívne budete schopný s nimi pracovať Už stredne veľké zmeny db schémy za behu projektu predstavujú nezanedbateľné náklady Pomôže vám to uvedomiť si mnohé súvislosti a prepojenia medzi prvkami v doméne
1. normalizácia
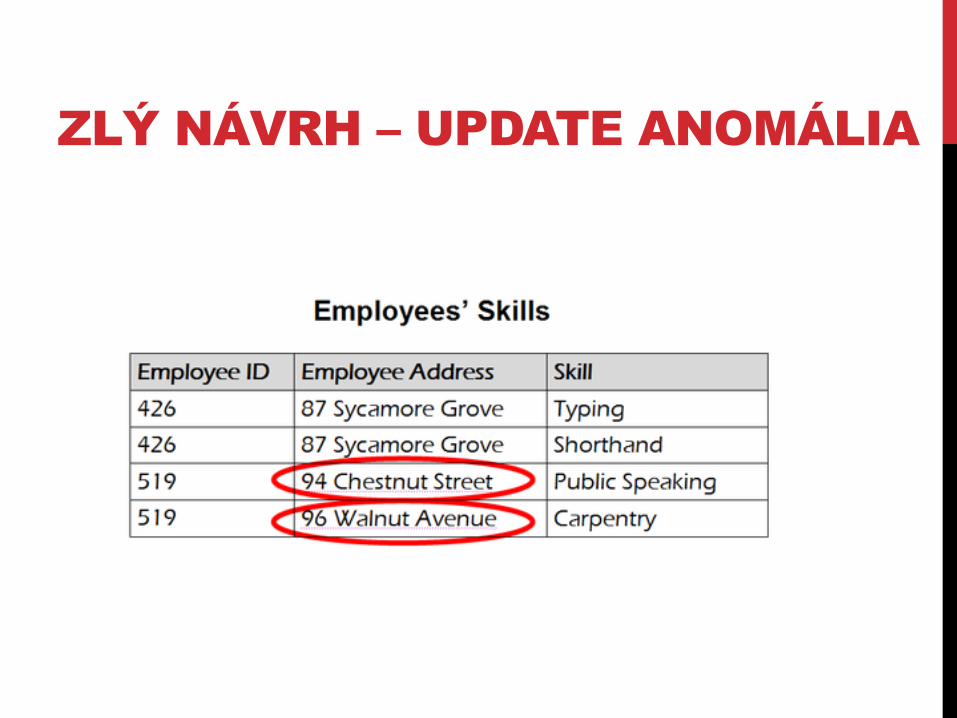
ZLÝ NÁVRH – UPDATE ANOMÁLIA

ZLÝ NÁVRH – INSERT ANOMÁLIA
- Aký učí Dr. Newsome kurz?

ZLÝ NÁVRH – DELETE ANOMÁLIA
- Čo sa stane ak Dr. Giddens prestane učiť ENG-206?
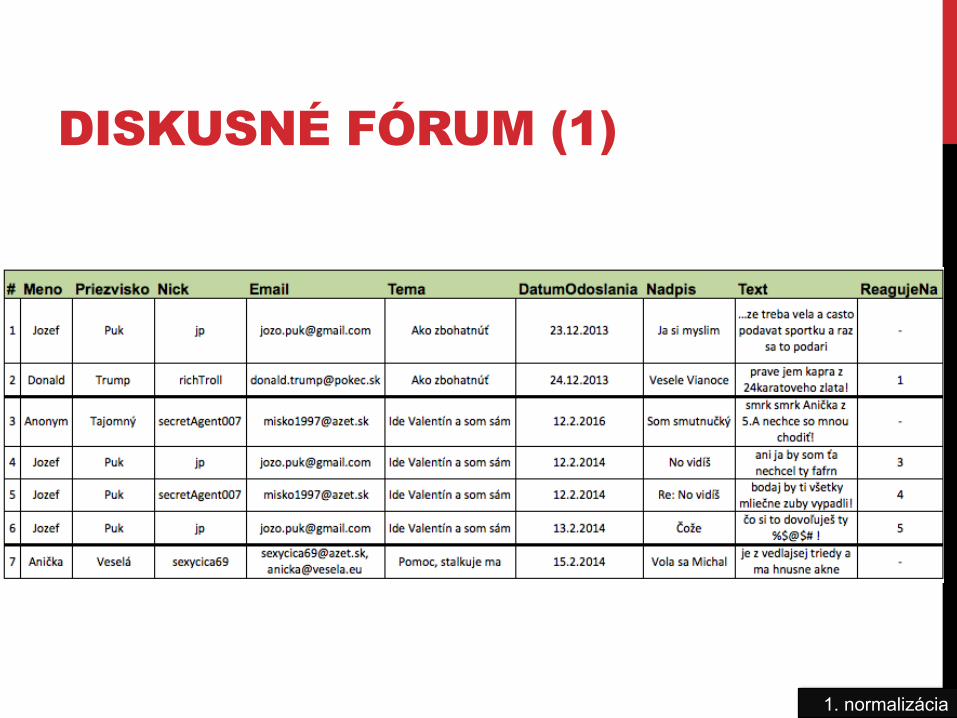
DISKUSNÉ FÓRUM (1)
1. normalizácia

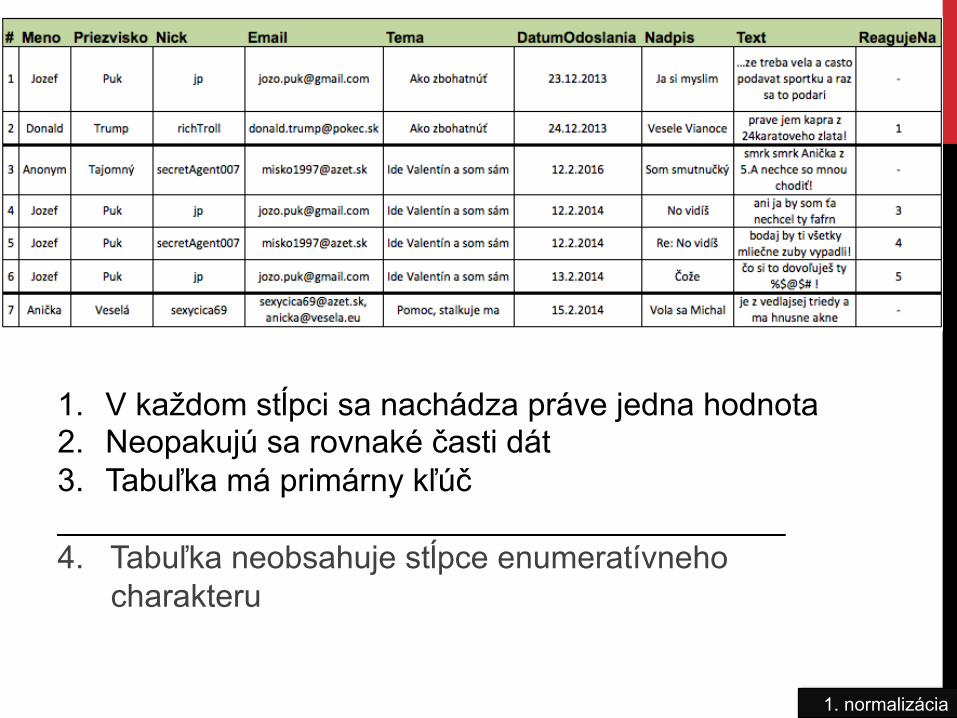
1NF/2NF/3NF Aby bola DB v prvej normálnej forme, musia platiť nasledovné podmienky (v každej tabuľke):
1. V každom stĺpci sa nachádza práve jedna hodnota 2. Neopakujú sa rovnaké časti dát 3. Tabuľka má primárny kľúč _________________________________________ 4. Tabuľka neobsahuje stĺpce enumeratívneho charakteru
1. normalizácia

1NF/2NF/3NF 1NF/1: V každom stĺpci sa nachádza práve jedna hodnota.
1. normalizácia

1NF/2NF/3NF 1NF/1: V každom stĺpci sa nachádza práve jedna hodnota.
Čo to znamená?
1. normalizácia
Dáta neobsahujú viacero hodnôt v jednom riadku, napríklad
adresa: “Bratislava, nám. SNP 21 Pezinok, Vinohradská 3”
Ale nie sú ani bez hodnôt: adresa: NULL

1NF/2NF/3NF 1NF/1: V každom stĺpci sa nachádza práve jedna hodnota.
Čo to znamená?
1. normalizácia
Dáta neobsahujú viacero hodnôt v jednom riadku, napríklad
adresa: “Bratislava, nám. SNP 21 Pezinok, Vinohradská 3”
Ale nie sú ani bez hodnôt: adresa: NULL
Vieme efektívne vyhľadávať v dátach na základe hodnoty atribútu + ľahšie updaty.
Načo je to dobré?

1NF/2NF/3NF 1NF/3: Tabuľka má primárny kľúč Čo to znamená?
1. normalizácia
Tabuľka má logický, alebo umelý jeden alebo viac atribútov, ktorý/é jednoznačne identifikuje/ú záznam (riadok), napr.
PSČ | Názov | Počet obyvateľov
VIN | značka | model
Deň | Mesiac | Krajina | Meniny má
Vieme každý záznam jednoznačne adresovať a teda s ním aj manipulovať.
Načo je to dobré?

1NF/2NF/3NF 1NF/4: Tabuľka neobsahuje stĺpce enumeratívneho charakteru
Čo to znamená?
1. normalizácia
Jeden atribút má jeden stĺpec, nie viac, ako napr. tu:
SELECT Id
FROM Clients WHERE FirstPhoneNumber = '555-123-4567' OR SecondPhoneNumber = '555-123-4567'
OR ThirdPhoneNumber = '555-123-4567';
Načo je to dobré? Aby sme sa vyhli takýmto
queries
1. normalizácia
1. V každom stĺpci sa nachádza práve jedna hodnota 2. Neopakujú sa rovnaké časti dát 3. Tabuľka má primárny kľúč _________________________________________ 4. Tabuľka neobsahuje stĺpce enumeratívneho charakteru
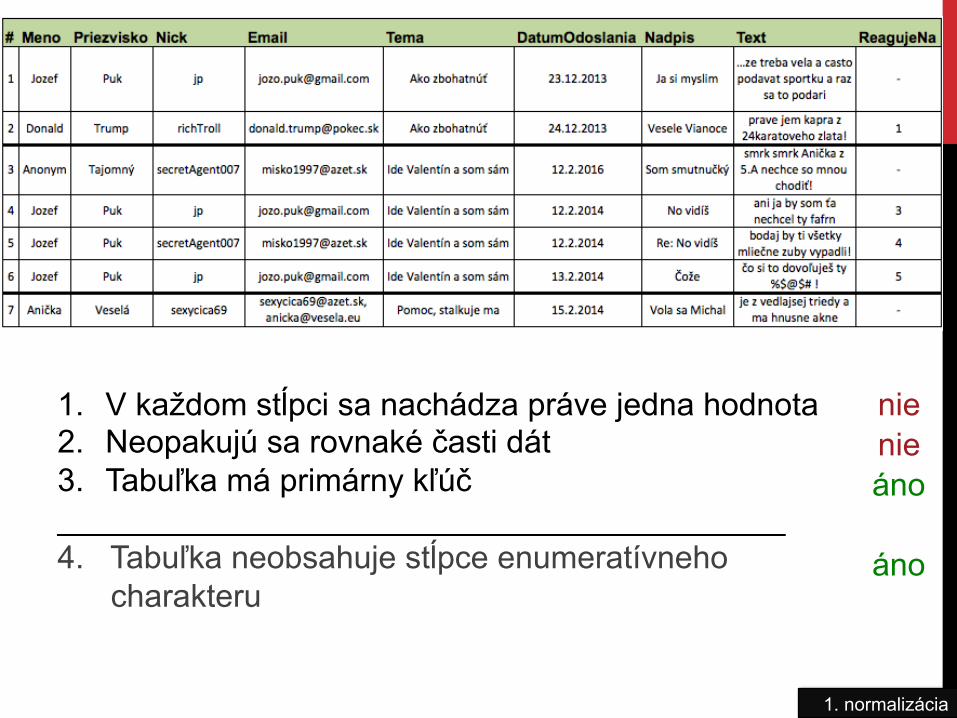
1. normalizácia
1. V každom stĺpci sa nachádza práve jedna hodnota 2. Neopakujú sa rovnaké časti dát 3. Tabuľka má primárny kľúč _________________________________________ 4. Tabuľka neobsahuje stĺpce enumeratívneho charakteru
nie nie áno
áno

ÚPRAVA DO 1NF
1. Ak sa v nejakom stĺpci T.a nachádza viac ako jedna hodnota: Vytvoríme reláciu A s cudzím kľúčom do T
2. Ak sa opakujú sa rovnaké časti dát T.a, T.b…: Vytvoríme reláciu X obsahujúcu T.a, T.b,… a do A pridáme cudzí kľúč do X
3. Ak tabuľka T nemá primárny kľúč: Vytvoríme umelý prirodzený kľúč T.id 4. Ak tabuľka T obsahuje stĺpce enumeratívneho charakteru T.a1, T.a2, … Vytvoríme reláciu A s cudzím kľúčom do T
1. normalizácia

0NF -> 1NF
Vyskúšajme si to v praxi na našom diskusnom fóre.

1NF/2NF/3NF Aby bola DB v druhej normálnej forme, musia platiť nasledovné podmienky:
1. DB je v 1NF 2. Ak má tabuľka primárny kľúč zložený z viac
atribútov, každý stĺpec v tabuľke, ktorý nepatrí do p.k. musí byť priamo závislý od celého p.k.
1. normalizácia

1NF/2NF/3NF Aby bola DB v druhej normálnej forme, musia platiť nasledovné podmienky:
1. DB je v 1NF 2. Ak má tabuľka primárny kľúč zložený z viac
atribútov, každý stĺpec v tabuľke, ktorý nepatrí do p.k. musí byť priamo závislý od celého p.k.
1. normalizácia

1NF/2NF/3NF Aby bola DB v druhej normálnej forme, musia platiť nasledovné podmienky:
1. DB je v 1NF 2. Ak má tabuľka primárny kľúč zložený z viac
atribútov, každý stĺpec v tabuľke, ktorý nepatrí do p.k. musí byť priamo závislý od celého p.k.
1. normalizácia

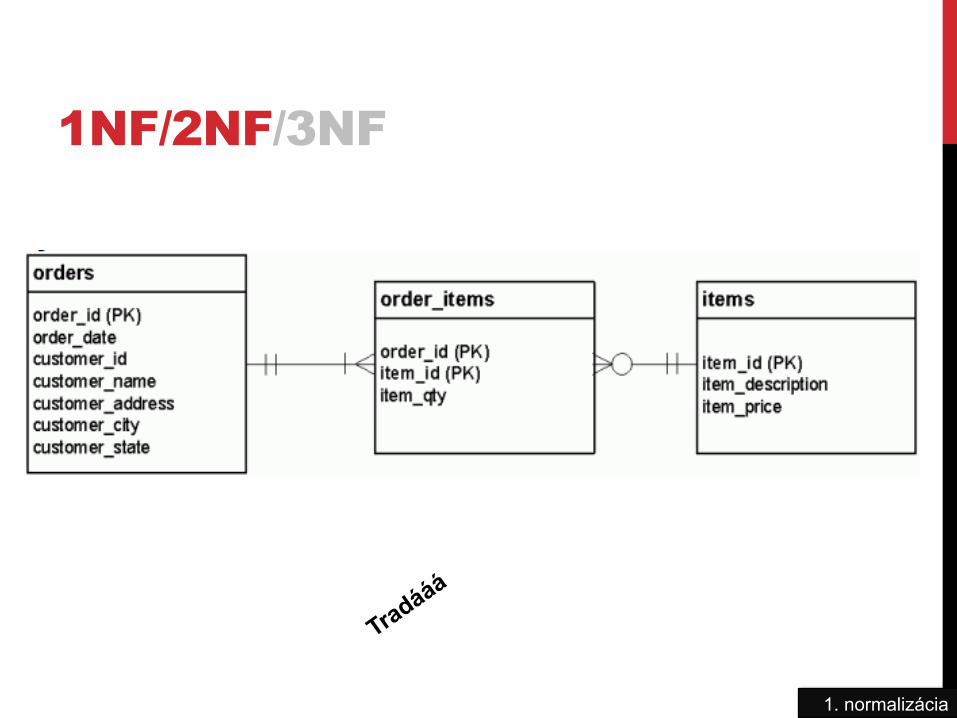
1NF/2NF/3NF
1. normalizácia
Príklad: • Order_id je číslo objednávky tovaru • Item_id je niečo, čo jednoznačne
popisuje tovar, napr. VIN číslo auta
• SPOLU tvoria p.k. relácie

1NF/2NF/3NF
1. normalizácia
Príklad: • Order_id je číslo objednávky tovaru • Item_id je niečo, čo jednoznačne
popisuje tovar, napr. VIN číslo auta
• SPOLU tvoria p.k. relácie
JE TO DOBRE?

1NF/2NF/3NF
1. normalizácia
Nie je. Stále vzniká priestor pre redundanciu. • customer_name – nezávisí na item_id a teda sa
potenciálne zjavuje opakovane pri rôznych objednávkach od toho istého zákazníka. To je už len krôčik od vzniku UPDATE/DELETE anomálii.
• customer_id - ??? • Item_price - ??? • Item_qty - ??? • order_total_price - ???

1NF/2NF/3NF
1. normalizácia
Nie je. Stále vzniká priestor pre redundanciu. • item_description – nezávisí na order_id a teda
sa potenciálne zjavuje opakovane pri rôznych objednávkach toho istého tovaru. To je už len krôčik od vzniku UPDATE/DELETE anomálii.
• customer_id - ??? • Item_price - ??? • order_total_price - ???
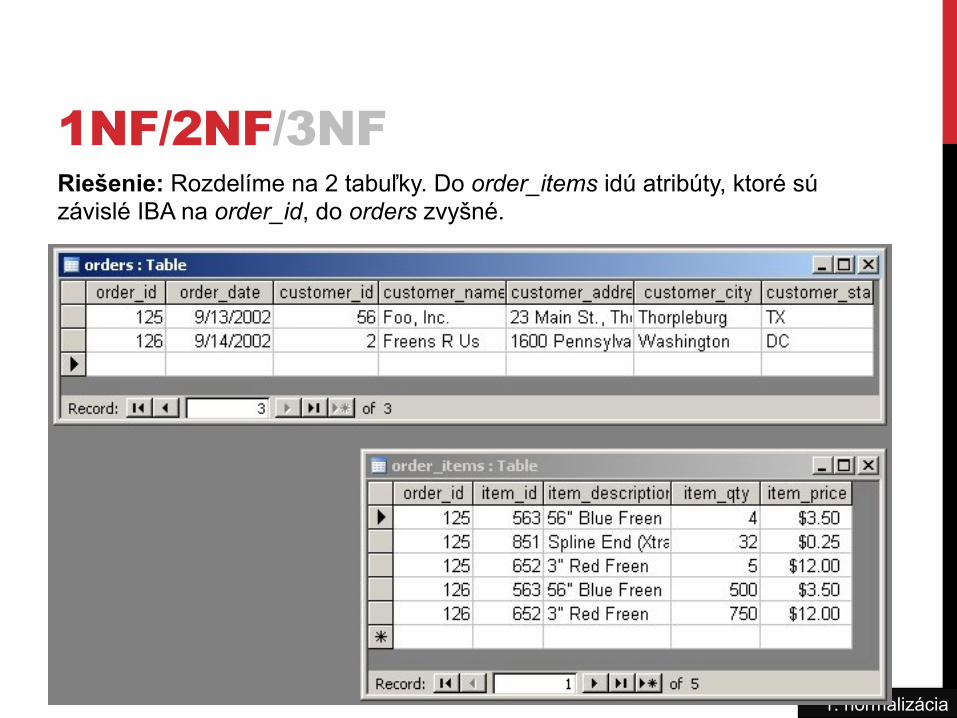
1NF/2NF/3NF
1. normalizácia
Riešenie: Rozdelíme na 2 tabuľky. Do order_items idú atribúty, ktoré sú závislé IBA na order_id, do orders zvyšné.

1NF/2NF/3NF
1. normalizácia
Je order_items v 2NF?
Pomôcka: 1. Tabuľka je v 1NF 2. Ak má tabuľka primárny kľúč zložený z viac atribútov, každý stĺpec
v tabuľke, ktorý nepatrí do p.k. musí byť priamo závislý od celého p.k.

1NF/2NF/3NF
1. normalizácia
Pomôcka: 1. Tabuľka je v 1NF 2. Ak má tabuľka primárny kľúč zložený z viac atribútov, každý stĺpec
v tabuľke, ktorý nepatrí do p.k. musí byť priamo závislý od celého p.k.
1NF/2NF/3NF
1. normalizácia

1NF/2NF/3NF
1. normalizácia
Zhrnutie: • V 2NF odstraňujeme potenciálnu redundanciu v tabuľkách s viacstĺpcovými primárnymi kľúčmi • Vznikajú nám nové 1:N, resp. M:N relácie

1NF/2NF/3NF
1. normalizácia
Reálny cieľ, každej dobre navrhnutej relačnej databázy je, aby bola (aspoň) v 3NF. Vážne.
1. Umožňuje písať queries bez bolesti hlavy. 2. Dáta o entitách sa dajú jednoducho aktualizovať,
nemiznú a dajú sa konzistentne vkladať nové. 3. Delenie DB na logické celky (ako keby “komponenty”) je
výrazne jednoduchšie.

1NF/2NF/3NF
1. normalizácia
Tabuľka je v 3NF ak: • Je v 2NF • Každý stĺpec, ktorý nie je súčasťou primárneho kľúča závisí len a len od p.k.

1NF/2NF/3NF
1. normalizácia
OK: • order_date závisí od order_id
Nie OK: • customer_name závisí od customer_id • customer_address závisí od customer_id • customer_city závisí od customer_id • customer_state závisí od customer_id
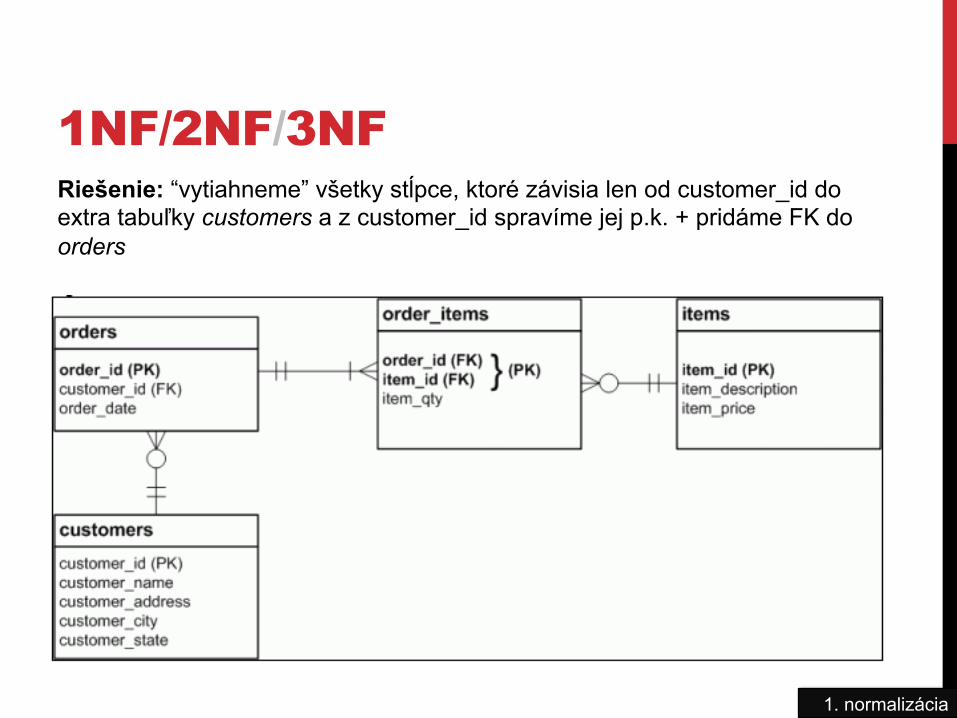
1NF/2NF/3NF
1. normalizácia
Riešenie: “vytiahneme” všetky stĺpce, ktoré závisia len od customer_id do extra tabuľky customers a z customer_id spravíme jej p.k. + pridáme FK do orders

VYŠŠIE NORMÁLNE FORMY
1. normalizácia
Dá sa zájsť aj ďalej BCNF (3,5NF) – v podstate všetky 3NF sú aj BCNF 4NF, 5NF – odstraňujú v praxi málo významné anomálie Viac napr. tu: http://web.archive.org/web/20080423014733/http://www.utexas.edu/its/archive/windows/database/datamodeling/rm/rm8.html


DENORMALIZÁCIA
- V poslednej dobe je “sexy” databázy denormalizovať
- Dôvod: škálovateľnosť, rýchlosť odozvy pre select
- Upúšťa sa od rôznych pravidiel z 1NF-* až 3NF-*
- Najčastejšie však dáta ostávajú aspoň 2NF - Vyhýbanie drahým spojeniam tabuliek v SELECT queries - Nárast redundancie

NENORMALIZOVAŤ ≠ DENORMALIZOVAŤ
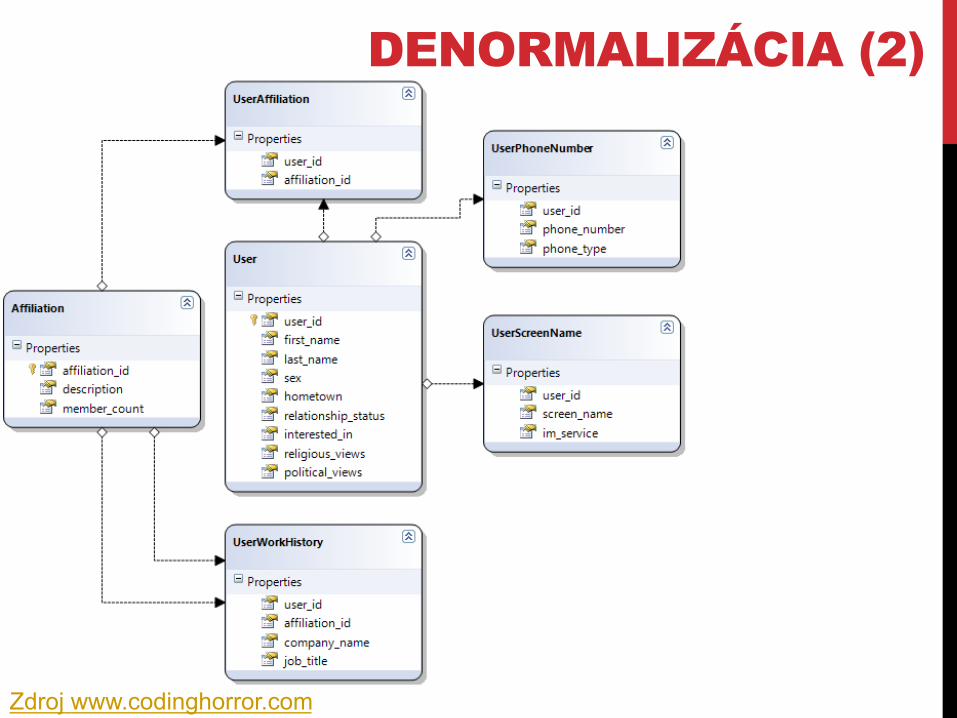
Zdroj www.codinghorror.com
DENORMALIZÁCIA (2)
Zdroj www.codinghorror.com
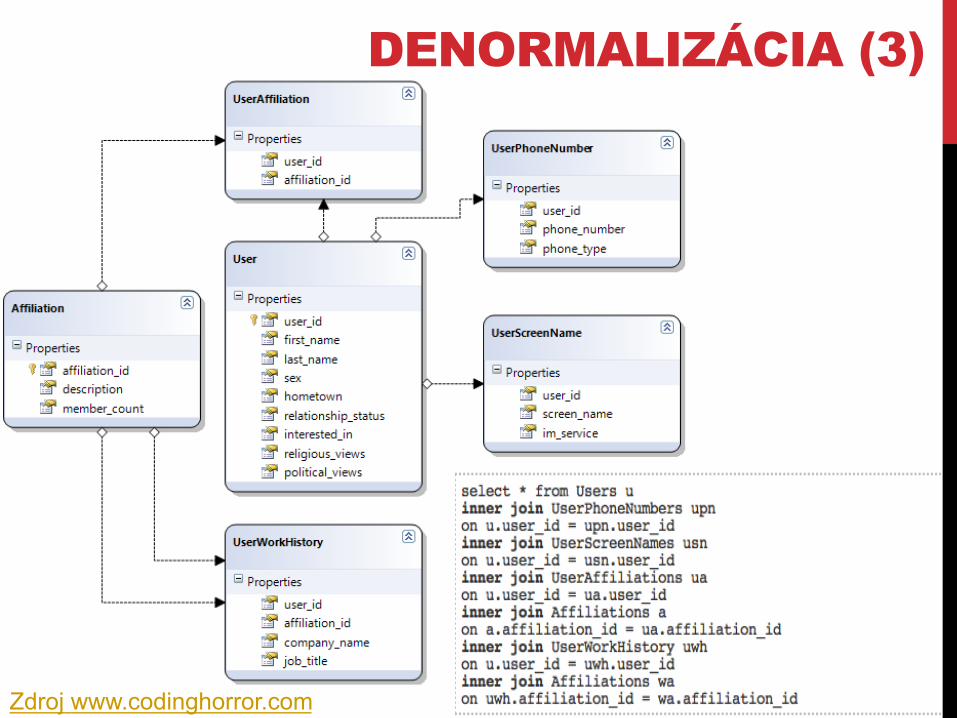
DENORMALIZÁCIA (3)
Zdroj www.codinghorror.com
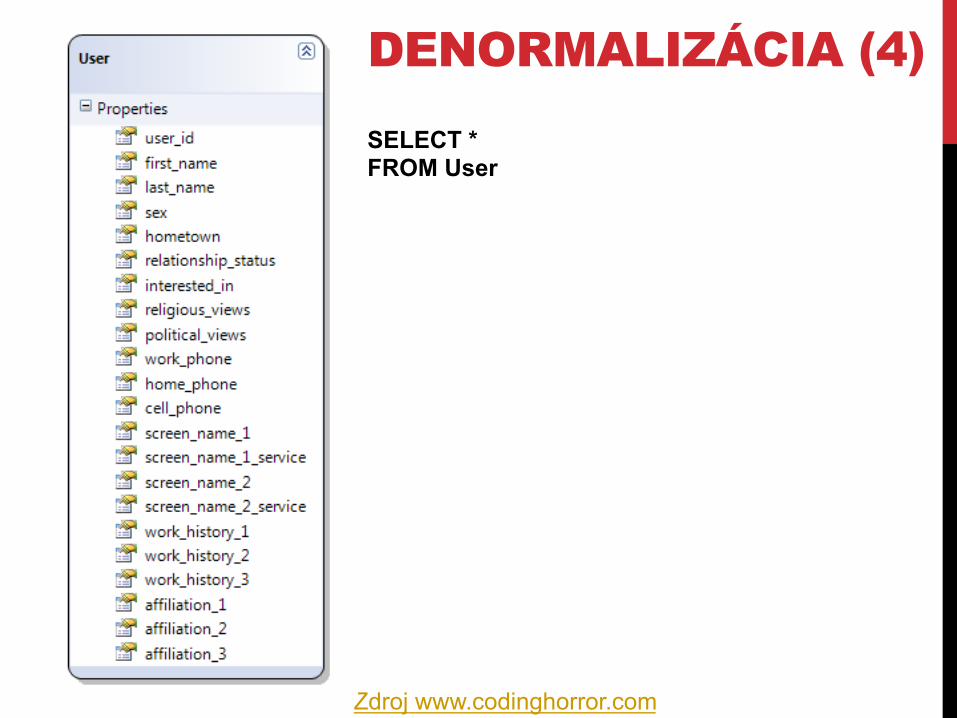
DENORMALIZÁCIA (4) SELECT * FROM User
Zdroj www.codinghorror.com
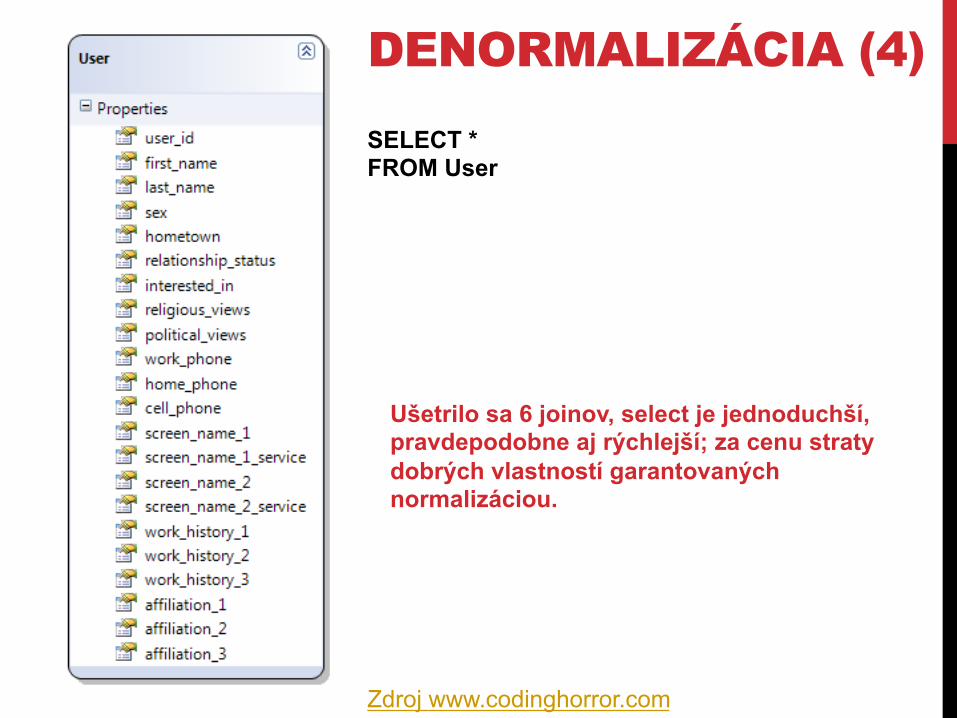
DENORMALIZÁCIA (4) SELECT * FROM User
Ušetrilo sa 6 joinov, select je jednoduchší, pravdepodobne aj rýchlejší; za cenu straty dobrých vlastností garantovaných normalizáciou.

PRÍSTUPY K DENORMALIZÁCII (1)
a) logická denormalizácia DB schémy
• denormalizujeme návrh • zachovanie konzistencie je zodpovednosťou
programátora • Vzťahy medzi tabuľkami už nie sú explicitné cez FK, ale implicitné. • Štandardne sa konzistencia udržuje pomocou triggerov
a constraintov

a) logická denormalizácia DB schémy
PRÍSTUPY K DENORMALIZÁCII (2)
CREATE TRIGGER diskutujuci_zmenil_meno_trigger AFTER UPDATE ON diskutujuci FOR EACH ROW WHEN (OLD.meno <> NEW.meno) EXECUTE PROCEDURE premenuj_uzivatela(NEW.id, NEW.meno);
CREATE TRIGGER diskutujuci_zmenil_meno_trigger AFTER DELETE ON diskutujuci ???
CREATE TRIGGER diskutujuci_zmenil_meno_trigger BEFORE INSERT ON diskutujuci ???

b) Denormalizácia prostredníctvom views
PRÍSTUPY K DENORMALIZÁCII (3)
• Denormalizovaná tabuľka v návrhu neexistuje – ten je dokonale normalizovaný
• Vytvárajú sa materializované pohľady (materialized view) • Relácia disponuje vlastným priestorom na FS • Relácia je definovaná SELECTom • Zásadná voľba z hľadiska udržania konzistencie je, kedy
repopulovať dáta
• Zodpovednosť za udržanie konzistencie je do istej miery prenesená na DBMS
• V PostgreSQL od verzie 9.3, limitovaná (rozumej minimálna) implementácia
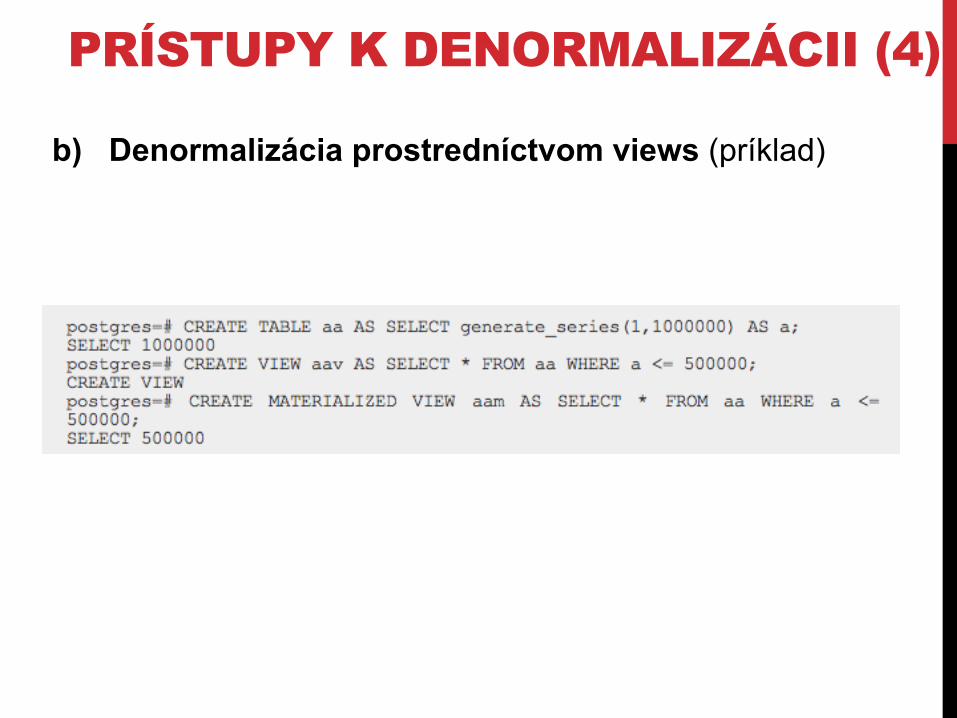
b) Denormalizácia prostredníctvom views (príklad)
PRÍSTUPY K DENORMALIZÁCII (4)

b) Denormalizácia prostredníctvom views (príklad)
PRÍSTUPY K DENORMALIZÁCII (4)

“Database denormalization is the kind of performance optimization that should be carried out as a last resort after trying things like creating database indexes, using SQL views and implementing application specific in-memory caching. However if you hit massive scale and are dealing with millions of queries a day across hundreds of millions to billions of records or have decided to go with database partitioning/sharding then you will likely end up resorting to denormalization.”
Zdroj: http://www.25hoursaday.com/weblog/CommentView.aspx?guid=cc0e740c-a828-4b9d-b244-4ee96e2fad4b

(DE)NORMALIZÁCIA – FURTHER READING (1)
Obšírnejšie vysvetlená normalizácia (vrátane BCNF, 5NF, 6NF) http://en.wikibooks.org/wiki/Relational_Database_Design/Normalization#Why_have_a_x.40.26.21NF_.3F
To isté len v bledoružovom
http://phlonx.com/resources/nf3/

(DE)NORMALIZÁCIA – FURTHER READING (1)
Zhrnutie niekoľkých prístupov k efektívnej denormalizácii http://database-programmer.blogspot.sk/2008/04/denormalization-patterns.html Case study, denormalizovanie bookmark tagging systému http://tagging.pui.ch/post/37027746608/tagsystems-performance-tests When not to normalize your SQL database http://www.25hoursaday.com/weblog/CommentView.aspx?guid=cc0e740c-a828-4b9d-b244-4ee96e2fad4b

ÚLOHA PRE AKTÍVNYCH NA ZÁVER
• Preveďte diskusné fórum zo začiatku prednášky do 3NF

PART 2: KNOW SQL WELL.
“It is impossible for a man to begin to learn what he has a conceit that he already knows.”

SELECT VIE TOHO VEĽA
• SQL ponúka veľmi bohatú syntax pre select. Väčšina programátorov ju využíva len sčasti • Je dobrým zvykom nechať čo najviac spracovania dát na DB, nie na middle-tier
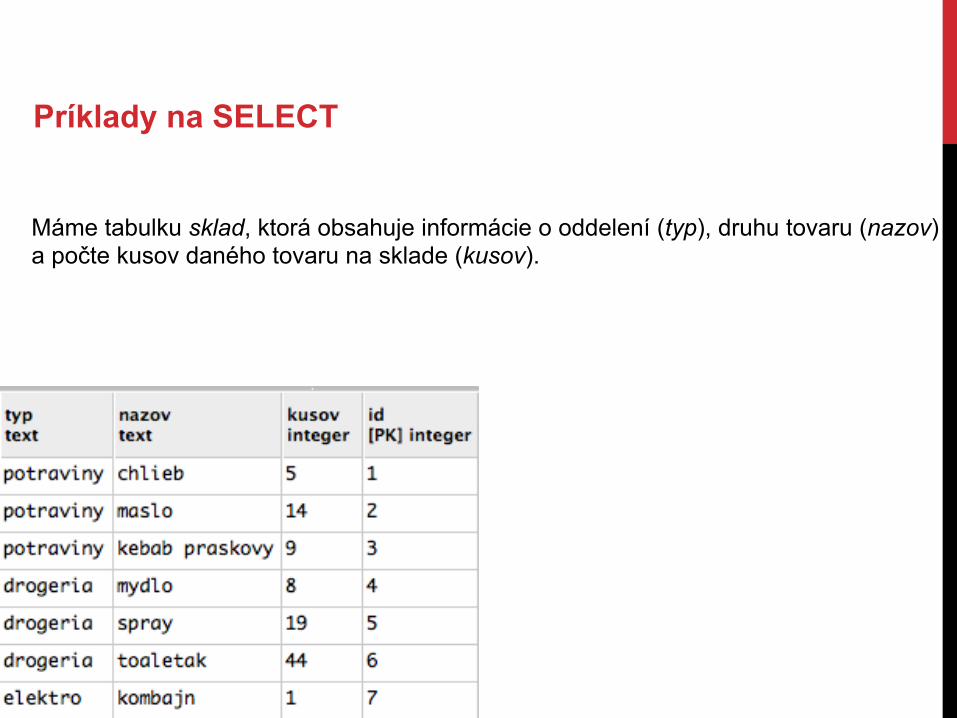
Príklady na SELECT
Máme tabulku sklad, ktorá obsahuje informácie o oddelení (typ), druhu tovaru (nazov) a počte kusov daného tovaru na sklade (kusov).
SELECT #0 Koľko je 47 * 42? J
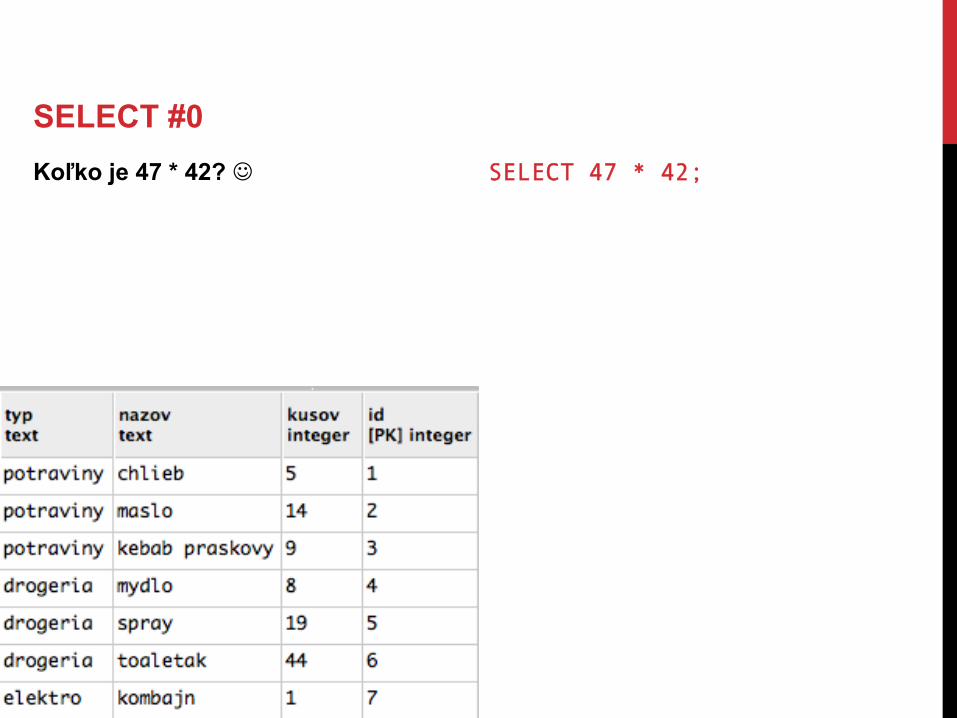
SELECT #0 Koľko je 47 * 42? J SELECT 47 * 42;
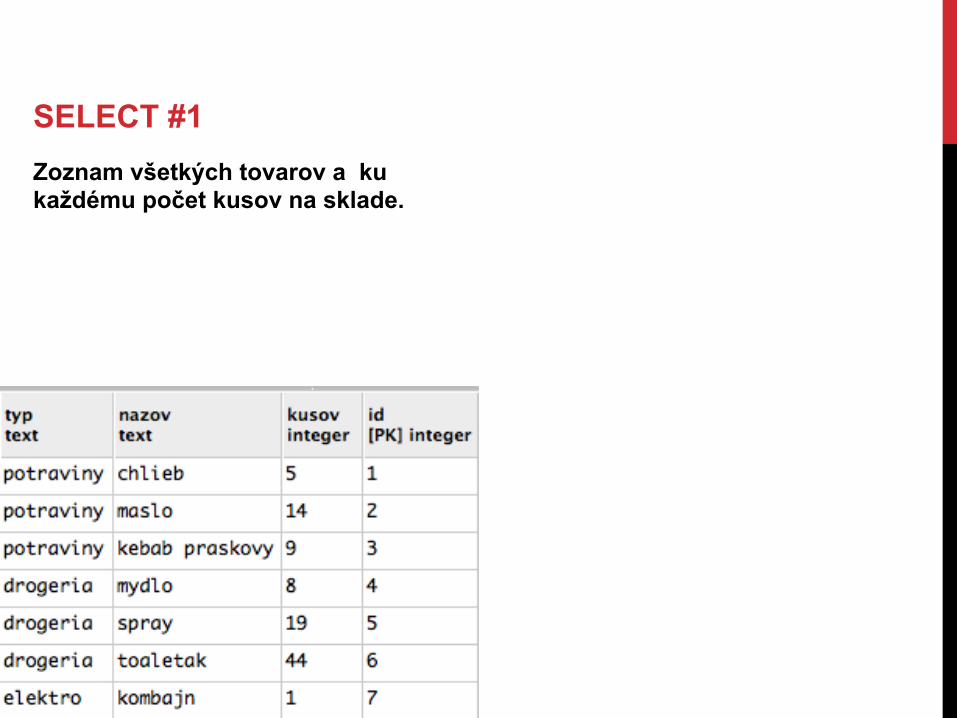
SELECT #1 Zoznam všetkých tovarov a ku každému počet kusov na sklade.
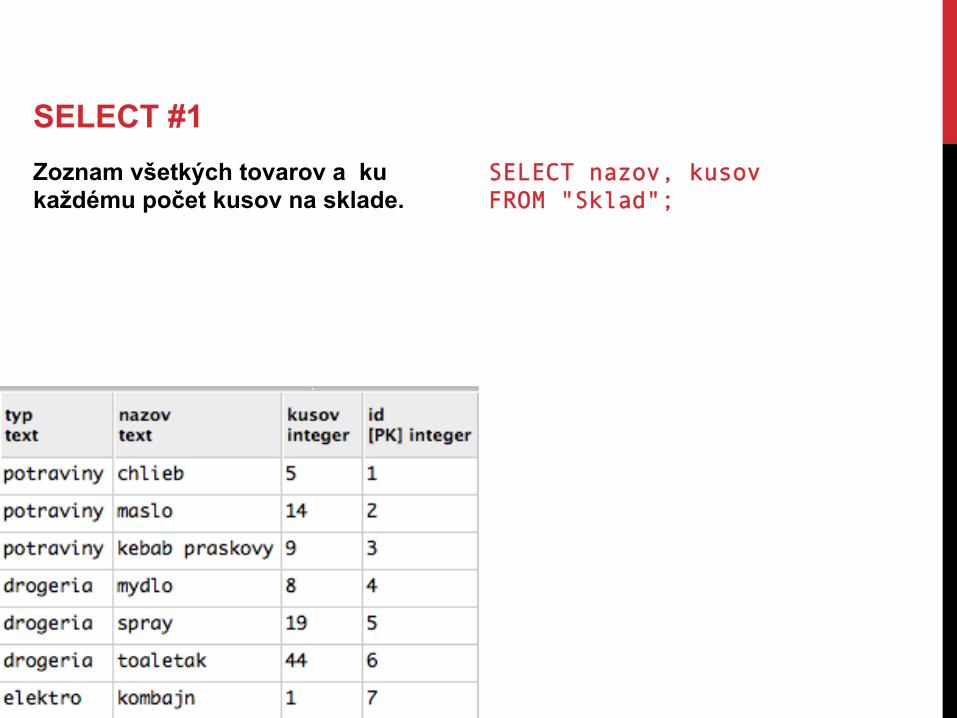
SELECT #1 Zoznam všetkých tovarov a ku každému počet kusov na sklade.
SELECT nazov, kusov FROM "Sklad";
SELECT #2 Zoznam oddelení.
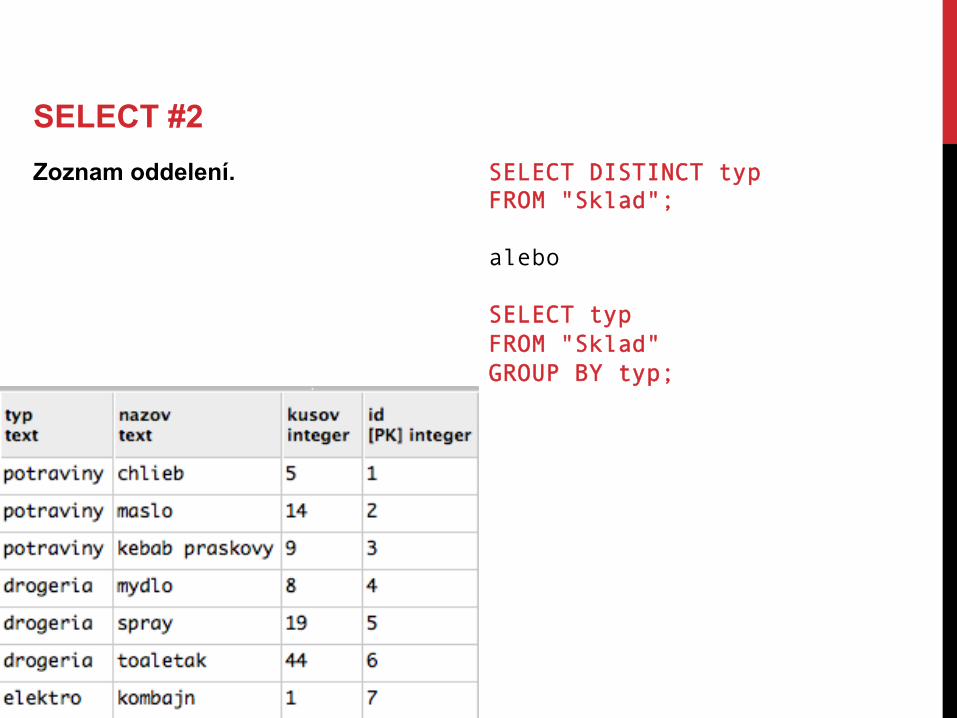
SELECT #2 Zoznam oddelení. SELECT DISTINCT typ
FROM "Sklad"; alebo SELECT typ FROM "Sklad" GROUP BY typ;
SELECT #3 Zoznam oddelení s aspoň 2 tovarmi na sklade.
SELECT #3 Zoznam oddelení s aspoň 2 tovarmi na sklade.
SELECT typ FROM "Sklad" GROUP BY typ HAVING COUNT(id) >= 2;
SELECT #4 Zoznam oddelení s menej ako 10 výrobkami na sklade.
SELECT #4 Zoznam oddelení s menej ako 10 výrobkami na sklade.
SELECT typ FROM "Sklad" GROUP BY typ HAVING SUM(kusov) < 10;
SELECT #5 Dve oddelenia s najväčším počtom položiek na sklade (zostupne).
SELECT #5 Dve oddelenia s najväčším počtom položiek na sklade (zostupne).
SELECT typ, SUM(kusov) AS pocet FROM "Sklad" GROUP BY typ ORDER BY pocet DESC LIMIT 2;
SELECT #6 Zoznam produktov, ktoré sú v oddelení s aspoň 2 inými.
SELECT nazov FROM "Sklad" WHERE typ IN (
SELECT typ FROM "Sklad" GROUP BY typ HAVING COUNT(*) > 2);
SELECT #6 Zoznam produktov, ktoré sú v oddelení s aspoň 2 inými.
SELECT nazov FROM ( SELECT typ, nazov, COUNT(*) OVER (PARTITION BY typ) AS Inych FROM "Sklad") X
WHERE X.Inych > 2;
SELECT #7 Zoznam obsahujúci dve najvypredanejšie položky z každého oddelenia.
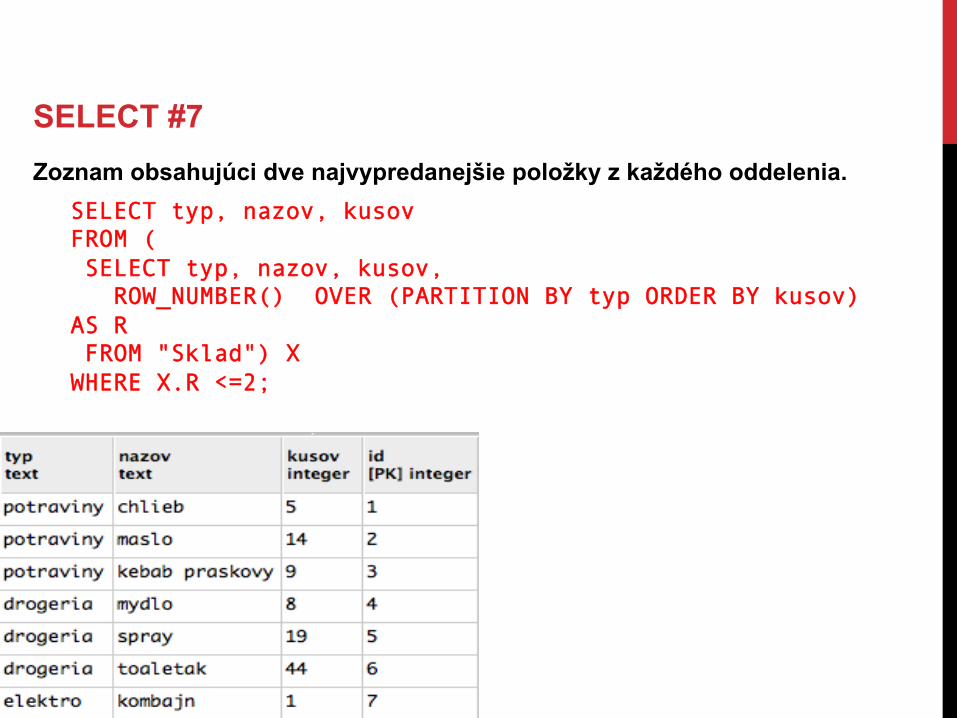
SELECT #7 Zoznam obsahujúci dve najvypredanejšie položky z každého oddelenia.
SELECT typ, nazov, kusov FROM ( SELECT typ, nazov, kusov, ROW_NUMBER() OVER (PARTITION BY typ ORDER BY kusov) AS R FROM "Sklad") X WHERE X.R <=2;

SELECT #7 Zoznam obsahujúci dve najvypredanejšie položky z každého oddelenia. • toto je naozaj užitočná query typu „Top N results for each group“. • bez window funkcii sa v SQL veľmi zle implementuje (viď MySQL)
Podobné use-cases: • Ukáž mi blogerov s ich 5 najnovšími článkami • Ukáž mi zoznam reštaurácii s piatimi najlepšími recenziami ku každej

SELECT #8 Zoznam tovarov a informacie o tom ci sa da alebo neda platit gastroliskami. Gastrolistkami sa daju platit iba potraviny.
SELECT nazov, (CASE WHEN typ='potraviny' THEN 'da sa platit aj gastrolistkom' ELSE 'len v hotovosti‘ END) AS info
FROM "Sklad"

SELECT – DÁTUMY A ČASY • Date ('2001-09-28’)
• Time ('01:00’)
• Timestamp (‘2001-09-28 01:00’)
• Interval (‘3 hours’)

SELECT – DÁTUMY A ČASY Koľkého je dnes?
SELECT now();
Takto o týždeň bude aký dátum?
SELECT date '2013-08-22' + interval '1 week’;

SELECT – DÁTUMY A ČASY Aký presne som starý dnes? SELECT age(timestamp '1988-08-22');
Koľko rokov, mesiacov a dní sa dožil Steve Jobs? SELECT age(timestamp '2011-10-05',timestamp '1955-02-24');
V koľkátom storočí to vlastne žijeme? SELECT EXTRACT(CENTURY FROM current_timestamp);
Atď:http://www.postgresql.org/docs/8.0/static/functions-datetime.html

SELECT – TEXTY Zoznam všetkých tovarov, ktoré majú v názve “cola”. SELECT nazov
FROM "Sklad”
WHERE lower(nazov) like ’%cola%’;
Zoznam všetkých tovarov, ktoré začínajú “Tesco” alebo “Coop”.
SELECT nazov
FROM "Sklad”
WHERE left(lower(nazov),5) IN (‘tesco’,’coop’);
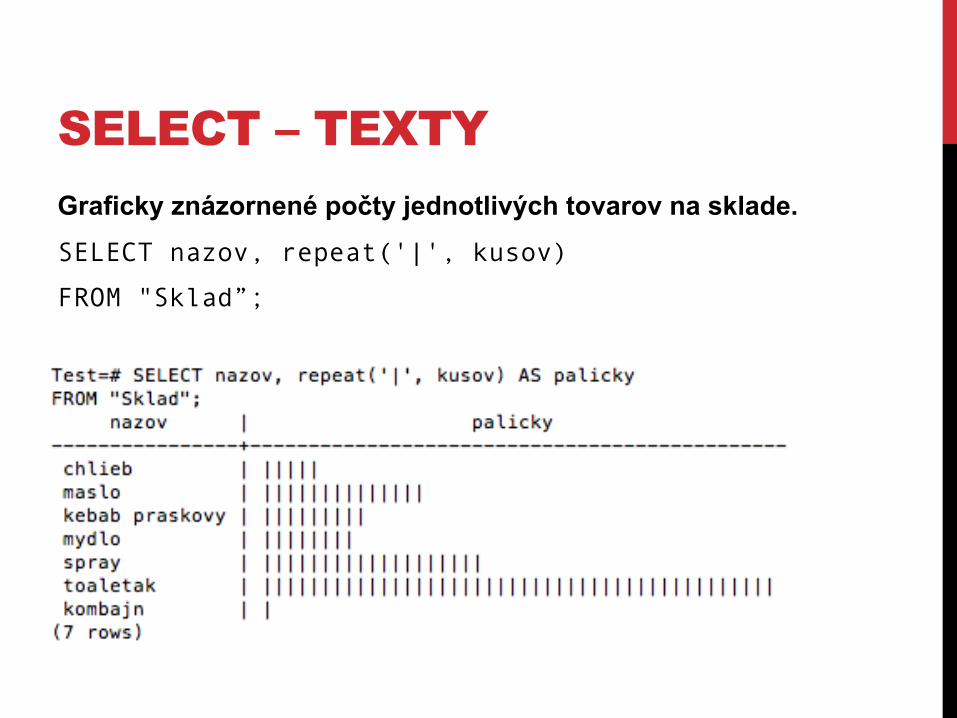
SELECT – TEXTY Graficky znázornené počty jednotlivých tovarov na sklade. SELECT nazov, repeat('|', kusov)
FROM "Sklad”;

GENERATE_SERIES() Funkcia generate_series() nevracia skalárnu hodnotu, ale tzv. set. 3 varianty:
• generate_series(start, stop) • generate_series(start, stop, step) • generate_series(tsp start, tsp stop, step interval) Napr. zoznam všetkých validných dátumov od 1.1. 2000:
• SELECT generate_series(timestamp '2000-01-01 00:00:00', now(),interval '1 day');

GENERATE_SERIES() Vďaka tejto funkcii sa dá v obmedzenej miere iterovať priamo v SQL:
SELECT candidate as prime
FROM generate_series(1,25) candidate
WHERE isPrime(candidate);

PROCEDURÁLNE ROZŠÍRENIE SQL
isPrime je naša vlastná stored procedure, ktorá je uložená priamo na DB. SELECT candidate as prime
FROM generate_series(1,25) candidate
WHERE isPrime(candidate);

PROCEDURÁLNE ROZŠÍRENIE SQL
isPrime je naša vlastná stored procedure, ktorá je uložená priamo na DB. SELECT candidate as prime
FROM generate_series(1,25) candidate
WHERE isPrime(candidate);
OTÁZKA: Ako prepísať túto query, aby bola 2x efektívnejšia?

ISPRIME V PYTHONE

…A V PGSQL

VŠELIČO PODSTATNÉ SME VYNECHALI… • http://www.postgresql.org/docs/9.1/static/functions-
conditional.html (fcie COALSCE, NULLIF, GREATEST,…)
• CAST, COLLATE, …
• Operátory na result setoch UNION, INTERSECT, EXCEPT
• EXISTS, ANY, ALL…
…našťastie, všetko potrebné info je tu J http://www.postgresql.org/docs/9.1/static/

PART 3: PATTERNS & ANTI-PATTERNS
(ad hoc desatoro udržateľnej DB)

1. KONVENCIE MUSIA BYŤ! Používajte konzistentne: • Pomenovanie databáz
• Pomenovanie tabuliek, stĺpcov a ďalších objektov
• Štýl procedurálneho kódu
• Uprednostnite vstavané mechanizmy pred ad hoc riešeniami
• Where applicable, uprednostnite normované formáty dát

1. KONVENCIE MUSIA BYŤ! • Mená tabuliek sú v jednotnom čísle (Pascal case)
• napr. Order, Person, AcademicYear, OrderXPerson • Ale toto rozhodne nie je štandardom (viď príklady v tejto
prednáške J)
• Mená stĺpcov sú v jednotnom čísle (camel case) • orderId, userName, …
• Štýl procedurálneho kódu • Snažte sa dodržiavať štandardy dané proc. jazykom
• Uprednostnite vstavané mechanizmy pred ad hoc riešeniami • Dátový typ serial pred vlastnými počítadlami, zabudované locky
namiesto rôznych ezoterických pokusov atď…

1. KONVENCIE MUSIA BYŤ! • Obe strany relačného atribútu by sa mali volať rovnako
• Čiže ak je p.k. v tabuľke Order pomenovaný orderId, tak v tabuľke OrderXItem by mal byť v cudzom kľúči atribút pomenovaný tiež orderId.
• Z toho implicitne vyplýva, že id nie je príliš vhodný názov stĺpca
• Bežné dáta ako tel.čísla, pohlavie, geografické súradnice
majú často štandardizovaný formát – využívajte ho. • Napr. pre zápis pohlavia existuje norma ISO/IEC 5218:

1. KONVENCIE MUSIA BYŤ! • Na veľa vecí neexistuje jeden štandard. Nejaký si zaveďte a
dodržujte ho. • Značne tým urýchlite vývoj • Selecty budú jednoduchšie na písanie aj pochopenie • Odstránite kognitívnu bariéru, keď si programátor musí
pamätať desiatky špeciálnych výnimiek v pomenovaniach • Zjednodušíte interoperabilitu s inými systémami

2. POUŽÍVAJTE CONSTRAINTY • Vstavané dátové typy sú občas veľmi všeobecné. To je na škodu,
pokiaľ nám to umožňuje narušiť zmysluplnosť dát.
Základné typy constraintov: • Unique key – naraz môže 1 hodnotu nadobúdať len 1 záznam
• napr. emailová adresa v tabuľke User • NOT NULL – atribút nemá zmysel bez vyplnenej hodnoty
• napr. v DB študentov nechceme mať študenta bez mena • Primary key – (Unique + NOT NULL) • Default – napr. príspievateľ do diskusie nech je radšej Anonym
ako NULL

2. POUŽÍVAJTE CONSTRAINTY • Vstavané dátové typy sú občas veľmi všeobecné. To je na škodu,
pokiaľ nám to umožňuje narušiť zmysluplnosť dát.
Custom constrainty:
• CHECK – počas návrhu definovaná podmienka, ktorú musí hodnota v stĺpci spĺňať, napr.
• Vek > 0 • Emailová adresa je v správnom formáte CREATE TABLE emails (
email varchar CONSTRAINT proper_email CHECK (email ~* ’%REGEX%') );

2. POUŽÍVAJTE CONSTRAINTY • Vstavané dátové typy sú občas veľmi všeobecné. To je na škodu,
pokiaľ nám to umožňuje narušiť zmysluplnosť dát.
Cudzie kľúče explicitne špecifikujte:
CREATE TABLE album( id CHAR(10) NOT NULL PRIMARY KEY, title VARCHAR(100), artist VARCHAR(100) );
CREATE TABLE track( album CHAR(10), dsk INTEGER, posn INTEGER, song VARCHAR(255), FOREIGN KEY (album) REFERENCES album(id) ON DELETE CASCADE )

2. POUŽÍVAJTE CONSTRAINTY • Vstavané dátové typy sú občas veľmi všeobecné. To je na škodu,
pokiaľ nám to umožňuje narušiť zmysluplnosť dát.
Automatizované zachovanie referenčnej integrity: … [ON <udalost> <spravanie> ]
• Udalosť: INSERT / UPDATE / DELETE
• Správanie:
• NO ACTION • RESTRICT – zabráni akcii, ak by sa mala narušiť r.i. • CASCADE – zmeny sa vyšíria do referencujúcich tabuliek • SET NULL / SET DEFAULT – referencujúci stĺpec sa nastaví
na NULL, alebo na svoju defaultnú hodnotu

3. ZAPOJTE VIEWS DO HRY View (po sľovensky pohľad, eh) je perzistentný objekt, ktorý predstavuje výsledok SELECTu.
CREATE VIEW comedies AS
SELECT *
FROM films
WHERE kind = 'Comedy';
SELECT * FROM comedies;

3. ZAPOJTE VIEWS DO HRY VÝHODY VIEWS
• Umožňujú skryť komplexitu zložitejších selectov
• Umožnujú znovupoužiteľnosť kódu (berte s rezervou)
• A takisto selektívne udeľovať práva na prístup k dátam rôznym užívateľom

3. ZAPOJTE VIEWS DO HRY Considerations:
• Môže dôjsť k čiastočnej degradácii výkonu (profilujte)
• Mierne prírastok práce, pri zmene underlying schémy (w.r.t. view)
• Pozor na materializované views, tie fungujú inak

3. ZAPOJTE VIEWS DO HRY Considerations:
• Môže dôjsť k čiastočnej degradácii výkonu (profilujte)
• Mierne prírastok práce, pri zmene underlying schémy (w.r.t. view)
• Pozor na materializované views, tie fungujú inak

4. ZVÁŽTE PREPARE PRE ČASTO POUŽÍVANÉ STMT
Predspracovanie často používaných statements umožňuje preskočiť:
• Parsovanie dotazu • Analýzu • Automatické prepisovanie (optimalizáciu) dotazu
Pri jednotlivých spusteniach sa už dotaz len vykoná podľa plánu.

4. ZVÁŽTE PREPARE PRE ČASTO POUŽÍVANÉ STMT
• Prepared stmt môžeme zmazať príkazom DEALLOCATE name [ALL]

4. ZVÁŽTE PREPARE PRE ČASTO POUŽÍVANÉ STMT
Prepared stmt existujú: • Na strane servra • LEN počas trvania jednej session
Preto majú najväčší prínos ak: • Jedna session obsluhuje veľa podobných stmt • Statement je zložitý (napr. veľa joinov) z hľadiska
predspracovania
5. V NAJHORŠOM POMÔŽE CONNECTION POOLING, ČI CLIENT-SIDE CACHE

5. V NAJHORŠOM POMÔŽE CONNECTION POOLING, ČI CLIENT-SIDE CACHE
Connection pool umožňuje znovupoužívať konekcie do DB, čím sa šetrí čas na nadväzovanie, otváranie a zatváranie spojenia. Môže znamenať signifikantne lepší výkon pri rušných systémoch, kde je veľa menších konekcií Riešené 3rd party softvérom, resp. knižnicami (pgBouncer)

5. V NAJHORŠOM POMÔŽE CONNECTION POOLING, ČI CLIENT-SIDE CACHE
• Client-side cache je väčšinou proprietárne riešenie, kedy sa populárne dáta uchovávajú na médiu s nižšou latenciou ako skutočná DB.
• Často sa používa napr. Memcached, alebo priamo FS
• Treba si premyslieť refresh dát, invalidáciu cache a s tým spojené problémy

6. ATOMICKÉ OPERÁCIE VYKONÁVAJTE V TRANSAKCIÁCH
Príklad atomickej operácie:
prevod_penazi(a,b, suma): if (zostatok(a) >= suma) zmen_zostatok(a, -suma) zmen_zostatok(b, +suma)
1 2 3 4
Kvízová otázka: Čo sa stane, ak medzi príkazmi 3 a 4 padne server?

6. ATOMICKÉ OPERÁCIE VYKONÁVAJTE V TRANSAKCIÁCH
Príklad atomickej operácie:
prevod_penazi(a,b, suma): if (zostatok(a) >= suma) zmen_zostatok(a, -suma) zmen_zostatok(b, +suma)
Kvízová otázka: Čo sa stane, ak medzi príkazmi 3 a 4 padne server?
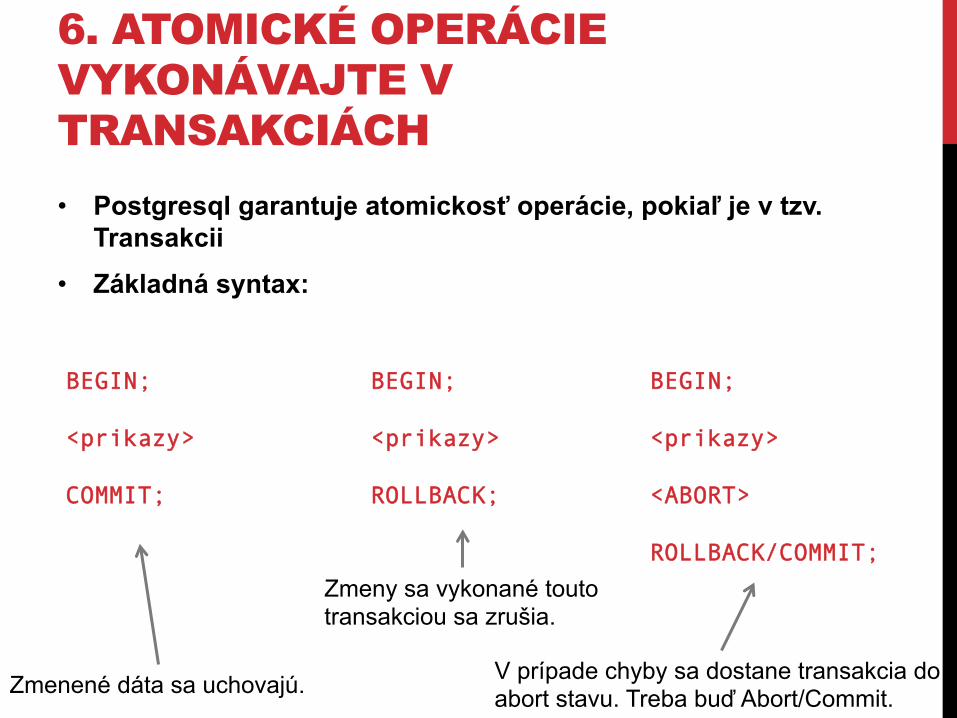
6. ATOMICKÉ OPERÁCIE VYKONÁVAJTE V TRANSAKCIÁCH • Postgresql garantuje atomickosť operácie, pokiaľ je v tzv.
Transakcii • Základná syntax:
BEGIN; <prikazy> COMMIT;
BEGIN; <prikazy> ROLLBACK;
BEGIN; <prikazy> <ABORT> ROLLBACK/COMMIT;
Zmenené dáta sa uchovajú.
Zmeny sa vykonané touto transakciou sa zrušia.
V prípade chyby sa dostane transakcia do abort stavu. Treba buď Abort/Commit.

6. HESLÁ UKLADAJTE BEZPEČNE
• Heslá používateľov sú diskrétna informácia, ktorá sa dá ľahko zneužiť Ako toto riziko minimalizovať? • Vynúťte, aby užívatelia používali netriviálne heslá • Heslá do DB ukladajte bezpečne

6. HESLÁ UKLADAJTE BEZPEČNE
! Vždy predpokladajte, že útočník má prístup ku všetkým dátam vo vašej databáze ! Taktika 1:
plaintext ….. Pass = “internet” Útok: • Útočník priamo prečíta dáta z DB • V mnohých prípadoch dokonca DB ani nepotrebuje, stačí skúšať slovníkové slová

6. HESLÁ UKLADAJTE BEZPEČNE
! Vždy predpokladajte, že útočník má prístup ku všetkým dátam vo vašej databáze ! Taktika 2:
hash md5 ….. Pass = “c3581516868fb3b71746931cac66390e”
Útok: ?

6. HESLÁ UKLADAJTE BEZPEČNE
! Vždy predpokladajte, že útočník má prístup ku všetkým dátam vo vašej databáze ! Taktika 2:
hash md5 ….. Pass = “c3581516868fb3b71746931cac66390e”
Útok: http://www.md5decrypt.org (cca 1 sekunda)

6. HESLÁ UKLADAJTE BEZPEČNE
! Vždy predpokladajte, že útočník má prístup ku všetkým dátam vo vašej databáze ! Taktika 2:
hash md5 ….. Pass = “c3581516868fb3b71746931cac66390e”
Útok: http://www.md5decrypt.org (cca 1 sekunda)
+ slovníková metóda

6. HESLÁ UKLADAJTE BEZPEČNE
! Vždy predpokladajte, že útočník má prístup ku všetkým dátam vo vašej databáze ! Taktika 3: (pgCrypto)
digest(plain_psw||salt, "sha256"). Salt je nejaký dostatočne dlhý a dostatočne tajný string (napr. hash z privátneho kľúča?) Slabé miesto: ???

6. HESLÁ UKLADAJTE BEZPEČNE
! Vždy predpokladajte, že útočník má prístup ku všetkým dátam vo vašej databáze ! Taktika 3: (pgCrypto)
digest(plain_psw||salt, "sha256"). Slabé miesto: Užívatelia s rovnakým heslom majú rovnaký záznam v stĺpci password. (Toto môže ale nemusí byť problém)

6. HESLÁ UKLADAJTE BEZPEČNE
! Vždy predpokladajte, že útočník má prístup ku všetkým dátam vo vašej databáze ! Taktika 4: (pgCrypto)
digest(plain_psw||salt||userId, "sha256"). Toto by malo stačiť na praktické účely.

7. BOJUJTE PROTI SQL INJECTION
Viac info na: • http://www.sqlinjectionwiki.com/Categories.aspx?catId=4 • http://www.codeproject.com/Articles/9378/SQL-Injection-Attacks-and-Some-Tips-on-How-to-Prev

8. S FUNKČNÝMI INDEXAMI SA DAJÚ ROBIŤ DIVY
Trik z MySQL [war story]: • Tabuľka s veľkým množstvom záznamov (cca 10M)
a stĺpcom typu TEXT, obsahujúcim dlhé stringy • Časté dotazy na rovnosť na stĺpec typu TEXT
• Jedna query cca 3-8 sekúnd. Riešenie?

8. S FUNKČNÝMI INDEXAMI SA DAJÚ ROBIŤ DIVY
Trik z MySQL [war story]: Riešenie? • Namiesto testovania text=“…” sa vo where
podmienke testovalo • crc32_text = crc32(“…”) AND text = “…”
• crc32(<string>) je číslo, indexovateľné, malé, rýchle

8. S FUNKČNÝMI INDEXAMI SA DAJÚ ROBIŤ DIVY
V PostgreSQL sú zabudované funkčné indexy, čiže indexovať sa dá nielen hodnota stĺpca, ale aj nejaký výraz, napr. Definícia: CREATE INDEX idxName ON User(lower(name)); Použitie: SELECT userId FROM User WHERE lower(name)=“…”;

9. KEĎ HIERARCHIA TAK PORIADNE
• Hierarchické dáta používa väčšina aplikácii • Stromová štruktúra webu (sitemap) • Organizačná štruktúra spoločnosti • Diskusné vlákna • Taxonómie biznis objektov
• Väčšinou sú však neefektívne reprezentované

9. KEĎ HIERARCHIA TAK PORIADNE
• Prístup 1: JSON/XML • OK V prípade, že s jednotlivými prvkami hierarchie nechceme robiť osobitne, je statická a konečná • V hociakom inom prípade zle

9. KEĎ HIERARCHIA TAK PORIADNE
• Prístup 2: Adjacency list • Syn má atribút parentId, ktorý ukazuje na uzol
bezprostredne vyššie v hierarchii • root má parenta samého seba
Otázky: 1. Ako vložíme nový uzol? 2. Ako zistíme, či je uzol list? 3. Ako zistíme cestu k uzlu ak poznáme jeho ID? 4. Ako získame podstrom uzlu ak poznáme jeho ID?

9. KEĎ HIERARCHIA TAK PORIADNE
• Prístup 3: Materialized path • Každý uzol má v semištruktúrovanej podobe uloženú
cestu od koreňa v atribúte, napr. “cat” | “1.1.1.2” • Na väčšinu queries sa využíva operátor LIKE
Otázky: 1. Ako vložíme nový uzol? 2. Ako zistíme, či je uzol list? 3. Ako zistíme cestu k uzlu ak poznáme jeho ID? 4. Ako získame podstrom uzlu ak poznáme jeho ID?
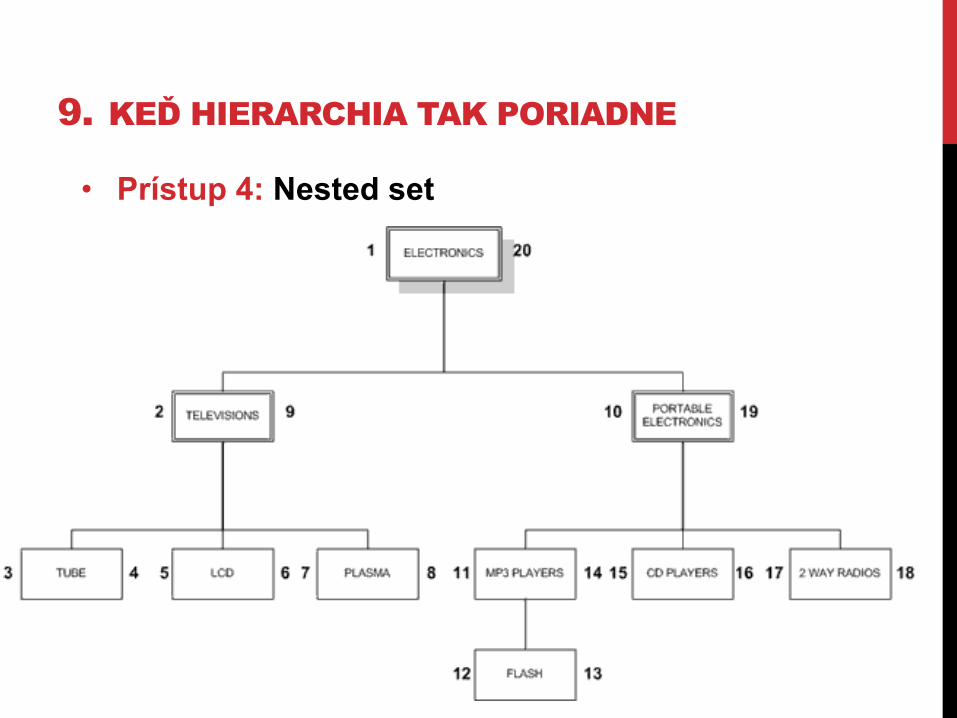
9. KEĎ HIERARCHIA TAK PORIADNE • Prístup 4: Nested set
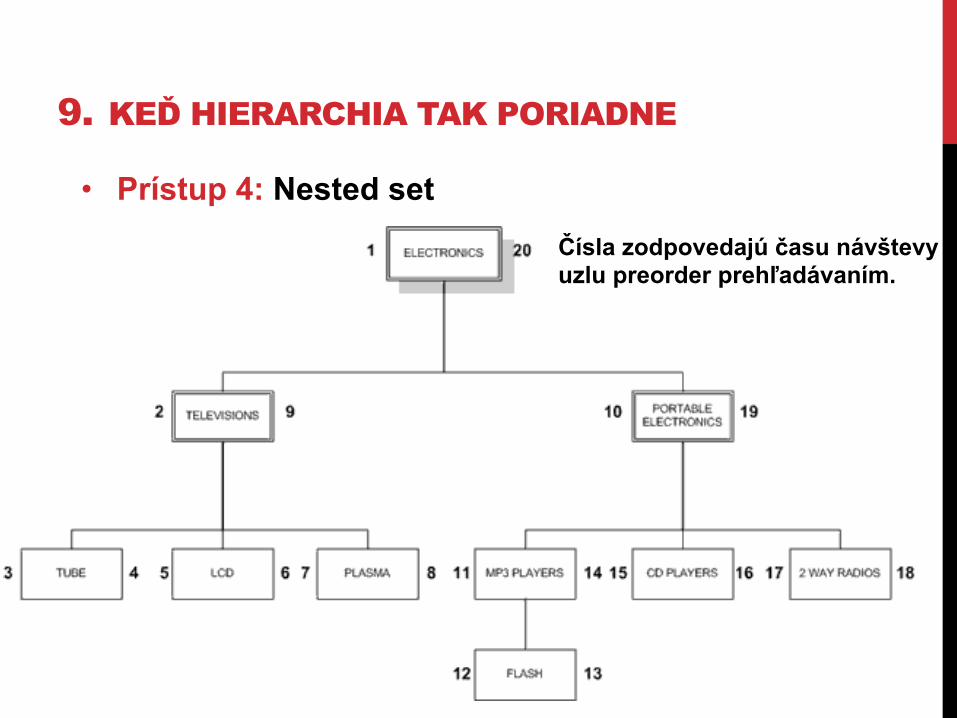
9. KEĎ HIERARCHIA TAK PORIADNE • Prístup 4: Nested set
Čísla zodpovedajú času návštevy uzlu preorder prehľadávaním.

9. KEĎ HIERARCHIA TAK PORIADNE • Prístup 4: Nested set
• Opäť príklad diskusného fóra. Strom reprezentujeme v nested set modeli takto:

9. KEĎ HIERARCHIA TAK PORIADNE • Prístup 4: Nested set • Opäť príklad diskusného fóra. Strom reprezentujeme v nested set modeli takto:
A. Ako získame všetky listové uzly?

9. KEĎ HIERARCHIA TAK PORIADNE • Prístup 4: Nested set • Opäť príklad diskusného fóra. Strom reprezentujeme v nested set modeli takto:
B. Ako získame cestu k koreňu?

9. KEĎ HIERARCHIA TAK PORIADNE C. Ako získame niečo takéto?

SELECT REPEAT(CAST(' ' AS TEXT), CAST(COUNT(parent."id") - 1 AS int)*3) ||LEFT(P."text",40)|| '...' AS prispevok,
COUNT(P."postId") AS hlbka
FROM "PostTree" AS node inner join
“PostTree" AS parent
ON (node."indexLeft" BETWEEN parent."indexLeft" AND parent."indexRight") inner join
"Post" AS P ON P."postId" = node."postId”
GROUP BY P."postId", node."indexLeft”
ORDER BY node."indexLeft";

9. KEĎ HIERARCHIA TAK PORIADNE • Prístup 4: Nested set • Opäť príklad diskusného fóra. Strom reprezentujeme v nested set modeli takto:
D. Ako vložíme nový uzol?

• Viac o nested set modeli napr. tu: http://falsinsoft.blogspot.sk/2013/01/tree-in-sql-database-nested-set-model.html
• Celko - Trees and Hierarchies in SQL for Smarties
(Elsevier, 2004)

10. NEPRESTÁVAJTE SA UČIŤ Full-text search, čiastočné indexy, psql, triggers, ILIKE, práca s XML, logovanie, sledovanie výkonu, DCL, cursors, pgdump, pgAdmin, ER diagramy, star schemas, snowflake, roles, explain, auto-vacuum, delete vs. truncate, autocommit, isolation, transaction log, server restart, analyze tables, explain extended, execution trees, query cache, file sorting, postgres configuration files, OLAP, geographical database, table inheritance, shard ing, ver t ica l sca l ing, DML, authentification

if (time_left) { ask_everyone(“pomôžem vám s projektom?”);
} else { ďakujem_za_pozornosť(); exit;
} Prednáška online: http://okruhlica.eu/prednasky/spot Kontakt na mňa: [email protected]


















