
Agenda
30
Maestría en Bioinformática Bases de Datos y Sistemas de Información SQL: SELECT Ing. Alfonso Vicente, PMP [email protected]
-
Upload
andromeda-marinos -
Category
Documents
-
view
25 -
download
1
description
Maestría en Bioinformática Bases de Datos y Sistemas de Información SQL: SELECT Ing. Alfonso Vicente, PMP [email protected]. Agenda. Proyección y selección DISTINCT Funciones escalares ORDER BY GROUP BY / Funciones de agregación. SELECT en una tabla Joins. Agenda. - PowerPoint PPT Presentation
Transcript of Agenda

Maestría en Bioinformática
Bases de Datos y Sistemas de Información
SQL: SELECT
Ing. Alfonso Vicente, [email protected]
Agenda
Proyección y selección DISTINCT Funciones escalares ORDER BY GROUP BY / Funciones de
agregación
SELECT en una tablaJoins

Agenda
Producto cartesiano Equi joins Outer joins
SELECT en una tablaJoins

Agenda
Proyección y selección DISTINCT Funciones escalares ORDER BY GROUP BY / Funciones de
agregación
SELECT en una tablaJoins

SELECT en una tabla
Proyección y selección
• La proyección permite seleccionar las columnas, la selección permite seleccionar las tuplas

SELECT en una tabla
Proyección y selección
• Sintaxis básica
SELECT <lista_columnas> -- proyecciónFROM <tabla>WHERE <predicado>; -- selección
• Ejemplo
SELECT id, nombre, apellido, mailFROM empleadosWHERE sueldo > 80000;

SELECT en una tabla
DISTINCT
• Al realizar proyección, se pueden perder las claves y pueden aparecer tuplas repetidas
• La cláusula DISTINCT permite eliminar las tuplas duplicadas
• Ejemplo
SELECT DISTINCT apellidoFROM empleadosWHERE sueldo > 80000;

SELECT en una tabla
Funciones escalares
• Los predicados pueden incluir funciones escalares built-in (predefinidas) o creadas por el usuario. Algunas son: +, -, *, /, abs, pow, length, substr, hex, locate, replace, add_months, to_char, nlv, coalesce (muchas dependen del RDBMS)
• Ejemplos:
SELECT id, nombre, apellido, mailFROM empleadosWHERE length(nombre) > 10;
SELECT id, nombre, apellido, mailFROM empleadosWHERE soundex(nombre) = soundex('maicol'); -- Sólo en DB2

SELECT en una tabla
Funciones escalares
• Hay funciones para modificar los nulos, de forma de interpretarlos y presentarlos correctamente en un reporte
• Ejemplo:
SELECT id, nombre, apellido, nvl(to_char(sueldo), 'no percibe sueldo') sueldoFROM empleadosWHERE sueldo < 20000 or sueldo is null;

SELECT en una tabla
ORDER BY
• No se puede asumir ningún orden, a menos que se explicite mediante la cláusula ORDER BY
• Ejemplos:
SELECT sueldo, nombre, apellido, mailFROM empleadosWHERE departamento = 3 ORDER BY sueldo DESC;
SELECT apellido, nombre, telefonoFROM empleadosORDER BY apellido, nombre;

SELECT en una tabla
GROUP BY / Funciones de agregación
• La cláusula GROUP BY permite agrupar los datos que tengan valores iguales por algún conjunto de columnas
• Ejemplos:
SELECT departamento, count(*)FROM empleadosGROUP BY departamentoORDER BY departamento;
SELECT departamento, min(sueldo)FROM empleadosGROUP BY departamentoORDER BY departamento;

SELECT en una tabla
GROUP BY / Funciones de agregación
• Funciones de agregación: count, min, max, sum, avg (otras dependen del RDBMS)
• HAVING: Permite filtrar sobre los resultados de las funciones de agregación
• Ejemplo: departamentos y cantidad de empleados, de los departamentos que tengan al menos 10 empleados
SELECT departamento, count(*)FROM empleadosGROUP BY departamentoHAVING count(*) >= 10;

Agenda
Producto cartesiano Equi joins Outer joins
SELECT en una tablaJoins

Joins
Producto cartesiano
• Basados en la idea de producto y división entre relaciones
• El producto cartesiano entre dos relaciones R1 x R2, es la combinación de todas las parejas (t1, t2) donde t1 es una tupla de R1 y t2 es una tupla de R2
• Si R1 tiene cardinalidad N y R2 cardinalidad M el producto cartesiano R1 x R2 tendrá cardinalidad N x M
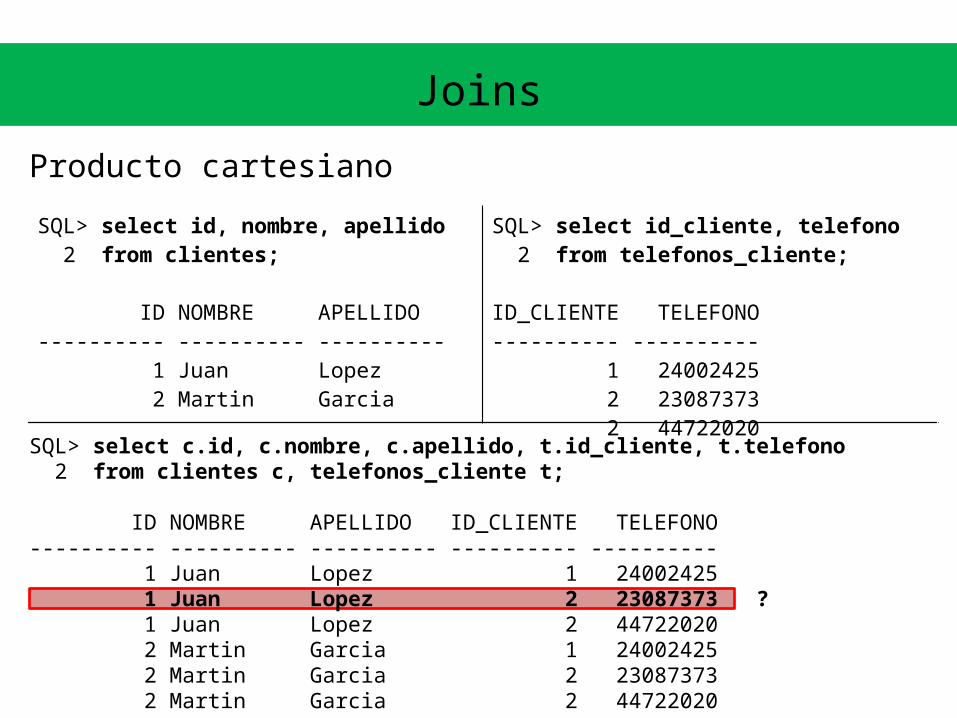
• ¿Qué obtenemos del producto cartesiano de una tabla de clientes con 2.000 tuplas y una tabla de teléfonos con 4.000 tuplas? ¿todas las tuplas nos interesan?
Joins
Producto cartesiano
SQL> select c.id, c.nombre, c.apellido, t.id_cliente, t.telefono 2 from clientes c, telefonos_cliente t;
ID NOMBRE APELLIDO ID_CLIENTE TELEFONO---------- ---------- ---------- ---------- ---------- 1 Juan Lopez 1 24002425 1 Juan Lopez 2 23087373 ? 1 Juan Lopez 2 44722020 2 Martin Garcia 1 24002425 2 Martin Garcia 2 23087373 2 Martin Garcia 2 44722020
SQL> select id, nombre, apellido 2 from clientes;
ID NOMBRE APELLIDO---------- ---------- ---------- 1 Juan Lopez 2 Martin Garcia
SQL> select id_cliente, telefono 2 from telefonos_cliente;
ID_CLIENTE TELEFONO---------- ---------- 1 24002425 2 23087373 2 44722020

Joins
Equi joins
• Nos interesan las tuplas donde matchea el valor de clientes.id con el de telefonos_cliente.id_cliente
SQL> select c.id, c.nombre, c.apellido, t.id_cliente, t.telefono 2 from clientes c, telefonos_cliente t 3 where c.id = t.id_cliente;
ID NOMBRE APELLIDO ID_CLIENTE TELEFONO---------- ---------- ---------- ---------- ---------- 1 Juan Lopez 1 24002425 2 Martin Garcia 2 23087373 2 Martin Garcia 2 44722020
• Ya que el ID se repite, podemos omitir una de las columnas, o incluso omitir las dos ya que es una surrogate key
Joins
Equi joins
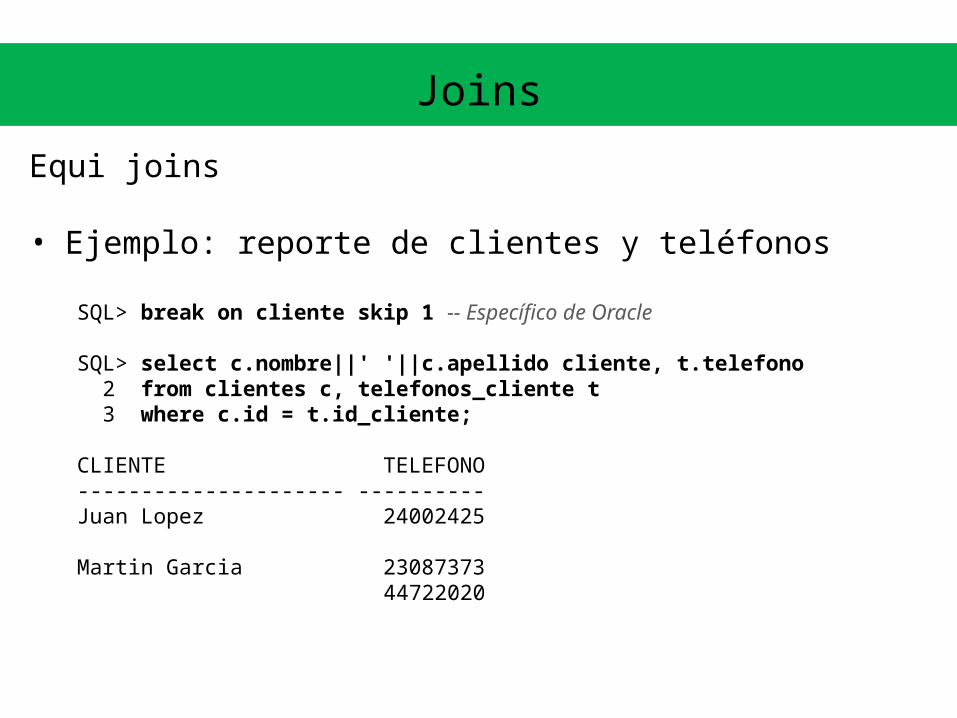
• Ejemplo: reporte de clientes y teléfonos
SQL> break on cliente skip 1 -- Específico de Oracle
SQL> select c.nombre||' '||c.apellido cliente, t.telefono 2 from clientes c, telefonos_cliente t 3 where c.id = t.id_cliente;
CLIENTE TELEFONO--------------------- ----------Juan Lopez 24002425
Martin Garcia 23087373 44722020
Joins
Outer joins
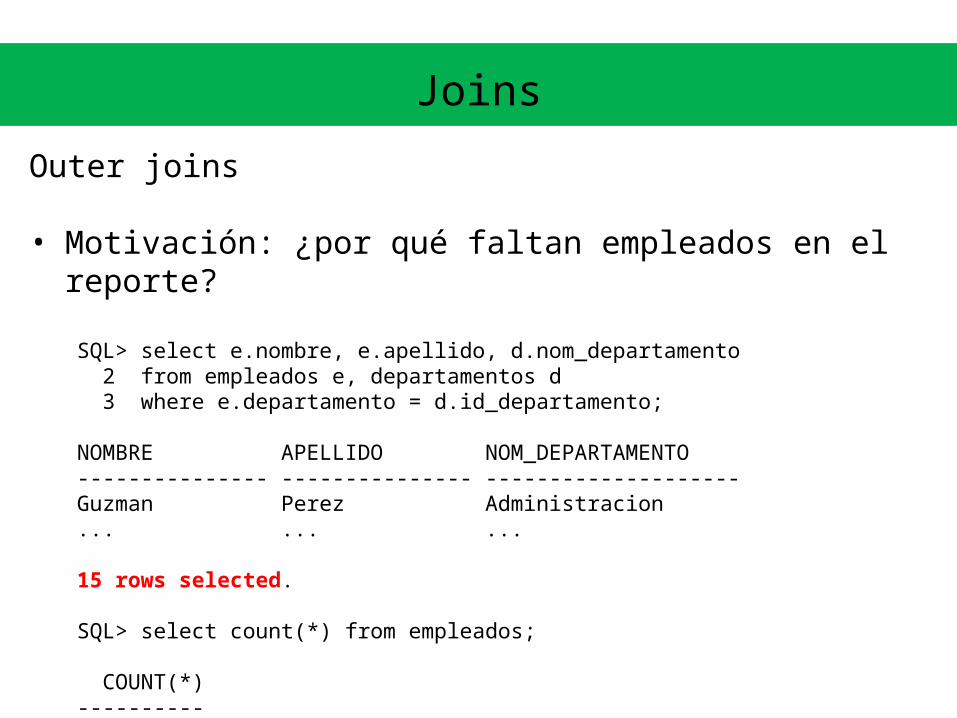
• Motivación: ¿por qué faltan empleados en el reporte?
SQL> select e.nombre, e.apellido, d.nom_departamento 2 from empleados e, departamentos d 3 where e.departamento = d.id_departamento;
NOMBRE APELLIDO NOM_DEPARTAMENTO--------------- --------------- --------------------Guzman Perez Administracion... ... ...
15 rows selected.
SQL> select count(*) from empleados;
COUNT(*)---------- 18

Joins
Outer joins
• No hay un departamento con ID NULL en la tabla de departamentos, y aunque lo hubiera, NULL = NULL se evalúa como falso
• Podemos querer relajar el join para aceptar tuplas de una de las tablas aunque tengan valor NULL en alguna columna por la que se realiza el join
• En el caso anterior, querríamos las tuplas “de la izquierda”:
Nombre Apellido Departamento ---------- ---------- ------------
Matías Pereyra <null>

Joins
Outer joins
• El outer join permite hacer exactamente eso (left, nos da las columnas de la izquierda que no matchean):
SQL> select e.nombre, e.apellido, d.nom_departamento 2 from empleados e left outer join departamentos d 3 on e.departamento = d.id_departamento;
NOMBRE APELLIDO NOM_DEPARTAMENTO--------------- --------------- --------------------Luis Rodriguez Administracion... ... ...Luisa Herrera InvestigacionMatias PereyraJuana GarciaJorge Lopez
18 rows selected.

Joins
Outer joins
• Right, nos da las columnas de la derecha que no matchean:
SQL> select e.nombre, e.apellido, d.nom_departamento 2 from empleados e right outer join departamentos d 3 on e.departamento = d.id_departamento;
NOMBRE APELLIDO NOM_DEPARTAMENTO--------------- --------------- --------------------Guzman Perez Administracion... ... ...Emiliano Pereira InvestigacionAstrid Brandner InvestigacionSantiago Fontenla InvestigacionGuillermo Eastman InvestigacionMartin Beracochea Investigacion Sistemas
16 rows selected.

Joins
Outer joins
• Left outer join nos introduce tuplas en el join, que sólo existen en la tabla de la izquierda
• Right outer join nos introduce tuplas en el join, que sólo existen en la tabla de la derecha
• Existe también el full outer join, que nos introduce en el join las tuplas que introduce el left y el right outer join (probarlo)
• Oracle tiene una sintaxis alternativa (pero propietaria) para especificar los outer joins en el predicado:
where e.departamento(+) = d.id_departamento;

Joins
Subconsultas
• El resultado de una consulta (result-set) se puede usar como subconsulta para predicar en otra
• Ejemplo: queremos los empleados de Ventas e Investigación
SQL> select nombre, apellido 2 from empleados 3 where departamento in ( 4 select id_departamento 5 from departamentos 6 where nom_departamento in ('Ventas', 'Investigacion') 7 );
• Usamos “in” porque el result-set es un conjunto …

Joins
Subconsultas
• Si estamos seguros que el result-set es de cardinalidad 1, podemos usar “=“
• Ejemplo: queremos los empleados de Ventas
SQL> select nombre, apellido 2 from empleados 3 where departamento = ( 4 select id_departamento 5 from departamentos 6 where nom_departamento = 'Ventas' 7 );
NOMBRE APELLIDO--------------- ---------------Fernando Pereyra... ...

Joins
Subconsultas
• Si nos equivocamos, y el result-set es de cardinalidad > 1, obtendremos un error
SQL> select nombre, apellido 2 from empleados 3 where departamento = ( 4 select id_departamento 5 from departamentos 6 ); select id_departamento *ERROR at line 4:ORA-01427: single-row subquery returns more than one row

Joins
Operaciones de conjuntos
• Se pueden realizar las operaciones de conjuntos UNION, INTERSECT y MINUS, con sus variantes “ALL”
SQL> select sysdate fecha from dual 2 union select sysdate fecha from dual;
FECHA----------23/05/2012
SQL> select sysdate fecha from dual 2 union all select sysdate fecha from dual;
FECHA----------23/05/201223/05/2012

Ejercicios
Ejercicios
• Obtener los nombres y apellidos de los empleados que tendrán más de un año de antigüedad al 01/06/2012
• Obtener los subtotales de sueldos de cada departamento y el total de sueldos, en la misma consulta
• Obtener el nombre de todos los empleados, con el nombre de su cargo y el nombre de su departamento

Ejercicios
Nombres y apellidos de los empleados que tendrán más de un año de antigüedad al 01/06/2012
SQL> select nombre, apellido 2 from empleados 3 where add_months(fecha_ingreso, 12) 4 <= to_date('01/06/2012', 'dd/mm/yyyy');
NOMBRE APELLIDO--------------- ---------------Matias Pereyra... ...Rodrigo LemosEmiliano PereiraAstrid BrandnerSantiago FontenlaGuillermo Eastman
14 rows selected.

Ejercicios
Subtotales de sueldos de cada departamento y el total de sueldos, en la misma consulta
SQL> select nvl(d.nom_departamento, 'Sin departamento') departamento, 2 sum(e.sueldo) sueldos 3 from empleados e left outer join departamentos d 4 on e.departamento = d.id_departamento 5 group by d.nom_departamento 6 union all 7 select 'Total', sum(sueldo) 8 from empleados;
DEPARTAMENTO SUELDOS-------------------- ----------Ventas 232000Investigacion 547000Sin departamento 100000Administracion 232000Total 1111000

Ejercicios
Nombre de todos los empleados, con el nombre de su cargo y el nombre de su departamento
SQL> select e.nombre, e.apellido, c.nom_cargo, d.nom_departamento 2 from (empleados e left outer join departamentos d 3 on e.departamento = d.id_departamento), cargos c 4 where e.cargo = c.id_cargo;
NOMBRE APELLIDO NOM_CARGO NOM_DEPARTAMENTO--------------- ------------ ---------------------- -----------------Rosana Nu??ez Administrativo senior Administracion... ... ... ...Karina Garcia Subgerente InvestigacionLuisa Herrera Gerente InvestigacionMatias Pereyra DirectorJuana Garcia Socio DirectorJorge Lopez Socio Director
18 rows selected.


















