
Accelerazione FPGA per applicazioni di gaming · 4 Introduzione Le FPGA nascono nel 1985, da...
34
Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Calcolatori Elettronici 1 Accelerazione FPGA per applicazioni di gaming Anno Accademico 2013/2014 Candidato: Catello Rosario Ciofffi matr. N46/1344
Transcript of Accelerazione FPGA per applicazioni di gaming · 4 Introduzione Le FPGA nascono nel 1985, da...

Scuola Politecnica e delle Scienze di Base Corso di Laurea in Ingegneria Informatica Elaborato finale in Calcolatori Elettronici 1
Accelerazione FPGA per applicazioni di gaming
Anno Accademico 2013/2014 Candidato: Catello Rosario Ciofffi matr. N46/1344

A tutti i miei cari e a coloro che mi hanno sostenuto.

Indice
Indice .................................................................................................................................................. III
Introduzione ......................................................................................................................................... 4
Capitolo 1: FPGA................................................................................................................................. 5
1.1 Architettura ................................................................................................................................ 6
1.1.1 Blocchi logici configurabili ............................................................................................... 7
1.1.2 Linee di interconnessione ................................................................................................. 8
1.1.3 Blocchi di ingresso/uscita.................................................................................................. 9
1.2 Tecnologie di programmazione ................................................................................................. 9
1.2.1 Memoria statica ............................................................................................................... 10
1.2.2 Flash ................................................................................................................................. 10
1.2.3 Anti-Fuse .......................................................................................................................... 10
1.3 Cenni sulla progettazione su FPGA ......................................................................................... 11
Capitolo 2: Background ..................................................................................................................... 14
2.1 Algoritmi per la ricerca ............................................................................................................ 15
2.1.1 Minimax ........................................................................................................................... 15
2.1.2 Alpha-beta pruning ......................................................................................................... 18
2.1.3 Tavola di Trasposizione e algoritmo di Zobrist ........................................................... 19
2.1.4 Quiescence search ........................................................................................................... 21
Capitolo 3: Da software a hardware ................................................................................................... 23
3.1 Micro-Max ............................................................................................................................... 23
3.1.1 Rappresentazione pezzi .................................................................................................. 23
3.1.2 Rappresentazione tavola................................................................................................. 23
3.1.3 Variabili globali e macro ................................................................................................ 24
3.1.4 Descrizione del software ................................................................................................. 24
Descrizione Hardware .................................................................................................................... 28
Conclusioni ........................................................................................................................................ 33
Bibliografia ........................................................................................................................................ 34

4
Introduzione
Le FPGA nascono nel 1985, da un’intuizione di Ross Freeman e Bernard Vonderschmitt,
fondatori della Xilinx. L’idea era quella di unire l’user control e il time to market dei PLD
con gli stessi costi e le densità che offrivano i gate array. Le caratteristiche di flessibilità,
capacità di implementare funzioni complesse e con basso time to market trovano ancora
oggi ampio raggio d’azione in applicazioni embedded.
In questo elaborato si intende mostrare come le potenzialità delle FPGA, possano essere
sfruttate per realizzare in hardware, un software di gaming ottenendo così delle prestazioni
migliori. In particolare viene approfondito il gioco degli scacchi, tenendo come
riferimento il programma Micro-Max.
Nel Capitolo 1 viene approfondita la struttura delle FPGA, passando dalla tecnologia a
cenni sulla programmazione.
Nel Capitolo 2 si analizza l’architettura generale di un videogioco di scacchi,
approfondendo gli algoritmi fondamentali per la realizzazione di un’intelligenza
artificiale.
Il Capitolo 3 si divide in due parti. Nella prima viene fornita una descrizione del software
Micro-Max. Nella seconda si illustra un possibile progetto in hadware di alto livello di tale
software.

5
Capitolo 1: FPGA
Con l’acronimo FPGA (Field Programmable Gate Array), si indica una particolare classe
di circuiti integrati a logica programmabile. Tali dispositivi sono costituiti da milioni di
celle logiche, ognuna delle quali può specificare una determinata funzione booleana e può
comunicare con le altre tramite una rete di interconnessioni. La caratteristica principale
delle FPGA è che sono programmate direttamente dall’utente, senza la necessità di dover
produrre un dispositivo specifico per una determinata applicazione come nei dispositivi
ASIC (Application Specific Integrated Circuit). I principali produttori di FPGA sono
Xilinx e Altera.
Le FPGA presentano diversi vantaggi rispetto ai dispositivi ASIC. Per produzioni di
piccole e medie dimensioni, le FPGA sono delle soluzioni più economiche e con un time
to market (TTM) più veloce rispetto agli ASIC, che hanno bisogno di più tempo e denaro
per la realizzazione del primo dispositivo. Inoltre, le FPGA hanno una notevole
flessibilità, in quanto possono essere riconfigurate semplicemente riprogrammando il
dispositivo e hanno dei cicli di design più semplice (poiché il software di sviluppo si
prende carico del routing, del timing e della disposizione dei componenti). Tuttavia la
flessibilità dei dispositivi FPGA presenta dei costi. Infatti, le FPGA sono più grandi, più
lente e consumano più potenza dei dispositivi ASIC. Di conseguenza le FPGA sono
particolarmente inadatte per applicazioni General Purpose (basati sui microprocessori) o
Special Purpose, ambito dominato dagli ASIC. Nonostante questi svantaggi, le FPGA
rappresentano una valida alternativa per lo sviluppo di sistemi digitali grazie al basso costo
unitario, per il basso time to market e la enorme flessibilità.

6
1.1 Architettura
La struttura generale di una FPGA è composta dai seguenti componenti:
Configurable Logic Blocks (CLB);
Elementi di interconnessione programmabile;
Blocchi di I/O.
Tipicamente i CLB sono disposti in una matrice bidimensionale e interconnessi con risorse
di routing programmabili. I blocchi di I/O sono, invece, posizionati ai margini della
matrice e, come i CLB, sono connessi alle risorse di routing (Fig. 1).
Figura 1: Struttura di una FPGA.

7
1.1.1 Blocchi logici configurabili
Il blocco CLB è un componente fondamentale per le FPGA e ne rappresenta la base
logica. Le CLB possono essere costituite da transistor oppure da veri e propri processori.
In generale si utilizzano CLB basate su Look-Up Tables (LUT), le quali forniscono un
buon compromesso nella granularità dei blocchi logici. Il CLB più semplice è formato da
una LUT, un flip-flop tipicamente di tipo D e un multiplexer per selezionare l’uscita (Fig.
2).
Figura 2: Struttura di un CLB.
Figura 3: Struttura di una LUT a 2 ingressi.

8
La LUT è un componente capace di implementare una qualsiasi funzione di N variabili
Booleane. La struttura hardware di quest’ultima è costituita da una serie di celle di
memoria, tipicamente di tipo SRAM, connesse ad un insieme di multiplexer (Fig. 3).
In questo modo una LUT può essere in grado sia di generare una funzione logica che di
operare come un elemento di immagazzinamento di dati.
Le moderne FPGA sono composte anche da elementi più complessi di quelli sopra
descritti come, ad esempio, memorie, moltiplicatori, addizionatori, etc. Ciò è giustificato
dal fatto che includere tali componenti è più efficiente che implementarli tramite le LUT.
Ad esempio, nelle FPGA della Xilinx sono presenti delle memorie RAM aggiuntive
chiamate Block RAM (BRAM). Una BRAM può essere di tipo dual-port o single-port, nel
primo caso il singolo blocco è come se fosse costituito da due memorie indipendenti, nel
secondo solo da una memoria. Più BRAM possono essere collegate insieme in modo da
formare blocchi di memoria più grandi. Nel caso della famiglia Spartan-3 ogni BRAM
comprende circa 18 Kb di memoria, e a seconda dello specifico modello si possono avere
da 4 a 104 blocchi, per una memoria massima che va da 72 Kb a 1872 Kb.
1.1.2 Linee di interconnessione
La rete di routing programmabile è necessaria per connettere tra di loro i vari componenti
Figura 4: Island-style architecture.

9
di una FPGA. Questa rete consiste in una serie di collegamenti e swicth, configurabili
tramite tecnologia programmabile. Sulla base della disposizione delle risorse di routing, le
architetture FPGA possono essere di tipo island-style e gerarchiche.
L’architettura island-style (Fig. 4) è la più comune in ambito commerciale. In questo tipo
si distinguono gli switch box, che consentono la connessione delle linee di routing
orizzontali e verticali, e le connection box che connettono i blocchi logici alla rete di
routing.
Nell’architettura di tipo gerarchico i blocchi logici sono divisi in cluster separati, connessi
in modo ricorsivo tale da formare una struttura gerarchica.
1.1.3 Blocchi di ingresso/uscita
I blocchi di ingresso/uscita si occupano della gestione dei segnali input/output delle FPGA
attraverso il controllo dei pin del chip. Nei dispositivi Xilinx, per esempio, ogni blocco
controlla un pin che può essere configurato come input, output, bi-direzionale o tri-state.
Sono inoltre presenti delle resistenze di pull-up/pull-down che permettono di caratterizzare
lo stato del piedino nelle situazioni di alta impedenza.
1.2 Tecnologie di programmazione
Esistono diverse tecnologie di programmazione che influenzano l’architettura delle
interconnessioni e dei blocchi logici. Tra le principali tecnologie vi sono: memoria statica,
flash e anti-fuse.

10
1.2.1 Memoria statica
È la tecnologia più usata dalle case produttrici e consiste nell’usare celle di memoria
statica SRAM (Fig. 5) per la configurazione delle interconnessioni e dei blocchi logici.
L’utilizzo delle SRAM è diventato predominante nei dispositivi FPGA, a causa della
riprogrammabilità e poiché tali celle possono essere create tramite CMOS diminuendo le
dimensioni e i consumi di potenza dinamica. Tuttavia le SRAM sono dispositivi volatili
per cui è necessario introdurre elementi aggiuntivi in grado di ripristinarne lo stato. Ciò
determina un aumento dei costi e overhead.
1.2.2 Flash
Questa tecnologia consiste nell’utilizzare memorie EEPROM o flash. Essa ha il vantaggio
di avere dimensioni più ridotte e di non essere volatile. A differenza delle SRAM, però,
possono essere riprogrammate solo un numero limitato di volte. Inoltre non viene
utilizzato il processo standard CMOS.
1.2.3 Anti-Fuse
Tale tecnica prevedo l’utilizzo di elementi costituiti da un sottile strato di silicio amorfo
tra due strati di materiale conduttore. La programmazione avviene applicando al
Figura 5: Blocco di memoria statica.

11
dispositivo una tensione a rendere conduttivo lo strato di silicio in maniera permanente. Il
principale vantaggio di questa tecnologia risiede nelle dimensioni notevolmente ridotte.
Tuttavia una volta programmati i dispositivi anti-fuse non possono essere più riconfigurati
e ciò rappresenta un grave svantaggio.
1.3 Cenni sulla progettazione su FPGA
In genere le FPGA possono essere programmate utilizzando dei linguaggi di descrizione
dell’hardware (HDL) quali il VHDL e il Verilog, oppure disegnando lo schema del
circuito da implementare tramite un apposito software. Tipicamente le case produttrici di
FPGA forniscono gratuitamente dei software di sviluppo che facilitano la fase di
progettazione.
Il processo che converte la descrizione del circuito in un formato caricabile su una FPGA,
può essere diviso in cinque fasi:
Sintesi;
Simulazione;
Mapping;
Place e Route;
Figura 6: Dispositivo anti-fuse.

12
Generazione del bitstream.
La sintesi trasforma la descrizione del circuito in linguaggio HDL, in un circuito
composto da porte logiche e flip-flop.
Il mapping crea la corrispondenza tra i componenti del circuito ottenuti nella fase di
sintesi e i CLB che compongono la FPGA. In questa fase vengono effettuate anche delle
ottimizzazioni per ridurre lo spazio occupato oppure per aumentare le prestazioni.
Nella fase di place e route vengono assegnate le celle logiche a una specifica posizione
dell’FPGA e create le interconnessioni.
Una volta posizionati gli elementi circuitali e effettuate le connessioni, viene prodotto il
bitstream che attraverso un apposito loader viene scaricato sul dispositivo FPGA.
La simulazione è una fase intermedia in cui si verifica il corretto funzionamento del
circuito.

13

14
Capitolo 2: Background
L’applicazione che verrà approfondita in questo secondo capitolo è un videogioco di
scacchi. Gli algoritmi usati per l’intelligenza artificiale sono usati anche in altre
applicazioni.
In base alla teoria dei giochi, gli scacchi sono un gioco sequenziale a informazione perfetta
(cioè il giocatore ha conoscenza di tutte le mosse eseguite dall’avversario, delle sue
strategie e la loro utilità) e a somma zero (cioè la vittoria di un giocatore determina la
sconfitta dell’altro). Questo tipo di applicazioni possono essere analizzati usando un albero
delle mosse, in cui ogni nodo rappresenta uno stato del gioco (cioè una posizione dei pezzi
sulla scacchiera) e ogni ramo indica una particolare mossa da parte del giocatore di turno
verso un determinato stato. Ciò implica che data una qualsiasi posizione dei pezzi sulla
scacchiera, a questa possa corrispondere:
1. Una vittoria per il giocatore bianco;
2. Un pareggio;
3. Una vittoria per il giocatore nero;
La grandezza dell’albero di gioco, dovuta alla complessità delle regole degli scacchi,
rende praticamente impossibile effettuare per un dato stato una valutazione esatta. Per
questo motivo si utilizzano funzioni euristiche, che tengano conto del valore dei singoli
pezzi, della loro posizione, della fase di gioco, etc.
In un videogioco di scacchi convenzionale si distinguono tre componenti:
Un generatore di mosse;
Una funzione di ricerca;

15
Uno stimatore di posizione.
La funzione di ricerca comprende i meccanismi per l’esplorazione dell’albero delle mosse.
Raggiunto un nodo foglia dell’albero, lo stimatore deve assegnare a tale nodo un
opportuno valore, per ognuno di essi, il generatore deve fornire tutte le possibili mosse che
un determinato pezzo può eseguire in accordo alle regole degli scacchi.
A questi elementi vanno aggiunti anche un componente di comunicazione e un selettore
per la migliore mossa. Il primo è essenziale per poter comunicare le mosse in ingresso o in
uscita. Il secondo serve ad aumentare la velocità della ricerca.
2.1 Algoritmi per la ricerca
L’algoritmo utilizzato per implementare la funzione di ricerca è l’alpha-beta o potatura
alpha-beta, esso è un miglioramento del minimax. Di seguito viene fornita una panoramica
su tali algoritmi e le principali tecniche usate per migliorarne l’efficienza.
2.1.1 Minimax
Il minimax è un algoritmo ricorsivo usato per determinare la prossima mossa da effettuare.
Ad ogni possibile stato del gioco viene assegnato un valore. Tale valore indica la validità
di una mossa per un determinato giocatore.
Un possibile metodo è quello di assegnare a una posizione il valore +1, nel caso questa
porti a vittoria certa il giocatore A e -1 nel caso del giocatore B. Alternativamente si può
usare rispettivamente il valore +∞ o – ∞. Per questo motivo si dice che A è il giocatore
massimizzante e B quello minimizzante. Poichè nel caso degli scacchi non è
computazionalmente possibile analizzare l’intero albero delle mosse, quindi determinare
una vittoria o una sconfitta certa, ai nodi viene assegnato un valore finito determinato in
base a delle euristiche. Si può quindi limitare l’analisi effettuata dal minimax a un
determinato numero di mosse dette ply.
L’algoritmo inizia valutando i nodi foglia, situate al livello n dell’albero, tramite una

16
funzione di valutazione. Si procede, quindi, assegnando ad ogni nodo che si trova alla
profondità n-1 il minimo dei valori che è stato assegnato ai nodi figli. Ai nodi del livello n-
2 viene assegnato, invece, il massimo valore dei nodi figli di livello n-1. L’algoritmo
continua così fino a raggiungere il nodo radice a cui sarà assegnato il valore associato al
nodo che minimizza la massima perdita da parte del giocatore di turno.
Poiché il valore della posizione per il giocatore A è uguale alla negazione del valore della
posizione per il giocatore B, l'algoritmo può essere scritto in un modo più semplice, non
facendo alcuna distinzione tra il giocatore massimizzante e quello minimizzante. Tale
variante del minimax ritorna il valore negato di ogni sotto-albero e massimizza sempre il
punteggio, da qui il nome di negamax.
Di seguito viene fornito uno pseudocodice sia per il minimax che per il negamax.
function minimax(node, depth, maximizingPlayer)
if depth = 0 or node is a terminal node
return the heuristic value of node
if maximizingPlayer
bestValue := -∞
for each child of node
Figura 7: Esempio minimax.

17
val := minimax(child, depth - 1, FALSE)
bestValue := max(bestValue, val)
return bestValue
else
bestValue := +∞
for each child of node
val := minimax(child, depth - 1, TRUE)
bestValue := min(bestValue, val)
return bestValue
//chiamata iniziale per il giocatore massimizzante
minimax(origin, depth, TRUE)
function negamax(node, depth, color)
if depth = 0 or node is a terminal node
return color * the heuristic value of node
bestValue := -∞
foreach child of node
val := -negamax(child, depth - 1, -color)
bestValue := max( bestValue, val )
return bestValue
//chimata iniziale per il giocatore A
rootValue := negamax( rootNode, depth, 1)
//chiamata iniziale per il giocatore B
rootValue := negamax( rootNode, depth, -1)

18
2.1.2 Alpha-beta pruning
Per migliorare i tempi della ricerca, l'algoritmo minimax può essere ottimizzato
utilizzando un meccanismo che prende il nome di alpha-beta pruning ovvero potatura
alpha-beta. Il vantaggio di tale meccanismo è quello di eliminare rami dell'albero senza
che il risultato finale sia compromesso. Infatti il punteggio dei nodi che appartengono ai
rami eliminati non influisce sul valore del nodo radice. Il miglioramento che si ottiene
rispetto al semplice minimax o negamax, è quello di poter analizzare nello stesso tempo un
albero con una profondità quasi raddoppiata.
L'algoritmo mantiene due variabili, alpha e beta, che rappresentano rispettivamente il
massimo punteggio ottenibile dal giocatore massimizzante e il minimo punteggio
ottenibile dal giocatore minimizzante. Inizialmente alpha è posto uguale a meno infinito,
mentre beta a più infinito. La ricerca procede secondo l'algoritmo minimax, aggiornando i
valori di alpha e beta. Se per un nodo si ha che alpha diventa maggiore o uguale a beta, la
ricerca per quel determinato sotto-albero si interrompe (avviene la potatura) e procede
analizzando il successivo.
Lo pseudocodice relativo è il seguente.
function alphabeta(node, depth, α, β, maximizingPlayer)
if depth = 0 or node is a terminal node
return the heuristic value of node
if maximizingPlayer
for each child of node
α := max(α, alphabeta(child, depth - 1, α, β, FALSE))
if β ≤ α
break (* β cut-off *)
return α

19
else
for each child of node
β := min(β, alphabeta(child, depth - 1, α, β, TRUE))
if β ≤ α
break (* α cut-off *)
return β
//chiamata iniziale
alphabeta(origin, depth, -∞, +∞, TRUE)
Per migliorare ulteriormente la ricerca effettuata dal minimax con potatura alpha-beta si
può utilizzare la strategia iterative deepning. Essa consiste nell’eseguire ripetutamente una
ricerca depth-limited, incrementando ad ogni iterazione il livello di profondità. In questo
modo il numero di nodi che vengono esplorati è maggiore rispetto a una ricerca senza tale
strategia, ottenendo una migliore stima del valore dei nodi.
2.1.3 Tavola di Trasposizione e algoritmo di Zobrist
Gli algoritmi presentati precedentemente non hanno memoria nel senso che non tengono
traccia delle posizioni già esplorate. Pertanto una stessa posizione può essere valutata più
volte, in quanto si può arrivare ad essa utilizzando differenti combinazioni di mosse dette
trasposizioni. La tavola di trasposizione è usata proprio per evitare questo problema. Una
volta trovata la valutazione di una determinata posizione, questa viene memorizzata nella
tavola e quando, durante la ricerca, viene incontrata nuovamente si può evitare di
effettuare ex novo la valutazione utilizzando il punteggio memorizzato.
Un problema della tavola di trasposizione è che la ricerca di posizioni collocate in maniera
casuale all’interno di essa può richiedere un tempo notevole. Per risolvere questo
problema si utilizza l’algoritmo di Zobrist. Tale algoritmo consiste nel generare stringhe di
bit casuali ognuna associata a una particolare combinazione posizione-pezzo (hash-key).

20
Ulteriori stringhe servono per l’en passant e l’arrocco. La hash-key viene ottenuta
effettuando un’operazione di XOR tra i valori casuali che appartengono alla combinazione
posizione-pezzo e alla scacchiera. Essa può essere facilmente aggiornata effettuando una
XOR con il valore della combinazione posizione-pezzo di origine e un’altra operazione di
XOR con il valore della combinazione di destinazione.
L’inconveniente con le hash-key è quello di avere delle collisioni sebbene con una
probabilità molto bassa. Una collisione avviene quando almeno due posizioni sono
mappate su una stessa hash-key.
Di seguito viene riportato un esempio di pseudocodice relativo all’usa dell’algoritmo di
zobrist negli scacchi.
//costanti
white_pawn := 1
white_rook := 2
// etc.
black_king := 12
function init_zobrist():
//la tavola viene riempita con valori casuali
table := matrice di dimensione 64×12
for i from 1 to 64: //loop sulla scacchiera
for j from 1 to 12: //loop sui pezzi
table[i][j] = random_bitstring()
function hash(board):
h := 0
for i from 1 to 64:
if board[i] != empty:
j := pezzo contenuto in board[i]

21
h := h XOR table[i][j]
return h
2.1.4 Quiescence search
Un problema che affligge l’intelligenza artificiale in numerosi giochi tra cui gli scacchi, è
l’horizon effect. Questo problema è dovuto alla limitazione della profondità di analisi
negli algoritmi di ricerca. Poiché solo una parte dell’albero è stata analizzata, per il
sistema può sembrare che un determinato evento possa essere evitato quando in effetti ciò
è impossibile. Ad esempio, l’algoritmo rileva che può catturare un pedone con la regina,
tuttavia a casa della limitazione sulla profondità non riesce a vedere che il pedone può
essere protetto da un altro pedone, che può catturare a sua volta la regina.
La quiescence search cerca di evitare l’insorgere di tale problema. Essa consiste
nell’effettuare una ricerca a maggiore profondità a partire da quei nodi che non sono
“calmi” in modo da rivelare ed evitare trappole nascoste o mosse particolarmente
svantaggiose. La definizione di nodi calmi o turbolenti, tuttavia, non è ben definita e
dipende dalla particolare implementazione.

22

23
Capitolo 3: Da software a hardware
3.1 Micro-Max
Il programma di riferimento utilizzato è Micro-max [16]. Segue una panoramica del software.
3.1.1 Rappresentazione pezzi
I pezzi sono rappresentati con 6 bit. I 3 bit meno significativi sono utilizzati per codificare
il tipo di pezzo in accordo alla seguente rappresentazione 1=P+, 2=P-, 3=C, 4=R, 5=A,
6=T, 7=D, lo 0 indica una casa vuota, mentre i bit 3 e 4 rappresentano il colore del pezzo.
Si usa la combinazione ‘01’ per il bianco e ‘10’ per il nero. Il bit più significativo (il bit 5)
vale ‘1’, se il pezzo non è stato mosso dalla sua posizione di partenza, ‘0’ se invece, è stato
mosso.
Di seguito una rappresentazione grafica.
3.1.2 Rappresentazione tavola
La scacchiera viene rappresentata con un vettore di 129 byte, in accordo col sistema
“0x88”, di cui 64 byte sono usati per contenerne i pezzi. Un byte è usato come dummy e i
restanti 64 sono vuoti. Se tale vettore viene visto come la linearizzazione di una matrice
8x16, la scacchiera si colloca nelle prime 8 colonne. In questo modo i 4 bit meno
significativi, del numero della casella, identificano la colonna, i 4 più significativi la riga.
Pertanto, utilizzando la maschera 0x88, si può sapere se una posizione appartiene o meno
alla scacchiera.

24
3.1.3 Variabili globali e macro
Le variabili globali utilizzate sono le seguenti:
V e M sono usate come
maschere per verificare la
posizione dei pezzi. S è usato
come dummy. INF è il
valore infinito usato
nell’algoritmo minimax. C
viene usata per effettuare la
conversione ASCII-posizione
sulla scacchiera. RootEval è
utilizzato per il punteggio differenziale aggiornato. Nodes indica il numero di nodi
esplorati. i serve a conservare temporaneamente la valutazione di alcuni termini. Rootep è
usato per contenere l’en passant flag per la prossima mossa. InputFrom e InputTo sono
le case di partenza e arrivo.
Le macro sono utilizzate per la creazione delle chiavi di hash.
3.1.4 Descrizione del software
La funzione che realizza l’intelligenza artificiale del programma può essere divisa in tre
parti: una per il Zobrist hashing, una per il generatore di mosse e l’ultima costituita
dall’algoritmo di ricerca.
La firma di tale funzione è:
I cui parametri sono:

25
Side per identificare il giocatore bianco o nero. Alpha, Beta e Depth usati per l’algoritmo
minimax con alpha-beta pruning. Eval è usato per la valutazione corrente. HashKeyLo e
HashKeyHi usati per la tavola di hash. epSqr utilizzato per passare la casa dove può
essere effettuato l’en passant oppure l’arrocco. LastTo contiene la casella di arrivo della
mossa precedente, nella prima chiamata, tale parametro può assumere valore 8 o 9 a
seconda che la funzione sia stata invocata per effettuare una mossa o controllarne la
validità.
Le variabili locali utilizzate sono:
J è una variabile contatore per il secondo ciclo del generatore. StepVec direzione
prelevata dal vettore delle direzioni. BestScore valore del punteggio migliore. Score usato
per contenere temporaneamente alcuni termini di valutazione IterDepth contatore
utilizzato per l’iterative deepening e indica la profondità. h usata per calcolare la
profondità rimanente. i (vedi var. globali) inizializzato a 8 per scorrere la tavola di hash.
SkipSqr indica la casella saltata nel caso di doppia mossa del pedone o re. RookSqr
indica la casella della torre se viene eseguito l’arrocco altrimenti contiene il valore dummy
S. victim pezzo candidato alla cattura. PieceType contiene il tipo di pezzo che è usato per
la mossa. Piece pezzo che sta eseguendo la mossa (a differenza di PieceType comprende
anche il colore e il bit virgin). FromSqr casella d’origine della mossa attuale. ToSqr
casella di destinazione della mossa attuale. BestFrom casella di origine della mossa
migliore. BestTo casella di destinazione di mossa migliore qualora il bit di valore 8 sia
settato, se è alzato il bit S la mossa non è un arrocco. CaptSqr casa in cui è situato il
pezzo victim. Nel caso di en passant viene settato il bit di valore 16. StartSqr casella di
partenza per il generatore.
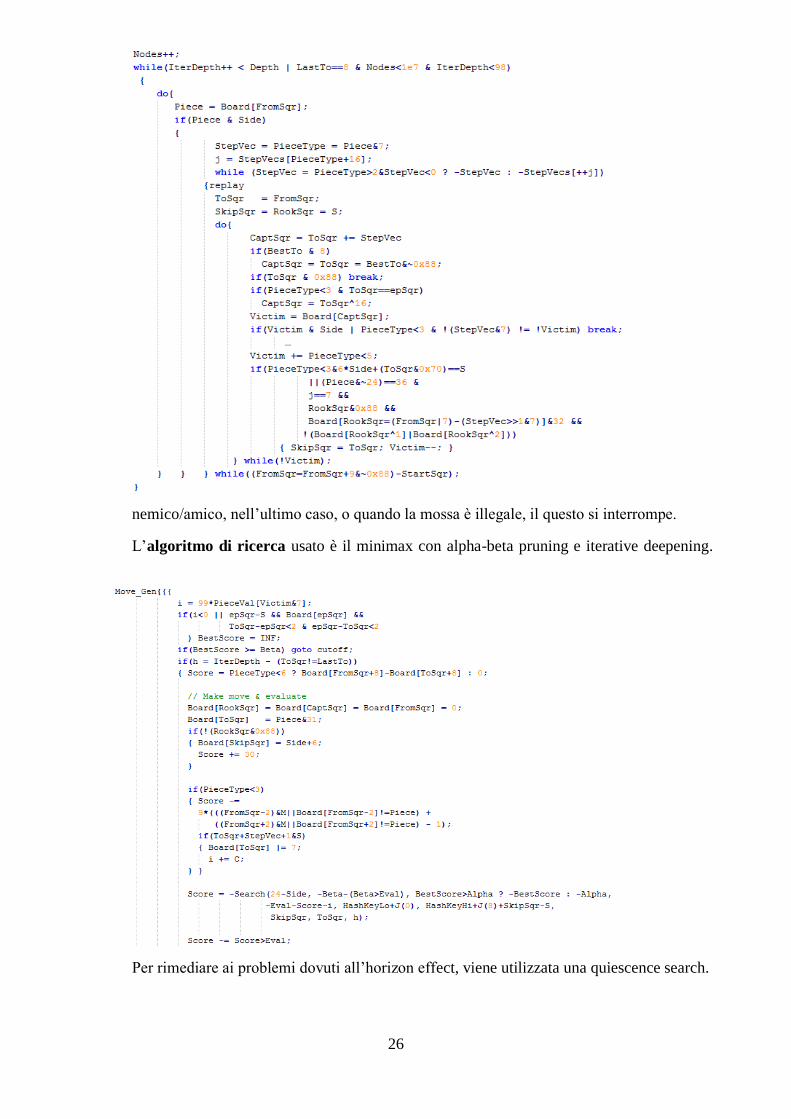
Il generatore è stato implementato tramite tre cicli innestati. Il più esterno scansiona la
scacchiera per trovare i pezzi che appartengono al giocatore di turno. Quando viene
rinvenuto un pezzo, il secondo ciclo effettua una ricerca per trovare la direzione valida
lungo la quale il pezzo si può muovere. L’ultimo ciclo verifica se lungo la direzione
considerata, il pezzo trova una casa vuota oppure occupata da un altro pezzo
26
nemico/amico, nell’ultimo caso, o quando la mossa è illegale, il questo si interrompe.
L’algoritmo di ricerca usato è il minimax con alpha-beta pruning e iterative deepening.
Per rimediare ai problemi dovuti all’horizon effect, viene utilizzata una quiescence search.
27
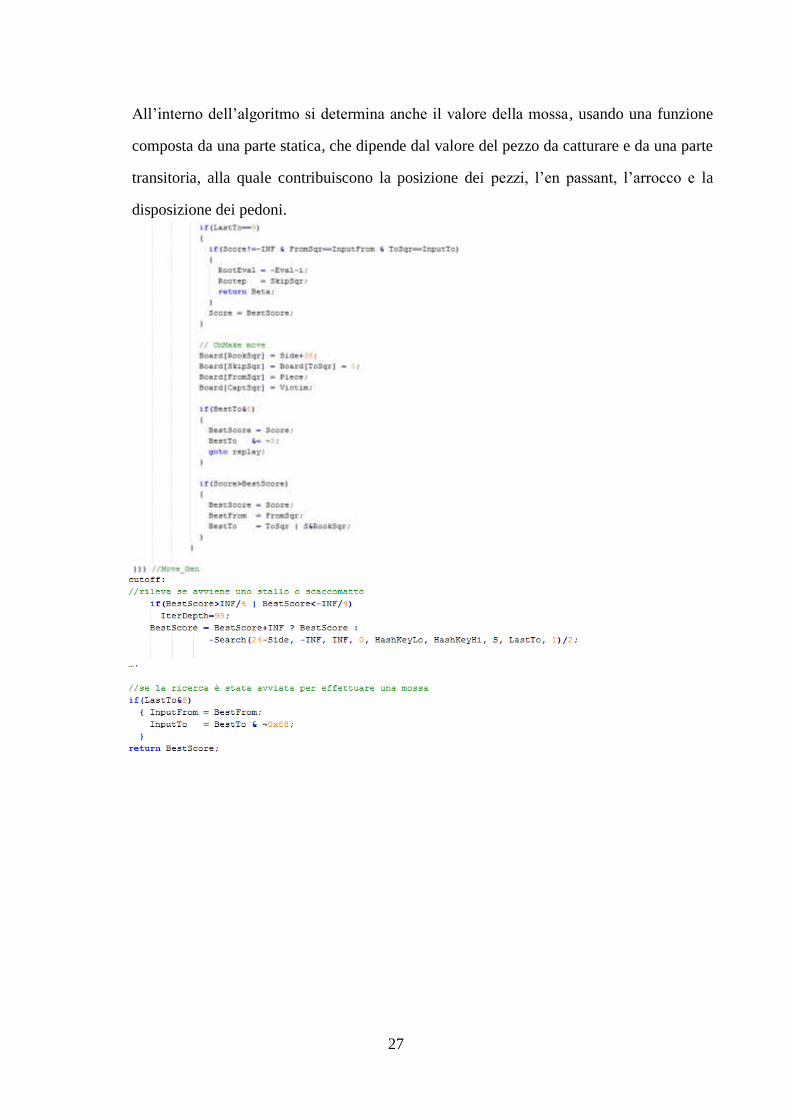
All’interno dell’algoritmo si determina anche il valore della mossa, usando una funzione
composta da una parte statica, che dipende dal valore del pezzo da catturare e da una parte
transitoria, alla quale contribuiscono la posizione dei pezzi, l’en passant, l’arrocco e la
disposizione dei pedoni.

28
La tavola di hash viene impiegata per conservare le mosse migliori e aumentare la
velocità della ricerca.
Il main ha il compito di inizializzare la scacchiera e la tavola di hash, di convertire la
mossa se inserita dall’utente, stampare a video lo stato della scacchiera e di richiamare la
funzione Search. In particolare, se la mossa non viene inserita, il programma invoca la
funzione di ricerca due volte. La prima con LastTo=8 e Depth=0 (serve a trovare la mossa
migliore e a settare le variabili globali InputFrom e InputTo, qualora l’utente non avesse
inserito alcuna mossa). La seconda volta che viene invocata, i parametri LastTo e Depth
vengono settati rispettivamente a 9 e 2 in modo da verificare la legalità della mossa, in
caso affermativo, questa viene effettuata.
Descrizione Hardware
In questo elaborato si fornirà solamente una descrizione di alto livello per quanto riguarda
l’implementazione hardware di un videogioco. Lo schema presentato in figura 7 può
essere utilizzato, effettuando opportune modifiche, in differenti applicazioni. Con
riferimento al gioco degli scacchi e in particolare al software Micro-Max, esso si compone
di tre blocchi fondamentali: il Controllore, il Datapath e il Controller RAM.
Il blocco Controllore è la realizzazione di una macchina a stati finiti, il cui compito è
quello di verificare che il flusso logico del programma sia eseguito correttamente. Esso
riceve in ingresso degli opportuni segnali di stato provenienti dal Datapath, che vengono
elaborati da un circuito fornendo in uscita dei segnali di controllo che abiliteranno o meno
differenti percorsi all’interno del Datapath.
Per aumentare l’efficienza della ricerca, in Micro-Max, viene utilizzata una tavola di hash.

29
Poiché la sua dimensione è dell’ordine dei MegaByte, quantità eccessiva per una singola
FPGA, bisogna prevedere l’utilizzo di una memoria esterna abbastanza capiente da
ospitarla. Per questo motivo, vi è la necessità di introdurre il controller RAM che ha il
compito di interfacciarsi con la memoria esterna fornendo le funzionalità di prelievo e
inserimento dei dati provenienti o destinati al datapath.
Il daptapath rappresenta il centro di calcolo del sistema. Esso è costituito da tre elementi:
i dati, gli operatori e i collegamenti. A seconda dei segnali di controllo provenienti dal
controllore, vengono abilitati differenti percorsi tra i dati e le operazioni. Inoltre, dal
datapath provengono anche i segnali di stato che consentono al controllore di poter
verificare l’esecuzione del programma.
In Figura viene riportato il datapath relativo alla funzione di ricerca utilizzata in Micro-
Max. Per ottenere il circuito, si è partiti con l’analizzare il codice, e ad ogni operazione
effettuata sui dati è stata assegnata una funzione logica. Successivamente sono stati uniti
tutti i circuiti ottenendo la rete finale.
Per poter implementare su FPGA tale datapath si è stimato l’uso di circa 3500 LTU, 232
Flip-Flop per le variabili globali, 550 Flip-Flop per le variabili locali, 8 locazioni da 32 bit,
Figura 7: Schema di alto livello.

30
32 locazioni da 8 bit e 129 locazioni da 8 bit, situate in BRAM differenti per collocare
rispettivamente il vettore PieceVal, il vettore StepVecs e il vettore Board.
Si noti come questa struttura è stata realizzata considerando solo un’esecuzione iterativa e
non ricorsiva della funzione, in quanto la traduzione in hardware di algoritmi ricorsivi è un
problema di non semplice risoluzione. Per realizzare una chiamata ricorsiva si possono
utilizzare due soluzioni differenti a seconda delle performance offerte dalla FPGA. Una
possibile soluzione alla ricorsione può essere quella di replicare n volte il datapath, ciò
permetterebbe di poter separare fisicamente i livelli delle chiamate, inoltre si potrebbe
sfruttare la capacità, offerta dalle FPGA, di effettuare calcoli in parallelo in modo da
esplorare contemporaneamente un certo numero di nodi figli di uno stesso genitore. Così
facendo i tempi di ricerca possono essere ulteriormente migliorati. Questa soluzione
tuttavia presenta l’inconveniente di essere particolarmente onerosa dal punto di vista del
numero di componenti utilizzati. Una seconda soluzione meno dispendiosa, ma che non
sfrutta appieno le potenzialità offerte dal parallelismo, consiste invece di replicare
solamente il blocco relativo alle variabili locali lasciando un’unica sezione che si occupa
di effettuare i calcoli.
Le considerazioni fino ad ora fatte, sono principalmente concetti di alto livello che
richiederebbero una fase di progettazione molto lunga. Ulteriori sviluppi che si potrebbero
fare a partire da questo elaborato, sono degli approfondimenti riguardo alla progettazione
di una macchina a stati finiti che realizzi il comportamento del programma e di una rete
che effettui l’interfacciamento con la RAM esterna. Si potrebbe inoltre effettuare la
realizzazione di un blocco di comunicazione che permetta di inserire e visualizzare le
mosse effettuate. Infine una volta ottenuto un progetto abbastanza dettagliato, la fase
finale sarebbe quella di implementazione su una FPGA reale analizzandone le prestazioni.

31
Figura 8: Datapath. In rosso sono evidenziati i dati, in blu le operazioni.

32

33
Conclusioni
Sebbene questa sia stata una sfida, per me, di sicuro è stata una grande esperienza di studio
stimolante che ha arricchito il mio bagaglio culturale e che mi ha permesso di
approfondire la conoscenza della tecnologia FPGA e degli algoritmi di intelligenza
artificiale applicati in ambito gaming. Spero, infine, che questo elaborato possa offrire
spunti interessanti per ulteriori approfondimenti, a coloro che ne siano stati incuriositi.

34
Bibliografia
[1] Introduction to FPGA Design with Vivado High-Level Synthesis.
[2] www.xilinx.com, http://www.xilinx.com/fpga/asic.htm.
[3] www.xilinx.com, http://www.xilinx.com/fpga/.
[4] www.xilinx.com, http://it.wikipedia.org/wiki/Field_Programmable_Gate_Array.
[5] Rodolfo Zunino, Introduzione ai dispositivi FPGA.
[6] Farooq, Umer, Marrakchi, Zied, Mehrez, Habib, Tree-based Heterogeneous FPGA
Architectures, Chapter 2 FPGA Architectures: An Overview.
[7] en.wikipedia.org, http://en.wikipedia.org/wiki/Minimax.
[8] en.wikipedia.org, http://en.wikipedia.org/wiki/Negamax.
[9] en.wikipedia.org, http://en.wikipedia.org/wiki/Alpha%E2%80%93beta_pruning.
[10] en.wikipedia.org, http://en.wikipedia.org/wiki/Transposition_table.
[11] en.wikipedia.org, http://en.wikipedia.org/wiki/Zobrist_hashing.
[12] en.wikipedia.org, http://en.wikipedia.org/wiki/Quiescence_search.
[13] Marc Boulé, An FPGA Move Generator for the Game of Chess.
[14] Caude E. Shannon, Programming a Computer for Playing Chess.
[15] Warren Miller, A Chess Playing FPGA.
[16] home.hccnet.nl/h.g.muller, http://home.hccnet.nl/h.g.muller/max-src2.html.
[17] Spartan-3 Generation FPGA User Guide.
[18] Using Block RAM in Spartan-3 Generation FPGAs.


















