モノタロウの商品データ連携について
23
モノタロウの 商品データ連携について IT部門Web APIグループ 中山洋一 2016.04.22 MonotaRO TechTalk #1
-
Upload
monotaro-it -
Category
Software
-
view
812 -
download
3
Transcript of モノタロウの商品データ連携について

モノタロウの商品データ連携について
IT部門Web APIグループ
中山洋一
2016.04.22 MonotaRO TechTalk #1

お話しする内容
MonotaRO の商品検索システムの
インデックス処理の話をします
• システム構成
• 具体的なSolrの利用方法
• 運用上の課題

私の立ち位置
中山 洋一 / MonotaRO Web APIグループ
• 商品データの基幹-Web連携を主に担当– 基幹システム: 商品部門、物流部門からの入力
– Webシステム: ECサイトでユーザに提示
経歴
• 2015/06 MonotaRO入社– Webサービスの経験なし
• 2000年ごろから OSS contributorとして活動– FreeBSD, Wanderlust, libupnp
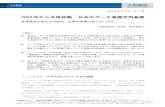
Solrを用いた商品検索
商品画像、商品名、価格、出荷目安、特長など

商品データの連携
•表側:
•裏側:
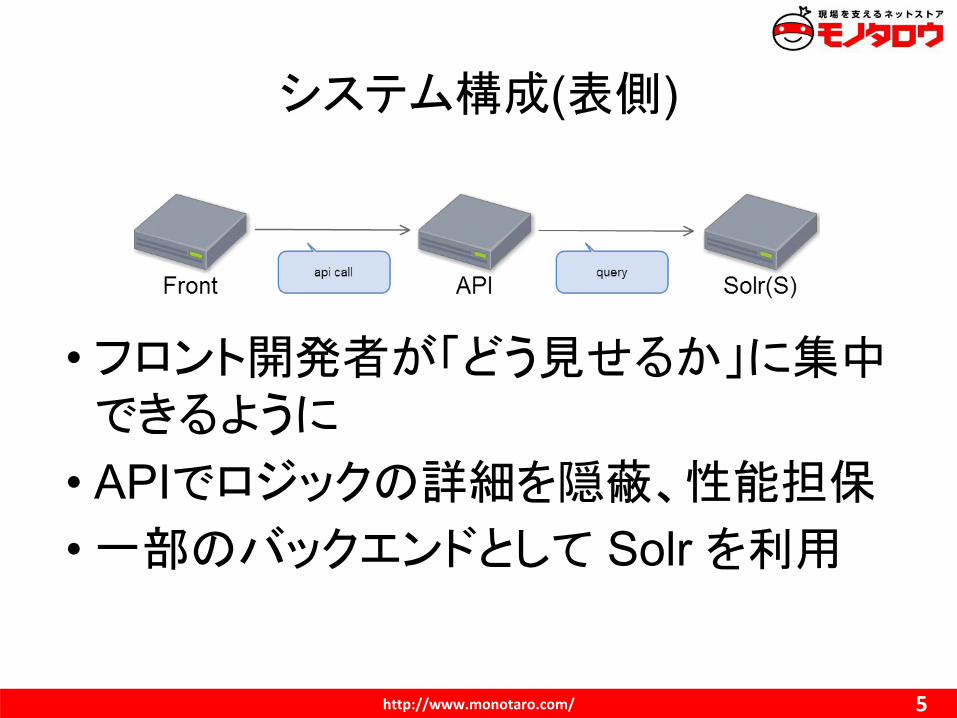
システム構成(表側)
• フロント開発者が「どう見せるか」に集中できるように
• APIでロジックの詳細を隠蔽、性能担保
• 一部のバックエンドとして Solr を利用

システム構成(裏側)
• 商品データを整形してSolrに入力
• 表側から参照されるサーバに配備
• ユーザが直接ふれない部分– 今日はこちらについて話す

前提
これから話すSolrの利用例の背景
• 販売価格が日単位で変わる
→力技で全部作り直し(実装をシンプルに)• コアをまたいでのデータの依存
→なるべくタイムラグなしで新しい情報を公開

インデクシング
shell script と Python で実装
• 商品データの取り込みと整形
– ローカルにDBスナップショットを作成
– Solrに渡す構造に整形
• 整形したデータをSolr(M)に送信
– XML生成してHTTP POST

商品データの取り込みと整形
• 日付指定でDBの差分ダンプを取得
• ローカルのDBに挿入
• SQLで schema.xml に沿うよう整形
– テーブル結合して情報をまとめる
– 価格や出荷目安を計算

Solr(M) への送信
Solr core (テーブル) ごとに
• 全削除
• XML生成とSolrへの送信
• コミット

全削除
http://solr-master:8983/solr/core-x/updateにXMLデータをHTTP POST
リクエストパラメータに stream.body= で指定してGETでも可
<delete> <query>*:*</query></delete>

Solr(M)に送信
http://solr-master:8983/solr/core-x/updateにXMLデータをHTTP POST
<add> <doc boost="0.1"> <field name="id">1</field> <field name="product_name">綿特日本一軍手600g(キナリ10ゲージ)</field> <field name="feature">10ゲージ、2本編みにより編み目が細かく泥、油などの異物が入り込みにくくなっています。着け具合も柔らかくフィット感のある軍手です。</field> <field name="sales_price">259</field> ... </doc> ...</add>

Solr(M)に送信
mutiprocessing.Process を利用して並列処理
• DBから読み込んで XML ファイルを書き出し
– IndexerのCPUを消費
• ファイルから XML を読み込んで Solr に送信
– Solr(M)のCPUを消費

コミット
docsPending に積みあがったデータを反映
ここまでの処理が成功していたら
http://solr-master:8983/solr/core-x/update?commit=trueでインデックスに反映
万が一異常発生した時には
http://solr-master:8983/solr/core-x/update?rollback=trueでロールバックしつつ開発者に通知する(発動したことはない)

レプリケーション
rsync レプリケーションを利用
• solr/scripts/ 以下に入っている
• README.txt より:These scripts are no longer actively maintained, improved, or tested,but they have been left in the source tree for use by legacy users whoare satisfied with their basic functionality.

レプリケーション(1)
コアごとに
• snapshooter (M) ... snapshot生成
• rsyncd-start (M) ... rsyncd 起動
• snappuller (S) ... rsync で snapshot を取得
• rsyncd-stop (M) ... rsyncd 停止
→スレーブに新しいインデックスを転送
(まだ公開しない)

レプリケーション(2)
コアごとに
• snapinstaller (S) … インデックスに反映
→タイミングをはかって実行、情報公開
– 日付の切り変わりに合わせて
– コア間のタイムラグを小さく

直面している課題
商品数増加にともない処理時間が伸びる取り扱い終了した商品も含め、1000万レコード超
• 日付が変わったころに反映したい
→たまに日付をまたいでしまう
• 業務時間内に更新された情報を反映したい
→開始を早められない

日々の対処
基本路線
– なるべくコストをかけない
– なるべく複雑化させない
具体的な対処としては
– サーバのスケールアップ
– 並列実行の調整
いたちごっこであるものの、わりとなんとかなっている

残っている課題
• インデックス時間との戦いがいたちごっこ
– コストと効果を見つつ小さなトライを繰り返し
• 本番相当のテストサーバがない
– スケールアップの弊害
– チューニングが本当に効くか事前に試せない

まとめ
• レコード数が増えても安定して稼動できてる
• システムの裏側に関してSolrのメンテナンスコストはほぼかかっていない
• Solrにデータ投入する部分のメンテナンスもほどほどのコストでできている
• 表側の対応によりリソースをかけられている