
5 Beskrivende mål -...
32
Beskrivende mål 101 5 Beskrivende mål Indkomstfordelingen i Danmark tæller godt 5 millioner indkomster. Med en bogstavhøjde på 3 millimeter og en linjeafstand på 2 millimeter, hvilket svarer til en normal typografisk opsætning, vil en liste med de godt 5 millioner ind- komster være omkring 25 km lang. Selvom man læser meget hurtigt og har fotografisk hukommelse, får man næppe et godt overblik over fordelingen af indkomster i Danmark ved at kigge på en sådan liste. For at få en begribelig ide om indkomstfordelingen i Danmark kan man i stedet definere nogle be- skrivende mål, som hver især afslører interessante aspekter af indkomstforde- lingen. Sådan et beskrivende mål kunne fx være middelindkomsten. Det kan også være den indkomst, der skiller de fattigste 10 % af befolkningen fra den øvrige befolkning. Da ét beskrivende mål selvfølgelig ikke alene kan beskrive en hel fordeling – middelindkomsten er ét tal imod de 5 millioner tal, som indkomstfordelingen består af – skal man imidlertid være påpasselig med at overfortolke beskrivende mål. I kapitel 2 introducerede vi forskellige beskrivende mål, blandt andet mid- delværdi og varians, som kunne bruges til at få et overblik over en virkelig population. I dette kapitel udvider vi brugen af disse beskrivende mål til sto- kastiske variabler. Dermed bliver vi i stand til at beskrive langt flere situatio- ner, hvor der også er usikkerhed involveret, fx udtrækninger fra superpopula- tioner. Beskrivende mål for stokastiske variabler kan inddeles i to klasser. Den ene klasse bygger på gennemsnitsbetragtninger. Middelindkomsten er et eksem- pel, men man kan også udlede beskrivende mål for spredningen af en forde- ling, som bygger på en gennemsnitsbetragtning. Overordnet set kaldes denne klasse af beskrivende mål for momenter. Den anden klasse af beskrivende mål bygger på opdelinger af en fordeling. Et eksempel på et sådant mål er den ind- komst, der skiller de fattigste 10 % af befolkningen fra den øvrige befolkning. Overordnet set kaldes denne klasse af beskrivende mål for fraktiler. Momenter behandles i afsnit 5.2 og fraktiler i afsnit 5.3. I afsnit 5.4 diskute- rer vi, hvordan man kan bruge (og misbruge) beskrivende mål. Vi ser på be- skrivende mål for sammenhænge mellem stokastiske variabler i afsnit 5.5, mens vi i afsnit 5.6 viser, hvordan Excel kan anvendes til udregning af be-
Transcript of 5 Beskrivende mål -...

Beskrivende mål 101
5 Beskrivende mål
Indkomstfordelingen i Danmark tæller godt 5 millioner indkomster. Med en
bogstavhøjde på 3 millimeter og en linjeafstand på 2 millimeter, hvilket svarer
til en normal typografisk opsætning, vil en liste med de godt 5 millioner ind
komster være omkring 25 km lang. Selvom man læser meget hurtigt og har
fotografisk hukommelse, får man næppe et godt overblik over fordelingen af
indkomster i Danmark ved at kigge på en sådan liste. For at få en begribelig
ide om indkomstfordelingen i Danmark kan man i stedet definere nogle be
skrivende mål, som hver især afslører interessante aspekter af indkomstforde
lingen. Sådan et beskrivende mål kunne fx være middelindkomsten. Det kan
også være den indkomst, der skiller de fattigste 10 % af befolkningen fra den
øvrige befolkning. Da ét beskrivende mål selvfølgelig ikke alene kan beskrive
en hel fordeling – middelindkomsten er ét tal imod de 5 millioner tal, som
indkomstfordelingen består af – skal man imidlertid være påpasselig med at
overfortolke beskrivende mål.
I kapitel 2 introducerede vi forskellige beskrivende mål, blandt andet mid
delværdi og varians, som kunne bruges til at få et overblik over en virkelig
population. I dette kapitel udvider vi brugen af disse beskrivende mål til sto
kastiske variabler. Dermed bliver vi i stand til at beskrive langt flere situatio
ner, hvor der også er usikkerhed involveret, fx udtrækninger fra superpopula
tioner.
Beskrivende mål for stokastiske variabler kan inddeles i to klasser. Den ene
klasse bygger på gennemsnits betragtninger. Middelindkomsten er et eksem
pel, men man kan også udlede beskrivende mål for spredningen af en forde
ling, som bygger på en gennemsnitsbetragtning. Overordnet set kaldes denne
klasse af beskrivende mål for momenter. Den anden klasse af beskrivende mål
bygger på opdelinger af en fordeling. Et eksempel på et sådant mål er den ind
komst, der skiller de fattigste 10 % af befolkningen fra den øvrige befolkning.
Overordnet set kaldes denne klasse af beskrivende mål for fraktiler.
Momenter behandles i afsnit 5.2 og fraktiler i afsnit 5.3. I afsnit 5.4 diskute
rer vi, hvordan man kan bruge (og misbruge) beskrivende mål. Vi ser på be
skrivende mål for sammenhænge mellem stokastiske variabler i afsnit 5.5,
mens vi i afsnit 5.6 viser, hvordan Excel kan anvendes til udregning af be

102 Beskrivende mål
skrivende mål. Igennem hele kapitlet er de beskrivende mål defineret som be
skrivende mål for en fordeling af en stokastisk variabel i stedet for som beskri
vende mål for en virkelig population, som tilfældet var i kapitel 2. I afsnit 5.1
vil vi forklare, hvorfor vi vælger denne mere generelle tilgang i dette kapitel,
herunder hvordan sammenhængen er mellem beskrivende mål for en forde
ling af en stokastisk variabel og for en virkelig population.
5.1 Beskrivende mål og stokastiske variabler
I kapitel 2 introducerede vi en række beskrivende mål for en virkelig popula
tion. Disse mål inkluderede middelværdien, variansen og medianen og be
skrev aspekter ved en eksisterende virkelig population. Det er ideen bag så
danne beskrivende mål, vi nu vil overføre til stokastiske variabler, som kan
håndtere mere generelle situationer, hvor der er usikkerhed involveret, og hvor
populationen kan være en superpopulation.
I kapitel 2 definerede vi andelsfunktionen, g(z), for en virkelig population.
Den fortæller os, hvordan elementerne i populationen fordeler sig, dvs. hvor
stor en del af elementerne i populationen, der fx har indkomsten z1, z2, z3, osv.
Middelværdien for en vir kelig population kan derfor betragtes som en sum
marisk beskrivelse af andelsfunktionen.
Vi indførte stokastiske variabler i kapitel 4 for at kunne bearbejde kompli
cerede situationer med usikkerhed. Sandsynlighederne for de forskellige vær
dier af en stokastisk variabel er udtrykt i dens fordeling. Et beskrivende mål for
en fordeling af en stokastisk variabel er derfor en summarisk beskrivelse af
sandsynlighedsfunktionen (eller tæthedsfunktionen, hvis den stokastiske va
riabel er kon tinuert).
Forbindelsen mellem en virkelig population og fordelingen af en stoka stisk
variabel forklarede vi i kapitel 4. Når værdien af den stokastiske variabel er
givet ved værdien af det element, der udtrækkes fra en virkelig population, og
når alle elementer i populationen har samme chance for udvælgelse, så er
sandsynlighedsfunktionen, f, lig med andelsfunktionen, g. Når dette er tilfæl
det, kan vi tænke på fordelingen af den stokastiske variabel som en fordeling
af populationen. Faktisk vil vi i sådanne tilfælde ofte omtale sandsynligheds
fordelingen for den stokastiske variabel som populationsfordelingen, og de be
skrivende mål for populationsfordelingen vil blive kaldt for populationsstør-
relser.
Fordelen ved at definere de beskrivende mål ud fra fordelingen af den sto
kastiske variabel er, at vi så også kan bruge dem i de situationer, hvor den
stokastiske variabel ikke svarer til en udtrækning fra en virkelig population.
Dette gælder fx i forbindelse med udtrækninger fra superpopulationer, eller

5.2 Momenter 103
når der er tale om udtrækninger fra virkelige populationer, hvor alle elemen
ter ikke har samme chance for udvælgelse. Lad os illustrere denne tankegang
med et par eksempler:
Eksempel 5.1: I forbindelse med indkomstfordelingen fra starten af kapitlet kan vi definere
følgende eksperiment: „Udvælg en person og lad den stokastiske variabel, X,
angive vedkommendes indkomst.“ Hvis alle personer har samme chance for
udvælgelse, så vil sandsynlighedsfunktionen for X være lig med andels
funktionen for populationen. Dermed har X samme „fordeling“ som popu
lationen. Hvis en andel på 0,1 af befolkningen tjener mere end 300.000 kr., så
er der tilsvarende sandsynligheden 0,1 for, at X antager en værdi større end
300.000. Om vi beskriver fordelingen af populationen eller fordelingen af X,
gør derfor ingen forskel i dette tilfælde.
Eksempel 5.2: I eksemplet fra kapitel 3 med en 30årig obligation er kursen i morgen kl.
12.00 en stokastisk variabel, Y, som har en given sandsynlighedsfordeling.
Der er fx sandsynligheden 0,3 for, at kursen vil ligge under 100. Sandsyn
lighedsfordelingen for denne variabel kan imidlertid ikke umiddelbart
for tolkes som andele i superpopulationen af kurser. Men vi kan stadig be
skrive sandsynlighedsfordelingen for Y ved hjælp af en række beskrivende
mål.
I mange af eksemplerne i dette kapitel vil der være den i eksempel 5.1 nævnte
sammenhæng mellem fordelingen af den stokastiske variabel og en virkelig
population. Det er dog vigtigt at huske på, at de beskrivende mål også finder
anvendelse i en lang række andre situationer, hvor fordelingen af den stokasti
ske variabel ikke svarer til fordelingen af en underliggende virkelig populati
on, som tilfældet fx er i eksempel 5.2.
5.2 Momenter
Det mest kendte moment for en stokastisk variabel, X, er middelværdien, også
kaldet den forventede værdi. Middelværdien betegnes typisk med bogstavet µ
eller E(X), hvor E’et står for „expectation“ (forventning). Et andet ofte brugt
moment er variansen, som beskriver, hvor meget de mulige værdier af X gen
nemsnitligt er spredt i forhold til middelværdien. Variansen betegnes typisk
med s 2 eller V(X).
Fortolkningen af et moment er den samme, uanset om den stokastiske va
riabel er diskret eller kontinuert. Beregningsteknisk er der dog en forskel, så vi
En virkelig
population
En super
population

104 Beskrivende mål
betragter de to tilfælde separat. Da intuitionen er nemmest at opnå med en
diskret stokastisk variabel, vil afsnittene om kontinuerte stokastiske varia bler
primært indeholde de nødvendige formler.
5.2.1 Forventet værdi af en diskret stokastisk variabel
Ideen med en forventet værdi af en stokastisk variabel, X, er at finde et tal,
som svarer til gennemsnittet af alle de værdier af X, man ville få, hvis man
kunne gentage realiseringen af X uendeligt mange gange. Formelt er den for
ventede værdi af en diskret stokastisk variabel defineret som:
Den forventede værdi er altså en sammenvejning af alle de mulige værdier,
hvor vi vægter med sandsynlighederne for at få de pågældende værdier. Man
kalder også den forventede værdi af en stokastisk variabel, X, for middelvær
dien, og man betegner den med det græske bogstav µ.
Eksempel 5.3: Lad X være en stokastisk variabel, der angiver antallet af øjne, når vi kaster
med en terning. Da sandsynligheden for en ener er en sjettedel osv., er den
forventede værdi af X givet ved:
5.2.1 Forventet værdi af en diskret stokastisk variabel
Ideen med en forventet værdi af en stokastisk variabel, 𝑋𝑋𝑋𝑋, er at finde et tal, som svarer til gennemsnittet af alle de værdier af 𝑋𝑋𝑋𝑋, man ville få, hvis man kunne gentage realiseringen af 𝑋𝑋𝑋𝑋 uendeligt mange gange. Formelt er den forventede værdi af en diskret stokastisk variabel defineret som:
Den forventede værdi (middelværdien), 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋), af en diskret stokastisk variabel, 𝑋𝑋𝑋𝑋, med sandsynlighedsfunktion, 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥), er givetved:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = �𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖) = 𝑥𝑥𝑥𝑥1 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + 𝑥𝑥𝑥𝑥2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥2) + ⋯+ 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
hvor 𝑥𝑥𝑥𝑥1, 𝑥𝑥𝑥𝑥2,⋯ , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, 𝑋𝑋𝑋𝑋 kan antage.
Den forventede værdi er altså en sammenvejning af alle de mulige værdier, hvor vi vægter med sandsynlighederne for at få de pågældende værdier. Man kalder også den forventede værdi af en stokastisk variabel, 𝑋𝑋𝑋𝑋, for middelværdien, og man betegner den med det græske bogstav 𝜇𝜇𝜇𝜇.
Eksempel 5.3: Et terningspil ñ del 1
Lad 𝑋𝑋𝑋𝑋 vÊ re en stokastisk variabel, der angiver antallet af ¯jne, nÂr vi kaster med en terning. Da sandsynligheden for en ener er en sjettedel osv., er den forventede vÊ rdi af 𝑋𝑋𝑋𝑋 givet ved:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = 1 ∙16
+ 2 ∙16
+ 3 ∙16
+ 4 ∙16
+ 5 ∙16
+ 6 ∙16
= 3,5
MiddelvÊ rdien af et terningslag er sÂledes 3,5. Men det er en vÊ rdi, man ikke kan sl med terningen. Fortolkningen af den forventede vÊ rdi er, at hvis vi kaster terningen mange gange, dvs. gentager eksperimentet, s vil gennemsnittet af de realiserede vÊ rdier af 𝑋𝑋𝑋𝑋 nÊ rme sig 3,5. BemÊ rk, hvordan dette harmonerer med fortolkningen af begrebet sandsynlighed fra
Middelværdien af et terningslag er således 3,5. Men det er en værdi, man ikke
kan slå med terningen. Fortolkningen af den forventede værdi er, at hvis vi
kaster terningen mange gange, dvs. gentager eksperimentet, så vil gennem
snittet af de realiserede værdier af X nærme sig 3,5. Bemærk, hvordan dette
harmo nerer med fortolkningen af begrebet sandsynlighed fra kapitel 3, som
andelen af gange en hændelse indtræffer, når man gentager et eksperiment i
det uendelige.
Den forventede værdi (middelværdien), E(X), af en diskret stokastisk variabel, X, med sandsynlighedsfunktion, f(x), er givet ved:
5.2.1 Forventet værdi af en diskret stokastisk variabel
Ideen med en forventet værdi af en stokastisk variabel, 𝑋𝑋𝑋𝑋, er at finde et tal, som svarer til gennemsnittet af alle de værdier af 𝑋𝑋𝑋𝑋, man ville få, hvis man kunne gentage realiseringen af 𝑋𝑋𝑋𝑋 uendeligt mange gange. Formelt er den forventede værdi af en diskret stokastisk variabel defineret som:
Den forventede værdi (middelværdien), 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋), af en diskret stokastisk variabel, 𝑋𝑋𝑋𝑋, med sandsynlighedsfunktion, 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥), er givetved:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = �𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖) = 𝑥𝑥𝑥𝑥1 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + 𝑥𝑥𝑥𝑥2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥2) + ⋯+ 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
hvor 𝑥𝑥𝑥𝑥1, 𝑥𝑥𝑥𝑥2,⋯ , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, 𝑋𝑋𝑋𝑋 kan antage.
Den forventede værdi er altså en sammenvejning af alle de mulige værdier, hvor vi vægter med sandsynlighederne for at få de pågældende værdier. Man kalder også den forventede værdi af en stokastisk variabel, 𝑋𝑋𝑋𝑋, for middelværdien, og man betegner den med det græske bogstav 𝜇𝜇𝜇𝜇.
Eksempel 5.3: Et terningspil ñ del 1
Lad 𝑋𝑋𝑋𝑋 vÊ re en stokastisk variabel, der angiver antallet af ¯jne, nÂr vi kaster med en terning. Da sandsynligheden for en ener er en sjettedel osv., er den forventede vÊ rdi af 𝑋𝑋𝑋𝑋 givet ved:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = 1 ∙16
+ 2 ∙16
+ 3 ∙16
+ 4 ∙16
+ 5 ∙16
+ 6 ∙16
= 3,5
MiddelvÊ rdien af et terningslag er sÂledes 3,5. Men det er en vÊ rdi, man ikke kan sl med terningen. Fortolkningen af den forventede vÊ rdi er, at hvis vi kaster terningen mange gange, dvs. gentager eksperimentet, s vil gennemsnittet af de realiserede vÊ rdier af 𝑋𝑋𝑋𝑋 nÊ rme sig 3,5. BemÊ rk, hvordan dette harmonerer med fortolkningen af begrebet sandsynlighed fra
hvor x1, x1, ···, xN er de værdier, X kan antage.
Et terningspil
– del 1

5.2 Momenter 105
Fysisk kan man fortolke middelværdien som et balancepunkt. Hvis man fore
stiller sig, at en sandsynlighed er et vægtlod, og sandsynlighedsfordelin gen er
alle vægtlodderne placeret på en vippe, så er middelværdien det sted, man skal
understøtte vippen for at få den i balance. Figur 5.1 illustrerer dette for ek
sempel 5.3.
Hvis en fordeling er symmetrisk omkring et punkt, symmetripunktet, så er
middelværdien lig med dette symmetripunkt. I eksempel 5.3 er sandsynlig
hedsfordelingen symmetrisk omkring punktet 3,5, som det ses i figur 5.1: Den
ene side af fordelingen er en spejling af den anden, hvis man spejler i punktet
3,5.
Eksempel 5.3 er et eksempel på en stokastisk variabel, der antager de sam
me værdier som elementerne i den virkelige population, den trækkes fra,
nemlig 1, 2, 3, 4, 5 og 6. Da alle elementer i populationen har samme chance
for udvælgelse, er sandsynlighedsfunktionen, f, lig med andelsfunktionen, g.
Populationen har derfor også middelværdien µ = 3,5.
Som vi så i kapitel 2, så svarer denne middelværdi af populationen til, at vi
udregner gennemsnittet for de N elemen ter, som den virkelige population be
står af. Det sker ved at finde den totale sum og dividere med antallet af ele
menter, Npop:
kapitel 3, som andelen af gange en hÊ ndelse indtrÊ ffer, nÂr man gentager et eksperiment i det uendelige.
Fysisk kan man fortolke middelværdien som et balancepunkt. Hvis man forestiller sig, at en sandsynlighed er et vægtlod, og sandsynlighedsfordelingen er alle vægtlodderne placeret på en vippe, så er middelværdien det sted, man skal understøtte vippen for at få den i balance. Figur 5.1 illustrerer dette for eksempel 5.3.
[Indsæt figur 5.1: Middelværdi som balancepunkt]
Hvis en fordeling er symmetrisk omkring et punkt, symmetripunktet, så er middelværdien lig med dette symmetripunkt. I eksempel 5.3 er sandsynlighedsfordelingen symmetrisk omkring punktet 3,5, som det ses i figur 5.1: Den ene side af fordelingen er en spejling af den anden, hvis man spejler i punktet 3,5.
Eksempel 5.3 er et eksempel på en stokastisk variabel, der antager de samme værdier som elementerne i den virkelige population, den trækkes fra, nemlig 1, 2, 3, 4, 5 og 6. Da alle elementer i populationen har samme chance for udvælgelse, er sandsynlighedsfunktionen, 𝑓𝑓𝑓𝑓, lig med andelsfunktionen, 𝑔𝑔𝑔𝑔 Populationen har derfor også middelværdien 𝜇𝜇𝜇𝜇 = 3,5.
Som vi så i kapitel 2, så svarer denne middelværdi af populationentil, at vi udregner gennemsnittet for de 𝑁𝑁𝑁𝑁 elementer, som den virkelige population består af. Det sker ved at finde den totale sum og dividere med antallet af elementer, 𝑁𝑁𝑁𝑁𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝 :
Populationsmiddelværdi =𝑧𝑧𝑧𝑧1 + 𝑧𝑧𝑧𝑧2 + ⋯+ 𝑧𝑧𝑧𝑧𝑁𝑁𝑁𝑁
𝑁𝑁𝑁𝑁𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝
hvor z1, z2, …, zN, er alle elementerne i populationen. I eksempel 5.3 er popu
lationsmiddelværdien:
hvor 𝑧𝑧𝑧𝑧1, 𝑧𝑧𝑧𝑧2, … , 𝑧𝑧𝑧𝑧𝑁𝑁𝑁𝑁 er alle elementerne i populationen. I eksempel 5.3 er
populationsmiddelværdien: 1+2+3+4+5+6
6= 3,5. Lad os tage et eksem-
pel mere:
Eksempel 5.4: En skoleklasse ñ del 1
Antag, at alle elever i en klasse med 10 elever har samme chance for udvÊ lgelse, og lad den stokastiske variabel, 𝑌𝑌𝑌𝑌, angive den udvalgtes h¯jde. H¯jderne i cm for de 10 elever er som f¯lger: 134, 128, 164, 143, 144, 137, 122, 134, 140, 129. H¯jden 134 cm forekommer i to tilfÊ lde. Dermed udg¯r denne h¯jde andelen 2/10, hvorimod de ¯vrige h¯jder i populationen hver udg¯r en andel p 1/10. H¯jden 134 cm skal derfor tilskrives sandsynligheden 2/10, mens de ¯vrige 8 h¯jder hver tilskrives sandsynligheden 1/10. Dermed er den forventede vÊ rdi af 𝑌𝑌𝑌𝑌 lig med:
𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) = 122 ∙1
10+ 128 ∙
110
+ 129 ∙1
10+ 134 ∙
110
+ 137 ∙1
10+ 140 ∙
110
+ 143
∙1
10+ 144 ∙
110
+ 164 ∙1
10= 137,5
MiddelvÊ rdien af 𝑌𝑌𝑌𝑌 er sÂledes 137,5 cm, som ogs er populationens middel-vÊ rdi.
Vi kan også være interesserede i forventningen til en funktion af en stokastisk variabel. Hvis ℎ(𝑋𝑋𝑋𝑋) er en funktion af den stokastiske variabel, 𝑋𝑋𝑋𝑋, så er ℎ(𝑋𝑋𝑋𝑋) selv en stokastisk variabel, som man kan beregne den forventede værdi af.
Eksempel 5.5: Et terningspil ñ del 2
Lad 𝑋𝑋𝑋𝑋 vÊ re den stokastiske variabel fra eksempel 5.3, der angiver antallet af ¯jne, nÂr vi kaster en terning. Antag, at terningkastet indgÂr i et spil, hvor man fÂr 2 gange antallet af ¯jne retur i kroner. Antag ogsÂ, at det koster 5 kroner at deltage i spillet. Vi kan da definere en ny stokastisk variabel, 𝑌𝑌𝑌𝑌, som angiver gevinsten ved spillet. Den er givet ved: 𝑌𝑌𝑌𝑌 = −5 + 2 ∙ 𝑋𝑋𝑋𝑋 = ℎ(𝑋𝑋𝑋𝑋). Hvis man slÂr en ener, s antager 𝑋𝑋𝑋𝑋 vÊ rdien 1, og 𝑌𝑌𝑌𝑌 antager derfor vÊ rdien−5 + 2 ∙ 1 = −3. Da 𝑋𝑋𝑋𝑋 kan antage vÊ rdierne 1, 2, 3, 4, 5, og 6, s kan 𝑌𝑌𝑌𝑌antage vÊ rdierne −3,−1, 1, 3, 5, og 7. Det vil sige, er man heldig og slÂr en sekser, s tjener man (netto) 7 kroner.
Lad os tage et eksem pel mere:
Eksempel 5.4: Antag, at alle elever i en klasse med 10 elever har samme chance for udvæl
gelse, og lad den stokastiske variabel, Y, angive den udvalgtes højde. Højder
ne i cm for de 10 elever er som følger: 134, 128, 164, 143, 144, 137, 122, 134,
140, 129. Højden 134 cm forekommer i to tilfælde. Dermed udgør denne høj
de an delen 2/10, hvorimod de øvrige højder i populationen hver udgør en
58 Beskrivende mål for fordelinger
Den forventede værdi er altså en sammenvejning af alle de mulige værdier,
hvor vi vægter med sandsynlighederne for at få de pågældende værdier. Man
kalder også den forventede værdi af en stokastisk variabel, X, for middelvær-
dien, og man betegner den med det græske bogstav m .
Eksempel 4.3 Lad X være en stokastisk variabel, der angiver antallet af øjne, når vi kaster
med en terning. Da sandsynligheden for en ener er en sjettedel osv., er den
forventede værdi af X givet ved:
E X( ) ,= ⋅ + ⋅ + ⋅ + ⋅ + ⋅ + ⋅ =11
62
1
63
1
64
1
65
1
66
1
63 5
Middelværdien af et terningslag er således 3,5. Men det er en værdi, man ikke
kan slå med terningen. Fortolkningen af den forventede værdi er, at hvis vi
realiserer X mange gange, dvs. gentager eksperimentet, så vil gennemsnittet
af de realiserede værdier af X nærme sig 3,5. Bemærk, hvordan dette harmo-
nerer med fortolkningen af sandsynlighed fra kapitel 2 som andelen af gange
en hændelse indtræffer, når man gentager et eksperiment i det uendelige.
Fysisk kan man fortolke middelværdien som et balancepunkt. Hvis man
forestiller sig, at en sandsynlighed er et vægtlod, og sandsynlighedsfordelin-
gen er alle vægtlodderne placeret på en vippe, så er middelværdien det sted,
man skal understøtte vippen for at få den i balance. Figur 4.1 illustrerer dette
for eksempel 4.3.
0 1 2 3 4 5 6 7
Hvis en fordeling er symmetrisk omkring et punkt, symmetripunktet, så er
middelværdien lig med dette symmetripunkt. I eksempel 4.3 er sandsynlig-
hedsfordelingen symmetrisk omkring punktet 3,5, som det ses i figur 4.1,
hvor den ene side af fordelingen er en spejling af den anden, hvis man spejler
i punktet 3,5.
Eksempel 4.3 er et eksempel på en stokastisk variabel, der antager de sam-
me værdier som elementerne i den virkelige population, den trækkes fra,
nemlig 1, 2, 3, 4, 5 og 6. Da alle elementer i populationen har samme chance
for udvælgelse, er sandsynlighedsfunktionen, f, lig med andelsfunktionen, g.
I et sådant tilfælde siger vi, at populationen også har middelværdien m = 3,5.
Et terningspil
– del 1
Figur 4.1
Middelværdi
som balance-
punkt
Statistik_04.InD 19/03/03, 9:5358
Figur 5.1
Middelværdi
som balan ce
punkt
En skoleklasse
– del 1

106 Beskrivende mål
andel på 1/10. Højden 134 cm skal derfor tilskrives sandsynligheden 2/10,
mens de øv rige 8 højder hver tilskrives sandsynligheden 1/10. Dermed er den
forventede værdi af Y lig med:
hvor 𝑧𝑧𝑧𝑧1, 𝑧𝑧𝑧𝑧2, … , 𝑧𝑧𝑧𝑧𝑁𝑁𝑁𝑁 er alle elementerne i populationen. I eksempel 5.3 er
populationsmiddelværdien: 1+2+3+4+5+6
6= 3,5. Lad os tage et eksem-
pel mere:
Eksempel 5.4: En skoleklasse ñ del 1
Antag, at alle elever i en klasse med 10 elever har samme chance for udvÊ lgelse, og lad den stokastiske variabel, 𝑌𝑌𝑌𝑌, angive den udvalgtes h¯jde. H¯jderne i cm for de 10 elever er som f¯lger: 134, 128, 164, 143, 144, 137, 122, 134, 140, 129. H¯jden 134 cm forekommer i to tilfÊ lde. Dermed udg¯r denne h¯jde andelen 2/10, hvorimod de ¯vrige h¯jder i populationen hver udg¯r en andel p 1/10. H¯jden 134 cm skal derfor tilskrives sandsynligheden 2/10, mens de ¯vrige 8 h¯jder hver tilskrives sandsynligheden 1/10. Dermed er den forventede vÊ rdi af 𝑌𝑌𝑌𝑌 lig med:
𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) = 122 ∙1
10+ 128 ∙
110
+ 129 ∙1
10+ 134 ∙
110
+ 137 ∙1
10+ 140 ∙
110
+ 143
∙1
10+ 144 ∙
110
+ 164 ∙1
10= 137,5
MiddelvÊ rdien af 𝑌𝑌𝑌𝑌 er sÂledes 137,5 cm, som ogs er populationens middel-vÊ rdi.
Vi kan også være interesserede i forventningen til en funktion af en stokastisk variabel. Hvis ℎ(𝑋𝑋𝑋𝑋) er en funktion af den stokastiske variabel, 𝑋𝑋𝑋𝑋, så er ℎ(𝑋𝑋𝑋𝑋) selv en stokastisk variabel, som man kan beregne den forventede værdi af.
Eksempel 5.5: Et terningspil ñ del 2
Lad 𝑋𝑋𝑋𝑋 vÊ re den stokastiske variabel fra eksempel 5.3, der angiver antallet af ¯jne, nÂr vi kaster en terning. Antag, at terningkastet indgÂr i et spil, hvor man fÂr 2 gange antallet af ¯jne retur i kroner. Antag ogsÂ, at det koster 5 kroner at deltage i spillet. Vi kan da definere en ny stokastisk variabel, 𝑌𝑌𝑌𝑌, som angiver gevinsten ved spillet. Den er givet ved: 𝑌𝑌𝑌𝑌 = −5 + 2 ∙ 𝑋𝑋𝑋𝑋 = ℎ(𝑋𝑋𝑋𝑋). Hvis man slÂr en ener, s antager 𝑋𝑋𝑋𝑋 vÊ rdien 1, og 𝑌𝑌𝑌𝑌 antager derfor vÊ rdien−5 + 2 ∙ 1 = −3. Da 𝑋𝑋𝑋𝑋 kan antage vÊ rdierne 1, 2, 3, 4, 5, og 6, s kan 𝑌𝑌𝑌𝑌antage vÊ rdierne −3,−1, 1, 3, 5, og 7. Det vil sige, er man heldig og slÂr en sekser, s tjener man (netto) 7 kroner.
Middelværdien af Y er således 137,5 cm, som også er populationens middel
værdi.
Vi kan også være interesserede i forventningen til en funktion af en stokastisk
variabel. Hvis h(X) er en funktion af den stokastiske variabel, X, så er h(X)
selv en stokastisk variabel, som man kan beregne den forventede værdi af.
Eksempel 5.5: Lad X være den stokastiske variabel fra eksempel 5.3, der angiver antallet af
øjne, når vi kaster en terning. Antag, at terningkastet indgår i et spil, hvor man
får 2 gange antallet af øjne retur i kroner. Antag også, at det koster 5 kroner at
deltage i spillet. Vi kan da definere en ny stokastisk variabel, Y, som angiver
gevinsten ved spillet. Den er givet ved: Y = –5 + 2 · X = h(X). Hvis man slår en
ener, så antager X værdien 1, og Y antager derfor værdien –5 + 2 · 1 = –3. Da
X kan antage værdierne 1, 2, 3, 4, 5, og 6, så kan Y antage værdierne –3, –1, 1,
3, 5, og 7. Det vil sige, er man heldig og slår en sekser, så tjener man (netto) 7
kroner.
Man kan udregne den forventede værdi af en funktion af X ved hjælp af sand
synlighedsfordelingen for X:
Et terningspil
– del 2
Den forventede værdi af en funktion, h(X), af en diskret stokastisk variabel, X, med sandsynlighedsfunktion, f(x), er givet ved:
E(h(X)) =
Man kan udregne den forventede værdi af en funktion af 𝑋𝑋𝑋𝑋 ved hjælp af sandsynlighedsfordelingen for 𝑋𝑋𝑋𝑋:
Den forventede værdi af en funktion, ℎ(𝑋𝑋𝑋𝑋), af en diskret stokastisk variabel, 𝑋𝑋𝑋𝑋, med sandsynlighedsfunktion, 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥), er givet ved:
𝐸𝐸𝐸𝐸(ℎ(𝑋𝑋𝑋𝑋)) = �ℎ(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
= ℎ(𝑥𝑥𝑥𝑥1) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + ℎ(𝑥𝑥𝑥𝑥2) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥2) + ⋯+ ℎ(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)
hvor 𝑥𝑥𝑥𝑥1, 𝑥𝑥𝑥𝑥2, … , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, 𝑋𝑋𝑋𝑋 kan antage.
Den eneste forskel i forhold til udtrykket for den forventede værdi af 𝑋𝑋𝑋𝑋 er, at værdien ℎ(𝑥𝑥𝑥𝑥) har erstattet 𝑥𝑥𝑥𝑥.
Eksempel 5.6: Et terningspil ñ del 3
I eksempel 5.5 kan man sÂledes udregne den forventede vÊ rdi af 𝑌𝑌𝑌𝑌 som:
𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸(−5 + 2 ∙ 𝑋𝑋𝑋𝑋) = −3 ∙16
+ (−1) ∙16
+ 1 ∙16
+ 3 ∙16
+ 5 ∙16
+ 7 ∙16
= 2
Den forventede vÊ rdi af spillet, som koster 5 kroner at deltage i, men hvor man vinder 2 gange antallet af ¯jne i kroner, er sÂledes 2 kr. Det kan man fortolke som den gennemsnitlige gevinst per spil, hvis man gentog spillet uendeligt mange gange. SÂdant et spil vil Danske Spil med garanti ikke udbyde!
Hvis man allerede har udregnet den forventede værdi af 𝑋𝑋𝑋𝑋, så er der nogle særlige tilfælde, hvor man kan udregne den forventede værdi af ℎ(𝑋𝑋𝑋𝑋) uden at skulle lave lange beregninger. Disse tilfælde opstår, når𝑌𝑌𝑌𝑌 = 𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋, hvor 𝑎𝑎𝑎𝑎 og 𝑏𝑏𝑏𝑏 er konstanter. For eksempel, hvis man vil skifte måleenhed på en stokastisk variabel, 𝑋𝑋𝑋𝑋, så vil den stokastiske variabel med den ny måleenhed kunne skrives som 𝑌𝑌𝑌𝑌 = 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋. I disse
h(xi) · f(xi)
= h(x1) · f(x1) + h(x2) · f(x2) + ··· + h(xN) · f(xN)
hvor x1, x2, …, xN, er de værdier, X kan antage.
hvor 𝑧𝑧𝑧𝑧1, 𝑧𝑧𝑧𝑧2, … , 𝑧𝑧𝑧𝑧𝑁𝑁𝑁𝑁 er alle elementerne i populationen. I eksempel 5.3 er
populationsmiddelværdien: 1+2+3+4+5+6
6= 3,5. Lad os tage et eksem-
pel mere:
Eksempel 5.4: En skoleklasse ñ del 1
Antag, at alle elever i en klasse med 10 elever har samme chance for udvÊ lgelse, og lad den stokastiske variabel, 𝑌𝑌𝑌𝑌, angive den udvalgtes h¯jde. H¯jderne i cm for de 10 elever er som f¯lger: 134, 128, 164, 143, 144, 137, 122, 134, 140, 129. H¯jden 134 cm forekommer i to tilfÊ lde. Dermed udg¯r denne h¯jde andelen 2/10, hvorimod de ¯vrige h¯jder i populationen hver udg¯r en andel p 1/10. H¯jden 134 cm skal derfor tilskrives sandsynligheden 2/10, mens de ¯vrige 8 h¯jder hver tilskrives sandsynligheden 1/10. Dermed er den forventede vÊ rdi af 𝑌𝑌𝑌𝑌 lig med:
𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) = 122 ∙1
10+ 128 ∙
110
+ 129 ∙1
10+ 134 ∙
110
+ 137 ∙1
10+ 140 ∙
110
+ 143
∙1
10+ 144 ∙
110
+ 164 ∙1
10= 137,5
MiddelvÊ rdien af 𝑌𝑌𝑌𝑌 er sÂledes 137,5 cm, som ogs er populationens middel-vÊ rdi.
Vi kan også være interesserede i forventningen til en funktion af en stokastisk variabel. Hvis ℎ(𝑋𝑋𝑋𝑋) er en funktion af den stokastiske variabel, 𝑋𝑋𝑋𝑋, så er ℎ(𝑋𝑋𝑋𝑋) selv en stokastisk variabel, som man kan beregne den forventede værdi af.
Eksempel 5.5: Et terningspil ñ del 2
Lad 𝑋𝑋𝑋𝑋 vÊ re den stokastiske variabel fra eksempel 5.3, der angiver antallet af ¯jne, nÂr vi kaster en terning. Antag, at terningkastet indgÂr i et spil, hvor man fÂr 2 gange antallet af ¯jne retur i kroner. Antag ogsÂ, at det koster 5 kroner at deltage i spillet. Vi kan da definere en ny stokastisk variabel, 𝑌𝑌𝑌𝑌, som angiver gevinsten ved spillet. Den er givet ved: 𝑌𝑌𝑌𝑌 = −5 + 2 ∙ 𝑋𝑋𝑋𝑋 = ℎ(𝑋𝑋𝑋𝑋). Hvis man slÂr en ener, s antager 𝑋𝑋𝑋𝑋 vÊ rdien 1, og 𝑌𝑌𝑌𝑌 antager derfor vÊ rdien−5 + 2 ∙ 1 = −3. Da 𝑋𝑋𝑋𝑋 kan antage vÊ rdierne 1, 2, 3, 4, 5, og 6, s kan 𝑌𝑌𝑌𝑌antage vÊ rdierne −3,−1, 1, 3, 5, og 7. Det vil sige, er man heldig og slÂr en sekser, s tjener man (netto) 7 kroner.

5.2 Momenter 107
Den eneste forskel i forhold til udtrykket for den forventede værdi af X er, at
h(x) har erstattet x.
Eksempel 5.6: I eksempel 5.5 kan man således udregne den forventede værdi af Y som:
Man kan udregne den forventede værdi af en funktion af 𝑋𝑋𝑋𝑋 ved hjælp af sandsynlighedsfordelingen for 𝑋𝑋𝑋𝑋:
Den forventede værdi af en funktion, ℎ(𝑋𝑋𝑋𝑋), af en diskret stokastisk variabel, 𝑋𝑋𝑋𝑋, med sandsynlighedsfunktion, 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥), er givet ved:
𝐸𝐸𝐸𝐸(ℎ(𝑋𝑋𝑋𝑋)) = �ℎ(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
= ℎ(𝑥𝑥𝑥𝑥1) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + ℎ(𝑥𝑥𝑥𝑥2) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥2) + ⋯+ ℎ(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)
hvor 𝑥𝑥𝑥𝑥1, 𝑥𝑥𝑥𝑥2, … , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, 𝑋𝑋𝑋𝑋 kan antage.
Den eneste forskel i forhold til udtrykket for den forventede værdi af 𝑋𝑋𝑋𝑋 er, at værdien ℎ(𝑥𝑥𝑥𝑥) har erstattet 𝑥𝑥𝑥𝑥.
Eksempel 5.6: Et terningspil ñ del 3
I eksempel 5.5 kan man sÂledes udregne den forventede vÊ rdi af 𝑌𝑌𝑌𝑌 som:
𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸(−5 + 2 ∙ 𝑋𝑋𝑋𝑋) = −3 ∙16
+ (−1) ∙16
+ 1 ∙16
+ 3 ∙16
+ 5 ∙16
+ 7 ∙16
= 2
Den forventede vÊ rdi af spillet, som koster 5 kroner at deltage i, men hvor man vinder 2 gange antallet af ¯jne i kroner, er sÂledes 2 kr. Det kan man fortolke som den gennemsnitlige gevinst per spil, hvis man gentog spillet uendeligt mange gange. SÂdant et spil vil Danske Spil med garanti ikke udbyde!
Hvis man allerede har udregnet den forventede værdi af 𝑋𝑋𝑋𝑋, så er der nogle særlige tilfælde, hvor man kan udregne den forventede værdi af ℎ(𝑋𝑋𝑋𝑋) uden at skulle lave lange beregninger. Disse tilfælde opstår, når𝑌𝑌𝑌𝑌 = 𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋, hvor 𝑎𝑎𝑎𝑎 og 𝑏𝑏𝑏𝑏 er konstanter. For eksempel, hvis man vil skifte måleenhed på en stokastisk variabel, 𝑋𝑋𝑋𝑋, så vil den stokastiske variabel med den ny måleenhed kunne skrives som 𝑌𝑌𝑌𝑌 = 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋. I disse
Den forventede værdi af spillet, som det koster 5 kroner at deltage i, men
hvor man vinder 2 gange antallet af øjne i kroner, er således 2 kr. Det kan
man for tolke som den gennemsnitlige gevinst per spil, hvis man gentog spil
let uen deligt mange gange. Et sådant spil vil Danske Spil med garanti ikke
udbyde!
Hvis man allerede har udregnet den forventede værdi af X, så er der nogle
særli ge tilfælde, hvor man kan udregne den forventede værdi af h(X) uden at
skulle lave lange beregninger. Disse tilfælde opstår, når Y = a + b · X, hvor a og
b er konstanter. For eksempel, hvis man vil skifte måle enhed på en stokastisk
variabel, X, så vil den stokastiske variabel med den ny måleenhed ofte kunne
skrives som Y = b · X. I disse tilfælde kan vi udtrykke den forventede værdi af
Y direkte som en funktion af den forventede værdi af X. Præcis hvordan frem
går af følgende regneregler:
Der gælder altså følgende: Forventningen til en sum, E(a + b · X), er lig med
summen af forventningerne til leddene i summen, E(a) og E(b · X). Des
uden er forventningen til en konstant, E(a), blot lig med konstanten selv.
Forvent ningen til en konstant ganget med en stokastisk variabel, E(b · X), er
lig med konstanten ganget med forventningen til den stokastiske variabel,
b · E(X).
Et terningspil
– del 3
Regneregler for forventede værdier:
i) E(a) = a
ii) E(b · X) = b · E(X)
iii) E(a + b · X) = E(a) + E(b · X) = a + b · E(X)
hvor X er en diskret stokastisk variabel, og a og b er konstanter.

108 Beskrivende mål
Eksempel 5.7: I eksempel 5.4 ønsker vi nu i stedet at måle elevernes højde i meter. Dvs. vi
de finerer en ny stokastisk variabel Z = 0,01 · Y, hvor Y er variablen fra eksem
pel 5.4. Hvis Y angiver højden for den udtrukne person i cm, vil Z derfor give
os højden i meter. Middelværdien af Z er da: E(Z) = 0,01 · E(Y) = 0,01 · 137,5
= 1,375 meter.
Eksempel 5.8: I eksempel 5.5 er Y en funktion af X, som opfylder den tredje regneregel i
boksen ovenfor. Når vi kender middelværdien af X, kan vi derfor springe den
lidt om stændelige udregning i eksempel 5.6 over og i stedet udregne middel
værdien af Y som: E(Y) = E(–5 + 2 · X) = –5 + 2 · E(X) = –5 + 2 · 3,5 = 2.
Det er værd at understrege, at den forventede værdi af en funktion af X,
E(h(X)), generelt ikke er lig med funktionen af den forventede værdi, h(E(X)).
Det næste eksempel illustrerer dette.
Eksempel 5.9: Den stokastiske variabel, X, kan antage værdierne 3 og 5 med sandsynlig hed
0,5 for hver af dem. Dermed er E(X) = 3 · 0,5 + 5 · 0,5 = 4. Lad Y = X2. Da
X = 3 med sandsynlighed 0,5, så er Y = 9 med sandsynlighed 0,5. Tilsvaren de
er X = 5 med sandsynlighed 0,5, og dermed er Y = 25 med sandsynlig hed 0,5.
Den forventede værdi af Y er derfor E(Y) = 9 · 0,5 + 25 · 0,5 = 17. Så E(Y) =
E(X2) = 17, mens (E(X))2 = 42 = 16.
5.2.2 Forventet værdi af en kontinuert stokastisk variabel
For at beregne den forventede værdi af en kontinuert stokastisk variabel skal
man bruge integralregning. Tænk på eksemplerne 4.12 og 4.13 fra sidste ka
pitel, hvor en virksomhed skulle forudsige næste års vareproduktion. Her var
sandsynlighederne for de enkelte udfald nul, fordi der var uendeligt mange
udfald. Til gengæld var der en positiv sandsynlighed for en produktion mel
lem 10 og 11 tons. Som i tilfældet med en diskret stokastisk variabel skal vi
have foretaget en sammenvejning af sandsynligheder og værdier af udfald. Da
sandsynligheden for et bestemt udfald er 0 for en kontinuert stokastisk varia
bel, viser det sig, at vi i stedet for kan bruge tæthedsfunktionen. Sam
menvejningen sker ved at integrere tæthedsfunktionen ganget med værdier ne
af udfaldene. Formelt er beregningsformlen som følger:
En skoleklasse
– del 2
Et terningspil
– del 4
En ikkelineær
funktion

5.2 Momenter 109
Vi vil ikke anvende integralregning ret meget i denne bog. Alligevel kan vi
sagtens arbejde med forventede værdier af kontinuerte stokastiske variabler.
Der gæl der nemlig de samme regneregler for kontinuerte stokastiske variabler
som for diskrete stokastiske variabler. Disse regneregler er gengivet her:
Eksempel 5.10: Lad X være den kontinuerte stokastiske variabel fra eksempel 4.124.14, som
angav virksomhedens vareproduktion næste år. Vi antog, at alle udfald mel
lem 10 og 20 tons var lige sandsynlige. Dermed er fordelingen symmetrisk
omkring 15 tons, så middelværdien af X er lig med 15 tons. Ved hjælp af
integralreg ning kan man vise, at dette er korrekt:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = � 𝑥𝑥𝑥𝑥 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥)𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥∞
−∞
Vi vil ikke anvende integralregning ret meget i denne bog. Alligevel kan vi sagtens arbejde med forventede værdier af kontinuerte stokastiske variabler. Der gælder nemlig de samme regneregler for kontinuerte stokastiske variabler som for diskrete stokastiske variabler. Disse regneregler er gengivet her:
Regneregler for forventede værdier:
𝑖𝑖𝑖𝑖) 𝐸𝐸𝐸𝐸(𝑎𝑎𝑎𝑎) = 𝑎𝑎𝑎𝑎
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝐸𝐸𝐸𝐸(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏 ∙ 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝐸𝐸𝐸𝐸(𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝐸𝐸𝐸𝐸(𝑎𝑎𝑎𝑎) + 𝐸𝐸𝐸𝐸(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)
hvor 𝑋𝑋𝑋𝑋 er en kontinuert stokastisk variabel, og 𝑎𝑎𝑎𝑎 og 𝑏𝑏𝑏𝑏 er konstanter.
Eksempel 5.10: Vareproduktion ñ del 1
Lad 𝑋𝑋𝑋𝑋 vÊ re den kontinuerte stokastiske variabel fra eksempel 4.12-4.14, som angav virksomhedens vareproduktion nÊ ste Âr. Vi antog, at alle udfald mellem 10 og 20 tons var lige sandsynlige. Dermed er fordelingen symmetrisk omkring 15 tons, s middelvÊ rdien af 𝑋𝑋𝑋𝑋 er lig med 15 tons. Ved hjÊ lp af integralregning kan man vise, at dette er korrekt:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = � 𝑥𝑥𝑥𝑥 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥)𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥∞
−∞= � 𝑥𝑥𝑥𝑥 ∙ 0,1𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥
20
10= 0,1 ∙ (0,5 ∙ 202 − 0,5 ∙ 102) = 15
Antag nu, at der gÂr 250 kilo til spilde undervejs i produktionen. Lad 𝑌𝑌𝑌𝑌 vÊ re den stokastiske variabel, der angiver nettomÊ ngden i kilo: 𝑌𝑌𝑌𝑌 = 1000 ∙ 𝑋𝑋𝑋𝑋 −250, da 𝑋𝑋𝑋𝑋 er mÂlt i tons, og 𝑌𝑌𝑌𝑌 skal mÂles i kg. MiddelvÊ rdien af 𝑌𝑌𝑌𝑌 kan man finde ved at bruge regnereglerne ovenfor: 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸(1000 ∙ 𝑋𝑋𝑋𝑋 − 250) =1000 ∙ 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) − 250 = 1000 ∙ 15 − 250 = 14750 kg.
Antag nu, at der går 250 kilo til spilde undervejs i produktionen. Lad Y være
den stokastiske variabel, der angiver nettomængden i kilo: Y = 1000 · X –
250, da X er målt i tons, og Y skal måles i kg. Middelværdien af Y kan man
finde ved at bruge regnereglerne ovenfor: E(Y) = E(1000 · X – 250) = 1000 ·
E(X) – 250 = 1000 · 15 – 250 = 14750 kg.
5.2.3 Varians af en diskret stokastisk variabel
Efter at have udregnet middelværdien er man måske interesseret i at vide, hvor
meget værdierne spreder sig omkring middelværdien. Antag, at vi har en stoka
stisk variabel, X, som antager værdierne 40 og 60 med lige stor sandsyn lighed.
Den forventede værdi (middelværdien), E(X), af en kontinuert stokastisk variabel, X, med tæthedsfunktion, f(x), er givet ved:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = � 𝑥𝑥𝑥𝑥 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥)𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥∞
−∞
Vi vil ikke anvende integralregning ret meget i denne bog. Alligevel kan vi sagtens arbejde med forventede værdier af kontinuerte stokastiske variabler. Der gælder nemlig de samme regneregler for kontinuerte stokastiske variabler som for diskrete stokastiske variabler. Disse regneregler er gengivet her:
Regneregler for forventede værdier:
𝑖𝑖𝑖𝑖) 𝐸𝐸𝐸𝐸(𝑎𝑎𝑎𝑎) = 𝑎𝑎𝑎𝑎
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝐸𝐸𝐸𝐸(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏 ∙ 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝐸𝐸𝐸𝐸(𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝐸𝐸𝐸𝐸(𝑎𝑎𝑎𝑎) + 𝐸𝐸𝐸𝐸(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)
hvor 𝑋𝑋𝑋𝑋 er en kontinuert stokastisk variabel, og 𝑎𝑎𝑎𝑎 og 𝑏𝑏𝑏𝑏 er konstanter.
Eksempel 5.10: Vareproduktion ñ del 1
Lad 𝑋𝑋𝑋𝑋 vÊ re den kontinuerte stokastiske variabel fra eksempel 4.12-4.14, som angav virksomhedens vareproduktion nÊ ste Âr. Vi antog, at alle udfald mellem 10 og 20 tons var lige sandsynlige. Dermed er fordelingen symmetrisk omkring 15 tons, s middelvÊ rdien af 𝑋𝑋𝑋𝑋 er lig med 15 tons. Ved hjÊ lp af integralregning kan man vise, at dette er korrekt:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = � 𝑥𝑥𝑥𝑥 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥)𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥∞
−∞= � 𝑥𝑥𝑥𝑥 ∙ 0,1𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥
20
10= 0,1 ∙ (0,5 ∙ 202 − 0,5 ∙ 102) = 15
Antag nu, at der gÂr 250 kilo til spilde undervejs i produktionen. Lad 𝑌𝑌𝑌𝑌 vÊ re den stokastiske variabel, der angiver nettomÊ ngden i kilo: 𝑌𝑌𝑌𝑌 = 1000 ∙ 𝑋𝑋𝑋𝑋 −250, da 𝑋𝑋𝑋𝑋 er mÂlt i tons, og 𝑌𝑌𝑌𝑌 skal mÂles i kg. MiddelvÊ rdien af 𝑌𝑌𝑌𝑌 kan man finde ved at bruge regnereglerne ovenfor: 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸(1000 ∙ 𝑋𝑋𝑋𝑋 − 250) =1000 ∙ 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) − 250 = 1000 ∙ 15 − 250 = 14750 kg.
Regneregler for forventede værdier:
i) E(a) = a
ii) E(b · X) = b · E(X)
iii) E(a + b · X) = E(a) + E(b · X) = a + b · E(X)
hvor X er en kontinuert stokastisk variabel, og a og b er konstanter.
Vareproduk
tion – del 1

110 Beskrivende mål
Middelværdien er da E(X) = 50. Antag, at vi har en anden stokastisk variabel, Y,
som antager værdierne 0 og 100, også her med lige stor sandsynlighed. Mid
delværdien er igen E(Y) = 50, men de to variabler har tydeligvis forskel lige for
delinger. Fordelingen for Y er spredt mere ud end fordelingen for X.
For at få et beskrivende mål for denne spredning kan man undersøge den
forventede kvadrerede spredning omkring middelværdien. Dette mål kaldes
variansen og betegnes med V(X) eller s 2.
Denne definition gælder, uanset om den stokastiske variabel er diskret eller
kontinuert. Det er beregningen af de forventede værdier, E(X2) og E(X), som
adskiller diskrete og kontinuerte stokastiske variabler. For en diskret stoka
stisk variabel kan variansen udregnes som følger:
Udregningen af V(X) er den samme, som hvis vi skulle udregne den forven
tede værdi af den stokastiske variabel, Y, givet ved Y = h(X) = (X – E(X))2 = (X
– µ)2. Variansen er således en sammenvejning af de enkelte værdier (fratruk
ket middelværdien og kvadreret), hvor man vægter med sandsynligheden for
de pågældende værdier.
Lad os udregne variansen i nogle af eksemplerne fra tidligere:
Variansen, V(X), af en stokastisk variabel, X, er defineret som:
V(X) = E([X – E(X)]2) = s2
Variansen kan også udregnes som:
V(X) = E(X2) – (E(X))2 = E(X2) – µ2
hvor µ = E(X).
Variansen af en diskret stokastisk variabel, X, med sandsynlighedsfunktion, f(x), udregnes som:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = �(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
= (𝑥𝑥𝑥𝑥1 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + ⋯+ (𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)
hvor 𝜇𝜇𝜇𝜇 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) og 𝑥𝑥𝑥𝑥1, … , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, som 𝑋𝑋𝑋𝑋 kan antage.
Udregningen af 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) er den samme, som hvis vi skulle udregne den forventede værdi af den stokastiske variabel, 𝑌𝑌𝑌𝑌, givet ved 𝑌𝑌𝑌𝑌 = ℎ(𝑋𝑋𝑋𝑋) =(𝑋𝑋𝑋𝑋 − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋))2 = (𝑋𝑋𝑋𝑋 − 𝜇𝜇𝜇𝜇)2. Variansen er således en sammenvejning af de enkelte værdier (fratrukket middelværdien og kvadreret), hvor man vægter med sandsynligheden for de pågældende værdier.
Lad os udregne variansen i nogle af eksemplerne fra tidligere:
Eksempel 5.11: Et terningspil ñ del 5
I terningspillet fra eksempel 5.3 bliver variansen:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = (1 − 3,5)2 ∙16
+ (2 − 3,5)2 ∙16
+ (3 − 3,5)2 ∙16
+ (4 − 3,5)2 ∙16
+ (5 − 3,5)2 ∙16
+ (6 − 3,5)2 ∙16
= 2,9167
Alternativt kan vi f¯rst finde 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2):
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) = 12 ∙16
+ 22 ∙16
+ 32 ∙16
+ 42 ∙16
+ 52 ∙16
+ 62 ∙16
= 15,167
og udregne variansen som:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)2 = 15,167 − 3,52 = 2,9167
Eksempel 5.12: En skoleklasse ñ del 3
For den stokastiske variabel, 𝑌𝑌𝑌𝑌, fra eksempel 5.4 er variansen givet ved: 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = (122 − 137,5)2 ∙ 1
10+ (128 − 137,5)2 ∙ 1
10+ (129 − 137,5)2 ∙ 1
10+
(134 − 137,5)2 ∙ 210
+ (137 − 137,5)2 ∙ 110
+ (140 − 137,5)2 ∙ 110
+ (143 −
137,5)2 ∙ 110
+ (144 − 137,5)2 ∙ 110
+ (164 − 137,5)2 ∙ 110
= 120,85 .
hvor µ = E(X), og x1, …, xN, er de værdier, som X kan antage.

5.2 Momenter 111
Eksempel 5.11: I terningspillet fra eksempel 5.3 bliver variansen:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = �(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
= (𝑥𝑥𝑥𝑥1 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + ⋯+ (𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)
hvor 𝜇𝜇𝜇𝜇 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) og 𝑥𝑥𝑥𝑥1, … , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, som 𝑋𝑋𝑋𝑋 kan antage.
Udregningen af 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) er den samme, som hvis vi skulle udregne den forventede værdi af den stokastiske variabel, 𝑌𝑌𝑌𝑌, givet ved 𝑌𝑌𝑌𝑌 = ℎ(𝑋𝑋𝑋𝑋) =(𝑋𝑋𝑋𝑋 − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋))2 = (𝑋𝑋𝑋𝑋 − 𝜇𝜇𝜇𝜇)2. Variansen er således en sammenvejning af de enkelte værdier (fratrukket middelværdien og kvadreret), hvor man vægter med sandsynligheden for de pågældende værdier.
Lad os udregne variansen i nogle af eksemplerne fra tidligere:
Eksempel 5.11: Et terningspil ñ del 5
I terningspillet fra eksempel 5.3 bliver variansen:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = (1 − 3,5)2 ∙16
+ (2 − 3,5)2 ∙16
+ (3 − 3,5)2 ∙16
+ (4 − 3,5)2 ∙16
+ (5 − 3,5)2 ∙16
+ (6 − 3,5)2 ∙16
= 2,9167
Alternativt kan vi f¯rst finde 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2):
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) = 12 ∙16
+ 22 ∙16
+ 32 ∙16
+ 42 ∙16
+ 52 ∙16
+ 62 ∙16
= 15,167
og udregne variansen som:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)2 = 15,167 − 3,52 = 2,9167
Eksempel 5.12: En skoleklasse ñ del 3
For den stokastiske variabel, 𝑌𝑌𝑌𝑌, fra eksempel 5.4 er variansen givet ved: 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = (122 − 137,5)2 ∙ 1
10+ (128 − 137,5)2 ∙ 1
10+ (129 − 137,5)2 ∙ 1
10+
(134 − 137,5)2 ∙ 210
+ (137 − 137,5)2 ∙ 110
+ (140 − 137,5)2 ∙ 110
+ (143 −
137,5)2 ∙ 110
+ (144 − 137,5)2 ∙ 110
+ (164 − 137,5)2 ∙ 110
= 120,85 .
Alternativt kan vi først finde E(X2):
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = �(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
= (𝑥𝑥𝑥𝑥1 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + ⋯+ (𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)
hvor 𝜇𝜇𝜇𝜇 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) og 𝑥𝑥𝑥𝑥1, … , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, som 𝑋𝑋𝑋𝑋 kan antage.
Udregningen af 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) er den samme, som hvis vi skulle udregne den forventede værdi af den stokastiske variabel, 𝑌𝑌𝑌𝑌, givet ved 𝑌𝑌𝑌𝑌 = ℎ(𝑋𝑋𝑋𝑋) =(𝑋𝑋𝑋𝑋 − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋))2 = (𝑋𝑋𝑋𝑋 − 𝜇𝜇𝜇𝜇)2. Variansen er således en sammenvejning af de enkelte værdier (fratrukket middelværdien og kvadreret), hvor man vægter med sandsynligheden for de pågældende værdier.
Lad os udregne variansen i nogle af eksemplerne fra tidligere:
Eksempel 5.11: Et terningspil ñ del 5
I terningspillet fra eksempel 5.3 bliver variansen:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = (1 − 3,5)2 ∙16
+ (2 − 3,5)2 ∙16
+ (3 − 3,5)2 ∙16
+ (4 − 3,5)2 ∙16
+ (5 − 3,5)2 ∙16
+ (6 − 3,5)2 ∙16
= 2,9167
Alternativt kan vi f¯rst finde 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2):
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) = 12 ∙16
+ 22 ∙16
+ 32 ∙16
+ 42 ∙16
+ 52 ∙16
+ 62 ∙16
= 15,167
og udregne variansen som:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)2 = 15,167 − 3,52 = 2,9167
Eksempel 5.12: En skoleklasse ñ del 3
For den stokastiske variabel, 𝑌𝑌𝑌𝑌, fra eksempel 5.4 er variansen givet ved: 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = (122 − 137,5)2 ∙ 1
10+ (128 − 137,5)2 ∙ 1
10+ (129 − 137,5)2 ∙ 1
10+
(134 − 137,5)2 ∙ 210
+ (137 − 137,5)2 ∙ 110
+ (140 − 137,5)2 ∙ 110
+ (143 −
137,5)2 ∙ 110
+ (144 − 137,5)2 ∙ 110
+ (164 − 137,5)2 ∙ 110
= 120,85 .
og udregne variansen som:
V(X) = E(X2) – µ2 = 15,167 – 3,52 = 2,9167
Eksempel 5.12: For den stokastiske variabel, Y, fra eksempel 5.4 er variansen givet ved:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = �(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
= (𝑥𝑥𝑥𝑥1 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + ⋯+ (𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)
hvor 𝜇𝜇𝜇𝜇 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) og 𝑥𝑥𝑥𝑥1, … , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, som 𝑋𝑋𝑋𝑋 kan antage.
Udregningen af 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) er den samme, som hvis vi skulle udregne den forventede værdi af den stokastiske variabel, 𝑌𝑌𝑌𝑌, givet ved 𝑌𝑌𝑌𝑌 = ℎ(𝑋𝑋𝑋𝑋) =(𝑋𝑋𝑋𝑋 − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋))2 = (𝑋𝑋𝑋𝑋 − 𝜇𝜇𝜇𝜇)2. Variansen er således en sammenvejning af de enkelte værdier (fratrukket middelværdien og kvadreret), hvor man vægter med sandsynligheden for de pågældende værdier.
Lad os udregne variansen i nogle af eksemplerne fra tidligere:
Eksempel 5.11: Et terningspil ñ del 5
I terningspillet fra eksempel 5.3 bliver variansen:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = (1 − 3,5)2 ∙16
+ (2 − 3,5)2 ∙16
+ (3 − 3,5)2 ∙16
+ (4 − 3,5)2 ∙16
+ (5 − 3,5)2 ∙16
+ (6 − 3,5)2 ∙16
= 2,9167
Alternativt kan vi f¯rst finde 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2):
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) = 12 ∙16
+ 22 ∙16
+ 32 ∙16
+ 42 ∙16
+ 52 ∙16
+ 62 ∙16
= 15,167
og udregne variansen som:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)2 = 15,167 − 3,52 = 2,9167
Eksempel 5.12: En skoleklasse ñ del 3
For den stokastiske variabel, 𝑌𝑌𝑌𝑌, fra eksempel 5.4 er variansen givet ved: 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = (122 − 137,5)2 ∙ 1
10+ (128 − 137,5)2 ∙ 1
10+ (129 − 137,5)2 ∙ 1
10+
(134 − 137,5)2 ∙ 210
+ (137 − 137,5)2 ∙ 110
+ (140 − 137,5)2 ∙ 110
+ (143 −
137,5)2 ∙ 110
+ (144 − 137,5)2 ∙ 110
+ (164 − 137,5)2 ∙ 110
= 120,85 .
Man kan også som mål for spredningen benytte kvadratroden af variansen: Man kan også som mål for spredningen benytte kvadratroden af
variansen: 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋) = �𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋). Denne størrelse kalder man for
standardafvigelsen, og den er opgjort i de samme måleenheder som den stokastiske variabel, 𝑋𝑋𝑋𝑋, for hvilken den er udregnet:
Standardafvigelsen, 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋), af en stokastisk variabel, 𝑋𝑋𝑋𝑋, med varians, 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋), er givet ved:
𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋) = �𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋)
Eksempel 5.13: Et terningspil ñ del 6
Standardafvigelsen af den stokastiske variabel, 𝑋𝑋𝑋𝑋, fra eksempel 5.11 er givet ved:
𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋) = �𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = �2,9167 = 1,708
Ligesom for middelværdier har vi også nogle regneregler for varianser og standardafvigelser:1
Regneregler for varians og standardafvigelse:
𝑖𝑖𝑖𝑖) 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎) = 0 ⇒ 𝜎𝜎𝜎𝜎(𝑎𝑎𝑎𝑎) = 0
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝑉𝑉𝑉𝑉(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏2 ∙ 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏2 ∙ 𝜎𝜎𝜎𝜎2 ⇒ 𝜎𝜎𝜎𝜎(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = |𝑏𝑏𝑏𝑏| ∙ 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋)
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑉𝑉𝑉𝑉(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏2 ∙ 𝜎𝜎𝜎𝜎2 ⇒ 𝜎𝜎𝜎𝜎(𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = |𝑏𝑏𝑏𝑏| ∙ 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋)
hvor 𝑋𝑋𝑋𝑋 er en diskret stokastisk variabel, 𝑎𝑎𝑎𝑎 og 𝑏𝑏𝑏𝑏 er konstanter, og
𝜎𝜎𝜎𝜎2 = 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋).
1 Man kan udlede disse regler fra reglerne for forventede værdier i afsnit 5.2.1, idet variansen, som nævnt ovenfor, er at betragte som en forventning til en funktion, ℎ(𝑋𝑋𝑋𝑋).
Denne størrelse kalder man for standardafvigelsen, og den er
opgjort i de samme måleenheder som den stokastiske variabel, X, for hvilken
den er udregnet:
Eksempel 5.13: Standardafvigelsen af den stokastiske variabel, X, fra eksempel 5.11 er givet
ved:
Man kan også som mål for spredningen benytte kvadratroden af
variansen: 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋) = �𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋). Denne størrelse kalder man for
standardafvigelsen, og den er opgjort i de samme måleenheder som den stokastiske variabel, 𝑋𝑋𝑋𝑋, for hvilken den er udregnet:
Standardafvigelsen, 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋), af en stokastisk variabel, 𝑋𝑋𝑋𝑋, med varians, 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋), er givet ved:
𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋) = �𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋)
Eksempel 5.13: Et terningspil ñ del 6
Standardafvigelsen af den stokastiske variabel, 𝑋𝑋𝑋𝑋, fra eksempel 5.11 er givet ved:
𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋) = �𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = �2,9167 = 1,708
Ligesom for middelværdier har vi også nogle regneregler for varianser og standardafvigelser:1
Regneregler for varians og standardafvigelse:
𝑖𝑖𝑖𝑖) 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎) = 0 ⇒ 𝜎𝜎𝜎𝜎(𝑎𝑎𝑎𝑎) = 0
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝑉𝑉𝑉𝑉(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏2 ∙ 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏2 ∙ 𝜎𝜎𝜎𝜎2 ⇒ 𝜎𝜎𝜎𝜎(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = |𝑏𝑏𝑏𝑏| ∙ 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋)
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑉𝑉𝑉𝑉(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏2 ∙ 𝜎𝜎𝜎𝜎2 ⇒ 𝜎𝜎𝜎𝜎(𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = |𝑏𝑏𝑏𝑏| ∙ 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋)
hvor 𝑋𝑋𝑋𝑋 er en diskret stokastisk variabel, 𝑎𝑎𝑎𝑎 og 𝑏𝑏𝑏𝑏 er konstanter, og
𝜎𝜎𝜎𝜎2 = 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋).
1 Man kan udlede disse regler fra reglerne for forventede værdier i afsnit 5.2.1, idet variansen, som nævnt ovenfor, er at betragte som en forventning til en funktion, ℎ(𝑋𝑋𝑋𝑋).
Et terningspil
– del 5
En skoleklasse
– del 3
Standardafvigelsen, s(X), af en stokastisk variabel, X, med varians, V(X), er givet ved:
Man kan også som mål for spredningen benytte kvadratroden af
variansen: 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋) = �𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋). Denne størrelse kalder man for
standardafvigelsen, og den er opgjort i de samme måleenheder som den stokastiske variabel, 𝑋𝑋𝑋𝑋, for hvilken den er udregnet:
Standardafvigelsen, 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋), af en stokastisk variabel, 𝑋𝑋𝑋𝑋, med varians, 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋), er givet ved:
𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋) = �𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋)
Eksempel 5.13: Et terningspil ñ del 6
Standardafvigelsen af den stokastiske variabel, 𝑋𝑋𝑋𝑋, fra eksempel 5.11 er givet ved:
𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋) = �𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = �2,9167 = 1,708
Ligesom for middelværdier har vi også nogle regneregler for varianser og standardafvigelser:1
Regneregler for varians og standardafvigelse:
𝑖𝑖𝑖𝑖) 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎) = 0 ⇒ 𝜎𝜎𝜎𝜎(𝑎𝑎𝑎𝑎) = 0
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝑉𝑉𝑉𝑉(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏2 ∙ 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏2 ∙ 𝜎𝜎𝜎𝜎2 ⇒ 𝜎𝜎𝜎𝜎(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = |𝑏𝑏𝑏𝑏| ∙ 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋)
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑉𝑉𝑉𝑉(𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = 𝑏𝑏𝑏𝑏2 ∙ 𝜎𝜎𝜎𝜎2 ⇒ 𝜎𝜎𝜎𝜎(𝑎𝑎𝑎𝑎 + 𝑏𝑏𝑏𝑏 ∙ 𝑋𝑋𝑋𝑋) = |𝑏𝑏𝑏𝑏| ∙ 𝜎𝜎𝜎𝜎(𝑋𝑋𝑋𝑋)
hvor 𝑋𝑋𝑋𝑋 er en diskret stokastisk variabel, 𝑎𝑎𝑎𝑎 og 𝑏𝑏𝑏𝑏 er konstanter, og
𝜎𝜎𝜎𝜎2 = 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋).
1 Man kan udlede disse regler fra reglerne for forventede værdier i afsnit 5.2.1, idet variansen, som nævnt ovenfor, er at betragte som en forventning til en funktion, ℎ(𝑋𝑋𝑋𝑋).
Et terningspil
– del 6
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = �(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
= (𝑥𝑥𝑥𝑥1 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + ⋯+ (𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)
hvor 𝜇𝜇𝜇𝜇 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) og 𝑥𝑥𝑥𝑥1, … , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, som 𝑋𝑋𝑋𝑋 kan antage.
Udregningen af 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) er den samme, som hvis vi skulle udregne den forventede værdi af den stokastiske variabel, 𝑌𝑌𝑌𝑌, givet ved 𝑌𝑌𝑌𝑌 = ℎ(𝑋𝑋𝑋𝑋) =(𝑋𝑋𝑋𝑋 − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋))2 = (𝑋𝑋𝑋𝑋 − 𝜇𝜇𝜇𝜇)2. Variansen er således en sammenvejning af de enkelte værdier (fratrukket middelværdien og kvadreret), hvor man vægter med sandsynligheden for de pågældende værdier.
Lad os udregne variansen i nogle af eksemplerne fra tidligere:
Eksempel 5.11: Et terningspil ñ del 5
I terningspillet fra eksempel 5.3 bliver variansen:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = (1 − 3,5)2 ∙16
+ (2 − 3,5)2 ∙16
+ (3 − 3,5)2 ∙16
+ (4 − 3,5)2 ∙16
+ (5 − 3,5)2 ∙16
+ (6 − 3,5)2 ∙16
= 2,9167
Alternativt kan vi f¯rst finde 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2):
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) = 12 ∙16
+ 22 ∙16
+ 32 ∙16
+ 42 ∙16
+ 52 ∙16
+ 62 ∙16
= 15,167
og udregne variansen som:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)2 = 15,167 − 3,52 = 2,9167
Eksempel 5.12: En skoleklasse ñ del 3
For den stokastiske variabel, 𝑌𝑌𝑌𝑌, fra eksempel 5.4 er variansen givet ved: 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = (122 − 137,5)2 ∙ 1
10+ (128 − 137,5)2 ∙ 1
10+ (129 − 137,5)2 ∙ 1
10+
(134 − 137,5)2 ∙ 210
+ (137 − 137,5)2 ∙ 110
+ (140 − 137,5)2 ∙ 110
+ (143 −
137,5)2 ∙ 110
+ (144 − 137,5)2 ∙ 110
+ (164 − 137,5)2 ∙ 110
= 120,85 .
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = �(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖)𝑁𝑁𝑁𝑁
𝑖𝑖𝑖𝑖=1
= (𝑥𝑥𝑥𝑥1 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥1) + ⋯+ (𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁)
hvor 𝜇𝜇𝜇𝜇 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) og 𝑥𝑥𝑥𝑥1, … , 𝑥𝑥𝑥𝑥𝑁𝑁𝑁𝑁 er de værdier, som 𝑋𝑋𝑋𝑋 kan antage.
Udregningen af 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) er den samme, som hvis vi skulle udregne den forventede værdi af den stokastiske variabel, 𝑌𝑌𝑌𝑌, givet ved 𝑌𝑌𝑌𝑌 = ℎ(𝑋𝑋𝑋𝑋) =(𝑋𝑋𝑋𝑋 − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋))2 = (𝑋𝑋𝑋𝑋 − 𝜇𝜇𝜇𝜇)2. Variansen er således en sammenvejning af de enkelte værdier (fratrukket middelværdien og kvadreret), hvor man vægter med sandsynligheden for de pågældende værdier.
Lad os udregne variansen i nogle af eksemplerne fra tidligere:
Eksempel 5.11: Et terningspil ñ del 5
I terningspillet fra eksempel 5.3 bliver variansen:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = (1 − 3,5)2 ∙16
+ (2 − 3,5)2 ∙16
+ (3 − 3,5)2 ∙16
+ (4 − 3,5)2 ∙16
+ (5 − 3,5)2 ∙16
+ (6 − 3,5)2 ∙16
= 2,9167
Alternativt kan vi f¯rst finde 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2):
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) = 12 ∙16
+ 22 ∙16
+ 32 ∙16
+ 42 ∙16
+ 52 ∙16
+ 62 ∙16
= 15,167
og udregne variansen som:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋2) − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)2 = 15,167 − 3,52 = 2,9167
Eksempel 5.12: En skoleklasse ñ del 3
For den stokastiske variabel, 𝑌𝑌𝑌𝑌, fra eksempel 5.4 er variansen givet ved: 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = (122 − 137,5)2 ∙ 1
10+ (128 − 137,5)2 ∙ 1
10+ (129 − 137,5)2 ∙ 1
10+
(134 − 137,5)2 ∙ 210
+ (137 − 137,5)2 ∙ 110
+ (140 − 137,5)2 ∙ 110
+ (143 −
137,5)2 ∙ 110
+ (144 − 137,5)2 ∙ 110
+ (164 − 137,5)2 ∙ 110
= 120,85 .

112 Beskrivende mål
Ligesom for middelværdier har vi også nogle regneregler for varianser og
standardafvigelser:1
Variansen er således upåvirket af, at der lægges en konstant, a, til. Intuitio nen
er, at en additiv konstant ikke flytter på afstanden mellem de mulige værdier,
den stokastiske variabel kan antage. Dermed ændrer konstanten ikke på af
standen mellem de enkelte værdier og middelværdien. En konstant, b, har
derimod betydning, når den ganges på værdierne af X. Hvis b er større end 1,
vil den sprede værdierne mere og dermed øge den samlede varians. Reglerne
for standardafvigelse fås ved at tage kvadratroden af variansudtrykkene.
Eksempel 5.14: Variablen Y i eksempel 5.5 er givet ved: Y = –5 + 2 · X, hvor vi fra eksempel
5.11 ved, at variansen af X er 2,9167. Dermed kan man udregne variansen af
Y ved brug af regnereglerne:
V(Y) = V(–5 + 2 · X) = 22 · V(X) = 4 · 2,9167 = 11,67
Standardafvigelsen af Y bliver følgelig:
Variansen er således upåvirket af, at der lægges en konstant, 𝑎𝑎𝑎𝑎, til. Intuitionen er, at en additiv konstant ikke flytter på afstanden mellem de mulige værdier, den stokastiske variabel kan antage. Dermed ændrer konstanten ikke på afstanden mellem de enkelte værdier og middelværdien. En konstant, 𝑏𝑏𝑏𝑏, har derimod betydning, når den ganges på værdierne af 𝑋𝑋𝑋𝑋. Hvis 𝑏𝑏𝑏𝑏 er større end 1, vil den sprede værdierne mere og dermed øge den samlede varians. Reglerne for standardafvigelse fås ved at tage kvadratroden af variansudtrykkene.
Eksempel 5.14: Et terningspil ñ del 7
Variablen 𝑌𝑌𝑌𝑌 i eksempel 5.5 er givet ved: 𝑌𝑌𝑌𝑌 = −5 + 2 ∙ 𝑋𝑋𝑋𝑋, hvor vi fra eksempel 5.11 ved, at variansen af 𝑋𝑋𝑋𝑋 er 2,9167. Dermed kan man udregne variansen af 𝑌𝑌𝑌𝑌 ved brug af regnereglerne:
𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = 𝑉𝑉𝑉𝑉(−5 + 2 ∙ 𝑋𝑋𝑋𝑋) = 22 ∙ 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 4 ∙ 2,9167 = 11,67
Standardafvigelsen af 𝑌𝑌𝑌𝑌 bliver f¯lgelig:
𝜎𝜎𝜎𝜎(𝑌𝑌𝑌𝑌) = �𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = 3,416
5.2.4 Varians af en kontinuert stokastisk variabel
Variansen af en kontinuert stokastisk variabel er defineret på nøjagtig samme måde som for en diskret stokastisk variabel. Den eneste forskel er måden, den udregnes på. Da middelværdien af en kontinuert stokastisk variabel involverer integralregning, så gør udregningen afvariansen det også.
Variansen af en kontinuert stokastisk variabel, 𝑋𝑋𝑋𝑋, med tæthedsfunktion, 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥), udregnes som:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = � (𝑥𝑥𝑥𝑥 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥)𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥∞
−∞
hvor 𝜇𝜇𝜇𝜇 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋).
5.2.4 Varians af en kontinuert stokastisk variabel
Variansen af en kontinuert stokastisk variabel er defineret på nøjagtig samme
måde som for en diskret stokastisk variabel. Den eneste forskel er måden, den
udregnes på. Da middelværdien af en kontinuert stokastisk variabel involve
rer integralregning, så gør udregningen af variansen det også.
1. Man kan udlede disse regler fra reglerne for forventede værdier i afsnit 5.2.1, idet vari-ansen, som nævnt ovenfor, er at betragte som en forventning til en funktion, h(X).
Regneregler for varians og standardafvigelse:
i) V(a) = 0 ⇒ s(a) = 0
ii) V(b · X) = b2 · V(X) = b2 · s2 ⇒ s(b · X) = |b| · s(X)
iii) V(a + b · X) = V(b · X) = b2 · s2 ⇒ s(a + b · X) = |b| · s(X)
hvor X er en diskret stokastisk variabel, a og b er konstanter, og s2 = V(X).
Et terningspil
– del 7

5.2 Momenter 113
Regnereglerne for varians og standardafvigelse er de samme som i tilfældet
med en diskret stokastisk variabel:
5.2.5 Momenter generelt
Variansen af en stokastisk variabel, X, er defineret som den forventede værdi
af én bestemt funktion af denne stokastiske variabel, nemlig [X – E(X)]2. Ide
en var at se på den forventede kvadrerede afvigelse fra middelværdien af den
stokastiske variabel. Men man kunne jo også opløfte X – E(X) i tredje eller
fjerde potens i stedet for i anden potens. Alle disse muligheder kaldes under ét
for momenter og er defineret i næste boks:
Middelværdien er lig med det første moment: m1 = E(X1) = E(X), og varian
sen er lig med det andet centrale moment: m*2 = E([X – E(X)]2).
Det tredje centrale moment, m*3 = E([X – E(X)]3) beskriver, hvor skæv for
delingen af X er. Hvis fordelingen af X er symmetrisk, så er det tredje cen trale
moment 0. Endelig sker det også, at man er interesseret i det fjerde cen trale
moment: m*4 = E([X – E(X)]4). Det vægter værdier af X langt fra mid delværdien
Regneregler for varians og standardafvigelse:
i) V(a) = 0 ⇒ s(a) = 0
ii) V(b · X) = b2 · V(X) = b2 · s2 ⇒ s(b · X) = |b| · s(X)
iii) V(a + b · X) = V(b · X) = b2 · s2 ⇒ s(a + b · X) = |b| · s(X)
hvor X er en kontinuert stokastisk variabel, a og b er konstanter, og s2 = V(X).
Variansen af en kontinuert stokastisk variabel, X, med tæthedsfunktion, f(X), ud regnes som:
Variansen er således upåvirket af, at der lægges en konstant, 𝑎𝑎𝑎𝑎, til. Intuitionen er, at en additiv konstant ikke flytter på afstanden mellem de mulige værdier, den stokastiske variabel kan antage. Dermed ændrer konstanten ikke på afstanden mellem de enkelte værdier og middelværdien. En konstant, 𝑏𝑏𝑏𝑏, har derimod betydning, når den ganges på værdierne af 𝑋𝑋𝑋𝑋. Hvis 𝑏𝑏𝑏𝑏 er større end 1, vil den sprede værdierne mere og dermed øge den samlede varians. Reglerne for standardafvigelse fås ved at tage kvadratroden af variansudtrykkene.
Eksempel 5.14: Et terningspil ñ del 7
Variablen 𝑌𝑌𝑌𝑌 i eksempel 5.5 er givet ved: 𝑌𝑌𝑌𝑌 = −5 + 2 ∙ 𝑋𝑋𝑋𝑋, hvor vi fra eksempel 5.11 ved, at variansen af 𝑋𝑋𝑋𝑋 er 2,9167. Dermed kan man udregne variansen af 𝑌𝑌𝑌𝑌 ved brug af regnereglerne:
𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = 𝑉𝑉𝑉𝑉(−5 + 2 ∙ 𝑋𝑋𝑋𝑋) = 22 ∙ 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 4 ∙ 2,9167 = 11,67
Standardafvigelsen af 𝑌𝑌𝑌𝑌 bliver f¯lgelig:
𝜎𝜎𝜎𝜎(𝑌𝑌𝑌𝑌) = �𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) = 3,416
5.2.4 Varians af en kontinuert stokastisk variabel
Variansen af en kontinuert stokastisk variabel er defineret på nøjagtig samme måde som for en diskret stokastisk variabel. Den eneste forskel er måden, den udregnes på. Da middelværdien af en kontinuert stokastisk variabel involverer integralregning, så gør udregningen afvariansen det også.
Variansen af en kontinuert stokastisk variabel, 𝑋𝑋𝑋𝑋, med tæthedsfunktion, 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥), udregnes som:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = � (𝑥𝑥𝑥𝑥 − 𝜇𝜇𝜇𝜇)2 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥)𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥∞
−∞
hvor 𝜇𝜇𝜇𝜇 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋).hvor µ = E(X).
Det k’te moment, mk, af en stokastisk variabel, X, er: mk = E(Xk)
Det k’te centrale moment, m*k, af en stokastisk variabel, X, er:
m*k = E([X – E(X)]k)

114 Beskrivende mål
højt. Derfor er dette beskrivende mål ofte brugt, hvis man vil beskrive sand
synligheden for ekstreme værdier i forhold til middelværdien.
Der findes fordelinger for hvilke, der ikke eksisterer momenter. Dette kan
ske, hvis der er for høj sandsynlighed for ekstreme (dvs. store negative eller
store positive) værdier af den stokastiske variabel. For at forstå dette, kan man
bruge billedet om middelværdien som det punkt, hvor man skal understøtte
en vippe med vægtlodder for at holde den i balance, se figur 5.1. Hvis der er
vægtlodder ekstremt langt ude på vippen, og disse er for tunge, så brækker
vippen. Det næste eksempel viser en situation, hvor middelværdien af en sto
kastisk variabel ikke eksisterer.
Eksempel 5.15: Antag at den diskrete stokastiske variabel, X, kan antage følgende værdier: x
= 2, 4, 8, 16, …, med sandsynlighederne f(x) = 1–X . Dvs. X kan antage vilkår
ligt høje værdier, dog med mindre og mindre sandsynlighed. Først tjekker vi,
at f(x) rent faktisk er en sandsynlighedsfunktion. Ifølge afsnit 4.2.1 skal
sandsynlighederne summere til 1. Man kan her vise at den uendelige sum:
interesseret i det fjerde centrale moment: 𝑚𝑚𝑚𝑚4∗ = 𝐸𝐸𝐸𝐸([𝑋𝑋𝑋𝑋 − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)]4). Det
vægter værdier af 𝑋𝑋𝑋𝑋 langt fra middelværdien højt. Derfor er dette beskrivende mål ofte brugt, hvis man vil beskrive sandsynligheden for ekstreme værdier i forhold til middelværdien.
Der findes fordelinger for hvilke, der ikke eksisterer momenter. Dette kan ske, hvis der er for høj sandsynlighed for ekstreme (dvs. store negative eller store positive) værdier af den stokastiske variabel. For at forstå dette, kan man bruge billedet om middelværdien som det punkt, hvor man skal understøtte en vippe med vægtlodder for at holde den i balance, se figur 5.1. Hvis der er vægtlodder ekstremt langt ude på vippen, og disse er for tunge, så brækker vippen. Det næste eksempel viser en situation, hvor middelværdien af en stokastisk variabel ikke eksisterer.
Eksempel 5.15: Ingen middelvÊ rdi
Antag at den diskrete stokastiske variabel, 𝑋𝑋𝑋𝑋, kan antage f¯lgende vÊ rdier: 𝑥𝑥𝑥𝑥 = 2,4,8,16, …. med sandsynlighederne 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥) = 1
𝑥𝑥𝑥𝑥. Dvs. 𝑋𝑋𝑋𝑋 kan
antage vilkÂrligt h¯je vÊ rdier, dog med mindre og mindre sandsynlighed. F¯rst tjekker vi, at 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥) rent faktisk er en sandsynlighedsfunktion. If¯lge afsnit 4.2.1 skal sandsynlighederne summere til 1. Man kan her vise at den uendelige sum
𝑓𝑓𝑓𝑓(2) + 𝑓𝑓𝑓𝑓(4) + 𝑓𝑓𝑓𝑓(8) + 𝑓𝑓𝑓𝑓(16) + ⋯ = 12
+ 14
+ 18
+ 116
+ ⋯
faktisk summerer til 1. Da ogs 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥) ≥ 0 f¯lger det af afsnit 4.2.1, at 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥) er en sandsynlighedsfunktion.
MiddelvÊ rdien af en diskret stokastisk variabel er defineret som summenaf alle de vÊ rdier, den stokastiske variabel kan antage, ganget med deres respektive sandsynligheder. Foretager man denne udregning fÂr man:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = 2 ∙ 𝑓𝑓𝑓𝑓(2) + 4 ∙ 𝑓𝑓𝑓𝑓(4) + 8 ∙ 𝑓𝑓𝑓𝑓(8) + 16 ∙ 𝑓𝑓𝑓𝑓(16) + ⋯
= 2 ∙12
+ 4 ∙14
+ 8 ∙18
+ 16 ∙1
16+ ⋯ = 1 + 1 + 1 + 1 + ⋯
Man fÂr alts en uendelig sum af et-taller og dermed et uendeligt stort tal. Derfor eksisterer middelvÊ rdien af 𝑋𝑋𝑋𝑋 ikke.
faktisk summerer til 1. Da også f(x) ≥ 0, følger det af afsnit 4.2.1, at f(x) er en
sandsynlighedsfunktion.
Middelværdien af en diskret stokastisk variabel er defineret som summen
af alle de værdier, den stokastiske variabel kan antage, ganget med deres re
spektive sandsynligheder. Foretager man denne udregning får man:
interesseret i det fjerde centrale moment: 𝑚𝑚𝑚𝑚4∗ = 𝐸𝐸𝐸𝐸([𝑋𝑋𝑋𝑋 − 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋)]4). Det
vægter værdier af 𝑋𝑋𝑋𝑋 langt fra middelværdien højt. Derfor er dette beskrivende mål ofte brugt, hvis man vil beskrive sandsynligheden for ekstreme værdier i forhold til middelværdien.
Der findes fordelinger for hvilke, der ikke eksisterer momenter. Dette kan ske, hvis der er for høj sandsynlighed for ekstreme (dvs. store negative eller store positive) værdier af den stokastiske variabel. For at forstå dette, kan man bruge billedet om middelværdien som det punkt, hvor man skal understøtte en vippe med vægtlodder for at holde den i balance, se figur 5.1. Hvis der er vægtlodder ekstremt langt ude på vippen, og disse er for tunge, så brækker vippen. Det næste eksempel viser en situation, hvor middelværdien af en stokastisk variabel ikke eksisterer.
Eksempel 5.15: Ingen middelvÊ rdi
Antag at den diskrete stokastiske variabel, 𝑋𝑋𝑋𝑋, kan antage f¯lgende vÊ rdier: 𝑥𝑥𝑥𝑥 = 2,4,8,16, …. med sandsynlighederne 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥) = 1
𝑥𝑥𝑥𝑥. Dvs. 𝑋𝑋𝑋𝑋 kan
antage vilkÂrligt h¯je vÊ rdier, dog med mindre og mindre sandsynlighed. F¯rst tjekker vi, at 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥) rent faktisk er en sandsynlighedsfunktion. If¯lge afsnit 4.2.1 skal sandsynlighederne summere til 1. Man kan her vise at den uendelige sum
𝑓𝑓𝑓𝑓(2) + 𝑓𝑓𝑓𝑓(4) + 𝑓𝑓𝑓𝑓(8) + 𝑓𝑓𝑓𝑓(16) + ⋯ = 12
+ 14
+ 18
+ 116
+ ⋯
faktisk summerer til 1. Da ogs 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥) ≥ 0 f¯lger det af afsnit 4.2.1, at 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥) er en sandsynlighedsfunktion.
MiddelvÊ rdien af en diskret stokastisk variabel er defineret som summenaf alle de vÊ rdier, den stokastiske variabel kan antage, ganget med deres respektive sandsynligheder. Foretager man denne udregning fÂr man:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = 2 ∙ 𝑓𝑓𝑓𝑓(2) + 4 ∙ 𝑓𝑓𝑓𝑓(4) + 8 ∙ 𝑓𝑓𝑓𝑓(8) + 16 ∙ 𝑓𝑓𝑓𝑓(16) + ⋯
= 2 ∙12
+ 4 ∙14
+ 8 ∙18
+ 16 ∙1
16+ ⋯ = 1 + 1 + 1 + 1 + ⋯
Man fÂr alts en uendelig sum af et-taller og dermed et uendeligt stort tal. Derfor eksisterer middelvÊ rdien af 𝑋𝑋𝑋𝑋 ikke.
Man får altså en uendelig sum af ettaller og dermed et uendeligt stort tal.
Derfor eksisterer middelværdien af X ikke i dette tilfælde.
For stort set alle de fordelinger, som vi præsenterer senere i denne bog, eksi
sterer både middelværdien og variansen.
5.3 Fraktiler
Fraktiler giver en alternativ måde at sammenfatte en fordeling på. Hvor mo
menter bygger på gennemsnitsbetragtninger, så bygger fraktiler på opdelin ger.
Den mest anvendte fraktil er medianen. Kort fortalt er medianen for en stoka
Ingen
middel værdi

5.3 Fraktiler 115
stisk variabel, X, den værdi, som X er større end eller lig med med sand
synlighed 0,5 og mindre end eller lig med med sandsynlighed 0,5. Rent visu elt
så deler medianen derfor sandsynlighedsfordelingen for X på midten, som il
lustreret i figur 5.2, hvor tæthedsfunktionen for en kontinuert stokastisk va
riabel, X, er afbildet.
Man kan også finde værdier af X, som opdeler fordelingen på en anden måde
end med 0,5 til hver side. Disse værdier kalder man generelt for pfraktiler,
hvor p angiver den del af fordelingen, der ligger til ven stre for pfraktilen. Den
generelle definition af en pfraktil, som gælder både for kontinuerte og di
skrete stokastiske variabler, er lidt snørklet. Derfor tager vi først det letteste
tilfælde, som – for en gangs skyld – forekommer, når den stokastiske variabel
er kontinuert. For en kontinuert stokastisk variabel, X, er pfraktilen den (el
ler de) værdi(er) af x, som, når de sættes ind i den kumu lative sandsynligheds
funktion, F(x), giver p.
Eksempel 5.16: Den kontinuerte stokastiske variabel, X, fra eksempel 5.10, som angav en
virksomheds vareproduktion, havde følgende kumulative sand synlig heds
funk tion, jf. eksempel 4.14:
𝐹𝐹𝐹𝐹�𝑞𝑞𝑞𝑞𝑝𝑝𝑝𝑝� = 𝑝𝑝𝑝𝑝
Eksempel 5.16: Vareproduktion ñ del 2
Den kontinuerte stokastiske variabel, 𝑋𝑋𝑋𝑋, fra eksempel 5.10, som angav en virksomheds vareproduktion, havde f¯lgende kumulerede sandsynlighedsfunktion, jf. eksempel 4.14:
𝐹𝐹𝐹𝐹(𝑥𝑥𝑥𝑥) = �0 ℎ𝑣𝑣𝑣𝑣𝑖𝑖𝑖𝑖𝑣𝑣𝑣𝑣 𝑥𝑥𝑥𝑥 < 100,1 ∙ (𝑥𝑥𝑥𝑥 − 10) ℎ𝑣𝑣𝑣𝑣𝑖𝑖𝑖𝑖𝑣𝑣𝑣𝑣 10 ≤ 𝑥𝑥𝑥𝑥 ≤ 201 ℎ𝑣𝑣𝑣𝑣𝑖𝑖𝑖𝑖𝑣𝑣𝑣𝑣 20 < 𝑥𝑥𝑥𝑥
Medianen (0,5-fraktilen), 𝑞𝑞𝑞𝑞0,5, for 𝑋𝑋𝑋𝑋 bestemmes som en l¯sning til 𝐹𝐹𝐹𝐹�𝑞𝑞𝑞𝑞0,5� = 0,5, dvs. 0,1 ∙ �𝑞𝑞𝑞𝑞0,5 − 10� = 0,5, som giver 𝑞𝑞𝑞𝑞0,5 = 15. Medianen er alts den samme som middelvÊ rdien i dette tilfÊ lde, jf. eksempel 5.10. 0,05-fraktilen findes p tilsvarende vis:
𝐹𝐹𝐹𝐹�𝑞𝑞𝑞𝑞0,05� = 0,05 ⇔ 0,1 ∙ �𝑞𝑞𝑞𝑞0,05 − 10� = 0,05 ⇔ 𝑞𝑞𝑞𝑞0,05 = 10,5
En stokastisk variabel kan dog godt have flere medianværdier (og p-fraktiler), som illustreret i det følgende eksempel.
Eksempel 5.17: Multiple medianvÊ rdier
Antag, at en kontinuert stokastisk variabel, 𝑋𝑋𝑋𝑋, har sandsynlighed 0,5 for at ligge mellem 1 og 2 og sandsynlighed 0,5 for at ligge mellem 3 og 4. TÊ thedsfunktionen for 𝑋𝑋𝑋𝑋 er tegnet i figur 5.3. I dette tilfÊ lde er der derfor sandsynlighed 0 for, at 𝑋𝑋𝑋𝑋 antager en vÊ rdi mellem 2 og 3. Men samtidig vil alle vÊ rdier mellem 2 og 3 dele sandsynlighedsmassen i to lige store dele. Derfor vil alle vÊ rdier mellem 2 og 3 opfylde kravet til en 0,5-fraktil if¯lge definitionen i boksen ovenfor. SÂ disse vÊ rdier er alle medianvÊ rdier.
[Indsæt figur 5.3: Tæthedsfunktion med multiple medianer]
Figur 5.2:
Tæthedsfunk-
tion og median
stokastiske variabel er kontinuert. For en kontinuert stokastisk variabel, X, er
p -fraktilen den (eller de) værdi(er) af x, som, når de sættes ind i den kumu-
lerede sandsynlighedsfunktion, F(x), giver p.
p -fraktilen for en kontinuert stokastisk variabel, X, med kumuleret sandsynlig-hedsfunktion, F(x), er en værdi, q
p, således at:
F q pp( ) =
Eksempel 4.15 Den kontinuerte stokastiske variabel, X, fra eksempel 4.10, som angav en
virksomheds vareproduktion, havde følgende kumulerede sandsynligheds-
funktion, jf. eksempel 3.14:
F x
hvis x
x hvis x
hvis x
( ) , ( )=<
⋅ − ≤ <≤
0 10
0 1 10 10 20
1 20
Medianen (0,5-fraktilen), q0,5
, for X bestemmes som en løsning til F(q0,5
) =
0,5, dvs. 0,1 · (q0,5
– 10) = 0,5, som giver q0,5
= 15. Medianen er altså den samme
som middelværdien i dette tilfælde, jf. eksempel 4.10.
0,05-fraktilen findes på tilsvarende vis:
F q q q( ) , , ( ) , ,, , ,0 05 0 05 0 050 05 0 1 10 0 05 10 5= ⇔ ⋅ − = ⇔ =
En stokastisk variabel kan dog godt have flere medianværdier (og p -frakti-
ler), som illustreret i det følgende eksempel.
Eksempel 4.16 Antag, at en kontinuert stokastisk variabel, X, har sandsynlighed 0,5 for at
ligge mellem 1 og 2 og sandsynlighed 0,5 for at ligge mellem 3 og 4. Tætheds-
funktionen for X er tegnet i figur 4.3. I dette tilfælde er der derfor sandsyn-
median�
�(�)
4.3 Fraktiler 67
Vareproduktion
– del 2
Multiple medi-
anværdier
Figur 4.2
Tæthedsfunk-
tion og median
Statistik_04.InD 18/03/03, 12:5567
p-fraktilen for en kontinuert stokastisk variabel, X, med kumulativ sandsynlighedsfunktion, F(x), er en værdi, qp, således at:
F(qp) = p
Vareproduk-
tion – del 2

116 Beskrivende mål
Medianen (0,5-fraktilen), for X bestemmes som en løsning til F(q0,5) = 0,5,
dvs. 0,1 · (q0,5 – 10) = 0,5, som giver q0,5 = 15. Medianen er altså den samme
som middelværdien i dette tilfælde, jf. eksempel 5.10. 0,05-fraktilen findes på
tilsvarende vis:
𝐹𝐹𝐹𝐹�𝑞𝑞𝑞𝑞𝑝𝑝𝑝𝑝� = 𝑝𝑝𝑝𝑝
Eksempel 5.16: Vareproduktion ñ del 2
Den kontinuerte stokastiske variabel, 𝑋𝑋𝑋𝑋, fra eksempel 5.10, som angav en virksomheds vareproduktion, havde f¯lgende kumulerede sandsynlighedsfunktion, jf. eksempel 4.14:
𝐹𝐹𝐹𝐹(𝑥𝑥𝑥𝑥) = �0 ℎ𝑣𝑣𝑣𝑣𝑖𝑖𝑖𝑖𝑣𝑣𝑣𝑣 𝑥𝑥𝑥𝑥 < 100,1 ∙ (𝑥𝑥𝑥𝑥 − 10) ℎ𝑣𝑣𝑣𝑣𝑖𝑖𝑖𝑖𝑣𝑣𝑣𝑣 10 ≤ 𝑥𝑥𝑥𝑥 ≤ 201 ℎ𝑣𝑣𝑣𝑣𝑖𝑖𝑖𝑖𝑣𝑣𝑣𝑣 20 < 𝑥𝑥𝑥𝑥
Medianen (0,5-fraktilen), 𝑞𝑞𝑞𝑞0,5, for 𝑋𝑋𝑋𝑋 bestemmes som en l¯sning til 𝐹𝐹𝐹𝐹�𝑞𝑞𝑞𝑞0,5� = 0,5, dvs. 0,1 ∙ �𝑞𝑞𝑞𝑞0,5 − 10� = 0,5, som giver 𝑞𝑞𝑞𝑞0,5 = 15. Medianen er alts den samme som middelvÊ rdien i dette tilfÊ lde, jf. eksempel 5.10. 0,05-fraktilen findes p tilsvarende vis:
𝐹𝐹𝐹𝐹�𝑞𝑞𝑞𝑞0,05� = 0,05 ⇔ 0,1 ∙ �𝑞𝑞𝑞𝑞0,05 − 10� = 0,05 ⇔ 𝑞𝑞𝑞𝑞0,05 = 10,5
En stokastisk variabel kan dog godt have flere medianværdier (og p-fraktiler), som illustreret i det følgende eksempel.
Eksempel 5.17: Multiple medianvÊ rdier
Antag, at en kontinuert stokastisk variabel, 𝑋𝑋𝑋𝑋, har sandsynlighed 0,5 for at ligge mellem 1 og 2 og sandsynlighed 0,5 for at ligge mellem 3 og 4. TÊ thedsfunktionen for 𝑋𝑋𝑋𝑋 er tegnet i figur 5.3. I dette tilfÊ lde er der derfor sandsynlighed 0 for, at 𝑋𝑋𝑋𝑋 antager en vÊ rdi mellem 2 og 3. Men samtidig vil alle vÊ rdier mellem 2 og 3 dele sandsynlighedsmassen i to lige store dele. Derfor vil alle vÊ rdier mellem 2 og 3 opfylde kravet til en 0,5-fraktil if¯lge definitionen i boksen ovenfor. SÂ disse vÊ rdier er alle medianvÊ rdier.
[Indsæt figur 5.3: Tæthedsfunktion med multiple medianer]
En stokastisk variabel kan dog godt have flere medianværdier (og p-fraktiler),
som illustreret i det følgende eksempel.
Eksempel 5.17: Antag, at en kontinuert stokastisk variabel, X, har sandsynlighed 0,5 for at
ligge mellem 1 og 2 og sandsynlighed 0,5 for at ligge mellem 3 og 4. Tætheds-
funktionen for X er tegnet i figur 5.3. I dette tilfælde er der derfor sandsyn-
lighed 0 for, at X antager en værdi mellem 2 og 3. Men samtidig vil alle vær-
dier mellem 2 og 3 dele sandsynlighedsmassen i to lige store dele. Derfor vil
alle værdier mellem 2 og 3 opfylde kravet til en 0,5-fraktil ifølge definitionen
i boksen ovenfor. Så disse værdier er alle medianværdier.
Når man som i eksempel 5.17 har et interval af værdier, som alle opfylder
kravet til at være en p-fraktil, så vælger man typisk den midterste værdi i in-
tervallet. I eksempel 5.17 bliver 2,5 således medianen. Et tilsvarende problem
har vi, når vi har med diskrete stokastiske variabler at gøre. Lad os derfor
kigge nærmere på dem.
Eksempel 5.18: Lad X være den diskrete stokastiske variabel, der angiver antallet af øjne ved
et terningslag. Vi ved fra tidligere, at sandsynlighedsfordelingen for X er føl-
gende:
Multiple
medianværdier
68 Beskrivende mål for fordelinger
lighed 0 for, at X antager en værdi mellem 2 og 3. Men samtidig vil alle vær-
dier mellem 2 og 3 dele sandsynlighedsmassen i to lige store dele. Derfor vil
alle værdier mellem 2 og 3 opfylde kravet til en 0,5-fraktil ifølge definitionen
i boksen ovenfor. Så de er alle medianværdier.
1 2 3 4�
0,5 �(�)
Typisk gør man dog det, at når man som i eksempel 4.16 har et interval af
værdier, som alle opfylder kravet til at være en p -fraktil, så vælger man den
midterste værdi i intervallet. I eksempel 4.16 bliver 2,5 således medianen. Et
tilsvarende problem har vi, når vi har med diskrete stokastiske variabler at
gøre, så lad os kigge nærmere på dem.
Eksempel 4.17 Lad X være den diskrete stokastiske variabel, der angiver antallet af øjne ved
et terningslag. Vi ved fra tidligere, at sandsynlighedsfordelingen for X er føl-
gende:
f f f f f f( ) / , ( ) / , ( ) / , ( ) / , ( ) / , ( ) /1 1 6 2 1 6 3 1 6 4 1 6 5 1 6 6 1 6= = = = = =
Der er altså sandsynlighed 0,5 for at få en værdi af X mindre end 3,1, men
der er også sandsynlighed 0,5 for at få en værdi mindre end 3,8. Så hvilken
værdi er medianen? Som i tilfældet med kontinuerte variabler vælger man
typisk den midterste værdi af det interval af værdier, der alle deler sandsyn-
lighedsmassen i to lige store dele. Værdien 3,5 bliver derfor medianen i dette
tilfælde.
Hovedproblemet med at formulere betingelsen for en p -fraktil for en diskret
stokastisk variabel stammer fra det faktum, at den kumulerede sandsynlig-
hedsfunktion, F, for en diskret stokastisk variabel er en trappefunktion, se fx
figur 3.1. Man kan derfor typisk ikke løse ligningen F(qp) = p, som er betin-
gelsen for en p -fraktil, når den stokastiske variabel er kontinuert. Nedenfor
giver vi en formel definition af en p -fraktil, som gælder for både kontinuerte
og diskrete stokastiske variabler. For kontinuerte variabler reduceres defini-
tionen dog til den allerede viste definition i boksen ovenfor:
Et terningspil
– del 8
Figur 4.3
Tæthedsfunk-
tion med mul-
tiple medianer
Statistik_04.InD 18/03/03, 12:5668
Figur 5.3:
Tæthedsfunk-
tion med
multiple
medianer
Et terningspil
– del 8

5.3 Fraktiler 117
Når man som i eksempel 5.17 har et interval af værdier, som alle opfylder kravet til at være en p-fraktil, så vælger man typisk den midterste værdi i intervallet. I eksempel 5.17 bliver 2,5 således medianen. Et tilsvarende problem har vi, når vi har med diskrete stokastiske variabler at gøre. Lad os derfor kigge nærmere på dem.
Eksempel 5.18: Et terningspil ñ del 8
Lad 𝑋𝑋𝑋𝑋 vÊ re den diskrete stokastiske variabel, der angiver antallet af ¯jne ved et terningslag. Vi ved fra tidligere, at sandsynlighedsfordelingen for 𝑋𝑋𝑋𝑋 er f¯lgende:
𝑓𝑓𝑓𝑓(1) =16
, 𝑓𝑓𝑓𝑓(2) =16
, 𝑓𝑓𝑓𝑓(3) =16
, 𝑓𝑓𝑓𝑓(4) =16
, 𝑓𝑓𝑓𝑓(5) =16
,
𝑓𝑓𝑓𝑓(6) =16
Der er alts sandsynlighed 0,5 for at f en vÊ rdi af 𝑋𝑋𝑋𝑋 mindre end 3,1, men der er ogs sandsynlighed 0,5 for at f en vÊ rdi mindre end 3,8. S hvilken vÊ rdi er medianen? Som i tilfÊ ldet med kontinuerte variabler vÊ lger man typisk den midterste vÊ rdi af det interval af vÊ rdier, der alle deler sandsynlighedsmassen i to lige store dele. VÊ rdien 3,5 bliver derfor medianen i dette tilfÊ lde.
Hovedproblemet med at formulere betingelsen for en p-fraktil for en diskret stokastisk variabel stammer fra det faktum, at den kumulerede sandsynlighedsfunktion, 𝐹𝐹𝐹𝐹, for en diskret stokastisk variabel er en trappefunktion, se fx figur 4.1. Man kan derfor typisk ikke løse
ligningen 𝐹𝐹𝐹𝐹�𝑞𝑞𝑞𝑞𝑝𝑝𝑝𝑝� = 𝑝𝑝𝑝𝑝, som er definitionen af en p-fraktil for en
kontinuert stokastisk variabel. Nedenfor giver vi en formel definition af en p-fraktil, som gælder for både kontinuerte og diskrete stokastiske variabler. For kontinuerte variabler reducerer definitionen dog til den allerede viste definition i boksen ovenfor:
Definition af p-fraktil:
Der er altså sandsynlighed 0,5 for at få en værdi af X mindre end 3,1, men der
er også sandsynlighed 0,5 for at få en værdi mindre end 3,5. Så hvilken værdi
er medianen? Som i tilfældet med kontinuerte variabler vælger man typisk
den midterste værdi af det interval af værdier, der alle deler sandsynligheds-
massen i to lige store dele. Værdien 3,5 bliver derfor medianen i dette tilfæl-
de.
Hovedproblemet med at formulere betingelsen for en p-fraktil for en diskret
stokastisk variabel stammer fra det faktum, at den kumulative sandsynlig-
hedsfunktion, F, for en diskret stokastisk variabel er en trappefunktion, se fx
figur 4.1. Man kan derfor typisk ikke løse ligningen F(qp) – P, som er definiti-
onen af en p-fraktil for en kontinuert stokastisk variabel. Nedenfor giver vi en
formel definition af en p-fraktil, som gælder for både kontinuerte og diskrete
stokastiske variabler. For kontinuerte variabler reducerer defini tionen dog til
den allerede viste definition i boksen ovenfor:
Den første betingelse siger, at et udfald mindre end p-fraktilen højst må have
sandsynlighed p, mens den anden betingelse siger, at sandsynligheden for at få
et udfald større end p-fraktilen skal være mindre end eller lig med 1 – p. Den-
ne snørklede definition er nødvendig, fordi den kumulative sandsynlig-
hedsfunktion for en diskret stokastisk variabel er en trappefunktion og der-
med ikke kontinuert. „Ånden“ i en p-fraktil er dog den samme som i tilfæl det
med en kontinuert stokastisk variabel.
Eksempel 5.19: Den diskrete stokastiske variabel, Y, der antager værdien 1, når en mønt lan-
der på plat, og værdien 2, når den lander på krone, har følgende kumulative
sandsynlighedsfunktion:
Definition af p-fraktil: For en stokastisk variabel, X, med kumulativ sandsynlighedsfunktion, F(x), er værdien, qp, en p-fraktil hvis og kun hvis:
i) P(X < qp) ≤ p
ii) P(X > qp) ≤ 1 – p
Plat og krone
Når man som i eksempel 5.17 har et interval af værdier, som alle opfylder kravet til at være en p-fraktil, så vælger man typisk den midterste værdi i intervallet. I eksempel 5.17 bliver 2,5 således medianen. Et tilsvarende problem har vi, når vi har med diskrete stokastiske variabler at gøre. Lad os derfor kigge nærmere på dem.
Eksempel 5.18: Et terningspil ñ del 8
Lad 𝑋𝑋𝑋𝑋 vÊ re den diskrete stokastiske variabel, der angiver antallet af ¯jne ved et terningslag. Vi ved fra tidligere, at sandsynlighedsfordelingen for 𝑋𝑋𝑋𝑋 er f¯lgende:
𝑓𝑓𝑓𝑓(1) =16
, 𝑓𝑓𝑓𝑓(2) =16
, 𝑓𝑓𝑓𝑓(3) =16
, 𝑓𝑓𝑓𝑓(4) =16
, 𝑓𝑓𝑓𝑓(5) =16
,
𝑓𝑓𝑓𝑓(6) =16
Der er alts sandsynlighed 0,5 for at f en vÊ rdi af 𝑋𝑋𝑋𝑋 mindre end 3,1, men der er ogs sandsynlighed 0,5 for at f en vÊ rdi mindre end 3,8. S hvilken vÊ rdi er medianen? Som i tilfÊ ldet med kontinuerte variabler vÊ lger man typisk den midterste vÊ rdi af det interval af vÊ rdier, der alle deler sandsynlighedsmassen i to lige store dele. VÊ rdien 3,5 bliver derfor medianen i dette tilfÊ lde.
Hovedproblemet med at formulere betingelsen for en p-fraktil for en diskret stokastisk variabel stammer fra det faktum, at den kumulerede sandsynlighedsfunktion, 𝐹𝐹𝐹𝐹, for en diskret stokastisk variabel er en trappefunktion, se fx figur 4.1. Man kan derfor typisk ikke løse
ligningen 𝐹𝐹𝐹𝐹�𝑞𝑞𝑞𝑞𝑝𝑝𝑝𝑝� = 𝑝𝑝𝑝𝑝, som er definitionen af en p-fraktil for en
kontinuert stokastisk variabel. Nedenfor giver vi en formel definition af en p-fraktil, som gælder for både kontinuerte og diskrete stokastiske variabler. For kontinuerte variabler reducerer definitionen dog til den allerede viste definition i boksen ovenfor:
Definition af p-fraktil:

118 Beskrivende mål
Definition af p -fraktil:
For en stokastisk variabel, X, med kumuleret sandsynlighedsfunktion, F(x), er værdien, q
p, en p -fraktil hvis og kun hvis:
i) P(X < qp) £ p
ii) P(X > qp) £ 1 – p
Specielle navne for fraktiler:
q0,5
kaldes medianen.q
0,25 og q
0,75 kaldes kvartiler.
q0,1
, q0,2
,…, q0,9
kaldes deciler.q
0,01, q
0,02,…, q
0,99 kaldes percentiler.
Den første betingelse siger, at et udfald mindre end p -fraktilen højst må have
sandsynlighed p, mens den anden betingelse siger, at sandsynligheden for at
få et udfald større end p -fraktilen skal være mindre end eller lig med 1-p.
Denne snørklede definition er nødvendig, fordi den kumulerede sandsynlig-
hedsfunktion for en diskret stokastisk variabel er en trappefunktion og der-
med ikke kontinuert. “Ånden” i en p -fraktil er dog den samme som i tilfæl-
det med en kontinuert stokastisk variabel.
Eksempel 4.18 Den diskrete stokastiske variabel, Y, der antager værdien 1, når en mønt lan-
der på plat, og værdien 2, når den lander på krone, har følgende kumulerede
sandsynlighedsfunktion:
F y
y
y
y
( )
,
,
,
=<≤ <≥
0 1
1 2
0,5 1 2
Lad os prøve at finde den nederste kvartil, som er 0,25-fraktilen. Hvis vi prø-
ver at bruge definitionen af en p -fraktil for en kontinuert stokastisk variabel,
�–1 1 (= �0,25) 20
1
0,5
0,25
�(�)
4.3 Fraktiler 69
Plat og krone
Figur 4.4
Kumuleret
sandsynlighed
og 0,25-fraktil
Statistik_04.InD 18/03/03, 12:5669
Figur 5.4:
Kumuleret
sandsynlighed
og 0,25-fraktil
Specielle navne for fraktiler:
q0,5 kaldes medianen.
q0,25 og q0,75 kaldes kvartiler.
q0,1, q0,2, …, q0,9 kaldes deciler.
q0,01, q0,02, …, q0,99 kaldes percentiler.
0 , y < 1F(y) = 0,5 , 1 ≤ y < 2 1 , y ≥ 2
Lad os prøve at finde den nederste kvartil, som er 0,25-fraktilen. Hvis vi prø-
ver at bruge definitionen af en p-fraktil for en kontinuert stokastisk variabel,
så vil det ikke virke, da det er umuligt at løse F(q0,25) = 0,25 for en værdi af
q0,25. Se figur 5.4. Men da Y er diskret, skal vi bruge den generelle definition
af en p-fraktil. En kandidat til 0,25-fraktilen er værdien 1. Vi tjekker der for
betingelserne i) og ii) fra boksen ovenfor. For i) fås P(Y < 1) = 0, som er min-
dre end 0,25. For ii) fås P(Y > 1) = 1 – P(Y ≤ 1) = 1 – 0,5 = 0,5, som er mindre
end 1 – 0,25 = 0,75. Begge betingelser er altså opfyldt, og dermed er 1 en
0,25-fraktil. Grafisk er 0,25-fraktilen den værdi af y, hvor F(y) springer op
over 0,25.
Afslutningsvis bemærker vi, at fraktiler, modsat momenter, altid eksisterer. En
række fraktiler har endvidere specielle navne, som det fremgår af boksen ne-
denfor.

5.4 Valg af beskrivende mål 119
5.4 Valg af beskrivende mål
En gennemsnitlig beboer i København har færre end to ben. Dette udsagn
vækker mistanke om, at en stor miljøkatastrofe må have ramt hovedstaden.
Men udsagnet er faktisk korrekt, hvis der bare er én beboer i København, som
kun har ét ben (og ingen har mere end to!). Man skal derfor være påpasselig
med fortolkningen af beskrivende mål, som for eksempel en middelværdi,
selvom udregnin gerne er korrekte. Ligeså vigtigt er det at vælge beskrivende
mål, som i sammenhængen giver et relevant billede af en fordeling. I tilfældet
med antal ben blandt de københavnske beboere kunne det således være mere
interessant at kende sandsynligheden for, at en tilfældigt udvalgt beboer har to
ben.
Et andet eksempel er valget af beskrivende mål for en indkomstfordeling.
Antag, at den sto kastiske variabel, X, angiver en simpel tilfældigt udvalgt ind-
byggers indkomst. Hvis den forventede værdi af X er høj, betyder det så, at
man kan konkludere, at indbyggerne er rige? Nej, det betyder, at de i gennem-
snit er rige. Hvis hovedparten af indbyggerne er fattige, men de få rige er eks-
tremt rige, så er middelindkomsten høj. Medianindkomsten vil derimod være
lav, fordi den ikke er særlig påvirket af, at der findes en lille gruppe rige perso-
ner. For medianen gør det ingen forskel, om de rigeste 49 % er lidt rige eller
stenrige. Både middelværdien og medianen er gyldige beskrivende mål, men
de fortæller to vidt forskellige historier om de samme indbyggere.
Middelværdien og medianen har det til fælles, at de begge giver et bud på
den centrale ten dens i en fordeling. Medianen bygger primært på sandsynlighe-
den for udfaldene, hvorimod middelværdien medtager udfaldenes størrelse.
Hvilket af de to mål, der giver den bedste beskrivelse af fordelingens midte eller
den „typiske“ observation, afhænger af det, vi ønsker at undersø ge.
I en symmetrisk fordeling er medianen og middelværdien lig hinanden. I
praksis kan man dog komme til at lave målefejl. For eksempel kan man i ind-
komstfordelingen komme til at sætte et 0 for meget på nogle af de høje ind-
komster. Målefejl af denne type vil typisk påvirke udregningen af middelvær-
dien mere end udregningen af medianen. Man siger derfor, at medianen er
mere robust over for sådanne målefejl.
5.4.1 Modalværdi
Et ofte (måske lidt for ofte) brugt beskrivende mål er modalværdien for en
stokastisk variabel. Modelværdien kaldes også typetallet og er den mest sand-
synlige værdi i en fordeling. Hvis den stokastiske variabel er givet ved en sim-
pel tilfældig udtræk ning fra en virkelig population, så er modalværdien den
oftest forekommen de værdi i populationen.
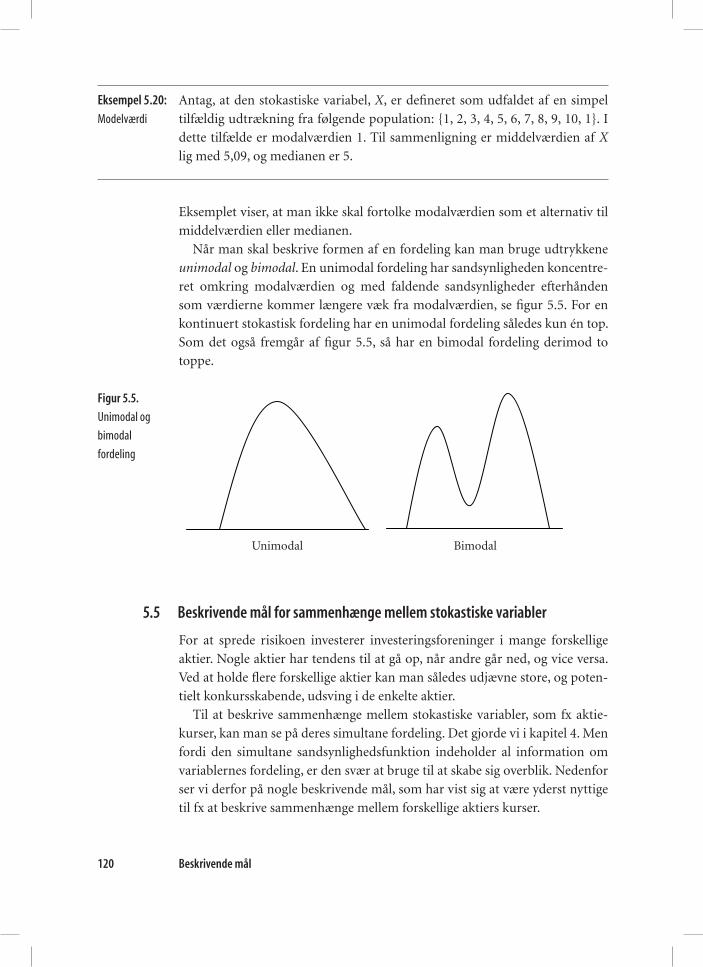
120 Beskrivende mål
Eksempel 5.20: Antag, at den stokastiske variabel, X, er defineret som udfaldet af en simpel
tilfældig udtrækning fra følgende population: {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 1}. I
dette tilfælde er modalværdien 1. Til sammenligning er middelværdien af X
lig med 5,09, og medianen er 5.
Eksemplet viser, at man ikke skal fortolke modalværdien som et alternativ til
middelværdien eller medianen.
Når man skal beskrive formen af en fordeling kan man bruge udtrykkene
unimodal og bimodal. En unimodal fordeling har sandsynligheden koncentre-
ret omkring modalværdien og med faldende sandsynligheder efterhånden
som værdierne kommer længere væk fra modalværdien, se figur 5.5. For en
kontinuert stokastisk fordeling har en unimodal fordeling således kun én top.
Som det også fremgår af figur 5.5, så har en bimodal fordeling derimod to
toppe.
5.5 Beskrivende mål for sammenhænge mellem stokastiske variabler
For at sprede risikoen investerer investeringsforeninger i mange forskellige
aktier. Nogle aktier har tendens til at gå op, når andre går ned, og vice versa.
Ved at holde flere forskellige aktier kan man således udjævne store, og poten-
tielt konkursskabende, udsving i de enkelte aktier.
Til at beskrive sammenhænge mellem stokastiske variabler, som fx aktie-
kurser, kan man se på deres simultane fordeling. Det gjorde vi i kapitel 4. Men
fordi den simultane sandsynlighedsfunktion indeholder al information om
variablernes fordeling, er den svær at bruge til at skabe sig overblik. Nedenfor
ser vi derfor på nogle beskrivende mål, som har vist sig at være yderst nyttige
til fx at beskrive sammenhænge mellem forskellige aktiers kurser.
Modelværdi
Eksemplet viser at man ikke skal fortolke modalværdien som et alternativ til middelværdi eller median.
Når man skal beskrive formen af en fordeling kan man bruge udtrykkene unimodal og bimodal. En unimodal fordeling har sandsynligheden koncentreret omkring modalværdien og med faldende sandsynligheder efterhånden som værdierne kommer længere væk fra modalværdien, se figur 5.5. For en kontinuert stokastisk fordeling har en unimodal fordeling således kun én top. Som det ogsåfremgår af figur 5.5, så har en bimodal fordeling derimod to toppe.
Figur 5.5. Unimodal og bimodal fordeling
Unimodal Bimodal
5.5 Beskrivende mål for sammenhænge mellem stokastiske variabler
For at sprede risikoen investerer investeringsforeninger i mange forskellige aktier. Nogle aktier har tendens til at gå op, når andre går ned, og vice versa. Ved at holde flere forskellige aktier kan man således udjævne store, og potentielt konkursskabende, udsving i de enkelte aktier.
Til at beskrive sammenhænge mellem stokastiske variabler, som fx aktiekurser, kan man se på deres simultane fordeling. Det gjorde vi i kapitel 4. Men fordi den simultane sandsynlighedsfunktion indeholder
Figur 5.5.
Unimodal og
bimodal
fordeling
Unimodal Bimodal

5.5 Beskrivende mål for sammenhænge mellem stokastiske variabler 121
5.5.1 Forventet værdi af en sum af stokastiske variabler
Afkastet på en aktie kan man beskrive som en stokastisk variabel, X. Antag, at
der også er en anden aktie med afkast givet ved den stokastiske variabel, Y. Vi
kan nu sammensætte en portefølje (en samling) af aktier, hvor a er antal ak-
tier af den første type, og b er antal aktier af den anden type. Dermed vil vo res
samlede afkast blive givet ved den stokastiske variabel, Z:
Z = a · X + b · Y
Hvad er nu det forventede afkast af denne portefølje? Dette kan bestemmes
ud fra følgende generelle formel for den forventede værdi af en sum af stoka-
stiske variabler, som både gælder for diskrete og kontinuerte variabler:
Den forventede værdi af summen af to stokastiske variabler afhænger ikke af,
hvordan de to stokastiske variabler samvarierer. Den afhænger udelukkende
af de to stokastiske variablers individuelle forventede værdier.
Det forventede afkast af porteføljen, Z, er derfor lig med det forventede af-
kast af de a X-aktier og de b Y-aktier:
E(Z) = a · E(X) + b · E(Y)
5.5.2 Kovarians
Et mål for risikoen af en portefølje er variansen af porteføljen, V(Z) = V(a · X +
b · Y). Variansen af en sum af stokastiske variabler, uanset om disse er diskrete eller
kontinuerte, afhænger af variansen af hver enkelt stokastisk varia bel, men også af
kovariansen. I kapitel 2 udregnede vi kovariansen mellem 2 populationskarakteri-
stika. Kovariansen mellem to stokastisk variabler er tilsvarende defineret som:
Den forventede værdi af en sum af stokastiske variabler (diskrete eller kontinuerte) er givet ved:
E(a · X + b · Y) = E(a · X) + E(b · Y) = a · E(X) + b · E(Y)
hvor a og b er konstanter.
Kovariansen, Cov(X, Y), mellem to stokastiske variabler, X og Y, er defineret ved:
Cov(X, Y) = E[(X – µX) · (Y – µY)]
hvor µX = E(X) og µY = E(Y). En alternativ formel for udregning af kovariansen er:
Cov(X, Y) = E(X · Y) – µX · µY

122 Beskrivende mål
Udregningen af de forventede værdier er forskellig alt efter, om de stokastiske
variabler er diskrete eller kontinuerte. For to diskrete stokastiske variabler kan
man udregne kovariansen som:
Sumtegnene Σxi Σyj
betyder, at der summeres over alle kombinationer af vær-
dier, som X og Y kan antage.
Kovariansen udtrykker noget om, hvordan de to variabler samvarierer. En
positiv kovarians betyder, at høje værdier af Y er mest sandsynlige sammen
med høje værdier af X, og tilsvarende at lave værdier af Y er mest sandsyn lige
sammen med lave værdier af X. Omvendt betyder en negativ kovarians, at lave
værdier af X er mest sandsynlige sammen med høje værdier af Y og omvendt.
Det følgende eksempel illustrerer udregningen af en kovarians for to di-
skrete stokastiske variabler:
Eksempel 5.21: Betragt de stokastiske variabler, X og Y, fra afsnit 4.3, som angav henholds-
vis, om en virksomhed gik fallit (X = 0) eller ej (X = 1), og om markedet blev
ugunstigt (Y = 0) eller gunstigt (Y = 1). Deres simultane sandsynlighedsfunk-
tion var givet i tabel 4.2. Kovariansen for disse to variabler findes ved først at
beregne de forventede værdier:
µX = E(X) = 0 · fX(0) + 1 · fX(1) = 0 · 0,3 + 1 · 0,7 = 0,7
µY = E(Y) = 0 · fY(0) + 1 · fY(1) = 0 · 0,4 + 1 · 0,6 = 0,6
hvor man skal huske, at det er de marginale sandsynligheder, der anvendes.
Dernæst beregnes E(X · Y):
Sumtegnene ∑ ∑ 𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 betyder, at der summeres over alle
kombinationer af værdier, som 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌 kan antage.Kovariansen udtrykker noget om, hvordan de to variabler
samvarierer. En positiv kovarians betyder, at høje værdier af 𝑌𝑌𝑌𝑌 er mest sandsynlige sammen med høje værdier af 𝑋𝑋𝑋𝑋, og tilsvarende at lave værdier af 𝑌𝑌𝑌𝑌 er mest sandsynlige sammen med lave værdier af 𝑋𝑋𝑋𝑋.Omvendt betyder en negativ kovarians, at lave værdier af 𝑋𝑋𝑋𝑋 er mest sandsynlige sammen med høje værdier af 𝑌𝑌𝑌𝑌 og omvendt.
Det følgende eksempel illustrerer udregningen af en kovarians for to diskrete stokastiske variabler:
Eksempel 5.21: Markedsudvikling og virksomhedsfallit
Betragt de stokastiske variabler, 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌, fra afsnit 4.3, som angav henholdsvis, om en virksomhed gik fallit (𝑋𝑋𝑋𝑋 = 0) eller ej (𝑋𝑋𝑋𝑋 = 1), og om markedet blev ugunstigt (𝑌𝑌𝑌𝑌 = 0) eller gunstigt (𝑌𝑌𝑌𝑌 = 1). Deres simultane sandsynlighedsfunktion var givet ved tabel 4.2. Kovariansen for disse to variabler findes ved f¯rst at beregne de forventede vÊ rdier:
𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = 0 ∙ 𝑓𝑓𝑓𝑓𝑋𝑋𝑋𝑋(0) + 1 ∙ 𝑓𝑓𝑓𝑓𝑋𝑋𝑋𝑋(1) = 0 ∙ 0,3 + 1 ∙ 0,7 = 0,7
𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌 = 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) = 0 ∙ 𝑓𝑓𝑓𝑓𝑌𝑌𝑌𝑌(0) + 1 ∙ 𝑓𝑓𝑓𝑓𝑌𝑌𝑌𝑌(1) = 0 ∙ 0,4 + 1 ∙ 0,6 = 0,6
hvor man skal huske, at det er de marginale sandsynligheder, der anvendes. DernÊ st beregnes 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋 ∙ 𝑌𝑌𝑌𝑌):
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋 ∙ 𝑌𝑌𝑌𝑌) = ��𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 ∙ 𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 ∙ 𝑓𝑓𝑓𝑓�𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 ,𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 �𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖
= 0 ∙ 0 ∙ 𝑓𝑓𝑓𝑓(0, 0) + 1 ∙ 0 ∙ 𝑓𝑓𝑓𝑓(1, 0) + 0 ∙ 1 ∙ 𝑓𝑓𝑓𝑓(0, 1) + 1 ∙ 1 ∙ 𝑓𝑓𝑓𝑓(1, 1)= 0 ∙ 0 ∙ 0,2 + 1 ∙ 0 ∙ 0,2 + 0 ∙ 1 ∙ 0,1 + 1 ∙ 1 ∙ 0,5 = 0,5
Dermed bliver kovariansen givet ved:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋 ∙ 𝑌𝑌𝑌𝑌) − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 ∙ 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌 = 0,5 − 0,7 ∙ 0,6 = 0,08
I eksempel 5.21 er kovariansen lig 0,08. Dette fortæller os, at der er størst chance for fallit (𝑋𝑋𝑋𝑋 = 0), når markedet er ugunstigt (𝑌𝑌𝑌𝑌 = 0), og
Kovariansen mellem to diskrete stokastiske variabler, X og Y, udregnes som:
5.5.2 Kovarians
Et mål for risikoen af en portefølje er variansen af porteføljen,𝑉𝑉𝑉𝑉(𝑍𝑍𝑍𝑍) = 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎 ∙ 𝑋𝑋𝑋𝑋 + 𝑏𝑏𝑏𝑏 ∙ 𝑌𝑌𝑌𝑌). Variansen af en sum af stokastiske variabler, uanset om disse er diskrete eller kontinuerte, afhænger af variansen af hver enkelt stokastisk variabel, men også af et mål for samvariationen kaldet kovariansen. Kovariansen er defineret som:
Kovariansen, 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌), mellem to stokastiske variabler, 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌, er defineret ved:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸[(𝑋𝑋𝑋𝑋 − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋) ∙ (𝑌𝑌𝑌𝑌 − 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌)]
hvor 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) og 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌 = 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌). En alternativ formel for udregning afkovariansen er:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋 ∙ 𝑌𝑌𝑌𝑌) − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 ∙ 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌
Udregningen af en forventet værdi er forskellig alt efter, om den stokastiske variabel er diskret eller kontinuert. For to diskrete stokastiske variabler kan man udregne kovariansen som:
Kovariansen mellem to diskrete stokastiske variabler, 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌,udregnes som:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = ��(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋) ∙ �𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 − 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌� ∙ 𝑓𝑓𝑓𝑓�𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 , 𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 �𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖
eller:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = ���𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 ∙ 𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 ∙ 𝑓𝑓𝑓𝑓�𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 ,𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 �𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖
� − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 ∙ 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌
hvor 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋), 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌 = 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) og 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥,𝑦𝑦𝑦𝑦) er den simultane sandsynlighedsfunktion.
eller:
5.5.2 Kovarians
Et mål for risikoen af en portefølje er variansen af porteføljen,𝑉𝑉𝑉𝑉(𝑍𝑍𝑍𝑍) = 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎 ∙ 𝑋𝑋𝑋𝑋 + 𝑏𝑏𝑏𝑏 ∙ 𝑌𝑌𝑌𝑌). Variansen af en sum af stokastiske variabler, uanset om disse er diskrete eller kontinuerte, afhænger af variansen af hver enkelt stokastisk variabel, men også af et mål for samvariationen kaldet kovariansen. Kovariansen er defineret som:
Kovariansen, 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌), mellem to stokastiske variabler, 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌, er defineret ved:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸[(𝑋𝑋𝑋𝑋 − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋) ∙ (𝑌𝑌𝑌𝑌 − 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌)]
hvor 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) og 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌 = 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌). En alternativ formel for udregning afkovariansen er:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋 ∙ 𝑌𝑌𝑌𝑌) − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 ∙ 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌
Udregningen af en forventet værdi er forskellig alt efter, om den stokastiske variabel er diskret eller kontinuert. For to diskrete stokastiske variabler kan man udregne kovariansen som:
Kovariansen mellem to diskrete stokastiske variabler, 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌,udregnes som:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = ��(𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋) ∙ �𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 − 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌� ∙ 𝑓𝑓𝑓𝑓�𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 , 𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 �𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖
eller:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = ���𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 ∙ 𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 ∙ 𝑓𝑓𝑓𝑓�𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖 ,𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗 �𝑦𝑦𝑦𝑦𝑗𝑗𝑗𝑗𝑥𝑥𝑥𝑥𝑖𝑖𝑖𝑖
� − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 ∙ 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌
hvor 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋), 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌 = 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) og 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥,𝑦𝑦𝑦𝑦) er den simultane sandsynlighedsfunktion.
hvor µx = E(X), µy = E(Y), og f(x, y) er den simultane sandsynlighedsfunk tion.
Markeds-
udvikling og
virksomheds-
fallit

5.5 Beskrivende mål for sammenhænge mellem stokastiske variabler 123
Dermed bliver kovariansen givet ved:
Cov(X, Y) = E(X · Y) – µX · µY = 0,5 – 0,7 · 0,6 = 0,08
I eksempel 5.21 er kovariansen lig 0,08. Dette fortæller os, at der er størst
chance for fallit (X = 0), når markedet er ugunstigt (Y = 0), og størst chance
for at undgå fallit (X = 1), når markedet er gunstigt (Y = 1).
Når man skal udregne kovariansen mellem to kontinuerte stokastiske va
riabler, så skal man bruge integralregning. Sumtegnene i udregningen af ko
variansen mellem to diskrete stokastiske variabler skal udskiftes med inte
graletegn, og den simultane sandsynlighedsfunktion skal udskiftes med den
simultane tæthedsfunktion. Fortolkningen er dog nøjagtig som før:
Vi har også nogle regneregler for kovarianser, som gælder, uanset om de sto
kastiske variabler er kontinuerte eller diskrete. Disse er:
Kovariansen mellem to kontinuerte stokastiske variabler, X og Y, udregnes som:
størst chance for at undgå fallit (𝑋𝑋𝑋𝑋 = 1), når markedet er gunstigt(𝑌𝑌𝑌𝑌 = 1).
Når man skal udregne kovariansen mellem to kontinuerte stokastiske variabler, så skal man bruge integralregning. Sumtegnene i udregningen af kovariansen mellem to diskrete stokastiske variabler skal udskiftes med integraletegn, og den simultane sandsynlighedsfunktion skal udskiftes med den simultane tæthedsfunktion. Fortolkningen er dog nøjagtig som før:
Kovariansen mellem to kontinuerte stokastiske variabler, 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌,udregnes som:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = �(𝑥𝑥𝑥𝑥 − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋) ∙ (𝑦𝑦𝑦𝑦 − 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥,𝑦𝑦𝑦𝑦)𝑑𝑑𝑑𝑑𝑦𝑦𝑦𝑦𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥𝑥𝑥𝑥𝑥 ,𝑦𝑦𝑦𝑦
eller:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = ��𝑥𝑥𝑥𝑥 ∙ 𝑦𝑦𝑦𝑦 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥, 𝑦𝑦𝑦𝑦)𝑑𝑑𝑑𝑑𝑦𝑦𝑦𝑦𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥𝑥𝑥𝑥𝑥 ,𝑦𝑦𝑦𝑦
� − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 ∙ 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌
hvor 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋), 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌 = 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) og 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥,𝑦𝑦𝑦𝑦) er den simultane tæthedsfunktion.
Vi har også nogle regneregler for kovarianser, som gælder, uanset om de stokastiske variabler er kontinuerte eller diskrete. Disse er:
Regneregler for kovarianser:
𝑖𝑖𝑖𝑖) 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑌𝑌𝑌𝑌,𝑋𝑋𝑋𝑋)
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑎𝑎𝑎𝑎 ∙ 𝑋𝑋𝑋𝑋, 𝑏𝑏𝑏𝑏 ∙ 𝑌𝑌𝑌𝑌) = 𝑎𝑎𝑎𝑎 ∙ 𝑏𝑏𝑏𝑏 ∙ 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌)
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑎𝑎𝑎𝑎 + 𝑋𝑋𝑋𝑋, 𝑏𝑏𝑏𝑏 + 𝑌𝑌𝑌𝑌) = 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌)
𝑖𝑖𝑖𝑖𝑝𝑝𝑝𝑝) 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋 + 𝑍𝑍𝑍𝑍,𝑌𝑌𝑌𝑌) = 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) + 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑍𝑍𝑍𝑍,𝑌𝑌𝑌𝑌)
eller:
størst chance for at undgå fallit (𝑋𝑋𝑋𝑋 = 1), når markedet er gunstigt(𝑌𝑌𝑌𝑌 = 1).
Når man skal udregne kovariansen mellem to kontinuerte stokastiske variabler, så skal man bruge integralregning. Sumtegnene i udregningen af kovariansen mellem to diskrete stokastiske variabler skal udskiftes med integraletegn, og den simultane sandsynlighedsfunktion skal udskiftes med den simultane tæthedsfunktion. Fortolkningen er dog nøjagtig som før:
Kovariansen mellem to kontinuerte stokastiske variabler, 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌,udregnes som:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = �(𝑥𝑥𝑥𝑥 − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋) ∙ (𝑦𝑦𝑦𝑦 − 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌) ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥,𝑦𝑦𝑦𝑦)𝑑𝑑𝑑𝑑𝑦𝑦𝑦𝑦𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥𝑥𝑥𝑥𝑥 ,𝑦𝑦𝑦𝑦
eller:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = ��𝑥𝑥𝑥𝑥 ∙ 𝑦𝑦𝑦𝑦 ∙ 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥, 𝑦𝑦𝑦𝑦)𝑑𝑑𝑑𝑑𝑦𝑦𝑦𝑦𝑑𝑑𝑑𝑑𝑥𝑥𝑥𝑥𝑥𝑥𝑥𝑥 ,𝑦𝑦𝑦𝑦
� − 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 ∙ 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌
hvor 𝜇𝜇𝜇𝜇𝑋𝑋𝑋𝑋 = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋), 𝜇𝜇𝜇𝜇𝑌𝑌𝑌𝑌 = 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) og 𝑓𝑓𝑓𝑓(𝑥𝑥𝑥𝑥,𝑦𝑦𝑦𝑦) er den simultane tæthedsfunktion.
Vi har også nogle regneregler for kovarianser, som gælder, uanset om de stokastiske variabler er kontinuerte eller diskrete. Disse er:
Regneregler for kovarianser:
𝑖𝑖𝑖𝑖) 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑌𝑌𝑌𝑌,𝑋𝑋𝑋𝑋)
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑎𝑎𝑎𝑎 ∙ 𝑋𝑋𝑋𝑋, 𝑏𝑏𝑏𝑏 ∙ 𝑌𝑌𝑌𝑌) = 𝑎𝑎𝑎𝑎 ∙ 𝑏𝑏𝑏𝑏 ∙ 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌)
𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖𝑖) 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑎𝑎𝑎𝑎 + 𝑋𝑋𝑋𝑋, 𝑏𝑏𝑏𝑏 + 𝑌𝑌𝑌𝑌) = 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌)
𝑖𝑖𝑖𝑖𝑝𝑝𝑝𝑝) 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋 + 𝑍𝑍𝑍𝑍,𝑌𝑌𝑌𝑌) = 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) + 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑍𝑍𝑍𝑍,𝑌𝑌𝑌𝑌)
hvor µX = E(X), µY = E(Y), og f(x, y) er den simultane tæthedsfunk tion.
Regneregler for kovarianser:
i) Cov(X, Y) = Cov(Y, X)
ii) Cov(a · X, b · Y) = a · b · Cov(X, Y)
iii) Cov(a + X, b + Y) = Cov(X, Y)
iv) Cov(X + Z, Y) = Cov(X, Y) + Cov(Z, Y)
hvor X, Y, og Z er (diskrete eller kontinuerte) stokastiske variabler, og a og b er konstanter.

124 Beskrivende mål
Vi er nu klar til at præsentere udtrykket for variansen af en sum af sto kastiske
variabler, og dermed variansen på vores aktieportefølje: V(Z) =
V(a · X + b · Y):
Her har vi i det sidste skridt udnyttet regel ii) fra boksen med regneregler for
kovarianser. Variansen af en sum af stokastiske variabler er således lig med
summen af varianserne plus to gange kovariansen.
Eksempel 5.22: Lad X og Y være to kontinuerte stokastiske variabler, som angiver det frem
tidige afkast på to forskellige aktier: AktieX og AktieY. Vi antager, at middel
værdierne af X og Y begge er lig med 4, og varianserne, V(X) og V(Y), begge
er lig 2. Dermed kan effekten af kovariansen nemmest illustreres. Antag, at
kovariansen mellem X og Y er lig med –1. Hvis man vælger at købe 2 stk. af
AktieX, får man således et forventet afkast på:
E(2 · X) = 2 · E(X) = 2 · 4 = 8
med en varians på:
V(2 · X) = 4 · V(X) = 4 · 2 = 8
Man får samme forventede afkast og varians, hvis man i stedet køber 2 stk. af
AktieY, da vi antog, at den havde samme middelværdi og varians som AktieX.
Køber man derimod 1 stk. af hver aktie, har man et forventet afkast på:
E(X · Y) = E(X) + E(Y) = 4 + 4 = 8
hvilket er det samme, som hvis man havde enten to aktier af type X eller to af
type Y. Variansen på porteføljen er derimod:
V(X + Y) = V(X) + V(Y) + 2 · Cov(X, Y) = 2 + 2 + 2 · (–1) = 2
hvilket er fire gange mindre, end hvis man havde enten to aktier af type X
el ler to af type Y. Ved at sprede investeringen over to aktier kan man således
reducere variansen på afkastet, uden at det går ud over det forventede afkast!
Årsagen er, at når X giver et lavt afkast, så giver Y typisk et højt afkast. På
denne måde nedsætter man sandsynligheden for store udsving i det samlede
afkast.
Variansen af en sum af stokastiske variabler:
hvor 𝑋𝑋𝑋𝑋, 𝑌𝑌𝑌𝑌 og 𝑍𝑍𝑍𝑍 er (diskrete eller kontinuerte) stokastiske variabler, og 𝑎𝑎𝑎𝑎 og 𝑏𝑏𝑏𝑏 er konstanter.
Vi er nu klar til at præsentere udtrykket for variansen af en sum af sto-kastiske variabler, og dermed variansen på vores aktieportefølje:𝑉𝑉𝑉𝑉(𝑍𝑍𝑍𝑍) = 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎 ∙ 𝑋𝑋𝑋𝑋 + 𝑏𝑏𝑏𝑏 ∙ 𝑌𝑌𝑌𝑌):
Variansen af en sum af stokastiske variabler:
𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎 ∙ 𝑋𝑋𝑋𝑋 + 𝑏𝑏𝑏𝑏 ∙ 𝑌𝑌𝑌𝑌) = 𝑉𝑉𝑉𝑉(𝑎𝑎𝑎𝑎 ∙ 𝑋𝑋𝑋𝑋) + 𝑉𝑉𝑉𝑉(𝑏𝑏𝑏𝑏 ∙ 𝑌𝑌𝑌𝑌) + 2 ∙ 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑎𝑎𝑎𝑎 ∙ 𝑋𝑋𝑋𝑋, 𝑏𝑏𝑏𝑏 ∙ 𝑌𝑌𝑌𝑌)= 𝑎𝑎𝑎𝑎2 ∙ 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) + 𝑏𝑏𝑏𝑏2 ∙ 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) + 2 ∙ 𝑎𝑎𝑎𝑎 ∙ 𝑏𝑏𝑏𝑏 ∙ 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌)
Her har vi i det sidste skridt udnyttet regel ii) fra boksen med regneregler for kovarianser. Variansen af en sum af stokastiske variabler er således lig med summen af varianserne plus to gange kovariansen.
Eksempel 5.22: Risikodiversificering ñ del 1
Lad 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌 vÊ re to kontinuerte stokastiske variabler, som angiver det fremtidige afkast p to forskellige aktier: AktieX og AktieY. Vi antager, at middelvÊ rdierne af 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌 begge er lig med 4, og varianserne, 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) og𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌), begge er lig 2. Dermed kan effekten af kovariansen nemmest illustreres. Antag, at kovariansen mellem 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌 er lig med −1. Hvis man vÊ lger at k¯be 2 stk. af AktieX, fÂr man sÂledes et forventet afkast pÂ:
𝐸𝐸𝐸𝐸(2 ∙ 𝑋𝑋𝑋𝑋) = 2 ∙ 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) = 2 ∙ 4 = 8
med en varians pÂ:
𝑉𝑉𝑉𝑉(2 ∙ 𝑋𝑋𝑋𝑋) = 4 ∙ 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) = 4 ∙ 2 = 8
Man fÂr samme forventede afkast og varians, hvis man i stedet k¯ber 2 stk. af AktieY, da vi antog, at den havde samme middelvÊ rdi og varians som AktieX. K¯ber man derimod 1 stk. af hver aktie, har man et forventet afkastpÂ:
𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋 + 𝑌𝑌𝑌𝑌) = 𝐸𝐸𝐸𝐸(𝑋𝑋𝑋𝑋) + 𝐸𝐸𝐸𝐸(𝑌𝑌𝑌𝑌) = 4 + 4 = 8
Risikodiversifi
cering – del 1

5.5 Beskrivende mål for sammenhænge mellem stokastiske variabler 125
5.5.3 Korrelationskoefficient
Et problem med kovariansen som mål for samvariationen mellem to stokasti
ske variabler er, at dens størrelse afhænger af måleenheden for de stokastiske
variabler. Ganger vi de stokastiske variabler, X og Y, med to konstanter, a og b,
så ganger vi også kovariansen op med disse:
Cov(a · X, b · Y) = a · b · Cov(X, Y)
Dette følger af regneregel ii) ovenfor. Hvis man således omdefinerer X fra fx
centimeter til meter, som vi gjorde i kapitel 4, så ændrer man også kovari
ansen mellem X og Y. For at få et mål for samvariationen, der er uafhængigt af
sådanne ligegyldige transformationer af de stokastiske variabler, anvender
man ofte korrelationskoefficienten. Denne findes ved at dividere kovariansen
med kvadratroden af produktet af varianserne:
Korrelationskoefficienten har samme fortegn som kovariansen, men vil altid
ligge mellem –1 og 1. Hvis korrelationskoefficienten er 1 eller –1 siges de to
va riabler at være henholdsvis perfekt positivt og perfekt negativt korrelerede.
Eksempel 5.23: Korrelationskoefficienten for X og Y fra eksempel 5.22 kan beregnes til:
Korrelationskoefficienten har samme fortegn som kovariansen, men vil altid ligge mellem −1 og 1. Hvis korrelationskoefficienten er 1eller −1 siges de to variabler at være henholdsvis perfekt positivt og perfekt negativt korrelerede.
Eksempel 5.23: Risikodiversificering ñ del 2
Korrelationskoefficienten for 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌 fra eksempel 5.22 kan beregnes til:
𝜌𝜌𝜌𝜌(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) =𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌)
�𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) ∙ 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌)=
−1√2 ∙ 2
= −12
I afsnit 4.3.5 introducerede vi begreberne afhængighed og uafhængighed mellem to stokastiske variabler til at analysere sammenhængen mellem dem. Uafhængighed er et stærkere begreb end kovarians, idet uafhængighed mellem to stokastiske variabler medfører, at kovariansen mellem dem er 0. En kovarians mellem to stokastiske variabler på 0 medfører derimod ikke, at de er uafhængige. Denne forskel er illustreret i en af opgaverne til kapitlet.
5.6 Beskrivende mål ved hjælp af Excel
Vi skal nu se, hvordan vi kan anvende Excel til at beregne beskrivende mål for fordelinger. Vi vil fokusere på det tilfælde, hvor vi har en virkelig population. Her kan Excel udregne fx middelværdien for en stokastisk variabel, når denne er givet ved værdien af det element, der udtrækkes, og når alle elementer i populationen har samme sandsynlighed for udvælgelse. Excel udregner nemlig populationsmiddelværdien, som jo er den samme som middelværdien af den stokastiske variabel i dette tilfælde.I regnearket har vi vist en virkelig population bestående af de 27 lande i EU. Antag, at vi trækker et land tilfældigt i populationen og lader den stokastiske variabel, 𝑋𝑋𝑋𝑋, angive befolkningen (i millioner personer) og 𝑌𝑌𝑌𝑌 BNP per capita (indbygger).
I afsnit 4.3.5 introducerede vi begreberne afhængighed og uafhængighed mel
lem to stokastiske variabler til at analysere sammenhængen mellem dem. Uaf
hængighed er et stærkere begreb end kovarians, idet uafhængighed mel lem to
stokastiske variabler medfører, at kovariansen mellem dem er 0. En kovarians
mellem to stokastiske variabler på 0 medfører derimod ikke, at de er uafhæn
gige. Denne forskel er illustreret i en af opgaverne til kapitlet.
Korrelationskoefficienten, p(X, Y), for to stokastiske variabler, X og Y, er givet ved:
hvilket er det samme, som hvis man havde enten to aktier af type 𝑋𝑋𝑋𝑋 eller to af type 𝑌𝑌𝑌𝑌. Variansen p portef¯ljen er derimod:
𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋 + 𝑌𝑌𝑌𝑌) = 𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) + 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌) + 2 ∙ 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) = 2 + 2 + 2 ∙ (−1) = 2
hvilket er fire gange mindre, end hvis man havde enten to aktier af type 𝑋𝑋𝑋𝑋 el-ler to af type 𝑌𝑌𝑌𝑌. Ved at sprede investeringen over to aktier kan man sÂledes reducere variansen p afkastet, uden at det gÂr ud over det forventede afkast! Årsagen er, at nÂr 𝑋𝑋𝑋𝑋 giver et lavt afkast, s giver 𝑌𝑌𝑌𝑌 typisk et h¯jt afkast. P denne mÂde nedsÊ tter man sandsynligheden for store udsving i det samlede afkast.
5.5.3 Korrelationskoefficient
Et problem med kovariansen som mål for samvariationen mellem to stokastiske variabler er, at dens størrelse afhænger af måleenheden for de stokastiske variabler. Ganger vi de stokastiske variabler, 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌,med to konstanter, 𝑎𝑎𝑎𝑎 og 𝑏𝑏𝑏𝑏, så ganger vi også kovariansen op meddisse:
𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝 (𝑎𝑎𝑎𝑎 ∙ 𝑋𝑋𝑋𝑋, 𝑏𝑏𝑏𝑏 ∙ 𝑌𝑌𝑌𝑌 ) = 𝑎𝑎𝑎𝑎 ∙ 𝑏𝑏𝑏𝑏 ∙ 𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋 ,𝑌𝑌𝑌𝑌)
Dette følger af regneregel ii) ovenfor. Hvis man således omdefinerer 𝑋𝑋𝑋𝑋 fra fx centimeter til meter, som vi gjorde i kapitel 4, så ændrer man også kovariansen mellem 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌. For at få et mål for samvariationen, der er uafhængigt af sådanne ligegyldige transformationer af de stokastiske variabler, anvender man ofte korrelationskoefficienten. Denne findes ved at dividere kovariansen med kvadratroden af produktet af varianserne:
Korrelationskoefficienten, 𝜌𝜌𝜌𝜌(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌), for to stokastiske variabler, 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌, er givet ved:
𝜌𝜌𝜌𝜌(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌) =𝐶𝐶𝐶𝐶𝑝𝑝𝑝𝑝𝑝𝑝𝑝𝑝(𝑋𝑋𝑋𝑋,𝑌𝑌𝑌𝑌)
�𝑉𝑉𝑉𝑉(𝑋𝑋𝑋𝑋) ∙ 𝑉𝑉𝑉𝑉(𝑌𝑌𝑌𝑌)
Risikodiversifi
cering – del 2
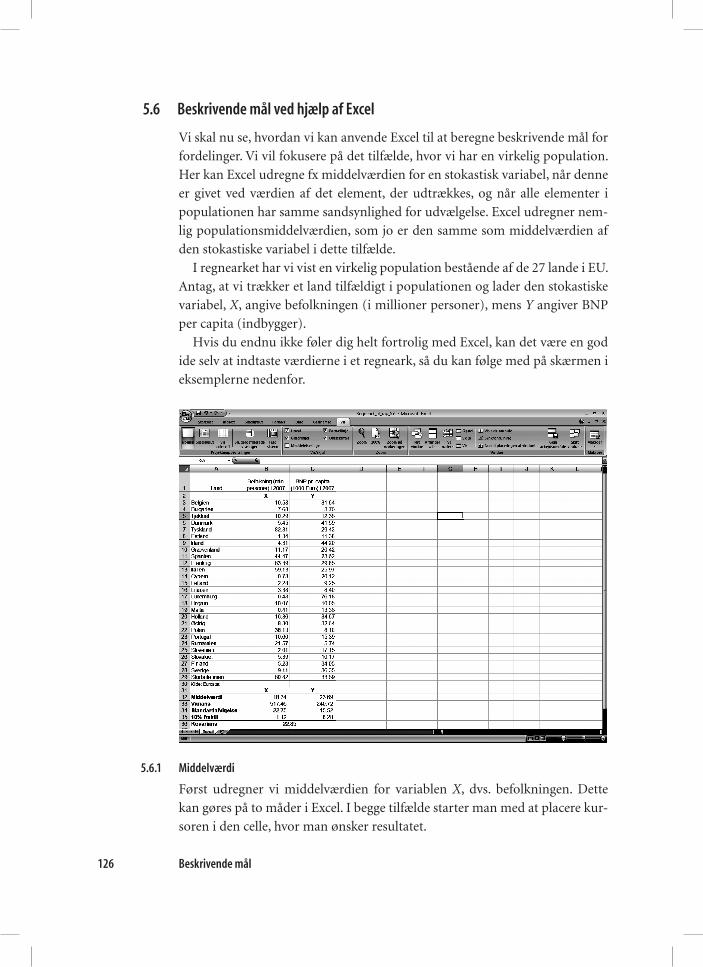
126 Beskrivende mål
5.6 Beskrivende mål ved hjælp af Excel
Vi skal nu se, hvordan vi kan anvende Excel til at beregne beskrivende mål for
fordelinger. Vi vil fokusere på det tilfælde, hvor vi har en virkelig popula tion.
Her kan Excel udregne fx middelværdien for en stokastisk variabel, når denne
er givet ved værdien af det element, der udtrækkes, og når alle elemen ter i
populationen har samme sandsynlighed for udvælgelse. Excel udregner nem
lig populationsmiddelværdien, som jo er den samme som middelværdien af
den stokastiske variabel i dette tilfælde.
I regnearket har vi vist en virkelig population bestående af de 27 lande i EU.
Antag, at vi trækker et land tilfældigt i populationen og lader den stokastiske
variabel, X, angive befolkningen (i millioner personer), mens Y angiver BNP
per capita (indbygger).
Hvis du endnu ikke føler dig helt fortrolig med Excel, kan det være en god
ide selv at indtaste værdierne i et regneark, så du kan følge med på skærmen i
eksemplerne nedenfor.
5.6.1 Middelværdi
Først udregner vi middelværdien for variablen X, dvs. befolkningen. Dette
kan gøres på to måder i Excel. I begge tilfælde starter man med at placere kur
soren i den celle, hvor man ønsker resultatet.

5.6 Beskrivende mål ved hjælp af Excel 127
1. Den „guidede“ metode foregår ved at klikke på Formler i den øverste menu
og derefter på Indsæt funktion. Da fremkommer følgende boks:
Her vælges kategorien Statistisk i den øverste dropdown menu, og i det
nederste vindue kan man nu se de statistiske funktioner, der er tilgængeli
ge i Excel. Vi skal her klikke på MIDDEL og dernæst OK. Vi ser da føl
gende skærmbillede:
I rubrikken ud for Tal1 skal man angive cellereferencerne for populations
elementerne, dvs. hvor de befinder sig i regnearket. I dette tilfælde skal vi
skrive B3:B29, fordi værdierne findes i cellerne mellem B3 og B29. Alterna
tivt kan man klikke på regnskabsikonet til højre for rubrikken ved Tal1.
Man kan nu med musen markere de celler, hvor populationselementerne

128 Beskrivende mål
befinder sig, hvorefter man trykker Return. Excel vil nu selv skrive B3:B29 i rubrikken ud for Tal1. Derefter klikker man OK, og middelværdien frem
kommer da i den celle, man startede øvelsen i.
2. Den hurtige metode foregår ved direkte at skrive: =MIDDEL(B3:B29) i den celle, hvor man ønsker resultatet.
5.6.2 Varians og standardafvigelse
Beregning af varians og standardafvigelse foregår på helt samme måde, blot
skal man skrive =VARIANSP(B3:B29) og =STDAFVP(B3:B29), hvis man
bruger den hurtige metode, eller vælge VARIANSP og STDAFVP under Ind-sæt funktion, hvis man foretrækker den guidede fremgangsmåde.
Øvelse: Udregn ved hjælp af Excel variansen og standardafvigelserne for X og Y.
5.6.3 Kovarians og korrelationskoefficient
Vi kan også finde kovariansen og korrelationskoefficienten for de to stokasti
ske variabler ved hjælp af Excel. Ønsker vi fx kovariansen mellem X og Y i
ovenstå ende eksempel, gør vi følgende:
1. Den „guidede“ metode: Vælg KOVARIANS under Indsæt funktion. I den
fremkomne dialogboks angives cellereferencerne for X ud for Vektor1,
dvs. B3:B29, og cellereferencerne for Y ud for Vektor2, dvs. C3:C29. Deref
ter tryk kes OK.
2. Ved den hurtige metode skrives blot: =KOVARIANS(B3:B29;C3:C29) di
rekte i cellen.

5.7 Opgaver 129
Korrelationskoefficienten findes på helt tilsvarende vis ved blot at anven de
funktionen KORRELATION. Fx kan man skrive =KORRELATION (B3:B29;C3:C29) i cellen, hvor man ønsker resultatet.
Øvelse: Find korrelationen mellem X og Y ved hjælp af Excel. Plot derefter værdierne
af X og Y mod hinanden i et diagram (funktionen til dette findes under Indsæt
i den øverste menu). Bekræfter figuren den beregnede korrelation?
5.7 Opgaver
1) Repetitionsspørgsmål:
a) Nævn de forskellige momenter, vi har stiftet bekendtskab med i dette
ka pitel.
b) Hvordan udregnes den forventede værdi af en diskret stokastisk varia
bel?
c) Hvad er forskellen på variansen og standardafvigelsen af en stokastisk
va riabel?
d) Hvad er en fraktil?
e) Hvad udtrykker kovariansen mellem to stokastiske variabler? Hvordan
udregnes den?
f) Hvad er sammenhængen mellem kovariansen og korrelationskoefficien
ten?
g) Hvilke værdier kan korrelationskoefficienten antage?
h) Hvordan udregnes forventningen af en sum af stokastiske variabler?
i) Hvordan udregnes variansen af en sum af stokastiske variabler?
2) Lad X være en diskret stokastisk variabel med sandsynlighedsfunktion
som i tabellen.
a) Bestem den forventede værdi af X.
b) Find E(2 + 5,4 · X) og E(√X)c) Beregn V(X).
d) Hvad er variansen af 3 · X?
x f(x) = P(X = x)
1 0,12
3 0,43
4 0,07
5 0,30
0 0,08

130 Beskrivende mål
3) Lad Y være en kontinuert stokastisk variabel med: E(Y) = 3,2 og E(Y2) =
14,1.
a) Beregn variansen og standardafvigelsen af Y.
b) Find også variansen af 7 · Y + 0,25.
c) Beregn E(7 + 2 · Y2).
4) I et lotteri findes tre slags lodder, hvor gevinsten er henholdsvis 0 kr., 100
kr. og 100.000 kr. Der findes 90.000 lodder af den første type, 9.999 af den
anden type og kun ét af den tredje type.
a) Hvad er den forventede gevinst på et tilfældigt udtrukket lod?
b) Antag, at alle lodder sælges. Hvad skal et lod da minimum koste for, at
lot teriet gennemføres uden tab for arrangøren?
c) Et lod koster 25 kr. Hvad er det forventede overskud for arrangøren,
hvis der sælges 9000 lodder?
5) En stokastisk variabel, X, har middelværdi 10 og varians 50.
a) Beregn middelværdi og varians af den stokastiske variabel, Y =
10 + 5 · X.
b) Find middelværdien af Y = (X – 10)2 og Z = X2 (udnyt at V(X) = E(X2)
– [E(X)]2).
6) Lad X og Y være to kontinuerte stokastiske variabler med følgende
fordelings funktioner:
𝐹𝐹𝐹𝐹(𝑥𝑥𝑥𝑥) = �0 , 𝑥𝑥𝑥𝑥 ≤ 0𝑥𝑥𝑥𝑥/3 , 0 < 𝑥𝑥𝑥𝑥 ≤ 31 , 𝑥𝑥𝑥𝑥 > 3
𝐹𝐹𝐹𝐹(𝑦𝑦𝑦𝑦) = �0 , 𝑦𝑦𝑦𝑦 ≤ 4(1 − 𝑦𝑦𝑦𝑦/4)2 , 4 < 𝑦𝑦𝑦𝑦 ≤ 81 , 𝑦𝑦𝑦𝑦 > 8
a) Find medianen for henholdsvis 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌.b) Find 0,05-fraktilen og 0,95-fraktilen for 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌.
7) Lad 𝑌𝑌𝑌𝑌 være en stokastisk variabel, der kan antage syv forskellige værdier. Fordelingsfunktionen (den kumulerede sandsynlighedsfunktion) for 𝑌𝑌𝑌𝑌 er givet i tabellen.a) Bestem medianen for 𝑌𝑌𝑌𝑌.b) Find 0,1-fraktilen og 0,75-fraktilen.
𝑦𝑦𝑦𝑦 𝐹𝐹𝐹𝐹(𝑦𝑦𝑦𝑦) = 𝑃𝑃𝑃𝑃(𝑌𝑌𝑌𝑌 ≤ 𝑦𝑦𝑦𝑦)0 0,00831 0,06922 0,25533 0,55854 0,83645 0,97236 1
8) Betragt eksperimentet fra opgave 4 i kapitel 4, hvor 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌 var stokastiske variabler (indikatorer) for henholdsvis køn og arbejdsskift med simultane sandsynligheder som i tabellen.a) Beregn kovariansen mellem 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌.b) Find korrelationskoefficienten for 𝑋𝑋𝑋𝑋 og 𝑌𝑌𝑌𝑌.c) Hvad fortæller dine resultater dig om sammenhængen mellem
køn og arbejdsskift?
𝑌𝑌𝑌𝑌 = 1 𝑌𝑌𝑌𝑌 = 0
a) Find medianen for henholdsvis X og Y.
b) Find 0,05fraktilen og 0,95fraktilen for X og Y.
7) Lad Y være en stokastisk variabel, der kan antage syv forskellige værdier.
Fordelingsfunktionen (den kumulative sandsynlighedsfunktion) for Y er
givet i tabellen nedenfor.
a) Bestem medianen for Y.
b) Find 0,1fraktilen og 0,75fraktilen.

5.7 Opgaver 131
y F(y) = P(Y ≤ y)
0 0,0083
1 0,0692
2 0,2553
3 0,5585
4 0,8364
5 0,9723
6 1
8) Betragt eksperimentet fra opgave 4 i kapitel 4, hvor X og Y var stokastiske
variabler (indikato rer) for henholdsvis køn og arbejdsskift med si multane
sandsynligheder som i tabellen nedenfor.
a) Beregn kovariansen mellem X og Y.
b) Find korrelationskoefficienten for X og Y.
c) Hvad fortæller dine resultater dig om sammenhængen mellem køn og
ar bejdsskift?
Y = 1 Y = 0
X = 1 0,35 0,23
X = 0 0,15 0,27
9) Lad X og Y være to stokastiske variabler med simultane sandsynligheder
som i tabellen nedenfor.
a) Beregn kovariansen mellem X og Y.
b) Er X og Y uafhængige?
c) Find den marginale sandsynligheds funktion for X.
d) Find også den betingede sandsynlighedsfunktion for X givet Y = 1.
e) Fortolk dine resultater.
f) Find de forventede værdier af X og Y.
g) Find varianserne af X og Y.
h) Lad den stokastiske variabel Z være givet ved Z = 2 · X + 3 · Y. Beregn
den forventede værdi og variansen af Z.
Y = 0 Y = 1 Y = 2
X = 0 0,15 0,1 0,15
X = 1 0,10 0,0 0,10
X = 2 0,15 0,1 0,15

132 Beskrivende mål
10) Lad X og Y være to stokastiske variabler med E(X) = 2,3 og E(Y) = 1,4. Lad
endvidere standardafvigelserne af X og Y være henholdsvis 1,1 og 0,8,
mens kovariansen er 0,2.
a) Beregn den forventede værdi af Z = 2 · X + 3,3 · Y.
b) Find variansen af Z.


















