
第2回nips+読み会: Learning to learn by gradient decent by gradient decent
33
Learning to learn by gradient decent by gradient decent @第2回NIPS+読み会・関西 2016/12/26 発表者:大阪大学 都築拓
-
Upload
taku-tsuzuki -
Category
Data & Analytics
-
view
29 -
download
0
Transcript of 第2回nips+読み会: Learning to learn by gradient decent by gradient decent

Learning to learn by gradient decent by gradient decent
@第2回NIPS+読み会・関西 2016/12/26
発表者:大阪大学 都築拓

・自己紹介
・都築拓 (@tsukamakiri) ・大阪大学生命機能研究科M1
細胞の状態推定,予測 @理化学研究所Qbic
実験プロトコル最適化 @RoboDc Biology InsDtute
・理化学研究所Qbic生化学シミュレーションチーム研究生
・研究内容

・Outline
• 概要 • 問題設定 • 先行研究 • 本論文のアイデア • 実験結果 • まとめ,今後の展望

・Outline
• 概要 • 問題設定 • 先行研究 • 本論文のアイデア • 実験結果 • まとめ,今後の展望

・論文概要 ・この論文はどんなものか?
・先行研究と比べて何がすごいか?
・キーアイデアは?
・どんな結果が得られたか?
-‐最適化問題において,目的関数を最適化するための勾配方による 最適化アルゴリズム(OpDmizer)自体を勾配法により学習させる
-‐OpDmizerをLSTMとして表現し,逆誤差伝播によりそれを最適化 -‐目的関数の成分ごと独立に,パラメタを共有したLSTMで最適化を行うことで 最適化すべきOpDmizerのパラメタ数を小さく抑える
-‐OpDmizerを直接最適化する,meta-‐learningの枠組みを,Deeplearning による画像識別,合成課題という,大規模な課題に適用
-‐MNIST, CIFAR のラベリングタスク,及びNeural Artによる画風合成タスクで,既存のOpDmizerを凌ぐ性能を確認

・Outline
• 概要 • 問題設定 • 先行研究 • 本論文のアイデア • 実験結果 • まとめ,今後の展望
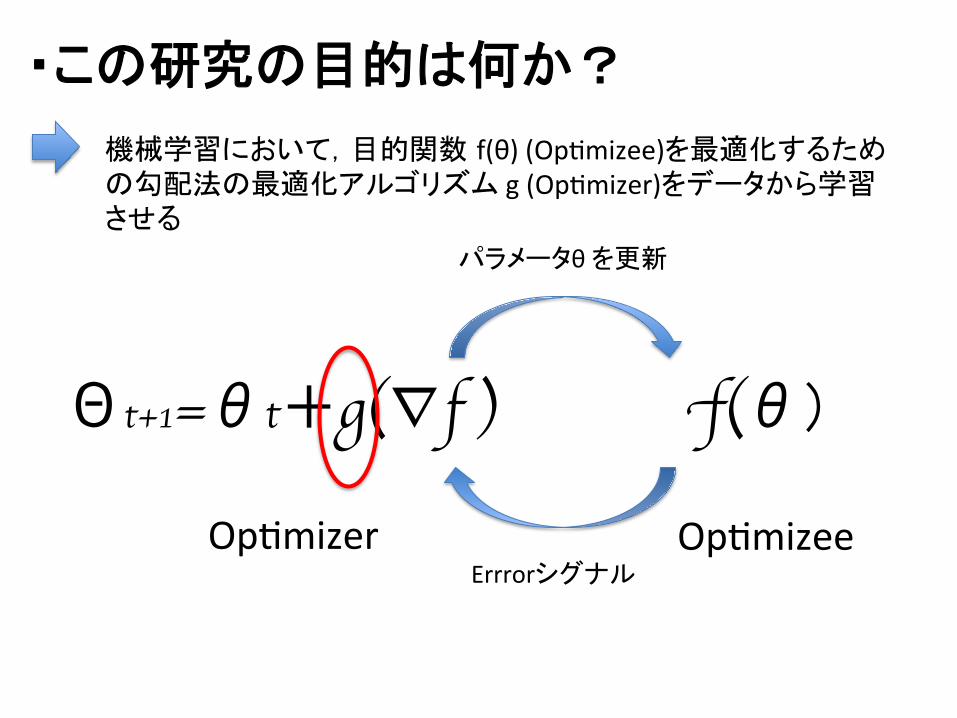
・この研究の目的は何か?
機械学習において,目的関数 f(θ) (OpDmizee)を最適化するための勾配法の最適化アルゴリズム g (OpDmizer)をデータから学習させる
f(θ) Θt+1=θt+g(∇f )
OpDmizer OpDmizee
パラメータθ を更新
Errrorシグナル
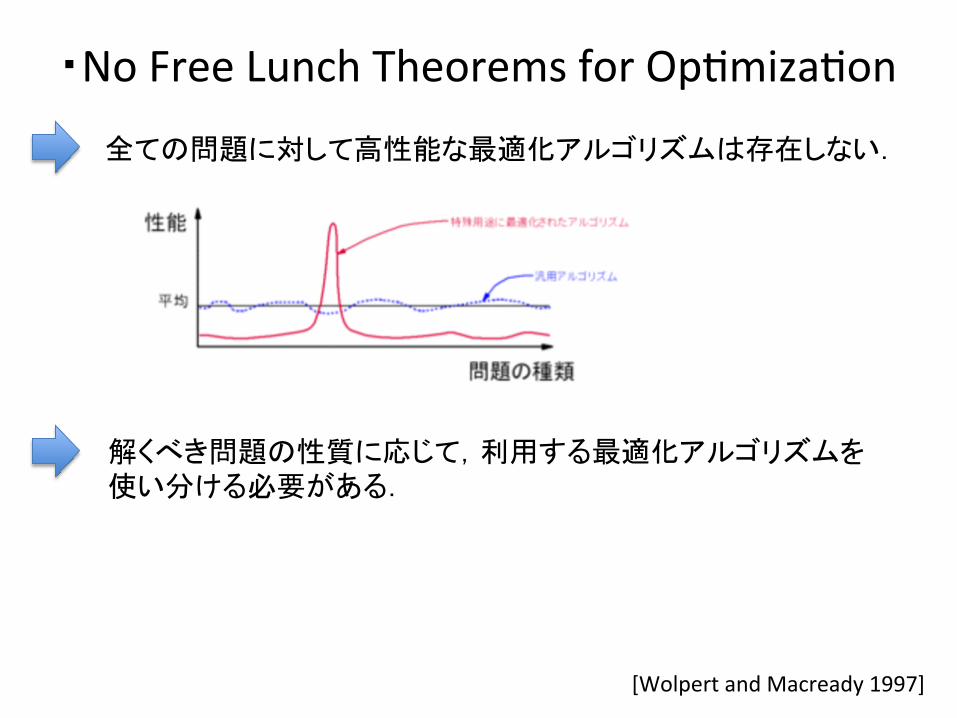
・No Free Lunch Theorems for OpDmizaDon
全ての問題に対して高性能な最適化アルゴリズムは存在しない.
[Wolpert and Macready 1997]
解くべき問題の性質に応じて,利用する最適化アルゴリズムを 使い分ける必要がある.

・現状,gはヒューリスティックに作り込まれている
勾配法をベースに,高次元で,非凸な目的関数に対しても良い性能を示すような最適化アルゴリズムは多く“作り込まれて”いる
・momentumSGD [Nesterov 1983, Tseng 1998] ・Adagrad [Duchi et al. 2011] ・RMSprop [Tieleman and Hinton 2012] ・ADAM [Kingma and Ba 2015]
参考:hap://postd.cc/opDmizing-‐gradient-‐descent/
例: 勾配降下法(一番単純な場合)
-‐ナイーブすぎて,これは多くの場合うまくいかない

・問題意識
問題に応じて,データから自動で最適な変換 g を学習させることはできないだろうか?
-‐もっとTask specificに g を作り込むことができれば性能は上がる ( No Free Lunch Theorem [Wolpert and Macready 1997] )
-‐現状,g はある程度の汎用性を持つ形で作られている

・Outline
• 概要 • 問題設定 • 先行研究 • 本論文のアイデア • 実験結果 • まとめ,今後の展望
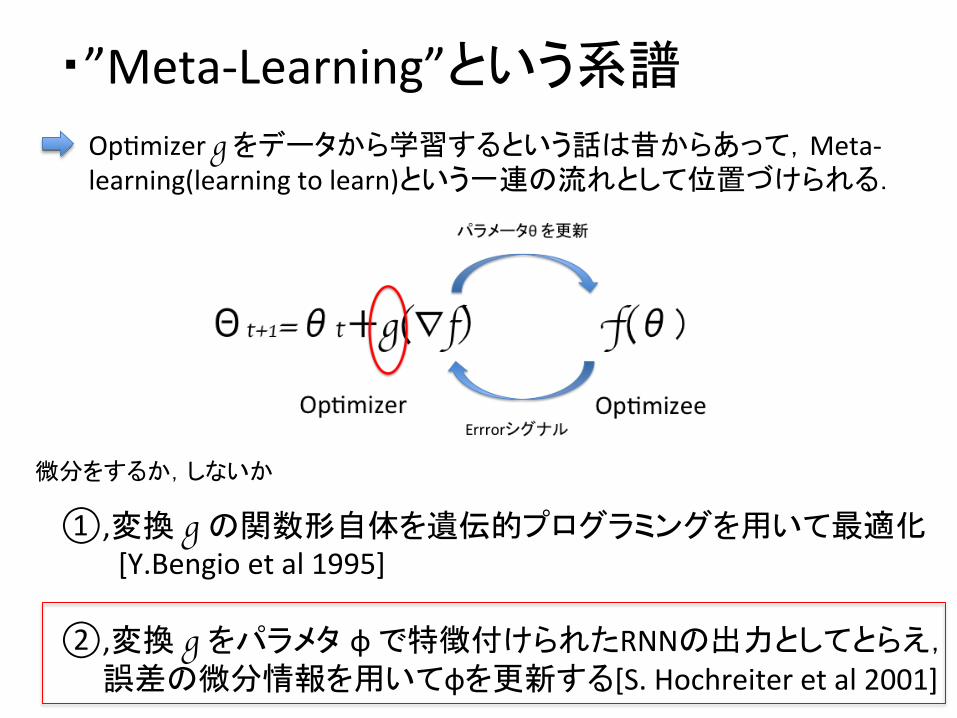
・”Meta-‐Learning”という系譜
OpDmizer g をデータから学習するという話は昔からあって,Meta-‐learning(learning to learn)という一連の流れとして位置づけられる.
①,変換 g の関数形自体を遺伝的プログラミングを用いて最適化 [Y.Bengio et al 1995] ②,変換 g をパラメタ φ で特徴付けられたRNNの出力としてとらえ, 誤差の微分情報を用いてφを更新する[S. Hochreiter et al 2001]
微分をするか,しないか

・問題設定:[S. Hochreiter et al 2001],[M.Andrychowicz et al. 2016]
L(φ)がφに関して微分可能であれば,OpDmizer g(φ) を,期待損失 L(φ) の微分情報を用いて逆誤差伝播で最適化できる.
-‐ OpDmizer g をパラメータφで直接特徴付ける g(∇f, φ)
-‐ そのため,OpDmizeeの最適なパラメタθ*は,θ(f, φ)と書ける
-‐ そのため,期待損失関数 L(φ) はφの関数として書ける
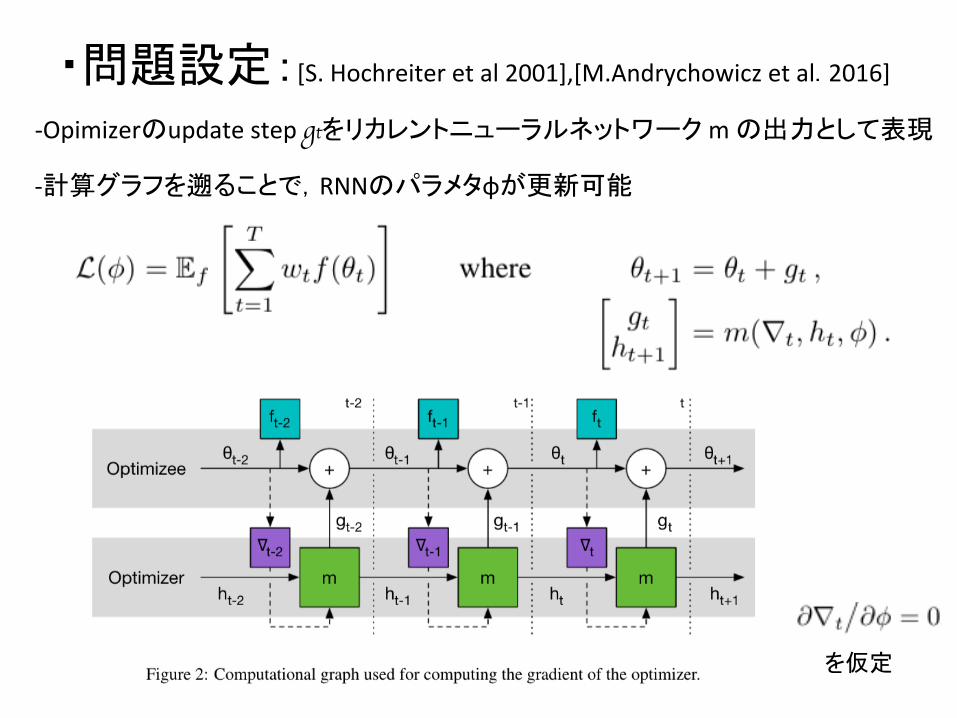
・問題設定:[S. Hochreiter et al 2001],[M.Andrychowicz et al. 2016] -‐Opimizerのupdate step gtをリカレントニューラルネットワーク m の出力として表現
-‐計算グラフを遡ることで,RNNのパラメタφが更新可能
を仮定

ナゼOpDmizerはRNNなのだろうか?
過去の勾配情報を利用することで探索は効率化される
過去の勾配情報のいれ方にもいろいろある.
例:momentum SGD
RNNを採用することによって, 過去の勾配情報の寄与のいれ方も含めて学習させてしまおうという狙い

・Outline
• 概要 • 問題設定 • 先行研究 • 本論文のアイデア • 実験結果 • まとめ,今後の展望
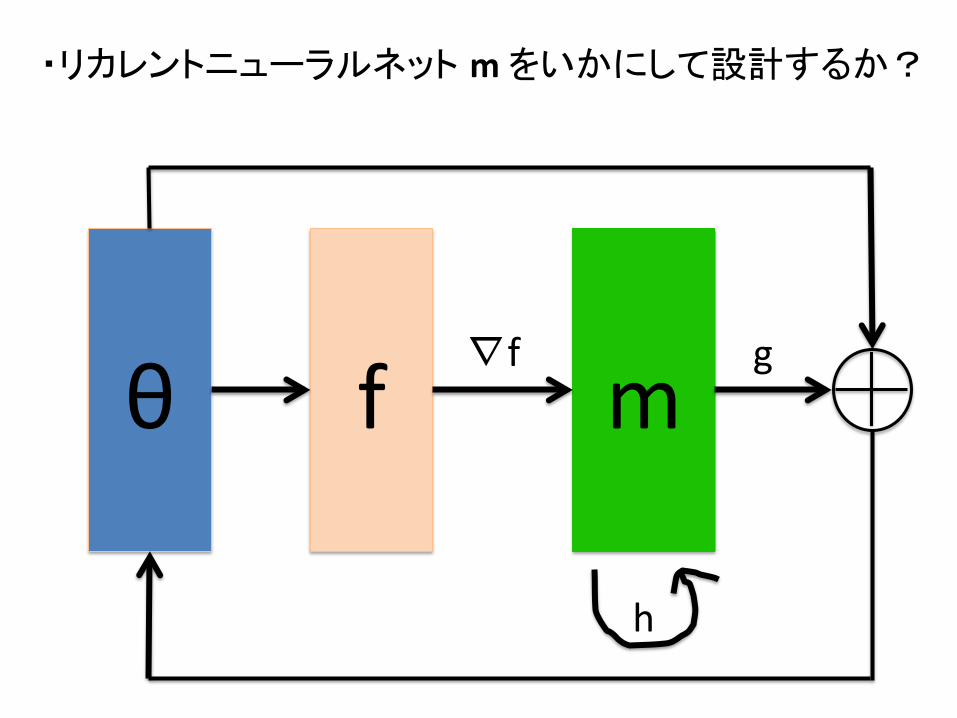
・リカレントニューラルネット m をいかにして設計するか?
m f ∇f
h
θ g
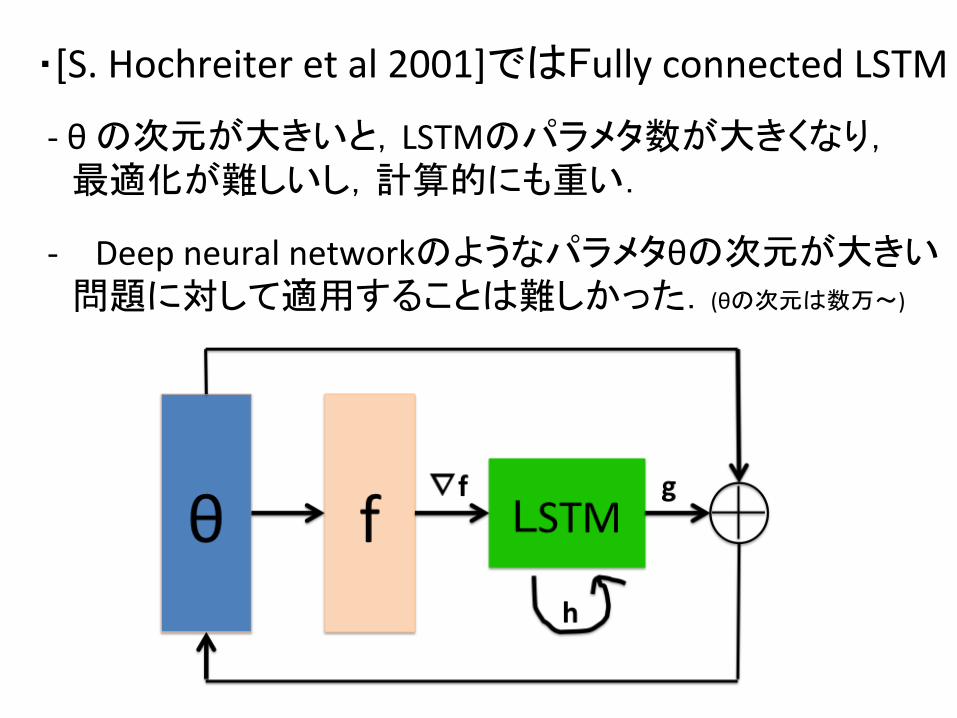
・[S. Hochreiter et al 2001]ではFully connected LSTM
-‐ θ の次元が大きいと,LSTMのパラメタ数が大きくなり, 最適化が難しいし,計算的にも重い.
-‐ Deep neural networkのようなパラメタθの次元が大きい 問題に対して適用することは難しかった.(θの次元は数万〜)

・Coordinatewise LSTM opDmizer
・本論文の提案手法
-‐目的:
-‐アイデア:
・θが高次元なモデルに対しても,最適化可能な OpDmizer m を構築したい.
・θの各成分(θ1~θn)を個別に最適化するn個のLSTM LSTM1~LSTMn を構築する. ・n個のLSTM,LSTM1~LSTMn は 共通のパラメタをシェアしている.
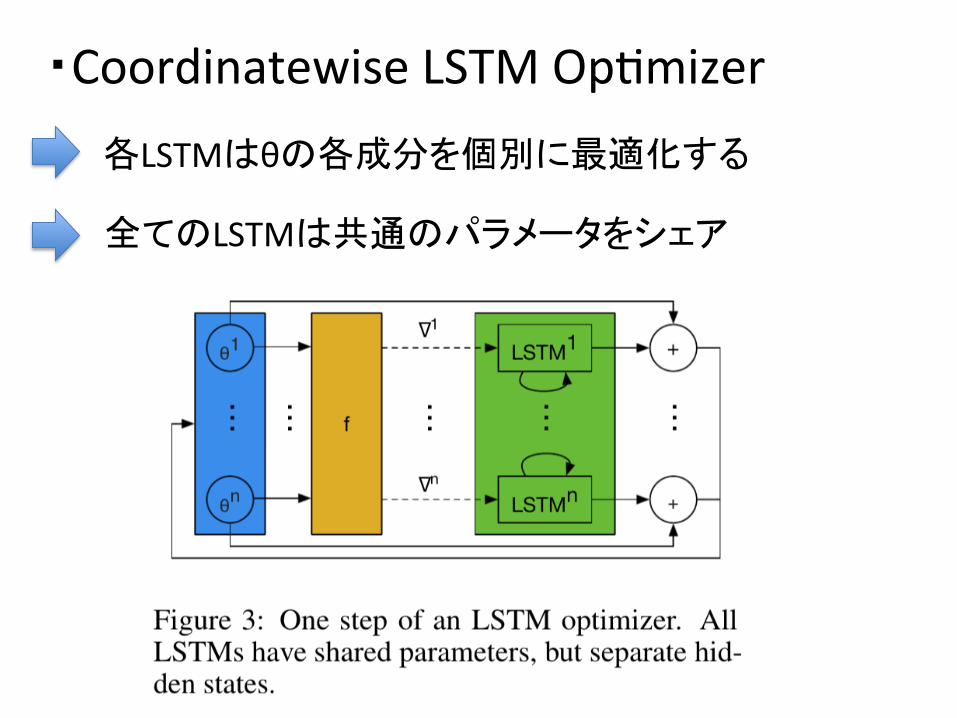
各LSTMはθの各成分を個別に最適化する
・Coordinatewise LSTM OpDmizer
全てのLSTMは共通のパラメータをシェア

・Outline
• 概要 • 問題設定 • 先行研究 • 本論文のアイデア • 実験結果 • まとめ

①:QuadraDc funcDons Task
・実験
②:MNIST classificaDon Task
③:CIFAR-‐10 classificaDon Task
④:Neural Art Task
以下の4つのタスクで性能を検証
-‐従来法(SGD, RMSprop, ADAM, NAG)と性能を比較した
なお,TensorflowのコードはGithubに落ちている (haps://github.com/deepmind/learning-‐to-‐learn)

・実験条件
-‐ 期待損失L(φ)における,各時刻の f にかかる重みwtは全て1とする
-‐ 各 LSTM OpDmizer の 隠れ層は2層, 隠れユニット数は20とした.
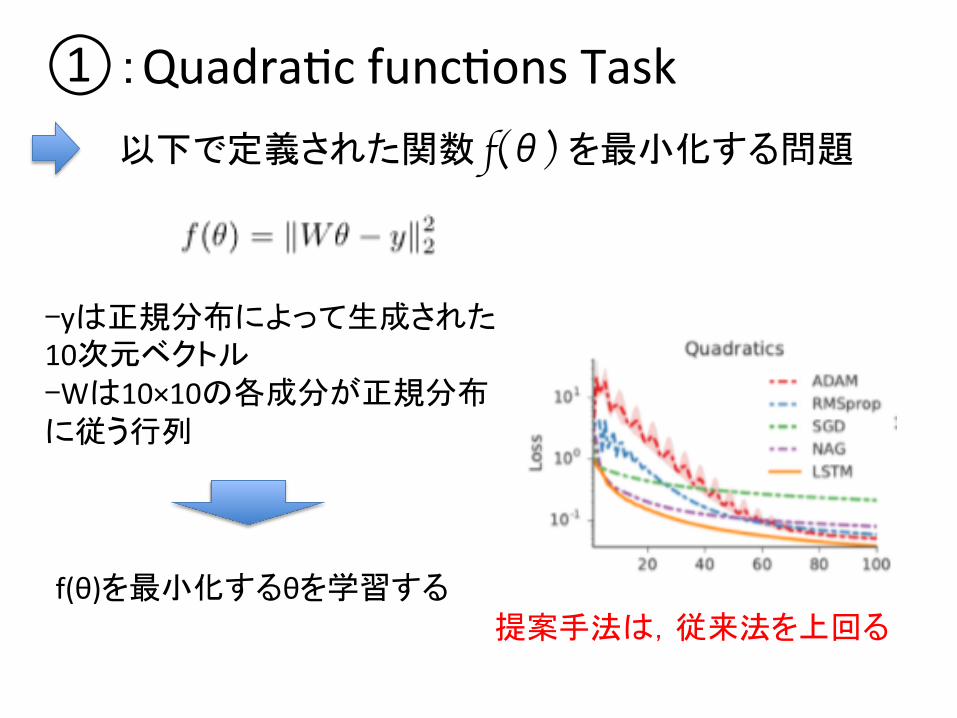
①:QuadraDc funcDons Task 以下で定義された関数 f(θ) を最小化する問題
提案手法は,従来法を上回る
-yは正規分布によって生成された 10次元ベクトル -Wは10×10の各成分が正規分布 に従う行列
f(θ)を最小化するθを学習する
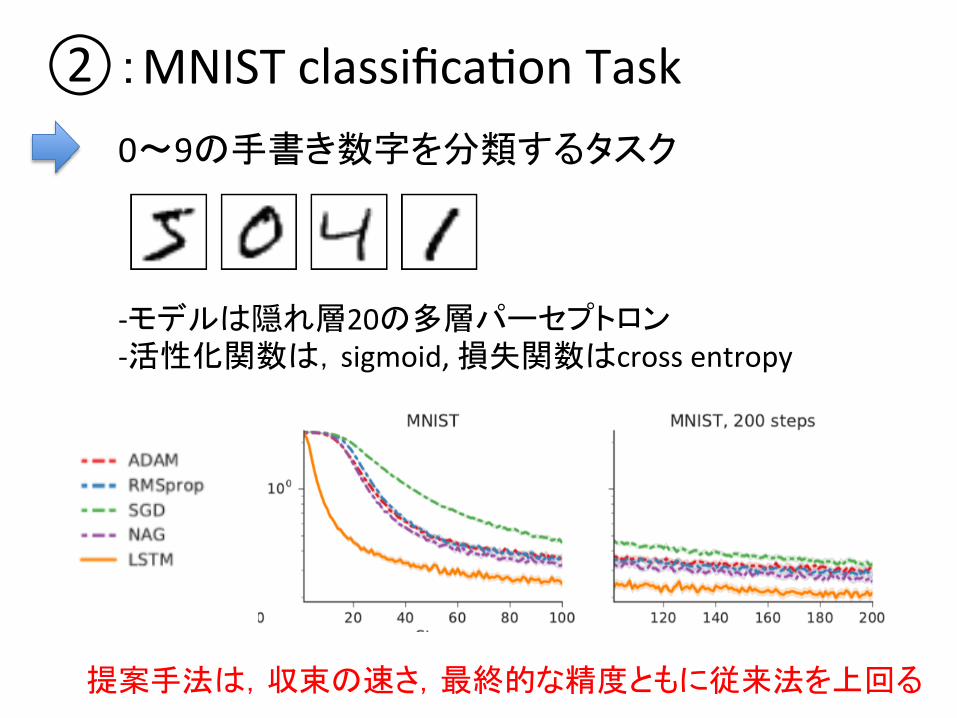
②:MNIST classificaDon Task 0〜9の手書き数字を分類するタスク
-‐モデルは隠れ層20の多層パーセプトロン -‐活性化関数は,sigmoid, 損失関数はcross entropy
提案手法は,収束の速さ,最終的な精度ともに従来法を上回る
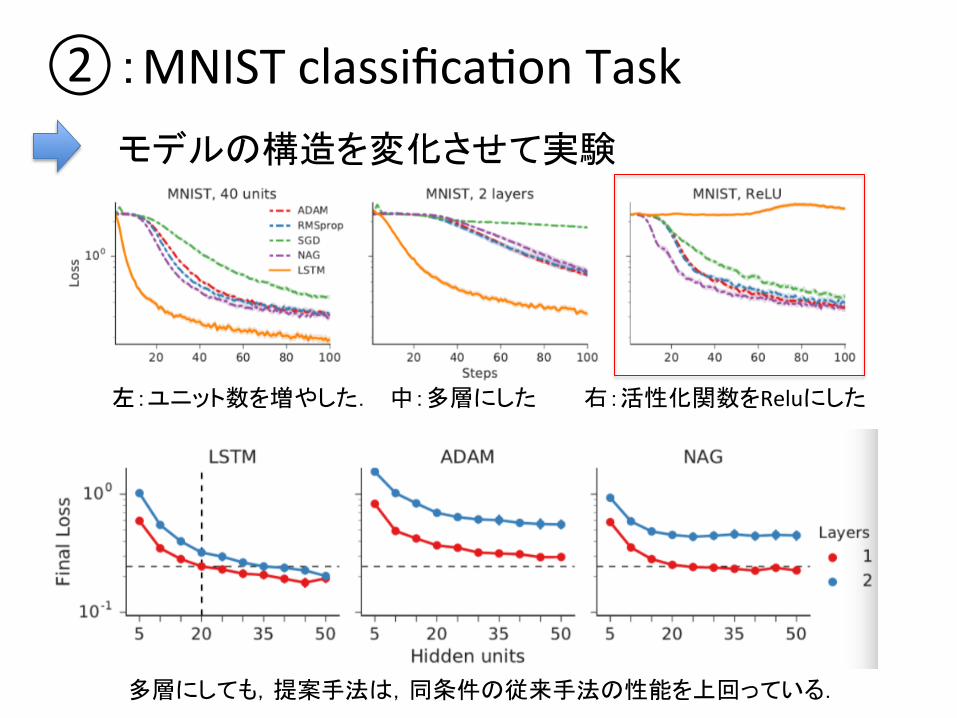
②:MNIST classificaDon Task モデルの構造を変化させて実験
左:ユニット数を増やした. 中:多層にした 右:活性化関数をReluにした
多層にしても,提案手法は,同条件の従来手法の性能を上回っている.

③:CIFAR-‐10 classificaDon Task 自然画像を10クラスに分類するタスク
-‐畳み込み+Maxpooling3層+隠れユニット数32の全結合層 -‐活性化関数はReLU, 各層でbatch normalizaDonを適用
・使用したモデル:
・注意点:
-‐全結合層を最適化するLSTMと, 畳み込み層を最適化するLSTMは,別のものを使用
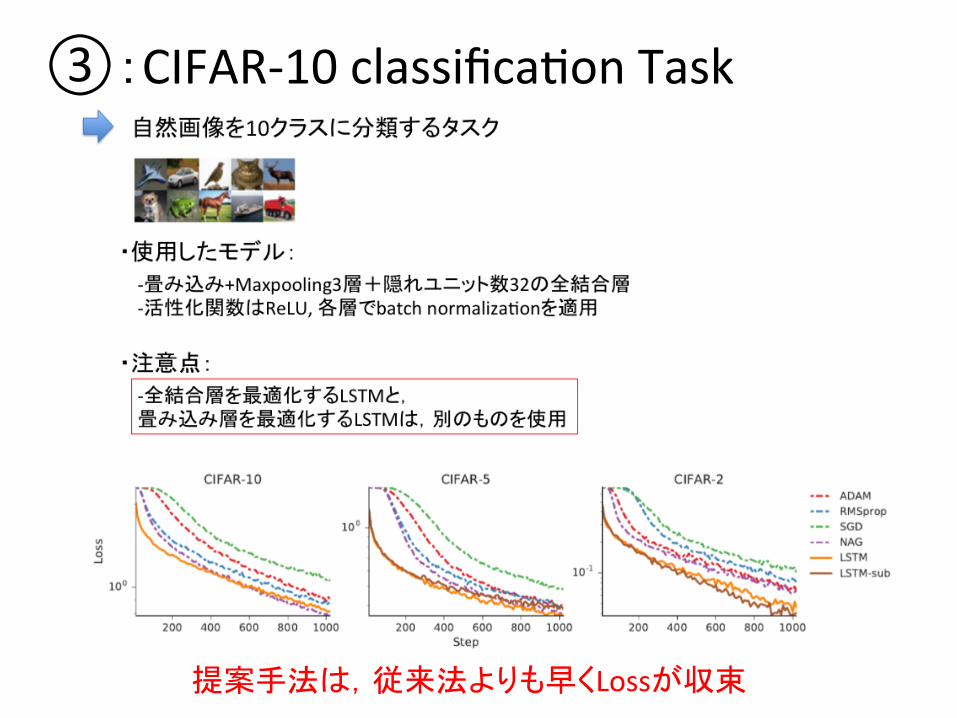
③:CIFAR-‐10 classificaDon Task
提案手法は,従来法よりも早くLossが収束
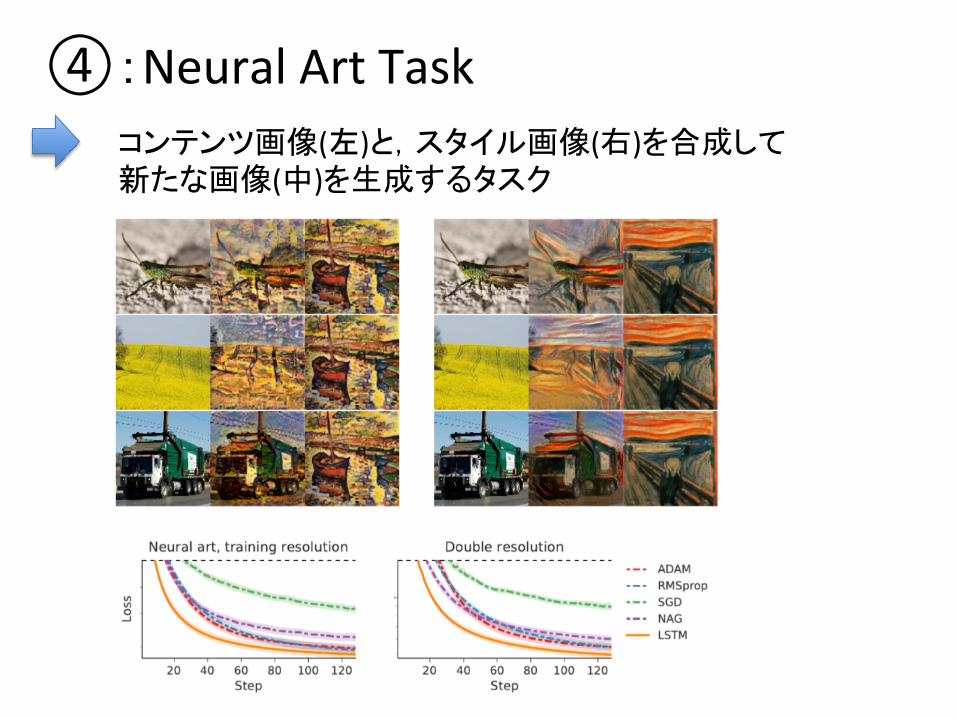
④:Neural Art Task コンテンツ画像(左)と,スタイル画像(右)を合成して 新たな画像(中)を生成するタスク

・Outline
• 概要 • 問題設定 • 先行研究 • 本論文のアイデア • 実験結果 • まとめ,今後の展望

・まとめ ・この論文はどんなものか?
・先行研究と比べて何がすごいか?
・キーアイデアは?
・どんな結果が得られたか?
-‐最適化問題において,目的関数を最適化するための 最適化アルゴリズム(OpDmizer)自体をデータから学習させる
-‐OpDmizerをLSTMとしてモデル化し,逆誤差伝播によりそれを最適化 -‐目的関数の成分ごと独立に,パラメタを共有したLSTMで最適化を行うことで 最適化すべきOpDmizerのパラメタ数を小さく抑える
-‐OpDmizerを直接最適化する,meta-‐learningの枠組みを,Deeplearning による画像識別,合成課題という,現代的で大規模な課題に適用
-‐MNIST, CIFAR のラベリングタスク,及びNeural Artによる画風合成タスクで,既存のOpDmizerを凌ぐ性能を確認

・今後の展望
-‐Transfer learningへの適用 ・似たクラスの問題は,OpDmizerのパラメタφが 同じような値をとるはず. ・よって,ある問題Aを学習済みのOpDmizerは, それとよく似た性質を持つ問題Bをより少ない 学習で解くことができるはず -‐OpDmizerのパラメタφをクラスタリングすることで, あるタスクとあるタスクの“類似度”のようなものを 定量的に評価できるのではないか?

・参考文献


















