2015EDM: A Framework for Multifaceted Evaluation of Student Models (Polygon)
41
A Framework for Mul/faceted Evalua/on of Student Models Yun Huang 1 José P. GonzálezBrenes 2 Rohit Kumar 3 Peter Brusilovsky 1 1 University of PiDsburgh 2 Pearson Research & InnovaIon Network 3 Speech, Language and MulImedia Raytheon BBN Technologies 1
-
Upload
yun-huang -
Category
Technology
-
view
27 -
download
1
Transcript of 2015EDM: A Framework for Multifaceted Evaluation of Student Models (Polygon)

A Framework for Mul/faceted Evalua/on of Student Models Yun Huang1 José P. González-‐Brenes2 Rohit Kumar3 Peter Brusilovsky1
1University of PiDsburgh 2Pearson Research & InnovaIon Network 3Speech, Language and MulImedia Raytheon BBN Technologies
1

Outline
2
• IntroducIon • The Polygon EvaluaIon Framework • Studies and Results • Conclusions

MoIvaIon
• Usually, when we compare two student models, only a single model single dimension (predicIve performance) is evaluated • We can get different “well-‐fiDed” models from the same data! • To illustrate, let’s firstly briefly go through two effecIve student models …
3
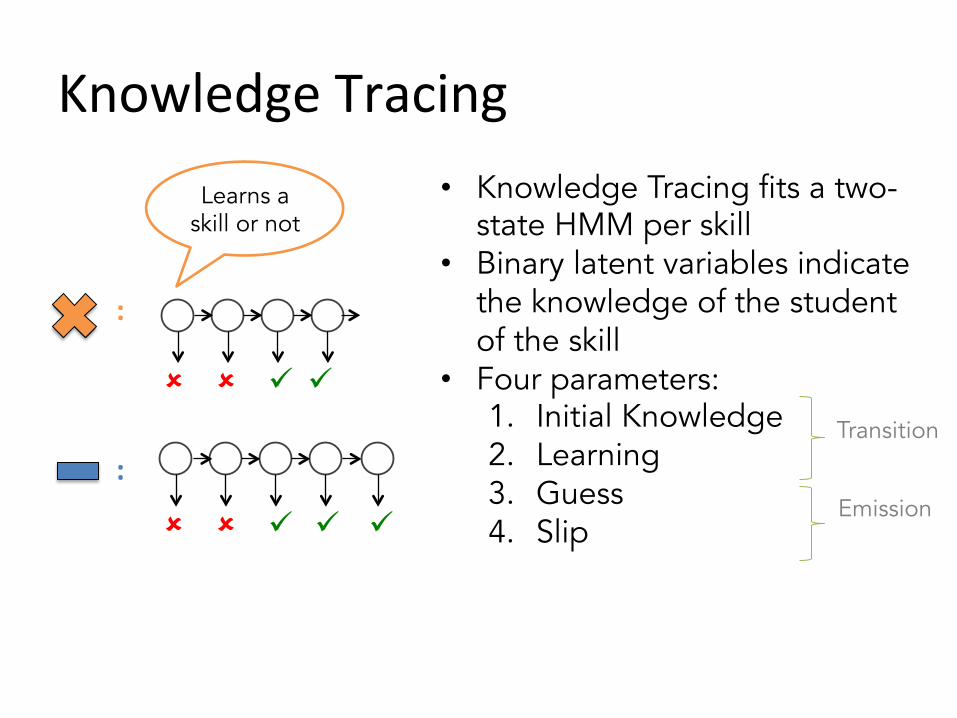
Learns a skill or not
:
:
û û ü ü ü
û û ü ü
• Knowledge Tracing fits a two-state HMM per skill
• Binary latent variables indicate the knowledge of the student of the skill
• Four parameters: 1. Initial Knowledge 2. Learning 3. Guess 4. Slip
Transition
Emission
Knowledge Tracing

Feature-‐Aware Student Knowledge Tracing
5
• General model: Knowledge Tracing + features • Features : contextual informaIon • Item difficulty • Student ability • Requested hints? • ...
• How do features come in: replacing the binomial distribuIons by logisIc regression distribuIons.
• Details in our 2014 EDM paper (General Features in Knowledge Tracing to Model Mul=ple Subskills, Temporal Item Response Theory, and Expert Knowledge. )
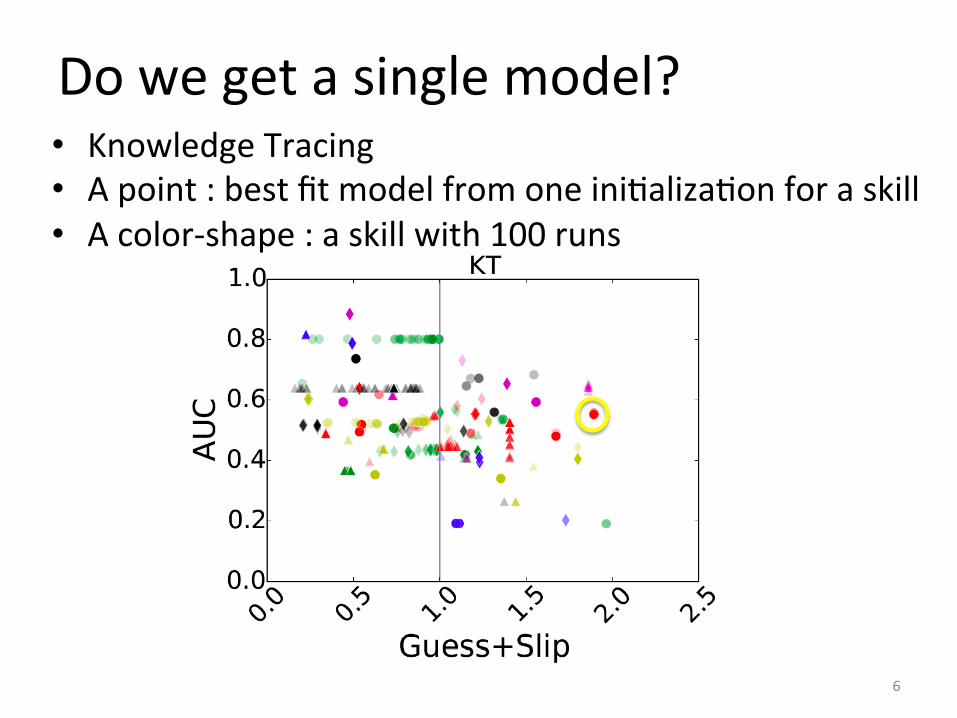
6
• Knowledge Tracing • A point : best fit model from one iniIalizaIon for a skill • A color-‐shape : a skill with 100 runs
Do we get a single model?

What about a more complex student model?
7
• Less spreading. Seems to get a single model.
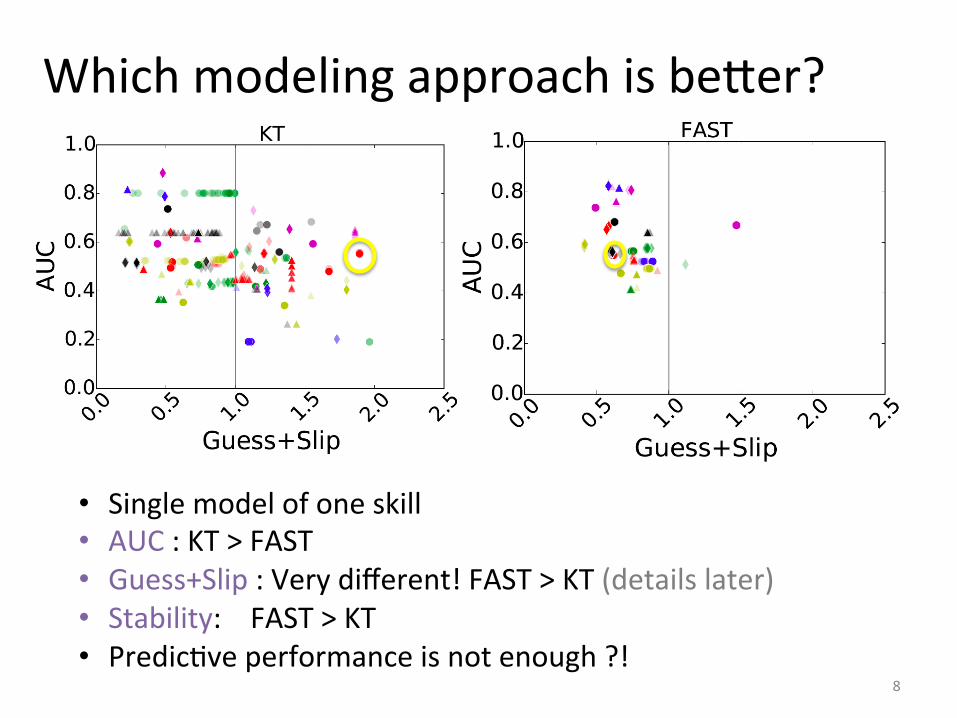
Which modeling approach is beDer?
8
• Single model of one skill • AUC : KT > FAST • Guess+Slip : Very different! FAST > KT (details later) • Stability: FAST > KT • PredicIve performance is not enough ?!

PredicIve performance is not enough …
9
Prior literatures poinIng out different dimensions can be found: • Beck et al ’07 : • IdenIcal global opImum predicIve models can
correspond to different sets of parameter esImates (idenIfiability problem)
• Extremely low learning rates are implausible (heurisIc) • A posiIve correlaIon between a word’s frequency and its
Init parameter (domain-‐specific)

10
• Baker et al ‘08 : • SomeImes, we get models where a student is
more likely to get a correct answer if he/she does not know a skill than if he/she does (model degeneracy problem).
• Empirical values for detecIon: • The probability that a student knows a skill should be higher than before the student’s first 3 acIons.
• A student should master the skill ater 10 correct responses in a row.
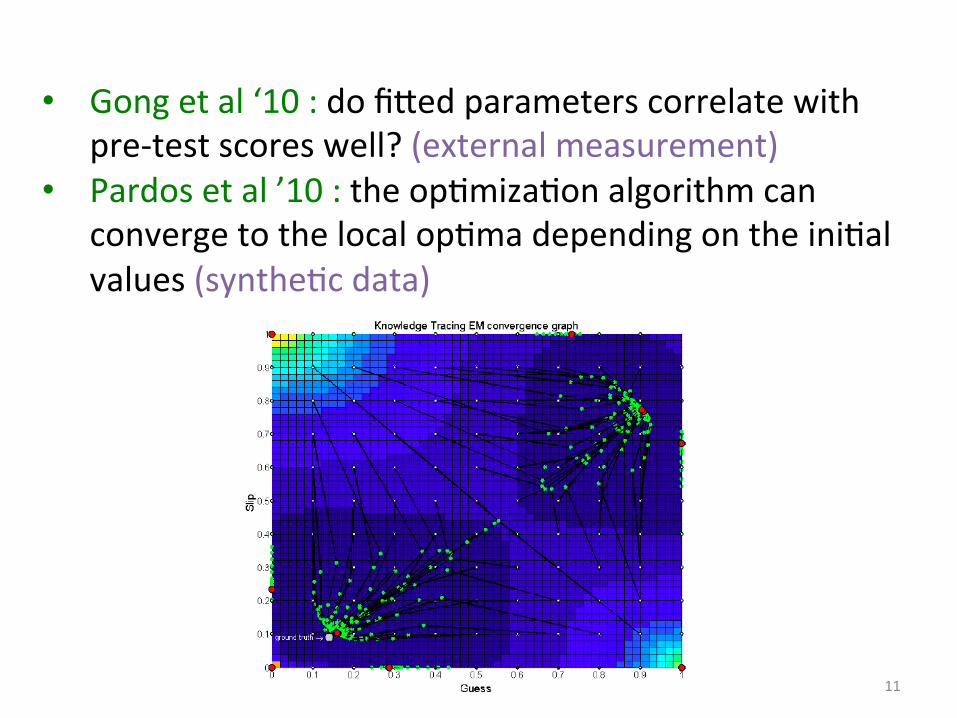
11
• Gong et al ‘10 : do fiDed parameters correlate with pre-‐test scores well? (external measurement)
• Pardos et al ’10 : the opImizaIon algorithm can converge to the local opIma depending on the iniIal values (syntheIc data)

12
• Van De Sande ’13 : empirical degeneracy can be precisely idenIfied by some theoreIcal condiIons.
• Van De Sande ’13, Gweon ‘15: present different (and even contradictory) views of Beck’s idenIfiability problem.
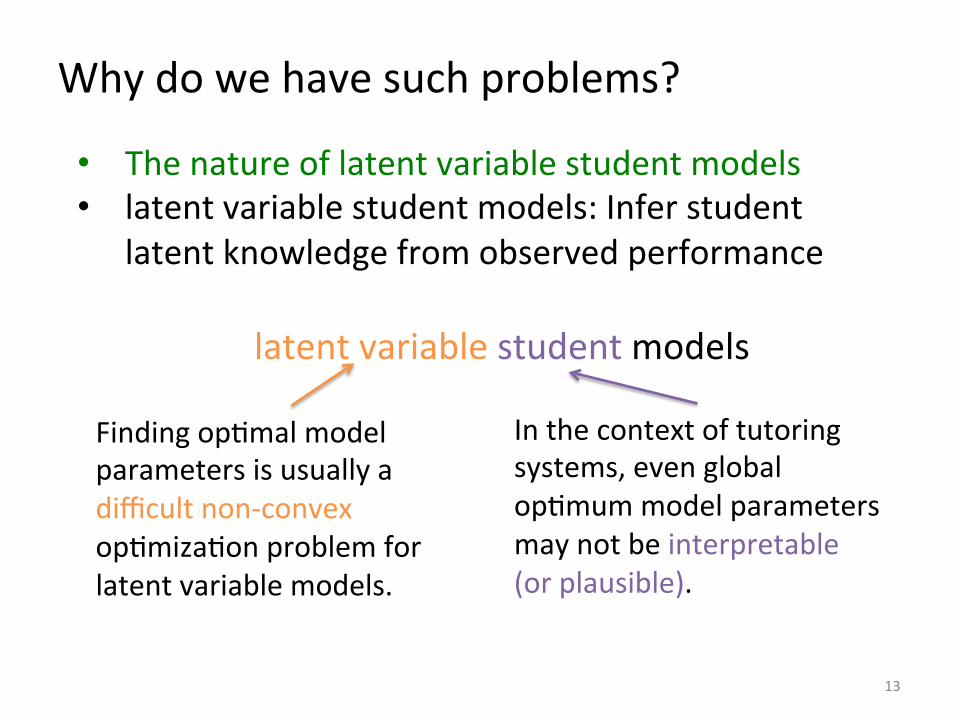
Why do we have such problems?
13
• The nature of latent variable student models • latent variable student models: Infer student
latent knowledge from observed performance
latent variable student models
Finding opImal model parameters is usually a difficult non-‐convex opImizaIon problem for latent variable models.
In the context of tutoring systems, even global opImum model parameters may not be interpretable (or plausible).

Can we get a unified, generalizable evaluaIon framework to detect such
problems?
14

Outline
15
• IntroducIon • The Polygon EvaluaIon Framework • Studies and Results • Conclusions

Polygon: A MulIfaceted EvaluaIon framework
Plausibility (PLAU)
Consistency (CONS)
PredicIve Performance (PRED)
16
How well does the model predict?
How interpretable (plausible) are the parameters for tutoring systems?
If we train the model under different sevngs, does the model give same (similar) parameters?

Procedurals 1. Define potenIal metrics to instanIate the framework 2. Run Knowledge Tracing and Feature-‐Aware Student
Knowledge Tracing with 100 random iniIalizaIons. 3. Metric selecIon 4. Model examinaIon and comparison in terms of • MulIple Random Restarts • Single models (details in paper)
5. ImplicaIons for Single Model SelecIon
17

ConstrucIng PotenIal Metrics
18
• Each metric is computed for one skill (knowledge component, i.e., KC). • We then aggregate mulIple skills to get the overall picture.
• Metrics can evaluate a single restart model and mulIple restart models (except for consistency metrics).
• Each metric ranges from 0 to 1. • Higher posiIve value indicaIng higher quality.

PredicIve Performance • AUC and P-‐RAUC.
19
• IntuiIon: A good model should predicts well. • AUC gives an overall summary of diagnosIc accuracy.
• 0.5: random classier, 1.0: perfect accuracy. • Each random restart : AUCr • Across 100 random restarts: P-‐RAUC
Welcome to consider other metrics if you have concerns.

Plausibility • Guess+Slip<1 (GS) and P-‐RGS
20
• IntuiIon: A good model should comply with the idea that knowing a skill generally leads to correct performance.
• Van De Sande ’13 proves a condiIon guaranteeing Knowledge Tracing not to have empirical degeneraIon:
• Across 100 random restarts: P-‐RGS
indicator funcIon (0/1)

Plausibility • Non-‐decreasing predicted probability of Learned (NPL) and P-‐RNPL. • General to all latent variable models. • IntuiIon: we take the perspecIve that a decreasing predicted probability of learned implies pracIces hurt learning, which is not plausible. (We are aware of the other perspec=ve where it is interpreted as a decrease in the model's belief. )
21
s: student t: pracIce opportunity O: observed historical pracIces
D: #datapoints

Consistency
• Consistency of AUC, GS, NPL (C-‐RAUC, C-‐RGS, C-‐ RNPL) • For example, to compute the consistency of AUC:
22
uncorrected sample standard deviaIon
• IntuiIon: A good model should be more likely to converge to points with higher predicIve performance and plausibility, and give more stable predicIons and inferences.

Consistency
23
whether a student ever reached mastery of a skill
PercenIle of students ever reached mastery of a skill
• Consistency of the predicted probability of mastery (C-‐RPM) • IntuiIon: what’s the impact on students? • We define probability of mastery PM as follows:
• Across 100 random restarts: C-‐RPM

Consistency • Cohesion of the parameter vector space (C-‐RPV)
24
• IntuiIon: What about the knowledge curve? • Van De Sande ’13 shows that we need all four parameters
to define the overall behavior of Knowledge Tracing during the predicIon phase (when knowledge esImaIon is updated by prior observaIons).
Mean of the vector
Euclidean distance

Metric SelecIon
25
• Allows flexible metrics to instanIate each dimension. Here we present some simple ones.
• How many is enough? Our principles: • cover all three dimensions • have the least overlap.
• We examine the scaDerplot and correlaIon of each pair of the metrics and conduct significance tests.

Outline
26
• IntroducIon • The Polygon EvaluaIon Framework • Studies and Results • Conclusions
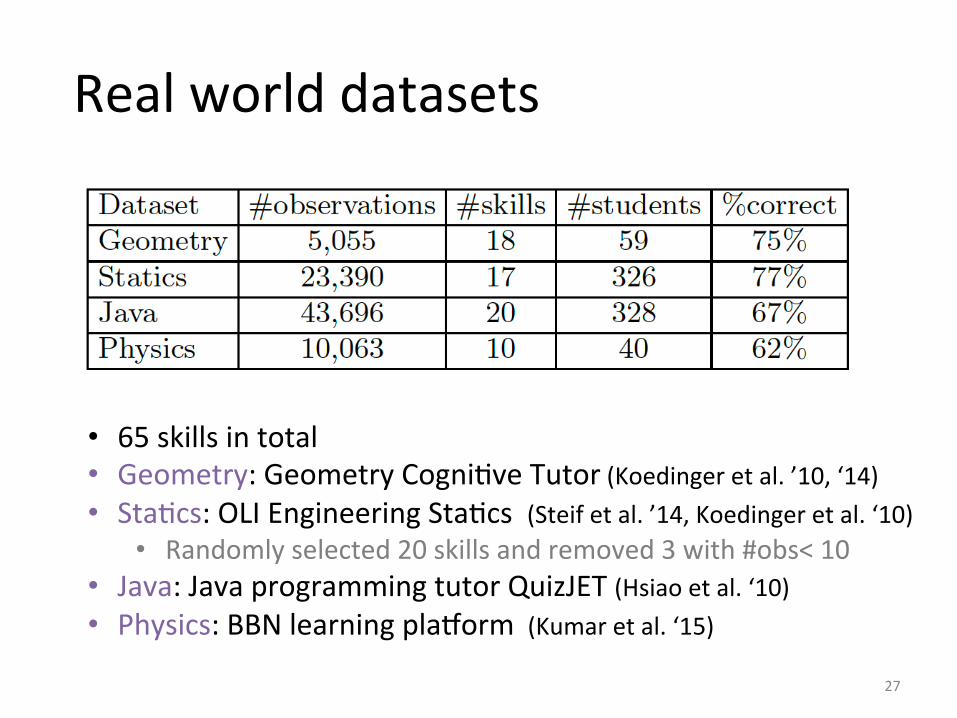
Real world datasets
27
• 65 skills in total • Geometry: Geometry CogniIve Tutor (Koedinger et al. ’10, ‘14) • StaIcs: OLI Engineering StaIcs (Steif et al. ’14, Koedinger et al. ‘10)
• Randomly selected 20 skills and removed 3 with #obs< 10 • Java: Java programming tutor QuizJET (Hsiao et al. ‘10) • Physics: BBN learning plazorm (Kumar et al. ‘15)

Experimental Setup • IniIalize: uniformly at random for 100 Imes.
• init, learn, guess, slip: (0, 1) • Feature weights: (-‐10, 10)
• Randomly 80% students on train set, remaining on test set. • Compare standard Knowledge Tracing (KT) and Feature-‐Aware Knowledge Tracing (FAST) with different features
• FAST: • Geometry, StaIcs, Java: binary item indicator • Physics: binary problem decomposi=on requested
indicator • Features are incorporated into all four parameters (init,
learn, guess, slip) in our study.
28
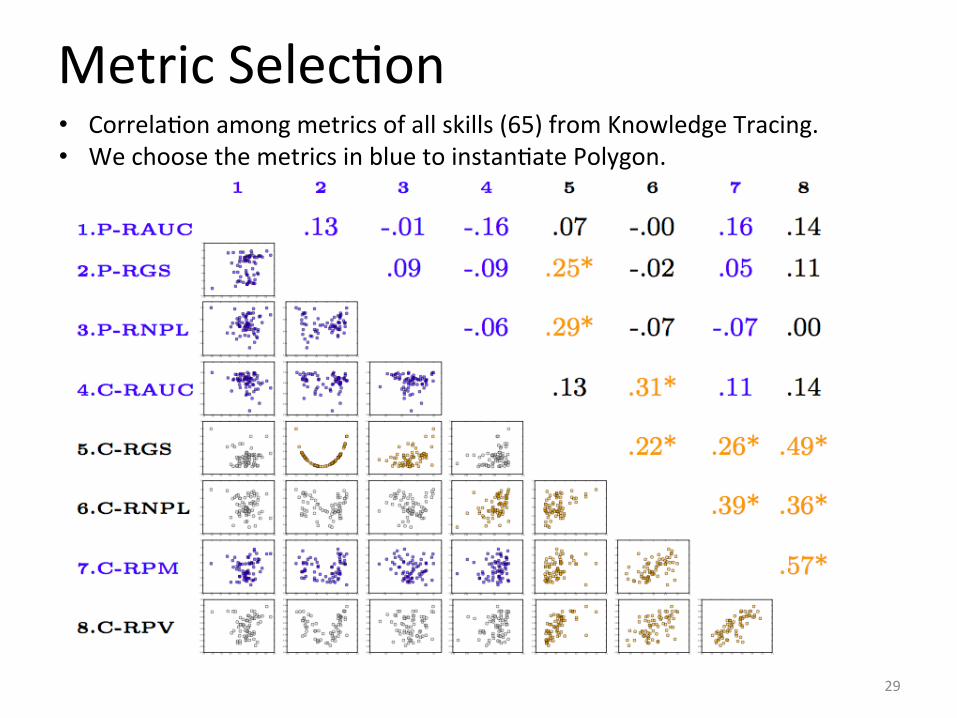
Metric SelecIon
29
• CorrelaIon among metrics of all skills (65) from Knowledge Tracing. • We choose the metrics in blue to instanIate Polygon.
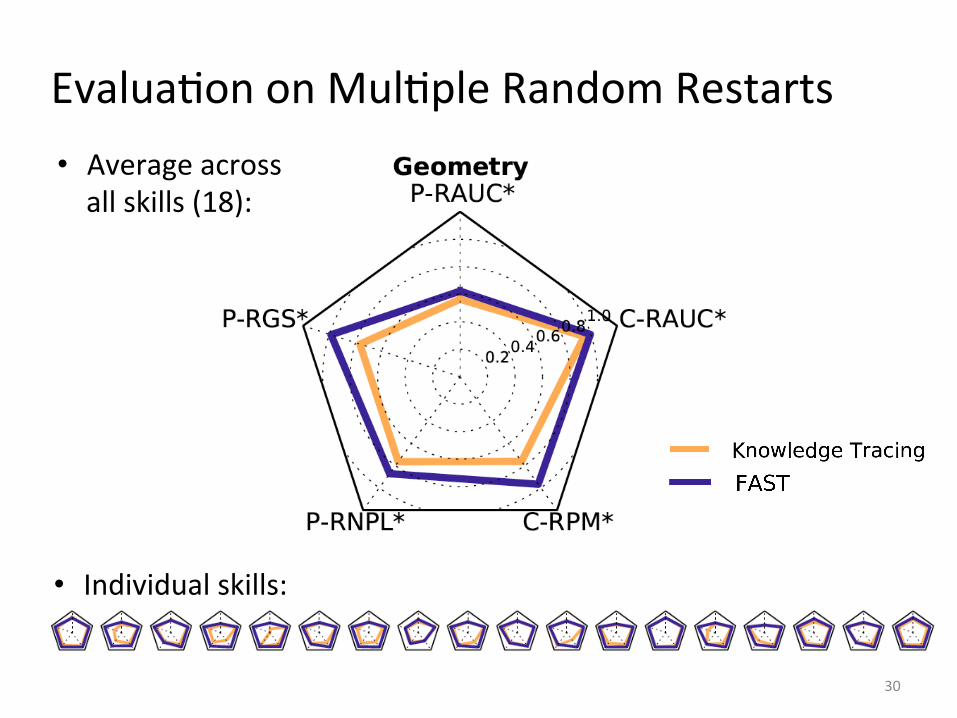
EvaluaIon on MulIple Random Restarts
30
• Average across all skills (18):
• Individual skills:

EvaluaIon on MulIple Random Restarts
31
• FAST’s Polygon areas in most cases cover Knowledge Tracing’s. • FAST’s plausibility improvement varies across datasets.
• On Physic dataset, the skill definiIon may be too coarse-‐grained and FAST may be more vulnerable to bad skill definiIons.
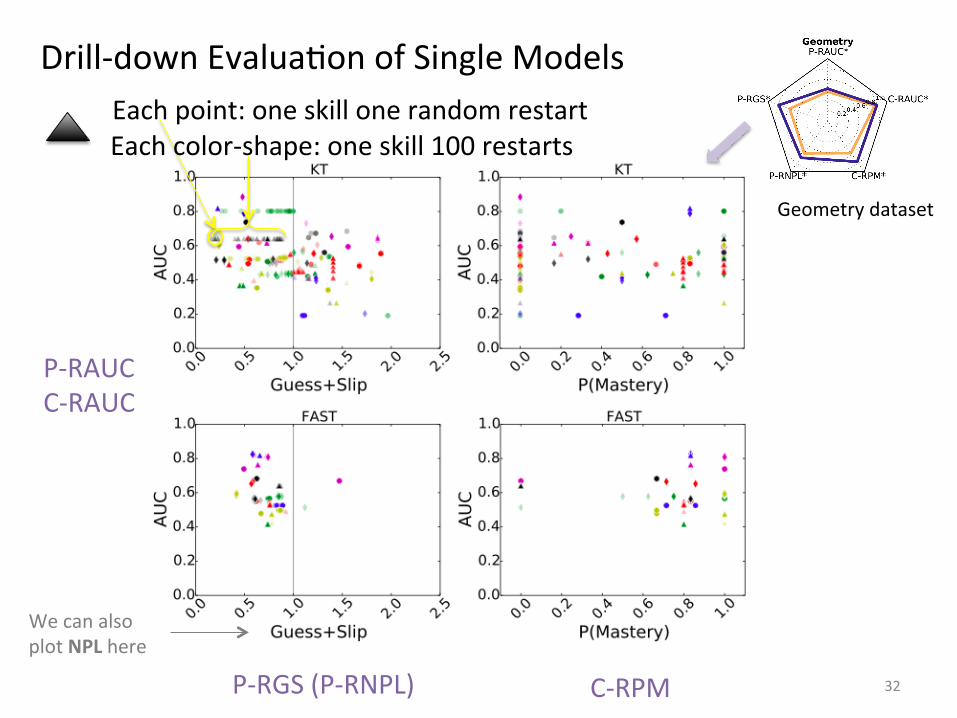
Drill-‐down EvaluaIon of Single Models
32
Geometry dataset
Each point: one skill one random restart Each color-‐shape: one skill 100 restarts
P-‐RAUC C-‐RAUC
We can also plot NPL here
P-‐RGS (P-‐RNPL) C-‐RPM
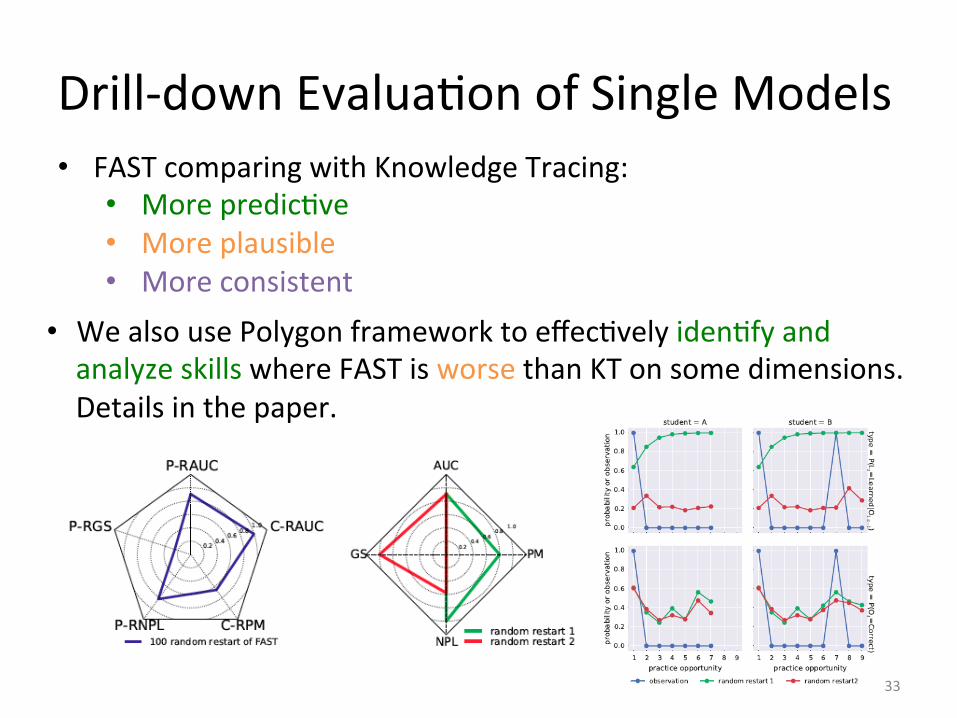
Drill-‐down EvaluaIon of Single Models
33
• FAST comparing with Knowledge Tracing: • More predicIve • More plausible • More consistent
• We also use Polygon framework to effecIvely idenIfy and analyze skills where FAST is worse than KT on some dimensions. Details in the paper.

How can we choose a single model?
• Overall, more than 35% of skills show negaIve correlaIons between predicIve performance and plausibility with non-‐trivial magnitude (.5~.6)!
34
• Choose the one with the highest AUC?
For example, among all 65 skills for Knowledge Tracing, 41 skills have posiIve correlaIon between AUC and GS across 100 restarts. The average correlaIon is 0.6.

How can we choose a single model?
35
• Choose the one with the highest log likelihood on train set?
• Similarly, more than 46% of skills show negaIve correlaIons between predicIve performance and plausibility with non-‐trivial magnitude (.5)!
• A pracIcal way to select a single model with high quality in all dimensions is sIll under quesIon.
• Polygon framework provides important insights.

Outline
36
• IntroducIon • The Polygon EvaluaIon Framework • Studies and Results • Conclusions
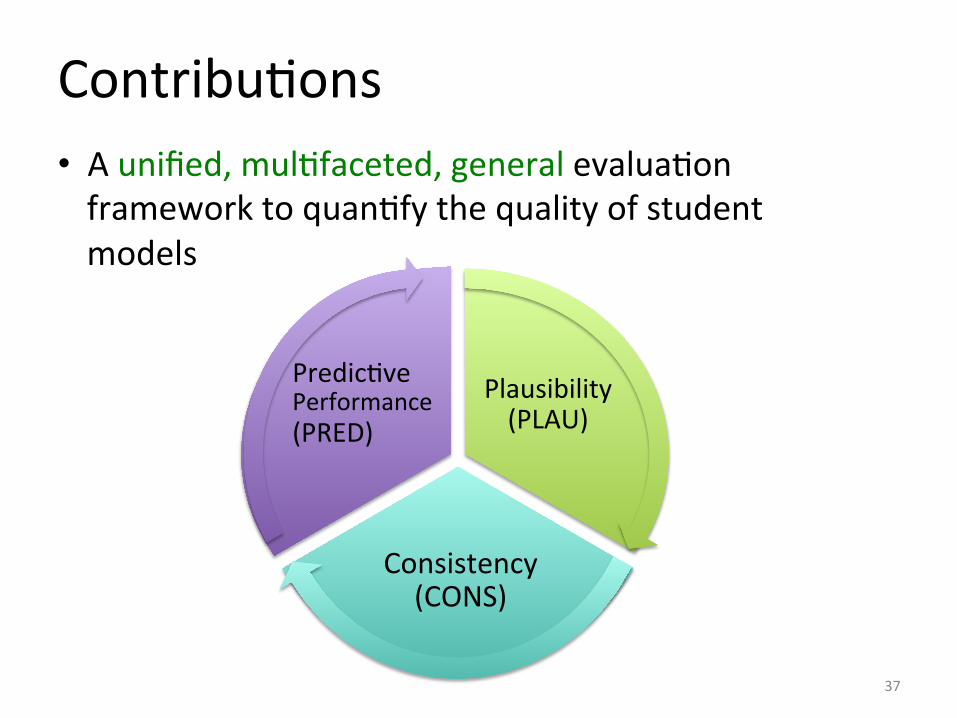
ContribuIons • A unified, mulIfaceted, general evaluaIon framework to quanIfy the quality of student models
37
Plausibility (PLAU)
Consistency (CONS)
PredicIve Performance (PRED)

Conclusions
• A recent model FAST with proper features can promise higher predicIve performance, plausibility and consistency than Knowledge Tracing.
• One reason can be: Features indirectly constrain the opImizaIon algorithm to search within regions with both high fitness and plausibility.
38

Conclusions • Our study is sIll exploratory and serves as a first step towards more theoreIcal, deeper understanding of the parameter space of complex student models. • BeDer metrics? More dimensions? • Combine these three dimensions in a single metric? • RelaIon with external measurements? • Well-‐defined vs. ill-‐defined knowledge components? • …
39

Thank you for listening!
40
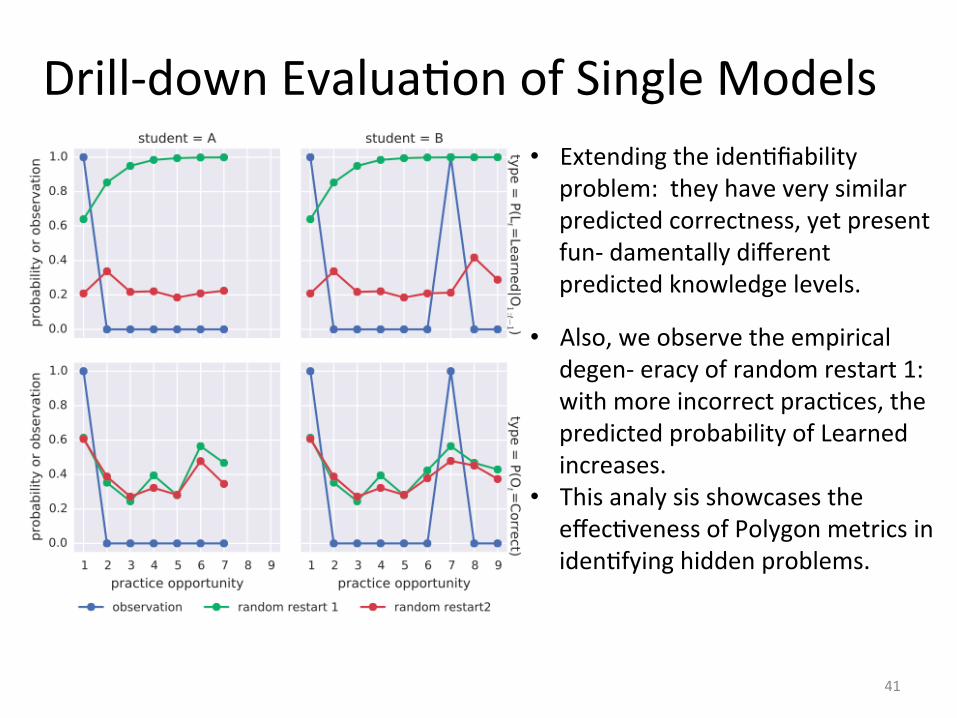
Drill-‐down EvaluaIon of Single Models
41
• Extending the idenIfiability problem: they have very similar predicted correctness, yet present fun-‐ damentally different predicted knowledge levels.
• Also, we observe the empirical degen-‐ eracy of random restart 1: with more incorrect pracIces, the predicted probability of Learned increases.
• This analy sis showcases the effecIveness of Polygon metrics in idenIfying hidden problems.