
2013.07.15 はじパタlt scikit-learnで始める機械学習
20
scikit-learnで始める機械学習 2013/7/16@ はじパタ LT
-
Upload
motoya-wakiyama -
Category
Documents
-
view
18.612 -
download
0
Transcript of 2013.07.15 はじパタlt scikit-learnで始める機械学習

scikit-learnで始める機械学習
2013/7/16@はじパタLT

理論を勉強したら、やっぱり実践したい
理想
0から自分で実装したプログラムで課題を解決していく
現実
パッケージをつなぎ合わせて問題に取り組む
汎用性や処理速度を気にすると、パッケージを使うのが
現実的
→パッケージを使った機械学習の方法を紹介
何の話?

twitterID:wwacky
6月末で会社を辞めて無職生活中
8月からまたサラリーマンになります
最近Python、Hadoopを勉強中
今まではJava、Rがメイン
ゲーム・登山をやってます
登山はまだにわかですが
自己紹介

機械学習のパッケージ
R勢 e1071(SVM、クラスタリングとか)
gbm(AdaBoost+回帰など)
kernlab(SVM、カーネル主成分とか)
mboost(boosting)
nnet(ニューラルネットワーク)
randomForest
rpart
etc.
定番 LIBSVM
その他 weka (Java)
nltk (Python)
新興勢力 Apache Mahout
Jubatus
scikit-learn
という勝手な印象

機械学習のパッケージ
R勢 e1071(SVM、クラスタリングとか)
gbm(AdaBoost+回帰など)
kernlab(SVM、カーネル主成分とか)
mboost(boosting)
nnet(ニューラルネットワーク)
randomForest
rpart
etc.
定番 LIBSVM
その他 weka (Java)
nltk (Python)
新興勢力 Apache Mahout
Jubatus
scikit-learn
という勝手な印象
今日話すのはこいつ

python用の機械学習ライブラリ(モジュール)
シンプルかつ効率的な多目的ツール(らしい)
pythonでデータ分析をする人の必須ツール(って聞いた)
ということで、気になってたので使ってみた
scikit-learnって何?
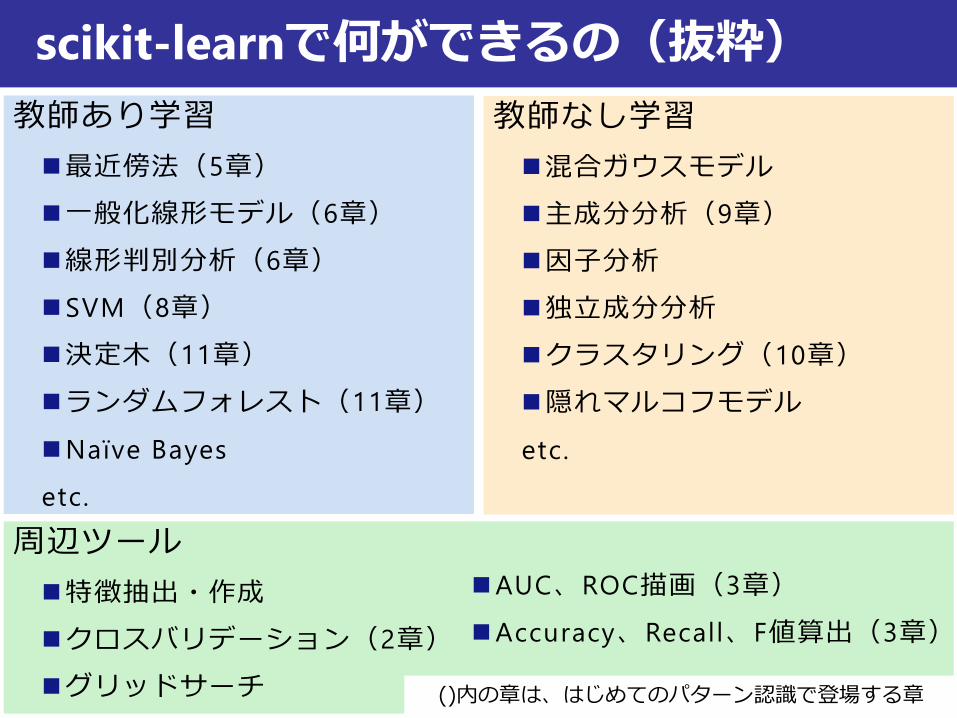
教師なし学習
混合ガウスモデル
主成分分析(9章)
因子分析
独立成分分析
クラスタリング(10章)
隠れマルコフモデル
etc.
教師あり学習
最近傍法(5章)
一般化線形モデル(6章)
線形判別分析(6章)
SVM(8章)
決定木(11章)
ランダムフォレスト(11章)
Naïve Bayes
etc.
scikit-learnで何ができるの(抜粋)
周辺ツール
特徴抽出・作成
クロスバリデーション(2章)
グリッドサーチ
AUC、ROC描画(3章)
Accuracy、Recall、F値算出(3章)
()内の章は、はじめてのパターン認識で登場する章
教師なし学習
混合ガウスモデル
主成分分析(9章)
因子分析
独立成分分析
クラスタリング(10章)
隠れマルコフモデル
etc.
教師あり学習
最近傍法(5章)
一般化線形モデル(6章)
線形判別分析(6章)
SVM(8章)
決定木(11章)
ランダムフォレスト(11章)
Naïve Bayes
etc.
scikit-learnで何ができるの(抜粋)
周辺ツール
特徴抽出・作成
クロスバリデーション(2章)
グリッドサーチ
AUC、ROC描画(3章)
Accuracy、Recall、F値算出(3章)
()内の章は、はじめてのパターン認識で登場する章

Webで検索してください(汗
まあ、そんなに説明することもないかと
Windows版
インストーラをダウンロードして実行するだけ
Mac版
MacPortsだとデフォルトでインストールされているPythonにイ
ンストールされるみたい
別にPythonをインストールしているならeasy_installかpipの方
がいいと思う
インストールするには?
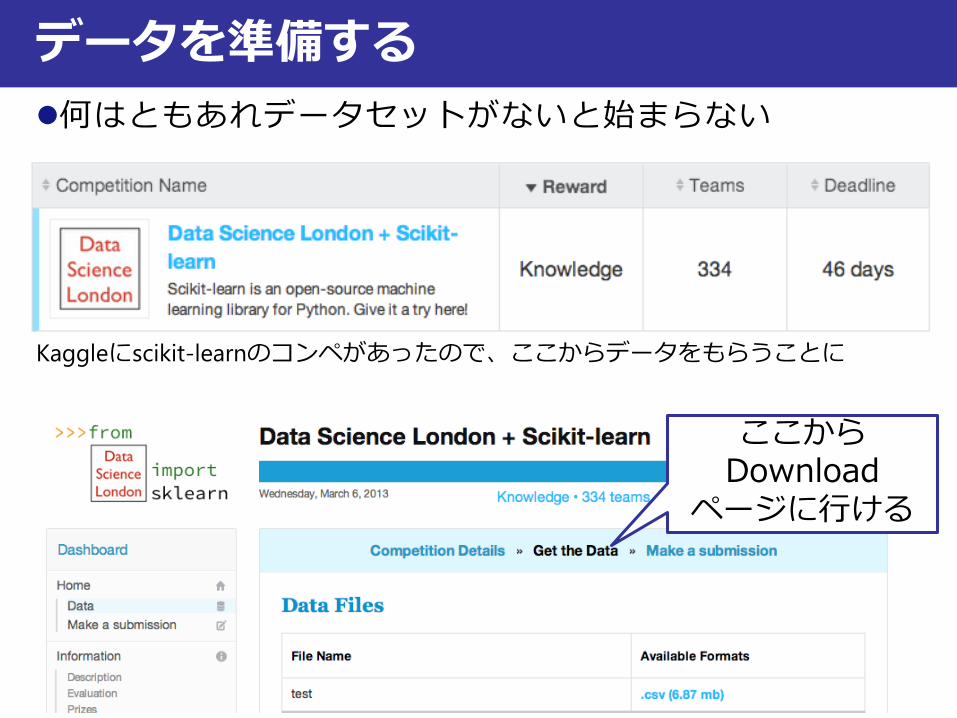
何はともあれデータセットがないと始まらない
データを準備する
Kaggleにscikit-learnのコンペがあったので、ここからデータをもらうことに
ここからDownload
ページに行ける

データの中身
0.29940251144353242,-1.2266241875260637,・・・ -1.1741758544222554,0.33215734209952552,・・・ 1.1922220828945145,-0.41437073477092423,・・・ 1.573270119628208,-0.58031780024933788,・・・ -0.61307141665395515,-0.64420413382117836,・・・ :
1 0 0 1 0 :
ラベル 1000サンプル
特徴量 1000サンプル×40変数
Kaggleにデータの説明がないのが残念(本当は背景情報も欲しいところ)
1000行
40変数

Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy as np
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature)

Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy as np
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature)
ライブラリの読み込み

Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy as np
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature)
ファイルからデータを読み込む。
numpyのデータ形式に変換。

Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy as np
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature)
モデルを定義(ここではSupport Vector Classifier)
fit関数を使って教師データからパラメータを推定

Rと同じぐらいのコード量で動かせる
とりあえず動かす
import numpy as np
from sklearn import svm
trainFeature = np.genfromtxt(open(train.csv', 'r'), delimiter = ',')
trainLabel = np.genfromtxt(open(trainLabels.csv', 'r'), delimiter = ',')
clf = svm.SVC(kernel='rbf', C=1)
clf.fit(trainFeature, trainLabel)
testFeature = np.genfromtxt(open('test.csv', 'r'), delimiter = ',')
result = clf.predict(testFeature) 判別したいデータの特徴量を読み込んで、predict関数を使って判別

モデルを変える時は、定義部分を変更するだけ。後は一緒。
全モデル同じ方法かは調べてませんが・・・。
scikit-learnのいいところ①
from sklearn import svm :
clf = svm.SVC()
clf.fit(trainFeature, trainLabel) :
from sklearn import neighbors :
clf = neighbors.KNeighborsClassifier()
clf.fit(trainFeature, trainLabel) :
from sklearn.ensemble import RandomForestClassifier :
clf = RandomForestClassifier()
clf.fit(trainFeature, trainLabel) :
SVMの時
k近傍法の時
RandomForestの時
まあ、パラメータは把握した方がいいですが

クロスバリデーション、パラメータのグリッドサーチも簡単
scikit-learnのいいところ②
from sklearn import cross_validation
clf = svm.SVC()
scores = cross_validation.cross_val_score(clf, trainFeature, trainLabel, cv=5, n_jobs=-1) print scores #結果表示
from sklearn.grid_search import GridSearchCV tuned_parameters = [ #グリッドサーチの探索範囲設定
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']},
] clf = GridSearchCV(svm.SVC(C=1), tuned_parameters, n_jobs = -1) #設定
clf.fit(trainFeature, trainLabel, cv=5) #グリッドサーチに使うデータの入力
print clf.best_estimator_ #パラメータが一番よかったモデルを表示
パラメータのグリッドサーチ
クロスバリデーション
クロスバリデーション、グリッドサーチは特徴量とラベルをnumpyの配列にしておかないとエラーになるので注意
0:00:00
0:01:26
0:02:53
0:04:19
0:05:46
0:07:12
0:08:38
指定なし 1 2 3 4 -1
処理
時間[hh:m
m:ss]
n_jobs
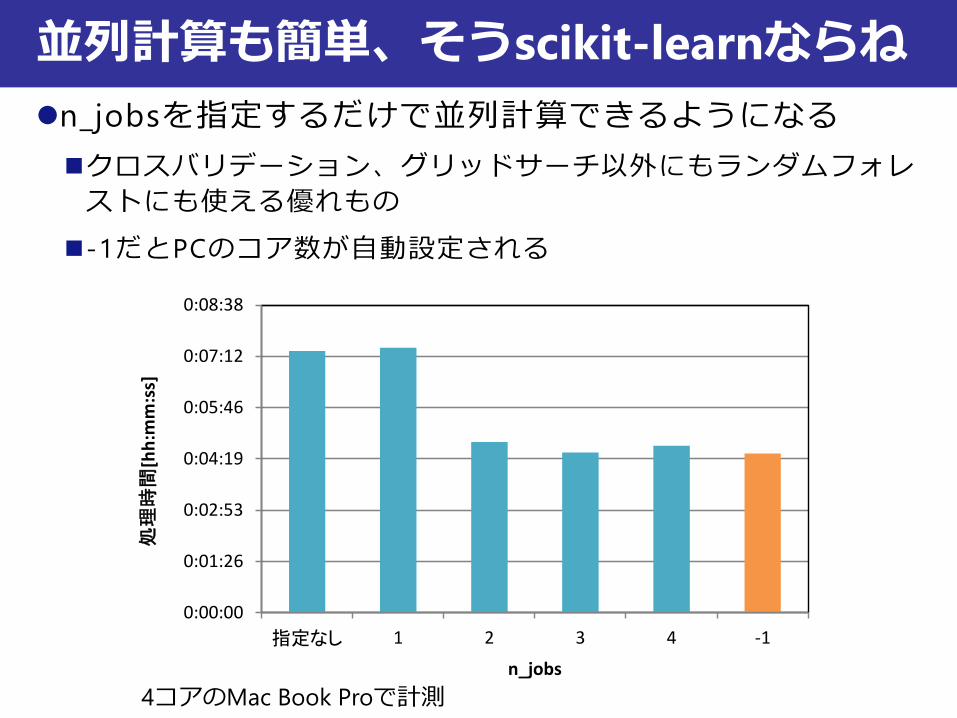
n_jobsを指定するだけで並列計算できるようになる
クロスバリデーション、グリッドサーチ以外にもランダムフォレ
ストにも使える優れもの
-1だとPCのコア数が自動設定される
並列計算も簡単、そうscikit-learnならね
4コアのMac Book Proで計測
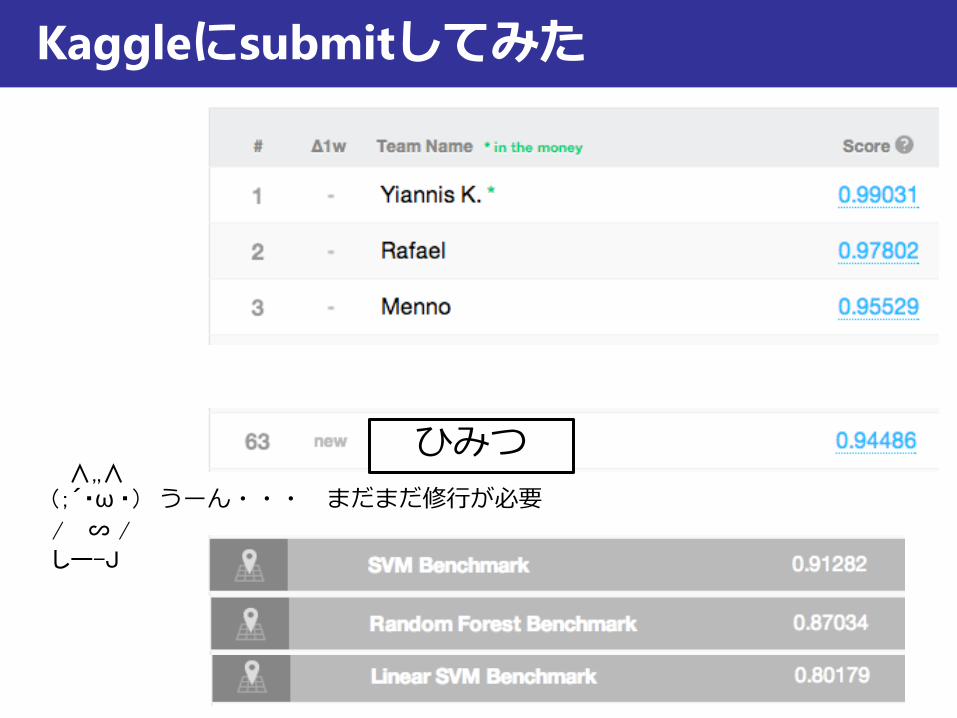
Kaggleにsubmitしてみた
∧,,∧ (;´・ω ・) うーん・・・ まだまだ修行が必要
/ ∽ / しー-J
ひみつ


















