©2012 Paula Matuszek CSC 9010: Text Mining Applications: Document Clustering l Dr. Paula Matuszek l...
39
©2012 Paula Matuszek CSC 9010: Text Mining Applications: Document Clustering Dr. Paula Matuszek Paula.Matuszek@villanova. edu [email protected] (610) 647-9789
-
Upload
damian-lund -
Category
Documents
-
view
214 -
download
0
Transcript of ©2012 Paula Matuszek CSC 9010: Text Mining Applications: Document Clustering l Dr. Paula Matuszek l...

©2012 Paula Matuszek
CSC 9010: Text Mining Applications:
Document Clustering
Dr. Paula Matuszek [email protected] [email protected] (610) 647-9789

©2012 Paula Matuszek
Document Clustering Clustering documents: group documents into
“similar” categories Categories are not predefined Examples
– Process news articles to see what today’s stories are
– Review descriptions of calls to a help line to see what kinds of problems people are having
– Get an overview of search results– Infer a set of labels for future training of a classifier
Unsupervised learning: no training examples and no test set to evaluate

Some Examples
search.carrot2.org/stable/search http://yippy.com/ news.google.com

Clustering Basics Collect documents Compute similarity among documents Group documents together such that
– documents within a cluster are similar– documents in different clusters are different
Summarize each cluster Sometimes -- assign new documents to
the most similar cluster
3
.
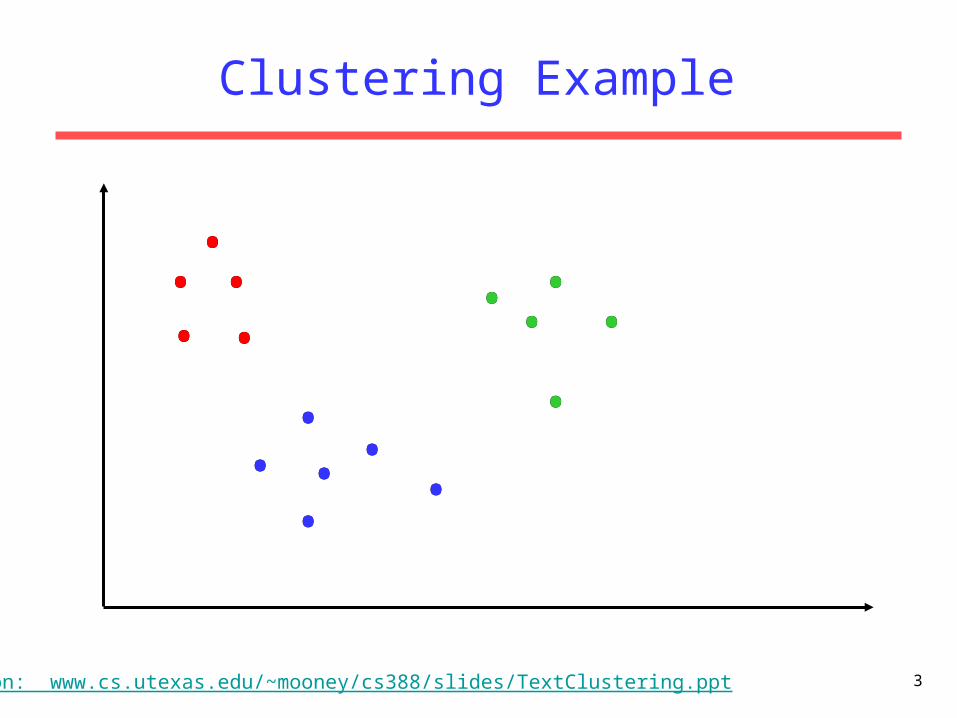
Clustering Example
.
...
. .. ..
..
....
.
...
. .. ..
..
....
.
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

Measures of Similarity Semantic similarity -- but this is hard. Statistical similarity: BOW
– Number of words in common– count
– Weighted words in common– words get additional weight based on inverse
document frequency: more similar if two documents share an infrequent word
– With document as a vector:– Euclidean Distance– Cosine Similarity

Euclidean Distance
Euclidean distance: distance between two measures summed across each feature– Squared differences to give more weight to
larger difference
dist(xi, xj) = sqrt((xi1-xj1)2+(xi2-xj2)2+..+(xin-xjn)2)

Based on home.iitk.ac.in/~mfelixor/Files/non-numeric-Clustering-seminar.pp
Cosine similarity measurement
Cosine similarity is a measure of similarity between two vectors by measuring the cosine of the angle between them.
The result of the Cosine function is equal to 1 when the angle is 0, and it is less than 1 when the angle is of any other value.
As the angle between the vectors shortens, the cosine angle approaches 1, meaning that the two vectors are getting closer, meaning that the similarity of whatever is represented by the vectors increases.

Clustering Algorithms Hierarchical
– Bottom up (agglomerative)– Top-down (not common in text)
Flat – K means
Probabilistic– Expectation Maximumization (E-M)

7
Hierarchical Agglomerative Clustering (HAC)
Starts with all instances in a separate cluster and then repeatedly joins the two clusters that are most similar until there is only one cluster.
The history of merging forms a binary tree or hierarchy.
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

8
HAC Algorithm
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt
Start with all instances in their own cluster.
Until there is only one cluster:– Among the current clusters, determine
the two clusters, ci and cj, that are most similar.
– Replace ci and cj with a single cluster ci c∪ j

9
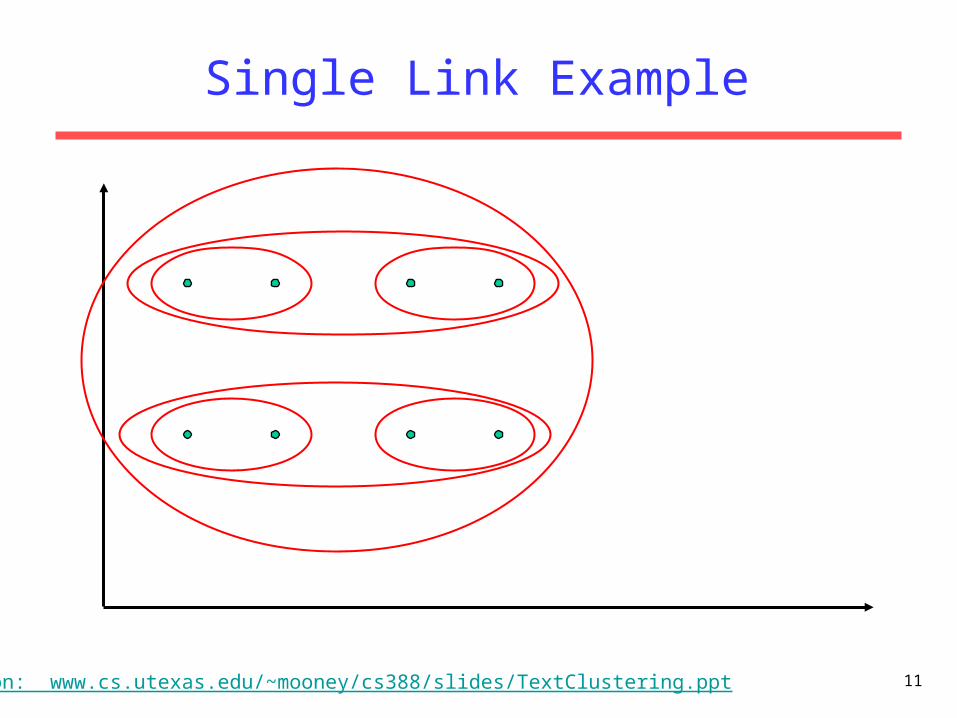
Cluster Similarity How to compute similarity of two clusters
each possibly containing multiple instances?– Single Link: Similarity of two most similar
members.– Can result in “straggly” (long and thin) clusters due
to chaining effect.
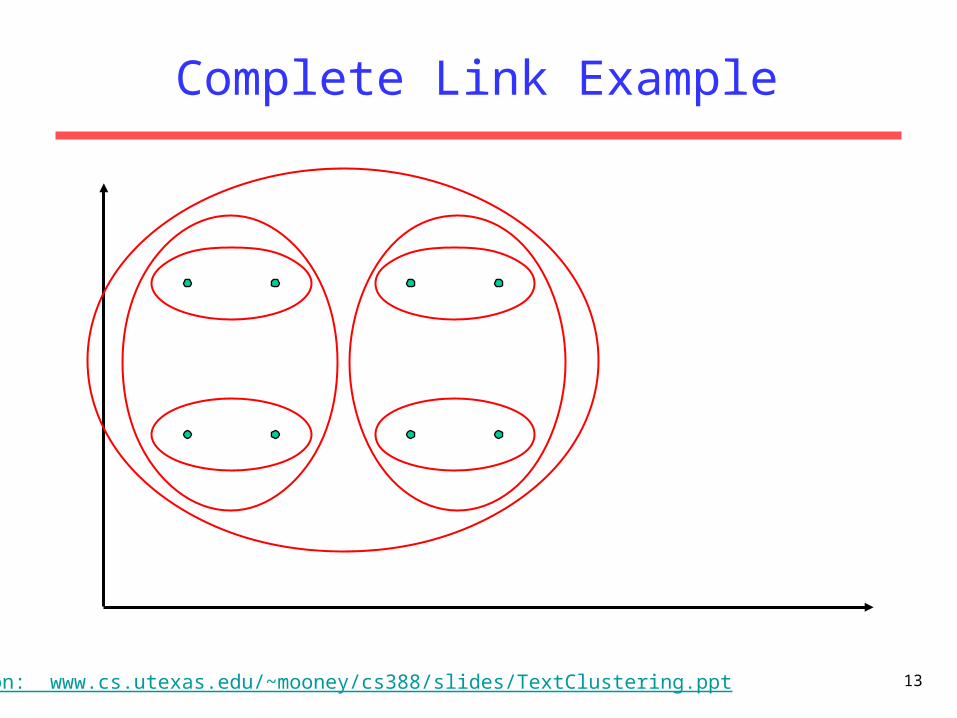
– Complete Link: Similarity of two least similar members.
– Makes more “tight,” spherical clusters that are typically preferable
– More sensitive to outliers
– Group Average: Average similarity between members.
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt
11
Single Link Example
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt
13
Complete Link Example
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

16
Group Average Agglomerative Clustering
Use average similarity across all pairs within the merged cluster to measure the similarity of two clusters.
Compromise between single and complete link.
Averaged across all ordered pairs in the merged cluster instead of unordered pairs between the two clusters (to encourage tighter final clusters).
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

http://www.csee.umbc.edu/~nicholas/676/MRSslides/lecture17-clustering.ppt
Dendogram: Hierarchical Clustering
Clustering obtained by cutting the dendrogram at a desired level: each connected component forms a cluster.

Partitioning (Flat) Algorithms
Partitioning method: Construct a partition of n documents into a set of K clusters
Given: a set of documents and the number K
Find: a partition of K clusters that optimizes the chosen partitioning criterion– Globally optimal: exhaustively enumerate all
partitions– Effective heuristic methods: K-means
algorithm.
http://www.csee.umbc.edu/~nicholas/676/MRSslides/lecture17-clustering.ppt

18
Non-Hierarchical Clustering
Typically must provide the number of desired clusters, k.
Randomly choose k instances as seeds, one per cluster.
Form initial clusters based on these seeds. Iterate, repeatedly reallocating instances to
different clusters to improve the overall clustering.
Stop when clustering converges or after a fixed number of iterations.
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

19
K-Means Assumes instances are real-valued
vectors. Clusters based on centroids, center of
gravity, or mean of points in a cluster, c: Reassignment of instances to clusters is
based on distance to the current cluster centroids.
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

21
K-Means Algorithm
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt
Let d be the distance measure between instances.
Select k random instances {s1, s2,… sk} as seeds.
Until clustering converges or other stopping criterion:– For each instance xi:
– Assign xi to the cluster cj such that d(xi, sj) is minimal.
– (Update the seeds to the centroid of each cluster)– For each cluster cj, sj = μ(cj)
22
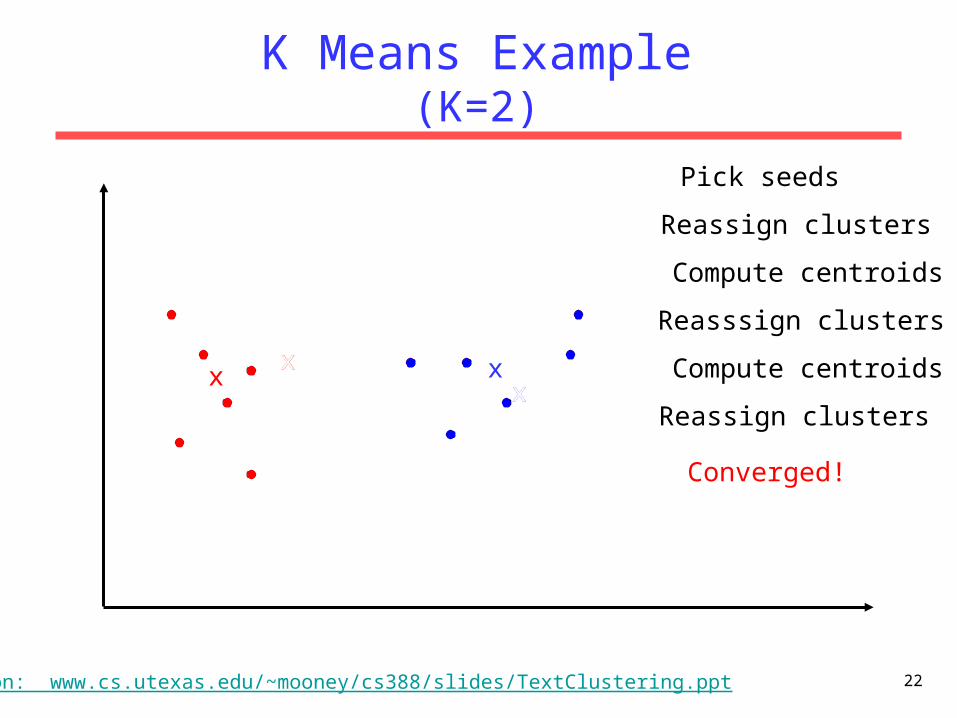
K Means Example(K=2)
Pick seeds
Reassign clusters
Compute centroids
xx
Reasssign clusters
xx xx Compute centroids
Reassign clusters
Converged!
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

Termination conditions Several possibilities, e.g.,
– A fixed number of iterations.– Doc partition unchanged.– Centroid positions don’t change.
http://www.csee.umbc.edu/~nicholas/676/MRSslides/lecture17-clustering.ppt

Seed Choice Results can vary based on
random seed selection. Some seeds can result in
poor convergence rate, or convergence to sub-optimal clusterings.– Select good seeds using a
heuristic (e.g., doc least similar to any existing mean)
– Try out multiple starting points– Initialize with the results of
another method.
In the above, if you startwith B and E as centroidsyou converge to {A,B,C}and {D,E,F}If you start with D and Fyou converge to {A,B,D,E} {C,F}
Example showingsensitivity to seeds
http://www.csee.umbc.edu/~nicholas/676/MRSslides/lecture17-clustering.ppt
A B
D E
C
F

How Many Clusters? Number of clusters K is given
– Partition n docs into predetermined # of clusters Finding the “right” number of clusters is part of the
problem
K not specified in advance– Solve an optimization problem: penalize
having lots of clusters– application dependent, e.g., compressed
summary of search results list.
– Tradeoff between having more clusters (better focus within each cluster) and having too many clusterhttp://www.csee.umbc.edu/~nicholas/676/MRSslides/lecture17-clustering.ppt

Weaknesses of k-means The algorithm is only applicable to
numeric data The user needs to specify k. The algorithm is sensitive to outliers
– Outliers are data points that are very far away from other data points.
– Outliers could be errors in the data recording or some special data points with very different values.
www.cs.uic.edu/~liub/teach/cs583-fall-05/CS583-unsupervised-learning.ppt

www.cs.uic.edu/~liub/teach/cs583-fall-05/CS
Strengths of k-means Strengths:
– Simple: easy to understand and to implement– Efficient: Time complexity: O(tkn), – where n is the number of data points, – k is the number of clusters, and – t is the number of iterations. – Since both k and t are small. k-means is
considered a linear algorithm. K-means is the most popular clustering
algorithm. In practice, performs well on text.
www.cs.uic.edu/~liub/teach/cs583-fall-05/CS583-unsupervised-learning.ppt

26
Buckshot Algorithm Combines HAC and K-Means clustering. First randomly take a sample of
instances of size √n Run group-average HAC on this sample,
which takes only O(n) time. Use the results of HAC as initial seeds
for K-means. Overall algorithm is O(n) and avoids
problems of bad seed selection.Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

27
Text Clustering HAC and K-Means have been applied to text in a
straightforward way. Typically use normalized, TF/IDF-weighted vectors
and cosine similarity. Optimize computations for sparse vectors. Applications:
– During retrieval, add other documents in the same cluster as the initial retrieved documents to improve recall.
– Clustering of results of retrieval to present more organized results to the user.
– Automated production of hierarchical taxonomies of documents for browsing purposes.
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

28
Soft Clustering Clustering typically assumes that each
instance is given a “hard” assignment to exactly one cluster.
Does not allow uncertainty in class membership or for an instance to belong to more than one cluster.
Soft clustering gives probabilities that an instance belongs to each of a set of clusters.
Each instance is assigned a probability distribution across a set of discovered categories (probabilities of all categories must sum to 1).Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

29
Expectation Maximumization (EM)
Probabilistic method for soft clustering. Direct method that assumes k clusters:
{c1, c2,… ck} Soft version of k-means. Assumes a probabilistic model of
categories that allows computing P(ci | E) for each category, ci, for a given example, E.
For text, typically assume a naïve-Bayes category model.Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

30
EM Algorithm Iterative method for learning probabilistic
categorization model from unsupervised data. Initially assume random assignment of examples to
categories. Learn an initial probabilistic model by estimating
model parameters θ from this randomly labeled data. Iterate following two steps until convergence:
– Expectation (E-step): Compute P(ci | E) for each example given the current model, and probabilistically re-label the examples based on these posterior probability estimates.
– Maximization (M-step): Re-estimate the model parameters, θ, from the probabilistically re-labeled data.
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

31
EM
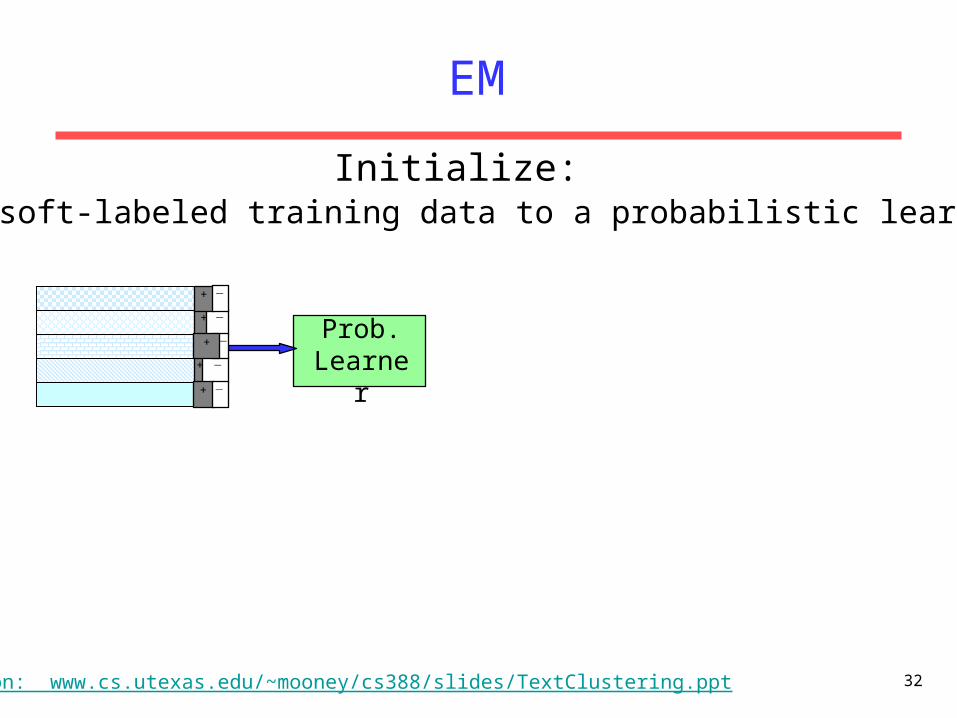
Unlabeled Examples
+ −
+ −
+ −
+ −
−+
Assign random probabilistic labels to unlabeled dataInitialize:
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt
32
EM
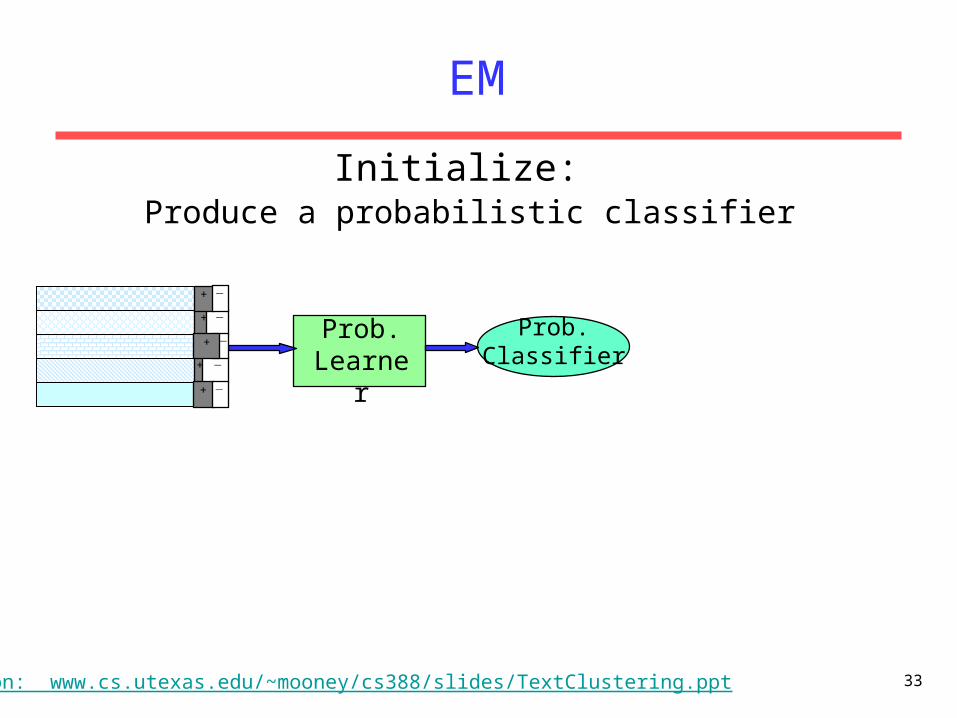
Prob. Learner
+ −
+ −
+ −
+ −
−+
Give soft-labeled training data to a probabilistic learnerInitialize:
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt
33
EM
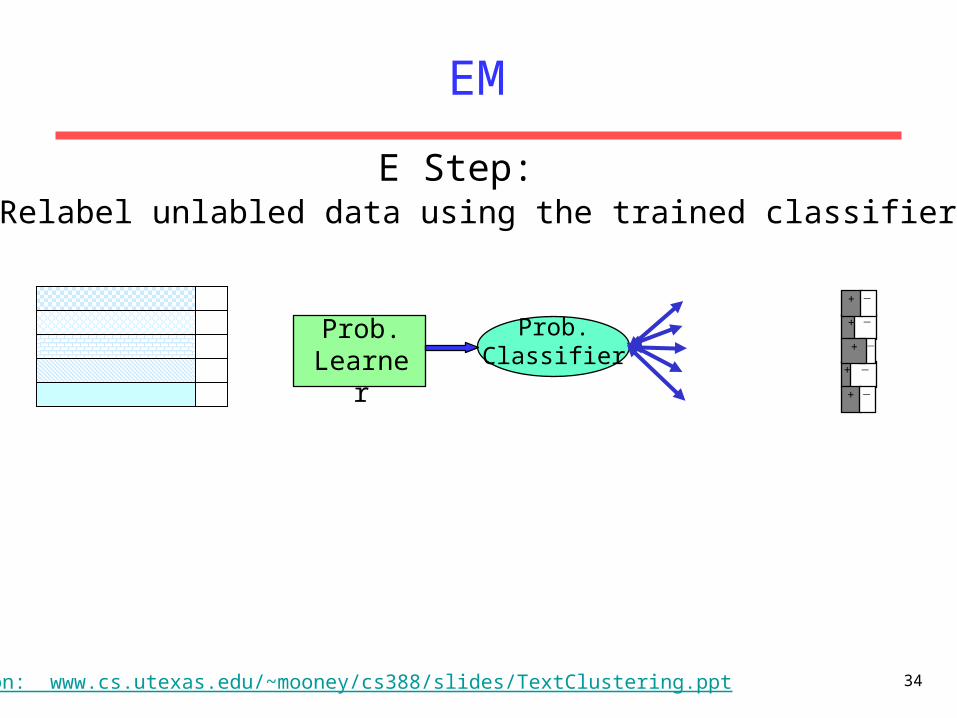
Prob. Learner
Prob.Classifier
+ −
+ −
+ −
+ −
−+
Produce a probabilistic classifierInitialize:
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt
34
EM
Prob. Learner
Prob.Classifier
Relabel unlabled data using the trained classifier
+ −
+ −
+ −
+ −
−+
E Step:
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt
35
EM
Prob. Learner
+ −
+ −
+ −
+ −
−+Prob.
Classifier
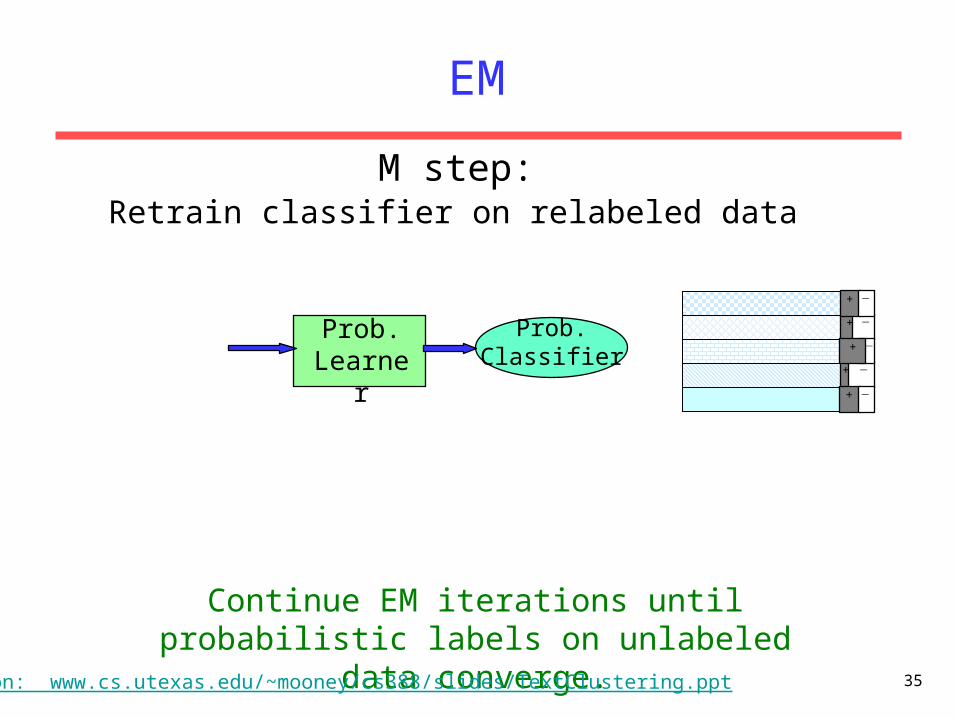
Continue EM iterations until probabilistic labels on unlabeled data converge.
Retrain classifier on relabeled dataM step:
Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

46
Issues in Clustering How to evaluate clustering?
– Internal: – Tightness and separation of clusters (e.g. k-means
objective)
– Fit of probabilistic model to data
– External– Compare to known class labels on benchmark
data (purity)
Improving search to converge faster and avoid local minima.
Overlapping clustering.Based on: www.cs.utexas.edu/~mooney/cs388/slides/TextClustering.ppt

How to Label Text Clusters Show titles of typical documents
– Titles are easy to scan– Authors create them for quick scanning!– But you can only show a few titles which
may not fully represent cluster Show words/phrases prominent in
cluster– More likely to fully represent cluster– Use distinguishing words/phrases– But harder to scan
22cs.wellesley.edu/~cs315/315_PPTs/L17-Clustering/lecture_17.ppt

Summary: Text Clustering Clustering can be useful in seeing “shape” of a
document corpus Unsupervised learning; training examples not
needed– easier and faster– more appropriate when you don’t know the categories
Goal is to create clusters with similar documents– typically using BOW with TF*IDF as representation– typically using cosine-similarity as metric
Difficult to evaluate results– useful?– expert opinion?– In practice, only moderately successful