Introduction to Hadoop 2.0 & YARN | Hadoop 2.0 & YARN Fundamentals | Hadoop 2.0 & YARN Architecture
Upload
hiroyuki-yamadaCategory
view
417download
0
1,000,000 foot view of Hadoop-like
parallel data processing systems
2014.10.11 @DSIRNLP
Hiroyuki Yamada (feeblefakie)

自己紹介
• 山田浩之 (feeblefakie)
• 最近書いた書籍のプロフィールから• 日本アイ・ビー・エム株式会社を経て,ヤフー株式会社にて分散型全文検索エンジンの研究開発に従事。2008年上期未踏IT人材発掘・育成事業において高性能分散型検索エンジンの開発によりスーパークリエータに認定。現在は東京大学生産技術研究所にて高性能並列データベースの研究開発に従事。博士(情報理工学)。
• システム屋です

宗教家(東横イン評論家)と本を書きました
• 今日の発表とは全然関係ありません
• 買わないと明日クラスでいじめられるよ
ジュンク堂Power Push!
池袋本店総合3位(一時期)

データベースがない!
• DSIRNLPの対象範囲:
• データ構造とアルゴリズム、情報検索、自然言語処理、データマイニング、機械学習、強化学習、人工知能、並行プログラミング、情報理論、データ圧縮など、ですが、●●使ってみた!という発表以外ならどんなテーマ・発表でも大体OKです。
• データベース関係の話をします
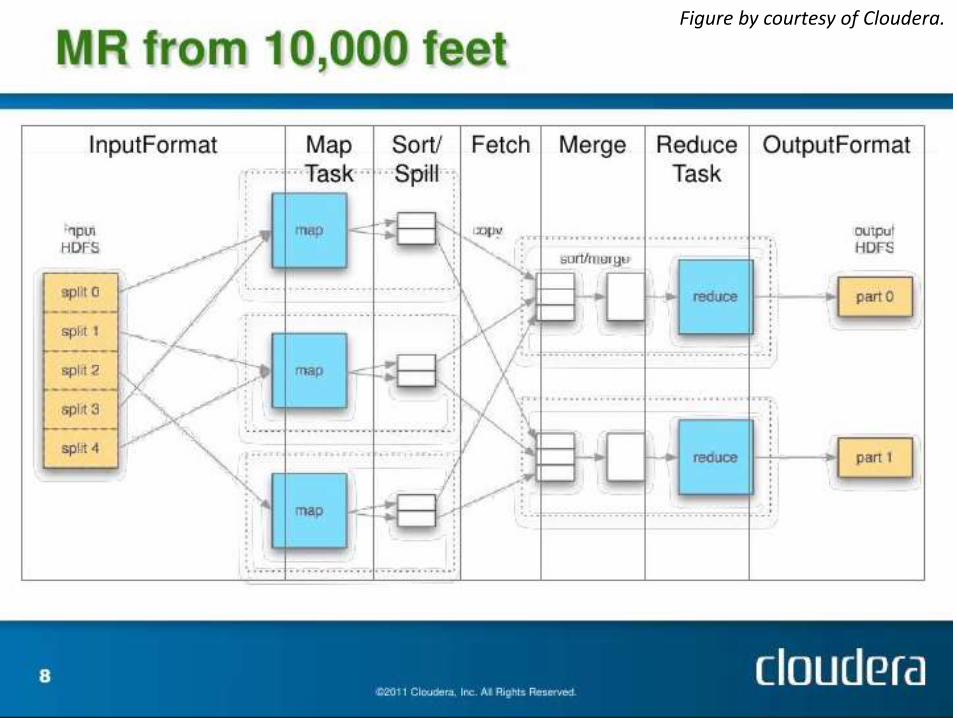
Figure by courtesy of Cloudera.

Hadoop-like parallel data processing
systems from 1,000,000 feet
• Hadoop等の並列データ処理系
– Hadoop, Hive, Impala, Presto, Spark, Tez
• 玉石混淆の処理系の本質を紹介
– Impala, Prestoって何で速いの?
– Spark, Tezって何?

MapReduce: A major step backwards
• By D. DeWitt and M. Stonebraker
• MapReduce is not novel
http://homes.cs.washington.edu/~billhowe/mapreduce_a_major_step_backwards.html
The MapReduce community seems to feel that they have discovered an entirely new paradigm for
processing large data sets. In actuality, the techniques employed by MapReduce are more than 20
years old. The idea of partitioning a large data set into smaller partitions was first proposed in
"Application of Hash to Data Base Machine and Its Architecture" [11] as the basis for a new type of join
algorithm. In "Multiprocessor Hash-Based Join Algorithms," [7], Gerber demonstrated how
Kitsuregawa's techniques could be extended to execute joins in parallel on a shared-nothing [8]
cluster using a combination of partitioned tables, partitioned execution, and hash based splitting.
DeWitt [2] showed how these techniques could be adopted to execute aggregates with and without
group by clauses in parallel. DeWitt and Gray [6] described parallel database systems and how they
process queries. Shatdal and Naughton [9] explored alternative strategies for executing aggregates in
parallel.
Teradata has been selling a commercial DBMS utilizing all of these techniques for more than 20
years; exactly the techniques that the MapReduce crowd claims to have invented.

Hadoop
• I/F:map(), reduce()(Procedural)
• 処理モデル:ハッシクラスタリングを用いた並列マージソート
• Unary Operator => σ, π, aggregation
• 強引にBinary Operator化 =>

Hive
• I/F:SQL(Declarative)
• 処理モデル:ハッシクラスタリングを用いた並列マージソート w/ Left-Deep Tree
• Sort-Merge Join (Reduce-side Join)
• Co-partitioned/Broadcast Hash Join (Map-
side Join)

Impala, Presto
• I/F:SQL(Declarative)• 処理モデル:In-memory Hash Join w/ Right-
Deep Tree
• Partitioned+Pipelined Hash Join (Repartition, Broadcast)– In memory only, No Grace, No Hybrid
• Hiveとの差– Hash Join vs. Sort Merge Join
– In-memory based (Pipeline) vs. Disk-based (External Sort)
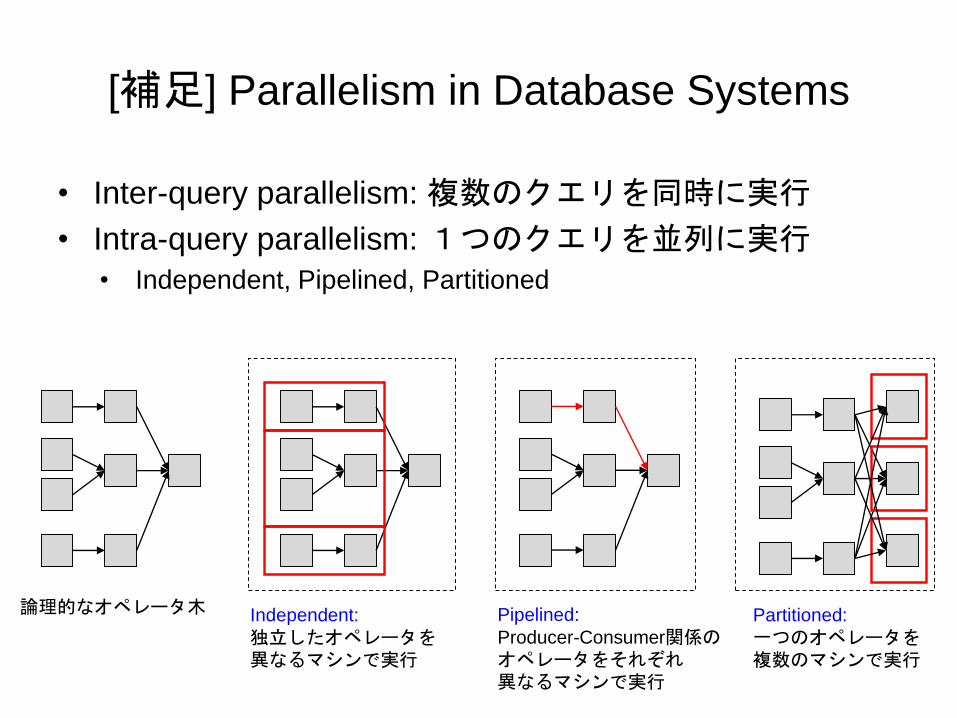
[補足] Parallelism in Database Systems
• Inter-query parallelism: 複数のクエリを同時に実行
• Intra-query parallelism: 1つのクエリを並列に実行• Independent, Pipelined, Partitioned
Pipelined:
Producer-Consumer関係のオペレータをそれぞれ異なるマシンで実行
Independent:
独立したオペレータを異なるマシンで実行
Partitioned:
一つのオペレータを複数のマシンで実行
論理的なオペレータ木
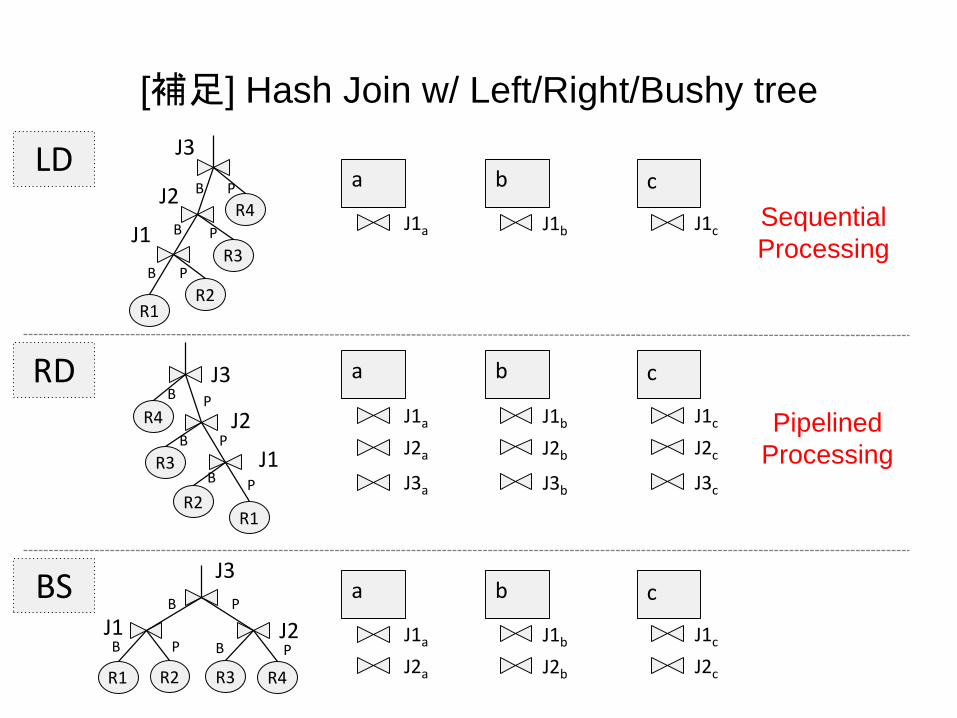
[補足] Hash Join w/ Left/Right/Bushy tree
R1R2
R4
R3
R1R2
R4
R3
R1 R2 R4R3
J1
J2
J3
J1
J2
J3
J1 J2
J3
J1a
a b c
a b c
a b c
B P
P
P
B
B
B P
B
B
P
P
B P PB
B P
Sequential
Processing
Pipelined
Processing
J1b J1c
J1a J1b J1c
J2a J2b J2c
J3a J3b J3c
J1a J1b J1c
J2a J2b J2c
LD
RD
BS
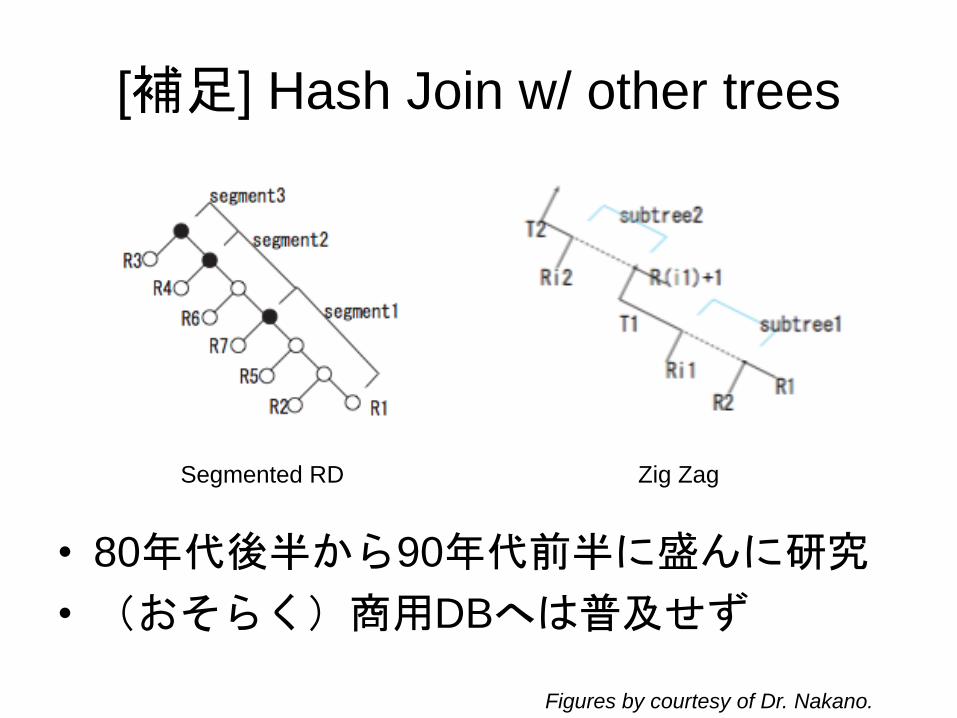
[補足] Hash Join w/ other trees
Segmented RD Zig Zag
Figures by courtesy of Dr. Nakano.
• 80年代後半から90年代前半に盛んに研究
• (おそらく)商用DBへは普及せず

Spark, Tez
• I/F:手続き (Procedural)
• 処理モデル:DAG
– 任意の(または決められた)処理オペレータを連結してDAGを構成
– cf. Dryad [Isard’07], Hyracks [Borkar’11]
• 抽象的な並列データ処理フレームワーク– Hadoop, Impala, Prestoを作ることも論理的には可能
– DAGを自分で書きたい?
ロゴダサい

Spark SQL, Hive on Tez
• SQL on top of DAG
– DAGの最適化は探索空間の爆発により困難
– Treeにおいても木の形を限定して探索
• 結局Treeを用いた最適化–下がDAGである意味がなくなっている
– Left-deep, Bushy in Hive on Tez (H2 2014)
–論理的にはImpala, Prestoと同じ

まとめ
• 最近のオープンソース並列データ処理系を抽象的に観察
• 基本は80年代から90年代の並列データベース技術
• 個々のプロダクトよりも本質の理解へ
– Hadoop処理系を知りたいなら並列DBの理解が近道