
ニューラルネットワークの概要と深層化takenawa/learning/intro.pdf ·...
17
ニューラルネットワークの概要と深層化 竹縄 知之 東京海洋大学 深層学習入門 竹縄 知之 (海洋大) ニューラルネットワーク 1 / 17
Transcript of ニューラルネットワークの概要と深層化takenawa/learning/intro.pdf ·...

ニューラルネットワークの概要と深層化
竹縄 知之
東京海洋大学
深層学習入門
竹縄 知之 (海洋大) ニューラルネットワーク 1 / 17

1 ディープラーニングとは
2 ニューラルネットワーク学習 3つの基本原理
3 深層化へ向けて
竹縄 知之 (海洋大) ニューラルネットワーク 2 / 17

ディープラーニングとは
沢山の層を持つ複雑なニューラルネットワークによる機械学習のこと.
画像の解析(映っているものの内容を分析したり,画像から物体を抽出する)や音声や文章の解析(内容を分析したり,翻訳したり)について,近年,人と同程度か上回るレベルで高速に行えるようになり,急速に普及している.
竹縄 知之 (海洋大) ニューラルネットワーク 3 / 17

1 ディープラーニングとは
2 ニューラルネットワーク学習 3つの基本原理
3 深層化へ向けて
竹縄 知之 (海洋大) ニューラルネットワーク 4 / 17
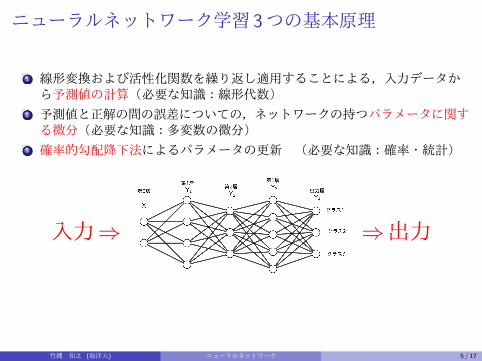
ニューラルネットワーク学習 3つの基本原理
1 線形変換および活性化関数を繰り返し適用することによる,入力データから予測値の計算(必要な知識:線形代数)
2 予測値と正解の間の誤差についての,ネットワークの持つパラメータに関する微分(必要な知識:多変数の微分)
3 確率的勾配降下法によるパラメータの更新 (必要な知識:確率・統計)
入力⇒ ⇒出力
竹縄 知之 (海洋大) ニューラルネットワーク 5 / 17

1. 線形変換および活性化関数による予測値の計算ニューラルネットワークの各層は複数のニューロン(グラフの頂点)からなる.第 i 層の m番目のニューロンにおける演算は,線形変換してから非線形変換を施したもの:{
a(i)m = x
(i−1)0 w
(i)0m + x
(i−1)1 w
(i)1m + · · ·+ x
(i−1)L−1 w
(i)L−1,m + b
(i)m
y(i)m = f
(a(i)m
)である.ここで,(x
(i−1)0 , · · · , x (i−1)
L−1 )は前の層の出力値,w(i)lm および b
(i)m は重み
パラメータと呼ばれる値.また,f (a)は活性化関数と呼ばれる非線形関数であり,典型的なものは,ReLU(Rectified Linear Unit):
f (a) =
{0 (a ≤ 0のとき)
a (a > 0のとき)
である.上式は行列やベクトルを使うと{a(i) = x(i−1)W + b(i)
y(i) = f(a(i)
)と書ける.ただし,ベクトルは横ベクトルであり,関数 f は a(i)の各成分に作用するものとする(このような作用のさせ方をブロードキャストという).
竹縄 知之 (海洋大) ニューラルネットワーク 6 / 17

2. 誤差のパラメータによる微分
関数の微分とは,関数の入力を少し変化させたときに,出力がその何倍変化するかを表す量であった.ニューラルネットワークの場合,重みパラメータを入力,予測値と正解との差から決まる誤差を出力としたときの微分を計算する必要がある.重みパラメータは沢山あるので多変数の微分.層も沢山あるので合成関数の微分になっている.ただし,ディープラーニング用のライブラリ(Tnsorflow,Chainer, Pytorch など)では自動的に計算される.
竹縄 知之 (海洋大) ニューラルネットワーク 7 / 17

誤差関数
ニューラルネットワークで考える問題は,出力値が数値かクラス(類)かによって,回帰問題と分類問題に分けられるが,以下の誤差関数がよく用いられる.
回帰問題のとき:出力 y,正解ラベル t をどちらもスカラー値とするとき,E = (y − t)2 を 2乗誤差という.
L個のクラスへの分類問題のとき:出力 y,正解ラベル tはどちらも L次元のベクトルであって,出力は
yl ≥ 0, y0 + · · ·+ yL−1 = 1
と正規化されていて,正解ラベルは tl =
{1 (l が正解のとき)
0 (そうでないとき)となって
いる(ワンホット表現)とき,E = −L−1∑l=0
tl log yl を交差エントロピー誤
差という.なお,正規化は E が入力や重みパラメータに関して微分可能であるように行う.
竹縄 知之 (海洋大) ニューラルネットワーク 8 / 17

チェインルール
多変数の合成関数の微分の公式はチェインルールと呼ばれる.
例えば,z = z(u, v), u = u(x , y), v = v(x , y)と書かれ,関数 z は全微分可能,u,v は偏微分可能なとき,
∂z
∂x=∂z
∂u
∂u
∂x+
∂z
∂v
∂v
∂x∂z
∂y=∂z
∂u
∂u
∂y+
∂z
∂v
∂v
∂y
が成り立つ.第一式は,x から矢印をたどって z に至る道が 2つあることに対応し,第一式は,y から矢印をたどって z に至る道が 2つあることに対応する.
竹縄 知之 (海洋大) ニューラルネットワーク 9 / 17

3. 確率的勾配降下法を用によるパラメータの更新
確率的勾配降下法(Stochastic Gradient Decent)のアルゴリズム:1 パラメータW の値を適当にとる.2 正解付きの入力データの集合から,いくつかのサンプル(ミニバッチ)をランダムに選ぶ.
3 入力から予測値を計算する
4 正解との誤差 E のパラメータW に関する微分∂E
∂Wを計算
5 実定数 λ > 0に対して,パラメーW を
W ←W − λ∂E
∂W
と更新して 2に戻る.
各層の出力は,ミニバッチサイズ ×ニューロン数型の 2階の配列である.
竹縄 知之 (海洋大) ニューラルネットワーク 10 / 17
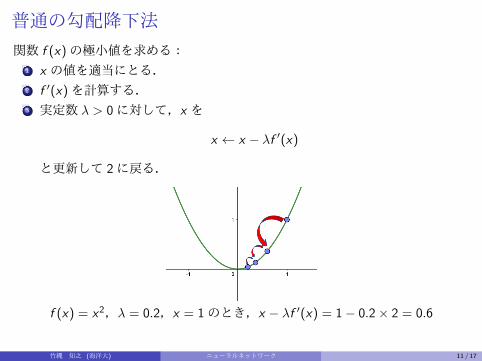
普通の勾配降下法
関数 f (x)の極小値を求める:1 x の値を適当にとる.2 f ′(x)を計算する.3 実定数 λ > 0に対して,x を
x ← x − λf ′(x)
と更新して 2に戻る.
f (x) = x2,λ = 0.2,x = 1のとき,x − λf ′(x) = 1− 0.2× 2 = 0.6
竹縄 知之 (海洋大) ニューラルネットワーク 11 / 17

SGDの例:回帰直線の計算データセット (x0, y0), (x1, y1), . . . , (xN−1, yN−1)に対して回帰直線 y = ax + bをSGDで求める.
1 a,bの値を適当にとる.2 データセットから K 個のサンプルをランダムに選び,改めて
(x0, t0), (x1, t1), . . . , (xK−1, tK−1)とおく.3 yk = axk + bで予測値 yk を計算する.
4 正解との 2乗誤差 E =K−1∑k=0
(yk − tk)2 のパラメータ a,bに関する微分は
∂E
∂a=
∂
∂a
K−1∑k=0
(yk − tk)2 =
K−1∑k=0
2(yk − tk)∂yk∂a
= 2K−1∑k=0
(yk − tk)xk
∂E
∂b=
∂
∂b
K−1∑k=0
(yk − tk)2 =
K−1∑k=0
2(yk − tk)∂yk∂b
= 2K−1∑k=0
(yk − tk)
5 実定数 λ > 0に対して,パラメー a,bを
a← a− λ∂E
∂a, b ← b − λ
∂E
∂b
と更新して 2に戻る.竹縄 知之 (海洋大) ニューラルネットワーク 12 / 17
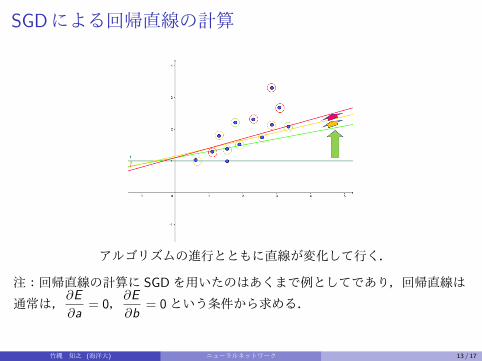
SGDによる回帰直線の計算
アルゴリズムの進行とともに直線が変化して行く.
注:回帰直線の計算に SGDを用いたのはあくまで例としてであり,回帰直線は
通常は,∂E
∂a= 0,
∂E
∂b= 0という条件から求める.
竹縄 知之 (海洋大) ニューラルネットワーク 13 / 17

1 ディープラーニングとは
2 ニューラルネットワーク学習 3つの基本原理
3 深層化へ向けて
竹縄 知之 (海洋大) ニューラルネットワーク 14 / 17

ニューラルネットワークの特徴
多くのパラメータによる豊富な表現力を有する.
学習の目的は訓練データに対して誤差を小さくすることそのものではなく,未知の入力データに対して正しく予想すること.
上の二つの事柄は一般には排反な事象であり,豊富な表現力を持つ予測機を訓練しすぎると,未知のデータに対する予測能力(汎化(はんか)性能)はかえって落ちる.この状態を過学習という.
SGDは収束は遅いが,過学習を防ぐには有利.入力データをランダムに変形するなどの手法(データ増大)も有効.
層が増える(5,6層以上)と学習がうまく進まなくなり,その対策として,最適化法 SGDの改良,ドロップアウト,バッチ正規化,重みパラメータの初期値の取り方の工夫などがあるが,ネットワークの構造自体を変えた方が効果が大きい.(ただし,これらはあくまでも実験による結果であって,理論的な説明はまだないようである.)
竹縄 知之 (海洋大) ニューラルネットワーク 15 / 17

畳み込みニューラルネットワーク
畳み込みニューラルネットワークは次ページで紹介する畳み込み演算を用いたニューラルネットワークである.
通常のニューラルネットワークでは,ある層のニューロンの出力値を計算するのに,前の層の全てのニューロンの出力値を用いる.畳み込み演算では,前の層のあるニューロンの「近く」のニューロンの値のみを用いることにより,「近さ」という情報を取り出しやすくする.
畳み込み演算を行う層の出力は,ミニバッチサイズ×縦×横×チャンネル数型の 4階の配列である.
これはディープラーニングにおいて最も基本的な手法であり,ディープラーニングで用いられるネットワークは多くが畳み込みニューラルネットワークおよびその拡張である.
竹縄 知之 (海洋大) ニューラルネットワーク 16 / 17

畳み込み演算例えば,チャンネル数が入力,出力ともに1で,前の層の出力値 X およびフィルターと呼ばれる重みパラメータ F が
X =
1 2 3 45 6 7 89 10 11 1213 14 15 16
, F =1 1 12 0 1−1 −1 0
であるとき,畳み込み演算の出力は
Y =y00 y01y10 y11
=4 820 24
となる.ここで,y00はフィルターと X から左上隅のそれと同じ形の部分を取り出したもの(をそれぞれベクトルとみなしたときの)の内積
y00 =(1, 2, 3, 5, 6, 7, 9, 10, 11) · (1, 1, 1, 2, 0, 1,−1,−1, 0)= 1 + 2 + 3 + 10 + 7− 9− 10 = 4
であり,y01 は X からとる部分を右に 1ずらしたもの,y10 は下に 1ずらしたもの,y11 は右にも下にも 1ずらしたものとなっている.
竹縄 知之 (海洋大) ニューラルネットワーク 17 / 17














![ディープラーニング(深層学習)Deep Learning 深層学習[1]は,狭い意味では,層の数が多い(深い) ニューラルネットワーク(neural network)をモデルとし](https://static.fdocument.pub/doc/165x107/5ea530d50a2c6709a9411599/fffffffici-deep-learning-c1ioecioeoeii.jpg)



