
使用 Spark 計算 differential expression
22
使用 Spark 計算 Differential Expression Jian-Long Huang 2015/11/26
-
Upload
drake-huang -
Category
Data & Analytics
-
view
304 -
download
5
Transcript of 使用 Spark 計算 differential expression

使用 Spark 計算 Differential Expression
Jian-Long Huang2015/11/26

[分析] 同一個RNA序列檔,可任選其中兩個 conditions 進行 differential analysis (最好能擴展成任選兩個 groups of conditions) 輸出 gene list。
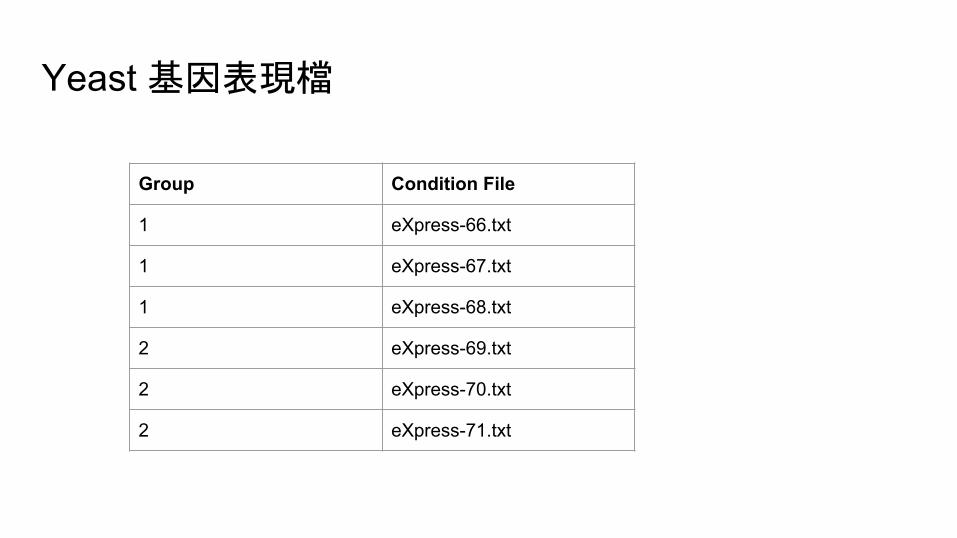
Yeast 基因表現檔
Group Condition File
1 eXpress-66.txt
1 eXpress-67.txt
1 eXpress-68.txt
2 eXpress-69.txt
2 eXpress-70.txt
2 eXpress-71.txt

寫個 script 分析?

程式分析流程
1. 建立 gene name, group, condition 和 expression value 的對應表。
2. 根據每條 gene,計算:
a. c1 = merge(c1-1 to c1-3), c2 = merge(c2-1 to c2-3)
b. de = diff(c1, c2)
3. 輸出符合 de > t1 or de < t2 的 gene。

gene_name group (condition) file_id fpkm
YNL087W 1 66 1.175314e+02
YNL087W 1 67 1.357084e+02
YNL087W 1 68 1.268189e+02
YNL087W 2 69 6.900545e+01
YNL087W 2 70 6.410089e+01
YNL087W 2 71 6.238413e+01

問題?
● 計算速度慢
○ 無法即時查詢
○ 過濾條件隨時更改
● 對記憶體資源掌控差

Apache Spark● 開源叢集運算框架。
● 最初由加州大學柏克萊分校AMPLab所開發,後捐贈 Apache 基金會。
● 使用記憶體內運算技術,將中間結果保存在記憶體內進行分析運算。
● 提供高階 API (Scala, Java, Python and R) 進行程式設計。
● 提供交互式 Scala, Python shell。

Resilient Distributed Dataset (RDD) 彈性分散式資料集
● 一種抽象資料結構,任何資料在 Spark 中都被表示為 RDD● 分散式記憶體,資料分散儲存在多個機器上面。
● 具備高階函數如 filter, map, reduce,可以進行併行操作。
● RDD 建立方法
○ 從已存在 RDD 建立
○ 從文件系統或 HDFS 的文件建立

filter
v1, v2, v3, v4, v5 func(x) => true/false v1, v3, v5

map
v1, v2, v3, v4, v5 func(x) => x’ v1’, v2’, v3’, v4’, v5’

reduceByKey
(k1, v1)(k1, v2)(k1, v3)(k2, v1)(k2, v2)(k3, v1)(k3, v2)
func(x, y) => z(k1, u)(k2, u)(k3, u)

aggregateByKey
(k1, v1)(k1, v2)(k2, v1)(k2, v2)(k3, v1)(k3, v2)
1st: seqOp(zeroValue, y) => znext: seqOp(x, y) => z
combOp(x, y) => z
zeroValue (starting value)
(k1, u)(k2, u)(k3, u)
Combine partitions
Combine values in a partition

reduceByKey vs. aggregateByKey● aggregateByKey 可以設定初始值,且返回值的類型不需要和 RDD 中 value 的
類型一致,但 reduceByKey 返回值類型需要一致。
● 用途:○ reduceByKey 適用於值與值之間計算不需要按順序,如連乘、連加。
○ aggregateByKey 適用於需利用多個值之計算,如計算平均需要 sum 和 count 兩種值。
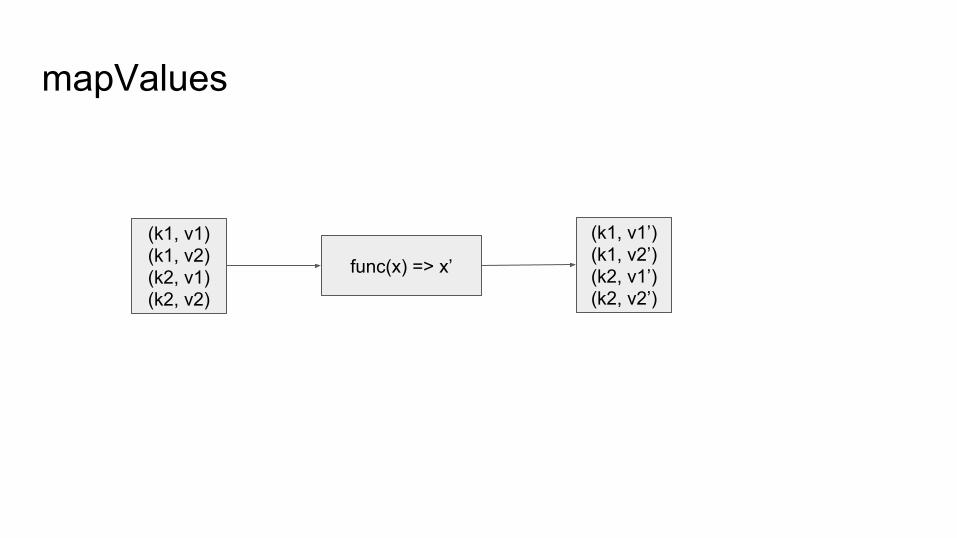
mapValues
(k1, v1)(k1, v2)(k2, v1)(k2, v2)
func(x) => x’
(k1, v1’)(k1, v2’)(k2, v1’)(k2, v2’)

join
(k1, v1)(k1, v2)(k2, v3)(k2, v4)
(k1, u1)(k1, u2)(k2, u3)(k3, u4)
join
(k1, (v1, u1))(k1, (v1, u2))(k1, (v2, u1))(k1, (v2, u2))(k2, (v3, u3))(k2, (v4, u3))

Other RDD Actions● count(): 返回 elements 數量
● first(): 返回第一個 element● take(n): 返回前 n 個 element● collect(): 返回陣列類型值

File
Spark workflow 1: FPKM average in a condition
line1line2line3line4line5
File
File
(YNL087W, 1.175314e+02)(YKR061W, 3.579905e+01)(YOR316C-A, 3.258783e+01)(YGR274C, 2.608256e+02)(YER126C, 2.694234e+01)
filter, map(YNL087W, (380.05, 3))(YKR061W, (78.57, 3))(YOR316C-A, (0.0, 3))(YGR274C, (101.61, 3))(YER126C, (771.36, 3))
aggregateByKey
(YNL087W, 126.68)(YKR061W, 26.19)(YOR316C-A, 0.0)(YGR274C, 33.87)(YER126C, 257.12)
mapValues
計算 FPKM 總和和 condition 數
移除 header,輸出 name-fpkm
pair
計算 FPKM 平均

Spark workflow 2: Differential expression
(YNL087W, 126.68)(YKR061W, 26.19)(YOR316C-A, 0.0)(YGR274C, 33.87)(YER126C, 257.12)
(YNL087W, 77.68)(YKR061W, 31.19)(YOR316C-A, 2.1)(YGR274C, 34.87)(YER126C, 259.12)
join
(YNL087W, (126.68, 77.68))(YKR061W, (26.19, 31.19))(YOR316C-A, (0.0, 2.1))(YGR274C, (33.87, 34.87))(YER126C, (257.12, 559.12))
(YNL087W, 1.63)(YKR061W, 0.83)(YOR316C-A, 0)(YGR274C, 0.97)(YER126C, 0.45)
mapValues(YER126C, 0.45)
filter
計算 differential expression
(fpkm1 / fpkm2)
合併兩個 group移除沒有差異表現的結果

安裝 Spark 和 IPython Notebook● docker-spark● docker run -it -p 8088:8088 -p 8042:8042 -p 8080:8080 -h mr-spark --name
mr-spark -v /home/jlhg/mapreduce:/share sequenceiq/spark:1.5.1 bash
● Container 內建 Python 版本為 2.6,用 pyenv 安裝 Python 2.7
● 安裝 IPython:pip install ipython[all]
● 啟動 IPython Notebook:IPYTHON_OPTS="notebook --ip=mr-spark --port=8080" /usr/local/spark/bin/pyspark
● Web UI: http://<host_ip>:8080

Example scriptspark-de.py: https://gist.github.com/jlhg/56a3d833a7cc4ce3238c
# Put yeast data to HDFS
$ hdfs dfs -put /share/yeast
# Submit spark task
$ spark-submit /share/spark-de.py

參考資料
● Spark Quick Start (Official)● Spark Programming Guide (Official)● Spark 編程指南繁體中文版
● Spark RDD API详解(一) Map和Reduce● How to more efficiently calculate the averages for each KEY in a Pairwise (K,
V) RDD in Apache Spark with Python
● Spark函数讲解:aggregateByKey
● 在Docker上用 IPython 開發 Spark的環境建置


















