
Анализ эффективности выполнения алгоритма...
37
Анализ эффективности выполнения алгоритма параллельной редукции в языке Cray Chapel http://cpct.sibsutis.ru/~apaznikov Пазников Алексей Александрович Институт физики полупроводников им. А.В. Ржанова СО РАН
-
Upload
alexey-paznikov -
Category
Science
-
view
295 -
download
1
Transcript of Анализ эффективности выполнения алгоритма...

Анализ эффективности выполнения
алгоритма параллельной редукции в языке Cray Chapel
http://cpct.sibsutis.ru/~apaznikov
Пазников Алексей АлександровичИнститут физики полупроводников им. А.В. Ржанова СО РАН

2
Глобальное разделённое адресное пространство (PGAS)

3
Параллельная редукция (reduce, reduction)
a1 a2 aDA[1:D] …
a1 a2 aDr = …
a3 a4 a5
a3
2 0A[1:5]
2 0 3r =
1 3 1
1++ + 1+ = 7

4
Все виды параллелизма
Учёт локальности данных
Низкоуровневое и высокоуровневое управление параллелизмом
Интуитивно понятный синтаксис
Язык Cray Chapel

1 use BlockDist;
2
3 proc main {
4 var Space = {1..n, 1..n};
5 var BlockSpace = Space dmapped
6 Block(boundingBox=Space);
7 var BA: [BlockSpace] real;
8
9 forall (i, j) in Space do
10 BA[i, j] = i * 10 + j;
11
12 var sum = + reduce BA;
13
14 writeln(“REDUCE: ”, sum);
15 }5
Пример редукции в Cray Chapel

1 use BlockDist;
2
3 proc main {
4 var Space = {1..n, 1..n};
5 var BlockSpace = Space dmapped
6 Block(boundingBox=Space);
7 var BA: [BlockSpace] real;
8
9 forall (i, j) in Space do
10 BA[i, j] = i * 10 + j;
11
12 var sum = + reduce BA;
13
14 writeln(“REDUCE: ”, sum);
15 }6
Пример редукции в Cray Chapel

1 use BlockDist;
2
3 proc main {
4 var Space = {1..n, 1..n};
5 var BlockSpace = Space dmapped
6 Block(boundingBox=Space);
7 var BA: [BlockSpace] real;
8
9 forall (i, j) in Space do
10 BA[i, j] = i * 10 + j;
11
12 var sum = + reduce BA;
13
14 writeln(“REDUCE: ”, sum);
15 }7
Пример редукции в Cray Chapel

1 use BlockDist;
2
3 proc main {
4 var Space = {1..n, 1..n};
5 var BlockSpace = Space dmapped
6 Block(boundingBox=Space);
7 var BA: [BlockSpace] real;
8
9 forall (i, j) in Space do
10 BA[i, j] = i * 10 + j;
11
12 var sum = + reduce BA;
13
14 writeln(“REDUCE: ”, sum);
15 }8
Пример редукции в Cray Chapel

9
Параллельная редукция (reduce, reduction)

10
Алгоритм редукции DefaultReduce

11
Алгоритм редукции DefaultReduce
Вычислительная трудоёмкость алгоритма DefaultReduce:T = O(|A| / N + N)

12
Алгоритм редукции BlockReduce (I этап)

13
Алгоритм редукции BlockReduce (I этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
1 coforall i in [1, 2, …, N] do // N – число вычислительных узлов
2 on i
3 SPLITDOMAIN(Ai, n) // Разбиение на n блоков – по числу ядер
4 coforall t in [1, 2, …, n] do
5 foreach x in Ait do
6 rit = rit x
7 foreach t in [1, 2…, n] do
8 ri = ri rit

14
Алгоритм редукции BlockReduce (I этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
1 coforall i in [1, 2, …, N] do // N – число вычислительных узлов
2 on i
3 SPLITDOMAIN(Ai, n) // Разбиение на n блоков – по числу ядер
4 coforall t in [1, 2, …, n] do
5 foreach x in Ait do
6 rit = rit x
7 foreach t in [1, 2…, n] do
8 ri = ri rit

15
Алгоритм редукции BlockReduce (I этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
1 coforall i in [1, 2, …, N] do // N – число вычислительных узлов
2 on i
3 SPLITDOMAIN(Ai, n) // Разбиение на n блоков – по числу ядер
4 coforall t in [1, 2, …, n] do
5 foreach x in Ait do
6 rit = rit x
7 foreach t in [1, 2…, n] do
8 ri = ri rit

16
Алгоритм редукции BlockReduce (I этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
1 coforall i in [1, 2, …, N] do // N – число вычислительных узлов
2 on i
3 SPLITDOMAIN(Ai, n) // Разбиение на n блоков – по числу ядер
4 coforall t in [1, 2, …, n] do
5 foreach x in Ait do
6 rit = rit x
7 foreach t in [1, 2…, n] do
8 ri = ri rit

17
Алгоритм редукции BlockReduce (I этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
1 coforall i in [1, 2, …, N] do // N – число вычислительных узлов
2 on i
3 SPLITDOMAIN(Ai, n) // Разбиение на n блоков – по числу ядер
4 coforall t in [1, 2, …, n] do
5 foreach x in Ait do
6 rit = rit x
7 foreach t in [1, 2…, n] do
8 ri = ri rit

18
Алгоритм редукции BlockReduce (I этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
1 coforall i in [1, 2, …, N] do // N – число вычислительных узлов
2 on i
3 SPLITDOMAIN(Ai, n) // Разбиение на n блоков – по числу ядер
4 coforall t in [1, 2, …, n] do
5 foreach x in Ait do
6 rit = rit x
7 foreach t in [1, 2…, n] do
8 ri = ri rit

…
19
Алгоритм редукции BlockReduce (II этап)
a1 a2A[1:D] …a3 a4 a5
r12 r34 r56
a6
r
r
1234
BARRIER
BARRIER
r5678
a7 a8
r78 …
…

20
Алгоритм редукции BlockReduce (II этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
…
9 while N > 1 do
10 while i + 1 < N do
11 begin
12 on ri
13 ri = ri ri + 1
14 i = i + 2
15 BARRIER([1, 2, …, N]) // Барьерная синхронизация потоков
16 REFRESH(N) // Обновление числа N ВУ
17 return r

21
Алгоритм редукции BlockReduce (II этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
…
9 while N > 1 do
10 while i + 1 < N do
11 begin
12 on ri
13 ri = ri ri + 1
14 i = i + 2
15 BARRIER([1, 2, …, N]) // Барьерная синхронизация потоков
16 REFRESH(N) // Обновление числа N ВУ
17 return r

22
Алгоритм редукции BlockReduce (II этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
…
9 while N > 1 do
10 while i + 1 < N do
11 begin
12 on ri
13 ri = ri ri + 1
14 i = i + 2
15 BARRIER([1, 2, …, N]) // Барьерная синхронизация потоков
16 REFRESH(N) // Обновление числа N ВУ
17 return r

23
Алгоритм редукции BlockReduce (II этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
…
9 while N > 1 do
10 while i + 1 < N do
11 begin
12 on ri
13 ri = ri ri + 1
14 i = i + 2
15 BARRIER([1, 2, …, N]) // Барьерная синхронизация потоков
16 REFRESH(N) // Обновление числа N ВУ
17 return r

24
Алгоритм редукции BlockReduce (II этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
…
9 while N > 1 do
10 while i + 1 < N do
11 begin
12 on ri
13 ri = ri ri + 1
14 i = i + 2
15 BARRIER([1, 2, …, N]) // Барьерная синхронизация потоков
16 REFRESH(N) // Обновление числа N ВУ
17 return r

25
Алгоритм редукции BlockReduce (II этап)
Входные данные: A[1:D] – распределённый массив, – ассоциативная операция редукции.
Выходные данные: r – результат применения редукции для A.
…
9 while N > 1 do
10 while i + 1 < N do
11 begin
12 on ri
13 ri = ri ri + 1
14 i = i + 2
15 BARRIER([1, 2, …, N]) // Барьерная синхронизация потоков
16 REFRESH(N) // Обновление числа N ВУ
17 return r
Вычислительная трудоёмкость алгоритма BlockReduce:
T = O(|A| / N + log(N))

compiler/AST/build.cpp
– вызов BlockReduce при генерации AST-дерева
modules/dists/BlockDist.chpl
modules/internal/ChapelArray.chpl
– функции получения локальной области
распределённого массива
modules/internal/ChapelReduceContr.chpl
modules/internal/FastReduce.chpl
– реализация алгоритма BlockReduce
https://bitbucket.org/apaznikov/chapel
Программная реализация
26

t, c
100 операций редукции массива A[1:D], 2 узла кластера Jet
27
Результаты экспериментов
D
BlockReduce DefReduce

28
Результаты экспериментов
100 операций редукции массива A[1:D], 4 узла кластера Jet
t, c
D
BlockReduce DefReduce
29
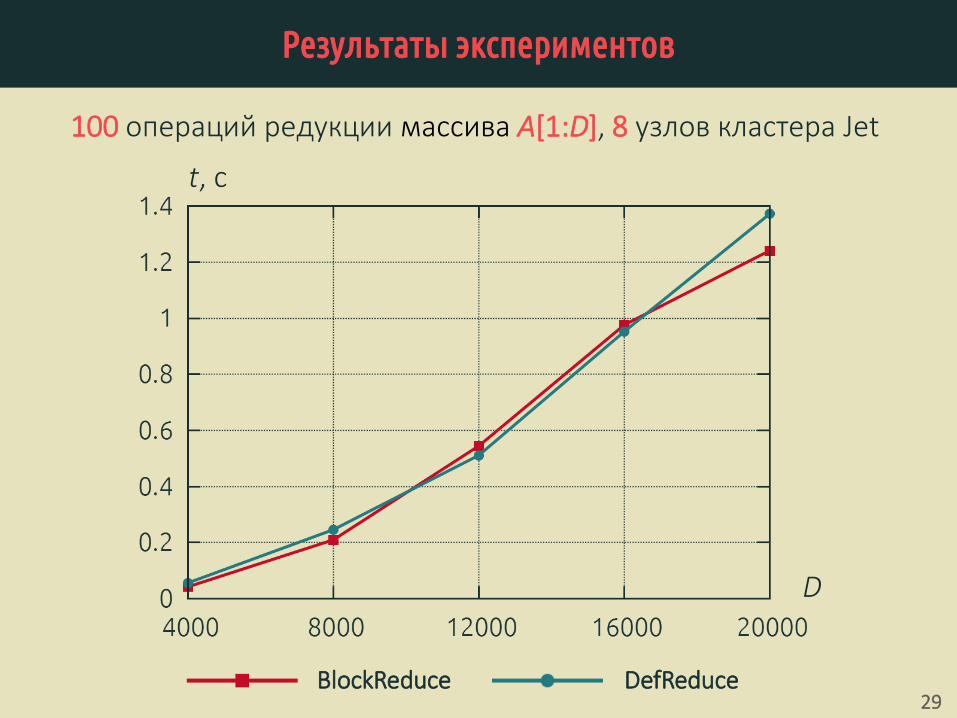
Результаты экспериментов
100 операций редукции массива A[1:D], 8 узлов кластера Jet
t, c
D
BlockReduce DefReduce

Программа miniMD, N узлов кластера Jet
30
Результаты экспериментов
t, c
N
BlockReduce DefReduce

31
Результаты экспериментов
Программа ptrans, N узлов кластера Jet
t, c
N
BlockReduce DefReduce

32
Предложен алгоритм редукции
BlockReduce в PGAS-языках. Алгоритм
реализован в Cray Chapel.
Сокращение времени выполнения
редукции на 5-10% на некотором
количестве узлов.
Получен метод технической реализации
операции редукции.
Результаты

http://cpct.sibsutis.ru ЦПВТ СибГУТИ
Спасибо за внимание!
[email protected] Пазников А.А.
https://bitbucket.org/apaznikov/chapel

Количество операций get
Но
мер
узл
а
Номер узла
Ко
ли
чест
во о
пер
аци
й
8
7
6
5
4
3
2
1
1 2 3 4 5 6 7 8
34
Результаты профилирования DefaultReduce
50
40
30
20
10
0

35
Результаты профилирования DefaultReduce
Количество операций put
Но
мер
узл
а
Номер узла
Ко
ли
чест
во о
пер
аци
й
8
7
6
5
4
3
2
1
1 2 3 4 5 6 7 8
12000
10000
8000
6000
4000
2000
0

36
Результаты профилирования BlockReduce
Количество операций get
Но
мер
узл
а
Номер узла
Ко
ли
чест
во о
пер
аци
й
8
7
6
5
4
3
2
1
1 2 3 4 5 6 7 8
80
70
60
50
40
30
20
10
0

37
Результаты профилирования BlockReduce
Количество операций put
Но
мер
узл
а
Номер узла
8
7
6
5
4
3
2
1
1 2 3 4 5 6 7 8
12000
10000
8000
6000
4000
2000
0
Ко
ли
чест
во о
пер
аци
й


















