
Data Mining 1 Mining...ถ้าไม่มีโครงสร้างจะเป็น text-mining, web-mining, image-mining
Upload
tsvetanka-georgievaCategory
view
116download
1
ДОБИВАНЕ НА АСОЦИАТИВНИ ПРАВИЛА
(ASSOCIATION RULE MINING)
доц. д-р Цветанка Георгиева-Трифонова

СЪДЪРЖАНИЕ Същност на добиването на асоциативни правила
Параметрите поддръжка (support) и сигурност (confidence)
Дефиниция на асоциативно правило
Задача за добиване на асоциативни правила
Често срещани набори от обкети
Априорно свойство
Априорен алгоритъм
Фактори, оказващи влияние върху сложността
Подобряване на ефективността на априорния алгоритъм
FP-growth алгоритъм
Откриване на асоциативни правила и OLAP технология
Базирани на ограничения асоциативни правила
Мерки на значимостта и полезността на асоциативни
правила 22Цветанка Георгиева Моделиране на информационни системи

СЪЩНОСТ НА ДОБИВАНЕТО НА АСОЦИАТИВНИ
ПРАВИЛА
3
Анализиране на закупените едновременно продукти (market basket analysis) Дадена е база от данни за продажби и за всяка
осъществена продажба се поддържа списък с продадените артикули;
Задачата е да се намерят правилата, които съпоставят множество от артикули, появяващи се в един и същи списък с друго множество от артикули.
Пример 30% от всички покупки от store.bg съдържат едновременно
"Моята първа енциклопедия за Космоса” и „История на България в приказки и разкази”;
65% от покупките от store.bg, които включват „Моята първа енциклопедия за Космоса”, включват също „История на България в приказки и разкази”.
R. Agrawal, T. Imielinski, A. Swami, Mining Association Rules between Sets of Items
in Large Databases, In Proceedings of the ACM SIGMOD, 1993
33Цветанка Георгиева Моделиране на информационни системи

СЪЩНОСТ НА ДОБИВАНЕТО НА АСОЦИАТИВНИ
ПРАВИЛА (2)
4
Търсене на шаблони, наречени асоциативни правила във вида:
Body ⇒ Head [support, confidence]
Body: характеристика на x, т.е. на трансакция, човек;
Head: характеристика, за която е вероятно да следва от Body;
support, confidence: мерки за валидност на правилото.
Примери
покупка(x, “мляко”) ⇒ покупка(x, “хляб”) [0.5%, 60%]
студент(x, “КН”) ∧ изпит(x, “БД”) ⇒ оценка(x, “отличен”) [1%, 75%]
Проблем
Дадени са:
(1) база от данни от трансакции;
(2) всяка трансакция е списък от обекти (items).
Да се намерят: всички правила, които съпоставят наличието на един набор от обекти с наличието на друг набор от обекти.
44Цветанка Георгиева Моделиране на информационни системи

ПОДДРЪЖКА И СИГУРНОСТ
5555Цветанка Георгиева Моделиране на информационни системи

ПОДДРЪЖКА И СИГУРНОСТ: ВЪЗМОЖНИ СИТУАЦИИ
6
Допускаме, че поддръжката на AB надвишава предварително
зададената минимална стойност;
TA е множеството от трансакции, които съдържат набора от обекти A.
6666Цветанка Георгиева Моделиране на информационни системи

ДЕФИНИЦИЯ НА АСОЦИАТИВНО ПРАВИЛО
7
Терминология и означения
Множество от всички обекти I, подмножество на I се нарича
набор от обекти (itemset);
Трансакция T (tid, A), A ⊆ I набор от обекти, идентификатор на
трансакция tid;
Множество D от всички трансакции (база от данни), трансакция
t∈D.
Дефиниция на асоциативно правило A ⇒ B [s, c]
A, B са набори от обекти (A, B ⊆ I);
A ∩ B е празното множество;
поддръжка s = P(A∪B): вероятността трансакция да съдържа
A∪B;
сигурност c = P(B|A): условната вероятност трансакция, която
съдържа A, да съдържа също B.
Примери
Обекти: I = {мляко, хляб, яйца, ябълка, банани}
Трансакция: (200, {мляко, хляб, яйца})
Асоциативно правило: {мляко} ⇒ {хляб} [0.50, 0.66]7777Цветанка Георгиева Моделиране на информационни системи

АСОЦИАТИВНО ПРАВИЛО – ОСНОВНИ ПОНЯТИЯ
Нека I = {i1, i2, …, in} е множеството от изследваните обекти
(елементи; items).
Пример за обекти са учебните предмети, изучавани от
студентите:
I = {Програмиране, Линейна алгебра, Аналитична
геометрия, Дискретна математика, Бази от данни,
Компютърна графика, Числени методи, Операционни
системи, Информационни системи}
Трансакции
набори от обекти T = {ij | ij I}, принадлежащи на I,
съхранявани в базата от данни и подлежащи на анализ.
Нека D = {T1, T2, …, Tm} е множеството от трансакциите,
информацията за които е достъпна за анализ.
88Цветанка Георгиева Моделиране на информационни системи

Примери за такива трансакции, съхранявани в StudentsDB
множествата от учебните предмети, необходими преди
изучаването на един и същи учебен предмет:
T1 = {Програмиране, Линейна алгебра, Аналитична геометрия};
T2 = {Програмиране, Бази от данни};
T3 = {Линейна алгебра, Аналитична геометрия, Дискретна
математика}.
множеството D може да бъде представено във вид на таблица:
99Цветанка Георгиева Моделиране на информационни системи
Идентификатор на трансакция Наименование на учебен предмет
1 Програмиране
1 Линейна алгебра
1 Аналитична геометрия
2 Програмиране
2 Бази от данни
3 Линейна алгебра
3 Аналитична геометрия
3 Дискретна математика

АСОЦИАТИВНО ПРАВИЛО – ОСНОВНИ ПОНЯТИЯ (2)
Множеството от трансакции, в които е включено набора от
обекти F, означаваме с
DF = {Tl | F Tl; l = 1, …, m}, където DF D.
Пример
DПрограмиране = {{Програмиране, Линейна алгебра,
Аналитична геометрия}, {Програмиране, Бази от данни}} –
множеството от трансакциите, съдържащи обекта
„Програмиране”.
1010Цветанка Георгиева Моделиране на информационни системи

АСОЦИАТИВНО ПРАВИЛО – ОСНОВНИ ПОНЯТИЯ (3)
Поддръжка supp(F) на набора от обекти F
отношението на броя на трансакциите, в които е включено
множеството F, към общия брой трансакции;
supp(F) =
Примери
supp({Програмиране}) = 0.6667, тъй като множеството
{Програмиране} участва в две трансакции, общият брой
трансакции е 3.
supp({Линейна алгебра, Аналитична геометрия}) = 0.6667.
1111Цветанка Георгиева Моделиране на информационни системи
||
||
D
DF

АСОЦИАТИВНО ПРАВИЛО – ОСНОВНИ ПОНЯТИЯ (4)
При откриване на асоциативни правила се задава
минимална стойност на поддръжката на търсените
множества от обекти suppmin.
Казваме, че даден набор от обекти F е често срещан
(frequent itemset), ако стойността на неговата поддръжка е
по-голяма от зададената минимална поддръжка,
т.е. supp(F) > suppmin.
Пример
Нека suppmin = 0.5, тогава наборът от обекти {Линейна
алгебра, Аналитична геометрия} е често срещан.
1212Цветанка Георгиева Моделиране на информационни системи

АСОЦИАТИВНО ПРАВИЛО – ОСНОВНИ ПОНЯТИЯ (5)
Едно асоциативно правило (association rule) е импликация от
вида X→Y, където X, Y I са набори от обекти и X∩Y = .
Множеството X се нарича предпоставка; Y – следствие;
Поддръжката supp(X → Y) е съотношението (в проценти) на
броя на трансакциите в D, които съдържат X Y към общия
брой на трансакциите, т.е.
supp(X → Y) = supp(X Y) =
Сигурността conf(X → Y) е съотношението (в проценти) на
броя на трансакциите в D, които съдържат X Y към броя на
трансакциите, които съдържат X, т.е.
conf(X → Y) = =
1313Цветанка Георгиева Моделиране на информационни системи
||
||
D
D YX
||
||
X
YX
D
D
)(
)(
Xsupp
YXsupp

АСОЦИАТИВНО ПРАВИЛО – ОСНОВНИ ПОНЯТИЯ (6)
Примери
supp({Линейна алгебра} → {Аналитична геометрия}) =
supp({Линейна алгебра, Аналитична геометрия}) = 0.6667.
учебните предмети, изискващи предварително изучаване
на линейна алгебра и аналитична геометрия представляват
66.67% от всички трансакции, включени в изследването.
conf({Линейна алгебра} → {Аналитична геометрия}) = 1 =
всички учебни предмети (т.е. 100%), които изискват
предварително изучаване на линейна алгебра, изискват и
предварително изучаване на аналитична геометрия.
1414Цветанка Георгиева Моделиране на информационни системи
})({
}),({
алгебраЛинейнаsupp
геометрияАналитичнаалгебраЛинейнаsupp

ЗАДАЧА ЗА ДОБИВАНЕ НА АСОЦИАТИВНИ ПРАВИЛА
Задачата за добиване на асоциативни правила е:
Да се генерират всички асоциативни правила, които имат
стойности на параметрите поддръжка и сигурност,
надхвърлящи предварително зададени съответно
минимална поддръжка suppmin и минимална сигурност
confmin.
1515Цветанка Георгиева Моделиране на информационни системи

ЗАДАЧА ЗА ДОБИВАНЕ НА АСОЦИАТИВНИ ПРАВИЛА (2)
Задачата за откриване на асоциативни правила се
подразделя на две подзадачи:
Да се намери множеството L от всички набори от обекти
със стойност на параметъра поддръжка, надвишаваща
минималната поддръжка suppmin, т.е. така наречените
често срещани набори от обекти.
Да се използват често срещаните набори от обекти, за да
се генерират търсените асоциативни правила.
За всяко X L се проверява сигурността на всички
асоциативни правила X \ Y → Y, Y X, Y ≠ и се
отстраняват тези, които не достигат confmin.
1616Цветанка Георгиева Моделиране на информационни системи
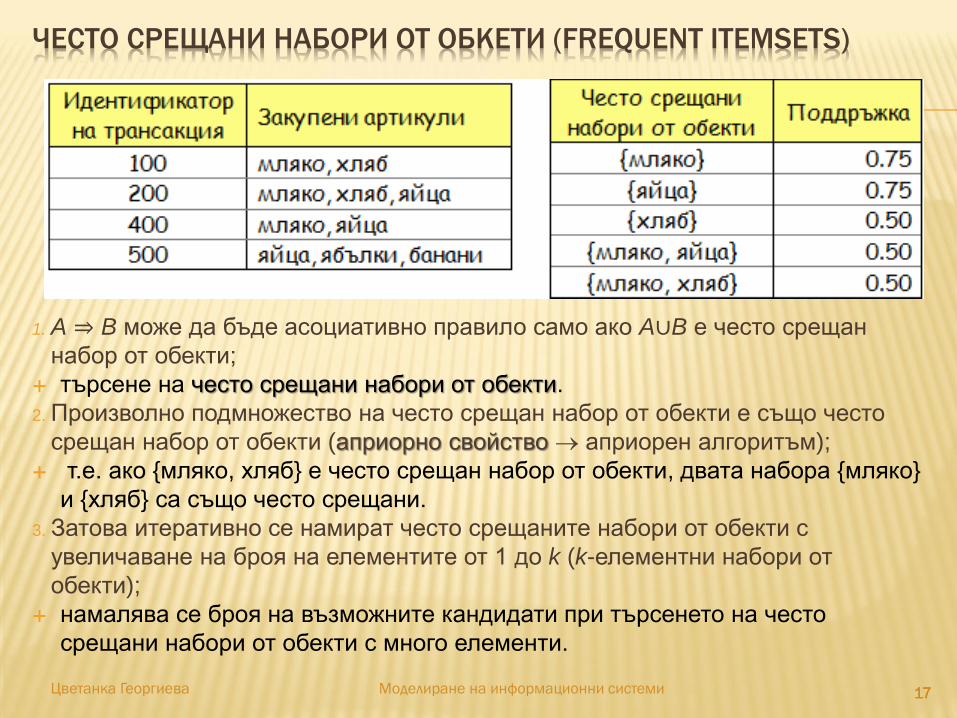
ЧЕСТО СРЕЩАНИ НАБОРИ ОТ ОБКЕТИ (FREQUENT ITEMSETS)
17
1. A ⇒ B може да бъде асоциативно правило само ако A∪B е често срещан
набор от обекти;
търсене на често срещани набори от обекти.
2. Произволно подмножество на често срещан набор от обекти е също често
срещан набор от обекти (априорно свойство априорен алгоритъм);
т.е. ако {мляко, хляб} е често срещан набор от обекти, двата набора {мляко}
и {хляб} са също често срещани.
3. Затова итеративно се намират често срещаните набори от обекти с
увеличаване на броя на елементите от 1 до k (k-елементни набори от
обекти);
намалява се броя на възможните кандидати при търсенето на често
срещани набори от обекти с много елементи.
17171717Цветанка Георгиева Моделиране на информационни системи
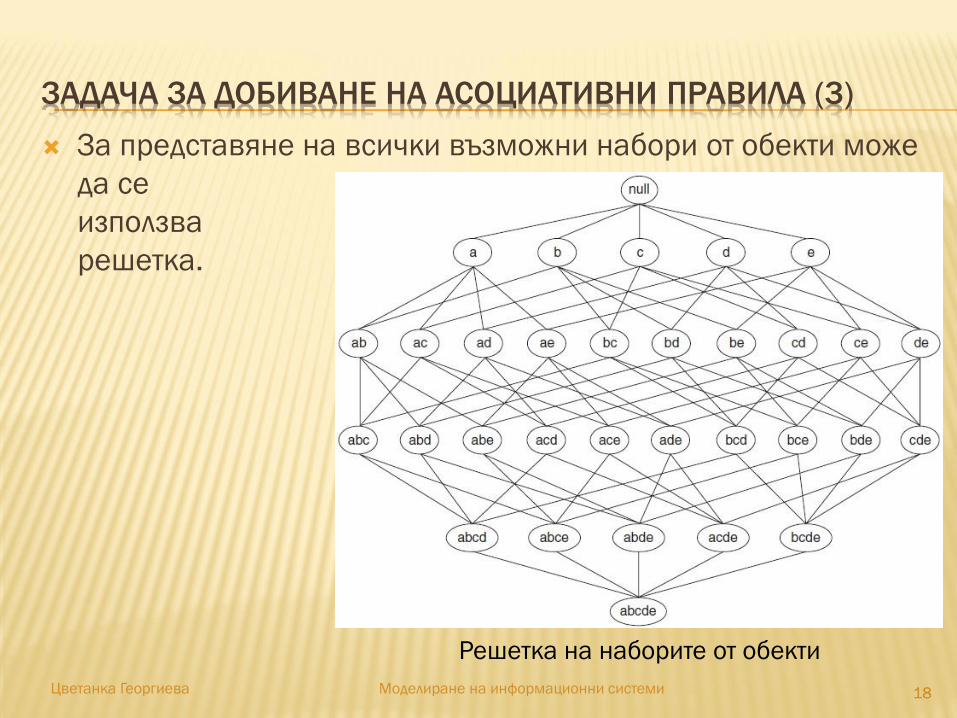
ЗАДАЧА ЗА ДОБИВАНЕ НА АСОЦИАТИВНИ ПРАВИЛА (3)
За представяне на всички възможни набори от обекти може
да се
използва
решетка.
1818Цветанка Георгиева Моделиране на информационни системи
Решетка на наборите от обекти

ИЗПОЛЗВАНЕ НА АПРИОРНОТО СВОЙСТВО
19
Ако са ни известни често срещаните (k-1)-елементни набори от обекти,
кои са кандидатите за често срещани k-елементни набори от обекти?
Ако са ни известни всички често срещани (k-1)-елементни набори от
обекти Lk-1, тогава можем да изградим множество от кандидати Ck за често
срещани k-елементни набори от обекти чрез съединяване на всеки два
често срещани (k-1)-елементни набора от обекти, които се различават по
точно един елемент: стъпка за съединяване (join step) ;
само тези набори от обекти биха могли да бъдат често срещани k-
елементни набори от обекти.
19191919Цветанка Георгиева Моделиране на информационни системи

АЛГОРИТЪМ ЗА ГЕНЕРИРАНЕ НА КАНДИДАТИ
20
Предполагаме, че елементите в Lk-1 са подредени в нарастващ ред,
тогава Ck се създава чрез SQL израза:INSERT INTO Ck (item1, …, itemk)
SELECT p.item1, p.item2, …, p.itemk-1, q.itemk-1FROM Lk-1 p, Lk-1 q
WHERE p.item1=q.item1 AND … AND
p.itemk-2=q.itemk-2 AND p.itemk-1 < q.itemk-1
2020202020Цветанка Георгиева Моделиране на информационни системи
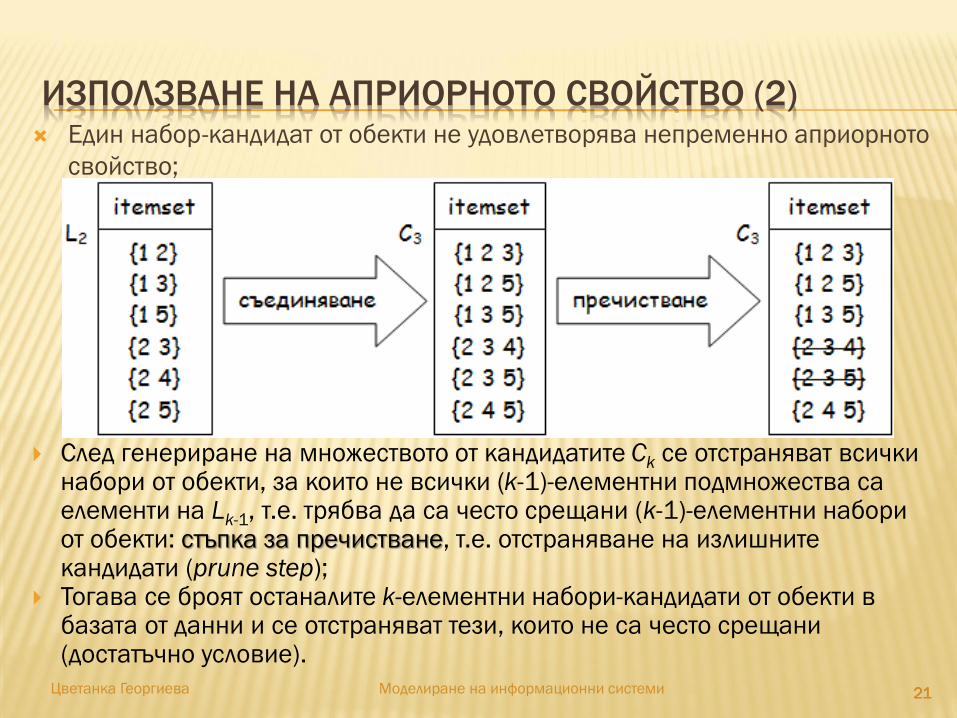
ИЗПОЛЗВАНЕ НА АПРИОРНОТО СВОЙСТВО (2)
21
Един набор-кандидат от обекти не удовлетворява непременно априорното
свойство;
След генериране на множеството от кандидатите Ck се отстраняват всички набори от обекти, за които не всички (k-1)-елементни подмножества са елементи на Lk-1, т.е. трябва да са често срещани (k-1)-елементни набори от обекти: стъпка за пречистване, т.е. отстраняване на излишните кандидати (prune step);
Тогава се броят останалите k-елементни набори-кандидати от обекти в базата от данни и се отстраняват тези, които не са често срещани (достатъчно условие).
2121212121Цветанка Георгиева Моделиране на информационни системи

АПРИОРЕН АЛГОРИТЪМ (ALGORITHM APRIORI)
Предложен е през 1994 година от Ракеш Агравал (Rakesh
Agrawal) и Рамакришнан Срикант (Ramakrishnan Srikant);
Основава се на априорното свойство (apriori property):
всяко непразно подмножество на често срещан набор от
обекти е също често срещан набор от обекти.
2222Цветанка Георгиева Моделиране на информационни системи

ГЕНЕРИРАНЕ НА ЧЕСТО СРЕЩАНИ НАБОРИ ОТ ОБЕКТИ:
АПРИОРНИЯТ АЛГОРИТЪМ
23
k:=1; Lk := {често срещани елементи в D};
Докато Lk !=∅{
Ck+1 := кандидати, генерирани от Lk чрез съединяване и пречистване;
За всяка трансакция T в базата от данни
се увеличава с 1 броят на всички набори-кандидати от
обекти в Ck+1, които се съдържат в T;
Lk+1 := кандидати в Ck+1 с min_support;
k := k+1; }
Извежда се ∪k Lk
2323232323Цветанка Георгиева Моделиране на информационни системи
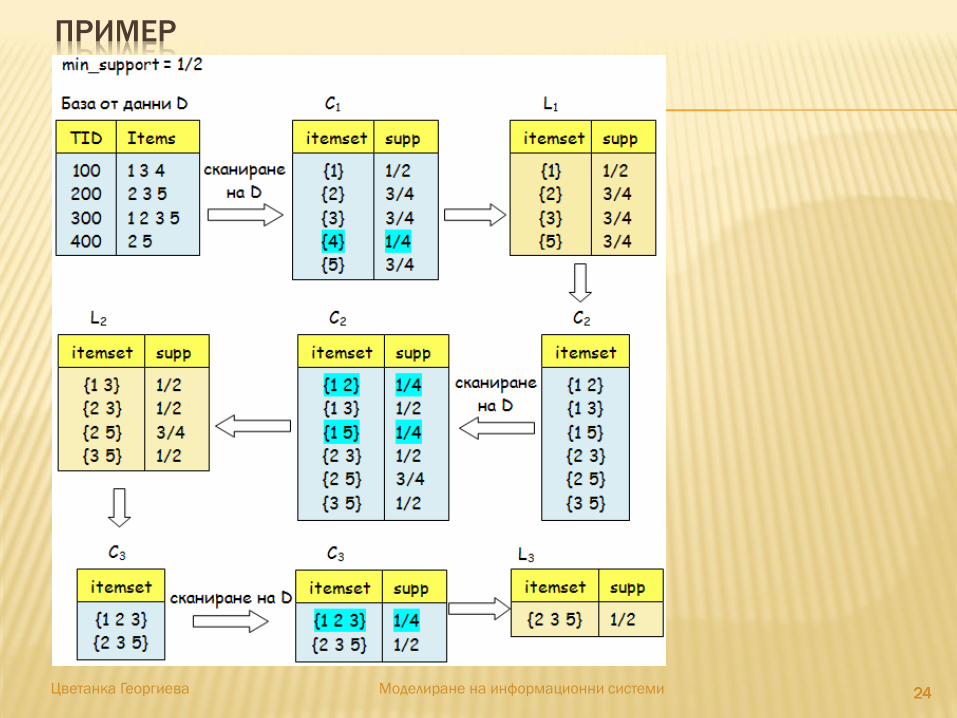
ПРИМЕР
242424242424Цветанка Георгиева Моделиране на информационни системи

ГЕНЕРИРАНЕ НА АСОЦИАТИВНИ ПРАВИЛА ОТ ЧЕСТО
СРЕЩАНИ НАБОРИ ОТ ОБЕКТИ
25
За всеки често срещан набор от обекти L се генерират всички
непразни подмножества S
За всяко непразно подмножество S се
извеждат правилата S ⇒ L\S, ако
(min_conf е минимална сигурност),
тъй като сигурността confidence(A ⇒ B) = P(B|A) =
min_conf)support(
)support(
S
L
min_conf)support(
)support(
A
BA
2525252525Цветанка Георгиева Моделиране на информационни системи

ПРИМЕР
26
Предполагаме, че минималната сигурност е min_conf =0.75.
L={2, 3, 5}, S={3, 5}, confidence(S ⇒ L\S)= support(L)/ support (S)=2/2,
затова {3, 5} ⇒ {2} е валидно асоциативно правило.
L={2, 3, 5}, S={2}, confidence(S ⇒ L\S)= support (L)/ support(S)=2/3,
затова {2} ⇒ {3, 5} не е валидно асоциативно правило.
2626262626Цветанка Георгиева Моделиране на информационни системи

АПРИОРЕН АЛГОРИТЪМ – ПРИМЕР
Нека suppmin = 0.3.
L1 = {Програмиране, Линейна
алгебра, Аналитична геометрия,
Дискретна математика, Бази от
данни}.
supp({Линейна алгебра}) = 2/3
= 0.667.
supp({Аналитична геометрия}) =
2/3 = 0.667,
supp({Дискретна математика}) =
1/3 = 0.333,
supp({Бази от данни}) = 1/3 =
0.333
3030Цветанка Георгиева Моделиране на информационни системи
Номер на
трансакция
Наименование на
учебен предмет
1 Програмиране
1 Линейна алгебра
1 Аналитична
геометрия
2 Програмиране
2 Бази от данни
3 Линейна алгебра
3 Аналитична
геометрия
3 Дискретна
математика
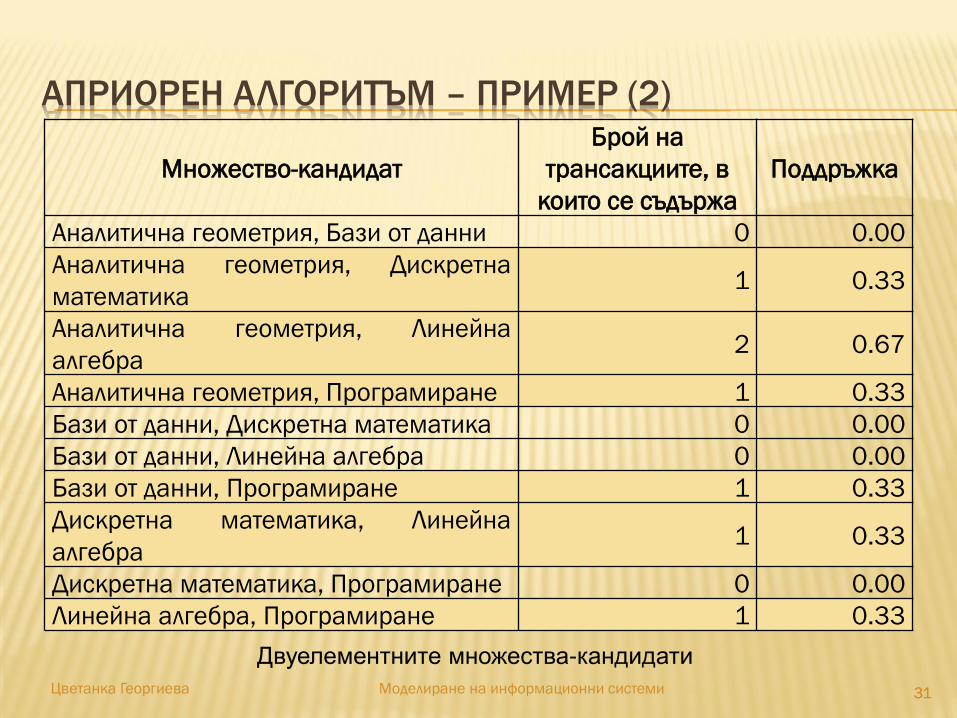
АПРИОРЕН АЛГОРИТЪМ – ПРИМЕР (2)
Множество-кандидат
Брой на
трансакциите, в
които се съдържа
Поддръжка
Аналитична геометрия, Бази от данни 0 0.00
Аналитична геометрия, Дискретна
математика1 0.33
Аналитична геометрия, Линейна
алгебра2 0.67
Аналитична геометрия, Програмиране 1 0.33
Бази от данни, Дискретна математика 0 0.00
Бази от данни, Линейна алгебра 0 0.00
Бази от данни, Програмиране 1 0.33
Дискретна математика, Линейна
алгебра1 0.33
Дискретна математика, Програмиране 0 0.00
Линейна алгебра, Програмиране 1 0.33
3131Цветанка Георгиева Моделиране на информационни системи
Двуелементните множества-кандидати

АПРИОРЕН АЛГОРИТЪМ – ПРИМЕР (3)
Тогава при suppmin = 0.3 за множеството от двуелементните
често срещани набори от обекти се получава:
L2 = {{Аналитична геометрия, Дискретна математика},
{Аналитична геометрия, Линейна алгебра}, {Аналитична
геометрия, Програмиране}, {Бази от данни, Програмиране},
{Дискретна математика, Линейна алгебра}, {Линейна
алгебра, Програмиране}}.
Образува се множество от триелементните множества-
кандидати
C3 = {{Аналитична геометрия, Дискретна математика, Линейна
алгебра}, {Аналитична геометрия, Дискретна математика,
Програмиране}, {Аналитична геометрия, Линейна алгебра,
Програмиране}}.
3232Цветанка Георгиева Моделиране на информационни системи

АПРИОРЕН АЛГОРИТЪМ – ПРИМЕР (4)
Множество-кандидат
Брой на
трансакциите, в
които се съдържа
Поддръжка
Аналитична геометрия,
Дискретна математика,
Линейна алгебра
1 0.33
Аналитична геометрия,
Дискретна математика,
Програмиране
0 0
Аналитична геометрия,
Линейна алгебра,
Програмиране
1 0.33
3333Цветанка Георгиева Моделиране на информационни системи
Триелементните множества-кандидати
L3 = {{Аналитична геометрия, Дискретна математика, Линейна
алгебра}, {Аналитична геометрия, Линейна алгебра,
Програмиране}}

АПРИОРЕН АЛГОРИТЪМ – ПРИМЕР (5)
C4 = {{Аналитична геометрия, Дискретна математика, Линейна
алгебра, Програмиране}} - никоя трансакция не го съдържа;
L4 = и алгоритъмът приключва изпълнението си;
Резултатът от изпълнението на алгоритъма е множеството
L = L1 L2 L3 = { {Програмиране}, {Линейна алгебра},
{Аналитична геометрия}, {Дискретна математика}, {Бази от данни},
{Аналитична геометрия, Дискретна математика}, {Аналитична
геометрия, Линейна алгебра}, {Аналитична геометрия,
Програмиране}, {Бази от данни, Програмиране}, {Дискретна
математика, Линейна алгебра}, {Линейна алгебра,
Програмиране}, {Аналитична геометрия, Дискретна математика,
Линейна алгебра}, {Аналитична геометрия, Линейна алгебра,
Програмиране} }.
3434Цветанка Георгиева Моделиране на информационни системи

АПРИОРЕН АЛГОРИТЪМ – ПРИМЕР (6)
Генерирането на асоциативните правила се извършава, като
се използват намерените често срещаните набори от обекти.
Ако X е често срещан набор от обекти, то е необходимо да се
намерят всички негови непразни подмножества Y (Y X, Y ≠
) и да се провери дали сигурността на асоциативното
правило X \ Y → Y надхвърля минималната confmin.
Пример
От често срещания набор от обекти
{Аналитична геометрия, Дискретна математика} се
получават правилата
{Аналитична геометрия} → {Дискретна математика} и
{Дискретна математика} → {Аналитична геометрия}.
3535Цветанка Георгиева Моделиране на информационни системи

АПРИОРЕН АЛГОРИТЪМ – ПРИМЕР (7)
conf({Аналитична геометрия} → {Дискретна математика}) = 0.5
conf({Дискретна математика} → {Аналитична геометрия}) = 1
Ако предварително зададената минимална стойност на
параметъра сигурност е 0.4, то и двете правила я надхвърля и
трябва да бъдат включени в крайния резултат.
По аналогичен начин се получават и останалите правила.
3636Цветанка Георгиева Моделиране на информационни системи
})({
}),({
геометрияАналитичнаsupp
математикаДискретна геометрияАналитичнаsupp
})({
}),({
математикаДискретна supp
геометрияАналитичнаматематикаДискретна supp

ФАКТОРИ, ОКАЗВАЩИ ВЛИЯНИЕ ВЪРХУ
СЛОЖНОСТТА
37
Изборът на минимална стойност на поддръжката По-малка стойност на минималната поддръжка води до
получаване на повече често срещани набори от обекти;
Това може да увеличи броя на кандидатите и на максималната дължина на често срещаните набори от обекти.
Размерността на набора от данни, т.е. броя на обектите Необходимо е повече място за съхраняване на поддръжката на
всеки обект;
Ако броят на често срещаните обекти също е голям, ще се увеличи времето за изчисляване и входно-изходни операции.
Размерът на базата от данни Тъй като априорният алгоритъм прави множество сканирания,
времето за изпълнение на алгоритъма може да се увеличи при нарастване на броя на трансакциите.
Средният брой на обектите в трансакция Може да увеличи максималната дължина на често срещаните
набори от обекти.
3737373737Цветанка Георгиева Моделиране на информационни системи

ПОДОБРЯВАНЕ НА ЕФЕКТИВНОСТТА НА АПРИОРНИЯ
АЛГОРИТЪМ
38
Намаляване на трансакциите Трансакция, която не съдържа нито един често срещан k-
елементен набор от обекти, е безполезна при следващите сканирания.
Разделяне (partitioning) Произволен набор от обекти, който е потенциално често
срещан в базата от данни, трябва да бъде често срещан в поне едно от подразделенията на базата от данни [A. Savasere, E. Omiecinski, S. Navathe, An effcient algorithm for mining association rules in large databases, In 21st VLDB Conf., 1995].
Семплиране (sampling) Избират се шаблони от базата от данни и се търсят често
срещани набори от данни в извадка от база от данни, като се използва съответно по-ниска минимална стойност на поддръжката [H. Toivonen, Sampling large databases for association rules, In 22nd VLDB Conf., 1996].
3838383838Цветанка Георгиева Моделиране на информационни системи

ПОДОБРЯВАНЕ НА ЕФЕКТИВНОСТТА НА АПРИОРНИЯ
АЛГОРИТЪМ (2)
39
Паралелно изчисляване (parallel computing) Разделят се кандидатите, както и базата от данни за обработка
от различни процесори [R. Agrawal, J. C. Shafer, Parallel Mining of Association Rules, IEEE Trans. on Knowledge and Data Eng., 1996].
Хеш таблица (hash table) Намалява се размерът на множеството от кандидатите чрез
филтриране на k-елементните набори от обекти от хеш-таблицата, ако хеш-записът няма минимална поддръжка [J. S. Park, M.S. Chen, P.S. Yu, An Effective Hash-Based Algorithm for Mining Association Rules, ACM SIGMOD Int. Conf. on Management of Data, 1995].
Дървовидни структури от данни
Използва се дърво на често срещаните шаблони и базата от данни се сканира само два пъти, за да се намерят често срещаните шаблони без генериране на кандидати [J. Han, J Pei, Mining frequent patterns by pattern growth: methodology and implications, ACM SIGKDD Explorations Newsletter, 2000].
3939393939Цветанка Георгиева Моделиране на информационни системи

ХЕШ ТАБЛИЦА
40
Хеш таблица H2 за двуелементните набори-кандидати от обекти;
Тази хеш таблица е получена при сканиране на трансакциите от горната таблица, докато се определя L1;
Ако минималният брой е 3, тогава наборите от обекти в запис 0, 1, 3, 4 не могат да бъдат често срещани и затова не се включват в C2.
Например, h{i1,i2} = (1 х 10 + 2) mod 7 = 12 mod 7 = 5.
404040404040Цветанка Георгиева Моделиране на информационни системи
Номер на
трансакция
Набори от обекти
1 i1, i2, i5
2 i2, i4
3 i2, i3
4 i1, i2, i4
5 i1, i3
6 i2, i3
7 i1, i3
8 i1, i2, i3, i5
9 i1, i2, i3
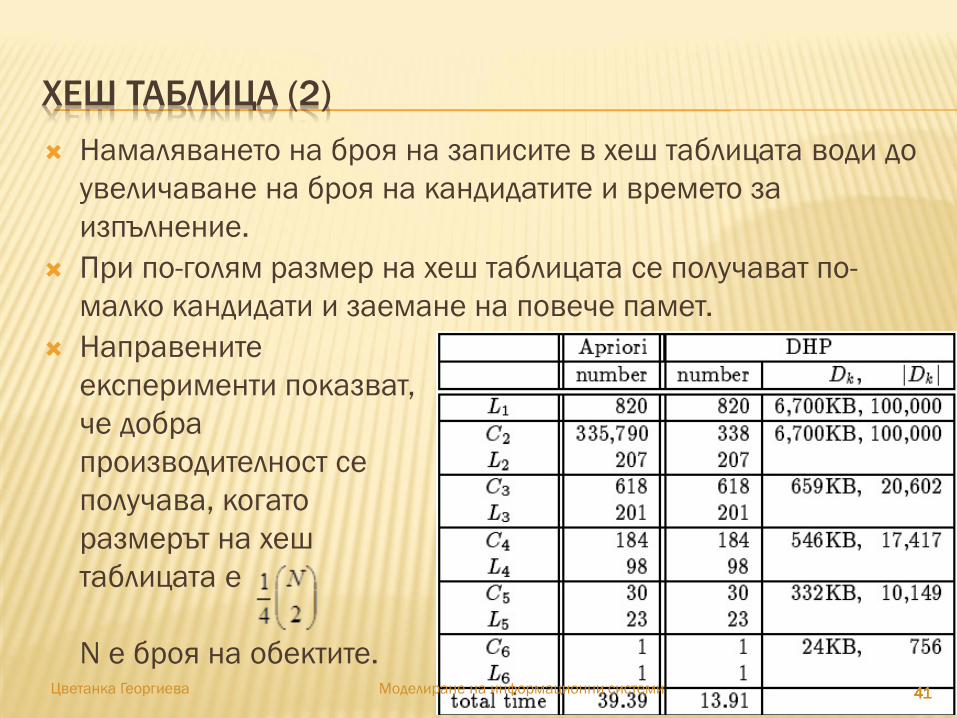
ХЕШ ТАБЛИЦА (2)
41
Намаляването на броя на записите в хеш таблицата води до
увеличаване на броя на кандидатите и времето за
изпълнение.
При по-голям размер на хеш таблицата се получават по-
малко кандидати и заемане на повече памет.
Направените
експерименти показват,
че добра
производителност се
получава, когато
размерът на хеш
таблицата е
N е броя на обектите.414141414141Цветанка Георгиева Моделиране на информационни системи

FP-GROWTH АЛГОРИТЪМ
Първо, базата от данни се компресира в специално дърво на
често срещани шаблони (FP-дърво), но се запазва
информация, асоциираната с наборите от обекти.
След това тази компресирана база от данни се разделя на
множество от условни бази от данни (conditional pattern
bases), всяка от които е асоциирана с един често срещан
обект.
424242424242Цветанка Георгиева Моделиране на информационни системи

FP-GROWTH АЛГОРИТЪМ – ПРИМЕР
Номер на
трансакция
Набори от обекти
1 i1, i2, i5
2 i2, i4
3 i2, i3
4 i1, i2, i4
5 i1, i3
6 i2, i3
7 i1, i3
8 i1, i2, i3, i5
9 i1, i2, i3
434343434343Цветанка Георгиева Моделиране на информационни системи
Нека минималната
поддръжка е 20%.
Първото сканиране на базата
от данни има за цел да се намери
честотата на срещане на
обектите i1, i2, i3, i4, i5 и се
намира техният приоритет.
Обект Честота Приоритет
i1 6 2
i2 7 1
i3 6 3
i4 2 4
i5 2 5

FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (2)
444444444444Цветанка Георгиева Моделиране на информационни системи
Обектите в наборите от обекти в трансакциите се нареждат
според техния приоритет
Номер на
трансакция
Набори от обекти Обекти, наредени според техния
приоритет
1 i1, i2, i5 i2, i1, i5
2 i2, i4 i2, i4
3 i2, i3 i2, i3
4 i1, i2, i4 i2, i1, i4
5 i1, i3 i1, i3
6 i2, i3 i2, i3
7 i1, i3 i1, i3
8 i1, i2, i3, i5 i2, i1, i3, i5
9 i1, i2, i3 i2, i1, i3

FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (3)
454545454545Цветанка Георгиева Моделиране на информационни системи
Второто сканиране на базата от данни има за цел
построяване на FP-дървото
Създава се коренът на дървото с
етикет “NULL”.
За набора от данни {i2, i1, i5} в
първата трансакция се добавят
върхове на дървото.
За набора от данни {i2, i4} от
втората трансакция се увеличава
броя на i2 и се добавя връх за i4.
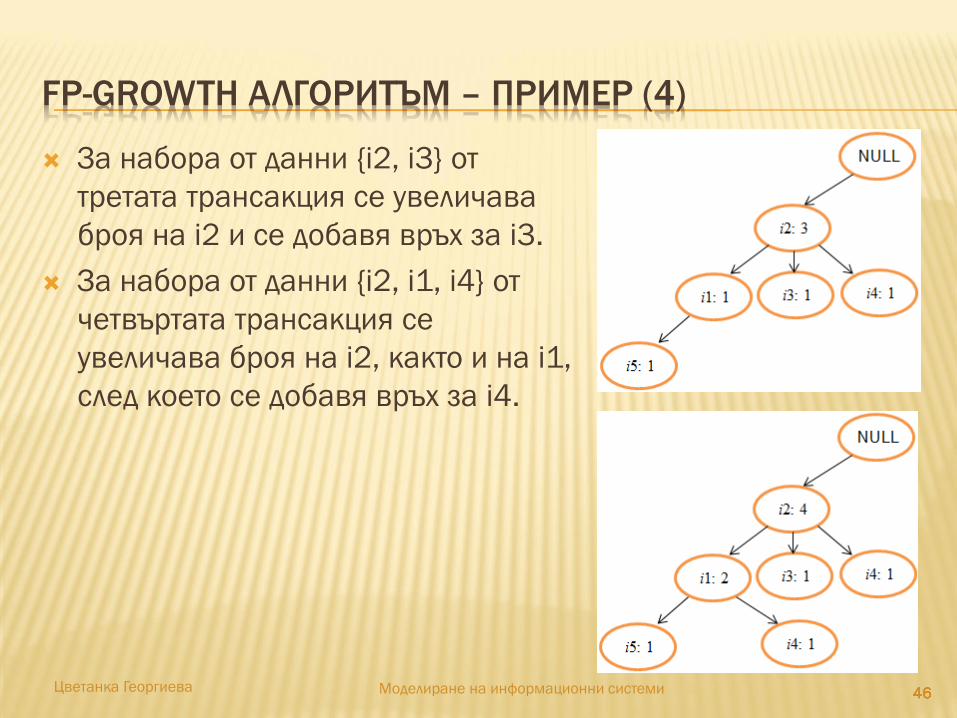
FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (4)
464646464646Цветанка Георгиева Моделиране на информационни системи
За набора от данни {i2, i3} от
третата трансакция се увеличава
броя на i2 и се добавя връх за i3.
За набора от данни {i2, i1, i4} от
четвъртата трансакция се
увеличава броя на i2, както и на i1,
след което се добавя връх за i4.
FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (5)
474747474747Цветанка Георгиева Моделиране на информационни системи
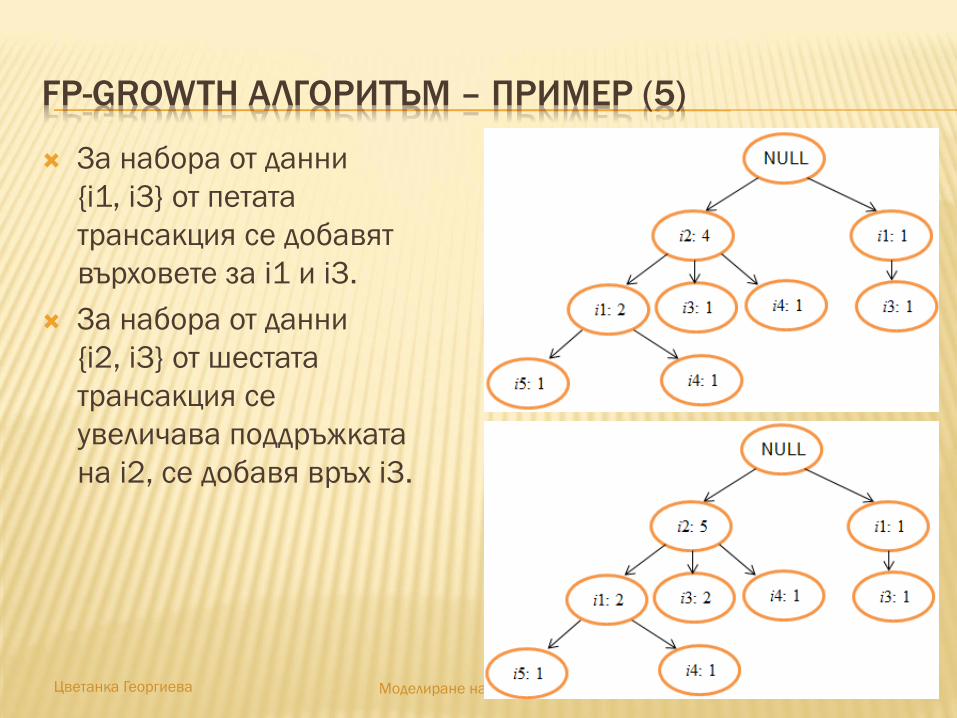
За набора от данни
{i1, i3} от петата
трансакция се добавят
върховете за i1 и i3.
За набора от данни
{i2, i3} от шестата
трансакция се
увеличава поддръжката
на i2, се добавя връх i3.
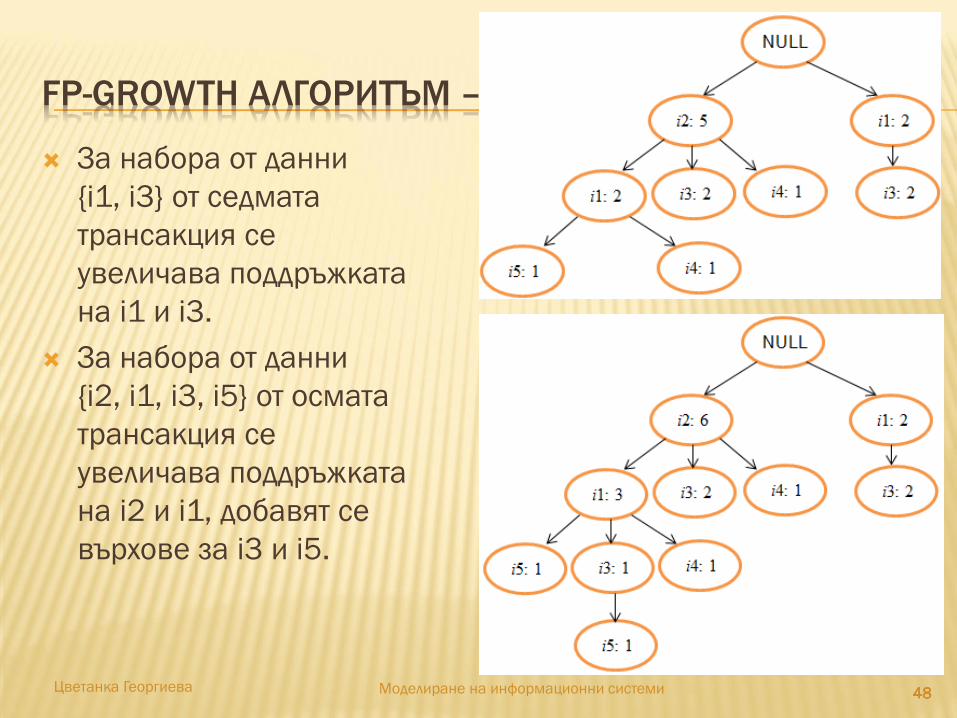
FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (6)
484848484848Цветанка Георгиева Моделиране на информационни системи
За набора от данни
{i1, i3} от седмата
трансакция се
увеличава поддръжката
на i1 и i3.
За набора от данни
{i2, i1, i3, i5} от осмата
трансакция се
увеличава поддръжката
на i2 и i1, добавят се
върхове за i3 и i5.
FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (7)
494949494949Цветанка Георгиева Моделиране на информационни системи
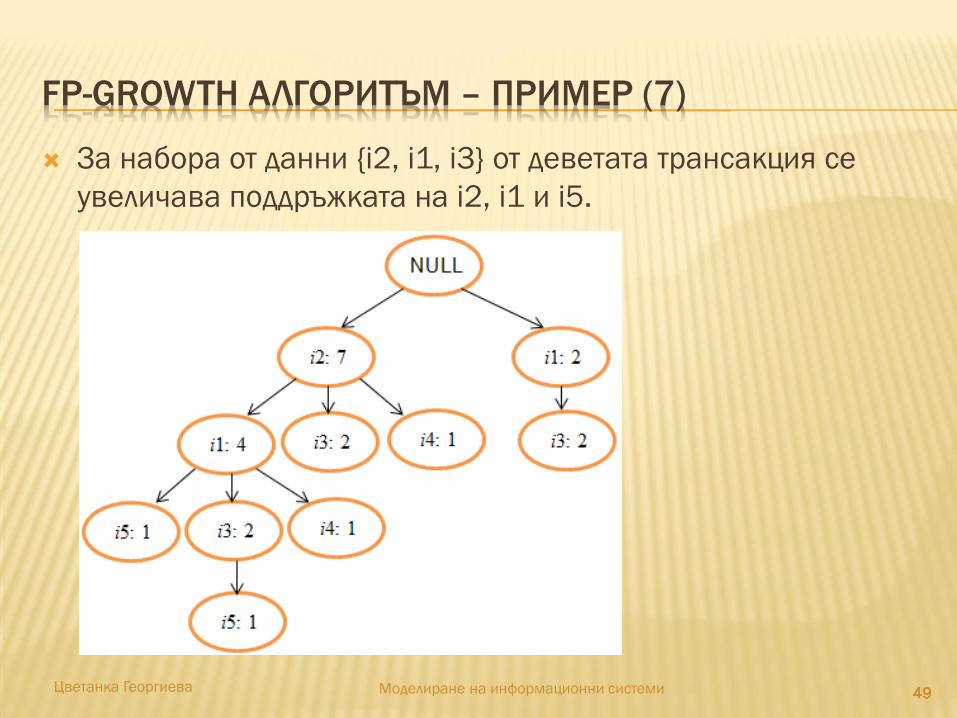
За набора от данни {i2, i1, i3} от деветата трансакция се
увеличава поддръжката на i2, i1 и i5.

FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (8)
505050505050Цветанка Георгиева Моделиране на информационни системи
FP-дървото съдържа и списък от указатели, които свързват
възлите с еднакви етикети.
Тези указатели се представени с пунктирани линии и
улесняват достъпа до отделните елементи в дървото.

FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (9)
515151515151Цветанка Георгиева Моделиране на информационни системи
FP-growth алгоритъмът генерира често срещани набори от
обекти от FP-дървото, като го обхожда отдолу нагоре.
Първоначално алгоритъмът започва да търси за често
срещани набори от обекти, които завършват на i5.
После тези, които завършват на i4, i3, i1, и накрая на i2.
Всяка трансакция съответства на път в FP-дървото.
Следователно, търсейки често срещаните набори от обекти,
завършващи на конкретен елемент, е достатъчно да се
изследват пътищата от FP-дървото, които съдържат този
конкретен възел.
Достъпът до тези пътища е бърз, заради указателите между
върховете с един и същ етикет.

FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (10)
525252525252Цветанка Георгиева Моделиране на информационни системи
Пътищата, които съдържат като листа даден обект, се наричат
префиксни пътища за обекта.
Те формират условната база данни на шаблона (conditional
pattern base).
Обект Префиксни
пътища
Поддръжка
на обект
i5 <i2, i1>
<i2, i1, i3>
1
1
i4 <i2, i1>
<i2>
1
1
i3 <i2, i1>
<i2>
<i1>
2
2
2
i1 <i2> 4
FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (11)
535353535353Цветанка Георгиева Моделиране на информационни системи
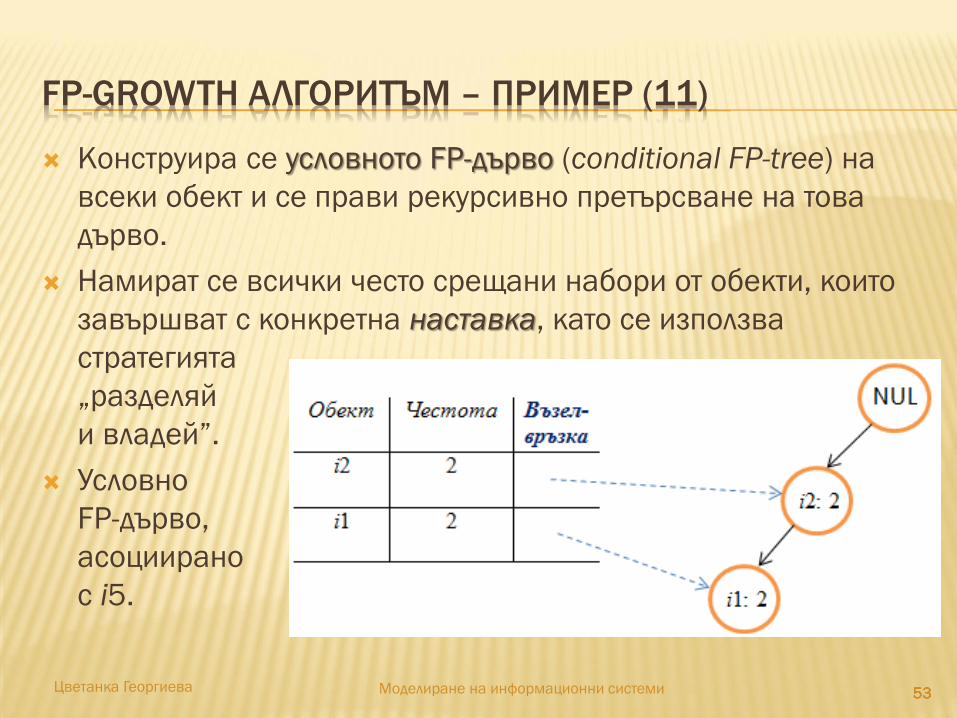
Конструира се условното FP-дърво (conditional FP-tree) на
всеки обект и се прави рекурсивно претърсване на това
дърво.
Намират се всички често срещани набори от обекти, които
завършват с конкретна наставка, като се използва
стратегията
„разделяй
и владей”.
Условно
FP-дърво,
асоциирано
с i5.

FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (12)
545454545454Цветанка Георгиева Моделиране на информационни системи
Условното FP-дърво, асоциирано с i5, има само един път:
<i2:2, i1:2>;
Обектът i3 не се включва в дървото, защото поддръжката му
е 1 и не надхвърля минималната;
От този път се генерират всички комбинации от често
срещани набори от обекти:
{i2, i5}, {i1, i5} и {i2, i1, i5}, поддръжката им е 2.

FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (13)
555555555555Цветанка Георгиева Моделиране на информационни системи
Условната база на шаблона за обекта i3 e
{(i2, i1: 2), (i2: 2), (i1: 2)};
Условното FP-дърво, асоциирано с i3, има два клона
<i2: 4, i1: 2> и <i1: 2>;
От него се генерират често срещаните набори от обекти:
{i2, i1, i3}: 2, {i2, i3}: 4, {i1, i3}: 4.

FP-GROWTH АЛГОРИТЪМ – ПРИМЕР (14)
565656565656Цветанка Георгиева Моделиране на информационни системи
Нарастването на шаблони се постига чрез обединението на
наставката с всеки често срещан набор от обекти,
генериран от условното FP-дърво.
Обект Условна база
на шаблона
Условно FP-дърво Често срещан
набор от
обекти
Поддръжка
i5 {(i2, i1: 1),
(i2, i1, i3: 1)}
<i2: 2, i1: 2> {i2, i1, i5}
{i2, i5}
{i1, i5}
2
2
2
i4 {(i2, i1: 1),
(i2: 1)}
<i2: 2> {i2, i4} 2
i3 {(i2, i1: 2),
(i2: 2),
(i1: 2)}
<i2: 4, i1: 2>
<i1: 2>
{i2, i1, i3}
{i2, i3}
{i1, i3}
2
4
4
i1 {(i2: 4)} <i2: 4> {i2, i1} 4

ОТКРИВАНЕ НА АСОЦИАТИВНИ ПРАВИЛА И OLAP
ТЕХНОЛОГИЯ
57
OLAP-базираното добиване на асоциативни правила
Интегрира OLAP технологията с добиването на асоциативни
правила;
Алгоритмите за добиване на данни могат да бъдат прилагани
върху различните части и върху различни нива на обобщаване
в съответния куб с данни;
Обобщените стойности, необходими за откриването на
асоциативните правила, са изчислени и съхранени в куба с
данни, което улеснява проверяването и филтрирането.
Поддръжката и сигурността на асоциативните правила могат да
бъдат изчислени директно въз основа на стойностите в
съответните обобщени клетки на куба с данни.
J. Han, OLAP Mining: An Integration of OLAP with Data Mining, In Proc. IFIP
Conf. Data Semantics, 1997
5757575757Цветанка Георгиева Моделиране на информационни системи

БАЗИРАНИ НА ОГРАНИЧЕНИЯ АСОЦИАТИВНИ
ПРАВИЛА
58
Генериране на извънредно голям брой асоциативни правила
За крайните потребители е почти невъзможно да обхванат или
потвърдят такъв голям брой асоциативни правила.
Подходи за намаляване на броя на асоциативните правила
Задаване на ограничения за данните; атрибутите; формиране на
правилото;
Подобряване на ефективността на алгоритмите за добиване на
данни.
Примери
P(x, y) ∧ Q(x, w) покупка(x, “компютър”)
покупка(x, y) ∧ покупка(x, w) покупка(x, “компютър”)
Y. Fu, J. Han, Meta-rule-guided mining of association rules in relational
databases, In Proc. of the Int. Workshop on Integration of Knowledge
Discovery with Deductive and Object-Oriented Databases, 1995
M. Kamber, J. Han, J. Chiang, Using Data Cubes for Metarule-Guided Mining
of Multi-Dimensional Association Rules, Technical Report, Simon Fraser
University, 19975858585858Цветанка Георгиева Моделиране на информационни системи

МЕРКИ НА ЗНАЧИМОСТТА И ПОЛЕЗНОСТТА НА
АСОЦИАТИВНИ ПРАВИЛА Значимостта (lift importance) на едно правило се дефинира
по следния начин:
lift(X → Y) = =
Ако lift(X → Y) >1.0, това показва, че трансакциите,
съдържащи X, съдържат Y по-често, отколкото
трансакциите, които не съдържат X.
Пример
lift({Аналитична геометрия} → {Дискретна математика}) =
= = 1.5
5959Цветанка Георгиева Моделиране на информационни системи
)(
)(
Ysupp
YXconf
)()(
)(
YsuppXsupp
YXsupp
})({
}){}({
математикаДискретнаsupp
математикаДискретнагеометрияАналитичнаconf
31
21
Sergey Brin, Rajeev Motwani, Jeffrey D. Ullman, and Shalom Tsur, Dynamic itemset
counting and implication rules for market basket data, ACM SIGMOD International
Conference on Management of Data, 1997

МЕРКИ НА ЗНАЧИМОСТТА И ПОЛЕЗНОСТТА НА
АСОЦИАТИВНИ ПРАВИЛА (2)
Убедеността (conviction) на едно правило се дефинира като:
conv(X → Y) =
Убедеността съпоставя вероятността X да се появи без Y, ако
X и Y са независими, с действителната честота на
появяванията на X без Y.
Пример
conv({Аналитична геометрия} → {Дискретна математика}) =
= = 1.33
В този пример стойността на параметъра убеденост 1.33 показва,
че правилото би било некоректно 33.33% (т.е. 1.33 пъти) по-често,
ако асоциацията между {Аналитична геометрия} и {Дискретна
математика} е напълно случайна.
6060Цветанка Георгиева Моделиране на информационни системи
) ( - 1
)( - 1
YXconf
Ysupp
}){}({ - 1
})({- 1
математикаДискретнагеометрияАналитичнаconf
математикаДискретнаsupp
211
311

ЛИТЕРАТУРА
Ian H. Witten, Frank Eibe, Mark A. Hall, Data Mining: Practical
Machine Learning Tools and Techniques, Third Edition, Morgan
Kaufmann Publishers, 2011
J. Han, M. Kamber, Data Mining: Concepts and Techniques,
Morgan Kaufmann Publishers, 2006
6161Цветанка Георгиева Моделиране на информационни системи
6262Цветанка Георгиева
Цветанка Георгиева-Трифонова, 2017
Някои права запазени.
Презентацията е достъпна под лиценз Creative Commons,
Признание-Некомерсиално-Без производни,
https://creativecommons.org/licenses/by-nc-nd/4.0/legalcode


















