제 9 장 클러스터 컴퓨터
44
제 제 9 9 제 제제제제 제제제 제 제제제제 제제제 9.1 제제제제 제제제제 제제 제 제제 9.2 제제제제 제제제제제 제제 제제제 제제제 (SSI) 9.3 제제제제 제제제제 제제 제제
description
제 9 장 클러스터 컴퓨터. 9.1 클러스터 컴퓨터의 구조 및 분류 9.2 클러스터 미들웨어와 단일 시스템 이미지 (SSI) 9.3 클러스터 컴퓨터의 사례 분석. 컴퓨터 클러스터링 (Computer Clustering). 개념 : 네트워크에 접속된 다수의 컴퓨터들 ( PC , 워크스테이션 , 혹은 다중프로세서시스템 ) 을 통합하여 하나의 거대한 병렬컴퓨팅 환경을 구축하는 기법 출현 배경 o 대부분 컴퓨터들에서 프로세서들이 연산을 수행하지 않는 유휴 사이클 (idle cycle) 들이 상당히 많다 . - PowerPoint PPT Presentation
Transcript of 제 9 장 클러스터 컴퓨터

제제 99 장 클러스터 컴퓨터장 클러스터 컴퓨터
9.1 클러스터 컴퓨터의 구조 및 분류
9.2 클러스터 미들웨어와 단일 시스템 이미지(SSI)
9.3 클러스터 컴퓨터의 사례 분석

Parallel Computer Architecture 1-2
컴퓨터 클러스터링 (Computer Clustering)
개 념 : 네 트 워 크 에 접 속 된 다 수 의 컴 퓨 터 들 (PC,
워크스테이션 , 혹은 다중프로세서시스템 ) 을 통합하여
하나의 거대한 병렬컴퓨팅 환경을 구축하는 기법
출현 배경
o 대부분 컴퓨터들에서 프로세서들이 연산을 수행하지 않는 유휴
사이클 (idle cycle) 들이 상당히 많다 .
o 고속의 네트워크가 개발됨으로써 컴퓨터들 간의 통신 시간이 현저히
줄어들게 되었다 .
o 컴퓨터의 주요 부품들 ( 프로세서 , 기억장치 , 등 ) 의 고속화 및
고집적화로 인하여 PC 및 워크스테이션들의 성능이 크게 높아졌다 .
o 슈퍼컴퓨터 혹은 고성능 서버의 가격이 여전히 매우 높다 .

Parallel Computer Architecture 1-3
클러스터링을 이용하여 구축할 수 있는 컴퓨팅 환경
병렬처리 (Parallel Processing) : 다수의 프로세서들을 이용하여
MPP(massively parallel processors) 혹 은
DSM(distributed shared memory) 형 병렬처리시스템을 구성할
수 있다 .
네트워크 RAM(Network RAM) : 각 노드 ( 워크스테이션 혹은 PC)
의 기억장치들을 통합하여 거대한 분산 공유 - 기억장치를 구성할 수
있으며 , 이것은 가상 기억장치와 파일 시스템의 성능을 크게 높여준다 .
소프트웨어 RAID(S/W RAID) : 서로 다른 노드에 접속된 디스크들을
가상적 배열 (virtual array) 로 구성함으로써 낮은 가격으로 가용성
(availability) 이 높 은 분 산 소 프 트 웨 어 RAID(distributed
software RAID: ds-RAID) 를 제공할 수 있다 .

Parallel Computer Architecture 1-4
9.1 클러스터 컴퓨터의 구조 및 분류
9.1.1 클러스터 컴퓨터의 기본 구조
클러스터 컴퓨터 : 독립적인 컴퓨터들이 네트워크를 통하여 상호연결 되어 하나의 컴퓨팅 자원으로서 동작하는 병렬처리 혹은 분산처리시스템의 한 형태
클러스터 : 다수의 노드 (node) 들로 구성
노드 : 단일 프로세서시스템 혹은 다중프로세서시스템으로 구성
클러스터의 구현 : 단일 캐비닛 혹은 LAN 에 접속된 형태
클러스터 설계의 핵심 목표 : 사용자에게 하나의 시스템으로 보여야 한다 ( 단일 시스템 이미지 (Single System
Image: SSI))

Parallel Computer Architecture 1-5
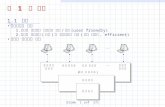
클러스터 컴퓨터의 전형적인 기본 구조

Parallel Computer Architecture 1-6
클러스터 컴퓨터의 주요 구성 요소들
노드 컴퓨터들 (PC, 워크스테이션 , 혹은 SMP)
운영체제 (OS)
고속 네트워크 (Gigabit Ethernet 혹은 Myrinet)
네트워크 인터페이스 하드웨어 통신 소프트웨어 클러스터 미들웨어 ( 단일 시스템 이미지 및 시스템
가용성 지원 )
병렬 프로그래밍 환경 및 도구들 ( 병렬 컴파일러 , PVM, MPI 등 )
직렬 , 병렬 혹은 분산 응용들

Parallel Computer Architecture 1-7
클러스터 컴퓨터의 주요 구성 요소들 ( 계속 )
클러스터 노드 : 통합된 컴퓨팅 자원으로서 , 혹은
독립적인 컴퓨터로서 동작
클러스터 미들웨어 : 단일 시스템 이미지 (single
system image: 통합 시스템 이미지 (unified
system image)) 를 제공해주며 , 시스템 가용성
(system availability) 을 지원하기 위한 시스템
S/W.

Parallel Computer Architecture 1-8
9.1.2 클러스터 컴퓨터의 분류
노드 H/W 구성에 따른 분류 PC 클러스터 (cluster of PCs: COPs)
워크스테이션 클러스터 (cluster of workstations: COWs)
다중프로세서 클러스터 (cluster of multiprocessors:
CLUMPs)
노드 내부 H/W 및 OS 에 따른 분류 동일형 클러스터 (homogeneous cluster): 모든 노드들이
유사한 하드웨어 구조를 가지며 , 동일한 OS 를 탑재 .
혼합형 클러스터 (heterogeneous cluster): 노드들이 다른
구조 및 하드웨어 부품들 ( 프로세서 포함 ) 로 구성되며 , 서로 다른
OS 를 탑재 . 미들웨어와 통신 인터페이스의 구현이 더 복잡 .

Parallel Computer Architecture 1-9
클러스터 컴퓨터의 분류 ( 계속 )
동일형 클러스터의 OS 에 따른 분류
Linux 클러스터 ( 예 : Beowulf)
Solaris 클러스터 ( 예 : Berkeley NOW)
NT 클러스터 ( 예 : HPVM)
AIX 클러스터 ( 예 : IBM SP2)
Digital VMS 클러스터
HP-UX 클러스터
Microsoft Wolfpack 클러스터

Parallel Computer Architecture 1-10
클러스터 컴퓨터의 분류 ( 계속 )
상호연결망에 따른 분류
개방형 클러스터 (exposed cluster) : 클러스터가
외부에 노출되어 외부 사용자들도 쉽게 접속하여 사용할 수 있는
클러스터로서 , 클러스터 노드들이 주로 인터넷과 같은 공공
네트워크 (public network) 에 의해 연결된다 .
폐쇄형 클러스터 (enclosed cluster) : 외부와
차단되는 클러스터로서 , 주로 Myrinet 과 같은 특수
네트워크를 이용한 사설 네트워크 (private network) 로
연결된다 .

Parallel Computer Architecture 1-11
클러스터 컴퓨터의 분류 ( 계속 )
개방형 클러스터의 구성도

Parallel Computer Architecture 1-12
클러스터 컴퓨터의 분류 ( 계속 )
개방형 클러스터의 특징
클러스터 노드들은 반드시 메시지를 이용하여 통신해야 하는데 , 그
이유는 공공의 표준 통신망들은 항상 메시지 - 기반 (message-
based) 이기 때문이다 .
다양한 통신 환경들을 지원해야 하는 표준 프로토콜을 사용해야
하기 때문에 통신 오버헤드가 상당히 높다 .
통신 채널이 안전하지 못하다 . 즉 , 보안이 보장되지 못한다 .
따라서 클러스터 내부 통신의 보안을 위해서는 추가적인 작업이
필요하다 .
구축하기 매우 용이하다 . 사실상 하드웨어는 추가될 것이 거의 없
고 , 각 노드에 클러스터링을 위한 소프트웨어들만 탑재하면 된다 .

Parallel Computer Architecture 1-13
클러스터 컴퓨터의 분류 ( 계속 )
폐쇄형 클러스터의 구성도

Parallel Computer Architecture 1-14
클러스터 컴퓨터의 분류 ( 계속 )
폐쇄형 클러스터의 특징 노드들 간의 통신이 공유 기억장치 , 공유 디스크 , 혹은 메시지 등과
같은 여러 수단에 의해 이루어질 수 있다 .
표준 프로토콜을 사용할 필요가 없기 때문에 통신 오버헤드가 매우
낮아지며 , 국제위원회의 동의를 받을 필요가 없으므로 프로토콜을
더욱 신속하게 정의하고 구현할 수 있다 .
통신 보안이 보장될 수 있어서 , 노드들 간의 데이터 전송이 노드 내부
통신만큼 안전하게 이루어질 수 있다 .
외부 트래픽 (traffic) 의 영향을 받지 않기 때문에 통신 지연이
줄어든다 .
공개형에 비하여 구현 비용이 더 많이 들고 , 외부 통신망과의 접속을
위해서는 브리지와 같은 별도의 통신 설비가 필요하다 .

Parallel Computer Architecture 1-15
클러스터 컴퓨터의 분류 ( 계속 )
노드의 소유권에 따른 분류
전용 클러스터 (dedicated cluster) : 특정 사용자가
어느 한 노드 컴퓨터를 별도로 소유할 수 없다 . 즉 , 클러스터 내의
모든 자원들이 공유되며 , 병렬컴퓨팅이 전체 클러스터에 의해
수행된다
비전용 클러스터 (non-dedicated cluster) : 각
사용자가 특정 노드 컴퓨터에 대한 소유권을 가지고 사용할 수 있
다 . 즉 , 사용자가 지정된 노드 컴퓨터를 사용하다가 , 큰 응용을
병렬로 처리할 때만 노드 컴퓨터들을 통합하여 사용된다 ---
병렬처리는 프로세서들의 사이클 스틸링 (cycle stealing) 을
이용하여 수행 .

Parallel Computer Architecture 1-16
9.2 클러스터 미들웨어와 SSI
여러 개의 컴퓨터들을 상호 연결하여 구성되는 컴퓨터
클러스터가 하나의 통합된 자원 (unified resource) 으로서
사용될 수 있다면 , 그 시스템은 “단일 시스템 이미지 (single
system image: 이하 SSI 라고 함 ) 를 가지고 있다” 라고
말한다 .
SSI 는 OS 와 프로그래밍 환경 ( 도구 )/ 응용 프로그램
사이에 위치하는 미들웨어 계층 (middleware layer) 에
의해 지원된다

Parallel Computer Architecture 1-17
미들웨어의 S/W 하부구조
SSI 인프라 (single system image infra) : OS 와
접착되어 (glue) 있으며 , 모든 노드들로 하여금 시스템 자원들을 통합적으로 액세스 할 수 있게 해준다
SA 인프라 (system availability infra) : 클러스터
내의 모든 노드들에게 체크포인팅 (checkpointing: 결함 발생에 대비하여 중간 결과들을 저장 ), 자동 페일오버(automatic failover: 어느 노드에 결함이 발생하면 다른 노드가 그 작업을 대신 수행 ) 및 페일백 (failback: 원래 노드로 작업 수행 복원 ) 등의 기능을 가지도록 함으로써 ,
부분적인 결함 발생시에도 클러스터가 계속하여 응용들을 처리할 수 있도록 해준다 .

Parallel Computer Architecture 1-18
SSI 지원에 따른 이점들
사용자들로 하여금 자신의 응용 프로그램이 실제 어느 노드에서
실행되고 있는지 알 필요가 없도록 해준다 .
시스템 운영자 혹은 사용자로 하여금 특정 자원 ( 프로세서 , 기억장치 ,
디스크 등 ) 이 실제 어디에 위치하고 있는지 알 필요가 없도록 해준다 .
또한 필요할 경우에는 시스템 운영자가 자원들의 위치를 파악할 수
있도록 지원한다 .
시스템 관리가 중앙집중식 혹은 분산식 중의 어느 것으로든 가능하다 .
시스템 관리를 단순화시켜 준다 : 여러 자원들에 영향을 미치는
동작들이 하나의 명령에 의해 수행될 수 있다 .
시스템 운영자 및 시스템 프로그래머의 작업 영역을 제한하지 않는다 :
즉 , 어느 노드에서든 시스템 관리 및 시스템 프로그래밍이 가능해진다 .

Parallel Computer Architecture 1-19
9.2.1 미들웨어의 설계 목표 투명한 자원 관리 (transparent resource
management) 사용자들로 하여금 하부 시스템 구조를 알지 못하는 상태에서도
클러스터를 쉽고 효과적으로 이용할 수 있게 해주어야 한다 . [ 예 ] 단일 엔트리 지점 (single entry point) 을 가진 클러스터에서는 사용자가 어느 노드에서든 로그 - 인 할 수 있으며 , 필요한 S/W 는 어느 한 노드에만 저장해두면 공통으로 사용될 수 있다 . ( 비교 : 분산 시스템에서는 그 S/W 를 필요로 하는 모든 노드들에 각각 설치해야 한다 .)
자원의 할당 (allocation), 해제 (de-allocation) 및 복제(replication) 와 같은 자원 관리에 완전한 투명성을 제공하기 위해서는 , 그들의 구현에 관한 세부적 사항들이 사용자 프로세스에게는 보이지 않아야 한다 .
사용자는 프로세서나 기억장치 혹은 디스크와 같은 자원들이 어디에 위치하든 쉽게 이용하거나 액세스 할 수 있게 된다 .

Parallel Computer Architecture 1-20
미들웨어의 설계 목표 ( 계속 )
선형적 성능 (scalable performance) 시스템 크기와 작업부하의 패턴이 제한되지 않아야 한다 . 즉 ,
새로운 노드 ( 컴퓨터 ) 를 네트워크에 접속하고 필요한 소프트웨어를 탑재하면 시스템을 확장시킬 수 있고 , 반대로 축소시킬 수도 있어야 한다 .
시스템 크기를 변경시켰을 때 , 시스템의 성능도 그에 비례하여(uniformly) 높아지거나 낮아져야 한다 .
노드를 추가하더라도 프로토콜이나 API 를 변경할 필요가 없어야 한다 .
어떤 형태의 작업부하들에 대해서도 균등한 작업 분배 및 병렬처리를 지원할 수 있는 기능을 포함하고 있어야 한다 . [ 예 ] 새로운 작업이 어떤 노드로 들어오면 , 현재 작업부하가 가장 적은 노드로 할당시켜줄 수 있어야 한다 .
클러스터의 효율을 높이기 위하여 , SSI 서비스들에 의한 오버헤드가 낮아야 한다 .

Parallel Computer Architecture 1-21
미들웨어의 설계 목표 ( 계속 )
보강된 가용성 (enhanced availability)
미들웨어 서비스들은 시스템에 어떤 결함이 발생하더라도 항상 지원될
수 있어야 한다 . 즉 , 그러한 시스템 결함이 사용자 응용 처리에는
영향을 주지 않은 상태에서 복구될 수 있어야 한다 . 이것은
체크포인팅 (checkpointing) 과 결함허용 기술들 (hot standby,
mirroring, failover 및 failback 기능 ) 에 의해 이루어질 수
있다 .
[ 예 ] 파일 시스템이 여러 노드들에 분산되어 있는 상태에서 그 중의
어떤 노드에 결함이 발생했다면 , 데이터 자원 및 처리 소프트웨어를
다른 시스템으로 이주시키고 (failover 기능 ), 결함이 복구된
후에는 그들을 원래 노드로 복원시켜줄 수 있어야 한다 (failback
기능 ).

Parallel Computer Architecture 1-22
9.2.2 미들웨어에 의해 제공되는 서비스들
단일 엔트리 지점 (single entry point): 분산시스템에서
사용자가 각 노드에 로그 - 인 ( 예 : telnet
node1.cluster.myuniv.ac.kr) 하는 방식과는 달리 ,
클러스터에서는 단일 시스템과 같은 방식으로 로그 - 인 ( 예 :
telnet cluster.myuniv.ac.kr) 할 수 있게 해준다 .
단일 파일 계층 (single file hierarchy): 시스템에 로그 -
인한 사용자가 클러스터의 여러 노드들에 분산 저장되어 있는
파일시스템을 동일한 루트 디렉토리 밑에 있는 한 계층의 파일
및 디렉토리들로 볼 수 있게 해준다 .

Parallel Computer Architecture 1-23
미들웨어에 의해 제공되는 서비스들 ( 계속 )
단일 관리 /제어 지점 (single management/control point):
하나의 윈도우를 통하여 클러스터 전체를 모니터하고 제어할 수 있게
해준다 .
단일 가상 네트워킹 (single virtual networking): 클러스터 내에
모든 노드들이 외부 네트워크에 물리적으로 연결되어 있지 않더라도 ,
클러스터 도메인 (clus-ter domain) 에서 제공되는 가상 네트워크를
통하여 외부 네트워크에 연결할 수 있다 . 예를 들어 , 클러스터 내의
하나의 노드만 외부 네트워크에 물리적으로 연결되어 있는 경우에도 ,
다른 노드들은 이 노드가 제공하는 가상 네트워크를 통하여 외부
네트워크와 접속할 수 있다 .
단일 기억장치 공간 (single memory space): 노드들에 분산되어
있는 모든 기억장치들을 공유시킴으로써 하나의 거대한 주기억장치 공간을
형성해준다 .

Parallel Computer Architecture 1-24
미들웨어에 의해 제공되는 서비스들 ( 계속 )
단일 작업관리 시스템 (single job management system):
사용자는 어느 노드에서든 작업을 제출 (submit) 할 수 있으며 , 그
작업이 어느 노드에 의해 처리될지는 알 수 없다 . 작업들은 작업
스케줄러 (job scheduler) 에 의해 부하가 적은 노드에 배정되며 ,
아래의 모드들 중의 하나로 처리된다 :
배치 모드 (batch mode): 클러스터의 모든 자원들이 하나의 사용자
작업을 위해 전용으로 사용되는 모드
인터엑티브 모드 (interactive mode): 클러스터 자원들이 여러 개의
사용자 작업들에 의해 시분할 (time-sharing) 되는 모드
병렬 모드 (parallel mode): 병렬 프로세스들이 MPI 및 PVM
환경에서 처리되는 모드

Parallel Computer Architecture 1-25
미들웨어에 의해 제공되는 서비스들 ( 계속 )
단일 I/O 공간 (single I/O space: SIOS): 어느 노드에서든 , 지역 혹은 원격에 위치한 주변장치나 디스크 드라이브들에 대한 I/O 동작을 수행할 수 있게 해준다 . 즉 ,
SIOS 는 클러스터 노드들에 접속된 디스크들과 RAID 및 기타 주변장치들에 대하여 전체적으로 하나의 I/O 주소 공간을 형성한다 .
단일 사용자 인터페이스 (single user interface): 사용자가 클러스터를 하나의 GUI(graphic user
interface) 를 통하여 사용할 수 있게 해준다 . 또한 GUI 는 일반적인 컴퓨터에서 사용하는 것들과 동일한 형태와 느낌을 가질 수 있는 것으로 지원한다 ( 예 : Solaris OpenWin
혹은 Windows NT GUI).

Parallel Computer Architecture 1-26
미들웨어에 의해 제공되는 서비스들 ( 계속 )
단일 프로세스 공간 (single process space): 프로세스들이 클러스터 전체적으로 유일한 프로세스 ID 를 가지게 한다 . 그렇게 되면 , 어느 한 노드에 있는 프로세스가 같은 노드 혹은 원격 노드에 자식 프로세스 (child process)
를 생성할 수 있고 , 원격 노드에 있는 다른 프로세스들과 시그널 (signal) 혹은 파이프 (pipes) 와 같은 내부 프로세스 통신 방식들을 이용하여 통신도 할 수 있다

Parallel Computer Architecture 1-27
미들웨어에 의해 제공되는 서비스들 ( 계속 )
체크포인팅 (checkpointing) 및 프로세스 이주 (process
migration) : 체크포인팅은 결함 발생에 대비하여
주기적으로 프로세스들의 상태와 중간 계산 결과들을
저장해주는 것이다 . 만약 어느 노드에 결함이 발생한다면 ,
그 노드에서 처리되던 프로세스들을 다른 노드로 이주시켜서
그 동안 수행된 작업량의 손상 없이 계속 처리될 수 있게
해준다 . 또한 , 프로세스 이주는 클러스터 노드들 간에 동적
부하 균등화 (dynamic load balancing) 도 가능하도록
해준다 .

Parallel Computer Architecture 1-28
미들웨어 패키지들의 SSI 및 SA 서비스 지원 여부
------------------------------------------------------------------------------------------------------------------------
지원 서비스 GLUnix TreadMarks CODINE LSF
--------------------------------------------------------------------
단일 제어 지점 지원 X O O O
단일 엔트리 지점 O X X X
단일 파일 계층 지원 O O O O
단일 기억장치 공간 X O X X
단일 프로세스 공간 O X X X
단일 I/O 공간 X X X X
단일 네트워킹 X X X X
단일 작업관리 O O O O
체크포인팅 X X O O
프로세스 이주 X X O O
결함허용 O X O O ------------------------------------------------------------------------------------------------------------------------

Parallel Computer Architecture 1-29
클러스터 미들웨어 모듈들 간의 기능적 상관 관계

Parallel Computer Architecture 1-30
9.3 클러스터 컴퓨터의 사례 분석
9.3.1 NOW Network of Workstations
1994~1998년 , U. C. Berkeley 대학에서 수행된
NOW 프로젝트에서 실험용으로 개발된 클러스터 컴퓨터
상용화된 워크스테이션들과 스위치 - 기반 네트워크 부품들을
이용하여 대규모 병렬컴퓨터시스템 구현이 가능함을 입증
주요 기술 : 네트워크 인터페이스 H/W, 고속 통신 프로토
콜 , 분산 파일 시스템 , 분산 스케줄링 , 작업 제어 , 등
TOP500 슈퍼컴퓨터 리스트 190 위 (1996년 11월 기
준 )

Parallel Computer Architecture 1-31
NOW ( 계속 )
105 개의 SUN Ultra 170 워크스테이션들이
Myricom network 에 의해 연결
노드 구성
프로세서 : 167 MHz UltrasSparc 1
microprocessor
512KByte 캐쉬 , 128 Mbyte 주기억장치 및 2.3
Gbyte 하드 디스크
네트워크 소자 : Myricom 의 Myrinet 스위치
각 스위치 : 160MBytes/s 양방향 포트

Parallel Computer Architecture 1-32
NOW 노드의 내부 구조

Parallel Computer Architecture 1-33
NOW ( 계속 )
NOW 의 네트워크들
Myrinet : 클러스터 노드들 간의 고속 통신망 구성
ATM 백본 : 클러스터 외부와의 통신 채널
직렬 포트 : 터미널 집중기 (terminal concentrator)
–- 모든 노드들의 콘솔을 직접 액세스
AC선 : 전력 분산 네트워크
Myrinet 망 : Fat tree 토폴로지로 구성

Parallel Computer Architecture 1-34
서브 클러스터의 구성도
각 Myrinet 스위치 : 8 개 포트 포함 서브클러스터 당 35 개
WSs
전체 NOW 시스템 : 3 개의 서브 클러스터들로 구성 전체
105 개 노드들로 구성

Parallel Computer Architecture 1-35
NOW ( 계속 )
OS : Solaris Unix
미들웨어 : GLUnix(Global Layer Unix)
프로세서 관리 , 자원 관리 , 파일시스템 관리 , 스케쥴링 지원
네트워크 프로세스 ID(NPIDs) 및 가상 노드 번호 (VNNs) 을
사용함으로써 , 클러스터 전체적으로 사용될 수 있는 이름 공간
(namespace) 형성
NPID : 시스템 전체적으로 사용될 수 있는 프로세스 ID, 순차적
프로그램 및 병렬프로그램에 모두 지정
VNN : 병렬 프로그램에서 프로세스들 간 통신 지원에 사용
통신 : AM(Active Message) 사용 --- 단순화된 RPC

Parallel Computer Architecture 1-36
NOW 시스템의 S/W 계층

Parallel Computer Architecture 1-37
NOW ( 계속 )
네트워크 RAM : 작업을 처리하지 않는 워크스테이션의
주기억장치 (RAM) 들을 다른 워크스테이션들이 사용할
수 있도록 해줌
Serverless : 별도의 서버가 없으며 , 유휴 상태의
어느 노드든 서버로서 동작 가능

Parallel Computer Architecture 1-38
9.3.2 HPVM
High Performance Virtual Machine
1998년부터 일리노이대학에서 진행된 HPVM
프로젝트에서 개발
PC, 워크스테이션 등과 같은 낮은 가격의
COTS(commodity-off-the-shelf : 상용화된 부품 )
를 이용하여 슈퍼컴퓨터 성능을 가진 컴퓨팅 환경을 구축
주요 목표
표준 API 들과 고속의 통신 제공
통합 스케쥴링 및 자원 관리
이질성의 관리 (managing heterogeneity)

Parallel Computer Architecture 1-39
HPVM ( 계속 )
FM(Fast Message) : NOW 의 AM 을 개선시킨
통신 방식으로서 , 표준 API S/W(MPI, SHMEM,
Put/Get, Glabal Arrays 등 ) 제공
HPVM 은 FM 위에서 응용 프로그램들이 처리되는
형태들 가짐
FM : 플랫폼에 독립적 (platform-independent)
HPVM 은 일종의 미들웨어 혹은 가상 기계 (virtual
machine) 로 볼 수 있음 .

Parallel Computer Architecture 1-40
HPVM 의 구조

Parallel Computer Architecture 1-41
HPVM ( 계속 )
HPVM-III 클러스터 (1998년 일리노이대학에서 실제
구현 )
두 개의 300MHz Pentium-II 프로세서들을 장착한
SMP 시스템 128 개를 160 MBytes/s Myrinet
네트워크 및 100Mbps 이더넷으로 연결한 시스템
노드 당 512 MByte main memory, 4 GByte hard
disk 장착
OS : Windows NT 4.0

Parallel Computer Architecture 1-42
9.3.3 Beowulf
Beowulf 프로젝트 : NASA 의 지원하에 대용량 데이터의 고속
처리를 위한 과학계산용 슈퍼컴퓨터 개발을 목표로 추진
최초의 Beowulf 시스템 (1994년 )
노드 수 : 16 개
노드 : 80486DX4 마이크로프로세서 , 256MByte 주기억장
치 , 500MByte 하드디스크로 구성
네트워크 : 10baseT, 10base2 의 10Mbps 이더넷으로 연결
프로세서간 통신 프로토콜 : TCP/IP
프로세서간 통신 성능이 시스템 S/W 에 의해 제한
다수의 이더넷을 이용한 병렬 데이터 전송 (channel
bonding) 기술 이용

Parallel Computer Architecture 1-43
Beowulf ( 계속 )
Beowulf 시스템의 특징
특정 형태의 구성을 가지는 시스템을 의미하지 않는다
최소한의 COTS H/W 들로 구성되고 , Linux, MPI(Message
Passing Interface) 및 PVM(Parallel Virtual Machine)
과 같은 일반적인 S/W 들을 사용하여 구축한 과학계산용 PC
클러스터시스템의 통칭
Beowulf 프로젝트가 성공하고 지속적으로 발전된 이유
마이크로프로세서 및 네트워크 장비의 성능 향상 및 가격 하락
OS(Linux) 소스 코드의 공개 , 메시지 전송 라이브러리의 표준화
저가의 고성능 Beowulf 구축 가능

Parallel Computer Architecture 1-44
Beowulf ( 사례 시스템 )
Beowulf 리눅스 클러스터
128 개의 Alpha 프로세서들로 구성
영화 ‘타이타닉’의 영상처리에 사용
Avalon 시스템
미국 Los Alamos National Lab 에서 구축
70 개의 Alpha Linux Box 로 구성
당시 TOP500 슈퍼컴퓨터 리스트에 315 위로 등록