§ 第 8 章 虚拟变量模型
86
§第8第 第第第第第第 第第第第第第第第第 一、 第 第第第第第第第第第 、 第 第第第第第第 、 第 第第第第第第第 、 第 第第第第第第第第第 、 第 第第第第第第第第第 、
-
Upload
raymond-riley -
Category
Documents
-
view
138 -
download
0
description
§ 第 8 章 虚拟变量模型. 一、虚拟变量的基本含义 二、虚拟变量的设置原则 三、虚拟变量作用 四、虚拟变量的引入 五、虚拟变量的特殊应用 六、虚拟被解释变量模型. 一、虚拟变量的基本含义. 许多经济变量是 可以定量度量 的,其取值可用数值表示, 如: 商品需求量、价格、收入、产量等 但也有一些影响经济变量的因素 无法定量度量 , 如: 职业、性别对收入的影响,战争、自然灾害对 GDP 的影响,季节对某些产品(如冷饮)销售的影响等等,反映这些 定性因素 的变量被称为 品质变量 ,这些变量由于各种原因不能计量 。 - PowerPoint PPT Presentation
Transcript of § 第 8 章 虚拟变量模型

§第 8 章 虚拟变量模型
一、虚拟变量的基本含义 二、虚拟变量的设置原则 三、虚拟变量作用 四、虚拟变量的引入 五、虚拟变量的特殊应用 六、虚拟被解释变量模型

一、虚拟变量的基本含义
许多经济变量是可以定量度量的,其取值可用数值表示,如:商品需求量、价格、收入、产量等
但也有一些影响经济变量的因素无法定量度量,如:职业、性别对收入的影响,战争、自然灾害对 GDP 的影响,季节对某些产品(如冷饮)销售的影响等等,反映这些定性因素的变量被称为品质变量 ,这些变量由于各种原因不能计量 。
为了在模型中能够反映这些因素的影响,并提高模型的精度,需要将它们“量化” .

这种“量化”通常是通过人为地虚构出来一种特殊的变量来完成的。即根据这些因素的属性类型,构造只取“ 0” 或“ 1” 的人工变量,通常称为虚拟变量( dummy variables ),文献中习惯用 表示。• 例如,反映性别这个属性的虚拟变量可取为:
一般地,在虚拟变量的设置中:用 1 表示这种属性或特征存在,用 0 表示这种属性或特征不存在。或者说,设置虚拟变量时 , 将比较类型、肯定类型取值为 1 ;而将基础类型、否定类型取值为 0 。
iD
女男
0
1iD
大学以下学历大学以上学历
0
1iD再如:

虚拟变量模型概念: 把 包 含 虚 拟 变 量 的 模 型 称 为 虚 拟 变 量 模 型(Dummy Variable Model) , 若仅有解释变量中包含虚拟变量,称为虚拟解释变量模型;若被解释变量是虚拟变量,称为虚拟被解释变量模型,或称为离散选择模型。 一个以性别为虚拟变量考察企业职工薪金的模型:
iiii DXY 210
其中: Yi 为企业职工的薪金, Xi 为工龄, Di=1 ,若是男性, Di=0 ,若是女性。

研究居民住房消费支出 和居民可支配收入 之间的数量关系。回归模型的设定为:现在要考虑城镇居民和农村居民之间的差异,如何办?为了对 “城镇居民”、“农村居民”进行区分,分析各自在住房消费支出 上的差异,设 为城镇 ;
为农村 , 则模型为
( 模型有截距,“居民属性”定性变量只有两个相互排斥的属性状态( ),故只设定一个虚拟变量。 )
虚拟变量陷阱 ( 一个例子 )
iXiY0 1 1i i iY = + X +u ()
0 1 1 1 2i i iY = + X + D +u ( )
1 = 1iDiY
1 = 0iD
2m

若对两个相互排斥的属性 “居民属性” ,仍然引入 个虚拟变量,则有
则模型( 1 )为
则对任一家庭都有: ,即产生完全共线,陷入了“虚拟变量陷阱”。“ 虚拟变量陷阱”的实质是:完全多重共线性。
21
=0iD
农村居民城镇居民
0 1 1 1 2 2 3i i iY X D D u ()
1 2 1D + D =
11
=0iD
城镇居民农村居民
1 2 1 0D + D - =
2m
虚拟变量陷阱

二、虚拟变量的设置原则 虚拟变量的个数须按以下原则确定: 每一定性变量所需的虚拟变量个数要比该定性变量的类别数少 1 ,即如果定性变量有 m 个类型,只在模型中引入 m-1 个虚拟变量。每个虚拟变量定义为:
个属性类型非第类型
iDi
0
个属性i第1)1,,2,1( mi
i
i
iD
m
当第 i种属性类型出现时,第 i
个虚拟变量取 1,其它都取 0时,则表示出现第
种属性类型。 虚拟变量皆取 0 ,而当所有

例 : 虚拟变量反映季节变动的影响 已知冷饮的销售量 Y 除受 k 种定量变量 Xk 的
影响外,还受春、夏、秋、冬四季变化的影响,要考察该四季的影响,只需引入三个虚拟变量即可:
0
11tD
其他春季
0
12tD
其他夏季
0
13tD
其他秋季
则冷饮销售量的模型为:ttttktktt DDDXXY 332211110
在上述模型中,若再引入第四个虚拟变量
0
14tD
其他冬季
则冷饮销售模型变量为:tttttktktt DDDDXXY 44332211110
其矩阵形式为: μα
βD)(X,Y

如果只取六个观测值,其中春季与夏季取了两次,秋、冬各取到一次观测值,则式中的:
显然, (X,D) 中的第 1列可表示成后 4列的线性组合,从而 (X,D) 不满秩,参数无法唯一求出。 这就是所谓的“虚拟变量陷阱”,应避免。
00011
00101
10001
01001
00101
00011
)(
616
515
414
313
212
111
k
k
k
k
k
k
XX
XX
XX
XX
XX
XX
DX,
k
1
0
β
4
3
2
1
α

1. 可以检验和度量用文字所表示的定性因素的影响
例如,为了反映甲、乙两种不同的工艺过程对产量的影响,可以在生产函数中引入描述甲、乙两种不同的工艺过程的虚拟变量:
通过对模型中 的显著性检验来确定甲、乙两种不同的工艺过程是否对产量有显著影响。
三、虚拟变量的作用
ii uDLnKLnLLnALnQ 1
0 iD
由甲工艺过程生产由乙工艺过程生产

2. 可以测量变量在不同时期的影响
例如:研究我国国民生产总值 Y随时间 X 而增长的过程,需要考虑反常年份这一特殊因素的影响。若定义
则引入虚拟变量的模型为
通过对参数 进行 检验,可以检验反常年份对社会总产值有无显著影响,就把受反常年份影响的时期从总过程中区分出来
正常年份反常年份
0
1tD
tttt uDXY 210
2 t

3. 可以用来处理异常数据的影响。
例如,变量 Y和 X 在长期中基本满足线性回归模型的各个假设,但在时刻有一个突发情况,使得 Y 出现一个 k单位的暂时性波动。如果用线性回归模型 分析这两个变量的关系,其误差项的均值是
解决的办法是引进一个针对性 的虚拟变量,其定义为 新的回归模型为:
解决了均值非 0 的问题
iiiuXY
10
0
00)(
iik
iiuE i 当
当
0
0
1
0
ii
iiDi 当
当
iIii vkDXY 10 iii kDuv 其中
0
0
01
000)()()(
iikk
iikDEuEvE iii

四、虚拟变量的引入方式 在计量经济模型中引入虚拟解释变量,一般地有三种方式:加法方式、乘法方式和混合方式。
1.加法方式: 所谓加法方式,即将虚拟变量直接作为一个解释变量引入模型,它同其他解释变量之间是相加的关系。当不同类型模型的斜率相同,截距不相同时,可考虑以加法形式引入虚拟变量。 以加法方式引入虚拟变量时,主要考虑的问题是定性因素的属性和引入虚拟变量的个数。
iiii DXY 210

( 1 )解释变量只有一个定性变量而无定量变量,而且定性变量为两种相互排斥的属性;
( 2 )解释变量分别为一个定性变量(两种属性) 和一个定量解释变量;
( 3 )解释变量分别为一个定性变量(两种以上属性)和一个定量解释变量;
( 4 )解释变量分别为两个定性变量(各自分别是两种属性)和一个定量解释变量;
加法方式分为四种情形讨论:

( 1 )一个两种属性定性解释变量而无定量变量的情形
0 1
0
i i
i i
Y
Y
城市( )
0 1i i iY D 例如:模型形式:
Y为香烟消费量;
0 1
0
E = 1 = +
E = 0 =
i i
i i
Y | D
Y | D
那么: ( )
1
0iD
城市其中: = (比较的基础:农村)
农村
农村

( 2) 一个定性解释变量(两种属性)和一个定量解释变量的情形
0 1
1
0
i i i i
i
Y = D + X + μ
Y X D
例如:
城市其中: -支出; -收入;
农村
0 1
0
| , 1
| , 0
i i i i
i i i i
E Y X D X
E Y X D X
( )
( )
0 1
0
i i i
i i i
Y = + + X + μ
Y = + X + μ
( ) 城市
农村

0
1
0 1ˆˆ ˆ( )i iY X
0ˆˆ
i iY X
几何意义:两个函数有相同的斜率,但有不同的截距
Y
X

( 3 )一个定性解释变量(三种属性)和一个定量解释变量的情形
在工资模型中如果我们考虑的是员工的受教育程度,比如可以将员工的分为:高中以下,高中毕业和大学及其以上三种。如果虚拟变量设为
高中以下 其他 高中毕业 其他 大学及其以上 其他
1
1
0D
2
1
0D
3
1
0D

则 1 2 3 1D D D
将会出现多重共线性,因此需要去掉一个虚拟变量。 假设模型为:
1
1
0D
2
1
0D
高中其他大学及其以上其他
模型变为:估计出的回归方程为:
高中以下:高中:大学及其以上:
iii DDXY 231210
iii uDDDXY 34231210
iii XDDXYE 1021 )0,0,|(
iii XDDXYE 12021 )()0,1,|(
iii XDDXYE 13021 )()1,0,|(
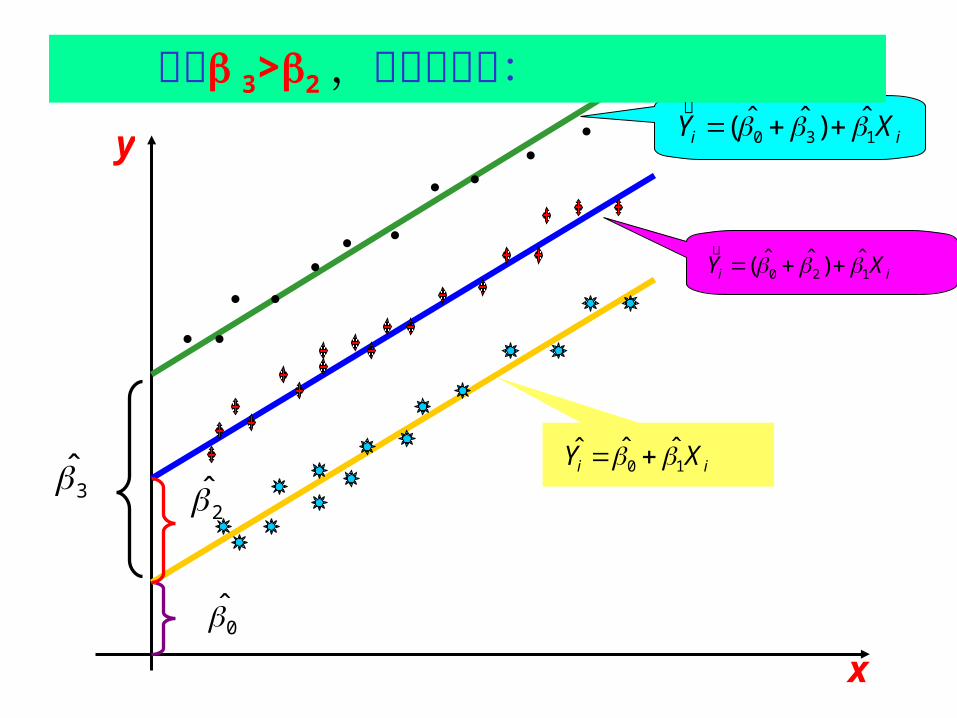
y
x
假定 3>2 ,其几何意义:ii XY 130
ˆ)ˆˆ(
ii XY 120ˆ)ˆˆ(
ii XY 10ˆˆˆ
32
0

( 3 )一个定性解释变量(四种属性)和一个定量解释变量的情形
0 1 1 2 2 3 3
1 2
3
4
1 1
0 0
1
0
i i i
Y X D
Y D D D X
D D
D
例如:季度有 种特性例如:啤酒售量 、人均收入 、季度 ;
一季度 二季度其中:
其 它 其 它
三季度其 它

1 1 2 3 0 1
1 2 1 3 0 2
1 3 1 2 0 3
1 1 2 3 0
E , 1, 0
E , 1, 0 ( )
E , 1, 0 ( )
E , 0
i i
i i
i i
i i
Y | X D D D X
Y | X D D D X
Y | X D D D X
Y | X D D D X
一季度:
二季度:
三季度:
四季度:
基准:四季度
( )
四个季节对某些商品的需求量分别为:
模型中系数 、 、 、 分别反映了四、一、二、三、一季度对该商品的平均影响程度,根据这些系数的统计检验就可以判断季度因素对该商品的需求量是否存在着显著影响。
10 2 3

( 4 )两个定性解释变量(均为两种属性)和一个定量解释变量的情形
运用 OLS得到回归结果,再用 t检验讨论因素是否对模型有影响。

男性、城市居民
男性、农村居民 1 2 0 1E = 1, = 0 = +i i iY | X ,D D X ( )+
1 2 0E | , 0, 0i i iY X D D X
1 2 0 1 2E | , 1, 1i i iY X D D X ( )
1 2 0 2E | , 0, 1 ( )i i iY X D D X
女性、城
+
市居民
女性、农村居民
各类型居民香烟消费量分别为:
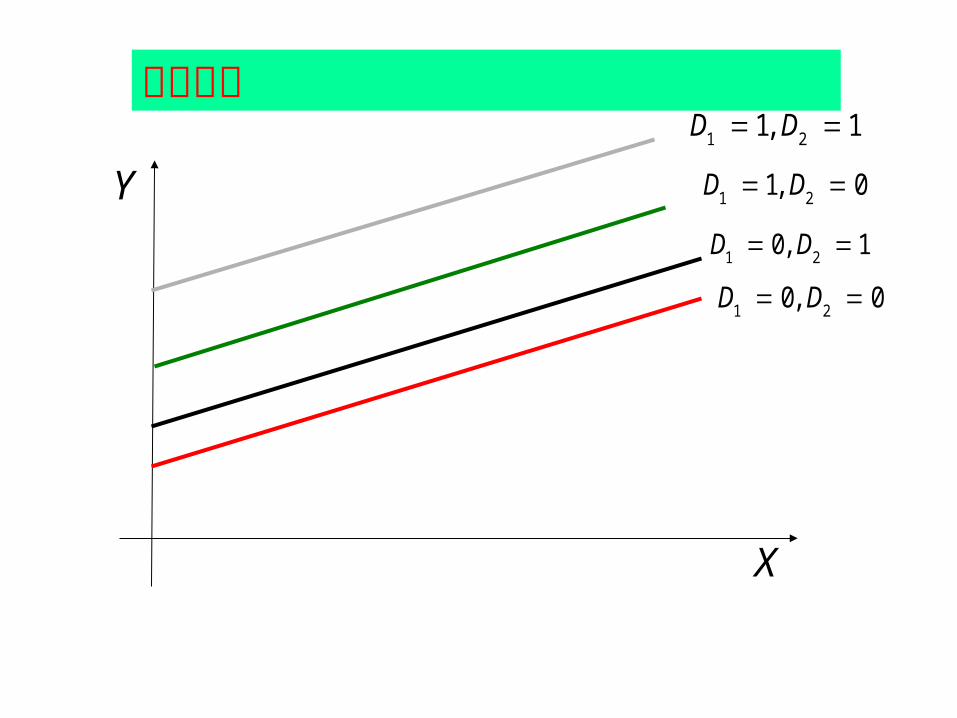
D D 1 21, 1
D D 1 20, 1
0D D 1 21,
0 0D D 1 2,
Y
X
几何意义

0 1 1 2 2 ...t t t k kt t tY D D D X u
加法方式引入虚拟变量的一般表达式 :
基本分析方法 : 条件期望。
1 2 0 1 1 2 2E( / , ,..., ) ...t t t kt t t k kt tY D D D D D D X
加法方式引入虚拟变量的主要作用为: 1. 在有定量解释变量的情形下,主要改变方程 截距; 2. 在没有定量解释变量的情形下,主要用于方 差分析。

基本思想 :以乘法方式引入虚拟变量时,是在所设立的模型中,将 虚拟解释变量与其它解释变量 的乘积,作为新的解释变量出现在模型中,以达到其调整设模型斜率系数的目的。或者将模型斜率系数表示为虚拟变量的函数,以达到相同的目的。乘法引入方式的特点 : ( 1 )截距不变; ( 2 )斜率发生变化;
iX
2.乘法方式

例:研究文化用品消费支出 Y 受收入 X 、居民身份D 的影响,模型形式:
截距不变但斜率发生变化的情形:
1 2
1 2
1
( )
1
0
E | , 1 ( )
E | , 0
t t t t t
t
t t t t
t t t t
Y X D X
Y X D
Y X D X
Y X D X
城市其中: 消费支出; 收入;
农村
城市居民
农村居民
在农村居民的基础上进行比较,(只有斜率系数发生改变)。
图 8-5 农村和城市的文化用品消费
O

3.混合方式:截距和斜率均发生变化
0 1 1 2
0 1 1 2
1
( )
1
0
E | , 1 ( )
E | , 0
t t t t t t
t
t t t t
t t t t
Y X D D X
Y X D
Y X D X
Y X D X
城市其中: 消费支出; 收入;
农村
城市
农村
在正常年份基础上比较,截距和斜率系数都改变.
例 : 同样研究消费支出 Y 、收入 X 、居民身份D 间的影响关系。模型形式:
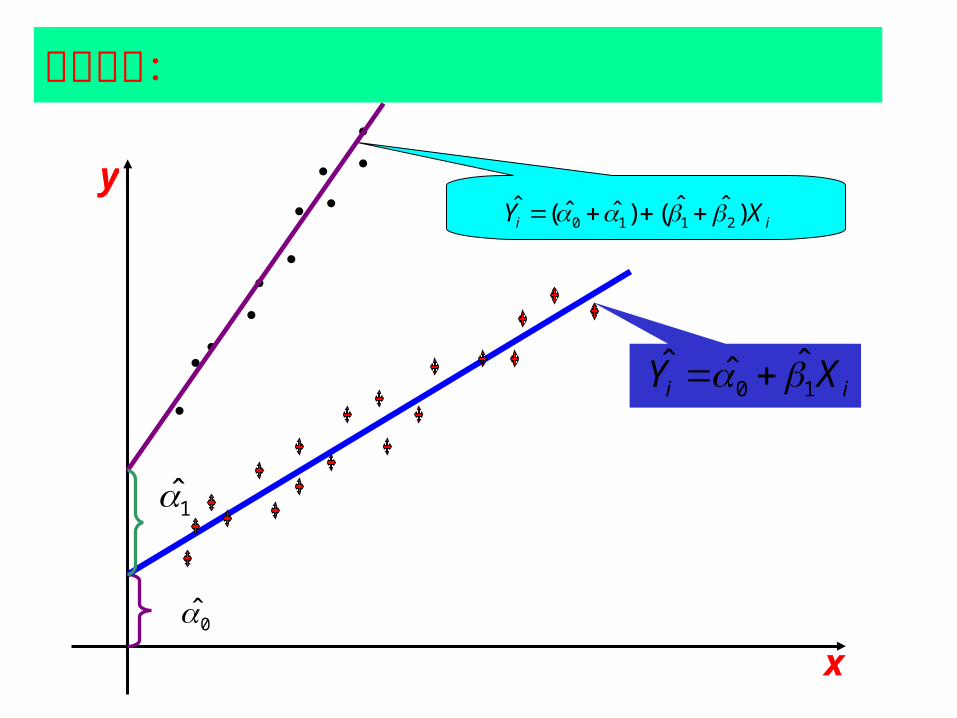
y
x
0 1ˆ ˆi iY X
几何意义:
1
0
0 1 1 2ˆ ˆˆ ˆ ˆ( ) ( )i iY X

在计量经济学中,通常引入虚拟变量的方式分为加法方式和乘法方式以及混合方式三种:即
实质 : 加法方式引入虚拟变量改变的是截距; 乘法方式引入虚拟变量改变的是斜率; 混合方式引入虚拟变量既改变截距又改变斜率
0t t tY X u 1 D
1t t tY X u 2 tX D
0 1
1 2
i i i Y = + βX +u
= + D
= + D
原模型
加法方式引入
乘法方式引入
:
虚拟变量的引入小结:

五、虚拟解释变量特殊应用
所谓特殊应用是指将引入虚拟解释变量的加法方式、乘法方式进行综合使用。基本分析方式:仍然是条件期望分析。本课主要讨论( 1 )分段回归分析;( 2 )交互效应分析;( 3 )结构变化分析

在经济发生转折时期,可通过建立临界指标的虚拟变量模型来反映数量因素的不同阶段。 例如,进口消费品数量 Y主要取决于国民收入 X的多少,中国在改革开放前后, Y对 X 的回归关系明显不同。 这时,可以 t*=1979年为转折期,以 1979年的国民收入 Xt* 为临界值,设如下虚拟变量:
0
1tD
*
*
tt
tt
则进口消费品的回归模型可建立如下:
tttttt DXXXY )( *210
1.分段回归分析

用OLS 法得到该模型的回归方程为:
0ttttt DXXXY )(ˆˆˆˆ *
210 几何意义:
1979年之前,回归模型的斜率为 ;1979年之前,回归模型的斜率为 ;
若统计检验表明, 显著不为零,则我国居民的消费行为在 1979年前后发生了明显改变。
10ˆˆ
图 8-7 时间分段前后的进口消费品数量
XO
Y
ttt XXY )ˆˆ()ˆˆ(ˆ21
*20
tt XY 10ˆˆˆ
*20
ˆˆtX
0
2

例 : 是否发展油菜籽生产与是否发展养蜂生产的差异对农副产品总收益的影响研究。模型设定为 :
( 1 )式中 , 以加法形式引入虚拟变量暗含何假设 ?
0 1 1 2 2
1 2
1
11
0 0
i i i i i
i i
Y D D X u
Y X
D D
()
其中:(农副产品收益); (农副产品投入)
发展养蜂生产发展油菜籽生产;
其他 其他
2.交互效应分析

上式以加法形式引入,暗含的假设为:菜籽生产和养蜂生产是分别独立地影响农副品生产总收益。但是,在发展油菜籽生产时,同时也发展养蜂生产,所取得的农副产品生产总收益,可能会高于不发展养蜂生产的情况。即在是否发展油菜籽生产与养蜂生产的虚拟变量 和 间,很可能存在着一定的交互作用,且这种交互影响对被解释变量农副产品生产收益会有影响。
( 1 )
0 1 1 2 2i i i i iY X D D u
1iD 2iD

为了反映交互效应,将( 1 )变为:
同时发展油菜籽和养蜂生产:
发展油菜籽生产:
发展养蜂生产:
基础类型: 0i i iY X u
0 2i i iY X u ( )
0 1i i iY X u ( )
0 1 2 3i i iY X u ( )
0 1 1 2 2 3 1 2i i i i i i iY D D D D X u
基本思想 : 在模型中引入相关的两个变量的乘积
如何检验交互效应是否存在?

3.结构稳定性分析模型结构的稳定性是指两个不同时期 ( 或不同空间 ) 研究同一性质的问题时所建立的同一形式的回归模型的参数之间有无显著差异,如果存在着差异,则认为模型结构不稳定。
在现实经济生活中,往往由于某些重要因素的影响,解释变量和被解释变量之间关系可能会发生结构变化;
如我国由于经济体制的变化,改革开放前后国民经济总量指标之间的关系都会发生变化;或者研究我国发达地区和不发达地区投资对经济增长的影响,也会因地区不同而产生结构差异等等。
这一问题可通过引入乘法形式的虚拟变量来解决

例:以 Y 为储蓄, X 为收入,为反映 1992年前后储蓄与收入之间的结构关系有无明显变化,可引入虚拟变量进行检验。设根据两个样本估计的回归模型分别为:1992年前: Yi=1+ 1 Xi+1i i=1,2…,n1
1992年后: Yi= 2 +2Xi+2i i=1,2…,n2 设置虚拟变量:
将样本 1 和样本 2 的数据合并,估计以下模型:
然后利用 t检验判断 、 的系数的显著性 .
年以后年以前
19920
19921iD
iiiiii eXDDXY )()( 121211
iD ii XD
于是有: iiii XXDYE 10),0|(
iiii XXDYE )()(),1|( 4130

则有可能出现下述四种情况中的一种:
(1) 1=2 ,且 1 =2 ,即两个回归相同,说明两个回 归 模 型 之 间没有显著差 异 , 称 为 重合回 归( Coincident Regressions );模型结构是稳定的 .
(2) 1 2, 但 1 =2 ,说明两个回归模型之间的斜率相同,两个回归模型结构的差异仅在其截距,称为平行回归( Parallel Regressions) ;
(3) 1= 2 ,但 1 2 ,说明两个回归模型之间的截距相同,两个回归模型结构的差异仅在其斜率,称为汇合回归 (Concurrent Regressions) ;
(4) 12 ,且 12 ,即两个回归完全不同,存在着结构差异称为相异回归( Dissimilar Regressions )。

不同截距、斜率的组合图形
重合回归:截距斜率均相同 平行回归:截距不同斜率相同
共点回归:截距相同斜率不同 交叉(不同)回归:截距斜率均不同

结构变化小结 结构变化的实质是检验所设定的模型在样本期内是否为同一模型。显然,平行回归、共点回归、不同的回归三个模型均不是同一模型。
平行回归模型的假定是斜率保持不变(加法类型,包括方差分析);
共点回归模型的假定是截距保持不变(乘法类型,又被称为协方差分析);
不同的回归的模型的假定是截距、斜率均为变动的(加法、乘法类型的组合)。

邹氏结构变化的检验为了检验两个模型的结构是否相同,可提出原假设:两个回归方程的结构相同,然后看看能否拒绝这个假设 , 这个检验称为 Chow检验 .
设两个样本待检验回归模型为 :
样本 1( n1 个)样本 2 (n2个 )
邹检验的基本假定 :
将 n1与 n2 个观察值合并,并用以估计以下回归:),0(~),0(~ 2
2
2
1 tt uNu 和
1 2 2 1i i k ki iY X X u
1 2 2 2j j k kj iY X X u
是独立分布的和 tt uu 21
1 2 2 3i i k ki iY X X u

(1).假设原假设为真 (2).用OLS 对这两个方程分别进行估计,可得到各
自的残差平方和 和 ,并求和 计算合并后的模型的残差平方和 (3).统计量 :
(4).查 F 分布表,得临界值(5).结论 :F> 的值 , 则拒绝回归相同的假设 , 即拒绝结构稳定性假定 ;另外 ,若 F的 P 值低 , 则拒绝结构稳定性假定 .
)2,(~)2(
)(21
21
knnkknnRSS
kRSSRSSF
UR
URR
F
检验步骤 :
1RSS 2RSS 21 RSSRSSRSSUR
11 , 22 ,…, kk
RRSS
F

1. 用虚拟变量只需做一个回归。2. 一个回归可以做各种检验。截距检验和斜率检验都可以一次完成。
3.邹至庄检验没有明确告诉是哪一个系数发生变化,而虚拟变量模型则可以很清楚看出这一点。
4.合并后样本容量变大,估计精度也有所提高
虚拟变量法相比邹至庄检验的优越性:

被解释变量也可以是定性变量,因此,可以用虚拟变量表示。虚拟被解释变量在日常经济活动中常表现在人们的决策行为上,即对某一问题人们要作出“是”或“否”的回答,如是否购买家用汽车,是否购买人寿保险,企业是否在某个地区投资等。
当被解释变量只取有限个离散值,特别是只取两个值时,所建立的模型被称为离散选择模型。离散选择模型的目的是对被解释变量取值的概率建模,而不是直接预测其取值。常用的模型有线性概率模型和非线性概率模型(包括 Logit 模型和 Probit 模型)。
六、虚拟被解释变量

§1 线性概率模型( LPM)
)|0(1
)|1(
)|(
0
1
一、模型
21
21
ii
ii
iii
i
iii
XYP
XYP
XXYE
X
Y
uXY
LPM
-是则不拥有住房的概率就
概率为记家庭拥有住房的条件
条件期望:
表示家庭收入
,没有住房,如果拥有住房
其中,
为以下形式:以双变量模型为例,则

1)|(0
10
)|1(
))|1(1(0)|1(1
)|(
ii
i
ii
iiii
ii
XYE
p
XYP
XYPXYP
XYE
有约束条件之间与必须落在概率
注意:
二者相等。
率的关系是怎样的?问:条件期望与条件概
1 2( / )i i iE Y X X P 即
条件期望事实上可解释为 Y 在给定 X 下事件(家庭拥有住宅)的条件概率,该线性模型称为线性概率模型 ( LPM )

1 2
1 2 i
1 2 i
1
(
1 1 P
0 1 P
:
i
i i i i
i
i i i
i i i
i
u
Y u Y X
u
Y u X
Y u X
u
、 的非正态性
只取两个值,而 ),
因此 也取两个值。
当 时, 概率为
当 时, 概率为
显然,我们不能再假定 是正态分布的:
实际上它遵循二项分布
的估计问题二、LPM
前面假设干扰项服从正态分布。但在线性概率模型中干扰的正态性不成立
ii
iii PP
XXu
1
1~ 1010

后果
虽然 u 不服从正态分布,即对参数的估计不会产生影响,因为 OLS估计
的无偏性、有效性与 u 的概率分布无关。但进行检验 t、 F检验等统计推断时,却要求误差项服从正态分布。
根据中心极限定理可知,在大样本情况下二项分布趋近于正态分布,所以这时仍然可以在正态分布假定下进行统计推断。
OLS但是 点估计仍然是无偏的。

是同方差的。但是不能说
和即使具有异方差性)(
i
jii
u
jiuuEuE
u
),(0)(0)(
1
概率
总和 1
iu
iX21
iX211 iP1
iP
的异方差性:、 iu2

2
2
2 21 2 1 2
2 21 2 1 2 1 2 1 2
1 2 1 2
var( ) [ ( )] ( ) ( ( ) 0)
var( ) ( )
( ) (1 ) (1 ) ( )
( ) (1 ) (1 ) ( )
( )(1 )
(1 )
(
i i i i i
i i
i i i i
i i i i
i i
i i
i
u E u E u E u E u
u E u
X P X P
X X X X
X X
P P
u Y X
条件期望=条件概率)的方差与 的条件期望有关,而后者当然又依赖与 的取
iu OLS
值。
不是同方差性的。因此具有异方差性,这时就不能用
估计模型中的参数。
随机误差项的方差
ii
iii PP
XXu
1
1~ 1010

1 2
(2)
, ( ),
(1 )
/ / / /
i i i
i i i i i i i
OLS
WLS
P P w
Y w w X w u w
OLS
校正当异方差性出现时, 估计虽然无偏,却不是有效的。解决异方差的方法是进行模型变换 用加权最小二乘法 给
模型两边同除以 ,得:
则新方程得扰动项是同方差的。因此可用 估计其中的参数。

0 1
(3)
ˆ ˆˆ
ˆ ˆˆ (1 )
3
1 [0,1]
0 0 1 1
2 log
[0,
i
i i
i i i i
w
OLS Y X
w w Y Y
LPM
it probit
权数 是未知的,如何处理?
用 方法估计原回归方程得到
再由此求 的估计值
、条件期望的值域区间问题()在 中,条件期望值可能超出 区间;可以将小于 的值改为 ;大于的值改为。这是人为的把大概率事件当作必然事件,把小概率事件当作不可能事件。()在 模型和 模型中,可以保证条件期望的值域区间在 1]。

线性概率模型:一个数值例子
我们用一个数值例子来说明线性概率模型的一些问题。表 8.1给出 40 各家庭的住宅所有权 Y( 1 =拥有住宅, 0 =不拥有住宅)和家庭收入X (千美元)的虚构数据。根据这些数据,用OLS估计的线性概率模型如下:
( 0.1128 )( 0.0082 ) t =( -7.6984 )( 12.515 ) ( 8.1 )
ˆ 0.9457 0.1021i iY X
2 0.8048R
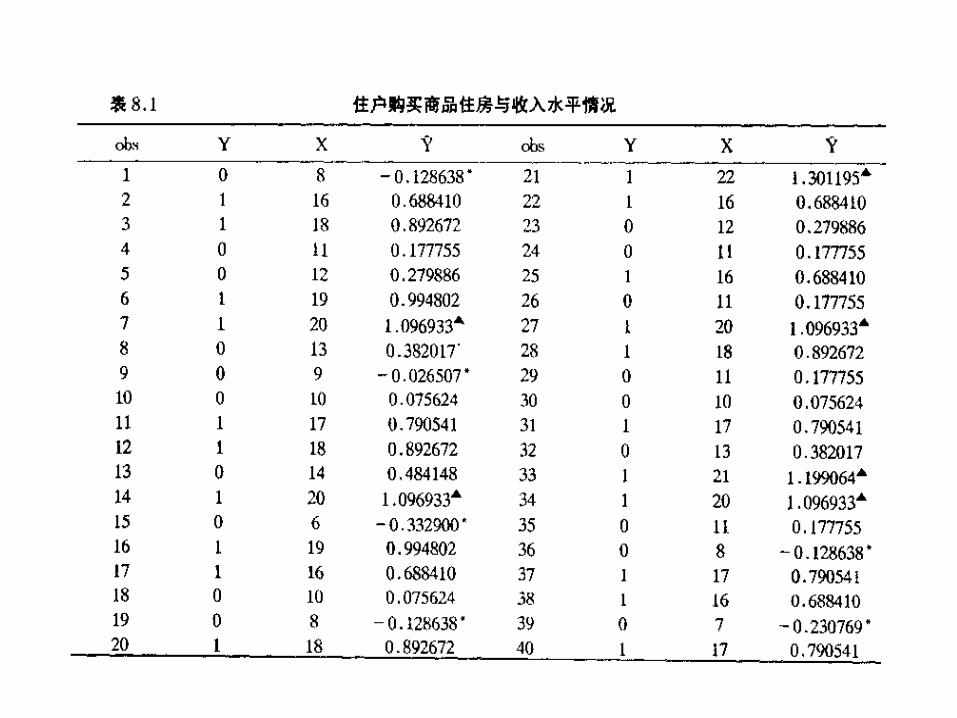

解释首先我们来解释这一回归。截距值 -0.9457给出零
收入的家庭拥有自己的住房的概率。由于是负值,而概率又不可能是负值,我们就把该值当作零看待,这样做在本例中是说得过去的。
斜率值 0.1021意味着收入每增加 1 单位,平均地说拥有住宅的概率增加 0.1021 或约 10%。
当然,对某一给定的收入水平,我们可以从( 8.1 )估计出拥有住宅的实际概率。例如,对于 X =12( 12000美元),估计拥有住宅
的概率是ˆ( / 12) 0.9457 12(0.1021)
.iY X 0 2795=

WLS估计 就是说,收入为 12000 美元的家庭拥有住宅
的概率为 28%。对于上面的估计受异方差的影响,因此我们可以用 WLS 来获得更有效的估计值。由于某些
是负的,和某些 大于 1 ,对于这些 来说, 将是负的,因此删去这些值 。得到的 WLS 回归为:1
1.2456 0.1196i i
i i i
Y X
w w w
iY
iYiY ˆ iw
( 0.1206 ) ( 0.0069 ) t = ( -10.332 ) ( 17.454 )
2 0.9214R

4 、拟和优度通常情况下,拟和优度不会太高,在 0.2至 0.6 之间,当实际的散点非常密集在点 A和 B 处时, 才会高。
1
Y
LPM
X0
受约束
)(b
……….
……….1
Y LPM
X0
无约束
)(a
……….
……….A
B
2R

非线性概率模型
2
ˆ1 2 3 [0,1]
4
i i i
LPM
u u Y
R
问题的提出: 的局限:
() 非正态() 异方差() 在 之外
() 一般比较小
应当指出的是,虽然我们可以采用 WLS 解决异方差性问题、增大样本容量减轻非正态性问题,通过约束迫使所估的事件 Y发生的概率落入 0-1 ,但是,LPM与经济意义的要求不符:随着 X 的变化, X
对的 “边际效应”保持不变。即不论 X 的变化是在什么水平上发生的,参数都不发生变化,显然这与现实经济所发生的情况是不符的。

§2 对数单位模型( Logit Model)
因此,表现概率平均变化比较理想的模型应当具有这样的特征:( 1 )随着 增加, 也增加,但不超出 0-1 这个区间。
( 2 )随着 X 变小 ,概率趋于零的速度越来越慢,而随着 X 变得很大,概率趋于 1 的速度也越来越慢”。 P随 X 变化而变化,且变化速率不是常数, P和 X 之间是非线性关系。
( 1/ )i iP E Y X
X
1
P
0
iX

1 2( )
1 2
1 2
1
1( 1| ) ( | ) (1)
1: ( 1| ) ( | )
11
10 1
i
i
i i i i i X
i i i i i i
i
i Z
i i
Logit
Logit
P P Y X E Y Xe
LPM P P Y X E Y X X
Z X
Pe
Z P
-
一、 模型、 模型中条件概率的表达式
比较
令
则()变为
(1)当 从 变到 , 从 变为。
(2)有一个拐点,在拐点之前,随Z或X增大,P的增长速度越来越快;在拐点之后,随Z或X增大,P的增
1
长速度越来越慢,逐渐趋近于 。
这是一个(累积)逻辑斯蒂分布函数为名的模型
( 对数单位模型 )
这些特征正好满足前面讨论的非线性概率模型的要求。

机会表示有利于拥有住房的
则且表示拥有住房的概率,如:
-
”(“、线性化与 机会比率
1:42.0/8.0)1/(
8.0
1
1
11
1
1
) 2
21
21
21
)(
)(
ii
ii
X
i
i
Xi
Xi
PP
PP
eP
Pe
P
eP
ratioodds
i
i
i
即一个家庭拥有住房的概率对不拥有住房的概率之比。

现在 就是有利于拥有住房的机会比率——一个家庭将拥有住房的概率对不拥有住房的概率之比。对 取自然对数得:
即机会比率的对数 不仅对 为线性,而且对参数也是线性。 被称为对数单位模型。
1iP P
ln( )1
ii
i
PL
P
1 2 iX
iL iX
L
3. 对数单位模型
1 2
1iXi
i
Pe
P

1 、 从0 变到 1 ,对数单位从 变到 2 、虽然 对 为线性,但概率本身却不然。3 、斜率系数给出 每单位变化的 的变化,它告知
人们随着收入变化一单位,有利于拥有住房的对数—机会比率是怎样变化的。截距是当收入为零时的有利于拥有住房的对数—机会比率的值。4 、对给定的某个收入水平,我们其实想估计的并
不是有利于拥有住房的机会比,而是拥有住房本身的概率。5 、对数单位模型假定机会比率的对数与 有线性
关系。
P L X
X L
X
对数模型的特点:

会出现无穷大量。这些数代入模型的左边
。否则有住宅的数据,那么当家庭拥庭困难。如果只有个别家数值。这时会遇到一些
,还需要知道对数值除了解释变量的数据外
为了估计模型
模型的估计二、
0,1
)1
ln( 21
ii
i
iii
ii
PP
L
uXP
PL
Logit
在这种情形下只有用最大似然估计求解,另外的一种估计方法,当我们拥有的数据如下表所示时可以用 OLS 求解。

用OLS 求解
1. 数据构造
( 收入以 的家庭个数)
(其中拥有住房的家庭数)
6 40 8
8 50 12
10 60 18
… … …
40 25 20
iX iN iX in
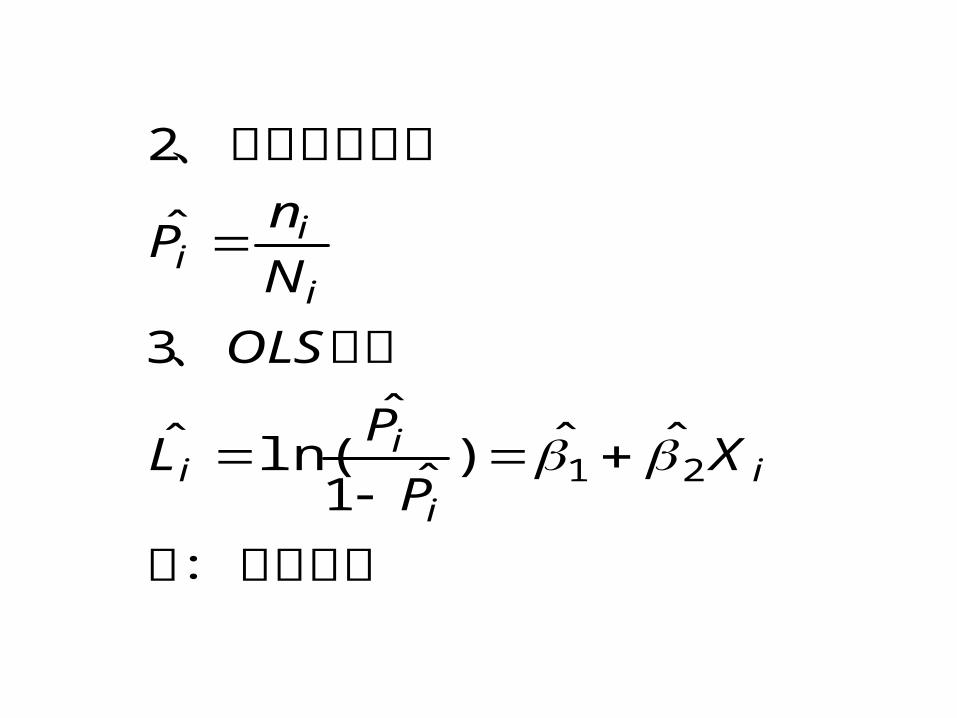
注:有异方差
估计、
、频率代替概率
ii
ii
i
ii
XP
PL
OLS
N
nP
21ˆˆ)
ˆ1
ˆln(ˆ
3
ˆ
2
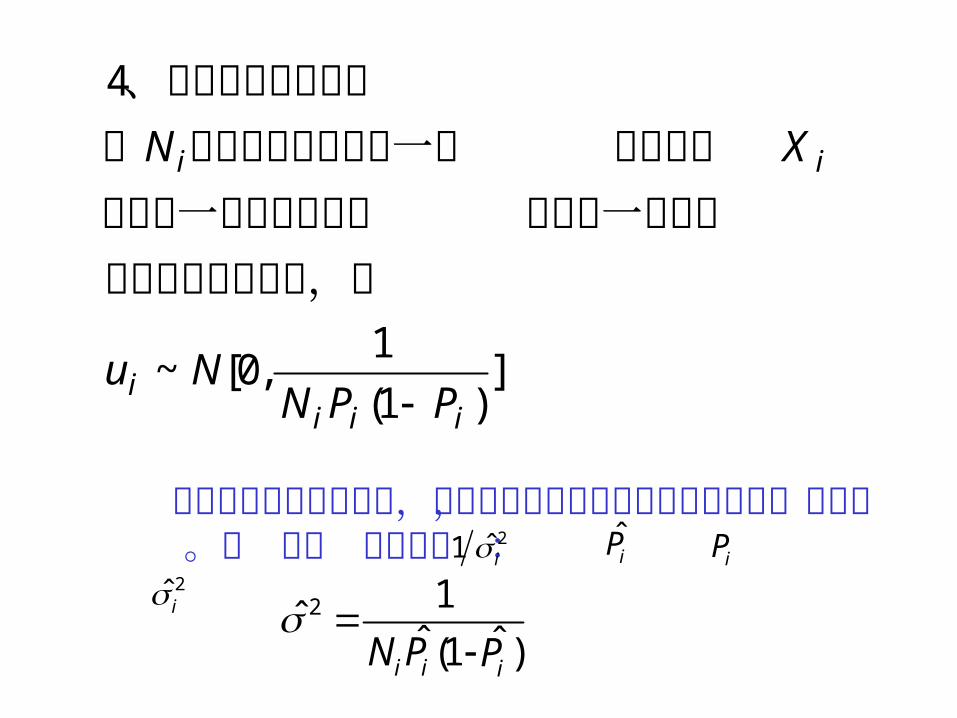
])1(
1,0[~
4
iiii
ii
PPNNu
XN
分布的二次式变量,则视为同一个独立中的每一次观测都可以
定收入组相当大于且如果在一给当、随机扰动项的分布
显然模型中存在异方差,因此我们考虑使用加权最小二乘法,权重取 。用 代替 则可求出 :
2ˆ1 i iPiP
2ˆi 2 1ˆ
ˆ (1 )i iN P
iP

。注:样本应当合理得大设。建立置信区间和检验假用
估计用
模型的回归步骤、
OLSstep
UXwL
OLSstep
PPNw
wuwXwwLstep
P
PLstep
N
nPstep
Logit
iiii
iiii
iiiiiii
i
ii
i
ii
:5
/
:4
)ˆ1(ˆ1
////ˆ:3
)ˆ1
ˆln(ˆ:2
ˆ:1
5
*21
*
21

1325.4
20
)ˆ1(ˆ1
/20/
,20
20
2921.0ˆ
9627.0
4456.1429.14
0054.01115.0
0787.0/5932.1ˆ
log
*
2
2
**
iiiii
iii
PPNwXX
X
R
t
XwL
it
i
概率?单位的家庭拥有住房的问:收入水平为
)()()()(
子模型估计的一个数值例三、

495.0ˆ
9803.0ˆ1
ˆ
)ˆ1
ˆln(ˆ
0199.0ˆˆ
09441.0ˆ
ˆ
*
*
i
L
i
i
i
ii
ii
P
eP
P
P
PL
wLL
L
i
得
得
而
再求
代入回归式得

为了解释二分应变量,有必要使用适当 CDF。对数单位模型使用的是累积逻辑斯蒂函数。在实际应用中发现正态CDF效果也不错。使用正态 CDF的估计模型通常称为概率单位模型。
引入概率单位模型有两种途径:一是模仿前面逻辑斯蒂函数的形式,直接用正态分布函数替换;二是依据麦克法登的效用理论或行为的理性选择引入概率单位模型。
§3 概率单位模型 (probit Model)

直接用正态分布函数替换
用正态分布函数去拟合 S曲线时,所得到的模型就是著名的 Probit 模型。 Probit 模型的具体形式为:
dteXFP iX tii
10
2 2/10
2
1)(
将其转化成线性模型: ii XPF 101 )(
对于模型上式,一般也是采用极大似然估计法 进行估计。 Probit 模型和 Logit 模型都是对线性概率模型的改进,两者的区别在于趋于 0或 1 的速率不同。逻辑分布函数趋于 0或 1 的速率慢于正态分布函数的速率。

Logit模型与 Probit模型的比较
)X(i i10e1
1P
i10 2X 2/t
i10i dte2
1)X(FP
逻辑分布函数趋于 0 和 1 的速度慢于正态分布函数的速度
P
0
1
Logit
Probit1 、几何形状

下面根据效用理论阐明使用概率单位模型的动机。 表示一种不可观测的效用指数, 表示收入,
仍然研究家庭拥有住房的概率。
当 越大时,认为拥有住房的概率越大。现在假定有这样一个临界值 ,当 时,
该家庭拥有住房,否则不拥有。
iI iX
1 2i iI X iI
*iI *
i iI I

在正态性假定下, 的概率可由标准化正态CDF算出。
t 是标准化正态变量, 。
*i II I
2* / 21Pr( 1) Pr( ) ( )
2
iI ti i i iP Y I I F I e dt
21 2 / 21
2
iX te dt
~ (0,1)t N


根据获得关于效用函数 以及 和 的信息,可得到:
如果我们掌握了的分组数据,便可由 计算出 ,一旦有了 ,就可很轻松的估计 和在对数单位分析中, 被称为正态等效离差
(n.e.d.) 。当 时, 将是负数,在实际中通常把 5 加到 上,其结果称为概率单位 .
iI 1 21( )i iI F P
1 2 iX
iP
iI iI 1 2
iI
0.5iP iI
iI

现在估计 和 。通过下面的式子: 概率单位模型的估计步骤:1 、从分组数据中估计出 。2 、根据 ,从标准正态 CDF中求出 n.e.d.=3 、用 作为回归的应变量。4 、由于随机误差项存在异方差,因此还要进行数据转换或用 WLS估计出最后结果。
5 、用普通方式进行假设检验,但得到的结果只在大样本下有效,同时 已没有多大价值
Pr . . . 5obit n e d 1 2
1 2i i iI X u
iP
iPiI
iI
2R

概率单位模型的例子
根据所给的数据,可以估计出如下结果。以 n.e.d.作为应变量:
以概率单位作为应变量:
除截距外,两种回归结果没有差别。
2
ˆ 1.0088 0.0481
( 17.330)(19.105) 0.9786
i iI X
t R
2
Pr 3.9911 0.0481
(68.560)(19.105) 0.9786
i iobit X
t R

比较对数单位与概率单位的估计值 :虽然对数单位模型和概率单位模型给出性质相同的结果,但是两个模型参数的估计值不可直接比较。一般两者参数有如下关系:
另外, LPM的系数与对数单位模型的系数有如下关系:
不含截距项时 含有截距项时
log Pr0.625 it obit
log0.25LPM it
log0.25 0.5LPM it

模型的检验与评价 对 Logit 模型的检验包括参数的显著性检验、
拟合优度检验等 1.参数的显著性检验 ①原假设是 ②由于参数的最大似然估计量具有渐进正态性,
因此检验统计量为: ③对给定的显著性水平 当 时,不能拒绝原假设,认为变量的系数
不能通过显著性检验;当 时,可以拒绝原假设,认为变量的系数能够通过显著性检验。
0 : 0iH
)ˆ(
ˆ
i
i
i
SEZ
/ 2iZ Z
/ 2iZ Z

2.拟合优度检验 模型参数估计后,选取适当的截断值 P (
),将观测数据分为两组: 归入第一组, 归入第二组,其中 。如果样本中的一个观测数据 Y 的取值为 0 并且该样本属于第一组,或者一个观测数据 Y 的取值为 1 并且属于第二组,就称这个观测数据是分组恰当的;否则就称这个观测数据是分组不恰当的。显然,如果模型估计与实际观测数据比较一致,则大多数的观测数据应该是分组恰当的。因此,可以利用分组恰当观测数据占总样本的比例来衡量模型的拟合优度。这种检验方法称为期望 -预测表检验。
0 1P 1
1 zP
e
1
1 zP
e
110
ˆˆ Xz

§4 托比( tobit)模型
托比模型是概率的拓展,还是以住房为例,对因变量我们不仅想知道有或是没有,还要问一个消费者相对于其收入花在购房上的金额。出现一个问题:如果一个消费者不买住房就得不到这类消费者的住房支出数据。托比模型就是针对这种情况而言的。

截取样本:仅对某些观测有因变量的信息的样本。
本课程对此不作要求)、用最大似然法估计(
否则的话
若
、托比模型
2
0
0
1
21
RHSuX
Y iii