
Комплексна я оценка демографических потерь вследствие преждевременной смертности в Украине

Поиск шаблонов и машинное обучение для демографических событий
(Pattern Mining and Machine Learningfor Demographic Sequences)
Баев Олег Дмитриевич
Москва, 2015

Содержание
• Демографические данные
• Машинное обучение: деревья решений
• Деревья решений для предсказания– первого события– последующего события– пола человека
• Анализ последовательностей
2

Задача
Dmitry I. Ignatov, Ekaterina Mitrofanova, Anna Muratova, Danil Gizdatullin:
Pattern Mining and Machine Learning for Demographic Sequences (2015)
• Исследование демографических данных с помощью методов машинного обучения и интеллектуального анализа данных
• Цель - выявление шаблонов (закономерностей) значимых событий в жизни людей и приобретение знаний
3

Демографические данные
Независимый институт социальной политики (НИСП):
Обследование «Родители и дети, мужчины и женщины в семье и обществе»
• 4857 человек: 1545 мужчин и 3312 женщин
• 11 поколений: каждое по 5 лет с 1930 по 1984 гг.
4

Информация о человеке
5
• дата рождения
• пол (мужской, женский)
• поколение
• уровень образования (общее, высшее, профессиональное)
• место жительства (город, городок, село)
• религиозность (да, нет)
• частота посещения церкви (раз в неделю, несколько раз в неделю, минимум раз в месяц, несколько раз в год, никогда)
• даты значимых событий в жизни:
– завершение обучения
– первый опыт работы
– отделение от родителей
– первые отношения
– первый брак
– рождение первого ребёнка
– расставание
– развод

Исследуемые вопросы
• Какие наиболее характерные для различных групп людей первые значимые события в жизни?
• Какие различия между мужчинами и женщинами с точки зрения демографического поведения?
• Какие нетривиальные, но устойчивые шаблоны (закономерности) можно выделить в жизни людей?
• Какое наиболее ожидаемое последующее событие в жизни людей после определённых событий?
6
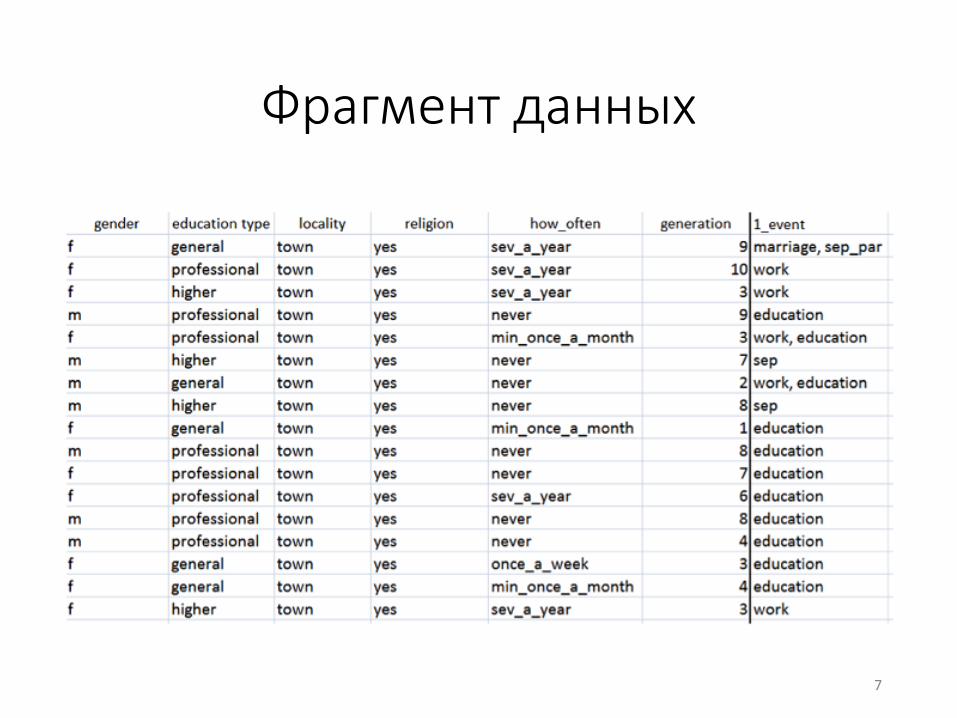
Фрагмент данных
7

Предобработка данных
• разделение событий на атомарные события
• получение примерно одинакового количества мужчин и женщин при помощи WEKA: SMOTE (Synthetic Minority Oversampling TEchnique)
• в итоге: сбалансированные данные
8

Машинное обучение
9
• Сравнение классификаторов:
– Classification Tree
– kNN
– SVM
• Предсказание первого события
• Примерно одинаковая точность (0.40 – 0.45)
• Выбран метод деревьев решений

Почему деревья принятия решений?
• представление в виде “если-то” правил
• простота интерпретации результатов
• модель “белого ящика”
10
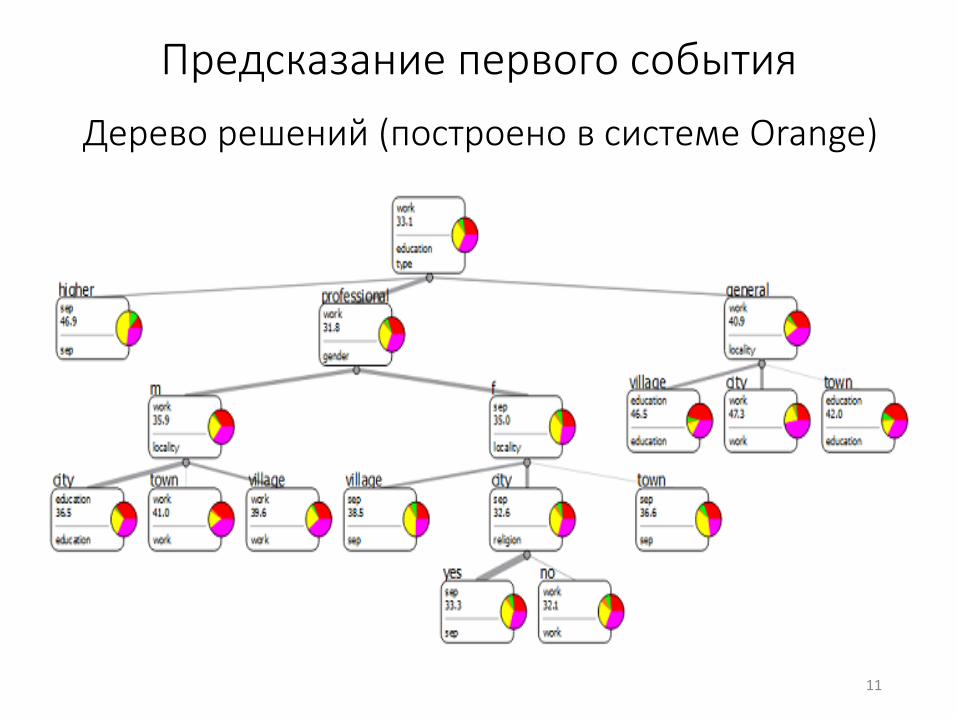
Предсказание первого события
Дерево решений (построено в системе Orange)
11

Анализ последовательностей событий
Кодирование информации о событиях и их временной взаимосвязи
• BE – двоичное кодирование
(‘0’ - событие не произошло, ‘1’ - произошло)
• TE – временное кодирование
(возраст в месяцах, когда произошло событие)
• PE – попарное кодирование
(для двух событий a и b:
‘<‘ - a предшествует b или b ещё не произошло,
‘>’ - a следует за b или a ещё не произошло,
‘=‘ - a и b произошли в одно время
‘n/a’ - a и b ещё не произошли)12
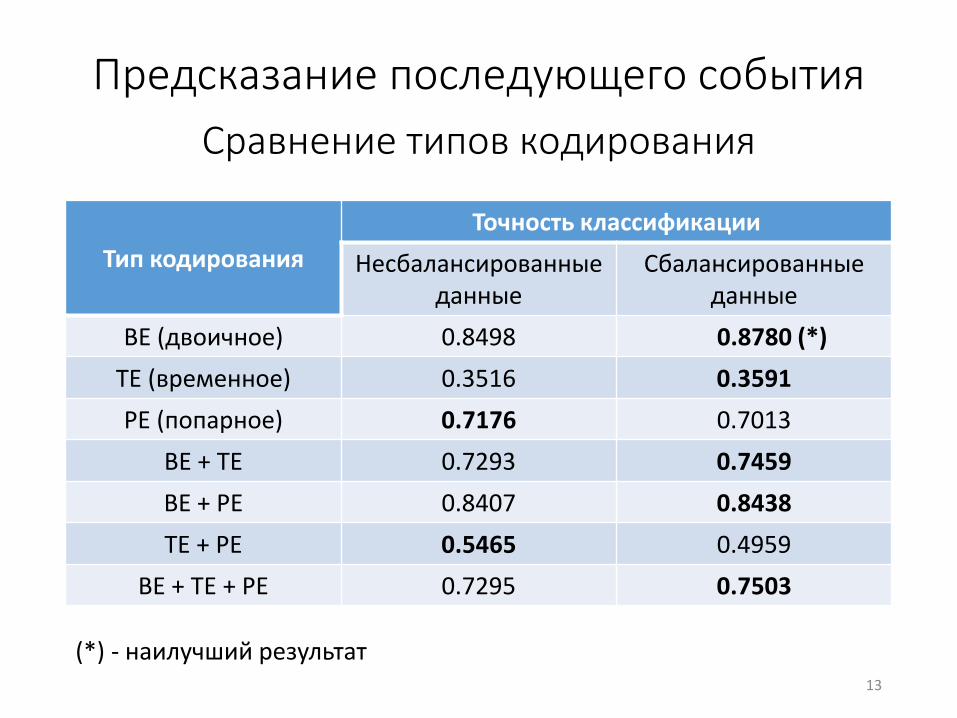
Предсказание последующего события
Сравнение типов кодирования
Тип кодирования
Точность классификации
Несбалансированныеданные
Сбалансированные данные
BE (двоичное) 0.8498 0.8780 (*)
TE (временное) 0.3516 0.3591
PE (попарное) 0.7176 0.7013
BE + TE 0.7293 0.7459
BE + PE 0.8407 0.8438
TE + PE 0.5465 0.4959
BE + TE + PE 0.7295 0.7503
13
(*) - наилучший результат

Предсказание последующего события
Матрица несоответствий
14
предсказаносоответствие с исходными данными
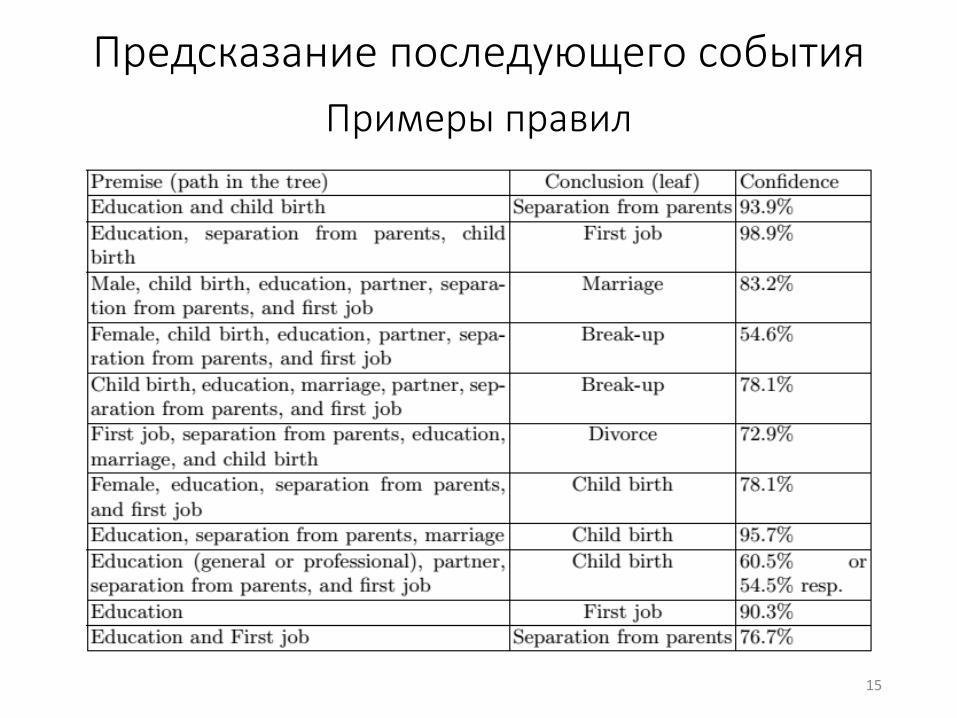
Предсказание последующего события
Примеры правил
15
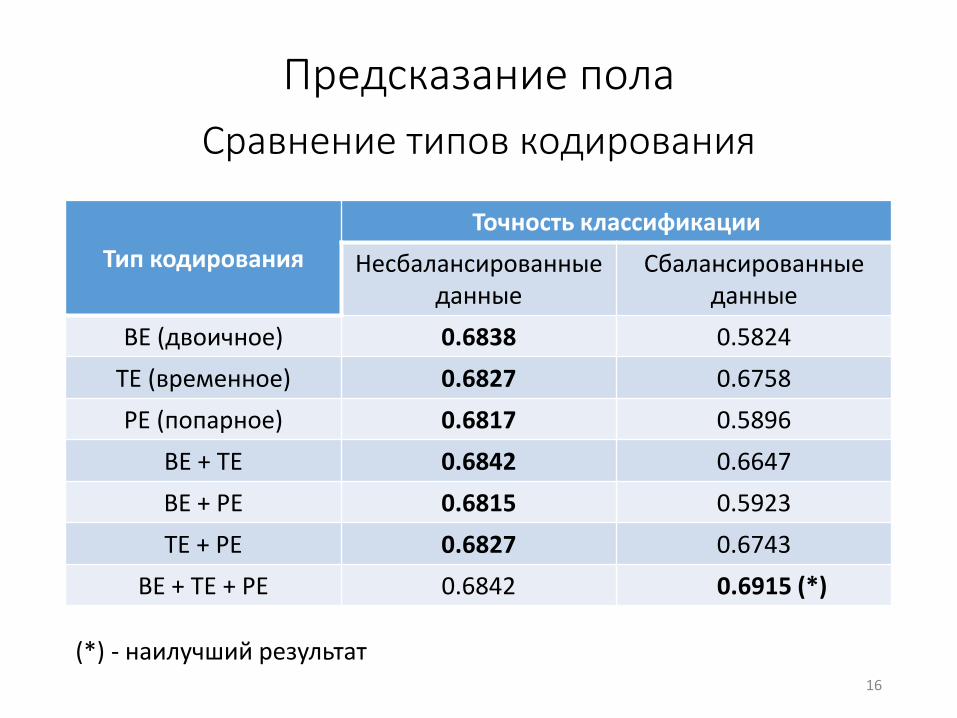
Предсказание пола
Сравнение типов кодирования
Тип кодирования
Точность классификации
Несбалансированныеданные
Сбалансированные данные
BE (двоичное) 0.6838 0.5824
TE (временное) 0.6827 0.6758
PE (попарное) 0.6817 0.5896
BE + TE 0.6842 0.6647
BE + PE 0.6815 0.5923
TE + PE 0.6827 0.6743
BE + TE + PE 0.6842 0.6915 (*)
16
(*) - наилучший результат
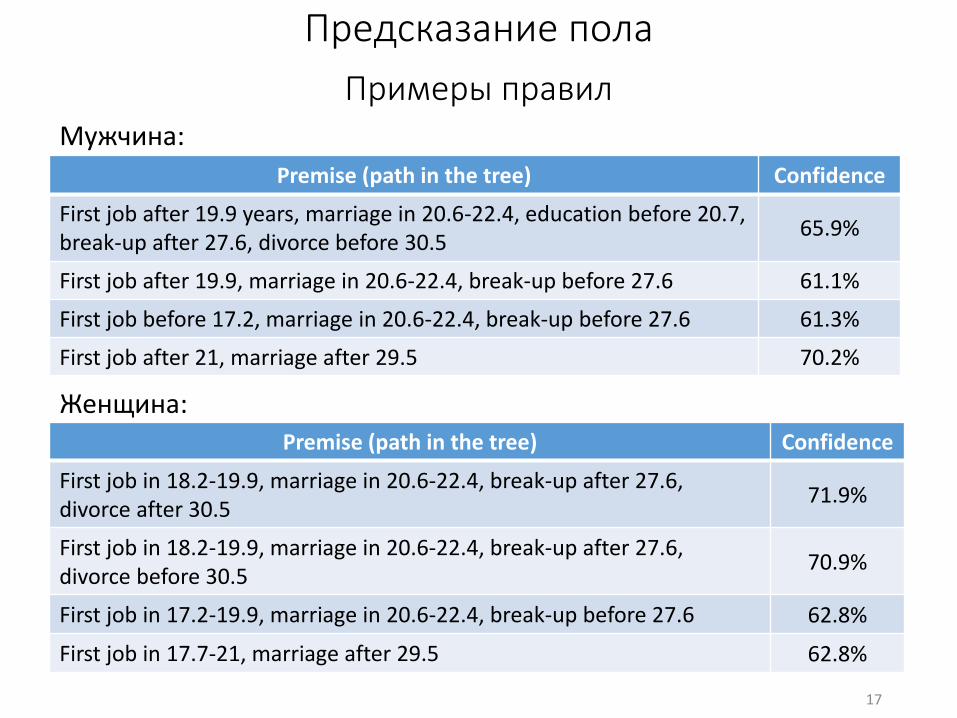
Предсказание пола
Примеры правилМужчина:
Женщина:
17
Premise (path in the tree) Confidence
First job after 19.9 years, marriage in 20.6-22.4, education before 20.7, break-up after 27.6, divorce before 30.5
65.9%
First job after 19.9, marriage in 20.6-22.4, break-up before 27.6 61.1%
First job before 17.2, marriage in 20.6-22.4, break-up before 27.6 61.3%
First job after 21, marriage after 29.5 70.2%
Premise (path in the tree) Confidence
First job in 18.2-19.9, marriage in 20.6-22.4, break-up after 27.6, divorce after 30.5
71.9%
First job in 18.2-19.9, marriage in 20.6-22.4, break-up after 27.6, divorce before 30.5
70.9%
First job in 17.2-19.9, marriage in 20.6-22.4, break-up before 27.6 62.8%
First job in 17.7-21, marriage after 29.5 62.8%

Анализ последовательностей (Sequence Mining)
• Предметный набор (itemset) – непустой набор предметов (атомарных
событий)
𝑒 = 𝑎1, 𝑎2, … , 𝑎𝑛
• Последовательность (sequence) – упорядоченный список предметных
наборов (событий)
𝑠 = 𝑒1, 𝑒2, … , 𝑒𝑚
• α = 𝑎1, 𝑎2, … , 𝑎𝑛 называется подпоследовательностью (subsequence)
𝛽 = 𝑏1, 𝑏2, … , 𝑏𝑚 и обозначается
α ⊑ 𝛽 ⟺ ∃ 1 ≤ 𝑗1 < 𝑗2 < ⋯ < 𝑗𝑛 ≤ m ∶ 𝑎1 ⊆ 𝑏𝑗1, 𝑎2 ⊆ 𝑏𝑗2, … , 𝑎𝑛 ⊆ 𝑏𝑗𝑛
• Поддержка (support) последовательности α в базе данных D – количество
последовательностей в D, содержащих α:
𝑠𝑢𝑝𝐷 𝛼 = # 𝑠|𝑠 ∈ 𝐷 & 𝛼 ⊑ 𝑠18

Последовательностный шаблон(sequential pattern)
Это:
• Максимальная (closed) последовательность –последовательность, не содержащаяся в какой-либо другой последовательности с той же поддержкой
И
• Частая (frequent) последовательность –последовательность, имеющая поддержку выше заданного порога (minsup)
19
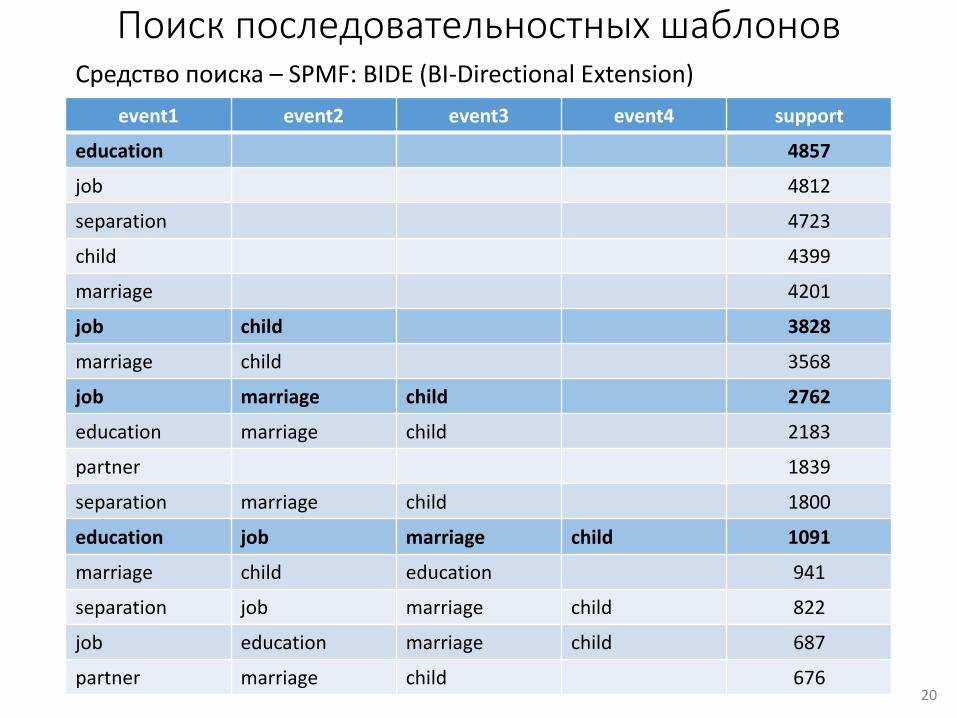
Поиск последовательностных шаблонов
event1 event2 event3 event4 support
education 4857
job 4812
separation 4723
child 4399
marriage 4201
job child 3828
marriage child 3568
job marriage child 2762
education marriage child 2183
partner 1839
separation marriage child 1800
education job marriage child 1091
marriage child education 941
separation job marriage child 822
job education marriage child 687
partner marriage child 67620
Средство поиска – SPMF: BIDE (BI-Directional Extension)

Возникающий шаблон (emergent pattern)
• Возникающая (emergent) последовательность – частая последовательность, которая чаще встречается в одном конкретном классе, чем в других
• Уровень роста (growth rate) последовательности s для двух классов:
• Последовательность является возникающей, если её уровень роста выше заданного порога
21

Поиск возникающих шаблонов
• Средство поиска – SPMF: PrefixSpan(Prefix-projected Sequential pattern mining)
• Два класса: мужчины и женщины
• Вклад (contribution) последовательности s в класс Ci :
22
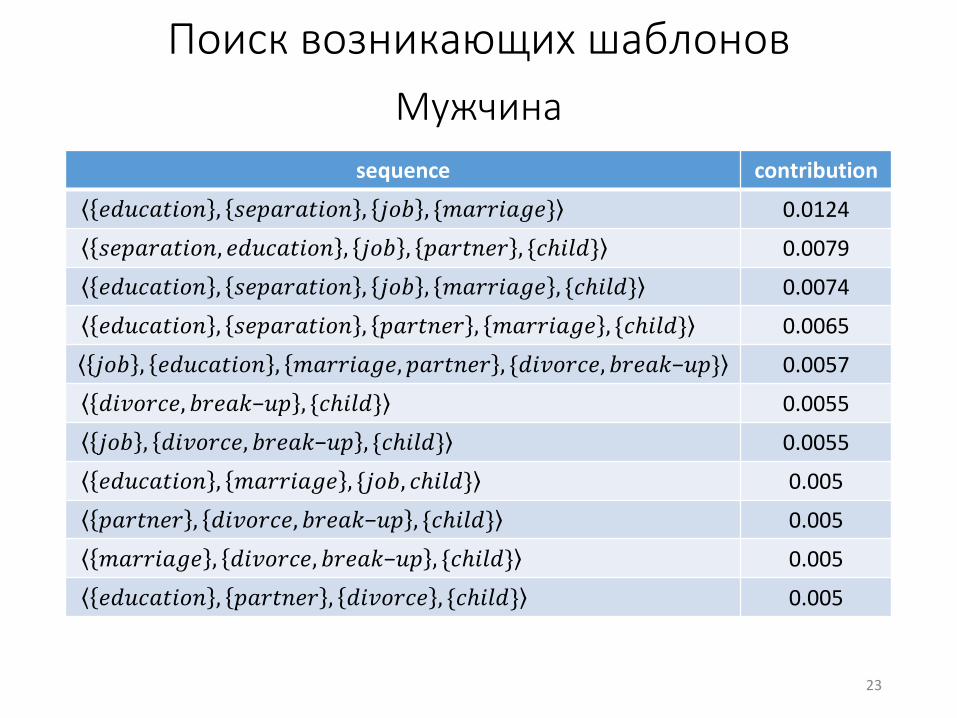
Поиск возникающих шаблонов
Мужчина
sequence contribution
𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑠𝑒𝑝𝑎𝑟𝑎𝑡𝑖𝑜𝑛 , 𝑗𝑜𝑏 , {𝑚𝑎𝑟𝑟𝑖𝑎𝑔𝑒} 0.0124
𝑠𝑒𝑝𝑎𝑟𝑎𝑡𝑖𝑜𝑛, 𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑗𝑜𝑏 , 𝑝𝑎𝑟𝑡𝑛𝑒𝑟 , {𝑐ℎ𝑖𝑙𝑑} 0.0079
𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑠𝑒𝑝𝑎𝑟𝑎𝑡𝑖𝑜𝑛 , 𝑗𝑜𝑏 , 𝑚𝑎𝑟𝑟𝑖𝑎𝑔𝑒 , {𝑐ℎ𝑖𝑙𝑑} 0.0074
𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑠𝑒𝑝𝑎𝑟𝑎𝑡𝑖𝑜𝑛 , 𝑝𝑎𝑟𝑡𝑛𝑒𝑟 , 𝑚𝑎𝑟𝑟𝑖𝑎𝑔𝑒 , {𝑐ℎ𝑖𝑙𝑑} 0.0065
𝑗𝑜𝑏 , 𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑚𝑎𝑟𝑟𝑖𝑎𝑔𝑒, 𝑝𝑎𝑟𝑡𝑛𝑒𝑟 , {𝑑𝑖𝑣𝑜𝑟𝑐𝑒, 𝑏𝑟𝑒𝑎𝑘−𝑢𝑝} 0.0057
𝑑𝑖𝑣𝑜𝑟𝑐𝑒, 𝑏𝑟𝑒𝑎𝑘−𝑢𝑝 , {𝑐ℎ𝑖𝑙𝑑} 0.0055
𝑗𝑜𝑏 , 𝑑𝑖𝑣𝑜𝑟𝑐𝑒, 𝑏𝑟𝑒𝑎𝑘−𝑢𝑝 , {𝑐ℎ𝑖𝑙𝑑} 0.0055
𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑚𝑎𝑟𝑟𝑖𝑎𝑔𝑒 , {𝑗𝑜𝑏, 𝑐ℎ𝑖𝑙𝑑} 0.005
𝑝𝑎𝑟𝑡𝑛𝑒𝑟 , 𝑑𝑖𝑣𝑜𝑟𝑐𝑒, 𝑏𝑟𝑒𝑎𝑘−𝑢𝑝 , {𝑐ℎ𝑖𝑙𝑑} 0.005
𝑚𝑎𝑟𝑟𝑖𝑎𝑔𝑒 , 𝑑𝑖𝑣𝑜𝑟𝑐𝑒, 𝑏𝑟𝑒𝑎𝑘−𝑢𝑝 , {𝑐ℎ𝑖𝑙𝑑} 0.005
𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑝𝑎𝑟𝑡𝑛𝑒𝑟 , 𝑑𝑖𝑣𝑜𝑟𝑐𝑒 , {𝑐ℎ𝑖𝑙𝑑} 0.005
23
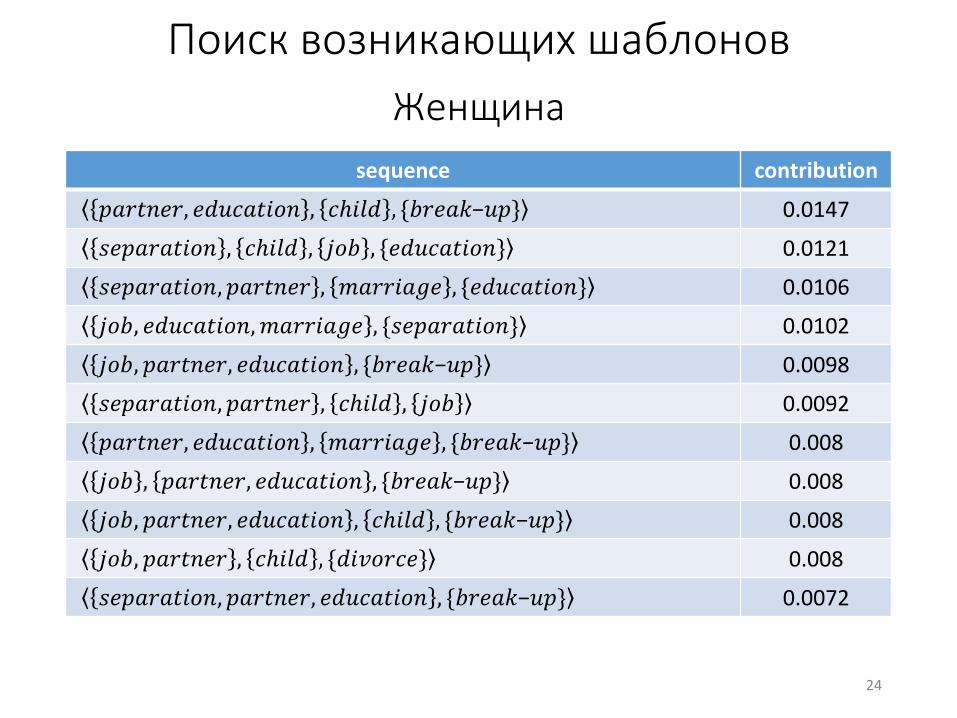
Поиск возникающих шаблонов
Женщина
sequence contribution
𝑝𝑎𝑟𝑡𝑛𝑒𝑟, 𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑐ℎ𝑖𝑙𝑑 , {𝑏𝑟𝑒𝑎𝑘−𝑢𝑝} 0.0147
𝑠𝑒𝑝𝑎𝑟𝑎𝑡𝑖𝑜𝑛 , 𝑐ℎ𝑖𝑙𝑑 , 𝑗𝑜𝑏 , {𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛} 0.0121
𝑠𝑒𝑝𝑎𝑟𝑎𝑡𝑖𝑜𝑛, 𝑝𝑎𝑟𝑡𝑛𝑒𝑟 , 𝑚𝑎𝑟𝑟𝑖𝑎𝑔𝑒 , {𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛} 0.0106
𝑗𝑜𝑏, 𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛,𝑚𝑎𝑟𝑟𝑖𝑎𝑔𝑒 , {𝑠𝑒𝑝𝑎𝑟𝑎𝑡𝑖𝑜𝑛} 0.0102
𝑗𝑜𝑏, 𝑝𝑎𝑟𝑡𝑛𝑒𝑟, 𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , {𝑏𝑟𝑒𝑎𝑘−𝑢𝑝} 0.0098
𝑠𝑒𝑝𝑎𝑟𝑎𝑡𝑖𝑜𝑛, 𝑝𝑎𝑟𝑡𝑛𝑒𝑟 , 𝑐ℎ𝑖𝑙𝑑 , 𝑗𝑜𝑏 0.0092
𝑝𝑎𝑟𝑡𝑛𝑒𝑟, 𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑚𝑎𝑟𝑟𝑖𝑎𝑔𝑒 , {𝑏𝑟𝑒𝑎𝑘−𝑢𝑝} 0.008
𝑗𝑜𝑏 , 𝑝𝑎𝑟𝑡𝑛𝑒𝑟, 𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , {𝑏𝑟𝑒𝑎𝑘−𝑢𝑝} 0.008
𝑗𝑜𝑏, 𝑝𝑎𝑟𝑡𝑛𝑒𝑟, 𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , 𝑐ℎ𝑖𝑙𝑑 , {𝑏𝑟𝑒𝑎𝑘−𝑢𝑝} 0.008
𝑗𝑜𝑏, 𝑝𝑎𝑟𝑡𝑛𝑒𝑟 , 𝑐ℎ𝑖𝑙𝑑 , {𝑑𝑖𝑣𝑜𝑟𝑐𝑒} 0.008
𝑠𝑒𝑝𝑎𝑟𝑎𝑡𝑖𝑜𝑛, 𝑝𝑎𝑟𝑡𝑛𝑒𝑟, 𝑒𝑑𝑢𝑐𝑎𝑡𝑖𝑜𝑛 , {𝑏𝑟𝑒𝑎𝑘−𝑢𝑝} 0.0072
24

Заключение
• Методы интеллектуального анализа данных не ограничены конкретной областью применения
• Они предназначены для поиска неочевидных, объективных и полезных на практике закономерностей, которые скрыты в больших объёмах данных
25

Спасибо за внимание!
26


















