

Современная операционная система: что надо знать...
21
Современная операционная система: что надо знать разработчику Александр Крижановский NatSys Lab., Tempesta Technologies [email protected]
-
Upload
ontico -
Category
Engineering
-
view
6.816 -
download
2
Transcript of Современная операционная система: что надо знать...

Современная операционная система: что надо знать разработчику
Александр Крижановский
NatSys Lab., Tempesta [email protected]

Disclamer
Компоненты ОС Linux – да, но через призму...
…моего личнго мнения → welcome to holy war :)
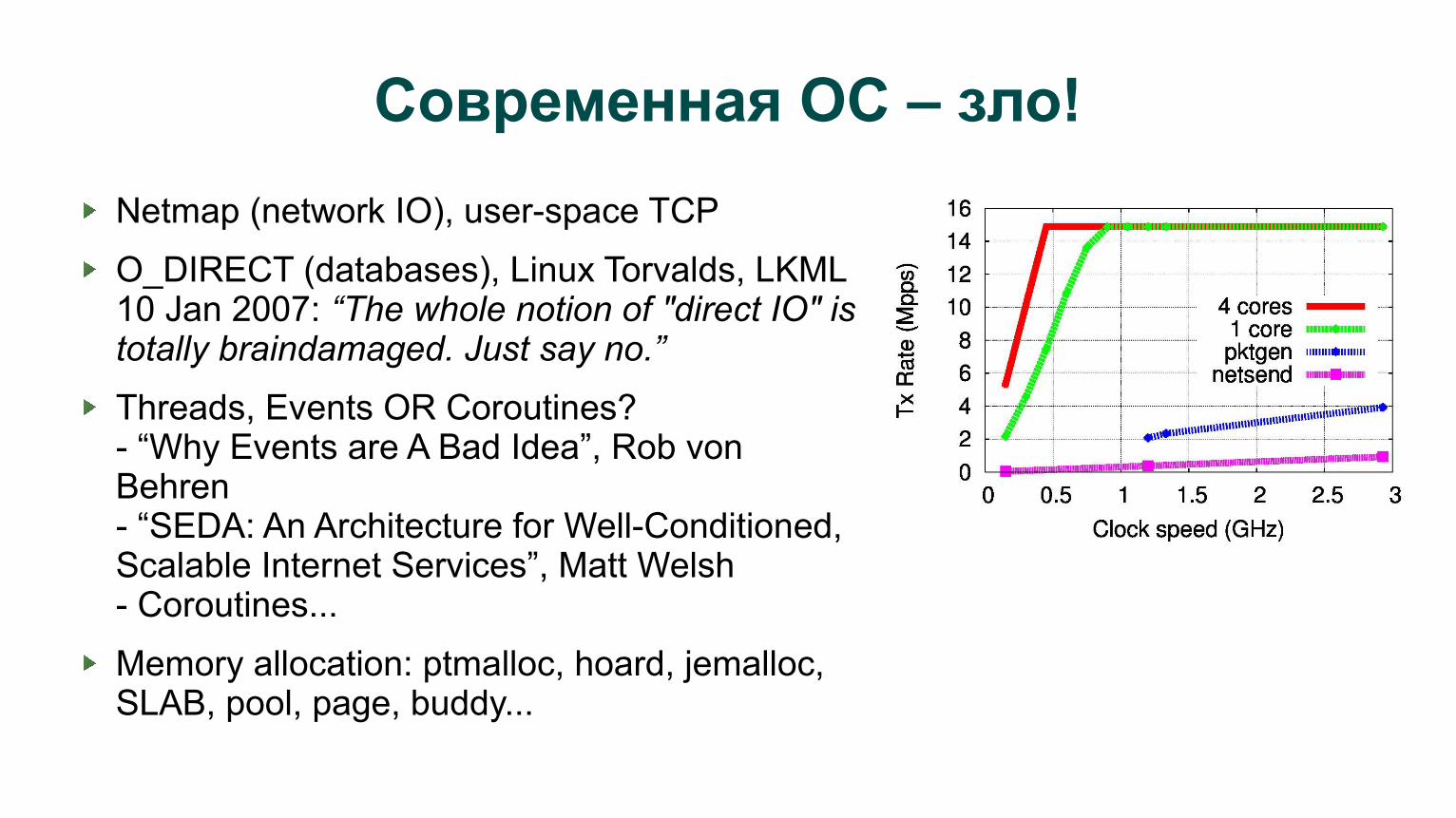
Современная ОС – зло!
Netmap (network IO), user-space TCP
O_DIRECT (databases), Linux Torvalds, LKML 10 Jan 2007: “The whole notion of "direct IO" is totally braindamaged. Just say no.”
Threads, Events OR Coroutines?- “Why Events are A Bad Idea”, Rob von Behren- “SEDA: An Architecture for Well-Conditioned, Scalable Internet Services”, Matt Welsh- Coroutines...
Memory allocation: ptmalloc, hoard, jemalloc, SLAB, pool, page, buddy...

...но не для десктопа
Gentoo с легким оконным менеджером:$ ps -A|wc -l112
Kernel stuff, X, fluxbox, Xterm, bash, skype, thunderbird, firefox, ooffice, gcc, ./a.out ….=> и у каждого это свое
$ grep -c processor /proc/cpuinfo4$ grep MemTotal /proc/meminfo MemTotal: 8123396 kB$ numactl -sphyscpubind: 0 1 2 3 No NUMA support available on this system.

Что делает прогрессивная часть человечества?
“...standard servers running an in-house OS. The key to achieve that performance was to disable IRQs, no syscalls, no context switching, no kernel, no memcopy, new stack etc.Basically in few hundreds ticks a packet hits the nginx or whatever application runs on it.”
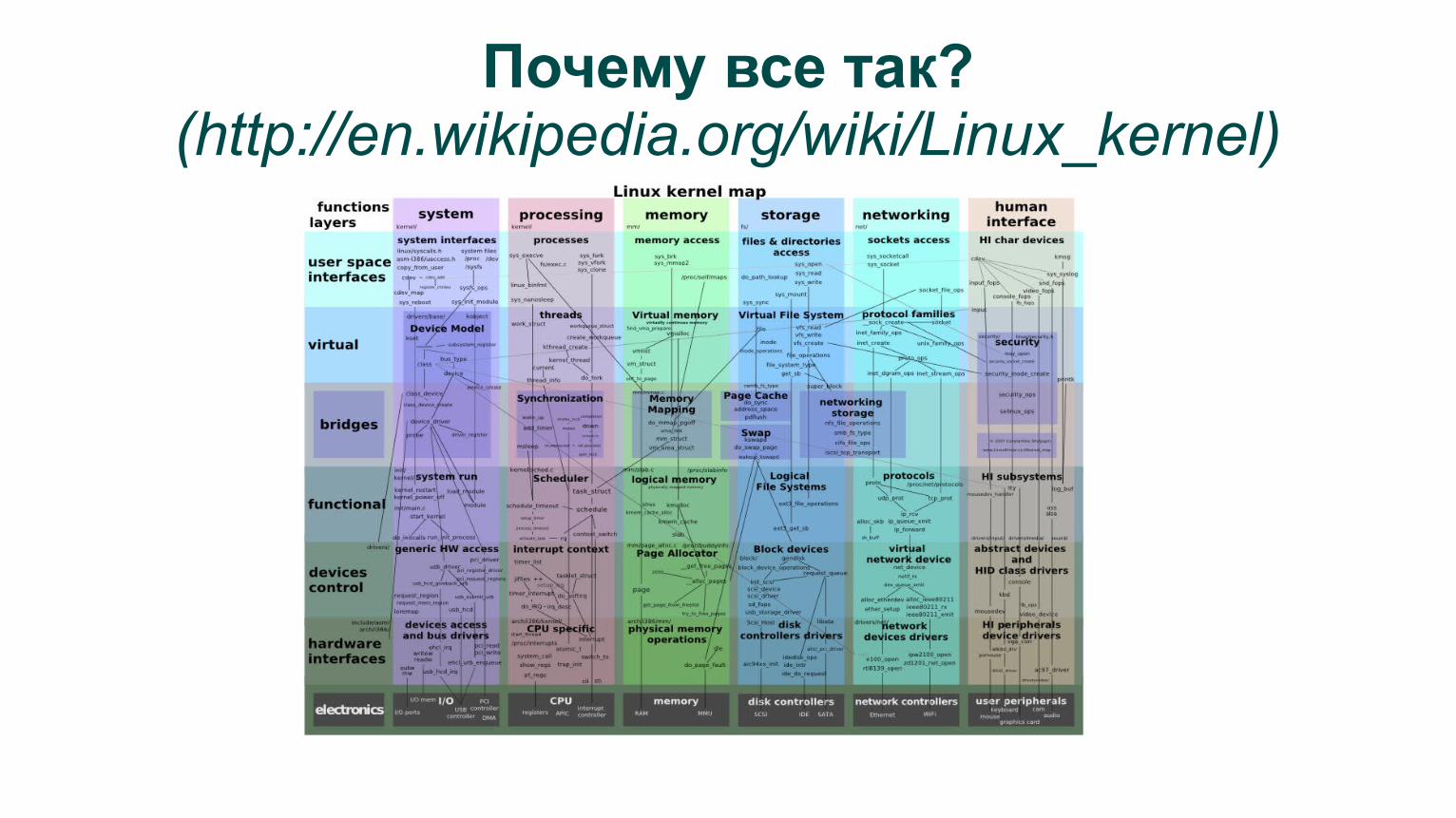
Почему все так?(http://en.wikipedia.org/wiki/Linux_kernel)

Processing
Процессы как-то спроведливо и оптимально планируются по ядрам, получают свои time slice'ы...
Процессы и потоки – это удобство, для производительности есть ядра CPU и “железные потоки”
Context switch! Инвалидация TLB и L1{d,c} кэшей! Вымывание L2{d,c} и L3{d,c} кэшей+ kernel/user switch - дешев
NUMA миграция контекста - перепланирование на другую ноду
Shared memory – прямой доступ к удаленной ноде
Ulrich Drepper, “What Every Programmer Should Know about Memory”
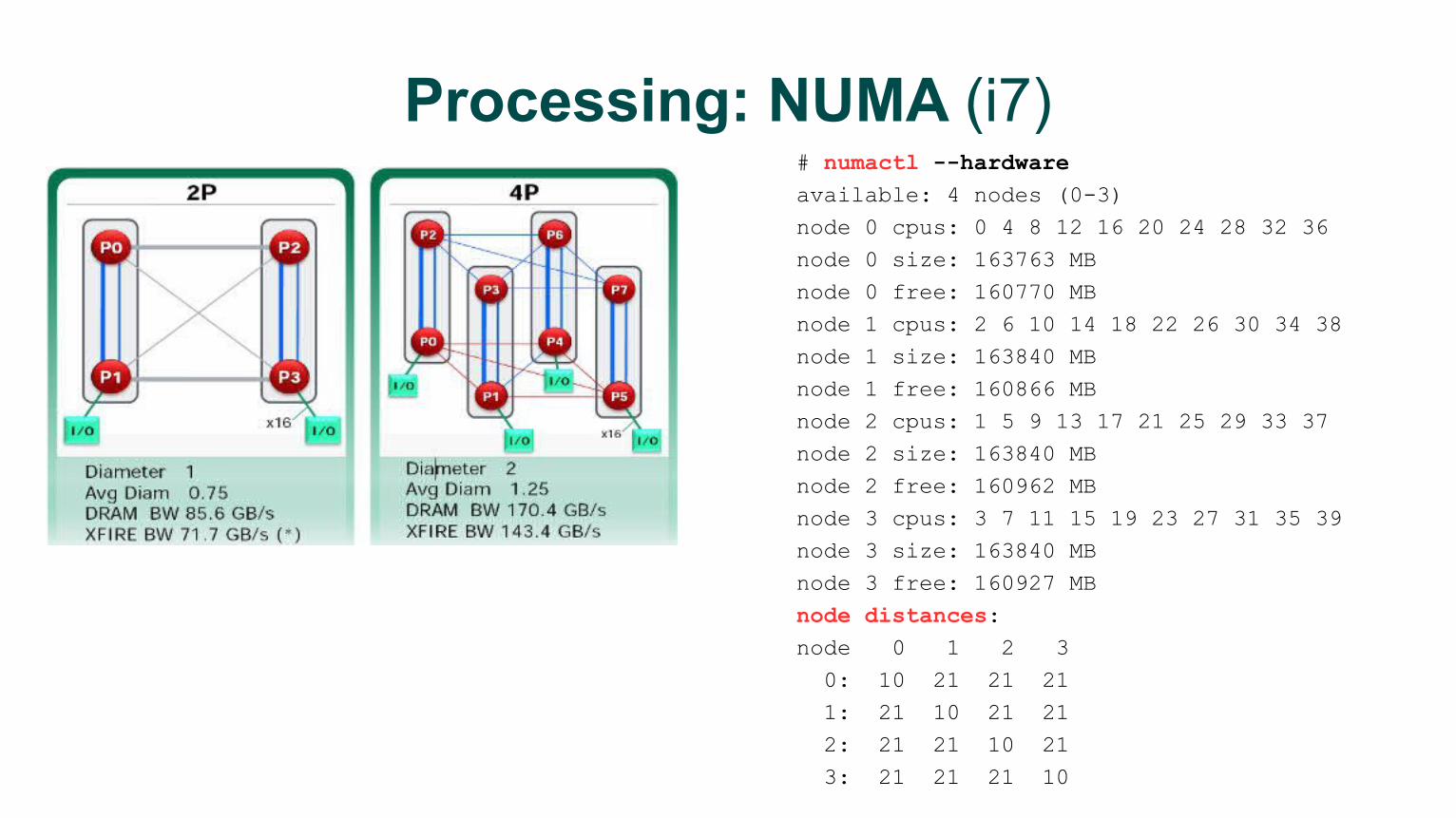
Processing: NUMA (i7)# numactl --hardware
available: 4 nodes (0-3)
node 0 cpus: 0 4 8 12 16 20 24 28 32 36
node 0 size: 163763 MB
node 0 free: 160770 MB
node 1 cpus: 2 6 10 14 18 22 26 30 34 38
node 1 size: 163840 MB
node 1 free: 160866 MB
node 2 cpus: 1 5 9 13 17 21 25 29 33 37
node 2 size: 163840 MB
node 2 free: 160962 MB
node 3 cpus: 3 7 11 15 19 23 27 31 35 39
node 3 size: 163840 MB
node 3 free: 160927 MB
node distances:
node 0 1 2 3
0: 10 21 21 21
1: 21 10 21 21
2: 21 21 10 21
3: 21 21 21 10

Processing: best practices(1 машина – 1 задача!)
Spin locks, lock-free & Ko. - только в пределах одного процессора=> мини-кластеры внутри одной NUMA машины со своими очередями, локами и пр.
=> Минимизация разделяемых данныхex. std::shared_ptr использует reference counter – целую переменную, разделяемую и модифицируемую всеми потоками
False sharing => выравнивайте данные
=> Привязывайте процессы# dd if=/dev/zero count=2000000 bs=8192 | nc 1.1.1.1 80
16384000000 bytes (16 GB) copied, 59.4648 seconds, 276 MB/s
# taskset 0x400 dd if=/dev/zero count=2000000 bs=8192 | taskset 0x200 nc 1.1.1.1 80
16384000000 bytes (16 GB) copied, 39.8281 seconds, 411 MB/s
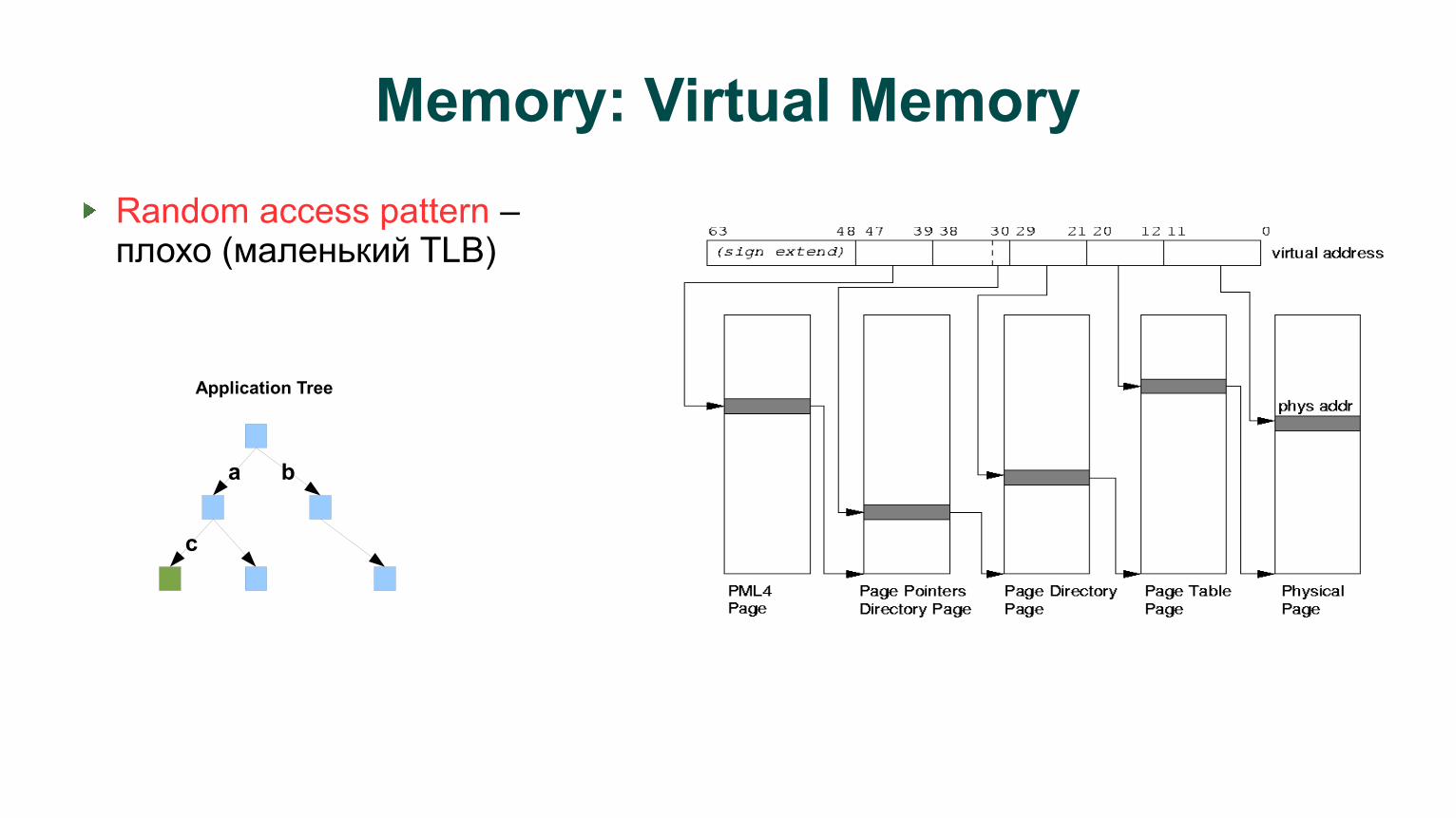
Memory: Virtual Memory
Random access pattern – плохо (маленький TLB)
a b
c
Application Tree

Memory: вытеснение страниц
Привет, Базы данных!(ex. InnoDB buffer pool)
Linux [kswapd/N], [writeback]
linux/Documentation/sysctl/vm.txt:
● vm.dirty_background_{ratio,bytes} – точка начала отложенных сбросов● vm.dirty_{ratio,bytes} – точка начала сброса страниц самим процессом● vm.dirty_expire_centisecs – время устаревания страниц● vm.dirty_writeback_centisecs – время между отложенными сбросами● vm.vfs_cache_presure – вымещение dentries/inodes vs. pagecache
active list
inactive list
add
freeP
P
P
P
P P
P
P
hit

Memory: (Transparrent) Huge Pages
Подходит не всем (ex. некоторые БД)+ меньший TLB miss, лучшая работа с page table- TLB маленький, тяжело выделить страницу
$ grep -o 'pdpe1gb\|pse' /proc/cpuinfo| sort -updpe1gb # 1GBpse # 2MB
Linux 2.6.38, для анонимных страниц (не связанных с файлами)
CONFIG_TRANSPARENT_HUGEPAGE
/sys/kernel/mm/transparent_hugepage/
madvise(..., …, MADV_HUGEPAGE)
https://lwn.net/Articles/423584/
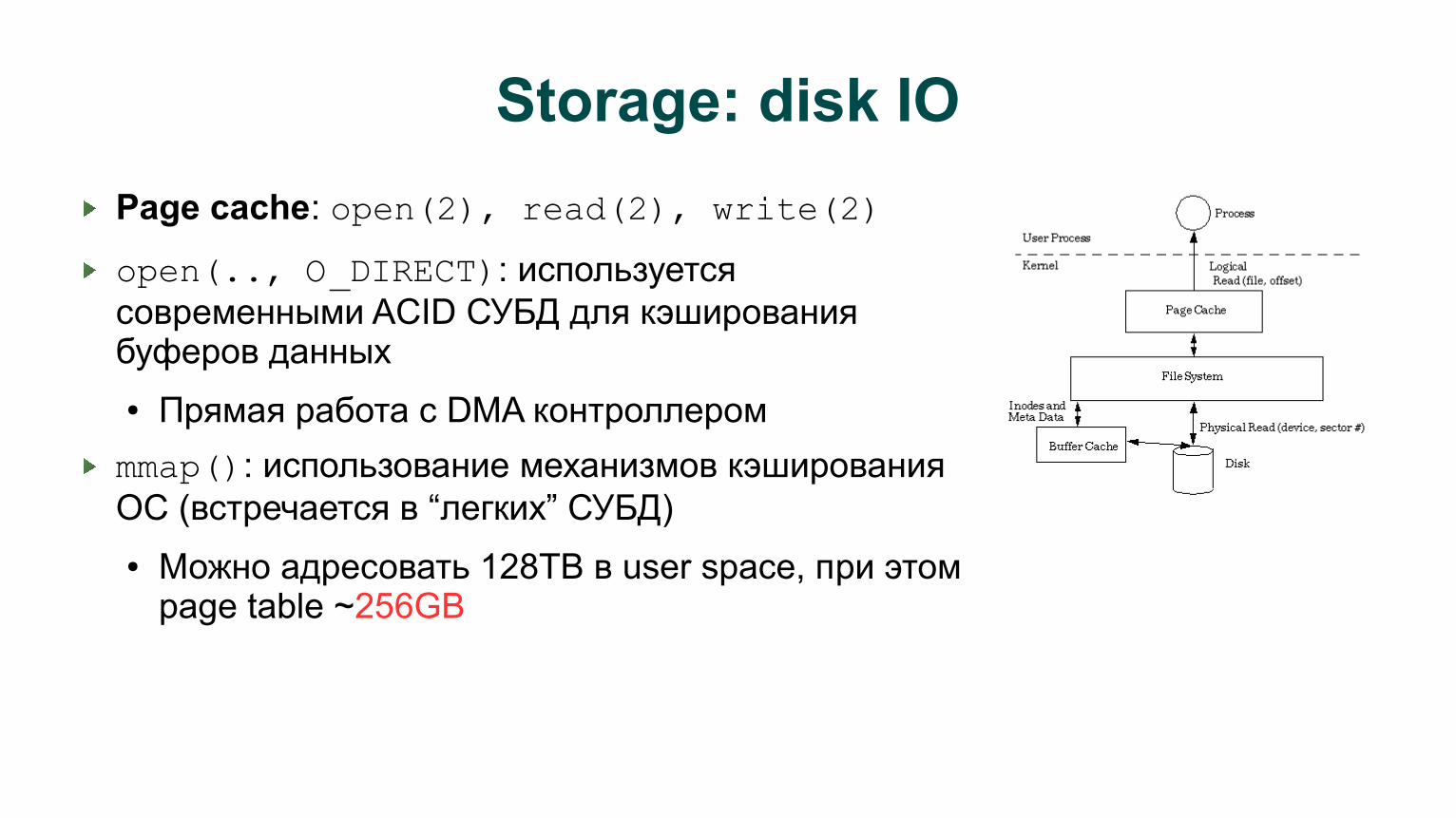
Storage: disk IO
Page cache: open(2), read(2), write(2)
open(.., O_DIRECT): используется современными ACID СУБД для кэширования буферов данных
● Прямая работа с DMA контроллером
mmap(): использование механизмов кэширования ОС (встречается в “легких” СУБД)
● Можно адресовать 128TB в user space, при этом page table ~256GB

Storage: IO scheduler
Современные SAS/SATA контроллеры имеютсобственные аналогичные механизмы планирования
Уровень блочного ввода-вывода(между ФС и драйвером устройства)
Накапливает, переупорядочивает и отдает наввод-вывод драйверу запросы ввода-вывода
Noop (No Operation): простой FIFO без переупорядочивания, слитие запросов для снижения нагрузки на CPU при IO (полагается на TCQ/NCQ)
Deadline: циклический, почти RT (рекомендуется для СУБД)
CFQ (Complete Fair Queuing): IO QoS для процессов, имеет возможность настройки баланса между latency и пропускной способностью

Storage: IO оптимизация
Планировщик
● /sys/block/{dev}/queue/scheduler – алгоритм планировщика
● /sys/block/{dev}/queue/nr_requests – длина очереди планировщика IO (latency vs. throughput)
● /sys/block/{dev}/queue/read_ahead_kb - префетчинг
Системные вызовы
● msync() – синхронизация mmap()'ленных страниц
● fsync() – сброс кэшированных блоков
● madvise()/posix_fadvise() – access hints
● mlock() – запретить свопинг
● fallocate() – предвыделение блоков
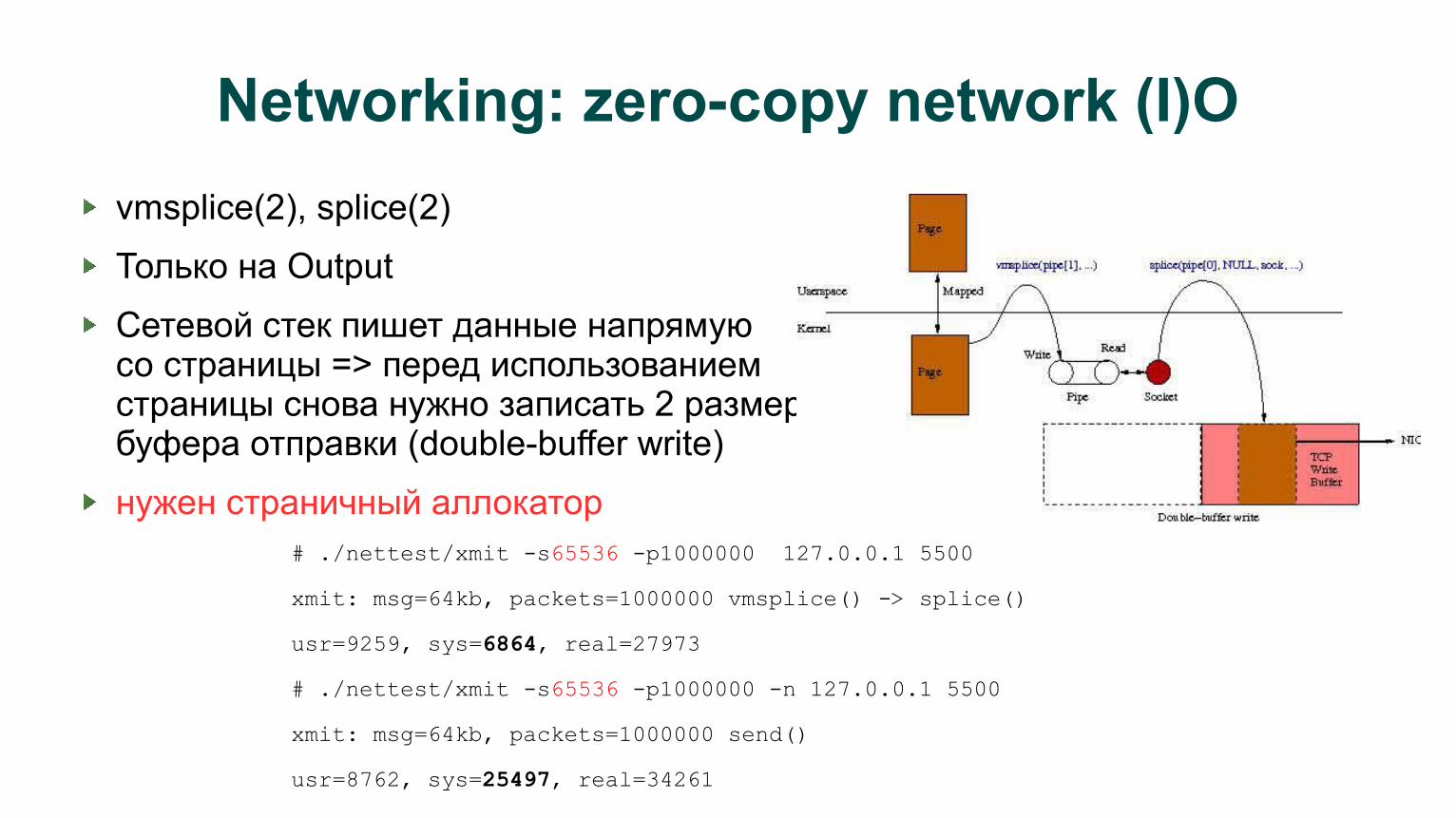
Networking: zero-copy network (I)O
vmsplice(2), splice(2)
Только на Output
Сетевой стек пишет данные напрямуюсо страницы => перед использованиемстраницы снова нужно записать 2 размерабуфера отправки (double-buffer write)
нужен страничный аллокатор # ./nettest/xmit -s65536 -p1000000 127.0.0.1 5500
xmit: msg=64kb, packets=1000000 vmsplice() -> splice()
usr=9259, sys=6864, real=27973
# ./nettest/xmit -s65536 -p1000000 -n 127.0.0.1 5500
xmit: msg=64kb, packets=1000000 send()
usr=8762, sys=25497, real=34261

Networking: Параллельность обработки
Параллельность: MSI-X, irq round-robin$ grep eth0 /proc/interrupts$ echo 1 > /proc/irq/$q0/smp_affinity$ echo 2 > /proc/irq/$q1/smp_affinity$ echo 4 > /proc/irq/$q2/smp_affinity…
RPS (Receive Packet Steering) позволяет «разбрасывать» пакеты по softirq на разных ядрах если MSI-X недостаточно (или железо вообще не может параллелить прерывания)$ for i in `seq 0 7`; do echo fffffff > /sys/class/net/eth0/queues/rx-$i/rps_cpus;done
RFS (Receive Flow Steering) позволяет отправлять пакеты на CPU прикладного процесса

Networking: CPU offloading
Jumbo frames (MTU <= 9KB)
IP fragments на уровне сетевого адаптера (IPv4/IPv6, TCP, UDP)● GRO (Generic Receive Offloading)● GSO (Generic Segmentation Offloading)

Networking: Qdisc
(В основном про роутеры и приоритизацию потоков)
Queueing Discipline (Qdisc), tc(8)
Очереди
Дерево классов обслуживания
Фильтры определяют класс
http://www.linuxjournal.com/content/queueing-linux-network-stack

Networking: sysctl
net.core.somaxconn – listen(2) backlog
net.core.tcp_max_syn_backlog – TCP SYN backlog
net.ipv4.tcp_fin_timeout – таймаут для FIN_WAIT_2 соединений
net.ipv4.tcp_tw_recycle – переиспользование TIME-WAIT сокетов
net.ipv4.{tcp_mem, tcp_rmem, tcp_wmem} – размер TCP буферов
net.ipv4.{tcp_keepalive_time, tcp_keepalive_probes, tcp_keepalive_intvl} – управление TCP Keep-Alive
….
Linux/Documentation/networking/ip-sysctl.txt


















