
Технологии программирования
90
Министерство образования и науки Российской Федерации Федеральное агентство по образованию Южно-Уральский государственный университет Кафедра «Информатика» 681.3.06(07) Г938 А.В. Гуйдо ТЕХНОЛОГИИ ПРОГРАММИРОВАНИЯ Учебное пособие Под редакцией Б.М. Суховилова Электронное издание Челябинск Издательский центр ЮУрГУ 2010
Transcript of Технологии программирования

Министерство образования и науки Российской Федерации
Федеральное агентство по образованию
Южно-Уральский государственный университет
Кафедра «Информатика»
681.3.06(07)
Г938
А.В. Гуйдо
ТЕХНОЛОГИИ ПРОГРАММИРОВАНИЯ
Учебное пособие
Под редакцией Б.М. Суховилова
Электронное издание
Челябинск
Издательский центр ЮУрГУ
2010

2
УДК 681.3.066(075.8)
Г938
Одобрено
учебно-методической комиссией
факультета «Экономика и управление»
Рецензенты:
Е.М. Сартасов, С.З. Зильберман
Г939
Гуйдо, А.В.
Технологии программирования: учебное пособие / А.В. Гуйдо; под
ред. Б.М. Суховилова. – Челябинск: Издательский центр ЮУрГУ, 2010. –
89 с.
Учебное пособие содержит обзор технологий, используемых при
разработке программного обеспечения. В него включены следующие
технологии: управление версиями исходного кода, системы отслеживания
ошибок, гибкие методы разработки ПО на примере экстремального
программирования, технология объектно-реляционного отображения,
рефакторинг и непрерывная интеграция.
Учебное пособие ориентировано на студентов специальности 080801
«Информатика».
УДК 681.3.066(075.8)
© Издательский центр ЮУрГУ, 2010

3
ВВЕДЕНИЕ
Разработка современного программного обеспечения (ПО) представляет собой сложный
процесс, состоящий из множества составляющих. Требования к ПО постоянно повышаются.
Необходимо разрабатывать ПО в условиях регулярно меняющихся требований, с высокими
качественными показателями, в жестких временных и бюджетных рамках. В дополнение к
этому, ПО становится более сложным, и появляется много новых предметных областей. Над
проектом часто работает не один разработчик, а целая команда и необходимо обеспечить
слаженную работу команды. Чтобы справится с этими факторами, и получить в результате
качественный программный продукт разработчикам необходимо применять различные
инструментальные средства и технологии. Часть таких технологий рассмотрена в данном
пособии.
Для современных проектов характерны регулярные изменения в требованиях. Это связано,
во многом, с тем, что заранее сложно предусмотреть все детали проекта. Часто проекты
разрабатываются под растущий бизнес заказчика. В этих условиях ПО должно следовать за
требованиями бизнеса. Чтобы облегчить решение этой задачи, были созданы гибкие методы
разработки [14, 16]. В пособии рассмотрен один из гибких методов под названием
«Экстремальное программирование» [18, 19, 20, 15].
Хорошо налаженное взаимодействие между всеми членами команды разработки и
пользователями системы – залог успешного проекта. Чтобы разработчики могли работать над
общими исходными кодами проекта (и другими артефактами) им необходима система контроля
версий. Она позволит вести всю историю модификаций исходных кодов, поможет выполнить
совмещение изменений в исходных кодах без потери правок, даст возможность команде
работать в географически разделенной среде и предоставит ряд других преимуществ.
Применение подобной системы один из признаков успешной команды разработчиков [9]. В
данном пособии рассмотрена одна из таких систем под названием Subversion (SVN).
В ПО регулярно появляются дефекты их нужно учитывать и устранять. Пользователи
успешного продукта заинтересованы в расширении его функциональности и просят
разработчиков добавить новые возможности. Если эти два процесса оставить без внимания, то
качество ПО будет низким. Существуют специализированные системы для отслеживания
сообщений об ошибках и отслеживания запросов на новые возможности ПО. Эти системы
позволяют упорядочить взаимодействие разработчиков, тестеров и пользователей.
Руководители проекта с помощью подобных систем могут отслеживать состояние проекта. В
пособии рассмотрение данной темы выполняется на примере системы Mantis.
Для поддержания высокого качества ПО, оно должно быть всесторонне протестировано.
Существуют различные способы тестирования. Их можно условно разделить на ручное и
автоматическое тестирование. У каждого способа есть своя область применения. Необходимо в
проекте иметь обе разновидности тестирования. Важной особенностью автоматического
тестирования является его быстрое выполнение, частое выполнение и воспроизводимый
результат. Тесты позволяют формально зафиксировать многие требования к ПО и проводить
проверку этих требований. Это особенно ценно при многократном изменении требований. В
пособии рассмотрено применение модульного тестирования на примере NUnit.
При разработке сложных информационных систем все большую популярность приобретает
разработка на основе предметной области [27]. Этот подход предполагает явное выделение
сущностей предметной области в виде классов языка программирования. Вся основная логика
обработки реализуется в классах предметной области. Остальные части системы (подсистема
хранения, пользовательский интерфейс, коммуникационная подсистема) являются
подчиненными для модели предметной области. Этот подход позволяет реализовывать
сложную логику обработки, получить гарантию корректной работы (с помощью тестирования)
и предоставляет возможность длительной модификации требований к системе. К недостаткам
подхода можно отнести сложности сохранения объектов-сущностей в реляционную базу
данных. Для решения этой задачи используется технология объектно-реляционного
отображения. В пособии она рассмотрена на примере NHibernate.

4
При реализации новой функциональности качество проекта часто снижается. Это часто
связано с необходимостью получения быстрых результатов в ущерб внутреннему качеству.
Если это оставить без внимания, то проект может сильно деградировать. Чтобы исправить
ситуацию существует практика рефакторинга кода [36]. Она предполагает чередование двух
активностей при разработке ПО: создание нового функционала и улучшение внутренней
структуры кода без изменения его внешнего поведения. В пособии рассмотрено, что такое
рефакторинг, когда его следует применять и типовые приемы рефакторинга.
Чтобы из исходных кодов собрать работающую версию ПО может потребоваться
выполнить множество шагов. Если эти шаги выполнять вручную, то это может привести к
регулярным ошибкам. При работе над проектом нескольких разработчиков возникает проблема
объединения результатов их работы в единую работающую систему. Чем дольше откладывать
этот процесс, тем больше нестыковок обнаружится в дальнейшем. Для решения этих двух
проблем существует практика непрерывной интеграции. Она позволяет собирать весть проект
при каждом изменении исходного кода в хранилище. Это уменьшает проблему интеграции и
позволяет в любое время иметь готовую и протестированную версию проекта со всеми его
артефактами. В пособии данная технология рассматривается на примере сервера непрерывной
интеграции CruiseControl.NET.
Практическое применение технологий ориентировано на платформу Microsoft .NET.

5
УПРАВЛЕНИЕ ВЕРСИЯМИ ИСХОДНОГО КОДА
Управление исходными текстами является маленькой частью большой и сложной науки
управления созданием программного обеспечения. Тем не менее, это одна из важнейших частей
с точки зрения автоматизации [1].
Существует множество различных точек зрения на то, каким должен быть процесс
разработки программного обеспечения. Тем не менее, команда программистов создаѐт код,
который развивается и меняется со временем. В связи с этим можно отметить несколько
фактов:
В коде исправляются старые и появляются новые ошибки, добавляются новые возможности
и удаляются устаревшие участки кода, забывается то, что было в коде раньше – код
нуждается в истории. Иначе невозможно установить, когда появилась проблема, какое
изменение породило ошибку и кто, в конце-то концов, виноват.
Разработчики могут выполнять различные эксперименты над кодом. Если их результат
неудовлетворительный – необходим откат к стабильной версии.
Необходимо сообщать о причинах модификации файлов для упрощения дальнейшего
сопровождения кода – код нуждается в отслеживании причин изменений.
Если проект разрабатывается командой, в которой больше одного участника – код
нуждается в синхронизации. Иначе команда окажется перед лицом невоспроизводимых
ошибок, постоянных проверок на совместимость и изнурительных периодических авралов
для сбора всего написанного кода в одну работающую систему.
Если результаты работы команды используются вне самой команды – код нуждается в
воспроизводимости. Иначе команда не сможет повторить какую-то предыдущую версию,
которая имеется у пользователя, решить его проблему и выдать ему исправленную версию
независимо от состояния кода в настоящий момент.
Различные версии проекта могут разрабатываться параллельно – необходимы средства
работы с ветвями разработки.
Таким образом, необходим инструмент, позволяющий централизованно хранить, получать и
обновлять исходные тексты, отслеживать историю, получать версию кода по некоторым
критериям и выполнять ряд автоматических операций с кодом.
Существует большое количество подобных инструментов. Одним из них является
Subversion (http://subversion.tigris.org). Далее управление версиями рассматривается на примере
этой системы в ОС Windows. Одним из вариантов Subversion сервера для платформы Windows
является VisualSVN (http://www.visualsvn.com/server). В его составе так же содержатся утилиты
для работы c Subversion (svn.exe, svnadmin.exe и др.) Подробная информация об использовании
SVN изложена в [2].
Subversion – это бесплатная система управления версиями с открытым исходным кодом.
Subversion позволяет управлять файлами и каталогами, а так же сделанными в них изменениями
во времени. Subversion является централизованной системой контроля версий.
Subversion разработана как замена системы CVS и имеет ряд существенных преимуществ
[3]:
Отслеживается история файлов, каталогов и их метаданных файлов.
Используется сплошная нумерация правок на все хранилище.
Все фиксации являются атомарными.
Широкие коммуникационные возможности. К хранилищам Subversion можно
получить доступ, как по внутреннему протоколу, так и по протоколу http(s).
Операции работы с метками и ветвями разработки требуют незначительное
количество ресурсов.
Применены специальные средства для сокращения сетевого трафика.
Эффективная работа и с текстовыми, и с двоичными файлами.
Существует ряд свободно доступных Subversion хранилищ в Интернет (например,
http://code.google.com, http://svn.xp-dev.com, https://opensvn.csie.org). Можно развернуть своѐ
хранилище или использовать уже готовое в Сети.

6
Основные термины
Хранилище (repository, репозиторий) – место, где система управления версиями хранит
все файлы вместе с историей их изменения и другой служебной информацией.
Рабочая копия (working copy, рабочий каталог) – каталог на локальном компьютере, в
котором выполняются изменения и который связан с хранилищем. Связь предполагает наличие
возможности отслеживания изменений.
Правка (revision, ревизия, редакция, версия документа) – зафиксированный в
хранилище набор изменений. Правка так же задает зафиксированное состояние хранилища или
отдельной ветви разработки. Системы управления версиями различают правки по номерам,
которые назначаются автоматически.
Головная правка (head) – последняя правка в хранилище.
Добавление (add) – помещение файла или каталога в хранилище в первый раз. Далее
файл/каталог будет находиться под контролем версий.
Извлечение (check out) – загрузка части хранилища, создание рабочей копии. После
извлечения рабочая копия сохраняет связь с хранилищем.
Фиксация (check in, commit) – отправка изменений в хранилище. В хранилище создается
новая правка. Далее остальные пользователи могут загрузить последние изменения.
История изменений (changelog, history) – список изменений, выполненных с файлом со
времени его создания.
Обновление (update) – синхронизация файлов в рабочей копии с последними
изменениями из хранилища. Эта операция позволяет получить последние версии файлов.
Откат (revert) – удаление локальных изменений в рабочей копии и загрузка базовой
правки (на которой были основаны изменения) из хранилища.
Ветвь (branch) – направление разработки, независимое от других. Ветвь представляет
собой копию части (как правило, одного каталога) хранилища, в которую можно вносить свои
изменения, не влияющие на другие ветви. Ветви, как правило, создаются для отдельных версий
продуктов или внесения крупных рискованных изменений. Документы в разных ветвях имеют
одинаковую историю до точки ветвления и разные – после неѐ.
Ствол (trunk) – основная ветвь/линия разработки в хранилище. Политика работы со
стволом может отличаться от проекта к проекту, но в целом она такова: большинство
изменений вносится в ствол; если требуется серьѐзное изменение, способное привести к
нестабильности, создаѐтся ветвь, которая сливается со стволом, когда нововведение будет в
достаточной мере испытано. Перед выпуском очередной версии создаѐтся «релизная» ветвь, в
которую в дальнейшем вносятся только исправления ошибок.
Сравнение (diff) – Обнаружение разницы между двумя файлами или каталогами. Удобно
использовать для просмотра изменений, сделанных между правками.
Слияние (merge) – объединение независимых изменений в единую версию файла.
Осуществляется, когда два человека изменили один и тот же файл или при переносе изменений
из одной ветки в другую.
Конфликт (conflict) – ситуация, когда несколько пользователей сделали изменения
одного и того же фрагмента файла. Конфликт обнаруживается, когда один пользователь
зафиксировал свои изменения, а второй пытается зафиксировать и система сама не может
корректно слить конфликтующие изменения. Поскольку программа может быть недостаточно
разумна для того чтобы определить, какое изменение является «корректным», второму
пользователю нужно самому разрешить конфликт.
Разрешение (resolve) – устранение конфликта и отправка корректной версии файла в
хранилище. При разрешении конфликта не должны теряться важные изменения.
Блокирование (locking) – захват контроля над файлом, для предотвращения его
модификации со стороны других пользователей. Режим актуален для файлов, в которых
проблематично сливать изменения, например, для файлов с изображениями.
Хранилище
Хранилище содержит информацию в форме дерева файлов – типичном представлении
файлов и каталогов.

7
Особенностью хранилища является то, что оно хранит все изменения, которые выполнены с
его файлами и каталогами.
В штатном режиме у разработчика нет прямого доступа к хранилищу, т.к. он может
располагаться на удаленном сервере сети. Вместо этого необходимо использовать svn-команды
для получения, обновления и других манипуляций с файлами, находящимися под управлением
системы контроля версий. Таким образом, в системе выделяются серверная и клиентская части.
Однако существует локальный режим работы, где обе части могут функционировать на одном
компьютере.
Хранилище в Subversion представлено в виде последовательности неизменяемых
деревьев файлов и каталогов, называемых правками. Неизменяемость означает, что однажды
созданная правка не может быть изменена. Новая правка создается на базе предыдущей с
помощью выполнения ряда команд модификации. Создание правки является атомарной
операцией. Неизменность правки позволяет эффективно использовать дисковое пространство за
счет хранения только команд модификации для создания очередной правки. Правка фиксирует
состояние всего хранилища, а не отдельного файла. Клиент может обратиться к любой правке
(сохраненному в хранилище дереву каталогов). Последняя правка называется головной
(HEAD).
Каталог, в котором находятся рабочие файлы на локальной машине разработчика,
называется рабочей копией.
Указание пути к хранилищу
Чтобы указать системе, где находится хранилище, необходимо указать его идентификатор.
Получить доступ к хранилищу Subversion можно различными способами – на локальном диске
или через ряд сетевых протоколов. Местоположение хранилища всегда определяется при
помощи URL. Таблица 1 показывает соответствие разных URL-схем возможным методам
доступа.
Таблица 1. URL для доступа к хранилищу.
Схема Метод доступа file:/// прямой доступ к хранилищу (на локальном диске) http:// доступ через протокол WebDAV (если Subversion-сервер работает через Apache) https:// то же, что и http://, но с SSL-шифрованием svn:// доступ через собственный протокол к серверу svnserve svn+ssh:// то же, что и svn://, но через SSH-соединение
Примеры:
http://svn.example.com/repos/calc
https://svn.example.com/repos/calc
file:///c:/repos/calc
Создание хранилища
Локальное хранилище Subversion можно создать с помощью следующей команды: svnadmin create D:\repos
После выполнения команды в каталоге D:\repos будут созданы специальные файлы и
каталоги для представления хранилища. К такому хранилищу можно локально обращаться по
URL: file:///D:/repos. Если каталог хранилища будет другой, то нужно скорректировать
соответственно его URL в последующих примерах.
Для создания хранилища, доступного по сети, нужно воспользоваться инструментами
серверной части.
Правки
В процессе работы над проектом файлы претерпевают изменения, добавляются новые и
исчезают ненужные. Изменения файлов в рабочей копии не приводят к изменениям хранилища,
сколько бы дней или даже месяцев вы над ними не работали. Каждый раз, когда происходит
фиксация изменений, создаѐтся новое состояние хранилища, которое называется правкой (рис.
1). Каждая правка получает уникальный номер, на единицу больший номера предыдущей
правки. Начальная правка только что созданного хранилища в Subversion получает номер 0 и не
содержит ничего, кроме пустого корневого каталога.

8
Рис. 1. Правки
Начнем изучение Subversion на примере хранилища с одним файлом – list.txt. В этот файл
будут помещаться список различных продуктов (рис. 2).
Рис. 2. Изменение файла в хранилище со временем
Создание правки является атомарной операцией. Это означает, что либо все изменения
вносятся в хранилище, и создается новая правка, либо изменения не вносятся вообще.
Для работы с Subversion необходима рабочая копия. Рабочая копия получается в результате
извлечения части или всего хранилища в локальный каталог. Для выполнения учебных
примеров создадим отдельный каталог (например, svn_work). В него будем извлекать рабочие
копии. Извлечем пустое хранилище в рабочую копию под названием main. Команду нужно
выполнять в каталоге svn_work. svn checkout file:///D:/repos main
Внутри рабочей копии (main) создадим файл list.txt, добавим в него строку «Хлеб» (в конце
должен быть символ перехода на новую строку). Сейчас созданный файл не связан с
хранилищем. Необходимо выполнить команду добавления файла в хранилище. svn add list.txt
A list.txt
Вывод команды говорит об успешной пометке файла на добавление. Чтобы новый файл (и
другие модификации) попали в хранилище необходимо выполнить команду фиксации. svn commit list.txt -m "Первый файл в хранилище"
Adding list.txt
Transmitting file data .
Committed revision 1.
Подробную информацию о синтаксисе команд можно получить с помощью команды svn
help или в [2].
Хлеб Хлеб Молоко
Хлеб Молоко Соль
Хлеб Соль Молоко Помидоры
r1 r2 r3 r4
HEAD
list.txt
№ правки

9
Совмещение и обновление
Subversion помнит, какая правка у вас находится в рабочем каталоге. Это необходимо,
чтобы правильно совместить несколько изменений, произошедших с файлом одновременно (в
разных рабочих копиях).
Предположим, что два разработчика одновременно начали работать над одним и тем же
файлом, и в момент начала этого процесса в хранилище была правка 1. По истечении
определенного времени мы имеем в хранилище правку 1 и в двух рабочих каталогах изменения
к этой правке. Предположим также, что работа в каталоге №2 закончена и изменения
отправляются в хранилище. В хранилище появляется новая правка и ей присваивается номер 2.
В каталоге №2 тоже содержится правка 2. Однако в каталоге №1 по-прежнему находятся
изменения относительно правки 1 (рис. 3).
Рис. 3. Несколько редакций одного файла
Теперь, если мы захотим отправить изменения в хранилище из рабочего каталога №1,
система откажет нам в операции, поскольку каталог №1 устарел и сформировать правку 3 в
хранилище невозможно. Поэтому каталог №1 необходимо обновить, при этом произойдѐт
совмещение (merge) редакций. Иными словами, изменения от 1 до 2, имеющиеся в хранилище,
будут применены к файлам в рабочем каталоге. При этом изменения, сделанные локально, не
пропадают и, в результате, в рабочем каталоге окажется правка 2 с изменениями, сделанными
локально. После этого можно отправить файл в хранилище и получить правку 3, в которой
присутствуют изменения, сделанные в обоих рабочих каталогах. Далее нужно обновить каталог
№2 (там находится правка 2) до правки 3.
В большинстве случаев разработчики вносят в код изменения, которые не противоречат
друг другу. Такие изменения Subversion может слить самостоятельно. В редких случаях
изменения противоречат друг другу, например, разработчики изменяют одну и ту же строку, но
по-разному. В таком случае Subversion сообщает о конфликте и разработчик должен выполнить
слияние вручную.
Импорт проекта
При внедрении системы контроля версий у разработчиков, как правило, уже имеется база
исходного кода и возникает задача импорта еѐ в хранилище. Для еѐ решения в Subversion
существует команда svn import. Перед выполнением импорта необходимо удалить все файлы
проекта, которые не нужно помещать в хранилище.
После выполнения импорта локальный каталог не будет иметь связи с хранилищем. Чтобы
происходило отслеживание изменений нужно извлечь из хранилища импортированный проект
в рабочую копию (команда svn checkout). В рабочей копии кроме файлов проекта будет
содержаться скрытый каталог «.svn». Он необходимо для отслеживания выполненных
изменений в рабочей копии.
При использовании графического клиента TortoiseSVN более удобно импорт заменить
следующей последовательность шагов:
извлечь рабочую копию, пока пустую (checkout);
скопировать в неѐ проект (локально);
выполнить операцию фиксации (commit).
В процессе фиксации можно выполнить:
добавление нужных файлов и каталогов;
Хранилище Правка 2
Рабочий каталог №1 Правка 1
Рабочий каталог №2 Правка 2

10
задать игнорирование не нужных файлов и каталогов;
указать комментарий к правке.
Изменение рабочей копии
Когда файлы и каталоги в рабочей копии находится под контролем версий, разработчик
может их модифицировать. После получения желаемого результата в рабочей копии
необходимо зафиксировать изменения в хранилище (команда svn commit).
Основные операции изменения рабочей копии:
добавление файла или каталога к хранилищу (svn add);
удаление файла или каталога из хранилища (svn delete);
изменение содержимого файла;
переименование/перенос файлов или каталогов (svn move);
копирование файлов или каталогов (svn copy)
операции для работы со свойствами файлов и каталогов (svn propdel, propedit,
propget, proplist, propset);
отмена локальных изменений в рабочей копии и получение базовой правки из
хранилища (svn revert).
Когда необходимо выполнить переименование или копирование, необходимо пользоваться
командами Subversion, а не операционной системы или файлового менеджера. Это связано с
тем, что при выполнении команд операционной системы или файлового менеджера
модифицируется только локальный каталог, а хранилище не информируется о произведенной
операции.
Операции удаления и переименования могут выполняться с указанием локального пути или
пути в хранилище (URL).
Локальный путь: svn del list.txt
URL: svn del file:///D:/repos/list.txt
После выполнения одной или нескольких локальных операций изменения рабочей копии
необходимо выполнить фиксацию изменений (svn commit). До выполнения фиксации
хранилище остается в неизменном виде.
Выполнение фиксации создает новую правку в хранилище. Ранее созданные правки
продолжают существовать в неизменном виде, как часть истории хранилища.
Параметр -m в командах позволяет задать комментарий к изменениям. Цель комментария –
описание результатов работы в целом, а не конкретных изменений. Комментарии являются
очень важной частью работы команды, поскольку позволяют другим разработчиком узнать, что
именно вы сделали, и скоординировать свою работу соответственно. Комментарий задается для
всей правки, а не для отдельного файла.
Свойства файлов и каталогов позволяют связать с элементами хранилища дополнительную
информацию. Эта информация влияет на поведение Subversion. Рассмотрим некоторые из них.
svn:ignore – задает маски игнорируемых файлов. Свойство активно используется клиентами
Subversion, чтобы не предлагать повторно добавлять в хранилище определенные файлы.
Пример: скомпилированные программы (*.exe), резервные копии (*.bak), временные файлы
(*.~*).
svn:keywords – задает набор ключевых слов (через пробел), для которых Subversion будет
выполнять подстановку (Author, Revision, Date, HeadURL, Id). Например, при указании
ключевого слова Date для файла в этом файле будут выполняться подстановки при фиксации
изменений вида:
$Date$ → $Date: 2009-09-26 12:23:35 +0600 (Сб, 26 сен 2009) $
Обновление рабочей копии и разрешение конфликтов
Современные системы контроля версий изначально создавались с поддержкой
многопользовательской работы. В один проект могут вносить изменения многие разработчики,
но обновление локальной рабочей копии не происходит автоматически. Для этого разработчик
должен явно вызвать команду update. В результате еѐ работы рабочая копия будет обновлена
изменения из хранилища. По умолчания загружаются самые свежие изменения.
11
После выполнения команд из раздела «Правки» у нас имеется хранилище с файлом list.txt, в
котором находится одна строка. Сымитируем работу двух разработчиков над одним проектом.
Для этого извлечем две рабочие копии проекта в разные каталоги. svn checkout file:///D:/repos copy1
A copy1\list.txt
Checked out revision 1.
svn checkout file:///D:/repos copy2
A copy2\list.txt
Checked out revision 1.
В каждой рабочей копии внесем изменения в файл list.txt (таблица 2).
Таблица 2. Модификация файла list.txt в рабочих копиях.
Начальная версия Версия в copy1 Версия в copy2
Хлеб Хлеб
Молоко
Хлеб
Соль
В первой рабочей копии выполним фиксацию изменений. Эта операция проходит успешно. svn commit -m "Добавили молоко"
Sending list.txt
Transmitting file data .
Committed revision 2.
Фиксация изменений во второй рабочей копии пройдет с ошибкой. svn commit -m "Добавили соль"
Sending list.txt
svn: Commit failed (details follow):
svn: File '/list.txt' is out of date
Вывод команды говорит о том, что рабочая копия №2 устарела. Файл list.txt во второй
рабочей копии был создан на основе правки №1, а сейчас в хранилище этот файл
модифицирован в правке №2. Необходимо выполнить обновление рабочей копии. Эта операция
загрузит из хранилища последние изменения. Изменения могут быть применены к рабочей
копии автоматически или в ручном режиме (при наличии конфликтов). В нашем случае возник
конфликт. svn update
Conflict discovered in 'list.txt'.
Select: (p) postpone, (df) diff-full, (e) edit,
(mc) mine-conflict, (tc) theirs-conflict,
(s) show all options: p
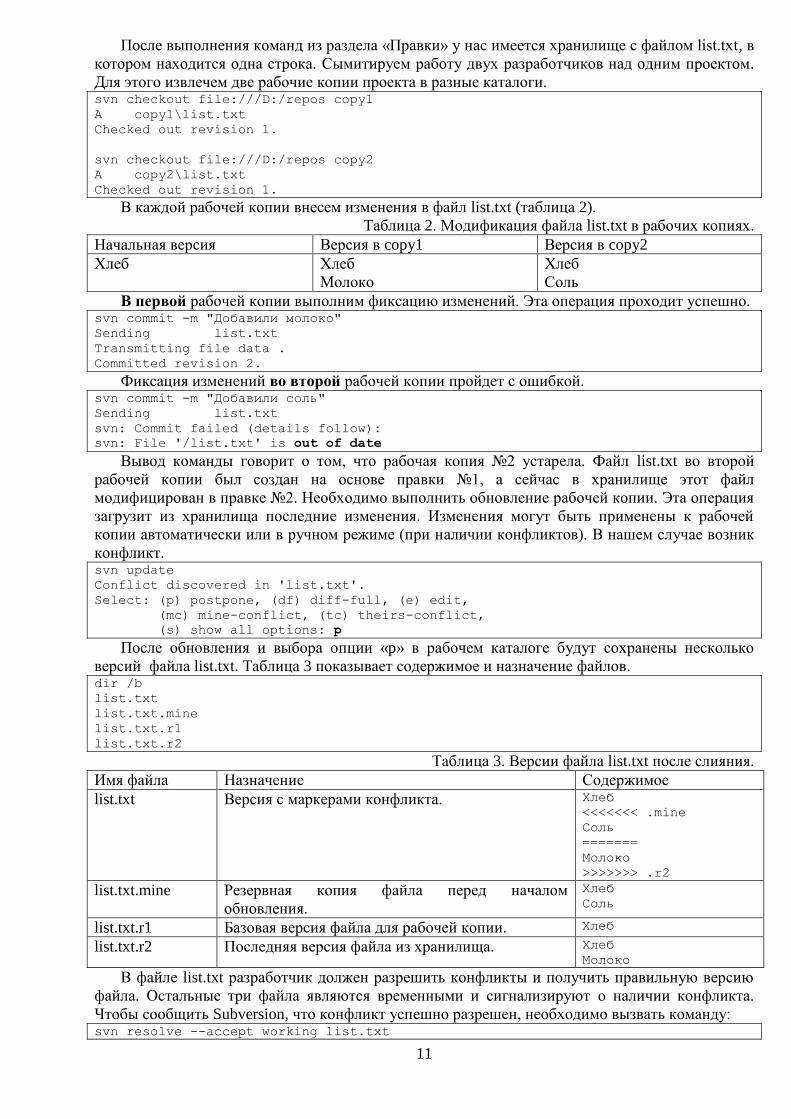
После обновления и выбора опции «p» в рабочем каталоге будут сохранены несколько
версий файла list.txt. Таблица 3 показывает содержимое и назначение файлов. dir /b
list.txt
list.txt.mine
list.txt.r1
list.txt.r2
Таблица 3. Версии файла list.txt после слияния.
Имя файла Назначение Содержимое
list.txt Версия с маркерами конфликта. Хлеб
<<<<<<< .mine
Соль
=======
Молоко
>>>>>>> .r2
list.txt.mine Резервная копия файла перед началом
обновления.
Хлеб
Соль
list.txt.r1 Базовая версия файла для рабочей копии. Хлеб
list.txt.r2 Последняя версия файла из хранилища. Хлеб
Молоко
В файле list.txt разработчик должен разрешить конфликты и получить правильную версию
файла. Остальные три файла являются временными и сигнализируют о наличии конфликта.
Чтобы сообщить Subversion, что конфликт успешно разрешен, необходимо вызвать команду: svn resolve --accept working list.txt

12
В результате еѐ работы будут удалены три временных файла.
После разрешения конфликта разработчик должен проверить работоспособность всего
проекта. Если проект с дефектами попадет в хранилище, то это может негативно отразиться на
работе других разработчиков.
Далее можно будет зафиксировать новое состояние файла list.txt c тремя строками во
второй рабочей копии. svn commit -m "в файле теперь три строки"
Sending list.txt
Transmitting file data .
Committed revision 3.
После успешной фиксации необходимо обновить (svn update) первую рабочую копию для
получения последних изменений (правка 3) из хранилища.
При извлечении или обновлении можно извлечь не только головную, но и одну из
предыдущих правок. Для этого в командах svn update, svn checkout нужно указать правку с
помощью ключа «–r».
Очень важно, что при определенной дисциплине над проектом могут работать множество
разработчиков. Каждый из них может действовать независимо от других и при этом не терять
изменения друг друга.
Метки, ветки и слияние
В крупных проектах разработчикам часто приходится вести несколько независимых
направлений разработки на основе общей базы кода. Для этого есть две основные причины.
1. Сопровождение нескольких выпущенных версий продукта.
2. Разработка крупных блоков экспериментальной функциональности.
В первом случае каждая выпущенная версия становиться отдельным направлением
разработки. При обнаружении ошибок в программе они исправляются в соответствующих
версиях. Новая функциональность добавляется только в последнюю версию.
Во втором случае разработчику необходимо долго (более недели) работать над
экспериментальной функциональностью. Если промежуточные результаты работы
зафиксировать в основной линии разработки, то это может нарушить еѐ работоспособность.
Если код вообще не отправлять в хранилище есть риск его потери и службы хранилища
(например, просмотр последней истории) на нем не будут работать. В этом случае можно
выделить экспериментальную функциональность в отдельную ветку разработки. Основная
линия разработки не будет подвергаться риску, а экспериментальная функциональность будет
надежно храниться в хранилище и для неѐ будут доступны все сервисы хранилища. После
успешного завершения экспериментальной функциональности можно выполнить слияние
экспериментальной ветви и основной линии разработки. Если экспериментальная ветвь
оказалась не нужной, то еѐ можно просто удалить. Эта ветвь останется как часть истории
хранилища, а в новых правках еѐ уже не будет.
Кроме ветвей разработчикам часто необходимо пометить текущее состояние проекта, для
последующей ссылки на него. Это делается с помощью меток. Метки можно ставить при
каждой (в т.ч. внутренней) сборке проекта. Это позволит при обнаружении пользователем
ошибки получить именно ту версию исходных кодов, на которой эта ошибка проявляется.
Реализация меток и веток в Subversion
Subversion не имеет прямой поддержки веток и меток. Реализация этих понятий
выполняется с помощью договоренностей и операций над файловой системой хранилища. В
Subversion ветки и метки являются способом интерпретации пользователем файловой
структуры хранилища. Далее описывается один из распространенных способов организации
веток и меток.
На верхнем уровне хранилища необходимо создать три каталога:
trunk
branches
tags
В каталог trunk необходимо поместить основную линию разработки. В каталог branches
будет копироваться основная линия разработки (trunk) под нужным именем для создания

13
отельной ветви разработки. В каталог tags копируется основная линия разработки для создания
метки.
Разница между ветками (branches) и метками (tags) условна. Она заключается в том, что в
каталогах с метками разработчики договариваются не выполнять модификаций, а в ветках это
допустимо.
Копирование основной линии разработки в новую ветку или метку должно выполняться
командами Subversion. Эти операции реализованы эффективно, они не приводят избыточному
расходу памяти, снижению скорости дальнейшей работы и трате других ресурсов независимо
от объема и количества копируемых файлов. Разработчик может создавать столько меток и
веток, столько ему нужно.
Структура хранилища может быть сформирована в начале проекта или реорганизована по
мере необходимости. Рассмотрим пример добавления функциональности меток и веток к
нашему хранилищу с одним файлом list.txt. rem Загружаем содержимое хранилища в отдельную рабочую копию
svn checkout file:///d:/repos new_layout
rem Переходим в каталог рабочей копии и создаем в ней три каталога
cd new_layout
md trunk
md branches
md tags
rem Помечаем созданные каталоги на добавление в хранилище
svn add trunk
svn add branches
svn add tags
rem Переносим файлы проекта (у нас он сейчас один) в trunk
svn move list.txt trunk
rem Фиксируем новую структуру хранилища
svn commit -m "новая структура каталогов"
Приведенный пример использует рабочую копию для внесения изменений. Все изменения
фиксируются в одной правке. Реорганизацию хранилища можно выполнить без извлечения
рабочей копии, работая напрямую с хранилищем. svn mkdir file:///d:/repos/trunk -m "добавили trunk"
svn mkdir file:///d:/repos/branches -m "добавили branches"
svn mkdir file:///d:/repos/tags -m "добавили tags"
svn move file:///d:/repos/list.txt file:///d:/repos/trunk -m "перенесли list.txt в
trunk"
При таком способе в хранилище последовательно создаются четыре правки для каждой
команды.
Рассмотрим слияние нескольких ветвей разработки. Для этого добавим в основную линию
разработки файл readme.txt. svn checkout file:///d:/repos/trunk for_readme
cd for_readme
echo Header for readme > readme.txt
svn add readme.txt
svn commit -m "add readme"
Данная последовательность команд извлекает основную линию разработки (trunk) в
рабочую копию под именем for_readme, далее в этой копии создается файл readme.txt, файл
добавляется к хранилищу и выполняется фиксация изменений.
Использование веток и меток
Файл list.txt нашего проекта находится сейчас в основной лини разработки (trunk). Он
содержит три строки (Хлеб Молоко Соль). Сохраним это состояние проекта с помощью метки. svn copy file:///d:/repos/trunk file:///d:/repos/tags/three_line -m "метка для
трех строк"
Метки и ветки для Subversion являются обычными каталогами. Их можно извлекать в
рабочие копии для просмотра и редактирования.

14
Ветка создается аналогичным образом. svn copy file:///d:/repos/trunk file:///d:/repos/branches/branch1 -m "ветка для
экспериментальной разработки"
На рис. 4 приведена структура хранилища после добавления метки и ветки.
Рис. 4. Структура хранилища после добавления ветки и метки
Извлечем две рабочие копии. Одна для работы над основной линией разработки, а другая
для работы в ветке. svn checkout file:///d:/repos/trunk 4th_line_in_trunk
svn checkout file:///d:/repos/branches/branch1 4th_line_in_branch
Модифицируем каждую рабочую копию. Таблица 4 отражает содержимое
модифицированных копий.
Таблица 4. Изменения файлов в рабочих копиях.
Файл Рабочая копия для основной
линии разработки
(4th_line_in_trunk)
Рабочая копия для ветки
(4th_line_in_branch)
list.txt Хлеб
Помидоры Молоко
Соль
Хлеб
Молоко
Перец Соль
readme.txt Header for readme
Измененя в trunk
Header for readme
Изменения в ветке
Зафиксируем изменения в рабочих копиях (svn commit). Важно, что при этом работа ведется
в разных ветках (для Subversion в разных каталогах хранилища) и конфликтов при фиксации не
происходит.
После успешного завершения разработки экспериментальной ветки нужно передать
изменения в основную линию разработки. Для этого существуют команды сравнения каталогов
в хранилище (svn diff) и применения изменений (svn merge). Выявим различия, которые
произошли в функциональной ветке с момента еѐ создания до текущего момента. Чтобы
показать/применить изменения необходимо знать диапазон правок, в которые они включены. В
этом может помочь команда svn log. Если выполнить еѐ в каталоге ветки разработки, то можно
увидеть зафиксированные правки. Нас интересует правка №8. Для определения правки, когда
произошло копирование ветки можно воспользоваться следующей командой. > svn log --verbose --stop-on-copy file:///d:/repos/branches/branch1
------------------------------------------------------------------------
r8 | Алексей | 2009-09-27 13:21:12 +0600 (Вс, 27 сен 2009) | 1 line
Changed paths:
M /branches/branch1/list.txt
M /branches/branch1/readme.txt
добавили перец
------------------------------------------------------------------------

15
r7 | Алексей | 2009-09-27 13:10:49 +0600 (Вс, 27 сен 2009) | 1 line
Changed paths:
A /branches/branch1 (from /trunk:6)
ветка для экспериментальной разработки
------------------------------------------------------------------------
В рабочей копии основной линии разработки выполним операцию сравнения. svn diff -r 7:9 file:///d:/repos/branches/branch1
===================================================================
--- list.txt (revision 7)
+++ list.txt (revision 9)
@@ -1,3 +1,4 @@
Хлеб
Соль
+Перец
Молоко
Index: readme.txt
===================================================================
--- readme.txt (revision 7)
+++ readme.txt (revision 9)
@@ -1 +1,2 @@
Header for readme
+Изменения в ветке
Из-за различия в кодировках русские буквы в консоли могут отображаться некорректно.
Для просмотра вывода команд его можно перенаправить вывод команды в файл.
Вывод команды показывает, что в ветке было добавлено по одной строке в два файла.
После просмотра различий выполним слияние. svn merge -r 7:9 file:///d:/repos/branches/branch1
--- Merging r8 through r9 into '.':
U list.txt
Conflict discovered in 'readme.txt'.
Select: (p) postpone, (df) diff-full, (e) edit,
(mc) mine-conflict, (tc) theirs-conflict,
(s) show all options: p
C readme.txt
Summary of conflicts:
Text conflicts: 1
Один файл (list.txt) был успешно совмещен, а при совмещении другого (readme.txt) возник
конфликт. Таблица 5 отражает содержимое версий файла readme.txt. Пример разрешения
конфликта приведен выше в разделе «Обновление рабочей копии и разрешение конфликтов».
Таблица 5. Версии файла readme.txt после слияния.
readme.txt readme.txt.merge-
left.r7
readme.txt.merge-
right.r9
readme.txt.working
<<<<<<< .working
Header for readme
Измененя в trunk
=======
Header for readme
Изменения в ветке
>>>>>>> .merge-
right.r9
Header for readme Header for readme
Изменения в ветке
Header for readme
Измененя в trunk
Теперь рабочая копия основной линии разработки содержит все необходимые правки и
можно зафиксировать изменения. При фиксации в комментарии необходимо указать диапазон
правок, который был применен. Это упростит последующие слияния новых изменений и
поможет предотвратить повторное применение одних и тех же изменений.
Визуальное слияние
Существует более простой способ слияния изменений в двух ветвях разработки. Он не
требует отслеживания точки ветвления и запоминания примененных модификаций. Способ
заключается в выгрузке обоих ветвей разработки и запуске процедуры синхронизации
каталогов. Для этого можно применить визуальную утилиту WinMerge. С еѐ помощью можно
svn diff -r 7:9 file:///d:/repos/branches/branch1 > output.txt

16
сравнивать каталоги (рис. 5) и файлы (рис. 6). Программа отмечает отличающиеся блоки и
позволяет переносить их в обоих направления. Таблица 6 отражает характеристики визуального
слияния.
Рис. 5. Сравнение каталогов с помощью WinMerge.
Рис. 6. Сравнение и синхронизация файла с помощью WinMerge.
Таблица 6. Характеристики визуального слияния.
Достоинства Недостатки
Не требует знаний о структуре
хранилища, истории версий
или слияний.
Требуется извлечь обе ветки локально. Если проект большой
и нужно применить изменения из нескольких веток, а сервер
доступен по медленному каналу связи, то это может
осложнить работу.
Источником или получателем
изменений могут быть
каталоги, не связанные с
системой контроля версий
Автоматического совмещения изменений не происходит.
Каждое изменение нужно сливать вручную, даже если при
автоматическом слиянии оно могло быть обработано без
вмешательства пользователя (например, синхронизация файла
list.txt).
Способ прост и нагляден. Происходит потеря истории слияния. В целевой версии не
остается информации о том, с чем произошло слияние.
Существуют утилиты, которые позволяют не только упростить, но и автоматизировать
процесс слияния двух файлов или каталогов, но для их работы нужно три источника:
1. Базовая версия (Base).
2. Наши изменения относительно базовой версии (My).
3. Чужие (те, что мы объединяем) изменения относительно базовой версии (Their).
На рис. 7 приведена схема трехстороннего слияния. Важно, чтобы сливаемые файлы имели
общую базовую версию, и она была явно указана. Подобную схему слияния могут реализовать
утилиты TortoiseMerge, kdiff3 и другие.

17
Рис. 7. Трехстороннее слияние.
Графический клиент
До сих пор работу c Subversion мы рассматривали в консольном режиме. Этот режим
позволяет раскрыть все возможности этой системы и включить работу с Subversion в различные
сценарии обработки, например, в проект непрерывной интеграции. При регулярной работе с
Subversion на больших проектах выполнение консольных команд может показаться
утомительным, особенно при ручном слиянии конфликтов. На этот случай разработаны
различные графические клиенты Subversion. Они позволяют выполнять основные операции с
хранилищем в более удобной визуальной форме.
Одним из наиболее удобных клиентов Subversion является проект TorsoiseSVN
(http://www.tortoisesvn.org). Он является расширение проводника Windows. Дополнительно
удобно применять пакет WinMerge (http://winmerge.org) для сравнения и слияния файлов и
каталогов.
Распределенные системы контроля версий
Поколения систем контроля версий
В последние два десятилетия системы контроля версий стали фактически обязательным
инструментов в крупных проектах. Со временем появилось большое количество (более 20)
систем подобного класса. Рассмотрим три поколения подобных систем.
Представители первого поколения были ориентированы на работу с отдельными файлами, и
это уже было большим усовершенствованием по сравнению с ручным контролем версий.
Обязательное выполнение блокировки и работа на одном компьютере ограничивали их область
применения малыми командами разработчиков (RCS).
Следующее поколение было ориентировано на работу в локальной сети и имело
централизованную архитектуру, появилась возможность управлять целым проектом, а не
отдельными файлами. Увеличение размера проектов и количества пользователей привело к
повышенной нагрузке на сервер центрального хранилища и каналы связи. Отсутствие связи
делало недоступными большинство операций с хранилищем. Разработчики Open Source
проектов имеют возможность выгружать исходные коды из таких открытых на чтение
хранилищ, но вести локальную разработку с контролем версий нет возможности (Subversion,
CVS, Perforce, Rational ClearCase).
Третье поколение систем контроля версий ориентировано на отказ от одного центрального
хранилища и переход на взаимодействие вида «каждый с каждым». Это позволяет передавать
изменения между заинтересованными разработчиками и вести локальную разработку с
контролем версий. На смену ограничениям централизации приходит возможность выбора
способа взаимодействия распределенных/рассредоточенных систем через Интернет (Mercurial,
Git, BitKeeper, Bazaar, Monotone). При определенной настройке распределенные системы могут
функционировать как централизованные хранилища [5].
Преимущества распределенных решений
Каждый разработчик имеет свою локальную копию хранилища. Это позволяет
достаточно часто выполнять фиксации и получить подробную историю изменений в своем
хранилище. Централизованные системы вынуждают разработчика делать фиксации крупного
Результат
Base
My
Their

18
размера из-за ограничений по содержимому и скорости доступа к удаленному хранилищу.
Ограничения по содержимому предполагают фиксацию законченных блоков, а не
промежуточных результатов, т.к. эти правки будут доступны другим разработчикам.
Полноценная работа при отсутствии связи. Многие команды разработчиков состоят из
нескольких частей, эти части географически распределены и связаны каналами связи. При
использовании центрального хранилища и проблемах со связью работа разработчиков будет
затруднена. Если используется распределенное хранилище, то каждая часть команды (или
каждый разработчик) использует свою реплику хранилища и полноценно с ней работает.
Синхронизацию хранилищ можно выполнить при появлении связи.
Распределенные хранилища обладают большей производительностью (до 10 раз) и
масштабируемостью. Повышение производительности достигается за счет замены
большинства обращений к удаленному (центральному) хранилищу на обращение к хранилищу
на своем компьютере или в своей локальной сети. Масштабируемость повышается путем
создания дополнительных реплик хранилища для новых групп пользователей.
Улучшенная поддержка отслеживания изменений. Распределенные системы построены
вокруг отслеживания изменений в хранилище. Вся история хранилища представлена
последовательностью наборов изменений. Изменения имеют глобально-уникальные
идентификаторы и могут группами передаваться между хранилищами.
Улучшенная поддержка ветвления и слияния. Создание копий хранилища является
примером внешнего ветвления. Внутри одного хранилища так же возможно ведение нескольких
ветвей. Существуют стандартные механизмы для слияния ветвей. В хранилище сохраняется
история слияний. Создание внешней ветви (клонирование хранилища) и работа в этой ветви не
приводит к модификации основного хранилища. Это особенно важно для проектов с сотнями
или даже тысячами разработчиков. Если созданные ветви оказываются ненужными, то они не
засоряют основное хранилище.
Гибкая архитектура. Архитектура репликации выбирается пользователями хранилища, а
не задается как архитектурное ограничение.
Об основных преимуществах распределенных систем контроля версий на примере Git
Линус Торавльдс рассказал в своем выступлении [8].
Недостатки распределенных решений
Необходимость в резервных копиях. Многие новые изменения расположены только в
локальных хранилищах разработчиков и их нет в центральном хранилище. В случае сбоя
локального хранилища информация будет потеряна, поэтому для многих локальных хранилищ
необходимо создавать резервные копии.
Нет самой последней версии. Из-за распределенности и наличия множества ветвей
затруднительно определить, где находятся самые последние правки.
Правки не имеют порядковых номеров. В условиях распределенности вместо порядковых
номеров правок используются хэшы для набора изменений. Они имею длину в несколько
десятков символов и на них менее удобно ссылаться, чем на номера [5].
Отсутствуют средства работы с частью проекта. Распределенные системы
рассчитаны на работу со всем проектом как с единым целым. Это затрудняет загрузку части
хранилища и накладывает ограничение на разбиение проекта по отдельным хранилищам.
Основные приемы работы с распределенными хранилищами
Распределенные системы, как правило, не нуждаются в одном центральном хранилище.
Вместо этого у каждого разработчика или небольшой группы разработчиков имеется своя
реплика хранилища. Рядовые действия разработчика (извлечение рабочей копии, добавление и
удаление элементов, фиксация изменений) выполняются с локальным хранилищем и не
требуют обращений к удаленному хранилищу. Эта часть работы аналогична работе с
централизованными системами в локальном режиме.
По сравнению с типовыми командами централизованных систем контроля версий (рис. 8) в
распределенных системах появились (рис. 9) команды для синхронизации хранилищ.
Основными (на примере Mercurial) являются следующие:
clone – создание копии хранилища;
pull – принять правки из указанного хранилища в локальное хранилище;

19
push – отправить правки из локального хранилища в указанное;
merge – слияние импортированных правок внутри хранилища.
Если при синхронизации хранилищ отключить команду push, то это позволит радикально
решить проблему доступа на запись к хранилищу для внешних пользователей. Внешние
пользователи не имеют доступа на запись к хранилищу, но администратор хранилища забирает
(pull) нужные изменения из доверенных источников [8].
Рис. 8. Схема работы централизованного хранилища
Рис. 9. Схема работы распределенной системы хранилищ
checkout update commit merge
pull
push
clone
Хранилище
checkout
update
commit
Рабочая копия

20
СИСТЕМЫ ОТСЛЕЖИВАНИЯ ОШИБОК
Отслеживание ошибки (bug tracking) – это процесс, включающий в себя обнаружение
ошибки, ее описание, исправление и проверку этого исправления, т.е. процесс “слежения” за
багом как в течение его жизненного цикла, так и жизненного цикла разработки в целом.
Что такое баг (bug)? Прежде всего, под багом понимают ошибку в программе,
проявляющуюся при ее использовании. Багом можно назвать так же и недокументированные
или нежелательные, "побочные" реакции программы на действия пользователя, равно как и при
использовании ее одновременно с другим ПО или в другой аппаратной конфигурации.
Существуют и другие определения багов. В своей книге "Тестирование программного
обеспечения" Сэм Канер [11] приводит определение: "Если программа не делает того, чего
пользователь от нее вполне обосновано ожидает, значит налицо программная ошибка”.
Не существует ни абсолютного определения ошибок, ни точного критерия наличия их в
программе. Можно лишь сказать, насколько программа не справляется со своей задачей – это
исключительно субъективная характеристика.
Определение ошибок как расхождения между программой и ее спецификацией – не верно.
Так как даже точно соответствующая спецификации программа содержит ошибки в том случае,
если есть ошибки и в самой спецификации.
В литературе можно встретить целый ряд синонимов этого понятия. Помимо бага довольно
часто встречаются такие термины как ошибка (error), проблема (problem), дефект (defect),
неисправность (fault). Но какой бы термин мы не использовали, суть его остается неизменной.
Система отслеживания ошибок (Bug tracking system, BTS) – это программный
продукт, основанный на использовании базы данных и контролирующий все этапы
жизненного цикла ошибок в ПО: от инициализации до момента исправления. Конечная
цель BTS – улучшение качества разработки программных продуктов.
Программа класса BTS, как правило, представляет собой базу данных и web-приложение,
доступное через Интернет или в локальной сети компании-разработчика. Ряд систем имеют
поддержку web-служб для подключения специализированных клиентов. Единая база данных
обеспечивает централизованный доступ ко всем документам (программам, спецификациям,
графикам, планам и т.п.). Информация о каждом шаге работы с документом становится
доступна всем заинтересованным лицам. Например, если документ помечен как "ошибка" (bug),
то об этом будет оповещена группа разработчиков. Документ, помеченный как "запрос"
(requirement), попадет в почтовые ящики отдела маркетинга и технической поддержки.
Механизм контроля обращений различных пользователей к документу позволяет получить
полную картину того, кем из сотрудников была найдена ошибка, и кто из клиентов ожидает
увидеть в следующей версии то или иное новшество.
Хорошей практикой является вынесение формы для создания bug-report на Web-страничку
компании, предоставив, таким образом, клиентам удобный способ сообщить об ошибке.
Большинство систем отслеживания ошибок имеют возможность составлять не только
отчеты о багах (Bug Report), но и вносить запрос свойства (Feature Request), что позволяет
тестировщикам вносить свои предложения по улучшению тестируемой программы.
Система отслеживания ошибок должна поддерживать три этапа:
сбор данных об ошибке;
отслеживание ошибки;
решение проблемы.
Существует большое разнообразие систем отслеживания ошибок, например:
Mantis (http://www.mantisbt.org);
Bugzilla (http://www.bugzilla.org);
JIRA (http://www.atlassian.com/software/jira);
Trac (http://trac.edgewall.org).
История бага
По легенде, 9 сентября 1945 года учѐные Гарвардского университета, тестировавшие
вычислительную машину Mark II Aiken Relay Calculator, нашли мотылька, застрявшего между
контактами электромеханического реле и Грейс Хоппер произнесла этот термин [12].

21
Извлечѐнное насекомое (рис. 10) было вклеено в технический дневник, с сопроводительной
надписью: “First actual case of bug being found” (пер. “первый случай в практике, когда был
обнаружен жучок”). Этот забавный факт положил начало использованию слова “баг” в
значении “ошибка”.
Рис. 10. Первый найденный баг
Зачем нужны BTS
Для компании по производству ПО внедрение BTS – своего рода политический ход.
Информация о проекте, известная ранее лишь начальнику и нескольким программистам,
становится доступной широкому кругу разработчиков и менеджеров. В результате ведение
проекта превращается в реально контролируемый процесс, что позволяет в ряде случаев
предотвратить появление заведомо невыполнимых проектов. Более того, облегчается
коммуникация между специалистами отдела качества (QA) и программистом при работе над
конкретными ошибками.
Ведение базы данных ошибок в программе – один из признаков хорошей
программистской команды [9]. К сожалению, далеко не все разработчики еѐ используют.
Одно из типичных программистских заблуждений – это вера в то, что можно сведения обо всех
ошибках удержать в памяти или на отрывных листочках.
Если вы пишете код, пусть даже в одиночку, и не ведѐте систематизированный учѐт всех
найденных в коде ошибок, вы обречены поставлять низкокачественный продукт [10]. В
хороших командах база данных учѐта ошибок не просто используется, это становится
привычкой. И программисты начинают еѐ использовать для поддержки своих рабочих планов,
список назначенных им ошибок делают стартовой страницей своего браузера.
Главной деятельностью тестировщика является обнаружение багов. Но ошибку мало найти.
О найденной проблеме нужно сообщить программисту, который затем исправит ее, или
другому ответственному за это члену команды. Однако и это еще не все. После того как ошибка
исправлена, необходимо будет провести тест, который выявлял ее ранее, еще раз – чтобы
убедится, что это исправление действительно имеет место. Далее необходимо провести целый
набор тестов для того, чтобы удостоверится в том, что сделанное исправление не нарушило
работу других частей программы.
Выполнение описанных задач без специализированной системы (BTS) становиться крайне
затруднительным.

22
Пример обработки одной ошибки
Рассмотрим пример Джоэля Спольски [10] по обработке одной ошибки. Возьмѐм для
примера ошибку 1203. Вот какую информацию о ней выдаѐт база данных:
ID-Номер 1203
Проект Bee Flogger 2.0
Раздел Ftp Клиент
Название Загрузка файла роняет ftp сервер
Назначено Закрыто
Статус Закрыто-Решено-Исправлено
Важность 2 - Необходимо исправить
Архитектура 2.0 Alpha
Версия Сборка 2019
Компьютер Макинтош iMac Джилл. MacOS 9.0, 128Mb ОЗУ, 1024x768, миллионы цветов
Описание
1 ноября 2000 Открыто Джилл, очень-очень хорошим тестером.
* Запустить Bee Flogger
* Создать новый документ без имени содержащий букву "а"
* Щѐлкнуть кнопку ftp на панели
* Попробовать загрузить документ по ftp на сервер
ОШИБКА: ftp сервер не отвечает.
Команда ps -augx показывает, что ftp сервер вообще не выполняется.
В корневом каталоге содержится дамп памяти.
ТРЕБУЕТСЯ: ftp сервер не должен падать.
1 ноября 2000 Джилл, очень-очень хороший тестер, поручила
работу над ошибкой Вилли, ведущему разработчику.
2 ноября 2000 (вчера) Решено - Исправлять не будем - Вилли,
ведущий разработчик.
Не наш код, Джилл. Это proftpd, входящий в поставку Linux.
2 ноября 2000 (вчера) Возобновлено (поручено Вилли, ведущему
разработчику) Джилл, очень-очень хоршим тестером.
Неубедительно. Мне никогда не удавалось уронить proftpd другими ftp
клиентами. Наш же клиент роняет его каждый раз. Ftp серверы сами по
себе не падают.
3 ноября 2000 (сегодня) Вилли, ведущий разработчик поручил
работу над ошибкой Майку, простому программисту.
Майк, взгляни-ка сюда. Может твой код в клиенте делает что-то не то?
3 ноября 2000 (сегодня) Решено - Исправлено. Майк, простой
программист.
Я думаю, что я передавал имя пользователя вместо пароля или что-то типа
того...
3 ноября 2000 (сегодня) Реактивировано (поручено Майку,
простому программисту) - Джилл, очень-очень хорошим тестером.
Всѐ то же самое в 2001-й сборке.

23
3 ноября 2000 (сегодня) Отредактировано Майком, простым
программистом.
О как! Очень странно. Надо будет взглянуть внимательнее.
3 ноября 2000 (сегодня) Отредактировано Майком, простым
программистом.
Мне кажется это в MikeyStrCpy()...
3 ноября 2000 (сегодня) Решено - Исправлено Майком, простым
программистом.
Уфффф!!! Исправлено!
3 ноября 2000 (сегодня) Закрыто Джилл, очень-очень хорошим
тестером.
Похоже-таки исправлено в сборке 2022 - закрываю.
Итак, вот что произошло.
Майк, простой программист, колдовал над новой возможностью своей превосходной
программы для макинтошей: ftp клиентом. В один прекрасный момент из хулиганских
побуждений он написал свою собственную функцию копирования строк.
На этот раз никто не ждал, что Майк забудет завершить копируемую строку нулѐм. И
ошибка осталась незамеченной, потому что при отладке строка копировалась в заранее
обнулѐнную область памяти.
Позже на той же неделе, Джилл, очень-очень хороший тестер, терзала код, нажимая все
клавиши подряд и выполняя другие, столь же коварные тесты. Внезапно произошло что-то
очень странное – ftp сервер, на котором она проверяла клиента, упал! А ведь Джилл даже не
дышала на ftp сервер. Она просто пыталась загрузить на него файл, используя код для Mac-а,
написанный Майком.
Поскольку Джилл была очень-очень хорошим тестером, она аккуратно вела запись всех
своих действий. Она перезагрузила всѐ, что было можно. Начала повторять свои действия на
чистой машине, и – гляньте-ка – это случилось снова! Ftp сервер опять упал! Дважды за один
день! Вот тебе, Линукс!
Джилл взглянула на запись своих действий. Там было порядка двадцати шагов. Некоторые
из них, похоже, не имели отношения к проблеме. После некоторых экспериментов Джилл
сократила число действий до четырѐх, которые всегда вызывали ошибку. Теперь она была
готова описать ошибку.
Джилл ввела информацию об ошибке в базу данных. Кстати, даже сам процесс записи
информации об ошибке требует определенной дисциплины: бывают хорошие описания, а
бывают и плохие.
Короче, Джилл ввела информацию об ошибке. В хорошей системе учѐта ошибок работа над
ошибкой автоматически поручается ведущему разработчику проекта. Ошибкой, пока она не
закрыта, в каждый заданный момент времени должен заниматься только один человек.
Вилли, ведущий разработчик, взглянул на описание ошибки и решил, что, вероятно, что-то
не в порядке с ftp сервером, и пометил еѐ как "исправить невозможно". В конце концов, не они
же писали код ftp сервера.
Когда ошибка разрешена, она назначается обратно тому, кто открыл еѐ. Это важный
момент. Ошибка не исчезает только потому, что программист так решил. Золотое правило
гласит, что закрыть ошибку может только тот, кто еѐ открыл. Программист может только
"решить" ошибку, в смысле – "ага, я думаю, ошибка исправлена", но реально закрыть ошибку и
убрать еѐ из списка может только человек, увидевший еѐ впервые. Только он может

24
подтвердить, что ошибка, в самом деле, исправлена, или согласиться с тем, что по каким-либо
причинам исправить еѐ невозможно.
Джилл получила е-мэйл: ошибка опять вернулась к ней. Она посмотрела комментарии
Вилли. Что-то ей показалось неверным. Много людей годами использует этот ftp сервер с
различными приложениями, и он не падает. Это происходит только когда используется код
Майка. Джилл реактивировала ошибку, объяснив своѐ решение, и вернула еѐ на рассмотрение
Вилли. Вилли поручил ошибку Майку для исправления.
Майк изучил ошибку, думал долго и упорно, но, тем не менее, сделал неверные выводы. Он
исправил несколько несвязанных между собой ошибок и решил, что в их число попала ошибка
Джилл.
Ошибка вернулась к Джилл с описанием "решена-исправлена". Джилл попробовала
повторить шаги, ведущие к ошибке, и глядите-ка, ftp сервер опять упал. Она опять
реактивировала ошибку и теперь поручила еѐ исправление непосредственно Майку.
Майк был озадачен, но, в конце концов, он нашѐл источник ошибки. Он исправил еѐ,
проверил, и – эврика! Ftp сервер больше не падал. Опять он пометил ошибку как "решено-
исправлено". Джилл тоже повторила все действия, приводившие к ошибке, и убедилась, что
ошибка исправлена. После этого она с чистой совестью закрыла еѐ [10].
Классификация программных ошибок
Сэм Канер в своей книге "Тестирование программного обеспечения" [11] приводит список
из более чем 400 стандартных ошибок. Существует также их классификация по группам.
• Ошибки пользовательского интерфейса.
• Обработка ошибок.
• Ошибки, связанные с граничными условиями.
• Ошибки вычислений.
• Начальное и последующее состояния.
• Ошибки управления потоком.
• Ошибки обработки или интерпретация данных.
• Повышенные нагрузки.
• Аппаратное обеспечение.
• Контроль версий и идентификаторов.
• Ошибки тестирования.
К сожалению, далеко не все системы отслеживания ошибок используют одну и ту же
классификацию. Более того, благодаря гибкости настроек большинства из них можно с
легкостью менять используемые понятия на те, которые вам более привычны или приняты в
вашей компании.
Ошибки можно классифицировать по различным параметрам:
1. Серьезность для пользователя (severity)
2. Приоритет еѐ решения для разработчика (priority)
3. Функциональная область/категория (category) для каждого проекта выбирается
индивидуально.
4. Частота проявления / воспроизводимость (reproducibility)
Для серьезности можно взять следующие значения:
дополнение – требуется новая возможность
тривиально – несущественные замечания (придирки)
текст – грамматические ошибки, неверный цвет и др. интерфейсные ошибки
минимально – ошибка незначительная, еѐ можно обойти
незначительный – ошибка в не основной функциональности
значительный – наличие ошибки затрудняем выполнение основных функций
авария – крах программы или ОС в определенном режиме
блокировка – пользователь не может далее работать с системой
Приоритет определяется внутри команды разработчиков и задает, в какой
последовательности разработчики должны устранять замечания.
За основу классификации была взята классификация BTS Mantis.

25
Структура хорошего отчета по ошибке
Цель сообщения об ошибке – позволить программисту увидеть перед собой, как
программа дает сбой.
Каждое хорошее описание ошибки должно содержать ровно три вещи [10]:
1. Какие шаги привели к ошибке.
2. Что вы ожидали увидеть.
3. Что вы, в самом деле, увидели.
Основные атрибуты отчета об ошибке
Прежде всего, следует помнить о том, что составленный отчет может, а скорее всего и
будет, подвергаться изменениям не только тестером, но и другими членами команды. Кроме
того, отчет может быть составлен как на бумаге, так и с помощью специально созданных для
этого программ - систем отслеживания проблем (bug tracking system). Исходя из этого, можно
составить некий универсальный список пунктов (граф) отчета:
1. Идентификатор (Identifier).
2. Название тестируемой программы (Program).
3. Функциональная область (Area).
4. Автор отчета (Reported by).
5. Кому назначено (Delegated).
6. Дата составления (Date).
7. Дата последней модификации (Last modify).
8. Серьезность проблемы (Severity).
9. Приоритет (Priority).
10. Статус (состояние) (Status).
11. Повторяемость (Recurrence)
12. Краткое описание (Description).
13. Детальное описание (Report).
14. Обходной путь (Workaround).
15. Конфигурация (Configuration).
16. Аттачмент (приложения) (Attachment).
17. Комментарии (Comments).
18. История (History).
19. Номер версии тестируемой программы (Version).
20. Номер ее сборки (Build).
Советы Джоэля Спольски по использованию BTS
1. Хороший тестер должен всегда стремиться сократить до минимума число действий,
необходимых для воспроизведения ошибки. Следование этому правилу может оказать
неоценимую помощь программисту, который будет искать эту ошибку.
2. Помните, что закрыть ошибку может только тот, кто еѐ открыл. Кто угодно может
решить еѐ; но только тот, кто первым увидел ошибку, может быть уверен, что то, что он видел -
исправлено.
3. Существует много способов разрешить ошибку. Например, можно сделать это
следующими способами: исправлена, не подлежит исправлению, отложено, не
воспроизводится, повторная, особенность дизайна.
4. Не воспроизводится – значит, что никто не смог воспроизвести ошибку. Программисты
часто используют этот вердикт, если в описании ошибки опущены шаги для воспроизведения
ошибки.
5. Вы должны аккуратно отслеживать версии программы. Каждая сборка программы,
которая передается тестеру, должна иметь номер версии, чтобы несчастный тестер не проверял
ошибку, которая и не должна быть исправлена в этой версии.
6. Если вы программист, и вам не удается сподвигнуть тестеров на использование базы
данных учѐта ошибок, перестаньте обращать внимание на информацию об ошибках,
переданных вам в любой другой форме. Если ваш тестер присылает вам информацию об
ошибке по электронной почте, отправляйте его письма обратно с короткой припиской:

26
"пожалуйста, поместите эту информацию в базу данных. Я не имею возможности отслеживать
информацию об ошибках, поданных с помощью электронной почты".
7. Если вы тестер, и у вас проблемы с программистами, которые не используют базу данных
учѐта ошибок, не давайте им информацию об ошибках ни в какой другой форме. Помещайте
информацию в базу данных, она сама сообщит им об этом через электронную почту.
8. Если вы программист, и некоторые из ваших коллег не используют базу данных учѐта
ошибок, начните назначать им ошибки через базу. В конце концов, до них дойдѐт.
9. Если вы менеджер, и вам кажется, что никто не использует базу данных учѐта ошибок,
которую вы выбили большой кровью, начните назначать программистам новые задачи в форме
ошибок. Система отслеживания ошибок также является отличным средством учѐта
заданий.
10. Избегайте соблазна добавить новые поля в базу данных ошибок. Примерно раз в
месяц кому-нибудь в голову приходит "светлая" идея добавить к базе данных новое поле. Вам
приносят самые разные мудрые идеи, например: указывать файл, в котором обнаружена
ошибка; или вести учѐт, в каком проценте повторов ошибка воспроизводится; вести учѐт версий
всех DLL, которые были запущены на компьютере, когда произошла ошибка; и так далее.
Очень важно не поддаваться этим идеям. Иначе рано или поздно экран ввода информации об
ошибке будет представлять собой форму с тысячью полей, которые необходимо заполнить, и
никто не будет вводить эту информацию. Чтобы база данных учѐта ошибок приносила толк, ее
должны использовать все. И если ввод информации об ошибке будет требовать слишком
больших усилий, люди найдут обходные пути.
Жизненный цикл ошибки
Итак, тест проведен, ошибка найдена, при этом сомнений в том, что ошибка имеет место -
нет. Что делать дальше? Необходимо сообщить разработчику (программисту) о том, что
ошибка найдена, т.е. написать отчет о проблеме (bug report).
В bugtraking системе заведѐм разделы (проекты и продукты). Кто-то (пользователь, другой
разработчик и т.д.) находит нужный раздел и вводит сообщение об ошибке. Появился bug в
статусе “новый”.
У каждого бага есть свой владелец. Когда баг в статусе “новый”, он автоматически
назначается ответственному ("assigned to"). Баг можно (и часто нужно) переназначить
ответственному (reassign).
На практике чаще всего используются следующие состояния багов:
Новый (new)
Неподтверждѐнный (unconfirmed)
Назначен (assigned)
Решен (resolved)
o Не ошибка (resolved-invalid)
o Дубль (resolved-duplication)
o Исправлен (resolved-fixed)
Закрыт (closed)
New (новый) – баг только открыт и еще не был обработан. Когда тестер открывает баг, то
первым информацию о нем получает некто по умолчанию (для разных тестируемых систем это
может быть разные люди), читает его, и переправляет этот баг программисту, который
непосредственно будет его исправлять.
Баг переходит в состояние assigned (назначен). По мере работы, этот программист может
переадресовать баг другому программисту, который, например, знает данную часть системы
лучше. К сожалению, это порождает ситуации, когда баг "плутает" от одного разработчика к
другому несколько месяцев.
Assigned (назначен) – конкретный программист получил этот баг и теперь должен с ним
разобраться – исправлять свою или чужую ошибку.
В случае если баг не является "ошибкой" (тестер ошибся), то он превращается в Resolved-
Invalid и переправляется тестеру обратно.

27
Если баг о той же проблеме уже есть, и над ним работают, то баг превращается в Resolved-
Duplication. Например, ошибка была описана ранее и была исправлена, но исправленный код
еще не поступил к тестерам.
Когда программист ошибку исправил, то баг превращается в Resolved-Fixed. Сам
программист эти состояния и выставляет.
Resolved (Fixed, Invalid, Duplication) – ошибка исправлена и возвращена тестерам для
проверки.
Если баг в состоянии Resolved-Invalid, то тестер обязан еще раз убедиться, ошибка была или
нет. Другими словами перетестировать.
Когда баг в состоянии Resolved-Duplication то тестер должен убедиться, что действительно,
другой, аналогичный баг существует, его номер обычно программист указывает в своем
комментарии. Доверяй, но проверяй.
В случае, когда баг Resolve-Fixed тестер проверяет (тестирует проблему) опять. Если
ошибка исправлена – Closed. Если ошибка не исправлена – баг открывается опять (Unconfirmed,
Assigned)
Closed – ошибка исправлена, повторно протестирована, и исправленный код помещен в
живую систему, или новая сборка выпущена.
Различные BTS могут поддерживать различные виды жизненного цикла бага. На рис. 11
приведены основные состояния бага и типовые переходы между состояниями.
новый (new)
неподтвержден (unconfirmed)
назначен (assigned)
решен (resolved)
закрыт (closed)
Рис. 11. Переходы между состояниями бага
Рассмотрение конкретной BTS на примере Mantis
Система отслеживания ошибок Mantis представляет собой Web-приложение, написанное на
PHP и является свободно распространяемым. Для еѐ работы необходим СУБД MySQL и Web
сервер Apache. Система так же может быть адаптирована к СУБД PostgreSQL и другому Web
серверу, поддерживающему PHP.
Существует специальная версия проекта, которая работает без отдельной установки
серверной части (эти части включены в сам проект) – Instant Mantis
(http://www.mantisbt.org/wiki/doku.php/mantisbt:instantmantis). Данная возможность удобна в
следующих случаях:
Для быстрого развертывания проекта Mantis в малых проектах.
Для переноса системы (можно все хранить на flash-карте и переносить с компьютера
на компьютер).
Если нет достаточных прав для установки серверных компонент.
На изолированных машинах при отсутствии доступа к Интернет.
Домашняя страница проекта: http://www.mantisbt.org/
Способ взаимодействия с пользователем
Создание пользователей, проектов и категорий
При регистрации пользователя необходимо указать реальное имя пользователя, login, адрес
электронной почты (e-mail) и уровень доступа по умолчанию. Предусмотрены следующие
уровни доступа:
Зритель
Автор
28
Редактор
Разработчик
Менеджер
Администратор
Пользователю на e-mail будет отправлен запрос на подтверждение регистрации со ссылкой
на Web-сайт системы. При переходе по ссылке пользователь должен установить свой пароль и
далее может работать с системой.
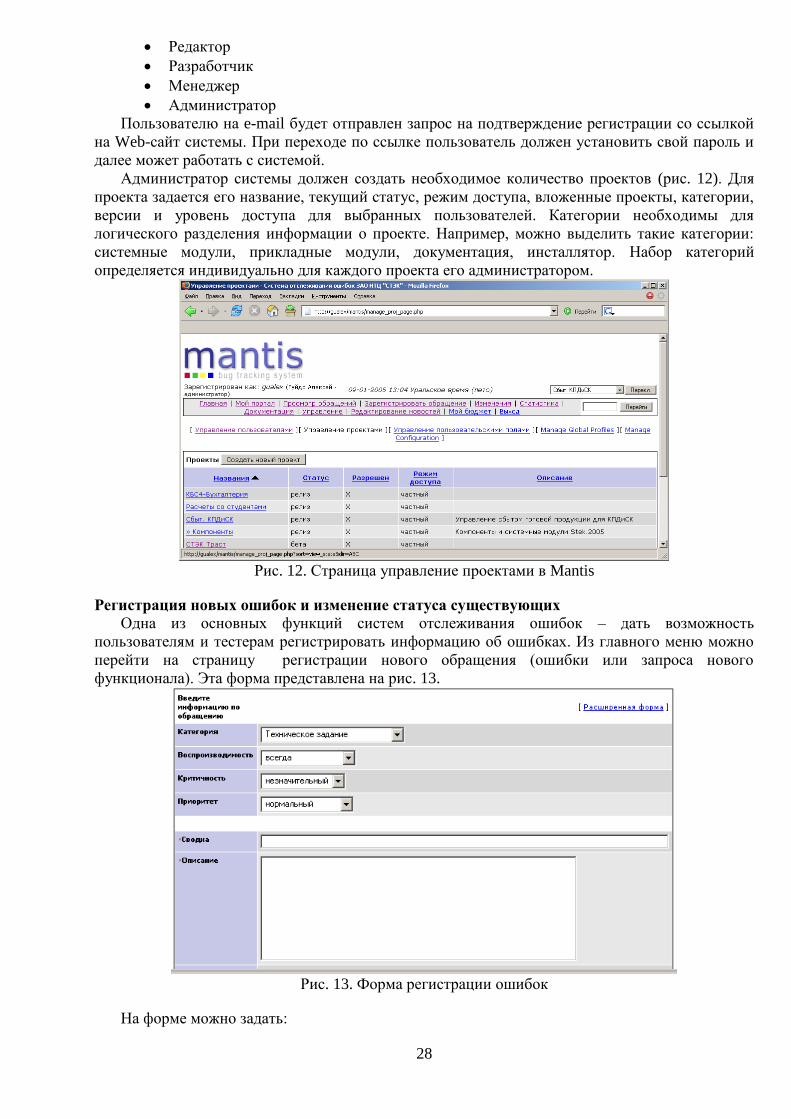
Администратор системы должен создать необходимое количество проектов (рис. 12). Для
проекта задается его название, текущий статус, режим доступа, вложенные проекты, категории,
версии и уровень доступа для выбранных пользователей. Категории необходимы для
логического разделения информации о проекте. Например, можно выделить такие категории:
системные модули, прикладные модули, документация, инсталлятор. Набор категорий
определяется индивидуально для каждого проекта его администратором.
Рис. 12. Страница управление проектами в Mantis
Регистрация новых ошибок и изменение статуса существующих
Одна из основных функций систем отслеживания ошибок – дать возможность
пользователям и тестерам регистрировать информацию об ошибках. Из главного меню можно
перейти на страницу регистрации нового обращения (ошибки или запроса нового
функционала). Эта форма представлена на рис. 13.
Рис. 13. Форма регистрации ошибок
На форме можно задать:

29
Категорию
Воспроизводимость
Критичность
Приоритет
Сводку
Дополнительную информацию
Прикрепленный файл
Режим доступа
Существует упрощенный и расширенный режим регистрации обращений.
Просмотр списка ошибок под различными фильтрами
Система предоставляет возможность фильтровать список зарегистрированных ошибок по
различным атрибутам и сортировать полученный список (рис. 14). Фильтры задаются с
помощью фильтра в верхней части окна. Сортировка задается с помощью клика по названию
колонки в таблице. Возможен просмотр обращений, как по отдельному проекту, так и по всем
доступным проектам.
Рис. 14. Просмотр списка обращений

30
ГИБКАЯ РАЗРАБОТКА ПО
Современная ситуация в разработке программного обеспечения весьма далека от идеала.
Системы регулярно поставляются позже намеченного срока и с превышением бюджета, если
поставляются вообще. Системы часто не удовлетворяют заказчиков, и мы вынуждены
разрабатывать их снова и снова [15].
В идеальном случае разработка программы начинается с формирования четкого
представления о системе. В идеальном случае четкое осознание проекта приводит к появлению
первой версии программы.
Дальнейшие события могут принять нежелательный характер. Неаккуратно написанная
программа приводит к значительному усложнению процесса технического сопровождения.
В конечном итоге усилия, требуемые для выполнения даже простейших изменений,
становятся настолько обременительными, что разработчики и ведущие менеджеры требуют
выполнение повторной разработки программного проекта.
Подобные действия редко приводят к успеху. Несмотря на то, что разработчики проекта
руководствуются наилучшими намерениями, они четко сознают, что "стреляют по движущейся
мишени". Старая система непрерывно развивается и изменяется, а новый проект должен
развиваться "в русле" этих изменений. В связи с этим в новом проекте накапливаются
различные недостатки еще задолго до выпуска первой рабочей версии программы.
Манифест
Чтобы разрешить проблемы, стоящие перед разработчиками программного обеспечения, в
феврале 2001 года был создан Альянс гибкой разработки программного обеспечения [16]. Эта
группа людей приняла манифест, в котором поддержала лучшие способы разработки
программ, а затем, опираясь на этот манифест, сформировала набор принципов, которые
определяли критерий процесса гибкой разработки программного обеспечения. Положения
манифеста:
• Люди и их взаимодействие важнее, чем процессы и средства.
• Работающее ПО важнее, чем исчерпывающая документация.
• Сотрудничество с заказчиком важнее, чем обсуждение условий контракта.
• Реагирование на изменения важнее, чем следование плану.
Принципы гибкой разработки ПО
Роберт Мартин в свой работе [14] выделил ряд принципов гибкой разработки. Рассмотрим
эти принципы подробно.
Соответствие требованиям заказчика
Наша первостепенная задача – достичь соответствия требованиям заказчика,
непрерывно поставляя ему в оптимальные сроки высококачественное ПО. Существует
взаимосвязь между качеством и поставкой частично функционирующей системы на раннем
этапе разработки. Чем меньшими функциональными возможностями обладает программный
продукт на раннем этапе разработки, тем выше качество окончательной версии. Чем чаще
происходит поставка частей программного продукта, чем выше качество конечного продукта.
Совокупность методик гибкой разработки ПО предусматривает доставку разработанного
компонента проекта на раннем этапе разработки и последующие частые поставки модулей по
мере выполнения проекта. Наша цель – поставить элементарную систему на протяжении
первых нескольких недель после начала выполнения проекта. Затем каждые две недели мы
стремимся поставлять системные модули с растущими функциональными возможностями.
Заказчики могут принять решение начать эксплуатацию системных модулей, если они считают,
что они обладают достаточным уровнем функциональных возможностей. Или же они могут
решить просто пересмотреть имеющиеся функциональные возможности и сообщить
разработчикам об изменениях, которые необходимо внести в программный продукт.
Приветствие изменений
Следует приветствовать изменения требований, даже если они происходят на
позднем этапе разработки. Правила гибкой разработки ПО рассматривают изменения как
преимущество в конкурентной борьбе. Участники процесса гибкой разработки ПО не
опасаются изменений. Они рассматривают модификацию требований как положительный

31
момент, поскольку при этом предполагается, что команда получила дополнительную
информацию о том, каким образом следует соответствовать требованиям потребительского
рынка. Команда, участвующая в гибкой разработке ПО, усердно и настойчиво трудится над
сохранением гибкости структуры ПО. Благодаря этому в случае изменения требований влияние
на систему будет минимальным.
Частая поставка рабочего ПО
Следует часто поставлять рабочее ПО: от одного раза в две недели до одного раза в два
месяца, стремясь к соблюдению более сжатых сроков. Команда разработчиков должна
поставлять рабочий программный продукт, причем в максимально сжатые сроки (по истечению
нескольких первых недель) и часто (каждые последующие несколько недель). При этом не
следует довольствоваться поставками пачек документов или планов. Наше внимание
сосредоточено на задаче поставить ПО, соответствующее требованиям заказчика.
Совместная работа заказчиков и разработчиков
Бизнесмены и разработчики обязаны ежедневно совместно трудиться над проектом
на протяжении всего процесса его выполнения. Чтобы обеспечить быстрое выполнение
проекта, между заказчиками, разработчиками и организаторами проекта следует установить
тесное и постоянное взаимодействие. Программный проект не должен соответствовать
принципу "сделали забыл", поэтому проект должен находиться под постоянным руководством.
Мотивированные индивиды
Выполняйте проекты с привлечением мотивированных индивидов. Предоставьте им
соответствующую среду разработки и необходимую поддержку, причем доверьте им
выполнение поставленных задач. В проекте гибкой разработки ПО люди рассматриваются в
качестве важнейшего фактора успеха. Все другие факторы – процесс, среда разработки,
менеджмент и прочие – считаются второстепенными и могут изменяться, если они оказывают
на людей неблагоприятное воздействие. Например, если среда разработки в офисе препятствует
работе команды, ее следует изменить. Если определенные этапы процесса препятствуют работе
команде, их следует изменить.
Интерактивное общение
Наиболее результативный и эффективный метод передачи информации команде, а
также в рамках самой команды заключается в интерактивном общении. В проекте гибкой
разработки ПО люди общаются друг с другом. Основной метод коммуникации – это общение.
Документы можно создавать, но невозможно охватить всю информацию в письменном виде.
Команде, работающей над проектом гибкой разработки ПО, не требуются спецификации,
планы и проекты, выраженные в письменной форме. Эти документы могут быть сформированы,
если возникнет безотлагательная и существенная потребность в этом, но они не являются
абсолютной необходимостью. Главное – это общение.
Рабочее ПО – критерий прогресса
Рабочее программное обеспечение – это первостепенный критерий прогресса. Прогресс
в проектах гибкой разработки ПО отслеживается путем оценки части ПО, которая в текущий
момент времени удовлетворяет требования заказчика. Прогресс подобных проектов не связан с
текущим этапом их выполнения, а также не может оцениваться на основе объема выпущенной
документации или кода инфраструктуры, разработанного в результате их выполнения.
Программный проект считается выполненным на 30%, если получен на 30%
функционирующий программный продукт.
Устойчивое развитие
Проекты гибкой разработки ПО способствуют устойчивому развитию. Спонсоры,
разработчики и пользователи должны уметь поддерживать постоянный темп работы. Проект
гибкой разработки ПО – это не спринтерский забег, а марафон. Команда не срывается с места
на полной скорости и не пытается удержать эту скорость на протяжении всего проекта. Вместо
этого она продвигается быстрым, но равномерным шагом. Слишком быстрое продвижение
ведет к истощению сил, появлению недостатков и, в конечном счете, – к неудаче. Команды
гибкой разработки ПО сами поддерживают свой темп. Они не позволяют себе слишком устать.
Они не заимствуют частичку завтрашней энергии для того, чтобы успеть сделать чуть больше

32
сегодня. Они работают на скорости, позволяющей поддерживать высочайшие стандарты
качества на протяжении всего проекта.
Акцент на высоком уровне качества
Постоянный акцент на высоком техническом уровне качества и хорошем
проектировании повышает быстроту разработки. Высокое качество – это ключ к
достижению высокой скорости разработки. Быстрого продвижения можно достичь путем
поддержки максимального уровня качества и прочности программного продукта.
Следовательно, все члены команды гибкой разработке ПО обязаны создавать код с
качественными характеристиками высочайшего уровня. Следует избегать формирования
"неразберихи", обещая устранить ее при первой же возможности. Если происходит какая-либо
путаница, устраняйте ее до конца текущего рабочего дня.
Необходимость в простоте.
Команды по гибкой разработке ПО не пытаются построить грандиозную суперсистему.
Вместо этого они всегда избирают простейший путь, который согласуется с поставленными
целями. Они не придают большого значения прогнозированию завтрашних проблем и не
пытаются оградить себя от них уже сегодня. Вместо этого сегодня они делают самую простую и
высококачественную работу, будучи уверенными в том, что им удастся легко внести
необходимые изменения, если в будущем возникнут какие-либо проблемы.
Самоорганизующиеся команды
Наилучшие архитектуры, требования и проекты возникают у самоорганизующихся
команд. Команда гибкой разработки ПО является самоорганизующейся. Обязанности не
передаются отдельным членам команды, а учитывается лишь команда в целом. Лишь сама
команда определяет наилучший способ их реализации. Члены команды гибкой разработки ПО
совместно работают над всеми аспектами проекта. Каждый из них имеет право внести свой
вклад в общее дело. Ни один из членов команды не несет ответственность за архитектуру,
требования или тесты. Команда разделяет эти обязанности, и каждый член команды может
влиять на этот процесс.
Гибкое поведение
Периодически команда делает выводы об эффективности своей работы и
соответственно модифицирует и адаптирует свою линию поведения. Команда по гибкой
разработке ПО непрерывно подстраивает собственную организацию, правила, обычаи,
взаимосвязи и т.д. Команда по гибкой разработке ПО осознает, что среда разработки постоянно
изменяется и что она сама должна меняться вместе со средой, чтобы сохранить быстрый темп
разработки.

33
ЭКСТРЕМАЛЬНОЕ ПРОГРАММИРОВАНИЕ (XP)
Экстремальное программирование – один из наиболее известных методов гибкой
разработки ПО. Он включает несколько простых взаимосвязанных методик, причем сумма
целого превышает результат простого суммирования отдельных составляющих компонентов.
ХР комбинирует лучшие практики, использовавшиеся в индустрии производства
программного обеспечения на протяжении долгих лет. В ХР эти практики применяются
совершенно по-новому и приводят к значительно более впечатляющим результатам.
Экстремальное программирование основано на том, что процесс разработки
программного обеспечения – это процесс тесного и интенсивного взаимодействия между
людьми. Хорошая методика разработки программ должна с максимальной эффективностью
использовать сильные человеческие качества и сглаживать человеческие недостатки. ХР лучше
других методик учитывает весь комплекс факторов, оказывающих влияние на людей, занятых
разработкой программ. За последнее десятилетие ХР является одной из наиболее радикальных
инновацией в индустрии производства программного обеспечения. В рамках ХР каждому
участнику проекта назначается определенная роль с соответствующим набором полномочий.
ХР способствует тому, что все участники проекта исполняют назначенные им роли, а
следовательно, каждый из них действует в границах своей компетенции. Благодаря этому люди,
принимающие участие в проекте, эффективно работают, как единая команда.
В работе [17] Рой Миллер приводит краткое описание основных элементов экстремального
программирования. Более полная информация содержится в работе Кента Бека [18]. Далее
рассмотрим основные элементы XP.
Разработка программного продукта, решающего поставленную бизнес-задачу, выглядит как
диалог, в котором принимает участие каждая из заинтересованных сторон. Заказчики
формулируют пожелания (stories), назначают им приоритеты (priorities), создают
приемочные тесты (acceptance tests), а также снабжают программистов и менеджеров всей
необходимой информацией тогда, когда это необходимо. Программисты сообщают заказчикам
предварительные оценки трудозатрат (estimates), а позже передают им работающий код в
совокупности с тестами модулей (unit test). Менеджеры выступают посредниками – они
уравновешивают требования заказчиков и затраты, необходимые для реализации этих
требований программистами. Кроме того, менеджеры разрешают споры и определяют, какие
ресурсы требуются для работы над проектом с учетом постоянно меняющихся бизнес-условий.
XP определяет базовый набор ценностей и практик, позволяющих программистам
эффективно заниматься тем, что у них получается лучше всего: разрабатывать программы. ХР
позволяет отказаться от ненужных артефактов, характерных для большинства тяжеловесных
методик разработки, так как подобные артефакты затрудняют движение к цели и изматывают
разработчиков. Сложно вызвать интерес менеджмента к методике, которая обладает столь
экстравагантным названием: "экстремальное программирование". Однако если ваша компания
действительно желает повысить эффективность процесса разработки программ, руководство
компании должно, невзирая на имя, со всей серьезностью рассмотреть все те преимущества,
которыми обладает ХР.
Кент Бек (Kent Beck) сформулировал ключевые ценности ХР в своей книге «Экстремальное
программирование» [18]. Здесь мы опишем их очень коротко:
1. Коммуникация (Communication). Если при работе над проектом возникает проблема,
зачастую ее причиной является то, что в какой-то момент времени кто-то не сказал кому-то
что-то очень важное. В ХР возникновение подобной проблемы маловероятно. При
работаете над проектом в стиле ХР, вы фактически не можете избежать общения.
2. Простота (Simplicity). ХР всегда предлагает решать задачу самым простым способом из
всех возможных (simplest thing that could possibly work). Кент выражает эту мысль
следующим образом: «ХР предполагает, что лучше сегодня написать самый простой код,
чем потратить время на разработку более сложного кода, а завтра узнать, что этот код вам
не нужен».
3. Обратная связь (Feedback). Чем раньше вы начнете получать отзывы о разрабатываемом
продукте от заказчика, от команды разработчиков и от реальных конечных пользователей и

34
чем чаще вы будете это делать, тем точнее вы сможете выбирать дальнейшее направление
развития вашего проекта. Это позволит вам всегда оставаться на правильном пути.
4. Храбрость (Courage). Если вы двигаетесь не с самой высокой скоростью, вас постигнет
неудача. Вы должны обладать храбростью для того, чтобы в нужные моменты времени
совершать правильные поступки. Например, вы должны обладать достаточной храбростью
для того, чтобы отказаться от кода, на разработку которого вы потратили значительное
время.
Каким образом поставить свою работу на фундамент этих ценностей? Для этого существует
набор практик, которых разработчики должны строго придерживаться в своей повседневной
работе.
Практики XP
1. Игра в планирование (Planning Game) – диалог между заказчиками и разработчиками с
целью определить текущие задачи, приоритеты и сроки реализации.
2. Тестирование (Testing) – как программисты, так и заказчики пишут тесты, позволяющие в
любой момент времени убедиться в корректности работы системы.
3. Парное программирование (Pair Programming) – любой код разрабатывается одновременно
двумя программистами, работающими на одном компьютере.
4. Рефакторинг (Refactoring) – улучшение кода путем его переработки.
5. Простой дизайн (Simple Design) – постоянное видоизменение дизайна системы с целью
его улучшения.
6. Коллективное владение кодом (Collective Code Ownership) – правом вносить изменения в
любой код системы обладает любой член команды.
7. Постоянная интеграция (Continuous Integration) – интеграция продукта выполняется
постоянно, по несколько раз в день.
8. Заказчик на месте разработки (On-Site Customer) – рядом с разработчиками постоянно
находится представитель заказчика, который работает вместе с ними.
9. Частые выпуски версий (Small Releases) – каждая следующая версия продукта выходит
вскоре после выхода предыдущей версии. Новые версии продукта внедряются в
эксплуатацию как можно чаще.
10. 40-часовая рабочая неделя (40-hour Week) – разработчики не должны работать
сверхурочно, так как от этого снижается производительность и качество их работы.
11. Стандарты кодирования (Coding Standards) – все участники команды должны
придерживаться общих стандартов кодирования.
12. Метафора системы (System Metaphor) – простая аналогия, интуитивно понятная всем
участникам проекта, описывающая собой внутреннее строение и функционирование
системы.
Cлово «экстремальное» в названии методики ХР означает в основном две вещи:
1. ХР использует каждую из этих практик в «экстремальной» форме, то есть с максимально
возможной интенсивностью.
2. ХР комбинирует эти практики таким образом, что величина результата превышает
величину суммы составляющих.
Что это означает? Если перепроверка (review) кода – это хорошо, значит, мы будем делать
это постоянно, для этого мы будем программировать в парах. Если тестирование – это хорошо,
значит, мы будем заниматься этим постоянно, для этого мы будем вначале писать тесты, а
потом – тестируемый код. Если документация зачастую не соответствует реальному состоянию
кода, значит, мы будем писать необходимый минимум документации, а всю необходимую
информацию о строении и функционировании программы будем извлекать из кода и
прилагаемых к нему тестов. ХР не гарантирует того, что люди все время будут совершать
только правильные действия, однако ХР облегчает им эту задачу и смягчает серьезность
проблем, возникающих в результате ошибок. Практики в ХР комбинируются таким образом,
что каждая из них способствует реализации других практик благодаря этому значительно
увеличивается скорость и эффективность работы над проектом.
Рассмотрим подробнее каждую из этих практик и роль, которую они играют в ХР.

35
Игра в планирование (Planning Game)
ХР – признает тот факт, что, приступая к работе над проектом, вы не можете предусмотреть
абсолютно все. ХР предполагает, что ответы на большую часть вопросов, имеющих отношение
к разрабатываемой системе и техническому заданию, будут найдены в процессе работы над
продуктом. Получив в свое распоряжение рабочую версию продукта, заказчик сможет точнее
понять, что ему нужно, и скорректировать свои требования. Программисты, получив от
заказчика новые пожелания и коррективы, смогут без особых осложнений внести в продукт
необходимые изменения и реализовать новую, ранее не предусмотренную функциональность.
Подобный обмен информацией происходит постоянно. Требования заказчика и поведение
продукта постоянно меняется. Традиционные методики, как правило, игнорируют возможность
каких-либо изменений. ХР, напротив, подразумевает, что изменения неизбежны и даже
полезны. Для обмена информацией между заказчиком и разработчиками применяется игра в
планирование (Planning Game).
Сущность планирования заключается в распределении ответственности между заказчиками
и разработчиками. Деловые люди (заказчики) принимают решения о важности того или иного
элемента программы, а разработчики рассчитывают стоимость его проектирования и
внедрения.
Основная цель игры в планирование – быстро сформировать приблизительный план работы
и постоянно обновлять его по мере того, как условия задачи становятся все более четкими.
Артефактами игры в планирование является набор бумажных карточек, на которых записаны
пожелания заказчика (customer stories), и приблизительный план работы по выпуску
следующих одной или нескольких небольших версий продукта.
Критическим фактором, благодаря которому такой стиль планирования оказывается
эффективным, является то, что в данном случае заказчик отвечает за принятие бизнес-решений,
а команда разработчиков отвечает за принятие технических решений. Если не выполняется это
правило, весь процесс распадается на части.
Пользовательские истории
Для того чтобы приступить к планированию проекта, необходимо иметь общее
представление о требованиях, предъявляемых к конечному результату работы, но совсем не
обязательно заранее вдаваться в детали. Достаточно четко представлять себе все необходимые
условия. Об отдельных деталях на данном этапе можно знать только то, что они существуют.
Мелкие детали, как правило, меняются со временем, особенно когда заказчик присутствует
при процессе создания системы. Наблюдение за рождением и развитием системы лучше всего
помогает формулированию и уточнению технических требований. Поэтому точное, но
преждевременное описание различных второстепенных компонентов (до того, как они близки к
завершению) зачастую может привести к напрасной трате времени и сил.
Когда работа организована в соответствии с принципами экстремального
программирования, разработчики постоянно находятся в курсе всех требований благодаря их
обсуждению с заказчиком. Связь с пользователями осуществляется путем проведения бесед,
посвященных различным аспектам разработки программного продукта.
Пользовательские истории выступают в качестве инструмента планирования
заказчика, с помощью которого он может отслеживать соблюдение технических требований на
всех этапах разработки проекта.
Прежде чем приступить к работе над новой версией программного продукта, в начале
каждого цикла разработчики знакомят клиентов со сметой, которая зависит от затрат,
понесенных на предыдущих этапах. Заказчики сами решают, какие изменения, и
усовершенствования должны быть внесены в программу, не выходя за рамки существующего
бюджета.
Команда разработчиков решает следующие задачи:
формирует оценку времени, которое предположительно потребуется для того, чтобы
реализовать каждое из пожеланий;
оценивает затраты, связанные с выбором той или иной технологии, на основе которой
будет выполняться реализация;
распределяет задачи между членами команды;

36
оценивает риск, связанный с реализацией каждого из пожеланий;
определяет порядок, в котором будут реализованы пожелания, являющиеся частью
текущей итерации (если рискованные пожелания реализовать в первую очередь, можно
снизить общий риск).
Заказчик решает следующие задачи:
определяет объем работ (scope), то есть набор пожеланий для выпуска (release) и набор
пожеланий для итерации (iteration);
определяет дату завершения работы над выпуском (release);
назначает приоритеты (priorities), то есть, исходя из полезности различных функций с
точки зрения бизнеса, определяет, какие из функций продукта должны быть реализованы
в первую очередь.
Планирование должно выполняться достаточно часто. Благодаря этому и заказчик, и
разработчики могут своевременно изменить план в случае, если в силу вступают новые
непредвиденные обстоятельства.
Чтобы проект увенчался успехом, процесс разработки должен гарантировать заказчикам и
разработчикам определенные неотчуждаемые права [19].
«Билль о правах» заказчика
У вас есть право получить общий план работ и узнать, что может быть сделано, когда и за
какие деньги.
У вас есть право получить максимум выгоды из каждой недели работы программистов.
У вас есть право по заданным вами тестам регулярно контролировать ход выполнения
проекта на работающей версии системы.
У вас есть право менять свои решения, заменять одно функциональное свойство системы
другим и менять приоритеты, не платя за это чрезмерные суммы разработчикам.
У вас есть право получать информацию о любых неожиданных изменениях в ходе работ,
что позволит вам вовремя уменьшить общий объем задач и сохранить первоначальные
сроки поставки системы. Вы также можете прекратить проект в любое время и получить
при этом работающую версию системы, разработка функциональности которой была
оплачена вами на текущий день.
«Билль о правах» программиста
У вас есть право знать, что именно нужно сделать и каков приоритет каждой задачи.
У вас есть право в любое время производить качественный программный продукт.
У вас есть право просить и получать помощь от коллег, начальства и заказчиков.
У вас есть право самостоятельно оценивать объем трудозатрат по задачам, а потом
вносить в эти оценки изменения.
У вас есть право взять на себя ответственность и не ждать, пока ее на вас возложат.
Необходимо позаботится о такой среде, которая позволила бы и разработчикам, и
заказчикам понять взаимные страхи и признать свои права и обязанности. Если этого не будет,
мы не сможем действовать смело.
Тестирование (Testing)
В ХР используется две разновидности тестирования:
тестирование модулей (unit testing);
приемочное тестирование (acceptance testing).
Тестирование модулей
Тесты модулей (unit tests) разрабатываются программистами по мере того, как они пишут
код. Тесты функциональности (acceptance tests) разрабатываются заказчиком после того, как
он формулирует пожелания (stories). Тесты модулей в любой момент времени сообщают
разработчику о том, что разработанный код функционирует корректно. Приемочные тесты
сообщают всей команде о том, что разрабатываемый продукт делает именно то, чего хочет
пользователь.
Если предположить, что для разработки команда использует объектно-ориентированный
язык, разработчики пишут тесты для каждого метода, корректность работы которого может

37
быть нарушена. Разработка тестов для метода выполняется до того, как будет написан рабочий
код этого метода. После того как разработаны все возможные тесты, разрабатывается код
метода. Реализация метода должна быть такой, чтобы обеспечить выполнение всех тестов, и не
более того. Благодаря тому, что код тестов пишется до того, как разрабатывается код метода,
вы получаете:
наиболее полный набор всевозможных тестов;
наиболее простой код, который (скорее всего) реализует заданную функциональность;
четкое представление о том, какую задачу решает код.
Подробно практика разработки через тестирование (Test-Driven Development) изложена в
книге Кента Бека [20].
Разработчик не может быть уверен в правильности написанного им кода до тех пор, пока не
сработают абсолютно все тесты модулей разрабатываемой системы. Тесты модулей позволяют
разработчикам убедиться в том, что их код работает корректно. Они также помогают другим
разработчикам понять, зачем нужен тот или иной фрагмент кода и как он функционирует.
Тесты модулей – это удобная разновидность документации. Тесты модулей также позволяют
разработчику без каких-либо опасений выполнять рефакторинг (refactoring) кода, то есть
вносить в код улучшающие его изменения. В любое время разработчик может без страха
модифицировать любой фрагмент кода системы, – тесты модулей немедленно сообщат ему о
том, что корректность работы системы в результате этого не пострадала или, напротив, что
работоспособность кода нарушена. Тесты модулей должны выполняться автоматически, в
результате их работы разработчик должен получить четкий, недвусмысленный ответ: «код
работоспособен» или «код неработоспособен».
Когда вы пишете программный код, который тестируется надлежащим образом, то в
результате получаете, как минимум, контролепригодный продукт. Кроме того, появляется
дополнительный стимул к созданию блочной структуры программы (блоки легко тестировать
независимо друг от друга). Блочная структура, кроме того, что она позволяет уменьшить время
тестирования, дает возможность не переписывать весь код заново при внесении изменений, а
ограничиваться заменой отдельных элементов программы.
Описанные возможности, имеющие отношение к тестированию и тестам модулей,
реализованы в семействе библиотек xUnit. В настоящее время библиотеки этого семейства
используются огромным количеством разработчиков. Каждая из этих библиотек позволяет
разработчикам создавать тесты, в состав каждого из которых входит одно или несколько
тестовых условий (assertions). Если каждое из условий теста удовлетворяется, считается, что
тест выполнен. Запуск всех тестов можно инициировать из GUI (графического интерфейса),
щелкнув на специальной кнопке. Результаты выполнения тестов в виде набора текстовых
сообщений отображаются в главном окне. Для наглядности в главном окне графического
интерфейса каждой из библиотек присутствует большой хорошо заметный цветной индикатор
законченности процесса тестирования. Индикатор реализован в виде горизонтальной полосы,
которая окрашивается в зеленый цвет в случае, если все тесты успешно выполнены, и в
красный в случае, если хотя бы один тест не сработал. Эта полоса является символом, который
часто используют в разговорах об ХР. Выражение «зеленая полоса» (green bar) означает, что все
тесты успешно выполнены (рис. 15), а выражение «красная полоса» (red bar) означает, что, по
крайней мере, один, а возможно и несколько тестов не сработали.

38
Рис. 15. Пример зеленой полосы в среде NUnit
Приемочные тесты
Заказчик отвечает за разработку приемочных тестов (acceptance tests) для каждого из
сформулированных им пожеланий (story). Заказчик может написать приемочные тесты
самостоятельно, однако это вовсе не обязательно. Он может привлечь для этой цели других
сотрудников организации (например, сотрудников отдела контроля качества, бизнес-
аналитиков и др.). Приемочные тесты позволяют заказчику убедиться в том, что система
действительно обладает возможностями, о реализации которых он просил разработчиков.
Кроме того, приемочные тесты позволяют проверить корректность функционирования
разрабатываемого продукта. Приемочные тесты должны запускаться автоматически.
Разработчики должны запускать приемочные тесты достаточно часто, чтобы убедиться в том,
что в ходе реализации новых функций системы никоим образом не нарушена корректность
работы существующих механизмов. Как правило, для разработки приемочных тестов заказчики
используют помощь со стороны команды разработчиков.
Приемочные тесты позволяют заказчику получить представление о том, насколько успешно
продвигается работа над проектом. Приемочные тесты также позволяют заказчикам принимать
обоснованное решение о том, готова ли очередная версия (release) продукта к использованию
или нет.
Программирование парами (Pair Programming)
В ХР любой программный код разрабатывается одновременно двумя программистами,
работающими на одном компьютере с одной мышью и одной клавиатурой. Эффективность
такого подхода вовсе не так низка, как это может показаться. Программирование в паре (pair
programming) обладает следующими преимуществами:
любые решения в области дизайна принимаются не одной головой, а двумя;
какую бы часть системы вы не взяли, в ней будут хорошо разбираться, по крайней мере,
два человека;
если разработкой одного участка кода занимаются одновременно два человека, снижается
вероятность ошибок, неаккуратного кода, отсутствия необходимых тестов и т. п.;
партнеры в парах постоянно меняются, благодаря чему знание о внутреннем устройстве
разрабатываемой системы быстро распространяется между членами команды;
происходит постоянная перепроверка (review) чужого кода: один партнер пишет код,
другой просматривает этот код.
Программирование в паре на самом деле эффективнее, чем программирование в одиночку.
Возможно, когда вы начнете программировать в паре, вам придется смириться с небольшим
снижением скорости вашей работы, но это только в начале. В дальнейшем вы с лихвой окупите
понесенные потери.

39
Рефакторинг (Refactoring)
Код имеет тенденцию к ухудшению качества по мере усложнения всей системы. Каждый
раз, когда в программу вносятся усовершенствования или исправляются ошибки, ее работа
ухудшается. Если этот процесс оставить без внимания, то это может привести к непоправимым
последствиям, неразберихе и полному хаосу.
Коллективы, практикующие методику экстремального программирования, стараются
избежать этого, применяя частый рефакторинг. Рефакторинг представляет собой процесс
такого изменения программной системы, при котором не меняется внешнее поведение кода, но
улучшается его внутренняя структура. Каждая отдельная трансформация крайне проста и
незначительна, однако вместе они оказывают значительное влияние на программную
архитектуру.
После каждой трансформации проводится тестирование данного блока, дабы убедиться в
том, что изменения не привели к появлению ошибок. Затем вносится следующее изменение,
проводится тест и т.д. Благодаря такому алгоритму работы система всегда находится в
полностью работоспособном состоянии.
Наличие тестов является крайне желательным условием начала рефакторинга. Без них
трудно обнаружить деструктивные изменения и вовремя на них среагировать.
Лучше проводить процесс рефакторинга постоянно, чем использовать его по завершении
проекта, при выпуске новой версии продукта или в конце каждого цикла/дня. Подробнее
рефакторинг рассмотрен в отдельном разделе данного пособия.
Простой дизайн (Simple Design)
Большинство команд, работающих в соответствии с методикой экстремального
программирования, стараются создавать максимально простые в использовании и
выразительные программные продукты. Кроме того, они фокусируют свое внимание только на
текущих требованиях заказчиков, которые необходимо реализовать на данном цикле
разработки. О будущих изменениях речь в данном случае не идет – всему свое время. Вместо
того чтобы пытаться прогнозировать будущие запросы клиентов, разработчики при
необходимости изменяют общий дизайн всей системы "на лету", подстраиваясь под требования
заказчика.
Это означает, что разработчики не начинают свою работу с создания какой-либо
инфраструктуры системы. Они также не начинают свою деятельность с создания базы данных
или промежуточного ПО. В первую очередь программисты воплощают в жизнь первый пакет
требований заказчика максимально простым способом из всех возможных. Инфраструктура
наращивается постепенно и усложняется только по мере надобности.
Критики утверждают, что ХР пренебрегает дизайном. Это неправда. Большинство
традиционных тяжеловесных подходов основываются на том, что перед началом работы вы
должны хорошенько сконцентрировать свое внимание на цели, затем проложить к ней наиболее
оптимальный маршрут, а затем следовать этому маршруту без каких-либо отклонений. Такой
способ основан на ошибочном предположении о том, что изначально заданные условия задачи
не могут меняться в течение всего времени работы. ХР отказывается от этого предположения.
ХР исходит из того, что в процессе работы условия задачи могут неоднократно измениться, а
значит, разрабатываемый продукт не следует проектировать заблаговременно целиком и
полностью. Если в самом начале работы вы пытаетесь от начала и до конца детально
спроектировать всю систему, вы напрасно тратите время. ХР предполагает, что проектирование
– это настолько важный процесс, что его необходимо выполнять постоянно в течение всего
времени работы над проектом. Проектирование должно выполняться небольшими этапами, с
учетом постоянно изменяющихся требований. В каждый момент времени мы пытаемся
использовать наиболее простой дизайн, который подходит для решения текущей задачи. При
этом мы меняем его по мере того, как условия задачи меняются.
Что такое самый простой дизайн, который подходит для решения задачи (simplest design
that could possibly work)? Согласно Кенту [18], это дизайн, который:
Обеспечивает корректное срабатывание всех тестов.
Не содержит дублирующегося кода.

40
Хорошо выражает намерения программиста для каждого из участков кода.
Включает наименьшее количество классов и методов.
Если система обладает простым дизайном, это не значит, что она маленькая или
тривиальная. Дизайн должен быть настолько простым, насколько это возможно, и при этом он
должен решать поставленную задачу. Не следует включать в дизайн дополнительные
возможности, которые не используются.
Коллективное владение кодом (Collective Code Ownership)
Любой из участников команды обладает правом вносить изменения в любое место кода с
целью его улучшения. Код системы принадлежит всем участникам команды, а это значит, что
ответственность за него несут все участники команды. В большинстве традиционных методик
весь код системы разделен на зоны ответственности, – каждый фрагмент кода принадлежит
тому, кто его разработал. Если кто-либо другой желает как-либо видоизменить код, он обязан
получить на это разрешение у владельца кода. Такая схема ведет к тому, что процесс
совершенствования кода системы затрудняется. Если вы хотите изменить код, вы обязаны
спросить на это разрешение. В ХР этого делать не нужно. Вы можете изменить любой код в
любом месте, не спрашивая ни у кого разрешений. Благодаря этому правилу каждый, кто
желает улучшить систему, делает это.
В ХР код принадлежит всем, это значит, что если вы решили модифицировать код, вы
несете ответственность за его корректную работу. Это значит, что все тесты модулей (unit tests)
должны корректно срабатывать как до модификации, так и после модификации. Если,
попытавшись улучшить код, вы нарушили корректную работу одного или нескольких тестов,
вы обязаны восстановить корректное срабатывание всех тестов вне зависимости от того, в
каком месте системы вы осуществляете модификацию. Это невозможно без соблюдения
строгой дисциплины.
Постоянная интеграция (Continuous Integration)
Программисты разрабатывают новый код и встраивают его в общую систему несколько раз
в день. Остальные просто копируют ранее созданные коды.
Коллективы разработчиков, работающих в рамках технологии экстремального
программирования, применяют неблокируемый контроль исходных текстов. Это означает, что
программисты могут тестировать программный модуль в любое время, вне зависимости от
того, кто еще может в данный момент проводить тестирование. При этом нужно быть готовым
к постоянному внесению изменений, сделанных коллегами.
Пара программистов работает над отдельной задачей час или два. Они разрабатывают
программный код и соответствующую ему процедуру тестирования. В первую очередь
программисты должны убедиться, что все тесты по-прежнему работают. Затем они встраивают
свой фрагмент кода в общую систему. После успешной интеграции система вновь проходит
процесс сборки. Нужно снова выполнить все тесты, чтобы проверить все функции программы
после добавления в нее нового модуля. В случае обнаружения новых ошибок они устраняются,
а процедура тестирования запускается с самого начала.
Таким образом, разработчики собирают систему заново по несколько раз в день. Они снова
и снова проходят все стадии сборки от начала до конца.
Подробно данная практика рассмотрена в отдельном разделе данного пособия.
Заказчик в команде (On-Site Customer)
Чтобы работать с оптимальной скоростью, команда разработчиков ХР должна постоянно
поддерживать контакт с заказчиком. Для этого представитель заказчика должен постоянно
находиться рядом с разработчиками. Он должен пояснять смысл пожеланий (stories) и
принимать важные бизнес-решения, которые не могут быть приняты самими разработчиками.
Если представитель заказчика будет постоянно находиться рядом с разработчиками,
разработчики смогут избежать простоев, связанных с тем, что они вынуждены ждать
пояснений, уточнений и решений со стороны заказчика.
ХР не утверждает, что карточка, на которой записано пожелание заказчика (customer
story), содержит все необходимое для того, чтобы программист написал весь необходимый код.
Записанное на карточке пожелание – это лишь приглашение к дальнейшему устному разговору

41
между заказчиком и разработчиком, нацеленному на прояснение и освежение в памяти
сопутствующих деталей. Идея состоит в том, что при общении лицом к лицу снижается
вероятность непонимания. Постоянное присутствие представителя заказчика рядом с
разработчиками – это наиболее эффективное решение данной проблемы. Основная идея этой
практики состоит в том, что заказчик должен быть в любой момент времени доступен для
ответов на возникающие у разработчиков вопросы и для уточнения общего направления работы
на основании бизнес-условий. Иногда для этого вовсе не обязательно, чтобы заказчик
постоянно находился в непосредственной близости от разработчиков.
Частые выпуски версий (Small Releases)
При работе по методике экстремального программирования каждые две недели
производится работоспособный программный продукт. Каждый из таких двухнедельных
циклов позволяет получать ПО, отвечающее определенным требованиям заинтересованных
сторон. В конце каждого цикла полученные результаты демонстрируются всем участникам
проекта в целях получения отзывов.
План рабочего цикла
Отдельный рабочий цикл обычно длится две недели. За это время в программный продукт
могут быть внесены некоторые (обычно второстепенные) изменения. При этом используются
пользовательские истории и сведения о размере предоставляемого бюджетного
финансирования.
Бюджет отдельного цикла устанавливается путем определения соотношения расходов и
объема работы, проделанной на предыдущем этапе. Заказчик может сам выбрать необходимые
усовершенствования ПО в пределах доступных средств.
После начала выполнения рабочего цикла заказчик уже не может изменять свои требования
или устанавливать новые приоритеты. Разработчики же вольны сами распределять требования
клиента на отдельные задачи и выполнять их в оптимальном порядке.
План выпуска версий
Коллектив разработчиков часто создает план выпуска версий, в котором описываются
шесть ближайших циклов разработки программного продукта. Выпуск новой версии
программы обычно занимает три месяца. План выпуска включает отобранный заказчиком
список требований, которые расположены согласно установленным приоритетам, при этом их
количество должно соответствовать размеру выделенного бюджета.
Размер бюджета устанавливается разработчиками, исходя из расходов на выпуск
предыдущей версии ПО. Заказчик может сам отбирать все необходимые требования,
предъявляемые к программе, а также усовершенствования в пределах установленной сметы.
Притча
Метеорологическая служба одной страны истратила базиллион долларов на разработку
новейшей системы предсказания погоды. Лампочки сияют, отчеты печатаются, вращаются
разные колесики, все выглядит очень впечатляюще. Более того, прогнозы, которые выдает
чудо-машина, верны на целых 70%! Заказчик, заплативший базиллион долларов, в полном
восхищении.
А потом кто-то нашел гораздо, более дешевый способ предсказывать погоду с той же
точностью: завтра будет такая же погода, какая была сегодня [18].
Аналогичный простой способ используется в XP для определения трудозатрат на
реализацию нового функционала. Производительность команды на следующей итерации
принимается такой же, как и на предыдущей. Если скорость работы команды окажется выше,
чем на предыдущей итерации, то можно реализовать дополнительный набор пожеланий. Если
скорость окажется ниже, то можно исключить из текущей итерации несколько
низкоприоритетных пожеланий.
Равномерная работа
Процесс разработки ПО – это не спринтерский рывок, а скорее – забег на марафонскую
дистанцию. Команда, взявшая чересчур резвый старт, рискует выдохнуться задолго до финиша.
Чтобы прийти к финишу вовремя, необходимо двигаться в постоянном темпе, что позволит

42
сохранить энергию и поддерживать внимательность на должном уровне. Наиболее подходящим
эпитетом здесь будет "медленно, но уверенно".
Даже если разработчики обладают способностью в течение длительного времени работать
сверхурочно, это не значит, что они должны этим заниматься. Рано или поздно им надоест
такая работа, и они уволятся, или у них возникнут личные проблемы, которые негативно
повлияют на их производительность. Сверхурочная работа – это не решение проблемы,
возникшей на пути проекта. На самом деле это симптом еще более серьезной проблемы.
Одним из принципов экстремального программирования (несмотря на название) является
запрет сверхурочной работы. Единственным исключением может стать последняя неделя перед
выпуском финальной версии продукта, по аналогии с рывком, который спортсмены делают
перед финишной чертой.
Стандарты кодирования (Coding Standards)
Все члены команды в ходе работы должны соблюдать требования общих стандартов
кодирования. Благодаря этому:
1. Члены команды не тратят время на глупые споры о вещах, которые фактически никак не
влияют на скорость работы над проектом;
2. Обеспечивается эффективное выполнение остальных практик.
Если в команде не используются единые стандарты кодирования, разработчикам становится
сложнее выполнять рефакторинг (refactoring), то есть улучшать общий код. При смене
партнеров в парах возникает больше затруднений, поэтому смена партнеров осуществляется не
так часто, как нужно; в общем и целом, продвижение проекта вперед затрудняется.
В рамках ХР необходимо добиться того, чтобы было сложно понять, кто является автором
того или иного участка кода, – вся команда работает унифицировано, как один человек.
Команда должна сформировать набор правил, а затем каждый член команды должен следовать
этим правилам в процессе кодирования. Перечень правил не должен быть исчерпывающим или
слишком объемным. Задача состоит в том, чтобы сформулировать общие указания, благодаря
которым код станет понятным для каждого из членов команды. Стандарт кодирования
поначалу должен быть простым, затем он будет эволюционировать по мере того, как команда
обретает опыт. Вы не должны тратить на предварительную разработку стандарта слишком
много времени.
Метафора системы (System Metaphor)
Что такое архитектура программы? Архитектура – это некоторое представление о
компонентах системы и о том, как они взаимосвязаны между собой. Разработчики используют
архитектуру для того, чтобы понять, в каком месте системы добавляется новая
функциональность, с чем она будет взаимодействовать и какую форму она должна принять.
Метафора системы (System Metaphor) – это аналог того, что в большинстве методик
называют архитектурой. Метафора системы дает команде представление о том, каким образом
система работает в настоящее время, в каких местах добавляются новые компоненты, и какую
форму они должны принять.
Подобрав хорошую метафору, вы облегчаете команде понимание того, каким образом
устроена ваша система. Иногда сделать это непросто.
Метафора – общая картина, отображающая всю систему в целом, т.е. такое видение
системы, которое делает очевидным расположение и функционирование каждого отдельного
модуля. Если "форма" модуля кажется неподходящей, значит, что-то с ним не так.
Зачастую метафора сводится к правильному именованию и визуализации элементов
программы. Такая система позволяет не только определить по названию назначение отдельного
модуля, но и видеть его связь с другими компонентами.
Открытая рабочая среда
Команда разработчиков работает в общей открытой комнате. В помещении
устанавливаются столы с компьютерами на них (два или три на каждом столе). Перед каждым
компьютером должно стоять два стула для пары программистов. На стенах развешиваются
необходимые для работы графики, диаграммы, таблицы и так далее.

43
Наилучший звуковой фон – негромкий гул от разговоров. Каждая пара должна находиться в
пределах слышимости всех остальных. При этом каждый имеет возможность услышать о
проблемах коллег и прийти к ним на помощь. Каждый знает о состоянии дел у своих соседей.
Такая организация рабочего пространства способствует интенсивной коммуникации.
ХР – это комбинация практик
Экстремальное программирование – это набор простых и конкретных методик,
предназначенных для гибкой разработки ПО.
Эффективность комбинации практик существенно превышает сумму эффективности
каждой из практик по отдельности. Вы можете применить одну из практик или некоторое
подмножество практик и получить значительное повышение эффективности труда. Однако
максимальная эффективность достигается тогда, когда абсолютно все эти практики
применяются одновременно в комбинации. Вся сила этих практик проявляется в том, что они
взаимодействуют друг с другом. Иногда это называют синергетическим эффектом ХР.
Сначала вы должны понять, каким образом практики взаимодействуют друг с другом.
Когда вы поймете это, вы сможете адаптировать их для вашей конкретной рабочей среды.
Помните, что ХР – это не основная ваша цель, это всего лишь средство для достижения цели.
Основная цель состоит в том, чтобы разрабатывать превосходное программное обеспечение
быстро, не ломая при этом человеческих жизней [17].
Экстремальное программирование 2.0
Спустя пять лет после выхода первого издания книги Кента Бека [18] было опубликовано
второе издание [21,22] в этом издании многие позиции экстремального программирования были
пересмотрены. Далее рассмотрим основные нововведения.
К четырем базовым ценностям XP добавлена пятая – уважение. Все четыре предыдущие
ценности подразумевают уважение членов команды друг к другу. Если программисты не
уважают друг друга и свою работу, то ни одна методология им не поможет. Необходимо
проявлять уважение к коллегам по работе, их труду, к вашей компании, а также к тем, в чью
жизнь войдет написанное вами приложение.
В новой редакции подчеркивается важность человеческого фактора в разработке
программного обеспечения. Программное обеспечение создается людьми и для людей.
Чтобы разработка ПО была экономически эффективна необходимо перенести получение
прибыли на как можно более ранний период. Рубль, заработанный сегодня, ценится выше, чем
рубль, заработанный завтра. Необходимо применять инкрементальный дизайн, чтобы уже на
ранний этапах можно было поставить работоспособное ПО.
Чтобы проект успешно развивался необходимо обеспечить взаимную выгоду всех
заинтересованных сторон. Если проектом будут заниматься не мотивированные люди, то это
приведет к быстрому накоплению дефектов в различных частях проекта.
Для повышения эффективности рекомендуется применять одни и те же подходы для
решения различных задач на различных этапах проекта. Например, одна из основных
составляющих методологии ХР состоит в том, чтобы сначала написать тесты, которые заведомо
не будут проходить, а уже потом – написать код, после которого тесты пройдут успешно. То же
самое можно «масштабировать» на разные уровни временной шкалы: в течение целого квартала
вы составляете перечень задач, которые должно решать приложение, а потом короткие
«рассказы», которые описывают их более подробно. В начале недели вы выбираете те
«рассказы», где описаны задачи, над которыми вы будете работать в течение этой недели, а уже
потом пишете тесты приемки (acceptance tests) и, в конце концов, приступаете к программному
коду, благодаря которому эти тесты будут работать. Если сузить временной промежуток до
нескольких часов – вы сначала пишете unit тесты, а затем код, который обеспечивает их
выполнение.
Важным фактором успешного внедрения XP является постоянное развитие. Необходимо
каждый день искать и находить лучшие способы решения задач.
Чтобы решать действительно сложные задачи в команде должны быть специалисты из
разных областей знаний и люди с разным восприятием мира. Такой командой сложнее
управлять, но она способна находить неожиданные решения в сложных ситуациях.

44
Эффективно работающие программисты не просто пишут код. Они спрашивают себя, как
они работают и почему они делают данную систему именно так, а не иначе. Людям нужно
четко видеть причины, стоящие за успехом (или провалом) их продукта.
В методологии ХР принято считать, что все виды деятельности по разработке ПО должны
протекать непрерывно, подобно потоку. Этим она отличается от других методологий, где
разработка распадается на последовательность определенных фаз, последней из которых
является выпуск программного продукта.
Чтобы решить сложную задачу, нужно на неѐ посмотреть с разных сторон, начать еѐ решать
различными способами. В этом случае, если одно решение окажется несостоятельным, другие
могут помочь предотвратить катастрофу. В таких случаях в итоге избыточность с лихвой
окупается.
Не бойтесь неудач, пробуйте различные решения. Куда хуже откладывать что-то до
последнего момента, пытаясь найти единственно верное решение. Нет неудач – есть только
обратная связь.
Качество всегда должно быть на высоте. Снижение качества ради любых других целей –
порочная практика.
Вносить изменения в систему необходимо небольшими блоками. После каждой такой
модификации необходимо удостовериться в работоспособности системы. Поддерживать
систему в работоспособном состоянии гораздо проще и дешевле, чем из неработоспособной
системы сделать работоспособную. Крупные модификации могут надолго вывести систему из
работоспособного состояния. Постоянная работоспособность системы положительно влияет
психологический климат в команде.
Планы итераций должны быть реалистичными. В такой план нужно включать задачи,
которые можно не выполнить, при недостатке времени. Это позволит даже при появлении
непредвиденных обстоятельств придерживаться плана.
Команда разработчиков должна сидеть в одном большом помещении – это облегчает
общение.
Команда должна работать как одно целое, членов команды должно объединять чувство
принадлежности к общему делу.
В рабочем помещении должны быть информативные плакаты и прочие наглядные пособия,
которые показывали бы статус проекта и другую информацию о проделанной работе.
Для лучшего взаимопонимания заказчиков и разработчиков рекомендуется заключать не
один большой контракт на разработку, а серию меньших контрактов. Это позволит снизить
риски, лучше понять требования к системе и более точно описать объем работ по проекту.
Стоимость работ по проекту необходимо увязывать с объемом функциональности. Это
позволит избежать конфликтных ситуаций, когда заказчику нужны новые функции, а
разработчик, считает, что бюджет на разработку исчерпан.
Когда команда успешно работает, не стоит изменять еѐ кадровый состав и структуру без
особой необходимости. Те связи, которые возникают между людьми, воистину бесценны,
поэтому старайтесь перераспределять людей как можно реже.
Вместо увеличения нагрузки на команду и раздувания еѐ объема предпочтительнее
выделять отдельных членов команды для организации новых команд.
У системы должна быть только одна официальная версия исходного кода. Отдельные
функциональные ветки должны быть краткосрочными. Их следует удалять сразу после
завершения работы над ними и совмещения изменений с основной версией.

45
ТЕХНОЛОГИЯ ОБЪЕКТНО-РЕЛЯЦИОННОГО ОТОБРАЖЕНИЯ
Сохраняемость – это одна из фундаментальных задач, при разработке приложений.
Большинству приложений требуется сохранять данные. Сохраняемость используется для
хранения наших данных, даже когда наше приложение не работает.
Рассмотрим пример приложения для оформления заказов. Оно позволяет пользователям
сохранять информацию о заказах и товарах, а так же получать доступ к этой информации, когда
потребуется. Мы сталкиваемся с проблемой выбора механизма сохраняемости. Существуют
различные решения, например, использование текстовых файлов, реляционной или объектно-
ориентированной базы данных.
Реляционные базы данных (РСУБД) пользуются большой популярностью при разработке
бизнес-приложений. На платформе .NET существуют средства для работы с РСУБД. Они
позволяют нам соединяться с базой данных и выполнять SQL команды. Дополнительно
существует возможность использования типового решения DataSet (или Record Set)[23]. Оно
позволяет хранить набор таблиц в оперативной памяти и с помощью адаптеров производить
обмен данными с РСУБД.
В бизнес-приложениях возникает необходимость работы с классами бизнес-сущностей. В
отличие от DataSet эти классы не являются отражением структуры база данных, а
сконцентрированы на решении бизнес-проблемы. Вместе эти классы образуют модель
предметной области [23].
В объектно-ориентированных приложениях сохраняемость позволяет объектам переживать
процессы и приложения, которые их создали [24]. Состояние объекта сохраняется на диск.
Позже объект с тем же состоянием может быть создан заново. Возможно сохранение не только
одиночного объекта, но и целого графа взаимосвязанных объектов.
Не всем объектам необходимо сохранять свое состояние во внешней памяти. Например,
элементам управления в Windows-приложении нет необходимости сохранять свое состояние во
внешней памяти на длительный срок. Такие объекты называются временными (transient).
Многие .NET приложения содержат как временные, так и хранимые объекты (persistent).
Необходимо иметь отдельную подсистему для управления хранимыми объектами.
Приложения, использующие модель предметной области не работают напрямую с
табличным представлением бизнес-сущностей (например, как DataSet), приложения имеют
свою собственную объектно-ориентированную модель бизнес-сущностей. Бизнес-логика
реализуется на объектно-ориентированном языке программирования, а не помещается в базу
данных.
В приложениях с нетривиальной бизнес-логикой модель предметной области позволяет
сократить дублирование кода, увеличить повторное использование кода и снизить затраты на
сопровождение.
Многие современные приложения используют многоуровневую архитектуру. Она разделяет
приложение на несколько подсистем, каждая из которых сконцентрирована на решении своей
задачи.
В бизнес-приложении (рис. 16) можно выделить следующие слои:
Пользовательский интерфейс (Presentation Layer). Слой содержит логику
пользовательского интерфейса. Для web-приложения здесь содержится код формирования
web-страниц, управление вводом данных со стороны пользователя и управление
навигацией.
Бизнес-логика (Business Layer). Слой реализует модель предметной области. В нем
реализуются основные бизнес-правила и требования к системе, которые являются частью
предметной области.
Слой сохраняемости (Persistence Layer). Слой сохраняемости – это группа классов и
компонент, которая взаимодействует с хранилищем данных для сохранения и загрузки
объектов приложения. В этом слое реализовано отображение между бизнес-сущностями и
базой данных. Объектно-реляционные преобразователи работают в этом слое.
База данных (Database). База данных находится вне приложения и непосредственно
хранит состояние системы.

46
Вспомогательные классы и утилиты (Utility and helper class). Каждому приложению
необходим набор инфраструктурных классов, например, классы обработки исключений,
классы для логирования, классы для конфигурирования приложения и др.
Рис. 16. Многоуровневая архитектура
Подходы к сохранению бизнес-сущностей на платформе .NET
Существуют различные подходы для реализации слоя сохранения, каждый имеет свои
преимущества и недостатки. Далее рассмотрим основные подходы и для каждого рассмотрим:
реализацию сущностей;
взаимодействие с БД, выполнение CRUD (Create, Retrieve, Update, Delete) операции;
взаимодействие с пользовательским интерфейсом.
Использование DataSet
Среда Visual Studio позволяет сгенерировать слой сохраняемости с помощью дизайнеров на
основе существующей базы данных буквально за несколько щелчков мышки. Сгенерированные
классы могут взаимодействовать с БД для сохранения и загрузки данных в DataSet.
Сопровождение такого решения значительно сложнее, чем первоначальное создание.
Бизнес-сущности в DataSet представлены набором таблиц. Это упрощает взаимодействие с
БД.
У решения имеется ряд недостатков:
Отсутствует загрузка по требованию.
Затруднена реализация мелкозернистой структуры объектов с распределением поведения.
Отсутствуют возможности наследования и полиморфизма.
Состояние бизнес-сущностей не инкапсулировано.
При представлении сложной модели предметной области в виде таблиц теряется еѐ
семантическая целостность.
Данное решение приспособлено для эффективной организации пользовательского
интерфейса. Большинство элементов управления, как для Windows-приложений, так и для
Web-приложений поддерживают взаимодействие с DataSet.
Мастера среды разработки предоставляют возможность генерации простых CRUD
операций. Для более сложных случаев необходимо ручное написание SQL-запросов.
Ручное кодирование слоя сохраняемости
Данный способ позволяет получить полный контроль над процессом сохранения/загрузки
объектов. Главным недостатком способа является большей объем рутиной работы, как на этапе
первичной реализации, так и на этапе сопровождения. Здесь можно добиться максимального
уровня производительности и задействовать все необходимые возможности конкретной СУБД.
Пользовательский интерфейс
Бизнес-логика
Слой сохраняемости
Вспомога-
тельные
классы и
утилиты
База данных

47
Способ допускает использование специальных утилит (http://www.mygenerationsoftware.com)
для генерации слоя доступа к данным на основе схемы БД или других артефактов.
Данный подход не накладывает ограничений на способ представления сущностей. В
примере с системой оформления заказов (рис. 17) мы можем создать класс Customer, Order,
OrderItem. Между объектами этих классов можно задать определенные отношения. Например,
Customer имеет коллекцию объектов класса Order и Order имеет ссылку на объект класса
Customer.
Объектно-ориентированное представление сущностей сильно отличается от реляционного
представления. Без применения вспомогательных средств реализация сохранения объектов
данным способом крайне утомительная.
Рис. 17. Классы системы оформления заказов
Реализация пользовательского интерфейса (UI) в данном решении осложняется
многообразием вариантов представления сущностей. Сущности могут быть не пригодны к
непосредственному представлению в пользовательском интерфейсе и необходимо выполнять
преобразование при просмотре и редактировании. Не все элементы управления его
поддерживают. В рассмотренном примере свойство Customer класса Order проблематично
отобразить в пользовательском интерфейсе. Для решения задачи показа заказа можно создать
представление заказа для просмотра, как показано на рис. 18 и использовать его в UI.
Рис. 18.Представление заказа
Для реализации взаимодействия с БД необходимо написать или сгенерировать большой
объем кода и SQL-запросов. Написание простейших CRUD – операций может быть
автоматизировано.
Применение ORM решений на примере NHibernate
Объектно-реляционное отображение (ORM) – это автоматическое сохранение объектов
языка программирования в таблицы реляционной базы данных с использованием метаданных,
которые описывают это отображение [29].
ORM решения обладают богатыми возможностями по сохранению и загрузке объектов.
Допускается работа, как с одиночными объектами, так и целыми графами связанных объектов.
В задаче оформления заказов сохранение заказа и его элементов может выглядеть так: Public void Save (Order order)
{
using (var session = GetSession())
{
session.Save(order);
}
}
Существует большое количество различных ORM решений, более 60 [25, 26]. Разные
решения накладывают разные ограничения на классы нашей предметной области. К таким
ограничениям можно отнести:
требование наследования от определенного базового класса,
реализацию определенного интерфейса,

48
ограничение на типы коллекций и ассоциаций,
использование сгенерированных классов.
Решение NHibernate относится к классу ненавязчивых решений (non-intrusive) и не
предъявляет подобных требований. Главное требование к классам сущностей – наличие
конструктора без параметров. Кроме классов-сущностей необходимо сообщить NHibernate как
их следует отображать на БД.
ORM решения имеют те же особенности показа сущностей, что и при ручном кодировании
механизма сохраняемости.
ORM средства самостоятельно генерируют SQL-запросы к БД. Пользователь максимально
(но не полностью) изолирован от подробностей работы с БД. ORM средства учитывают
особенности конкретной СУБД. Это может потребоваться на этапе тонкой оптимизации
производительности. Многие ORM-средства позволяют выполнять отображение классов
предметной области на различные СУБД с учетом индивидуальных особенностей.
Зачем нужен NHibernate?
NHibernate является одним из ORM решений. Он был изначально разработан на платформе
Java и после был перенесен на платформу .NET.
Основная задача этого решения – освободить разработчика от написания большей части
(порядка 95%) кода, связанного с сохраняемостью, например, написания сложных SQL
запросов и переносом данных из результата запроса в поля одного или нескольких объектов
[29].
Данное решение поддерживает большой объем возможностей, таких как:
поддержка множества РСУБД (более 20);
транзакции;
контроль конфликтов одновременного доступа (версионирование, исключение
потерянного обновления, оптимистическая блокировка);
встроенное кэширование;
поддержка идентичности (identity) объектов;
поддержка запросов;
связи между объектами;
группирование SQL команд в один запрос;
полиморфные запросы;
проверка на модификацию;
возможность отмены изменений объекта;
отложенная загрузка;
ручное управление отложенной загрузкой;
каскадные обновления;
возможность отладки;
безопасное использование в многопоточном режиме;
события жизненного цикла объектов;
стратегия обработки исключительных ситуаций;
загрузка данных без загрузки объекта;
составные первичные ключи;
CRUD-операции над сущностями;
поддержка разбиения результатов запроса на страницы;
поддержка произвольных типов данных, в том числе сложных;
поддержка агрегатных запросов.
Реализация этих возможностей вручную – крайне утомительное занятие [35].
Преимущества ORM решений
Продуктивность.
Разработчик освобождается от написания рутинного кода и это увеличивает
продуктивность.

49
Удобство сопровождения.
Стандартные решения проще поддерживать в долгосрочной перспективе, чем кустарные
поделки.
Независимость от производителя.
Существует возможность смены поставщика РСУБД с минимальными издержками. Это
снижает проектные риски, расширяет рынок разрабатываемого продукта и позволяет выполнять
тестирование на быстрых РСУБД в оперативной памяти.
Производительность.
Зрелые ORM решения, такие как NHibernate, поставляются с набором средств оптимизации,
которые можно активировать при отображении сложных предметных областей. Реализация
подобных оптимизаций в кустарных системах может потребовать много усилий.
Несоответствие парадигмы
Представление сущностей в реляционной БД сильно отличается от представления
сущностей в объектно-ориентированных языках программирования. Это явление называют
несоответствием парадигмы (paradigm mismatch) [29]. Несоответствие порождает ряд проблем.
Проблема гранулярности
Допустим, что в примере с заказами адрес покупателя нужно хранить не как простую
строку, а как отдельный объект со своими свойствами и методами (рис. 19). У адреса может
быть выделен индекс, страна, город, улица.
Рис. 19. Покупатель и его адрес
Выделять таблицу для хранения адреса не всегда оправдано. Необходимо иметь
возможность сохранять данные адреса в таблице покупателя. Например, в таблице вида: create table CUSTOMERS (
NAME varchar(50) not null,
ADDRESS_STREET varchar(50),
ADDRESS_CITY varchar(15),
ADDRESS_ZIPCODE varchar(5),
ADDRESS_COUNTRY varchar(15)
)
Данный пример иллюстрирует проблему гранулярности, когда у нас таблиц получается
меньше, чем классов предметной области.
Частным случаем является проблема злоупотребления элементарными типами данных.
Разработчики часто используют элементарные типы (строки, целые и дробные числа) вместо
создания объектов для представления адресов, телефонов, денежных единиц и др. типов. Это
приводит к тому, что логика обработки и проверки отделена от самих значений. Следствием
этого может стать дублирование кода.
Проблема поддержки наследования и полиморфизма
Объектно-ориентированные языки программирования (ООЯП) поддерживают такое
понятие, как наследование, а в РСУБД его нет. В нашем примере может существовать
несколько видов покупателей: физическое лицо и юридическое лицо (рис. 20). Для отображения
иерархии наследования существуют несколько стратегий.

50
Рис. 20. Иерархия класса Customer
Необходимо иметь возможность выполнять полиморфные запросы. Т.е. при запросе
объектов класса Customer должны быть найдены, в том числе, и объекты классов
IndividualCustomer и LegalCustomer.
Проблема идентичности
Созданные объекты предметной области необходимо идентифицировать. Способы
идентификации при размещении объекта в памяти и при его сохранении в БД различаются.
Идентичность записи в БД задается с помощью первичного ключа. При работе с
реляционными БД рекомендуется использовать суррогатные ключи. Это такие первичные
ключи, которые не имеют значения для пользователя, а служат только для идентификации
записи. Данное решение эффективно с точки зрения производительности, простоты реализации
и позволяет исключить модификацию идентичности при возникновении новых
пользовательских требований.
Идентичность объекта в памяти не является эквивалентом значения первичного ключа. В
ООЯП, например в C#, существует отдельно понятие идентичности и эквивалентности
объектов.
Проблемы, связанные с ассоциациями
Отображение ассоциаций и управление ассоциациями сущностей является основной
задачей любого решения для сохранения объектов. В ООЯП ассоциации представлены с
помощью объектных ссылок (object references), а в РСУБД ассоциации представлены с
помощью внешних ключей, содержащих копию значения первичного ключа. Объектные
ссылки по своей природе однонаправленные. Для навигации в обоих направлениях необходимо
реализовать ассоциации дважды. Это можно увидеть на примере классов нашей предметной
области: public class Customer {
...
public List<Order> Orders { get; set; }
}
public class Order {
...
public Customer Customer { get; set; }
}
Поддержка согласованности ассоциаций возлагается на разработчика. С другой стороны,
внешние ключи в РСУБД являются двунаправленными. Навигация для РСУБД не имеет
смысла, т.к. мы используем соединение таблиц и проекции.
Проблема заключается в соединении полностью открытой модели данных, которая не
зависит от нашего приложения с навигационной моделью данных нашего специфичного
приложения.
Ассоциации вида многие-ко-многим в языке программирования реализуются с помощью
двух классов и трех таблиц в РСУБД. Третья таблица является таблицей-связкой.

51
Проблема навигации
Это фундаментальное отличие способа доступа к данным в языке программирования и в
РСУБД. В C# для получения города покупателя мы используем код вида:
order.Customer.Address.City. Мы перемещаемся от одного объекта к другому с помощью
ссылок. Подобный способ доступа для РСУБД является неэффективным. Для получения
приемлемой производительности необходимо уменьшить количество запросов к серверу БД.
Этого можно достичь с помощью использования соединений и загрузки сразу нескольких
записей. Для загрузки конкретного заказа можно использовать запрос: select * from ORDER o where o.ID = 1234
Если нам нужно загрузить еще и информацию о покупателе нужно воспользоваться
запросом: select *
from ORDER o left outer join CUSTOMER c on o.CUSTOMER_ID = c.ID
where o.ID = 1234
Для эффективного использования соединений необходимо заранее знать, какую часть графа
объектов необходимо использовать. Если такой информации нет, то объекты будут загружаться
по мере обращения. Это приводит к проблеме «N+1 select problem». Например, загрузка
группы заказов одним запросом, N запросов (на каждый заказ) для получения информации о
покупателе.
“Hello World” с NHibernate
Рассмотрим применение NHibernate на простом примере. Наше консольное приложение
подготовит структуру БД, создаст несколько объектов, сохранит их в БД, а потом загрузит
ранее сохраненные объекты.
В примере необходимо выполнить следующие шаги:
1. Создать консольное приложение NHibernateHelloWorld.
2. Создать класс Customer.
3. Создать файл отображения Customer.hbm.xml.
4. Включить файл отображения как ресурс в сборку.
5. Подключить сборки NHibernate.
6. Создать пустую БД MSSQL Server.
7. Создать файл конфигурации приложения и поместить в него настройки NHibernate.
8. Настроить фабрику сессий.
9. Создать структуру БД.
10. Создать набор тестовых объектов и сохранить их в БД.
11. Загрузить объекты из БД и вывести их на консоль.
Результат работы приложения приведен на рис. 21. Далее рассмотри содержимое файлов
приложения.
Файл Customer.cs: namespace NHibernateHelloWorld
{
public class Customer
{
public int Id { get; set; }
public string Name { get; set; }
public string Address { get; set; }
}
}
Файл отображения Customer.hbm.xml: <?xml version="1.0" encoding="utf-8" ?>
<hibernate-mapping xmlns="urn:nhibernate-mapping-2.2"
assembly="NHibernateHelloWorld">
<class name="NHibernateHelloWorld.Customer" lazy="false">
<id name="Id" column="id">
<generator class="native"/>
</id>
<property name="Name"/>
<property name="Address"/>
</class>

52
</hibernate-mapping>
Файл конфигурации приложения (app.config): <?xml version="1.0" encoding="utf-8" ?>
<configuration>
<configSections>
<section name="hibernate-configuration"
type="NHibernate.Cfg.ConfigurationSectionHandler, NHibernate"/>
</configSections>
<hibernate-configuration xmlns="urn:nhibernate-configuration-2.2">
<session-factory>
<property name="show_sql"> true </property>
<property
name="connection.driver_class">NHibernate.Driver.SqlClientDriver</property>
<property name="connection.connection_string">
Server=.\SQLEXPRESS;initial catalog=NHibernateHelloWorld;Integrated
Security=SSPI
</property>
<property name="adonet.batch_size">10</property>
<property name="dialect">NHibernate.Dialect.MsSql2000Dialect</property>
</session-factory>
</hibernate-configuration>
</configuration>
Файл Program.cs: using NHibernate;
using NHibernate.Cfg;
using NHibernate.Tool.hbm2ddl;
using System;
namespace NHibernateHelloWorld
{
class Program
{
static ISessionFactory _sessionFactory;
static Configuration cfg;
static void Main(string[] args)
{
CreateSessionFactory();
CreateDbSchema();
CreateAndStoreCustomers();
RetriveAndPrintCustomers();
}
private static void RetriveAndPrintCustomers()
{
using (var session = _sessionFactory.OpenSession())
{
var list =
session.CreateCriteria(typeof(Customer)).List<Customer>();
foreach (var customer in list)
{
Console.WriteLine("{0}, {1}, {2}", customer.Id, customer.Name,
customer.Address);
}
}
}
private static void CreateAndStoreCustomers()
{
using (var session = _sessionFactory.OpenSession())
{
Customer ivanov = new Customer() { Name = "Иванов И.И.", Address =
"г. Челябинск ..." };
Customer pertov = new Customer() { Name = "Петров П.П.", Address =

53
"г. Москва ..." };
session.Save(ivanov);
session.Save(pertov);
session.Flush();
}
}
private static void CreateDbSchema()
{
SchemaExport se = new SchemaExport(cfg);
se.Drop(true, true);
se.Create(true, true);
}
private static void CreateSessionFactory()
{
cfg = new Configuration();
cfg.AddAssembly(typeof(Customer).Assembly);
_sessionFactory = cfg.BuildSessionFactory();
}
}
}
Рис. 21. Результат работы программы
Особенности примера
Сборка и пространство имен в примере должно называться NHibernateHelloWorld. В
противном случае нужно скорректировать файл настройки отображения.
Для файла настройки отображения важно задать расширение .hbm.xml и помещение его как
ресурс в сборку.
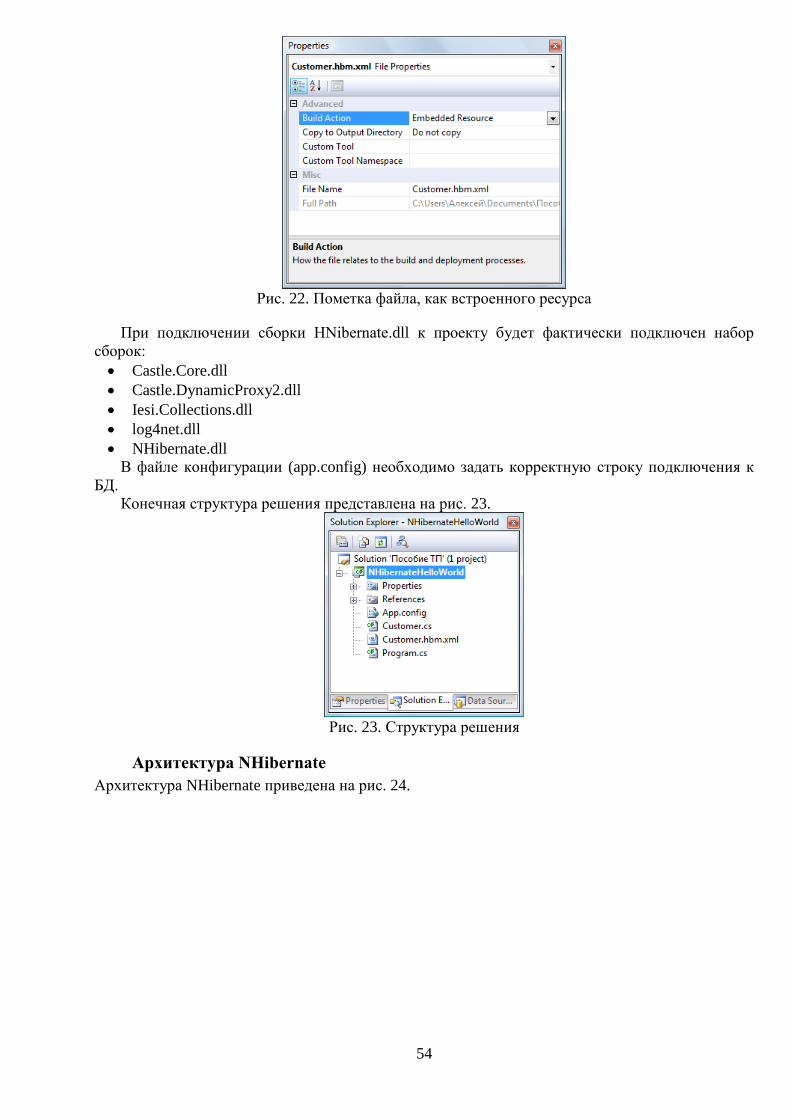
54
Рис. 22. Пометка файла, как встроенного ресурса
При подключении сборки HNibernate.dll к проекту будет фактически подключен набор
сборок:
Castle.Core.dll
Castle.DynamicProxy2.dll
Iesi.Collections.dll
log4net.dll
NHibernate.dll
В файле конфигурации (app.config) необходимо задать корректную строку подключения к
БД.
Конечная структура решения представлена на рис. 23.
Рис. 23. Структура решения
Архитектура NHibernate
Архитектура NHibernate приведена на рис. 24.

55
Рис. 24. Архитектура NHibernate
В ней можно выделить следующие элементы:
Временные объекты (Transient Objects) – это объекты приложения, не предназначенные
для сохранения в БД. При создании объекта он становиться временным.
Хранимые объекты (Persistent Objects) – это объекты, связанные с некоторой сессией
NHibernate и предназначенные для сохранения в БД. При загрузке объекты считаются
хранимыми по умолчанию. Когда мы выполняем команду Save, объект становится
хранимым.
Фабрика сессий (SessionFactory) содержит информацию о настройках отображения
классов на конкретную БД. Она может создавать сессии. Обычно в приложении создается
одна фабрика сессий (если идет взаимодействие с одной БД). Фабрика сессий является
потокобезопасной и может использоваться в многопоточной среде. Инициализация
фабрики сессий занимает продолжительное время (порядка секунды при десятке
хранимых классов). Перед использованием она должна быть сконфигурирована.
Сессия (Session) является реализацией шаблона Unit of Work [23] при работе с БД. Одну
сессию нельзя использовать из различных потоков. При возникновении проблем
(исключений) при взаимодействии внутри сессии еѐ необходимо закрыть и повторить
операцию в новой сессии. Сессия позволяет приложению взаимодействовать с БД,
выполняя операции загрузки, сохранения, обновления и удаления объектов. Загрузка
новых объектов из БД при навигации по связям возможна только при наличии активной
сессии. Сессия хранит набор SQL-команд, которые необходимо выполнить и выполняет
их с учетов возможных оптимизаций. Например, при сохранении нескольких объектов
группа SQL-команд INSERT может быть объединена в один запрос к серверу. Хранимые
объекты связаны с некоторой сессией. Благодаря этому сессия может определить, какие
объекты были модифицированы, чтобы выполнить соответствующие SQL команды.
Транзакция (Transaction) позволяет операции с БД данных выполнять по принципу: либо
все, либо ничего. Это позволяет при модификации большого кол-ва объектов
поддерживать БД в согласованном состоянии.
Конфигурирование NHibernate
Для отображения наших объектов на БД необходимо задать ряд параметров. Главные из
них задают поставщика БД и соединение с БД. Конфигурирование может выполняться
программно или с помощью файла конфигурации. В любом случае необходимо создать объект
класса Configuration. При конфигурировании просматриваются файлы конфигурации:
hibernate.cfg.xml, app.config, web.config. На основе сформированной конфигурации создается
фабрика сессий.

56
Пример файла конфигурации приложения и создания фабрики сессий приведен в разделе
HelloWorld.
Настройка отображения
Важным моментом при конфигурировании является указание классов, которые будут
отображаться на БД и настроек отображения этих классов.
Поиск файлов с настройкой отображения будет происходить в сборках, указанных при
конфигурировании фабрики сессий. Эти файлы должны быть помещены в сборку как ресурс
(Embedded Resource). В один файл можно поместить настройки отображения нескольких
классов, но рекомендуется для каждого класса создавать отдельный файл. Имя файла
формируется путем добавления расширения «.hbm.xml» к имени класса, например,
Customer.hbm.xml. Расширение является важным.
Отображение классов
При создании хранимых классов рекомендуется придерживаться следующих правил:
1. Для хранимых свойств классов использовать именно свойства, а не поля.
2. У хранимого класса должен быть конструктор без параметров (обязательное
условие).
3. Необходимо реализовать свойство идентификации.
4. Не использовать sealed классы, все открытые методы, свойства и события делать
виртуальными (для поддержки lazy load).
Пример файла отображения: <hibernate-mapping xmlns="urn:nhibernate-mapping-2.2">
<class name="Order" table="orders">
<id name="Id" column="id">
<generator class="native"/>
</id>
<property name="Date" column="order_date"/>
<property name="OrderSum" />
<property name="Discount" />
<many-to-one name="Customer" column="customer_id" />
<list name="Items" table="line_items" lazy="true" >
<key column="order_id"/>
<index column="line_number" />
<composite-element class="OrderItem" >
<property name="Quantity" column="quantity"/>
<property name="Cost"/>
<property name="Summa"/>
<many-to-one name="Product" column="product_id" />
</composite-element>
</list>
<set name="Pays" inverse="true" lazy="true">
<key column="order_id"/>
<one-to-many class="Pay"/>
</set>
</class>
</hibernate-mapping>
При написании файла отображения необходимо задать пространство имен XML. Это
позволит проверять структурную корректность файла отображения по XSD схеме и
использовать IntelliSense при редактировании. Для проверки по схеме нужно подключить схему
nhibernate-mapping.xsd из дистрибутива NHibernate.
Если в элементе <hibernate-mapping> мы не задали атрибуты assembly и namespace, то при
задании имен классов нужно указывать полные имена, включая сборку. Рассмотрим кратко
основные элементы файла отображения. Более подробную информацию можно найти в [28, 29,
31].
class
Мы можем определить хранимый класс с помощью элемента class: <class

57
name="ClassName"
table="tableName" lazy="true|false"
>
<id ... />
<discriminator ... />
<version ... />
<timestamp ... />
<property ... />
<many-to-one ... />
<subclass ... />
<joined-subclass ... />
...
</class>
name: Имя хранимого класса.
table: Имя таблицы базы данных.
lazy (опциональный): Загрузка по требованию может быть отключена с помощью этого
параметра. Это нужно, если по каким-либо причинам нет возможности использовать proxy-
классы для ленивой загрузки. Основная причина – ограничения безопасности.
id
Большинство классов имеют свойство для хранения уникального идентификатора объекта.
Элемент <id> задает отображение этого свойства на поле первичного ключа. <id name="PropertyName" >
<generator class="native"/>
</id>
name: Имя свойства-идентификатора.
NHibernate поддерживает несколько стратегий генерации значения поля идентификации. В
данном примере выбирается оптимальный вариант для текущей БД.
discriminator
Элемент <discriminator> требуется для сохранения иерархии классов при
использовании стратегии таблица-на-иерархию классов. В этом поле хранится значение, по
которому можно определить класс хранимого объекта для данной записи. <discriminator
column="discriminator_column"
/>
column: поле таблицы, в котором будет храниться идентификатор.
version
Элемент <version> применяется для реализации оптимистической блокировки и является
необязательным элементом. Он задает свойство класса и колонку таблицы, которые будут
хранить информацию о версии записи. Этот подход применяется при организации длинных
транзакций. <version
column="version_column"
name="PropertyName"
/>
column: Имя колонки в таблице, где будет храниться версия.
name: Имя свойства хранимого объекта.
timestamp
Элемент <timestamp> позволяет реализовать альтернативную стратегию
оптимистической блокировки. С его помощью сохраняется не версия объекта, а метка времени. <timestamp
column="timestamp_column"
name="PropertyName"
/>
column: Имя поля для хранения метки времени в таблице.
name: Имя свойства хранимого класса с типом DateTime.

58
property
Элемент <property> позволяет задать отображение простых свойств хранимого класса. Это
основной элемент отображения. <property
name="propertyName"
column="column_name"
/>
name: имя свойства.
column (опционально): имя колонки таблицы.
many-to-one
Элемент <many-to-one> позволяет задать отображение простой ссылки на другой хранимый
объект. <many-to-one
name="PropertyName"
column="column_name"
cascade="all|none|save-update|delete"
fetch="join|select"
/>
name: Имя свойства-ссылки.
column (опционально): Имя поля таблицы.
cascade (опционально): Атрибут задает правило выполнения каскадной операции над
дочерним объектом при модификации родительского.
fetch (опционально): Задает способ загрузки целевого объекта: либо с помощь outer-join
вместе с родительским объектом, либо одиночными запросами по мере обращения.
component
Элемент <component> позволяет отображать свойства дочернего объекта на поля таблицы
родительского объекта. Компоненты могут содержать свои свойства, компоненты и коллекции. <component
name="PropertyName"
>
<property ...../>
<many-to-one .... />
........
</component>
name: Имя свойства-компонента.
Внутри элемента необходимо разместить отображение его свойств.
subclass
При отображении иерархии классов необходимо задать отображение каждого дочернего
класса в иерархии. Для стратегии отображения таблица-на-иерархию классов используется
элемент <subclass> (это рекомендуемая стратегия). <subclass
name="ClassName"
discriminator-value="discriminator_value"
>
<property .... />
.....
</subclass>
name: Имя подкласса.
discriminator-value: Значение поля дискриминатора для данного подкласса. Оно позволяет
среди всех записей таблицы выбрать те, которые относятся к отображаемому подклассу.
Внутри элемента задается отображение свойств подкласса.
joined-subclass
Специфические свойства подкласса можно поместить в отдельную таблицу (стратегия
таблица-на-дочерний класс). Для этого используется элемент <joined-subclass>. <joined-subclass
name="ClassName"
table="TableName"
>

59
<key .... >
<property .... />
.....
</joined-subclass>
name: Имя подкласса.
table: Имя таблицы, для хранения специфических свойств подкласса.
Отображение коллекций
NHibernate поддерживает отображение нескольких видов коллекций объектов. Далее
приведен список основных коллекций, их описаний и соответствующих типов .NET. Коллекция Интерфейс Реализация Описание
<list> IList<T> List<T> Упорядоченная коллекция элементов.
<bag> IList<T> List<T> Неупорядоченная коллекция элементов.
<map> IDictionary<K,V> Dictionary<K,V> Словарь (пары ключ/значение)
<set> ISet<T> HashedSet<T> Множество элементов. Повторения не
допускаются.
При отображении коллекций задается набор типовых атрибутов:
name: Имя коллекции.
table: Таблица для хранения элементов коллекции.
lazy: Атрибут позволяет включить ленивую загрузку коллекции.
inverse: Ассоциации могут быть двунаправленные. В этом случае при модификации
коллекции каждая из двух сторон ассоциации сохраняет изменения в БД. Чтобы избежать
двойного сохранения объекта с одной из сторон коллекцию можно сделать инвертированной.
<list> <list ... >
<key .../>
<index ... />
<one-to-many ... />
<composite-element ... />
</list>
key: Поле для хранения ссылки на хозяина коллекции.
index: Поле для хранения порядкового номера объекта в коллекции.
element: Отображение простого свойства для объекта коллекции.
one-to-many: Отображение ссылки на хранимый объект для объекта коллекции.
composite-element: Отображение компонента для объекта коллекции.
<bag> <bag ... >
<key .../>
<element ... />
<one-to-many ... />
<composite-element ... />
</ bag>
key: Поля для хранения ссылки на хозяина коллекции.
element: Отображение простого свойства для объекта коллекции.
one-to-many: Отображение ссылки на сущность из объекта коллекции.
composite-element: Отображение компонента для объекта коллекции.
<map> <map ... >
<key .../>
<index ... />
<element ... />
<one-to-many ... />
<composite-element ... />
</map>
key: Поля для хранения ссылки на хозяина коллекции.
index: Поля для хранения порядкового номера объекта в коллекции.
element: Отображение простого свойства для объекта коллекции.
one-to-many: Отображение ссылки на сущность из объекта коллекции.

60
composite-element: Отображение компонента для объекта коллекции.
Стратегии отображения наследования
NHibernate позволяет отображать на БД не только отдельные классы, но и их иерархии.
Наличие такой возможности позволяет выполнять полиморфные запросы. При указании
базового класса в качестве критерия запроса будут найдены и объекты производных классов.
Таблица на конкретный класс
Данный способ (рис. 25) предполагает, что каждый конкретный класс отображается на свою
таблицу.
Рис. 25. Стратегия отображения «Таблица на конкретный класс»
Таблица на иерархию классов
При данном способе (рис. 26) вся иерархия классов (все их свойства) отображается на одну
таблицу БД. Чтобы определить, к какому типу объекта относится запись, используется поле с
дискриминатором. Данный способ следует использовать по умолчанию. В этом случае с БД
будет удобнее работать сторонними SQL средствами.
Рис. 26. Стратегия отображения «Таблица на иерархию классов»
Таблица на подкласс
При данном способе (рис. 27) в таблице для базового класса храниться общая для иерархии
информация, а специфические подробности хранятся в таблицах дочерних классов.

61
Рис. 27. Стратегия отображения «Таблица на подкласс»
Генерация структуры базы данных
При старте NHibernate приложения нам необходимо иметь базу данных с подходящей
структурой. Мы эту базу можем создать и модифицировать в ручном режиме или сгенерировать
еѐ на основе наших хранимых классов и настройки отображения. Для этого используется класс
SchemaExport. SchemaExport se = new SchemaExport(cfg);
se.Drop(true, true);
se.Create(true, true);
Манипулирование объектами
В предыдущем разделе были рассмотрены вопросы создания хранимых классов, их
отображения и создания схемы БД для их хранения. Сейчас мы рассмотрим вопросы
манипуляции объектами. Для этого у нас должна быть создана сессия, с помощью фабрики
сессий.
Сохранение и удаление объектов
Чтобы сохранить объект необходимо у сессии вызвать один из методов Save, Update,
SaveOrUpdate и передать ему объект.
Метод Save применяется для новых временных объектов (transient instance). Он приводит к
инициализации свойства с идентификатором.
Метод Update обновляет хранимый объект. У объекта уже должно быть задано свойство с
идентификатором.
SaveOrUpdate вызывает один из методов Save или Update в зависимости от состояния
объекта.
Пример использования: public void SaveCustomer(Customer customer)
{
using (var session = _sessionFactory.OpenSession())
{
session.Save(customer);
session.Flush();
}

62
}
Для удаления присутствует метод Delete. Пример использования: public void DeleteCustomer(Customer customer)
{
using (var session = _sessionFactory.OpenSession())
{
session.Delete(customer);
session.Flush();
}
}
NHibernate учитывает настройки каскадных операций.
Прозрачная отложенная запись
NHibernate реализует возможность прозрачной отложенной записи (transparent write behind).
Она предполагает, что изменения объектов предметной области не отправляются сразу в БД.
Вместо этого, NHibernate объединяет несколько модификаций в один запрос к SQL-серверу.
Это позволяет увеличить производительность.
Изменение свойств хранимых объектов не приводит к выполнению SQL-запросов на
модификацию. Модификации происходят при явном указании (вызов метода Flush).
Загрузка объектов с помощью критериев
В NHibernate загрузка объектов выполняется в два этапа:
1. Явная загрузка одного или нескольких корневых объектов.
2. Навигация по свойствам загруженного объекта. Это приводит к прозрачной загрузке
целевых объектов.
Явная загрузка может быть выполнена с помощью критерия. Критерий позволяет
организовать загрузку объектов по определенному условию или критерию. Главным условием
является тип объекта. Дополнительно можно задать ограничение на значения различных
свойств. Например, возможна загрузка объекта с определенным идентификатором или загрузка
заказов за определенный период. var customers =
session.CreateCriteria(typeof(Customer))
.Add(Expression.Eq("Address", "г. Москва ..."))
.List<Customer>();
Применение Fluent NHibernate
Использование файлов конфигурации NHibernate может вызвать проблему расхождения
структуры хранимых классов и настроек отображения. Это может произойти при модификации
(рефакторинге) хранимых классов. Для решения этой проблемы была разработана библиотека
Fluent NHibernate[33]. Она позволяет описать отображение в виде кода на языке
программирования (C#). Такой подход предоставляет больше возможностей при проверке
отображения на этапе компиляции и позволяет выполнять рефакторинг хранимых классов без
разрушения настроек отображения. Пример использования: public class OrderMap : ClassMap<Order>
{
public OrderMap()
{
Id(x => x.Id);
Map(x => x.Discount);
Map(x => x.OrderSum);
Map(x => x.Date);
References(x => x.Customer);
HasMany<OrderItem>(x => x.Items)
.Component(m =>
{
m.Map(x => x.Quantity);
m.Map(x => x.Cost);
m.Map(x => x.Summa);
m.References(x => x.Product, "product_id");
}).AsList();

63
HasMany(x => x.Pays).AsSet();
}
}
В библиотеке активно используются лямбда-выражения вида x => x.Discount.
Существует возможность настройки отображения для:
Свойства с идентификатором: Id(x => x.Id)
Простых свойств: Map(x => x.OrderSum)
Ссылок на хранимые объекты: References(x => x.Customer)
Коллекций различного вида: HasMany<OrderItem>(x => x.Items) …
Дополнительно, библиотека предоставляет средства для конфигурирования фабрики
сессий, например: _sessionFactory = Fluently.Configure()
.Database(SQLiteConfiguration.Standard.UsingFile(DbFile))
.Mappings(m => m.FluentMappings.AddFromAssemblyOf<Customer>())
.ExposeConfiguration(BuildSchema)
.BuildSessionFactory();

64
РЕФАКТОРИНГ
Рефакторинг представляет собой процесс такого изменения программной системы,
при котором не меняется внешнее поведение кода, но улучшается его внутренняя
структура [36]. Это способ систематического приведения кода в порядок, при котором шансы
появления новых ошибок минимальны. При проведении рефакторинга кода вы улучшаете его
дизайн уже после того, как он написан.
Цель рефакторинга – упростить понимание и модификацию программного обеспечения.
Можно выполнить много изменений в программном обеспечении, в результате которых его
видимое поведение измениться незначительно или вообще не измениться. Рефакторингом
будут только такие изменения, которые сделаны с целью облегчения понимания исходного
кода. Противоположным примером может служить оптимизация производительности. Как и
рефакторинг, оптимизации производительности обычно не изменяет поведения компонента (за
исключением скорости его работы), она лишь изменяет его внутреннее устройство. Цели,
однако, различны. Оптимизация производительности часто затрудняет понимание кода, но она
необходима для достижения желаемого результата.
Рефакторинг не меняет видимого поведения программного обеспечения. Оно
продолжает выполнять прежние функции. Никто – ни конечный пользователь, ни программист
не сможет сказать по внешнему виду, что что-то изменилось.
Применение рефакторинга при разработке программного обеспечения разделяет время
между двумя различными видами деятельности – вводом новых функций и изменением
структуры. Добавление новых функций не должно менять структуру существующего кода:
просто вводятся новые функции. Прогресс можно оценивать, добавляя тесты и добиваясь их
нормальной работы. При проведении рефакторинга необходимо не добавлять функции, а
только улучшать структуру кода. Новые тесты не добавляются. Тесты изменяются только тогда,
когда это абсолютно необходимо, чтобы проверить изменения в интерфейсе.
Рефакторинг – это инструмент, который можно использовать для нескольких целей. В своей
книге [36] Фаулер приводит пример рефакторинга фрагмента программы для видеопроката.
Зачем нужно проводить рефакторинг
Рефакторинг улучшает дизайн программного обеспечения
Без рефакторинга дизайн программы приходит в негодность. По мере внесения в код
изменений, связанных с реализацией краткосрочных целей или производимых без полного
понимания организации кода, последний утрачивает свою структурированность. Разобраться в
проекте, читая код, становятся все труднее. Рефакторинг помогает навести порядок в коде.
Убираются фрагменты, оказавшиеся не на своем месте. Утрата кодом структурности носит
накопительный характер. Чем сложнее разобраться во внутреннем устройстве кода, тем труднее
его сохранить и тем быстрее происходит его распад. Регулярное проведение рефакторинга
помогает сохранить форму кода. Важной частью улучшения дизайна является устранение
дублирования.
Рефакторинг облегчает понимание программного обеспечения
Разрабатываемая нами программа адресована не только компьютеру для еѐ последующего
исполнения. Пройдет некоторое время, и кому-нибудь потребуется прочесть наш код, чтобы
внести в него изменения. Об этом пользователе часто забывают. Экономия человеческого
времени на сопровождение программы важнее экономии процессорного времени на
исполнении программы. Рефакторинг помогает сделать код более легким для чтения и
понимания. При рефакторинге мы берем код, который работает, но не отличается идеальной
структурой. Потратив немного времени на рефакторинг, можно добиться того, чтобы код лучше
информировал о своей цели.
Рефакторинг помогает найти ошибки
Лучшее понимание кода помогает выявлять в нем ошибки. При написании кода
разработчик часто делает различные неочевидные допущения. Ими могут быть: определенная
последовательность вызова методов, ограничения на исходные данные, формат представления
данных и др. При нарушении этих допущений программа начинает работать некорректно.

65
После прояснения структуры программы некоторые сделанные допущения становятся
настолько ясными, что это помогает обнаружить ошибки в коде.
Рефакторинг помогает быстрее писать программы
Хороший дизайн системы важен для быстрой разработки программного обеспечения. В его
отсутствии время будет тратиться не на добавление новых функций, а на поиск и исправление
ошибок. Модификация занимает больше времени, когда приходится разбираться в системе и
искать дублирующийся код. Добавление новой функции требует большего объема
кодирования, если на исходный код наложено несколько слоев заплаток.
Когда проводить рефакторинг
Применяйте рефакторинг при добавлении новой функции
При добавлении новой функции необходимо разобраться с тем контекстом, в который эта
функция добавляется. Чтобы разобраться в участке малознакомого или плохо написанного кода
имеет смысл выполнить его рефакторинг. Это делает назначение кода более очевидным.
Существующий код может иметь дизайн, который не способствует добавлению нового
функционала. С помощью рефакторинга можно модифицировать дизайн в нужном
направлении.
Рефакторинг процесс быстрый и ровный. После рефакторинга добавление новой функции
происходит более гладко и занимает меньше времени.
Применяйте рефакторинг, если требуется исправить ошибку
При исправлении ошибки рефакторинг помогает сделать код более простым и понятным. В
простом и понятном коде ошибку найти проще, чем в его варианте до рефакторинга. Можно
применить такое эвристическое правило: если мы получаем сообщение об ошибке, то
необходимо выполнить рефакторинг, потому что код был недостаточно ясным, и мы не смогли
увидеть ошибку.
Применяйте рефакторинг при просмотре кода
Ряд компаний по производству программного обеспечения применяют практику
просмотров кода (code review). Благодаря чему знания о проекте становятся достоянием всей
команды. Более опытные разработчики передают свои знания менее опытным разработчикам.
Рефакторинг способствует получению более конкретных результатов от просмотра кода.
Рекомендуется просмотры проводить группами из двух человек: рецензент и автор. В рамках
экстремального программирования это идея доведена до придела в виде практики парного
программирования.
Запахи кода
При выполнении рефакторинга необходимо определиться, когда следует его проводить.
Кент Бек предложил для различных дефектов кода использовать метафору запахов, т.к. описать
формальные критерии своевременности рефакторинга затруднительно.
Далее приводятся несколько наиболее распространенных запахов кода.
Дублирование кода
Увидев одинаковые кодовые структуры в нескольких местах, можно быть уверенным, что
если удастся их объединить, программа от этого только выиграет.
Дублирование кода обычно возникает, когда нужно иметь несколько разновидностей
одного кода. Разработчик просто копирует кусок кода в нужные места. Этот подход позволяет
быстро решить текущую проблему (создание нового функционала), но создает проблемы
последующего сопровождения (в несколько участков кода нужно вносить синхронные
изменения).
Если одно выражение присутствует в нескольких методах одного класса, то можно
применить рефакторинг «Выделение метода».
Длинный метод
Чем длиннее метод, тем труднее понять, как он работает и для чего предназначен. Для
облегчения восприятия кода следует соблюдать принцип персональной ответственности и
стараться ограничить размер метода одним экраном.

66
В ранних средах исполнения и языках программирования создание малых методов и их
многочисленные вызовы могли снизить производительность приложений. При разработке
большинства современных приложений эта проблема потеряла актуальность. Главное – создать
качественный продукт, удобный для сопровождения.
Большие методы необходимо разбить на несколько меньших по размеру и дать им
подходящие имена. В этом нам помогают различные практики рефакторинга, например
«Выделение метода» и «Переименование метода». Необходимо активно применять
декомпозицию методов.
Эвристическое правило: если возникает необходимость прокомментировать код, то
необходимо выделить этот код в отдельный метод и дать ему осмысленное имя.
Большой класс
Если класс пытается выполнить слишком много работы, это часто проявляется в
чрезмерном количестве атрибутов и методов. Нарушение принципа персональной
ответственности осложняет тестирование класса (т.к. он имеет много внешних зависимостей) и
его повторное использование. Для устранения проблемы можно воспользоваться
рефакторингом «Выделение класса». Большой класс может явиться следствием дублирования
кода и его нужно устранить.
Большие классы пользовательского интерфейса могут получиться из-за объединения кода
пользовательского интерфейса и кода бизнес-логики. В этом случае код необходимо разместить
по нескольким классам, каждый из которых решает свою задачу.
Расходящиеся модификации
Расходящиеся модификации имеют место, когда один и тот же класс модифицируется
различными способами по различным причинам. Это может спровоцировать поломку одной
части функциональности, при внесении изменений в другую часть. Для каждой из
реализованных ответственностей, необходимо создать отдельный класс.
Для каждой причины изменения класса необходимо определить набор методов, которые
будут подвержены изменениям, и выделить их в отдельный класс с помощью «Выделения
класса».
Стрельба дробью
Если при изменении функционала необходимо выполнить синхронные изменения в
нескольких классах, то имеет место данных запах кода. Когда изменения разбросаны повсюду,
их трудно находить и можно пропустить важное изменение.
Для решения данной проблемы можно воспользоваться «Перемещением метода» и
«Перемещением поля».
Завистливые функции
Смысл объектов в том, что они позволяют хранить данные вместе с методами их обработки.
Классический пример дурного запаха – метод, который больше интересуется не тем классом, в
котором находится, а каким-то другим. Чаще всего предметом зависти являются данные.
Исправить положение можно с помощью рефакторинга «Перенос метода».
Группы данных
Если несколько элементов данных в том же составе встречаются в нескольких местах, то
имеет место данных запах кода. Эту группу данных необходимо объединить в общий класс.
Для этого можно задействовать рефакторинг «Граничный объект». Это позволит сократить
списки параметров методов и упростить их понимание.
Чтобы проверить, составляют ли несколько элементов данных группу, можно удалить один
из элементов и проверить, сохранили ли смысл остальные. Если нет, то это сигнал для
объединения группы в отдельный объект.
Операторы типа switch
Одним из отличительных признаков объектно-ориентированного кода служит
сравнительная немногочисленность операторов типа switch. Часто один и тот же блок switch
оказывается разбросанным по различным местам программы. При добавлении в переключатель
нового варианта приходится искать все эти блоки switch и модифицировать их. Понятие

67
полиморфизма в ООП предоставляет элегантный способ справиться с этой проблемой. Один из
рефакторингов для решения проблемы: «Замена условной логики полиморфизмом».
Ленивый класс
Чтобы сопровождать каждый класс и разобраться в нем, требуются определенные затраты.
Класс, существование которого не окупается выполняемыми им функциями, должен быть
ликвидирован.
Теоретическая общность
Этот запах возникает, если мы сейчас закладываем в программу избыточные возможности,
которые предположительно потребуются в будущем, но сейчас не нужны. Полученный код
труднее понять и сопровождать. Код хуже тестируется, т.к. для конечных пользователей он
сейчас бесполезен.
Временное поле
Запах проявляется, если в объекте поле задается только при определенных обстоятельствах.
Такой код труден для понимания. Можно сломать голову, пытаясь понять, для чего существует
некоторое поле, когда не удается найти, где оно используется. Это особенно актуально, при
отсутствии исходных кодов.
Часто временные поля возникают, когда сложному алгоритму требуются несколько
переменных для взаимодействия со своими частями.
Посредник
Посредник не имеет своих обязанностей, а только делегирует (частично или полностью)
выполнение методов другим объектам. Посредника следует удалить, как бесполезный балласт.
Клиенты посредника могут напрямую обращаться к целевым объектам.
Неуместная близость
Некоторые классы могут быть слишком сильно осведомлены об устройстве друг друга. Это
затрудняет их модификацию и использование по отдельности. Запах может проявиться при
неуместном использовании наследования, т.к. наследники имеют больше информации о
базовом классе, чем его клиенты.
Неполнота библиотечного класса
Если разработчики библиотечного класса (для широкого круга использования) реализуют
не все методы абстракции, то это создает проблемы клиентам этого класса. Проблема
осложняется тем, что эти классы могут быть недоступны для модификации. Можно привести
пример с системой генерации отчетов, которая позволяет печатать отчет, но не позволяет
сохранить его в файл.
Классы данных
Такие классы содержат только поля и код для их чтения и установки. Такие классы –
бессловесные хранилища данных, ими манипулируют другие классы.
Комментарии
Комментарии являются скорее не самостоятельным запахом кода, а средством для скрытия
других дефектов. Комментарии поясняют смысл трудного для понимания кода.
Рекомендуется реорганизовать код таким образом, чтобы комментарии ему были уже не
нужны. Это можно сделать с помощью «Выделения метода» и «Переименования метода».
Примеры методов рефакторинга
Рассмотрим несколько методов проведения рефакторинга. При описании метода
указывается ситуация (проблема), способ еѐ решения и пример или иллюстрация. Примеры
кода приведены на C#.
Выделение метода
Есть фрагмент кода, который можно сгруппировать.
Преобразуйте фрагмент кода в метод, название которого объясняет его назначение. public void PrintOwing(double Amount)
{
printBanner();

68
Console.WriteLine("name: ", _name);
Console.WriteLine("amount: ", Amount);
}
public void PrintOwing(double Amount)
{
printBanner();
PrintDetails(Amount);
}
private void PrintDetails(double Amount)
{
Console.WriteLine("name: ", _name);
Console.WriteLine("amount: ", Amount);
}
Встраивание метода
Тело метода столь же понятно, как и его название.
Поместите тело метода в код, который его вызывает, и удалите метод. int getRating()
{
return moreThenFiveLateDeliveries() ? 2 : 1;
}
private bool moreThenFiveLateDeliveries()
{
return _numerOfLateDeliveries > 5;
}
int getRating()
{
return (_numerOfLateDeliveries > 5) ? 2 : 1;
}
Встраивание временной переменной
Имеется временная переменная, которой один раз присваивается простое выражение, и эта
переменная мешает проведению других рефакторингов.
Замените этим выражением все ссылки на данную переменную. double basePrice = anOrder.basePrice();
return basePrice > 1000;
return anOrder.basePrice() > 1000
Замена временной переменной вызовом метода
Временная переменная используется для хранения значения выражения.
Преобразуйте выражение в метод. Замените все ссылки на временную переменную вызовом
метода. Новый метод может быть использован в других методах. public double GetPrice()
{
double basePrice = _quantity * _itemPrice;
if (basePrice > 1000)
return basePrice * 0.95;
else
return basePrice * 0.96;
}
public double GetPrice()
{
if (basePrice() > 1000)
return basePrice * 0.95;
else

69
return basePrice * 0.96;
}
private double basePrice()
{
return _quantity * _itemPrice;
}
Введение поясняющей переменной
Имеется сложное выражение.
Поместите результат выражения или его части во временную переменную, имя которой
поясняет его назначение. if ((platform.ToUpper().IndexOf("MAC") > -1) &&
(browser.ToUpper().IndexOf("IE") > -1) &&
wasInitialized() && resize > 0)
{
}
var isMacOs = platform.ToUpper().IndexOf("MAC") > -1;
var IsIEBrowser = browser.ToUpper().IndexOf("IE") > -1;
var wasResized = resize > 0;
if (isMacOs && IsIEBrowser && wasInitialized() && wasResized)
{
}
Расщепление временной переменной
Имеется временная переменная, которой неоднократно присваивается значение, но это не
переменная цикла и не временная переменная для накопления результата.
Создайте для каждого отдельного присваивания отдельную временную переменную. double temp = 2*(_height + _width);
Console.WriteLine(temp);
temp = _height*_width;
Console.WriteLine(temp);
double perimeter = 2*(_height + _width);
Console.WriteLine(perimeter);
double area = _height*_width;
Console.WriteLine(area);
Перемещение метода
Метод чаще использует элементы другого класса, а не того, в котором он определен.
Создайте новый метод с аналогичным телом в том классе, который чаще всего им
пользуется. Замените тело прежнего метода простым делегированием или удалите его вообще.
Перемещение поля
Поле используется или будет использоваться другим классом чаще, чем классом, в котором
оно определено.
Создайте в целевом классе новое поле и отредактируйте всех его пользователей.
Выделение класса
Некоторый класс выполняет работу, которую следует поделить между двумя классами.
Создайте новый класс и переместите соответствующие поля и методы из старого класса в
новый.

70
getTelephoneNumber()
name
officeAreaCode
officeNumber
Person
getTelephoneNumber()
name
Person
getTelephoneNumber()
areaCode
number
Telephone Number
1
officeTelephone
Рис. 28. Пример выделения метода
Замена данных объектом
Есть некоторый элемент данных, для которого требуется дополнительные данные или
поведение.
Преобразуйте элемент данных в объект.
customer : string
Order
Ordername : string
Customer
Рис. 29. Пример замены данных объектом
Замена магического числа символической константой
Есть числовой литерал, имеющий определенный смысл.
Создайте константу, дайте ей имя, соответствующие смыслу, и замените ею число. double PotentialEnergy(double Mass, double Height)
{
return Mass * 9.81 * Height;
}
const double GRAVITATIONAL_CONSTANT = 9.81;
double PotentialEnergy(double Mass, double Height)
{
return Mass * GRAVITATIONAL_CONSTANT * Height;
}
Декомпозиция условного оператора
Имеется сложная условная цепочка проверок (if-then-else)
Выделите методы из условия, части «then» и частей «else» if ((date < SUMMER_START) || (date > SUMMER_END))
{
Charge = Quantity * _winterRate + _winterServiceCharge;
}
else
{
Charge = Quantity * _summerRate;
}
if (NotSummer(date))
{
Charge = WinterCharge(Quantity);
}
else
{
Charge = SummerCharge(Quantity);
}

71
Замена вложенного условного оператора граничным условием
Метод использует условное поведение, из которого неясен нормальный путь выполнения.
Используйте граничные условия для всех граничных случаев. double GetPayAmount()
{
double result;
if (_isDead) result = deadAmount();
else
{
if (_isSeparated) result = separatedAmount();
else
{
if (_isRetired) result = retiredAmount();
else result = normalAmount();
}
}
return result;
}
double GetPayAmount()
{
if (_isDead)
return deadAmount();
if (_isSeparated)
return separatedAmount();
if (_isRetired)
return retiredAmount();
return normalAmount();
}

72
НЕПРЕРЫВНАЯ ИНТЕГРАЦИЯ
При разработке ПО часто над проектом работает целая команда разработчиков. После
создания некоторого функционального блока его необходимо встроить в общую систему. Если
это действие выполняется редко (реже одного раза в день), то объединение всех частей проекта
в рабочую систему может вызвать трудности. Чем дольше откладывается интеграция, тем
сложнее еѐ провести. Наиболее опасный случай – начать проводить интеграцию только в конце
проекта. Проблем в этом случае избежать не удастся.
Процесс интеграции ПО – не новая проблема. При увеличении сложности проекта и
количества занятых разработчиков повышается необходимость в автоматизации процесса
интеграции.
Решением данной проблемы является практика непрерывной интеграции (Continuous
Integration, CI). Она предполагает частое выполнение интеграции и поддержание проекта все
время в работоспособном состоянии. Предварительные затраты на настройку среды
непрерывной интеграции и повышение дисциплины окупаются снижением затрат на ручную
интеграцию и снижением рисков несвоевременного выпуска проекта, позднего обнаружения
ошибок, снижения качества проекта.
Как показано на рис. 30 система непрерывной интеграции состоит из нескольких
компонентов.
1. Сервер CI со сценарием сборки.
2. Хранилище исходного кода.
3. Механизм обратной связи (для оповещения о результатах сборки).
4. Машины разработчиков.
Хранилище с контролем
версий Subversion
Сервер CI
на машине
интеграционного
построения
Опрос
Разработчик
Разработчик
Разработчик
Механизм
обратной связи
Передача
изменений
Передача
изменений
Передача
изменений
Построение
Сценарий
построения
Компиляция исходного
кода, запуск проверок,
запуск инспекций,
развертывание ПО
Рис. 30. Компоненты системы непрерывной интеграции
Основные термины
Построение (build) – набор действий, выполняемых при компиляции, проверке, инспекции
и развертывании ПО.
Инспекция (inspection) – анализ исходного или бинарного кодов по внутренним критериям
качества.
Интеграция (integration) – действие по объединению отдельных артефактов исходного
кода вместе, позволяющее проверить их совместную работу.
Непрерывная интеграция – способ разработки программного обеспечения, при котором
все участники группы осуществляют частую интеграцию результатов своей работы. Обычно
каждый человек выполняет интеграцию ежедневно, что приводит к нескольким интеграциям в
день. Результат каждой интеграции автоматически проверяется набором тестов [37].
Интеграционное построение (integration build) – действие по объединению компонентов в
систему ПО. Интеграционное построение осуществляется на отдельной машине.

73
Закрытое построение – построение, выполняемое на локальной рабочей станции
разработчика перед передачей изменений в хранилище с контролем версий для уменьшения
вероятности того, что последние изменения нарушат интеграционное построение.
Сценарий построения – это единый сценарий, или набор сценариев, используемых для
компиляции, проверки, инспекции и развертывания ПО.
Проверка (testing) – общий процесс проверки работоспособности разработанного ПО.
Можно выделить:
проверку модулей;
проверку компонент;
проверку системы.
Значение непрерывной интеграции
Непрерывная интеграция позволяет добиться [38]:
снижения риска;
уменьшения количества повторяемых процессов, выполняемых вручную;
наличия развертываемого ПО в любое время;
улучшения контроль проекта;
повышения доверия к проекту.
При использовании CI дефекты обнаруживаются и устраняются быстрее. Это достигается
выполнением всесторонних проверок вскоре после внесения изменений в исходный код, а не на
финальном этапе проекта.
Применение непрерывной интеграции позволяет отслеживать различные качественные
показатели проекта (например, процент покрытия кода тестами) на протяжении всего времени
жизни проекта.
Одной из серьезных проблем при разработке ПО являются скрытые предположения. Они
могут выполняться на одном компьютере, но не выполняться на другом. В этом случае проект
будет вести себя по-разному на различных компьютерах. Чтобы уменьшить влияние этой
проблемы в рамках CI предполагается сборка проекта на специально выделенной машине и все
исходные артефакты для сборки должны загружаться из хранилища исходного кода. Это
гарантирует, что все необходимое для сборки хранится в надежном месте (хранилище
исходного кода) и процесс сборки может быть воспроизведен.
Если многоступенчатая сборка проекта осуществляется вручную, то есть вероятность еѐ
ошибочного выполнения. Применение CI позволяет выполнять сборку каждый раз одинаково.
Чтобы проблемы интеграции не накапливались, непрерывная интеграция позволяет
осуществлять сборку проекта при каждом изменении исходного кода в хранилище.
Для конечного пользователя результатом работы команды разработчиков является готовое
к использованию программное обеспечение. При использовании CI разработчик вносит
незначительные изменения в исходный код и интегрирует их с остальной частью кода. Этот
процесс повторяется регулярно. Если возникают какие-либо проблемы, участники проекта тут
же об этом будут проинформированы и немедленно их устранят. Эта практика позволяет все
время иметь готовую и свежую версию разрабатываемого ПО.
CI позволяет всем заинтересованным лицам получать объективную и своевременную
информацию о состоянии проекта. Она является основой грамотных управленческих решений и
позволяет отслеживать тенденции проекта.
Откладывание интеграции на поздний период может создать чувство неуверенности в
успехе проекта. Постоянная интеграция устраняет эту проблему. Постоянное наличие
работоспособной версии проекта увеличивает доверие к проекту всех заинтересованных
сторон.
Снижение риска
Одна из важных проблем при разработке ПО – это управление рисками. Причиной провала
многих проектов стала потеря контроля над рисками. Непрерывная интеграция позволяет
снизить ряд рисков при разработке ПО. Далее приведены основные риски.
Отсутствие развертываемого ПО.
Позднее выявление дефектов.

74
Плохой контроль проекта.
Низкокачественное ПО.
Чем дольше откладывается интеграция, тем сложнее еѐ выполнить позднее. Это приводит к
ещѐ большему откладыванию интеграции на поздний срок и к серьезным проблемам в конце
проекта. При таком подходе заинтересованные лица лишены возможности регулярно получать
работоспособные версии ПО в растущим функционалом и выпуск финальной версии может
быть задержан. Практика CI снижает этот риск с помощью частых сборок проекта и
поддержания его в работоспособном состоянии. Исправление обнаруженных дефектов имеет
больший приоритет, чем добавление нового функционала. Автоматизация процесса сборки
позволяет сократить его время, выполнять сборку часто и по одному и тому же сценарию.
Затраты на исправление дефектов сильно зависят от времени обнаружения дефекта. Чем
раньше он обнаружен, тем меньше стоимость его устранения. При наличии системы CI и
достаточного объема автоматических проверок дефекты обнаруживаются уже через несколько
минут, после помещения кода в хранилище. Это позволяет предпринимать своевременные меры
по их устранению. Чтобы оценить качество тестов, можно использовать метрику покрытия кода
тестами.
Все заинтересованные лица должны получать своевременные сообщения о ходе проекта.
Например, выполнение финальной сборки может служить сигналом для начала работы группы
ручного тестирования. Если информирование выполняется часто и вручную это может
потребовать определенных трудозатрат. Системы непрерывной интеграции имеют средства для
автоматизации оповещения заинтересованных лиц.
Построение при каждом изменении
Чем меньше проходит времени между последующими успешными сборками, тем проще
такие сборки осуществить. Развитием этой идеи является сборка при каждом изменении
исходного кода в хранилище. Чтобы внедрить эту практику, необходимо автоматизировать
построение. Автоматизированное построение осуществляется с помощью специальных утилит
(например, NAnt, MSBuild, Maven). Они позволяют описать построение в виде сценария и
запускать этот сценарий сборки, когда потребуется. Эти утилиты имеют гибкую конфигурацию.
Рекомендуется использовать готовые утилиты, вместо написания своих собственных. Это
сэкономит время и повысит надежность процесса сборки.
Сценарий может быть запущен разработчиком для проведения закрытого построения или
может быть запущен сервером CI при интеграционном построении.
Автоматизация построения позволит сократить многие предположения, например, наличие
определенных библиотек или каталогов. Сценарий построения не должен быть привязан к
конкретной машине. Он должен быть работоспособен при старте с любого компьютера
разработчиков или сервера сборки.
Современные среды разработки (IDE) позволяют собирать и запускать проекты прямо из
них. Этот способ сборки хорош для малых проектов, но он имеет существенные недостатки.
Основной из них: неявные настройки среды сборки, о которых разработчик может и не
догадываться. При переносе на другую машину процесс сборки может не проходить или
проходить с отличиями. Многие унаследованные проекты имеют особенные и не
документированные настройки среды разработки. Разворачивание таких сред представляет
определенную проблему и не всегда можно быть уверенным, что среда развернута правильно.
Важно отделить процесс сборки от IDE и обеспечить его идентичное выполнение на всех
машинах разработчиков и на сборочном сервере. В этом случае будет уменьшена зависимость
от «волшебных» машин с хитрыми настройками.
Мартин Фаулер [37] советует, все артефакты, необходимые для сборки проекта, получать из
системы контроля версий. Это позволит избежать ситуации «на моей машине все работает». К
таким артефактам можно отнести:
компоненты и библиотеки,
файлы конфигурации,
файлы с данными,
сценарии построения.

75
Автоматизация построения является предварительным условием для внедрения
непрерывной интеграции. После автоматизации построения проект можно собрать по одной
команде. Эта идея отражена в метафоре кнопки интеграции. Это повышает надежность
процесса сборки.
Для организации эффективной среды непрерывной интеграции необходимо тщательно
разработать структуру каталогов. Частая модификация каталогов репозитория может создать
определенные проблемы участникам проекта.
Полный цикл сборки различных проектов может занимать различное время, от нескольких
минут до нескольких часов. При длительном цикле сборке важно обеспечить ранний сбой
построения. Это позволит получать информацию о сбое не через несколько часов, а через
несколько минут. Этого можно достичь, разделив процесс сборки на несколько частей,
например, на две. В первую часть входят операции, которые выполняются быстро и имеют
высокий шанс обнаружения ошибок. Во вторую часть помещаются оставшиеся длительные
операции. К ним могут относиться: сложные проверки, связанные с БД, тесты с использованием
удаленных служб, интеграционные тесты.
Современное ПО может разрабатываться для множества платформ. Сервер CI должен иметь
возможность выполнять сборку и тестирование под все необходимые платформы.
Для эффективной организации непрерывной интеграции необходимо иметь отдельную
машину для интеграционного построения. Это позволит разработчикам ориентироваться при
сборке не на настройки своего компьютера, а на эталонную среду сервера интеграции. Данная
практика предотвращает зависимость от «волшебных» машин со специальными настройками и
упрощает обмен исходными текстами между разработчиками. В случае длительного процесса
сборки мощность сервера интеграции может быть увеличена или может быть применена
распределенная сборка.
Необходимо обеспечить быстрое построение (до 10 минут). Это позволит разработчикам
иметь своевременную обратную связь. Для ускорения построения необходимо измерить время
различных этапов построения и оптимизировать наиболее длительные.
Типы и механизмы построения
Сборка проекта может происходить по различным причинам. Можно выделить три типа
построения: закрытое построение на машине разработчика, интеграционное построение на
сервере интеграции и финальное построение.
Закрытое построение осуществляется разработчиком перед передачей кода в хранилище.
Перед его выполнением разработчик должен совместить свои новые наработки с последними
изменениями из хранилища. Данное построение используется для снижения вероятности сбоя
интеграционного построения. В ходе построения разработчик должен выполнить необходимый
набор проверок.
При появлении изменений в хранилище начинается интеграционное построение. Оно
выполняется на сервере CI. Его цель – убедиться, что исходный код в головной линии
разработки успешно компилируется и проходит все необходимые проверки. Интеграционное
построение можно разделить на несколько этапов для раннего обнаружения сбоев.
Финальное построение готовит программное обеспечение к выпуску для пользователей.
При финальном построении выполняется максимальное количество проверок. Результатом
финального построения должно быть ПО готовое к развертыванию и передаче тестерам или
пользователям.
Процесс сборки может быть инициирован различными способами.
Построение по требованию. Разработчик явно дает команду на построение. Способ
удобен, если построение занимает длительное время и проводить его в автоматическом
режиме не целесообразно.
Построение по расписанию. Распространенным примером этого способа являются ночные
сборки. Можно использовать сервер CI или использовать планировщик задач, например,
cron.
Построение при изменении. Сервер CI отслеживает изменения в хранилище исходного
кода и при их появлении инициирует процесс сборки.

76
Элементы сборки
Для крупного проекта процесс сборки может состоять из множества шагов.
Автоматизированное построение и непрерывная интеграция позволяют добиться
воспроизводимых результатов и снизить влияние человеческого фактора на результат сборки. В
зависимости от проекта в процесс сборки могут входить различные элементы. Рассмотрим
часто используемые элементы.
Очистка среды сборки. Сборка проекта часто происходит в одном и том же месте. Чтобы
артефакты предыдущей сборки не повлияли на результат сборки текущей необходимо
выполнить очистку. В простейшем случае она может состоять в удалении содержимого
каталога. В более сложных сценариях может потребоваться выборочная очистка.
Получение исходного кода из хранилища. Чтобы процесс сборки был воспроизводимым,
все необходимые артефакты для сборки должны быть загружены из системы контроля версий.
Это позволит избавиться от привязки сборки к конкретному компьютеру. Примерами
предотвращенных проблем могут быть:
1. Привязка проекта к библиотекам. Библиотека может присутствовать на одном
компьютере и отсутствовать на другом, на разных компьютерах библиотека может
иметь различные версии, на разных компьютерах библиотека может быть
установлена в различные каталоги. Чтобы устранить эту проблему в рамках CI
предполагается хранение библиотек в хранилище в отдельном каталоге. Это
позволит на всех сборочных компьютерах иметь необходимую версию библиотек в
известном месте.
2. Неполный набор исходных текстов. При передаче исходных текстов между
разработчиками некоторые файлы могут быть пропущены. В результате на новом
месте проект не соберется.
Расположение артефактов проекта в хранилище с контролем версий и полная сборка
проекта на выделенной машине (сервере CI) позволит быть уверенным, что все необходимое
для сборки находится в одном месте и может быть извлечено оттуда.
Компиляция исходного кода. На этом этапе из исходных текстов на языке
программирования создаются программы на машинном языке. Современные средства
разработки позволяют компилировать проекты как из IDE, так и с помощью утилит командной
строки. Здесь задействуется вторая возможность. На платформе .NET существуют компиляторы
для различных языков, например, для языка C# используется компилятор csc.exe. Для сложных
проектов могут быть задействованы утилиты комплексной сборки, такие как MSBuild, NAnt.
Проверки и тестирование. Для получения качественного программного продукта
необходимо иметь возможность проверить работоспособность всех наиболее важных режимов
работы. Эта проверка должна быть автоматизирована, т. к. иначе еѐ сложно будет выполнять
часто в полном объеме. Наличие проверок позволяет разработчикам действовать смело, т. к. без
проверок нет уверенности, что новые изменения не нарушат работу уже законченного
функционала. Проверки могут являться разновидностью актуальной (синхронизированной с
кодом) документации. Для проведения автоматических проверок в процессе сборки можно
задействовать утилиты модульного тестирования семейства xUnit, например, NUnit для
платформы .NET.
Инспекции. При разработке проекта команде разработчиков следует придерживаться
определенных стандартов кодирования. Чтобы их обеспечить, можно воспользоваться
инспекциями. Они позволяют выявить такие дефекты, как некорректное именование элементов
программы или наличие дублирования кода. Инспекции могут быть встроены в процесс сборки
и сообщать о нарушении правил при каждом построении.
Создание дистрибутива. Кроме создания исполняемых файлов в ряде проектов
необходимо подготовить дистрибутив, готовый к развертыванию. Это может потребовать
копирование ряда файлов в определенные каталоги с последующим созданием дистрибутива.
Проект может поставляться в различных комплектациях. Для каждой комплектации
необходимо создать свой дистрибутив. Автоматизация процесса снижает влияние
человеческого фактора и увеличивает качество конечного продукта.

77
Развертывание. Для ряда проектов, например, для web-сайтов, на этапе сборки нужно
выполнить развертывания проекта в среде тестирования. Регулярное развертывание позволяет
снизить количество проблем при развертывании в производственной среде.
Создание документации. Современные среды разработки позволяют встроить часть
документации в сам исходный код. Эта практика позволяет обеспечивать высокую
синхронность документации и кода. Если документация на код создается на отдельном этапе
разработки (а не синхронно с кодом) после разработки кода, то велика вероятность еѐ
устаревания из-за расхождения с кодом. Практика документирования кода помогает решить
это проблему. В процесс сборки можно встроить шаги построения документации на код на
основе самого кода. Такая документация будет профессионально оформлена, и соответствовать
последней версии кода.
Связь с другими практиками
Непрерывная интеграция связана с различными современными практиками разработки ПО.
Рассмотрим некоторые из них.
Модульное тестирование. Для гибких методов разработки характерно применение
модульного тестирования. Оно позволяет разработчикам убедиться в работоспособности
отдельных элементов ПО и активно усовершенствовать структуру ПО, не опасаясь появления
скрытых дефектов. В процессе непрерывной интеграции модульное тестирование является
основным инструментом оценки качества ПО.
Стандарты кодирования. Стандарты кодирования помогаю команде работать
унифицировано, и не делить код на сферы влияния. Стандарты кодирования – это набор правил,
которых разработчики должны строго придерживаться в проекте. Проверку соответствия им
можно встроить в процесс сборки. Проверка соответствия стандартам выполняется
преимущественно с помощью статического анализа кода. Примером утилит данного класса
является FxCop и CheckStyle. С помощью динамического анализа можно определить величину
покрытия кода тестами.
Рефакторинг. Код имеет тенденцию к ухудшению качества по мере внесения в него
изменений. Для предотвращения этого используется практика рефакторинга. Чтобы быть
уверенным в корректном проведении шагов рефакторинга необходим набор тестов и их
регулярное выполнение. Непрерывная интеграция предполагает выполнение этих условий, и,
как следствие, повышает качество выполнения рефакторинга.
Малые выпуски. Малые выпуски улучшают обратную связь и позволяют демонстрировать
новый функционал заинтересованным сторонам небольшими законченными порциями.
Непрерывная интеграция предполагает частую сборку проекта и отслеживание его состояния. У
команды разработчиков всегда имеется свежая версия проекта, которая прошла все
необходимые проверки.
Коллективное владение кодом. Коллективное владение кодом позволяет проекту быть
менее чувствительным к изменению кадрового состава команды. Так же улучшается реакция на
изменения в требованиях к продукту и оперативность исправления ошибок. В каждой части
системы разбирается несколько человек, и они могут вносить необходимые модификации.
Непрерывная интеграция предполагает наличие хранилища с контролем версий и
размещение всего исходного кода в нем. Это позволяет упростить передачу изменений
исходного кода проекта всем желающим. Наличие модульного тестирования позволяет снизить
вероятность внесения ошибок исходный код. Этот подход работает независимо от того, чей код
правиться, свой или другого разработчика. Главное – наличие представительного набора тестов.
Инструментальные средства
Чтобы внедрить полноценный процесс непрерывной интеграции разработчику необходимо
задействовать ряд инструментальных средств. Обширный обзор подобных средств приведен в
[38]. Рассмотрим некоторые из них.
Сервера непрерывной интеграции.
Для организации непрерывной интеграции необходимо серверное ПО. Оно позволяет
отслеживать изменения исходных кодов в хранилище, выполнять сборку и публиковать еѐ
результаты. Важно использовать готовые пакеты, а не изобретать велосипед. К продуктам

78
подобного класса можно отнести: CruiseControl.NET, TeamCity, MS Team Foundation Server,
Hudson.
Утилиты сборки
Процесс сборки может быть достаточно сложным. Чем сложнее процесс, тем важнее
описать его формально и выполнять в автоматическом режиме. Утилиты MSBuild, NAnt, Maven
(и ряд других) позволяют это сделать. Собираемые проекты описываются в виде целей,
зависящих друг от друга. Внутри цели указываются шаги по еѐ достижению. При сборке
указывается цель. Утилиты определяют дочерние цели, выполняют их рекурсивно, а потом
собираю основную цель.
Проверка соответствия кода стандартам кодирования
Для контроля соответствия кода определенным стандартам можно воспользоваться
средствами статического анализа кода. Одним из них является FxCop, он проверяет
соответствие набору правил от Microsoft под названием .NET Framework Design Guidelines.
Создание документации на основе кода
Если исходный код определенным образом прокомментировать, то на основе этих
комментариев можно создать комплект документации. Для этих целей можно использовать
продукты Sandcastle и NDoc.
Модульное тестирование
В процессе непрерывной интеграции необходимо иметь возможность проверить
корректность работы созданного ПО. Важным требованием к средствам проверки является их
полная автоматизация т. к. набор проверок может быть большим, он должен выполняться
быстро и без участия человека. На платформе .NET можно воспользоваться утилитами: NUnit,
mbUnit. Список инструментов модульного тестирования для различных платформ приведен в
[39].
Системы контроля версий
Для хранения и обмена исходными кодами в т. ч. между разработчиком и сервером
непрерывной интеграции необходимо хранилище с контролем версий. Существует большое
разнообразие подобных систем, например, Subversion, Git, Mercurial, CVS.
Определение покрытия кода тестами
Чтобы оценить качество набора тестов можно воспользоваться инструментами определения
покрытия кода тестами. Можно воспользоваться утилитой NCover. Низкий процент покрытия
говорит о том, что многие части системы не тестируются автоматически.
Обнаружение дублирования кода
Чем больше в коде дублирования, тем сложнее его понимать и сопровождать. Для контроля
дублирования можно воспользоваться утилитой Simian. Еѐ вызов может быть встроен в процесс
сборки. После сборки можно будет ознакомиться с объемом дублирования в проекте.
Основные правила CI
Передавайте код часто
При использовании CI необходимо часто (раз в несколько часов) передавать код в
хранилище. Это позволит упростить процедуру слияния новых изменений с существующей
базой кода и уменьшит количество конфликтов. Рекомендуется передавать код после
выполнения каждого законченного изменения, реализации новой функции или исправления
ошибки.
Не передавайте сбойный код
Перед передачей кода разработчик должен в свою локальную копию получить все
последние изменения. При передаче кода разработчик должен проверить его корректную
работу. Для этого можно использовать закрытое построение. Это позволит избежать появления
в хранилище сбойного кода. Сбойный код в хранилище может быть загружен другими
разработчиками и это осложнит их работу.
Ликвидируйте проблемы построения немедленно
Если в хранилище появляется сбойный код, то необходимо незамедлительно приступить к
исправлению ошибок. Чем раньше будет исправлена ошибка, тем меньше вероятность, что эта

79
ошибка попадет в рабочие копии разработчиков. Для данной практики необходима система
оповещения разработчиков. Сервера CI такую возможность предоставляют.
Пишите автоматические тесты
Непрерывная интеграция подразумевает агрессивную и частую модификацию кода. Чтобы
эти шаги не повредили проект, он должен иметь надежные и автоматические процедуры
тестирования. Для CI особенно важен автоматизм, т. к. сборки происходят часто и вручную
контролировать их качество проблематично.
Все проверки и инспекции должны быть пройдены
При сбое тестирования хоть в одном тесте или при нарушении правил инспекции
необходимо забраковать все построение. Это позволит выявлять проблемы на раннем этапе и
своевременно их устранять.
Выполняйте закрытое построение
Хорошей практикой для предотвращения сбоев интеграционного построения является
применение закрытого построения. При его выполнении разработчик в своей рабочей копии
получает последние изменения исходных кодов из хранилища и объединяет их со своими
наработками. Далее происходит процесс сборки, и выполняются необходимые проверки.
Избегайте получение сбойного кода
Если в хранилище все же появился сбойный код, то об этом должны быть оповещены все
члены команды. В этой ситуации разработчикам не рекомендуется получать код из хранилища.
После устранения проблемы разработчики будут проинформированы и смогут выполнить
обновление своих рабочих копий.
Пример применения
Цель данного примера – создать среду непрерывной интеграции для тестового проекта.
Наш проект – библиотека с классом калькулятора. Калькулятор умеет выполнять четыре
арифметических действия. Для нашего проекта необходим набор unit-тестов. Исходные коды
проекта и тестов должны находиться в хранилище исходных кодов Subversion. Сборка проекта
должна выполняться на сервере непрерывной интеграции CruiseControl.NET при внесении
изменений в исходный код в хранилище или при явной команде.
Начальный проект
Создадим решение, состоящее из двух проектов: Calculator, CalculatorTest. В проект
Calculator поместим файл Calculator.cs следующего содержания. public class Calculator
{
public static double Add(double a, double b)
{
return a + b;
}
public static double Sub(double a, double b)
{
return a - b;
}
public static double Mul(double a, double b)
{
return a * b;
}
public static double Div(double a, double b)
{
return a / b;
}
}
В проект CalculatorTest поместим файл CalculatorTest.cs следующего содержания. using NUnit.Framework;
[TestFixture]

80
public class CalculatorTest
{
[Test]
public void TestAdd()
{
Assert.AreEqual(3, Calculator.Add(1, 2));
}
[Test]
public void TestSub()
{
Assert.AreEqual(10, Calculator.Sub(9, -1));
}
[Test]
public void TestMul()
{
Assert.AreEqual(15, Calculator.Mul(3, 5));
}
[Test]
public void TestDiv()
{
Assert.AreEqual(3.33, Calculator.Div(10, 3), 0.01);
}
}
На рис. 31 приведена структура каталогов тестового решения. В каталог lib нужно
поместить сборку nunit.framework.dll. Далее создать каталог Tools с подкаталогом NUnit и
поместить в него следующие файлы из пакета NUnit:
nunit.core.dll;
nunit.core.interfaces.dll;
nunit.util.dll;
nunit-console.exe;
nunit-console.exe.config;
nunit-console-runner.dll.
Наличие библиотеки и утилит в хранилище позволит не зависеть от расположения этих
библиотек на сервере сборки, и централизовано распространять новые версии библиотек и
утилит.
Рис. 31. Структура каталогов тестового решения
В проекте CalculatorTest необходимо добавить ссылки на сборку первого проекта и на
библиотеку NUnit (рис. 32).
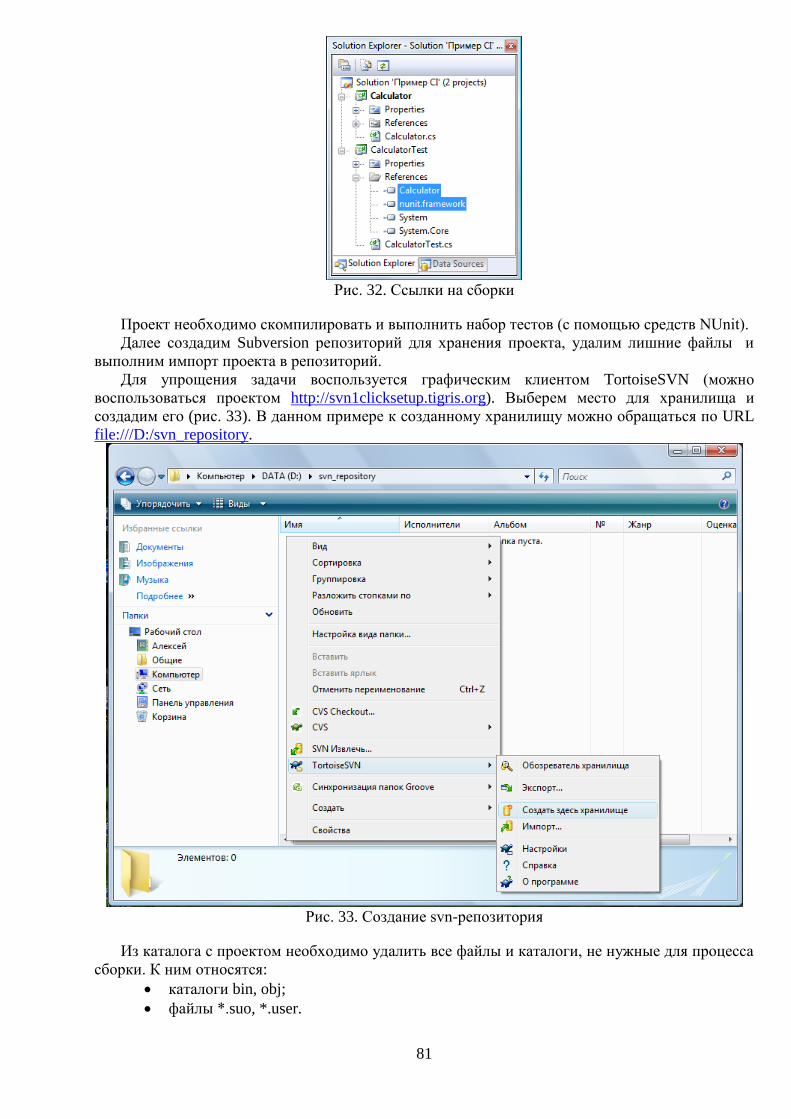
81
Рис. 32. Ссылки на сборки
Проект необходимо скомпилировать и выполнить набор тестов (с помощью средств NUnit).
Далее создадим Subversion репозиторий для хранения проекта, удалим лишние файлы и
выполним импорт проекта в репозиторий.
Для упрощения задачи воспользуется графическим клиентом TortoiseSVN (можно
воспользоваться проектом http://svn1clicksetup.tigris.org). Выберем место для хранилища и
создадим его (рис. 33). В данном примере к созданному хранилищу можно обращаться по URL
file:///D:/svn_repository.
Рис. 33. Создание svn-репозитория
Из каталога с проектом необходимо удалить все файлы и каталоги, не нужные для процесса
сборки. К ним относятся:
каталоги bin, obj;
файлы *.suo, *.user.

82
Выполним импорт проекта в хранилище в каталог file:///D:/svn_repository/DemoCI. Для
этого в каталоге с очищенным проектом вызовем команду TortoiseSVN\Импорт (рис. 33) из
контекстного меню проводника. Протокол импорта можно видеть на рис. 34. Он позволяет
проконтролировать отсутствие лишних файлов в проекте.
Рис. 34. Протокол импорта проекта
Теперь у нас есть проект с тестами в хранилище. Теперь развернем сервер непрерывной
интеграции CruiseControl.NET (далее CC.NET). Его дистрибутив можно скачать по адресу
http://confluence.public.thoughtworks.org/display/CCNET/Welcome+to+CruiseControl.NET.
CC.NET состоит из двух частей: сервера интеграции и web-приложения для мониторинга
(webdashboard). Для работы web-приложения необходимо установить на компьютере службы
IIS с поддержкой ASP.NET. При установке webdashboard происходит создание web-
приложения и регистрация ASP.NET обработчиков для него.
При работе с операционной системой Windows Vista и выше (с IIS 7.0) есть две
особенности:
1. Регистрацию ASP.NET обработчиков нужно выполнить вручную. Для этого нужно
отредактировать файл CruiseControl.NET\webdashboard\web.config.
2. Редактирование файлов конфигурации (например,
CruiseControl.NET\server\ccnet.config) нужно выполнять с правами администратора.
Пример файла CruiseControl.NET\webdashboard\web.config для IIS 7.0. <?xml version="1.0" encoding="utf-8"?>
<configuration>
<appSettings>
<add key="DashboardConfigLocation" value="dashboard.config" />
</appSettings>
<system.web>
<compilation defaultLanguage="c#" debug="true" />
<customErrors mode="RemoteOnly" />
<authentication mode="Windows" />
<trace enabled="false" requestLimit="10" pageOutput="true"
traceMode="SortByTime" localOnly="true" />
<sessionState mode="InProc" stateConnectionString="tcpip=127.0.0.1:42424"
sqlConnectionString="data source=127.0.0.1;user id=sa;password="
cookieless="false" timeout="20" />
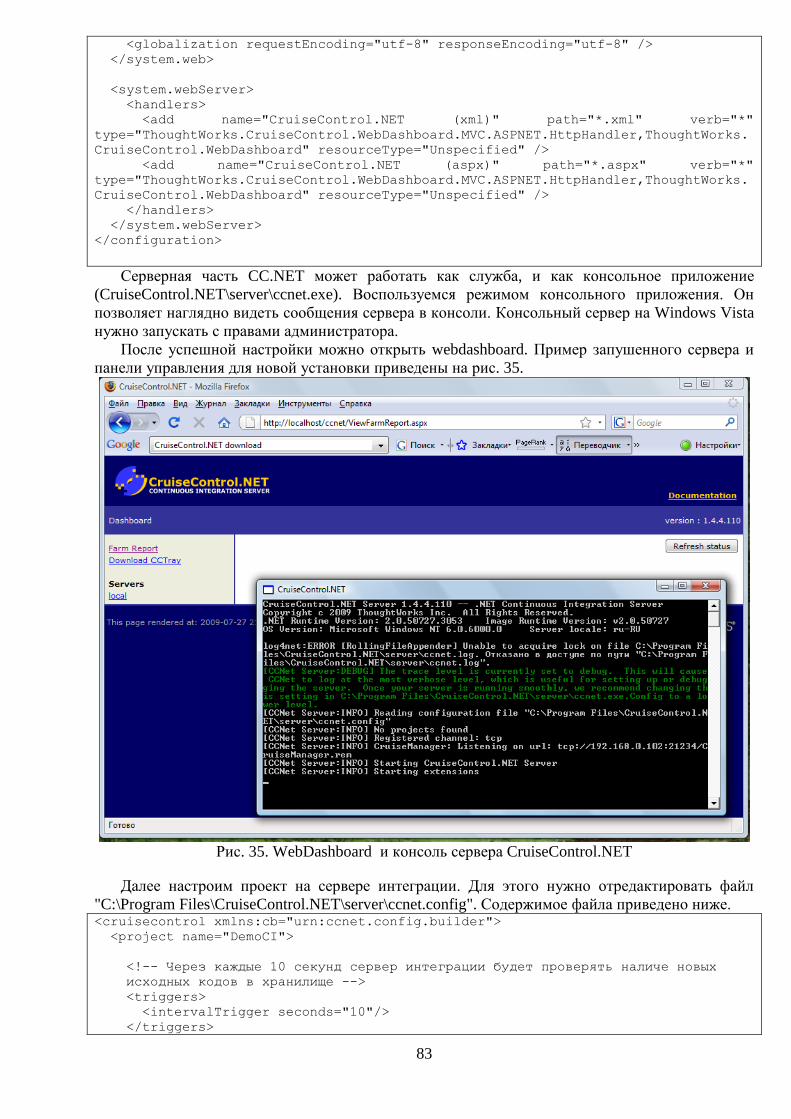
83
<globalization requestEncoding="utf-8" responseEncoding="utf-8" />
</system.web>
<system.webServer>
<handlers>
<add name="CruiseControl.NET (xml)" path="*.xml" verb="*"
type="ThoughtWorks.CruiseControl.WebDashboard.MVC.ASPNET.HttpHandler,ThoughtWorks.
CruiseControl.WebDashboard" resourceType="Unspecified" />
<add name="CruiseControl.NET (aspx)" path="*.aspx" verb="*"
type="ThoughtWorks.CruiseControl.WebDashboard.MVC.ASPNET.HttpHandler,ThoughtWorks.
CruiseControl.WebDashboard" resourceType="Unspecified" />
</handlers>
</system.webServer>
</configuration>
Серверная часть CC.NET может работать как служба, и как консольное приложение
(CruiseControl.NET\server\ccnet.exe). Воспользуемся режимом консольного приложения. Он
позволяет наглядно видеть сообщения сервера в консоли. Консольный сервер на Windows Vista
нужно запускать с правами администратора.
После успешной настройки можно открыть webdashboard. Пример запушенного сервера и
панели управления для новой установки приведены на рис. 35.
Рис. 35. WebDashboard и консоль сервера CruiseControl.NET
Далее настроим проект на сервере интеграции. Для этого нужно отредактировать файл
"C:\Program Files\CruiseControl.NET\server\ccnet.config". Содержимое файла приведено ниже. <cruisecontrol xmlns:cb="urn:ccnet.config.builder">
<project name="DemoCI">
<!-- Через каждые 10 секунд сервер интеграции будет проверять наличе новых
исходных кодов в хранилище -->
<triggers>
<intervalTrigger seconds="10"/>
</triggers>

84
<!-- Указываем Subversion (svn) как систему контроля версий для проекта.
Элемент trunkUrl задает адрес хранилища и каталог с проектом в нем.-->
<sourcecontrol type="svn">
<trunkUrl>file:///D:/svn_repository/DemoCI</trunkUrl>
</sourcecontrol>
<tasks>
<!-- После загрузки проекта из хранилища его необходимо собрать. -->
<msbuild>
<executable>C:\WINDOWS\Microsoft.NET\Framework\v3.5\MSBuild.exe</executable>
<projectFile>Пример CI.sln</projectFile>
<buildArgs> /p:Configuration=Debug /p:ReferencePath="..\lib"</buildArgs>
<targets>Build</targets>
<timeout>15</timeout>
<logger>ThoughtWorks.CruiseControl.MsBuild.XmlLogger,C:\Program
Files\CruiseControl.NET\server\thoughtworks.cruisecontrol.msbuild.dll</logger>
</msbuild>
<!-- После сборки нужно выполнить набор тестов. -->
<nunit>
<path> Tools\NUnit\nunit-console.exe </path>
<assemblies>
<assembly>CalculatorTest\bin\Debug\CalculatorTest.dll</assembly>
</assemblies>
</nunit>
</tasks>
</project>
</cruisecontrol>
После модификации конфигурационного файла сервер интеграции проведет сборку
проекта. В неѐ будут включены следующие шаги:
Получение исходных кодов из хранилища.
Компиляция проекта.
Выполнение модульных тестов.
После выполнения сборки можно посмотреть различные отчеты о еѐ выполнении (
рис. 36).
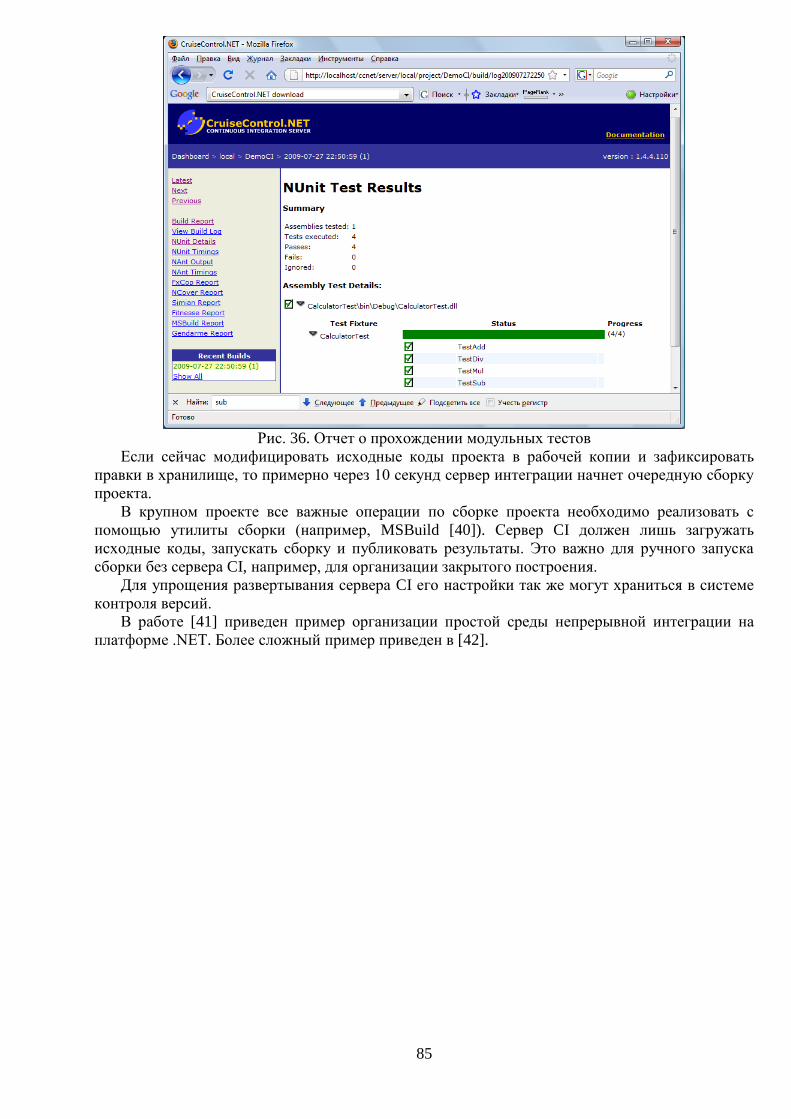
85
Рис. 36. Отчет о прохождении модульных тестов
Если сейчас модифицировать исходные коды проекта в рабочей копии и зафиксировать
правки в хранилище, то примерно через 10 секунд сервер интеграции начнет очередную сборку
проекта.
В крупном проекте все важные операции по сборке проекта необходимо реализовать с
помощью утилиты сборки (например, MSBuild [40]). Сервер CI должен лишь загружать
исходные коды, запускать сборку и публиковать результаты. Это важно для ручного запуска
сборки без сервера CI, например, для организации закрытого построения.
Для упрощения развертывания сервера CI его настройки так же могут храниться в системе
контроля версий.
В работе [41] приведен пример организации простой среды непрерывной интеграции на
платформе .NET. Более сложный пример приведен в [42].

86
БИБЛИОГРАФИЧЕСКИЙ СПИСОК
1. Рыженков, И. Краткое руководство по CVS. – http://www.rsdn.ru/article/devtools/cvs.xml.
2. Управление версиями в Subverion. – http://svnbook.red-bean.com.
3. Subverion. – http://ru.wikipedia.org/wiki/Subversion.
4. A Visual Guide to Version Control. – http://betterexplained.com/articles/a-visual-guide-to-
version-control
5. Intro to Distributed Version Control. – http://betterexplained.com/articles/intro-to-distributed-
version-control-illustrated.
6. O'Sullivan, B. Mercurial: The Definitive Guide. – http://hgbook.red-bean.com
7. Сравнение систем контроля версий. – http://wiki.opennet.ru/CVSComparison.
8. Torvalds, L. Tech Talk: Linus Torvalds on git. –
http://www.youtube.com/watch?v=4XpnKHJAok8.
9. Спольски, Д. 12 шагов к лучшему коду. –
http://russian.joelonsoftware.com/Articles/TheJoelTest.html
10. Спольски, Д. Работа над ошибками малой кровью. –
http://russian.joelonsoftware.com/Articles/PainlessBugTracking.html
11. Канер, С. Тестирование программного обеспечения. Фундаментальные концепции
менеджмента бизнес-приложений: Пер. с англ. / С. Канер, Д Фолк, Е. К. Нгуен. – К.: Изд-во
«ДиаСофт», 2001. – 544 с.
12. Баг. – http://ru.wikipedia.org/wiki/%D0%91%D0%B0%D0%B3.
13. Документация на Mantis. – http://manual.mantisbt.org/mantis.manual.zip.
14. Мартин, Р. Быстрая разработка программ: принципы, примеры, практика.: Пер. с англ. – М.:
Издательский дом «Вильямс», 2004. – 752 с.
15. Амблер, С. Гибкие технологии: экстремальное программирование и унифицированный
процесс разработки. – СПб.: Питер, 2005. – 412 с.
16. Манифест гибкой разработки. – http://www.agilemanifesto.org.
17. Ауэр, К. Экстремальное программирование: постановка процесса. С первых шагов и до
победного конца. / К. Ауэр, Р.Миллер. – СПБ.: Питер, 2004. – 368 с.
18. Бек, К. Экстремальное программирование. – СПб.: Питер, 2002. – 224 с.
19. Бек, К. Экстремальное программирование: планирование. Библиотека программиста. /
К. Бек, М. Фаулер. – СПб.: Питер, 2003. – 144 с.
20. Бек, К. Экстремальное программирование: разработка через тестирование. Библиотека
программиста. – СПб.: Питер, 2003. – 224 с.
21. Beck, K. Extreme Programming Explained: Embrace Change 2nd ed. – Addison-Wesley, 2004 –
224 p.
22. Экстремальное программирование - 2.0. –
http://www.maxkir.com/sd/extreme_programming_2.html.
23. Фаулер, М. Архитектура корпоративных программных приложений.: Пер. с англ. – М.:
Издательский дом “Вильямс”, 2004. – 544 с.
24. Буч, Г. Объектно-ориентированный анализ и проектирование с примерами приложений, 3-е
изд.: Пер. с англ. – М.: Издательский дом “Вильямс”, 2008. – 720 с.
25. Object-relational mapping vendors. – http://www.service-architecture.com/products/object-
relational_mapping.html.
26. List of object-relational mapping software. – http://en.wikipedia.org/wiki/List_of_object-
relational_mapping_software
27. Evans, E. Domain-Driven Design: Tackling Complexity in the Heart of Software. – Boston:
Addison Wesley, 2003. – 560 c.
28. Henri, P. NHibernate in Action. – New York: Manning, 2008. – 309 с.
29. Bauer, C. Java Persistence with Hibernate. / C. Bauer, G. King. – New York: Manning, 2007. –
876 с.
30. Нильссон, Д. Применение DDD и шаблонов проектирования: проблемно-ориентированное
проектирование приложений с примерами на C# и .NET.: Пер. с англ. – М.: ООО «И.Д.
Вильямс», 2008. – 560 с.

87
31. NHibernate Reference Documentation. – https://www.hibernate.org/5.html.
32. Schenker, G. Your very first NHibernate application – Part 1. –
http://dotnetslackers.com/articles/ado_net/Your-very-first-NHibernate-application-Part-1.aspx.
33. Fluent NHibernate. – http://fluentnhibernate.org
34. McCafferty, B. NHibernate Best Practices with ASP.NET, 1.2nd Ed. –
http://www.codeproject.com/KB/architecture/NHibernateBestPractices.aspx.
35. Reasons Not To Write Your Own Object Relational Mapper. –
http://ayende.com/Blog/archive/2006/05/12/25ReasonsNotToWriteYourOwnObjectRelationalMa
pper.aspx.
36. Фаулер, М. Рефакторинг: улучшение существующего кода.: Пер. с англ. – СПб: Символ-
Плюс, 2005. – 432 с.
37. Fowler, M. – Continuous Integration. –
http://www.martinfowler.com/articles/continuousIntegration.html
38. Дюваль, П. Непрерывная интеграция: улучшение качества программного обеспечения и
снижение риска.: Пер. с англ. / П. Дюваль, С. Матиас, Э. Гловер. – М.: ООО “И.Д.
Вильямс”, 2008. – 240 с.
39. Модульное тестирование. – http://ru.wikipedia.org/wiki/Модульное_тестирование
40. Чистяков, В. MSBuild. – http://www.rsdn.ru/article/devtools/msbuild-05.xml
41. Карцев, Е. Построение «правильного» процесса разработки на платформе .NET. –
http://www.developers.org.ua/archives/jony/2009/06/16/dot-net-development-process.
42. Lotz, C. Continuous Integration From Theory to Practice, 2nd Edition. –
http://dotnet.org.za/blogs/cjlotz/Continuous%20Integration%20-
%20From%20Theory%20to%20Practice,%202nd%20Ed.zip

88
ОГЛАВЛЕНИЕ Введение .................................................................................................................................................. 3
Управление версиями исходного кода ................................................................................................. 5
Основные термины ............................................................................................................................. 6
Хранилище .......................................................................................................................................... 6
Правки ................................................................................................................................................. 7
Совмещение и обновление ................................................................................................................ 9
Импорт проекта .................................................................................................................................. 9
Изменение рабочей копии ............................................................................................................... 10
Обновление рабочей копии и разрешение конфликтов ............................................................... 10
Метки, ветки и слияние ................................................................................................................... 12
Графический клиент......................................................................................................................... 17
Распределенные системы контроля версий ................................................................................... 17
Системы отслеживания ошибок ......................................................................................................... 20
История бага ..................................................................................................................................... 20
Зачем нужны BTS ............................................................................................................................. 21
Пример обработки одной ошибки .................................................................................................. 22
Классификация программных ошибок........................................................................................... 24
Структура хорошего отчета по ошибке ......................................................................................... 25
Основные атрибуты отчета об ошибке .......................................................................................... 25
Советы Джоэля Спольски по использованию BTS ....................................................................... 25
Жизненный цикл ошибки ................................................................................................................ 26
Рассмотрение конкретной BTS на примере Mantis ....................................................................... 27
Способ взаимодействия с пользователем ...................................................................................... 27
Просмотр списка ошибок под различными фильтрами ............................................................... 29
Гибкая разработка ПО ......................................................................................................................... 30
Манифест .......................................................................................................................................... 30
Принципы гибкой разработки ПО .................................................................................................. 30
Экстремальное программирование (XP) ............................................................................................ 33
Практики XP ..................................................................................................................................... 34
Игра в планирование (Planning Game) ........................................................................................... 35
Тестирование (Testing) ..................................................................................................................... 36
Программирование парами (Pair Programming) ............................................................................ 38
Рефакторинг (Refactoring) ............................................................................................................... 39
Простой дизайн (Simple Design) ..................................................................................................... 39
Коллективное владение кодом (Collective Code Ownership) ........................................................ 40
Постоянная интеграция (Continuous Integration) ........................................................................... 40
Заказчик в команде (On-Site Customer) .......................................................................................... 40
Частые выпуски версий (Small Releases) ....................................................................................... 41
Равномерная работа ......................................................................................................................... 41

89
Стандарты кодирования (Coding Standards) .................................................................................. 42
Метафора системы (System Metaphor) ........................................................................................... 42
Открытая рабочая среда .................................................................................................................. 42
ХР – это комбинация практик ......................................................................................................... 43
Экстремальное программирование 2.0 .......................................................................................... 43
Технология объектно-реляционного отображения ........................................................................... 45
Подходы к сохранению бизнес-сущностей на платформе .NET ................................................. 46
Зачем нужен NHibernate?................................................................................................................. 48
Преимущества ORM решений ........................................................................................................ 48
Несоответствие парадигмы ............................................................................................................. 49
“Hello World” с NHibernate .............................................................................................................. 51
Архитектура NHibernate .................................................................................................................. 54
Конфигурирование NHibernate ....................................................................................................... 55
Настройка отображения ................................................................................................................... 56
Отображение коллекций .................................................................................................................. 59
Стратегии отображения наследования ........................................................................................... 60
Генерация структуры базы данных ................................................................................................ 61
Манипулирование объектами ......................................................................................................... 61
Применение Fluent NHibernate ........................................................................................................ 62
Рефакторинг .......................................................................................................................................... 64
Зачем нужно проводить рефакторинг ............................................................................................ 64
Когда проводить рефакторинг ........................................................................................................ 65
Запахи кода ....................................................................................................................................... 65
Примеры методов рефакторинга .................................................................................................... 67
Непрерывная интеграция ..................................................................................................................... 72
Основные термины ........................................................................................................................... 72
Значение непрерывной интеграции ................................................................................................ 73
Снижение риска ................................................................................................................................ 73
Построение при каждом изменении ............................................................................................... 74
Типы и механизмы построения ....................................................................................................... 75
Элементы сборки .............................................................................................................................. 76
Связь с другими практиками ........................................................................................................... 77
Инструментальные средства ........................................................................................................... 77
Основные правила CI ....................................................................................................................... 78
Пример применения ......................................................................................................................... 79
Библиографический список ................................................................................................................. 86

90
Электронное издание
Алексей Валерьевич Гуйдо
ТЕХНОЛОГИИ ПРОГРАММИРОВАНИЯ
Учебное пособие
Под редакцией Б.М. Суховилова
Издательский центр Южно-Уральского государственного университета
Подписано в печать 10.03.2010. Формат 6084 1/8. Усл. печ. л. 10,46. Заказ 67.


















