
5おもな生理障害 すじ腐れ¼•.おもな...-55-5おもな生理障害5おもな生理障害 すじ腐れ 症状 ①果実成熟後半に果実表面に濃い褐色斑点が現れたり、
Upload
junya-shimazuCategory
view
112download
4
障害にならないためにどうするか 障害になったらどうするか
2015. 04. 21 ビアバッシュLT @ DMM.com Labo

島津 純哉 • 北海道札幌市生まれ • 金沢大学 → DMM.comラボ • サーバーサイドエンジニア(フロントも少し兼任) • 好きなマンガ 孤独のグルメ

2013年9月サービスイン
1年半運用に携わってきました

ブラウザでも動きます
アプリはほぼWebView
フロントエンドHTML + CSS + Javascript
サーバーサイドPHP + MySQL + Apache + CentOS

運用でやってきたこと• 新機能、イベント追加作成 • カスタマーサポート対応 • システムリファクタリング • ユーザー動向の分析 • パフォーマンスチューニング • 障害対策・対応 • etc…

運用でやってきたこと• 新機能、イベント追加作成 • カスタマーサポート対応 • システムリファクタリング • ユーザー動向の分析 • パフォーマンスチューニング • 障害対策・対応 ← 今日のお話 • etc…

障害対応ってどんなことしてるの?

実際に起こった障害
• DBまわりのトラブル • ミドルウェアレベルのトラブル • ハードウェアレベルのトラブル • DDOS攻撃 • 連携先APIでのトラブル

DDOS 1%
ハードウェアレベルのトラブル 4%
ミドルウェアレベルのトラブル 4%
APIトラブル 14%
DBトラブル 78%

DDOS 3%
ハードウェアレベルのトラブル 3%
ミドルウェアレベルのトラブル 3%
APIトラブル 14%
DBトラブル 78%
ほとんどDBまわりのトラブル …ということで、本日はDBに着目したお話です
DBにおけるトラブル
クエリの遅延
ハードウェアの性能限界

DBにおけるトラブル
クエリの遅延 → 多かった
ハードウェアの性能限界 → ほとんどなかった

いつ起こるの?
• 今じゃない
• ユーザーのアクセスが増えてきたとき
• 参照するデータ件数が増えてきたとき

クエリ遅延を防ぐためにしていた3つのこと
1. 安全なクエリをつくる
2. スロークエリの監視
3. スケーラブルな設計

クエリ遅延を防ぐためにしていた3つのこと
1. 安全なクエリをつくる
2. スロークエリの監視
3. スケーラブルな設計

1. 安全なクエリをつくる
• EXPLAIN しながらインデックスを最適化
• ひと手間かけてテスト環境でダミーデータを用意するのが大事
• データの増え方、アクセス頻度まで考える

type ALL, indexは危険
keyNULLは危険
rows 件数がやたら多いのは危険
Explainで見てすぐわかる危険なクエリ

1. 安全なクエリをつくる
2. スロークエリの監視
3. スケーラブルな設計
クエリ遅延を防ぐためにしていた3つのこと

2.スロークエリの監視
• 1秒以上かかったクエリを記録
• 基本的に発生しないようにする
• 発生したらすぐ直す (分析用のクエリで発生するものは例外としていた)

監視ツール Munin


遅延発生時 平常時

1. 安全なクエリをつくる
2. スロークエリの監視
3. スケーラブルな設計
クエリ遅延を防ぐためにしていた3つのこと

3. スケーラブルな設計
負荷に合わせて増設できるようにしておく

3. スケーラブルな設計
master slave
参照のみ書き込み & 参照
レプリケーション

3. スケーラブルな設計
master slave
master slave
UserDB (ユーザーデータ)
CommonDB (それ以外のデータ)
垂直分割

3. スケーラブルな設計
master slave
master slave
UserDB-1(user_id % 2 = 0のユーザーデータ)
CommonDB
master slave
UserDB-2(user_id % 2 = 1のユーザーデータ)
水平分割 (sharding)

3. スケーラブルな設計
• ユーザーデータは水平分割したDBにもつ
• 参照の増加に合わせてslaveを増やす
• 更新の増加に合わせてさらにUserDBを水平分割

障害が起こったらどうするの?

障害になったら起こること
• サービスの遅延
• サーバーアラート発生
• カスタマーサポート

DBの障害対応とは
遅延のトリガーになっているクエリを探すこと

クエリ遅延を見つけるためにしていた3つのこと
1. アラート・Muninの確認
2. スロークエリのログファイルを見る
3. プロセスリストを見る

クエリ遅延を見つけるためにしていた3つのこと
1. アラート・Muninの確認
2. スロークエリのログファイルを見る
3. プロセスリストを見る

1. アラート, Munin確認
発生した時間、対象のサーバーを知る

遅延発生時 平常時

クエリ遅延を見つけるためにしていた3つのこと
1. アラート・Muninの確認
2. スロークエリのログファイルを見る
3. プロセスリストを見る

多すぎてよくわからない/(^o^)\

生のログはわかりにくいのでmysqldumpslow(コマンド)を使って見やすく


・・・
※(簡単のため以下略)

実行時間(平均)実行回数 対象のクエリ

実行時間(平均)実行回数 対象のクエリ
わかりやすくなった\(^o^)/遅い順, 件数順などソートもできます

クエリ遅延を見つけるためにしていた3つのこと
1. アラート・Muninの確認
2. スロークエリのログファイルを見る
3. プロセスリストを見る

3. プロセスリストを見る
• mysql > show full processlist;
• 実行中のクエリをすべて表示するコマンド
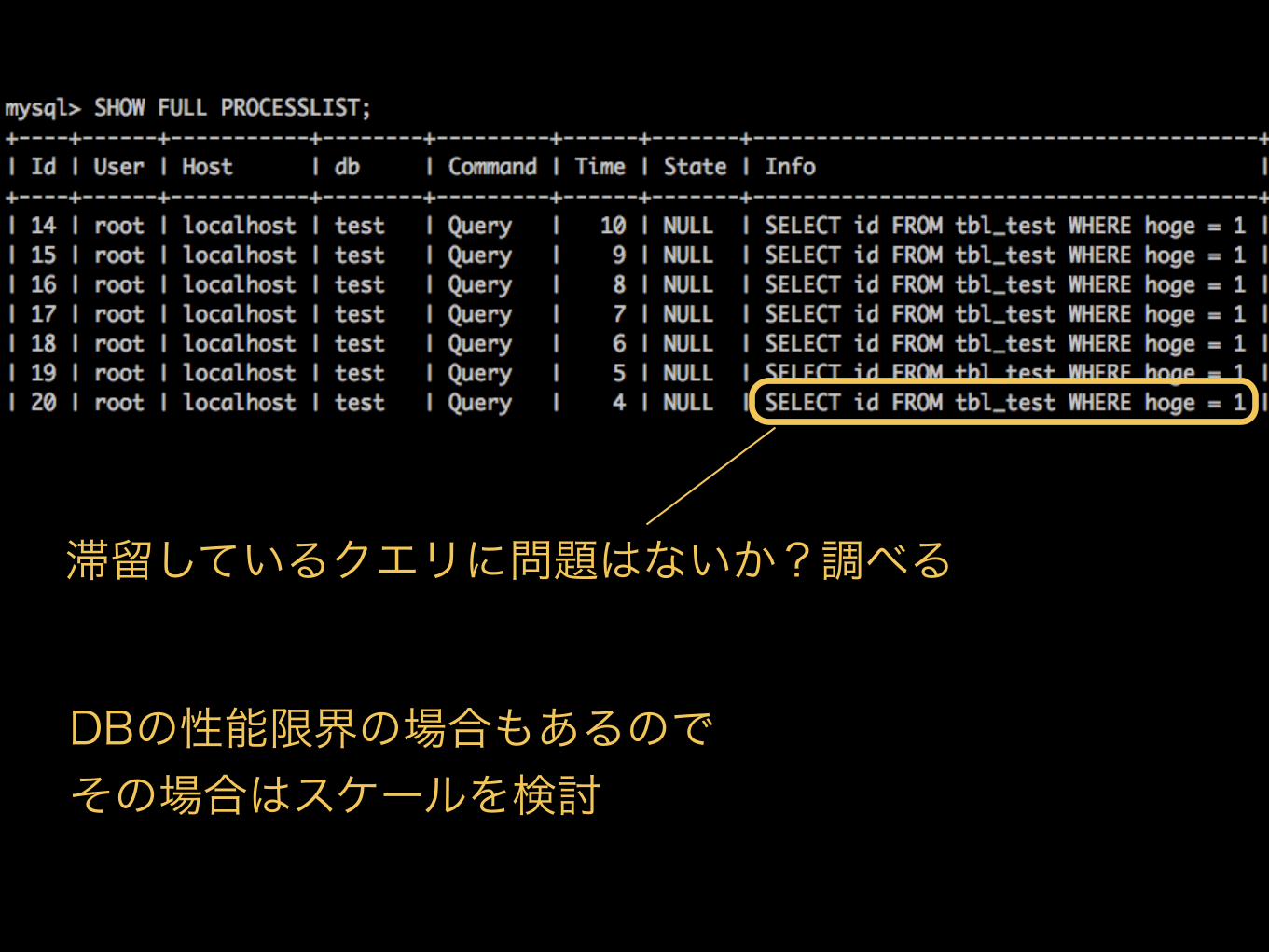
滞留しているクエリに問題はないか?調べる
DBの性能限界の場合もあるので その場合はスケールを検討

原因が特定できたら(根本的対策)
case1. プログラム(クエリ)をその場で修正
case2. テーブルのインデックス最適化 (要メンテナンス、件数によっては時間がかかるので注意)
case3. サーバーの増設・増強 (データセンターだと難しいが、クラウドなら)

原因が特定できたら(暫定的対策)
case1. 問題箇所の機能だけ停止してサービス再開
case2. 一部ユーザーをアクセス制限して負荷軽減
case3. そのまま様子見で収束を待つ (ピーク終了が見込めるとき)
…以上の対策をしたのちに根本的対策を行う。

ざっくりまとめ
障害を防ぐのも、障害になったときも
まずはスロークエリに着目するのが大事

ご静聴ありがとうございました

細かくまとめDB障害にならないために
• EXPLAINしながらインデックスの最適化
• 監視のポイントはslow query
• 設計はスケーラブルに
DB障害になったら
• slow query ログファイルの確認
• show processlist


















